
1. Introduzione
Panoramica
In questo lab, creerai una pipeline di sanificazione dei dati automatizzata per proteggere le informazioni sensibili utilizzate nello sviluppo dell'AI. Utilizzi Sensitive Data Protection di Google Cloud (in precedenza Cloud DLP) per ispezionare, classificare e anonimizzare le informazioni che consentono l'identificazione personale (PII) in una serie di formati di dati, tra cui testo non strutturato, tabelle strutturate e immagini.
Context
Sei il campione della sicurezza e della privacy del tuo team di sviluppo e il tuo obiettivo è stabilire un flusso di lavoro che identifichi le informazioni sensibili e le renda anonime prima di renderle disponibili a sviluppatori e modelli. Il tuo team ha bisogno di dati realistici e di alta qualità per ottimizzare e testare una nuova applicazione di AI generativa, ma l'utilizzo di dati dei clienti non elaborati pone sfide significative in termini di privacy.
La tabella seguente elenca i rischi per la privacy che ti preoccupano maggiormente di mitigare:
Rischio | Attenuazione |
Esposizione di PII in file di testo non strutturati (ad es. log delle chat di assistenza, moduli di feedback). | Crea un modello di anonimizzazione che sostituisca i valori sensibili con il relativo infoType, preservando il contesto e rimuovendo l'esposizione. |
Perdita dell'utilità dei dati nei set di dati strutturati (CSV) quando vengono rimosse le PII. | Utilizza le trasformazioni dei record per oscurare in modo selettivo gli identificatori (come i nomi) e applicare tecniche come il mascheramento dei caratteri per conservare gli altri caratteri nella stringa, in modo che gli sviluppatori possano comunque eseguire test con i dati. |
Esposizione di PII dal testo incorporato nelle immagini (ad es. documenti scansionati, foto degli utenti). | Crea un modello di anonimizzazione specifico per le immagini che oscuri il testo trovato all'interno delle immagini. |
Oscuramento manuale incoerente o soggetto a errori in diversi tipi di dati. | Configura un singolo job automatizzato di Sensitive Data Protection che applichi in modo coerente il modello di anonimizzazione corretto in base al tipo di file che elabora. |
Obiettivi didattici
In questo lab imparerai a:
- Definisci un modello di ispezione per rilevare tipi specifici di informazioni sensibili (infoType).
- Crea regole di anonimizzazione distinte per dati non strutturati, strutturati e di immagini.
- Configura ed esegui un singolo job che applica automaticamente la corretta oscuramento in base al tipo di file ai contenuti di un intero bucket.
- Verifica la trasformazione corretta dei dati sensibili in una posizione di output sicura.
2. Configurazione del progetto
Account Google
Se non hai ancora un Account Google personale, devi crearne uno.
Utilizza un account personale anziché un account di lavoro o della scuola.
Accedi alla console Google Cloud
Accedi alla console Google Cloud utilizzando un Account Google personale.
Abilita fatturazione
Riscatta i crediti Google Cloud (facoltativo)
Per partecipare a questo workshop, devi disporre di un account di fatturazione con del credito. Per iniziare, utilizza i crediti del banner nella parte superiore di questo codelab. Se hai già collegato un account di fatturazione, puoi saltare questo passaggio.
Configurare un account di fatturazione personale
Se hai configurato la fatturazione utilizzando i crediti Google Cloud, puoi saltare questo passaggio.
Per configurare un account di fatturazione personale, vai qui per abilitare la fatturazione nella console Cloud.
Alcune note:
- Il completamento di questo lab dovrebbe costare meno di 1 $in risorse cloud.
- Per evitare ulteriori addebiti, puoi seguire i passaggi alla fine di questo lab per eliminare le risorse.
- I nuovi utenti hanno diritto alla prova senza costi di 300$.
Creare un progetto (facoltativo)
Se non hai un progetto attuale che vuoi utilizzare per questo lab, creane uno nuovo qui.
3. Abilita le API
Configura Cloud Shell
Una volta creato il progetto, segui questi passaggi per configurare Cloud Shell.
Avvia Cloud Shell
Vai a shell.cloud.google.com e, se viene visualizzato un popup che ti chiede di autorizzare, fai clic su Autorizza.
Imposta ID progetto
Esegui questo comando nel terminale Cloud Shell per impostare l'ID progetto corretto. Sostituisci <your-project-id> con l'ID progetto effettivo copiato dal passaggio di creazione del progetto precedente.
gcloud config set project <your-project-id>
Ora dovresti vedere che nel terminale Cloud Shell è selezionato il progetto corretto.
Abilitare Sensitive Data Protection
Per utilizzare il servizio Sensitive Data Protection e Cloud Storage, devi assicurarti che queste API siano abilitate nel tuo progetto Google Cloud.
- Nel terminale, abilita le API:
gcloud services enable dlp.googleapis.com storage.googleapis.com
In alternativa, puoi attivare queste API andando su Sicurezza > Sensitive Data Protection e Cloud Storage nella console e facendo clic sul pulsante Attiva se ti viene chiesto per ogni servizio.
4. Crea bucket con dati sensibili
Crea un bucket di input e output
In questo passaggio, crei due bucket: uno per contenere i dati sensibili che devono essere esaminati e un altro in cui Sensitive Data Protection archivierà i file di output de-identificati. Puoi anche scaricare file di dati campione e caricarli nel bucket di input.
- Nel terminale, esegui questi comandi per creare un bucket per i dati di input e uno per l'output, quindi popola il bucket di input con i dati di esempio di
gs://dlp-codelab-data:PROJECT_ID=$(gcloud config get-value project) gsutil mb gs://input-$PROJECT_ID gsutil mb gs://output-$PROJECT_ID
Aggiungere dati sensibili al bucket di input
In questo passaggio, scarichi da GitHub i file di dati di esempio contenenti PII di test e li carichi nel bucket di input.
- In Cloud Shell, esegui questo comando per clonare il repository
devrel-demos, che contiene i dati di esempio richiesti per questo lab.REPO_URL="https://github.com/GoogleCloudPlatform/devrel-demos.git" TARGET_PATH="security/sample-data" OUTPUT_FOLDER="sample-data" git clone --quiet --depth 1 --filter=blob:none --sparse "$REPO_URL" temp_loader cd temp_loader git sparse-checkout set "$TARGET_PATH" cd .. mv "temp_loader/$TARGET_PATH" "$OUTPUT_FOLDER" rm -rf temp_loader - A questo punto, copia i dati di esempio nel bucket di input che hai creato in precedenza:
gsutil -m cp -r sample-data/* gs://input-$PROJECT_ID/ - Vai a Cloud Storage > Bucket e fai clic sul bucket di input per visualizzare i dati che hai importato.
5. Creare un modello di ispezione
In questa attività, crei un modello che indica a Sensitive Data Protection cosa cercare. In questo modo, puoi concentrare l'ispezione sugli infoTypes pertinenti ai tuoi dati e alla tua area geografica, migliorando il rendimento e l'accuratezza.
Creare un modello di ispezione
In questo passaggio, definisci le regole per i dati sensibili che devono essere esaminati. Questo modello verrà riutilizzato dai job di anonimizzazione per garantire la coerenza.
- Nel menu di navigazione, vai a Sensitive Data Protection > Configurazione > Modelli.
- Fai clic su Crea modello.
- In Tipo di modello, seleziona Ispeziona (trova dati sensibili).
- Imposta l'ID modello su
pii-finder. - Fai clic su Continua per passare a Configura il rilevamento.
- Fai clic su Gestisci infoType.
- Utilizzando il filtro, cerca i seguenti infoTypes e seleziona la casella di controllo accanto a ciascuno:
CREDIT_CARD_EXPIRATION_DATECREDIT_CARD_NUMBERDATE_OF_BIRTHDRIVERS_LICENSE_NUMBEREMAIL_ADDRESSGCP_API_KEYGCP_CREDENTIALSORGANIZATION_NAMEPASSWORDPERSON_NAMEPHONE_NUMBERUS_SOCIAL_SECURITY_NUMBER
- Seleziona anche gli altri che ti interessano e fai clic su Fine.
- Controlla la tabella risultante per assicurarti che tutti questi infoType siano stati aggiunti.
- Fai clic su Crea.
6. Crea modelli di anonimizzazione
A questo punto, crea tre modelli di anonimizzazione separati per gestire diversi formati di dati. In questo modo, puoi controllare in modo granulare il processo di trasformazione, applicando il metodo più appropriato per ogni tipo di file. Questi modelli funzionano in combinazione con il modello di ispezione che hai appena creato.
Crea un modello per i dati non strutturati
Questo modello definirà come vengono anonimizzati i dati sensibili trovati in testo in formato libero, come i log della chat o i moduli di feedback. Il metodo scelto sostituisce il valore sensibile con il nome del relativo infoType, preservando il contesto.
- Nella pagina Modelli, fai clic su Crea modello.
- Definisci il modello di anonimizzazione:
Proprietà
Valore (digita o seleziona)
Tipo di modello
Anonimizza (rimuovi dati sensibili)
Tipo di trasformazione dati
InfoType
ID modello
de-identify-unstructured - Fai clic su Continua per passare a Configura anonimizzazione.
- In Metodo di trasformazione, seleziona Trasformazione: Sostituisci con nome infoType.
- Fai clic su Crea.
- Fai clic su Testa.
- Esegui il test di un messaggio contenente PII per vedere come verrà trasformato:
Hi, my name is Alex and my SSN is 555-11-5555. You can reach me at +1-555-555-5555.
Creare un modello per i dati strutturati
Questo modello ha come target specifico le informazioni sensibili all'interno di set di dati strutturati, come i file CSV. Lo configurerai in modo da mascherare i dati in modo da preservarne l'utilità per i test, pur anonimizzando i campi sensibili.
- Torna alla pagina Modelli e fai clic su Crea modello.
- Definisci il modello di anonimizzazione:
Proprietà
Valore (digita o seleziona)
Tipo di modello
Anonimizza (rimuovi dati sensibili)
Tipo di trasformazione dati
Registra
ID modello
de-identify-structured - Continua con la configurazione dell'anonimizzazione.Poiché questo modello si applica ai dati strutturati, spesso possiamo prevedere i campi o le colonne che conterranno determinati tipi di dati sensibili. Sai che il file CSV utilizzato dalla tua applicazione contiene email degli utenti in
user_ide chemessagespesso contiene PII provenienti dalle interazioni con i clienti. Non ti preoccupi della mascheraturaagent_idperché si tratta di dipendenti e le conversazioni devono essere attribuibili. Compila questa sezione come segue:- Campi o colonne da trasformare:
user_id,message. - Tipo di trasformazione: corrispondenza in base a infoType
- Metodo di trasformazione: fai clic su Aggiungi trasformazione
- .
- Trasformazione: maschera con carattere.
- Caratteri da ignorare: punteggiatura statunitense.
- Campi o colonne da trasformare:
- Fai clic su Crea.
Creare un modello per i dati delle immagini
Questo modello è progettato per anonimizzare il testo sensibile trovato incorporato nelle immagini, ad esempio documenti scansionati o foto inviate dagli utenti. Sfrutta il riconoscimento ottico dei caratteri (OCR) per rilevare e oscurare le informazioni personali.
- Torna alla pagina Modelli e fai clic su Crea modello.
- Definisci il modello di anonimizzazione:
Proprietà
Valore (digita o seleziona)
Tipo di modello
Anonimizza (rimuovi dati sensibili)
Tipo di trasformazione dati
Immagine
ID modello
de-identify-image - Fai clic su Continua per passare a Configura anonimizzazione.
- InfoType da trasformare: Qualsiasi infoType rilevato definito in un modello di ispezione o in una configurazione di ispezione e non specificato in altre regole.
- Fai clic su Crea.
7. Crea ed esegui un job di anonimizzazione
Una volta definiti i modelli, crea un unico job che applichi il modello di anonimizzazione corretto in base al tipo di file rilevato e ispezionato. In questo modo, il processo di protezione dei dati sensibili viene automatizzato per i dati archiviati in Cloud Storage.
Configurare i dati di input
In questo passaggio, specifica l'origine dei dati che devono essere anonimizzati, ovvero un bucket Cloud Storage contenente vari tipi di file con informazioni sensibili.
- Vai a Sicurezza > Sensitive Data Protection tramite la barra di ricerca.
- Fai clic su Ispezione nel menu.
- Fai clic su Crea job e trigger di job.
- Configura il job:
Proprietà
Valore (digita o seleziona)
ID job
pii-removerTipo di spazio di archiviazione
Google Cloud Storage
Tipo di località
Esegui la scansione di un bucket con regole di inclusione/esclusione facoltative
Nome bucket
input-[your-project-id]
Configura il rilevamento e le azioni
Ora colleghi i modelli creati in precedenza a questo job, indicando a Sensitive Data Protection come ispezionare le PII e quale metodo di anonimizzazione applicare in base al tipo di contenuti.
- Modello di ispezione:
projects/[your-project-id]/locations/global/inspectTemplates/pii-finder - In Aggiungi azioni, seleziona Crea una copia anonimizzata e configura i modelli di trasformazione in modo che siano quelli che hai creato.
- Si apre un popup per
Confirm whether you want to de-identify the findings, fai clic su DISATTIVA CAMPIONAMENTO.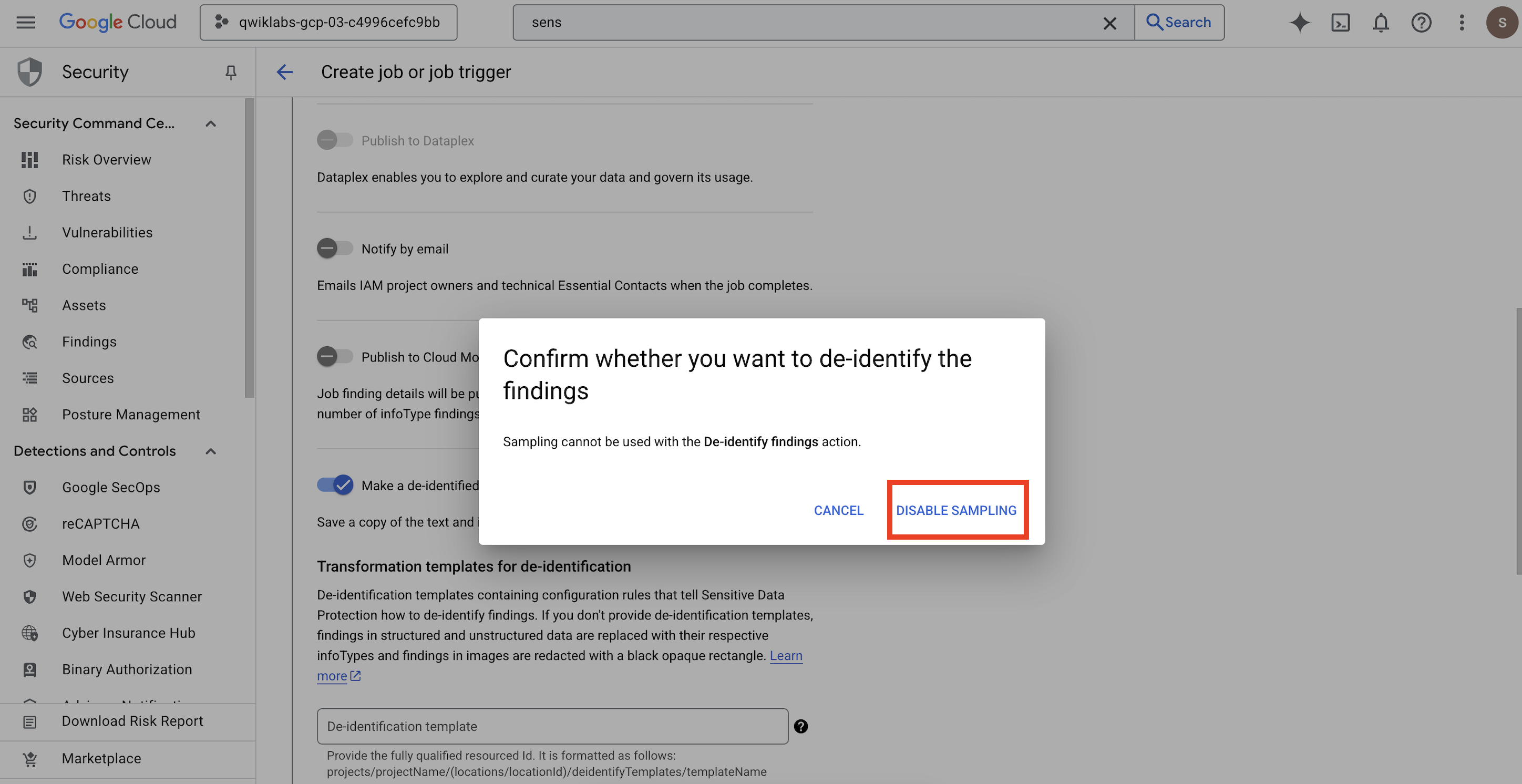
Proprietà
Valore (digita o seleziona)
Modello di anonimizzazione
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-unstructuredModello di anonimizzazione strutturato
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-structuredTemplate di oscuramento delle immagini
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-image - Configura la posizione di output di Cloud Storage:
- URL:
gs://output-[your-project-id]
- URL:
- In Pianificazione, lascia la selezione Nessuna per eseguire il job immediatamente.
- Fai clic su Crea.
- Si apre un popup per
Confirm job or job trigger create, fai clic su CONFERMA CREAZIONE.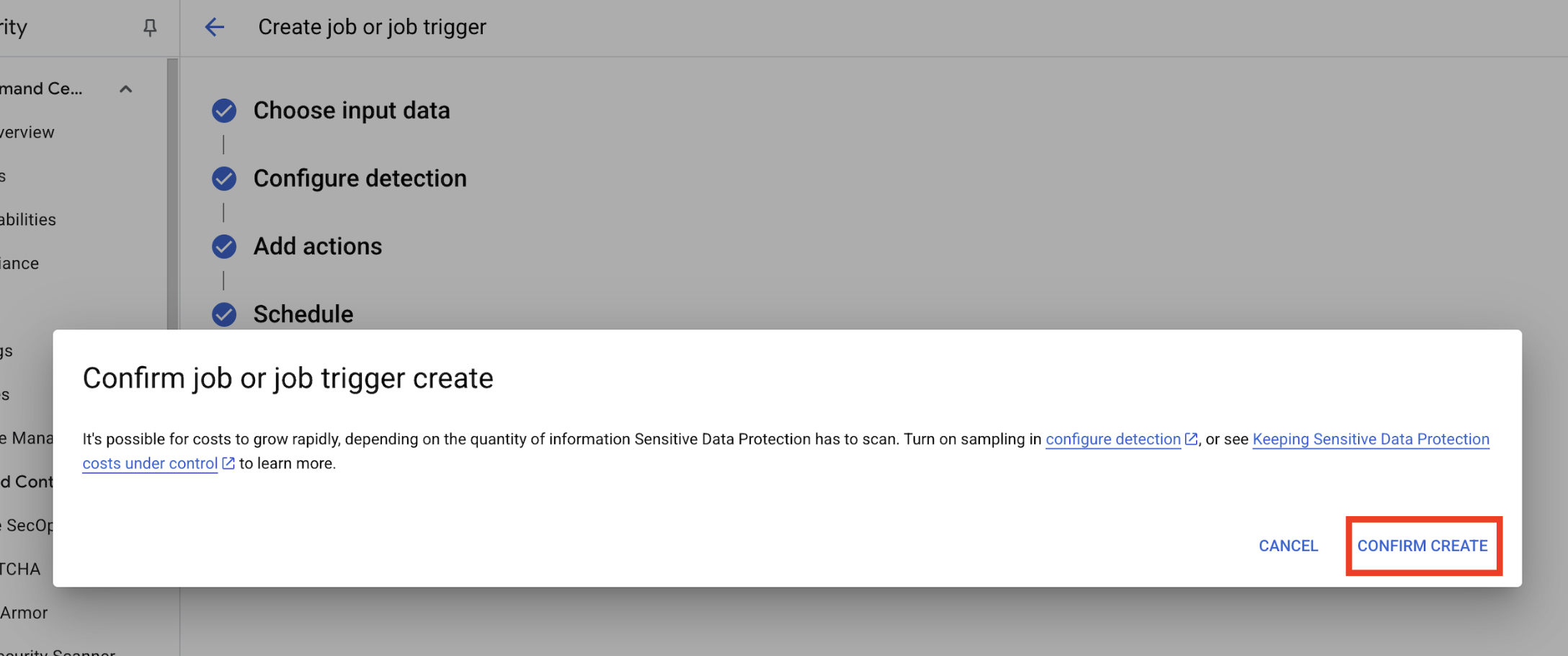
8. Controlla i risultati
Il passaggio finale consiste nel verificare che i dati sensibili siano stati oscurati correttamente e senza errori in tutti i tipi di file nel bucket di output. In questo modo, la pipeline di deidentificazione funziona come previsto.
Esaminare lo stato del job
Monitora il job per assicurarti che venga completato correttamente e rivedi il riepilogo dei risultati prima di controllare i file di output.
- Nella scheda Dettagli job, attendi che il job mostri lo stato Fine.
- Nella sezione Panoramica, esamina il numero di risultati e le percentuali di ogni infoType rilevato.
- Fai clic su Configurazione.
- Scorri verso il basso fino ad Azioni e fai clic sul bucket di output per visualizzare i dati anonimizzati:
gs://output-[your-project-id].
Confrontare i file di input e output
In questo passaggio, esamini manualmente i file anonimizzati per verificare che la sanificazione dei dati sia stata applicata correttamente in base ai tuoi modelli.
- Immagini: apri un'immagine dal bucket di output. Verifica che tutto il testo sensibile sia stato oscurato nel file di output.
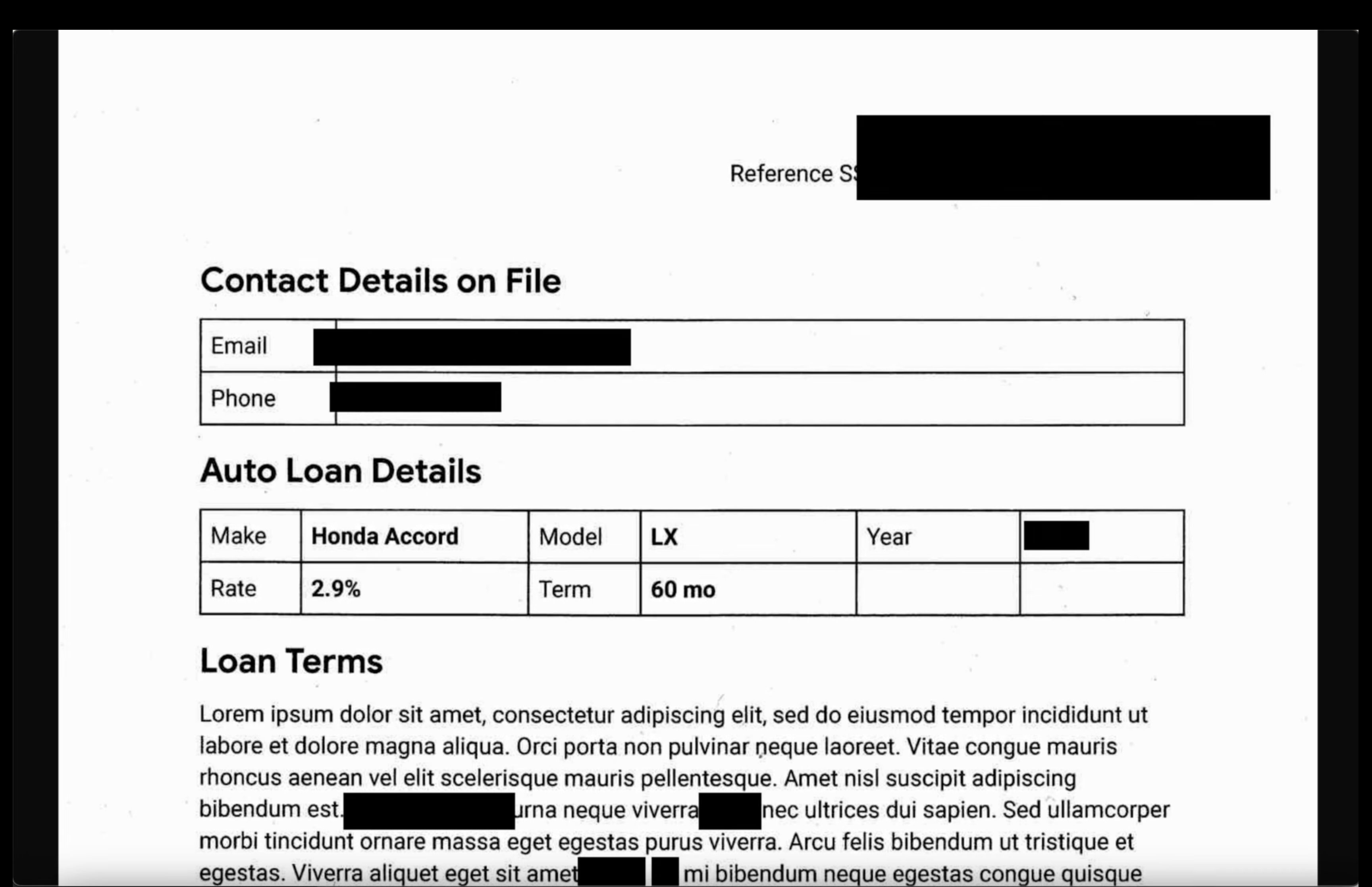
- Log non strutturati: visualizza un file di log da entrambi i bucket. Verifica che le PII nel log di output siano state sostituite con il nome dell'infoType (ad es.
[US_SOCIAL_SECURITY_NUMBER]). - CSV strutturati: apri un file CSV da entrambi i bucket. Verifica che le email e i codici fiscali degli utenti nel file di output siano mascherati con
####@####.com.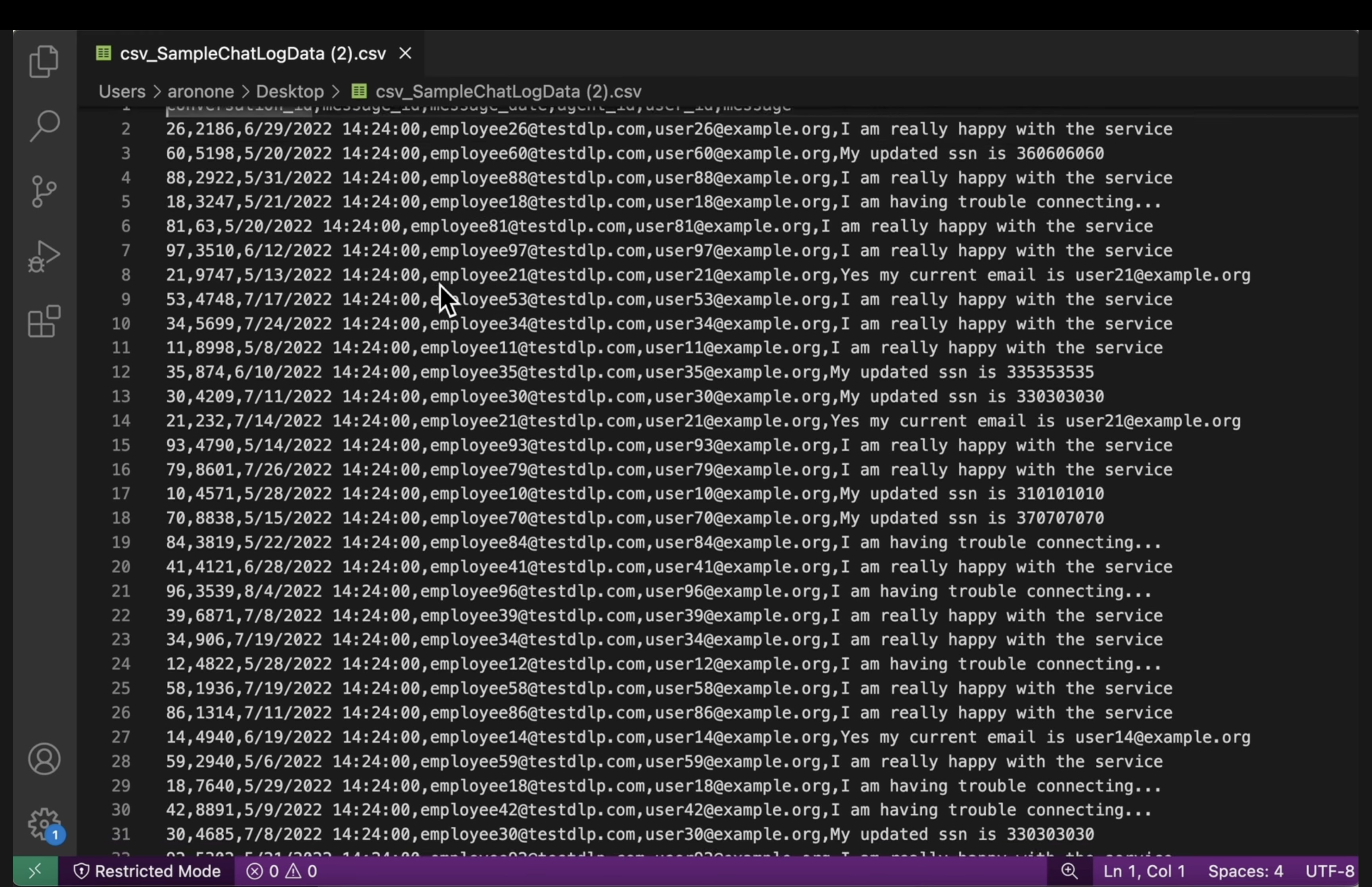
9. Dal lab alla realtà: come utilizzare questo strumento nei tuoi progetti
I principi e le configurazioni che hai applicato sono il progetto per proteggere i progetti di AI reali su Google Cloud. Le risorse che hai appena creato (il modello di ispezione, i modelli di anonimizzazione e il job automatizzato) fungono da modello iniziale sicuro per qualsiasi nuovo processo di importazione dei dati.
La pipeline di sanificazione automatizzata dei dati: l'acquisizione sicura dei dati
Come utilizzare questa opzione nella configurazione
Ogni volta che il tuo team deve importare nuovi dati grezzi dei clienti per lo sviluppo dell'AI, li indirizzerai tramite una pipeline che incorpora il job Sensitive Data Protection che hai configurato. Anziché ispezionare e oscurare manualmente, sfrutti questo workflow automatizzato. In questo modo, i data scientist e i modelli di AI interagiscono solo con i dati anonimizzati, riducendo in modo significativo i rischi per la privacy.
Connessione alla produzione
In un ambiente di produzione, questo concetto viene ulteriormente sviluppato:
- Automazione con trigger di job: anziché eseguire manualmente il job, configureresti un trigger di job ogni volta che viene caricato un nuovo file nel bucket Cloud Storage di input. In questo modo viene creato un processo di rilevamento e deidentificazione completamente automatizzato e senza intervento manuale.
- Integrazione con data lake/warehouse: i dati di output deidentificati vengono in genere inseriti in un data lake sicuro (ad es. su Cloud Storage) o in un data warehouse (ad es. BigQuery) per ulteriori analisi e addestramento del modello, garantendo il mantenimento della privacy durante l'intero ciclo di vita dei dati.
Strategie di anonimizzazione granulare: trovare un equilibrio tra privacy e utilità
Come utilizzare questa opzione nella configurazione
I diversi modelli di anonimizzazione (non strutturati, strutturati, immagini) che hai creato sono fondamentali. Applicheresti strategie differenziate simili in base alle esigenze specifiche dei tuoi modelli di AI. In questo modo, il team di sviluppo può disporre di dati di alta utilità per i propri modelli senza compromettere la privacy.
Connessione alla produzione
In un ambiente di produzione, questo controllo granulare diventa ancora più critico per:
- infoType e dizionari personalizzati: per i dati sensibili altamente specifici o specifici del dominio, devi definire infoType e dizionari personalizzati all'interno di Sensitive Data Protection. Ciò garantisce un rilevamento completo personalizzato in base al contesto unico della tua attività.
- Crittografia con protezione del formato (FPE): per gli scenari in cui i dati deidentificati devono mantenere il formato originale (ad es. i numeri di carta di credito per i test di integrazione), devi esplorare tecniche di deidentificazione avanzate come la crittografia con protezione del formato. Ciò consente di eseguire test nel rispetto della privacy con pattern di dati realistici.
Monitoraggio e controllo: garantire la conformità continua
Come utilizzare questa opzione nella configurazione
Monitoreresti continuamente i log di Sensitive Data Protection per assicurarti che tutta l'elaborazione dei dati rispetti le tue norme sulla privacy e che nessuna informazione sensibile venga esposta inavvertitamente. La revisione regolare dei riepiloghi e dei risultati dei job fa parte di questo audit continuo.
Connessione alla produzione
Per un sistema di produzione solido, considera queste azioni chiave:
- Invia i risultati a Security Command Center: per una gestione integrata delle minacce e una visualizzazione centralizzata della tua postura di sicurezza, configura i job Sensitive Data Protection in modo da inviare un riepilogo dei risultati direttamente a Security Command Center. In questo modo, gli avvisi e gli approfondimenti sulla sicurezza vengono consolidati.
- Avvisi e risposta agli incidenti: configurerai avvisi di Cloud Monitoring in base ai risultati di Sensitive Data Protection o agli errori dei job. In questo modo, il tuo team di sicurezza viene immediatamente informato di eventuali potenziali violazioni delle norme o problemi di elaborazione, consentendo una rapida risposta agli incidenti.
10. Conclusione
Complimenti! Hai creato correttamente un flusso di lavoro di sicurezza dei dati in grado di rilevare e anonimizzare automaticamente le PII in più tipi di dati, rendendoli sicuri per l'utilizzo nello sviluppo dell'AI e nell'analisi downstream.
Riepilogo
In questo lab hai completato le seguenti attività:
- Definito un modello di ispezione per rilevare tipi specifici di informazioni sensibili (infoType).
- Ha creato regole di anonimizzazione distinte per dati non strutturati, strutturati e delle immagini.
- Configurato ed eseguito un singolo job che ha applicato automaticamente la corretta oscuramento in base al tipo di file ai contenuti di un intero bucket.
- È stata verificata la trasformazione riuscita dei dati sensibili in una posizione di output sicura.
Passaggi successivi
- Invia risultati a Security Command Center: per una gestione delle minacce più integrata, configura l'azione del job in modo da inviare un riepilogo dei risultati direttamente a Security Command Center.
- Automatizza con Cloud Functions: in un ambiente di produzione, puoi attivare automaticamente questo job di ispezione ogni volta che viene caricato un nuovo file nel bucket di input utilizzando una Cloud Function.