
1. Pengantar
Ringkasan
Di lab ini, Anda akan membangun pipeline sanitasi data otomatis untuk melindungi informasi sensitif yang digunakan dalam pengembangan AI. Anda menggunakan Sensitive Data Protection Google Cloud (sebelumnya Cloud DLP) untuk memeriksa, mengklasifikasikan, dan menghapus identifikasi Informasi Identitas Pribadi (PII) di berbagai format data, termasuk teks tidak terstruktur, tabel terstruktur, dan gambar.
Konteks
Anda adalah pendukung keamanan dan privasi di tim pengembangan Anda, dan tujuan Anda adalah membuat alur kerja yang mengidentifikasi informasi sensitif dan menganonimkannya sebelum membuatnya tersedia bagi developer dan model. Tim Anda memerlukan data yang realistis dan berkualitas tinggi untuk menyesuaikan dan menguji aplikasi AI Generatif baru, tetapi penggunaan data pelanggan mentah menimbulkan tantangan privasi yang signifikan.
Tabel berikut mencantumkan risiko privasi yang paling Anda khawatirkan untuk dimitigasi:
Risiko | Mitigasi |
Eksposur PII dalam file teks tidak terstruktur (misalnya, log chat dukungan, formulir masukan). | Buat template de-identifikasi yang mengganti nilai sensitif dengan infoType-nya, sehingga mempertahankan konteks sekaligus menghilangkan eksposur. |
Hilangnya kegunaan data dalam set data terstruktur (CSV) saat PII dihapus. | Gunakan transformasi rekaman untuk menyamarkan pengidentifikasi secara selektif (seperti nama) dan menerapkan teknik seperti penyamaran karakter untuk mempertahankan karakter lain dalam string, sehingga developer tetap dapat menguji dengan data tersebut. |
Eksposur PII dari teks yang disematkan dalam gambar (misalnya, dokumen yang dipindai, foto pengguna). | Buat template de-identifikasi khusus gambar yang menyamarkan teks yang ditemukan dalam gambar. |
Penyensoran manual yang tidak konsisten atau rentan terhadap error di berbagai jenis data. | Mengonfigurasi satu tugas Sensitive Data Protection otomatis yang secara konsisten menerapkan template de-identifikasi yang benar berdasarkan jenis file yang diprosesnya. |
Yang akan Anda pelajari
Di lab ini, Anda akan mempelajari cara:
- Tentukan template inspeksi untuk mendeteksi jenis informasi sensitif (infoType) tertentu.
- Buat aturan de-identifikasi yang berbeda untuk data tidak terstruktur, terstruktur, dan gambar.
- Konfigurasi dan jalankan satu tugas yang secara otomatis menerapkan penyensoran yang benar berdasarkan jenis file ke konten seluruh bucket.
- Verifikasi keberhasilan transformasi data sensitif di lokasi output yang aman.
2. Penyiapan project
Akun Google
Jika belum memiliki Akun Google pribadi, Anda harus membuat Akun Google.
Gunakan akun pribadi, bukan akun kantor atau sekolah.
Login ke Konsol Google Cloud
Login ke Konsol Google Cloud menggunakan Akun Google pribadi.
Aktifkan Penagihan
Menukarkan kredit Google Cloud (opsional)
Untuk menjalankan workshop ini, Anda memerlukan akun penagihan dengan sejumlah kredit. Gunakan kredit dari banner di bagian atas codelab ini untuk memulai. Jika sudah terhubung ke akun penagihan, Anda dapat melewati langkah ini.
Menyiapkan akun penagihan pribadi
Jika menyiapkan penagihan menggunakan kredit Google Cloud, Anda dapat melewati langkah ini.
Untuk menyiapkan akun penagihan pribadi, buka di sini untuk mengaktifkan penagihan di Konsol Cloud.
Beberapa Catatan:
- Menyelesaikan lab ini akan dikenai biaya kurang dari $1 USD untuk resource Cloud.
- Anda dapat mengikuti langkah-langkah di akhir lab ini untuk menghapus resource agar tidak dikenai biaya lebih lanjut.
- Pengguna baru memenuhi syarat untuk mengikuti Uji Coba Gratis senilai$300 USD.
Membuat project (opsional)
Jika Anda tidak memiliki project saat ini yang ingin digunakan untuk lab ini, buat project baru di sini.
3. Mengaktifkan API
Mengonfigurasi Cloud Shell
Setelah project Anda berhasil dibuat, lakukan langkah-langkah berikut untuk menyiapkan Cloud Shell.
Meluncurkan Cloud Shell
Buka shell.cloud.google.com dan jika Anda melihat pop-up yang meminta Anda untuk memberikan otorisasi, klik Authorize.
Tetapkan ID Project
Jalankan perintah berikut di terminal Cloud Shell untuk menetapkan Project ID yang benar. Ganti <your-project-id> dengan Project ID Anda yang sebenarnya yang disalin dari langkah pembuatan project di atas.
gcloud config set project <your-project-id>
Sekarang Anda akan melihat bahwa project yang benar telah dipilih di terminal Cloud Shell.
Mengaktifkan Sensitive Data Protection
Untuk menggunakan layanan Sensitive Data Protection dan Cloud Storage, Anda harus memastikan bahwa API ini diaktifkan di project Google Cloud Anda.
- Di terminal, aktifkan API:
gcloud services enable dlp.googleapis.com storage.googleapis.com
Atau, Anda dapat mengaktifkan API ini dengan membuka Security > Sensitive Data Protection dan Cloud Storage di konsol, lalu mengklik tombol Enable jika diminta untuk setiap layanan.
4. Membuat bucket dengan data sensitif
Membuat bucket input dan output
Pada langkah ini, Anda akan membuat dua bucket: satu untuk menyimpan data sensitif yang perlu diperiksa, dan satu lagi tempat Sensitive Data Protection akan menyimpan file output yang dide-identifikasi. Anda juga dapat mendownload file data sampel dan menguploadnya ke bucket input.
- Di terminal, jalankan perintah berikut untuk membuat satu bucket untuk data input dan satu bucket untuk output, lalu isi bucket input dengan data contoh dari
gs://dlp-codelab-data:PROJECT_ID=$(gcloud config get-value project) gsutil mb gs://input-$PROJECT_ID gsutil mb gs://output-$PROJECT_ID
Menambahkan data sensitif ke bucket input
Pada langkah ini, Anda akan mendownload file data sampel yang berisi PII pengujian dari GitHub dan menguploadnya ke bucket input Anda.
- Di Cloud Shell, jalankan perintah berikut untuk meng-clone repositori
devrel-demos, yang berisi data sampel yang diperlukan untuk lab ini.REPO_URL="https://github.com/GoogleCloudPlatform/devrel-demos.git" TARGET_PATH="security/sample-data" OUTPUT_FOLDER="sample-data" git clone --quiet --depth 1 --filter=blob:none --sparse "$REPO_URL" temp_loader cd temp_loader git sparse-checkout set "$TARGET_PATH" cd .. mv "temp_loader/$TARGET_PATH" "$OUTPUT_FOLDER" rm -rf temp_loader - Selanjutnya, salin data sampel ke bucket input yang Anda buat sebelumnya:
gsutil -m cp -r sample-data/* gs://input-$PROJECT_ID/ - Buka Cloud Storage > Buckets, lalu klik bucket input untuk melihat data yang Anda impor.
5. Membuat template pemeriksaan
Dalam tugas ini, Anda akan membuat template yang memberi tahu Sensitive Data Protection apa yang harus dicari. Dengan demikian, Anda dapat memfokuskan pemeriksaan pada infoTypes yang relevan dengan data dan geografi Anda, sehingga meningkatkan performa dan akurasi.
Membuat template pemeriksaan
Pada langkah ini, Anda menentukan aturan untuk data sensitif yang perlu diperiksa. Template ini akan digunakan kembali oleh tugas de-identifikasi Anda untuk memastikan konsistensi.
- Dari menu navigasi, buka Sensitive Data Protection > Configuration > Templates.
- Klik Create Template.
- Untuk Jenis template, pilih Periksa (temukan data sensitif).
- Tetapkan Template ID ke
pii-finder. - Lanjutkan ke Konfigurasi deteksi.
- Klik Kelola infoType.
- Dengan menggunakan filter, telusuri infoTypes:
CREDIT_CARD_EXPIRATION_DATECREDIT_CARD_NUMBERDATE_OF_BIRTHDRIVERS_LICENSE_NUMBEREMAIL_ADDRESSGCP_API_KEYGCP_CREDENTIALSORGANIZATION_NAMEPASSWORDPERSON_NAMEPHONE_NUMBERUS_SOCIAL_SECURITY_NUMBER
- Pilih juga opsi lain yang Anda minati, lalu klik Selesai.
- Periksa tabel yang dihasilkan untuk memastikan semua infoType ini telah ditambahkan.
- Klik Buat.
6. Membuat template de-identifikasi
Selanjutnya, Anda membuat tiga template de-identifikasi terpisah untuk menangani format data yang berbeda. Hal ini memberi Anda kontrol terperinci atas proses transformasi, dengan menerapkan metode yang paling tepat untuk setiap jenis file. Template ini berfungsi bersama dengan template inspeksi yang baru saja Anda buat.
Membuat template untuk data tidak terstruktur
Template ini akan menentukan cara data sensitif yang ditemukan dalam teks bentuk bebas, seperti log chat atau formulir masukan, dianonimkan. Metode yang dipilih akan mengganti nilai sensitif dengan nama infoType-nya, sehingga mempertahankan konteks.
- Di halaman Templates, klik Create Template.
- Tentukan template de-identifikasi:
Properti
Nilai (ketik atau pilih)
Template type
Lakukan de-identifikasi (menghapus data sensitif)
Data transformation type
InfoType
Template ID
de-identify-unstructured - Lanjutkan ke Mengonfigurasi de-identifikasi.
- Di bagian Transformation method, pilih Transformasi: Replace with infoType name.
- Klik Buat.
- Klik Uji.
- Uji pesan yang berisi PII untuk melihat cara pesan tersebut akan ditransformasi:
Hi, my name is Alex and my SSN is 555-11-5555. You can reach me at +1-555-555-5555.
Membuat template untuk data terstruktur
Template ini secara khusus menargetkan informasi sensitif dalam kumpulan data terstruktur, seperti file CSV. Anda akan mengonfigurasinya untuk menyamarkan data dengan cara yang mempertahankan utilitas data untuk pengujian sekaligus melakukan de-identifikasi kolom sensitif.
- Kembali ke halaman Templates, lalu klik Create Template.
- Tentukan template de-identifikasi:
Properti
Nilai (ketik atau pilih)
Template type
Lakukan de-identifikasi (menghapus data sensitif)
Data transformation type
Rekam
Template ID
de-identify-structured - Lanjutkan ke Mengonfigurasi penghapusan identitas.Karena template ini berlaku untuk data terstruktur, kami sering kali dapat memprediksi kolom atau kolom yang akan berisi jenis data sensitif tertentu. Anda tahu bahwa CSV yang digunakan aplikasi Anda memiliki email pengguna di bawah
user_iddan bahwamessagesering berisi PII dari interaksi pelanggan. Anda tidak perlu khawatir menyamarkanagent_idkarena mereka adalah karyawan dan percakapan harus dapat diatribusikan. Isi bagian ini sebagai berikut:- Kolom yang akan ditransformasi:
user_id,message. - Transformation type: Match on infoType
- Metode transformasi: klik Tambahkan Transformasi
- Transformasi: Menyamarkan dengan karakter.
- Karakter yang akan diabaikan: Tanda Baca AS.
- Kolom yang akan ditransformasi:
- Klik Buat.
Membuat template untuk data gambar
Template ini dirancang untuk menganonimkan teks sensitif yang ditemukan dalam gambar, seperti dokumen yang dipindai atau foto yang dikirimkan pengguna. Fitur ini memanfaatkan pengenalan karakter optik (OCR) untuk mendeteksi dan menyamarkan PII.
- Kembali ke halaman Templates, lalu klik Create Template.
- Tentukan template de-identifikasi:
Properti
Nilai (ketik atau pilih)
Template type
Lakukan de-identifikasi (menghapus data sensitif)
Data transformation type
Gambar
Template ID
de-identify-image - Lanjutkan ke Mengonfigurasi de-identifikasi.
- InfoType yang akan diubah: Semua infoType terdeteksi yang ditetapkan dalam template inspeksi atau konfigurasi inspeksi yang tidak ditentukan di aturan lainnya.
- Klik Buat.
7. Membuat dan menjalankan tugas penghapusan identifikasi
Setelah template ditentukan, Anda akan membuat satu tugas yang menerapkan template de-identifikasi yang benar berdasarkan jenis file yang terdeteksi dan diperiksa. Hal ini mengotomatiskan proses perlindungan data sensitif untuk data yang disimpan di Cloud Storage.
Mengonfigurasi data input
Pada langkah ini, Anda menentukan sumber data yang perlu di-de-identifikasi, yaitu bucket Cloud Storage yang berisi berbagai jenis file dengan informasi sensitif.
- Buka Security > Sensitive Data Protection melalui kotak penelusuran.
- Klik Pemeriksaan di menu.
- Klik Create job and job triggers.
- Konfigurasi tugas:
Properti
Nilai (ketik atau pilih)
Job ID
pii-removerStorage type
Google Cloud Storage
Location type
Pindai bucket dengan aturan sertakan/kecualikan yang bersifat opsional
Bucket name
input-[your-project-id]
Mengonfigurasi deteksi dan tindakan
Sekarang Anda menautkan template yang dibuat sebelumnya ke tugas ini, yang memberi tahu Sensitive Data Protection cara memeriksa PII dan metode de-identifikasi yang akan diterapkan berdasarkan jenis konten.
- Template pemeriksaan:
projects/[your-project-id]/locations/global/inspectTemplates/pii-finder - Di bagian Add actions, pilih Make a de-identified copy dan konfigurasi template transformasi menjadi template yang Anda buat.
- Pop-up akan terbuka agar Anda dapat
Confirm whether you want to de-identify the findings, klik NONAKTIFKAN PENGAMBILAN SAMPEL.
Properti
Nilai (ketik atau pilih)
Template de-identifikasi
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-unstructuredStructured de-identification template
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-structuredTemplate Penyamaran Gambar
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-image - Konfigurasi lokasi output Cloud Storage:
- URL:
gs://output-[your-project-id]
- URL:
- Di bagian Schedule, biarkan pilihan sebagai None untuk menjalankan tugas secara langsung.
- Klik Buat.
- Pop-up akan terbuka ke
Confirm job or job trigger create, klik KONFIRMASI PEMBUATAN.
8. Verifikasi hasilnya
Langkah terakhir adalah mengonfirmasi bahwa data sensitif telah berhasil dan benar disamarkan di semua jenis file dalam bucket output. Hal ini memastikan pipeline anonimisasi Anda berfungsi seperti yang diharapkan.
Meninjau status tugas
Pantau tugas untuk memastikan tugas selesai dengan berhasil dan tinjau ringkasan temuan sebelum memeriksa file output.
- Di tab Detail tugas, tunggu hingga tugas menampilkan status Selesai.
- Di bagian Ringkasan, tinjau jumlah temuan dan persentase setiap infoType yang terdeteksi.
- Klik Konfigurasi.
- Scroll ke bawah ke Actions, lalu klik bucket output untuk melihat data yang di-de-identifikasi:
gs://output-[your-project-id].
Membandingkan file input dan output
Pada langkah ini, Anda akan memeriksa file yang telah di-de-identifikasi secara manual untuk mengonfirmasi bahwa pembersihan data telah diterapkan dengan benar sesuai dengan template Anda.
- Gambar: Buka gambar dari bucket output. Pastikan semua teks sensitif telah disamarkan dalam file output.
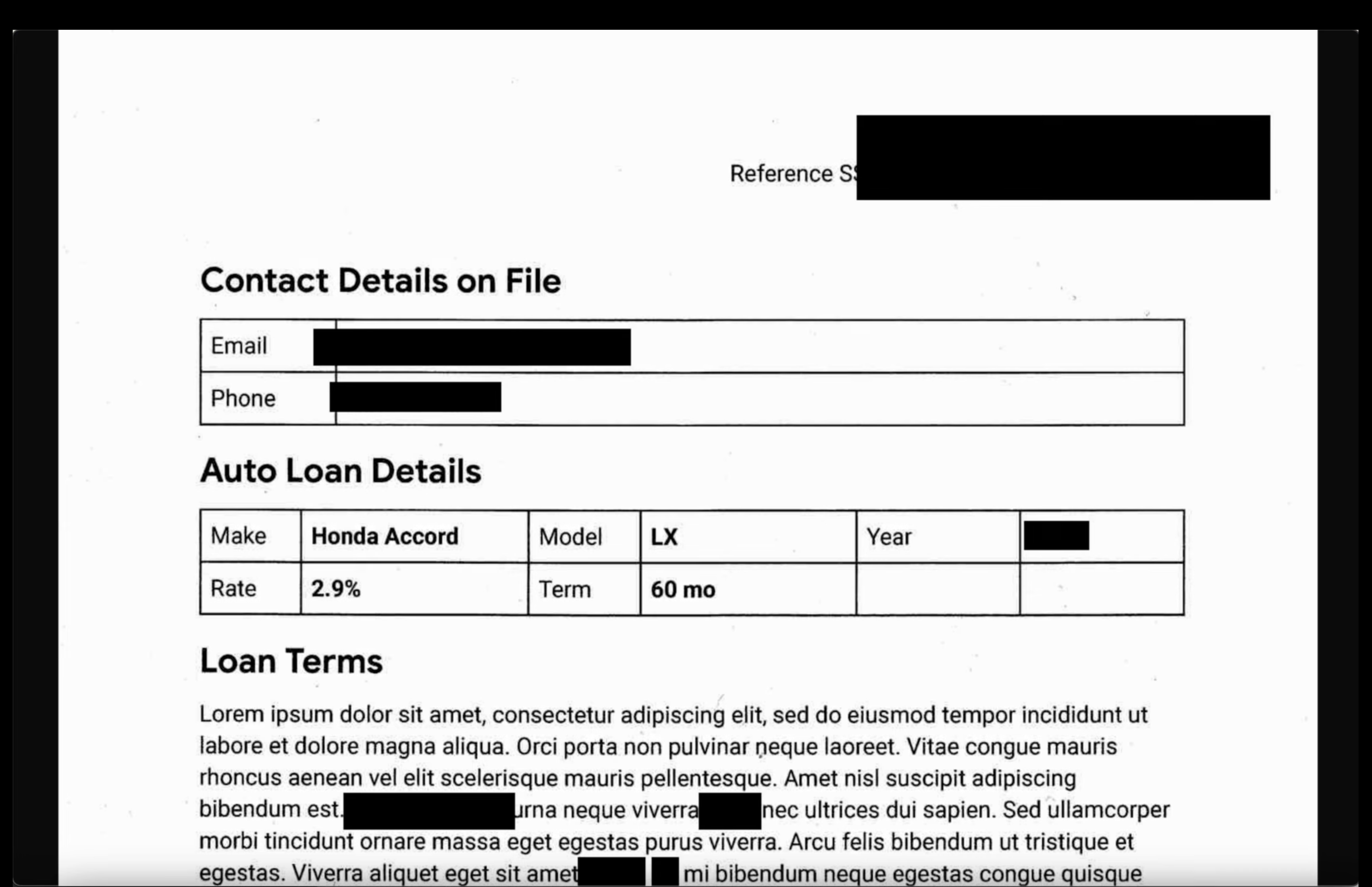
- Log tidak terstruktur: Melihat file log dari kedua bucket. Konfirmasi bahwa PII dalam log output telah diganti dengan nama infoType (misalnya,
[US_SOCIAL_SECURITY_NUMBER]). - CSV terstruktur: Buka file CSV dari kedua bucket. Pastikan email pengguna dan SSN dalam file output ditutup-tutupi dengan
####@####.com.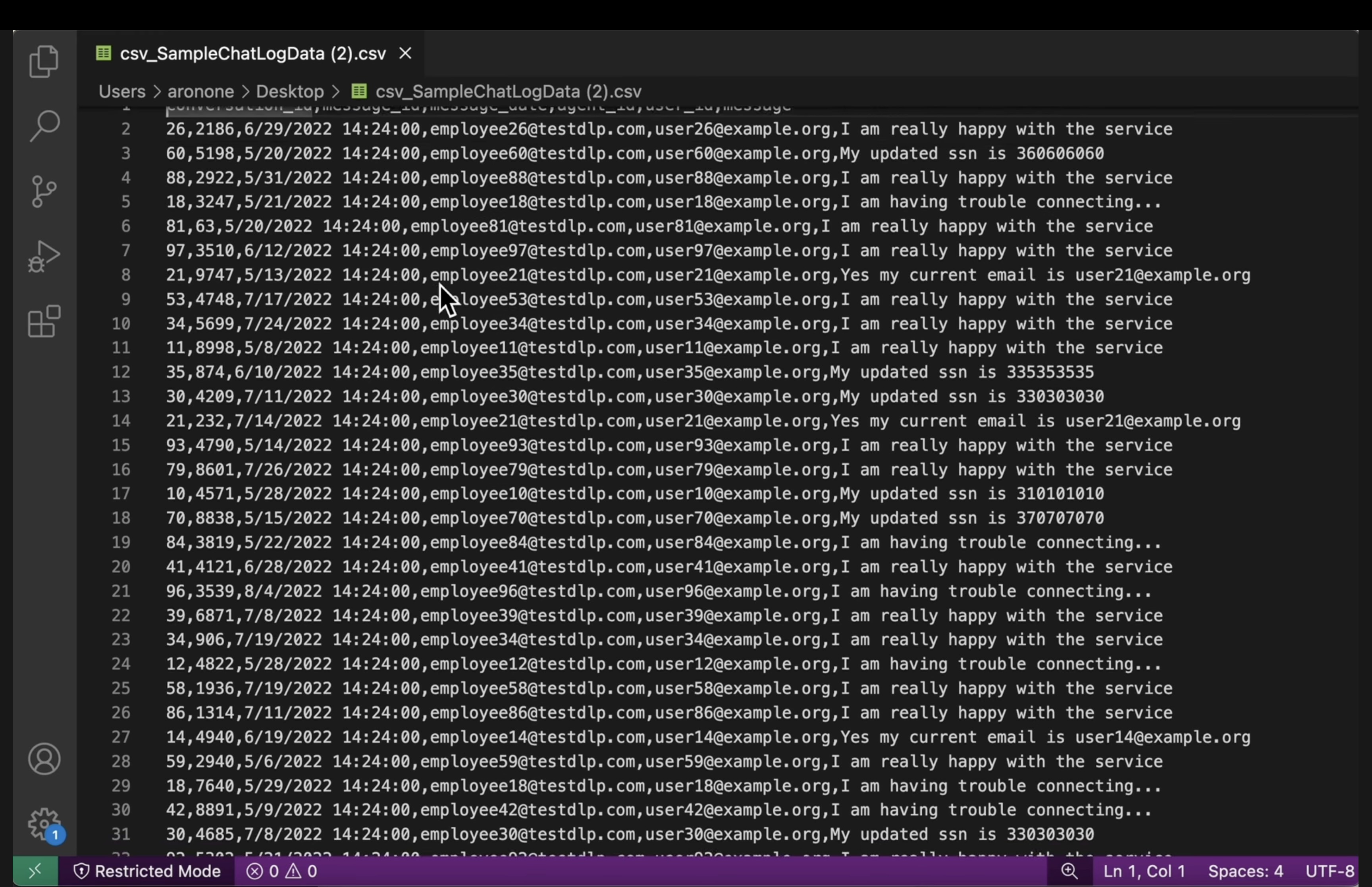
9. Dari lab ke kenyataan: Cara menggunakan ini dalam project Anda sendiri
Prinsip dan konfigurasi yang telah Anda terapkan adalah blueprint untuk mengamankan project AI dunia nyata di Google Cloud. Resource yang baru saja Anda buat—template inspeksi, template de-identifikasi, dan tugas otomatis—berfungsi sebagai template awal yang aman untuk setiap proses penyerapan data baru.
Pipeline sanitasi data otomatis: Asupan data aman Anda
Cara menggunakannya dalam penyiapan Anda
Setiap kali tim Anda perlu menyerap data pelanggan mentah baru untuk pengembangan AI, Anda akan mengarahkannya melalui pipeline yang menggabungkan tugas Sensitive Data Protection yang Anda konfigurasi. Alih-alih memeriksa dan menyamarkan secara manual, Anda memanfaatkan alur kerja otomatis ini. Hal ini memastikan bahwa data scientist dan model AI hanya berinteraksi dengan data yang telah dianonimkan, sehingga secara signifikan mengurangi risiko privasi.
Menghubungkan ke produksi
Dalam lingkungan produksi, Anda akan membawa konsep ini lebih jauh dengan:
- Otomatisasi dengan pemicu tugas: Daripada menjalankan tugas secara manual, Anda dapat menyiapkan pemicu tugas setiap kali file baru diupload ke bucket Cloud Storage input Anda. Hal ini akan membuat proses deteksi dan penghilangan identitas yang sepenuhnya otomatis dan tanpa intervensi.
- Integrasi dengan data lake/warehouse: Data output yang di-de-identifikasi biasanya dimasukkan ke dalam data lake yang aman (misalnya, di Cloud Storage) atau data warehouse (misalnya, BigQuery) untuk analisis lebih lanjut dan pelatihan model, sehingga memastikan privasi tetap terjaga di seluruh siklus proses data.
Strategi de-identifikasi terperinci: Menyeimbangkan privasi dan utilitas
Cara menggunakannya dalam penyiapan Anda
Template de-identifikasi yang berbeda (tidak terstruktur, terstruktur, gambar) yang Anda buat adalah kunci. Anda akan menerapkan strategi diferensiasi serupa berdasarkan kebutuhan spesifik model AI Anda. Hal ini memungkinkan tim pengembangan Anda memiliki data utilitas tinggi untuk model mereka tanpa mengorbankan privasi.
Menghubungkan ke produksi
Dalam lingkungan produksi, kontrol terperinci ini menjadi lebih penting untuk:
- InfoType dan kamus kustom: Untuk data sensitif yang sangat spesifik atau khusus domain, Anda akan menentukan infoType dan kamus kustom dalam Sensitive Data Protection. Hal ini memastikan deteksi komprehensif yang disesuaikan dengan konteks bisnis unik Anda.
- Enkripsi yang mempertahankan format (FPE): Untuk skenario saat data yang dide-identifikasi harus mempertahankan format aslinya (misalnya, nomor kartu kredit untuk pengujian integrasi), Anda dapat mempelajari teknik de-identifikasi lanjutan seperti Enkripsi yang Mempertahankan Format. Hal ini memungkinkan pengujian yang aman untuk privasi dengan pola data yang realistis.
Pemantauan dan audit: Memastikan kepatuhan berkelanjutan
Cara menggunakannya dalam penyiapan Anda
Anda akan terus memantau log Sensitive Data Protection untuk memastikan bahwa semua pemrosesan data mematuhi kebijakan privasi Anda dan tidak ada informasi sensitif yang terekspos secara tidak sengaja. Meninjau ringkasan dan temuan tugas secara rutin adalah bagian dari audit berkelanjutan ini.
Menghubungkan ke produksi
Untuk sistem produksi yang tangguh, pertimbangkan tindakan utama berikut:
- Mengirim temuan ke Security Command Center: Untuk pengelolaan ancaman terintegrasi dan tampilan terpusat postur keamanan Anda, konfigurasi tugas Sensitive Data Protection Anda untuk mengirim ringkasan temuan secara langsung ke Security Command Center. Bagian ini menggabungkan insight dan pemberitahuan keamanan.
- Pemberitahuan dan respons insiden: Anda akan menyiapkan pemberitahuan Cloud Monitoring berdasarkan temuan Sensitive Data Protection atau kegagalan tugas. Hal ini memastikan bahwa tim keamanan Anda segera diberi tahu tentang potensi pelanggaran kebijakan atau masalah pemrosesan, sehingga memungkinkan respons insiden yang cepat.
10. Kesimpulan
Selamat! Anda telah berhasil membuat alur kerja keamanan data yang dapat secara otomatis menemukan dan melakukan de-identifikasi PII di berbagai jenis data, sehingga aman untuk digunakan dalam pengembangan AI dan analisis hilir.
Rangkuman
Di lab ini, Anda telah menyelesaikan tugas berikut:
- Menentukan template inspeksi untuk mendeteksi jenis informasi sensitif (infoType) tertentu.
- Membuat aturan de-identifikasi yang berbeda untuk data tidak terstruktur, terstruktur, dan gambar.
- Mengonfigurasi dan menjalankan satu tugas yang secara otomatis menerapkan penyensoran yang benar berdasarkan jenis file ke konten seluruh bucket.
- Memverifikasi keberhasilan transformasi data sensitif di lokasi output yang aman.
Langkah berikutnya
- Mengirim temuan ke Security Command Center: Untuk pengelolaan ancaman yang lebih terintegrasi, konfigurasi tindakan tugas untuk mengirim ringkasan temuan langsung ke Security Command Center.
- Mengotomatiskan dengan Cloud Functions: Di lingkungan produksi, Anda dapat memicu tugas pemeriksaan ini secara otomatis setiap kali file baru diupload ke bucket input menggunakan Cloud Function.