
1. Einführung
Übersicht
In diesem Lab wird die entscheidende Lücke zwischen der Entwicklung eines leistungsstarken Multi-Agenten-Systems und der Bereitstellung für den realen Einsatz geschlossen. Die lokale Entwicklung von Agenten ist ein guter Anfang, für Produktionsanwendungen ist jedoch eine Plattform erforderlich, die skalierbar, zuverlässig und sicher ist.
In diesem Lab stellen Sie ein Multi-Agenten-System, das mit dem Google Agent Development Kit (ADK) erstellt wurde, in einer Produktionsumgebung in der Google Kubernetes Engine (GKE) bereit.
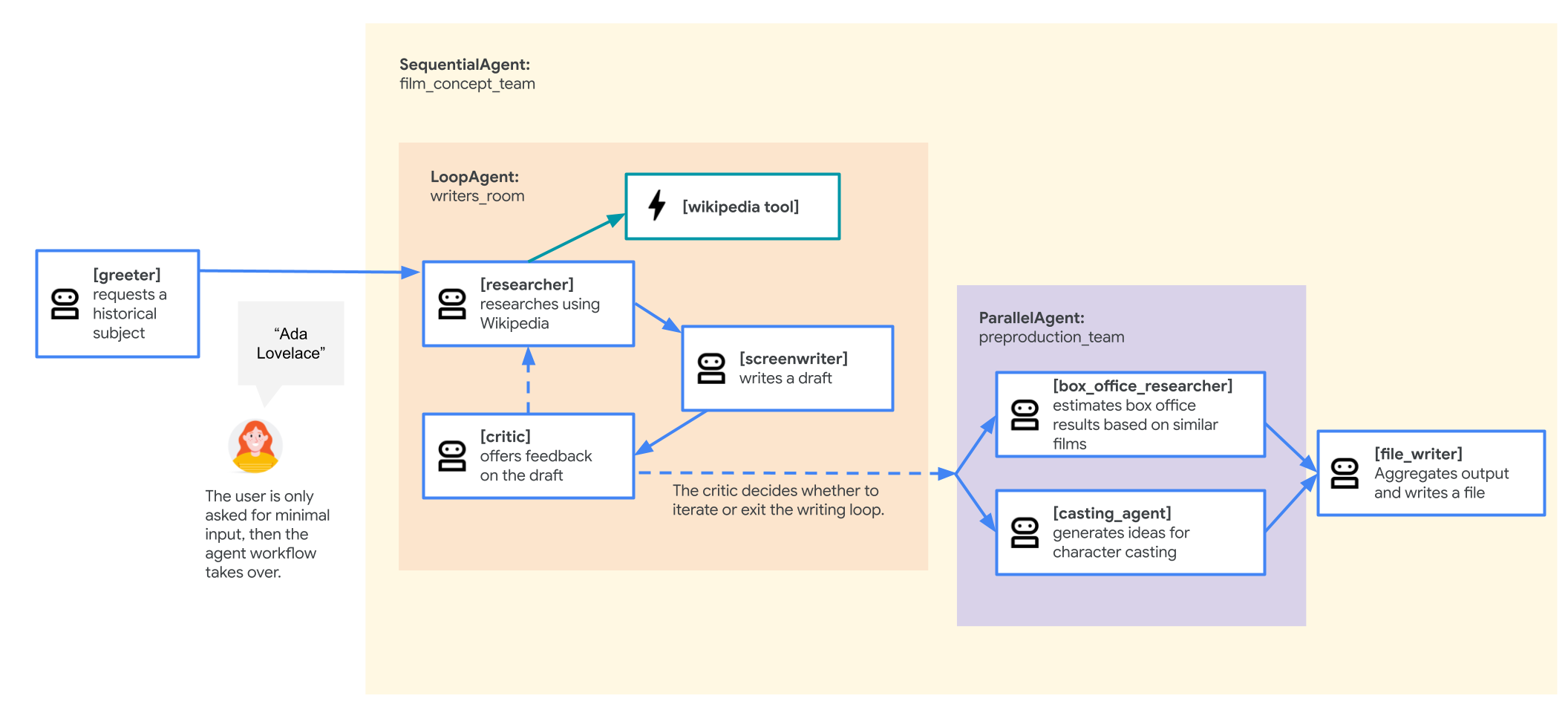
Agent für das Filmkonzeptteam
Die in diesem Lab verwendete Beispielanwendung ist ein „Filmkonzeptteam“, das aus mehreren zusammenarbeitenden Agenten besteht: einem Researcher, einem Drehbuchautor und einem Dateischreiber. Diese Agents arbeiten zusammen, um einem Nutzer dabei zu helfen, Ideen für eine Filmpitch über eine historische Figur zu sammeln und zu strukturieren.
Warum in GKE bereitstellen?
Damit Ihr Agent den Anforderungen einer Produktionsumgebung gerecht wird, benötigen Sie eine Plattform, die auf Skalierbarkeit, Sicherheit und Kosteneffizienz ausgelegt ist. Google Kubernetes Engine (GKE) bietet diese leistungsstarke und flexible Grundlage für die Ausführung Ihrer containerisierten Anwendung.
Das bietet mehrere Vorteile für Ihre Produktionsarbeitslast:
- Automatische Skalierung und Leistung: Mit dem HorizontalPodAutoscaler (HPA) können Sie unvorhersehbaren Traffic bewältigen. Er fügt Agentenreplikate automatisch hinzu oder entfernt sie, je nach Last. Für anspruchsvollere KI-Arbeitslasten können Sie Hardwarebeschleuniger wie GPUs und TPUs anhängen.
- Kostengünstige Ressourcenverwaltung: Optimieren Sie die Kosten mit GKE Autopilot, das die zugrunde liegende Infrastruktur automatisch verwaltet, sodass Sie nur für die Ressourcen bezahlen, die Ihre Anwendung anfordert.
- Integrierte Sicherheit und Beobachtbarkeit: Stellen Sie mit Workload Identity eine sichere Verbindung zu anderen Google Cloud-Diensten her. So müssen Sie keine Dienstkontoschlüssel verwalten und speichern. Alle Anwendungslogs werden automatisch an Cloud Logging gestreamt, um eine zentrale Überwachung und Fehlerbehebung zu ermöglichen.
- Kontrolle und Portabilität: Vermeiden Sie Anbieterabhängigkeit mit Open-Source-Kubernetes. Ihre Anwendung ist portierbar und kann in jedem Kubernetes-Cluster ausgeführt werden, lokal oder in anderen Clouds.
Lerninhalte
Aufgaben in diesem Lab:
- Stellen Sie einen GKE Autopilot-Cluster bereit.
- Anwendung mit einem Dockerfile containerisieren und das Image per Push an Artifact Registry übertragen
- Verbinden Sie Ihre Anwendung sicher mit Google Cloud APIs mithilfe von Workload Identity.
- Kubernetes-Manifeste für ein Deployment und einen Dienst schreiben und anwenden
- Eine Anwendung mit einem LoadBalancer im Internet freigeben
- Autoscaling mit einem HorizontalPodAutoscaler (HPA) konfigurieren.
2. Projekt einrichten
Google-Konto
Wenn Sie noch kein privates Google-Konto haben, müssen Sie ein Google-Konto erstellen.
Verwenden Sie stattdessen ein privates Konto.
In der Google Cloud Console anmelden
Melden Sie sich mit einem privaten Google-Konto in der Google Cloud Console an.
Abrechnung aktivieren
Privates Rechnungskonto einrichten
Wenn Sie die Abrechnung mit Google Cloud-Guthaben eingerichtet haben, können Sie diesen Schritt überspringen.
Aktivieren Sie die Abrechnung in der Cloud Console, um ein privates Rechnungskonto einzurichten.
Hinweise:
- Die Kosten für Cloud-Ressourcen für dieses Lab sollten weniger als 1 $betragen.
- Sie können die Schritte am Ende dieses Labs ausführen, um Ressourcen zu löschen und so weitere Kosten zu vermeiden.
- Neue Nutzer haben Anspruch auf die kostenlose Testversion mit einem Guthaben von 300$.
Projekt erstellen (optional)
Wenn Sie kein aktuelles Projekt haben, das Sie für dieses Lab verwenden möchten, erstellen Sie hier ein neues Projekt.
3. Cloud Shell-Editor öffnen
- Klicken Sie auf diesen Link, um direkt zum Cloud Shell-Editor zu gelangen.
- Wenn Sie heute an irgendeinem Punkt zur Autorisierung aufgefordert werden, klicken Sie auf Autorisieren, um fortzufahren.
- Wenn das Terminal nicht unten auf dem Bildschirm angezeigt wird, öffnen Sie es:
- Klicken Sie auf Ansehen.
- Klicken Sie auf Terminal
 .
.
- Legen Sie im Terminal Ihr Projekt mit diesem Befehl fest:
gcloud config set project [PROJECT_ID]- Beispiel:
gcloud config set project lab-project-id-example - Wenn Sie sich nicht mehr an Ihre Projekt-ID erinnern, können Sie alle Ihre Projekt-IDs mit folgendem Befehl auflisten:
gcloud projects list
- Beispiel:
- Es sollte folgende Meldung angezeigt werden:
Updated property [core/project].
4. APIs aktivieren
Wenn Sie GKE, Artifact Registry, Cloud Build und Vertex AI verwenden möchten, müssen Sie die entsprechenden APIs in Ihrem Google Cloud-Projekt aktivieren.
- Aktivieren Sie die APIs im Terminal:
gcloud services enable \ container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.comOperation "operations/acf.p2-176675280136-b03ab5e4-3483-4ebf-9655-43dc3b345c63" finished successfully.
Einführung der APIs
- Mit der Google Kubernetes Engine API (
container.googleapis.com) können Sie den GKE-Cluster erstellen und verwalten, auf dem Ihr Agent ausgeführt wird. GKE bietet eine verwaltete Umgebung für das Deployment, die Verwaltung und die Skalierung von Containeranwendungen in der Google-Infrastruktur. - Die Artifact Registry API (
artifactregistry.googleapis.com) bietet ein sicheres, privates Repository zum Speichern des Container-Images Ihres Agents. Es ist die Weiterentwicklung von Container Registry und lässt sich nahtlos in GKE und Cloud Build einbinden. - Die Cloud Build API (
cloudbuild.googleapis.com) wird vom Befehlgcloud builds submitverwendet, um Ihr Container-Image in der Cloud aus Ihrem Dockerfile zu erstellen. Es handelt sich um eine serverlose CI/CD-Plattform, die Ihre Builds in der Google Cloud-Infrastruktur ausführt. - Die Vertex AI API (
aiplatform.googleapis.com) ermöglicht es Ihrem bereitgestellten Agent, mit Gemini-Modellen zu kommunizieren, um seine Kernaufgaben auszuführen. Sie bietet die einheitliche API für alle KI-Dienste von Google Cloud.
5. Bereiten Sie Ihre Entwicklungsumgebung vor
Verzeichnisstruktur erstellen
- Erstellen Sie im Terminal das Projektverzeichnis und die erforderlichen Unterverzeichnisse:
mkdir -p ~/adk_multiagent_systems/workflow_agents cd ~/adk_multiagent_systems - Führen Sie im Terminal den folgenden Befehl aus, um das Verzeichnis im Cloud Shell-Editor-Explorer zu öffnen.
cloudshell open-workspace ~/adk_multiagent_systems - Der Explorer-Bereich auf der linken Seite wird aktualisiert. Sie sollten nun die von Ihnen erstellten Verzeichnisse sehen.
Wenn Sie in den folgenden Schritten Dateien erstellen, werden diese in diesem Verzeichnis angezeigt.
Startdateien erstellen
Als Nächstes erstellen Sie die erforderlichen Startdateien für die Anwendung.
- Erstellen Sie
callback_logging.py, indem Sie im Terminal Folgendes ausführen. Diese Datei enthält das Logging für die Observability.cat <<EOF > ~/adk_multiagent_systems/callback_logging.py """ Provides helper functions for observability. Handles formatting and sending agent queries, responses, and tool calls to Google Cloud Logging to aid in monitoring and debugging. """ import logging import google.cloud.logging from google.adk.agents.callback_context import CallbackContext from google.adk.models import LlmResponse, LlmRequest def log_query_to_model(callback_context: CallbackContext, llm_request: LlmRequest): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_request.contents and llm_request.contents[-1].role == 'user': if llm_request.contents[-1].parts and "text" in llm_request.contents[-1].parts: last_user_message = llm_request.contents[-1].parts[0].text logging.info(f"[query to {callback_context.agent_name}]: " + last_user_message) def log_model_response(callback_context: CallbackContext, llm_response: LlmResponse): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_response.content and llm_response.content.parts: for part in llm_response.content.parts: if part.text: logging.info(f"[response from {callback_context.agent_name}]: " + part.text) elif part.function_call: logging.info(f"[function call from {callback_context.agent_name}]: " + part.function_call.name) EOF - Erstellen Sie
workflow_agents/__init__.py, indem Sie im Terminal Folgendes ausführen. Dadurch wird das Verzeichnis als Python-Paket markiert.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/__init__.py """ Marks the directory as a Python package and exposes the agent module, allowing the ADK to discover and register the agents defined within. """ from . import agent EOF - Erstellen Sie
workflow_agents/agent.py, indem Sie im Terminal Folgendes ausführen. Diese Datei enthält die Kernlogik für Ihr Multi-Agent-Team.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/agent.py """ Defines the core multi-agent workflow. Configures individual agents (Researcher, Screenwriter, File Writer), assigns their specific tools, and orchestrates their collaboration using the ADK's SequentialAgent pattern. """ import os import logging import google.cloud.logging from callback_logging import log_query_to_model, log_model_response from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent, LoopAgent, ParallelAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool # import from google.genai import types from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL") print(model_name) # Tools def append_to_state( tool_context: ToolContext, field: str, response: str ) -> dict[str, str]: """Append new output to an existing state key. Args: field (str): a field name to append to response (str): a string to append to the field Returns: dict[str, str]: {"status": "success"} """ existing_state = tool_context.state.get(field, []) tool_context.state[field] = existing_state + [response] logging.info(f"[Added to {field}] {response}") return {"status": "success"} def write_file( tool_context: ToolContext, directory: str, filename: str, content: str ) -> dict[str, str]: target_path = os.path.join(directory, filename) os.makedirs(os.path.dirname(target_path), exist_ok=True) with open(target_path, "w") as f: f.write(content) return {"status": "success"} # Agents file_writer = Agent( name="file_writer", model=model_name, description="Creates marketing details and saves a pitch document.", instruction=""" PLOT_OUTLINE: { PLOT_OUTLINE? } INSTRUCTIONS: - Create a marketable, contemporary movie title suggestion for the movie described in the PLOT_OUTLINE. If a title has been suggested in PLOT_OUTLINE, you can use it, or replace it with a better one. - Use your 'write_file' tool to create a new txt file with the following arguments: - for a filename, use the movie title - Write to the 'movie_pitches' directory. - For the 'content' to write, extract the following from the PLOT_OUTLINE: - A logline - Synopsis or plot outline """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[write_file], ) screenwriter = Agent( name="screenwriter", model=model_name, description="As a screenwriter, write a logline and plot outline for a biopic about a historical character.", instruction=""" INSTRUCTIONS: Your goal is to write a logline and three-act plot outline for an inspiring movie about a historical character(s) described by the PROMPT: { PROMPT? } - If there is CRITICAL_FEEDBACK, use those thoughts to improve upon the outline. - If there is RESEARCH provided, feel free to use details from it, but you are not required to use it all. - If there is a PLOT_OUTLINE, improve upon it. - Use the 'append_to_state' tool to write your logline and three-act plot outline to the field 'PLOT_OUTLINE'. - Summarize what you focused on in this pass. PLOT_OUTLINE: { PLOT_OUTLINE? } RESEARCH: { research? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], ) researcher = Agent( name="researcher", model=model_name, description="Answer research questions using Wikipedia.", instruction=""" PROMPT: { PROMPT? } PLOT_OUTLINE: { PLOT_OUTLINE? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } INSTRUCTIONS: - If there is a CRITICAL_FEEDBACK, use your wikipedia tool to do research to solve those suggestions - If there is a PLOT_OUTLINE, use your wikipedia tool to do research to add more historical detail - If these are empty, use your Wikipedia tool to gather facts about the person in the PROMPT - Use the 'append_to_state' tool to add your research to the field 'research'. - Summarize what you have learned. Now, use your Wikipedia tool to do research. """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[ LangchainTool(tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())), append_to_state, ], ) film_concept_team = SequentialAgent( name="film_concept_team", description="Write a film plot outline and save it as a text file.", sub_agents=[ researcher, screenwriter, file_writer ], ) root_agent = Agent( name="greeter", model=model_name, description="Guides the user in crafting a movie plot.", instruction=""" - Let the user know you will help them write a pitch for a hit movie. Ask them for a historical figure to create a movie about. - When they respond, use the 'append_to_state' tool to store the user's response in the 'PROMPT' state key and transfer to the 'film_concept_team' agent """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], sub_agents=[film_concept_team], ) EOF
Ihre Dateistruktur sollte jetzt so aussehen: 
Virtuelle Umgebung einrichten
- Erstellen und aktivieren Sie im Terminal eine virtuelle Umgebung mit
uv. So wird sichergestellt, dass die Projektabhängigkeiten nicht mit dem System-Python in Konflikt stehen.uv venv source .venv/bin/activate
Installationsanforderungen
- Führen Sie den folgenden Befehl im Terminal aus, um die Datei
requirements.txtzu erstellen.cat <<EOF > ~/adk_multiagent_systems/requirements.txt # Lists all Python dependencies required to run the multi-agent system, # including the Google ADK, LangChain community tools, and web server libraries. langchain-community==0.4.1 wikipedia==1.4.0 google-adk==1.27.5 fastapi==0.135.2 uvicorn==0.42.0 EOF - Installieren Sie die erforderlichen Pakete in Ihrer virtuellen Umgebung im Terminal.
uv pip install -r requirements.txt
Umgebungsvariablen einrichten
- Verwenden Sie den folgenden Befehl im Terminal, um die Datei
.envzu erstellen. Ihre Projekt-ID und Region werden automatisch eingefügt.cat <<EOF > ~/adk_multiagent_systems/.env GOOGLE_CLOUD_PROJECT="$(gcloud config get-value project)" GOOGLE_CLOUD_PROJECT_NUMBER="$(gcloud projects describe $(gcloud config get-value project) --format='value(projectNumber)')" GOOGLE_CLOUD_LOCATION="us-central1" GOOGLE_GENAI_USE_VERTEXAI=true MODEL="gemini-2.5-flash" EOF - Laden Sie die Variablen im Terminal in Ihre Shell-Sitzung.
source .env
Zusammenfassung
In diesem Abschnitt haben Sie die lokale Grundlage für Ihr Projekt geschaffen:
- Die Verzeichnisstruktur und die erforderlichen Agent-Starterdateien (
agent.py,callback_logging.py,requirements.txt) wurden erstellt. - Sie haben Ihre Abhängigkeiten mithilfe einer virtuellen Umgebung (
uv) isoliert. - Konfigurierte Umgebungsvariablen (
.env) zum Speichern projektspezifischer Details wie Ihrer Projekt-ID und Region.
6. Agent-Datei ansehen
Sie haben den Quellcode für das Lab eingerichtet, einschließlich eines vorgefertigten Multi-Agenten-Systems. Bevor Sie die Anwendung bereitstellen, sollten Sie wissen, wie die Agents definiert sind. Die Kernlogik des Agents befindet sich in workflow_agents/agent.py.
- Verwenden Sie im Cloud Shell-Editor den Datei-Explorer auf der linken Seite, um zu
adk_multiagent_systems/workflow_agents/zu navigieren und die Dateiagent.pyzu öffnen. - Sehen Sie sich die Datei kurz an. Sie müssen nicht jede Zeile verstehen, aber achten Sie auf die allgemeine Struktur:
- Einzelne Agents:In der Datei werden drei verschiedene
Agent-Objekte definiert:researcher,screenwriterundfile_writer. Jedem Agent wird ein bestimmtesinstruction(sein Prompt) und eine Liste dertoolszugewiesen, die er verwenden darf (z. B. dasWikipediaQueryRun-Tool oder ein benutzerdefinierteswrite_file-Tool). - Agent-Zusammensetzung:Die einzelnen Agents werden zu einem
SequentialAgentnamensfilm_concept_teamverkettet. Dadurch wird das ADK angewiesen, diese Agents nacheinander auszuführen und den Status von einem zum nächsten zu übergeben. - Der Root-Agent:Ein
root_agentnamens „greeter“ wird definiert, um die erste Nutzerinteraktion zu verarbeiten. Wenn der Nutzer einen Prompt eingibt, speichert dieser Agent ihn im Anwendungsstatus und übergibt dann die Steuerung an denfilm_concept_team-Workflow.
- Einzelne Agents:In der Datei werden drei verschiedene
Wenn Sie diese Struktur verstehen, können Sie besser nachvollziehen, was Sie bereitstellen: nicht nur einen einzelnen Agent, sondern ein koordiniertes Team von spezialisierten Agents, die vom ADK orchestriert werden.
7. Erstellen Sie einen GKE Autopilot-Cluster
Nachdem Sie Ihre Umgebung vorbereitet haben, müssen Sie die Infrastruktur bereitstellen, auf der Ihre Agent-Anwendung ausgeführt wird. Sie erstellen einen GKE Autopilot-Cluster, der als Grundlage für Ihre Bereitstellung dient. Wir verwenden den Autopilot-Modus, weil er die komplexe Verwaltung der zugrunde liegenden Knoten, der Skalierung und der Sicherheit des Clusters übernimmt, sodass Sie sich ganz auf die Bereitstellung Ihrer Anwendung konzentrieren können.
- Erstellen Sie im Terminal einen neuen GKE Autopilot-Cluster mit dem Namen
adk-cluster.gcloud container clusters create-auto adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT - Nachdem der Cluster erstellt wurde, konfigurieren Sie
kubectl, um eine Verbindung zu ihm herzustellen. Führen Sie dazu Folgendes im Terminal aus:gcloud container clusters get-credentials adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT~/.kube/config). Ab diesem Zeitpunkt ist daskubectl-Befehlszeilentool authentifiziert und wird angewiesen, mit Ihremadk-clusterzu kommunizieren.
Zusammenfassung
In diesem Abschnitt haben Sie die Infrastruktur bereitgestellt:
- Sie haben einen vollständig verwalteten GKE Autopilot-Cluster mit
gclouderstellt. - Sie haben Ihr lokales
kubectl-Tool so konfiguriert, dass es sich authentifiziert und mit dem neuen Cluster kommuniziert.
8. Anwendung containerisieren und per Push übertragen
Der Code Ihres Agents ist derzeit nur in Ihrer Cloud Shell-Umgebung vorhanden. Damit Sie die Anwendung in GKE ausführen können, müssen Sie sie zuerst in ein Container-Image packen. Ein Container-Image ist eine statische, portable Datei, die den Code Ihrer Anwendung und alle zugehörigen Abhängigkeiten enthält. Wenn Sie dieses Image ausführen, wird daraus ein aktiver Container.
Dieser Prozess umfasst drei wichtige Schritte:
- Einstiegspunkt erstellen: Definieren Sie eine
main.py-Datei, um die Agent-Logik in einen ausführbaren Webserver umzuwandeln. - Container-Image definieren: Erstellen Sie ein Dockerfile, das als Blaupause für die Erstellung Ihres Container-Images dient.
- Erstellen und übertragen: Mit Cloud Build wird das Dockerfile ausgeführt, das Container-Image erstellt und in Google Artifact Registry übertragen, einem sicheren Repository für Ihre Images.
Anwendung auf die Bereitstellung vorbereiten
Ihr ADK-Agent benötigt einen Webserver, um Anfragen zu empfangen. Die Datei main.py dient als Einstiegspunkt und verwendet das FastAPI-Framework, um die Funktionen Ihres Agents über HTTP verfügbar zu machen.
- Erstellen Sie im Stammverzeichnis des Verzeichnisses
adk_multiagent_systemsim Terminal eine neue Datei mit dem Namenmain.py.cat <<EOF > ~/adk_multiagent_systems/main.py """ Serves as the application entry point. Initializes the FastAPI web server, discovers the agents defined in the workflow directory, and exposes them via HTTP endpoints for interaction. """ import os import uvicorn from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Get the directory where main.py is located AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) # Configure the session service (e.g., SQLite for local storage) SESSION_SERVICE_URI = "sqlite:///./sessions.db" # Configure CORS to allow requests from various origins for this lab ALLOWED_ORIGINS = ["http://localhost", "http://localhost:8080", "*"] # Enable the ADK's built-in web interface SERVE_WEB_INTERFACE = True # Call the ADK function to discover agents and create the FastAPI app app: FastAPI = get_fast_api_app( agents_dir=AGENT_DIR, session_service_uri=SESSION_SERVICE_URI, allow_origins=ALLOWED_ORIGINS, web=SERVE_WEB_INTERFACE, ) # You can add more FastAPI routes or configurations below if needed # Example: # @app.get("/hello") # async def read_root(): # return {"Hello": "World"} if __name__ == "__main__": # Get the port from the PORT environment variable provided by the container runtime # Run the Uvicorn server, listening on all available network interfaces (0.0.0.0) uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("PORT", 8080))) EOFuvicorn-Server führt diese Anwendung aus und überwacht den Host0.0.0.0, um Verbindungen von jeder IP-Adresse zu akzeptieren, und den Port, der durch die UmgebungsvariablePORTangegeben wird. Diese Variable legen wir später in unserem Kubernetes-Manifest fest.
An dieser Stelle sollte Ihre Dateistruktur im Explorer-Bereich des Cloud Shell-Editors so aussehen: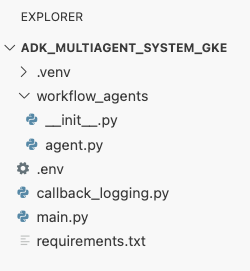
ADK-Agent mit Docker containerisieren
Um unsere Anwendung in GKE bereitzustellen, müssen wir sie zuerst in ein Container-Image packen. Dieses enthält den Code unserer Anwendung sowie alle Bibliotheken und Abhängigkeiten, die für die Ausführung erforderlich sind. Wir verwenden Docker, um dieses Container-Image zu erstellen.
- Erstellen Sie im Stammverzeichnis des Verzeichnisses
adk_multiagent_systemsim Terminal eine neue Datei mit dem NamenDockerfile.cat <<'EOF' > ~/adk_multiagent_systems/Dockerfile # Defines the blueprint for the container image. Installs dependencies, # sets up a secure non-root user, and specifies the startup command to run the # agent web server. # Use an official lightweight Python image as the base FROM python:3.13-slim # Set the working directory inside the container WORKDIR /app # Create a non-root user for security best practices RUN adduser --disabled-password --gecos "" myuser # Copy and install dependencies first to leverage Docker's layer caching COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt # Copy all application code into the container COPY . . # Create the directory where the agent will write files at runtime # The -p flag ensures the command doesn't fail if the directory already exists RUN mkdir -p movie_pitches # Change ownership of EVERYTHING in /app to the non-root user # Without this, the running agent would be denied permission to write files. RUN chown -R myuser:myuser /app # Switch the active user from root to the non-root user USER myuser # Add the user's local binary directory to the system's PATH ENV PATH="/home/myuser/.local/bin:$PATH" # Define the command to run when the container starts CMD ["sh", "-c", "uvicorn main:app --host 0.0.0.0 --port $PORT"] EOF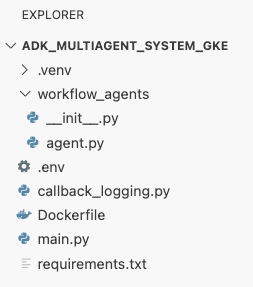
Container-Image erstellen und per Push an Artifact Registry übertragen
Nachdem Sie ein Dockerfile haben, verwenden Sie Cloud Build, um das Image zu erstellen und in Artifact Registry zu übertragen. Artifact Registry ist eine sichere, private Registry, die in Google Cloud-Dienste eingebunden ist. GKE ruft das Image aus dieser Registry ab, um Ihre Anwendung auszuführen.
- Erstellen Sie im Terminal ein neues Artifact Registry-Repository zum Speichern des Container-Images.
gcloud artifacts repositories create adk-repo \ --repository-format=docker \ --location=$GOOGLE_CLOUD_LOCATION \ --description="ADK repository" - Verwenden Sie im Terminal den Befehl
gcloud builds submit, um Ihr Container-Image zu erstellen und in das Repository zu übertragen.gcloud builds submit \ --tag $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo/adk-agent:latest \ --project=$GOOGLE_CLOUD_PROJECT \ .Dockerfileauszuführen. Das Image wird in der Cloud erstellt, mit der Adresse Ihres Artifact Registry-Repositorys getaggt und automatisch dorthin übertragen. - Prüfen Sie im Terminal, ob das Image erstellt wurde:
gcloud artifacts docker images list \ $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo \ --project=$GOOGLE_CLOUD_PROJECT
Zusammenfassung
In diesem Abschnitt haben Sie Ihren Code für die Bereitstellung verpackt:
- Sie haben einen
main.py-Einstiegspunkt erstellt, um Ihre Agents in einen FastAPI-Webserver einzubinden. - Sie haben eine
Dockerfiledefiniert, um Ihren Code und Ihre Abhängigkeiten in einem portierbaren Image zu bündeln. - Cloud Build wurde verwendet, um das Image zu erstellen und in ein sicheres Artifact Registry-Repository zu übertragen.
9. Kubernetes-Manifeste erstellen
Nachdem Ihr Container-Image erstellt und in Artifact Registry gespeichert wurde, müssen Sie GKE anweisen, wie es ausgeführt werden soll. Dazu gehören zwei Hauptaktivitäten:
- Berechtigungen konfigurieren: Sie erstellen eine dedizierte Identität für Ihren Agent im Cluster und gewähren ihr sicheren Zugriff auf die Google Cloud APIs, die sie benötigt (insbesondere Vertex AI).
- Anwendungsstatus definieren: Sie schreiben eine Kubernetes-Manifestdatei, ein YAML-Dokument, in dem alles, was für die Ausführung Ihrer Anwendung erforderlich ist, deklarativ definiert wird, einschließlich des Container-Images, der Umgebungsvariablen und der Art und Weise, wie die Anwendung im Netzwerk verfügbar gemacht werden soll.
Kubernetes-Dienstkonto für Vertex AI konfigurieren
Ihr KI-Agent benötigt die Berechtigung zur Kommunikation mit der Vertex AI API, um auf Gemini-Modelle zugreifen zu können. Die sicherste und empfohlene Methode zum Erteilen dieser Berechtigung in GKE ist Workload Identity. Mit Workload Identity können Sie eine Kubernetes-native Identität (ein Kubernetes-Dienstkonto) mit einer Google Cloud-Identität (einem IAM-Dienstkonto) verknüpfen. Dadurch entfällt die Notwendigkeit, statische JSON-Schlüssel herunterzuladen, zu verwalten und zu speichern.
- Erstellen Sie im Terminal das Kubernetes-Dienstkonto (
adk-agent-sa). Dadurch wird eine Identität für Ihren Agent im GKE-Cluster erstellt, die von Ihren Pods verwendet werden kann.kubectl create serviceaccount adk-agent-sa - Verknüpfen Sie im Terminal Ihr Kubernetes-Dienstkonto mit Google Cloud IAM, indem Sie eine Richtlinienbindung erstellen. Mit diesem Befehl wird Ihrem
adk-agent-sadie Rolleaiplatform.userzugewiesen, sodass die Vertex AI API sicher aufgerufen werden kann.gcloud projects add-iam-policy-binding projects/${GOOGLE_CLOUD_PROJECT} \ --role=roles/aiplatform.user \ --member=principal://iam.googleapis.com/projects/${GOOGLE_CLOUD_PROJECT_NUMBER}/locations/global/workloadIdentityPools/${GOOGLE_CLOUD_PROJECT}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \ --condition=None
Kubernetes-Manifestdateien erstellen
Kubernetes verwendet YAML-Manifestdateien, um den gewünschten Zustand Ihrer Anwendung zu definieren. Sie erstellen eine deployment.yaml-Datei mit zwei wichtigen Kubernetes-Objekten: einem Deployment und einem Service.
- Generieren Sie die Datei
deployment.yamlim Terminal.cat <<EOF > ~/adk_multiagent_systems/deployment.yaml # Defines the Kubernetes resources required to deploy the application to GKE. # Includes the Deployment (to run the container pods) and the Service # (to expose the application via a Load Balancer). apiVersion: apps/v1 kind: Deployment metadata: name: adk-agent spec: replicas: 1 selector: matchLabels: app: adk-agent template: metadata: labels: app: adk-agent spec: # Assign the Kubernetes Service Account for Workload Identity serviceAccountName: adk-agent-sa containers: - name: adk-agent imagePullPolicy: Always # The path to the container image in Artifact Registry image: ${GOOGLE_CLOUD_LOCATION}-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/adk-repo/adk-agent:latest # Define the resources for GKE Autopilot to provision resources: limits: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" requests: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" ports: - containerPort: 8080 # Environment variables passed to the application env: - name: PORT value: "8080" - name: GOOGLE_CLOUD_PROJECT value: ${GOOGLE_CLOUD_PROJECT} - name: GOOGLE_CLOUD_LOCATION value: ${GOOGLE_CLOUD_LOCATION} - name: GOOGLE_GENAI_USE_VERTEXAI value: "true" - name: MODEL value: "gemini-2.5-flash" --- apiVersion: v1 kind: Service metadata: name: adk-agent spec: # Create a public-facing Network Load Balancer with an external IP type: LoadBalancer ports: - port: 80 targetPort: 8080 selector: app: adk-agent EOF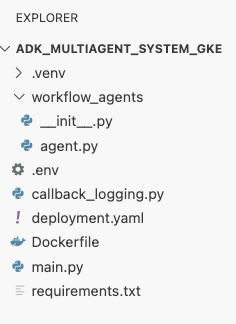
Zusammenfassung
In diesem Abschnitt haben Sie die Sicherheits- und Bereitstellungskonfiguration definiert:
- Sie haben ein Kubernetes-Dienstkonto erstellt und es mithilfe von Workload Identity mit Google Cloud IAM verknüpft. So können Ihre Pods sicher auf Vertex AI zugreifen, ohne dass Sie Schlüssel verwalten müssen.
- Es wurde eine
deployment.yaml-Datei generiert, in der das Deployment (wie die Pods ausgeführt werden) und der Dienst (wie sie über einen Load-Balancer bereitgestellt werden) definiert sind.
10. Anwendung in GKE bereitstellen
Nachdem Sie die Manifestdatei definiert und Ihr Container-Image in Artifact Registry hochgeladen haben, können Sie Ihre Anwendung jetzt bereitstellen. In dieser Aufgabe verwenden Sie kubectl, um Ihre Konfiguration auf den GKE-Cluster anzuwenden. Anschließend überwachen Sie den Status, um sicherzustellen, dass Ihr Agent ordnungsgemäß gestartet wird.
- Wenden Sie das
deployment.yaml-Manifest in Ihrem Terminal auf Ihren Cluster an.kubectl apply -f deployment.yamlkubectl applywird die Dateideployment.yamlan den Kubernetes API-Server gesendet. Der Server liest dann Ihre Konfiguration und orchestriert die Erstellung der Deployment- und Serviceobjekte. - Im Terminal können Sie den Status Ihres Deployments in Echtzeit prüfen. Warten Sie, bis die Pods den Status
Runninghaben.kubectl get pods -l=app=adk-agent --watch- Ausstehend: Der Pod wurde vom Cluster akzeptiert, aber der Container wurde noch nicht erstellt.
- Container erstellen: GKE ruft Ihr Container-Image aus Artifact Registry ab und startet den Container.
- Ausführung: Erfolgreich! Der Container wird ausgeführt und Ihre Agent-Anwendung ist live.
- Sobald der Status
Runningangezeigt wird, drücken Sie im Terminal STRG+C, um den Befehl „watch“ zu beenden und zur Eingabeaufforderung zurückzukehren.
Zusammenfassung
In diesem Abschnitt haben Sie die Arbeitslast gestartet:
- Verwenden Sie
kubectlapply, um Ihr Manifest an den Cluster zu senden. - Der Pod-Lebenszyklus wurde überwacht (Pending –> ContainerCreating –> Running), um sicherzustellen, dass die Anwendung erfolgreich gestartet wurde.
11. Mit dem Agent interagieren
Ihr ADK-Agent wird jetzt live in GKE ausgeführt und ist über einen öffentlichen Load-Balancer im Internet verfügbar. Sie stellen eine Verbindung zur Weboberfläche des Agenten her, um mit ihm zu interagieren und zu prüfen, ob das gesamte System korrekt funktioniert.
Externe IP-Adresse Ihres Dienstes finden
Um auf den Agent zuzugreifen, müssen Sie zuerst die öffentliche IP-Adresse abrufen, die GKE für Ihren Dienst bereitgestellt hat.
- Führen Sie im Terminal den folgenden Befehl aus, um die Details Ihres Dienstes abzurufen.
kubectl get service adk-agent - Suchen Sie nach dem Wert in der Spalte
EXTERNAL-IP. Es kann ein bis zwei Minuten dauern, bis die IP-Adresse zugewiesen wird, nachdem Sie den Dienst zum ersten Mal bereitgestellt haben. Wennpendingangezeigt wird, warten Sie eine Minute und führen Sie den Befehl noch einmal aus. Die Ausgabe sieht etwa so aus:NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE adk-agent-service LoadBalancer 10.120.12.234 34.123.45.67 80:31234/TCP 5mEXTERNAL-IPaufgeführte Adresse (z.B. 34.123.45.67) ist der öffentliche Einstiegspunkt für Ihren Agenten.
Bereitgestellten KI-Agenten testen
Sie können jetzt über die öffentliche IP-Adresse direkt über Ihren Browser auf die integrierte Weboberfläche des ADK zugreifen.
- Kopieren Sie die externe IP-Adresse (
EXTERNAL-IP) aus dem Terminal. - Öffnen Sie einen neuen Tab in Ihrem Webbrowser und geben Sie
http://[EXTERNAL-IP]ein. Ersetzen Sie dabei[EXTERNAL-IP]durch die kopierte IP-Adresse. - Jetzt sollten Sie die ADK-Weboberfläche sehen.
- Achten Sie darauf, dass im Drop-down-Menü für den Agent workflow_agents ausgewählt ist.
- Aktivieren Sie Tokenstreaming.
- Geben Sie
helloein und drücken Sie die Eingabetaste, um eine neue Unterhaltung zu beginnen. - Sehen Sie sich das Ergebnis an. Der KI-Agent sollte schnell mit seiner Begrüßung antworten: „Ich kann dir helfen, ein Konzept für einen Kinohit zu schreiben. Über welche historische Persönlichkeit möchtest du einen Film drehen?“
- Wenn Sie aufgefordert werden, eine historische Persönlichkeit auszuwählen, wählen Sie eine aus, die Sie interessiert. Hier einige Ideen:
the most successful female pirate in historythe woman who invented the first computer compilera legendary lawman of the American Wild West
Zusammenfassung
In diesem Abschnitt haben Sie die Bereitstellung überprüft:
- Die vom LoadBalancer zugewiesene externe IP-Adresse wurde abgerufen.
- Sie haben über einen Browser auf die ADK-Web-UI zugegriffen, um zu bestätigen, dass das Multi-Agent-System reagiert und funktioniert.
12. Autoscaling konfigurieren
Eine der größten Herausforderungen in der Produktion ist der Umgang mit unvorhersehbarem Nutzer-Traffic. Wenn Sie eine feste Anzahl von Replikaten wie in der vorherigen Aufgabe fest codieren, zahlen Sie entweder zu viel für inaktive Ressourcen oder riskieren eine schlechte Leistung bei Traffic-Spitzen. GKE löst dieses Problem mit automatischem Skalieren.
Sie konfigurieren einen HorizontalPodAutoscaler (HPA), einen Kubernetes-Controller, der die Anzahl der ausgeführten Pods in Ihrem Deployment automatisch an die CPU-Auslastung in Echtzeit anpasst.
- Erstellen Sie im Terminal des Cloud Shell-Editors eine neue
hpa.yaml-Datei im Stammverzeichnis des Verzeichnissesadk_multiagent_systems.cloudshell edit ~/adk_multiagent_systems/hpa.yaml - Fügen Sie der neuen
hpa.yaml-Datei den folgenden Inhalt hinzu:# Configures the HorizontalPodAutoscaler (HPA) to automatically scale # the number of running agent pods up or down based on CPU utilization # to handle varying traffic loads. apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: adk-agent-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: adk-agent minReplicas: 1 maxReplicas: 5 targetCPUUtilizationPercentage: 50adk-agent-Deployment ausgerichtet. So wird dafür gesorgt, dass immer mindestens ein Pod ausgeführt wird, es werden maximal fünf Pods festgelegt und Replikate werden hinzugefügt oder entfernt, um die durchschnittliche CPU-Auslastung bei etwa 50 % zu halten. An diesem Punkt sollte Ihre Dateistruktur im Explorer-Bereich des Cloud Shell-Editors so aussehen:
- Wenden Sie die HPA auf Ihren Cluster an, indem Sie sie in das Terminal einfügen.
kubectl apply -f hpa.yaml
Autoscaler prüfen
Der HPA ist jetzt aktiv und überwacht Ihre Bereitstellung. Sie können den Status prüfen, um die Funktion in Aktion zu sehen.
- Führen Sie im Terminal den folgenden Befehl aus, um den Status Ihres HPA abzurufen.
kubectl get hpa adk-agent-hpaNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE adk-agent-hpa Deployment/adk-agent 0%/50% 1 5 1 30s
Zusammenfassung
In diesem Abschnitt haben Sie die Optimierung für Produktionszugriff vorgenommen:
- Sie haben ein
hpa.yaml-Manifest erstellt, um Skalierungsregeln zu definieren. - Der HorizontalPodAutoscaler (HPA) wurde bereitgestellt, um die Anzahl der Pod-Replikate automatisch anhand der CPU-Auslastung anzupassen.
13. Für die Produktion vorbereiten
Hinweis: Die folgenden Abschnitte dienen nur zu Informationszwecken und enthalten keine weiteren auszuführenden Schritte. Sie sollen Ihnen Kontext und Best Practices für die Produktionsumstellung Ihrer Anwendung bieten.
Leistung durch Ressourcenzuweisung optimieren
In GKE Autopilot steuern Sie die Menge an CPU und Arbeitsspeicher, die für Ihre Anwendung bereitgestellt wird, indem Sie Ressourcen requests in Ihrem deployment.yaml angeben.
Wenn Ihr Agent langsam ist oder abstürzt, weil nicht genügend Arbeitsspeicher vorhanden ist, können Sie die Ressourcenzuweisung erhöhen. Bearbeiten Sie dazu den Block resources in Ihrer deployment.yaml-Datei und wenden Sie die Datei mit kubectl apply noch einmal an.
So verdoppeln Sie beispielsweise den Arbeitsspeicher:
# In deployment.yaml
# ...
resources:
requests:
memory: "2Gi" # Increased from 1Gi
cpu: "1000m"
# ...
Workflow mit CI/CD automatisieren
In diesem Lab haben Sie Befehle manuell ausgeführt. In der Praxis wird eine CI/CD-Pipeline (Continuous Integration/Continuous Deployment) erstellt. Wenn Sie ein Quellcode-Repository (z. B. GitHub) mit einem Cloud Build-Trigger verbinden, können Sie die gesamte Bereitstellung automatisieren.
Mit einer Pipeline kann Cloud Build bei jeder Codeänderung automatisch Folgendes ausführen:
- Erstellen Sie das neue Container-Image.
- Übertragen Sie das Image in Artifact Registry.
- Wenden Sie die aktualisierten Kubernetes-Manifeste auf Ihren GKE-Cluster an.
Secrets sicher verwalten
In diesem Lab haben Sie die Konfiguration in einer .env-Datei gespeichert und an Ihre Anwendung übergeben. Das ist für die Entwicklung praktisch, aber nicht sicher für sensible Daten wie API-Schlüssel. Als Best Practice wird empfohlen, Secret Manager zum sicheren Speichern von Secrets zu verwenden.
GKE ist nativ in Secret Manager integriert. So können Sie Secrets direkt in Ihre Pods einbinden, entweder als Umgebungsvariablen oder als Dateien, ohne dass sie jemals in Ihren Quellcode eingecheckt werden.
Hier ist der Abschnitt Ressourcen bereinigen, den Sie angefordert haben. Er wurde direkt vor dem Abschnitt Zusammenfassung eingefügt.
14. Ressourcen bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, können Sie entweder das Projekt löschen, das die Ressourcen enthält, oder das Projekt beibehalten und die einzelnen Ressourcen löschen.
GKE-Cluster löschen
Der GKE-Cluster ist der Hauptkostentreiber in diesem Lab. Wenn Sie sie löschen, fallen keine Compute-Gebühren mehr an.
- Führen Sie im Terminal den folgenden Befehl aus:
gcloud container clusters delete adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Artifact Registry-Repository löschen
Für in Artifact Registry gespeicherte Container-Images fallen Speicherkosten an.
- Führen Sie im Terminal den folgenden Befehl aus:
gcloud artifacts repositories delete adk-repo \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Projekt löschen (optional)
Wenn Sie ein neues Projekt speziell für dieses Lab erstellt haben und es nicht noch einmal verwenden möchten, löschen Sie es am besten.
- Führen Sie im Terminal den folgenden Befehl aus und ersetzen Sie
[YOUR_PROJECT_ID]durch Ihre tatsächliche Projekt-ID:gcloud projects delete [YOUR_PROJECT_ID]
15. Fazit
Glückwunsch! Sie haben eine ADK-Anwendung mit mehreren Agents erfolgreich in einem GKE-Cluster für die Produktion bereitgestellt. Dies ist ein wichtiger Schritt, der den Kernlebenszyklus einer modernen cloudnativen Anwendung abdeckt und Ihnen eine solide Grundlage für die Bereitstellung Ihrer eigenen komplexen agentenbasierten Systeme bietet.
Zusammenfassung
In diesem Lab haben Sie Folgendes gelernt:
- Stellen Sie einen GKE Autopilot-Cluster bereit.
- Container-Image mit einem
Dockerfileerstellen und per Push an Artifact Registry übertragen - Sichere Verbindung zu Google Cloud APIs mit Workload Identity herstellen
- Kubernetes-Manifeste für ein Deployment und einen Dienst schreiben
- Eine Anwendung mit einem LoadBalancer im Internet freigeben
- Autoscaling mit einem HorizontalPodAutoscaler (HPA) konfigurieren.