
১. ভূমিকা
সংক্ষিপ্ত বিবরণ
এই ল্যাবটি একটি শক্তিশালী মাল্টি-এজেন্ট সিস্টেম তৈরি করা এবং বাস্তব জগতে ব্যবহারের জন্য তা স্থাপন করার মধ্যকার গুরুত্বপূর্ণ ব্যবধানটি পূরণ করে। স্থানীয়ভাবে এজেন্ট তৈরি করা একটি চমৎকার সূচনা হলেও, প্রোডাকশন অ্যাপ্লিকেশনের জন্য এমন একটি প্ল্যাটফর্ম প্রয়োজন যা পরিবর্ধনযোগ্য, নির্ভরযোগ্য এবং সুরক্ষিত।
এই ল্যাবে, আপনি গুগল এজেন্ট ডেভেলপমেন্ট কিট (ADK) দিয়ে তৈরি একটি মাল্টি-এজেন্ট সিস্টেম নেবেন এবং সেটিকে গুগল কুবারনেটিস ইঞ্জিন (GKE)- এর একটি প্রোডাকশন-গ্রেড পরিবেশে ডেপ্লয় করবেন।
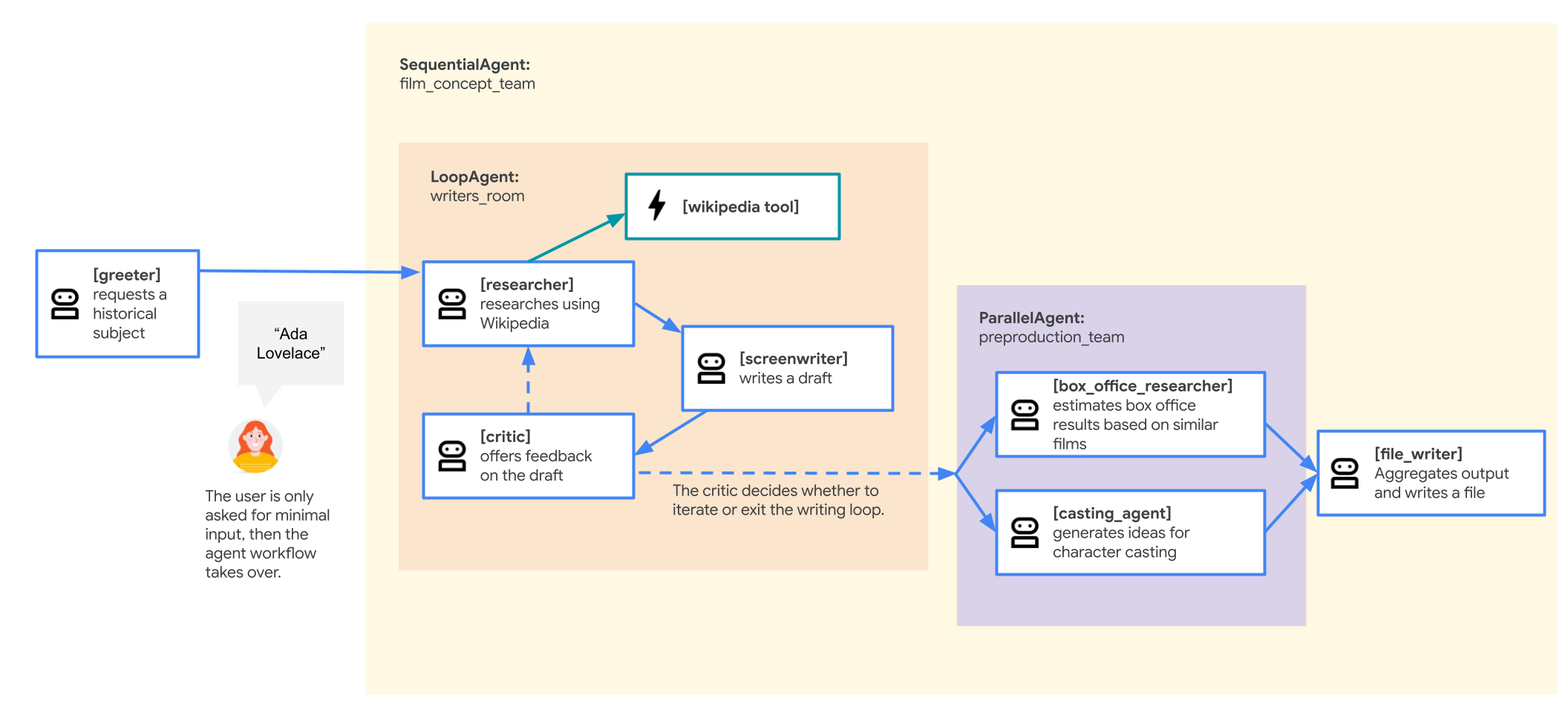
চলচ্চিত্র ধারণা দলের এজেন্ট
এই ল্যাবে ব্যবহৃত নমুনা অ্যাপ্লিকেশনটি হলো একটি 'ফিল্ম কনসেপ্ট টিম', যা একাধিক সহযোগী এজেন্ট নিয়ে গঠিত: একজন গবেষক, একজন চিত্রনাট্যকার এবং একজন ফাইল লেখক। এই এজেন্টরা একজন ব্যবহারকারীকে কোনো ঐতিহাসিক ব্যক্তিত্বকে নিয়ে একটি সিনেমার প্রস্তাবনা তৈরি ও তার রূপরেখা প্রণয়নে সাহায্য করার জন্য একসাথে কাজ করে।
GKE-তে কেন ডিপ্লয় করবেন?
প্রোডাকশন এনভায়রনমেন্টের চাহিদা মেটানোর জন্য আপনার এজেন্টকে প্রস্তুত করতে, স্কেলেবিলিটি, নিরাপত্তা এবং ব্যয়-সাশ্রয়ের কথা মাথায় রেখে তৈরি একটি প্ল্যাটফর্ম প্রয়োজন। গুগল কুবারনেটিস ইঞ্জিন (GKE) আপনার কন্টেইনারাইজড অ্যাপ্লিকেশন চালানোর জন্য এই শক্তিশালী এবং নমনীয় ভিত্তি প্রদান করে।
এটি আপনার উৎপাদন কাজের ক্ষেত্রে বেশ কিছু সুবিধা প্রদান করে:
- স্বয়ংক্রিয় স্কেলিং ও পারফরম্যান্স : হরাইজন্টালপড অটোস্কেলার (HPA)- এর মাধ্যমে অপ্রত্যাশিত ট্র্যাফিক সামলান, যা লোডের উপর ভিত্তি করে স্বয়ংক্রিয়ভাবে এজেন্ট রেপ্লিকা যোগ বা অপসারণ করে। আরও বেশি চাহিদাসম্পন্ন এআই ওয়ার্কলোডের জন্য, আপনি GPU এবং TPU-এর মতো হার্ডওয়্যার অ্যাক্সিলারেটর সংযুক্ত করতে পারেন।
- সাশ্রয়ী রিসোর্স ব্যবস্থাপনা : GKE Autopilot- এর মাধ্যমে খরচ অপ্টিমাইজ করুন, যা স্বয়ংক্রিয়ভাবে অন্তর্নিহিত পরিকাঠামো পরিচালনা করে, ফলে আপনার অ্যাপ্লিকেশন যে রিসোর্সগুলোর অনুরোধ করে, শুধু সেগুলোর জন্যই আপনাকে অর্থ প্রদান করতে হয়।
- সমন্বিত নিরাপত্তা ও পর্যবেক্ষণযোগ্যতা : ওয়ার্কলোড আইডেন্টিটি ব্যবহার করে অন্যান্য গুগল ক্লাউড পরিষেবার সাথে নিরাপদে সংযোগ স্থাপন করুন, যার ফলে পরিষেবা অ্যাকাউন্ট কী পরিচালনা ও সংরক্ষণের প্রয়োজন হয় না। কেন্দ্রীভূত পর্যবেক্ষণ এবং ডিবাগিংয়ের জন্য সমস্ত অ্যাপ্লিকেশন লগ স্বয়ংক্রিয়ভাবে ক্লাউড লগিং -এ স্ট্রিম করা হয়।
- নিয়ন্ত্রণ ও বহনযোগ্যতা : ওপেন-সোর্স কুবারনেটিসের মাধ্যমে ভেন্ডর লক-ইন এড়িয়ে চলুন। আপনার অ্যাপ্লিকেশনটি বহনযোগ্য এবং যেকোনো কুবারনেটিস ক্লাস্টারে, অন-প্রিমিসেসে বা অন্যান্য ক্লাউডে চলতে পারে।
আপনি যা শিখবেন
এই ল্যাবে, আপনি নিম্নলিখিত কাজগুলো কীভাবে সম্পাদন করতে হয় তা শিখবেন:
- একটি GKE অটোপাইলট ক্লাস্টার প্রস্তুত করুন।
- একটি Dockerfile ব্যবহার করে অ্যাপ্লিকেশনটিকে কন্টেইনারাইজ করুন এবং ইমেজটি Artifact Registry- তে পুশ করুন।
- Workload Identity ব্যবহার করে আপনার অ্যাপ্লিকেশনকে Google Cloud API-এর সাথে নিরাপদে সংযুক্ত করুন।
- একটি Deployment এবং Service-এর জন্য Kubernetes manifest লিখুন এবং প্রয়োগ করুন।
- একটি লোডব্যালান্সারের সাহায্যে কোনো অ্যাপ্লিকেশনকে ইন্টারনেটে উন্মুক্ত করুন।
- হরাইজন্টালপডঅটোস্কেলার (HPA) ব্যবহার করে অটোস্কেলিং কনফিগার করুন।
২. প্রজেক্ট সেটআপ
গুগল অ্যাকাউন্ট
যদি আপনার আগে থেকে কোনো ব্যক্তিগত গুগল অ্যাকাউন্ট না থাকে, তাহলে আপনাকে অবশ্যই একটি গুগল অ্যাকাউন্ট তৈরি করতে হবে।
কর্মক্ষেত্র বা শিক্ষা প্রতিষ্ঠানের অ্যাকাউন্টের পরিবর্তে ব্যক্তিগত অ্যাকাউন্ট ব্যবহার করুন ।
গুগল ক্লাউড কনসোলে সাইন-ইন করুন
আপনার ব্যক্তিগত গুগল অ্যাকাউন্ট ব্যবহার করে গুগল ক্লাউড কনসোলে সাইন-ইন করুন।
বিলিং সক্ষম করুন
একটি ব্যক্তিগত বিলিং অ্যাকাউন্ট তৈরি করুন
আপনি যদি গুগল ক্লাউড ক্রেডিট ব্যবহার করে বিলিং সেট আপ করেন, তাহলে এই ধাপটি এড়িয়ে যেতে পারেন।
একটি ব্যক্তিগত বিলিং অ্যাকাউন্ট তৈরি করতে, ক্লাউড কনসোলে বিলিং চালু করার জন্য এখানে যান ।
কিছু নোট:
- এই ল্যাবটি সম্পন্ন করতে ক্লাউড রিসোর্সে ১ মার্কিন ডলারেরও কম খরচ হওয়া উচিত।
- পরবর্তী চার্জ এড়াতে, এই ল্যাবের শেষে দেওয়া ধাপগুলো অনুসরণ করে আপনি রিসোর্সগুলো মুছে ফেলতে পারেন।
- নতুন ব্যবহারকারীরা ৩০০ মার্কিন ডলারের ফ্রি ট্রায়ালের জন্য যোগ্য।
একটি প্রকল্প তৈরি করুন (ঐচ্ছিক)
এই ল্যাবের জন্য ব্যবহার করার মতো আপনার যদি কোনো চলমান প্রজেক্ট না থাকে, তাহলে এখানে একটি নতুন প্রজেক্ট তৈরি করুন ।
৩. ক্লাউড শেল এডিটর খুলুন
- সরাসরি ক্লাউড শেল এডিটর- এ যেতে এই লিঙ্কে ক্লিক করুন।
- আজ যেকোনো সময়ে অনুমোদনের জন্য অনুরোধ করা হলে, চালিয়ে যাওয়ার জন্য 'অনুমোদন করুন' (Authorize) বোতামে ক্লিক করুন।
- যদি স্ক্রিনের নিচে টার্মিনালটি দেখা না যায়, তাহলে এটি খুলুন:
- ভিউ ক্লিক করুন
- টার্মিনালে ক্লিক করুন
- টার্মিনালে এই কমান্ডটি দিয়ে আপনার প্রজেক্ট সেট করুন:
gcloud config set project [PROJECT_ID]- উদাহরণ:
gcloud config set project lab-project-id-example - আপনি যদি আপনার প্রজেক্ট আইডি মনে রাখতে না পারেন, তাহলে নিম্নলিখিত উপায়ে আপনার সমস্ত প্রজেক্ট আইডি তালিকাভুক্ত করতে পারেন:
gcloud projects list
- উদাহরণ:
- আপনি এই বার্তাটি দেখতে পাবেন:
Updated property [core/project].
৪. এপিআই সক্রিয় করুন
GKE , Artifact Registry , Cloud Build , এবং Vertex AI ব্যবহার করার জন্য, আপনাকে আপনার Google Cloud প্রজেক্টে এগুলোর নিজ নিজ API সক্রিয় করতে হবে।
- টার্মিনালে এপিআইগুলো সক্রিয় করুন:
gcloud services enable \ container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.comOperation "operations/acf.p2-176675280136-b03ab5e4-3483-4ebf-9655-43dc3b345c63" finished successfully.
এপিআইগুলো চালু করা হচ্ছে
- গুগল কুবারনেটিস ইঞ্জিন এপিআই (
container.googleapis.com) আপনাকে আপনার এজেন্ট চালনাকারী GKE ক্লাস্টার তৈরি এবং পরিচালনা করার সুযোগ দেয়। GKE, গুগলের পরিকাঠামো ব্যবহার করে আপনার কন্টেইনারাইজড অ্যাপ্লিকেশনগুলো স্থাপন, পরিচালনা এবং স্কেল করার জন্য একটি নিয়ন্ত্রিত পরিবেশ প্রদান করে। - আর্টিফ্যাক্ট রেজিস্ট্রি এপিআই (
artifactregistry.googleapis.com) আপনার এজেন্টের কন্টেইনার ইমেজ সংরক্ষণের জন্য একটি সুরক্ষিত ও ব্যক্তিগত রিপোজিটরি প্রদান করে। এটি কন্টেইনার রেজিস্ট্রি-র একটি উন্নত সংস্করণ এবং GKE ও ক্লাউড বিল্ড-এর সাথে নির্বিঘ্নে সমন্বিত হয়। - আপনার Dockerfile থেকে ক্লাউডে কন্টেইনার ইমেজ বিল্ড করার জন্য
gcloud builds submitকমান্ডটি Cloud Build API (cloudbuild.googleapis.com) ব্যবহার করে। এটি একটি সার্ভারলেস CI/CD প্ল্যাটফর্ম যা গুগল ক্লাউড ইনফ্রাস্ট্রাকচারে আপনার বিল্ডগুলো সম্পাদন করে। - ভার্টেক্স এআই এপিআই (
aiplatform.googleapis.com) আপনার ডেপ্লয় করা এজেন্টকে তার মূল কাজগুলো সম্পাদনের জন্য জেমিনি মডেলের সাথে যোগাযোগ করতে সক্ষম করে। এটি গুগল ক্লাউডের সমস্ত এআই পরিষেবার জন্য একটি সমন্বিত এপিআই প্রদান করে।
৫. আপনার ডেভেলপমেন্ট পরিবেশ প্রস্তুত করুন
ডিরেক্টরি কাঠামো তৈরি করুন
- টার্মিনালে প্রজেক্ট ডিরেক্টরি এবং প্রয়োজনীয় সাবডিরেক্টরিগুলো তৈরি করুন:
mkdir -p ~/adk_multiagent_systems/workflow_agents cd ~/adk_multiagent_systems - টার্মিনালে , ক্লাউড শেল এডিটর এক্সপ্লোরারে ডিরেক্টরিটি খোলার জন্য নিম্নলিখিত কমান্ডটি চালান।
cloudshell open-workspace ~/adk_multiagent_systems - বাম দিকের এক্সপ্লোরার প্যানেলটি রিফ্রেশ হবে। এখন আপনি আপনার তৈরি করা ডিরেক্টরিগুলো দেখতে পাবেন।
পরবর্তী ধাপগুলোতে আপনি যখন ফাইল তৈরি করবেন, তখন এই ডিরেক্টরিতে ফাইলগুলো তৈরি হতে দেখবেন।
স্টার্টার ফাইল তৈরি করুন
এখন আপনি অ্যাপ্লিকেশনটির জন্য প্রয়োজনীয় স্টার্টার ফাইলগুলো তৈরি করবেন।
- টার্মিনালে নিম্নলিখিত কমান্ডটি চালিয়ে
callback_logging.pyতৈরি করুন। এই ফাইলটি অবজার্ভেবিলিটির জন্য লগিং পরিচালনা করে।cat <<EOF > ~/adk_multiagent_systems/callback_logging.py """ Provides helper functions for observability. Handles formatting and sending agent queries, responses, and tool calls to Google Cloud Logging to aid in monitoring and debugging. """ import logging import google.cloud.logging from google.adk.agents.callback_context import CallbackContext from google.adk.models import LlmResponse, LlmRequest def log_query_to_model(callback_context: CallbackContext, llm_request: LlmRequest): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_request.contents and llm_request.contents[-1].role == 'user': if llm_request.contents[-1].parts and "text" in llm_request.contents[-1].parts: last_user_message = llm_request.contents[-1].parts[0].text logging.info(f"[query to {callback_context.agent_name}]: " + last_user_message) def log_model_response(callback_context: CallbackContext, llm_response: LlmResponse): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_response.content and llm_response.content.parts: for part in llm_response.content.parts: if part.text: logging.info(f"[response from {callback_context.agent_name}]: " + part.text) elif part.function_call: logging.info(f"[function call from {callback_context.agent_name}]: " + part.function_call.name) EOF - টার্মিনালে নিম্নলিখিত কমান্ডটি চালিয়ে
workflow_agents/__init__.pyতৈরি করুন। এটি ডিরেক্টরিটিকে একটি পাইথন প্যাকেজ হিসেবে চিহ্নিত করে।cat <<EOF > ~/adk_multiagent_systems/workflow_agents/__init__.py """ Marks the directory as a Python package and exposes the agent module, allowing the ADK to discover and register the agents defined within. """ from . import agent EOF - টার্মিনালে নিম্নলিখিত কমান্ডটি চালিয়ে
workflow_agents/agent.pyফাইলটি তৈরি করুন। এই ফাইলটিতে আপনার একাধিক এজেন্টের দলের মূল কার্যপ্রণালী রয়েছে।cat <<EOF > ~/adk_multiagent_systems/workflow_agents/agent.py """ Defines the core multi-agent workflow. Configures individual agents (Researcher, Screenwriter, File Writer), assigns their specific tools, and orchestrates their collaboration using the ADK's SequentialAgent pattern. """ import os import logging import google.cloud.logging from callback_logging import log_query_to_model, log_model_response from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent, LoopAgent, ParallelAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool # import from google.genai import types from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL") print(model_name) # Tools def append_to_state( tool_context: ToolContext, field: str, response: str ) -> dict[str, str]: """Append new output to an existing state key. Args: field (str): a field name to append to response (str): a string to append to the field Returns: dict[str, str]: {"status": "success"} """ existing_state = tool_context.state.get(field, []) tool_context.state[field] = existing_state + [response] logging.info(f"[Added to {field}] {response}") return {"status": "success"} def write_file( tool_context: ToolContext, directory: str, filename: str, content: str ) -> dict[str, str]: target_path = os.path.join(directory, filename) os.makedirs(os.path.dirname(target_path), exist_ok=True) with open(target_path, "w") as f: f.write(content) return {"status": "success"} # Agents file_writer = Agent( name="file_writer", model=model_name, description="Creates marketing details and saves a pitch document.", instruction=""" PLOT_OUTLINE: { PLOT_OUTLINE? } INSTRUCTIONS: - Create a marketable, contemporary movie title suggestion for the movie described in the PLOT_OUTLINE. If a title has been suggested in PLOT_OUTLINE, you can use it, or replace it with a better one. - Use your 'write_file' tool to create a new txt file with the following arguments: - for a filename, use the movie title - Write to the 'movie_pitches' directory. - For the 'content' to write, extract the following from the PLOT_OUTLINE: - A logline - Synopsis or plot outline """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[write_file], ) screenwriter = Agent( name="screenwriter", model=model_name, description="As a screenwriter, write a logline and plot outline for a biopic about a historical character.", instruction=""" INSTRUCTIONS: Your goal is to write a logline and three-act plot outline for an inspiring movie about a historical character(s) described by the PROMPT: { PROMPT? } - If there is CRITICAL_FEEDBACK, use those thoughts to improve upon the outline. - If there is RESEARCH provided, feel free to use details from it, but you are not required to use it all. - If there is a PLOT_OUTLINE, improve upon it. - Use the 'append_to_state' tool to write your logline and three-act plot outline to the field 'PLOT_OUTLINE'. - Summarize what you focused on in this pass. PLOT_OUTLINE: { PLOT_OUTLINE? } RESEARCH: { research? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], ) researcher = Agent( name="researcher", model=model_name, description="Answer research questions using Wikipedia.", instruction=""" PROMPT: { PROMPT? } PLOT_OUTLINE: { PLOT_OUTLINE? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } INSTRUCTIONS: - If there is a CRITICAL_FEEDBACK, use your wikipedia tool to do research to solve those suggestions - If there is a PLOT_OUTLINE, use your wikipedia tool to do research to add more historical detail - If these are empty, use your Wikipedia tool to gather facts about the person in the PROMPT - Use the 'append_to_state' tool to add your research to the field 'research'. - Summarize what you have learned. Now, use your Wikipedia tool to do research. """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[ LangchainTool(tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())), append_to_state, ], ) film_concept_team = SequentialAgent( name="film_concept_team", description="Write a film plot outline and save it as a text file.", sub_agents=[ researcher, screenwriter, file_writer ], ) root_agent = Agent( name="greeter", model=model_name, description="Guides the user in crafting a movie plot.", instruction=""" - Let the user know you will help them write a pitch for a hit movie. Ask them for a historical figure to create a movie about. - When they respond, use the 'append_to_state' tool to store the user's response in the 'PROMPT' state key and transfer to the 'film_concept_team' agent """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], sub_agents=[film_concept_team], ) EOF
আপনার ফাইল কাঠামোটি এখন দেখতে এইরকম হবে: 
ভার্চুয়াল পরিবেশ সেট আপ করুন
- টার্মিনালে ,
uvব্যবহার করে একটি ভার্চুয়াল এনভায়রনমেন্ট তৈরি ও সক্রিয় করুন। এটি নিশ্চিত করে যে আপনার প্রোজেক্টের ডিপেন্ডেন্সিগুলো সিস্টেম পাইথনের সাথে সাংঘর্ষিক হবে না।uv venv source .venv/bin/activate
ইনস্টলেশনের প্রয়োজনীয়তা
-
requirements.txtফাইলটি তৈরি করতে টার্মিনালে নিম্নলিখিত কমান্ডটি চালান।cat <<EOF > ~/adk_multiagent_systems/requirements.txt # Lists all Python dependencies required to run the multi-agent system, # including the Google ADK, LangChain community tools, and web server libraries. langchain-community==0.4.1 wikipedia==1.4.0 google-adk==1.27.5 fastapi==0.135.2 uvicorn==0.42.0 EOF - টার্মিনালে আপনার ভার্চুয়াল এনভায়রনমেন্টে প্রয়োজনীয় প্যাকেজগুলো ইনস্টল করুন।
uv pip install -r requirements.txt
পরিবেশ ভেরিয়েবল সেট আপ করুন
- আপনার প্রজেক্ট আইডি এবং অঞ্চল স্বয়ংক্রিয়ভাবে যুক্ত করে
.envফাইলটি তৈরি করতে টার্মিনালে নিম্নলিখিত কমান্ডটি ব্যবহার করুন।cat <<EOF > ~/adk_multiagent_systems/.env GOOGLE_CLOUD_PROJECT="$(gcloud config get-value project)" GOOGLE_CLOUD_PROJECT_NUMBER="$(gcloud projects describe $(gcloud config get-value project) --format='value(projectNumber)')" GOOGLE_CLOUD_LOCATION="us-central1" GOOGLE_GENAI_USE_VERTEXAI=true MODEL="gemini-2.5-flash" EOF - টার্মিনালে , ভেরিয়েবলগুলো আপনার শেল সেশনে লোড করুন।
source .env
পুনরালোচনা
এই অংশে, আপনি আপনার প্রকল্পের জন্য স্থানীয় ভিত্তি স্থাপন করেছেন:
- ডিরেক্টরি কাঠামো এবং প্রয়োজনীয় এজেন্ট স্টার্টার ফাইলগুলো (
agent.py,callback_logging.py,requirements.txt) তৈরি করা হয়েছে। - একটি ভার্চুয়াল এনভায়রনমেন্ট (
uv) ব্যবহার করে আপনার ডিপেন্ডেন্সিগুলোকে আলাদা করুন। - আপনার প্রজেক্ট আইডি এবং অঞ্চলের মতো প্রজেক্ট-সংক্রান্ত বিবরণ সংরক্ষণ করার জন্য এনভায়রনমেন্ট ভেরিয়েবল (
.env) কনফিগার করা হয়েছে।
৬. এজেন্ট ফাইলটি অন্বেষণ করুন
আপনি ল্যাবের জন্য সোর্স কোড সেট আপ করেছেন, যার মধ্যে আগে থেকে লেখা একটি মাল্টি-এজেন্ট সিস্টেমও রয়েছে। অ্যাপ্লিকেশনটি ডেপ্লয় করার আগে, এজেন্টগুলো কীভাবে সংজ্ঞায়িত করা হয়েছে তা বোঝা সহায়ক হবে। এজেন্টের মূল লজিকটি workflow_agents/agent.py ফাইলে থাকে।
- ক্লাউড শেল এডিটরে, বাম দিকের ফাইল এক্সপ্লোরার ব্যবহার করে
adk_multiagent_systems/workflow_agents/ফোল্ডারে যান এবংagent.pyফাইলটি খুলুন। - এক মুহূর্ত সময় নিয়ে ফাইলটি দেখুন। আপনার প্রতিটি লাইন বোঝার দরকার নেই, কিন্তু এর মূল কাঠামোটি লক্ষ্য করুন:
- স্বতন্ত্র এজেন্ট: ফাইলটিতে তিনটি স্বতন্ত্র
Agentঅবজেক্ট সংজ্ঞায়িত করা হয়েছে:researcher,screenwriter, এবংfile_writer। প্রতিটি এজেন্টকে একটি নির্দিষ্টinstruction(তার প্রম্পট) এবং ব্যবহারের জন্য অনুমোদিতtoolsএকটি তালিকা দেওয়া হয় (যেমনWikipediaQueryRunটুল বা একটি কাস্টমwrite_fileটুল)। - এজেন্ট গঠন: স্বতন্ত্র এজেন্টগুলোকে
film_concept_teamনামক একটিSequentialAgentমধ্যে শৃঙ্খলিত করা হয়। এটি ADK-কে এই এজেন্টগুলোকে একের পর এক চালানোর নির্দেশ দেয় এবং একটি থেকে অন্যটিতে স্টেট প্রেরণ করে। - রুট এজেন্ট: প্রাথমিক ব্যবহারকারী ইন্টারঅ্যাকশন পরিচালনা করার জন্য 'greeter' নামের একটি
root_agentসংজ্ঞায়িত করা হয়েছে। যখন ব্যবহারকারী কোনো প্রম্পট প্রদান করেন, তখন এই এজেন্টটি তা অ্যাপ্লিকেশনের স্টেটে সংরক্ষণ করে এবং তারপরfilm_concept_teamওয়ার্কফ্লো-তে নিয়ন্ত্রণ হস্তান্তর করে।
- স্বতন্ত্র এজেন্ট: ফাইলটিতে তিনটি স্বতন্ত্র
এই কাঠামোটি বুঝতে পারলে আপনি কী স্থাপন করতে চলেছেন তা স্পষ্ট হয়: শুধু একটি একক এজেন্ট নয়, বরং ADK দ্বারা পরিচালিত বিশেষায়িত এজেন্টদের একটি সমন্বিত দল।
৭. একটি GKE অটোপাইলট ক্লাস্টার তৈরি করুন
আপনার পরিবেশ প্রস্তুত হয়ে গেলে, পরবর্তী ধাপ হলো সেই পরিকাঠামোটি প্রস্তুত করা যেখানে আপনার এজেন্ট অ্যাপ্লিকেশনটি চলবে। আপনি একটি GKE অটোপাইলট ক্লাস্টার তৈরি করবেন, যা আপনার ডেপ্লয়মেন্টের ভিত্তি হিসেবে কাজ করে। আমরা অটোপাইলট মোড ব্যবহার করি কারণ এটি ক্লাস্টারের অন্তর্নিহিত নোডগুলোর জটিল ব্যবস্থাপনা, স্কেলিং এবং নিরাপত্তা সামলে নেয়, ফলে আপনি সম্পূর্ণরূপে আপনার অ্যাপ্লিকেশন ডেপ্লয় করার উপর মনোযোগ দিতে পারেন।
- টার্মিনালে ,
adk-clusterনামে একটি নতুন GKE Autopilot ক্লাস্টার তৈরি করুন।gcloud container clusters create-auto adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT - ক্লাস্টারটি তৈরি হয়ে গেলে, টার্মিনালে এটি চালিয়ে
kubectlকনফিগার করুন:gcloud container clusters get-credentials adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT~/.kube/config) আপডেট করে। এই পর্যায় থেকে,kubectlকমান্ড-লাইন টুলটি প্রমাণীকৃত হবে এবং আপনারadk-clusterসাথে যোগাযোগ করার জন্য নির্দেশিত হবে।
পুনরালোচনা
এই বিভাগে, আপনি পরিকাঠামোটি প্রস্তুত করেছেন:
-
gcloudব্যবহার করে একটি সম্পূর্ণভাবে পরিচালিত GKE অটোপাইলট ক্লাস্টার তৈরি করা হয়েছে। - নতুন ক্লাস্টারের সাথে প্রমাণীকরণ ও যোগাযোগের জন্য আপনার স্থানীয়
kubectlটুলটি কনফিগার করা হয়েছে।
৮. অ্যাপ্লিকেশনটিকে কন্টেইনারাইজ করুন এবং পুশ করুন।
আপনার এজেন্টের কোড বর্তমানে শুধুমাত্র আপনার ক্লাউড শেল এনভায়রনমেন্টে বিদ্যমান। এটিকে GKE-তে চালানোর জন্য, আপনাকে প্রথমে এটিকে একটি কন্টেইনার ইমেজে প্যাকেজ করতে হবে। একটি কন্টেইনার ইমেজ হলো একটি স্ট্যাটিক, পোর্টেবল ফাইল যা আপনার অ্যাপ্লিকেশনের কোডকে তার সমস্ত ডিপেন্ডেন্সি সহ বান্ডল করে। যখন আপনি এই ইমেজটি চালান, তখন এটি একটি লাইভ কন্টেইনারে পরিণত হয়।
এই প্রক্রিয়ায় তিনটি মূল ধাপ রয়েছে:
- একটি এন্ট্রি পয়েন্ট তৈরি করুন : আপনার এজেন্ট লজিককে একটি চালনাযোগ্য ওয়েব সার্ভারে পরিণত করতে একটি
main.pyফাইল সংজ্ঞায়িত করুন। - কন্টেইনার ইমেজ নির্ধারণ করুন : একটি ডকারফাইল তৈরি করুন যা আপনার কন্টেইনার ইমেজ তৈরির জন্য একটি ব্লুপ্রিন্ট হিসেবে কাজ করবে।
- বিল্ড ও পুশ : ক্লাউড বিল্ড ব্যবহার করে ডকারফাইলটি এক্সিকিউট করুন, যা কন্টেইনার ইমেজ তৈরি করবে এবং আপনার ইমেজগুলোর জন্য একটি সুরক্ষিত রিপোজিটরি, গুগল আর্টিফ্যাক্ট রেজিস্ট্রি- তে তা পুশ করবে।
অ্যাপ্লিকেশনটি স্থাপনের জন্য প্রস্তুত করুন
আপনার ADK এজেন্টের অনুরোধ গ্রহণ করার জন্য একটি ওয়েব সার্ভার প্রয়োজন। main.py ফাইলটি এই এন্ট্রি পয়েন্ট হিসেবে কাজ করবে এবং FastAPI ফ্রেমওয়ার্ক ব্যবহার করে HTTP-এর মাধ্যমে আপনার এজেন্টের কার্যকারিতা প্রকাশ করবে।
- টার্মিনালে
adk_multiagent_systemsডিরেক্টরির রুটেmain.pyনামে একটি নতুন ফাইল তৈরি করুন।cat <<EOF > ~/adk_multiagent_systems/main.py """ Serves as the application entry point. Initializes the FastAPI web server, discovers the agents defined in the workflow directory, and exposes them via HTTP endpoints for interaction. """ import os import uvicorn from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Get the directory where main.py is located AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) # Configure the session service (e.g., SQLite for local storage) SESSION_SERVICE_URI = "sqlite:///./sessions.db" # Configure CORS to allow requests from various origins for this lab ALLOWED_ORIGINS = ["http://localhost", "http://localhost:8080", "*"] # Enable the ADK's built-in web interface SERVE_WEB_INTERFACE = True # Call the ADK function to discover agents and create the FastAPI app app: FastAPI = get_fast_api_app( agents_dir=AGENT_DIR, session_service_uri=SESSION_SERVICE_URI, allow_origins=ALLOWED_ORIGINS, web=SERVE_WEB_INTERFACE, ) # You can add more FastAPI routes or configurations below if needed # Example: # @app.get("/hello") # async def read_root(): # return {"Hello": "World"} if __name__ == "__main__": # Get the port from the PORT environment variable provided by the container runtime # Run the Uvicorn server, listening on all available network interfaces (0.0.0.0) uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("PORT", 8080))) EOFuvicornসার্ভার এই অ্যাপ্লিকেশনটি চালায় এবং যেকোনো আইপি অ্যাড্রেস থেকে সংযোগ গ্রহণ করার জন্য0.0.0.0হোস্টে ওPORTএনভায়রনমেন্ট ভেরিয়েবল দ্বারা নির্দিষ্ট পোর্টে লিসেন করে, যা আমরা পরে আমাদের Kubernetes ম্যানিফেস্টে সেট করব।
এই পর্যায়ে, ক্লাউড শেল এডিটরের এক্সপ্লোরার প্যানেলে আপনার ফাইল কাঠামোটি দেখতে এইরকম হওয়া উচিত: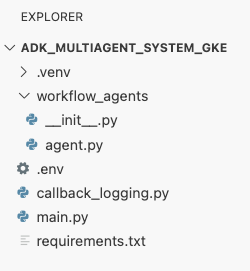
ডকার ব্যবহার করে ADK এজেন্টকে কন্টেইনারাইজ করুন
GKE-তে আমাদের অ্যাপ্লিকেশনটি ডেপ্লয় করার জন্য, প্রথমে এটিকে একটি কন্টেইনার ইমেজে প্যাকেজ করতে হবে, যা আমাদের অ্যাপ্লিকেশনের কোডের সাথে এটি চালানোর জন্য প্রয়োজনীয় সমস্ত লাইব্রেরি এবং ডিপেন্ডেন্সিগুলোকে একত্রিত করে। আমরা এই কন্টেইনার ইমেজটি তৈরি করতে ডকার ব্যবহার করব।
- টার্মিনালে
adk_multiagent_systemsডিরেক্টরির রুটেDockerfileনামে একটি নতুন ফাইল তৈরি করুন।cat <<'EOF' > ~/adk_multiagent_systems/Dockerfile # Defines the blueprint for the container image. Installs dependencies, # sets up a secure non-root user, and specifies the startup command to run the # agent web server. # Use an official lightweight Python image as the base FROM python:3.13-slim # Set the working directory inside the container WORKDIR /app # Create a non-root user for security best practices RUN adduser --disabled-password --gecos "" myuser # Copy and install dependencies first to leverage Docker's layer caching COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt # Copy all application code into the container COPY . . # Create the directory where the agent will write files at runtime # The -p flag ensures the command doesn't fail if the directory already exists RUN mkdir -p movie_pitches # Change ownership of EVERYTHING in /app to the non-root user # Without this, the running agent would be denied permission to write files. RUN chown -R myuser:myuser /app # Switch the active user from root to the non-root user USER myuser # Add the user's local binary directory to the system's PATH ENV PATH="/home/myuser/.local/bin:$PATH" # Define the command to run when the container starts CMD ["sh", "-c", "uvicorn main:app --host 0.0.0.0 --port $PORT"] EOF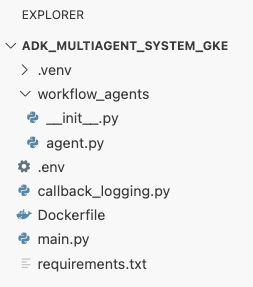
কন্টেইনার ইমেজটি বিল্ড করে আর্টিফ্যাক্ট রেজিস্ট্রি-তে পুশ করুন।
এখন যেহেতু আপনার একটি ডকারফাইল (Dockerfile) আছে, আপনি ক্লাউড বিল্ড (Cloud Build) ব্যবহার করে ইমেজটি বিল্ড করবেন এবং এটিকে আর্টিফ্যাক্ট রেজিস্ট্রি (Artifact Registry)-তে পুশ করবেন। আর্টিফ্যাক্ট রেজিস্ট্রি হলো গুগল ক্লাউড পরিষেবাগুলির সাথে সমন্বিত একটি সুরক্ষিত ও ব্যক্তিগত রেজিস্ট্রি। আপনার অ্যাপ্লিকেশনটি চালানোর জন্য জিকেই (GKE) এই রেজিস্ট্রি থেকে ইমেজটি পুল (pull) করবে।
- টার্মিনালে , আপনার কন্টেইনার ইমেজ সংরক্ষণের জন্য একটি নতুন আর্টিফ্যাক্ট রেজিস্ট্রি রিপোজিটরি তৈরি করুন।
gcloud artifacts repositories create adk-repo \ --repository-format=docker \ --location=$GOOGLE_CLOUD_LOCATION \ --description="ADK repository" - টার্মিনালে , আপনার কন্টেইনার ইমেজটি বিল্ড করতে এবং রিপোজিটরিতে পুশ করতে
gcloud builds submitব্যবহার করুন।gcloud builds submit \ --tag $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo/adk-agent:latest \ --project=$GOOGLE_CLOUD_PROJECT \ .Dockerfileএর ধাপগুলো কার্যকর করতে Cloud Build নামক একটি সার্ভারলেস CI/CD প্ল্যাটফর্ম ব্যবহার করে। এটি ক্লাউডে ইমেজটি বিল্ড করে, সেটিকে আপনার Artifact Registry রিপোজিটরির অ্যাড্রেস দিয়ে ট্যাগ করে এবং স্বয়ংক্রিয়ভাবে সেখানে পুশ করে দেয়। - টার্মিনাল থেকে ইমেজটি বিল্ড হয়েছে কিনা তা যাচাই করুন:
gcloud artifacts docker images list \ $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo \ --project=$GOOGLE_CLOUD_PROJECT
পুনরালোচনা
এই অংশে, আপনি ডেপ্লয়মেন্টের জন্য আপনার কোড প্যাকেজ করেছেন:
- আপনার এজেন্টগুলোকে একটি FastAPI ওয়েব সার্ভারে আবদ্ধ করার জন্য একটি
main.pyএন্ট্রি পয়েন্ট তৈরি করা হয়েছে। - আপনার কোড এবং ডিপেন্ডেন্সিগুলোকে একটি পোর্টেবল ইমেজে বান্ডল করার জন্য একটি
Dockerfileতৈরি করা হয়েছে। - ক্লাউড বিল্ড ব্যবহার করে ইমেজটি তৈরি করা হয়েছে এবং একটি সুরক্ষিত আর্টিফ্যাক্ট রেজিস্ট্রি রিপোজিটরিতে পুশ করা হয়েছে।
৯. কুবারনেটিস ম্যানিফেস্ট তৈরি করুন
এখন যেহেতু আপনার কন্টেইনার ইমেজটি তৈরি হয়ে আর্টিফ্যাক্ট রেজিস্ট্রি-তে সংরক্ষিত হয়েছে, আপনাকে GKE-কে এটি কীভাবে চালাতে হবে তার নির্দেশ দিতে হবে। এর জন্য দুটি প্রধান কাজ করতে হয়:
- অনুমতি নির্ধারণ : আপনি ক্লাস্টারের মধ্যে আপনার এজেন্টের জন্য একটি নির্দিষ্ট আইডেন্টিটি তৈরি করবেন এবং এটিকে এর প্রয়োজনীয় গুগল ক্লাউড এপিআইগুলোতে (বিশেষত, ভার্টেক্স এআই ) সুরক্ষিত অ্যাক্সেস প্রদান করবেন।
- অ্যাপ্লিকেশনের অবস্থা নির্ধারণ করা : আপনাকে একটি Kubernetes ম্যানিফেস্ট ফাইল লিখতে হবে, যা একটি YAML ডকুমেন্ট। এই ডকুমেন্টে আপনার অ্যাপ্লিকেশনটি চালানোর জন্য প্রয়োজনীয় সবকিছু, যেমন—কন্টেইনার ইমেজ, এনভায়রনমেন্ট ভেরিয়েবল এবং নেটওয়ার্কে এটি কীভাবে উন্মুক্ত হবে, তা ঘোষণামূলকভাবে সংজ্ঞায়িত করা থাকে।
Vertex AI-এর জন্য Kubernetes সার্ভিস অ্যাকাউন্ট কনফিগার করুন
জেমিনি মডেল অ্যাক্সেস করার জন্য আপনার এজেন্টের ভার্টেক্স এআই এপিআই (Vertex AI API)-এর সাথে যোগাযোগের অনুমতি প্রয়োজন। GKE-তে এই অনুমতি প্রদানের জন্য সবচেয়ে নিরাপদ ও প্রস্তাবিত পদ্ধতি হলো ওয়ার্কলোড আইডেন্টিটি (Workload Identity)। ওয়ার্কলোড আইডেন্টিটি আপনাকে একটি কুবারনেটিস-নেটিভ আইডেন্টিটি (একটি কুবারনেটিস সার্ভিস অ্যাকাউন্ট ) একটি গুগল ক্লাউড আইডেন্টিটির (একটি আইএএম সার্ভিস অ্যাকাউন্ট ) সাথে লিঙ্ক করার সুযোগ দেয়, যার ফলে স্ট্যাটিক JSON কী ডাউনলোড, পরিচালনা এবং সংরক্ষণ করার প্রয়োজনীয়তা সম্পূর্ণরূপে এড়ানো যায়।
- টার্মিনালে , Kubernetes সার্ভিস অ্যাকাউন্ট (
adk-agent-sa) তৈরি করুন। এটি GKE ক্লাস্টারের ভিতরে আপনার এজেন্টের জন্য একটি পরিচয় তৈরি করে যা আপনার পডগুলি ব্যবহার করতে পারবে।kubectl create serviceaccount adk-agent-sa - টার্মিনালে , একটি পলিসি বাইন্ডিং তৈরি করে আপনার Kubernetes সার্ভিস অ্যাকাউন্টকে Google Cloud IAM-এর সাথে লিঙ্ক করুন। এই কমান্ডটি আপনার
adk-agent-saকেaiplatform.userরোলটি প্রদান করে, যার ফলে এটি নিরাপদে Vertex AI API কল করতে পারে।gcloud projects add-iam-policy-binding projects/${GOOGLE_CLOUD_PROJECT} \ --role=roles/aiplatform.user \ --member=principal://iam.googleapis.com/projects/${GOOGLE_CLOUD_PROJECT_NUMBER}/locations/global/workloadIdentityPools/${GOOGLE_CLOUD_PROJECT}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \ --condition=None
Kubernetes ম্যানিফেস্ট ফাইল তৈরি করুন
Kubernetes আপনার অ্যাপ্লিকেশনের কাঙ্ক্ষিত অবস্থা নির্ধারণ করতে YAML ম্যানিফেস্ট ফাইল ব্যবহার করে। আপনাকে একটি deployment.yaml ফাইল তৈরি করতে হবে, যাতে দুটি অপরিহার্য Kubernetes অবজেক্ট থাকবে: একটি Deployment এবং একটি Service ।
- টার্মিনাল থেকে
deployment.yamlফাইলটি তৈরি করুন।cat <<EOF > ~/adk_multiagent_systems/deployment.yaml # Defines the Kubernetes resources required to deploy the application to GKE. # Includes the Deployment (to run the container pods) and the Service # (to expose the application via a Load Balancer). apiVersion: apps/v1 kind: Deployment metadata: name: adk-agent spec: replicas: 1 selector: matchLabels: app: adk-agent template: metadata: labels: app: adk-agent spec: # Assign the Kubernetes Service Account for Workload Identity serviceAccountName: adk-agent-sa containers: - name: adk-agent imagePullPolicy: Always # The path to the container image in Artifact Registry image: ${GOOGLE_CLOUD_LOCATION}-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/adk-repo/adk-agent:latest # Define the resources for GKE Autopilot to provision resources: limits: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" requests: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" ports: - containerPort: 8080 # Environment variables passed to the application env: - name: PORT value: "8080" - name: GOOGLE_CLOUD_PROJECT value: ${GOOGLE_CLOUD_PROJECT} - name: GOOGLE_CLOUD_LOCATION value: ${GOOGLE_CLOUD_LOCATION} - name: GOOGLE_GENAI_USE_VERTEXAI value: "true" - name: MODEL value: "gemini-2.5-flash" --- apiVersion: v1 kind: Service metadata: name: adk-agent spec: # Create a public-facing Network Load Balancer with an external IP type: LoadBalancer ports: - port: 80 targetPort: 8080 selector: app: adk-agent EOF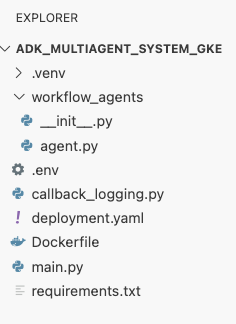
পুনরালোচনা
এই বিভাগে, আপনি নিরাপত্তা এবং স্থাপনা কনফিগারেশন সংজ্ঞায়িত করেছেন:
- একটি Kubernetes সার্ভিস অ্যাকাউন্ট তৈরি করে Workload Identity ব্যবহার করে সেটিকে Google Cloud IAM-এর সাথে লিঙ্ক করা হয়েছে, যার ফলে আপনার পডগুলো কী (key) পরিচালনা ছাড়াই নিরাপদে Vertex AI অ্যাক্সেস করতে পারবে।
- একটি
deployment.yamlফাইল তৈরি করা হয়েছে যা Deployment (পডগুলো কীভাবে চালানো হবে) এবং Service (লোড ব্যালেন্সারের মাধ্যমে কীভাবে সেগুলোকে উপলব্ধ করা হবে) সংজ্ঞায়িত করে।
১০. অ্যাপ্লিকেশনটি GKE-তে স্থাপন করুন।
আপনার ম্যানিফেস্ট ফাইল সংজ্ঞায়িত করা হয়ে গেলে এবং কন্টেইনার ইমেজ আর্টিফ্যাক্ট রেজিস্ট্রি-তে পুশ করা হয়ে গেলে, আপনি এখন আপনার অ্যাপ্লিকেশনটি ডেপ্লয় করার জন্য প্রস্তুত। এই টাস্কে, আপনি kubectl ব্যবহার করে আপনার কনফিগারেশন GKE ক্লাস্টারে প্রয়োগ করবেন এবং তারপর আপনার এজেন্টটি সঠিকভাবে চালু হচ্ছে কিনা তা নিশ্চিত করতে স্ট্যাটাস মনিটর করবেন।
- আপনার টার্মিনালে , আপনার ক্লাস্টারে
deployment.yamlম্যানিফেস্টটি প্রয়োগ করুন।kubectl apply -f deployment.yamlkubectl applyকমান্ডটি আপনারdeployment.yamlফাইলটিকে কুবারনেটিস এপিআই সার্ভারে পাঠিয়ে দেয়। এরপর সার্ভারটি আপনার কনফিগারেশন পড়ে এবং `Deployment` ও `Service` অবজেক্টগুলো তৈরির প্রক্রিয়াটি পরিচালনা করে। - টার্মিনালে রিয়েল-টাইমে আপনার ডিপ্লয়মেন্টের স্ট্যাটাস চেক করুন। পডগুলো
Runningঅবস্থায় আসা পর্যন্ত অপেক্ষা করুন।kubectl get pods -l=app=adk-agent --watch- অপেক্ষাধীন : পডটি ক্লাস্টার দ্বারা গৃহীত হয়েছে, কিন্তু কন্টেইনারটি এখনও তৈরি হয়নি।
- কন্টেইনার তৈরি হচ্ছে : GKE আর্টিফ্যাক্ট রেজিস্ট্রি থেকে আপনার কন্টেইনার ইমেজটি পুল করছে এবং কন্টেইনারটি চালু করছে।
- চলছে : সফল! কন্টেইনারটি চলছে এবং আপনার এজেন্ট অ্যাপ্লিকেশনটি লাইভ হয়েছে।
- স্ট্যাটাস '
Runningদেখালে, ওয়াচ কমান্ডটি বন্ধ করতে এবং কমান্ড প্রম্পটে ফিরে যেতে টার্মিনালে CTRL+C চাপুন।
পুনরালোচনা
এই বিভাগে, আপনি ওয়ার্কলোডটি চালু করেছেন:
- আপনার ম্যানিফেস্টটি ক্লাস্টারে পাঠাতে
kubectlapply ব্যবহার করুন। - অ্যাপ্লিকেশনটি সফলভাবে চালু হয়েছে কিনা তা নিশ্চিত করার জন্য পডের জীবনচক্র (পেন্ডিং -> কন্টেইনার ক্রিয়েটিং -> রানিং) পর্যবেক্ষণ করা হয়েছে।
১১. এজেন্টের সাথে যোগাযোগ করুন
আপনার ADK এজেন্ট এখন GKE-তে সরাসরি চলছে এবং একটি পাবলিক লোড ব্যালান্সারের মাধ্যমে ইন্টারনেটে সংযুক্ত আছে। আপনি এজেন্টের ওয়েব ইন্টারফেসে সংযোগ করে এটির সাথে ইন্টারঅ্যাক্ট করবেন এবং পুরো সিস্টেমটি সঠিকভাবে কাজ করছে কিনা তা যাচাই করবেন।
আপনার পরিষেবার বাহ্যিক আইপি ঠিকানা খুঁজুন
এজেন্ট অ্যাক্সেস করতে, আপনাকে প্রথমে সেই পাবলিক আইপি অ্যাড্রেসটি পেতে হবে যা GKE আপনার সার্ভিসের জন্য বরাদ্দ করেছে।
- আপনার সার্ভিসের বিস্তারিত তথ্য পেতে টার্মিনালে নিম্নলিখিত কমান্ডটি চালান।
kubectl get service adk-agent -
EXTERNAL-IPকলামে মানটি দেখুন। আপনি প্রথমবার সার্ভিসটি ডেপ্লয় করার পর আইপি অ্যাড্রেসটি অ্যাসাইন হতে এক বা দুই মিনিট সময় লাগতে পারে। যদি এটিpendingদেখায়, তবে এক মিনিট অপেক্ষা করুন এবং কমান্ডটি আবার চালান। আউটপুটটি দেখতে অনেকটা এইরকম হবে:NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE adk-agent-service LoadBalancer 10.120.12.234 34.123.45.67 80:31234/TCP 5mEXTERNAL-IPএর অধীনে তালিকাভুক্ত ঠিকানাটি (যেমন, 34.123.45.67) হলো আপনার এজেন্টের সর্বজনীন প্রবেশপথ।
স্থাপন করা এজেন্ট পরীক্ষা করুন
এখন আপনি পাবলিক আইপি অ্যাড্রেস ব্যবহার করে সরাসরি আপনার ব্রাউজার থেকে ADK-এর বিল্ট-ইন ওয়েব UI অ্যাক্সেস করতে পারবেন।
- টার্মিনাল থেকে এক্সটার্নাল আইপি অ্যাড্রেস (
EXTERNAL-IP) কপি করুন। - আপনার ওয়েব ব্রাউজারে একটি নতুন ট্যাব খুলুন এবং
http://[EXTERNAL-IP]টাইপ করুন, যেখানে[EXTERNAL-IP]এর জায়গায় আপনার কপি করা আইপি অ্যাড্রেসটি বসান। - এখন আপনি ADK ওয়েব ইন্টারফেসটি দেখতে পাবেন।
- এজেন্ট ড্রপ-ডাউন মেনুতে workflow_agents নির্বাচিত আছে কিনা তা নিশ্চিত করুন।
- টোকেন স্ট্রিমিং চালু করুন।
- নতুন কথোপকথন শুরু করতে
helloটাইপ করে এন্টার চাপুন। - ফলাফলটি পর্যবেক্ষণ করুন। এজেন্টটির উচিত দ্রুত সম্ভাষণ জানিয়ে উত্তর দেওয়া: "আমি আপনাকে একটি হিট সিনেমার জন্য পিচ লিখতে সাহায্য করতে পারি। আপনি কোন ঐতিহাসিক ব্যক্তিত্বকে নিয়ে সিনেমা বানাতে চান?"
- যখন কোনো ঐতিহাসিক চরিত্র বেছে নিতে বলা হয়, তখন আপনার পছন্দের একটি চরিত্র বেছে নিন। কয়েকটি উদাহরণ হলো:
-
the most successful female pirate in history -
the woman who invented the first computer compiler -
a legendary lawman of the American Wild West
-
পুনরালোচনা
এই বিভাগে, আপনি ডেপ্লয়মেন্টটি যাচাই করেছেন:
- লোডব্যালেন্সার দ্বারা বরাদ্দকৃত এক্সটার্নাল আইপি অ্যাড্রেসটি পাওয়া গেছে।
- মাল্টি-এজেন্ট সিস্টেমটি রেসপন্সিভ এবং কার্যকরী কিনা তা নিশ্চিত করার জন্য একটি ব্রাউজারের মাধ্যমে ADK ওয়েব UI অ্যাক্সেস করা হয়েছে।
১২. অটোস্কেলিং কনফিগার করুন
প্রোডাকশনের একটি প্রধান চ্যালেঞ্জ হলো অপ্রত্যাশিত ইউজার ট্র্যাফিক সামলানো। আগের টাস্কের মতো একটি নির্দিষ্ট সংখ্যক রেপ্লিকা হার্ড-কোড করার অর্থ হলো, আপনাকে হয় অলস রিসোর্সের জন্য অতিরিক্ত অর্থ ব্যয় করতে হবে, অথবা ট্র্যাফিকের আকস্মিক বৃদ্ধির সময় খারাপ পারফরম্যান্সের ঝুঁকি নিতে হবে। GKE অটোমেটিক স্কেলিংয়ের মাধ্যমে এর সমাধান করে।
আপনি একটি হরাইজন্টাল পড অটোস্কেলার (HPA) কনফিগার করবেন, যা একটি কুবারনেটিস কন্ট্রোলার এবং এটি রিয়েল-টাইম সিপিইউ ইউটিলাইজেশনের উপর ভিত্তি করে আপনার ডিপ্লয়মেন্টে চলমান পডের সংখ্যা স্বয়ংক্রিয়ভাবে সমন্বয় করে।
- ক্লাউড শেল এডিটর টার্মিনালে ,
adk_multiagent_systemsডিরেক্টরির রুটে একটি নতুনhpa.yamlফাইল তৈরি করুন।cloudshell edit ~/adk_multiagent_systems/hpa.yaml - নতুন
hpa.yamlফাইলে নিম্নলিখিত বিষয়বস্তু যোগ করুন:# Configures the HorizontalPodAutoscaler (HPA) to automatically scale # the number of running agent pods up or down based on CPU utilization # to handle varying traffic loads. apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: adk-agent-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: adk-agent minReplicas: 1 maxReplicas: 5 targetCPUUtilizationPercentage: 50adk-agentDeployment-কে টার্গেট করে। এটি নিশ্চিত করে যে সর্বদা অন্তত ১টি পড চালু থাকে, সর্বোচ্চ ৫টি পড সেট করে এবং গড় সিপিইউ ব্যবহার প্রায় ৫০%-এর কাছাকাছি রাখতে রেপ্লিকা যোগ বা অপসারণ করে। এই পর্যায়ে, ক্লাউড শেল এডিটরের এক্সপ্লোরার প্যানেলে আপনার ফাইল স্ট্রাকচারটি দেখতে এইরকম হওয়া উচিত:
- টার্মিনালে এটি পেস্ট করে আপনার ক্লাস্টারে HPA প্রয়োগ করুন।
kubectl apply -f hpa.yaml
অটোস্কেলার যাচাই করুন
এইচপিএ এখন সক্রিয় এবং আপনার ডেপ্লয়মেন্ট পর্যবেক্ষণ করছে। এটি কীভাবে কাজ করছে তা দেখতে আপনি এর স্ট্যাটাস পরিদর্শন করতে পারেন।
- আপনার HPA-এর অবস্থা জানতে টার্মিনালে নিম্নলিখিত কমান্ডটি চালান।
kubectl get hpa adk-agent-hpaNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE adk-agent-hpa Deployment/adk-agent 0%/50% 1 5 1 30s
পুনরালোচনা
এই বিভাগে, আপনি প্রোডাকশন ট্র্যাফিকের জন্য অপ্টিমাইজ করেছেন:
- স্কেলিং নিয়মাবলী নির্ধারণ করতে একটি
hpa.yamlম্যানিফেস্ট তৈরি করা হয়েছে। - সিপিইউ ব্যবহারের উপর ভিত্তি করে পড রেপ্লিকার সংখ্যা স্বয়ংক্রিয়ভাবে সমন্বয় করার জন্য হরাইজন্টাল পড অটোস্কেলার (HPA) স্থাপন করা হয়েছে।
১৩. উৎপাদনের জন্য প্রস্তুতি
দ্রষ্টব্য : নিম্নলিখিত বিভাগগুলি শুধুমাত্র তথ্যমূলক উদ্দেশ্যে দেওয়া হয়েছে এবং এতে পরবর্তী কোনো করণীয় পদক্ষেপ উল্লেখ নেই। আপনার অ্যাপ্লিকেশনটিকে প্রোডাকশনে নিয়ে যাওয়ার জন্য প্রাসঙ্গিক ধারণা এবং সর্বোত্তম অনুশীলন প্রদানের উদ্দেশ্যে এগুলি তৈরি করা হয়েছে।
রিসোর্স বরাদ্দের মাধ্যমে পারফরম্যান্স উন্নত করুন
In GKE Autopilot , you control the amount of CPU and memory provisioned for your application by specifying resource requests in your deployment.yaml .
যদি দেখেন মেমরির অভাবে আপনার এজেন্ট ধীরগতির হয়ে যাচ্ছে বা ক্র্যাশ করছে, তাহলে আপনি আপনার deployment.yaml ফাইলের resources ব্লকটি এডিট করে এবং kubectl apply দিয়ে ফাইলটি পুনরায় প্রয়োগ করে এর রিসোর্স বরাদ্দ বাড়াতে পারেন।
উদাহরণস্বরূপ, মেমরি দ্বিগুণ করতে:
# In deployment.yaml
# ...
resources:
requests:
memory: "2Gi" # Increased from 1Gi
cpu: "1000m"
# ...
CI/CD দিয়ে আপনার কর্মপ্রবাহ স্বয়ংক্রিয় করুন
এই ল্যাবে, আপনি ম্যানুয়ালি কমান্ডগুলো চালিয়েছেন। পেশাদারী রীতি হলো একটি CI/CD (Continuous Integration/Continuous Deployment) পাইপলাইন তৈরি করা। একটি সোর্স কোড রিপোজিটরিকে (যেমন GitHub) একটি ক্লাউড বিল্ড ট্রিগারের সাথে সংযুক্ত করার মাধ্যমে, আপনি সম্পূর্ণ ডেপ্লয়মেন্ট প্রক্রিয়াটিকে স্বয়ংক্রিয় করতে পারেন।
পাইপলাইন থাকলে, প্রতিবার আপনি কোনো কোড পরিবর্তন পুশ করলে, ক্লাউড বিল্ড স্বয়ংক্রিয়ভাবে নিম্নলিখিত কাজগুলো করতে পারে:
- নতুন কন্টেইনার ইমেজটি তৈরি করুন।
- ইমেজটি আর্টিফ্যাক্ট রেজিস্ট্রি-তে পুশ করুন।
- আপনার GKE ক্লাস্টারে আপডেট করা Kubernetes ম্যানিফেস্টগুলো প্রয়োগ করুন।
গোপনীয় তথ্য নিরাপদে পরিচালনা করুন
এই ল্যাবে, আপনি একটি .env ফাইলে কনফিগারেশন সংরক্ষণ করেছেন এবং আপনার অ্যাপ্লিকেশনে তা পাঠিয়েছেন। এটি ডেভেলপমেন্টের জন্য সুবিধাজনক হলেও এপিআই কী-এর মতো সংবেদনশীল ডেটার জন্য নিরাপদ নয়। সর্বোত্তম পন্থা হলো সিক্রেট নিরাপদে সংরক্ষণের জন্য সিক্রেট ম্যানেজার ব্যবহার করা।
GKE-এর সাথে সিক্রেট ম্যানেজারের একটি নেটিভ ইন্টিগ্রেশন রয়েছে, যা আপনাকে সিক্রেটগুলোকে আপনার সোর্স কোডে চেক ইন না করেই সরাসরি এনভায়রনমেন্ট ভেরিয়েবল বা ফাইল হিসেবে আপনার পডগুলোতে মাউন্ট করার সুযোগ দেয়।
আপনার অনুরোধ অনুযায়ী পরিষ্করণ ও সম্পদ বিভাগটি এখানে দেওয়া হলো, যা উপসংহার বিভাগের ঠিক আগে যুক্ত করা হয়েছে।
১৪. সম্পদ পরিষ্কার করুন
এই টিউটোরিয়ালে ব্যবহৃত রিসোর্সগুলোর জন্য আপনার গুগল ক্লাউড অ্যাকাউন্টে চার্জ হওয়া এড়াতে, হয় রিসোর্সগুলো যে প্রজেক্টে রয়েছে সেটি ডিলিট করে দিন, অথবা প্রজেক্টটি রেখে দিয়ে আলাদা আলাদা রিসোর্সগুলো ডিলিট করে দিন।
GKE ক্লাস্টারটি মুছে ফেলুন
এই ল্যাবের খরচের প্রধান কারণ হলো GKE ক্লাস্টার। এটি মুছে ফেললে কম্পিউট চার্জ বন্ধ হয়ে যায়।
- টার্মিনালে নিম্নলিখিত কমান্ডটি চালান:
gcloud container clusters delete adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
আর্টিফ্যাক্ট রেজিস্ট্রি রিপোজিটরিটি মুছে ফেলুন
আর্টিফ্যাক্ট রেজিস্ট্রি-তে সংরক্ষিত কন্টেইনার ইমেজগুলোর জন্য স্টোরেজ খরচ হয়।
- টার্মিনালে নিম্নলিখিত কমান্ডটি চালান:
gcloud artifacts repositories delete adk-repo \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
প্রকল্পটি মুছে ফেলুন (ঐচ্ছিক)
আপনি যদি বিশেষভাবে এই ল্যাবের জন্য একটি নতুন প্রজেক্ট তৈরি করে থাকেন এবং এটি আর ব্যবহার করার পরিকল্পনা না থাকে, তবে এটি পরিষ্কার করার সবচেয়ে সহজ উপায় হলো পুরো প্রজেক্টটি মুছে ফেলা।
- টার্মিনালে, নিম্নলিখিত কমান্ডটি চালান (
[YOUR_PROJECT_ID]এর জায়গায় আপনার আসল প্রজেক্ট আইডি বসান):gcloud projects delete [YOUR_PROJECT_ID]
১৫. উপসংহার
অভিনন্দন! আপনি সফলভাবে একটি প্রোডাকশন-গ্রেড GKE ক্লাস্টারে একটি মাল্টি-এজেন্ট ADK অ্যাপ্লিকেশন স্থাপন করেছেন। এটি একটি উল্লেখযোগ্য সাফল্য যা একটি আধুনিক ক্লাউড-নেটিভ অ্যাপ্লিকেশনের মূল জীবনচক্রকে অন্তর্ভুক্ত করে এবং আপনার নিজস্ব জটিল এজেন্টিক সিস্টেম স্থাপনের জন্য একটি মজবুত ভিত্তি প্রদান করে।
পুনরালোচনা
এই ল্যাবে, আপনি শিখেছেন:
- একটি GKE অটোপাইলট ক্লাস্টার প্রস্তুত করুন।
- একটি
Dockerfileব্যবহার করে একটি কন্টেইনার ইমেজ তৈরি করুন এবং এটিকে আর্টিফ্যাক্ট রেজিস্ট্রি- তে পুশ করুন। - Workload Identity ব্যবহার করে নিরাপদে Google Cloud API-এর সাথে সংযোগ করুন।
- একটি Deployment এবং Service-এর জন্য Kubernetes ম্যানিফেস্ট লিখুন।
- একটি লোডব্যালান্সারের সাহায্যে কোনো অ্যাপ্লিকেশনকে ইন্টারনেটে উন্মুক্ত করুন।
- হরাইজন্টালপডঅটোস্কেলার (HPA) ব্যবহার করে অটোস্কেলিং কনফিগার করুন।