
1. Introducción
Descripción general
Este lab cierra la brecha fundamental entre el desarrollo de un potente sistema multiagente y su implementación para el uso en el mundo real. Si bien crear agentes de forma local es un excelente comienzo, las aplicaciones de producción requieren una plataforma que sea escalable, confiable y segura.
En este lab, tomarás un sistema multiagente creado con el Kit de desarrollo de agentes (ADK) de Google y lo implementarás en un entorno de nivel de producción en Google Kubernetes Engine (GKE).
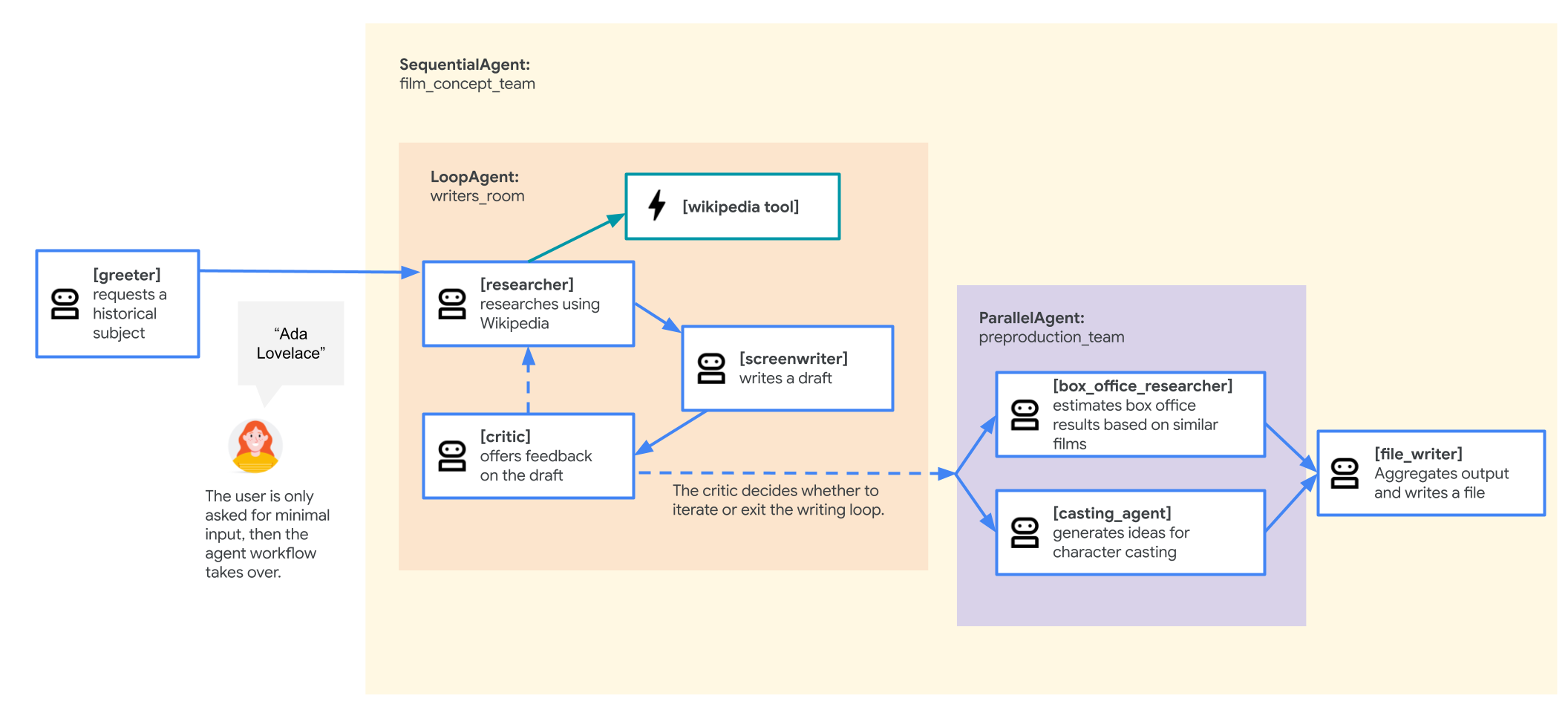
Agente del equipo de concepto de película
La aplicación de ejemplo que se usa en este lab es un "equipo de concepto de película" compuesto por varios agentes colaboradores: un investigador, un guionista y un escritor de archivos. Estos agentes trabajan en conjunto para ayudar a un usuario a generar ideas y crear un esquema para presentar una película sobre una figura histórica.
¿Por qué implementar en GKE?
Para preparar tu agente para las exigencias de un entorno de producción, necesitas una plataforma creada para la escalabilidad, la seguridad y la rentabilidad. Google Kubernetes Engine (GKE) proporciona esta base potente y flexible para ejecutar tu aplicación en contenedores.
Esto ofrece varias ventajas para tu carga de trabajo de producción:
- Rendimiento y escalamiento automáticos: Controla el tráfico impredecible con el HorizontalPodAutoscaler (HPA), que agrega o quita automáticamente réplicas de agentes según la carga. Para las cargas de trabajo de IA más exigentes, puedes conectar aceleradores de hardware, como GPU y TPU.
- Administración de recursos rentable: Optimiza los costos con GKE Autopilot, que administra automáticamente la infraestructura subyacente para que solo pagues por los recursos que solicita tu aplicación.
- Seguridad y observabilidad integradas: Conéctate de forma segura a otros servicios de Google Cloud con Workload Identity, lo que evita la necesidad de administrar y almacenar claves de cuentas de servicio. Todos los registros de la aplicación se transmiten automáticamente a Cloud Logging para la supervisión y depuración centralizadas.
- Control y portabilidad: Evita la dependencia de un solo proveedor con Kubernetes de código abierto. Tu aplicación es portátil y se puede ejecutar en cualquier clúster de Kubernetes, ya sea de forma local o en otras nubes.
Qué aprenderás
En este lab, aprenderás a realizar las siguientes tareas:
- Aprovisiona un clúster de GKE Autopilot.
- Crear un contenedor para una aplicación con un Dockerfile y enviar la imagen a Artifact Registry
- Conecta de forma segura tu aplicación a las APIs de Google Cloud con Workload Identity.
- Escribir y aplicar manifiestos de Kubernetes para una implementación y un servicio
- Exponer una aplicación a Internet con un LoadBalancer
- Configura el ajuste de escala automático con un HorizontalPodAutoscaler (HPA).
2. Configura el proyecto
Cuenta de Google
Si aún no tienes una Cuenta de Google personal, debes crear una.
Usa una cuenta personal en lugar de una cuenta de trabajo o institución educativa.
Accede a la consola de Google Cloud
Accede a la consola de Google Cloud con una Cuenta de Google personal.
Habilitar facturación
Configura una cuenta de facturación personal
Si configuraste la facturación con créditos de Google Cloud, puedes omitir este paso.
Para configurar una cuenta de facturación personal, ve aquí para habilitar la facturación en la consola de Cloud.
Algunas notas:
- Completar este lab debería costar menos de USD 1 en recursos de Cloud.
- Puedes seguir los pasos al final de este lab para borrar recursos y evitar cargos adicionales.
- Los usuarios nuevos pueden acceder a la prueba gratuita de USD 300.
Crear un proyecto (opcional)
Si no tienes un proyecto actual que quieras usar para este lab, crea uno nuevo aquí.
3. Abre el editor de Cloud Shell
- Haz clic en este vínculo para navegar directamente al editor de Cloud Shell.
- Si se te solicita autorización en algún momento, haz clic en Autorizar para continuar.
- Si la terminal no aparece en la parte inferior de la pantalla, ábrela:
- Haz clic en Ver.
- Haz clic en Terminal.
- En la terminal, configura tu proyecto con este comando:
gcloud config set project [PROJECT_ID]- Ejemplo:
gcloud config set project lab-project-id-example - Si no recuerdas el ID de tu proyecto, puedes enumerar todos tus IDs de proyecto con el siguiente comando:
gcloud projects list
- Ejemplo:
- Deberías ver el siguiente mensaje:
Updated property [core/project].
4. Habilita las APIs
Para usar GKE, Artifact Registry, Cloud Build y Vertex AI, debes habilitar sus APIs respectivas en tu proyecto de Google Cloud.
- En la terminal, habilita las APIs:
gcloud services enable \ container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.comOperation "operations/acf.p2-176675280136-b03ab5e4-3483-4ebf-9655-43dc3b345c63" finished successfully.
Presentamos las APIs
- La API de Google Kubernetes Engine (
container.googleapis.com) te permite crear y administrar el clúster de GKE que ejecuta tu agente. GKE proporciona un entorno administrado para implementar, administrar y escalar las aplicaciones alojadas en contenedores usando la infraestructura de Google. - La API de Artifact Registry (
artifactregistry.googleapis.com) proporciona un repositorio privado y seguro para almacenar la imagen del contenedor de tu agente. Es la evolución de Container Registry y se integra perfectamente en GKE y Cloud Build. - La API de Cloud Build (
cloudbuild.googleapis.com) se usa con el comandogcloud builds submitpara compilar tu imagen de contenedor en la nube a partir de tu Dockerfile. Es una plataforma de CI/CD sin servidores que ejecuta tus compilaciones en la infraestructura de Google Cloud. - La API de Vertex AI (
aiplatform.googleapis.com) permite que tu agente implementado se comunique con los modelos de Gemini para realizar sus tareas principales. Proporciona la API unificada para todos los servicios de IA de Google Cloud.
5. Prepara tu entorno de desarrollo
Crea la estructura de directorios
- En la terminal, crea el directorio del proyecto y los subdirectorios necesarios:
mkdir -p ~/adk_multiagent_systems/workflow_agents cd ~/adk_multiagent_systems - En la terminal, ejecuta el siguiente comando para abrir el directorio en el explorador del Editor de Cloud Shell.
cloudshell open-workspace ~/adk_multiagent_systems - Se actualizará el panel del explorador de la izquierda. Ahora deberías ver los directorios que creaste.
A medida que crees archivos en los siguientes pasos, verás que se completan en este directorio.
Crea archivos iniciales
Ahora crearás los archivos de inicio necesarios para la aplicación.
- Crea
callback_logging.pyejecutando el siguiente comando en la terminal. Este archivo controla el registro para la observabilidad.cat <<EOF > ~/adk_multiagent_systems/callback_logging.py """ Provides helper functions for observability. Handles formatting and sending agent queries, responses, and tool calls to Google Cloud Logging to aid in monitoring and debugging. """ import logging import google.cloud.logging from google.adk.agents.callback_context import CallbackContext from google.adk.models import LlmResponse, LlmRequest def log_query_to_model(callback_context: CallbackContext, llm_request: LlmRequest): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_request.contents and llm_request.contents[-1].role == 'user': if llm_request.contents[-1].parts and "text" in llm_request.contents[-1].parts: last_user_message = llm_request.contents[-1].parts[0].text logging.info(f"[query to {callback_context.agent_name}]: " + last_user_message) def log_model_response(callback_context: CallbackContext, llm_response: LlmResponse): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_response.content and llm_response.content.parts: for part in llm_response.content.parts: if part.text: logging.info(f"[response from {callback_context.agent_name}]: " + part.text) elif part.function_call: logging.info(f"[function call from {callback_context.agent_name}]: " + part.function_call.name) EOF - Crea
workflow_agents/__init__.pyejecutando el siguiente comando en la terminal. Esto marca el directorio como un paquete de Python.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/__init__.py """ Marks the directory as a Python package and exposes the agent module, allowing the ADK to discover and register the agents defined within. """ from . import agent EOF - Crea
workflow_agents/agent.pyejecutando el siguiente comando en la terminal. Este archivo contiene la lógica principal de tu equipo de varios agentes.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/agent.py """ Defines the core multi-agent workflow. Configures individual agents (Researcher, Screenwriter, File Writer), assigns their specific tools, and orchestrates their collaboration using the ADK's SequentialAgent pattern. """ import os import logging import google.cloud.logging from callback_logging import log_query_to_model, log_model_response from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent, LoopAgent, ParallelAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool # import from google.genai import types from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL") print(model_name) # Tools def append_to_state( tool_context: ToolContext, field: str, response: str ) -> dict[str, str]: """Append new output to an existing state key. Args: field (str): a field name to append to response (str): a string to append to the field Returns: dict[str, str]: {"status": "success"} """ existing_state = tool_context.state.get(field, []) tool_context.state[field] = existing_state + [response] logging.info(f"[Added to {field}] {response}") return {"status": "success"} def write_file( tool_context: ToolContext, directory: str, filename: str, content: str ) -> dict[str, str]: target_path = os.path.join(directory, filename) os.makedirs(os.path.dirname(target_path), exist_ok=True) with open(target_path, "w") as f: f.write(content) return {"status": "success"} # Agents file_writer = Agent( name="file_writer", model=model_name, description="Creates marketing details and saves a pitch document.", instruction=""" PLOT_OUTLINE: { PLOT_OUTLINE? } INSTRUCTIONS: - Create a marketable, contemporary movie title suggestion for the movie described in the PLOT_OUTLINE. If a title has been suggested in PLOT_OUTLINE, you can use it, or replace it with a better one. - Use your 'write_file' tool to create a new txt file with the following arguments: - for a filename, use the movie title - Write to the 'movie_pitches' directory. - For the 'content' to write, extract the following from the PLOT_OUTLINE: - A logline - Synopsis or plot outline """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[write_file], ) screenwriter = Agent( name="screenwriter", model=model_name, description="As a screenwriter, write a logline and plot outline for a biopic about a historical character.", instruction=""" INSTRUCTIONS: Your goal is to write a logline and three-act plot outline for an inspiring movie about a historical character(s) described by the PROMPT: { PROMPT? } - If there is CRITICAL_FEEDBACK, use those thoughts to improve upon the outline. - If there is RESEARCH provided, feel free to use details from it, but you are not required to use it all. - If there is a PLOT_OUTLINE, improve upon it. - Use the 'append_to_state' tool to write your logline and three-act plot outline to the field 'PLOT_OUTLINE'. - Summarize what you focused on in this pass. PLOT_OUTLINE: { PLOT_OUTLINE? } RESEARCH: { research? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], ) researcher = Agent( name="researcher", model=model_name, description="Answer research questions using Wikipedia.", instruction=""" PROMPT: { PROMPT? } PLOT_OUTLINE: { PLOT_OUTLINE? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } INSTRUCTIONS: - If there is a CRITICAL_FEEDBACK, use your wikipedia tool to do research to solve those suggestions - If there is a PLOT_OUTLINE, use your wikipedia tool to do research to add more historical detail - If these are empty, use your Wikipedia tool to gather facts about the person in the PROMPT - Use the 'append_to_state' tool to add your research to the field 'research'. - Summarize what you have learned. Now, use your Wikipedia tool to do research. """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[ LangchainTool(tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())), append_to_state, ], ) film_concept_team = SequentialAgent( name="film_concept_team", description="Write a film plot outline and save it as a text file.", sub_agents=[ researcher, screenwriter, file_writer ], ) root_agent = Agent( name="greeter", model=model_name, description="Guides the user in crafting a movie plot.", instruction=""" - Let the user know you will help them write a pitch for a hit movie. Ask them for a historical figure to create a movie about. - When they respond, use the 'append_to_state' tool to store the user's response in the 'PROMPT' state key and transfer to the 'film_concept_team' agent """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], sub_agents=[film_concept_team], ) EOF
Ahora, tu estructura de archivos debería verse así: 
Configura el entorno virtual
- En la terminal, crea y activa un entorno virtual con
uv. Esto garantiza que las dependencias de tu proyecto no entren en conflicto con el Python del sistema.uv venv source .venv/bin/activate
Requisitos de instalación
- Ejecuta el siguiente comando en la terminal para crear el archivo
requirements.txt.cat <<EOF > ~/adk_multiagent_systems/requirements.txt # Lists all Python dependencies required to run the multi-agent system, # including the Google ADK, LangChain community tools, and web server libraries. langchain-community==0.4.1 wikipedia==1.4.0 google-adk==1.27.5 fastapi==0.135.2 uvicorn==0.42.0 EOF - Instala los paquetes necesarios en tu entorno virtual en la terminal.
uv pip install -r requirements.txt
Configura variables de entorno
- Usa el siguiente comando en la terminal para crear el archivo
.env, e inserta automáticamente el ID y la región de tu proyecto.cat <<EOF > ~/adk_multiagent_systems/.env GOOGLE_CLOUD_PROJECT="$(gcloud config get-value project)" GOOGLE_CLOUD_PROJECT_NUMBER="$(gcloud projects describe $(gcloud config get-value project) --format='value(projectNumber)')" GOOGLE_CLOUD_LOCATION="us-central1" GOOGLE_GENAI_USE_VERTEXAI=true MODEL="gemini-2.5-flash" EOF - En la terminal, carga las variables en tu sesión de shell.
source .env
Resumen
En esta sección, estableciste la base local para tu proyecto:
- Se creó la estructura de directorios y los archivos de inicio del agente necesarios (
agent.py,callback_logging.py,requirements.txt). - Aislamiento de las dependencias con un entorno virtual (
uv) - Variables de entorno configuradas (
.env) para almacenar detalles específicos del proyecto, como el ID y la región.
6. Explora el archivo del agente
Configuraste el código fuente del lab, incluido un sistema multiagente escrito previamente. Antes de implementar la aplicación, es útil comprender cómo se definen los agentes. La lógica principal del agente reside en workflow_agents/agent.py.
- En el Editor de Cloud Shell, usa el explorador de archivos de la izquierda para navegar a
adk_multiagent_systems/workflow_agents/y abrir el archivoagent.py. - Tómate un momento para revisar el archivo. No necesitas entender cada línea, pero observa la estructura de alto nivel:
- Agentes individuales: El archivo define tres objetos
Agentdistintos:researcher,screenwriteryfile_writer. A cada agente se le asigna uninstructionespecífico (su instrucción) y una lista detoolsque puede usar (como la herramientaWikipediaQueryRuno una herramientawrite_filepersonalizada). - Composición del agente: Los agentes individuales se encadenan en un
SequentialAgentllamadofilm_concept_team. Esto le indica al ADK que ejecute estos agentes uno tras otro, pasando el estado de uno al siguiente. - El agente raíz: Se define un
root_agent(llamado "saludador") para controlar la interacción inicial del usuario. Cuando el usuario proporciona una instrucción, este agente la guarda en el estado de la aplicación y, luego, transfiere el control al flujo de trabajofilm_concept_team.
- Agentes individuales: El archivo define tres objetos
Comprender esta estructura ayuda a aclarar lo que estás a punto de implementar: no solo un agente, sino un equipo coordinado de agentes especializados orquestados por el ADK.
7. Crea un clúster de GKE Autopilot
Con el entorno preparado, el siguiente paso es aprovisionar la infraestructura en la que se ejecutará la aplicación del agente. Crearás un clúster de GKE Autopilot, que servirá como base para tu implementación. Usamos el modo Autopilot porque controla la administración compleja de los nodos, el escalamiento y la seguridad subyacentes del clúster, lo que te permite concentrarte únicamente en implementar tu aplicación.
- En la terminal, crea un clúster de GKE Autopilot nuevo llamado
adk-cluster.gcloud container clusters create-auto adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT - Una vez que se cree el clúster, ejecuta lo siguiente en la terminal para configurar
kubectly conectarte a él:gcloud container clusters get-credentials adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT~/.kube/config). A partir de este punto, la herramienta de línea de comandos dekubectlse autenticará y se dirigirá para comunicarse con tuadk-cluster.
Resumen
En esta sección, aprovisionaste la infraestructura:
- Se creó un clúster de GKE Autopilot completamente administrado con
gcloud. - Configuraste tu herramienta
kubectllocal para autenticarte y comunicarte con el clúster nuevo.
8. Organiza la aplicación en contenedores y envíala
Actualmente, el código de tu agente solo existe en tu entorno de Cloud Shell. Para ejecutarlo en GKE, primero debes empaquetarlo en una imagen de contenedor. Una imagen de contenedor es un archivo estático y portátil que agrupa el código de tu aplicación con todas sus dependencias. Cuando ejecutas esta imagen, se convierte en un contenedor activo.
Este proceso implica tres pasos clave:
- Crea un punto de entrada: Define un archivo
main.pypara convertir la lógica de tu agente en un servidor web ejecutable. - Define la imagen de contenedor: Crea un Dockerfile que actúe como un plano para compilar tu imagen de contenedor.
- Compilación y envío: Usa Cloud Build para ejecutar el Dockerfile, crear la imagen del contenedor y enviarla a Google Artifact Registry, un repositorio seguro para tus imágenes.
Prepara la aplicación para la implementación
Tu agente del ADK necesita un servidor web para recibir solicitudes. El archivo main.py actuará como este punto de entrada y usará el framework FastAPI para exponer la funcionalidad de tu agente a través de HTTP.
- En la raíz del directorio
adk_multiagent_systemsen la terminal, crea un archivo nuevo llamadomain.py.cat <<EOF > ~/adk_multiagent_systems/main.py """ Serves as the application entry point. Initializes the FastAPI web server, discovers the agents defined in the workflow directory, and exposes them via HTTP endpoints for interaction. """ import os import uvicorn from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Get the directory where main.py is located AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) # Configure the session service (e.g., SQLite for local storage) SESSION_SERVICE_URI = "sqlite:///./sessions.db" # Configure CORS to allow requests from various origins for this lab ALLOWED_ORIGINS = ["http://localhost", "http://localhost:8080", "*"] # Enable the ADK's built-in web interface SERVE_WEB_INTERFACE = True # Call the ADK function to discover agents and create the FastAPI app app: FastAPI = get_fast_api_app( agents_dir=AGENT_DIR, session_service_uri=SESSION_SERVICE_URI, allow_origins=ALLOWED_ORIGINS, web=SERVE_WEB_INTERFACE, ) # You can add more FastAPI routes or configurations below if needed # Example: # @app.get("/hello") # async def read_root(): # return {"Hello": "World"} if __name__ == "__main__": # Get the port from the PORT environment variable provided by the container runtime # Run the Uvicorn server, listening on all available network interfaces (0.0.0.0) uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("PORT", 8080))) EOFuvicornejecuta esta aplicación y escucha en el host0.0.0.0para aceptar conexiones desde cualquier dirección IP y en el puerto especificado por la variable de entornoPORT, que estableceremos más adelante en nuestro manifiesto de Kubernetes.
En este punto, la estructura de archivos que se ve en el panel del explorador del editor de Cloud Shell debería verse de la siguiente manera: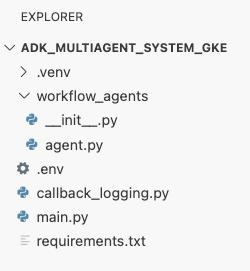
Aloja el agente del ADK en un contenedor con Docker
Para implementar nuestra aplicación en GKE, primero debemos empaquetarla en una imagen de contenedor, que agrupa el código de nuestra aplicación con todas las bibliotecas y dependencias que necesita para ejecutarse. Usaremos Docker para crear esta imagen de contenedor.
- En la raíz del directorio
adk_multiagent_systemsen la terminal, crea un archivo nuevo llamadoDockerfile.cat <<'EOF' > ~/adk_multiagent_systems/Dockerfile # Defines the blueprint for the container image. Installs dependencies, # sets up a secure non-root user, and specifies the startup command to run the # agent web server. # Use an official lightweight Python image as the base FROM python:3.13-slim # Set the working directory inside the container WORKDIR /app # Create a non-root user for security best practices RUN adduser --disabled-password --gecos "" myuser # Copy and install dependencies first to leverage Docker's layer caching COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt # Copy all application code into the container COPY . . # Create the directory where the agent will write files at runtime # The -p flag ensures the command doesn't fail if the directory already exists RUN mkdir -p movie_pitches # Change ownership of EVERYTHING in /app to the non-root user # Without this, the running agent would be denied permission to write files. RUN chown -R myuser:myuser /app # Switch the active user from root to the non-root user USER myuser # Add the user's local binary directory to the system's PATH ENV PATH="/home/myuser/.local/bin:$PATH" # Define the command to run when the container starts CMD ["sh", "-c", "uvicorn main:app --host 0.0.0.0 --port $PORT"] EOF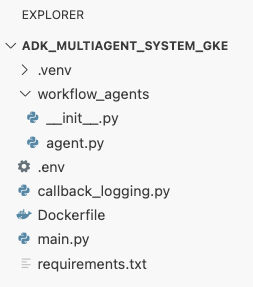
Compila y envía la imagen del contenedor a Artifact Registry
Ahora que tienes un Dockerfile, usarás Cloud Build para compilar la imagen y enviarla a Artifact Registry, un registro seguro y privado integrado en los servicios de Google Cloud. GKE extraerá la imagen de este registro para ejecutar tu aplicación.
- En la terminal, crea un repositorio nuevo de Artifact Registry para almacenar tu imagen de contenedor.
gcloud artifacts repositories create adk-repo \ --repository-format=docker \ --location=$GOOGLE_CLOUD_LOCATION \ --description="ADK repository" - En la terminal, usa
gcloud builds submitpara compilar la imagen de contenedor y enviarla al repositorio.gcloud builds submit \ --tag $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo/adk-agent:latest \ --project=$GOOGLE_CLOUD_PROJECT \ .Dockerfile. Compila la imagen en la nube, la etiqueta con la dirección de tu repositorio de Artifact Registry y la envía allí automáticamente. - Desde la terminal, verifica que se haya compilado la imagen:
gcloud artifacts docker images list \ $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo \ --project=$GOOGLE_CLOUD_PROJECT
Resumen
En esta sección, empaquetaste tu código para la implementación:
- Se creó un punto de entrada
main.pypara encapsular tus agentes en un servidor web de FastAPI. - Definiste un
Dockerfilepara agrupar tu código y las dependencias en una imagen portátil. - Se usó Cloud Build para compilar la imagen y enviarla a un repositorio seguro de Artifact Registry.
9. Crea manifiestos de Kubernetes
Ahora que tu imagen de contenedor está compilada y almacenada en Artifact Registry, debes indicarle a GKE cómo ejecutarla. Esto implica dos actividades principales:
- Configura permisos: Crearás una identidad dedicada para tu agente dentro del clúster y le otorgarás acceso seguro a las APIs de Google Cloud que necesita (específicamente, Vertex AI).
- Definir el estado de la aplicación: Escribirás un archivo de manifiesto de Kubernetes, un documento YAML que define de forma declarativa todo lo que tu aplicación necesita para ejecutarse, incluida la imagen del contenedor, las variables de entorno y cómo debe exponerse a la red.
Configura la cuenta de servicio de Kubernetes para Vertex AI
Tu agente necesita permiso para comunicarse con la API de Vertex AI y acceder a los modelos de Gemini. El método más seguro y recomendado para otorgar este permiso en GKE es Workload Identity. Workload Identity te permite vincular una identidad nativa de Kubernetes (una cuenta de servicio de Kubernetes) con una identidad de Google Cloud (una cuenta de servicio de IAM), lo que evita por completo la necesidad de descargar, administrar y almacenar claves JSON estáticas.
- En la terminal, crea la cuenta de servicio de Kubernetes (
adk-agent-sa). Esto crea una identidad para tu agente dentro del clúster de GKE que pueden usar tus Pods.kubectl create serviceaccount adk-agent-sa - En la terminal, vincula tu cuenta de servicio de Kubernetes a Cloud IAM de Google Cloud creando una vinculación de política. Este comando otorga el rol
aiplatform.usera tuadk-agent-sa, lo que le permite invocar de forma segura la API de Vertex AI.gcloud projects add-iam-policy-binding projects/${GOOGLE_CLOUD_PROJECT} \ --role=roles/aiplatform.user \ --member=principal://iam.googleapis.com/projects/${GOOGLE_CLOUD_PROJECT_NUMBER}/locations/global/workloadIdentityPools/${GOOGLE_CLOUD_PROJECT}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \ --condition=None
Crea los archivos de manifiesto de Kubernetes
Kubernetes usa archivos de manifiesto YAML para definir el estado deseado de tu aplicación. Crearás un archivo deployment.yaml que contendrá dos objetos esenciales de Kubernetes: una Deployment y un Service.
- Desde la terminal, genera el archivo
deployment.yaml.cat <<EOF > ~/adk_multiagent_systems/deployment.yaml # Defines the Kubernetes resources required to deploy the application to GKE. # Includes the Deployment (to run the container pods) and the Service # (to expose the application via a Load Balancer). apiVersion: apps/v1 kind: Deployment metadata: name: adk-agent spec: replicas: 1 selector: matchLabels: app: adk-agent template: metadata: labels: app: adk-agent spec: # Assign the Kubernetes Service Account for Workload Identity serviceAccountName: adk-agent-sa containers: - name: adk-agent imagePullPolicy: Always # The path to the container image in Artifact Registry image: ${GOOGLE_CLOUD_LOCATION}-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/adk-repo/adk-agent:latest # Define the resources for GKE Autopilot to provision resources: limits: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" requests: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" ports: - containerPort: 8080 # Environment variables passed to the application env: - name: PORT value: "8080" - name: GOOGLE_CLOUD_PROJECT value: ${GOOGLE_CLOUD_PROJECT} - name: GOOGLE_CLOUD_LOCATION value: ${GOOGLE_CLOUD_LOCATION} - name: GOOGLE_GENAI_USE_VERTEXAI value: "true" - name: MODEL value: "gemini-2.5-flash" --- apiVersion: v1 kind: Service metadata: name: adk-agent spec: # Create a public-facing Network Load Balancer with an external IP type: LoadBalancer ports: - port: 80 targetPort: 8080 selector: app: adk-agent EOF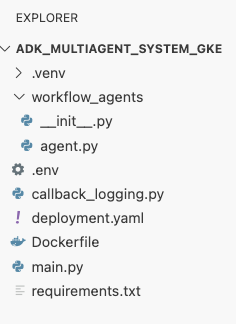
Resumen
En esta sección, definiste la configuración de seguridad y de implementación:
- Se creó una cuenta de servicio de Kubernetes y se vinculó a IAM de Google Cloud con Workload Identity, lo que permite que tus Pods accedan de forma segura a Vertex AI sin administrar claves.
- Se generó un archivo
deployment.yamlque define la implementación (cómo ejecutar los pods) y el servicio (cómo exponerlos a través de un balanceador de cargas).
10. Implementa la aplicación en GKE
Con el archivo de manifiesto definido y la imagen de contenedor enviada a Artifact Registry, ahora puedes implementar tu aplicación. En esta tarea, usarás kubectl para aplicar tu configuración al clúster de GKE y, luego, supervisarás el estado para asegurarte de que el agente se inicie correctamente.
- En tu terminal, aplica el manifiesto
deployment.yamla tu clúster.kubectl apply -f deployment.yamlkubectl applyenvía tu archivodeployment.yamlal servidor de la API de Kubernetes. Luego, el servidor lee tu configuración y coordina la creación de los objetos Deployment y Service. - En la terminal, verifica el estado de tu implementación en tiempo real. Espera a que los Pods estén en el estado
Running.kubectl get pods -l=app=adk-agent --watch- Pendiente: El clúster aceptó el pod, pero aún no se creó el contenedor.
- Creación del contenedor: GKE extrae la imagen del contenedor de Artifact Registry y lo inicia.
- Ejecución: Correcto. El contenedor se está ejecutando y tu aplicación de agente está activa.
- Cuando el estado muestre
Running, presiona CTRL + C en la terminal para detener el comando watch y volver al símbolo del sistema.
Resumen
En esta sección, iniciaste la carga de trabajo:
- Usaste
kubectlapply para enviar tu manifiesto al clúster. - Se supervisó el ciclo de vida del Pod (Pendiente -> ContainerCreating -> En ejecución) para garantizar que la aplicación se iniciara correctamente.
11. Interactúa con el agente
Tu agente del ADK ahora se está ejecutando en vivo en GKE y está expuesto a Internet a través de un balanceador de cargas público. Te conectarás a la interfaz web del agente para interactuar con él y verificar que todo el sistema funcione correctamente.
Busca la dirección IP externa de tu servicio
Para acceder al agente, primero debes obtener la dirección IP pública que GKE aprovisionó para tu servicio.
- En la terminal, ejecuta el siguiente comando para obtener los detalles de tu servicio.
kubectl get service adk-agent - Busca el valor en la columna
EXTERNAL-IP. Es posible que la dirección IP tarde uno o dos minutos en asignarse después de que implementes el servicio por primera vez. Si se muestra comopending, espera un minuto y vuelve a ejecutar el comando. El resultado será similar al siguiente:NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE adk-agent-service LoadBalancer 10.120.12.234 34.123.45.67 80:31234/TCP 5mEXTERNAL-IP(p.ej., 34.123.45.67) es el punto de entrada público a tu agente.
Prueba el agente implementado
Ahora puedes usar la dirección IP pública para acceder a la IU web integrada del ADK directamente desde tu navegador.
- Copia la dirección IP externa (
EXTERNAL-IP) del terminal. - Abre una pestaña nueva en tu navegador web y escribe
http://[EXTERNAL-IP], reemplazando[EXTERNAL-IP]por la dirección IP que copiaste. - Ahora deberías ver la interfaz web del ADK.
- Asegúrate de que workflow_agents esté seleccionado en el menú desplegable del agente.
- Activa Transmisión de tokens.
- Escribe
helloy presiona Intro para comenzar una nueva conversación. - Observa el resultado. El agente debería responder rápidamente con su saludo: "Puedo ayudarte a escribir una propuesta para una película exitosa. ¿Sobre qué figura histórica te gustaría hacer una película?"
- Cuando se te pida que elijas un personaje histórico, elige uno que te interese. Estas son algunas ideas:
the most successful female pirate in historythe woman who invented the first computer compilera legendary lawman of the American Wild West
Resumen
En esta sección, verificaste la implementación:
- Se recuperó la dirección IP externa asignada por el balanceador de cargas.
- Accedió a la IU web del ADK a través de un navegador para confirmar que el sistema multiagente responde y funciona correctamente.
12. Configurar ajuste de escala automático
Un desafío clave en la producción es controlar el tráfico de usuarios impredecible. Codificar de forma rígida una cantidad fija de réplicas, como hiciste en la tarea anterior, significa que pagas de más por recursos inactivos o corres el riesgo de tener un rendimiento deficiente durante los picos de tráfico. GKE resuelve este problema con el ajuste de escala automático.
Configurarás un HorizontalPodAutoscaler (HPA), un controlador de Kubernetes que ajusta automáticamente la cantidad de Pods en ejecución en tu Deployment según el uso de CPU en tiempo real.
- En la terminal del Editor de Cloud Shell, crea un archivo
hpa.yamlnuevo en la raíz del directorioadk_multiagent_systems.cloudshell edit ~/adk_multiagent_systems/hpa.yaml - Agrega el siguiente contenido al archivo
hpa.yamlnuevo:# Configures the HorizontalPodAutoscaler (HPA) to automatically scale # the number of running agent pods up or down based on CPU utilization # to handle varying traffic loads. apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: adk-agent-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: adk-agent minReplicas: 1 maxReplicas: 5 targetCPUUtilizationPercentage: 50adk-agent. Garantiza que siempre haya al menos 1 Pod en ejecución, establece un máximo de 5 Pods y agregará o quitará réplicas para mantener la utilización promedio de la CPU en torno al 50%.En este punto, la estructura de archivos que se ve en el panel del explorador en el Editor de Cloud Shell debería verse de la siguiente manera:
- Aplica el HPA a tu clúster pegando este código en la terminal.
kubectl apply -f hpa.yaml
Verifica el escalador automático
El HPA ahora está activo y supervisa tu implementación. Puedes inspeccionar su estado para verlo en acción.
- Ejecuta el siguiente comando en la terminal para obtener el estado de tu HPA.
kubectl get hpa adk-agent-hpaNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE adk-agent-hpa Deployment/adk-agent 0%/50% 1 5 1 30s
Resumen
En esta sección, optimizaste el tráfico de producción:
- Se creó un manifiesto
hpa.yamlpara definir reglas de escalamiento. - Se implementó el HorizontalPodAutoscaler (HPA) para ajustar automáticamente la cantidad de réplicas de Pod según el uso de CPU.
13. Preparación para la producción
Nota: Las siguientes secciones son solo para fines informativos y no contienen más pasos para ejecutar. Están diseñados para proporcionar contexto y prácticas recomendadas para llevar tu aplicación a producción.
Ajusta el rendimiento con la asignación de recursos
En GKE Autopilot, puedes controlar la cantidad de CPU y memoria aprovisionadas para tu aplicación especificando el recurso requests en tu deployment.yaml.
Si detectas que tu agente es lento o se bloquea debido a la falta de memoria, puedes aumentar su asignación de recursos editando el bloque resources en tu deployment.yaml y volviendo a aplicar el archivo con kubectl apply.
Por ejemplo, para duplicar la memoria, haz lo siguiente:
# In deployment.yaml
# ...
resources:
requests:
memory: "2Gi" # Increased from 1Gi
cpu: "1000m"
# ...
Automatiza tu flujo de trabajo con CI/CD
En este lab, ejecutaste comandos de forma manual. La práctica profesional es crear una canalización de CI/CD (integración continua/implementación continua). Si conectas un repositorio de código fuente (como GitHub) a un activador de Cloud Build, puedes automatizar toda la implementación.
Con una canalización, cada vez que envías un cambio de código, Cloud Build puede hacer lo siguiente de forma automática:
- Compila la nueva imagen del contenedor.
- Envía la imagen a Artifact Registry
- Aplica los manifiestos de Kubernetes actualizados a tu clúster de GKE.
Administra secretos de forma segura
En este lab, almacenaste la configuración en un archivo .env y la pasaste a tu aplicación. Esto es conveniente para el desarrollo, pero no es seguro para los datos sensibles, como las claves de API. La práctica recomendada es usar Secret Manager para almacenar secretos de forma segura.
GKE tiene una integración nativa con Secret Manager que te permite activar secretos directamente en tus Pods como variables de entorno o archivos, sin que se registren en tu código fuente.
Aquí está la sección Limpia los recursos que solicitaste, insertada justo antes de la sección Conclusión.
14. Limpia los recursos
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Borra el clúster de GKE
El clúster de GKE es el principal factor de costo en este lab. Si la borras, se detendrán los cargos de procesamiento.
- En la terminal, ejecuta el siguiente comando:
gcloud container clusters delete adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Borra el repositorio de Artifact Registry
Las imágenes de contenedor almacenadas en Artifact Registry generan costos de almacenamiento.
- En la terminal, ejecuta el siguiente comando:
gcloud artifacts repositories delete adk-repo \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Borra el proyecto (opcional)
Si creaste un proyecto nuevo específicamente para este lab y no planeas volver a usarlo, la forma más fácil de realizar una limpieza es borrar todo el proyecto.
- En la terminal, ejecuta el siguiente comando (reemplaza
[YOUR_PROJECT_ID]por el ID de tu proyecto):gcloud projects delete [YOUR_PROJECT_ID]
15. Conclusión
¡Felicitaciones! Implementaste correctamente una aplicación del ADK de varios agentes en un clúster de GKE apto para producción. Este es un logro significativo que abarca el ciclo de vida principal de una aplicación moderna nativa de la nube y te proporciona una base sólida para implementar tus propios sistemas complejos basados en agentes.
Resumen
En este lab, aprendiste a hacer lo siguiente:
- Aprovisiona un clúster de GKE Autopilot.
- Compila una imagen de contenedor con un
Dockerfiley envíala a Artifact Registry - Conéctate de forma segura a las APIs de Google Cloud con Workload Identity.
- Escribe manifiestos de Kubernetes para un objeto Deployment y un objeto Service.
- Exponer una aplicación a Internet con un LoadBalancer
- Configura el ajuste de escala automático con un HorizontalPodAutoscaler (HPA).