
1. 소개
개요
이 실습에서는 AI 개발에 사용되는 민감한 정보를 보호하기 위해 자동 데이터 살균 파이프라인을 빌드합니다. Google Cloud의 Sensitive Data Protection (이전 명칭: Cloud DLP)을 사용하여 비정형 텍스트, 구조화된 표, 이미지 등 다양한 데이터 형식에서 개인 식별 정보 (PII)를 검사, 분류, 익명화합니다.
컨텍스트
개발팀의 보안 및 개인 정보 보호 담당자로서 개발자와 모델이 민감한 정보를 사용할 수 있게 하기 전에 이를 식별하고 익명화하는 워크플로를 설정하는 것이 목표입니다. 팀에서 새로운 생성형 AI 애플리케이션을 조정하고 테스트하려면 현실적이고 고품질의 데이터가 필요하지만, 원시 고객 데이터를 사용하면 심각한 개인 정보 보호 문제가 발생합니다.
다음 표에는 완화하는 데 가장 관심이 있는 개인 정보 보호 위험이 나열되어 있습니다.
위험 | 완화 |
비정형 텍스트 파일에 PII가 노출됨 (예: 지원 채팅 로그, 의견 양식) | 민감한 값을 해당 infoType으로 대체하여 노출을 삭제하면서 컨텍스트를 보존하는 익명화 템플릿을 만듭니다. |
개인 식별 정보가 삭제되면 구조화된 데이터 세트 (CSV)의 데이터 유틸리티가 손실됩니다. | 레코드 변환을 사용하여 식별자 (예: 이름)를 선택적으로 수정하고 문자 마스킹과 같은 기법을 적용하여 문자열의 다른 문자를 보존하면 개발자가 데이터를 사용하여 계속 테스트할 수 있습니다. |
이미지에 삽입된 텍스트로 인한 PII 노출 (예: 스캔한 문서, 사용자 사진) | 이미지 내에서 발견된 텍스트를 수정하는 이미지 전용 익명화 템플릿을 만듭니다. |
다양한 데이터 유형에서 일관되지 않거나 오류가 발생하기 쉬운 수동 수정 | 처리하는 파일 유형에 따라 올바른 익명화 템플릿을 일관되게 적용하는 단일 자동화된 Sensitive Data Protection 작업을 구성합니다. |
학습할 내용
이 실습에서는 다음을 수행하는 방법에 대해 알아봅니다.
- 특정 민감한 정보 유형 (infoType)을 감지하도록 검사 템플릿을 정의합니다.
- 비정형, 정형, 이미지 데이터에 대해 별도의 익명화 규칙을 빌드합니다.
- 파일 유형에 따라 전체 버킷의 콘텐츠에 올바른 수정 사항을 자동으로 적용하는 단일 작업을 구성하고 실행합니다.
- 안전한 출력 위치에서 민감한 정보가 성공적으로 변환되었는지 확인합니다.
2. 프로젝트 설정
Google 계정
아직 개인 Google 계정이 없다면 Google 계정을 만들어야 합니다.
직장 또는 학교 계정 대신 개인 계정을 사용하세요.
Google Cloud 콘솔에 로그인
개인 Google 계정을 사용하여 Google Cloud 콘솔에 로그인합니다.
결제 사용 설정
Google Cloud 크레딧 사용 (선택사항)
이 워크숍을 진행하려면 크레딧이 있는 결제 계정이 필요합니다. 이 Codelab 상단의 배너에 있는 크레딧을 사용하여 시작하세요. 이미 결제 계정에 연결되어 있다면 이 단계를 건너뛰어도 됩니다.
개인 결제 계정 설정
Google Cloud 크레딧을 사용하여 결제를 설정한 경우 이 단계를 건너뛸 수 있습니다.
개인 결제 계정을 설정하려면 Cloud 콘솔에서 여기에서 결제를 사용 설정하세요.
참고 사항:
- 이 실습을 완료하는 데 드는 Cloud 리소스 비용은 미화 1달러 미만입니다.
- 이 실습이 끝나면 단계에 따라 리소스를 삭제하여 추가 요금이 발생하지 않도록 할 수 있습니다.
- 신규 사용자는 미화$300 상당의 무료 체험판을 이용할 수 있습니다.
프로젝트 만들기(선택사항)
이 실습에 사용할 현재 프로젝트가 없는 경우 여기에서 새 프로젝트를 만드세요.
3. API 사용 설정
Cloud Shell 구성
프로젝트가 성공적으로 생성되면 다음 단계에 따라 Cloud Shell을 설정합니다.
Cloud Shell 실행
shell.cloud.google.com으로 이동하고 승인을 요청하는 팝업이 표시되면 승인을 클릭합니다.
프로젝트 ID 설정
Cloud Shell 터미널에서 다음 명령어를 실행하여 올바른 프로젝트 ID를 설정합니다. <your-project-id>를 위의 프로젝트 생성 단계에서 복사한 실제 프로젝트 ID로 바꿉니다.
gcloud config set project <your-project-id>
이제 Cloud Shell 터미널에서 올바른 프로젝트가 선택되어 있는 것을 확인할 수 있습니다.
Sensitive Data Protection 사용 설정
Sensitive Data Protection 서비스와 Cloud Storage를 사용하려면 Google Cloud 프로젝트에서 이러한 API가 사용 설정되어 있어야 합니다.
- 터미널에서 API를 사용 설정합니다.
gcloud services enable dlp.googleapis.com storage.googleapis.com
또는 콘솔에서 보안 > Sensitive Data Protection 및 Cloud Storage로 이동하여 각 서비스에 대한 메시지가 표시되면 사용 설정 버튼을 클릭하여 이러한 API를 사용 설정할 수 있습니다.
4. 민감한 정보가 포함된 버킷 만들기
입력 및 출력 버킷 만들기
이 단계에서는 두 개의 버킷을 만듭니다. 하나는 검사해야 하는 민감한 정보를 저장하는 버킷이고, 다른 하나는 Sensitive Data Protection에서 익명화된 출력 파일을 저장하는 버킷입니다. 샘플 데이터 파일을 다운로드하여 입력 버킷에 업로드합니다.
- 터미널에서 다음 명령어를 실행하여 입력 데이터용 버킷 하나와 출력용 버킷 하나를 만든 다음
gs://dlp-codelab-data의 샘플 데이터로 입력 버킷을 채웁니다.PROJECT_ID=$(gcloud config get-value project) gsutil mb gs://input-$PROJECT_ID gsutil mb gs://output-$PROJECT_ID
입력 버킷에 민감한 정보 추가
이 단계에서는 GitHub에서 테스트 PII가 포함된 샘플 데이터 파일을 다운로드하여 입력 버킷에 업로드합니다.
- Cloud Shell에서 다음 명령어를 실행하여 이 실습에 필요한 샘플 데이터가 포함된
devrel-demos저장소를 클론합니다.REPO_URL="https://github.com/GoogleCloudPlatform/devrel-demos.git" TARGET_PATH="security/sample-data" OUTPUT_FOLDER="sample-data" git clone --quiet --depth 1 --filter=blob:none --sparse "$REPO_URL" temp_loader cd temp_loader git sparse-checkout set "$TARGET_PATH" cd .. mv "temp_loader/$TARGET_PATH" "$OUTPUT_FOLDER" rm -rf temp_loader - 다음으로 샘플 데이터를 이전에 만든 입력 버킷에 복사합니다.
gsutil -m cp -r sample-data/* gs://input-$PROJECT_ID/ - Cloud Storage > 버킷으로 이동하여 입력 버킷을 클릭하면 가져온 데이터를 확인할 수 있습니다.
5. 검사 템플릿 만들기
이 작업에서는 Sensitive Data Protection에 검색할 항목을 알려주는 템플릿을 만듭니다. 이를 통해 데이터 및 지역과 관련된 infoTypes에 검사를 집중하여 성능과 정확성을 개선할 수 있습니다.
검사 템플릿 만들기
이 단계에서는 검사해야 하는 민감한 정보의 구성 요소를 정의하는 규칙을 정의합니다. 이 템플릿은 일관성을 유지하기 위해 익명화 작업에서 재사용됩니다.
- 탐색 메뉴에서 Sensitive Data Protection > 구성 > 템플릿으로 이동합니다.
- 템플릿 만들기를 클릭합니다.
- 템플릿 유형에서 검사 (민감한 정보 찾기)를 선택합니다.
- 템플릿 ID를
pii-finder로 설정합니다. - 계속을 클릭하여 감지 구성으로 이동합니다.
- infoType 관리를 클릭합니다.
- 필터를 사용하여 다음 infoTypes을 검색하고 각 항목 옆에 있는 체크박스를 선택합니다.
CREDIT_CARD_EXPIRATION_DATECREDIT_CARD_NUMBERDATE_OF_BIRTHDRIVERS_LICENSE_NUMBEREMAIL_ADDRESSGCP_API_KEYGCP_CREDENTIALSORGANIZATION_NAMEPASSWORDPERSON_NAMEPHONE_NUMBERUS_SOCIAL_SECURITY_NUMBER
- 관심 있는 다른 항목도 선택하고 완료를 클릭합니다.
- 결과 테이블을 확인하여 이러한 모든 infoType이 추가되었는지 확인합니다.
- 만들기를 클릭합니다.
6. 익명화 템플릿 만들기
다음으로 다양한 데이터 형식을 처리하기 위해 세 개의 별도 익명화 템플릿을 만듭니다. 이를 통해 변환 프로세스를 세부적으로 제어하여 각 파일 유형에 가장 적합한 방법을 적용할 수 있습니다. 이러한 템플릿은 방금 만든 검사 템플릿과 함께 작동합니다.
비정형 데이터용 템플릿 만들기
이 템플릿은 채팅 로그나 피드백 양식과 같은 자유 형식 텍스트에서 발견된 민감한 정보가 익명화되는 방식을 정의합니다. 선택한 메서드는 민감한 값을 해당 infoType 이름으로 대체하여 컨텍스트를 보존합니다.
- 템플릿 페이지에서 템플릿 만들기를 클릭합니다.
- 익명화 템플릿을 정의합니다.
속성
값(입력 또는 선택)
템플릿 유형
익명화(민감한 정보 삭제)
데이터 변환 유형
infoType
템플릿 ID
de-identify-unstructured - 계속하여 익명화 구성으로 이동합니다.
- 변환 방법에서 변환: infoType 이름으로 교체를 선택합니다.
- 만들기를 클릭합니다.
- 테스트를 클릭합니다.
- PII가 포함된 메시지를 테스트하여 변환되는 방식을 확인합니다.
Hi, my name is Alex and my SSN is 555-11-5555. You can reach me at +1-555-555-5555.
정형 데이터용 템플릿 만들기
이 템플릿은 CSV 파일과 같은 구조화된 데이터 세트 내의 민감한 정보를 구체적으로 타겟팅합니다. 테스트를 위해 데이터 유용성을 유지하면서 민감한 필드를 익명화하는 방식으로 데이터를 마스킹하도록 구성합니다.
- 템플릿 페이지로 돌아가 템플릿 만들기를 클릭합니다.
- 익명화 템플릿을 정의합니다.
속성
값(입력 또는 선택)
템플릿 유형
익명화(민감한 정보 삭제)
데이터 변환 유형
녹화
템플릿 ID
de-identify-structured - 계속을 클릭하여 익명화 구성으로 이동합니다.이 템플릿은 구조화된 데이터에 적용되므로 특정 유형의 민감한 정보가 포함될 필드 또는 열을 예측할 수 있는 경우가 많습니다. 애플리케이션에서 사용하는 CSV에
user_id아래에 사용자 이메일이 있고message에는 고객 상호작용에서 비롯된 개인 식별 정보가 자주 포함되어 있습니다.agent_id는 직원이고 대화의 출처를 알 수 있으므로 마스킹하지 않아도 됩니다. 다음과 같이 이 섹션을 작성합니다.- 변환할 필드 또는 열:
user_id,message - 변환 유형: infoType 일치
- 변환 방법: 변환 추가를 클릭합니다.
- 변환: 문자로 마스킹
- 무시할 문자: 미국 구두점
- 변환할 필드 또는 열:
- 만들기를 클릭합니다.
이미지 데이터용 템플릿 만들기
이 템플릿은 스캔한 문서나 사용자가 제출한 사진과 같은 이미지에 삽입된 민감한 텍스트를 익명화하도록 설계되었습니다. 광학 문자 인식 (OCR)을 활용하여 개인 식별 정보를 감지하고 수정합니다.
- 템플릿 페이지로 돌아가 템플릿 만들기를 클릭합니다.
- 익명화 템플릿을 정의합니다.
속성
값(입력 또는 선택)
템플릿 유형
익명화(민감한 정보 삭제)
데이터 변환 유형
이미지
템플릿 ID
de-identify-image - 계속하여 익명화 구성으로 이동합니다.
- 변환할 infoType: 검사 템플릿이나 검사 구성에 정의되었으며 다른 규칙에 지정되지 않은 감지된 infoType
- 만들기를 클릭합니다.
7. 익명화 작업 만들고 실행하기
템플릿을 정의했으므로 이제 감지하고 검사하는 파일 유형에 따라 올바른 익명화 템플릿을 적용하는 단일 작업을 만듭니다. 이렇게 하면 Cloud Storage에 저장된 데이터의 민감한 정보 보호 프로세스가 자동화됩니다.
입력 데이터 구성
이 단계에서는 익명화해야 하는 데이터의 소스를 지정합니다. 여기서는 민감한 정보가 포함된 다양한 파일 유형이 포함된 Cloud Storage 버킷입니다.
- 검색창을 통해 보안 > Sensitive Data Protection으로 이동합니다.
- 메뉴에서 검사를 클릭합니다.
- 작업 및 작업 트리거 만들기를 클릭합니다.
- 작업을 구성합니다.
속성
값(입력 또는 선택)
작업 ID
pii-remover스토리지 유형
Google Cloud Storage
위치 유형
제외/포함 규칙(선택사항)으로 버킷 스캔
버킷 이름
input-[your-project-id]
감지 및 작업 구성
이제 이전에 만든 템플릿을 이 작업에 연결하여 Sensitive Data Protection에 콘텐츠 유형에 따라 PII를 검사하는 방법과 적용할 익명화 방법을 알려줍니다.
- 검사 템플릿:
projects/[your-project-id]/locations/global/inspectTemplates/pii-finder - 작업 추가에서 익명화된 사본 만들기를 선택하고 변환 템플릿을 사용자가 만든 템플릿으로 구성합니다.
Confirm whether you want to de-identify the findings할 수 있는 팝업이 열리면 샘플링 사용 중지를 클릭합니다.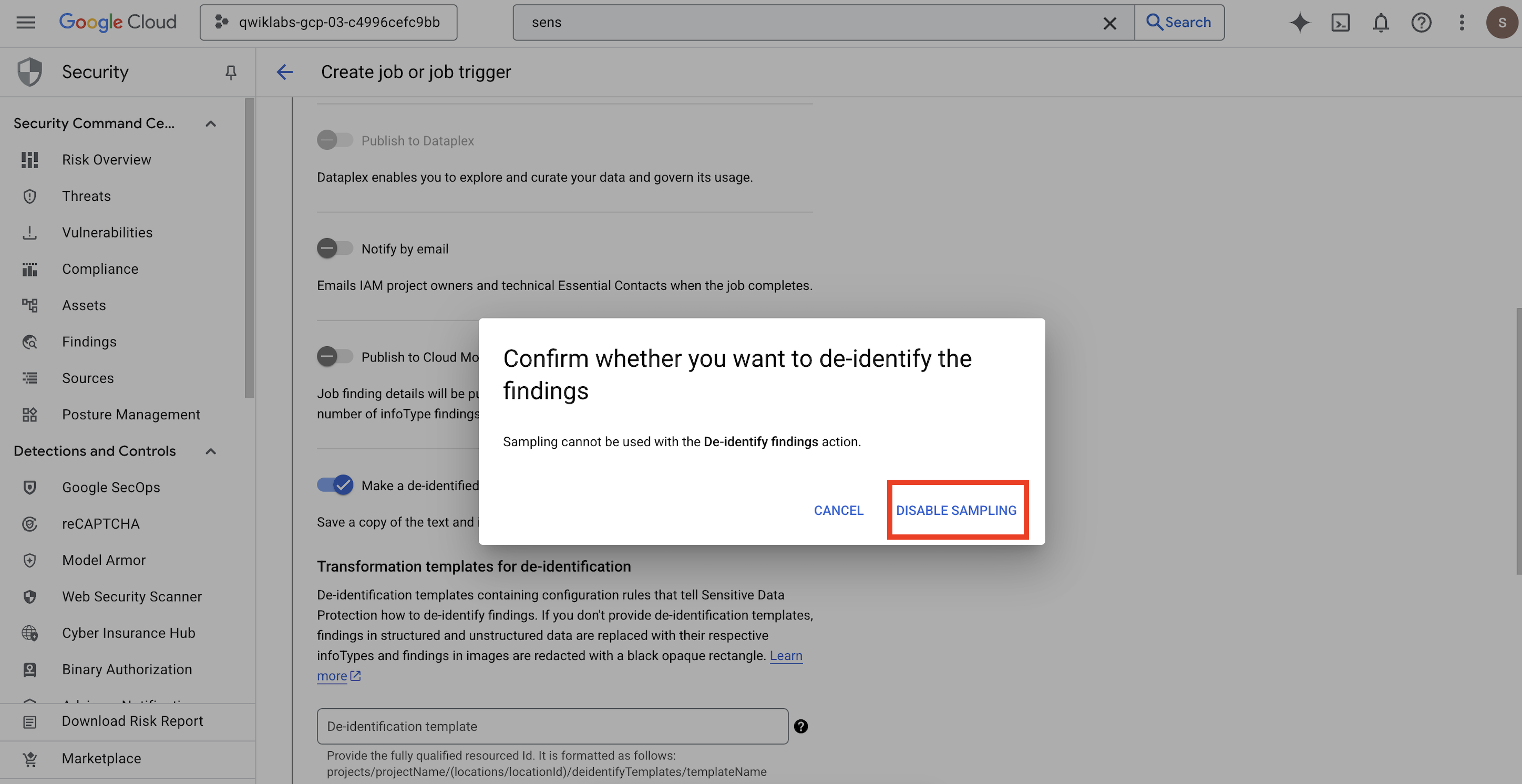
속성
값(입력 또는 선택)
익명화 템플릿
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-unstructured구조화된 익명화 템플릿
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-structured이미지 수정 템플릿
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-image- Cloud Storage 출력 위치를 구성합니다.
- URL:
gs://output-[your-project-id]
- URL:
- 일정에서 작업을 즉시 실행하려면 없음을 선택한 상태로 둡니다.
- 만들기를 클릭합니다.
Confirm job or job trigger create팝업이 열리면 생성 확인을 클릭합니다.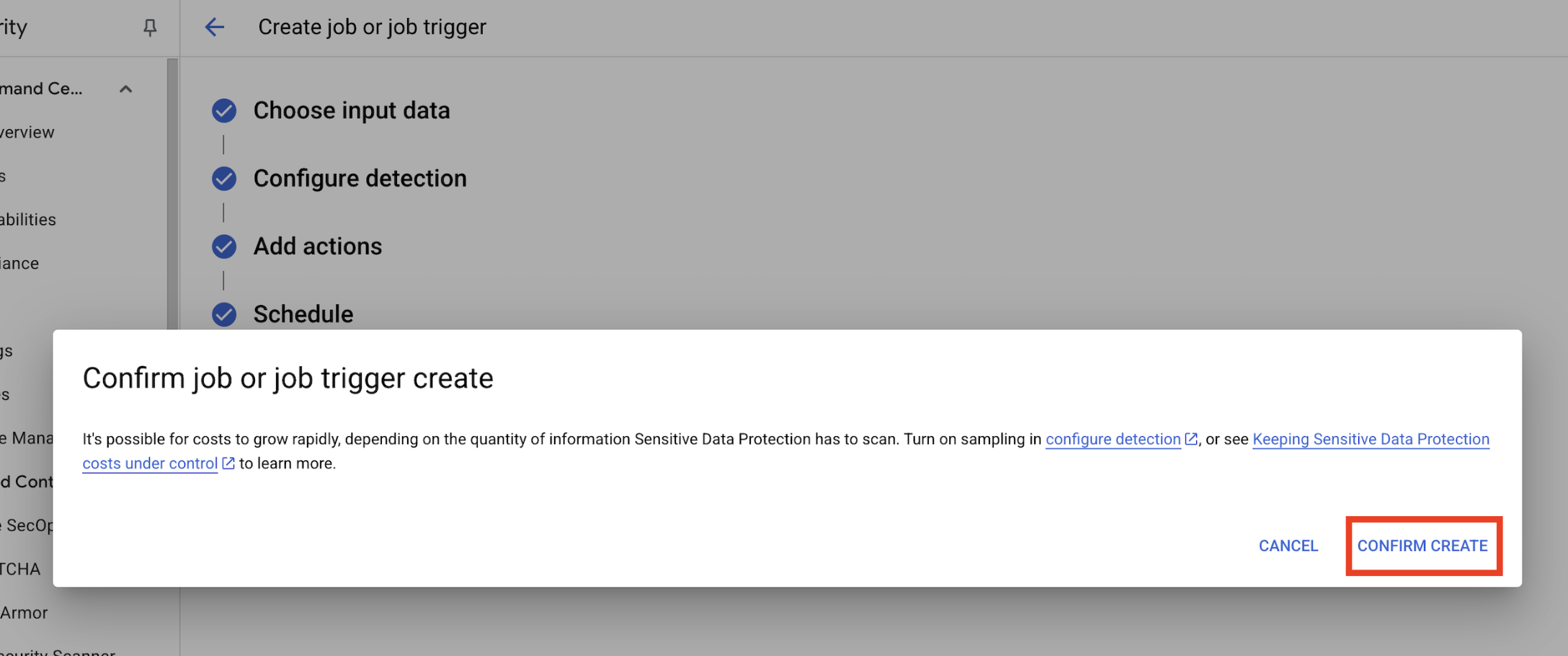
8. 결과 확인
마지막 단계는 출력 버킷의 모든 파일 유형에서 민감한 정보가 성공적으로 올바르게 수정되었는지 확인하는 것입니다. 이렇게 하면 익명화 파이프라인이 예상대로 작동합니다.
작업 상태 검토
작업이 성공적으로 완료되었는지 모니터링하고, 출력 파일을 확인하기 전에 발견사항 요약을 검토합니다.
- 작업 세부정보 탭에서 작업 상태가 완료로 표시될 때까지 기다립니다.
- 개요에서 발견 사항 수와 감지된 각 infoType의 비율을 검토합니다.
- 구성을 클릭합니다.
- 작업까지 아래로 스크롤하고 출력 버킷을 클릭하여 익명처리된 데이터를 확인합니다(
gs://output-[your-project-id]).
입력 및 출력 파일 비교
이 단계에서는 익명처리된 파일을 수동으로 검사하여 템플릿에 따라 데이터 정리 작업이 올바르게 적용되었는지 확인합니다.
- 이미지: 출력 버킷에서 이미지를 엽니다. 출력 파일에서 모든 민감한 텍스트가 수정되었는지 확인합니다.
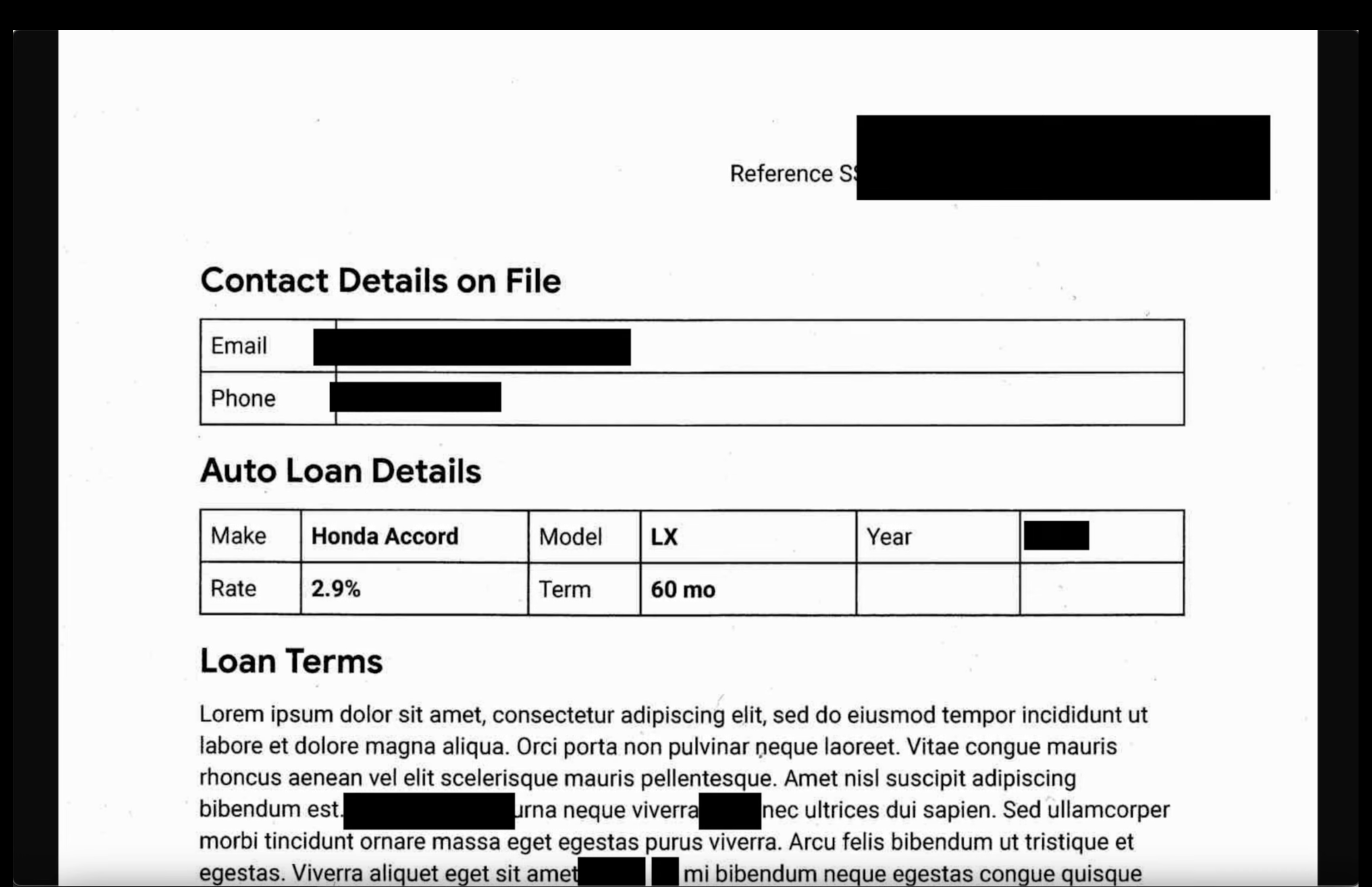
- 구조화되지 않은 로그: 두 버킷의 로그 파일을 확인합니다. 출력 로그의 PII가 infoType 이름 (예:
[US_SOCIAL_SECURITY_NUMBER])으로 대체되었는지 확인합니다. - 구조화된 CSV: 두 버킷에서 CSV 파일을 엽니다. 출력 파일의 사용자 이메일과 주민등록번호가
####@####.com로 마스킹되었는지 확인합니다.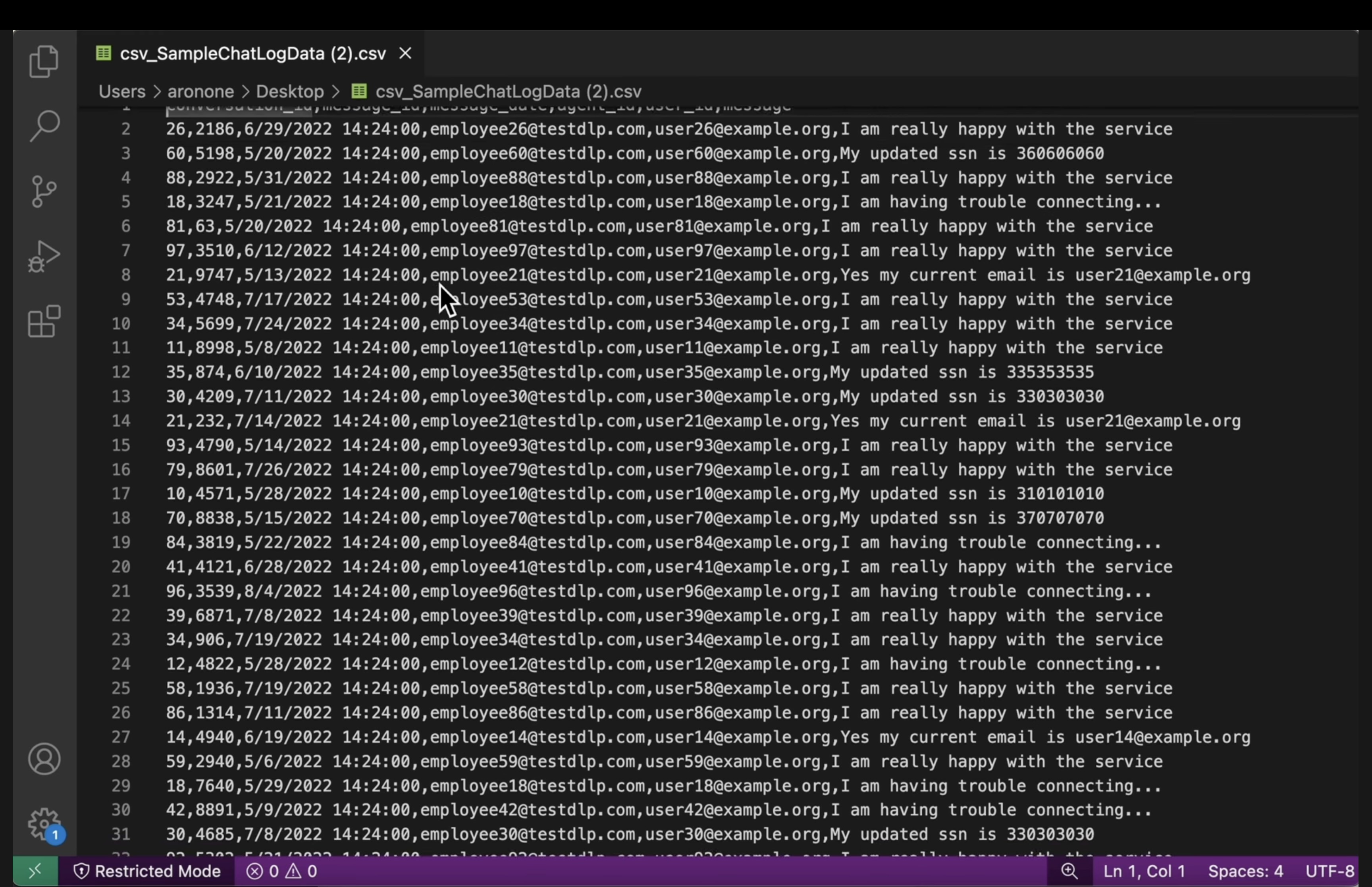
9. 실험실에서 현실로: 자체 프로젝트에서 사용하는 방법
적용한 원칙과 구성은 Google Cloud에서 실제 AI 프로젝트를 보호하기 위한 청사진입니다. 방금 빌드한 리소스(검사 템플릿, 익명화 템플릿, 자동화된 작업)는 새로운 데이터 수집 프로세스를 위한 안전한 시작 템플릿 역할을 합니다.
자동화된 데이터 살균 파이프라인: 안전한 데이터 수집
설정에서 이 기능을 사용하는 방법
팀에서 AI 개발을 위해 새로운 원시 고객 데이터를 수집해야 할 때마다 구성한 Sensitive Data Protection 작업을 통합하는 파이프라인을 통해 데이터를 전달합니다. 수동으로 검사하고 수정하는 대신 이 자동화된 워크플로를 활용합니다. 이를 통해 데이터 과학자와 AI 모델은 익명처리된 데이터와만 상호작용하므로 개인 정보 보호 위험이 크게 줄어듭니다.
프로덕션에 연결
프로덕션 환경에서는 다음을 통해 이 개념을 더욱 발전시킬 수 있습니다.
- 작업 트리거를 사용한 자동화: 작업을 수동으로 실행하는 대신 새 파일이 입력 Cloud Storage 버킷에 업로드될 때마다 작업 트리거를 설정합니다. 이렇게 하면 완전 자동화된 핸즈 오프 감지 및 익명화 프로세스가 생성됩니다.
- 데이터 레이크/웨어하우스와의 통합: 익명처리된 출력 데이터는 일반적으로 추가 분석 및 모델 학습을 위해 보안 데이터 레이크 (예: Cloud Storage) 또는 데이터 웨어하우스 (예: BigQuery)로 제공되므로 데이터 수명 주기 전반에 걸쳐 개인 정보 보호가 유지됩니다.
세부적인 익명화 전략: 개인 정보 보호와 유용성의 균형
설정에서 이 기능을 사용하는 방법
생성한 다양한 익명화 템플릿 (비정형, 정형, 이미지)이 중요합니다. AI 모델의 구체적인 요구사항에 따라 유사한 차별화된 전략을 적용할 수 있습니다. 이를 통해 개발팀은 개인 정보를 침해하지 않고 모델에 유용한 데이터를 확보할 수 있습니다.
프로덕션에 연결
프로덕션 환경에서는 다음과 같은 이유로 세부적인 제어가 더욱 중요해집니다.
- 커스텀 infoType 및 사전: 매우 구체적이거나 도메인별 민감한 정보의 경우 Sensitive Data Protection 내에서 커스텀 infoType 및 사전을 정의합니다. 이를 통해 고유한 비즈니스 컨텍스트에 맞게 포괄적인 감지가 가능합니다.
- 형식 보존 암호화 (FPE): 익명화된 데이터가 원래 형식을 유지해야 하는 시나리오 (예: 통합 테스트를 위한 신용카드 번호)의 경우 형식 보존 암호화와 같은 고급 익명화 기법을 살펴봅니다. 이를 통해 실제 데이터 패턴을 사용하여 개인 정보 보호 테스트를 실행할 수 있습니다.
모니터링 및 감사: 지속적인 규정 준수 보장
설정에서 이 기능을 사용하는 방법
Sensitive Data Protection 로그를 지속적으로 모니터링하여 모든 데이터 처리가 개인정보처리방침을 준수하고 민감한 정보가 실수로 노출되지 않도록 합니다. 작업 요약과 결과를 정기적으로 검토하는 것은 지속적인 감사의 일환입니다.
프로덕션에 연결
강력한 프로덕션 시스템을 위해서는 다음 주요 작업을 고려하세요.
- Security Command Center로 발견 항목 보내기: 통합 위협 관리 및 보안 상황의 중앙 집중식 보기를 위해 Sensitive Data Protection 작업이 발견 항목의 요약을 Security Command Center로 직접 전송하도록 구성합니다. 이를 통해 보안 알림과 통계가 통합됩니다.
- 알림 및 사고 대응: Sensitive Data Protection 발견 항목 또는 작업 실패에 따라 Cloud Monitoring 알림을 설정합니다. 이렇게 하면 보안팀에 잠재적인 정책 위반 또는 처리 문제가 즉시 통지되어 신속한 사고 대응이 가능합니다.
10. 결론
수고하셨습니다 여러 데이터 유형에서 PII를 자동으로 검색하고 익명화하여 다운스트림 AI 개발 및 분석에서 안전하게 사용할 수 있는 데이터 보안 워크플로를 성공적으로 빌드했습니다.
요약
이 실습에서는 다음 작업을 완료했습니다.
- 특정 민감한 정보 유형 (infoType)을 감지하도록 검사 템플릿을 정의했습니다.
- 비정형, 정형, 이미지 데이터에 대해 별도의 익명화 규칙을 빌드했습니다.
- 파일 유형에 따라 전체 버킷의 콘텐츠에 올바른 수정이 자동으로 적용되는 단일 작업을 구성하고 실행했습니다.
- 안전한 출력 위치에서 민감한 정보의 변환이 성공했는지 확인했습니다.
다음 단계
- Security Command Center에 발견 항목 전송: 더 통합된 위협 관리를 위해 발견 항목 요약을 Security Command Center로 직접 전송하도록 작업 작업을 구성합니다.
- Cloud Functions로 자동화: 프로덕션 환경에서는 Cloud Functions를 사용하여 새 파일이 입력 버킷에 업로드될 때마다 이 검사 작업을 자동으로 트리거할 수 있습니다.