
1. Giới thiệu
Tổng quan
Bạn là nhà phát triển tại một công ty tiếp thị du lịch. Bộ phận bán hàng của bạn đã quyết định rằng họ cần một ứng dụng trò chuyện mới để bắt kịp các công ty đặt phòng và tìm kiếm lớn hơn. Họ cũng từng nghe về AI tạo sinh nhưng chưa hiểu rõ lắm về công nghệ này. Các phòng ban khác cũng đã biết về sáng kiến này và họ muốn biết sáng kiến này có thể giúp cải thiện trải nghiệm của khách hàng như thế nào.
Bạn sẽ thực hiện
Trong phòng thí nghiệm này, bạn sẽ tạo một chatbot trợ lý du lịch bằng mô hình Gemini 2.5 Flash trên Vertex AI.
Ứng dụng này phải:
- Giúp người dùng đặt câu hỏi về chuyến đi, đặt chuyến đi và tìm hiểu về những địa điểm mà họ đang lên kế hoạch ghé thăm
- Cung cấp cho người dùng các cách để nhận trợ giúp về kế hoạch du lịch cụ thể của họ
- Có thể tìm nạp dữ liệu theo thời gian thực (chẳng hạn như thời tiết) bằng các công cụ
Bạn sẽ làm việc trong một môi trường Google Cloud được định cấu hình sẵn, cụ thể là trong Cloud Shell Editor. Giao diện người dùng cơ bản của ứng dụng web đã được thiết lập cho bạn, cùng với các quyền cần thiết để truy cập vào Vertex AI. Ứng dụng này được xây dựng bằng Streamlit.
Kiến thức bạn sẽ học được
Trong bài thực hành này, bạn sẽ tìm hiểu cách thực hiện các thao tác sau:
- Khám phá nền tảng Vertex AI để xác định các mô hình AI tạo sinh hiện có.
- Phát triển trong Cloud Shell Editor và cửa sổ dòng lệnh
- Sử dụng Gemini Code Assist để hiểu mã.
- Sử dụng Vertex AI SDK trong Python để gửi câu lệnh đến và nhận câu trả lời từ LLM Gemini.
- Áp dụng kỹ thuật cơ bản về thiết kế câu lệnh (hướng dẫn hệ thống, tham số mô hình) để tuỳ chỉnh đầu ra của LLM Gemini.
- Thử nghiệm và tinh chỉnh lặp đi lặp lại một ứng dụng trò chuyện dựa trên LLM bằng cách sửa đổi câu lệnh và tham số để cải thiện phản hồi.
- Xác định và sử dụng các công cụ với mô hình Gemini để bật tính năng gọi hàm.
- Tái cấu trúc mã để sử dụng phiên trò chuyện có trạng thái, đây là phương pháp hay nhất cho các ứng dụng đàm thoại.
2. Thiết lập dự án
Tài khoản Google
Nếu chưa có Tài khoản Google cá nhân, bạn phải tạo một Tài khoản Google.
Sử dụng tài khoản cá nhân thay vì tài khoản do nơi làm việc hoặc trường học cấp.
Đăng nhập vào Google Cloud Console
Đăng nhập vào Google Cloud Console bằng Tài khoản Google cá nhân.
Bật thanh toán
Sử dụng tín dụng Google Cloud (không bắt buộc)
Để tham gia hội thảo này, bạn cần có một tài khoản thanh toán có sẵn một số tín dụng. Hãy sử dụng tín dụng trong biểu ngữ ở đầu lớp học lập trình này để bắt đầu. Nếu đã kết nối với một tài khoản thanh toán, bạn có thể bỏ qua bước này.
Thiết lập tài khoản thanh toán cá nhân
Nếu thiết lập thông tin thanh toán bằng tín dụng Google Cloud, bạn có thể bỏ qua bước này.
Để thiết lập tài khoản thanh toán cá nhân, hãy truy cập vào đây để bật tính năng thanh toán trong Cloud Console.
Một số lưu ý:
- Việc hoàn thành bài thực hành này sẽ tốn ít hơn 1 USD cho các tài nguyên trên đám mây.
- Bạn có thể làm theo các bước ở cuối bài thực hành này để xoá tài nguyên nhằm tránh bị tính thêm phí.
- Người dùng mới đủ điều kiện dùng thử miễn phí trị giá 300 USD.
Tạo dự án (không bắt buộc)
Nếu bạn không có dự án hiện tại nào muốn sử dụng cho lớp học này, hãy tạo một dự án mới tại đây.
3. Mở Trình chỉnh sửa Cloud Shell
- Nhấp vào đường liên kết này để chuyển trực tiếp đến Cloud Shell Editor
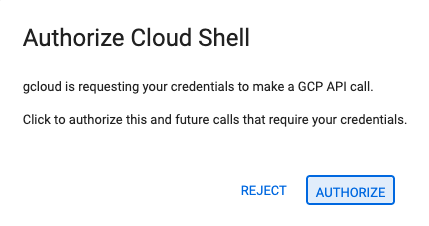
- Nếu được nhắc uỷ quyền vào bất kỳ thời điểm nào trong ngày hôm nay, hãy nhấp vào Uỷ quyền để tiếp tục.
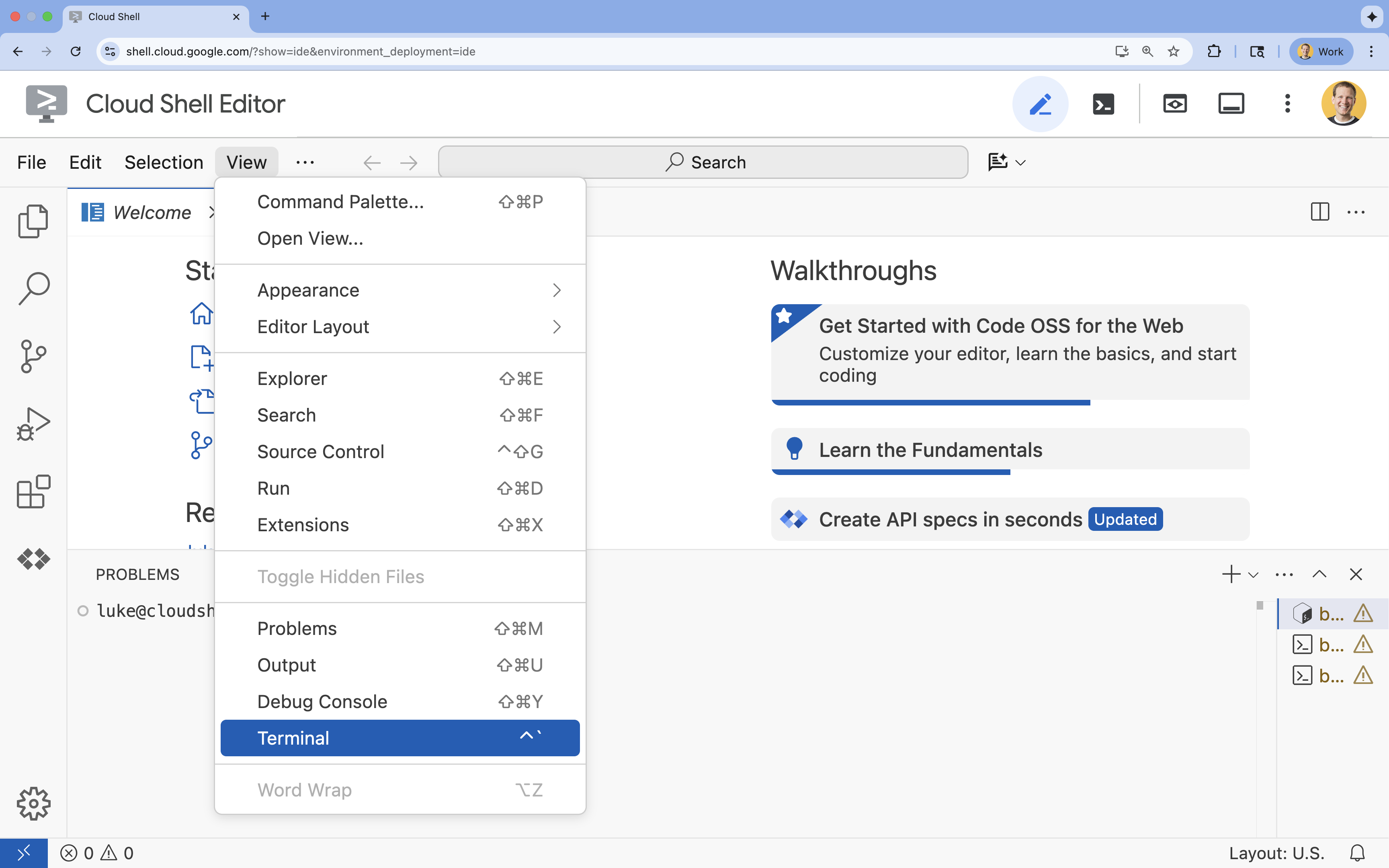
- Nếu thiết bị đầu cuối không xuất hiện ở cuối màn hình, hãy mở thiết bị đầu cuối:
- Nhấp vào Xem
- Nhấp vào Terminal (Thiết bị đầu cuối)
- Trong cửa sổ dòng lệnh, hãy thiết lập dự án bằng lệnh sau:
gcloud config set project [PROJECT_ID]- Ví dụ:
gcloud config set project lab-project-id-example - Nếu không nhớ mã dự án, bạn có thể liệt kê tất cả mã dự án bằng cách dùng lệnh:
gcloud projects list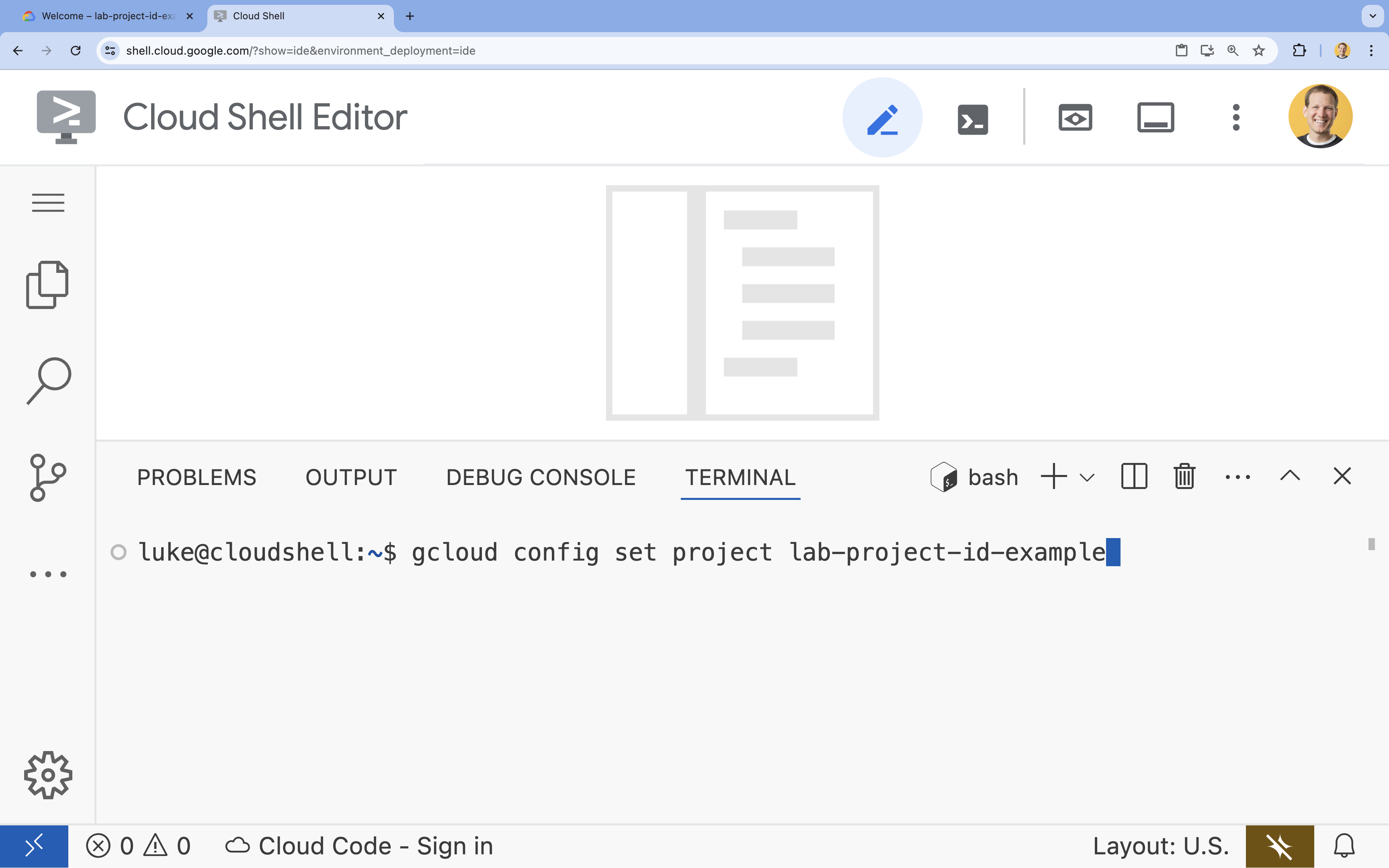
- Ví dụ:
- Bạn sẽ thấy thông báo sau:
Updated property [core/project].
4. Bật API
Để sử dụng Vertex AI SDK và tương tác với mô hình Gemini, bạn cần bật Vertex AI API trong dự án trên đám mây của Google.
- Trong dòng lệnh, hãy bật các API:
gcloud services enable \ aiplatform.googleapis.com
Giới thiệu về Vertex AI SDK cho Python
Để tương tác với các mô hình được lưu trữ trên Vertex AI từ ứng dụng Python, bạn sẽ sử dụng Vertex AI SDK cho Python. SDK này giúp đơn giản hoá quy trình gửi câu lệnh, chỉ định các tham số mô hình và nhận phản hồi mà không cần xử lý trực tiếp các điểm phức tạp của lệnh gọi API cơ bản.
Bạn có thể xem tài liệu toàn diện về Vertex AI SDK cho Python tại đây: Giới thiệu về Vertex AI SDK cho Python | Google Cloud.
5. Tạo môi trường ảo và cài đặt các phần phụ thuộc
Trước khi bắt đầu bất kỳ dự án Python nào, bạn nên tạo một môi trường ảo. Điều này sẽ tách biệt các phần phụ thuộc của dự án, ngăn chặn xung đột với các dự án khác hoặc các gói Python chung của hệ thống.
- Tạo một thư mục có tên là
wanderbotđể lưu trữ mã cho ứng dụng trợ lý du lịch của bạn. Chạy mã sau trong thiết bị đầu cuối:mkdir wanderbot && cd wanderbot - Tạo và kích hoạt môi trường ảo:
uv venv --python 3.12 source .venv/bin/activatewanderbot) trước lời nhắc của thiết bị đầu cuối, cho biết môi trường ảo đang hoạt động. URL sẽ có dạng như sau:
6. Tạo tệp ban đầu cho wanderbot
- Tạo và mở một tệp
app.pymới cho ứng dụng. Chạy mã sau trong terminal:cloudshell edit app.pycloudshell editsẽ mở tệpapp.pytrong trình chỉnh sửa ở phía trên cửa sổ dòng lệnh. - Dán đoạn mã khởi đầu ứng dụng sau đây vào
app.py:import streamlit as st from google import genai from google.genai import types import requests import logging # --- Defining variables and parameters --- REGION = "global" PROJECT_ID = None # TODO: Insert Project ID GEMINI_MODEL_NAME = "gemini-2.5-flash" temperature = .2 top_p = 0.95 system_instructions = None # --- Tooling --- # TODO: Define the weather tool function declaration # TODO: Define the get_current_temperature function # --- Initialize the Vertex AI Client --- try: # TODO: Initialize the Vertex AI client print(f"VertexAI Client initialized successfully with model {GEMINI_MODEL_NAME}") except Exception as e: st.error(f"Error initializing VertexAI client: {e}") st.stop() # TODO: Add the get_chat function here in Task 15. # --- Call the Model --- def call_model(prompt: str, model_name: str) -> str: """ This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions. It will be replaced in a later step with a more advanced version that handles tooling. """ try: # TODO: Prepare the content for the model # TODO: Define generate_content configuration (needed for system instructions and parameters) # TODO: Define response logging.info(f"[call_model_response] LLM Response: \"{response.text}\"") # TODO: Uncomment the below "return response.text" line # return response.text except Exception as e: return f"Error: {e}" # --- Presentation Tier (Streamlit) --- # Set the title of the Streamlit application st.title("Travel Chat Bot") # Initialize session state variables if they don't exist if "messages" not in st.session_state: # Initialize the chat history with a welcome message st.session_state["messages"] = [ {"role": "assistant", "content": "How can I help you today?"} ] # Display the chat history for msg in st.session_state.messages: st.chat_message(msg["role"]).write(msg["content"]) # Get user input if prompt := st.chat_input(): # Add the user's message to the chat history st.session_state.messages.append({"role": "user", "content": prompt}) # Display the user's message st.chat_message("user").write(prompt) # Show a spinner while waiting for the model's response with st.spinner("Thinking..."): # Get the model's response using the call_model function model_response = call_model(prompt, GEMINI_MODEL_NAME) # Add the model's response to the chat history st.session_state.messages.append( {"role": "assistant", "content": model_response} ) # Display the model's response st.chat_message("assistant").write(model_response) - Tạo và mở một tệp
requirements.txtmới cho mã xử lý ứng dụng. Chạy mã sau trong terminal:cloudshell edit requirements.txtcloudshell editsẽ mở tệprequirements.txttrong trình chỉnh sửa ở phía trên cửa sổ dòng lệnh. - Dán đoạn mã khởi đầu ứng dụng sau đây vào
requirements.txt.google-genai streamlit requests - Cài đặt các phần phụ thuộc Python bắt buộc cho dự án này. Chạy mã sau trong terminal:
uv pip install -r requirements.txt
7. Khám phá mã
Các tệp bạn tạo bao gồm một giao diện người dùng cơ bản của ứng dụng trò chuyện. Bao gồm:
app.py: Đây là tệp mà chúng ta sẽ làm việc. Hiện tại, báo cáo này có những thông tin sau:- nhập khẩu cần thiết
- biến môi trường và tham số (một số tham số là phần giữ chỗ)
- một hàm
call_modeltrống mà chúng ta sẽ điền vào - Mã Streamlit cho ứng dụng trò chuyện trên giao diện người dùng
requirements.txt:- bao gồm các yêu cầu về việc cài đặt để chạy
app.py
- bao gồm các yêu cầu về việc cài đặt để chạy
Bây giờ, hãy khám phá mã!
Mở Gemini Code Assist Chat
Gemini Code Assist Chat sẽ mở trong một bảng điều khiển ở bên phải trong Trình chỉnh sửa Cloud Shell. Nếu Gemini Code Assist Chat chưa mở, bạn có thể mở bằng cách làm theo các bước sau:
- Nhấp vào nút Gemini Code Assist (
 ) ở gần đầu màn hình.
) ở gần đầu màn hình. - Chọn Mở Gemini Code Assist Chat (Mở cuộc trò chuyện với Gemini Code Assist).
Sử dụng Gemini Code Assist để hiểu mã
Bạn có thể sử dụng Gemini Code Assist Chat để hiểu rõ hơn về mã.
- Làm nổi bật hoặc chọn phần mã bạn muốn.
- Nhập "Giải thích đoạn mã này" vào cuộc trò chuyện với Gemini.
- Nhấp vào Enter để gửi
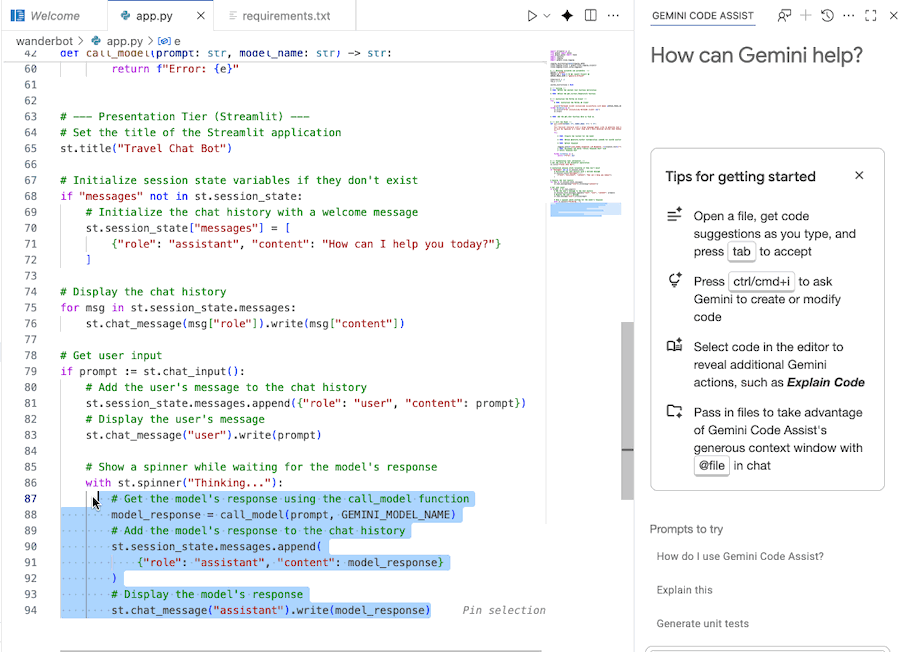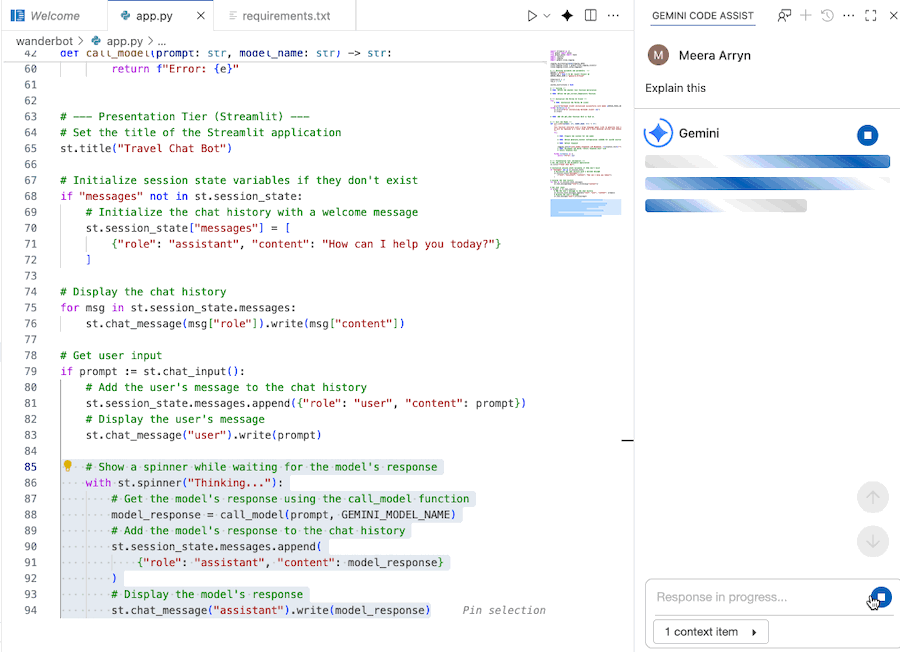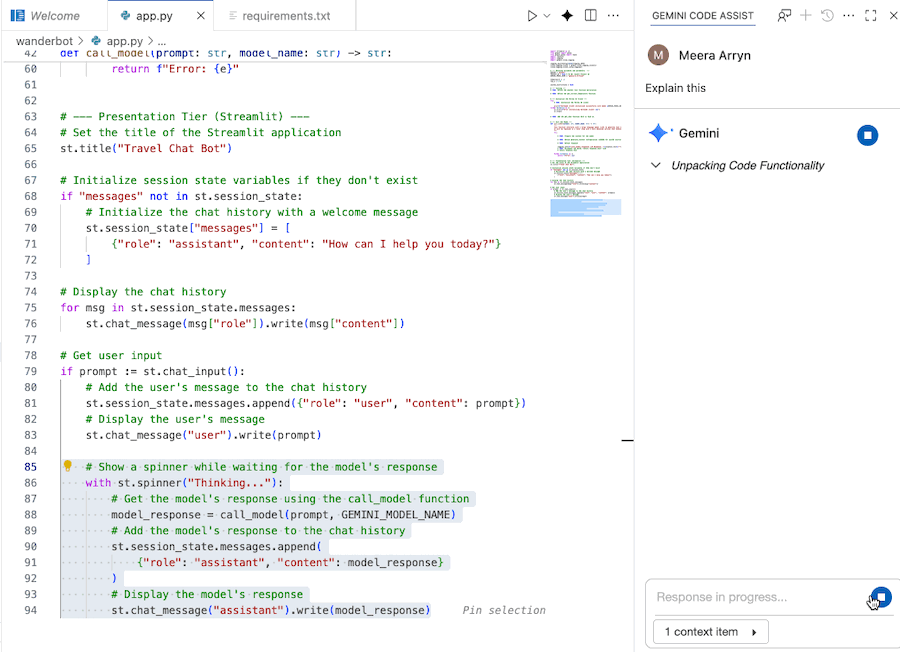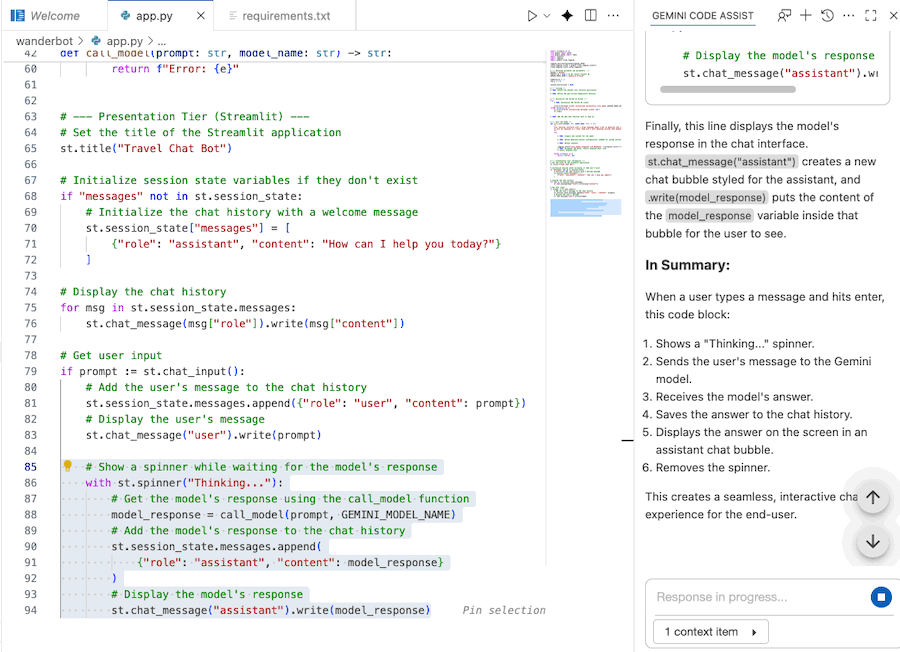
8. Khởi chạy ứng dụng web
Trước khi kết nối ứng dụng này với một LLM, hãy khởi chạy ứng dụng để xem ứng dụng hoạt động như thế nào ban đầu.
- Trong thư mục
wanderbot, hãy chạy lệnh sau trong terminal để khởi động ứng dụng Streamlit và giúp ứng dụng này có thể truy cập cục bộ trong môi trường Cloud Shell:streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Sau khi chạy lệnh, hãy nhấp vào nút Web Preview (Xem trước trên web) ở đầu trình chỉnh sửa Cloud Shell rồi chọn Preview on port 8080 (Xem trước trên cổng 8080).
Bạn sẽ thấy một giao diện trò chuyện đơn giản cho ứng dụng du lịch của mình. - Nhập một tin nhắn bất kỳ (ví dụ:
Hi!) rồi nhấn ENTER.
Bạn sẽ thấy tin nhắn xuất hiện trong nhật ký trò chuyện, nhưng bạn sẽ nhận được thông báo lỗi thay vì câu trả lời của trợ lý. Điều này là do ứng dụng chưa được kết nối với một mô hình ngôn ngữ lớn. Hãy quan sát hành vi này để hiểu được điểm xuất phát của phòng thí nghiệm.
9. Khởi chạy ứng dụng Vertex AI
Khám phá các mô hình hiện có trong Vertex AI
Nền tảng Vertex AI của Google Cloud cung cấp quyền truy cập vào nhiều mô hình AI tạo sinh. Trước khi tích hợp một khoá, bạn có thể khám phá các lựa chọn có sẵn trong Bảng điều khiển Google Cloud.
- Trong Google Cloud Console, hãy chuyển đến Model Garden. Bạn có thể làm việc này bằng cách tìm kiếm "Model Garden" trong thanh tìm kiếm ở đầu màn hình rồi chọn Vertex AI.(
 )
) - Duyệt qua các mô hình có sẵn. Bạn có thể lọc theo các yếu tố như phương thức, loại nhiệm vụ và tính năng.
Trong phòng thí nghiệm này, bạn sẽ sử dụng mô hình Gemini 2.5 Flash. Đây là lựa chọn phù hợp để tạo các ứng dụng trò chuyện có tính phản hồi do tốc độ xử lý của mô hình này.
Khởi chạy ứng dụng Vertex AI
Bây giờ, bạn sẽ sửa đổi phần --- Initialize the Vertex AI Client --- trong app.py để khởi chạy ứng dụng Vertex AI. Đối tượng ứng dụng này sẽ được dùng để gửi câu lệnh cho mô hình.
- Mở
app.pytrong Trình chỉnh sửa Cloud Shell. - Trong
app.py, hãy tìm dòngPROJECT_ID = None. - Thay thế
Nonebằng mã dự án trên Google Cloud trong dấu ngoặc kép. (ví dụ:PROJECT_ID = "google-cloud-labs")
Nếu không nhớ mã dự án, bạn có thể liệt kê tất cả mã dự án bằng cách dùng lệnh:gcloud projects list | awk '/PROJECT_ID/{print $2}' - Xác định ứng dụng: Bên trong khối
try, hãy khởi chạy ứng dụng Vertex AI.client = genai.Client( vertexai=True, project=PROJECT_ID, location=REGION, )
Cập nhật quá trình khởi tạo ứng dụng Vertex AI
Lúc này, phần Khởi chạy ứng dụng Vertex AI sẽ có dạng như sau:
# --- Initialize the Vertex AI Client ---
try:
client = genai.Client(
vertexai=True,
project=PROJECT_ID,
location=REGION,
)
print(f"VertexAI Client initialized successfully with model {GEMINI_MODEL_NAME}")
except Exception as e:
st.error(f"Error initializing VertexAI client: {e}")
st.stop()
10. Chuẩn bị dữ liệu và gọi mô hình
Giờ đây, bạn sẽ chuẩn bị nội dung để gửi đến mô hình và gọi mô hình Gemini.
- Tìm phần
--- Call the Model ---nơi hàmcall_modelđược xác định. - Xác định nội dung: Trong
# TODO: Prepare the content for the model, hãy xác định nội dung đầu vào sẽ được gửi đến mô hình. Đối với một câu lệnh cơ bản, đây sẽ là thông báo nhập của người dùng.contents = [prompt] - Xác định Phản hồi: Dán mã này bên dưới
# TODO: Define response.response = client.models.generate_content( model=model_name, contents=contents, ) - Trả về phản hồi: Huỷ nhận xét dòng sau:
return response.text - Kiểm tra dòng mà hàm
call_modelđang được gọi, ở cuối tệp trong khốiwith. Nếu bạn không hiểu điều gì đang xảy ra ở đây, hãy đánh dấu dòng đó và hỏi Gemini Code Assist để giải thích.
Cách rõ ràng hơn để xác định contents
Cách xác định contents ở trên hoạt động vì SDK đủ thông minh để hiểu rằng một danh sách chứa các chuỗi đại diện cho dữ liệu đầu vào văn bản của người dùng. Thao tác này sẽ tự động định dạng chính xác cho API mô hình.
Tuy nhiên, cách rõ ràng và cơ bản hơn để cấu trúc dữ liệu đầu vào là sử dụng các đối tượng types.Part và types.Content, như sau:
user_message_parts = [types.Part.from_text(text=prompt)]
contents = [
types.Content(
role="user", # Indicates the content is from the user
parts=user_message_parts, # A list, allowing multiple types of content
),
]
Đã cập nhật hàm call_model
Tại thời điểm này, hàm call_model sẽ có dạng như sau:
def call_model(prompt: str, model_name: str) -> str:
"""
This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions.
It will be replaced in a later step with a more advanced version that handles tooling.
"""
try:
contents = [prompt]
# TODO: Define generate_content configuration (needed later for system instructions and parameters)
response = client.models.generate_content(
model=model_name,
contents=contents,
)
logging.info(f"[call_model_response] LLM Response: \"{response.text}\"")
return response.text
except Exception as e:
return f"Error: {e}"
11. Kiểm thử ứng dụng được kết nối
- Trong cửa sổ dòng lệnh, hãy kết thúc quy trình đang chạy (CTRL+C)
- Chạy lại lệnh để khởi động lại ứng dụng Streamlit.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Làm mới ứng dụng Streamlit. Nếu ứng dụng Streamlit vẫn đang chạy, bạn chỉ cần làm mới trang xem trước trên web trong trình duyệt.
- Giờ đây, hãy nhập một câu hỏi vào ô nhập dữ liệu của cuộc trò chuyện, chẳng hạn như:
What is the best time of year to go to Iceland? - Nhấn ENTER.
Bạn sẽ thấy ứng dụng hiển thị thông báo của bạn, một biểu tượng "Đang suy nghĩ..." và sau đó là câu trả lời do mô hình Gemini tạo! Nếu có, tức là bạn đã kết nối thành công ứng dụng web của mình với một LLM trên Vertex AI. 🙌 🥳
12. Xác định chỉ dẫn hệ thống
Mặc dù kết nối cơ bản hoạt động, nhưng chất lượng và phong cách của các câu trả lời do LLM đưa ra chịu ảnh hưởng lớn của thông tin đầu vào mà LLM nhận được. Thiết kế câu lệnh là quá trình thiết kế và tinh chỉnh các dữ liệu đầu vào này (câu lệnh) để hướng dẫn mô hình tạo ra kết quả mong muốn.
Để làm được điều đó, bạn sẽ bắt đầu bằng cách tạo một số hướng dẫn hệ thống và truyền các hướng dẫn đó cho mô hình.
Bạn sẽ dùng tính năng Hỏi Gemini để tạo ra các chỉ dẫn hữu ích cho hệ thống.
- Trong
app.py, hãy tìm biếnsystem_instructionshiện đang được đặt thànhNone.system_instructions = NoneNonebằng một chuỗi nhiều dòng cung cấp hướng dẫn cho bot trợ lý du lịch của chúng tôi. - Hỏi Gemini Code Assist: Truyền câu lệnh sau vào Gemini Code Assist (hoặc tự nghĩ ra câu lệnh của riêng bạn!):
I am a developer at a travel marketing company, and my sales department has decided that they need a new chat application to keep up with the bigger booking and search companies. I'm building a simple travel assistant chatbot using the Gemini 2.5 Flash model on Vertex AI. The application should: - Helps users ask questions about travel, book travel, and learn about places they are going to go - Provides users ways to get help about their specific travel plans - Provides all this in a production quality way (multiple environments, logging and monitoring, etc.) Please create system instructions appropriate for that chat app. Be thorough. Do not alter the code in any way beyond providing me with system instructions. - Xác định
system_instructions: Đặtsystem_instructionsbằng với chỉ dẫn hệ thống mà bạn đã tạo bằng Gemini Code Assist. Ngoài ra, bạn có thể sử dụng những chỉ dẫn hệ thống này do Gemini tạo bằng một câu lệnh tương tự.system_instructions = """ You are a sophisticated travel assistant chatbot designed to provide comprehensive support to users throughout their travel journey. Your capabilities include answering travel-related questions, assisting with booking travel arrangements, offering detailed information about destinations, and providing support for existing travel plans. **Core Functionalities:** 1. **Travel Information and Recommendations:** * Answer user inquiries about travel destinations, including popular attractions, local customs, visa requirements, weather conditions, and safety advice. * Provide personalized recommendations for destinations, activities, and accommodations based on user preferences, interests, and budget. * Offer insights into the best times to visit specific locations, considering factors like weather, crowds, and pricing. * Suggest alternative destinations or activities if the user's initial choices are unavailable or unsuitable. 2. **Booking Assistance:** * Facilitate the booking of flights, hotels, rental cars, tours, and activities. * Search for available options based on user-specified criteria such as dates, destinations, budget, and preferences. * Present clear and concise information about available options, including pricing, amenities, and booking terms. * Guide users through the booking process, ensuring accurate information and secure transactions. * Provide booking confirmations and relevant details, such as booking references and contact information. 3. **Travel Planning and Itinerary Management:** * Assist users in creating detailed travel itineraries, including flights, accommodations, activities, and transportation. * Offer suggestions for optimizing travel plans, such as minimizing travel time or maximizing sightseeing opportunities. * Provide tools for managing and modifying existing itineraries, including adding or removing activities, changing booking dates, or upgrading accommodations. * Offer reminders and notifications for upcoming travel events, such as flight check-in or tour departure times. 4. **Customer Support and Troubleshooting:** * Provide prompt and helpful support to users with questions or issues related to their travel plans. * Assist with resolving booking discrepancies, cancellations, or modifications. * Offer guidance on travel-related emergencies, such as lost luggage or travel delays. * Provide access to relevant contact information for airlines, hotels, and other travel providers. **Interaction Guidelines:** * **Professionalism:** Maintain a polite, respectful, and professional tone in all interactions. * **Clarity and Conciseness:** Provide clear, concise, and easy-to-understand information. Avoid jargon or technical terms unless necessary and always explain them. * **Accuracy:** Ensure all information provided is accurate and up-to-date. Double-check details before sharing them with users. If unsure about something, admit that you don't know and offer to find the information. * **Personalization:** Tailor your responses and recommendations to the specific needs and preferences of each user. * **Proactive Assistance:** Anticipate user needs and offer relevant information or suggestions proactively. * **Error Handling:** Gracefully handle user errors or misunderstandings. Provide helpful guidance and alternative options when necessary. * **Confidentiality:** Respect user privacy and handle personal information with the utmost confidentiality and in compliance with data protection regulations. **Example Interactions:** **User:** "I want to go on a beach vacation in the Caribbean. I have a budget of $2000 per person for a week." **Chatbot:** "Certainly! The Caribbean offers many beautiful beach destinations within your budget. Some popular options include Punta Cana in the Dominican Republic, Cancun in Mexico, and Montego Bay in Jamaica. These destinations offer stunning beaches, all-inclusive resorts, and various activities. Would you like me to search for flights and accommodations for these locations based on your travel dates?" **User:** "My flight is delayed. What should I do?" **Chatbot:** "I'm sorry to hear about the delay. Please check with the airline for the updated departure time and any assistance they can offer. You may be entitled to compensation or rebooking options depending on the length of the delay and the airline's policy. Do you have your flight number handy so I can look up the current status for you?" **User:** "Tell me about the best time to visit Japan." **Chatbot:** "Japan is a fantastic destination with distinct seasons offering unique experiences. Spring (March-May) is famous for the beautiful cherry blossoms, while autumn (September-November) boasts stunning fall foliage. Both seasons have pleasant temperatures, making them ideal for sightseeing. Summer (June-August) can be hot and humid, but it's a great time for festivals and outdoor activities in the mountains. Winter (December-February) offers opportunities for skiing and snowboarding in the Japanese Alps, though some areas may experience heavy snowfall. To recommend the best time for you, could you tell me what you'd like to experience in Japan?" By following these instructions, you will be able to provide exceptional travel assistance and create a positive experience for every user. """ - Xác định cấu hình generate_content: Khởi chạy một đối tượng cấu hình mà bạn sẽ truyền các chỉ dẫn hệ thống này vào. Vì
system_instructionsđược xác định trên toàn cục trong tập lệnh của chúng ta, nên hàm có thể truy cập trực tiếp vào hàm này.generate_content_config = types.GenerateContentConfig( system_instruction=[ types.Part.from_text(text=system_instructions) ], ) logging.info(f"[generate_config_details] System Instruction: {generate_content_config.system_instruction[0].text}") - Để thêm hướng dẫn hệ thống vào phản hồi, hãy thêm tham số
configvào phương thứcgenerate_contentvà đặt tham số đó bằng đối tượnggenerate_content_configđã tạo ở trên.response = client.models.generate_content( model=model_name, contents=contents, config=generate_content_config, # This is the new line )
Đã cập nhật hàm call_model
Hàm call_model hoàn chỉnh giờ đây có dạng như sau:
def call_model(prompt: str, model_name: str) -> str:
"""
This function interacts with a large language model (LLM) to generate text based on a given prompt and system instructions.
It will be replaced in a later step with a more advanced version that handles tooling.
"""
try:
contents = [prompt]
generate_content_config = types.GenerateContentConfig(
system_instruction=[
types.Part.from_text(text=system_instructions)
],
)
logging.info(f"[generate_config_details] System Instruction: {generate_content_config.system_instruction[0].text}")
response = client.models.generate_content(
model=model_name,
contents=contents,
config=generate_content_config,
)
logging.info(f"[call_model_response] LLM Response: \"{response.text}\"")
return response.text
except Exception as e:
return f"Error: {e}"
13. Kiểm thử ứng dụng bằng Chỉ dẫn hệ thống
- Trong cửa sổ dòng lệnh, hãy kết thúc quy trình đang chạy (CTRL+C)
- Chạy lại lệnh để khởi động lại ứng dụng Streamlit.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Làm mới ứng dụng Streamlit. Nếu ứng dụng Streamlit vẫn đang chạy, bạn chỉ cần làm mới trang xem trước trên web trong trình duyệt.
- Hãy thử đặt lại câu hỏi cũ:
What is the best time of year to go to Iceland? - Nhấn ENTER.
So sánh cách phản hồi lần này với lần trước.
14. Xác định công cụ thời tiết
Cho đến nay, chatbot của chúng tôi có kiến thức, nhưng kiến thức đó chỉ giới hạn trong dữ liệu được dùng để huấn luyện chatbot. Công cụ này không thể truy cập vào thông tin theo thời gian thực. Đối với một bot du lịch, việc có thể tìm nạp dữ liệu trực tiếp như dự báo thời tiết là một lợi thế rất lớn.
Đây là nơi công cụ (còn gọi là gọi hàm) xuất hiện. Chúng ta có thể xác định một bộ công cụ (hàm Python) mà LLM có thể chọn gọi để lấy thông tin bên ngoài.
Cách hoạt động của công cụ
- Chúng tôi mô tả các công cụ của mình cho mô hình, bao gồm cả chức năng và các thông số mà công cụ đó sử dụng.
- Người dùng gửi một câu lệnh (ví dụ: "Thời tiết ở London thế nào?").
- Mô hình nhận được câu lệnh và nhận thấy người dùng đang hỏi về một điều gì đó mà mô hình có thể tìm hiểu bằng một trong các công cụ của mình.
- Thay vì phản hồi bằng văn bản, mô hình sẽ phản hồi bằng một đối tượng
function_callđặc biệt, cho biết công cụ mà mô hình muốn gọi và đối số tương ứng. - Mã Python của chúng ta nhận được
function_callnày, thực thi hàmget_current_temperaturethực tế với các đối số được cung cấp và nhận được kết quả (ví dụ: 15°C). - Chúng ta gửi kết quả này trở lại mô hình.
- Mô hình nhận được kết quả và tạo ra một câu trả lời bằng ngôn ngữ tự nhiên cho người dùng (ví dụ: "Nhiệt độ hiện tại ở London là 15°C").
Quy trình này cho phép mô hình trả lời các câu hỏi vượt xa dữ liệu huấn luyện, giúp mô hình trở thành một trợ lý mạnh mẽ và hữu ích hơn nhiều.
Xác định công cụ thời tiết
Nếu khách du lịch đang tìm kiếm lời khuyên về việc nên làm gì và đang lựa chọn giữa các hoạt động bị ảnh hưởng bởi thời tiết, thì công cụ thời tiết có thể sẽ hữu ích! Hãy tạo một công cụ cho mô hình của chúng ta để biết thời tiết hiện tại. Chúng ta cần hai phần: một khai báo hàm mô tả công cụ cho mô hình và hàm Python thực tế triển khai công cụ đó.
- Trong
app.py, hãy tìm nhận xét# TODO: Define the weather tool function declaration. - Bên dưới chú thích này, hãy thêm biến
weather_function. Đây là một từ điển cho mô hình biết mọi thông tin cần thiết về mục đích, tham số và đối số bắt buộc của hàm.weather_function = { "name": "get_current_temperature", "description": "Gets the current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco", }, }, "required": ["location"], }, } - Tiếp theo, hãy tìm biểu tượng bình luận
# TODO: Define the get_current_temperature function. Bên dưới, hãy thêm đoạn mã Python sau. Hàm này sẽ:- Gọi một API mã hoá địa lý để lấy toạ độ cho vị trí.
- Sử dụng các toạ độ đó để gọi API thời tiết.
- Trả về một chuỗi đơn giản có nhiệt độ và đơn vị.
def get_current_temperature(location: str) -> str: """Gets the current temperature for a given location.""" try: # --- Get Latitude and Longitude for the location --- geocode_url = f"https://geocoding-api.open-meteo.com/v1/search?name={location}&count=1&language=en&format=json" geocode_response = requests.get(geocode_url) geocode_data = geocode_response.json() if not geocode_data.get("results"): return f"Could not find coordinates for {location}." lat = geocode_data["results"][0]["latitude"] lon = geocode_data["results"][0]["longitude"] # --- Get Weather for the coordinates --- weather_url = f"https://api.open-meteo.com/v1/forecast?latitude={lat}&longitude={lon}¤t_weather=true" weather_response = requests.get(weather_url) weather_data = weather_response.json() temperature = weather_data["current_weather"]["temperature"] unit = "°C" return f"{temperature}{unit}" except Exception as e: return f"Error fetching weather: {e}"
15. Tái cấu trúc cho cuộc trò chuyện và công cụ
Hàm call_model hiện tại của chúng tôi sử dụng một lệnh gọi generate_content đơn giản, một lần. Điều này rất phù hợp với các câu hỏi đơn lẻ nhưng không lý tưởng cho cuộc trò chuyện nhiều lượt, đặc biệt là cuộc trò chuyện qua lại để tìm hiểu công cụ.
Phương pháp hay hơn là sử dụng phiên trò chuyện để duy trì bối cảnh của cuộc trò chuyện. Giờ đây, chúng ta sẽ tái cấu trúc mã để sử dụng một phiên trò chuyện. Điều này là cần thiết để triển khai công cụ một cách chính xác.
- Xoá hàm
call_modelhiện có. Chúng tôi sẽ thay thế bằng một phiên bản nâng cao hơn. - Thay vào đó, hãy thêm hàm
call_modelmới từ khối mã bên dưới. Hàm mới này chứa logic để xử lý vòng lặp gọi công cụ mà chúng ta đã thảo luận trước đó. Lưu ý rằng tệp này có một số nhận xét TODO mà chúng ta sẽ hoàn tất trong các bước tiếp theo.# --- Call the Model --- def call_model(prompt: str, model_name: str) -> str: """ This function interacts with a large language model (LLM) to generate text based on a given prompt. It maintains a chat session and handles function calls from the model to external tools. """ try: # TODO: Get the existing chat session or create a new one. message_content = prompt # Start the tool-calling loop while True: # TODO: Send the message to the model. # Check if the model wants to call a tool has_tool_calls = False for part in response.candidates[0].content.parts: if part.function_call: has_tool_calls = True function_call = part.function_call logging.info(f"Function to call: {function_call.name}") logging.info(f"Arguments: {function_call.args}") # TODO: Call the appropriate function if the model requests it. elif part.text: logging.info("No function call found in the response.") logging.info(response.text) # If no tool call was made, break the loop if not has_tool_calls: break # TODO: Return the model's final text response. except Exception as e: return f"Error: {e}" - Bây giờ, hãy thêm một hàm trợ giúp để quản lý phiên trò chuyện. Ở phía trên hàm
call_modelmới, hãy thêm hàmget_chat. Hàm này sẽ tạo một phiên trò chuyện mới với các hướng dẫn và định nghĩa công cụ của hệ thống, hoặc truy xuất phiên trò chuyện hiện có. Đây là một phương pháp hay để sắp xếp mã.def get_chat(model_name: str): if f"chat-{model_name}" not in st.session_state: # TODO: Define the tools configuration for the model # TODO: Define the generate_content configuration, including tools # TODO: Create a new chat session st.session_state[f"chat-{model_name}"] = chat return st.session_state[f"chat-{model_name}"]
Giờ đây, bạn đã thiết lập cấu trúc cho logic trò chuyện nâng cao có hỗ trợ công cụ của chúng ta!
16. Triển khai logic gọi công cụ
Bây giờ, hãy điền vào TODOs để làm cho logic gọi công cụ của chúng ta hoạt động đầy đủ.
Triển khai get_chat
- Trong hàm
get_chatbên dưới chú thích# TODO: Define the tools configuration..., hãy xác định đối tượngtoolsbằng cách tạo một phiên bảntypes.Tooltừ khai báoweather_function.tools = types.Tool(function_declarations=[weather_function]) - Trong
# TODO: Define the generate_content configuration..., hãy xác địnhgenerate_content_config, nhớ truyền đối tượngtoolsvào mô hình. Đây là cách mô hình học về những công cụ mà mô hình có thể sử dụng.generate_content_config = types.GenerateContentConfig( system_instruction=[types.Part.from_text(text=system_instructions)], tools=[tools] # Pass the tool definition here ) - Trong
# TODO: Create a new chat session, hãy tạo đối tượng trò chuyện bằng cách sử dụngclient.chats.create(), truyền vào tên mô hình và cấu hình của chúng ta.chat = client.chats.create( model=model_name, config=generate_content_config, )
Triển khai call_model
- Trong phần
# TODO: Get the existing chat session...của hàmcall_model, hãy gọi hàm trợ giúpget_chatmới.chat = get_chat(model_name) - Tiếp theo, hãy tìm
# TODO: Send the message to the model. Gửi tin nhắn của người dùng bằng phương thứcchat.send_message().response = chat.send_message(message_content) - Tìm
# TODO: Call the appropriate function.... Đây là nơi chúng ta kiểm tra xem mô hình muốn dùng hàm nào và thực thi hàm đó.
if function_call.name == "get_current_temperature":
result = get_current_temperature(**function_call.args)
function_response_part = types.Part.from_function_response(
name=function_call.name,
response={"result": result},
)
message_content = [function_response_part]
- Cuối cùng, hãy tìm
# TODO: Return the model's final text responserồi thêm câu lệnh trả về.return response.text
Đã cập nhật hàm get_chat
Hàm get_chat được cập nhật giờ đây sẽ có dạng như sau:
def get_chat(model_name: str):
if f"chat-{model_name}" not in st.session_state:
# Tools
tools = types.Tool(function_declarations=[weather_function])
# Initialize a configuration object
generate_content_config = types.GenerateContentConfig(
system_instruction=[types.Part.from_text(text=system_instructions)],
tools=[tools]
)
chat = client.chats.create(
model=model_name,
config=generate_content_config,
)
st.session_state[f"chat-{model_name}"] = chat
return st.session_state[f"chat-{model_name}"]
Đã cập nhật hàm call_model
Hàm call_model được cập nhật giờ đây sẽ có dạng như sau:
def call_model(prompt: str, model_name: str) -> str:
try:
chat = get_chat(model_name)
message_content = prompt
while True:
response = chat.send_message(message_content)
has_tool_calls = False
for part in response.candidates[0].content.parts:
if part.function_call:
has_tool_calls = True
function_call = part.function_call
logging.info(f"Function to call: {function_call.name}")
logging.info(f"Arguments: {function_call.args}")
if function_call.name == "get_current_temperature":
result = get_current_temperature(**function_call.args)
function_response_part = types.Part.from_function_response(
name=function_call.name,
response={"result": result},
)
message_content = [function_response_part]
elif part.text:
logging.info("No function call found in the response.")
logging.info(response.text)
if not has_tool_calls:
break
return response.text
except Exception as e:
return f"Error: {e}"
17. Kiểm thử ứng dụng có bật công cụ
Hãy cùng xem tính năng mới của bạn hoạt động!
- Trong cửa sổ dòng lệnh, hãy kết thúc quy trình đang chạy (CTRL+C)
- Chạy lại lệnh để khởi động lại ứng dụng Streamlit.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Làm mới ứng dụng Streamlit. Nếu ứng dụng Streamlit vẫn đang chạy, bạn chỉ cần làm mới trang xem trước trên web trong trình duyệt.
- Bây giờ, hãy đặt một câu hỏi sẽ kích hoạt công cụ mới của bạn, chẳng hạn như:
I'm looking for something to do in New York today. What do you recommend? Would it be a good day to go to Ellis Island? - Nhấn ENTER
So sánh câu trả lời này với các câu trả lời trước đó. Điểm khác biệt là gì?
Bạn sẽ thấy một phản hồi kết hợp nhiệt độ từ hàm của mình! Hãy kiểm tra cả thiết bị đầu cuối Cloud Shell. Bạn sẽ thấy các câu lệnh in xác nhận rằng hàm Python của bạn đã được thực thi.
18. Tinh chỉnh đầu ra của mô hình bằng các tham số
Tuyệt vời! Giờ đây, trợ lý du lịch có thể sử dụng các công cụ để tìm nạp dữ liệu bên ngoài theo thời gian thực, giúp trợ lý này trở nên mạnh mẽ hơn đáng kể.
Giờ đây, khi chúng ta đã nâng cao khả năng của mô hình, hãy tinh chỉnh cách mô hình phản hồi. Các tham số mô hình cho phép bạn kiểm soát kiểu và tính ngẫu nhiên của văn bản do LLM tạo. Bằng cách điều chỉnh các chế độ cài đặt này, bạn có thể làm cho đầu ra của bot tập trung và xác định hơn hoặc sáng tạo và đa dạng hơn.
Trong lớp học lập trình này, chúng ta sẽ tập trung vào temperature và top_p. (Tham khảo GenerateContentConfig trong tài liệu tham khảo API của chúng tôi để xem danh sách đầy đủ các tham số có thể định cấu hình và nội dung mô tả của các tham số đó.)
temperature: Kiểm soát tính ngẫu nhiên của đầu ra. Giá trị càng thấp (gần 0) thì đầu ra càng có tính xác định và tập trung hơn, trong khi giá trị càng cao (gần 2) thì tính ngẫu nhiên và sáng tạo càng tăng. Đối với một bot hỏi đáp hoặc trợ lý, bạn thường nên chọn nhiệt độ thấp hơn để có câu trả lời nhất quán và chính xác hơn.top_p: Xác suất tích luỹ tối đa của các mã thông báo cần xem xét khi lấy mẫu. Các mã thông báo được sắp xếp dựa trên xác suất được chỉ định để chỉ những mã thông báo có khả năng cao nhất được xem xét. Mô hình sẽ xem xét những mã thông báo có khả năng xảy ra nhất mà tổng xác suất của chúng lên đến giá trịtop_p. Giá trị thấp hơn sẽ hạn chế các lựa chọn về mã thông báo, dẫn đến đầu ra ít đa dạng hơn
Tham số cuộc gọi
- Tìm các biến
temperaturevàtop_pđược xác định ở đầuapp.py. Lưu ý rằng các hàm này chưa được gọi ở bất kỳ đâu. - Thêm
temperaturevàtop_pvào các tham số được xác định trongGenerateContentConfigtrong hàmget_chat.generate_content_config = types.GenerateContentConfig( temperature=temperature, top_p=top_p, system_instruction=[types.Part.from_text(text=system_instructions)], tools=[tools] # Pass the tool definition here )
Đã cập nhật hàm get_chat
Ứng dụng get_chat hiện có dạng như sau:
def get_chat(model_name: str):
if f"chat-{model_name}" not in st.session_state:
# Tools
tools = types.Tool(function_declarations=[weather_function])
# Initialize a configuration object
generate_content_config = types.GenerateContentConfig(
temperature=temperature,
top_p=top_p,
system_instruction=[types.Part.from_text(text=system_instructions)],
tools=[tools]
)
chat = client.chats.create(
model=model_name,
config=generate_content_config,
)
st.session_state[f"chat-{model_name}"] = chat
return st.session_state[f"chat-{model_name}"]
19. Kiểm thử bằng các tham số mô hình
- Trong cửa sổ dòng lệnh, hãy kết thúc quy trình đang chạy (CTRL+C)
- Chạy lại lệnh để khởi động lại ứng dụng Streamlit.
streamlit run app.py --browser.serverAddress=localhost --server.enableCORS=false --server.enableXsrfProtection=false --server.port 8080 - Làm mới ứng dụng Streamlit. Nếu ứng dụng Streamlit vẫn đang chạy, bạn chỉ cần làm mới trang xem trước trên web trong trình duyệt.
- Hãy thử đặt lại câu hỏi cũ,
I'm looking for something to do in New York today. What do you recommend? Would it be a good day to go to Ellis Island? - Nhấn ENTER
So sánh câu trả lời này với các câu trả lời trước đó.
20. Xin chúc mừng!
Bạn đã nâng cấp thành công ứng dụng Hỏi và đáp bằng công cụ, một tính năng mạnh mẽ cho phép ứng dụng dựa trên Gemini tương tác với các hệ thống bên ngoài và truy cập thông tin theo thời gian thực.
Tiếp tục thử nghiệm
Có nhiều cách để tiếp tục tối ưu hoá câu lệnh. Sau đây là một số điều cần cân nhắc:
- Điều chỉnh
temperaturevàtop_p, đồng thời xem cách các chỉ số này thay đổi câu trả lời do LLM đưa ra. - Hãy tham khảo
GenerateContentConfigtrong tài liệu tham khảo API của chúng tôi để xem danh sách đầy đủ các tham số có thể định cấu hình và nội dung mô tả của các tham số đó. Hãy thử xác định thêm các thông số và điều chỉnh chúng để xem điều gì sẽ xảy ra!
Tóm tắt
Trong phòng thí nghiệm này, bạn đã thực hiện những việc sau:
- Sử dụng Trình chỉnh sửa Cloud Shell và cửa sổ dòng lệnh để phát triển.
- Sử dụng Vertex AI Python SDK để kết nối ứng dụng của bạn với một mô hình Gemini.
- Áp dụng các chỉ dẫn hệ thống và thông số mô hình để hướng dẫn các câu trả lời của LLM.
- Tìm hiểu khái niệm về công cụ (gọi hàm) và lợi ích của công cụ này.
- Tái cấu trúc mã của bạn để sử dụng phiên trò chuyện có trạng thái, một phương pháp hay nhất cho AI đàm thoại.
- Xác định một công cụ cho mô hình bằng cách sử dụng khai báo hàm.
- Triển khai hàm Python để cung cấp logic của công cụ.
- Viết mã để xử lý các yêu cầu lệnh gọi hàm của mô hình và trả về kết quả.