
1. Introdução
Visão geral
Neste laboratório, você vai criar um pipeline automatizado de sanitização de dados para proteger informações sensíveis usadas no desenvolvimento de IA. Você usa a Proteção de Dados Sensíveis do Google Cloud (antiga Cloud DLP) para inspecionar, classificar e desidentificar informações de identificação pessoal (PII) em vários formatos de dados, incluindo texto não estruturado, tabelas estruturadas e imagens.
Contexto
Você é o campeão de segurança e privacidade na sua equipe de desenvolvimento, e seu objetivo é estabelecer um fluxo de trabalho que identifique e remova as informações sensíveis antes de disponibilizá-las para desenvolvedores e modelos. Sua equipe precisa de dados realistas e de alta qualidade para ajustar e testar um novo aplicativo de IA generativa, mas o uso de dados brutos de clientes apresenta desafios significativos de privacidade.
A tabela a seguir lista os riscos de privacidade que você mais quer mitigar:
Risco | Mitigação |
Exposição de PII em arquivos de texto não estruturados (por exemplo, registros de chat de suporte, formulários de feedback). | Crie um modelo de desidentificação que substitua os valores sensíveis pelo infoType deles, preservando o contexto e removendo a exposição. |
Perda da utilidade dos dados em conjuntos de dados estruturados (CSVs) quando as PIIs são removidas. | Use transformações de registros para encobrir seletivamente identificadores (como nomes) e aplicar técnicas como mascaramento de caracteres para preservar outros caracteres na string. Assim, os desenvolvedores ainda podem testar com os dados. |
Exposição de PII em textos incorporados em imagens (por exemplo, documentos digitalizados, fotos de usuários). | Crie um modelo de desidentificação específico para imagens que oculte o texto encontrado nelas. |
Redação manual inconsistente ou propensa a erros em diferentes tipos de dados. | Configure um único job automatizado da Proteção de Dados Sensíveis que aplique de forma consistente o modelo de desidentificação correto com base no tipo de arquivo processado. |
O que você vai aprender
Neste laboratório, você vai aprender a:
- Defina um modelo de inspeção para detectar tipos específicos de informações sensíveis (infoTypes).
- Crie regras de desidentificação distintas para dados não estruturados, estruturados e de imagem.
- Configure e execute um único job que aplica automaticamente a redação correta com base no tipo de arquivo ao conteúdo de um bucket inteiro.
- Verifique a transformação bem-sucedida de dados sensíveis em um local de saída seguro.
2. Configurar o projeto
Conta do Google
Se você ainda não tiver uma Conta do Google pessoal, crie uma.
Use uma conta pessoal em vez de uma conta escolar ou de trabalho.
Fazer login no console do Google Cloud
Faça login no console do Google Cloud usando uma Conta do Google pessoal.
Ativar faturamento
Resgatar créditos do Google Cloud (opcional)
Para fazer este workshop, você precisa de uma conta de faturamento com algum crédito. Use os créditos do banner na parte de cima deste codelab para começar. Se você já estiver conectado a uma conta de faturamento, pule esta etapa.
Configurar uma conta de faturamento pessoal
Se você configurou o faturamento usando créditos do Google Cloud, pule esta etapa.
Para configurar uma conta de faturamento pessoal, acesse este link e ative o faturamento no console do Cloud.
Algumas observações:
- A conclusão deste laboratório custa menos de US $1 em recursos do Cloud.
- Siga as etapas no final deste laboratório para excluir recursos e evitar mais cobranças.
- Novos usuários podem aproveitar o teste sem custos financeiros de US$300.
Criar um projeto (opcional)
Se você não tiver um projeto atual que gostaria de usar neste laboratório, crie um novo aqui.
3. Ative as APIs
Configure o Cloud Shell
Depois que o projeto for criado, siga estas etapas para configurar o Cloud Shell.
Iniciar o Cloud Shell
Acesse shell.cloud.google.com e, se aparecer um pop-up pedindo autorização, clique em Autorizar.
Definir ID do projeto
Execute o seguinte comando no terminal do Cloud Shell para definir o ID do projeto correto. Substitua <your-project-id> pelo ID do projeto copiado da etapa de criação acima.
gcloud config set project <your-project-id>
Agora você vai ver que o projeto correto está selecionado no terminal do Cloud Shell.
Ativar a proteção de dados sensíveis
Para usar o serviço Sensitive Data Protection e o Cloud Storage, verifique se essas APIs estão ativadas no seu projeto do Google Cloud.
- No terminal, ative as APIs:
gcloud services enable dlp.googleapis.com storage.googleapis.com
Outra opção é ativar essas APIs navegando até Segurança > Proteção de dados sensíveis e Cloud Storage no console e clicando no botão Ativar se solicitado para cada serviço.
4. Criar buckets com dados sensíveis
Criar um bucket de entrada e um de saída
Nesta etapa, você vai criar dois buckets: um para armazenar dados sensíveis que precisam ser inspecionados e outro em que a Proteção de Dados Sensíveis vai armazenar os arquivos de saída desidentificados. Você também vai baixar arquivos de dados de amostra e fazer upload deles para o bucket de entrada.
- No terminal, execute os comandos a seguir para criar um bucket de dados de entrada e outro de saída. Em seguida, preencha o bucket de entrada com dados de amostra de
gs://dlp-codelab-data:PROJECT_ID=$(gcloud config get-value project) gsutil mb gs://input-$PROJECT_ID gsutil mb gs://output-$PROJECT_ID
Adicionar dados sensíveis ao bucket de entrada
Nesta etapa, você vai baixar arquivos de dados de amostra com PII de teste do GitHub e fazer upload deles para o bucket de entrada.
- No Cloud Shell, execute o comando a seguir para clonar o repositório
devrel-demos, que contém os dados de exemplo necessários para este laboratório.REPO_URL="https://github.com/GoogleCloudPlatform/devrel-demos.git" TARGET_PATH="security/sample-data" OUTPUT_FOLDER="sample-data" git clone --quiet --depth 1 --filter=blob:none --sparse "$REPO_URL" temp_loader cd temp_loader git sparse-checkout set "$TARGET_PATH" cd .. mv "temp_loader/$TARGET_PATH" "$OUTPUT_FOLDER" rm -rf temp_loader - Em seguida, copie os dados de amostra para o bucket de entrada criado anteriormente:
gsutil -m cp -r sample-data/* gs://input-$PROJECT_ID/ - Acesse Cloud Storage > Buckets e clique no bucket de entrada para conferir os dados importados.
5. Criar um modelo de inspeção
Nesta tarefa, você vai criar um modelo que informa à Proteção de Dados Sensíveis o que procurar. Isso permite focar a inspeção em infoTypes relevantes para seus dados e sua geografia, melhorando o desempenho e a acurácia.
Criar um modelo de inspeção
Nesta etapa, você define as regras para o que constitui dados sensíveis que precisam ser inspecionados. Esse modelo será reutilizado pelos seus jobs de desidentificação para garantir a consistência.
- No menu de navegação, acesse Proteção de Dados Sensíveis > Configuração > Modelos.
- Clique em Criar modelo.
- Em Tipo de modelo, selecione Inspecionar (encontrar dados sensíveis).
- Defina o ID do modelo como
pii-finder. - Clique em Continuar para Configurar a detecção.
- Clique em Gerenciar infoTypes.
- Usando o filtro, pesquise os seguintes infoTypes e marque a caixa de seleção ao lado de cada um:
CREDIT_CARD_EXPIRATION_DATECREDIT_CARD_NUMBERDATE_OF_BIRTHDRIVERS_LICENSE_NUMBEREMAIL_ADDRESSGCP_API_KEYGCP_CREDENTIALSORGANIZATION_NAMEPASSWORDPERSON_NAMEPHONE_NUMBERUS_SOCIAL_SECURITY_NUMBER
- Selecione outros que também sejam do seu interesse e clique em Concluído.
- Confira a tabela resultante para garantir que todos esses InfoTypes foram adicionados.
- Clique em Criar.
6. Criar modelos de desidentificação
Em seguida, você vai criar três modelos de desidentificação separados para processar diferentes formatos de dados. Isso oferece controle granular sobre o processo de transformação, aplicando o método mais adequado para cada tipo de arquivo. Esses modelos funcionam em conjunto com o modelo de inspeção que você acabou de criar.
Criar um modelo para dados não estruturados
Esse modelo define como os dados sensíveis encontrados em texto livre, como registros de chat ou formulários de feedback, são desidentificados. O método escolhido substitui o valor sensível pelo nome do infoType, preservando o contexto.
- Na página Modelos, clique em Criar modelo.
- Defina o modelo de desidentificação:
Propriedade
Valor (digite ou selecione)
Tipo de modelo
Desidentificar (remover dados confidenciais)
Tipo de transformação de dados
InfoType
ID do modelo
de-identify-unstructured - Continue para Configurar desidentificação.
- Em Método de transformação, selecione a transformação: Substituir pelo nome do InfoType.
- Clique em Criar.
- Clique em Testar.
- Teste uma mensagem com PII para ver como ela será transformada:
Hi, my name is Alex and my SSN is 555-11-5555. You can reach me at +1-555-555-5555.
Criar um modelo para dados estruturados
Esse modelo tem como alvo específico informações sensíveis em conjuntos de dados estruturados, como arquivos CSV. Você vai configurar o mascaramento de dados de forma a preservar a utilidade dos dados para testes e, ao mesmo tempo, desidentificar campos sensíveis.
- Volte para a página Modelos e clique em Criar modelo.
- Defina o modelo de desidentificação:
Propriedade
Valor (digite ou selecione)
Tipo de modelo
Desidentificar (remover dados confidenciais)
Tipo de transformação de dados
Gravar
ID do modelo
de-identify-structured - Clique em Continuar para Configurar a desidentificação.Como esse modelo se aplica a dados estruturados, geralmente podemos prever os campos ou colunas que vão conter determinados tipos de dados sensíveis. Você sabe que o CSV usado pelo aplicativo tem e-mails de usuários em
user_ide quemessagegeralmente contém informações pessoais (PII) de interações com clientes. Você não precisa se preocupar em mascararagent_id, já que são funcionários e as conversas devem ser atribuíveis. Preencha esta seção da seguinte maneira:- Campos ou colunas para transformar:
user_id,message. - Tipo de transformação: correspondência no infoType
- Método de transformação: clique em Adicionar transformação
- Transformação: máscara com caractere.
- Caracteres a serem ignorados: pontuação dos EUA.
- Campos ou colunas para transformar:
- Clique em Criar.
Criar um modelo para dados de imagem
Esse modelo foi criado para desidentificar textos sensíveis encontrados em imagens, como documentos digitalizados ou fotos enviadas pelos usuários. Ele usa o reconhecimento óptico de caracteres (OCR) para detectar e encobrir as informações pessoais.
- Volte para a página Modelos e clique em Criar modelo.
- Defina o modelo de desidentificação:
Propriedade
Valor (digite ou selecione)
Tipo de modelo
Desidentificar (remover dados confidenciais)
Tipo de transformação de dados
Imagem
ID do modelo
de-identify-image - Continue para Configurar desidentificação.
- InfoTypes para transformar: Os InfoTypes detectados em um modelo ou uma configuração de inspeção que não foram especificados em outras regras.
- Clique em Criar.
7. Criar e executar um job de desidentificação
Com os modelos definidos, agora você vai criar um único job que aplica o modelo de desidentificação correto com base no tipo de arquivo detectado e inspecionado. Isso automatiza o processo de proteção de dados sensíveis para dados armazenados no Cloud Storage.
Configurar dados de entrada
Nesta etapa, você especifica a origem dos dados que precisam ser desidentificados, que é um bucket do Cloud Storage com vários tipos de arquivos com informações sensíveis.
- Acesse Segurança > Proteção de Dados Sensíveis na barra de pesquisa.
- Clique em Inspeção no menu.
- Clique em Criar gatilhos de jobs e jobs.
- Configure o job:
Propriedade
Valor (digite ou selecione)
ID do job
pii-removerTipo de armazenamento
Google Cloud Storage
Tipo de local
Verifique um bucket com regras de inclusão/exclusão opcionais
Nome do bucket
input-[your-project-id]
Configurar detecção e ações
Agora, vincule os modelos criados anteriormente a esse job, informando à Proteção de Dados Sensíveis como inspecionar PII e qual método de desidentificação aplicar com base no tipo de conteúdo.
- Modelo de inspeção:
projects/[your-project-id]/locations/global/inspectTemplates/pii-finder - Em Adicionar ações, selecione Fazer uma cópia de desidentificação e configure os modelos de transformação para serem os que você criou.
- Um pop-up vai aparecer para você
Confirm whether you want to de-identify the findings. Clique em DESATIVAR AMOSTRAGEM.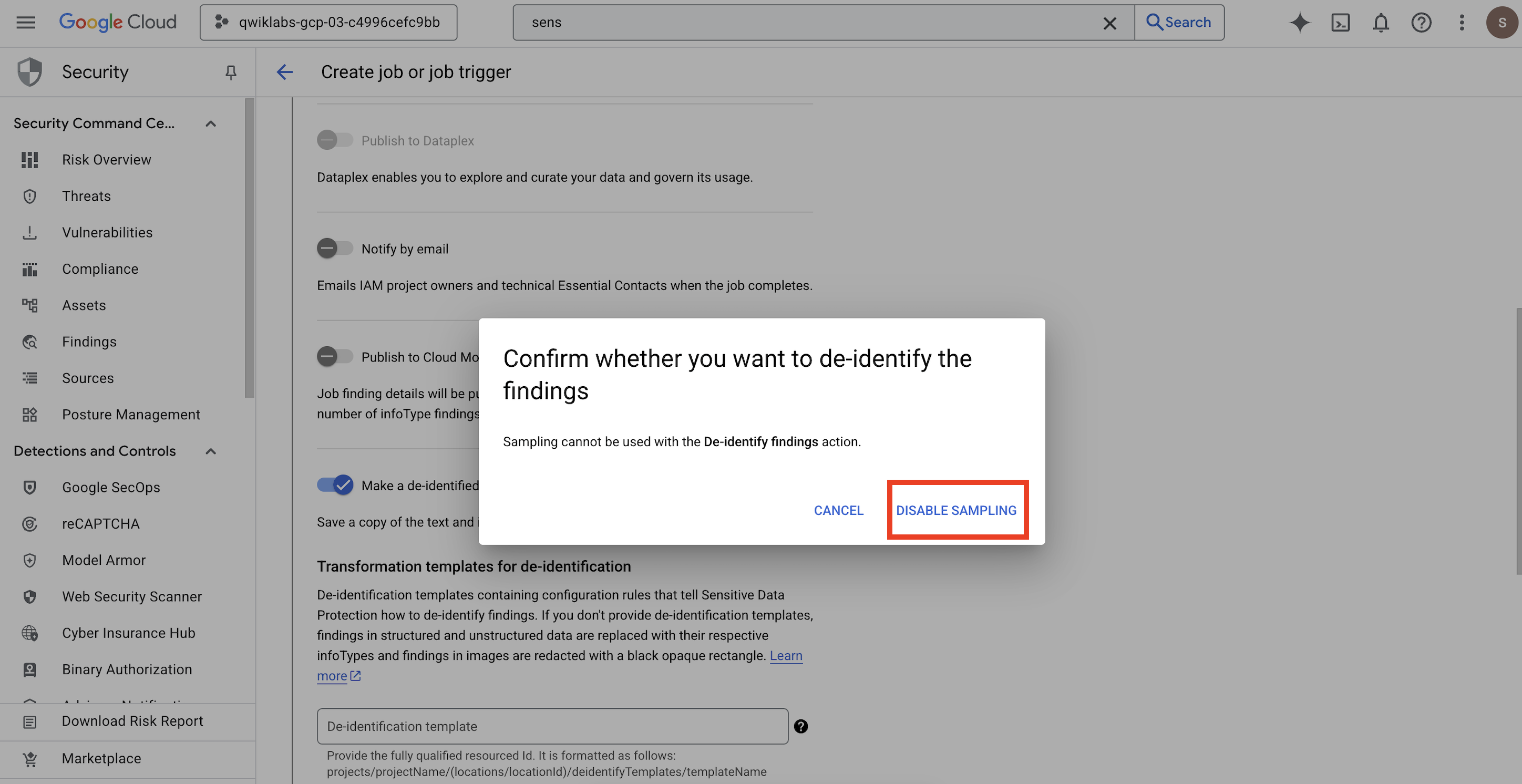
Propriedade
Valor (digite ou selecione)
Modelo de desidentificação
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-unstructuredModelo de desidentificação estruturado
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-structuredModelo de edição de imagem
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-image - Configure o local de saída do Cloud Storage:
- URL:
gs://output-[your-project-id]
- URL:
- Em Programação, deixe a seleção como Nenhuma para executar o job imediatamente.
- Clique em Criar.
- Um pop-up vai abrir para
Confirm job or job trigger create. Clique em CONFIRMAR CRIAÇÃO.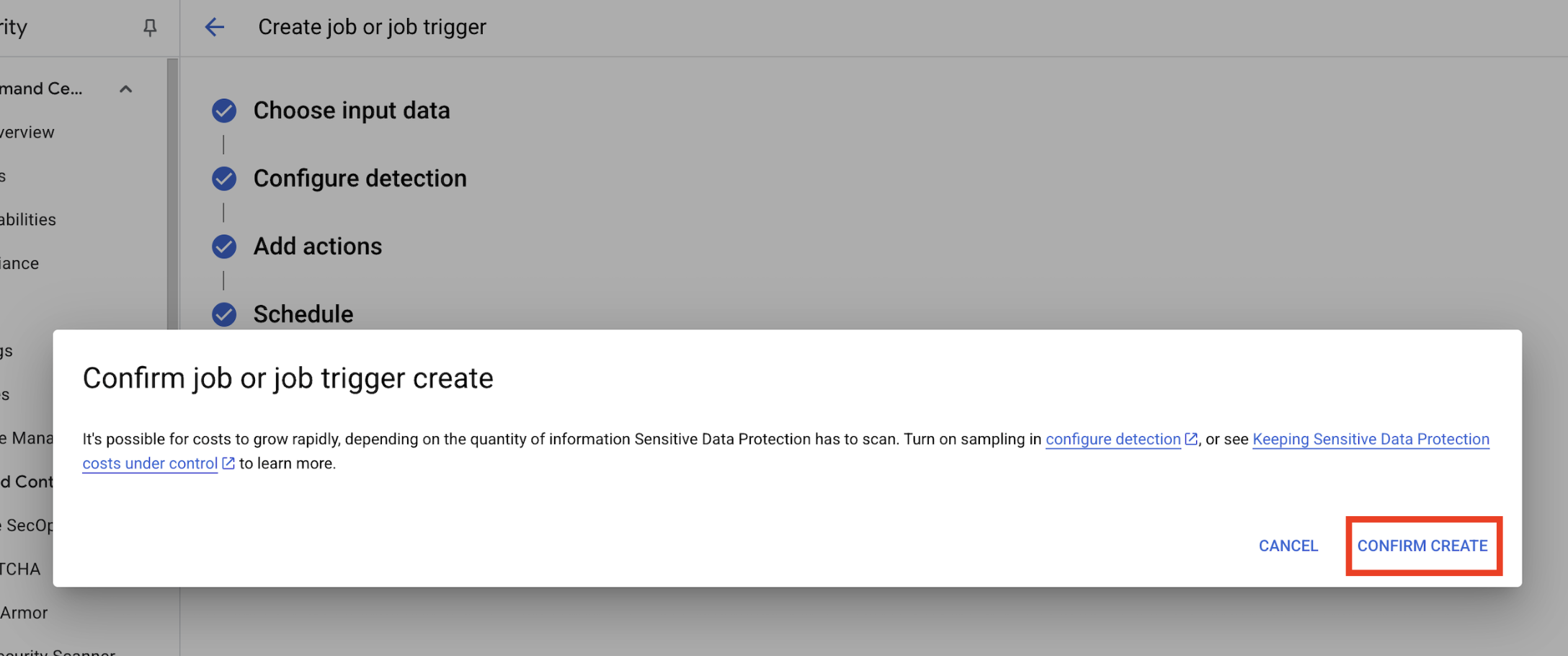
8. Verifique os resultados:
A etapa final é confirmar se os dados sensíveis foram ocultados com sucesso e corretamente em todos os tipos de arquivo no bucket de saída. Isso garante que seu pipeline de desidentificação funcione como esperado.
Analisar o status do job
Monitore o job para garantir que ele seja concluído com sucesso e revise o resumo das descobertas antes de verificar os arquivos de saída.
- Na guia Detalhes do job, aguarde até que o job mostre o status Concluído.
- Em Visão geral, confira o número de descobertas e as porcentagens de cada infoType detectado.
- Clique em Configuração.
- Role para baixo até Ações e clique no bucket de saída para ver os dados desidentificados:
gs://output-[your-project-id].
Comparar arquivos de entrada e saída
Nesta etapa, você vai inspecionar manualmente os arquivos desidentificados para confirmar se a sanitização de dados foi aplicada corretamente de acordo com seus modelos.
- Imagens: abra uma imagem do bucket de saída. Verifique se todo o texto sensível foi ocultado no arquivo de saída.
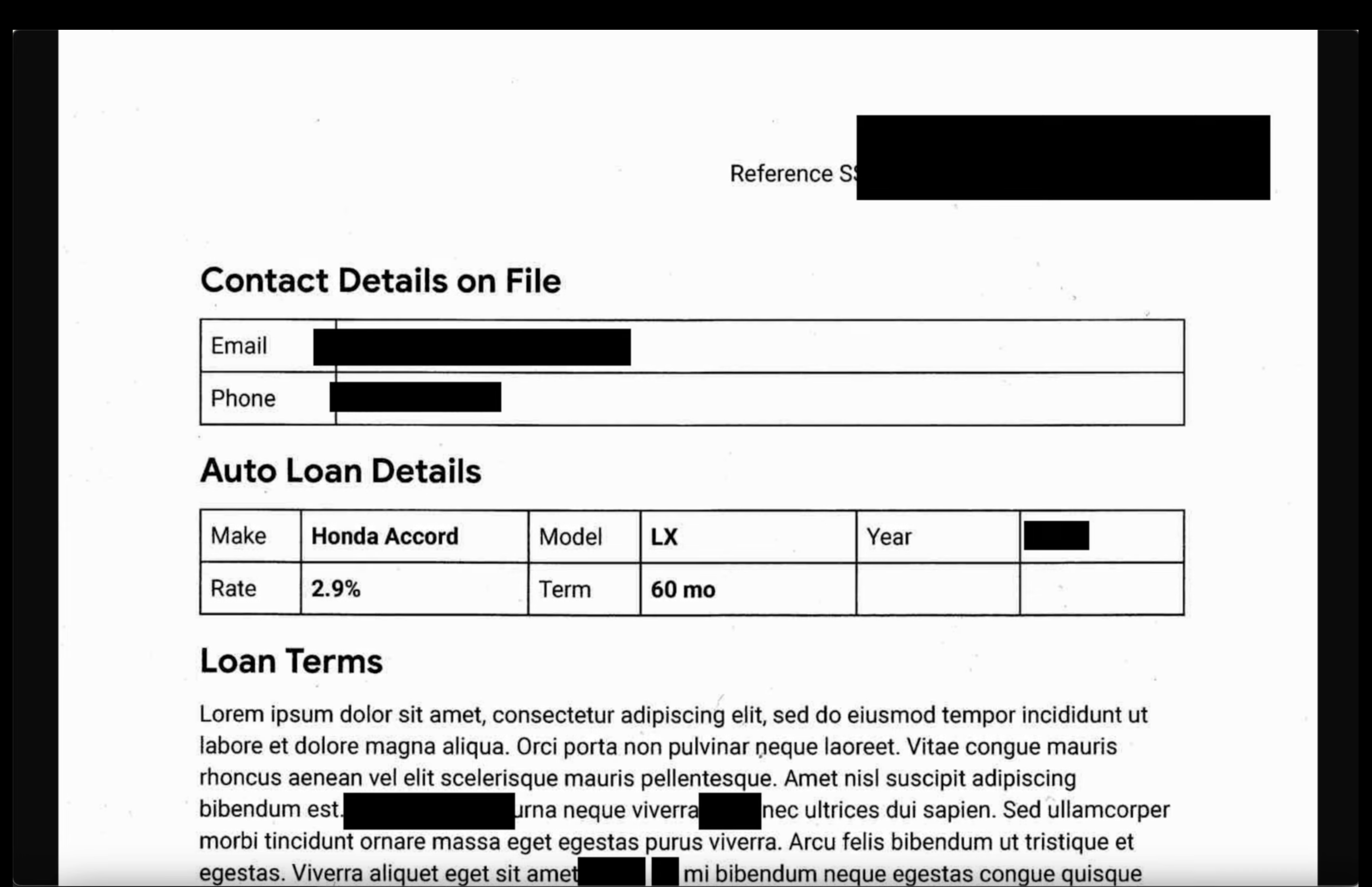
- Registros não estruturados: veja um arquivo de registro dos dois buckets. Confirme se as informações de identificação pessoal no registro de saída foram substituídas pelo nome do infoType (por exemplo,
[US_SOCIAL_SECURITY_NUMBER]). - CSVs estruturados: abra um arquivo CSV dos dois grupos. Verifique se os e-mails e os números de CPF dos usuários no arquivo de saída estão mascarados com
####@####.com.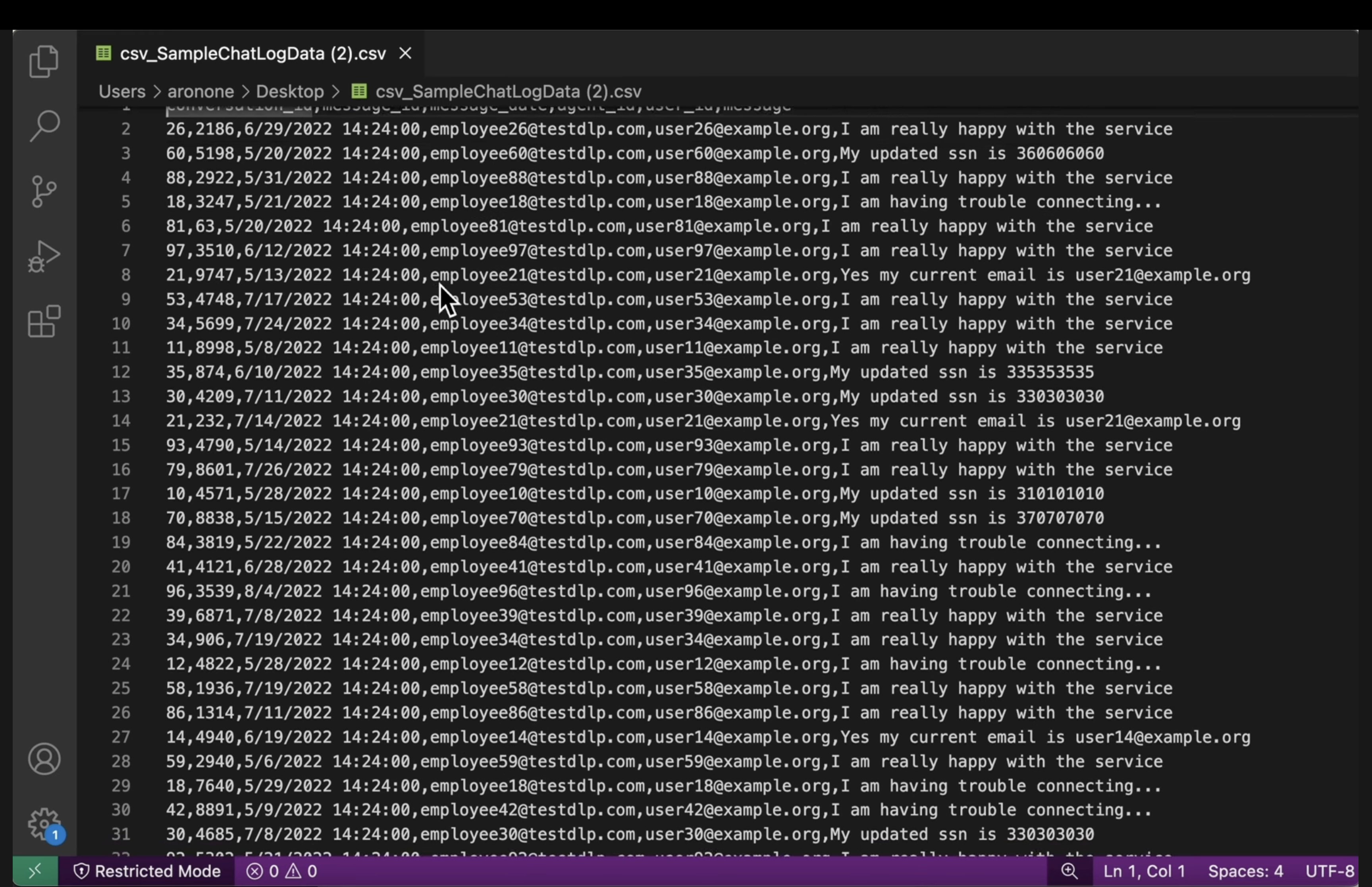
9. Do laboratório à realidade: como usar isso nos seus projetos
Os princípios e as configurações que você aplicou são o blueprint para proteger projetos de IA reais no Google Cloud. Os recursos que você acabou de criar (o modelo de inspeção, os modelos de desidentificação e o job automatizado) funcionam como um modelo inicial seguro para qualquer novo processo de ingestão de dados.
O pipeline automatizado de sanitização de dados: sua ingestão segura de dados
Como usar isso na sua configuração
Sempre que sua equipe precisar ingerir novos dados brutos de clientes para o desenvolvimento de IA, direcione-os por um pipeline que incorpore o job da Proteção de Dados Sensíveis configurado. Em vez de inspecionar e encobrir manualmente, você usa esse fluxo de trabalho automatizado. Isso garante que os cientistas de dados e os modelos de IA só interajam com dados sem identificação, reduzindo significativamente os riscos de privacidade.
Conexão com a produção
Em um ambiente de produção, você levaria esse conceito ainda mais longe:
- Automação com gatilhos de job: em vez de executar o job manualmente, configure um gatilho de job sempre que um novo arquivo for enviado para o bucket de entrada do Cloud Storage. Isso cria um processo de detecção e remoção de identificação totalmente automatizado e sem intervenção humana.
- Integração com data lakes/warehouses: os dados de saída desidentificados normalmente são inseridos em um data lake seguro (por exemplo, no Cloud Storage) ou em um data warehouse (por exemplo, o BigQuery) para análise e treinamento de modelos, garantindo a privacidade durante todo o ciclo de vida dos dados.
Estratégias granulares de desidentificação: equilibrando privacidade e utilidade
Como usar isso na sua configuração
Os diferentes modelos de desidentificação (não estruturados, estruturados, de imagem) que você criou são essenciais. Você aplicaria estratégias diferenciadas semelhantes com base nas necessidades específicas dos seus modelos de IA. Isso permite que sua equipe de desenvolvimento tenha dados de alta utilidade para os modelos sem comprometer a privacidade.
Conexão com a produção
Em um ambiente de produção, esse controle granular se torna ainda mais importante para:
- infoTypes e dicionários personalizados: para dados sensíveis altamente específicos ou de um domínio específico, defina infoTypes e dicionários personalizados na Proteção de dados sensíveis. Isso garante uma detecção abrangente adaptada ao contexto exclusivo da sua empresa.
- Criptografia com preservação de formato (FPE): para cenários em que os dados desidentificados precisam manter o formato original (por exemplo, números de cartão de crédito para testes de integração), use técnicas avançadas de desidentificação, como a criptografia com preservação de formato. Isso permite testes seguros para a privacidade com padrões de dados realistas.
Monitoramento e auditoria: garantindo a conformidade contínua
Como usar isso na sua configuração
Você monitoraria continuamente os registros da Proteção de Dados Sensíveis para garantir que todo o tratamento de dados esteja de acordo com suas políticas de privacidade e que nenhuma informação sensível seja exposta inadvertidamente. Revisar regularmente os resumos e as descobertas dos jobs faz parte dessa auditoria contínua.
Conexão com a produção
Para um sistema de produção robusto, considere estas ações principais:
- Enviar descobertas para o Security Command Center: para gerenciamento integrado de ameaças e uma visão centralizada da sua postura de segurança, configure seus jobs da Proteção de dados sensíveis para enviar um resumo das descobertas diretamente para o Security Command Center. Isso consolida alertas e insights de segurança.
- Alertas e resposta a incidentes: você configuraria alertas do Cloud Monitoring com base em descobertas da Proteção de Dados Sensíveis ou falhas de jobs. Isso garante que sua equipe de segurança seja notificada imediatamente sobre possíveis violações da política ou problemas de processamento, permitindo uma resposta rápida a incidentes.
10. Conclusão
Parabéns! Você criou um fluxo de trabalho de segurança de dados que pode descobrir e desidentificar automaticamente PII em vários tipos de dados, tornando-os seguros para uso em desenvolvimento de IA e análises downstream.
Recapitulação
Neste laboratório, você fez o seguinte:
- Defina um modelo de inspeção para detectar tipos específicos de informações sensíveis (infoTypes).
- Criou regras de desidentificação distintas para dados não estruturados, estruturados e de imagem.
- Configurou e executou um único job que aplicou automaticamente a redação correta com base no tipo de arquivo ao conteúdo de um bucket inteiro.
- Verificou a transformação bem-sucedida de dados sensíveis em um local de saída seguro.
Próximas etapas
- Enviar descobertas para o Security Command Center: para um gerenciamento de ameaças mais integrado, configure a ação do job para enviar um resumo das descobertas diretamente para o Security Command Center.
- Automatizar com o Cloud Functions: em um ambiente de produção, é possível acionar esse job de inspeção automaticamente sempre que um novo arquivo for enviado para o bucket de entrada usando uma função do Cloud.