
1. परिचय
खास जानकारी
इस लैब में, एआई डेवलपमेंट में इस्तेमाल की गई संवेदनशील जानकारी को सुरक्षित रखने के लिए, डेटा को सुरक्षित करने वाली ऑटोमेटेड पाइपलाइन बनाई जाती है. आपके पास Google Cloud की Sensitive Data Protection (पहले इसे Cloud DLP कहा जाता था) का इस्तेमाल करने का विकल्प होता है. इसकी मदद से, अलग-अलग फ़ॉर्मैट में मौजूद व्यक्तिगत पहचान से जुड़ी जानकारी (पीआईआई) की जांच की जा सकती है, उसे अलग-अलग कैटगरी में बांटा जा सकता है, और उसकी पहचान मिटाई जा सकती है. इसमें बिना स्ट्रक्चर वाला टेक्स्ट, स्ट्रक्चर्ड टेबल, और इमेज शामिल हैं.
Context
आपकी डेवलपमेंट टीम में, सुरक्षा और निजता से जुड़ी समस्याओं को हल करने की ज़िम्मेदारी आपकी है. आपका लक्ष्य एक ऐसा वर्कफ़्लो बनाना है जो संवेदनशील जानकारी की पहचान करे और उसे डेवलपर और मॉडल के लिए उपलब्ध कराने से पहले, उसकी पहचान छिपा दे. आपकी टीम को जनरेटिव एआई के नए ऐप्लिकेशन को बेहतर बनाने और उसकी जांच करने के लिए, भरोसेमंद और अच्छी क्वालिटी वाले डेटा की ज़रूरत होती है. हालांकि, ग्राहक के रॉ डेटा का इस्तेमाल करने से, निजता से जुड़ी गंभीर समस्याएं पैदा हो सकती हैं.
यहां दी गई टेबल में, निजता से जुड़े उन जोखिमों के बारे में बताया गया है जिन्हें कम करने के लिए, आपको सबसे ज़्यादा चिंता है:
जोखिम | गड़बड़ी की गंभीरता को कम करना |
बिना स्ट्रक्चर वाली टेक्स्ट फ़ाइलों में व्यक्तिगत पहचान से जुड़ी जानकारी का दिखना. उदाहरण के लिए, सहायता चैट के लॉग, सुझाव/राय देने या शिकायत करने वाले फ़ॉर्म. | एक पहचान छिपाने वाला टेंप्लेट बनाएं. यह टेंप्लेट, संवेदनशील वैल्यू को उनके infoType से बदल देता है. इससे, कॉन्टेक्स्ट को बनाए रखते हुए, संवेदनशील जानकारी को हटाया जा सकता है. |
व्यक्तिगत पहचान से जुड़ी जानकारी हटाने पर, स्ट्रक्चर्ड डेटासेट (सीएसवी) में डेटा के इस्तेमाल में कमी आती है. | रिकॉर्ड ट्रांसफ़ॉर्मेशन का इस्तेमाल करके, पहचान ज़ाहिर करने वाली जानकारी (जैसे कि नाम) को चुनिंदा तौर पर छिपाएं. साथ ही, स्ट्रिंग में मौजूद अन्य वर्णों को सुरक्षित रखने के लिए, वर्ण मास्किंग जैसी तकनीकों का इस्तेमाल करें. इससे डेवलपर, डेटा की मदद से अब भी टेस्ट कर पाएंगे. |
इमेज में एम्बेड किए गए टेक्स्ट से व्यक्तिगत पहचान से जुड़ी जानकारी का पता चलना. उदाहरण के लिए, स्कैन किए गए दस्तावेज़, उपयोगकर्ता की फ़ोटो. | इमेज के हिसाब से पहचान छिपाने वाला टेंप्लेट बनाएं. इससे इमेज में मौजूद टेक्स्ट को छिपाया जा सकेगा. |
अलग-अलग तरह के डेटा में, मैन्युअल तरीके से डेटा छिपाने की प्रोसेस में गड़बड़ी होना या एक जैसा तरीका इस्तेमाल न करना. | संवेदनशील डेटा की सुरक्षा से जुड़ा एक ऐसा ऑटोमेटेड जॉब कॉन्फ़िगर करें जो प्रोसेस की जाने वाली फ़ाइल के टाइप के आधार पर, सही डी-आइडेंटिफ़िकेशन टेंप्लेट को लगातार लागू करता हो. |
आपको क्या सीखने को मिलेगा
इस लैब में, आपको इनके बारे में जानकारी मिलेगी:
- संवेदनशील जानकारी के खास टाइप (infoTypes) का पता लगाने के लिए, inspection template तय करें.
- स्ट्रक्चर नहीं किए गए, स्ट्रक्चर किए गए, और इमेज डेटा के लिए अलग-अलग पहचान छिपाने के नियम बनाएं.
- एक ऐसा जॉब कॉन्फ़िगर और चलाया जा सकता है जो फ़ाइल टाइप के आधार पर, पूरे बकेट के कॉन्टेंट पर सही तरीके से डेटा छिपाने की सुविधा अपने-आप लागू करता है.
- पुष्टि करें कि संवेदनशील डेटा को सुरक्षित आउटपुट लोकेशन में बदल दिया गया है.
2. प्रोजेक्ट सेटअप करना
Google खाता
अगर आपके पास पहले से कोई निजी Google खाता नहीं है, तो आपको Google खाता बनाना होगा.
ऑफ़िस या स्कूल वाले खाते के बजाय, निजी खाते का इस्तेमाल करें.
Google Cloud Console में साइन इन करना
किसी निजी Google खाते का इस्तेमाल करके, Google Cloud Console में साइन इन करें.
बिलिंग चालू करें
Google Cloud क्रेडिट रिडीम करना (ज़रूरी नहीं है)
इस वर्कशॉप को चलाने के लिए, आपके पास कुछ क्रेडिट वाला बिलिंग खाता होना चाहिए. शुरू करने के लिए, इस कोडलैब के सबसे ऊपर मौजूद बैनर में दिए गए क्रेडिट का इस्तेमाल करें. अगर आपका खाता पहले से ही किसी बिलिंग खाते से कनेक्ट है, तो इस चरण को छोड़ा जा सकता है.
निजी बिलिंग खाता सेट अप करना
अगर आपने Google Cloud क्रेडिट का इस्तेमाल करके बिलिंग सेट अप की है, तो इस चरण को छोड़ें.
निजी बिलिंग खाता सेट अप करने के लिए, Cloud Console में बिलिंग की सुविधा चालू करने के लिए यहां जाएं.
ध्यान दें:
- इस लैब को पूरा करने में, Cloud संसाधनों पर 1 डॉलर से कम खर्च आना चाहिए.
- ज़्यादा शुल्क से बचने के लिए, संसाधनों को मिटाने का तरीका जानने के लिए, इस लैब के आखिर में दिए गए निर्देशों का पालन करें.
- नए उपयोगकर्ता, 300 डॉलर के मुफ़्त में आज़माने की सुविधा का फ़ायदा पा सकते हैं.
प्रोजेक्ट बनाना (ज़रूरी नहीं)
अगर आपको इस लैब के लिए किसी मौजूदा प्रोजेक्ट का इस्तेमाल नहीं करना है, तो यहां नया प्रोजेक्ट बनाएं.
3. एपीआई चालू करना
Cloud Shell को कॉन्फ़िगर करना
प्रोजेक्ट बन जाने के बाद, Cloud Shell को सेट अप करने के लिए, यह तरीका अपनाएं.
Cloud Shell लॉन्च करना
shell.cloud.google.com पर जाएं. अगर आपको पुष्टि करने के लिए कहा जाता है, तो पुष्टि करें पर क्लिक करें.
प्रोजेक्ट आईडी सेट करें
सही प्रोजेक्ट आईडी सेट करने के लिए, Cloud Shell टर्मिनल में यह कमांड चलाएं. <your-project-id> की जगह, प्रोजेक्ट बनाने के ऊपर दिए गए चरण से कॉपी किया गया अपना असल प्रोजेक्ट आईडी डालें.
gcloud config set project <your-project-id>
अब आपको Cloud Shell टर्मिनल में, सही प्रोजेक्ट चुना हुआ दिखेगा.
संवेदनशील डेटा की सुरक्षा की सुविधा चालू करना
Sensitive Data Protection सेवा और Cloud Storage का इस्तेमाल करने के लिए, आपको यह पक्का करना होगा कि आपके Google Cloud प्रोजेक्ट में ये एपीआई चालू हों.
- टर्मिनल में, इन एपीआई को चालू करें:
gcloud services enable dlp.googleapis.com storage.googleapis.com
इसके अलावा, इन एपीआई को चालू करने के लिए, कंसोल में सुरक्षा > संवेदनशील डेटा की सुरक्षा और Cloud Storage पर जाएं. इसके बाद, अगर हर सेवा के लिए कहा जाता है, तो चालू करें बटन पर क्लिक करें.
4. संवेदनशील डेटा वाले बकेट बनाना
इनपुट और आउटपुट बकेट बनाना
इस चरण में, आपको दो बकेट बनानी होंगी: एक में वह संवेदनशील डेटा होगा जिसकी जांच करनी है. दूसरी बकेट में, Sensitive Data Protection, पहचान छिपाकर बनाई गई आउटपुट फ़ाइलें सेव करेगा. आपके पास सैंपल डेटा फ़ाइलें डाउनलोड करने और उन्हें अपने इनपुट बकेट में अपलोड करने का विकल्प भी होता है.
- टर्मिनल में, इनपुट डेटा के लिए एक बकेट और आउटपुट के लिए एक बकेट बनाने के लिए, ये कमांड चलाएं. इसके बाद,
gs://dlp-codelab-dataसे सैंपल डेटा को इनपुट बकेट में डालें:PROJECT_ID=$(gcloud config get-value project) gsutil mb gs://input-$PROJECT_ID gsutil mb gs://output-$PROJECT_ID
इनपुट बकेट में संवेदनशील डेटा जोड़ना
इस चरण में, GitHub से सैंपल डेटा फ़ाइलें डाउनलोड की जाती हैं. इनमें टेस्ट पीआईआई शामिल होती है. इसके बाद, इन फ़ाइलों को अपने इनपुट बकेट में अपलोड किया जाता है.
- इस लैब के लिए ज़रूरी सैंपल डेटा वाली
devrel-demosरिपॉज़िटरी को क्लोन करने के लिए, Cloud Shell में यह कमांड चलाएं.REPO_URL="https://github.com/GoogleCloudPlatform/devrel-demos.git" TARGET_PATH="security/sample-data" OUTPUT_FOLDER="sample-data" git clone --quiet --depth 1 --filter=blob:none --sparse "$REPO_URL" temp_loader cd temp_loader git sparse-checkout set "$TARGET_PATH" cd .. mv "temp_loader/$TARGET_PATH" "$OUTPUT_FOLDER" rm -rf temp_loader - इसके बाद, सैंपल डेटा को उस इनपुट बकेट में कॉपी करें जिसे आपने पहले बनाया था:
gsutil -m cp -r sample-data/* gs://input-$PROJECT_ID/ - Cloud Storage > Buckets पर जाएं. इसके बाद, इंपोर्ट किए गए डेटा को देखने के लिए, इनपुट बकेट पर क्लिक करें.
5. जांच करने के लिए टेंप्लेट बनाना
इस टास्क में, आपको एक ऐसा टेंप्लेट बनाना होता है जिससे संवेदनशील डेटा की सुरक्षा को यह पता चल सके कि उसे किस तरह का डेटा ढूंढना है. इससे, आपको उन infoTypes पर ध्यान देने में मदद मिलती है जो आपके डेटा और इलाके के हिसाब से काम के हैं. इससे परफ़ॉर्मेंस और सटीकता बेहतर होती है.
जांच करने के लिए टेंप्लेट बनाना
इस चरण में, यह तय किया जाता है कि किस तरह के डेटा को संवेदनशील डेटा माना जाएगा और उसकी जांच की जाएगी. इस टेंप्लेट का फिर से इस्तेमाल किया जाएगा, ताकि यह पक्का किया जा सके कि पहचान से जुड़ी जानकारी हटाने की प्रोसेस में एक जैसा तरीका अपनाया गया है.
- नेविगेशन मेन्यू में, संवेदनशील डेटा की सुरक्षा > कॉन्फ़िगरेशन > टेंप्लेट पर जाएं.
- टेंप्लेट बनाएं पर क्लिक करें.
- टेंप्लेट टाइप के लिए, जांच करें (संवेदनशील डेटा ढूंढें) को चुनें.
- टेंप्लेट आईडी को
pii-finderपर सेट करें. - जारी रखें पर क्लिक करके, डिटेक्शन कॉन्फ़िगर करें पर जाएं.
- infoTypes मैनेज करें पर क्लिक करें.
- फ़िल्टर का इस्तेमाल करके, यहां दिए गए infoTypes खोजें और हर एक के बगल में मौजूद चेकबॉक्स पर सही का निशान लगाएं:
CREDIT_CARD_EXPIRATION_DATECREDIT_CARD_NUMBERDATE_OF_BIRTHDRIVERS_LICENSE_NUMBEREMAIL_ADDRESSGCP_API_KEYGCP_CREDENTIALSORGANIZATION_NAMEPASSWORDPERSON_NAMEPHONE_NUMBERUS_SOCIAL_SECURITY_NUMBER
- इसके अलावा, अपनी पसंद के अन्य विषय भी चुनें और हो गया पर क्लिक करें.
- नतीजे के तौर पर मिली टेबल देखें और पक्का करें कि ये सभी infoType जोड़े गए हों.
- बनाएं पर क्लिक करें.
6. पहचान छिपाने वाले टेंप्लेट बनाना
इसके बाद, अलग-अलग डेटा फ़ॉर्मैट को मैनेज करने के लिए, तीन अलग-अलग पहचान छिपाने वाले टेंप्लेट बनाए जाते हैं. इससे आपको डेटा ट्रांसफ़ॉर्मेशन की प्रोसेस पर ज़्यादा कंट्रोल मिलता है. साथ ही, हर फ़ाइल टाइप के लिए सबसे सही तरीका लागू किया जा सकता है. ये टेंप्लेट, अभी बनाए गए जांच वाले टेंप्लेट के साथ मिलकर काम करते हैं.
अनस्ट्रक्चर्ड डेटा के लिए टेंप्लेट बनाना
इस टेंप्लेट से यह तय होगा कि चैट लॉग या फ़ीडबैक फ़ॉर्म जैसे फ़्री-फ़ॉर्म टेक्स्ट में मिले संवेदनशील डेटा की पहचान कैसे हटाई जाएगी. चुना गया तरीका, संवेदनशील वैल्यू को उसके infoType नाम से बदल देता है. इससे कॉन्टेक्स्ट बना रहता है.
- टेंप्लेट पेज पर, टेंप्लेट बनाएं पर क्लिक करें.
- पहचान छिपाने वाला टेंप्लेट तय करें:
प्रॉपर्टी
वैल्यू (टाइप करें या चुनें)
टेंप्लेट का टाइप
पहचान ज़ाहिर करने वाली जानकारी हटाना (संवेदनशील डेटा हटाना)
डेटा ट्रांसफ़ॉर्मेशन का टाइप
InfoType
टेंप्लेट आईडी
de-identify-unstructured - डेटा की पहचान से जुड़ी जानकारी हटाने की सुविधा कॉन्फ़िगर करें पर जाकर, जारी रखें.
- बदलाव का तरीका में जाकर, बदलाव का तरीका चुनें: infoType के नाम से बदलें.
- बनाएं पर क्लिक करें.
- परीक्षण करें पर क्लिक करें.
- व्यक्तिगत पहचान से जुड़ी जानकारी वाले मैसेज की जांच करें, ताकि यह पता चल सके कि उसे कैसे बदला जाएगा:
Hi, my name is Alex and my SSN is 555-11-5555. You can reach me at +1-555-555-5555.
स्ट्रक्चर्ड डेटा के लिए टेंप्लेट बनाना
यह टेंप्लेट, खास तौर पर स्ट्रक्चर्ड डेटासेट में मौजूद संवेदनशील जानकारी को टारगेट करता है. जैसे, CSV फ़ाइलें. आपको इसे इस तरह से कॉन्फ़िगर करना होगा कि डेटा को मास्क किया जा सके. इससे टेस्टिंग के लिए डेटा का इस्तेमाल किया जा सकेगा. साथ ही, संवेदनशील फ़ील्ड की पहचान भी नहीं हो पाएगी.
- टेंप्लेट पेज पर वापस जाएं और टेंप्लेट बनाएं पर क्लिक करें.
- पहचान छिपाने वाला टेंप्लेट तय करें:
प्रॉपर्टी
वैल्यू (टाइप करें या चुनें)
टेंप्लेट का टाइप
पहचान ज़ाहिर करने वाली जानकारी हटाना (संवेदनशील डेटा हटाना)
डेटा ट्रांसफ़ॉर्मेशन का टाइप
रिकॉर्ड करें
टेंप्लेट आईडी
de-identify-structured - जारी रखें पर क्लिक करके, पहचान छिपाने की सुविधा को कॉन्फ़िगर करें पर जाएं. यह टेंप्लेट स्ट्रक्चर्ड डेटा पर लागू होता है. इसलिए, हम अक्सर उन फ़ील्ड या कॉलम का अनुमान लगा सकते हैं जिनमें कुछ तरह का संवेदनशील डेटा मौजूद होगा. आपको पता है कि आपका ऐप्लिकेशन जिस CSV फ़ाइल का इस्तेमाल करता है उसमें
user_idसे कम उपयोगकर्ताओं के ईमेल पते हैं. साथ ही,messageमें अक्सर ग्राहक इंटरैक्शन से जुड़ी निजी पहचान वाली जानकारी (पीआईआई) होती है. आपकोagent_idको मास्क करने की ज़रूरत नहीं है, क्योंकि वे कर्मचारी हैं और बातचीत का श्रेय उन्हें मिलना चाहिए. इस सेक्शन को इस तरह भरें:- बदलाव करने के लिए फ़ील्ड या कॉलम:
user_id,message. - बदलाव का टाइप: जानकारी किस तरह की है के आधार पर मैच करना
- ट्रांसफ़ॉर्मेशन का तरीका: ट्रांसफ़ॉर्मेशन जोड़ें पर क्लिक करें
- बदलाव: वर्ण के साथ मास्क करें.
- अनदेखा किए जाने वाले वर्ण: अमेरिका में इस्तेमाल होने वाले विराम चिह्न.
- बदलाव करने के लिए फ़ील्ड या कॉलम:
- बनाएं पर क्लिक करें.
इमेज डेटा के लिए टेंप्लेट बनाना
इस टेंप्लेट को इमेज में मौजूद संवेदनशील टेक्स्ट की पहचान छिपाने के लिए डिज़ाइन किया गया है. जैसे, स्कैन किए गए दस्तावेज़ या उपयोगकर्ता की सबमिट की गई फ़ोटो. यह ऑप्टिकल कैरेक्टर रिकग्निशन (ओसीआर) का इस्तेमाल करके, निजी पहचान से जुड़ी जानकारी का पता लगाता है और उसे छिपाता है.
- टेंप्लेट पेज पर वापस जाएं और टेंप्लेट बनाएं पर क्लिक करें.
- पहचान छिपाने वाला टेंप्लेट तय करें:
प्रॉपर्टी
वैल्यू (टाइप करें या चुनें)
टेंप्लेट का टाइप
पहचान ज़ाहिर करने वाली जानकारी हटाना (संवेदनशील डेटा हटाना)
डेटा ट्रांसफ़ॉर्मेशन का टाइप
इमेज
टेंप्लेट आईडी
de-identify-image - डेटा की पहचान से जुड़ी जानकारी हटाने की सुविधा कॉन्फ़िगर करें पर जाकर, जारी रखें.
- बदले जाने वाले InfoType: जांच के टेंप्लेट या जांच के कॉन्फ़िगरेशन में तय किए गए ऐसे InfoType जिनका पता लगाया गया है और जिन्हें अन्य नियमों में नहीं बताया गया है.
- बनाएं पर क्लिक करें.
7. पहचान छिपाने की प्रोसेस वाला जॉब बनाना और उसे चलाना
टेंप्लेट तय करने के बाद, अब एक सिंगल जॉब बनाएं. यह जॉब, फ़ाइल टाइप का पता लगाकर और उसकी जांच करके, सही डी-आइडेंटिफ़िकेशन टेंप्लेट लागू करती है. इससे, Cloud Storage में सेव किए गए डेटा के लिए, संवेदनशील डेटा की सुरक्षा से जुड़ी प्रोसेस अपने-आप पूरी हो जाती है.
इनपुट डेटा कॉन्फ़िगर करना
इस चरण में, आपको उस डेटा सोर्स के बारे में बताना होता है जिसमें मौजूद डेटा की पहचान छिपाने की ज़रूरत है. यह डेटा सोर्स, Cloud Storage बकेट होता है. इसमें अलग-अलग तरह की फ़ाइलें होती हैं, जिनमें संवेदनशील जानकारी होती है.
- खोज बार का इस्तेमाल करके, सुरक्षा > संवेदनशील डेटा की सुरक्षा पर जाएं.
- मेन्यू में, जांच पर क्लिक करें.
- Create job and job triggers पर क्लिक करें.
- जॉब को कॉन्फ़िगर करें:
प्रॉपर्टी
वैल्यू (टाइप करें या चुनें)
जॉब आईडी
pii-removerस्टोरेज का टाइप
Google Cloud Storage
जगह की जानकारी का टाइप
शामिल/बाहर रखने के नियमों के साथ बकेट को स्कैन करना (ज़रूरी नहीं)
बकेट का नाम
input-[your-project-id]
पहचान करने और कार्रवाइयों को कॉन्फ़िगर करना
अब इस नौकरी से, पहले बनाए गए टेंप्लेट लिंक करें. इससे Sensitive Data Protection को यह पता चलेगा कि व्यक्तिगत पहचान से जुड़ी जानकारी की जांच कैसे करनी है और कॉन्टेंट टाइप के आधार पर, पहचान छिपाने का कौनसा तरीका लागू करना है.
- जांच का टेंप्लेट:
projects/[your-project-id]/locations/global/inspectTemplates/pii-finder - कार्रवाइयां जोड़ें में जाकर, पहचान छिपाकर कॉपी बनाएं को चुनें. इसके बाद, ट्रांसफ़ॉर्मेशन टेंप्लेट को कॉन्फ़िगर करें, ताकि वे आपके बनाए गए टेंप्लेट हों.
- आपके लिए एक पॉप-अप खुलता है.
Confirm whether you want to de-identify the findingsके लिए, सैंपलिंग बंद करें पर क्लिक करें.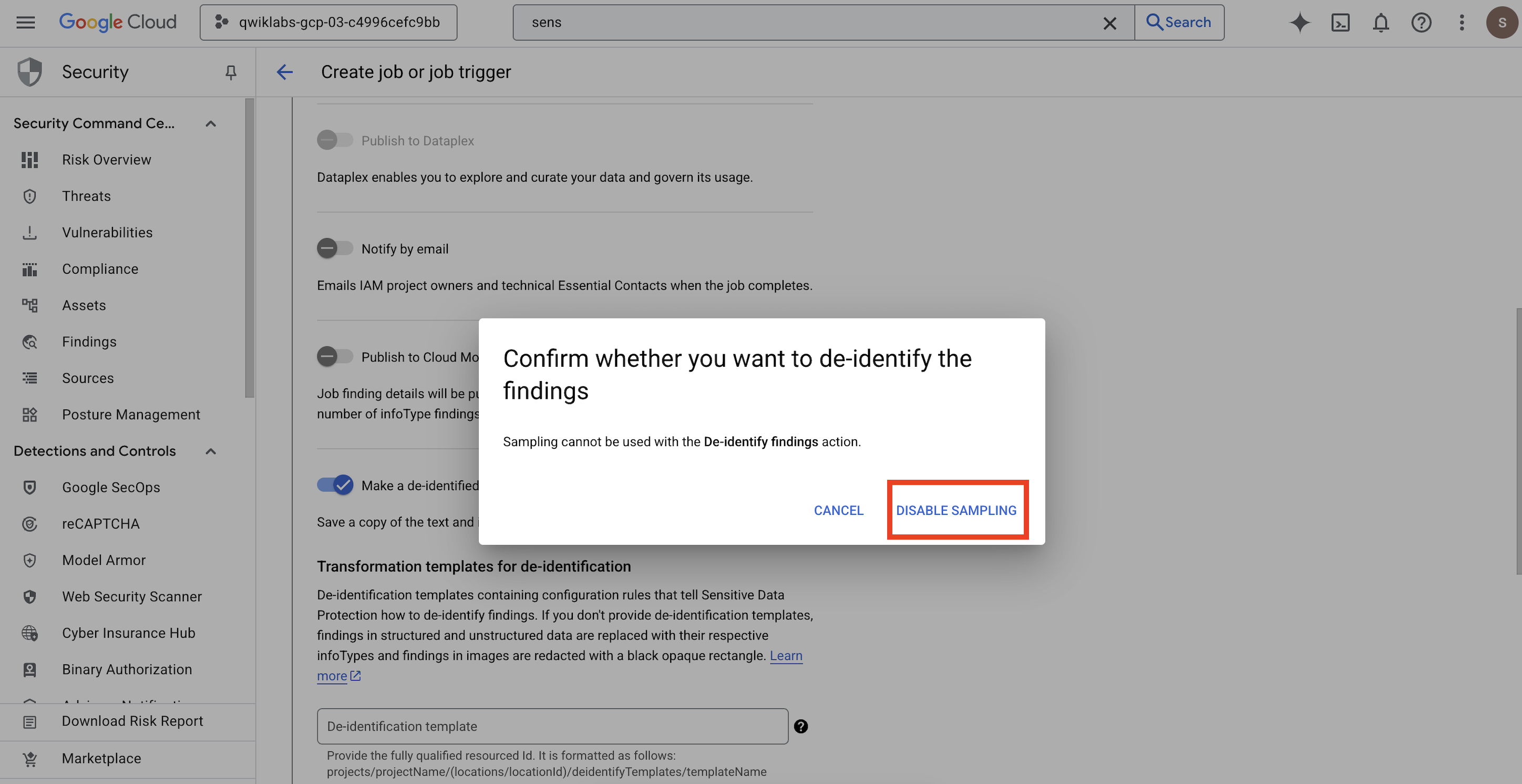
प्रॉपर्टी
वैल्यू (टाइप करें या चुनें)
पहचान ज़ाहिर करने वाली जानकारी हटाने का टेंप्लेट
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-unstructuredस्ट्रक्चर्ड डी-आइडेंटिफ़िकेशन टेंप्लेट
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-structuredइमेज में बदलाव करने का टेंप्लेट
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-image - Cloud Storage में आउटपुट फ़ाइल सेव करने की जगह कॉन्फ़िगर करें:
- यूआरएल:
gs://output-[your-project-id]
- यूआरएल:
- जॉब को तुरंत चलाने के लिए, शेड्यूल करें में जाकर, कोई नहीं को चुनें.
- बनाएं पर क्लिक करें.
Confirm job or job trigger createके लिए एक पॉप-अप खुलता है. बनाएं की पुष्टि करें पर क्लिक करें.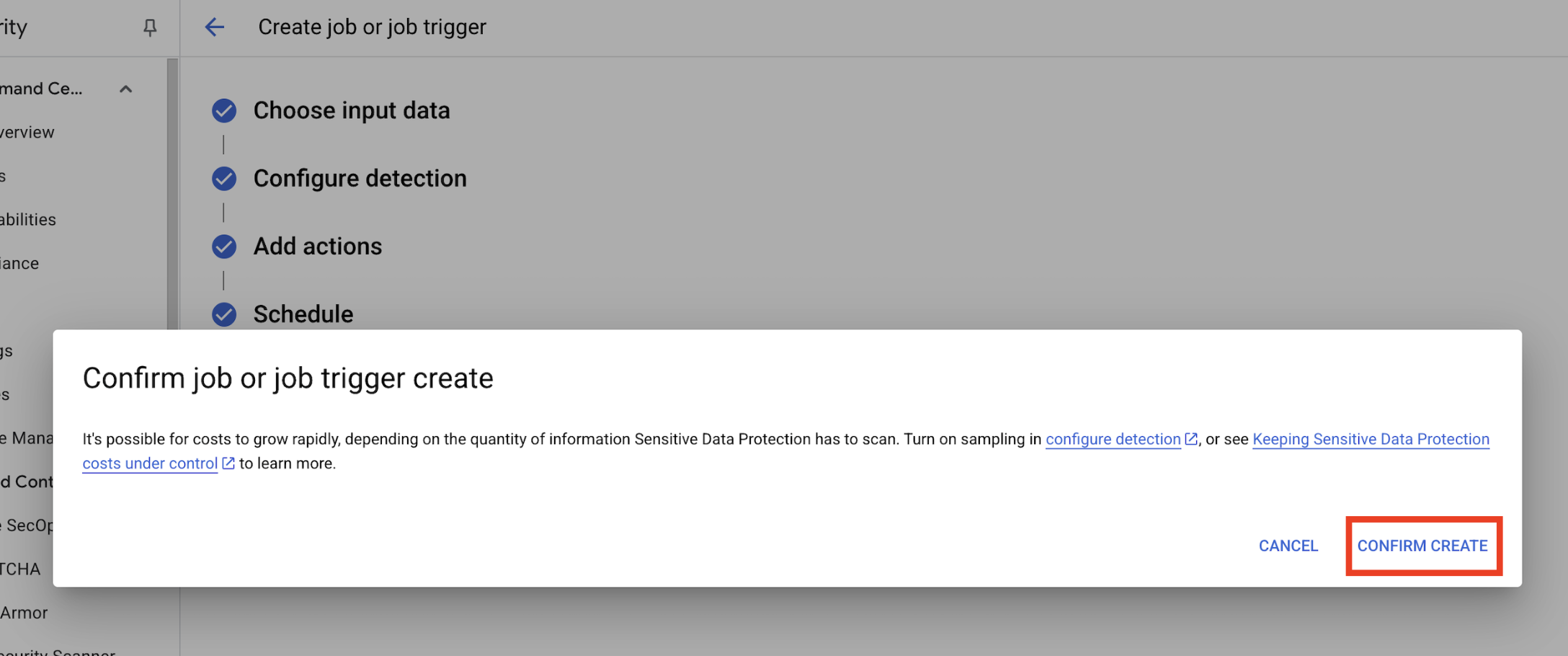
8. नतीजों की पुष्टि करना
आखिरी चरण में, यह पुष्टि की जाती है कि आउटपुट बकेट में मौजूद सभी फ़ाइल टाइप में, संवेदनशील डेटा को सही तरीके से छिपाया गया है. इससे यह पक्का किया जाता है कि आपकी डी-आइडेंटिफ़िकेशन पाइपलाइन उम्मीद के मुताबिक काम कर रही है.
नौकरी की स्थिति देखना
यह पक्का करने के लिए कि जॉब पूरी हो गई है, उस पर नज़र रखें. साथ ही, आउटपुट फ़ाइलों की जांच करने से पहले, नतीजों की खास जानकारी देखें.
- जॉब की जानकारी टैब में, जॉब के हो गया स्टेटस दिखने का इंतज़ार करें.
- खास जानकारी में जाकर, नतीजों की संख्या और पता लगाए गए हर infoType का प्रतिशत देखें.
- कॉन्फ़िगरेशन पर क्लिक करें.
- नीचे की ओर स्क्रोल करके कार्रवाइयां पर जाएं. इसके बाद, पहचान छिपाया गया डेटा देखने के लिए, आउटपुट बकेट पर क्लिक करें:
gs://output-[your-project-id].
इनपुट और आउटपुट फ़ाइलों की तुलना करना
इस चरण में, पहचान छिपाकर रखी गई फ़ाइलों की मैन्युअल तरीके से जांच की जाती है. इससे यह पुष्टि की जाती है कि आपके टेंप्लेट के मुताबिक, डेटा को सही तरीके से सैनिटाइज़ किया गया है.
- इमेज: आउटपुट बकेट से कोई इमेज खोलें. पुष्टि करें कि आउटपुट फ़ाइल में, सभी संवेदनशील टेक्स्ट को छिपा दिया गया हो.
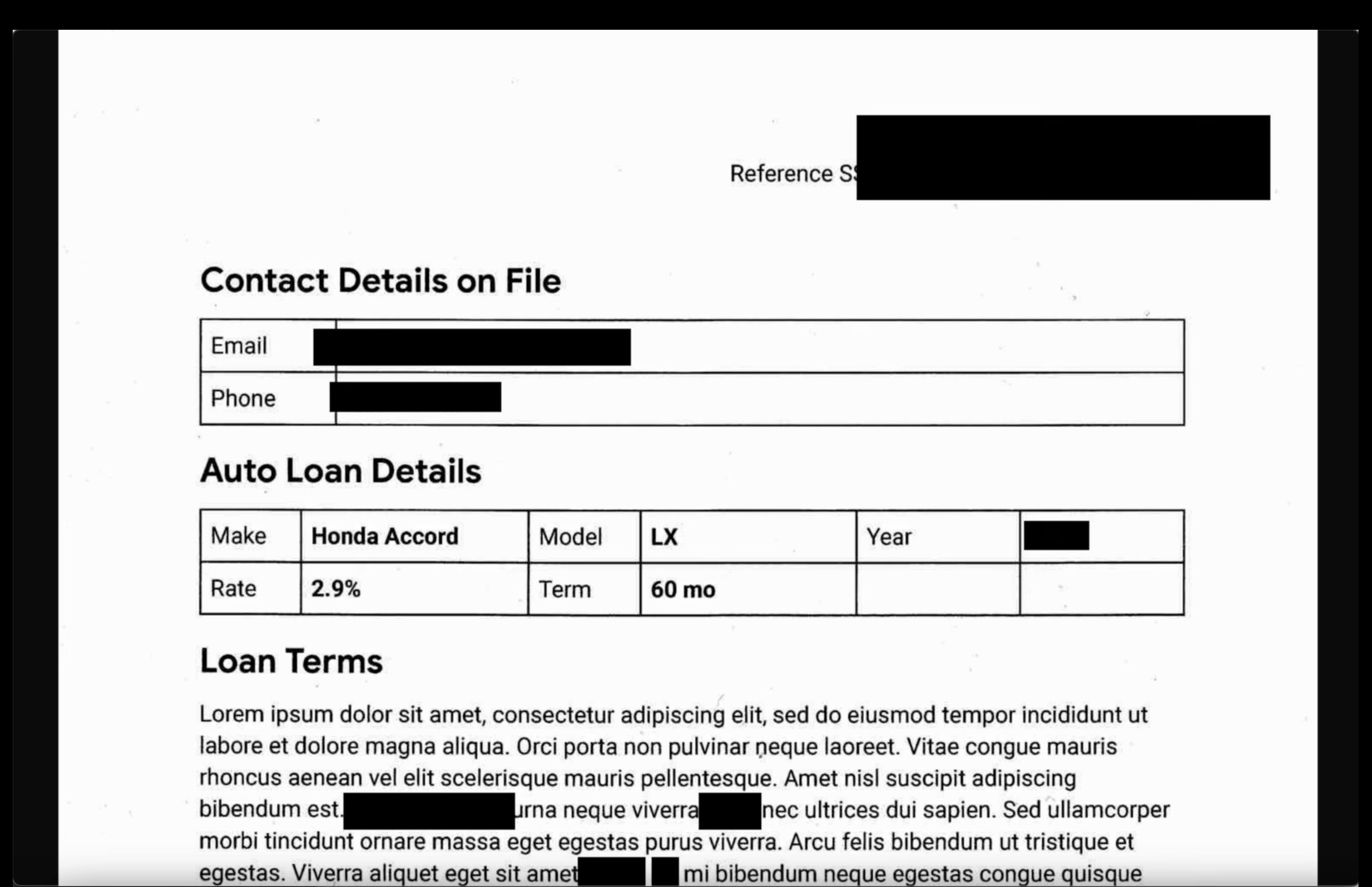
- अनस्ट्रक्चर्ड लॉग: दोनों बकेट से लॉग फ़ाइल देखें. पुष्टि करें कि आउटपुट लॉग में मौजूद व्यक्तिगत पहचान से जुड़ी जानकारी को infoType के नाम से बदल दिया गया है. उदाहरण के लिए,
[US_SOCIAL_SECURITY_NUMBER]. - स्ट्रक्चर्ड CSV फ़ाइलें: दोनों बकेट से CSV फ़ाइल खोलें. पुष्टि करें कि आउटपुट फ़ाइल में मौजूद उपयोगकर्ता के ईमेल पते और एसएसएन,
####@####.comसे मास्क किए गए हों.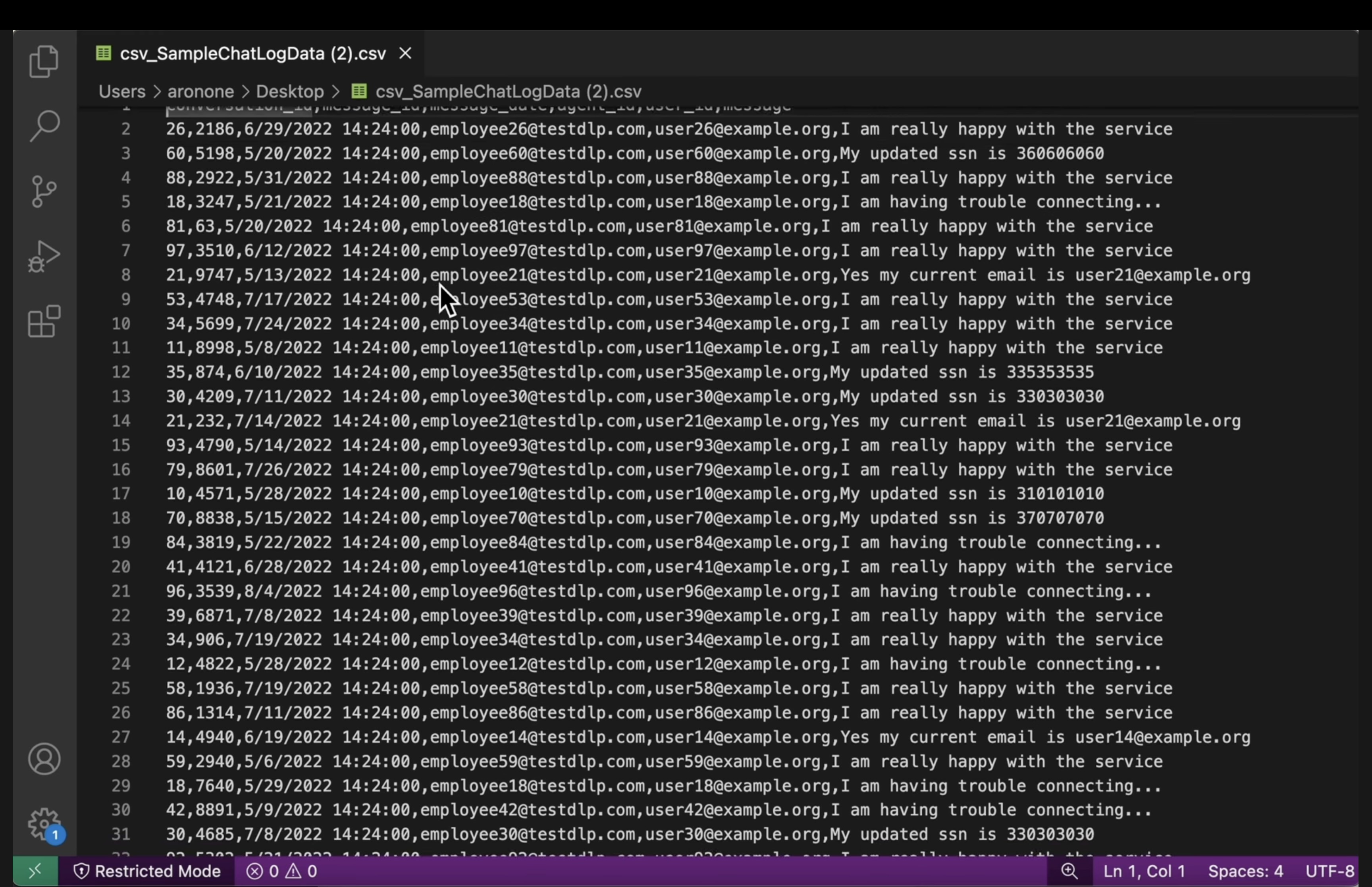
9. लैब से असल ज़िंदगी तक: इस सुविधा को अपने प्रोजेक्ट में कैसे इस्तेमाल करें
आपने जो सिद्धांत और कॉन्फ़िगरेशन लागू किए हैं वे Google Cloud पर, असल दुनिया के एआई प्रोजेक्ट को सुरक्षित करने के लिए ब्लूप्रिंट हैं. आपने अभी जो संसाधन बनाए हैं—जांच करने वाला टेंप्लेट, पहचान छिपाने वाले टेंप्लेट, और अपने-आप होने वाला काम—ये किसी भी नई डेटा इंटेक प्रोसेस के लिए, सुरक्षित स्टार्टर टेंप्लेट के तौर पर काम करते हैं.
डेटा को अपने-आप सुरक्षित करने वाली पाइपलाइन: सुरक्षित तरीके से डेटा पाना
इसे अपने सेटअप में इस्तेमाल करने का तरीका
जब भी आपकी टीम को एआई डेवलपमेंट के लिए, ग्राहक का नया रॉ डेटा इस्तेमाल करना हो, तब आपको उसे ऐसी पाइपलाइन से भेजना होगा जिसमें आपने संवेदनशील डेटा की सुरक्षा से जुड़ा काम कॉन्फ़िगर किया हो. मैन्युअल तरीके से जांच करने और डेटा छिपाने के बजाय, इस ऑटोमेटेड वर्कफ़्लो का इस्तेमाल करें. इससे यह पक्का किया जाता है कि डेटा साइंटिस्ट और एआई मॉडल सिर्फ़ ऐसे डेटा के साथ इंटरैक्ट करें जिसमें पहचान ज़ाहिर करने वाली जानकारी शामिल न हो. इससे निजता से जुड़े जोखिम काफ़ी हद तक कम हो जाते हैं.
प्रोडक्शन ट्रैक से कनेक्ट किया जा रहा है
प्रोडक्शन एनवायरमेंट में, इस कॉन्सेप्ट को और बेहतर बनाया जा सकता है. इसके लिए, ये काम किए जा सकते हैं:
- जॉब ट्रिगर की मदद से ऑटोमेशन: जॉब को मैन्युअल तरीके से चलाने के बजाय, जब भी आपके इनपुट Cloud Storage बकेट में कोई नई फ़ाइल अपलोड की जाती है, तब जॉब ट्रिगर सेट अप किया जाता है. इससे पूरी तरह से ऑटोमेटेड, बिना किसी मानवीय हस्तक्षेप के पहचान का पता लगाने और उसे हटाने की प्रोसेस तैयार होती है.
- डेटा लेक/वेयरहाउस के साथ इंटिग्रेशन: पहचान छिपाकर तैयार किया गया आउटपुट डेटा, आम तौर पर सुरक्षित डेटा लेक (जैसे, Cloud Storage पर) या डेटा वेयरहाउस (जैसे, BigQuery) में भेजा जाता है. इससे आगे के विश्लेषण और मॉडल ट्रेनिंग में मदद मिलती है. साथ ही, यह पक्का किया जाता है कि डेटा के पूरे लाइफ़साइकल में निजता बनी रहे.
विस्तृत पहचान से जुड़ी जानकारी हटाने की रणनीतियां: निजता और उपयोगिता के बीच संतुलन बनाना
इसे अपने सेटअप में इस्तेमाल करने का तरीका
आपने जो अलग-अलग पहचान छिपाने वाले टेंप्लेट (अनस्ट्रक्चर्ड, स्ट्रक्चर्ड, इमेज) बनाए हैं वे अहम हैं. आपको अपने एआई मॉडल की खास ज़रूरतों के हिसाब से, मिलती-जुलती अलग-अलग रणनीतियां लागू करनी होंगी. इससे आपकी डेवलपमेंट टीम को अपने मॉडल के लिए, काम का डेटा मिलता है. साथ ही, निजता से समझौता भी नहीं होता.
प्रोडक्शन ट्रैक से कनेक्ट किया जा रहा है
प्रोडक्शन एनवायरमेंट में, यह बेहतर कंट्रोल इन कामों के लिए और भी ज़्यादा ज़रूरी हो जाता है:
- कस्टम इन्फ़ोटाइप और डिक्शनरी: किसी खास या डोमेन से जुड़े संवेदनशील डेटा के लिए, Sensitive Data Protection में कस्टम इन्फ़ोटाइप और डिक्शनरी तय की जाती हैं. इससे आपके कारोबार के हिसाब से, सभी तरह की गड़बड़ियों का पता लगाया जा सकता है.
- फ़ॉर्मैट-प्रिज़र्विंग एन्क्रिप्शन (एफ़पीई): कुछ मामलों में, पहचान छिपाए गए डेटा को उसके ओरिजनल फ़ॉर्मैट में ही रखना होता है. जैसे, इंटिग्रेशन टेस्टिंग के लिए क्रेडिट कार्ड नंबर. ऐसे मामलों में, पहचान छिपाने की बेहतर तकनीकों का इस्तेमाल किया जाता है. जैसे, फ़ॉर्मैट-प्रिज़र्विंग एन्क्रिप्शन. इससे, निजता को सुरक्षित रखते हुए, डेटा के असल पैटर्न के साथ टेस्टिंग की जा सकती है.
निगरानी और ऑडिट करना: लगातार नीतियों का पालन करना
इसे अपने सेटअप में इस्तेमाल करने का तरीका
आपको संवेदनशील डेटा की सुरक्षा से जुड़े लॉग की लगातार निगरानी करनी होगी. इससे यह पक्का किया जा सकेगा कि डेटा प्रोसेसिंग, आपकी निजता नीतियों के मुताबिक हो रही है और गलती से भी कोई संवेदनशील जानकारी सार्वजनिक नहीं हुई है. इस लगातार ऑडिट में, नौकरी की खास जानकारी और नतीजों की समय-समय पर समीक्षा करना शामिल है.
प्रोडक्शन ट्रैक से कनेक्ट किया जा रहा है
बेहतर प्रोडक्शन सिस्टम के लिए, ये मुख्य कार्रवाइयां करें:
- सिक्योरिटी कमांड सेंटर को नतीजे भेजें: खतरे को मैनेज करने और सुरक्षा की स्थिति को एक ही जगह पर देखने के लिए, Sensitive Data Protection की जॉब कॉन्फ़िगर करें. इससे, नतीजों की खास जानकारी सीधे सिक्योरिटी कमांड सेंटर को भेजी जा सकेगी. इससे सुरक्षा से जुड़ी चेतावनियों और अहम जानकारी को एक जगह पर इकट्ठा किया जाता है.
- सूचनाएं पाना और उल्लंघन की स्थिति में कार्रवाई करना: आपको Sensitive Data Protection की जांच के नतीजों या नौकरी से जुड़ी गड़बड़ियों के आधार पर, Cloud Monitoring की सूचनाएं सेट अप करनी होंगी. इससे यह पक्का होता है कि आपकी सुरक्षा टीम को नीति के संभावित उल्लंघनों या प्रोसेसिंग से जुड़ी समस्याओं के बारे में तुरंत सूचना मिल जाए. इससे, किसी भी घटना पर तुरंत कार्रवाई की जा सकती है.
10. नतीजा
बधाई हो! आपने डेटा की सुरक्षा से जुड़ा एक ऐसा वर्कफ़्लो बनाया है जो कई तरह के डेटा में मौजूद पीआईआई का अपने-आप पता लगा सकता है और उसकी पहचान छिपा सकता है. इससे, डाउनस्ट्रीम एआई डेवलपमेंट और आंकड़ों के विश्लेषण में इसका इस्तेमाल सुरक्षित तरीके से किया जा सकता है.
रीकैप
इस लैब में, आपने ये काम किए:
- संवेदनशील जानकारी के खास टाइप (infoTypes) का पता लगाने के लिए, inspection template तय किया गया हो.
- स्ट्रक्चर नहीं किए गए, स्ट्रक्चर किए गए, और इमेज डेटा के लिए, पहचान छिपाने के अलग-अलग नियम बनाए गए हैं.
- कॉन्फ़िगर किया गया और एक ऐसा जॉब चलाया गया जो फ़ाइल टाइप के आधार पर, पूरे बकेट के कॉन्टेंट पर सही तरीके से डेटा छिपाने की सुविधा को अपने-आप लागू करता है.
- पुष्टि की गई कि संवेदनशील डेटा को सुरक्षित आउटपुट लोकेशन में ट्रांसफ़ॉर्म किया गया है.
अगले चरण
- Security Command Center को नतीजे भेजना: थ्रेट मैनेजमेंट को बेहतर तरीके से इंटिग्रेट करने के लिए, जॉब ऐक्शन को कॉन्फ़िगर करें. इससे, जांच के नतीजों की खास जानकारी सीधे Security Command Center को भेजी जा सकेगी.
- Cloud Functions की मदद से प्रोसेस को अपने-आप शुरू होने की सुविधा सेट अप करना: प्रोडक्शन एनवायरमेंट में, Cloud Functions का इस्तेमाल करके, इस जांच की प्रोसेस को अपने-आप शुरू होने की सुविधा सेट अप की जा सकती है. ऐसा तब होगा, जब इनपुट बकेट में कोई नई फ़ाइल अपलोड की जाएगी.