
۱. مقدمه
نمای کلی
در این آزمایشگاه، شما یک خط لوله خودکار پاکسازی دادهها برای محافظت از اطلاعات حساس مورد استفاده در توسعه هوش مصنوعی میسازید. شما از قابلیت حفاظت از دادههای حساس گوگل کلود (که قبلاً Cloud DLP نام داشت) برای بازرسی، طبقهبندی و شناساییزدایی اطلاعات شخصی قابل شناسایی (PII) در قالبهای مختلف داده، از جمله متن بدون ساختار، جداول ساختاریافته و تصاویر، استفاده میکنید.
زمینه
شما قهرمان امنیت و حریم خصوصی در تیم توسعه خود هستید و هدف شما ایجاد یک گردش کار است که اطلاعات حساس را شناسایی کرده و قبل از در دسترس قرار دادن آنها برای توسعهدهندگان و مدلها، آنها را از حالت شناسایی خارج کند. تیم شما برای تنظیم و آزمایش یک برنامه جدید هوش مصنوعی مولد به دادههای واقعبینانه و با کیفیت بالا نیاز دارد، اما استفاده از دادههای خام مشتری چالشهای قابل توجهی در زمینه حریم خصوصی ایجاد میکند.
جدول زیر فهرستی از خطرات حریم خصوصی را که شما بیشتر نگران کاهش آنها هستید، نشان میدهد:
ریسک | کاهش خطر |
افشای اطلاعات شخصی (PII) در فایلهای متنی بدون ساختار (مثلاً گزارشهای چت پشتیبانی، فرمهای بازخورد). | یک الگوی حذف هویت ایجاد کنید که مقادیر حساس را با infoType آنها جایگزین کند و ضمن حذف افشای اطلاعات، زمینه را حفظ کند. |
از دست دادن کاربرد دادهها در مجموعه دادههای ساختاریافته (CSV) هنگام حذف PII. | از تبدیلهای رکورد برای ویرایش انتخابی شناسهها (مانند نامها) استفاده کنید و تکنیکهایی مانند پوشش کاراکتر را برای حفظ سایر کاراکترهای رشته اعمال کنید، تا توسعهدهندگان همچنان بتوانند با دادهها آزمایش کنند. |
افشای اطلاعات شخصی از طریق متن جاسازیشده در تصاویر (مثلاً اسناد اسکنشده، عکسهای کاربر). | یک الگوی حذف هویت مخصوص تصویر ایجاد کنید که متن موجود در تصاویر را ویرایش کند. |
ویرایش دستی ناهماهنگ یا مستعد خطا در انواع مختلف داده. | یک کار واحد و خودکار برای حفاظت از دادههای حساس پیکربندی کنید که به طور مداوم الگوی صحیح حذف هویت را بر اساس نوع فایلی که پردازش میکند، اعمال کند. |
آنچه یاد خواهید گرفت
در این آزمایشگاه، شما یاد میگیرید که چگونه:
- یک الگوی بازرسی برای تشخیص انواع اطلاعات حساس خاص ( infoTypes ) تعریف کنید.
- قوانین متمایزی برای عدم شناسایی دادههای بدون ساختار، ساختاریافته و تصویر ایجاد کنید.
- یک کار واحد را پیکربندی و اجرا کنید که به طور خودکار ویرایش صحیح را بر اساس نوع فایل به محتویات کل یک سطل اعمال کند .
- تبدیل موفقیتآمیز دادههای حساس را در یک مکان خروجی امن تأیید کنید.
۲. راهاندازی پروژه
حساب گوگل
اگر از قبل حساب گوگل شخصی ندارید، باید یک حساب گوگل ایجاد کنید .
به جای حساب کاری یا تحصیلی از حساب شخصی استفاده کنید .
ورود به کنسول ابری گوگل
با استفاده از یک حساب کاربری شخصی گوگل، وارد کنسول ابری گوگل شوید.
فعال کردن صورتحساب
استفاده از اعتبار گوگل کلود (اختیاری)
برای اجرای این کارگاه، به یک حساب صورتحساب با مقداری اعتبار نیاز دارید. برای شروع از اعتبارهای موجود در بنر بالای این codelab استفاده کنید. اگر از قبل به یک حساب صورتحساب متصل هستید، میتوانید از این مرحله صرف نظر کنید.
یک حساب پرداخت شخصی تنظیم کنید
اگر صورتحساب را با استفاده از اعتبارهای Google Cloud تنظیم کردهاید، میتوانید از این مرحله صرف نظر کنید.
برای تنظیم یک حساب پرداخت شخصی، به اینجا بروید تا پرداخت را در کنسول ابری فعال کنید .
برخی نکات:
- تکمیل این آزمایشگاه باید کمتر از ۱ دلار آمریکا از طریق منابع ابری هزینه داشته باشد.
- شما میتوانید مراحل انتهای این آزمایش را برای حذف منابع دنبال کنید تا از هزینههای بیشتر جلوگیری شود.
- کاربران جدید واجد شرایط استفاده از دوره آزمایشی رایگان ۳۰۰ دلاری هستند.
ایجاد پروژه (اختیاری)
اگر پروژه فعلی ندارید که بخواهید برای این آزمایشگاه استفاده کنید، اینجا یک پروژه جدید ایجاد کنید .
۳. فعال کردن APIها
پیکربندی Cloud Shell
پس از ایجاد موفقیتآمیز پروژه، مراحل زیر را برای راهاندازی Cloud Shell انجام دهید.
راه اندازی پوسته ابری
به shell.cloud.google.com بروید و اگر پنجرهای را مشاهده کردید که از شما درخواست مجوز میکند، روی Authorize کلیک کنید.
تنظیم شناسه پروژه
دستور زیر را در ترمینال Cloud Shell اجرا کنید تا شناسه پروژه صحیح تنظیم شود. <your-project-id> را با شناسه پروژه واقعی خود که از مرحله ایجاد پروژه در بالا کپی کردهاید، جایگزین کنید.
gcloud config set project <your-project-id>
اکنون باید ببینید که پروژه صحیح در ترمینال Cloud Shell انتخاب شده است.
فعال کردن محافظت از دادههای حساس
برای استفاده از سرویس حفاظت از دادههای حساس و فضای ذخیرهسازی ابری، باید مطمئن شوید که این APIها در پروژه Google Cloud شما فعال هستند.
- در ترمینال، APIها را فعال کنید:
gcloud services enable dlp.googleapis.com storage.googleapis.com
از طرف دیگر، میتوانید این APIها را با رفتن به بخش امنیت > حفاظت از دادههای حساس و ذخیرهسازی ابری در کنسول و کلیک بر روی دکمه فعالسازی در صورت درخواست برای هر سرویس، فعال کنید.
۴. ایجاد سطلهایی با دادههای حساس
ایجاد یک سطل ورودی و خروجی
در این مرحله، شما دو سطل ایجاد میکنید: یکی برای نگهداری دادههای حساسی که نیاز به بررسی دارند، و دیگری جایی که Sensitive Data Protection فایلهای خروجیِ از رده خارجشده را ذخیره میکند. همچنین فایلهای داده نمونه را دانلود کرده و آنها را در سطل ورودی خود آپلود میکنید.
- در ترمینال، دستورات زیر را اجرا کنید تا یک سطل برای دادههای ورودی و یکی برای خروجی ایجاد شود، سپس سطل ورودی را با دادههای نمونه از
gs://dlp-codelab-dataپر کنید:PROJECT_ID=$(gcloud config get-value project) gsutil mb gs://input-$PROJECT_ID gsutil mb gs://output-$PROJECT_ID
دادههای حساس را به سطل ورودی اضافه کنید
در این مرحله، فایلهای داده نمونه حاوی اطلاعات شناسایی شخصی (PII) آزمایشی را از گیتهاب دانلود کرده و آنها را در مخزن ورودی خود بارگذاری میکنید.
- در Cloud Shell، دستور زیر را برای کلون کردن مخزن
devrel-demosکه شامل دادههای نمونه مورد نیاز برای این آزمایش است، اجرا کنید.REPO_URL="https://github.com/GoogleCloudPlatform/devrel-demos.git" TARGET_PATH="security/sample-data" OUTPUT_FOLDER="sample-data" git clone --quiet --depth 1 --filter=blob:none --sparse "$REPO_URL" temp_loader cd temp_loader git sparse-checkout set "$TARGET_PATH" cd .. mv "temp_loader/$TARGET_PATH" "$OUTPUT_FOLDER" rm -rf temp_loader - سپس، دادههای نمونه را در سطل ورودی که قبلاً ایجاد کردهاید، کپی کنید:
gsutil -m cp -r sample-data/* gs://input-$PROJECT_ID/ - به Cloud Storage > Buckets بروید و روی سطل ورودی کلیک کنید تا دادههایی که وارد کردهاید را ببینید.
۵. یک الگوی بازرسی ایجاد کنید
در این وظیفه، شما یک الگو ایجاد میکنید که به بخش حفاظت از دادههای حساس میگوید به دنبال چه چیزی بگردد. این به شما امکان میدهد تا بازرسی را روی انواع اطلاعاتی که مربوط به دادهها و جغرافیای شما هستند متمرکز کنید و عملکرد و دقت را بهبود بخشید.
ایجاد یک الگوی بازرسی
در این مرحله، شما قوانینی را برای دادههای حساسی که نیاز به بررسی دارند، تعریف میکنید. این الگو توسط کارهای شناسایی مجدد شما برای اطمینان از ثبات، مجدداً استفاده خواهد شد.
- از منوی پیمایش، به مسیر حفاظت از دادههای حساس > پیکربندی > الگوها بروید.
- روی ایجاد الگو کلیک کنید.
- برای نوع الگو (Template type )، گزینهی «بازرسی (یافتن دادههای حساس)» را انتخاب کنید.
- شناسه الگو را روی
pii-finderتنظیم کنید. - به پیکربندی تشخیص ادامه دهید .
- روی مدیریت انواع اطلاعات کلیک کنید.
- با استفاده از فیلتر، انواع اطلاعات زیر را جستجو کنید و کادر کنار هر کدام را علامت بزنید:
-
CREDIT_CARD_EXPIRATION_DATE -
CREDIT_CARD_NUMBER -
DATE_OF_BIRTH -
DRIVERS_LICENSE_NUMBER -
EMAIL_ADDRESS -
GCP_API_KEY -
GCP_CREDENTIALS -
ORGANIZATION_NAME -
PASSWORD -
PERSON_NAME -
PHONE_NUMBER -
US_SOCIAL_SECURITY_NUMBER
-
- هر مورد دیگری را که به آن علاقه دارید نیز انتخاب کنید و روی «انجام شد» کلیک کنید.
- جدول حاصل را بررسی کنید تا مطمئن شوید که همه این infoTypes ها اضافه شدهاند.
- روی ایجاد کلیک کنید.
۶. الگوهای حذف هویت ایجاد کنید
در مرحله بعد، شما سه الگوی حذف هویت جداگانه برای مدیریت فرمتهای مختلف داده ایجاد میکنید. این به شما کنترل دقیقی بر فرآیند تبدیل میدهد و مناسبترین روش را برای هر نوع فایل اعمال میکند. این الگوها در کنار الگوی بازرسی که اخیراً ایجاد کردهاید، کار میکنند.
ایجاد الگو برای دادههای بدون ساختار
این الگو نحوهی شناساییزدایی دادههای حساس موجود در متنهای آزاد، مانند گزارشهای چت یا فرمهای بازخورد، را تعریف میکند. روش انتخابشده، مقدار حساس را با نام infoType آن جایگزین میکند و زمینه را حفظ میکند.
- در صفحه قالبها ، روی ایجاد قالب کلیک کنید.
- الگوی حذف هویت را تعریف کنید:
ملک
مقدار (نوع یا انتخاب)
نوع الگو
عدم شناسایی (حذف دادههای حساس)
نوع تبدیل داده
نوع اطلاعات
شناسه الگو
de-identify-unstructured - به پیکربندی حذف هویت ادامه دهید .
- در زیر روش تبدیل (Transformation method )، گزینه تبدیل: جایگزینی با نام infoType را انتخاب کنید.
- روی ایجاد کلیک کنید.
- روی تست کلیک کنید.
- یک پیام حاوی PII را آزمایش کنید تا ببینید چگونه تبدیل میشود:
Hi, my name is Alex and my SSN is 555-11-5555. You can reach me at +1-555-555-5555.
ایجاد الگو برای دادههای ساختاریافته
این الگو بهطور خاص اطلاعات حساس درون مجموعه دادههای ساختاریافته ، مانند فایلهای CSV را هدف قرار میدهد. شما آن را طوری پیکربندی خواهید کرد که دادهها را به گونهای پنهان کند که کاربرد دادهها را برای آزمایش حفظ کند و در عین حال فیلدهای حساس را از شناسایی خارج کند.
- به صفحه قالبها برگردید و روی ایجاد قالب کلیک کنید.
- الگوی حذف هویت را تعریف کنید:
ملک
مقدار (نوع یا انتخاب)
نوع الگو
عدم شناسایی (حذف دادههای حساس)
نوع تبدیل داده
رکورد
شناسه الگو
de-identify-structured - ادامه پیکربندی عدم شناسایی . از آنجایی که این الگو برای دادههای ساختاریافته اعمال میشود، اغلب میتوانیم فیلدها یا ستونهایی را که حاوی انواع خاصی از دادههای حساس هستند، پیشبینی کنیم. میدانید که CSV که برنامه شما استفاده میکند، ایمیلهای کاربر را تحت
user_idدارد و آنmessageاغلب حاوی PII از تعاملات مشتری است. شما نگران پنهان کردنagent_idنیستید زیرا آنها کارمندان هستند و مکالمات باید قابل انتساب باشند. این بخش را به شرح زیر پر کنید:- فیلد(ها) یا ستون(ها) برای تبدیل :
user_id،message. - نوع تبدیل : تطابق با infoType
- روش تبدیل : روی افزودن تبدیل کلیک کنید
- دگرگونی : ماسکی با شخصیت.
- کاراکترهایی که باید نادیده گرفته شوند : علائم نگارشی آمریکایی.
- فیلد(ها) یا ستون(ها) برای تبدیل :
- روی ایجاد کلیک کنید.
ایجاد الگو برای دادههای تصویر
این الگو برای شناسایی متن حساس جاسازیشده در تصاویر ، مانند اسناد اسکنشده یا عکسهای ارسالی کاربر، طراحی شده است. این الگو از تشخیص کاراکتر نوری (OCR) برای شناسایی و ویرایش PII استفاده میکند.
- به صفحه قالبها برگردید و روی ایجاد قالب کلیک کنید.
- الگوی حذف هویت را تعریف کنید:
ملک
مقدار (نوع یا انتخاب)
نوع الگو
عدم شناسایی (حذف دادههای حساس)
نوع تبدیل داده
تصویر
شناسه الگو
de-identify-image - به پیکربندی حذف هویت ادامه دهید .
- انواع اطلاعات برای تبدیل: هرگونه نوع اطلاعات شناساییشده که در یک الگوی بازرسی یا پیکربندی بازرسی تعریف شدهاند و در قوانین دیگر مشخص نشدهاند .
- روی ایجاد کلیک کنید.
۷. یک کار حذف هویت ایجاد و اجرا کنید
با تعریف قالبهایتان، اکنون یک کار واحد ایجاد میکنید که الگوی صحیح حذف هویت را بر اساس نوع فایلی که شناسایی و بررسی میکند، اعمال میکند. این کار فرآیند حفاظت از دادههای حساس را برای دادههای ذخیره شده در فضای ذخیرهسازی ابری خودکار میکند.
پیکربندی دادههای ورودی
در این مرحله، منبع دادههایی را که نیاز به حذف هویت دارند، مشخص میکنید که یک مخزن ذخیرهسازی ابری حاوی انواع فایلهای مختلف با اطلاعات حساس است.
- از طریق نوار جستجو به بخش امنیت > حفاظت از دادههای حساس بروید.
- در منو، روی بازرسی کلیک کنید.
- روی ایجاد شغل و محرکهای شغل کلیک کنید.
- پیکربندی کار:
ملک
مقدار (نوع یا انتخاب)
شناسه شغل
pii-removerنوع ذخیره سازی
فضای ذخیرهسازی ابری گوگل
نوع مکان
اسکن یک سطل با قوانین اختیاری شامل/حذف
نام سطل
input-[your-project-id]
پیکربندی تشخیص و اقدامات
حالا شما قالبهای قبلاً ایجاد شده خود را به این کار پیوند میدهید و به Sensitive Data Protection میگویید که چگونه PII را بررسی کند و بر اساس نوع محتوا، کدام روش عدم شناسایی را اعمال کند.
- الگوی بازرسی :
projects/[your-project-id]/locations/global/inspectTemplates/pii-finder - در زیر «افزودن اقدامات» ، «ایجاد یک کپی بدون شناسایی» را انتخاب کنید و الگوهای تبدیل را طوری پیکربندی کنید که همان الگوهایی باشند که ایجاد کردهاید.
- یک پنجره بازشو برای شما باز میشود تا
Confirm whether you want to de-identify the findings، روی غیرفعال کردن نمونهبرداری کلیک کنید.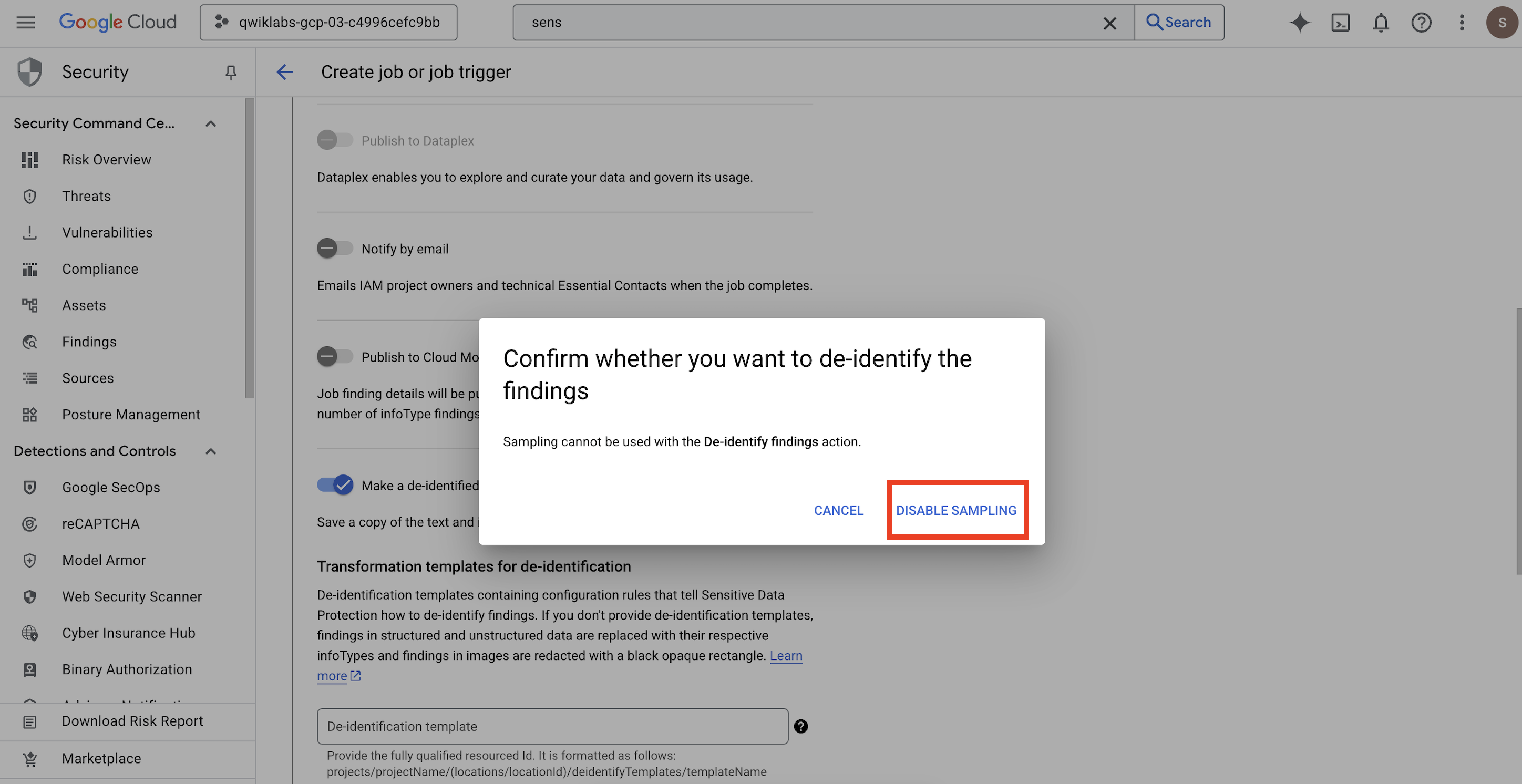
ملک
مقدار (نوع یا انتخاب)
الگوی عدم شناسایی
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-unstructuredالگوی ساختاریافتهی عدم شناسایی
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-structuredالگوی ویرایش تصویر
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-image - مکان خروجی Cloud Storage را پیکربندی کنید:
- آدرس اینترنتی :
gs://output-[your-project-id]
- آدرس اینترنتی :
- در قسمت Schedule ، گزینه None را انتخاب کنید تا کار بلافاصله اجرا شود.
- روی ایجاد کلیک کنید.
- یک پنجره بازشو برای
Confirm job or job trigger createباز میشود، روی تأیید ایجاد کلیک کنید.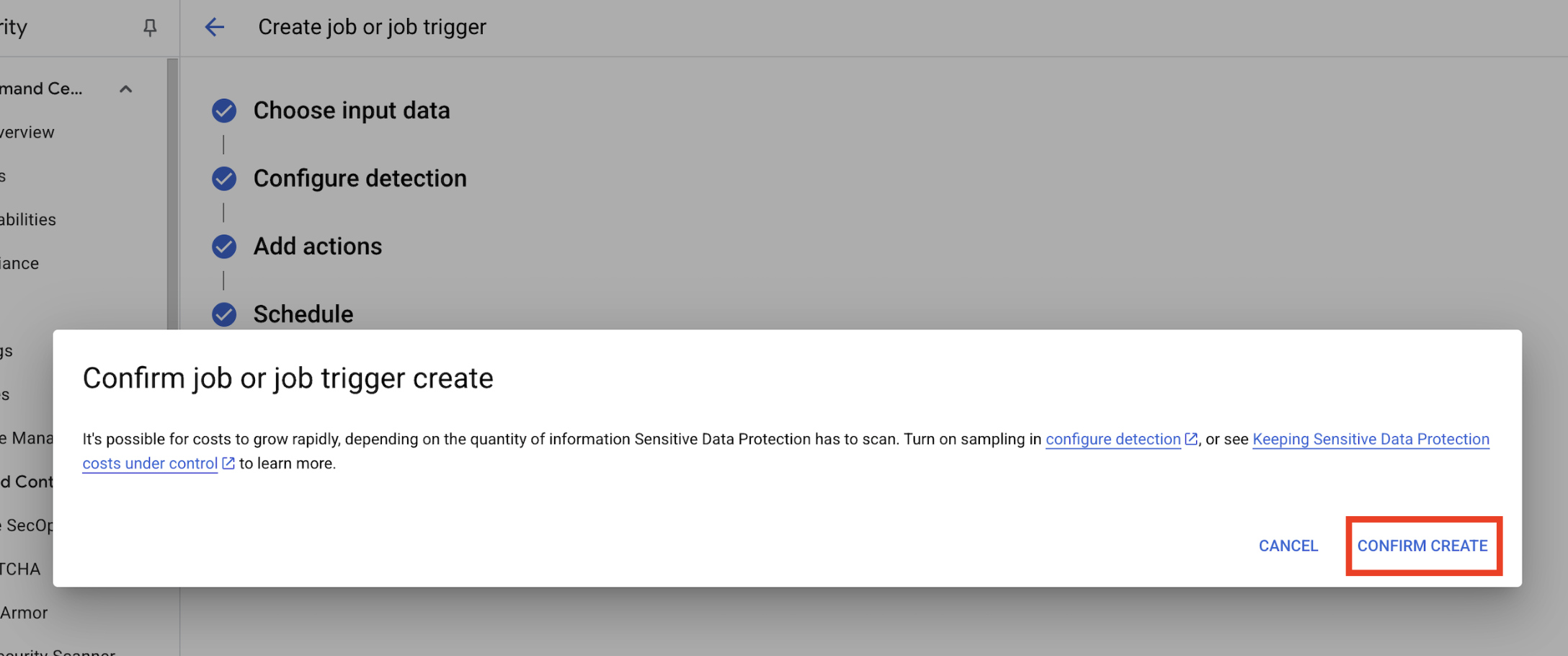
۸. نتایج را تأیید کنید
مرحله آخر تأیید این است که دادههای حساس با موفقیت و به درستی در تمام انواع فایلهای موجود در سطل خروجی ویرایش شدهاند. این کار تضمین میکند که خط لوله شناساییزدایی شما مطابق انتظار کار میکند.
بررسی وضعیت شغلی
برای اطمینان از اتمام موفقیتآمیز کار، بر آن نظارت کنید و خلاصه یافتهها را قبل از بررسی فایلهای خروجی مرور کنید.
- در برگه جزئیات کارها ، منتظر بمانید تا وضعیت کار « تمام شده» نمایش داده شود.
- در بخش Overview ، تعداد یافتهها و درصد هر infoType شناساییشده را بررسی کنید.
- روی پیکربندی کلیک کنید.
- به پایین اسکرول کنید تا به بخش «اقدامات» برسید و روی «باکت خروجی» کلیک کنید تا دادههای حذفشده را ببینید:
gs://output-[your-project-id].
مقایسه فایلهای ورودی و خروجی
در این مرحله، شما به صورت دستی فایلهای شناسایی نشده را بررسی میکنید تا تأیید کنید که پاکسازی دادهها طبق الگوهای شما به درستی اعمال شده است.
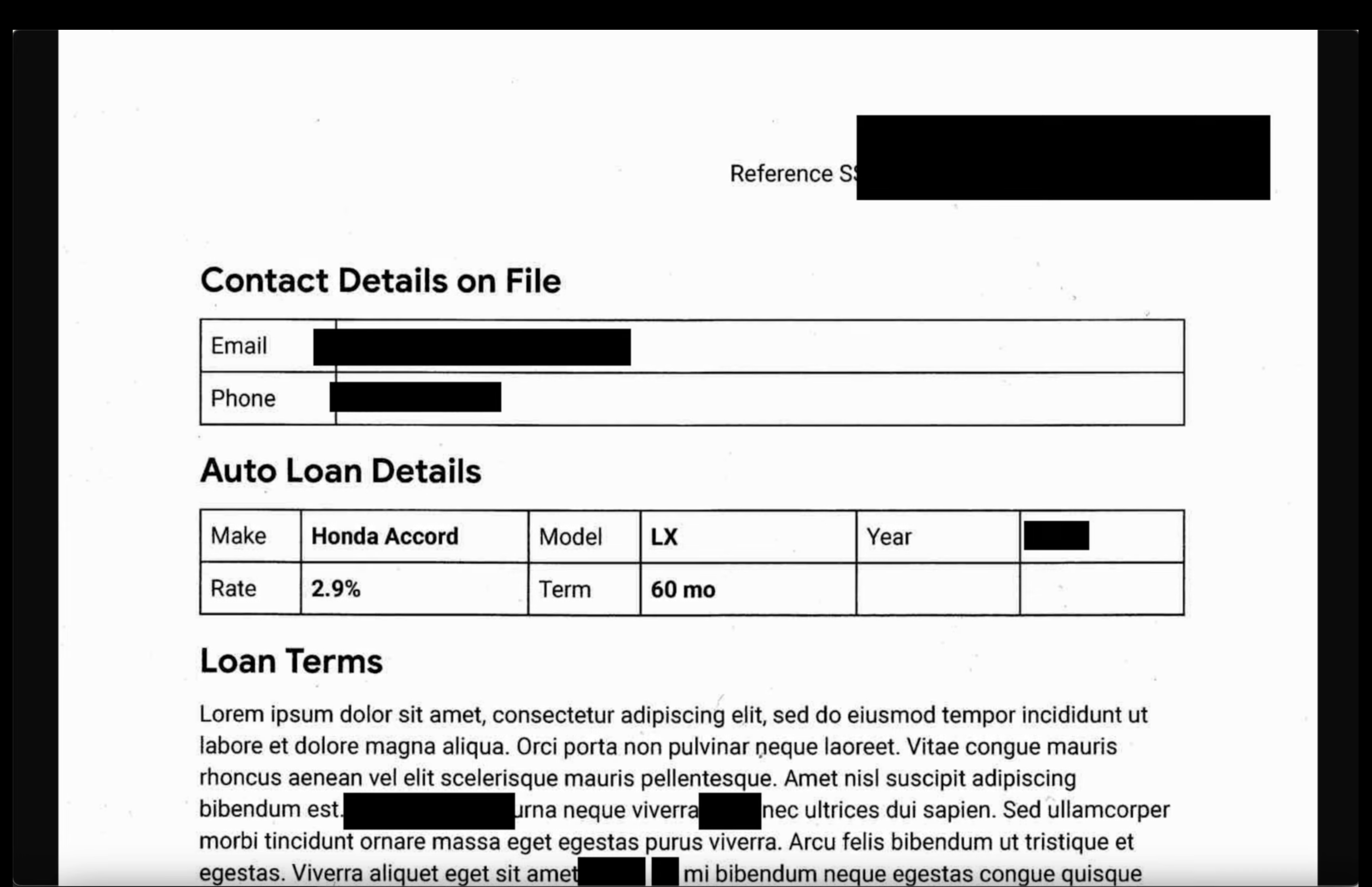
- تصاویر : یک تصویر را از پوشه خروجی باز کنید. تأیید کنید که تمام متن حساس در فایل خروجی ویرایش شده است.
- گزارشهای بدون ساختار : یک فایل گزارش از هر دو باکت را مشاهده کنید. تأیید کنید که PII در گزارش خروجی با نام infoType جایگزین شده است (مثلاً
[US_SOCIAL_SECURITY_NUMBER]). - CSV های ساختار یافته : یک فایل CSV از هر دو باکت باز کنید. تأیید کنید که ایمیلها و شمارههای تأمین اجتماعی کاربر در فایل خروجی با
####@####.comپوشانده شده باشند.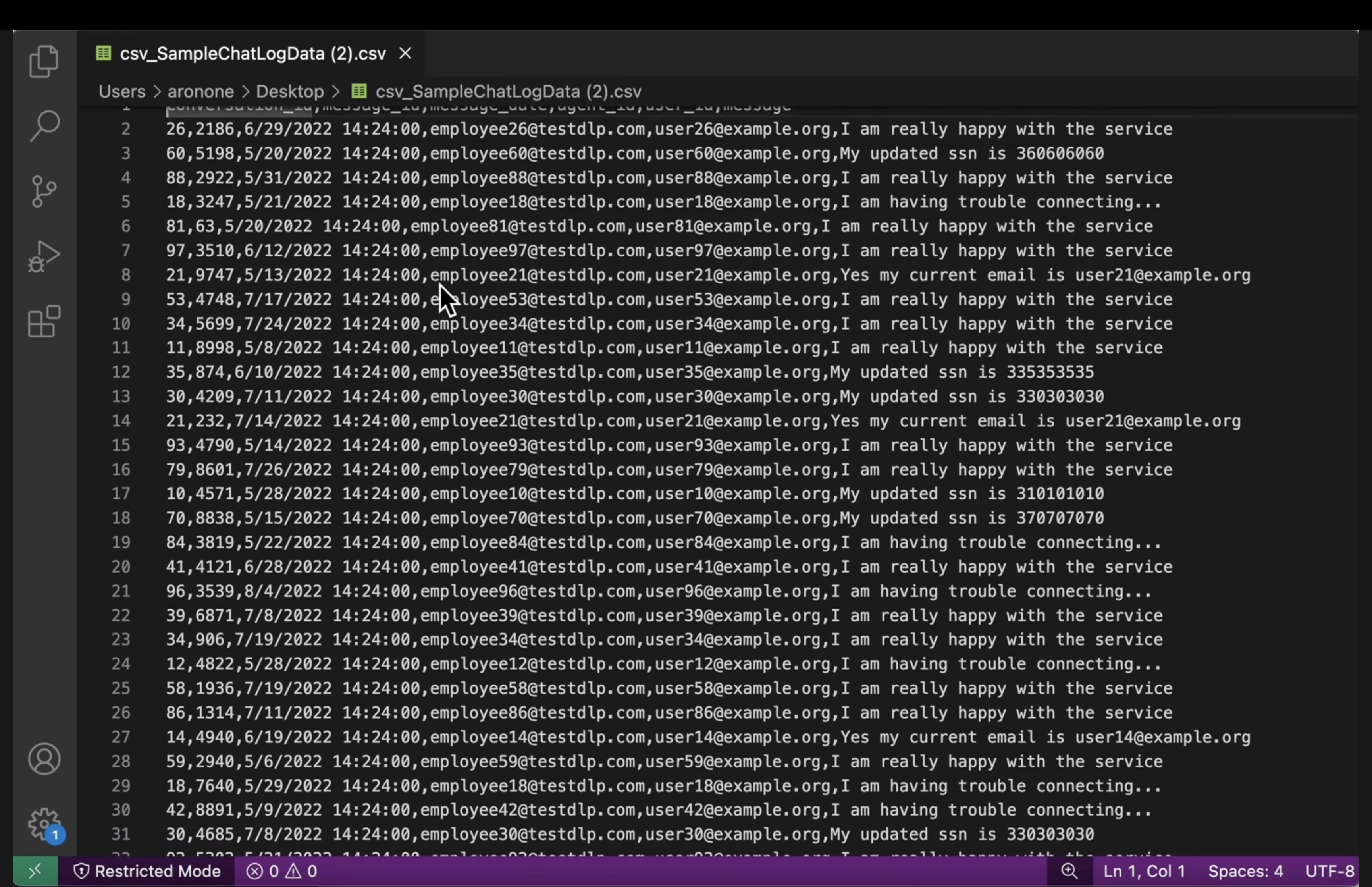
۹. از آزمایشگاه تا واقعیت: چگونه از این در پروژههای خود استفاده کنید
اصول و پیکربندیهایی که اعمال کردهاید، طرح اولیه برای ایمنسازی پروژههای هوش مصنوعی دنیای واقعی در Google Cloud هستند. منابعی که شما ساختهاید - الگوی بازرسی ، الگوهای حذف هویت و کار خودکار - به عنوان یک الگوی اولیه امن برای هر فرآیند جدید دریافت داده عمل میکنند.
فرآیند خودکار پاکسازی دادهها: دریافت ایمن دادهها توسط شما
چگونه از این در تنظیمات خود استفاده میکنید
هر بار که تیم شما نیاز به دریافت دادههای خام جدید مشتری برای توسعه هوش مصنوعی داشته باشد، آن را از طریق یک خط لوله که شامل کار حفاظت از دادههای حساس پیکربندی شده توسط شما است، هدایت میکنید. به جای بازرسی و ویرایش دستی، از این گردش کار خودکار استفاده میکنید. این تضمین میکند که دانشمندان داده و مدلهای هوش مصنوعی فقط با دادههای شناسایی نشده تعامل دارند و خطرات حریم خصوصی را به میزان قابل توجهی کاهش میدهند.
اتصال به تولید
در یک محیط عملیاتی، شما میتوانید این مفهوم را با موارد زیر حتی فراتر ببرید:
- اتوماسیون با محرکهای کار : به جای اجرای دستی کار، هر زمان که فایل جدیدی در مخزن ذخیرهسازی ابری ورودی شما آپلود میشود، یک محرک کار تنظیم میکنید. این یک فرآیند تشخیص و شناسایی کاملاً خودکار و بدون دخالت دست ایجاد میکند.
- ادغام با دریاچهها/انبارهای داده : دادههای خروجیِ بدون هویت معمولاً برای تجزیه و تحلیل بیشتر و آموزش مدل، به یک دریاچه داده امن (مثلاً در فضای ذخیرهسازی ابری) یا انبار داده (مثلاً BigQuery ) وارد میشوند و تضمین میکنند که حریم خصوصی در طول چرخه حیات دادهها حفظ میشود.
استراتژیهای شناساییزدایی جزئی: ایجاد تعادل بین حریم خصوصی و سودمندی
چگونه از این در تنظیمات خود استفاده میکنید
الگوهای مختلف حذف هویت (بدون ساختار، ساختاریافته، تصویری) که ایجاد کردهاید، کلیدی هستند. شما میتوانید استراتژیهای متمایز مشابهی را بر اساس نیازهای خاص مدلهای هوش مصنوعی خود اعمال کنید. این به تیم توسعه شما اجازه میدهد تا بدون به خطر انداختن حریم خصوصی، دادههای کاربردی بالایی برای مدلهای خود داشته باشد.
اتصال به تولید
در یک محیط عملیاتی، این کنترل جزئی برای موارد زیر حیاتیتر میشود:
- انواع اطلاعات و دیکشنریهای سفارشی : برای دادههای حساس بسیار خاص یا مختص یک دامنه، میتوانید انواع اطلاعات و دیکشنریهای سفارشی را در Sensitive Data Protection تعریف کنید. این امر تشخیص جامع و متناسب با زمینه کسبوکار منحصر به فرد شما را تضمین میکند.
- رمزگذاری با حفظ قالب (FPE) : برای سناریوهایی که دادههای از بین رفته باید قالب اصلی خود را حفظ کنند (مثلاً شماره کارتهای اعتباری برای آزمایش یکپارچهسازی)، باید تکنیکهای پیشرفتهی از بین رفتن هویت مانند رمزگذاری با حفظ قالب را بررسی کنید. این امر امکان آزمایش ایمن از نظر حریم خصوصی را با الگوهای دادهی واقعبینانه فراهم میکند.
نظارت و حسابرسی: اطمینان از رعایت مداوم
چگونه از این در تنظیمات خود استفاده میکنید
شما به طور مداوم گزارشهای حفاظت از دادههای حساس را رصد میکنید تا اطمینان حاصل کنید که تمام پردازش دادهها با سیاستهای حفظ حریم خصوصی شما مطابقت دارد و هیچ اطلاعات حساسی سهواً در معرض دید قرار نمیگیرد. بررسی منظم خلاصه کارها و یافتهها بخشی از این ممیزی مداوم است.
اتصال به تولید
برای یک سیستم تولید قوی، این اقدامات کلیدی را در نظر بگیرید:
- ارسال یافتهها به مرکز فرماندهی امنیت : برای مدیریت یکپارچه تهدیدات و مشاهده متمرکز وضعیت امنیتی خود، وظایف حفاظت از دادههای حساس خود را طوری پیکربندی کنید که خلاصهای از یافتههای خود را مستقیماً به مرکز فرماندهی امنیت ارسال کنند. این کار هشدارها و بینشهای امنیتی را تجمیع میکند.
- هشدار و واکنش به حادثه : شما میتوانید هشدارهای مانیتورینگ ابری را بر اساس یافتههای حفاظت از دادههای حساس یا خرابیهای کاری تنظیم کنید. این تضمین میکند که تیم امنیتی شما بلافاصله از هرگونه نقض احتمالی سیاست یا مشکلات پردازش مطلع میشود و امکان واکنش سریع به حادثه را فراهم میکند.
۱۰. نتیجهگیری
تبریک! شما با موفقیت یک گردش کار امنیت داده ایجاد کردهاید که میتواند به طور خودکار PII را در انواع مختلف داده کشف و شناسایی کند و آن را برای استفاده در توسعه و تجزیه و تحلیل هوش مصنوعی در پاییندست ایمن سازد.
خلاصه
در این آزمایشگاه، شما موارد زیر را انجام دادید:
- یک الگوی بازرسی برای تشخیص انواع اطلاعات حساس خاص ( infoTypes ) تعریف شده است.
- قوانین متمایزی برای عدم شناسایی دادههای بدون ساختار، ساختاریافته و تصویر ایجاد کرد.
- یک کار واحد پیکربندی و اجرا شد که بهطور خودکار ویرایش صحیح را بر اساس نوع فایل بر روی محتویات کل یک سطل اعمال میکرد.
- تبدیل موفقیتآمیز دادههای حساس در یک مکان خروجی امن تأیید شد.
مراحل بعدی
- ارسال یافتهها به مرکز فرماندهی امنیت : برای مدیریت یکپارچهتر تهدید، اقدام کار را طوری پیکربندی کنید که خلاصهای از یافتههای خود را مستقیماً به مرکز فرماندهی امنیت ارسال کند.
- خودکارسازی با توابع ابری : در یک محیط عملیاتی، میتوانید با استفاده از یک تابع ابری، هر زمان که یک فایل جدید در سطل ورودی آپلود میشود، این کار بازرسی را به طور خودکار آغاز کنید.