
1. はじめに
概要
このラボでは、Google Agent Development Kit(Google ADK)を使用して、複雑なマルチエージェント システムをオーケストレートする方法を学びます。シンプルなエージェント階層から、自動化されたコラボレーション ワークフローの構築に移行します。
作成するアプリの概要
2 つの異なるマルチエージェント システムを構築します。
- 「ブレインストーミング」エージェントと「観光スポット計画」エージェントの間で会話を転送することを学習するシンプルな旅行計画エージェント。
- 自動化されたエージェント(リサーチャー、脚本家、批評家など)の「ライターズ ルーム」を使用して、ループ内で連携してムービー全体を作成する、より高度な映画のピッチ ジェネレータ。
学習内容
- 親エージェントとサブエージェントの関係を作成する方法。
- ツールからセッション
stateにデータを書き込む方法。 - キー テンプレート(
{my_key?}など)を使用してstateから読み取る方法。 - ステップバイステップのワークフローに
SequentialAgentを使用する方法。 LoopAgentを使用して反復的な改善サイクルを作成する方法。ParallelAgentを使用して独立したタスクを同時に実行する方法。
2. マルチエージェント システム
Agent Development Kit(ADK)を使用すると、開発者は生成モデルからより信頼性が高く洗練された、複数ステップの動作を取得できます。ADK を使用すると、1 つの複雑なプロンプトではなく、複数のシンプルな エージェントのフローを構築して、作業を分担して問題に取り組むことができます。
このアプローチには、単一のモノリシック プロンプトを使用するよりもいくつかのメリットがあります。
- 設計の簡素化: 1 つの複雑なプロンプトを設計するよりも、小さくて専門的なエージェントのフローを設計して整理する方が簡単です。
- 信頼性: 専門分野に特化したエージェントは、大規模で複雑なエージェントよりも特定のタスクで信頼性が高くなります。
- 保守性: 小さな専用エージェントは、システムの他の部分に影響を与えることなく、簡単に修正または改善できます。
- モジュール性: 1 つのワークフロー用に構築されたエージェントを他のワークフローで簡単に再利用できます。
階層エージェント ツリー
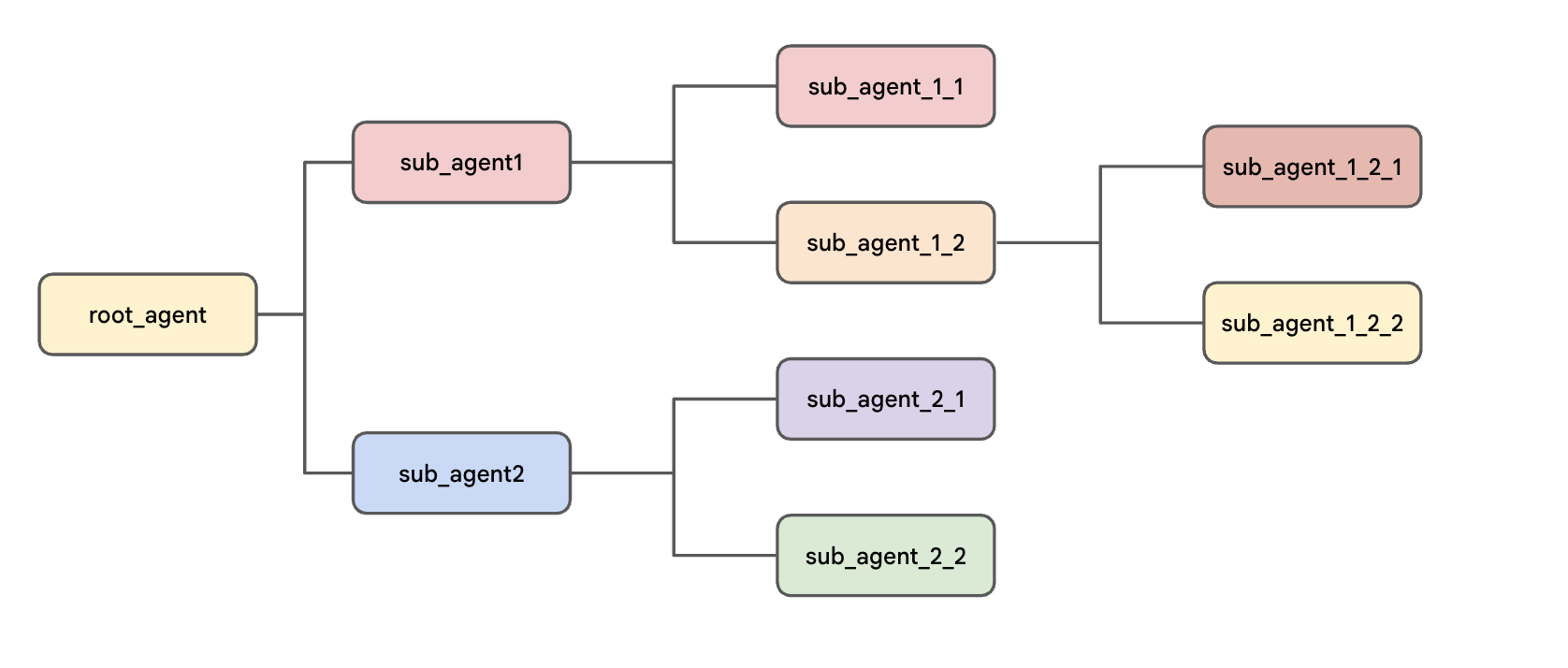
ADK では、エージェントをツリー構造で編成します。この階層は、会話のフローを制御するうえで重要です。どのエージェントがどのエージェントに会話を「渡す」ことができるかを制限するためです。これにより、システムの動作がより予測可能になり、デバッグが容易になります。利点:
- 直感的な設計: 実際のチームからヒントを得た構造になっているため、推論が容易です。
- 制御されたフロー: 階層により、タスクの委任を正確に制御できるため、デバッグに役立ちます。たとえば、説明が似通ったレポート作成エージェントが 2 つある場合でも、ツリー構造によって正しいレポート作成エージェントが呼び出されます。
構造全体は root_agent で始まります。このエージェントは親として機能し、1 つ以上のサブエージェントを持つことができます。サブエージェントは、独自のサブエージェントの親になることもでき、ツリーを形成します。
3. プロジェクトの設定
Google アカウント
個人の Google アカウントをお持ちでない場合は、Google アカウントを作成する必要があります。
仕事用または学校用アカウントではなく、個人アカウントを使用します。
Google Cloud コンソールにログインする
個人の Google アカウントを使用して Google Cloud コンソールにログインします。
課金を有効にする
Google Cloud クレジットを利用する(省略可)
このワークショップを実施するには、クレジットが設定された請求先アカウントが必要です。この Codelab の上部にあるバナーのクレジットを使用して、開始します。請求先アカウントにすでに接続している場合は、この手順をスキップできます。
個人用の請求先アカウントを設定する
Google Cloud クレジットを使用して課金を設定した場合は、この手順をスキップできます。
個人用の請求先アカウントを設定するには、Cloud コンソールでこちらに移動して課金を有効にします。
注意事項:
- このラボを完了するのにかかる Cloud リソースの費用は 1 米ドル未満です。
- このラボの最後の手順に沿ってリソースを削除すると、それ以上の料金は発生しません。
- 新規ユーザーは、300 米ドル分の無料トライアルをご利用いただけます。
プロジェクトの作成(省略可)
このラボで使用する現在のプロジェクトがない場合は、こちらで新しいプロジェクトを作成します。
4. Cloud Shell エディタを開く
- このリンクをクリックすると、Cloud Shell エディタに直接移動します。
- 本日、承認を求めるメッセージがどこかの時点で表示された場合は、[承認] をクリックして続行します。
- ターミナルが画面の下部に表示されない場合は、ターミナルを開きます。
- [表示] をクリックします。
- [ターミナル] をクリックします。
- ターミナルで、次のコマンドを使用してプロジェクトを設定します。
gcloud config set project [PROJECT_ID]- 例:
gcloud config set project lab-project-id-example - プロジェクト ID がわからない場合は、次のコマンドでプロジェクト ID をすべて一覧表示できます。
gcloud projects list
- 例:
- 次のようなメッセージが表示されます。
Updated property [core/project].
5. API を有効にする
Vertex AI API を使用して Gemini モデルを操作するには、Google Cloud プロジェクトで Vertex AI API を有効にする必要があります。
- ターミナルで API を有効にします。
gcloud services enable aiplatform.googleapis.com
Vertex AI SDK for Python の概要
Python アプリケーションから Vertex AI でホストされているモデルを操作するには、Vertex AI SDK for Python を使用します。この SDK を使用すると、基盤となる API 呼び出しの複雑さを直接処理することなく、プロンプトの送信、モデル パラメータの指定、レスポンスの受信のプロセスを簡素化できます。
Vertex AI SDK for Python の包括的なドキュメントについては、Vertex AI SDK for Python の概要 | Google Cloud をご覧ください。
6. プロジェクト環境を設定する
リポジトリのクローンを作成する
- ターミナルで、スターター ファイルを含むリポジトリのクローンを作成します。
git clone --depth 1 https://github.com/GoogleCloudPlatform/devrel-demos.git devrel-demos-multiagent-lab--depth 1フラグは最新バージョンのみを複製するため、高速です。 - ターミナルで、ラボ固有のフォルダをホーム ディレクトリに移動し、ラボの想定される構造に合わせて名前を変更します。
mv devrel-demos-multiagent-lab/ai-ml/build-multiagent-systems-with-adk/adk_multiagent_systems ~ - ターミナルで、このラボの正しい作業ディレクトリ(
adk_multiagent_systems)に移動します。cd ~/adk_multiagent_systems
ファイル構造を確認する
すべてのファイルが作成されたら、エクスプローラで adk_multiagent_systems フォルダを開いて、完全な構造を確認します。
- Cloud Shell エディタのメニューで、[ファイル] > [フォルダを開く...] を選択します。
![[Open Folder] が選択されている Cloud Shell エディタの [File] メニュー](https://codelabs.developers.google.com/static/codelabs/production-ready-ai-with-gc/3-developing-agents/img/open-folder-menu.png?hl=ja)
- ポップアップ表示されたボックスで、ユーザー名の後に
adk_multiagent_systems/というフォルダ情報を追加します。[OK] をクリックします。
次のようになります。![プロジェクト パスを含む [フォルダを開く] ダイアログ ボックス](https://codelabs.developers.google.com/static/codelabs/production-ready-ai-with-gc/3-developing-agents/img/open-folder.png?hl=ja)
- 左側のエクスプローラ パネルが更新されます。
parent_and_subagentsサブディレクトリとworkflow_agentsサブディレクトリを含む完全なプロジェクト構造が表示され、次のステップに進む準備が整います。
仮想環境を有効にする
- ターミナルで、
uvを使用して仮想環境を作成して有効にします。これにより、プロジェクトの依存関係がシステムの Python や他のプロジェクトと競合しないようになります。uv venv source .venv/bin/activate - ターミナルで、
requirements.txtファイルからgoogle-adkとその他の依存関係をインストールします。uv pip install -r requirements.txt
環境変数を設定する
- すでに
adk_multiagent_systemsディレクトリにいます。ターミナルで、環境変数を保存する.envファイルを作成します。cloudshell edit .env - エディタで開いた
.envファイルに次の内容を貼り付けます。GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="[YOUR-PROJECT-ID]" GOOGLE_CLOUD_LOCATION=global MODEL="gemini-2.5-flash" [YOUR-PROJECT-ID]は、実際の Google Cloud プロジェクト ID に置き換えます。(例:PROJECT_ID = "google-cloud-labs")
プロジェクト ID を忘れた場合は、ターミナルで次のコマンドを実行します。すべてのプロジェクトとその ID のリストが表示されます。gcloud projects list- ターミナルで、この
.envファイルをサブエージェント ディレクトリにコピーして、サブエージェントも変数にアクセスできるようにします。cp .env parent_and_subagents/.env cp .env workflow_agents/.env
7. 親エージェント、サブエージェント、ピア エージェント間の転送について確認する
会話は常に root_agent で始まります。デフォルトでは、親エージェントはサブエージェントの description を使用して、会話を転送するタイミングを決定します。サブエージェントの name を使用して、親エージェントの instruction でこれらの転送を明示的にガイドすることもできます。
これをテストしてみましょう。
- Cloud Shell エディタで
adk_multiagent_systems/parent_and_subagents/agent.pyを開きます。agent.pyファイルに 3 つのエージェントがあることに注目してください。root_agent(steeringという名前): ユーザーに質問して、転送先のサブエージェントを決定します。最初は、サブエージェントのdescriptionのみに依存します。travel_brainstormer: ユーザーが目的地をブレインストーミングするのに役立ちます。attractions_planner: 特定の国のおすすめスポットのリストを作成するのに役立ちます。
root_agentの作成コードに次の行を追加して、travel_brainstormerとattractions_plannerをroot_agentのサブエージェントにします。sub_agents=[travel_brainstormer, attractions_planner]- ターミナルで、エージェントとチャットします。
cd ~/adk_multiagent_systems adk run parent_and_subagents - ターミナルの
[user]:プロンプトで、次のように入力します。hello[steering]: Hi there! Do you already have a country in mind for your trip, or would you like some help deciding where to go?
- 次に、ターミナルでエージェントに次のように伝えます。
I could use some help deciding.[travel_brainstormer]: Okay! To give you the best recommendations, I need to understand what you're looking for in a trip. ...
[travel_brainstormer]タグに注目してください。root_agentは、サブエージェントのdescriptionのみに基づいて制御を転送しました。 - ターミナルの
user:プロンプトで、「exit」と入力して Enter キーを押し、会話を終了します。 - では、より明示的にしてみましょう。
agent.pyで、root_agentのinstructionに以下を追加します。If they need help deciding, send them to 'travel_brainstormer'. If they know what country they'd like to visit, send them to the 'attractions_planner'. - ターミナルで、エージェントをもう一度実行します。
adk run parent_and_subagents - ターミナルの
[user]:プロンプトで、次のように入力します。hello - 次のように回答します。
I would like to go to Japan.[attractions_planner]: Okay, I can help you with that! Here are some popular attractions in Japan: ...
attractions_plannerへの転送に注意してください。 - 次のように返信します。
Actually I don't know what country to visit.[travel_brainstormer]: Okay! I can help you brainstorm some countries for travel...
attractions_plannerのピアであるtravel_brainstormerに転送されたことがわかります。ピア間の転送はデフォルトで許可されています。 - ユーザー プロンプトで「
exit」と入力してセッションを終了します。
内容のまとめ
このセクションでは、エージェントの階層と会話フローの基本を学びました。
- 会話は常に
root_agentで始まります。 - 親エージェントは、
descriptionに基づいてサブエージェントに自動的に転送できます。 - 親
instructionにnameを指定してサブエージェントに転送することで、このフローを明示的に制御できます。 - デフォルトでは、エージェントは
peerエージェント(階層内の兄弟)に転送できます。
8. セッションの状態を使用して情報を保存および取得する
すべての ADK 会話には Session があり、セッション状態の辞書が含まれています。この状態にはすべてのエージェントがアクセスできるため、エージェント間で情報を渡したり、会話全体を通してデータ(リストなど)を維持したりするのに最適です。
状態への追加と読み取りを試してみましょう。
- ファイル
adk_multiagent_systems/parent_and_subagents/agent.pyに戻る # Toolsヘッダーの後に次の関数定義を貼り付けます。def save_attractions_to_state( tool_context: ToolContext, attractions: List[str] ) -> dict[str, str]: """Saves the list of attractions to state["attractions"]. Args: attractions [str]: a list of strings to add to the list of attractions Returns: None """ # Load existing attractions from state. If none exist, start an empty list existing_attractions = tool_context.state.get("attractions", []) # Update the 'attractions' key with a combo of old and new lists. # When the tool is run, ADK will create an event and make # corresponding updates in the session's state. tool_context.state["attractions"] = existing_attractions + attractions # A best practice for tools is to return a status message in a return dict return {"status": "success"}- この関数は
tool_context: ToolContextを受け取ります。このオブジェクトはセッションへのゲートウェイです。 tool_context.state["attractions"] = ...行は、セッションの状態辞書から直接読み取り、書き込みます。残りの処理は ADK が行います。
- この関数は
toolsパラメータを追加して、ツールをattractions_plannerエージェントに追加します。tools=[save_attractions_to_state]attractions_plannerエージェントの既存のinstructionに、次の箇条書きを追加します。- When they reply, use your tool to save their selected attraction and then provide more possible attractions. - If they ask to view the list, provide a bulleted list of { attractions? } and then suggest some more.- ターミナルで次のコマンドを使用して Agent Development Kit ウェブ UI を起動します。
adk webINFO: Started server process [2434] INFO: Waiting for application startup. +-------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8000. | +-------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit) - Cloud Shell ターミナルで、[ウェブ インターフェースを新しいタブで表示するには、[ウェブでプレビュー] ボタンをクリックして [ポートを変更] を選択します] をクリックします。
![[ウェブでプレビュー] メニュー](https://codelabs.developers.google.com/static/codelabs/production-ready-ai-with-gc/3-developing-agents/img/change-port.png?hl=ja)
- ポート番号「8000」を入力し、[変更してプレビュー] をクリックします。新しいブラウザタブが開き、ADK 開発 UI が表示されます。
- 左側の [エージェントを選択] プルダウンから、
parent_and_subagentsを選択します。 - 「
hello」と挨拶して会話を始めます。 - エージェントが挨拶したら、次のように返答します。
I'd like to go to Egypt.attractions_plannerに転送され、観光スポットのリストが表示されます。 - たとえば、次の観光スポットを選択します。
I'll go to the Sphinx - 「Okay, I've saved The Sphinx to your list...」のようなレスポンスが返されます。
- レスポンス ツールボックスをクリックして(チェックを入れます)、ツールの応答から作成されたイベントを確認します。
actions フィールドに、状態の変化を示すstateDeltaが含まれているはずです。 - エージェントのリストにある別の観光スポットを返信します。
- 左側のナビゲーション メニューで [X] をクリックして、先ほど確認したイベントのフォーカスを解除します。
- 左側のサイドバーで、[状態] タブをクリックします。セッションの状態に
attractions配列が表示され、選択した両方のアイテムが含まれているはずです。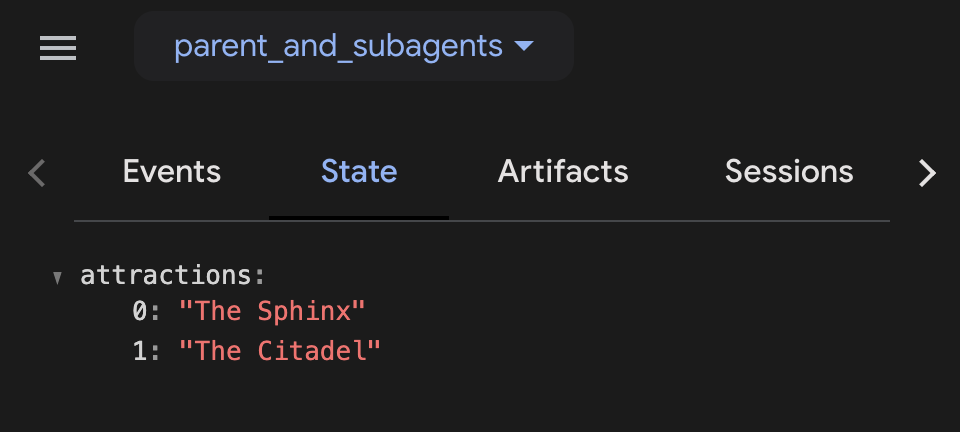
- エージェントに次のメッセージを送ります。
What is on my list? - エージェントのテストが完了したら、ウェブブラウザのタブを閉じ、Cloud Shell ターミナルで Ctrl+C キーを押してサーバーを停止します。
セクションのハイライト
このセクションでは、Session 状態を使用してデータを共有する方法について説明しました。
- 状態を書き込む: ツール内から
tool_context.stateオブジェクト(tool_context.state["my_list"] = [...]など)を使用して、状態辞書に書き込みます。 - 状態を読み取る: キー テンプレート(
Here is your list: {my_list?}など)を使用して、状態データをエージェントのinstructionに直接挿入します。 - 状態を検査する: [State] タブを使用すると、ADK Dev UI でセッションの状態をリアルタイムでモニタリングできます。
9. ワークフロー エージェント
これまでは、親エージェントがサブエージェントに転送し、ユーザーを待機する方法を見てきました。ワークフロー エージェントは異なります。ユーザー入力を待たずに、自動化されたフローでサブエージェントを次々と実行します。
これは、「計画と実行」や「下書きと修正」のパイプラインなど、自動化された複数ステップのタスクに最適です。ADK には、これを管理するための 3 つの組み込みワークフロー エージェントが用意されています。
SequentialAgentLoopAgentParallelAgent
このラボの残りの部分では、これらの 3 つのワークフロー エージェントを使用してマルチエージェント システムを構築します。
歴史上の人物をモチーフにした新作映画の企画書を作成するエージェントを構築します。エージェントが調査、反復的な執筆、レポートの生成を行います。
最終的に、システムは次のようになります。
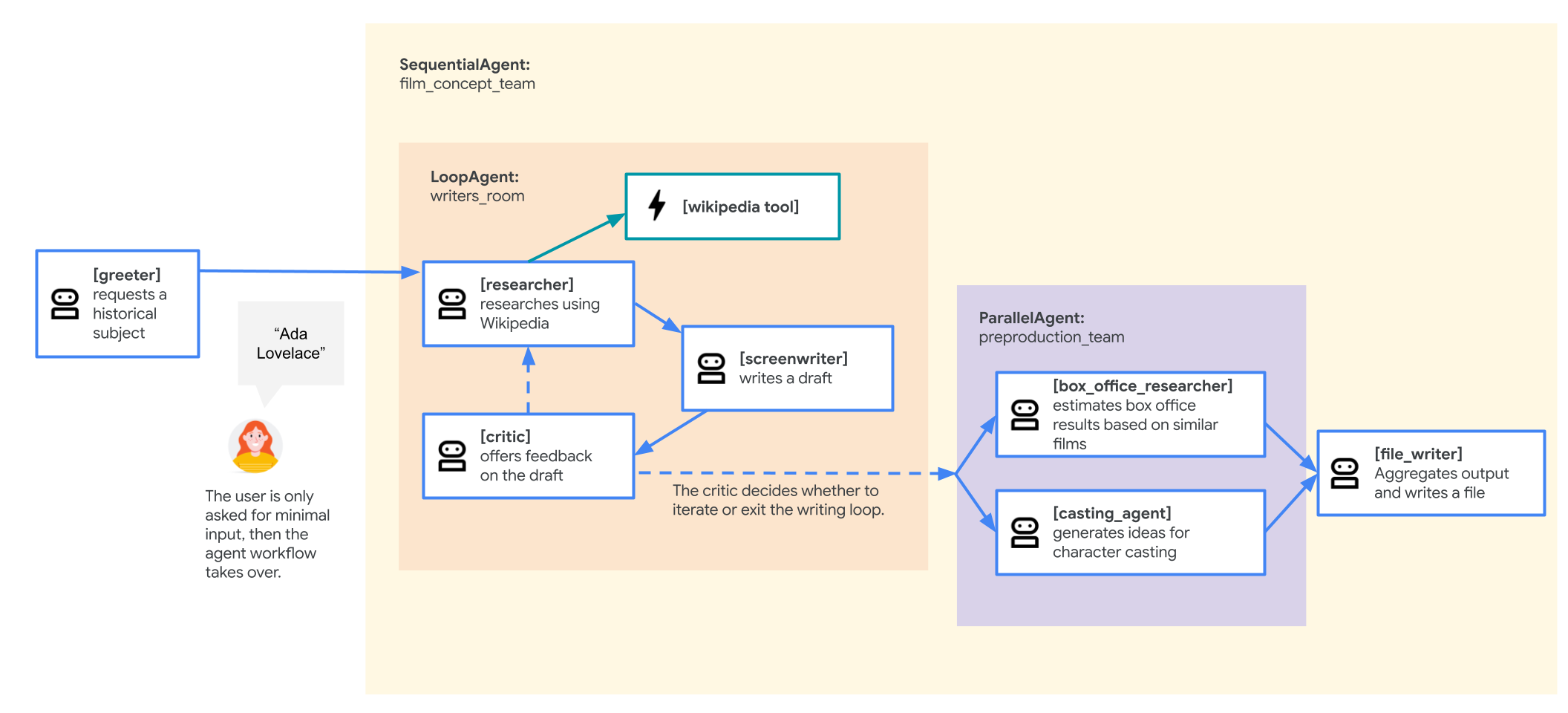
このシステムは、最もシンプルなワークフローから始めて、段階的に構築していきます。
10. SequentialAgent を使用してマルチエージェント システムを構築する
SequentialAgent は、サブエージェントを単純な線形シーケンスで実行するワークフロー エージェントです。sub_agents リスト内の各エージェントは、順番に 1 つずつ実行されます。これは、これから作成する映画の売り込みエージェントなど、特定の順序でタスクを実行する必要があるパイプラインに最適です。
この最初のバージョンは、次のような構造になります。
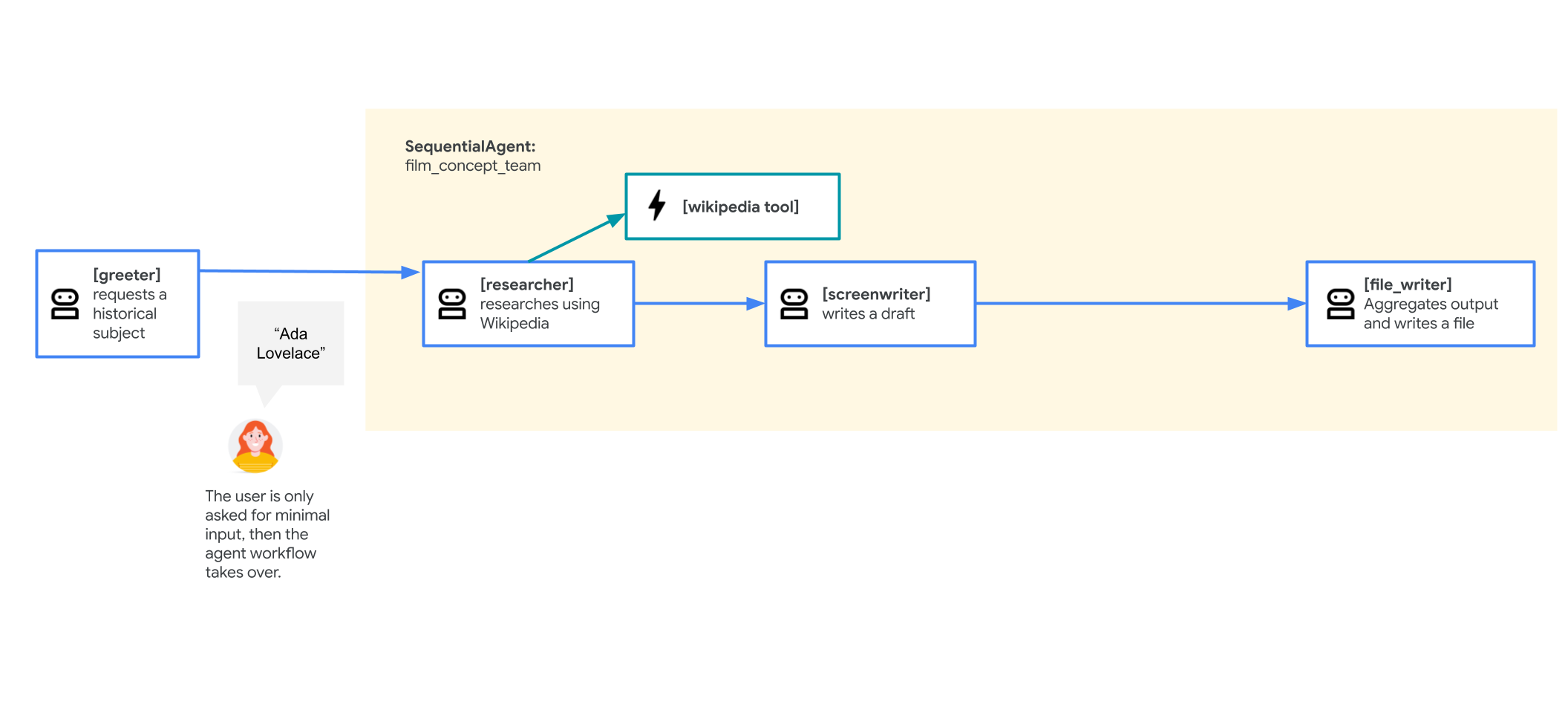
root_agent(greeter)がユーザーを歓迎し、映画のタイトルを取得します。- その後、
film_concept_teamという名前のSequentialAgentに転送されます。このSequentialAgentは次の処理を行います。researcherエージェントを実行して、Wikipedia から事実を取得します。screenwriterエージェントを実行して、これらの事実を使用してプロットを作成します。file_writerエージェントを実行して、最終的なプロットをファイルに保存します。
実行してみましょう。
- Cloud Shell エディタで
adk_multiagent_systems/workflow_agents/agent.pyを開きます。
このエージェント定義ファイルに目を通してください。サブエージェントを先に定義してから親エージェントに割り当てる必要があるため、会話の流れに沿ってファイルを読み取るには、ファイルの下から上に向かってエージェントを読み取ります。 append_to_stateツールに注目してください。このヘルパー関数を使用すると、エージェントはセッション状態のリストにデータを追加できます。これは、researcherとscreenwriterが作業を渡す方法です。- エージェントを試してみます。ターミナルで、ライブリロードを有効にしてウェブ インターフェースを起動します。
cd ~/adk_multiagent_systems adk web --reload_agents - Cloud Shell ターミナルで、[ウェブ インターフェースを新しいタブで表示するには、[ウェブでプレビュー] ボタンをクリックして [ポートを変更] を選択します] をクリックします。
- ポート番号「8000」を入力し、[変更してプレビュー] をクリックします。新しいブラウザタブが開き、ADK 開発 UI が表示されます。
- [エージェントを選択] プルダウンから、
workflow_agentsを選択します。 - 「
hello」と挨拶して会話を始めます。greeterエージェントが応答します。 - プロンプトが表示されたら、歴史上の人物を入力します。これらのいずれか、または独自のものを利用できます。
- 張仲景
- エイダ ラブレス
- マルクス・アウレリウス
SequentialAgentが引き継ぎます。中間メッセージは表示されません。researcher、screenwriter、file_writerが順に実行されます。エージェントは、シーケンス全体が完了した場合にのみ応答します。
失敗した場合は、右上の [+ New Session] をクリックしてもう一度試してください。- エージェントがファイルの書き込みを確認したら、Cloud Shell エディタの
movie_pitchesディレクトリで新しい.txtファイルを見つけて開き、出力を確認します。 - ADK 開発 UI で、チャット履歴の最後のエージェント アイコンをクリックして、イベントビューを開きます。
- イベントビューには、エージェント ツリーのグラフが視覚的に表示されます。
greeterがfilm_concept_teamを呼び出し、film_concept_teamが各サブエージェントを順番に呼び出していることがわかります。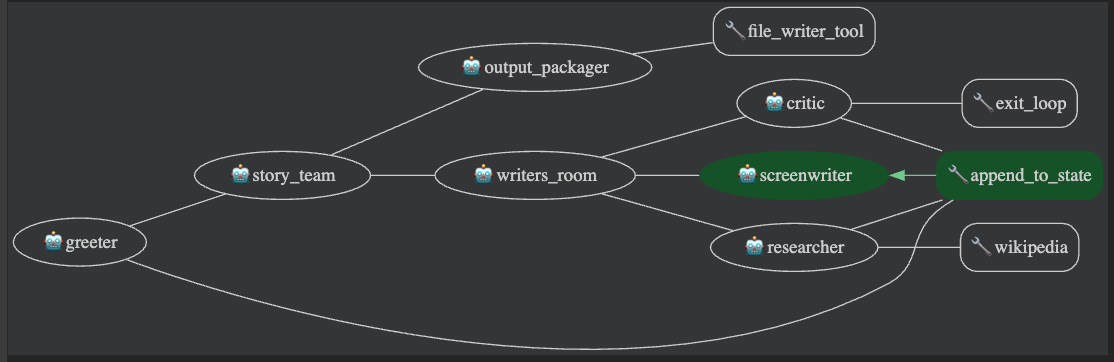
- グラフ内の任意のエージェントの [Request] タブと [Response] タブをクリックすると、セッションの状態など、渡された正確なデータを調べることができます。
セクションのハイライト
このセクションでは、ワークフロー エージェントを使用する方法について説明しました。
SequentialAgentは、ステップ間のユーザー入力を待たずに、サブエージェントを順番に 1 つずつ実行します。- これは「ワークフロー」です。ユーザーが
root_agentに話しかけ、root_agentが 作業 をSequentialAgentに渡して完了させるためです。 - シーケンス内のサブエージェントは、セッション状態(
{ PLOT_OUTLINE? }など)を使用して、前のエージェントの作業にアクセスします。 - Dev UI のイベントグラフを使用すると、エージェント間のワークフロー全体を可視化してデバッグできます。
11. 反復作業のために LoopAgent を追加する
LoopAgent は、サブエージェントを順番に実行し、最初から繰り返すワークフロー エージェントです。この「ループ」は、max_iterations カウントに達する、サブエージェントが組み込みの exit_loop ツールを呼び出すなどの条件が満たされるまで続きます。
これは、反復的な改善が必要なタスクに役立ちます。この LoopAgent を追加して、映画の企画書作成エージェントの「ライターズ ルーム」を作成します。これにより、researcher、screenwriter、新しい critic エージェントがループ内で動作し、critic が準備完了と判断するまで、各パスでプロットが改善されます。また、エージェントがアイデアを調査して洗練させることで、「古代の医者」のような曖昧なユーザー入力にも対応できるようになります。
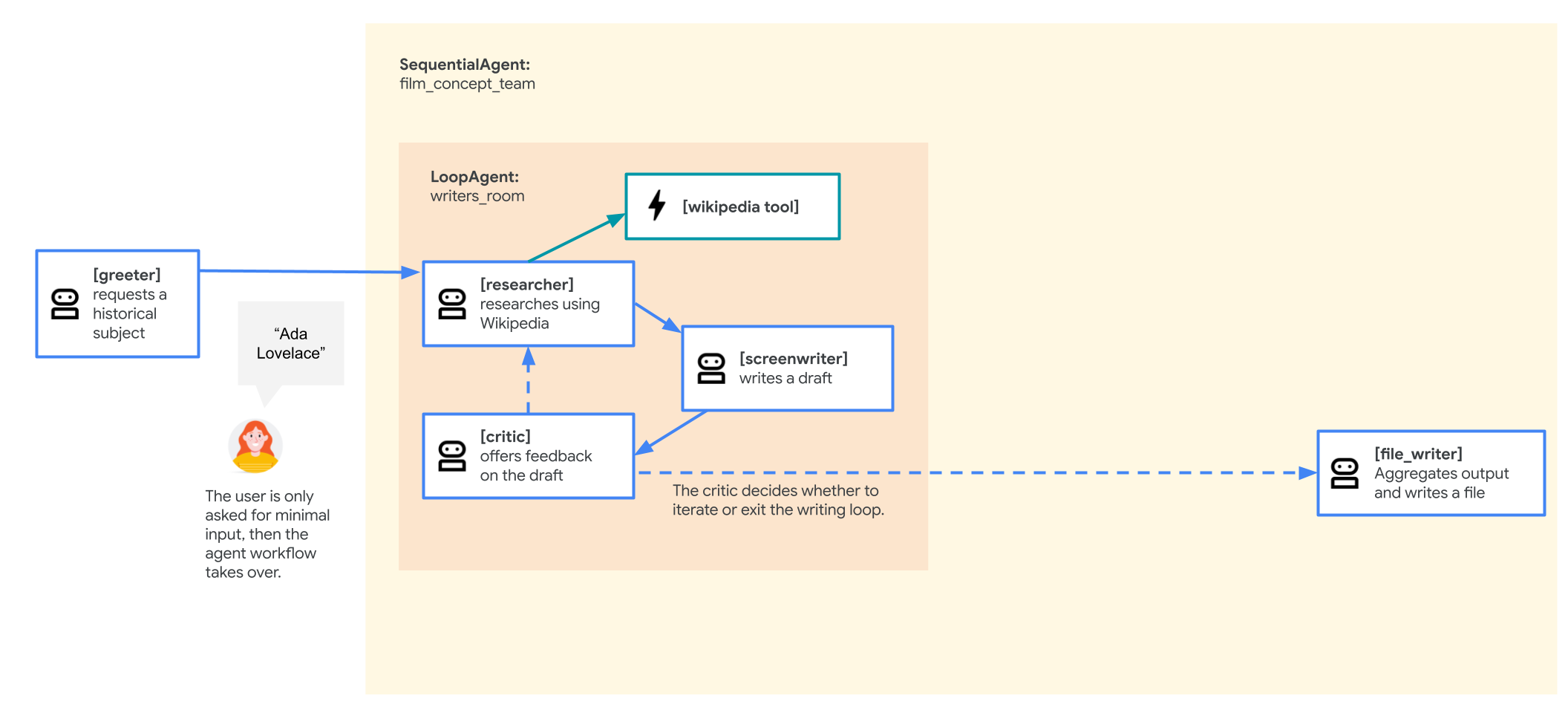
これらの変更を行うには、以下の操作を行います。
adk_multiagent_systems/workflow_agents/agent.pyで、exit_loopの import を追加します(他のgoogle.adkの import の近く)。from google.adk.tools import exit_loop- 新しい
criticエージェントを追加します。このエージェントがプロットを審査します。正常な場合はexit_loopを呼び出します。そうでない場合は、次のループのためにフィードバックを状態に追加します。
# Agentsセクションに次のエージェント定義を貼り付けます。critic = Agent( name="critic", model=model_name, description="Reviews the outline so that it can be improved.", instruction=""" INSTRUCTIONS: Consider these questions about the PLOT_OUTLINE: - Does it meet a satisfying three-act cinematic structure? - Do the characters' struggles seem engaging? - Does it feel grounded in a real time period in history? - Does it sufficiently incorporate historical details from the RESEARCH? If the PLOT_OUTLINE does a good job with these questions, exit the writing loop with your 'exit_loop' tool. If significant improvements can be made, use the 'append_to_state' tool to add your feedback to the field 'CRITICAL_FEEDBACK'. Explain your decision and briefly summarize the feedback you have provided. PLOT_OUTLINE: { PLOT_OUTLINE? } RESEARCH: { research? } """, before_model_callback=log_query_to_model, after_model_callback=log_model_response, tools=[append_to_state, exit_loop] ) writers_roomLoopAgentを作成します。これには、ループ内で動作する 3 つのエージェントが含まれます。
次のコードをfilm_concept_teamエージェント定義の上に貼り付けます。writers_room = LoopAgent( name="writers_room", description="Iterates through research and writing to improve a movie plot outline.", sub_agents=[ researcher, screenwriter, critic ], max_iterations=5, )- 新しい
writers_roomループを使用するようにfilm_concept_teamSequentialAgentを更新します。researcherとscreenwriterを単一のwriters_roomエージェントに置き換えます。既存のfilm_concept_team定義を次のように置き換えます。film_concept_team = SequentialAgent( name="film_concept_team", description="Write a film plot outline and save it as a text file.", sub_agents=[ writers_room, file_writer ], ) - ADK 開発 UI タブに戻り、右上の [+ 新しいセッション] をクリックします。
- 「
hello」と挨拶して新しい会話を始めます。 - メッセージが表示されたら、今回はより広範なトピックをエージェントに伝えます。以下にそのアイデアをご紹介します。
- 大衆向け製品を制作した工業デザイナー
- 地図製作者
- that guy who made crops yield more food
- ループが完了すると、エージェントはファイルを書き込みます。
adk_multiagent_systems/movie_pitchesディレクトリで生成されたファイルを確認します。 - Dev UI のイベントグラフを調べて、ループ構造を確認します。
セクションのハイライト
このセクションでは、LoopAgent の使用方法について説明しました。
LoopAgentは、サブエージェントのシーケンスを繰り返し、反復タスクの「内部ループ」を作成するワークフロー エージェントです。- ループ内のエージェントは、セッション状態を使用して、後続のパスで作業(
PLOT_OUTLINEなど)とフィードバック(CRITICAL_FEEDBACKなど)を互いに渡します。 - ループは、
max_iterationsの上限に達するか、エージェントがexit_loopツールを呼び出すことで停止できます。
12. 「並列処理と収集」に ParallelAgent を使用する
ParallelAgent は、すべてのサブエージェントを同時に(並行して)実行するワークフロー エージェントです。これは、2 つの異なる調査ジョブの実行など、タスクを独立したサブタスクに分割できる場合に有効です。
ParallelAgent を使用して、並行して動作する「プリプロダクション チーム」を作成します。あるエージェントが興行収入の可能性を調査し、別のエージェントが同時にキャスティングのアイデアをブレインストーミングします。これは「ファンアウトと収集」パターンと呼ばれることがよくあります。ParallelAgent が作業を「ファンアウト」し、後続のエージェント(file_writer)が結果を「収集」します。
最終的なエージェント フローは次のようになります。
greeter(ルート)がチャットを開始します。film_concept_team(SequentialAgent)に転送され、次の処理が実行されます。- プロットを作成する
writers_room(LoopAgent)。 - 新しい
preproduction_team(ParallelAgent)で、興行収入とキャスティングを同時に調べることができます。 - すべての結果を収集してファイルを保存する
file_writer。
- プロットを作成する
これらの変更を行うには、以下の操作を行います。
adk_multiagent_systems/workflow_agents/agent.pyで、新しいParallelAgentとそのサブエージェントを# Agentsヘッダーの下に貼り付けます。box_office_researcher = Agent( name="box_office_researcher", model=model_name, description="Considers the box office potential of this film", instruction=""" PLOT_OUTLINE: { PLOT_OUTLINE? } INSTRUCTIONS: Write a report on the box office potential of a movie like that described in PLOT_OUTLINE based on the reported box office performance of other recent films. """, output_key="box_office_report" ) casting_agent = Agent( name="casting_agent", model=model_name, description="Generates casting ideas for this film", instruction=""" PLOT_OUTLINE: { PLOT_OUTLINE? } INSTRUCTIONS: Generate ideas for casting for the characters described in PLOT_OUTLINE by suggesting actors who have received positive feedback from critics and/or fans when they have played similar roles. """, output_key="casting_report" ) preproduction_team = ParallelAgent( name="preproduction_team", sub_agents=[ box_office_researcher, casting_agent ] )film_concept_teamSequentialAgentのsub_agentsリストを更新して、新しいpreproduction_team(writers_roomとfile_writerの間)を含めます。既存のfilm_concept_team定義を次のように置き換えます。film_concept_team = SequentialAgent( name="film_concept_team", description="Write a film plot outline and save it as a text file.", sub_agents=[ writers_room, preproduction_team, file_writer ], )file_writerエージェントのinstructionを更新して、状態から新しいレポートを「収集」し、ファイルに追加するようにします。file_writerのinstruction文字列を次のように置き換えます。instruction=""" INSTRUCTIONS: - Create a marketable, contemporary movie title suggestion for the movie described in the PLOT_OUTLINE. If a title has been suggested in PLOT_OUTLINE, you can use it, or replace it with a better one. - Use your 'write_file' tool to create a new txt file with the following arguments: - for a filename, use the movie title - Write to the 'movie_pitches' directory. - For the 'content' to write, include: - The PLOT_OUTLINE - The BOX_OFFICE_REPORT - The CASTING_REPORT PLOT_OUTLINE: { PLOT_OUTLINE? } BOX_OFFICE_REPORT: { box_office_report? } CASTING_REPORT: { casting_report? } """,- ADK 開発 UI タブに戻り、[+ 新しいセッション] をクリックします。
helloと入力して会話を開始します。- プロンプトが表示されたら、新しい登場人物のタイプを入力します。以下にそのアイデアをご紹介します。
- Wi-Fi の技術を発明した女優
- カリスマ性のあるシェフ
- key players in the worlds fair exhibitions
- エージェントが作業を完了したら、
adk_multiagent_systems/movie_pitchesディレクトリにある最終ファイルを確認します。これで、プロット、興行収入レポート、キャスティング レポートがすべて 1 つのドキュメントにまとめられます。
セクションのハイライト
このセクションでは、ParallelAgent の使用方法について説明しました。
ParallelAgentは、サブエージェントを順番に実行するのではなく、同時に実行して作業を「ファンアウト」します。- これは、相互に依存しないタスク(2 つの異なるトピックの調査など)に非常に効率的です。
- 並列エージェントの結果は、後続のエージェントによって「収集」されます。これは、並列エージェントが作業をセッション状態(
output_keyを使用)に保存し、最終エージェント(file_writerなど)がそれらのキーを読み取ることで行われます。
13. カスタム ワークフロー エージェント
SequentialAgent、LoopAgent、ParallelAgent の事前定義されたワークフロー エージェントでニーズを満たせない場合は、CustomAgent を使用して新しいワークフロー ロジックを柔軟に実装できます。
サブエージェント間のフロー制御、条件付き実行、状態管理についてパターンを定義できます。このエージェントは、複雑なワークフローやステートフルなオーケストレーションに加えて、カスタム ビジネスロジックをフレームワークのオーケストレーション レイヤに統合したい場合にも有用です。
このラボでは CustomAgent の作成は扱いませんが、必要になったときに思い出せるようにその存在を覚えておきましょう。
14. 完了
Google Agent Development Kit(ADK)を使用して、高度なマルチエージェント システムを構築しました。単純な親子関係のエージェントから、クリエイティブ プロジェクトの調査、作成、改善を行う複雑な自動ワークフローをオーケストレートするまでに進歩しました。
内容のまとめ
このラボでは次の作業を行いました。
- 親エージェントとサブエージェントの関係を持つ階層ツリーでエージェントを整理します。
- 制御されたエージェント間の転送(
descriptionを使用した自動転送とinstructionを使用した明示的な転送の両方)。 - ツールを使用して、
tool_context.state辞書にデータを書き込みました。 - キー テンプレート(
{ PLOT_OUTLINE? }など)を使用して、セッション状態から読み取り、エージェントのプロンプトをガイドします。 SequentialAgentを実装して、簡単なステップバイステップのワークフロー(調査 -> 作成 -> 保存)を作成しました。criticエージェントとexit_loopツールでLoopAgentを使用して、反復的な改善サイクルを作成しました。ParallelAgentを使用して、独立したタスク(キャスティングや興行収入の調査など)を「ファンアウト」し、同時に実行しました。
継続的なテスト
学んだことを活かす方法はたくさんあります。以下のヒントをご覧ください。
- エージェントを追加する:
preproduction_teamParallelAgentに新しいエージェントを追加してみてください。たとえば、PLOT_OUTLINEに基づいて映画のキャッチコピーを作成するmarketing_agentを作成できます。 - ツールを追加する:
researcherエージェントにツールを追加します。Google 検索 API を使用して、Wikipedia に掲載されていない情報を検索するツールを作成できます。 CustomAgentを確認する: このラボでは、標準テンプレートに適合しないワークフローのCustomAgentについて説明しました。たとえば、セッション状態に特定のキーが存在する場合にのみエージェントを条件付きで実行するエージェントを構築してみます。