
1. Introducción
Descripción general
En este lab, compilarás una canalización de limpieza de datos automatizada para proteger la información sensible que se usa en el desarrollo de la IA. Usas Sensitive Data Protection de Google Cloud (antes Cloud DLP) para inspeccionar, clasificar y desidentificar la información de identificación personal (PII) en una variedad de formatos de datos, incluidos texto no estructurado, tablas estructuradas y imágenes.
Context
Eres el defensor de la seguridad y la privacidad en tu equipo de desarrollo, y tu objetivo es establecer un flujo de trabajo que identifique la información sensible y la anonimice antes de que esté disponible para los desarrolladores y los modelos. Tu equipo necesita datos realistas y de alta calidad para ajustar y probar una nueva aplicación de IA generativa, pero el uso de datos de clientes sin procesar plantea desafíos importantes en cuanto a la privacidad.
En la siguiente tabla, se enumeran los riesgos de privacidad que más te preocupan mitigar:
Riesgo | Mitigación |
Exposición de PII en archivos de texto no estructurados (p. ej., registros de chat de asistencia, formularios de comentarios) | Crea una plantilla de desidentificación que reemplace los valores sensibles por su infoType, lo que preserva el contexto y, a la vez, elimina la exposición. |
Pérdida de utilidad de los datos en conjuntos de datos estructurados (CSV) cuando se quita la IIP | Usa transformaciones de registros para ocultar de forma selectiva los identificadores (como los nombres) y aplicar técnicas como el enmascaramiento de caracteres para conservar otros caracteres en la cadena, de modo que los desarrolladores puedan seguir realizando pruebas con los datos. |
Exposición de la IIP a partir del texto incorporado en imágenes (p. ej., documentos escaneados, fotos de usuarios) | Crea una plantilla de desidentificación específica para imágenes que oculte el texto que se encuentra en las imágenes. |
Redacción manual inconsistente o propensa a errores en diferentes tipos de datos | Configura un solo trabajo automatizado de Sensitive Data Protection que aplique de forma coherente la plantilla de desidentificación correcta según el tipo de archivo que procesa. |
Qué aprenderás
En este lab, aprenderás a realizar las siguientes tareas:
- Define una plantilla de inspección para detectar tipos de información sensible específicos (infoTypes).
- Crea reglas de desidentificación distintas para los datos no estructurados, estructurados y de imágenes.
- Configurar y ejecutar un solo trabajo que aplique automáticamente la ocultación correcta según el tipo de archivo al contenido de un bucket completo
- Verifica la transformación correcta de los datos sensibles en una ubicación de salida segura.
2. Configura el proyecto
Cuenta de Google
Si aún no tienes una Cuenta de Google personal, debes crear una.
Usa una cuenta personal en lugar de una cuenta laboral o educativa.
Accede a la consola de Google Cloud
Accede a la consola de Google Cloud con una Cuenta de Google personal.
Habilitar facturación
Canjea créditos de Google Cloud (opcional)
Para realizar este taller, necesitas una cuenta de facturación con algo de crédito. Usa los créditos del banner que se encuentra en la parte superior de este codelab para comenzar. Si ya te conectaste a una cuenta de facturación, puedes omitir este paso.
Configura una cuenta de facturación personal
Si configuraste la facturación con créditos de Google Cloud, puedes omitir este paso.
Para configurar una cuenta de facturación personal, ve aquí para habilitar la facturación en la consola de Cloud.
Algunas notas:
- Completar este lab debería costar menos de USD 1 en recursos de Cloud.
- Puedes seguir los pasos al final de este lab para borrar recursos y evitar cargos adicionales.
- Los usuarios nuevos pueden acceder a la prueba gratuita de USD 300.
Crear un proyecto (opcional)
Si no tienes un proyecto actual que quieras usar para este lab, crea uno nuevo aquí.
3. Habilita las APIs
Configura Cloud Shell
Una vez que se haya creado tu proyecto correctamente, sigue estos pasos para configurar Cloud Shell.
Inicia Cloud Shell
Navega a shell.cloud.google.com y, si ves una ventana emergente que te pide que autorices, haz clic en Autorizar.
Configura el ID del proyecto
Ejecuta el siguiente comando en la terminal de Cloud Shell para establecer el ID del proyecto correcto. Reemplaza <your-project-id> por el ID del proyecto real que copiaste en el paso de creación del proyecto anterior.
gcloud config set project <your-project-id>
Ahora deberías ver que se seleccionó el proyecto correcto en la terminal de Cloud Shell.
Habilita Sensitive Data Protection
Para usar el servicio de Protección de datos sensibles y Cloud Storage, debes asegurarte de que estas APIs estén habilitadas en tu proyecto de Google Cloud.
- En la terminal, habilita las APIs:
gcloud services enable dlp.googleapis.com storage.googleapis.com
Como alternativa, puedes habilitar estas APIs navegando a Seguridad > Sensitive Data Protection y Cloud Storage en la consola, y haciendo clic en el botón Habilitar si se te solicita para cada servicio.
4. Crea buckets con datos sensibles
Crea un bucket de entrada y salida
En este paso, crearás dos buckets: uno para almacenar los datos sensibles que se deben inspeccionar y otro en el que Sensitive Data Protection almacenará los archivos de salida desidentificados. También descargarás archivos de datos de muestra y los subirás a tu bucket de entrada.
- En la terminal, ejecuta los siguientes comandos para crear un bucket para los datos de entrada y otro para los de salida. Luego, completa el bucket de entrada con datos de muestra de
gs://dlp-codelab-data:PROJECT_ID=$(gcloud config get-value project) gsutil mb gs://input-$PROJECT_ID gsutil mb gs://output-$PROJECT_ID
Agrega datos sensibles al bucket de entrada
En este paso, descargarás archivos de datos de muestra que contienen PII de prueba desde GitHub y los subirás a tu bucket de entrada.
- En Cloud Shell, ejecuta el siguiente comando para clonar el repositorio
devrel-demos, que contiene los datos de muestra necesarios para este lab.REPO_URL="https://github.com/GoogleCloudPlatform/devrel-demos.git" TARGET_PATH="security/sample-data" OUTPUT_FOLDER="sample-data" git clone --quiet --depth 1 --filter=blob:none --sparse "$REPO_URL" temp_loader cd temp_loader git sparse-checkout set "$TARGET_PATH" cd .. mv "temp_loader/$TARGET_PATH" "$OUTPUT_FOLDER" rm -rf temp_loader - A continuación, copia los datos de muestra en el bucket de entrada que creaste anteriormente:
gsutil -m cp -r sample-data/* gs://input-$PROJECT_ID/ - Ve a Cloud Storage > Buckets y haz clic en el bucket de entrada para ver los datos que importaste.
5. Crea una plantilla de inspección
En esta tarea, crearás una plantilla que le indicará a Sensitive Data Protection qué buscar. Esto te permite enfocar la inspección en los infoTypes que son relevantes para tus datos y tu ubicación geográfica, lo que mejora el rendimiento y la precisión.
Crea una plantilla de inspección
En este paso, definirás las reglas sobre lo que constituye datos sensibles que deben inspeccionarse. Tus trabajos de desidentificación reutilizarán esta plantilla para garantizar la coherencia.
- En el menú de navegación, ve a Sensitive Data Protection > Configuración > Plantillas.
- Haz clic en Crear plantilla.
- En Tipo de plantilla, selecciona Inspeccionar (buscar datos sensibles).
- Establece el ID de plantilla en
pii-finder. - Haz clic en Continuar para ir a Configurar detección.
- Haz clic en Administrar Infotipos.
- Con el filtro, busca los siguientes infoTypes y marca la casilla de verificación junto a cada uno:
CREDIT_CARD_EXPIRATION_DATECREDIT_CARD_NUMBERDATE_OF_BIRTHDRIVERS_LICENSE_NUMBEREMAIL_ADDRESSGCP_API_KEYGCP_CREDENTIALSORGANIZATION_NAMEPASSWORDPERSON_NAMEPHONE_NUMBERUS_SOCIAL_SECURITY_NUMBER
- Selecciona los demás que te interesen y haz clic en Listo.
- Revisa la tabla resultante para asegurarte de que se hayan agregado todos estos infoTypes.
- Haz clic en Crear.
6. Crea plantillas de desidentificación
A continuación, crearás tres plantillas de desidentificación independientes para controlar diferentes formatos de datos. Esto te brinda un control detallado sobre el proceso de transformación, ya que aplica el método más adecuado para cada tipo de archivo. Estas plantillas funcionan en conjunto con la plantilla de inspección que acabas de crear.
Crea una plantilla para datos no estructurados
Esta plantilla definirá cómo se desidentifican los datos sensibles que se encuentran en texto de formato libre, como los registros de chat o los formularios de comentarios. El método elegido reemplaza el valor sensible por el nombre de su infoType, lo que preserva el contexto.
- En la página Plantillas, haz clic en Crear plantilla.
- Define la plantilla de desidentificación:
Propiedad
Valor (escríbelo o selecciónalo)
Tipo de plantilla
Desidentificar (quitar datos sensibles)
Tipo de transformación de datos
Infotipo
ID de plantilla
de-identify-unstructured - Haz clic en Continuar para ir a Configurar la desidentificación.
- En Método de transformación, selecciona la transformación: Reemplazar por el nombre del infotipo.
- Haz clic en Crear.
- Haga clic en Probar.
- Prueba un mensaje que contenga PII para ver cómo se transformará:
Hi, my name is Alex and my SSN is 555-11-5555. You can reach me at +1-555-555-5555.
Crea una plantilla para datos estructurados
Esta plantilla se enfoca específicamente en la información sensible dentro de los conjuntos de datos estructurados, como los archivos CSV. Lo configurarás para enmascarar los datos de manera que se conserve la utilidad de los datos para las pruebas y, al mismo tiempo, se desidentifiquen los campos sensibles.
- Regresa a la página Plantillas y haz clic en Crear plantilla.
- Define la plantilla de desidentificación:
Propiedad
Valor (escríbelo o selecciónalo)
Tipo de plantilla
Desidentificar (quitar datos sensibles)
Tipo de transformación de datos
Grabar
ID de plantilla
de-identify-structured - Haz clic en Continuar para configurar la desidentificación.Como esta plantilla se aplica a datos estructurados, a menudo podemos predecir los campos o las columnas que contendrán ciertos tipos de datos sensibles. Sabes que el CSV que usa tu aplicación tiene correos electrónicos de usuarios en
user_idy quemessagea menudo contiene PII de las interacciones con los clientes. No te preocupa enmascararagent_id, ya que se trata de empleados y las conversaciones deben ser atribuibles. Completa esta sección de la siguiente manera:- Campos o columnas para transformar:
user_id,message. - Tipo de transformación: Coincidencia en el Infotipo
- Método de transformación: Haz clic en Agregar transformación.
- Transformación: Enmascaramiento con caracteres.
- Caracteres que se deben ignorar: Puntuación de EE.UU.
- Campos o columnas para transformar:
- Haz clic en Crear.
Crea una plantilla para datos de imágenes
Esta plantilla está diseñada para desidentificar el texto sensible que se encuentra incorporado en imágenes, como documentos escaneados o fotos enviadas por los usuarios. Aprovecha el reconocimiento óptico de caracteres (OCR) para detectar y ocultar la PII.
- Regresa a la página Plantillas y haz clic en Crear plantilla.
- Define la plantilla de desidentificación:
Propiedad
Valor (escríbelo o selecciónalo)
Tipo de plantilla
Desidentificar (quitar datos sensibles)
Tipo de transformación de datos
Imagen
ID de plantilla
de-identify-image - Haz clic en Continuar para ir a Configurar la desidentificación.
- Infotipos para transformar: Cualquier infotipo detectado definido en una configuración o plantilla de inspección que no se haya especificado en otras reglas.
- Haz clic en Crear.
7. Crea y ejecuta un trabajo de desidentificación
Con las plantillas definidas, ahora crearás un solo trabajo que aplique la plantilla de desidentificación correcta según el tipo de archivo que detecte e inspeccione. Esto automatiza el proceso de protección de datos sensibles para los datos almacenados en Cloud Storage.
Configura los datos de entrada
En este paso, especificarás la fuente de los datos que necesitan desidentificación, que es un bucket de Cloud Storage que contiene varios tipos de archivos con información sensible.
- Navega a Seguridad > Sensitive Data Protection a través de la barra de búsqueda.
- Haz clic en Inspección en el menú.
- Haz clic en Crear trabajo y activadores de trabajos.
- Configura el trabajo:
Propiedad
Valor (escríbelo o selecciónalo)
ID de tarea
pii-removerTipo de almacenamiento
Google Cloud Storage
Tipo de ubicación
Analiza un bucket con reglas de inclusión/exclusión opcionales
Nombre del bucket
input-[your-project-id]
Configura la detección y las acciones
Ahora vincularás las plantillas que creaste anteriormente a este trabajo, lo que le indicará a Sensitive Data Protection cómo inspeccionar la IIP y qué método de desidentificación aplicar según el tipo de contenido.
- Plantilla de inspección:
projects/[your-project-id]/locations/global/inspectTemplates/pii-finder - En Agregar acciones, selecciona Hacer una copia desidentificada y configura las plantillas de transformación para que sean las que creaste.
- Se abrirá una ventana emergente para que
Confirm whether you want to de-identify the findings. Haz clic en DISABLE SAMPLING.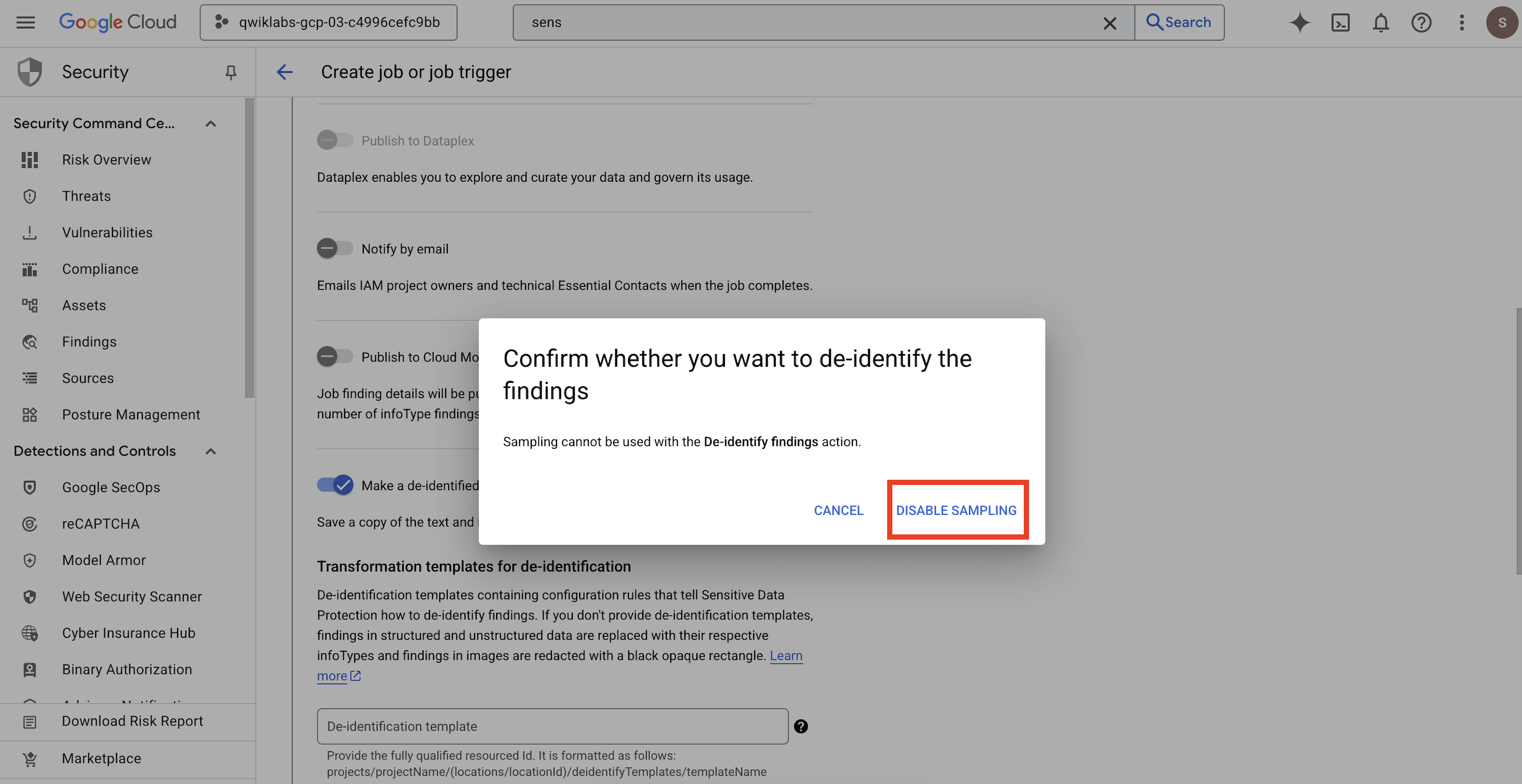
Propiedad
Valor (escríbelo o selecciónalo)
Plantilla de desidentificación
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-unstructuredPlantilla de desidentificación estructurada
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-structuredPlantilla de ocultamiento en imágenes
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-image - Configura la ubicación de salida de Cloud Storage:
- URL:
gs://output-[your-project-id]
- URL:
- En Programa, deja la selección como Ninguna para ejecutar el trabajo de inmediato.
- Haz clic en Crear.
- Se abrirá una ventana emergente en
Confirm job or job trigger create. Haz clic en CONFIRMAR CREACIÓN.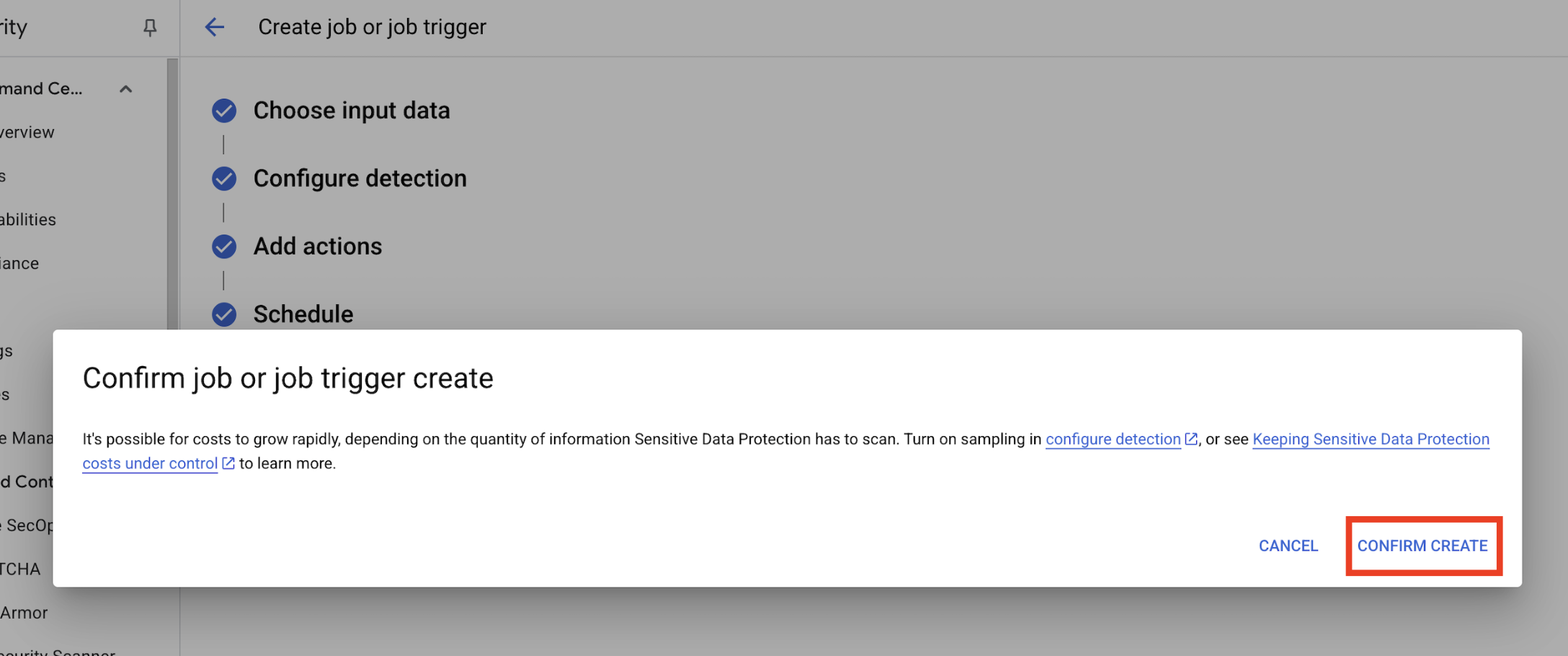
8. Verifica los resultados
El último paso es confirmar que los datos sensibles se hayan ocultado correctamente en todos los tipos de archivos del bucket de salida. Esto garantiza que tu canalización de seudoanonimización funcione según lo previsto.
Revisa el estado del trabajo
Supervisa el trabajo para asegurarte de que se complete correctamente y revisa el resumen de los hallazgos antes de verificar los archivos de salida.
- En la pestaña Detalles del trabajo, espera a que el trabajo muestre el estado Listo.
- En Resumen, revisa la cantidad de hallazgos y los porcentajes de cada infoType detectado.
- Haz clic en Configuración.
- Desplázate hacia abajo hasta Acciones y haz clic en el bucket de salida para ver los datos anonimizados:
gs://output-[your-project-id].
Compara archivos de entrada y salida
En este paso, inspeccionarás manualmente los archivos desidentificados para confirmar que la limpieza de datos se aplicó correctamente según tus plantillas.
- Imágenes: Abre una imagen del bucket de salida. Verifica que todo el texto sensible se haya ocultado en el archivo de salida.

- Registros sin estructura: Visualiza un archivo de registro de ambos buckets. Confirma que la PII del registro de salida se haya reemplazado por el nombre del infoType (p.ej.,
[US_SOCIAL_SECURITY_NUMBER]). - CSV estructurados: Abre un archivo CSV de ambos segmentos. Verifica que los correos electrónicos y los NSS de los usuarios en el archivo de resultado estén enmascarados con
####@####.com.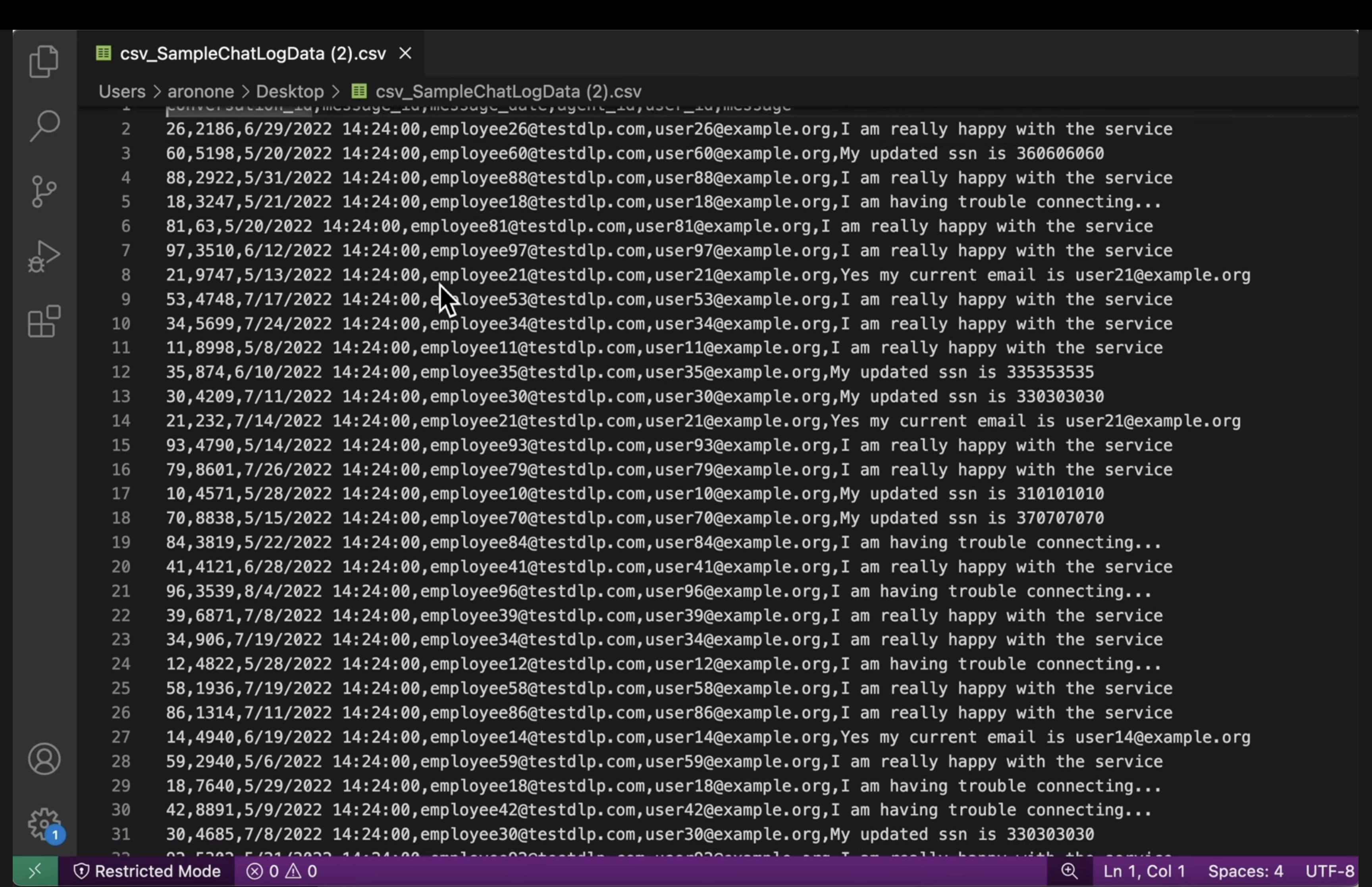
9. Del lab a la realidad: Cómo usarla en tus propios proyectos
Los principios y las configuraciones que aplicaste son el plano para proteger proyectos de IA del mundo real en Google Cloud. Los recursos que acabas de crear (la plantilla de inspección, las plantillas de desidentificación y el trabajo automatizado) actúan como una plantilla de inicio segura para cualquier proceso nuevo de ingreso de datos.
Canalización de limpieza de datos automatizada: Tu entrada de datos segura
Cómo usarías esto en tu configuración
Cada vez que tu equipo necesite transferir datos sin procesar nuevos de los clientes para el desarrollo de la IA, los dirigirás a través de una canalización que incorpore el trabajo de Sensitive Data Protection que configuraste. En lugar de inspeccionar y ocultar manualmente, aprovecha este flujo de trabajo automatizado. Esto garantiza que los científicos de datos y los modelos de IA solo interactúen con datos anonimizados, lo que reduce significativamente los riesgos de privacidad.
Conexión con producción
En un entorno de producción, llevarías este concepto aún más lejos de la siguiente manera:
- Automatización con activadores de trabajos: En lugar de ejecutar el trabajo de forma manual, configurarías un activador de trabajos cada vez que se suba un archivo nuevo a tu bucket de Cloud Storage de entrada. Esto crea un proceso de detección y anonimización completamente automatizado y sin intervención manual.
- Integración con data lakes o almacenes de datos: Los datos de salida anonimizados suelen enviarse a un data lake seguro (p.ej., en Cloud Storage) o a un almacén de datos (p.ej., BigQuery) para su posterior análisis y entrenamiento de modelos, lo que garantiza que se mantenga la privacidad durante todo el ciclo de vida de los datos.
Estrategias de desidentificación detalladas: Equilibrio entre privacidad y utilidad
Cómo usarías esto en tu configuración
Las diferentes plantillas de desidentificación (no estructurada, estructurada, de imagen) que creaste son clave. Aplicarías estrategias diferenciadas similares según las necesidades específicas de tus modelos de IA. Esto permite que tu equipo de desarrollo tenga datos de alta utilidad para sus modelos sin comprometer la privacidad.
Conexión con producción
En un entorno de producción, este control detallado se vuelve aún más importante para lo siguiente:
- Infotipos y diccionarios personalizados: Para los datos sensibles altamente específicos o específicos del dominio, definirías infotipos y diccionarios personalizados dentro de Sensitive Data Protection. Esto garantiza una detección integral adaptada al contexto único de tu empresa.
- Encriptación de preservación de formato (FPE): Para situaciones en las que los datos desidentificados deben conservar su formato original (p.ej., números de tarjetas de crédito para pruebas de integración), puedes explorar técnicas avanzadas de desidentificación, como la encriptación de preservación de formato. Esto permite realizar pruebas que preservan la privacidad con patrones de datos realistas.
Supervisión y auditoría: Garantiza el cumplimiento continuo
Cómo usarías esto en tu configuración
Supervisarías continuamente los registros de Sensitive Data Protection para asegurarte de que todo el procesamiento de datos cumpla con tus políticas de privacidad y de que no se exponga información sensible de forma involuntaria. Revisar periódicamente los resúmenes y los resultados de los trabajos forma parte de esta auditoría continua.
Conexión con producción
Para un sistema de producción sólido, considera estas acciones clave:
- Envía los hallazgos a Security Command Center: Para obtener una administración de amenazas integrada y una vista centralizada de tu postura de seguridad, configura tus trabajos de Sensitive Data Protection para que envíen un resumen de sus hallazgos directamente a Security Command Center. Esto consolida las alertas y las estadísticas de seguridad.
- Alertas y respuesta ante incidentes: Configurarías alertas de Cloud Monitoring basadas en los resultados de Sensitive Data Protection o en fallas de trabajos. Esto garantiza que tu equipo de seguridad reciba una notificación inmediata sobre cualquier posible incumplimiento de política o problema de procesamiento, lo que permite una respuesta rápida ante incidentes.
10. Conclusión
¡Felicitaciones! Creaste correctamente un flujo de trabajo de seguridad de los datos que puede descubrir y desidentificar automáticamente la PII en varios tipos de datos, lo que hace que sea seguro usarla en el desarrollo de IA y el análisis posteriores.
Resumen
En este lab, realizaste las siguientes tareas:
- Se definió una plantilla de inspección para detectar tipos específicos de información sensible (infoTypes).
- Se crearon reglas de desidentificación distintas para los datos no estructurados, estructurados y de imágenes.
- Configuró y ejecutó un solo trabajo que aplicó automáticamente la ocultación correcta según el tipo de archivo al contenido de un bucket completo.
- Se verificó la transformación exitosa de los datos sensibles en una ubicación de salida segura.
Próximos pasos
- Enviar resultados a Security Command Center: Para una administración de amenazas más integrada, configura la acción del trabajo para enviar un resumen de sus resultados directamente a Security Command Center.
- Automatiza con Cloud Functions: En un entorno de producción, puedes activar este trabajo de inspección automáticamente cada vez que se suba un archivo nuevo al bucket de entrada con una Cloud Function.