
1. Einführung
Übersicht
In diesem Lab erstellen Sie eine automatisierte Pipeline zur Bereinigung von Daten, um sensible Informationen zu schützen, die in der KI-Entwicklung verwendet werden. Sie verwenden Sensitive Data Protection von Google Cloud (früher Cloud DLP), um personenidentifizierbare Informationen (PII) in verschiedenen Datenformaten wie unstrukturiertem Text, strukturierten Tabellen und Bildern zu prüfen, zu klassifizieren und zu de-identifizieren.
Kontext
Sie sind der Sicherheits- und Datenschutzexperte in Ihrem Entwicklungsteam und Ihr Ziel ist es, einen Workflow zu erstellen, der vertrauliche Informationen identifiziert und anonymisiert, bevor sie Entwicklern und Modellen zur Verfügung gestellt werden. Ihr Team benötigt realistische, hochwertige Daten, um eine neue Anwendung für generative KI zu optimieren und zu testen. Die Verwendung von Rohdaten von Kunden birgt jedoch erhebliche Datenschutzrisiken.
In der folgenden Tabelle sind die Datenschutzrisiken aufgeführt, die Sie am meisten minimieren möchten:
Risiko | Problembehebung |
Offenlegung personenbezogener Daten in unstrukturierten Textdateien (z.B. Support-Chatprotokolle, Feedbackformulare). | Erstellen Sie eine De-Identifikationsvorlage, die sensible Werte durch ihren infoType ersetzt. So wird der Kontext beibehalten, ohne dass die Daten offengelegt werden. |
Verlust der Nützlichkeit von Daten in strukturierten Datasets (CSVs), wenn personenidentifizierbare Informationen entfernt werden. | Verwenden Sie Datensatztransformationen, um Kennungen wie Namen selektiv zu entfernen und Techniken wie Zeichenmaskierung anzuwenden, um andere Zeichen im String beizubehalten, damit Entwickler weiterhin mit den Daten testen können. |
Offenlegung personenidentifizierbarer Informationen in Text, der in Bilder eingebettet ist (z.B. gescannte Dokumente, Nutzerfotos). | Erstellen Sie eine bildspezifische De-Identifikationsvorlage, mit der Text in Bildern entfernt wird. |
Inkonsistente oder fehleranfällige manuelle Schwärzung bei verschiedenen Datentypen. | Konfigurieren Sie einen einzelnen, automatisierten Sensitive Data Protection-Job, der basierend auf dem verarbeiteten Dateityp immer die richtige De-Identifikationsvorlage anwendet. |
Lerninhalte
Aufgaben in diesem Lab:
- Definieren Sie eine Inspektionsvorlage, um bestimmte sensible Informationstypen (infoTypes) zu erkennen.
- Erstellen Sie separate De-Identifikationsregeln für unstrukturierte, strukturierte und Bilddaten.
- Konfigurieren und führen Sie einen einzelnen Job aus, der automatisch die richtige Schwärzung basierend auf dem Dateityp auf den Inhalt eines gesamten Buckets anwendet.
- Prüfen Sie, ob sensible Daten erfolgreich in einen sicheren Ausgabespeicherort transformiert wurden.
2. Projekt einrichten
Google-Konto
Wenn Sie noch kein privates Google-Konto haben, müssen Sie ein Google-Konto erstellen.
Verwenden Sie stattdessen ein privates Konto anstelle eines Kontos einer Bildungseinrichtung.
In der Google Cloud Console anmelden
Melden Sie sich mit einem privaten Google-Konto in der Google Cloud Console an.
Abrechnung aktivieren
Google Cloud-Guthaben einlösen (optional)
Für diesen Workshop benötigen Sie ein Rechnungskonto mit Guthaben. Verwenden Sie die Guthabenpunkte aus dem Banner oben in diesem Codelab, um loszulegen. Wenn Sie bereits mit einem Rechnungskonto verbunden sind, können Sie diesen Schritt überspringen.
Privates Rechnungskonto einrichten
Wenn Sie die Abrechnung mit Google Cloud-Guthaben eingerichtet haben, können Sie diesen Schritt überspringen.
Aktivieren Sie die Abrechnung in der Cloud Console, um ein privates Rechnungskonto einzurichten.
Hinweise:
- Die Kosten für Cloud-Ressourcen für dieses Lab sollten weniger als 1 $ betragen.
- Sie können die Schritte am Ende dieses Labs ausführen, um Ressourcen zu löschen und so weitere Kosten zu vermeiden.
- Neue Nutzer haben Anspruch auf den kostenlosen Testzeitraum mit einem Guthaben von 300 $.
Projekt erstellen (optional)
Wenn Sie kein aktuelles Projekt haben, das Sie für dieses Lab verwenden möchten, erstellen Sie hier ein neues Projekt.
3. APIs aktivieren
Cloud Shell konfigurieren
Nachdem Ihr Projekt erfolgreich erstellt wurde, führen Sie die folgenden Schritte aus, um Cloud Shell einzurichten.
Cloud Shell starten
Rufen Sie shell.cloud.google.com auf. Wenn Sie ein Pop-up-Fenster sehen, in dem Sie aufgefordert werden, die Autorisierung zu bestätigen, klicken Sie auf Autorisieren.
Projekt-ID festlegen
Führen Sie den folgenden Befehl im Cloud Shell-Terminal aus, um die richtige Projekt-ID festzulegen. Ersetzen Sie <your-project-id> durch Ihre tatsächliche Projekt-ID, die Sie im Schritt zur Projekterstellung oben kopiert haben.
gcloud config set project <your-project-id>
Im Cloud Shell-Terminal sollte nun das richtige Projekt ausgewählt sein.
Schutz sensibler Daten aktivieren
Damit Sie den Dienst „Sensitive Data Protection“ und Cloud Storage verwenden können, müssen diese APIs in Ihrem Google Cloud-Projekt aktiviert sein.
- Aktivieren Sie die APIs im Terminal:
gcloud services enable dlp.googleapis.com storage.googleapis.com
Alternativ können Sie diese APIs aktivieren, indem Sie in der Konsole zu Sicherheit > Sensitive Data Protection und Cloud Storage navigieren und für jeden Dienst auf die Schaltfläche Aktivieren klicken, wenn Sie dazu aufgefordert werden.
4. Buckets mit sensiblen Daten erstellen
Eingabe- und Ausgabebucket erstellen
In diesem Schritt erstellen Sie zwei Buckets: einen für sensible Daten, die geprüft werden müssen, und einen, in dem Sensitive Data Protection die de-identifizierten Ausgabedateien speichert. Sie laden auch Beispieldatendateien herunter und laden sie in Ihren Eingabe-Bucket hoch.
- Führen Sie im Terminal die folgenden Befehle aus, um einen Bucket für Eingabedaten und einen für Ausgabedaten zu erstellen. Füllen Sie dann den Eingabe-Bucket mit Beispieldaten aus
gs://dlp-codelab-data:PROJECT_ID=$(gcloud config get-value project) gsutil mb gs://input-$PROJECT_ID gsutil mb gs://output-$PROJECT_ID
Sensible Daten dem Eingabe-Bucket hinzufügen
In diesem Schritt laden Sie Beispieldatendateien mit personenidentifizierbaren Testinformationen von GitHub herunter und in Ihren Eingabe-Bucket hoch.
- Führen Sie in Cloud Shell den folgenden Befehl aus, um das
devrel-demos-Repository zu klonen, das die für dieses Lab erforderlichen Beispieldaten enthält.REPO_URL="https://github.com/GoogleCloudPlatform/devrel-demos.git" TARGET_PATH="security/sample-data" OUTPUT_FOLDER="sample-data" git clone --quiet --depth 1 --filter=blob:none --sparse "$REPO_URL" temp_loader cd temp_loader git sparse-checkout set "$TARGET_PATH" cd .. mv "temp_loader/$TARGET_PATH" "$OUTPUT_FOLDER" rm -rf temp_loader - Kopieren Sie als Nächstes die Beispieldaten in den zuvor erstellten Eingabe-Bucket:
gsutil -m cp -r sample-data/* gs://input-$PROJECT_ID/ - Rufen Sie Cloud Storage > Buckets auf und klicken Sie auf den Eingabe-Bucket, um die importierten Daten aufzurufen.
5. Prüfvorlage erstellen
In dieser Aufgabe erstellen Sie eine Vorlage, die Sensitive Data Protection mitteilt, wonach gesucht werden soll. So können Sie sich bei der Überprüfung auf infoTypes konzentrieren, die für Ihre Daten und geografischen Einheiten relevant sind, was die Leistung und Genauigkeit verbessert.
Prüfvorlage erstellen
In diesem Schritt definieren Sie die Regeln dafür, was als vertrauliche Daten gilt, die geprüft werden müssen. Diese Vorlage wird von Ihren De-Identifikationsjobs wiederverwendet, um die Konsistenz zu gewährleisten.
- Klicken Sie im Navigationsmenü auf Sensitive Data Protection > Konfiguration > Vorlagen.
- Klicken Sie auf Vorlage erstellen.
- Wählen Sie unter Vorlagentyp die Option Prüfen (sensible Daten finden) aus.
- Legen Sie die Vorlagen-ID auf
pii-finderfest. - Klicken Sie auf Weiter, um die Erkennung zu konfigurieren.
- Klicken Sie auf infoTypes verwalten.
- Suchen Sie mit dem Filter nach den folgenden infoTypes und setzen Sie ein Häkchen neben jedem:
CREDIT_CARD_EXPIRATION_DATECREDIT_CARD_NUMBERDATE_OF_BIRTHDRIVERS_LICENSE_NUMBEREMAIL_ADDRESSGCP_API_KEYGCP_CREDENTIALSORGANIZATION_NAMEPASSWORDPERSON_NAMEPHONE_NUMBERUS_SOCIAL_SECURITY_NUMBER
- Wählen Sie alle anderen aus, die Sie ebenfalls interessieren, und klicken Sie auf Fertig.
- Prüfen Sie die resultierende Tabelle, um sicherzustellen, dass alle diese infoTypes hinzugefügt wurden.
- Klicken Sie auf Erstellen.
6. De-Identifikationsvorlagen erstellen
Als Nächstes erstellen Sie drei separate Vorlagen für die De-Identifikation für verschiedene Datenformate. So haben Sie die Möglichkeit, den Transformationsprozess detailliert zu steuern und für jeden Dateityp die am besten geeignete Methode anzuwenden. Diese Vorlagen funktionieren in Verbindung mit der Prüfvorlage, die Sie gerade erstellt haben.
Vorlage für unstrukturierte Daten erstellen
In dieser Vorlage wird definiert, wie sensible Daten in Freitext wie Chatprotokollen oder Feedbackformularen de-identifiziert werden. Bei der ausgewählten Methode wird der sensible Wert durch den Namen seines infoType ersetzt, wodurch der Kontext erhalten bleibt.
- Klicken Sie auf der Seite Vorlagen auf Vorlage erstellen.
- De-Identifikationsvorlage definieren:
Immobilien
Wert (eingeben oder auswählen)
Vorlagentyp
De-identifizieren (sensible Daten entfernen)
Datentransformationstyp
infoType
Vorlagen-ID
de-identify-unstructured - Klicken Sie auf Weiter, um die De-Identifizierung zu konfigurieren.
- Wählen Sie unter Transformationsmethode die Transformation Durch infoType-Namen ersetzen aus.
- Klicken Sie auf Erstellen.
- Klicken Sie auf Testen.
- So testen Sie eine Nachricht mit personenidentifizierbaren Informationen, um zu sehen, wie sie transformiert wird:
Hi, my name is Alex and my SSN is 555-11-5555. You can reach me at +1-555-555-5555.
Vorlage für strukturierte Daten erstellen
Diese Vorlage ist speziell auf sensible Informationen in strukturierten Datasets wie CSV-Dateien ausgerichtet. Sie konfigurieren die Maskierung von Daten so, dass der Nutzen der Daten für Tests erhalten bleibt, sensible Felder aber trotzdem de-identifiziert werden.
- Kehren Sie zur Seite Vorlagen zurück und klicken Sie auf Vorlage erstellen.
- De-Identifikationsvorlage definieren:
Immobilien
Wert (eingeben oder auswählen)
Vorlagentyp
De-identifizieren (sensible Daten entfernen)
Datentransformationstyp
Aufnehmen
Vorlagen-ID
de-identify-structured - Fahren Sie mit der Konfiguration der De-Identifizierung fort. Da diese Vorlage für strukturierte Daten gilt, können wir die Felder oder Spalten, die bestimmte Arten sensibler Daten enthalten, häufig vorhersagen. Sie wissen, dass die CSV-Datei, die Ihre Anwendung verwendet, Nutzer-E-Mail-Adressen unter
user_identhält und dassmessagehäufig personenbezogene Daten aus Kundeninteraktionen enthält. Sie müssenagent_idnicht maskieren, da es sich um Mitarbeiter handelt und die Unterhaltungen zugeordnet werden sollten. Füllen Sie diesen Abschnitt wie folgt aus:- Feld(er) oder Spalt(e) für die Transformation:
user_id,message. - Transformationstyp: Übereinstimmung mit infoType
- Transformationsmethode: Klicken Sie auf Transformation hinzufügen.
- Transformation: Mit Zeichen maskieren.
- Zu ignorierende Zeichen: US-amerikanische Satzzeichen.
- Feld(er) oder Spalt(e) für die Transformation:
- Klicken Sie auf Erstellen.
Vorlage für Bilddaten erstellen
Diese Vorlage wurde entwickelt, um sensiblen Text zu de-identifizieren, der in Bildern eingebettet ist, z. B. in gescannten Dokumenten oder von Nutzern eingereichten Fotos. Dabei wird die optische Zeichenerkennung (OCR) verwendet, um die personenbezogenen Daten zu erkennen und zu entfernen.
- Kehren Sie zur Seite Vorlagen zurück und klicken Sie auf Vorlage erstellen.
- De-Identifikationsvorlage definieren:
Immobilien
Wert (eingeben oder auswählen)
Vorlagentyp
De-identifizieren (sensible Daten entfernen)
Datentransformationstyp
Bild
Vorlagen-ID
de-identify-image - Klicken Sie auf Weiter, um die De-Identifizierung zu konfigurieren.
- „infoTypes für die Transformation“: Alle erkannten InfoTypes, die in einer Inspektionsvorlage oder Inspektionskonfiguration definiert und nicht in anderen Regeln angegeben sind.
- Klicken Sie auf Erstellen.
7. De‑Identifikationsjob erstellen und ausführen
Nachdem Sie die Vorlagen definiert haben, erstellen Sie einen einzelnen Job, in dem die richtige De-Identifikationsvorlage basierend auf dem erkannten und geprüften Dateityp angewendet wird. Dadurch wird der Prozess zum Schutz sensibler Daten für Daten, die in Cloud Storage gespeichert sind, automatisiert.
Eingabedaten konfigurieren
In diesem Schritt geben Sie die Quelle der Daten an, die anonymisiert werden müssen. Das ist ein Cloud Storage-Bucket mit verschiedenen Dateitypen mit sensiblen Informationen.
- Rufen Sie über die Suchleiste Sicherheit > Sensitive Data Protection auf.
- Klicken Sie im Menü auf Prüfung.
- Klicken Sie auf Job und Job-Trigger erstellen.
- Konfigurieren Sie den Job:
Immobilien
Wert (eingeben oder auswählen)
Job-ID
pii-removerSpeichertyp
Google Cloud Storage
Standorttyp
Einen Bucket mit optionalen Ein- bzw. Ausschlussregeln scannen
Bucket-Name
input-[your-project-id]
Erkennung und Aktionen konfigurieren
Jetzt verknüpfen Sie die zuvor erstellten Vorlagen mit diesem Job. So wird Sensitive Data Protection mitgeteilt, wie nach personenidentifizierbaren Informationen gesucht werden soll und welche De-Identifikationsmethode je nach Inhaltstyp angewendet werden soll.
- Prüfvorlage:
projects/[your-project-id]/locations/global/inspectTemplates/pii-finder - Wählen Sie unter Aktionen hinzufügen die Option De‑identifizierte Kopie erstellen aus und konfigurieren Sie die Transformationsvorlagen, die Sie erstellt haben.
- Ein Pop‑up-Fenster wird geöffnet, in dem Sie
Confirm whether you want to de-identify the findingskönnen. Klicken Sie auf PROBENAHME DEAKTIVIEREN.
Immobilien
Wert (eingeben oder auswählen)
De-Identifikationsvorlage
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-unstructuredStrukturierte De-Identifikationsvorlage
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-structuredVorlage zur Bildentfernung
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-image - Cloud Storage-Ausgabespeicherort konfigurieren:
- URL:
gs://output-[your-project-id]
- URL:
- Lassen Sie unter Zeitplan die Auswahl auf Keine, um den Job sofort auszuführen.
- Klicken Sie auf Erstellen.
- Ein Pop‑up-Fenster mit
Confirm job or job trigger createwird geöffnet. Klicke auf ERSTELLEN BESTÄTIGEN.
8. Die Ergebnisse prüfen
Im letzten Schritt müssen Sie prüfen, ob die vertraulichen Daten in allen Dateitypen im Ausgabebucket erfolgreich und korrekt entfernt wurden. So wird sichergestellt, dass Ihre Anonymisierungspipeline wie erwartet funktioniert.
Jobstatus prüfen
Behalten Sie den Job im Blick, um sicherzugehen, dass er erfolgreich abgeschlossen wird, und sehen Sie sich die Zusammenfassung der Ergebnisse an, bevor Sie die Ausgabedateien prüfen.
- Warten Sie auf dem Tab Jobdetails, bis der Job den Status Fertig hat.
- Sehen Sie sich unter Übersicht die Anzahl der Ergebnisse und die Prozentsätze der einzelnen erkannten infoTypes an.
- Klicken Sie auf Konfiguration.
- Scrollen Sie nach unten zu Aktionen und klicken Sie auf den Ausgabe-Bucket, um die de‑identifizierten Daten zu sehen:
gs://output-[your-project-id].
Eingabe- und Ausgabedateien vergleichen
In diesem Schritt prüfen Sie die anonymisierten Dateien manuell, um zu bestätigen, dass die Daten gemäß Ihren Vorlagen korrekt bereinigt wurden.
- Bilder: Öffnen Sie ein Bild aus dem Ausgabebucket. Prüfen Sie, ob in der Ausgabedatei alle vertraulichen Textstellen entfernt wurden.

- Unstrukturierte Logs: Logdatei aus beiden Buckets ansehen. Prüfen Sie, ob personenbezogene Daten im Ausgabelog durch den infoType-Namen ersetzt wurden (z.B.
[US_SOCIAL_SECURITY_NUMBER]). - Strukturierte CSV-Dateien: Öffnen Sie eine CSV-Datei aus beiden Buckets. Prüfen Sie, ob die E‑Mail-Adressen und Sozialversicherungsnummern der Nutzer in der Ausgabedatei mit
####@####.commaskiert sind.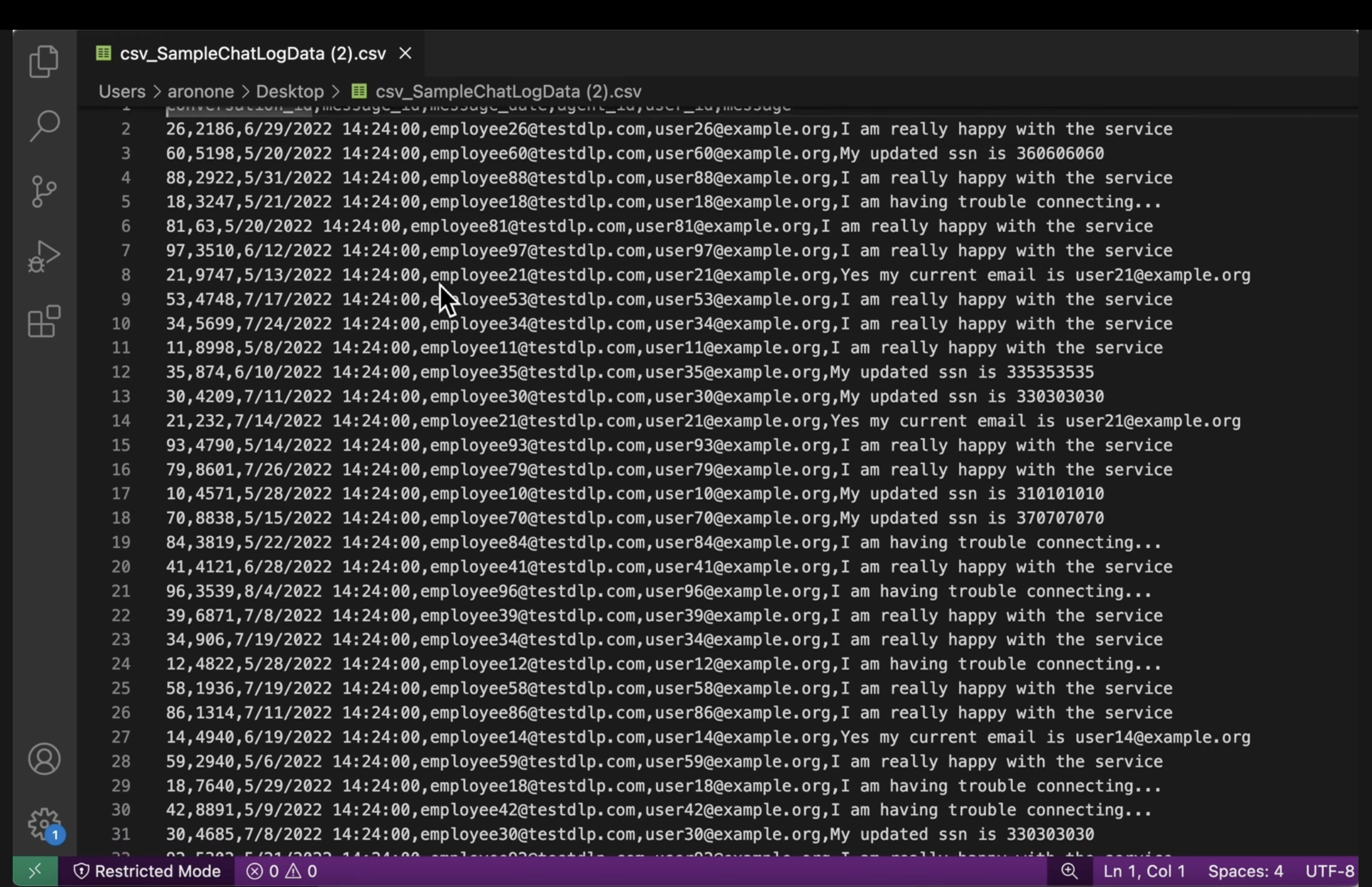
9. Vom Lab in die Praxis: So verwenden Sie das in Ihren eigenen Projekten
Die von Ihnen angewendeten Grundsätze und Konfigurationen sind der Blueprint für die Sicherung realer KI-Projekte in Google Cloud. Die Ressourcen, die Sie gerade erstellt haben – die Prüfvorlage, die De-Identifikationsvorlagen und der automatisierte Job – dienen als sichere Startvorlage für jeden neuen Datenerfassungsprozess.
Die automatisierte Pipeline zur Bereinigung von Daten: Ihre sichere Datenerfassung
So verwenden Sie das in Ihrer Einrichtung
Jedes Mal, wenn Ihr Team neue Rohkundendaten für die KI-Entwicklung aufnehmen muss, leiten Sie sie durch eine Pipeline, in die der von Ihnen konfigurierte Sensitive Data Protection-Job eingebunden ist. Statt die Daten manuell zu prüfen und zu entfernen, nutzen Sie diesen automatisierten Workflow. So wird sichergestellt, dass Data Scientists und KI-Modelle nur mit anonymisierten Daten interagieren, was die Datenschutzrisiken erheblich verringert.
Verbindung zur Produktionsumgebung
In einer Produktionsumgebung würden Sie dieses Konzept noch weiter ausbauen, indem Sie:
- Automatisierung mit Jobtriggern: Anstatt den Job manuell auszuführen, richten Sie einen Jobtrigger ein, wenn eine neue Datei in Ihren Cloud Storage-Eingabe-Bucket hochgeladen wird. So entsteht ein vollständig automatisierter, berührungsloser Prozess zur Erkennung und Anonymisierung.
- Integration mit Data Lakes/Warehouses: Die anonymisierten Ausgabedaten werden in der Regel in einen sicheren Data Lake (z. B. in Cloud Storage) oder ein Data Warehouse (z. B. BigQuery) für weitere Analysen und das Modelltraining eingespeist. So wird sichergestellt, dass der Datenschutz während des gesamten Datenlebenszyklus gewahrt bleibt.
Detaillierte Strategien zur De-Identifikation: Datenschutz und Nützlichkeit in Einklang bringen
So verwenden Sie das in Ihrer Einrichtung
Die verschiedenen De-Identifikationsvorlagen (unstrukturiert, strukturiert, Bild), die Sie erstellt haben, sind entscheidend. Sie würden ähnliche differenzierte Strategien basierend auf den spezifischen Anforderungen Ihrer KI-Modelle anwenden. So kann Ihr Entwicklungsteam Daten mit hohem Nutzen für seine Modelle verwenden, ohne die Privatsphäre zu beeinträchtigen.
Verbindung zur Produktionsumgebung
In einer Produktionsumgebung ist diese detaillierte Kontrolle noch wichtiger für:
- Benutzerdefinierte infoTypes und Wörterbücher: Für sehr spezifische oder domänenspezifische sensible Daten definieren Sie benutzerdefinierte infoTypes und Wörterbücher in Sensitive Data Protection. So wird eine umfassende Erkennung gewährleistet, die auf Ihren individuellen geschäftlichen Kontext zugeschnitten ist.
- Formaterhaltende Verschlüsselung (Format-Preserving Encryption, FPE): In Szenarien, in denen die de-identifizierten Daten ihr ursprüngliches Format beibehalten müssen (z.B. Kreditkartennummern für Integrationstests), sollten Sie erweiterte De-Identifikationstechniken wie die formaterhaltende Verschlüsselung in Betracht ziehen. So können Sie datenschutzkonforme Tests mit realistischen Datenmustern durchführen.
Monitoring und Prüfung: Kontinuierliche Compliance sicherstellen
So verwenden Sie das in Ihrer Einrichtung
Sie würden die Sensitive Data Protection-Protokolle kontinuierlich überwachen, um sicherzustellen, dass die gesamte Datenverarbeitung Ihren Datenschutzrichtlinien entspricht und keine sensiblen Informationen versehentlich offengelegt werden. Die regelmäßige Überprüfung von Jobzusammenfassungen und ‑ergebnissen ist Teil dieses kontinuierlichen Audits.
Verbindung zur Produktionsumgebung
Für ein robustes Produktionssystem sollten Sie die folgenden wichtigen Maßnahmen in Betracht ziehen:
- Ergebnisse an Security Command Center senden: Für ein integriertes Threat Management und eine zentrale Ansicht Ihres Sicherheitsstatus können Sie Ihre Sensitive Data Protection-Jobs so konfigurieren, dass eine Zusammenfassung der Ergebnisse direkt an Security Command Center gesendet wird. Dadurch werden Sicherheitswarnungen und Informationen zusammengefasst.
- Benachrichtigungen und Incident Response: Sie richten Cloud Monitoring-Benachrichtigungen basierend auf Sensitive Data Protection-Ergebnissen oder Jobfehlern ein. So wird Ihr Sicherheitsteam sofort über potenzielle Richtlinienverstöße oder Verarbeitungsprobleme informiert, was eine schnelle Incident Response ermöglicht.
10. Fazit
Das wars! Sie haben das Lab erfolgreich abgeschlossen. Sie haben einen Workflow für Datensicherheit erstellt, mit dem personenbezogene Daten automatisch in verschiedenen Datentypen erkannt und de-identifiziert werden können. So können sie sicher für die nachgelagerte KI-Entwicklung und ‑Analyse verwendet werden.
Zusammenfassung
In diesem Lab haben Sie Folgendes erreicht:
- Sie haben eine Inspektionsvorlage definiert, um bestimmte Arten von vertraulichen Informationen (infoTypes) zu erkennen.
- Es wurden separate De-Identifikationsregeln für unstrukturierte, strukturierte und Bilddaten erstellt.
- Sie haben einen einzelnen Job konfiguriert und ausgeführt, bei dem automatisch die richtige Schwärzung basierend auf dem Dateityp auf den Inhalt eines gesamten Buckets angewendet wurde.
- Die erfolgreiche Transformation sensibler Daten an einem sicheren Ausgabespeicherort wurde überprüft.
Nächste Schritte
- Ergebnisse an Security Command Center senden: Für ein integriertes Threat Management können Sie die Jobaktion so konfigurieren, dass eine Zusammenfassung der Ergebnisse direkt an Security Command Center gesendet wird.
- Mit Cloud Functions automatisieren: In einer Produktionsumgebung können Sie diesen Prüfjob automatisch auslösen, wenn eine neue Datei in den Eingabe-Bucket hochgeladen wird. Dazu verwenden Sie eine Cloud Functions-Funktion.