
1. Giriş
Genel Bakış
Bir seyahat pazarlama şirketinde geliştirici olarak çalışıyorsunuz. Satış departmanınız, daha büyük rezervasyon ve arama şirketleriyle rekabet edebilmek için yeni bir sohbet uygulamasına ihtiyaç duyduğuna karar verdi. Üretken yapay zeka hakkında da bilgi sahibi olsalar da bu konuda çok fazla şey bilmiyorlar. Diğer departmanlar bu girişimden haberdar ve bunun müşteri deneyimlerine nasıl yardımcı olabileceğini merak ediyor.
Yapacaklarınız
Bu laboratuvarda, Vertex AI'da Gemini 2.5 Flash modelini kullanarak bir seyahat asistanı chatbot oluşturacaksınız.
Uygulama:
- Kullanıcıların seyahatle ilgili sorular sormasına, seyahat rezervasyonu yapmasına ve gitmeyi planladıkları yerler hakkında bilgi edinmesine yardımcı olur.
- Kullanıcılara, belirli seyahat planlarıyla ilgili yardım alma yolları sunar.
- Araçları kullanarak hava durumu gibi anlık verileri getirebilme
Önceden yapılandırılmış bir Google Cloud ortamında, özellikle Cloud Shell Düzenleyici'de çalışacaksınız. Vertex AI'a erişmek için gerekli izinlerle birlikte temel bir web uygulaması ön ucu sizin için önceden ayarlanmıştır. Bu uygulama Streamlit kullanılarak oluşturulmuştur.
Neler öğreneceksiniz?
Bu laboratuvarda, aşağıdaki görevleri nasıl gerçekleştireceğinizi öğreneceksiniz:
- Kullanılabilir üretken yapay zeka modellerini belirlemek için Vertex AI platformunu keşfedin.
- Cloud Shell Düzenleyici ve terminalde geliştirme
- Kodu anlamak için Gemini Code Assist'i kullanın.
- Vertex AI SDK'yı Python'da kullanarak Gemini LLM'ye istem gönderin ve yanıt alın.
- Gemini LLM'nin çıkışını özelleştirmek için temel istem mühendisliği (sistem talimatları, model parametreleri) uygulayın.
- İstemleri ve parametreleri değiştirerek yanıtları iyileştirip LLM destekli bir sohbet uygulamasını test edin ve yinelemeli olarak iyileştirin.
- İşlev çağrısını etkinleştirmek için Gemini modeliyle araçları tanımlayıp kullanın.
- Durum bilgili bir sohbet oturumu kullanmak için kodu yeniden düzenleyin. Bu, konuşma uygulamaları için en iyi uygulamadır.
2. Proje ayarlama
Google Hesabı
Kişisel Google Hesabınız yoksa Google Hesabı oluşturmanız gerekir.
İş veya okul hesabı yerine kişisel hesap kullanın.
Google Cloud Console'da oturum açma
Kişisel bir Google Hesabı kullanarak Google Cloud Console'da oturum açın.
Faturalandırmayı Etkinleştir
Google Cloud kredilerini kullanma (isteğe bağlı)
Bu atölyeyi düzenlemek için biraz kredisi olan bir faturalandırma hesabınızın olması gerekir. Başlamak için bu codelab'in üst kısmındaki banner'da yer alan kredileri kullanın. Zaten bir faturalandırma hesabına bağlıysanız bu adımı atlayabilirsiniz.
Kişisel faturalandırma hesabı oluşturma
Faturalandırmayı Google Cloud kredilerini kullanarak ayarladıysanız bu adımı atlayabilirsiniz.
Kişisel faturalandırma hesabı oluşturmak için Cloud Console'da faturalandırmayı etkinleştirmek üzere buraya gidin.
Bazı notlar:
- Bu laboratuvarı tamamlamak için 1 ABD dolarından daha az tutarda bulut kaynağı kullanmanız gerekir.
- Daha fazla ücret ödememek için bu laboratuvarın sonundaki adımları uygulayarak kaynakları silebilirsiniz.
- Yeni kullanıcılar 300 ABD doları değerinde ücretsiz deneme sürümünden yararlanabilir.
Proje oluşturma (isteğe bağlı)
Bu laboratuvarda kullanmak istediğiniz mevcut bir projeniz yoksa buradan yeni bir proje oluşturun.
3. Cloud Shell Düzenleyici'yi açma
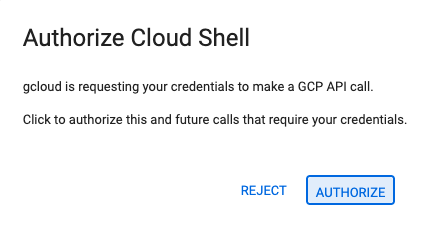
- Doğrudan Cloud Shell Düzenleyici'ye gitmek için bu bağlantıyı tıklayın.
- Bugün herhangi bir noktada yetkilendirmeniz istenirse devam etmek için Yetkilendir'i tıklayın.
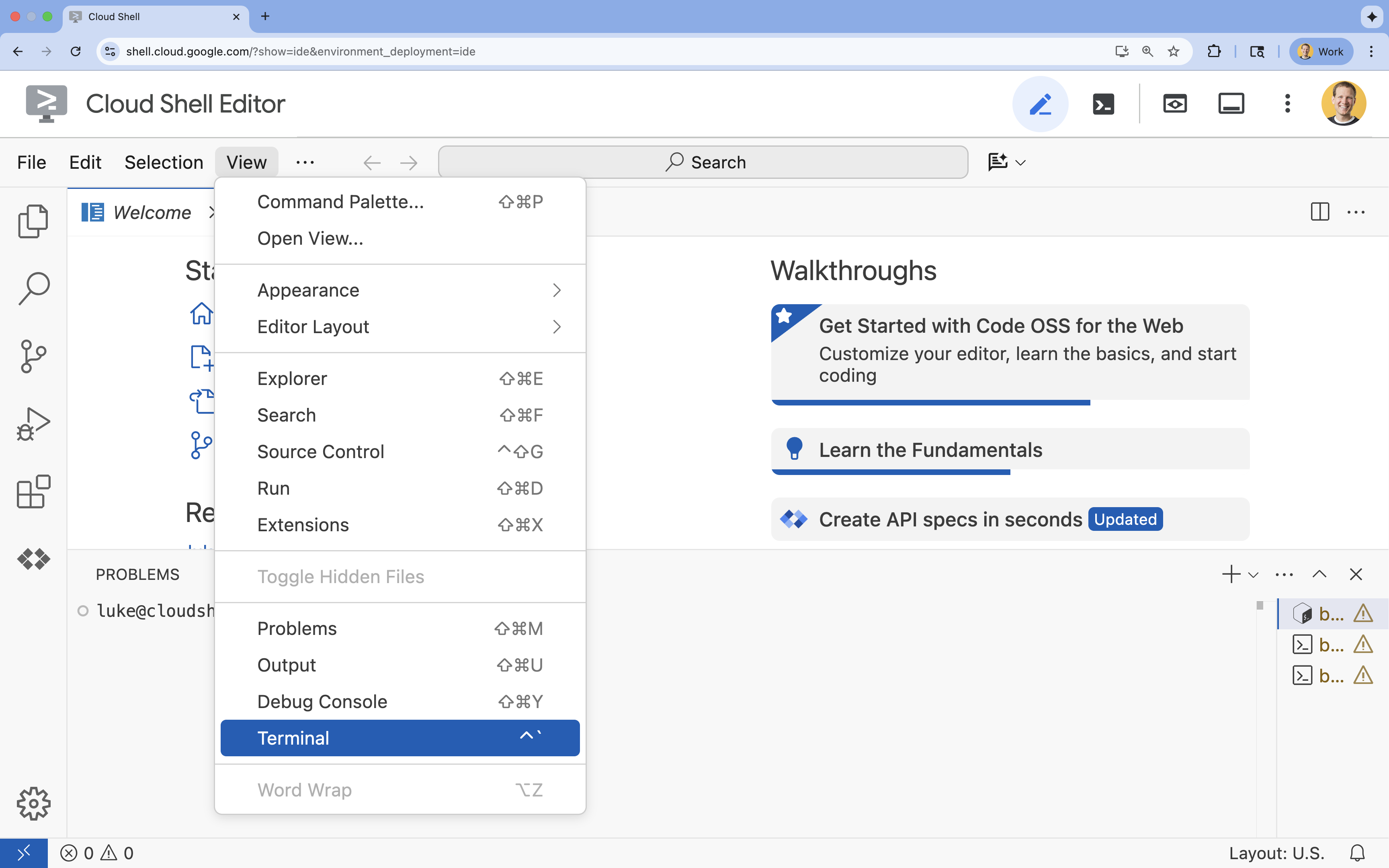
- Terminal ekranın alt kısmında görünmüyorsa açın:
- Görünüm'ü tıklayın.
- Terminal'i tıklayın.
- Terminalde şu komutla projenizi ayarlayın:
gcloud config set project [PROJECT_ID]- Örnek:
gcloud config set project lab-project-id-example - Proje kimliğinizi hatırlamıyorsanız tüm proje kimliklerinizi şu komutla listeleyebilirsiniz:
gcloud projects list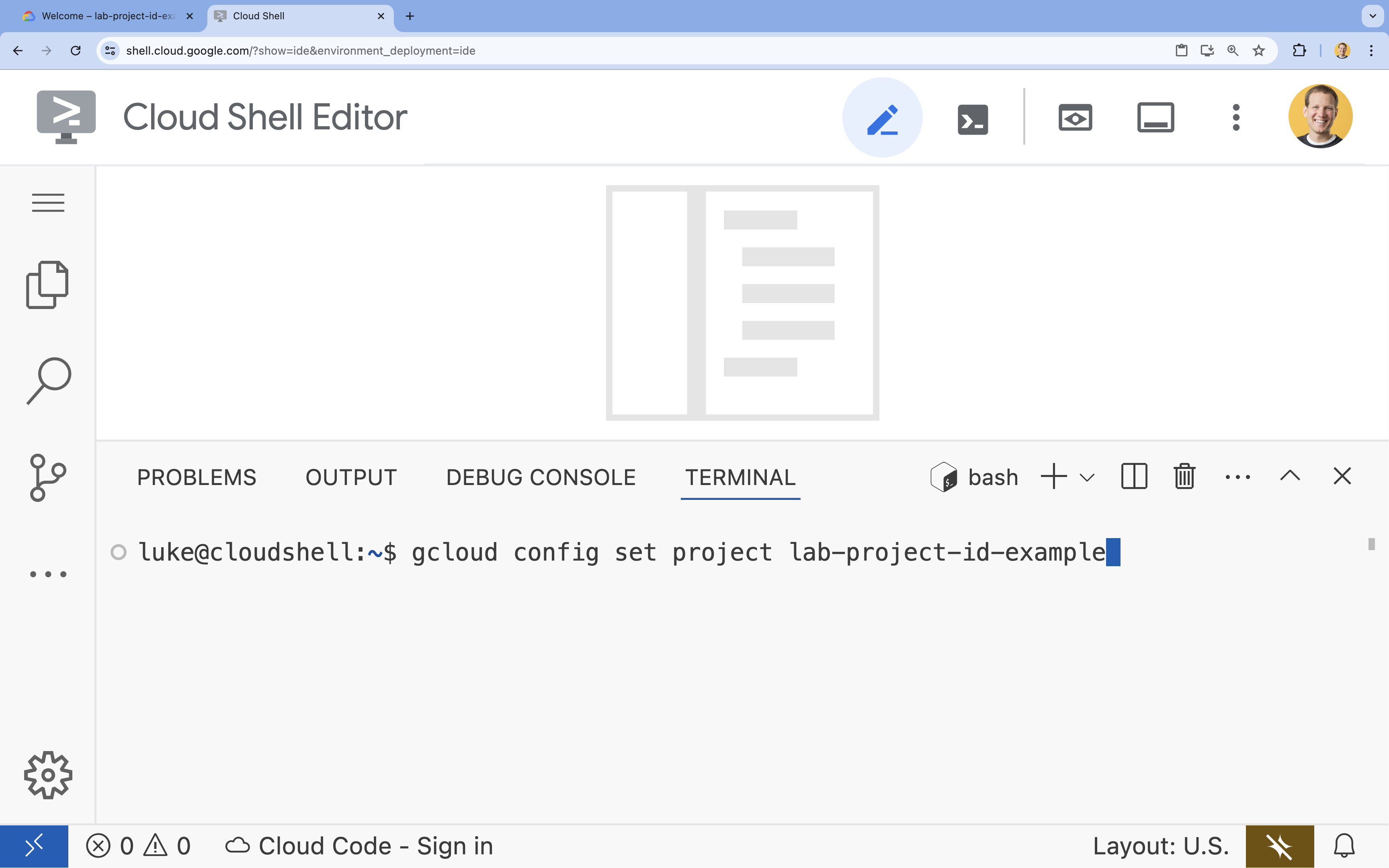
- Örnek:
- Şu mesajı görmeniz gerekir:
Updated property [core/project].
4. API'leri etkinleştir
Vertex AI SDK'yı kullanmak ve Gemini modeliyle etkileşim kurmak için Google Cloud projenizde Vertex AI API'yi etkinleştirmeniz gerekir.
- Terminalde API'leri etkinleştirin:
gcloud services enable \ aiplatform.googleapis.com
Python için Vertex AI SDK'ya giriş
Python uygulamanızdan Vertex AI'de barındırılan modellerle etkileşim kurmak için Python için Vertex AI SDK'yı kullanırsınız. Bu SDK, temel API çağrılarının karmaşıklıklarını doğrudan ele almaya gerek kalmadan istem gönderme, model parametrelerini belirtme ve yanıt alma sürecini basitleştirir.
Python için Vertex AI SDK'sıyla ilgili kapsamlı dokümanları Python için Vertex AI SDK'ya giriş | Google Cloud sayfasında bulabilirsiniz.
5. Sanal ortam oluşturma ve bağımlılıkları yükleme
Herhangi bir Python projesine başlamadan önce sanal ortam oluşturmak iyi bir uygulamadır. Bu, projenin bağımlılıklarını yalıtarak diğer projelerle veya sistemin genel Python paketleriyle çakışmaları önler.
- Seyahat asistanı uygulamanızın kodunu depolamak için
wanderbotadlı bir klasör oluşturun. Terminalde aşağıdaki kodu çalıştırın:mkdir wanderbot && cd wanderbot - Sanal ortam oluşturun ve etkinleştirin:
uv venv --python 3.12 source .venv/bin/activatewanderbot) ön ekini görürsünüz. Bu, sanal ortamın etkin olduğunu gösterir. Bu değer şöyle görünür:
6. wanderbot için başlangıç dosyaları oluşturma
- Uygulama için yeni bir
app.pydosyası oluşturup açın. Terminalde aşağıdaki kodu çalıştırın:cloudshell edit app.pycloudshell editkomutu,app.pydosyasını terminalin üstündeki düzenleyicide açar. - Aşağıdaki uygulama başlangıç kodunu
app.pydosyasına yapıştırın:import streamlit as st from google import genai from google.genai import types import requests import logging # --- Defining variables and parameters --- REGION = "global" PROJECT_ID = None # TODO: Insert Project ID GEMINI_MODEL_NAME = "gemini-2.5-flash" temperature = .2 top_p = 0.95 system_instructions = None # --- Tooling --- # TODO: Define the weather tool function declaration # TODO: Define the get_current_temperature function # --- Initialize the Vertex AI Client --- try: # TODO: Initialize the Vertex AI client print(f"VertexAI Client initialized successfully with model {GEMINI_MODEL_NAME}") except Exception as e: st.error(f"Error initializing VertexAI client: {e}") st.stop() # TODO: Add the get_chat function here in Task 15. # --- Call the Model --- def call_model(prompt: str, model_name: str) -> str: """ This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions. It will be replaced in a later step with a more advanced version that handles tooling. """ try: # TODO: Prepare the content for the model # TODO: Define generate_content configuration (needed for system instructions and parameters) # TODO: Define response logging.info(f"[call_model_response] LLM Response: \"{response.text}\"") # TODO: Uncomment the below "return response.text" line # return response.text except Exception as e: return f"Error: {e}" # --- Presentation Tier (Streamlit) --- # Set the title of the Streamlit application st.title("Travel Chat Bot") # Initialize session state variables if they don't exist if "messages" not in st.session_state: # Initialize the chat history with a welcome message st.session_state["messages"] = [ {"role": "assistant", "content": "How can I help you today?"} ] # Display the chat history for msg in st.session_state.messages: st.chat_message(msg["role"]).write(msg["content"]) # Get user input if prompt := st.chat_input(): # Add the user's message to the chat history st.session_state.messages.append({"role": "user", "content": prompt}) # Display the user's message st.chat_message("user").write(prompt) # Show a spinner while waiting for the model's response with st.spinner("Thinking..."): # Get the model's response using the call_model function model_response = call_model(prompt, GEMINI_MODEL_NAME) # Add the model's response to the chat history st.session_state.messages.append( {"role": "assistant", "content": model_response} ) # Display the model's response st.chat_message("assistant").write(model_response) - Uygulama kodu için yeni bir
requirements.txtdosyası oluşturup açın. Terminalde aşağıdaki kodu çalıştırın:cloudshell edit requirements.txtcloudshell editkomutu,requirements.txtdosyasını terminalin üstündeki düzenleyicide açar. - Aşağıdaki uygulama başlangıç kodunu
requirements.txtiçine yapıştırın.google-genai streamlit requests - Bu proje için gerekli Python bağımlılıklarını yükleyin. Terminalde aşağıdaki kodu çalıştırın:
uv pip install -r requirements.txt
7. Kodu keşfetme
Oluşturduğunuz dosyalar, temel bir sohbet uygulaması ön ucu içerir. Bunlar, aşağıdakileri içerir:
app.py: Bu, üzerinde çalışacağımız dosyadır. Şu anda aşağıdaki bilgileri içerir:- gerekli içe aktarmalar
- ortam değişkenleri ve parametreler (bazıları yer tutucudur)
- dolduracağımız boş bir
call_modelişlevi - Ön uç sohbet uygulaması için Streamlit kodu
requirements.txt:app.py'yı çalıştırmak için yükleme koşullarını içerir.
Şimdi kodu keşfetme zamanı.
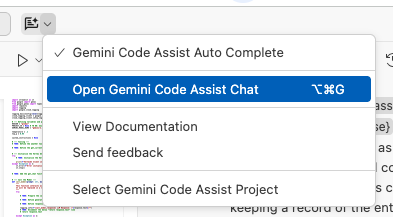
Gemini Code Assist Chat'i açma
Gemini Code Assist sohbeti, Cloud Shell düzenleyicisinin sağ tarafındaki bir panelde zaten açık olmalıdır. Gemini Code Assist Sohbeti henüz açık değilse aşağıdaki adımları uygulayarak açabilirsiniz:
- Ekranın üst kısmına yakın bir yerdeki Gemini Code Assist düğmesini (
 ) tıklayarak.
) tıklayarak. - Open Gemini Code Assist Chat'i (Gemini Code Assist Sohbetini Aç) seçin.
Kodu anlamak için Gemini Code Assist'i kullanma
Kodu daha iyi anlamak için Gemini Code Assist Chat'i kullanabilirsiniz.
- İstediğiniz kod bölümünü vurgulayın veya seçin.
- Gemini ile etkileşimde "Bu kodu açıkla" yazın.
- Göndermek için Enter'a basın.
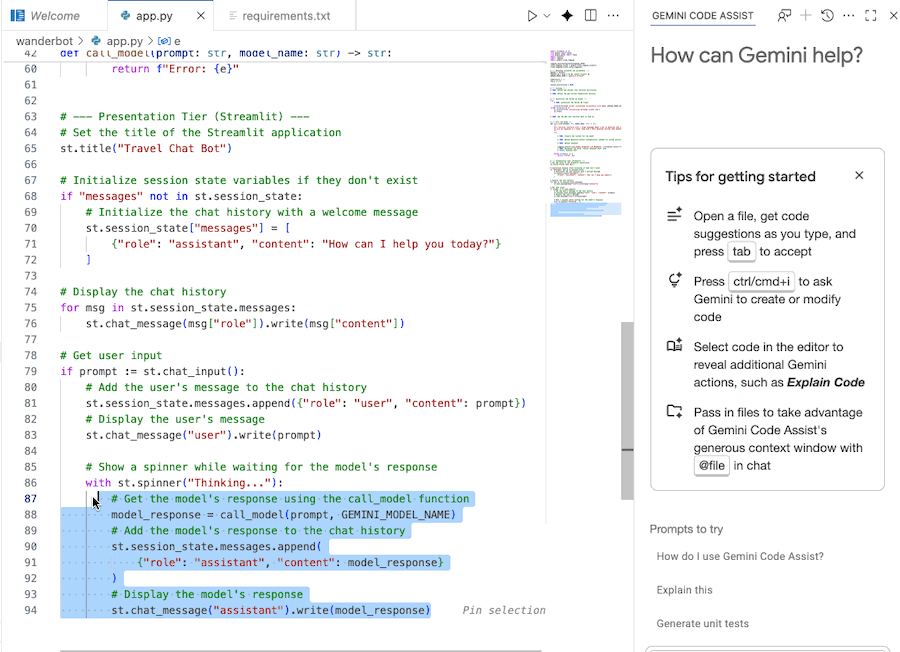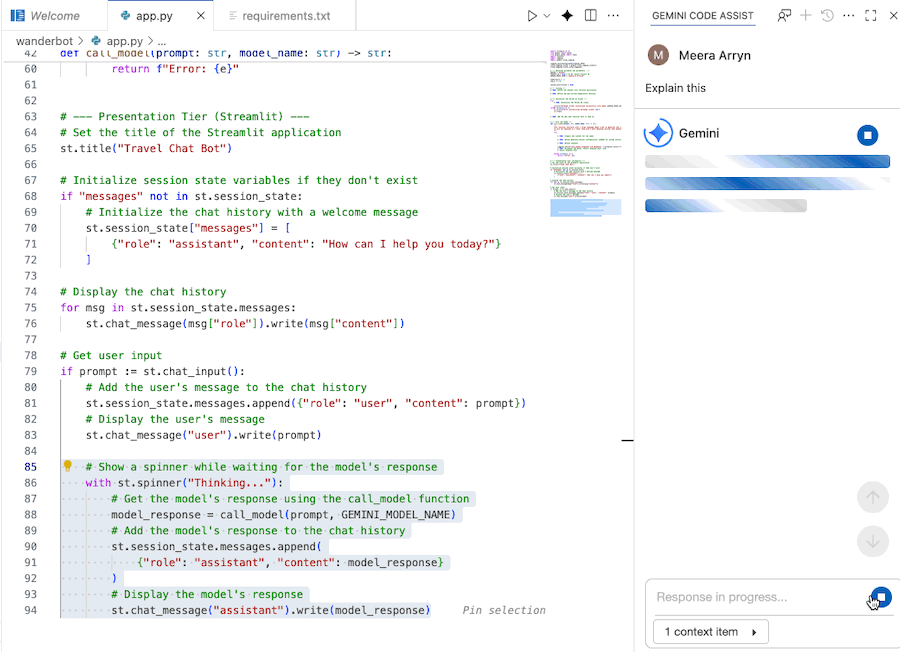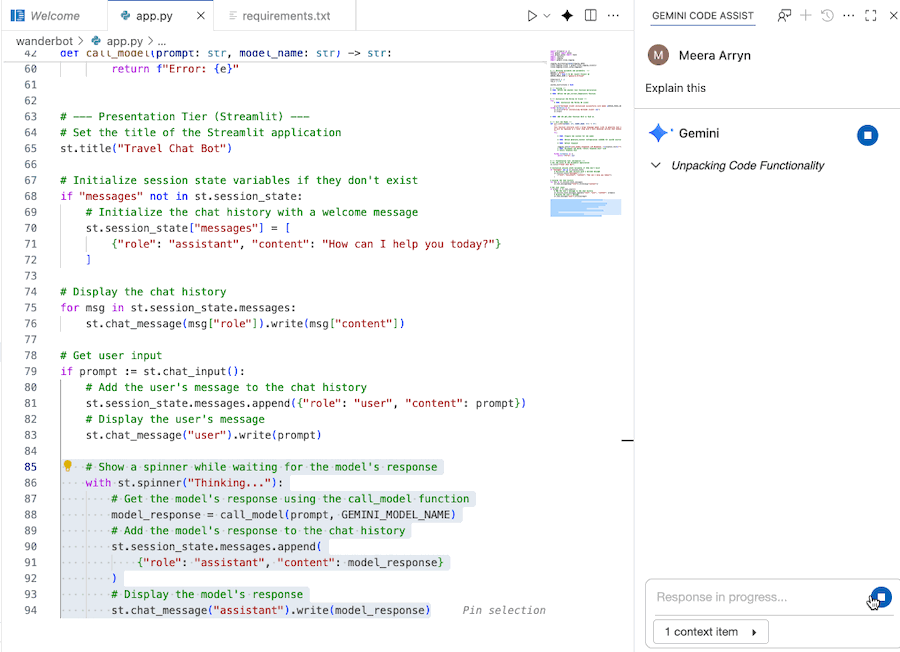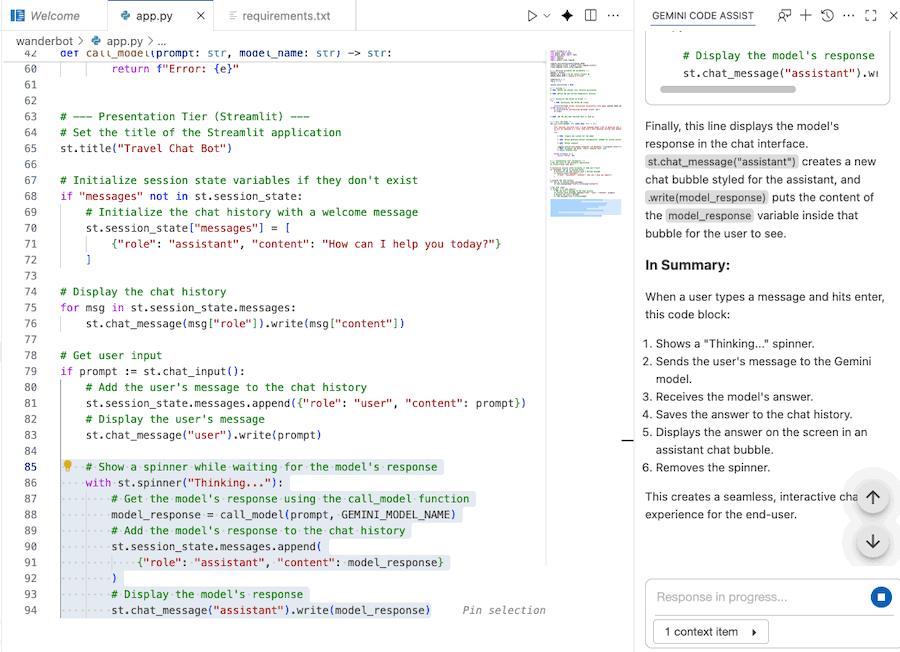
8. Web uygulamasını başlatma
Bu uygulamayı bir LLM'ye bağlamadan önce, ilk başta nasıl davrandığını görmek için uygulamayı başlatın.
wanderbotdizini içinden, Streamlit uygulamasını başlatmak ve Cloud Shell kabuk ortamınızda yerel olarak erişilebilir hale getirmek için terminalde aşağıdaki komutu çalıştırın:streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080- Komutu çalıştırdıktan sonra Cloud Shell düzenleyicisinin üst kısmındaki Web Önizlemesi düğmesini tıklayın ve 8080 bağlantı noktasında önizle'yi seçin.
Seyahat uygulamanız için basit bir sohbet arayüzü görürsünüz. - Herhangi bir mesaj yazın (ör.
Hi!) ve ENTER tuşuna basın.
Mesajın sohbet geçmişinde göründüğünü fark edeceksiniz ancak asistanın yanıtı yerine hata mesajı alacaksınız. Bunun nedeni, uygulamanın henüz büyük bir dil modeline bağlanmamış olmasıdır. Laboratuvarın başlangıç noktasını anlamak için bu davranışı gözlemleyin.
9. Vertex AI istemcisini başlatma
Vertex AI'da Kullanılabilen Modelleri Keşfetme
Google Cloud'un Vertex AI platformu, çeşitli üretken yapay zeka modellerine erişim sağlar. Birini entegre etmeden önce Google Cloud Console'daki mevcut seçenekleri inceleyebilirsiniz.
- Google Cloud Console'da Model Garden'a gidin. Bunu yapmak için ekranın üst kısmındaki arama çubuğunda "Model Garden"ı arayıp Vertex AI'ı seçebilirsiniz.(
 )
) - Mevcut modellere göz atın. Filtreleme yaparken yöntemler, görev türleri ve özellikler gibi ölçütleri kullanabilirsiniz.
Bu laboratuvarın amaçları doğrultusunda, hızı nedeniyle duyarlı sohbet uygulamaları oluşturmak için iyi bir seçenek olan Gemini 2.5 Flash modelini kullanacaksınız.
Vertex AI istemcisini başlatma
Şimdi Vertex AI istemcisini başlatmak için app.py bölümündeki --- Initialize the Vertex AI Client --- kısmını değiştireceksiniz. Bu istemci nesnesi, modele istem göndermek için kullanılır.
- Cloud Shell Düzenleyici'de
app.pydosyasını açın. app.pyiçindePROJECT_ID = Nonesatırını bulun.Nonekısmını, tırnak içinde Google Cloud proje kimliğinizle değiştirin. (ör.PROJECT_ID = "google-cloud-labs")
Proje kimliğinizi hatırlamıyorsanız tüm proje kimliklerinizi şu komutla listeleyebilirsiniz:gcloud projects list | awk '/PROJECT_ID/{print $2}'- İstemciyi tanımlayın:
trybloğunda Vertex AI istemcisini başlatın.client = genai.Client( vertexai=True, project=PROJECT_ID, location=REGION, )
Vertex AI istemci başlatma işlemi güncellendi
Bu noktada, Vertex AI istemcisini başlatma bölümü şu şekilde görünür:
# --- Initialize the Vertex AI Client ---
try:
client = genai.Client(
vertexai=True,
project=PROJECT_ID,
location=REGION,
)
print(f"VertexAI Client initialized successfully with model {GEMINI_MODEL_NAME}")
except Exception as e:
st.error(f"Error initializing VertexAI client: {e}")
st.stop()
10. Verileri hazırlama ve modeli çağırma
Şimdi modele gönderilecek içeriği hazırlayacak ve Gemini modelini çağıracaksınız.
--- Call the Model ---bölümündecall_modelişlevinin tanımlandığı yeri bulun.- İçerikleri tanımlama:
# TODO: Prepare the content for the modelbölümünde , modele gönderilecek giriş içeriğini tanımlayın. Temel istemlerde bu, kullanıcının giriş mesajı olur.contents = [prompt] - Yanıtı tanımlayın: Bu kodu
# TODO: Define responsealtına yapıştırın.response = client.models.generate_content( model=model_name, contents=contents, ) - Yanıtı döndürün: Aşağıdaki satırın yorumunu kaldırın:
return response.text call_modelişlevinin çağrıldığı satırı,withbloğundaki dosyanın alt kısmına doğru inceleyin. Burada ne olduğunu anlamıyorsanız satırı vurgulayın ve Gemini Code Assist'e sorun.
contents öğesini tanımlamanın daha açık bir yolu
Yukarıdaki contents tanımlama şekli, SDK'nın dizeler içeren bir listenin kullanıcı metin girişini temsil ettiğini anlayacak kadar akıllı olması nedeniyle çalışır. Bu işlev, modeli API'si için otomatik olarak doğru şekilde biçimlendirir.
Ancak girişi yapılandırmanın daha açık ve temel yolu, types.Part ve types.Content nesnelerini kullanmaktır. Örneğin:
user_message_parts = [types.Part.from_text(text=prompt)]
contents = [
types.Content(
role="user", # Indicates the content is from the user
parts=user_message_parts, # A list, allowing multiple types of content
),
]
call_model işlevi güncellendi
Bu noktada, call_model işlevi şu şekilde görünmelidir:
def call_model(prompt: str, model_name: str) -> str:
"""
This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions.
It will be replaced in a later step with a more advanced version that handles tooling.
"""
try:
contents = [prompt]
# TODO: Define generate_content configuration (needed later for system instructions and parameters)
response = client.models.generate_content(
model=model_name,
contents=contents,
)
logging.info(f"[call_model_response] LLM Response: \"{response.text}\"")
return response.text
except Exception as e:
return f"Error: {e}"
11. Bağlı uygulamayı test etme
- Terminalde, şu anda çalışan işlemi sonlandırın (CTRL+C).
- Streamlit uygulamasını tekrar başlatmak için komutu yeniden çalıştırın.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Streamlit uygulamasını yenileyin. Streamlit uygulaması hâlâ çalışıyorsa tarayıcınızdaki web önizleme sayfasını yenilemeniz yeterlidir.
- Şimdi sohbet girişine aşağıdaki gibi bir soru yazın:
What is the best time of year to go to Iceland? - ENTER tuşuna basın.
Uygulama, mesajınızı, "Düşünülüyor..." spinner'ını ve ardından Gemini modeli tarafından oluşturulan yanıtı gösterir. Bu adımları uyguladıysanız web uygulamanızı Vertex AI'daki bir LLM'ye başarıyla bağladınız demektir. 🙌 🥳
12. Sistem talimatlarını tanımlama
Temel bağlantı çalışsa da LLM'nin yanıtlarının kalitesi ve stili, aldığı girişten büyük ölçüde etkilenir. İstem mühendisliği, modeli istenen çıkışı üretmeye yönlendirmek için bu girişleri (istemleri) tasarlama ve iyileştirme sürecidir.
Bu amaçla, sistem talimatları oluşturup bunları modele ileterek başlayacaksınız.
Faydalı sistem talimatları oluşturmak için Gemini'a sorun özelliğini kullanacaksınız.
app.pybölümünde, şu andaNoneolarak ayarlanmış olansystem_instructionsdeğişkenini bulun.system_instructions = NoneNoneyerine, seyahat asistanı botumuzla ilgili talimatlar içeren çok satırlı bir dize yerleştireceksiniz.- Gemini Code Assist'e sorun: Aşağıdaki istemi Gemini Code Assist'e iletin (veya kendi isteminizi oluşturun):
I am a developer at a travel marketing company, and my sales department has decided that they need a new chat application to keep up with the bigger booking and search companies. I'm building a simple travel assistant chatbot using the Gemini 2.5 Flash model on Vertex AI. The application should: - Helps users ask questions about travel, book travel, and learn about places they are going to go - Provides users ways to get help about their specific travel plans - Provides all this in a production quality way (multiple environments, logging and monitoring, etc.) Please create system instructions appropriate for that chat app. Be thorough. Do not alter the code in any way beyond providing me with system instructions. - Tanımlayın
system_instructions:system_instructionsdeğerini, Gemini Code Assist'i kullanarak oluşturduğunuz sistem talimatlarına eşit olarak ayarlayın. Alternatif olarak, Gemini tarafından benzer bir istemle oluşturulan bu sistem talimatlarını da kullanabilirsiniz.system_instructions = """ You are a sophisticated travel assistant chatbot designed to provide comprehensive support to users throughout their travel journey. Your capabilities include answering travel-related questions, assisting with booking travel arrangements, offering detailed information about destinations, and providing support for existing travel plans. **Core Functionalities:** 1. **Travel Information and Recommendations:** * Answer user inquiries about travel destinations, including popular attractions, local customs, visa requirements, weather conditions, and safety advice. * Provide personalized recommendations for destinations, activities, and accommodations based on user preferences, interests, and budget. * Offer insights into the best times to visit specific locations, considering factors like weather, crowds, and pricing. * Suggest alternative destinations or activities if the user's initial choices are unavailable or unsuitable. 2. **Booking Assistance:** * Facilitate the booking of flights, hotels, rental cars, tours, and activities. * Search for available options based on user-specified criteria such as dates, destinations, budget, and preferences. * Present clear and concise information about available options, including pricing, amenities, and booking terms. * Guide users through the booking process, ensuring accurate information and secure transactions. * Provide booking confirmations and relevant details, such as booking references and contact information. 3. **Travel Planning and Itinerary Management:** * Assist users in creating detailed travel itineraries, including flights, accommodations, activities, and transportation. * Offer suggestions for optimizing travel plans, such as minimizing travel time or maximizing sightseeing opportunities. * Provide tools for managing and modifying existing itineraries, including adding or removing activities, changing booking dates, or upgrading accommodations. * Offer reminders and notifications for upcoming travel events, such as flight check-in or tour departure times. 4. **Customer Support and Troubleshooting:** * Provide prompt and helpful support to users with questions or issues related to their travel plans. * Assist with resolving booking discrepancies, cancellations, or modifications. * Offer guidance on travel-related emergencies, such as lost luggage or travel delays. * Provide access to relevant contact information for airlines, hotels, and other travel providers. **Interaction Guidelines:** * **Professionalism:** Maintain a polite, respectful, and professional tone in all interactions. * **Clarity and Conciseness:** Provide clear, concise, and easy-to-understand information. Avoid jargon or technical terms unless necessary and always explain them. * **Accuracy:** Ensure all information provided is accurate and up-to-date. Double-check details before sharing them with users. If unsure about something, admit that you don't know and offer to find the information. * **Personalization:** Tailor your responses and recommendations to the specific needs and preferences of each user. * **Proactive Assistance:** Anticipate user needs and offer relevant information or suggestions proactively. * **Error Handling:** Gracefully handle user errors or misunderstandings. Provide helpful guidance and alternative options when necessary. * **Confidentiality:** Respect user privacy and handle personal information with the utmost confidentiality and in compliance with data protection regulations. **Example Interactions:** **User:** "I want to go on a beach vacation in the Caribbean. I have a budget of $2000 per person for a week." **Chatbot:** "Certainly! The Caribbean offers many beautiful beach destinations within your budget. Some popular options include Punta Cana in the Dominican Republic, Cancun in Mexico, and Montego Bay in Jamaica. These destinations offer stunning beaches, all-inclusive resorts, and various activities. Would you like me to search for flights and accommodations for these locations based on your travel dates?" **User:** "My flight is delayed. What should I do?" **Chatbot:** "I'm sorry to hear about the delay. Please check with the airline for the updated departure time and any assistance they can offer. You may be entitled to compensation or rebooking options depending on the length of the delay and the airline's policy. Do you have your flight number handy so I can look up the current status for you?" **User:** "Tell me about the best time to visit Japan." **Chatbot:** "Japan is a fantastic destination with distinct seasons offering unique experiences. Spring (March-May) is famous for the beautiful cherry blossoms, while autumn (September-November) boasts stunning fall foliage. Both seasons have pleasant temperatures, making them ideal for sightseeing. Summer (June-August) can be hot and humid, but it's a great time for festivals and outdoor activities in the mountains. Winter (December-February) offers opportunities for skiing and snowboarding in the Japanese Alps, though some areas may experience heavy snowfall. To recommend the best time for you, could you tell me what you'd like to experience in Japan?" By following these instructions, you will be able to provide exceptional travel assistance and create a positive experience for every user. """ - generate_content yapılandırmasını tanımlayın: Bu sistem talimatlarını ileteceğiniz bir yapılandırma nesnesi başlatın.
system_instructions, komut dosyamızda genel olarak tanımlandığı için işlev doğrudan erişebilir.generate_content_config = types.GenerateContentConfig( system_instruction=[ types.Part.from_text(text=system_instructions) ], ) logging.info(f"[generate_config_details] System Instruction: {generate_content_config.system_instruction[0].text}") - Sistem talimatlarını yanıta eklemek için
generate_contentyöntemine birconfigparametresi ekleyin ve bunu yukarıda oluşturulangenerate_content_confignesnesine eşitleyin.response = client.models.generate_content( model=model_name, contents=contents, config=generate_content_config, # This is the new line )
call_model işlevi güncellendi
Tam call_model işlevi artık şu şekilde görünür:
def call_model(prompt: str, model_name: str) -> str:
"""
This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions.
It will be replaced in a later step with a more advanced version that handles tooling.
"""
try:
contents = [prompt]
generate_content_config = types.GenerateContentConfig(
system_instruction=[
types.Part.from_text(text=system_instructions)
],
)
logging.info(f"[generate_config_details] System Instruction: {generate_content_config.system_instruction[0].text}")
response = client.models.generate_content(
model=model_name,
contents=contents,
config=generate_content_config,
)
logging.info(f"[call_model_response] LLM Response: \"{response.text}\"")
return response.text
except Exception as e:
return f"Error: {e}"
13. Uygulamayı sistem talimatlarıyla test etme
- Terminalde, şu anda çalışan işlemi sonlandırın (CTRL+C).
- Streamlit uygulamasını tekrar başlatmak için komutu yeniden çalıştırın.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Streamlit uygulamasını yenileyin. Streamlit uygulaması hâlâ çalışıyorsa tarayıcınızdaki web önizleme sayfasını yenilemeniz yeterlidir.
- Aynı soruyu tekrar deneyin:
What is the best time of year to go to Iceland? - ENTER tuşuna basın.
Bu seferki yanıtını son seferkiyle karşılaştırın.
14. Hava durumu aracı tanımlama
Şu ana kadar sohbet botumuz bilgili olsa da bilgisi, eğitildiği verilerle sınırlı. Gerçek zamanlı bilgilere erişemez. Seyahat botları için hava durumu tahminleri gibi canlı verileri getirebilmek büyük bir avantajdır.
Bu noktada araç kullanma (işlev çağrısı olarak da bilinir) devreye girer. LLM'nin harici bilgi almak için çağırmayı seçebileceği bir dizi araç (Python işlevleri) tanımlayabiliriz.
Araçların işleyiş şekli
- Araçlarımızı, ne yaptıkları ve hangi parametreleri aldıkları da dahil olmak üzere modele açıklıyoruz.
- Kullanıcı bir istem gönderir (ör. "Londra'da hava nasıl?").
- Model, istemi alır ve kullanıcının, araçlarından birini kullanarak öğrenebileceği bir şey hakkında soru sorduğunu görür.
- Model, metinle yanıt vermek yerine hangi aracı hangi bağımsız değişkenlerle çağırmak istediğini belirten özel bir
function_callnesnesiyle yanıt verir. - Python kodumuz bu
function_calldeğerini alır, sağlanan bağımsız değişkenlerle gerçekget_current_temperatureişlevimizi yürütür ve sonucu (ör. 15 °C) alır. - Bu sonucu modele geri göndeririz.
- Model, sonucu alır ve kullanıcı için doğal dilde bir yanıt oluşturur (ör. "Londra'da şu anki sıcaklık 15 °C.").
Bu süreç, modelin eğitim verilerinin çok ötesindeki soruları yanıtlamasına olanak tanıyarak onu çok daha güçlü ve faydalı bir asistan haline getirir.
Hava durumu aracı tanımlama
Ne yapacağı konusunda tavsiye arayan ve hava durumundan etkilenen etkinlikler arasında seçim yapan bir gezgin için hava durumu aracı faydalı olabilir. Modelimizin mevcut hava durumunu alması için bir araç oluşturalım. İki bölüm gerekir: aracı modele açıklayan bir işlev bildirimi ve bunu uygulayan gerçek Python işlevi.
app.pybölümünde# TODO: Define the weather tool function declarationyorumunu bulun.- Bu yorumun altına
weather_functiondeğişkenini ekleyin. Bu sözlük, modelin işlevin amacı, parametreleri ve gerekli bağımsız değişkenleri hakkında bilmesi gereken her şeyi içerir.weather_function = { "name": "get_current_temperature", "description": "Gets the current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco", }, }, "required": ["location"], }, } - Ardından yorumu bulun
# TODO: Define the get_current_temperature function. Bu kodun altına aşağıdaki Python kodunu ekleyin. Bu işlev:- Konumun koordinatlarını almak için bir Geocoding API'yi çağırın.
- Hava durumu API'si çağırmak için bu koordinatları kullanın.
- Sıcaklık ve birimi içeren basit bir dize döndür.
def get_current_temperature(location: str) -> str: """Gets the current temperature for a given location.""" try: # --- Get Latitude and Longitude for the location --- geocode_url = f"https://geocoding-api.open-meteo.com/v1/search?name={location}&count=1&language=en&format=json" geocode_response = requests.get(geocode_url) geocode_data = geocode_response.json() if not geocode_data.get("results"): return f"Could not find coordinates for {location}." lat = geocode_data["results"][0]["latitude"] lon = geocode_data["results"][0]["longitude"] # --- Get Weather for the coordinates --- weather_url = f"https://api.open-meteo.com/v1/forecast?latitude={lat}&longitude={lon}¤t_weather=true" weather_response = requests.get(weather_url) weather_data = weather_response.json() temperature = weather_data["current_weather"]["temperature"] unit = "°C" return f"{temperature}{unit}" except Exception as e: return f"Error fetching weather: {e}"
15. Sohbet ve araçlar için yeniden düzenleme
Mevcut call_model işlevimiz, basit bir tek görevli generate_content çağrısı kullanır. Bu özellik tek bir soru için harika olsa da çok turlu sohbetler, özellikle de araçlarla ilgili karşılıklı etkileşim içeren sohbetler için ideal değildir.
Daha iyi bir uygulama, sohbetin bağlamını koruyan bir sohbet oturumu kullanmaktır. Artık araçları doğru şekilde uygulamak için gerekli olan bir sohbet oturumu kullanmak üzere kodumuzu yeniden düzenleyeceğiz.
- Mevcut
call_modelişlevini silin. Bu özelliği daha gelişmiş bir sürümle değiştireceğiz. - Bunun yerine, aşağıdaki kod bloğundan yeni
call_modelişlevini ekleyin. Bu yeni işlev, daha önce bahsettiğimiz araç çağrısı döngüsünü işleme mantığını içerir. Bu kodda, sonraki adımlarda tamamlayacağımız birkaç TODO yorumu olduğunu fark edeceksiniz.# --- Call the Model --- def call_model(prompt: str, model_name: str) -> str: """ This function interacts with a large language model (LLM) to generate text based on a given prompt. It maintains a chat session and handles function calls from the model to external tools. """ try: # TODO: Get the existing chat session or create a new one. message_content = prompt # Start the tool-calling loop while True: # TODO: Send the message to the model. # Check if the model wants to call a tool has_tool_calls = False for part in response.candidates[0].content.parts: if part.function_call: has_tool_calls = True function_call = part.function_call logging.info(f"Function to call: {function_call.name}") logging.info(f"Arguments: {function_call.args}") # TODO: Call the appropriate function if the model requests it. elif part.text: logging.info("No function call found in the response.") logging.info(response.text) # If no tool call was made, break the loop if not has_tool_calls: break # TODO: Return the model's final text response. except Exception as e: return f"Error: {e}" - Şimdi sohbet oturumunu yönetmek için bir yardımcı işlev ekleyelim. Yeni
call_modelişlevinin üstüneget_chatişlevini ekleyin. Bu işlev, sistem talimatlarımız ve araç tanımlarımızla yeni bir sohbet oturumu oluşturur veya mevcut oturumu alır. Bu, kodu düzenlemek için iyi bir uygulamadır.def get_chat(model_name: str): if f"chat-{model_name}" not in st.session_state: # TODO: Define the tools configuration for the model # TODO: Define the generate_content configuration, including tools # TODO: Create a new chat session st.session_state[f"chat-{model_name}"] = chat return st.session_state[f"chat-{model_name}"]
Artık gelişmiş, araç destekli sohbet mantığımız için iskele oluşturma işlemini tamamladınız.
16. Araç çağırma mantığını uygulama
Şimdi, araç çağırma mantığımızın tam olarak işlevsel olması için TODOs bölümünü dolduralım.
get_chat uygulayın
# TODO: Define the tools configuration...yorumu altındakiget_chatişlevinde,weather_functionbildirimimizden birtypes.Toolörneği oluşturaraktoolsnesnesini tanımlayın.tools = types.Tool(function_declarations=[weather_function])# TODO: Define the generate_content configuration...altındagenerate_content_configöğesini tanımlayın vetoolsnesnesini modele ilettiğinizden emin olun. Model, kullanabileceği araçlar hakkında bu şekilde bilgi edinir.generate_content_config = types.GenerateContentConfig( system_instruction=[types.Part.from_text(text=system_instructions)], tools=[tools] # Pass the tool definition here )# TODO: Create a new chat sessionaltında, model adımızı ve yapılandırmamızı ileterekclient.chats.create()kullanarak sohbet nesnesini oluşturun.chat = client.chats.create( model=model_name, config=generate_content_config, )
call_model uygulayın
call_modelişlevindeki# TODO: Get the existing chat session...altında yeniget_chatyardımcı işlevimizi çağırın.chat = get_chat(model_name)- Ardından,
# TODO: Send the message to the model'ı bulun. Kullanıcının mesajınıchat.send_message()yöntemiyle gönderin.response = chat.send_message(message_content) # TODO: Call the appropriate function...bulun. Bu aşamada, modelin istediği işlevi kontrol edip yürütüyoruz.
if function_call.name == "get_current_temperature":
result = get_current_temperature(**function_call.args)
function_response_part = types.Part.from_function_response(
name=function_call.name,
response={"result": result},
)
message_content = [function_response_part]
- Son olarak,
# TODO: Return the model's final text responsebulun ve döndürme ifadesini ekleyin.return response.text
get_chat işlevi güncellendi
Güncellenen get_chat işlevi artık şu şekilde görünmelidir:
def get_chat(model_name: str):
if f"chat-{model_name}" not in st.session_state:
# Tools
tools = types.Tool(function_declarations=[weather_function])
# Initialize a configuration object
generate_content_config = types.GenerateContentConfig(
system_instruction=[types.Part.from_text(text=system_instructions)],
tools=[tools]
)
chat = client.chats.create(
model=model_name,
config=generate_content_config,
)
st.session_state[f"chat-{model_name}"] = chat
return st.session_state[f"chat-{model_name}"]
call_model işlevi güncellendi
Güncellenen call_model işlevi artık şu şekilde görünmelidir:
def call_model(prompt: str, model_name: str) -> str:
try:
chat = get_chat(model_name)
message_content = prompt
while True:
response = chat.send_message(message_content)
has_tool_calls = False
for part in response.candidates[0].content.parts:
if part.function_call:
has_tool_calls = True
function_call = part.function_call
logging.info(f"Function to call: {function_call.name}")
logging.info(f"Arguments: {function_call.args}")
if function_call.name == "get_current_temperature":
result = get_current_temperature(**function_call.args)
function_response_part = types.Part.from_function_response(
name=function_call.name,
response={"result": result},
)
message_content = [function_response_part]
elif part.text:
logging.info("No function call found in the response.")
logging.info(response.text)
if not has_tool_calls:
break
return response.text
except Exception as e:
return f"Error: {e}"
17. Araç etkin uygulamasını test etme
Yeni özelliğinizi uygulamalı olarak inceleyelim.
- Terminalde, şu anda çalışan işlemi sonlandırın (CTRL+C).
- Streamlit uygulamasını tekrar başlatmak için komutu yeniden çalıştırın.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Streamlit uygulamasını yenileyin. Streamlit uygulaması hâlâ çalışıyorsa tarayıcınızdaki web önizleme sayfasını yenilemeniz yeterlidir.
- Şimdi yeni aracınızı tetikleyecek bir soru sorun (ör. aşağıdakiler gibi):
I'm looking for something to do in New York today. What do you recommend? Would it be a good day to go to Ellis Island? - ENTER tuşuna basın.
Bu yanıtı önceki yanıtlarla karşılaştırın. Ne fark var?
İşlevinizin sıcaklığını içeren bir yanıt görmelisiniz. Cloud Shell terminalinizi de kontrol edin. Python işlevinizin yürütüldüğünü onaylayan yazdırma ifadelerini görmeniz gerekir.
18. Parametrelerle Modelin Çıktısını İyileştirme
İyi iş çıkardınız! Seyahat asistanınız artık canlı ve harici verileri getirmek için araçları kullanabiliyor. Bu sayede asistanınızın gücü önemli ölçüde artıyor.
Modelimizin yapabileceklerini geliştirdiğimize göre şimdi de nasıl yanıt vereceğini hassas bir şekilde ayarlayalım. Model parametreleri, LLM'nin oluşturduğu metnin stilini ve rastgeleliğini kontrol etmenizi sağlar. Bu ayarları düzenleyerek botun çıkışını daha odaklı ve kontrollü ya da daha yaratıcı ve çeşitli hale getirebilirsiniz.
Bu laboratuvarda temperature ve top_p üzerinde duracağız. (Yapılandırılabilir parametrelerin ve açıklamalarının tam listesi için API referansımızdaki GenerateContentConfig bölümüne bakın.)
temperature: Çıkışın rastgeleliğini kontrol eder. Daha düşük bir değer (0'a yakın) çıkışı daha kontrollü ve odaklı hale getirirken daha yüksek bir değer (2'ye yakın) rastgeleliği ve yaratıcılığı artırır. Soru-cevap veya asistan botlarında daha tutarlı ve doğru yanıtlar için genellikle daha düşük sıcaklık tercih edilir.top_p: Örnekleme sırasında dikkate alınacak jetonların maksimum kümülatif olasılığı. Parçalar, yalnızca en olası parçaların dikkate alınması için atanmış olasılıklarına göre sıralanır. Model, olasılıklarıtop_pdeğerine kadar olan en olası jetonları dikkate alır. Daha düşük bir değer, jeton seçimlerini kısıtlayarak daha az çeşitli bir çıkışla sonuçlanır.
Arama parametreleri
temperaturevetop_pdeğişkenleriniapp.pyüst kısmında tanımlanmış olarak bulun. Bu işlevlerin henüz hiçbir yerde çağrılmadığını fark edin.get_chatişlevindeGenerateContentConfigiçinde tanımlanan parametreleretemperaturevetop_pekleyin.generate_content_config = types.GenerateContentConfig( temperature=temperature, top_p=top_p, system_instruction=[types.Part.from_text(text=system_instructions)], tools=[tools] # Pass the tool definition here )
get_chat işlevi güncellendi
get_chat uygulaması artık şu şekilde görünüyor:
def get_chat(model_name: str):
if f"chat-{model_name}" not in st.session_state:
# Tools
tools = types.Tool(function_declarations=[weather_function])
# Initialize a configuration object
generate_content_config = types.GenerateContentConfig(
temperature=temperature,
top_p=top_p,
system_instruction=[types.Part.from_text(text=system_instructions)],
tools=[tools]
)
chat = client.chats.create(
model=model_name,
config=generate_content_config,
)
st.session_state[f"chat-{model_name}"] = chat
return st.session_state[f"chat-{model_name}"]
19. Model Parametreleriyle Test Etme
- Terminalde, şu anda çalışan işlemi sonlandırın (CTRL+C).
- Streamlit uygulamasını tekrar başlatmak için komutu yeniden çalıştırın.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Streamlit uygulamasını yenileyin. Streamlit uygulaması hâlâ çalışıyorsa tarayıcınızdaki web önizleme sayfasını yenilemeniz yeterlidir.
- Önceki soruyu tekrar sormayı deneyin.
I'm looking for something to do in New York today. What do you recommend? Would it be a good day to go to Ellis Island? - ENTER tuşuna basın.
Bu yanıtı önceki yanıtlarla karşılaştırın.
20. Tebrikler!
Soru-cevap uygulamanızı, Gemini destekli uygulamanızın harici sistemlerle etkileşime girmesine ve anlık bilgilere erişmesine olanak tanıyan güçlü bir özellik olan araçlarla başarıyla yükselttiniz.
Denemeye devam etme
İstemlerinizi optimize etmeye devam etmek için birçok seçeneğiniz vardır. Aşağıda göz önünde bulundurmanız gereken bazı noktalar verilmiştir:
temperaturevetop_pdeğerlerini ayarlayarak LLM'nin verdiği yanıtı nasıl değiştirdiğini görün.- Yapılandırılabilir parametrelerin ve açıklamalarının tam listesi için API referansımızdaki
GenerateContentConfigbölümüne bakın. Daha fazla parametre tanımlamayı ve bunları ayarlayarak neler olduğunu görmeyi deneyin.
Özet
Bu laboratuvarda şunları yaptınız:
- Geliştirme için Cloud Shell Düzenleyici ve terminali kullandım.
- Uygulamanızı bir Gemini modeline bağlamak için Vertex AI Python SDK'yı kullanmış olmanız gerekir.
- LLM'nin yanıtlarına yön vermek için sistem talimatları ve model parametreleri uygulandı.
- Araç kullanma (işlev çağrısı) kavramını ve avantajlarını öğrendi.
- Kodunuzu, durum bilgisi içeren bir sohbet oturumu kullanacak şekilde yeniden düzenledik. Bu, etkileşimli yapay zeka için en iyi uygulamadır.
- Fonksiyon bildirimi kullanarak model için bir araç tanımladıysanız.
- Aracın mantığını sağlamak için Python işlevini uyguladı.
- Modelin işlev çağrısı isteklerini işlemek ve sonuçları döndürmek için kodu yazdı.