
1. はじめに
概要
このラボでは、AI 開発で使用される機密情報を保護するための自動データ サニタイゼーション パイプラインを構築します。Google Cloud の Sensitive Data Protection(以前の Cloud DLP)を使用して、非構造化テキスト、構造化テーブル、画像など、さまざまなデータ形式の個人情報(PII)を検査、分類、匿名化します。
コンテキスト
あなたは開発チームのセキュリティとプライバシーのチャンピオンです。あなたの目標は、機密情報を特定し、開発者やモデルが利用できるようにする前に匿名化するワークフローを確立することです。チームは、新しい生成 AI アプリケーションを調整してテストするために、現実的で高品質なデータを必要としていますが、生の顧客データを使用すると、プライバシーに関する重大な課題が生じます。
次の表に、軽減を最も重視するプライバシー リスクを示します。
リスク | 緩和策 |
非構造化テキスト ファイルでの PII の公開(サポート チャットログ、フィードバック フォームなど)。 | 機密値を infoType に置き換える匿名化テンプレートを作成し、コンテキストを保持しながら公開を削除します。 |
PII が削除された場合、構造化データセット(CSV)のデータ ユーティリティが失われる。 | レコード変換を使用して、識別子(名前など)を選択的に秘匿化し、文字マスキングなどの手法を適用して文字列内の他の文字を保持します。これにより、デベロッパーは引き続きデータを使用してテストできます。 |
画像に埋め込まれたテキストからの個人情報の漏洩(スキャンしたドキュメント、ユーザーの写真など)。 | 画像内のテキストを秘匿化する画像固有の匿名化テンプレートを作成します。 |
さまざまなデータタイプにわたって、手動による編集に一貫性がなく、エラーが発生しやすい。 | 処理するファイル形式に基づいて適切な匿名化テンプレートを一貫して適用する、単一の自動化された Sensitive Data Protection ジョブを構成します。 |
学習内容
このラボでは、次の方法について学びます。
- 特定の機密情報タイプ(infoType)を検出する検査テンプレートを定義します。
- 非構造化データ、構造化データ、画像データ用に個別の匿名化ルールを作成します。
- ファイル形式に基づいてバケット全体の内容に適切な匿名化を自動的に適用する単一のジョブを構成して実行します。
- 安全な出力場所でセンシティブ データの変換が成功したことを確認します。
2. プロジェクトの設定
Google アカウント
個人の Google アカウントをお持ちでない場合は、Google アカウントを作成する必要があります。
仕事用または学校用アカウントではなく、個人アカウントを使用します。
Google Cloud コンソールにログインする
個人の Google アカウントを使用して Google Cloud コンソールにログインします。
課金を有効にする
Google Cloud クレジットを利用する(省略可)
このワークショップを実施するには、クレジットが設定された請求先アカウントが必要です。この Codelab の上部にあるバナーのクレジットを使用して、開始します。請求先アカウントにすでに接続している場合は、この手順をスキップできます。
個人用の請求先アカウントを設定する
Google Cloud クレジットを使用して課金を設定した場合は、この手順をスキップできます。
個人用の請求先アカウントを設定するには、Cloud コンソールでこちらに移動して課金を有効にします。
注意事項:
- このラボを完了するのにかかる Cloud リソースの費用は 1 米ドル未満です。
- このラボの最後の手順に沿ってリソースを削除すると、それ以上の料金は発生しません。
- 新規ユーザーは、300 米ドル分の無料トライアルをご利用いただけます。
プロジェクトの作成(省略可)
このラボで使用する現在のプロジェクトがない場合は、こちらで新しいプロジェクトを作成します。
3. API を有効にする
Cloud Shell を構成する
プロジェクトが正常に作成されたら、次の手順で Cloud Shell を設定します。
Cloud Shell を起動する
shell.cloud.google.com に移動し、承認を求めるポップアップが表示されたら、[承認] をクリックします。
プロジェクト ID を設定する
Cloud Shell ターミナルで次のコマンドを実行して、正しいプロジェクト ID を設定します。<your-project-id> は、上記のプロジェクト作成手順でコピーした実際のプロジェクト ID に置き換えます。
gcloud config set project <your-project-id>
これで、Cloud Shell ターミナルで正しいプロジェクトが選択されていることがわかります。
Sensitive Data Protection を有効にする
Sensitive Data Protection サービスと Cloud Storage を使用するには、これらの API が Google Cloud プロジェクトで有効になっていることを確認する必要があります。
- ターミナルで API を有効にします。
gcloud services enable dlp.googleapis.com storage.googleapis.com
または、コンソールで [セキュリティ] > [Sensitive Data Protection] と [Cloud Storage] に移動し、各サービスでプロンプトが表示されたら [有効にする] ボタンをクリックして、これらの API を有効にすることもできます。
4. センシティブ データを含むバケットを作成する
入力バケットと出力バケットを作成する
このステップでは、検査が必要な機密データを保持するバケットと、Sensitive Data Protection が匿名化された出力ファイルを保存するバケットの 2 つを作成します。また、サンプルデータ ファイルをダウンロードして、入力バケットにアップロードします。
- ターミナルで次のコマンドを実行して、入力データ用のバケットと出力用のバケットを 1 つずつ作成し、
gs://dlp-codelab-dataからのサンプルデータを入力バケットに取り込みます。PROJECT_ID=$(gcloud config get-value project) gsutil mb gs://input-$PROJECT_ID gsutil mb gs://output-$PROJECT_ID
センシティブ データを入力バケットに追加する
このステップでは、テスト PII を含むサンプル データファイルを GitHub からダウンロードし、入力バケットにアップロードします。
- Cloud Shell で次のコマンドを実行して、このラボに必要なサンプルデータを含む
devrel-demosリポジトリのクローンを作成します。REPO_URL="https://github.com/GoogleCloudPlatform/devrel-demos.git" TARGET_PATH="security/sample-data" OUTPUT_FOLDER="sample-data" git clone --quiet --depth 1 --filter=blob:none --sparse "$REPO_URL" temp_loader cd temp_loader git sparse-checkout set "$TARGET_PATH" cd .. mv "temp_loader/$TARGET_PATH" "$OUTPUT_FOLDER" rm -rf temp_loader - 次に、先ほど作成した入力バケットにサンプルデータをコピーします。
gsutil -m cp -r sample-data/* gs://input-$PROJECT_ID/ - [Cloud Storage] > [バケット] に移動し、入力バケットをクリックして、インポートしたデータを表示します。
5. 検査テンプレートを作成する
このタスクでは、Sensitive Data Protection で検索する内容を指定するテンプレートを作成します。これにより、データと地域に関連する infoTypes に検査を集中させ、パフォーマンスと精度を向上させることができます。
検査テンプレートを作成する
このステップでは、検査が必要なセンシティブ データと見なされるデータのルールを定義します。このテンプレートは、一貫性を確保するために匿名化ジョブで再利用されます。
- ナビゲーション メニューから、[Sensitive Data Protection] > [構成] > [テンプレート] に移動します。
- [テンプレートを作成] をクリックします。
- [テンプレートの種類] で [検査(センシティブ データの検索)] を選択します。
- [テンプレート ID] を
pii-finderに設定します。 - 続行して、検出を構成します。
- [infoType を管理] をクリックします。
- フィルタを使用して、次の infoTypes を検索し、それぞれの横にあるチェックボックスをオンにします。
CREDIT_CARD_EXPIRATION_DATECREDIT_CARD_NUMBERDATE_OF_BIRTHDRIVERS_LICENSE_NUMBEREMAIL_ADDRESSGCP_API_KEYGCP_CREDENTIALSORGANIZATION_NAMEPASSWORDPERSON_NAMEPHONE_NUMBERUS_SOCIAL_SECURITY_NUMBER
- 関心のあるその他の項目も選択して、[完了] をクリックします。
- 結果のテーブルを確認して、これらのすべての infoType が追加されていることを確認します。
- [作成] をクリックします。
6. 匿名化テンプレートを作成する
次に、さまざまなデータ形式を処理するために、3 つの個別の匿名化テンプレートを作成します。これにより、変換プロセスをきめ細かく制御し、各ファイル形式に最適な方法を適用できます。これらのテンプレートは、作成した検査テンプレートと連携して動作します。
非構造化データ用のテンプレートを作成する
このテンプレートは、チャットログやフィードバック フォームなどの自由形式のテキストで検出されたセンシティブ データを匿名化する方法を定義します。選択した方法では、機密値が infoType 名に置き換えられ、コンテキストが保持されます。
- [テンプレート] ページで、[テンプレートを作成] をクリックします。
- 匿名化テンプレートを定義します。
プロパティ
値(入力または選択)
テンプレートの種類
匿名化(機密データの削除)
データ変換のタイプ
infoType
テンプレート ID
de-identify-unstructured - 続行して、匿名化を構成するに進みます。
- [変換方法] で、変換: [infoType 名での置換] を選択します。
- [作成] をクリックします。
- [Test] をクリックします。
- PII を含むメッセージをテストして、どのように変換されるかを確認します。
Hi, my name is Alex and my SSN is 555-11-5555. You can reach me at +1-555-555-5555.
構造化データ用のテンプレートを作成する
このテンプレートは、CSV ファイルなどの構造化データセット内の機密情報を対象としています。テスト用のデータ ユーティリティを維持しつつ機密フィールドを匿名化するように、この機能を構成します。
- [テンプレート] ページに戻り、[テンプレートを作成] をクリックします。
- 匿名化テンプレートを定義します。
プロパティ
値(入力または選択)
テンプレートの種類
匿名化(機密データの削除)
データ変換のタイプ
録画
テンプレート ID
de-identify-structured - 続行して、匿名化を構成します。このテンプレートは構造化データに適用されるため、特定の種類のセンシティブ データを含むフィールドまたは列を予測できることがよくあります。アプリケーションで使用する CSV の
user_idにユーザーのメールアドレスが含まれており、messageには顧客とのやり取りから得られた PII が含まれていることがよくあります。従業員であるため、会話は帰属可能であるため、agent_idのマスキングは考慮しません。このセクションに次のように入力します。- 変換するフィールドまたは列:
user_id、message。 - 変換タイプ: infoType に基づく一致
- 変換方法: [変換を追加] をクリックします。
- 変換: 文字でマスキングします。
- 無視する文字: 米国の句読点。
- 変換するフィールドまたは列:
- [作成] をクリックします。
画像データ用のテンプレートを作成する
このテンプレートは、スキャンしたドキュメントやユーザーが送信した写真など、画像内に埋め込まれている機密テキストを匿名化するように設計されています。光学式文字認識(OCR)を利用して、PII を検出して編集します。
- [テンプレート] ページに戻り、[テンプレートを作成] をクリックします。
- 匿名化テンプレートを定義します。
プロパティ
値(入力または選択)
テンプレートの種類
匿名化(機密データの削除)
データ変換のタイプ
画像
テンプレート ID
de-identify-image - 続行して、匿名化を構成するに進みます。
- 変換する InfoType: 検査テンプレートまたは検査構成で定義されているが、他のルールで指定されていない、検出されたすべての infoType。
- [作成] をクリックします。
7. 匿名化ジョブを作成して実行する
テンプレートを定義したら、検出および検査したファイル形式に基づいて適切な匿名化テンプレートを適用する単一のジョブを作成します。これにより、Cloud Storage に保存されているデータの機密データ保護プロセスが自動化されます。
入力データを構成する
このステップでは、匿名化が必要なデータのソースを指定します。これは、機密情報を含むさまざまなファイル形式を含む Cloud Storage バケットです。
- 検索バーを使用して、[セキュリティ] > [Sensitive Data Protection] に移動します。
- メニューの [検査] をクリックします。
- [Create job and job triggers] をクリックします。
- ジョブを構成します。
プロパティ
値(入力または選択)
ジョブ ID
pii-removerストレージの種類
Google Cloud Storage
ロケーション タイプ
オプションの「含める / 除外する」ルールでバケットをスキャンします
バケット名
input-[your-project-id]
検出とアクションを構成する
次に、以前に作成したテンプレートをこのジョブにリンクして、PII を検査する方法と、コンテンツ タイプに基づいて適用する匿名化方法を Sensitive Data Protection に伝えます。
- 検査テンプレート:
projects/[your-project-id]/locations/global/inspectTemplates/pii-finder - [アクションを追加] で、[匿名化コピーを作成する] を選択し、作成した変換テンプレートを構成します。
- ポップアップが開いて
Confirm whether you want to de-identify the findingsが表示されるので、[サンプリングを無効にする] をクリックします。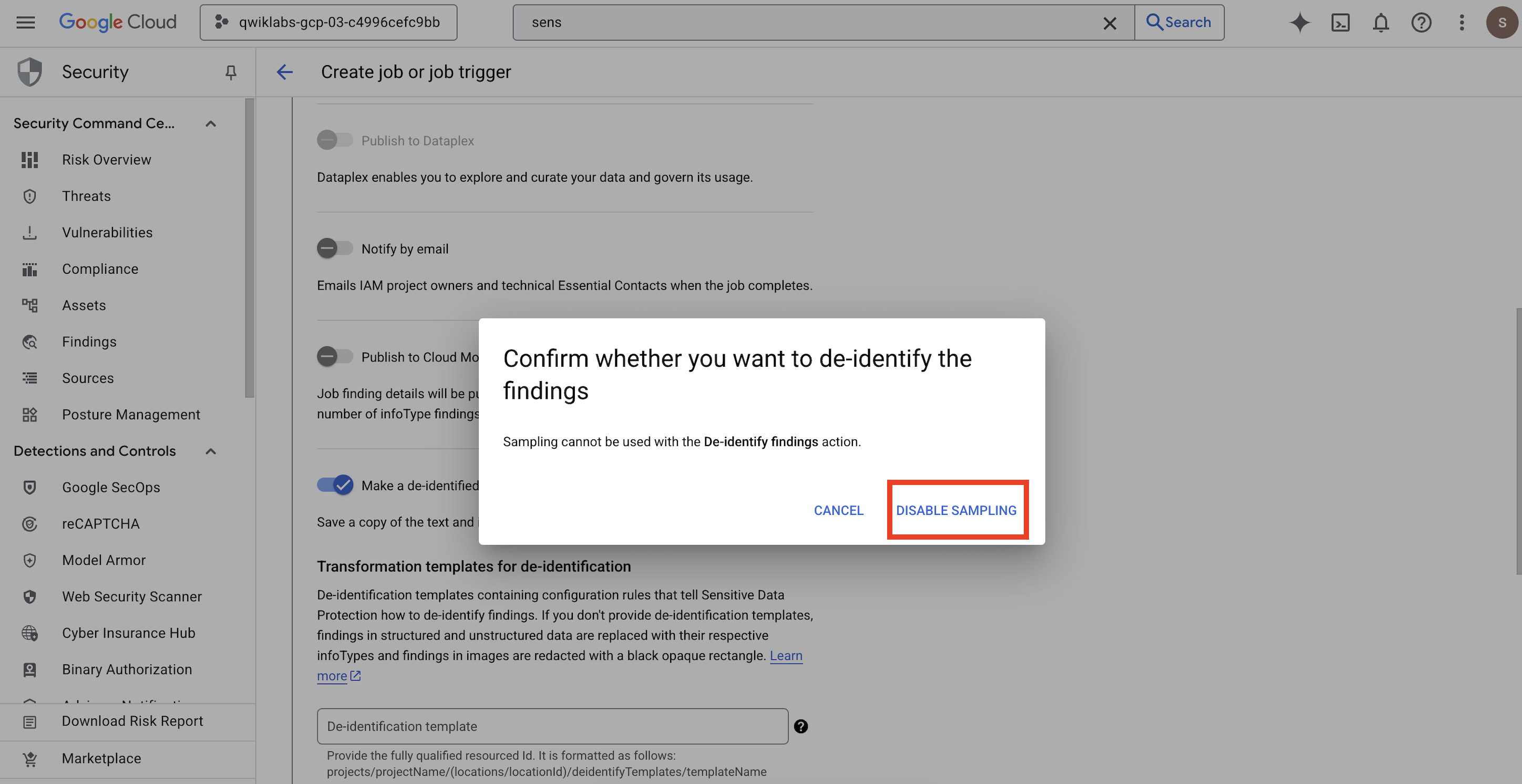
プロパティ
値(入力または選択)
匿名化テンプレート
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-unstructured構造化された匿名化テンプレート
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-structured画像の秘匿化テンプレート
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-image - Cloud Storage の出力先を構成します。
- URL:
gs://output-[your-project-id]
- URL:
- [スケジュール] で、ジョブをすぐに実行するため、[なし] のままにします。
- [作成] をクリックします。
Confirm job or job trigger createのポップアップが開いたら、[CONFIRM CREATE](作成を確認)をクリックします。![[ジョブまたはジョブトリガーの作成の確認] ポップアップのスクリーンショット](https://codelabs.developers.google.com/static/codelabs/production-ready-ai-with-gc/4-securing-ai-applications/img/confirm-create.png?hl=ja)
8. 結果を確認する
最後のステップは、出力バケット内のすべてのファイル形式で機密データが正しく匿名化されたことを確認することです。これにより、匿名化パイプラインが想定どおりに機能します。
ジョブのステータスを確認する
ジョブをモニタリングして正常に完了することを確認し、検出結果の概要を確認してから出力ファイルを確認します。
- [ジョブの詳細] タブで、ジョブのステータスが [完了] になるまで待ちます。
- [概要] で、検出された infoType の数と割合を確認します。
- [構成] をクリックします。
- [アクション] までスクロールし、出力バケットをクリックして匿名化されたデータを確認します(
gs://output-[your-project-id])。
入力ファイルと出力ファイルを比較する
このステップでは、匿名化されたファイルを検査して、テンプレートに従ってデータ サニタイゼーションが正しく適用されていることを確認します。
- 画像: 出力バケットから画像を開きます。出力ファイルで、すべての機密テキストが編集されていることを確認します。
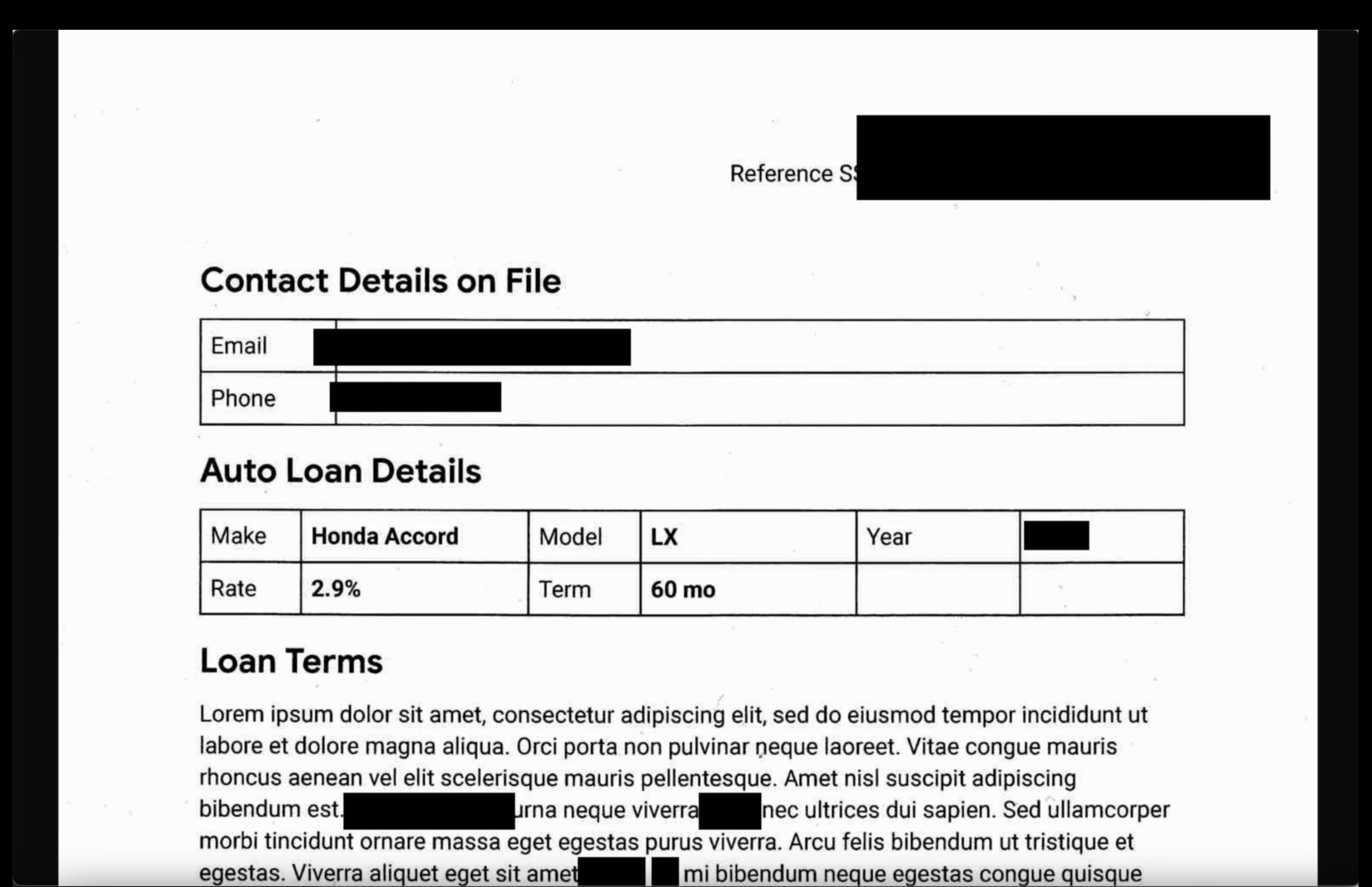
- 非構造化ログ: 両方のバケットからログファイルを表示します。出力ログ内の PII が infoType 名(
[US_SOCIAL_SECURITY_NUMBER]など)に置き換えられていることを確認します。 - 構造化 CSV: 両方のバケットから CSV ファイルを開きます。出力ファイル内のユーザーのメールアドレスと SSN が
####@####.comでマスクされていることを確認します。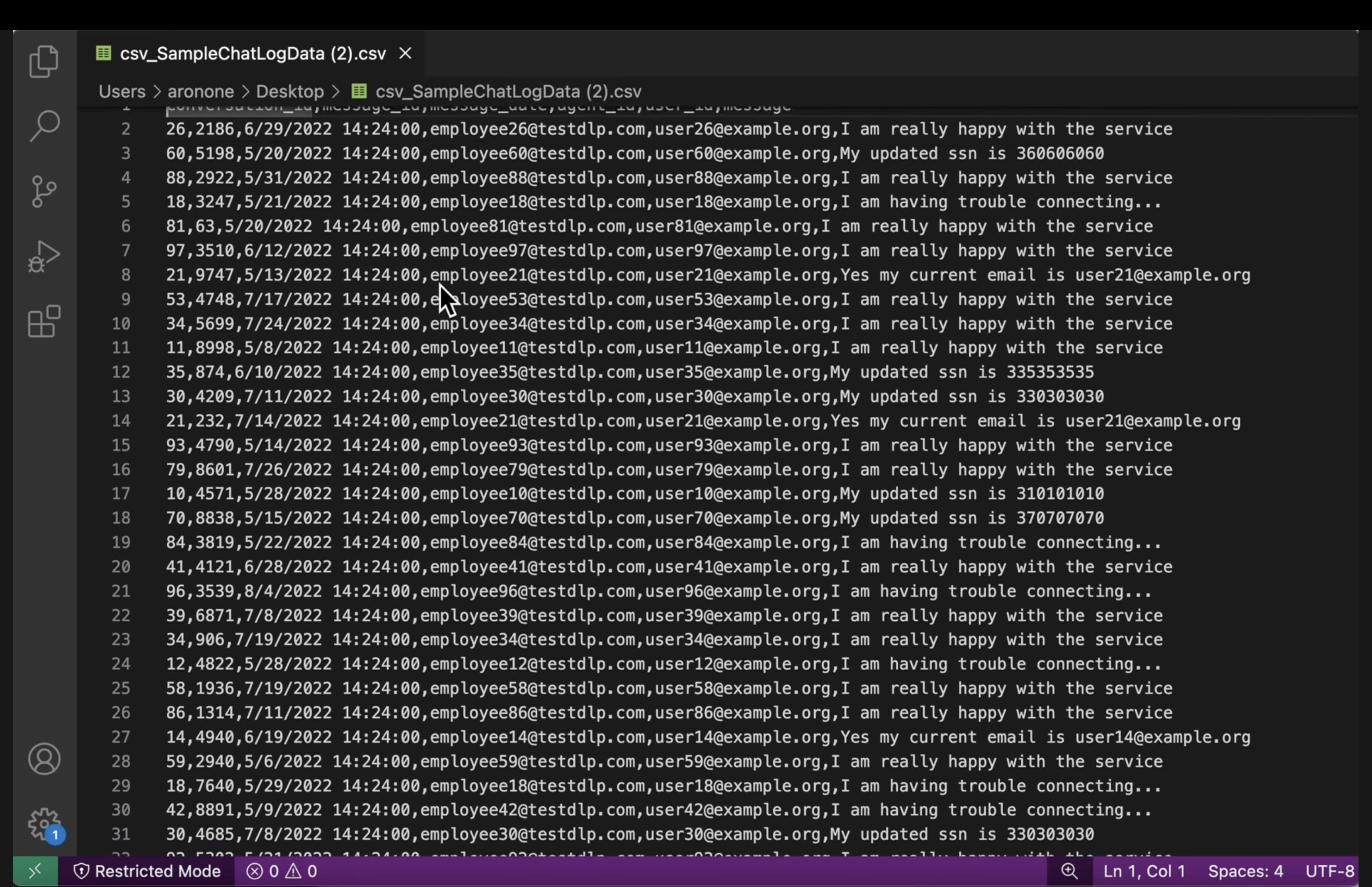
9. ラボから現実へ: 独自のプロジェクトでこれを使用する方法
適用した原則と構成は、Google Cloud で実際の AI プロジェクトを保護するためのブループリントです。作成したリソース(検査テンプレート、匿名化テンプレート、自動ジョブ)は、新しいデータ取り込みプロセスの安全なスターター テンプレートとして機能します。
自動化されたデータ サニタイゼーション パイプライン: 安全なデータ取り込み
設定での使用方法
チームが AI 開発用に新しい未加工の顧客データを取り込む必要があるたびに、構成した Sensitive Data Protection ジョブを組み込んだパイプラインを介してデータを転送します。手動で検査して編集する代わりに、この自動ワークフローを活用します。これにより、データ サイエンティストと AI モデルは匿名化されたデータのみを操作できるようになり、プライバシー リスクが大幅に軽減されます。
本番環境に接続する
本番環境では、次の方法でこのコンセプトをさらに発展させます。
- ジョブトリガーによる自動化: ジョブを手動で実行する代わりに、新しいファイルが入力 Cloud Storage バケットにアップロードされるたびに ジョブトリガーを設定します。これにより、完全に自動化されたハンズオフの検出と匿名化のプロセスが作成されます。
- データレイク/ウェアハウスとの統合: 匿名化された出力データは通常、安全なデータレイク(Cloud Storage など)またはデータ ウェアハウス(BigQuery など)に送られ、さらなる分析とモデル トレーニングに使用されます。これにより、データ ライフサイクル全体を通してプライバシーが維持されます。
きめ細かい匿名化戦略: プライバシーと有用性のバランス
設定での使用方法
作成したさまざまな匿名化テンプレート(非構造化、構造化、画像)が重要です。AI モデルの特定のニーズに基づいて、同様の差別化戦略を適用します。これにより、開発チームはプライバシーを侵害することなく、モデルに有用性の高いデータを使用できます。
本番環境に接続する
本番環境では、このきめ細かい制御は次の点でさらに重要になります。
- カスタム infoType と辞書: 非常に具体的なセンシティブ データやドメイン固有のセンシティブ データについては、Sensitive Data Protection 内でカスタム infoType と辞書を定義します。これにより、独自のビジネス コンテキストに合わせて包括的な検出を行うことができます。
- フォーマット保持暗号化(FPE): 匿名化されたデータが元の形式を保持する必要があるシナリオ(統合テスト用のクレジット カード番号など)では、フォーマット保持暗号化などの高度な匿名化手法を検討します。これにより、プライバシーを保護しながら、現実的なデータパターンでテストを行うことができます。
モニタリングと監査: 継続的なコンプライアンスの確保
設定での使用方法
Sensitive Data Protection ログを継続的にモニタリングして、すべてのデータ処理がプライバシー ポリシーに準拠し、機密情報が誤って公開されないようにします。ジョブの概要と結果を定期的に確認することは、この継続的な監査の一部です。
本番環境に接続する
堅牢な本番環境システムを構築するには、次の主なアクションを検討してください。
- 検出結果を Security Command Center に送信する: 統合された脅威管理とセキュリティ ポスチャーの一元的なビューを実現するには、検出結果の概要を Security Command Center に直接送信するように Sensitive Data Protection ジョブを構成します。これにより、セキュリティ アラートと分析情報が統合されます。
- アラートとインシデント対応: Sensitive Data Protection の検出結果またはジョブの失敗に基づいて Cloud Monitoring アラートを設定します。これにより、セキュリティ チームはポリシー違反や処理の問題の可能性を直ちに把握し、インシデントに迅速に対応できます。
10. まとめ
おめでとうございます!複数のデータ型にわたって PII を自動的に検出して匿名化し、ダウンストリームの AI 開発と分析で安全に使用できるようにするデータ セキュリティ ワークフローを構築しました。
内容のまとめ
このラボでは、次のことを行いました。
- 特定の機密情報タイプ(infoTypes)を検出する検査テンプレートを定義した。
- 非構造化データ、構造化データ、画像データ用に個別の匿名化ルールを構築しました。
- ファイル形式に基づいて適切な匿名化をバケット全体の内容に自動的に適用する単一のジョブを構成して実行しました。
- 安全な出力場所でセンシティブ データの変換が成功したことを確認しました。
次のステップ
- 検出結果を Security Command Center に送信する: より統合された脅威管理を行うには、検出結果の概要を Security Command Center に直接送信するようにジョブ アクションを構成します。
- Cloud Functions で自動化する: 本番環境では、Cloud Functions を使用して、新しいファイルが入力バケットにアップロードされるたびにこの検査ジョブを自動的にトリガーできます。