
1. 简介
概览
在本实验中,您将构建一个自动化数据清理流水线,以保护 AI 开发中使用的敏感信息。您可以使用 Google Cloud 的 Sensitive Data Protection(以前称为 Cloud DLP)来检查、分类和去标识化各种数据格式(包括非结构化文本、结构化表格和图片)中的个人身份信息 (PII)。
上下文
您是开发团队中的安全和隐私保护倡导者,您的目标是建立一个工作流程,在向开发者和模型提供敏感信息之前,先识别并去除这些信息的身份信息。您的团队需要使用真实的高质量数据来调整和测试新的生成式 AI 应用,但使用原始客户数据会带来严重的隐私权问题。
下表列出了您最关注的隐私风险缓解措施:
风险 | 应对措施 |
非结构化文本文件(例如支持聊天记录、反馈表单)中个人身份信息的暴露。 | 创建一个去标识化模板,该模板会将敏感值替换为其 infoType,从而在保留上下文的同时消除暴露风险。 |
移除个人身份信息后,结构化数据集 (CSV) 中的数据实用性会降低。 | 使用记录转换有选择地隐去标识符(例如名称),并应用字符遮盖等技术来保留字符串中的其他字符,以便开发者仍可使用这些数据进行测试。 |
图片中嵌入的文本泄露个人身份信息(例如扫描的文档、用户照片)。 | 创建专门用于图片的去标识化模板,以隐去图片中找到的文字。 |
不同数据类型之间存在不一致或容易出错的手动遮盖。 | 配置一项自动化 Sensitive Data Protection 作业,使其能够根据所处理的文件类型持续应用正确的去标识化模板。 |
学习内容
在本实验中,您将学习如何完成以下操作:
- 定义检查模板,以检测特定的敏感信息类型 (infoType)。
- 为非结构化数据、结构化数据和图片数据分别制定不同的去标识化规则。
- 配置并运行单个作业,该作业可根据文件类型自动应用正确的遮盖,以遮盖整个存储分区的内容。
- 验证敏感数据是否已成功转换到安全的输出位置。
2. 项目设置
Google 账号
如果您还没有个人 Google 账号,则必须先创建一个 Google 账号。
请改用个人账号,而不是工作账号或学校账号。
登录 Google Cloud 控制台
使用个人 Google 账号登录 Google Cloud 控制台。
启用结算功能
兑换 Google Cloud 赠金(可选)
如需运行此研讨会,您需要拥有一个有一定信用额度的结算账号。使用本 Codelab 顶部横幅中的积分开始学习。如果您已关联结算账号,则可以跳过此步骤。
设置个人结算账号
如果您使用 Google Cloud 抵用金设置了结算,则可以跳过此步骤。
如需设置个人结算账号,请点击此处在 Cloud 控制台中启用结算功能。
注意事项:
- 完成本实验的 Cloud 资源费用应不到 1 美元。
- 您可以按照本实验末尾的步骤删除资源,以避免产生更多费用。
- 新用户符合参与 $300 USD 免费试用计划的条件。
创建项目(可选)
如果您没有当前项目可用于此实验,请在此处创建一个新项目。
3. 启用 API
配置 Cloud Shell
成功创建项目后,请按以下步骤设置 Cloud Shell。
启动 Cloud Shell
前往 shell.cloud.google.com,如果看到要求您授权的弹出式窗口,请点击授权。
设置项目 ID
在 Cloud Shell 终端中执行以下命令,以设置正确的项目 ID。将 <your-project-id> 替换为从上述项目创建步骤中复制的实际项目 ID。
gcloud config set project <your-project-id>
现在,您应该会在 Cloud Shell 终端中看到已选择正确的项目。
启用 Sensitive Data Protection
如需使用 Sensitive Data Protection 服务和 Cloud Storage,您需要确保在您的 Google Cloud 项目中启用这些 API。
- 在终端中,启用以下 API:
gcloud services enable dlp.googleapis.com storage.googleapis.com
或者,您也可以在控制台中依次前往安全 > Sensitive Data Protection和 Cloud Storage,然后在系统提示时针对每项服务点击启用按钮,以启用这些 API。
4. 创建包含敏感数据的存储分区
创建输入和输出存储分区
在此步骤中,您将创建两个存储分区:一个用于存放需要检查的敏感数据,另一个用于存放 Sensitive Data Protection 将生成的去标识化输出文件。您还可以下载示例数据文件,并将其上传到输入存储分区。
- 在终端中,运行以下命令来创建一个用于输入数据的存储分区和一个用于输出数据的存储分区,然后使用
gs://dlp-codelab-data中的示例数据填充输入存储分区:PROJECT_ID=$(gcloud config get-value project) gsutil mb gs://input-$PROJECT_ID gsutil mb gs://output-$PROJECT_ID
向输入存储分区添加敏感数据
在此步骤中,您将从 GitHub 下载包含测试个人身份信息的示例数据文件,然后将其上传到输入存储分区。
- 在 Cloud Shell 中,运行以下命令以克隆
devrel-demos代码库,其中包含本实验所需的示例数据。REPO_URL="https://github.com/GoogleCloudPlatform/devrel-demos.git" TARGET_PATH="security/sample-data" OUTPUT_FOLDER="sample-data" git clone --quiet --depth 1 --filter=blob:none --sparse "$REPO_URL" temp_loader cd temp_loader git sparse-checkout set "$TARGET_PATH" cd .. mv "temp_loader/$TARGET_PATH" "$OUTPUT_FOLDER" rm -rf temp_loader - 接下来,将示例数据复制到您之前创建的输入存储分区:
gsutil -m cp -r sample-data/* gs://input-$PROJECT_ID/ - 前往 Cloud Storage > 存储分区,然后点击输入存储分区以查看您导入的数据。
5. 创建检查模板
在此任务中,您将创建一个模板,用于告知Sensitive Data Protection功能要查找哪些内容。这样一来,您就可以专注于与数据和地理位置相关的 infoTypes,从而提高性能和准确性。
创建检查模板
在此步骤中,您将定义构成需要检查的敏感数据的规则。您的去标识化作业将重复使用此模板,以确保一致性。
- 在导航菜单中,依次前往 Sensitive Data Protection > 配置 > 模板。
- 点击创建模板。
- 对于模板类型,选择检查(查找敏感数据)。
- 将模板 ID 设置为
pii-finder。 - 继续,进入配置检测。
- 点击管理 infoType。
- 使用过滤条件搜索以下 infoType,然后选中每个
-
infoType
CREDIT_CARD_EXPIRATION_DATECREDIT_CARD_NUMBERDATE_OF_BIRTHDRIVERS_LICENSE_NUMBEREMAIL_ADDRESSGCP_API_KEYGCP_CREDENTIALSORGANIZATION_NAMEPASSWORDPERSON_NAMEPHONE_NUMBERUS_SOCIAL_SECURITY_NUMBER- 您还可以选择感兴趣的其他主题,然后点击完成。
- 检查生成的表格,确保已添加所有这些 infoType。
- 点击创建。
6. 创建去标识化模板
接下来,您将创建三个单独的去标识化模板来处理不同的数据格式。这样一来,您就可以精细控制转换过程,并为每种文件类型应用最合适的方法。这些模板可与您刚刚创建的检查模板搭配使用。
为非结构化数据创建模板
此模板将定义如何对自由格式文本(例如聊天记录或反馈表单)中发现的敏感数据进行去标识化。所选方法会将敏感值替换为其 infoType 名称,从而保留上下文。
- 在模板页面上,点击创建模板。
- 定义去标识化模板:
属性
值(输入或选择)
模板类型
去标识化(移除敏感数据)
数据转换类型
InfoType
模板 ID
de-identify-unstructured - 继续以配置去标识化。
- 在转换方法下,选择转换:替换为 infoType 名称。
- 点击创建。
- 点击测试。
- 测试包含个人身份信息的邮件,看看系统会如何转换该邮件:
Hi, my name is Alex and my SSN is 555-11-5555. You can reach me at +1-555-555-5555.
为结构化数据创建模板
此模板专门针对结构化数据集(例如 CSV 文件)中的敏感信息。您将配置该功能,以遮盖数据,从而在保留数据效用的同时,仍能对敏感字段进行去标识化处理。
- 返回模板页面,然后点击创建模板。
- 定义去标识化模板:
属性
值(输入或选择)
模板类型
去标识化(移除敏感数据)
数据转换类型
录制
模板 ID
de-identify-structured - 继续配置去标识化。由于此模板适用于结构化数据,因此我们通常可以预测哪些字段或列会包含特定类型的敏感数据。您知道,应用使用的 CSV 文件在
user_id下包含用户电子邮件地址,并且message通常包含客户互动的 PII。您无需担心agent_id遮盖,因为这些是员工,对话应可归因。按如下方式填写此部分:- 要转换的字段或列:
user_id、message。 - 转换类型:按 infoType 匹配
- 转换方法:点击添加转换
- 转换:使用字符遮罩。
- 要忽略的字符:美国标点符号。
- 要转换的字段或列:
- 点击创建。
为图片数据创建模板
此模板旨在对图片(例如扫描的文档或用户提交的照片)中嵌入的敏感文本进行去标识化处理。它利用光学字符识别 (OCR) 来检测和遮盖 PII。
- 返回模板页面,然后点击创建模板。
- 定义去标识化模板:
属性
值(输入或选择)
模板类型
去标识化(移除敏感数据)
数据转换类型
图片
模板 ID
de-identify-image - 继续以配置去标识化。
- 要转换的 infoType:在检查模板或检查配置中定义但未在其他规则中指定的任何检测到的 infoType。
- 点击创建。
7. 创建并运行去标识化作业
定义好模板后,您现在可以创建一个作业,该作业会根据检测到的文件类型应用正确的去标识化模板并进行检查。这样一来,系统便可自动对存储在 Cloud Storage 中的数据执行敏感数据保护流程。
配置输入数据
在此步骤中,您需要指定需要去标识化的数据源,即包含各种文件类型(其中包含敏感信息)的 Cloud Storage 存储分区。
- 通过搜索栏找到安全 > Sensitive Data Protection。
- 点击菜单中的检查。
- 点击创建作业和作业触发器。
- 配置作业:
属性
值(输入或选择)
任务 ID
pii-remover存储类型
Google Cloud Storage
位置类型
使用可选的包含/排除规则扫描存储桶
存储桶名称
input-[your-project-id]
配置检测和操作
现在,您需要将之前创建的模板与此作业相关联,告知 Sensitive Data Protection 如何检查 PII,以及根据内容类型应用哪种去标识化方法。
- 检查模板:
projects/[your-project-id]/locations/global/inspectTemplates/pii-finder - 在添加操作下,选择创建去标识化副本,并将转换模板配置为您创建的模板。
- 系统会打开一个弹出式窗口,供您
Confirm whether you want to de-identify the findings,点击停用抽样。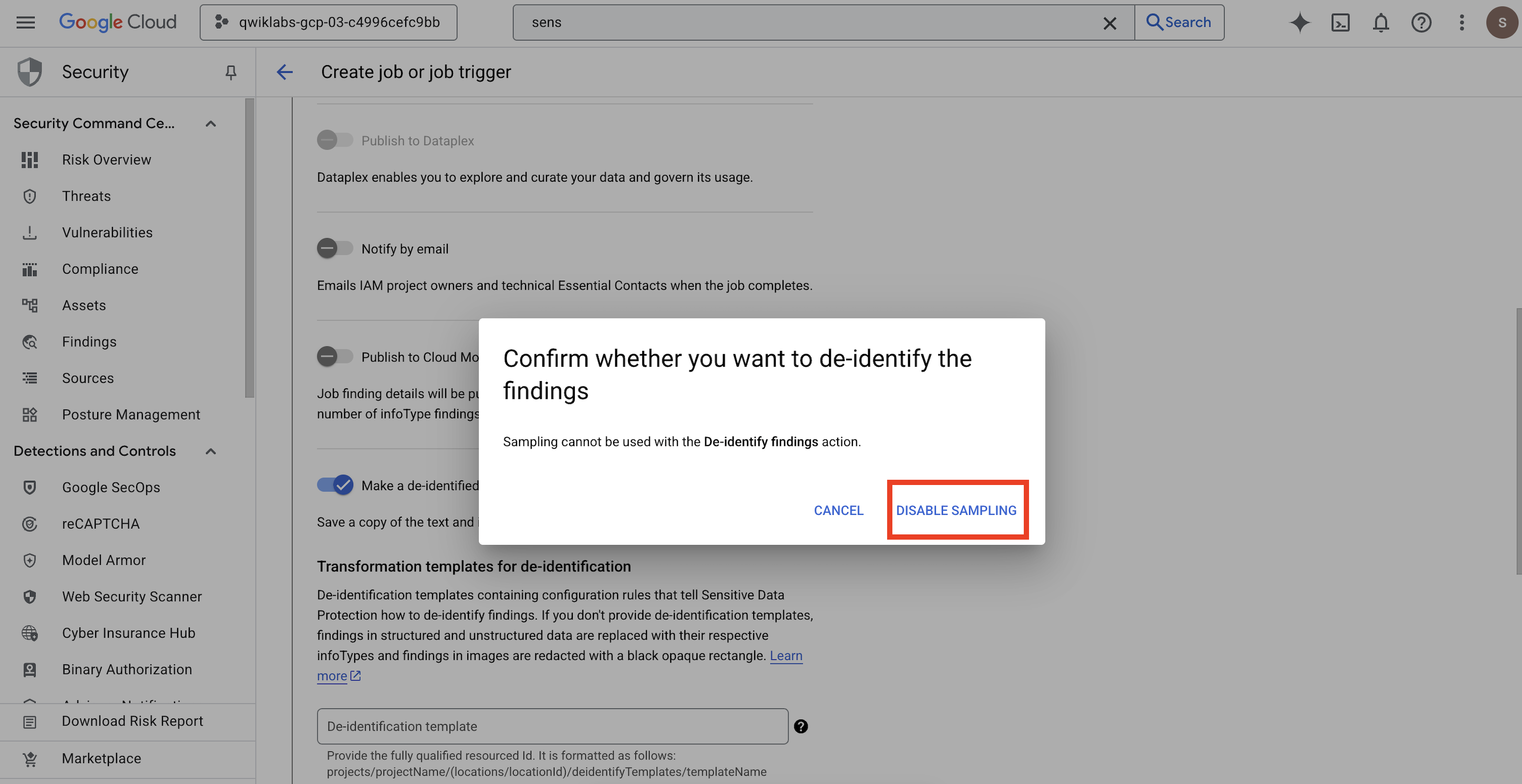
属性
值(输入或选择)
去标识化模板
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-unstructured结构化的去标识化模板
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-structured图片遮盖模板
projects/[your-project-id]/locations/global/deidentifyTemplates/de-identify-image - 配置 Cloud Storage 输出位置:
- 网址:
gs://output-[your-project-id]
- 网址:
- 在时间表下,将选择保留为无,以便立即运行作业。
- 点击创建。
- 系统会打开一个弹出式窗口,显示
Confirm job or job trigger create,点击确认创建。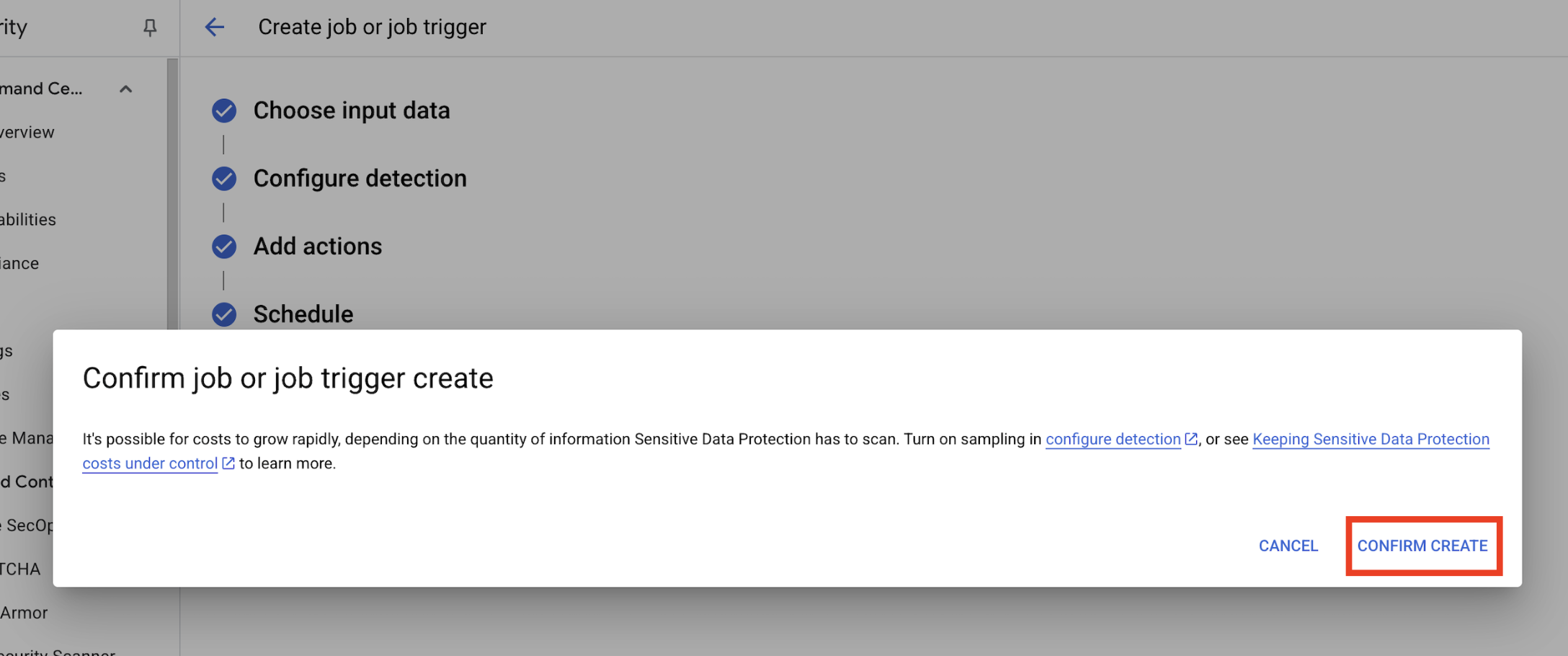
8. 验证结果
最后一步是确认输出存储分区中的所有文件类型中的敏感数据是否已成功且正确地隐去。这样可确保您的去标识化流水线按预期运行。
查看作业状态
监控作业,确保其成功完成,并在检查输出文件之前查看发现结果摘要。
- 在作业详情标签页中,等待作业显示“完成”状态。
- 在概览下,查看发现结果的数量以及检测到的每种 infoType 所占的百分比。
- 点击配置。
- 向下滚动到操作,然后点击输出存储分区以查看去标识化数据:
gs://output-[your-project-id]。
比较输入文件和输出文件
在此步骤中,您将手动检查去标识化的文件,以确认数据清理是否已根据您的模板正确应用。
- 映像:打开输出存储分区中的映像。验证输出文件中的所有敏感文本是否都已隐去。
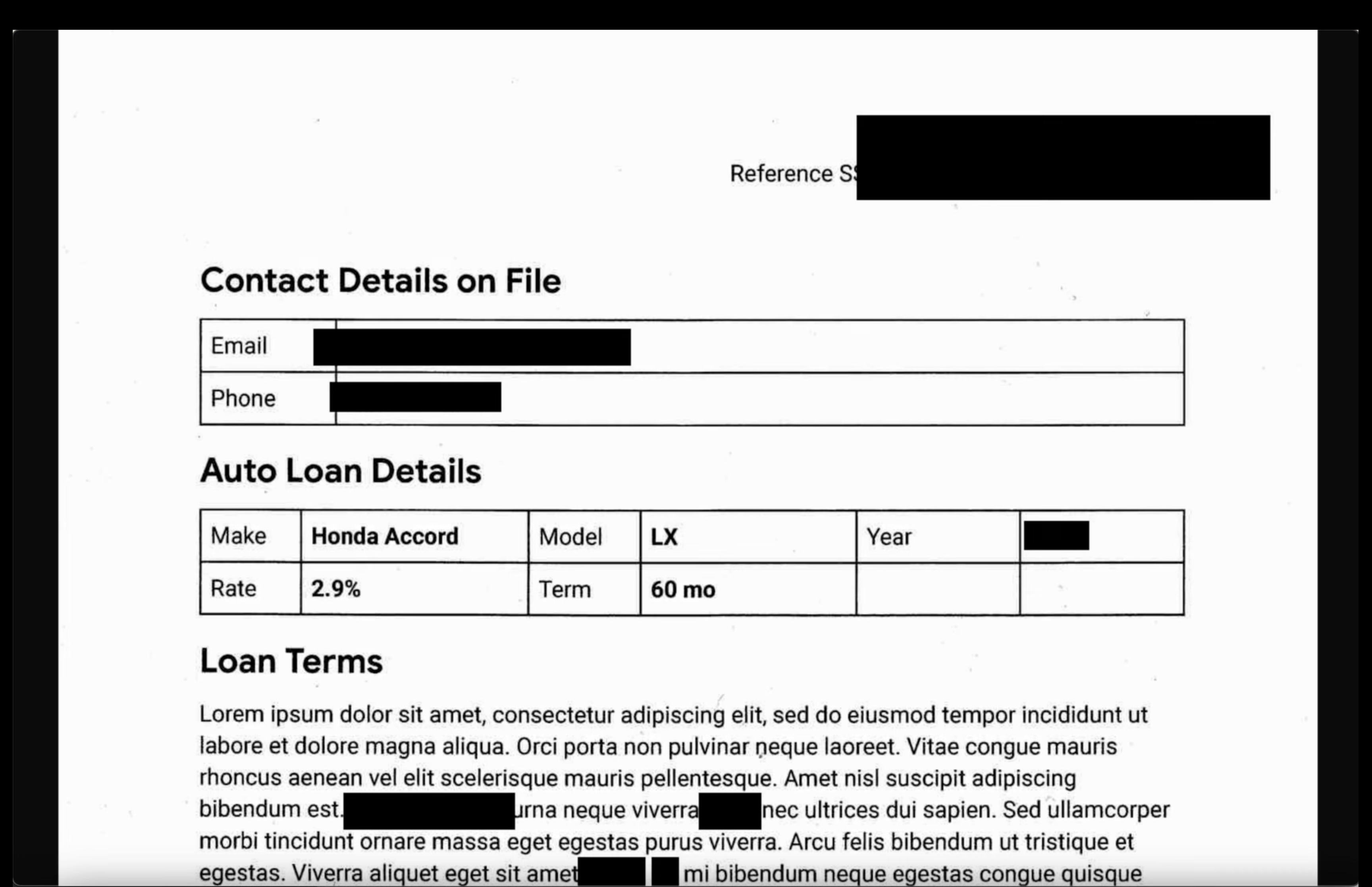
- 非结构化日志:查看两个存储分区中的日志文件。确认输出日志中的 PII 已替换为 infoType 名称(例如
[US_SOCIAL_SECURITY_NUMBER])。 - 结构化 CSV 文件:打开两个存储分区中的 CSV 文件。验证输出文件中的用户电子邮件地址和 SSN 是否已使用
####@####.com进行遮盖。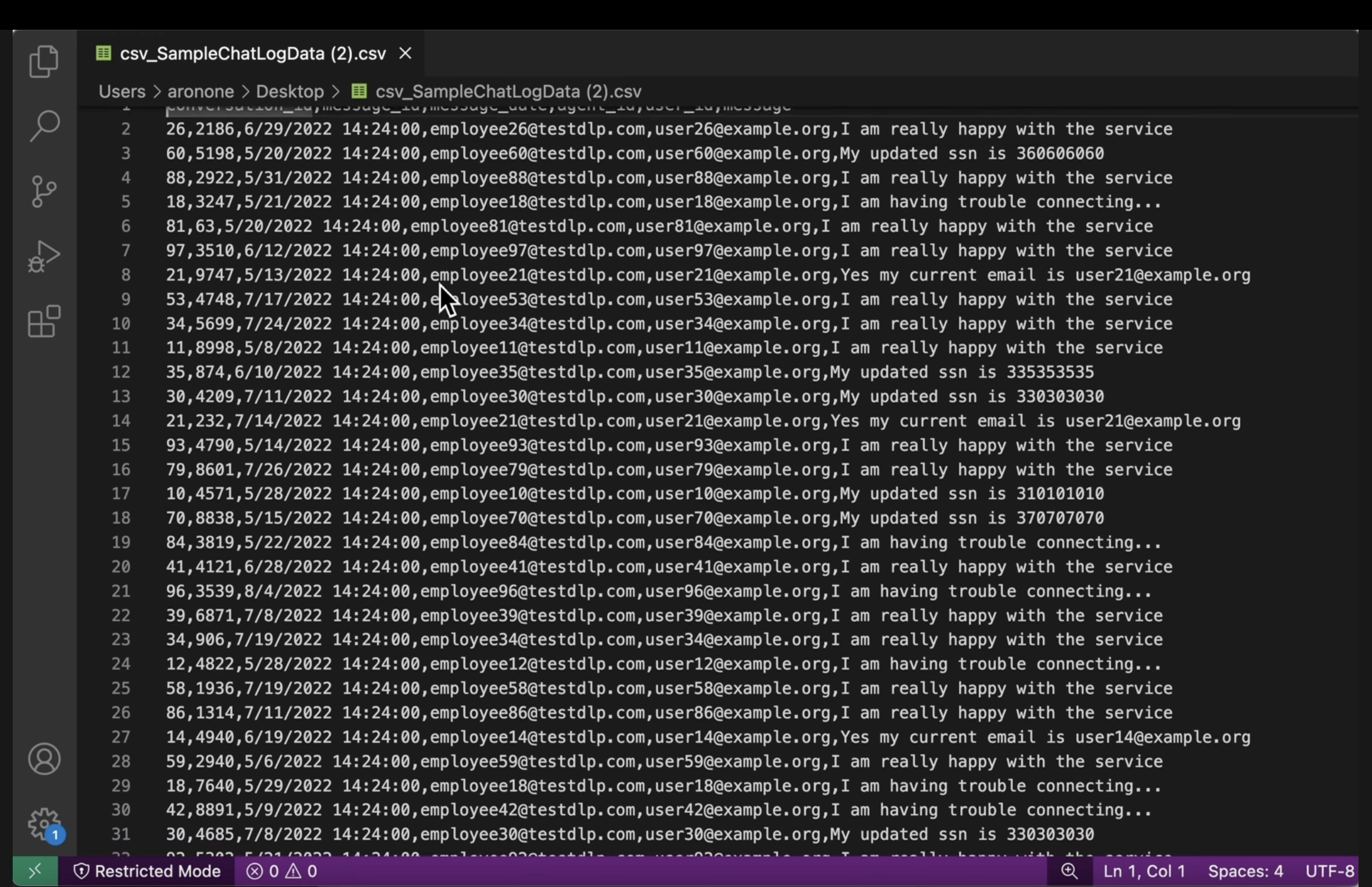
9. 从实验到现实:如何在自己的项目中使用此功能
您应用的原则和配置是保障 Google Cloud 上真实 AI 项目安全的蓝图。您刚刚构建的资源(检查模板、去标识化模板和自动化作业)可作为任何新数据提取流程的安全初始模板。
自动化数据清理流水线:安全的数据接收
如何在设置中使用此功能
每次团队需要提取新的原始客户数据以进行 AI 开发时,您都可以通过包含您配置的 Sensitive Data Protection 作业的流水线来引导数据。您无需手动检查和遮盖,而是利用这种自动化工作流程。这样可确保数据科学家和 AI 模型仅与去标识化数据进行交互,从而显著降低隐私风险。
连接到生产环境
在生产环境中,您可以通过以下方式进一步扩展此概念:
- 通过作业触发器实现自动化:您无需手动运行作业,而是可以设置作业触发器,以便在每次将新文件上传到输入 Cloud Storage 存储分区时触发作业。这样一来,系统便可完全自动地检测和去标识化数据,无需人工干预。
- 与数据湖/仓库集成:去标识化后的输出数据通常会馈送到安全的数据湖(例如在 Cloud Storage 上)或数据仓库(例如 BigQuery)中,以进行进一步的分析和模型训练,确保在整个数据生命周期内维护隐私。
精细的去标识化策略:平衡隐私保护和实用性
如何在设置中使用此功能
您创建的不同去标识化模板(非结构化、结构化、图片)至关重要。您需要根据 AI 模型的具体需求,应用类似的差异化策略。这样一来,您的开发团队便可获得实用性高的数据来训练模型,而无需担心隐私泄露。
连接到生产环境
在生产环境中,这种精细的控制对于以下方面变得更加重要:
- 自定义 infoType 和字典:对于高度特定或特定于网域的敏感数据,您可以在 Sensitive Data Protection 中定义自定义 infoType 和字典。这样可确保全面检测,并根据您独特的业务环境量身定制检测方案。
- 保留格式加密 (FPE):在去标识化数据必须保留其原始格式(例如,用于集成测试的信用卡号)的场景中,您可以探索高级去标识化技术,例如保留格式加密。这样一来,您就可以使用真实的数据模式进行隐私安全测试。
监控和审核:确保持续合规
如何在设置中使用此功能
您会持续监控 Sensitive Data Protection 日志,以确保所有数据处理都符合您的隐私权政策,并且不会意外泄露任何敏感信息。定期查看作业摘要和调查结果是此持续审核的一部分。
连接到生产环境
对于稳健的生产系统,请考虑以下关键操作:
- 将发现结果发送到 Security Command Center:为了实现集成式威胁管理并集中查看安全状况,请将 Sensitive Data Protection 作业配置为直接向 Security Command Center 发送发现结果摘要。此功能可整合安全提醒和数据洞见。
- 提醒和突发事件响应:您可以根据 Sensitive Data Protection 发现结果或作业失败情况设置 Cloud Monitoring 提醒。这样可确保您的安全团队立即收到有关任何潜在的政策违规行为或处理问题的通知,从而能够快速响应突发事件。
10. 总结
恭喜!您已成功构建一个数据安全工作流,该工作流可以自动发现和去标识化多种数据类型中的 PII,从而确保这些数据可安全地用于下游 AI 开发和分析。
回顾
在本实验中,您完成了以下任务:
- 定义了检查模板,用于检测特定的敏感信息类型 (infoType)。
- 为非结构化数据、结构化数据和图片数据分别构建了不同的去标识化规则。
- 配置并运行了单个作业,该作业可根据文件类型自动将正确的遮盖效果应用于整个存储分区的内容。
- 验证了敏感数据是否已成功转换到安全的输出位置。
后续步骤
- 将发现结果发送到 Security Command Center:为了实现更集成的威胁管理,请将作业操作配置为直接将发现结果摘要发送到 Security Command Center。
- 使用 Cloud Functions 实现自动化:在生产环境中,您可以使用 Cloud Function 在每次有新文件上传到输入存储分区时自动触发此检查作业。