
1. Introduction
Présentation
Dans cet atelier, vous allez créer un pipeline de nettoyage des données automatisé pour protéger les informations sensibles utilisées dans le développement de l'IA. Vous utilisez Sensitive Data Protection de Google Cloud (anciennement Cloud DLP) pour inspecter, classer et anonymiser les informations permettant d'identifier personnellement l'utilisateur (PII) dans différents formats de données, y compris le texte non structuré, les tableaux structurés et les images.
Context
Vous êtes le champion de la sécurité et de la confidentialité de votre équipe de développement. Votre objectif est d'établir un workflow qui identifie les informations sensibles et les anonymise avant de les mettre à la disposition des développeurs et des modèles. Votre équipe a besoin de données réalistes et de haute qualité pour ajuster et tester une nouvelle application d'IA générative, mais l'utilisation de données client brutes pose des problèmes de confidentialité importants.
Le tableau suivant liste les risques liés à la confidentialité que vous souhaitez le plus atténuer :
Risque | Atténuation |
Exposition d'informations permettant d'identifier personnellement les utilisateurs dans des fichiers texte non structurés (par exemple, journaux de chat d'assistance, formulaires de commentaires). | Créez un modèle d'anonymisation qui remplace les valeurs sensibles par leur infoType, en préservant le contexte tout en supprimant l'exposition. |
Perte d'utilité des données dans les ensembles de données structurés (fichiers CSV) lorsque les informations permettant d'identifier personnellement les utilisateurs sont supprimées. | Utilisez les transformations d'enregistrements pour masquer sélectivement les identifiants (comme les noms) et appliquer des techniques telles que le masquage de caractères afin de préserver les autres caractères de la chaîne. Les développeurs peuvent ainsi continuer à tester les données. |
Exposition des informations permettant d'identifier personnellement les utilisateurs à partir du texte intégré dans les images (par exemple, les documents numérisés ou les photos des utilisateurs). | Créez un modèle d'anonymisation spécifique aux images qui masque le texte trouvé dans les images. |
Masquage manuel incohérent ou sujet aux erreurs pour différents types de données. | Configurer un job Sensitive Data Protection unique et automatisé qui applique systématiquement le modèle d'anonymisation approprié en fonction du type de fichier qu'il traite. |
Points abordés
Dans cet atelier, vous allez apprendre à :
- Définissez un modèle d'inspection pour détecter des types d'informations sensibles spécifiques (infoTypes).
- Créez des règles d'anonymisation distinctes pour les données non structurées, structurées et d'image.
- Configurez et exécutez un seul job qui applique automatiquement la bonne méthode de masquage en fonction du type de fichier au contenu d'un bucket entier.
- Vérifiez que les données sensibles ont bien été transformées dans un emplacement de sortie sécurisé.
2. Configuration du projet
Compte Google
Si vous ne possédez pas encore de compte Google personnel, vous devez en créer un.
Utilisez un compte personnel au lieu d'un compte professionnel ou scolaire.
Se connecter à la console Google Cloud
Connectez-vous à la console Google Cloud à l'aide d'un compte Google personnel.
Activer la facturation
Utiliser des crédits Google Cloud (facultatif)
Pour suivre cet atelier, vous avez besoin d'un compte de facturation avec un certain crédit. Utilisez les crédits de la bannière en haut de cet atelier de programmation pour commencer. Si vous êtes déjà associé à un compte de facturation, vous pouvez ignorer cette étape.
Configurer un compte de facturation personnel
Si vous avez configuré la facturation à l'aide de crédits Google Cloud, vous pouvez ignorer cette étape.
Pour configurer un compte de facturation personnel, cliquez ici pour activer la facturation dans la console Cloud.
Remarques :
- Cet atelier devrait vous coûter moins de 1 USD en ressources Cloud.
- Vous pouvez suivre les étapes à la fin de cet atelier pour supprimer les ressources et éviter ainsi des frais supplémentaires.
- Les nouveaux utilisateurs peuvent bénéficier d'un essai sans frais pour un crédit de 300 $.
Créer un projet (facultatif)
Si vous n'avez pas de projet que vous souhaitez utiliser pour cet atelier, créez-en un.
3. Activer les API
Configurer Cloud Shell
Une fois votre projet créé, suivez les étapes ci-dessous pour configurer Cloud Shell.
Lancer Cloud Shell
Accédez à shell.cloud.google.com et, si une fenêtre pop-up vous invite à autoriser, cliquez sur Autoriser.
Définir un ID de projet
Exécutez la commande suivante dans le terminal Cloud Shell pour définir le bon ID de projet. Remplacez <your-project-id> par l'ID du projet que vous avez copié lors de l'étape de création du projet.
gcloud config set project <your-project-id>
Vous devriez maintenant voir que le bon projet est sélectionné dans le terminal Cloud Shell.
Activer la protection des données sensibles
Pour utiliser le service Sensitive Data Protection et Cloud Storage, vous devez vous assurer que ces API sont activées dans votre projet Google Cloud.
- Dans le terminal, activez les API :
gcloud services enable dlp.googleapis.com storage.googleapis.com
Vous pouvez également activer ces API en accédant à Sécurité > Protection des données sensibles et Cloud Storage dans la console, puis en cliquant sur le bouton Activer si vous y êtes invité pour chaque service.
4. Créer des buckets avec des données sensibles
Créer un bucket d'entrée et un bucket de sortie
Dans cette étape, vous allez créer deux buckets : un pour stocker les données sensibles à inspecter et un autre où Sensitive Data Protection stockera les fichiers de sortie anonymisés. Vous devez également télécharger des exemples de fichiers de données et les importer dans votre bucket d'entrée.
- Dans le terminal, exécutez les commandes suivantes pour créer un bucket pour les données d'entrée et un autre pour les données de sortie, puis remplissez le bucket d'entrée avec des exemples de données provenant de
gs://dlp-codelab-data:PROJECT_ID=$(gcloud config get-value project) gsutil mb gs://input-$PROJECT_ID gsutil mb gs://output-$PROJECT_ID
Ajouter des données sensibles au bucket d'entrée
Dans cette étape, vous allez télécharger des exemples de fichiers de données contenant des informations permettant de tester l'identification personnelle depuis GitHub, puis les importer dans votre bucket d'entrée.
- Dans Cloud Shell, exécutez la commande suivante pour cloner le dépôt
devrel-demos, qui contient les exemples de données nécessaires à cet atelier.REPO_URL="https://github.com/GoogleCloudPlatform/devrel-demos.git" TARGET_PATH="security/sample-data" OUTPUT_FOLDER="sample-data" git clone --quiet --depth 1 --filter=blob:none --sparse "$REPO_URL" temp_loader cd temp_loader git sparse-checkout set "$TARGET_PATH" cd .. mv "temp_loader/$TARGET_PATH" "$OUTPUT_FOLDER" rm -rf temp_loader - Ensuite, copiez les exemples de données dans le bucket d'entrée que vous avez créé précédemment :
gsutil -m cp -r sample-data/* gs://input-$PROJECT_ID/ - Accédez à Cloud Storage > Buckets, puis cliquez sur le bucket d'entrée pour afficher les données que vous avez importées.
5. Créer un modèle d'inspection
Dans cette tâche, vous allez créer un modèle qui indique à Sensitive Data Protection ce qu'il doit rechercher. Cela vous permet de concentrer l'inspection sur les infoTypes qui sont pertinents pour vos données et votre zone géographique, ce qui améliore les performances et la précision.
Créer un modèle d'inspection
Dans cette étape, vous définissez les règles qui déterminent ce qui constitue des données sensibles à inspecter. Ce modèle sera réutilisé par vos jobs d'anonymisation pour assurer la cohérence.
- Dans le menu de navigation, accédez à Sensitive Data Protection > Configuration > Modèles.
- Cliquez sur Créer un modèle.
- Pour le type de modèle, sélectionnez Inspecter (rechercher les données sensibles).
- Définissez l'ID du modèle sur
pii-finder. - Cliquez sur Continuer pour accéder à Configurer la détection.
- Cliquez sur Gérer les infoTypes.
- À l'aide du filtre, recherchez les infoTypes suivants et cochez la case à côté de chacun d'eux :
CREDIT_CARD_EXPIRATION_DATECREDIT_CARD_NUMBERDATE_OF_BIRTHDRIVERS_LICENSE_NUMBEREMAIL_ADDRESSGCP_API_KEYGCP_CREDENTIALSORGANIZATION_NAMEPASSWORDPERSON_NAMEPHONE_NUMBERUS_SOCIAL_SECURITY_NUMBER
- Sélectionnez également les autres catégories qui vous intéressent, puis cliquez sur OK.
- Vérifiez que tous ces infoTypes ont été ajoutés dans le tableau obtenu.
- Cliquez sur Créer.
6. Créer des modèles d'anonymisation
Vous allez ensuite créer trois modèles d'anonymisation distincts pour gérer différents formats de données. Vous pouvez ainsi contrôler précisément le processus de transformation et appliquer la méthode la plus appropriée à chaque type de fichier. Ces modèles fonctionnent avec le modèle d'inspection que vous venez de créer.
Créer un modèle pour des données non structurées
Ce modèle définit la façon dont les données sensibles trouvées dans du texte libre (comme les journaux de chat ou les formulaires de commentaires) sont anonymisées. La méthode choisie remplace la valeur sensible par le nom de son infoType, tout en préservant le contexte.
- Sur la page Modèles, cliquez sur Créer un modèle.
- Définissez le modèle d'anonymisation :
Propriété
Valeur (saisir ou sélectionner)
Type de modèle
Anonymiser (supprimer les données sensibles)
Type de transformation de données
InfoType
ID du modèle
de-identify-unstructured - Cliquez sur Continuer pour accéder à Configurer la suppression de l'identification.
- Sous Méthode de transformation, sélectionnez la transformation Remplacer par un nom d'infoType.
- Cliquez sur Créer.
- Cliquez sur Tester.
- Testez un message contenant des informations permettant d'identifier personnellement l'utilisateur pour voir comment il sera transformé :
Hi, my name is Alex and my SSN is 555-11-5555. You can reach me at +1-555-555-5555.
Créer un modèle pour des données structurées
Ce modèle cible spécifiquement les informations sensibles dans les ensembles de données structurées, tels que les fichiers CSV. Vous le configurerez pour masquer les données de manière à préserver leur utilité pour les tests tout en anonymisant les champs sensibles.
- Revenez à la page Modèles, puis cliquez sur Créer un modèle.
- Définissez le modèle d'anonymisation :
Propriété
Valeur (saisir ou sélectionner)
Type de modèle
Anonymiser (supprimer les données sensibles)
Type de transformation de données
Enregistrer
ID du modèle
de-identify-structured - Cliquez sur Continuer pour configurer l'anonymisation.Comme ce modèle s'applique aux données structurées, nous pouvons souvent prédire les champs ou les colonnes qui contiendront certains types de données sensibles. Vous savez que le fichier CSV utilisé par votre application contient les adresses e-mail des utilisateurs sous
user_idet quemessagecontient souvent des informations permettant d'identifier personnellement les utilisateurs à partir des interactions avec les clients. Vous n'avez pas à vous soucier du masquageagent_id, car il s'agit d'employés et les conversations doivent être attribuables. Remplissez cette section comme suit :- Champs ou colonnes à transformer :
user_id,message. - Type de transformation : "Correspondance par infoType"
- Méthode de transformation : cliquez sur Ajouter une transformation.
- Transformation : masquage avec un caractère.
- Caractères à ignorer : ponctuation américaine.
- Champs ou colonnes à transformer :
- Cliquez sur Créer.
Créer un modèle pour les données d'image
Ce modèle est conçu pour désidentifier le texte sensible intégré dans des images, comme des documents numérisés ou des photos envoyées par les utilisateurs. Elle utilise la reconnaissance optique des caractères (OCR) pour détecter et masquer les informations permettant d'identifier personnellement l'utilisateur.
- Revenez à la page Modèles, puis cliquez sur Créer un modèle.
- Définissez le modèle d'anonymisation :
Propriété
Valeur (saisir ou sélectionner)
Type de modèle
Anonymiser (supprimer les données sensibles)
Type de transformation de données
Image
ID du modèle
de-identify-image - Cliquez sur Continuer pour accéder à Configurer la suppression de l'identification.
- InfoTypes à transformer : Tous les infoTypes détectés définis dans un modèle d'inspection ou une configuration d'inspection, et non spécifiés dans d'autres règles.
- Cliquez sur Créer.
7. Créer et exécuter un job de désidentification
Maintenant que vous avez défini vos modèles, vous allez créer un job unique qui applique le modèle d'anonymisation approprié en fonction du type de fichier qu'il détecte et inspecte. Cela automatise le processus de protection des données sensibles pour les données stockées dans Cloud Storage.
Configurer les données d'entrée
Dans cette étape, vous spécifiez la source des données à anonymiser. Il s'agit d'un bucket Cloud Storage contenant différents types de fichiers avec des informations sensibles.
- Accédez à Sécurité > Sensitive Data Protection à l'aide de la barre de recherche.
- Cliquez sur Inspection dans le menu.
- Cliquez sur Créer un job et des déclencheurs de jobs.
- Configurez le job :
Propriété
Valeur (saisir ou sélectionner)
ID du job
pii-removerType de stockage
Google Cloud Storage
Type d'emplacement
Analyser un bucket comportant des règles Inclure/Exclure
Nom du bucket
input-[your-project-id]
Configurer la détection et les actions
Vous allez maintenant associer les modèles que vous avez créés à ce job. Vous indiquerez ainsi à Sensitive Data Protection comment inspecter les informations permettant d'identifier personnellement l'utilisateur et quelle méthode d'anonymisation appliquer en fonction du type de contenu.
- Modèle d'inspection :
projects/[your-project-id]/locations/global/inspectTemplates/pii-finder - Sous Ajouter des actions, sélectionnez Créer une copie anonymisée, puis configurez les modèles de transformation que vous avez créés.
- Un pop-up s'ouvre pour vous permettre de
Confirm whether you want to de-identify the findings. Cliquez sur DÉSACTIVER L'ÉCHANTILLONNAGE.
Propriété
Valeur (saisir ou sélectionner)
Modèle d'anonymisation
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-unstructuredModèle d'anonymisation de données structurées
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-structuredModèle de masquage d'image
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-image - Configurez l'emplacement de sortie Cloud Storage :
- URL :
gs://output-[your-project-id]
- URL :
- Sous Programmation, conservez la sélection Aucune pour exécuter le job immédiatement.
- Cliquez sur Créer.
- Un pop-up s'ouvre pour
Confirm job or job trigger create. Cliquez sur CONFIRMER LA CRÉATION.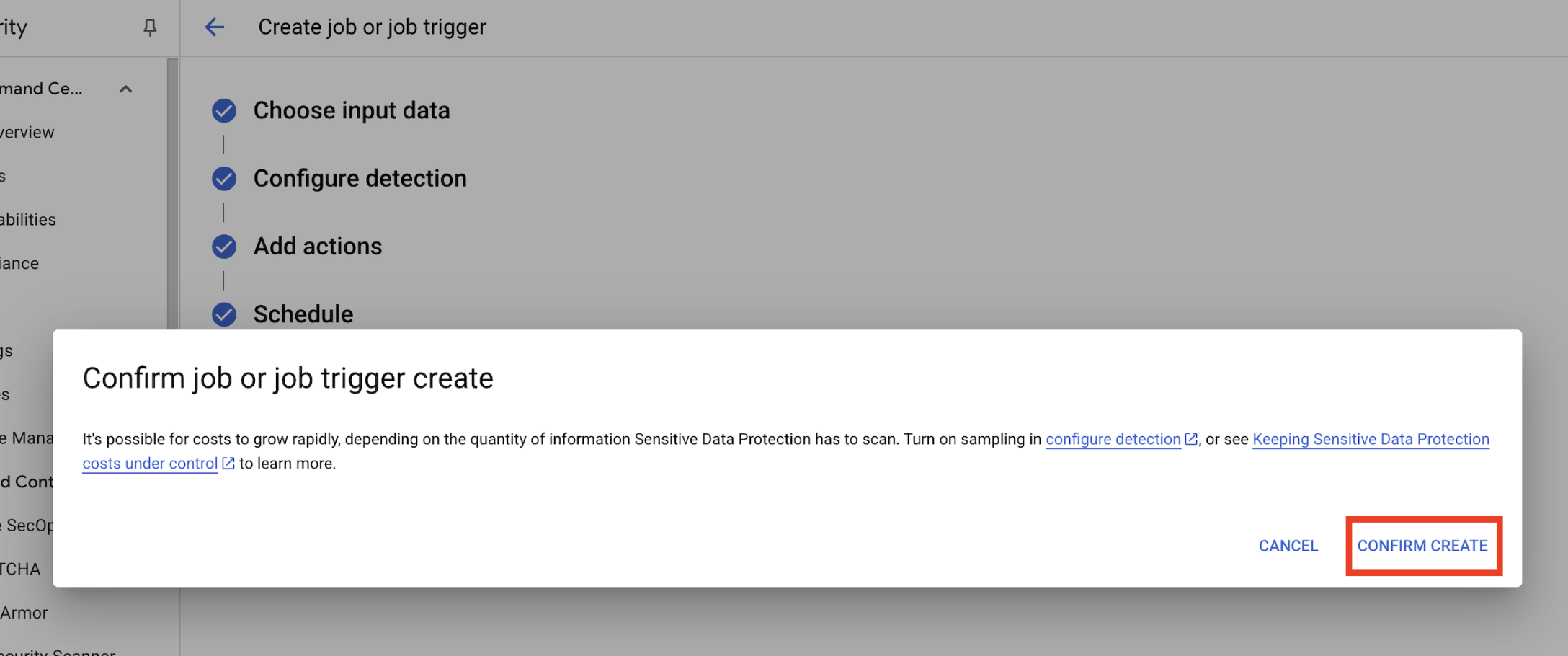
8. Vérifier les résultats
La dernière étape consiste à vérifier que les données sensibles ont été correctement masquées dans tous les types de fichiers du bucket de sortie. Cela permet de s'assurer que votre pipeline de désidentification fonctionne comme prévu.
Examiner l'état du job
Surveillez le job pour vous assurer qu'il se termine correctement et examinez le récapitulatif des résultats avant de consulter les fichiers de sortie.
- Dans l'onglet Informations sur le job, attendez que l'état du job soit Terminé.
- Sous Présentation, consultez le nombre de résultats et les pourcentages de chaque infoType détecté.
- Cliquez sur Configuration
- Faites défiler la page jusqu'à Actions, puis cliquez sur le bucket de sortie pour afficher les données anonymisées :
gs://output-[your-project-id].
Comparer les fichiers d'entrée et de sortie
Dans cette étape, vous allez inspecter manuellement les fichiers anonymisés pour vérifier que le nettoyage des données a été appliqué correctement conformément à vos modèles.
- Images : ouvrez une image à partir du bucket de sortie. Vérifiez que tout le texte sensible a été masqué dans le fichier de sortie.

- Journaux non structurés : affichez un fichier journal des deux buckets. Vérifiez que les informations permettant d'identifier personnellement l'utilisateur dans le journal de sortie ont été remplacées par le nom de l'infoType (par exemple,
[US_SOCIAL_SECURITY_NUMBER]). - Fichiers CSV structurés : ouvrez un fichier CSV à partir des deux buckets. Vérifiez que les adresses e-mail et les numéros de sécurité sociale des utilisateurs dans le fichier de sortie sont masqués avec
####@####.com.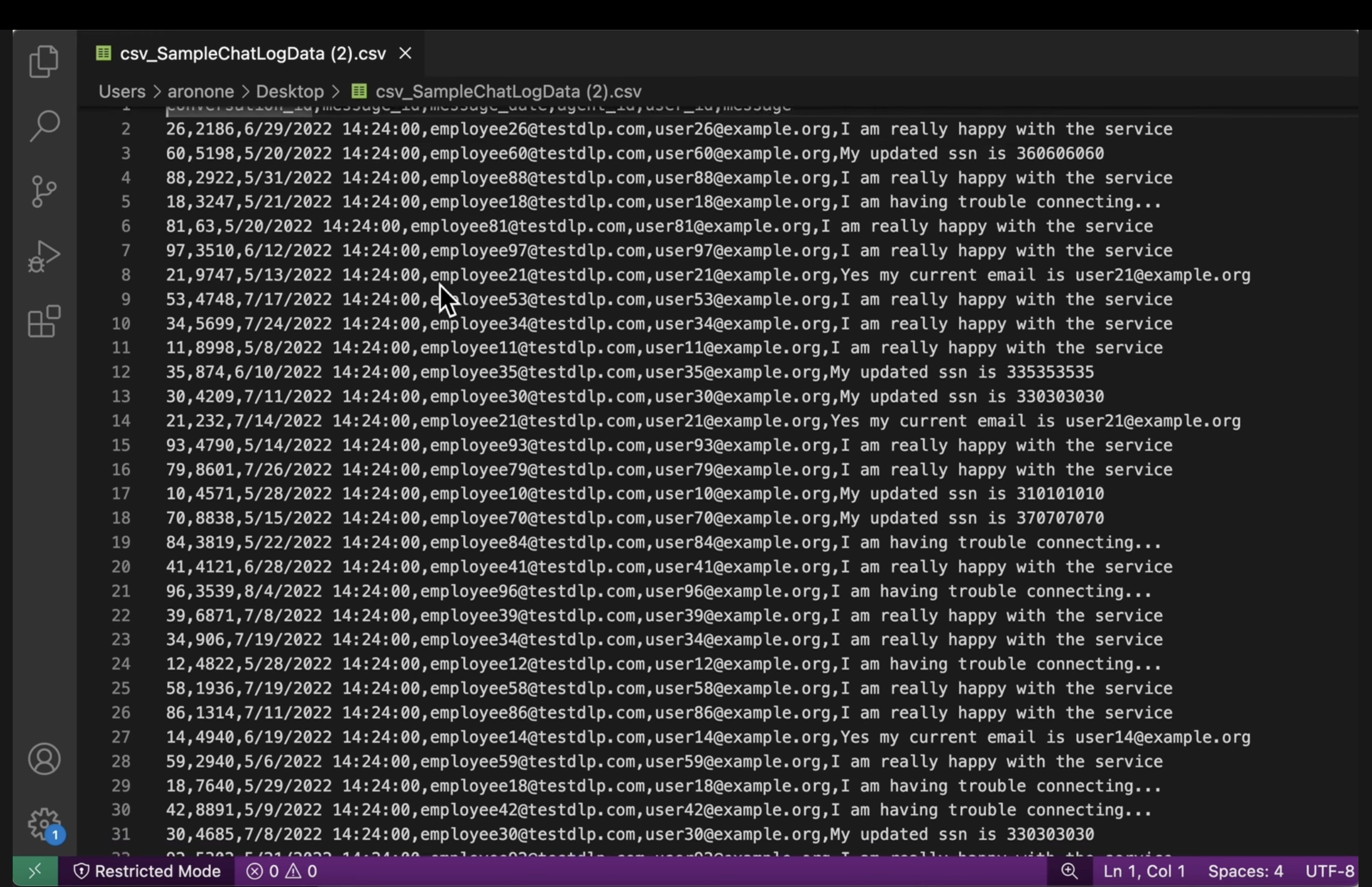
9. De l'atelier à la réalité : comment utiliser ce code dans vos propres projets
Les principes et les configurations que vous avez appliqués constituent le plan de sécurisation des projets d'IA concrets sur Google Cloud. Les ressources que vous venez de créer (le modèle d'inspection, les modèles d'anonymisation et le job automatisé) servent de modèle de démarrage sécurisé pour tout nouveau processus d'ingestion de données.
Pipeline de nettoyage des données automatisé : votre point d'entrée sécurisé pour les données
Comment utiliser cette fonctionnalité lors de la configuration
Chaque fois que votre équipe doit ingérer de nouvelles données client brutes pour le développement de l'IA, vous la dirigez vers un pipeline qui intègre le job Sensitive Data Protection que vous avez configuré. Au lieu d'inspecter et de masquer manuellement les données, vous utilisez ce workflow automatisé. Cela garantit que les data scientists et les modèles d'IA n'interagissent qu'avec des données anonymisées, ce qui réduit considérablement les risques liés à la confidentialité.
Se connecter à la production
Dans un environnement de production, vous pouvez aller encore plus loin en :
- Automatisation avec des déclencheurs de job : au lieu d'exécuter le job manuellement, vous configurez un déclencheur de job chaque fois qu'un nouveau fichier est importé dans votre bucket Cloud Storage d'entrée. Cela crée un processus de détection et de désidentification entièrement automatisé et sans intervention manuelle.
- Intégration aux lacs de données/entrepôts de données : les données de sortie anonymisées sont généralement intégrées à un lac de données sécurisé (par exemple, sur Cloud Storage) ou à un entrepôt de données (par exemple, BigQuery) pour une analyse plus approfondie et l'entraînement de modèles. Cela permet de garantir la confidentialité tout au long du cycle de vie des données.
Stratégies d'anonymisation précises : équilibrer confidentialité et utilité
Comment utiliser cette fonctionnalité lors de la configuration
Les différents modèles d'anonymisation (non structurés, structurés, image) que vous avez créés sont essentiels. Vous appliquerez des stratégies différenciées similaires en fonction des besoins spécifiques de vos modèles d'IA. Votre équipe de développement peut ainsi disposer de données très utiles pour ses modèles, sans compromettre la confidentialité.
Se connecter à la production
Dans un environnement de production, ce contrôle précis devient encore plus important pour :
- InfoTypes et dictionnaires personnalisés : pour les données sensibles très spécifiques ou propres à un domaine, vous devez définir des infoTypes et des dictionnaires personnalisés dans Sensitive Data Protection. Cela garantit une détection complète adaptée au contexte unique de votre entreprise.
- Chiffrement préservant le format (FPE) : dans les scénarios où les données anonymisées doivent conserver leur format d'origine (par exemple, les numéros de carte de crédit pour les tests d'intégration), vous pouvez explorer des techniques d'anonymisation avancées comme le chiffrement préservant le format. Cela permet d'effectuer des tests respectueux de la confidentialité avec des schémas de données réalistes.
Surveillance et audit : assurer une conformité continue
Comment utiliser cette fonctionnalité lors de la configuration
Vous surveillez en permanence les journaux Sensitive Data Protection pour vous assurer que tout traitement des données respecte vos règles de confidentialité et qu'aucune information sensible n'est exposée par inadvertance. L'examen régulier des résumés et des résultats des tâches fait partie de cet audit continu.
Se connecter à la production
Pour un système de production robuste, pensez aux actions clés suivantes :
- Envoyer les résultats à Security Command Center : pour une gestion intégrée des menaces et une vue centralisée de votre stratégie de sécurité, configurez vos jobs de protection des données sensibles afin qu'ils envoient un récapitulatif de leurs résultats directement à Security Command Center. Cela permet de regrouper les alertes et les insights de sécurité.
- Alertes et réponse aux incidents : vous devez configurer des alertes Cloud Monitoring en fonction des résultats de Sensitive Data Protection ou des échecs de jobs. Votre équipe de sécurité est ainsi immédiatement avertie de tout problème de traitement ou de non-respect potentiel des règles, ce qui permet une réponse rapide aux incidents.
10. Conclusion
Félicitations ! Vous avez réussi à créer un workflow de sécurité des données qui peut découvrir et anonymiser automatiquement les informations permettant d'identifier personnellement les utilisateurs dans plusieurs types de données, ce qui permet de les utiliser en toute sécurité dans le développement de l'IA et les analyses en aval.
Récapitulatif
Dans cet atelier, vous avez effectué les opérations suivantes :
- Définissez un modèle d'inspection pour détecter des types d'informations sensibles spécifiques (infoTypes).
- Nous avons créé des règles d'anonymisation distinctes pour les données non structurées, structurées et d'image.
- Il a configuré et exécuté un job unique qui appliquait automatiquement la bonne méthode de masquage en fonction du type de fichier au contenu d'un bucket entier.
- Vous avez vérifié que les données sensibles ont bien été transformées dans un emplacement de sortie sécurisé.
Étapes suivantes
- Envoyer les résultats à Security Command Center : pour une gestion des menaces plus intégrée, configurez l'action du job afin d'envoyer un résumé de ses résultats directement à Security Command Center.
- Automatiser avec Cloud Functions : dans un environnement de production, vous pouvez déclencher automatiquement ce job d'inspection chaque fois qu'un nouveau fichier est importé dans le bucket d'entrée à l'aide d'une fonction Cloud.