
1. Wprowadzenie
Przegląd
W tym laboratorium utworzysz zautomatyzowany potok sanityzacji danych, aby chronić informacje poufne używane w procesie tworzenia AI. Usługa Google Cloud Sensitive Data Protection (wcześniej Cloud DLP) służy do sprawdzania, klasyfikowania i deidentyfikacji informacji umożliwiających identyfikację konkretnej osoby w różnych formatach danych, w tym w tekście nieustrukturyzowanym, tabelach strukturalnych i obrazach.
Context
Jesteś w swoim zespole deweloperskim osobą odpowiedzialną za bezpieczeństwo i prywatność. Twoim celem jest opracowanie procesu, który identyfikuje informacje poufne i usuwa z nich dane umożliwiające identyfikację, zanim zostaną one udostępnione deweloperom i modelom. Twój zespół potrzebuje realistycznych danych wysokiej jakości, aby dostroić i przetestować nową aplikację opartą na generatywnej AI, ale używanie surowych danych o klientach wiąże się z poważnymi problemami dotyczącymi prywatności.
W tabeli poniżej znajdziesz listę zagrożeń dla prywatności, które najbardziej Cię niepokoją i które chcesz ograniczyć:
Ryzyko | Ograniczanie ryzyka |
Ujawnienie informacji umożliwiających identyfikację osób w nieustrukturyzowanych plikach tekstowych (np. w logach czatu pomocy, formularzach opinii). | Utwórz szablon deidentyfikacji, który zastępuje wartości wrażliwe ich infoType, zachowując kontekst, ale usuwając narażenie. |
Utrata użyteczności danych w strukturalnych zbiorach danych (plikach CSV) po usunięciu informacji umożliwiających identyfikację. | Użyj przekształceń rekordów, aby selektywnie redagować identyfikatory (np. imiona i nazwiska) i stosować techniki takie jak maskowanie znaków, aby zachować inne znaki w ciągu znaków, dzięki czemu programiści będą mogli nadal testować dane. |
Ujawnienie informacji umożliwiających identyfikację w tekście osadzonym w obrazach (np. w skanowanych dokumentach lub zdjęciach użytkowników). | Utwórz szablon deidentyfikacji przeznaczony do obrazów, który zasłania tekst znajdujący się na obrazach. |
Niespójne lub podatne na błędy ręczne redagowanie różnych typów danych. | Skonfiguruj jedno zautomatyzowane zadanie Sensitive Data Protection, które konsekwentnie stosuje odpowiedni szablon deidentyfikacji na podstawie typu przetwarzanego pliku. |
Czego się nauczysz
Z tego laboratorium dowiesz się, jak:
- Zdefiniuj szablon inspekcji, aby wykrywać określone typy informacji wrażliwych (obiekty infoType).
- Twórz odrębne reguły deidentyfikacji dla danych nieuporządkowanych, uporządkowanych i obrazów.
- Skonfiguruj i uruchom jedno zadanie, które automatycznie stosuje odpowiednie redagowanie na podstawie typu pliku do zawartości całego zasobnika.
- Sprawdź, czy dane wrażliwe zostały przekształcone w bezpiecznej lokalizacji wyjściowej.
2. Konfigurowanie projektu
Konto Google
Jeśli nie masz jeszcze osobistego konta Google, musisz je utworzyć.
Używaj konta osobistego zamiast konta służbowego lub szkolnego.
Logowanie się w konsoli Google Cloud
Zaloguj się w konsoli Google Cloud, korzystając z osobistego konta Google.
Włącz płatności
Odbieranie środków w Google Cloud (opcjonalnie)
Aby przeprowadzić te warsztaty, musisz mieć konto rozliczeniowe z określonymi środkami. Aby rozpocząć, użyj środków z banera u góry tego modułu. Jeśli masz już połączenie z kontem rozliczeniowym, możesz pominąć ten krok.
Konfigurowanie osobistego konta rozliczeniowego
Jeśli skonfigurujesz płatności za pomocą środków w Google Cloud, możesz pominąć ten krok.
Aby skonfigurować osobiste konto rozliczeniowe, włącz płatności w Cloud Console.
Uwagi:
- Pod względem opłat za zasoby chmury ukończenie tego modułu powinno kosztować mniej niż 1 USD.
- Jeśli chcesz uniknąć dalszych opłat, wykonaj czynności opisane na końcu tego modułu, aby usunąć zasoby.
- Nowi użytkownicy mogą skorzystać z bezpłatnego okresu próbnego o wartości 300 USD.
Tworzenie projektu (opcjonalnie)
Jeśli nie masz bieżącego projektu, którego chcesz użyć w tym ćwiczeniu, utwórz nowy projekt.
3. Włączanie interfejsów API
Konfigurowanie Cloud Shell
Po utworzeniu projektu wykonaj te czynności, aby skonfigurować Cloud Shell.
Uruchamianie Cloud Shell
Otwórz stronę shell.cloud.google.com. Jeśli pojawi się wyskakujące okienko z prośbą o autoryzację, kliknij Autoryzuj.
Ustawianie identyfikatora projektu
Aby ustawić prawidłowy identyfikator projektu, uruchom to polecenie w terminalu Cloud Shell. Zastąp <your-project-id> rzeczywistym identyfikatorem projektu skopiowanym w kroku tworzenia projektu powyżej.
gcloud config set project <your-project-id>
W terminalu Cloud Shell powinien być teraz wybrany prawidłowy projekt.
Włączanie ochrony danych wrażliwych
Aby korzystać z usługi ochrony danych wrażliwych i Cloud Storage, musisz włączyć te interfejsy API w projekcie Google Cloud.
- W terminalu włącz interfejsy API:
gcloud services enable dlp.googleapis.com storage.googleapis.com
Możesz też włączyć te interfejsy API, otwierając w konsoli Bezpieczeństwo > Sensitive Data Protection i Cloud Storage, a następnie klikając przycisk Włącz, jeśli pojawi się prośba o włączenie każdego z tych interfejsów.
4. Tworzenie zasobników z danymi wrażliwymi
Tworzenie zasobnika wejściowego i wyjściowego
W tym kroku utworzysz 2 zasobniki: jeden do przechowywania danych wrażliwych, które wymagają sprawdzenia, a drugi, w którym usługa Sensitive Data Protection będzie przechowywać pliki wyjściowe z anonimizowanymi danymi. Możesz też pobrać przykładowe pliki danych i przesłać je do zasobnika wejściowego.
- W terminalu uruchom te polecenia, aby utworzyć 1 zasobnik na dane wejściowe i 1 na dane wyjściowe, a potem wypełnij zasobnik wejściowy przykładowymi danymi z
gs://dlp-codelab-data:PROJECT_ID=$(gcloud config get-value project) gsutil mb gs://input-$PROJECT_ID gsutil mb gs://output-$PROJECT_ID
Dodawanie danych wrażliwych do zasobnika wejściowego
W tym kroku pobierzesz z GitHub przykładowe pliki danych zawierające testowe informacje umożliwiające identyfikację, a następnie prześlesz je do zasobnika wejściowego.
- Aby sklonować repozytorium
devrel-demos, które zawiera przykładowe dane wymagane w tym module, uruchom w Cloud Shell to polecenie:REPO_URL="https://github.com/GoogleCloudPlatform/devrel-demos.git" TARGET_PATH="security/sample-data" OUTPUT_FOLDER="sample-data" git clone --quiet --depth 1 --filter=blob:none --sparse "$REPO_URL" temp_loader cd temp_loader git sparse-checkout set "$TARGET_PATH" cd .. mv "temp_loader/$TARGET_PATH" "$OUTPUT_FOLDER" rm -rf temp_loader - Następnie skopiuj przykładowe dane do utworzonego wcześniej zasobnika wejściowego:
gsutil -m cp -r sample-data/* gs://input-$PROJECT_ID/ - Otwórz Cloud Storage > Zasobniki i kliknij zasobnik wejściowy, aby zobaczyć zaimportowane dane.
5. Tworzenie szablonu inspekcji
W tym zadaniu utworzysz szablon, który określa, czego ma szukać Sensitive Data Protection. Dzięki temu możesz skupić się na infoTypes, które są istotne dla Twoich danych i obszaru geograficznego, co zwiększa wydajność i dokładność.
Tworzenie szablonu inspekcji
W tym kroku określasz reguły dotyczące tego, co stanowi dane wrażliwe, które należy sprawdzić. Ten szablon będzie ponownie używany przez zadania deidentyfikacji, aby zapewnić spójność.
- W menu nawigacyjnym kliknij Sensitive Data Protection > Konfiguracja > Szablony.
- Kliknij Utwórz szablon.
- W polu Typ szablonu wybierz Przeprowadź inspekcję (znajduje dane wrażliwe).
- Ustaw Identyfikator szablonu na
pii-finder. - Kliknij Dalej, aby przejść do sekcji Konfigurowanie wykrywania.
- Kliknij Zarządzaj obiektami infoType.
- Używając filtra, wyszukaj te infoTypes i zaznacz pole wyboru obok każdego z nich:
CREDIT_CARD_EXPIRATION_DATECREDIT_CARD_NUMBERDATE_OF_BIRTHDRIVERS_LICENSE_NUMBEREMAIL_ADDRESSGCP_API_KEYGCP_CREDENTIALSORGANIZATION_NAMEPASSWORDPERSON_NAMEPHONE_NUMBERUS_SOCIAL_SECURITY_NUMBER
- Wybierz też inne, które Cię interesują, i kliknij Gotowe.
- Sprawdź tabelę wyników, aby upewnić się, że wszystkie te obiekty infoType zostały dodane.
- Kliknij Utwórz.
6. Tworzenie szablonów deidentyfikacji
Następnie tworzysz 3 osobne szablony deidentyfikacji do obsługi różnych formatów danych. Dzięki temu masz szczegółową kontrolę nad procesem przekształcania i możesz zastosować najbardziej odpowiednią metodę dla każdego typu pliku. Te szablony działają w połączeniu z utworzonym przez Ciebie szablonem inspekcji.
Tworzenie szablonu dla nieuporządkowanych danych
Ten szablon określa sposób deidentyfikacji danych wrażliwych znalezionych w tekście w formie dowolnej, np. w logach czatu lub formularzach opinii. Wybrana metoda zastępuje wartość wrażliwą nazwą jej infoType, zachowując kontekst.
- Na stronie Szablony kliknij Utwórz szablon.
- Zdefiniuj szablon deidentyfikacji:
Właściwość
Wartość (wpisz lub wybierz)
Typ szablonu
Deidentyfikuj (usuwa dane wrażliwe)
Typ przekształcenia danych
Obiekt InfoType
Identyfikator szablonu
de-identify-unstructured - Kliknij Dalej, aby przejść do sekcji Skonfiguruj deidentyfikację.
- W sekcji Metoda przekształcenia wybierz przekształcenie: Zastąp nazwą obiektu infoType.
- Kliknij Utwórz.
- Kliknij Przetestuj.
- Przetestuj wiadomość zawierającą informacje umożliwiające identyfikację, aby zobaczyć, jak zostanie przekształcona:
Hi, my name is Alex and my SSN is 555-11-5555. You can reach me at +1-555-555-5555.
Tworzenie szablonu danych strukturalnych
Ten szablon jest przeznaczony do wykrywania informacji poufnych w uporządkowanych zbiorach danych, takich jak pliki CSV. Skonfigurujesz ją tak, aby maskować dane w sposób, który zachowuje ich przydatność do testowania, a jednocześnie deidentyfikuje pola wrażliwe.
- Wróć na stronę Szablony i kliknij Utwórz szablon.
- Zdefiniuj szablon deidentyfikacji:
Właściwość
Wartość (wpisz lub wybierz)
Typ szablonu
Deidentyfikuj (usuwa dane wrażliwe)
Typ przekształcenia danych
Nagraj
Identyfikator szablonu
de-identify-structured - Kliknij Dalej, aby przejść do sekcji Konfigurowanie deidentyfikacji.Ponieważ ten szablon dotyczy danych strukturalnych, często możemy przewidzieć pola lub kolumny, które będą zawierać określone typy danych wrażliwych. Wiesz, że plik CSV używany przez Twoją aplikację zawiera adresy e-mail użytkowników w kolumnie
user_id, a kolumnamessageczęsto zawiera informacje umożliwiające identyfikację użytkownika pochodzące z interakcji z klientami. Nie musisz maskowaćagent_id, ponieważ są to pracownicy, a rozmowy powinny być przypisywane. Wypełnij tę sekcję w ten sposób:- Pola lub kolumny do przekształcenia:
user_id,message. - Typ przekształcenia: Dopasowanie do obiektu infoType
- Metoda przekształcenia: kliknij Dodaj przekształcenie.
- Przekształcenie: maska ze znakiem.
- Znaki, które mają zostać zignorowane: interpunkcja w języku angielskim.
- Pola lub kolumny do przekształcenia:
- Kliknij Utwórz.
Tworzenie szablonu danych o obrazach
Ten szablon został zaprojektowany do deidentyfikacji tekstu wrażliwego znajdującego się w obrazach, takich jak zeskanowane dokumenty lub zdjęcia przesłane przez użytkowników. Wykorzystuje optyczne rozpoznawanie znaków (OCR) do wykrywania i redagowania informacji umożliwiających identyfikację.
- Wróć na stronę Szablony i kliknij Utwórz szablon.
- Zdefiniuj szablon deidentyfikacji:
Właściwość
Wartość (wpisz lub wybierz)
Typ szablonu
Deidentyfikuj (usuwa dane wrażliwe)
Typ przekształcenia danych
Obraz
Identyfikator szablonu
de-identify-image - Kliknij Dalej, aby przejść do sekcji Skonfiguruj deidentyfikację.
- Obiekty infoType do przekształcenia: wszystkie wykryte obiekty infoType zdefiniowane w szablonie inspekcji lub konfiguracji inspekcji, których nie wskazano w innych regułach.
- Kliknij Utwórz.
7. Tworzenie i uruchamianie zadania deidentyfikacji
Po zdefiniowaniu szablonów możesz utworzyć jedno zadanie, które stosuje odpowiedni szablon deidentyfikacji na podstawie wykrytego i sprawdzonego typu pliku. Automatyzuje to proces ochrony danych wrażliwych w przypadku danych przechowywanych w Cloud Storage.
Konfigurowanie danych wejściowych
W tym kroku określasz źródło danych, które wymagają anonimizacji. Jest to zasobnik Cloud Storage zawierający różne typy plików z informacjami wrażliwymi.
- Na pasku wyszukiwania wpisz Zabezpieczenia > Sensitive Data Protection.
- W menu kliknij Inspekcja.
- Kliknij Utwórz zadanie i aktywatory zadania.
- Skonfiguruj zadanie:
Właściwość
Wartość (wpisz lub wybierz)
Identyfikator zadania
pii-removerTyp pamięci masowej
Google Cloud Storage
Typ lokalizacji
Przeskanuj zasobnik z opcjonalnymi regułami uwzględniania/wykluczania
Nazwa zasobnika
input-[your-project-id]
Konfigurowanie wykrywania i działań
Teraz połącz utworzone wcześniej szablony z tym zadaniem, aby poinformować usługę Sensitive Data Protection, jak przeprowadzać inspekcję pod kątem informacji umożliwiających identyfikację, oraz która metoda deidentyfikacji ma być stosowana w zależności od typu treści.
- Szablon kontroli:
projects/[your-project-id]/locations/global/inspectTemplates/pii-finder - W sekcji Dodaj działania wybierz Utwórz kopię z usuniętymi danymi umożliwiającymi identyfikację i skonfiguruj utworzone szablony przekształceń.
- Otworzy się wyskakujące okienko, w którym możesz
Confirm whether you want to de-identify the findings. Kliknij WYŁĄCZ PRÓBKOWANIE.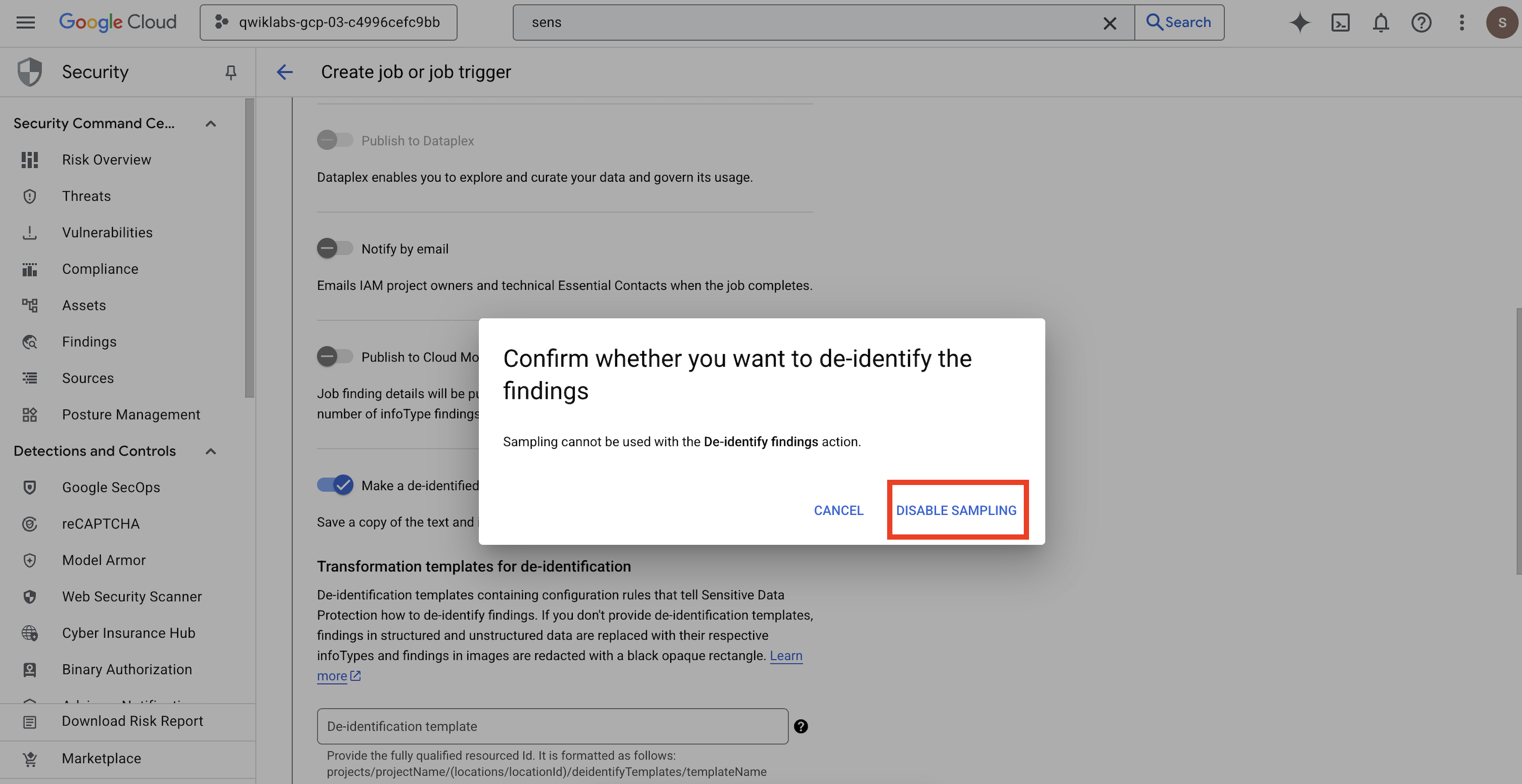
Właściwość
Wartość (wpisz lub wybierz)
Szablon deidentyfikacji
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-unstructuredSzablon deidentyfikacji uporządkowanych danych
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-structuredSzablon zasłaniania obrazów
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-image - Skonfiguruj lokalizację wyjściową w Cloud Storage:
- URL:
gs://output-[your-project-id]
- URL:
- W sekcji Harmonogram pozostaw opcję Brak, aby uruchomić zadanie od razu.
- Kliknij Utwórz.
- Otworzy się wyskakujące okienko
Confirm job or job trigger create. Kliknij POTWIERDŹ UTWORZENIE.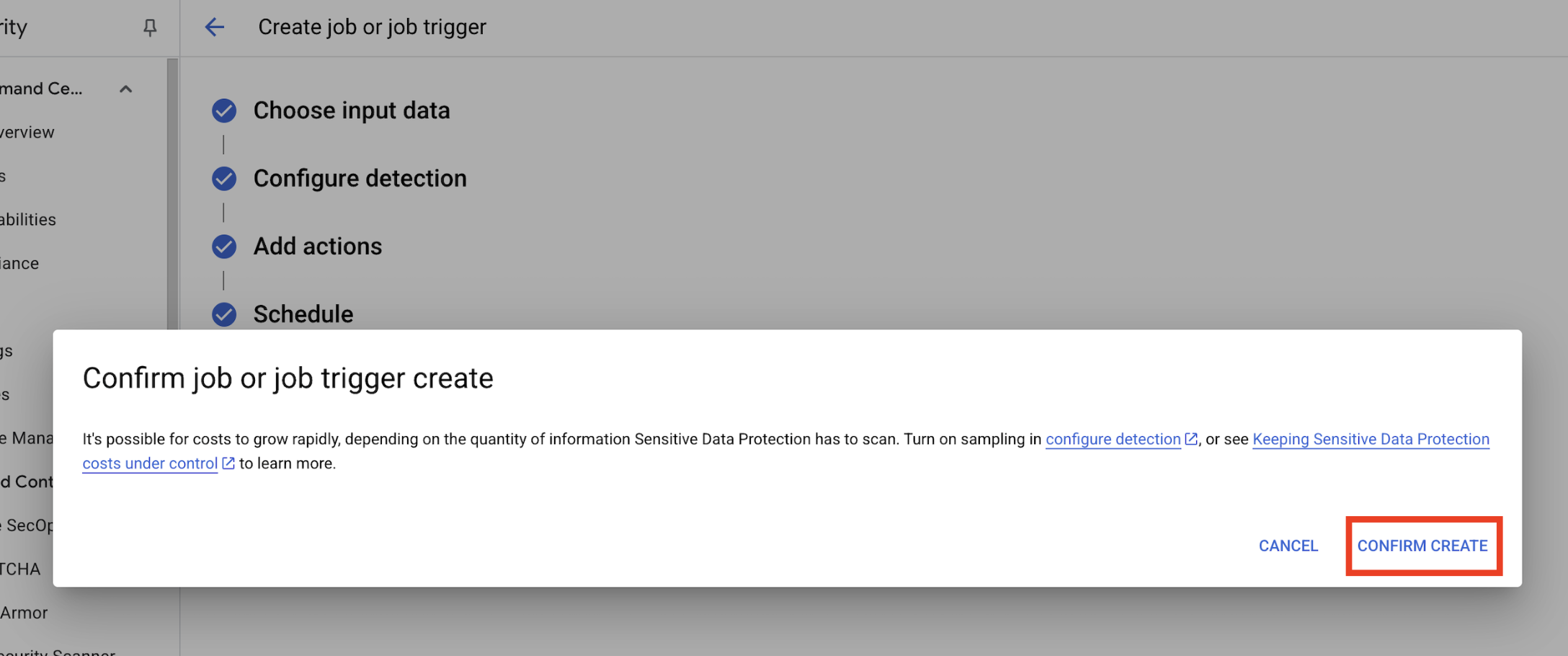
8. Sprawdź wyniki wyszukiwania
Ostatnim krokiem jest potwierdzenie, że dane wrażliwe zostały prawidłowo i skutecznie zanonimizowane we wszystkich typach plików w zasobniku wyjściowym. Dzięki temu potok anonimizacji będzie działać zgodnie z oczekiwaniami.
Sprawdzanie stanu zadania
Monitoruj zadanie, aby upewnić się, że zostało wykonane prawidłowo, i przed sprawdzeniem plików wyjściowych przejrzyj podsumowanie wyników.
- Na karcie Szczegóły zadań poczekaj, aż zadanie będzie miało stan Gotowe.
- W sekcji Przegląd sprawdź liczbę wyników i odsetek wykrytych obiektów infoType.
- Kliknij Konfiguracja.
- Przewiń w dół do sekcji Działania i kliknij wyjściowy kosz, aby wyświetlić dane po usunięciu informacji umożliwiających identyfikację:
gs://output-[your-project-id].
Porównywanie plików wejściowych i wyjściowych
Na tym etapie ręcznie sprawdzasz zanonimizowane pliki, aby potwierdzić, że anonimizacja danych została zastosowana prawidłowo zgodnie z Twoimi szablonami.
- Obrazy: otwórz obraz z zasobnika wyjściowego. Sprawdź, czy w pliku wyjściowym wszystkie informacje poufne zostały zredagowane.

- Logi nieustrukturyzowane: wyświetl plik logu z obu zasobników. Sprawdź, czy informacje umożliwiające identyfikację w danych wyjściowych zostały zastąpione nazwą infoType (np.
[US_SOCIAL_SECURITY_NUMBER]). - Ustrukturyzowane pliki CSV: otwórz plik CSV z obu koszy. Sprawdź, czy adresy e-mail użytkowników i numery SSN w pliku wyjściowym są zamaskowane za pomocą znaku
####@####.com.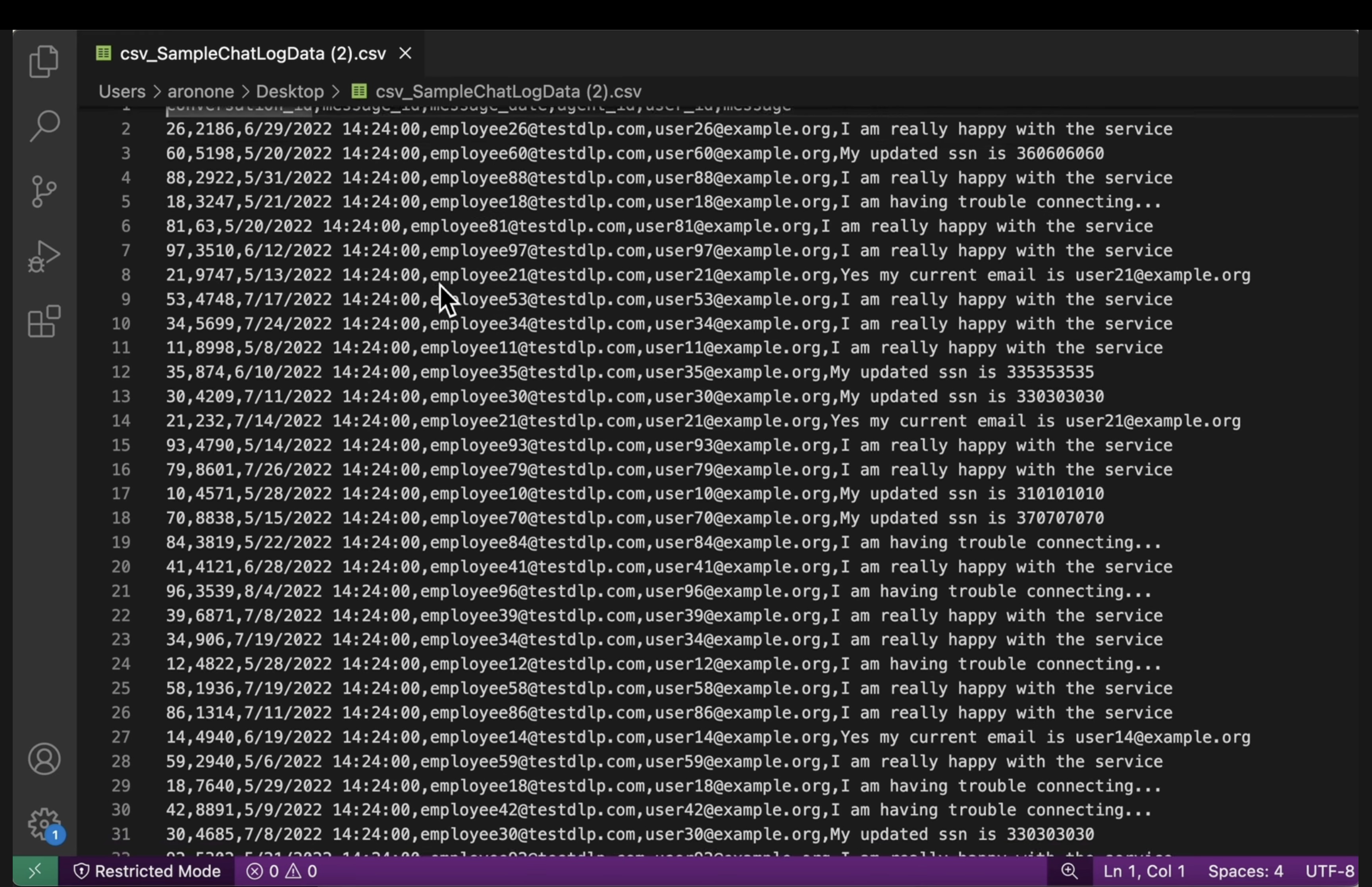
9. Od laboratorium do rzeczywistości: jak wykorzystać tę technologię we własnych projektach
Zastosowane zasady i konfiguracje stanowią plan zabezpieczania rzeczywistych projektów AI w Google Cloud. Utworzone zasoby – szablon inspekcji, szablony deidentyfikacji i automatyczne zadanie – stanowią bezpieczny szablon początkowy dla każdego nowego procesu pozyskiwania danych.
Automatyczny potok sanityzacji danych: bezpieczne pozyskiwanie danych
Jak użyć tego w konfiguracji
Za każdym razem, gdy Twój zespół będzie potrzebować nowych nieprzetworzonych danych o klientach do rozwoju AI, będzie je kierować przez potok, który obejmuje skonfigurowane przez Ciebie zadanie Sensitive Data Protection. Zamiast ręcznie sprawdzać i redagować dokumenty, możesz skorzystać z tego zautomatyzowanego procesu. Dzięki temu badacze danych i modele AI wchodzą w interakcje tylko z danymi pozbawionymi tożsamości, co znacznie zmniejsza ryzyko naruszenia prywatności.
Łączenie z wersją produkcyjną
W środowisku produkcyjnym możesz rozwinąć tę koncepcję, wykonując te czynności:
- Automatyzacja za pomocą aktywatorów zadań: zamiast ręcznie uruchamiać zadanie, możesz skonfigurować aktywator zadania, który będzie się uruchamiał za każdym razem, gdy nowy plik zostanie przesłany do wejściowego zasobnika Cloud Storage. Dzięki temu powstaje w pełni zautomatyzowany proces wykrywania i anonimizacji, który nie wymaga interwencji człowieka.
- Integracja z jeziorami danych i hurtowniami danych: zanonimizowane dane wyjściowe są zwykle przesyłane do bezpiecznego jeziora danych (np. w Cloud Storage) lub hurtowni danych (np. BigQuery) w celu dalszej analizy i trenowania modeli, co zapewnia zachowanie prywatności w całym cyklu życia danych.
Szczegółowe strategie anonimizacji: równoważenie prywatności i użyteczności
Jak użyć tego w konfiguracji
Kluczowe są różne utworzone przez Ciebie szablony deidentyfikacji (nieuporządkowane, uporządkowane, obraz). Podobne zróżnicowane strategie możesz stosować w zależności od konkretnych potrzeb modeli AI. Dzięki temu zespół programistów może korzystać z przydatnych danych do trenowania modeli bez naruszania prywatności użytkowników.
Łączenie z wersją produkcyjną
W środowisku produkcyjnym ta szczegółowa kontrola jest jeszcze ważniejsza w przypadku:
- Niestandardowe obiekty infoType i słowniki: w przypadku bardzo specyficznych lub branżowych danych wrażliwych możesz zdefiniować niestandardowe obiekty infoType i słowniki w ramach Sensitive Data Protection. Zapewnia to kompleksowe wykrywanie dostosowane do unikalnego kontekstu Twojej firmy.
- Szyfrowanie z zachowaniem formatu (FPE): w przypadku scenariuszy, w których dane po usunięciu identyfikatorów muszą zachować pierwotny format (np. numery kart kredytowych na potrzeby testów integracyjnych), warto rozważyć zaawansowane techniki usuwania identyfikatorów, takie jak szyfrowanie z zachowaniem formatu. Umożliwia to testowanie w sposób zapewniający ochronę prywatności przy użyciu realistycznych wzorców danych.
Monitorowanie i kontrola: zapewnianie ciągłej zgodności
Jak użyć tego w konfiguracji
Będziesz stale monitorować logi usługi Sensitive Data Protection, aby mieć pewność, że wszystkie procesy przetwarzania danych są zgodne z Twoimi zasadami ochrony prywatności i że żadne informacje poufne nie są przypadkowo ujawniane. Regularne sprawdzanie podsumowań zadań i wyników jest częścią tego ciągłego audytu.
Łączenie z wersją produkcyjną
Aby zapewnić solidny system produkcyjny, wykonaj te kluczowe działania:
- Wysyłanie wyników do Security Command Center: aby zintegrować zarządzanie zagrożeniami i uzyskać centralny widok stanu zabezpieczeń, skonfiguruj zadania Sensitive Data Protection tak, aby wysyłały podsumowanie wyników bezpośrednio do Security Command Center. Umożliwia to konsolidację alertów i statystyk dotyczących bezpieczeństwa.
- Alerty i reagowanie na incydenty: możesz skonfigurować alerty Cloud Monitoring na podstawie wyników Sensitive Data Protection lub błędów zadań. Dzięki temu Twój zespół ds. bezpieczeństwa będzie natychmiast powiadamiany o potencjalnych naruszeniach zasad lub problemach z przetwarzaniem, co umożliwi szybkie reagowanie na incydenty.
10. Podsumowanie
Gratulacje! Udało Ci się utworzyć przepływ pracy związany z bezpieczeństwem danych, który może automatycznie wykrywać i anonimizować informacje umożliwiające identyfikację w różnych typach danych, dzięki czemu można ich bezpiecznie używać w dalszym rozwoju AI i analizach.
Podsumowanie
W tym module:
- zdefiniowano szablon inspekcji do wykrywania określonych typów informacji wrażliwych (obiektów infoType);
- Utworzono odrębne reguły deidentyfikacji dla danych nieustrukturyzowanych, ustrukturyzowanych i obrazów.
- Skonfigurowano i uruchomiono jedno zadanie, które automatycznie stosowało odpowiednie redagowanie na podstawie typu pliku do zawartości całego zasobnika.
- Sprawdzanie, czy dane wrażliwe zostały przekształcone w bezpiecznej lokalizacji wyjściowej.
Dalsze kroki
- Wysyłanie wyników do Security Command Center: aby uzyskać bardziej zintegrowane zarządzanie zagrożeniami, skonfiguruj działanie zadania tak, aby wysyłało podsumowanie wyników bezpośrednio do Security Command Center.
- Automatyzacja za pomocą Cloud Functions: w środowisku produkcyjnym możesz automatycznie uruchamiać to zadanie inspekcji za każdym razem, gdy nowy plik zostanie przesłany do zasobnika wejściowego, za pomocą funkcji w Cloud Functions.