
۱. مقدمه
نمای کلی
این آزمایشگاه، شکاف حیاتی بین توسعه یک سیستم چندعاملی قدرتمند و استقرار آن برای استفاده در دنیای واقعی را پر میکند. در حالی که ساخت عاملها به صورت محلی شروع بسیار خوبی است، برنامههای کاربردی تولیدی به پلتفرمی نیاز دارند که مقیاسپذیر، قابل اعتماد و ایمن باشد.
در این آزمایشگاه، شما یک سیستم چندعاملی ساخته شده با کیت توسعه عامل گوگل (ADK) را برداشته و آن را در یک محیط عملیاتی روی موتور کوبرنتیز گوگل (GKE) مستقر خواهید کرد.
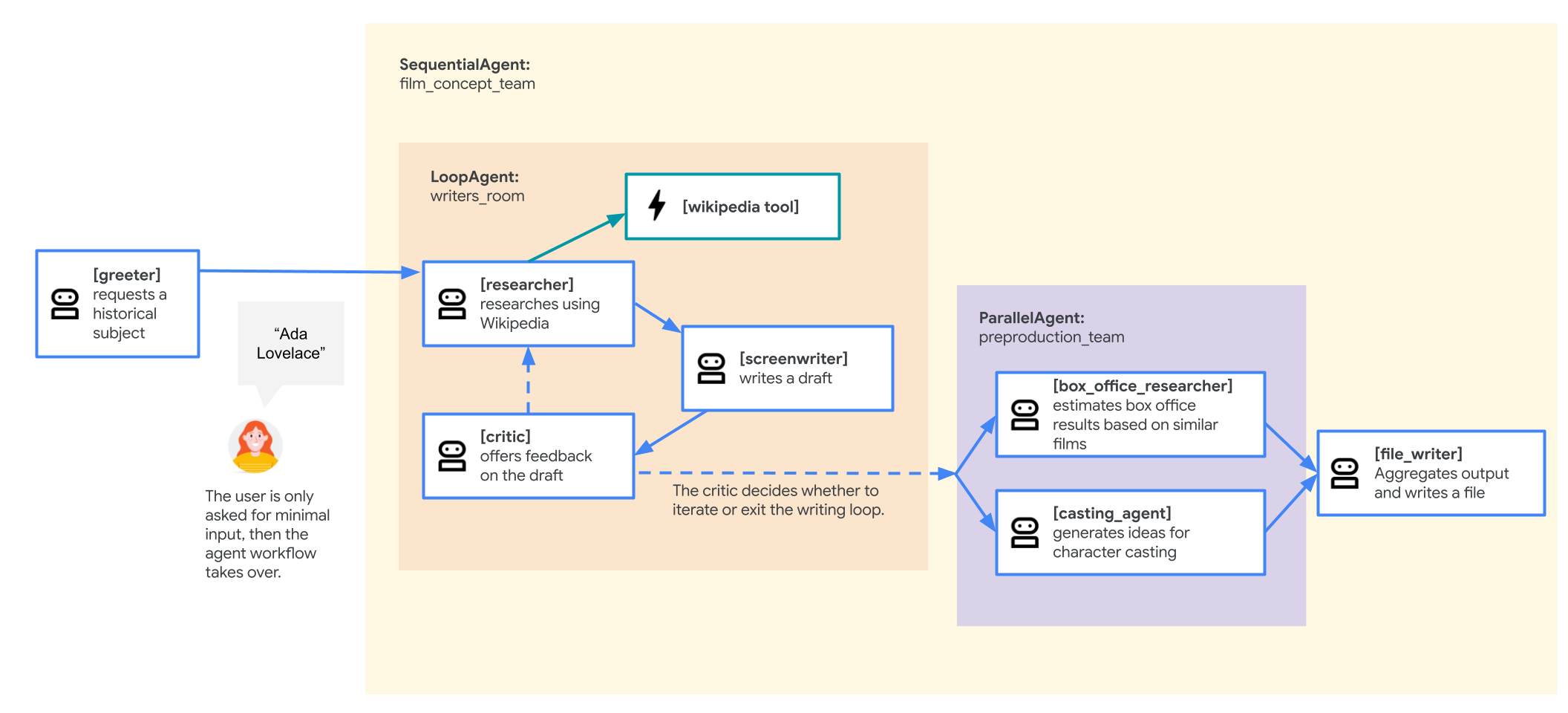
نماینده تیم ایدهپردازی فیلم
نمونه برنامهای که در این آزمایشگاه استفاده شده است، یک «تیم ایدهپردازی فیلم» است که از چندین عامل همکار تشکیل شده است: یک محقق، یک فیلمنامهنویس و یک نویسنده فایل. این عوامل با هم کار میکنند تا به کاربر در ایدهپردازی و طرح کلی یک فیلم درباره یک شخصیت تاریخی کمک کنند.
چرا باید در GKE مستقر شویم؟
برای آمادهسازی عامل خود برای نیازهای یک محیط عملیاتی، به پلتفرمی نیاز دارید که برای مقیاسپذیری، امنیت و صرفهجویی در هزینه ساخته شده باشد. موتور کوبرنتیز گوگل (GKE) این پایه قدرتمند و انعطافپذیر را برای اجرای برنامه کانتینر شده شما فراهم میکند.
این مزایای متعددی برای حجم کار تولیدی شما فراهم میکند:
- مقیاسبندی و عملکرد خودکار : ترافیک غیرقابل پیشبینی را با HorizontalPodAutoscaler (HPA) مدیریت کنید، که به طور خودکار کپیهای عامل را بر اساس بار اضافه یا حذف میکند. برای بارهای کاری هوش مصنوعی سنگینتر، میتوانید شتابدهندههای سختافزاری مانند GPUها و TPUها را متصل کنید.
- مدیریت منابع مقرون به صرفه : با GKE Autopilot که به طور خودکار زیرساختهای اساسی را مدیریت میکند، هزینهها را بهینه کنید، بنابراین شما فقط برای منابعی که برنامه شما درخواست میکند، هزینه پرداخت میکنید.
- امنیت و قابلیت مشاهده یکپارچه : با استفاده از Workload Identity به طور ایمن به سایر سرویسهای Google Cloud متصل شوید، که از نیاز به مدیریت و ذخیره کلیدهای حساب سرویس جلوگیری میکند. همه گزارشهای برنامه به طور خودکار برای نظارت و اشکالزدایی متمرکز به Cloud Logging منتقل میشوند.
- کنترل و قابلیت حمل : با استفاده از Kubernetes متنباز، از وابستگی به فروشنده اجتناب کنید. برنامه شما قابل حمل است و میتواند روی هر کلاستر Kubernetes، در محل یا در ابرهای دیگر اجرا شود.
آنچه یاد خواهید گرفت
در این آزمایشگاه، شما یاد میگیرید که چگونه وظایف زیر را انجام دهید:
- یک کلاستر خلبان خودکار GKE فراهم کنید.
- یک برنامه را با Dockerfile کانتینرایز کنید و تصویر را به Artifact Registry ارسال کنید.
- با استفاده از Workload Identity، برنامه خود را به طور ایمن به APIهای Google Cloud متصل کنید.
- مانیفستهای Kubernetes را برای یک Deployment و Service بنویسید و اعمال کنید.
- یک برنامه را با استفاده از LoadBalancer به اینترنت متصل کنید.
- مقیاسبندی خودکار را با یک HorizontalPodAutoscaler (HPA) پیکربندی کنید.
۲. راهاندازی پروژه
حساب گوگل
اگر از قبل حساب گوگل شخصی ندارید، باید یک حساب گوگل ایجاد کنید .
به جای حساب کاری یا تحصیلی از حساب شخصی استفاده کنید .
ورود به کنسول ابری گوگل
با استفاده از یک حساب کاربری شخصی گوگل، وارد کنسول ابری گوگل شوید.
فعال کردن صورتحساب
یک حساب پرداخت شخصی تنظیم کنید
اگر صورتحساب را با استفاده از اعتبارهای Google Cloud تنظیم کردهاید، میتوانید از این مرحله صرف نظر کنید.
برای تنظیم یک حساب پرداخت شخصی، به اینجا بروید تا پرداخت را در کنسول ابری فعال کنید .
برخی نکات:
- تکمیل این آزمایشگاه باید کمتر از ۱ دلار آمریکا از طریق منابع ابری هزینه داشته باشد.
- شما میتوانید مراحل انتهای این آزمایش را برای حذف منابع دنبال کنید تا از هزینههای بیشتر جلوگیری شود.
- کاربران جدید واجد شرایط استفاده از دوره آزمایشی رایگان ۳۰۰ دلاری هستند.
ایجاد پروژه (اختیاری)
اگر پروژه فعلی ندارید که بخواهید برای این آزمایشگاه استفاده کنید، اینجا یک پروژه جدید ایجاد کنید .
۳. ویرایشگر Cloud Shell را باز کنید
- برای دسترسی مستقیم به ویرایشگر Cloud Shell ، روی این لینک کلیک کنید.
- اگر امروز در هر مرحلهای از شما خواسته شد که مجوز دهید، برای ادامه روی تأیید کلیک کنید.
- اگر ترمینال در پایین صفحه نمایش داده نشد، آن را باز کنید:
- روی مشاهده کلیک کنید
- روی ترمینال کلیک کنید
- در ترمینال، پروژه خود را با این دستور تنظیم کنید:
gcloud config set project [PROJECT_ID]- مثال:
gcloud config set project lab-project-id-example - اگر نمیتوانید شناسه پروژه خود را به خاطر بیاورید، میتوانید تمام شناسههای پروژه خود را با استفاده از دستور زیر فهرست کنید:
gcloud projects list
- مثال:
- شما باید این پیام را ببینید:
Updated property [core/project].
۴. فعال کردن APIها
برای استفاده از GKE ، Artifact Registry ، Cloud Build و Vertex AI ، باید APIهای مربوط به آنها را در پروژه Google Cloud خود فعال کنید.
- در ترمینال ، APIها را فعال کنید:
gcloud services enable \ container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.comOperation "operations/acf.p2-176675280136-b03ab5e4-3483-4ebf-9655-43dc3b345c63" finished successfully.
معرفی API ها
- رابط برنامهنویسی کاربردی موتور کوبرنتیز گوگل (
container.googleapis.com) به شما امکان میدهد تا خوشه GKE را که عامل شما را اجرا میکند، ایجاد و مدیریت کنید. GKE یک محیط مدیریتشده برای استقرار، مدیریت و مقیاسبندی برنامههای کانتینر شده شما با استفاده از زیرساخت گوگل فراهم میکند. - رابط برنامهنویسی کاربردی (API) رجیستری آرتیفکت (
artifactregistry.googleapis.com) یک مخزن امن و خصوصی برای ذخیره تصویر کانتینر عامل شما فراهم میکند. این تکامل رجیستری کانتینر است و به طور یکپارچه با GKE و Cloud Build ادغام میشود. - رابط برنامهنویسی کاربردی ساخت ابری (
cloudbuild.googleapis.com) توسط دستورgcloud builds submitبرای ساخت تصویر کانتینر شما در فضای ابری از Dockerfile شما استفاده میشود. این یک پلتفرم CI/CD بدون سرور است که ساختهای شما را در زیرساخت Google Cloud اجرا میکند. - رابط برنامهنویسی کاربردی هوش مصنوعی ورتکس (
aiplatform.googleapis.com) به عامل مستقر شما این امکان را میدهد که با مدلهای Gemini ارتباط برقرار کند تا وظایف اصلی خود را انجام دهد. این رابط، رابط برنامهنویسی کاربردی یکپارچهای را برای همه سرویسهای هوش مصنوعی گوگل کلود فراهم میکند.
۵. محیط توسعه خود را آماده کنید
ساختار دایرکتوری را ایجاد کنید
- در ترمینال ، دایرکتوری پروژه و زیرشاخههای لازم را ایجاد کنید:
mkdir -p ~/adk_multiagent_systems/workflow_agents cd ~/adk_multiagent_systems - در ترمینال ، دستور زیر را اجرا کنید تا دایرکتوری در مرورگر ویرایشگر Cloud Shell باز شود.
cloudshell open-workspace ~/adk_multiagent_systems - پنل اکسپلورر در سمت چپ رفرش میشود. اکنون باید دایرکتوریهایی که ایجاد کردهاید را ببینید.
همانطور که در مراحل بعدی فایلها را ایجاد میکنید، خواهید دید که فایلها در این دایرکتوری قرار میگیرند.
ایجاد فایلهای آغازگر
اکنون فایلهای آغازین لازم برای برنامه را ایجاد خواهید کرد.
- با اجرای دستور زیر در ترمینال،
callback_logging.pyرا ایجاد کنید. این فایل، ثبت وقایع را برای مشاهدهپذیری مدیریت میکند.cat <<EOF > ~/adk_multiagent_systems/callback_logging.py """ Provides helper functions for observability. Handles formatting and sending agent queries, responses, and tool calls to Google Cloud Logging to aid in monitoring and debugging. """ import logging import google.cloud.logging from google.adk.agents.callback_context import CallbackContext from google.adk.models import LlmResponse, LlmRequest def log_query_to_model(callback_context: CallbackContext, llm_request: LlmRequest): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_request.contents and llm_request.contents[-1].role == 'user': if llm_request.contents[-1].parts and "text" in llm_request.contents[-1].parts: last_user_message = llm_request.contents[-1].parts[0].text logging.info(f"[query to {callback_context.agent_name}]: " + last_user_message) def log_model_response(callback_context: CallbackContext, llm_response: LlmResponse): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_response.content and llm_response.content.parts: for part in llm_response.content.parts: if part.text: logging.info(f"[response from {callback_context.agent_name}]: " + part.text) elif part.function_call: logging.info(f"[function call from {callback_context.agent_name}]: " + part.function_call.name) EOF - با اجرای دستور زیر در ترمینال،
workflow_agents/__init__.pyرا ایجاد کنید. این دستور، دایرکتوری را به عنوان یک بسته پایتون علامتگذاری میکند.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/__init__.py """ Marks the directory as a Python package and exposes the agent module, allowing the ADK to discover and register the agents defined within. """ from . import agent EOF - با اجرای دستور زیر در ترمینال،
workflow_agents/agent.pyرا ایجاد کنید. این فایل شامل منطق اصلی تیم چندعاملی شما است.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/agent.py """ Defines the core multi-agent workflow. Configures individual agents (Researcher, Screenwriter, File Writer), assigns their specific tools, and orchestrates their collaboration using the ADK's SequentialAgent pattern. """ import os import logging import google.cloud.logging from callback_logging import log_query_to_model, log_model_response from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent, LoopAgent, ParallelAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool # import from google.genai import types from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL") print(model_name) # Tools def append_to_state( tool_context: ToolContext, field: str, response: str ) -> dict[str, str]: """Append new output to an existing state key. Args: field (str): a field name to append to response (str): a string to append to the field Returns: dict[str, str]: {"status": "success"} """ existing_state = tool_context.state.get(field, []) tool_context.state[field] = existing_state + [response] logging.info(f"[Added to {field}] {response}") return {"status": "success"} def write_file( tool_context: ToolContext, directory: str, filename: str, content: str ) -> dict[str, str]: target_path = os.path.join(directory, filename) os.makedirs(os.path.dirname(target_path), exist_ok=True) with open(target_path, "w") as f: f.write(content) return {"status": "success"} # Agents file_writer = Agent( name="file_writer", model=model_name, description="Creates marketing details and saves a pitch document.", instruction=""" PLOT_OUTLINE: { PLOT_OUTLINE? } INSTRUCTIONS: - Create a marketable, contemporary movie title suggestion for the movie described in the PLOT_OUTLINE. If a title has been suggested in PLOT_OUTLINE, you can use it, or replace it with a better one. - Use your 'write_file' tool to create a new txt file with the following arguments: - for a filename, use the movie title - Write to the 'movie_pitches' directory. - For the 'content' to write, extract the following from the PLOT_OUTLINE: - A logline - Synopsis or plot outline """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[write_file], ) screenwriter = Agent( name="screenwriter", model=model_name, description="As a screenwriter, write a logline and plot outline for a biopic about a historical character.", instruction=""" INSTRUCTIONS: Your goal is to write a logline and three-act plot outline for an inspiring movie about a historical character(s) described by the PROMPT: { PROMPT? } - If there is CRITICAL_FEEDBACK, use those thoughts to improve upon the outline. - If there is RESEARCH provided, feel free to use details from it, but you are not required to use it all. - If there is a PLOT_OUTLINE, improve upon it. - Use the 'append_to_state' tool to write your logline and three-act plot outline to the field 'PLOT_OUTLINE'. - Summarize what you focused on in this pass. PLOT_OUTLINE: { PLOT_OUTLINE? } RESEARCH: { research? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], ) researcher = Agent( name="researcher", model=model_name, description="Answer research questions using Wikipedia.", instruction=""" PROMPT: { PROMPT? } PLOT_OUTLINE: { PLOT_OUTLINE? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } INSTRUCTIONS: - If there is a CRITICAL_FEEDBACK, use your wikipedia tool to do research to solve those suggestions - If there is a PLOT_OUTLINE, use your wikipedia tool to do research to add more historical detail - If these are empty, use your Wikipedia tool to gather facts about the person in the PROMPT - Use the 'append_to_state' tool to add your research to the field 'research'. - Summarize what you have learned. Now, use your Wikipedia tool to do research. """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[ LangchainTool(tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())), append_to_state, ], ) film_concept_team = SequentialAgent( name="film_concept_team", description="Write a film plot outline and save it as a text file.", sub_agents=[ researcher, screenwriter, file_writer ], ) root_agent = Agent( name="greeter", model=model_name, description="Guides the user in crafting a movie plot.", instruction=""" - Let the user know you will help them write a pitch for a hit movie. Ask them for a historical figure to create a movie about. - When they respond, use the 'append_to_state' tool to store the user's response in the 'PROMPT' state key and transfer to the 'film_concept_team' agent """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], sub_agents=[film_concept_team], ) EOF
ساختار فایل شما اکنون باید به این شکل باشد: 
محیط مجازی را تنظیم کنید
- در ترمینال ، با استفاده از
uvیک محیط مجازی ایجاد و فعال کنید. این کار تضمین میکند که وابستگیهای پروژه شما با پایتون سیستم تداخل نداشته باشند.uv venv source .venv/bin/activate
الزامات نصب
- دستور زیر را در ترمینال اجرا کنید تا فایل
requirements.txtایجاد شود.cat <<EOF > ~/adk_multiagent_systems/requirements.txt # Lists all Python dependencies required to run the multi-agent system, # including the Google ADK, LangChain community tools, and web server libraries. langchain-community==0.4.1 wikipedia==1.4.0 google-adk==1.27.5 fastapi==0.135.2 uvicorn==0.42.0 EOF - بستههای مورد نیاز را در محیط مجازی خود در ترمینال نصب کنید.
uv pip install -r requirements.txt
تنظیم متغیرهای محیطی
- از دستور زیر در ترمینال برای ایجاد فایل
.envاستفاده کنید، که به طور خودکار شناسه پروژه و منطقه شما را وارد میکند.cat <<EOF > ~/adk_multiagent_systems/.env GOOGLE_CLOUD_PROJECT="$(gcloud config get-value project)" GOOGLE_CLOUD_PROJECT_NUMBER="$(gcloud projects describe $(gcloud config get-value project) --format='value(projectNumber)')" GOOGLE_CLOUD_LOCATION="us-central1" GOOGLE_GENAI_USE_VERTEXAI=true MODEL="gemini-2.5-flash" EOF - در ترمینال ، متغیرها را در جلسه پوسته خود بارگذاری کنید.
source .env
خلاصه
در این بخش، شما پایه و اساس محلی پروژه خود را ایجاد کردید:
- ساختار دایرکتوری و فایلهای آغازگر لازم برای عامل (
agent.py،callback_logging.py،requirements.txt) ایجاد شد. - وابستگیهای خود را با استفاده از یک محیط مجازی (
uv) ایزوله کنید. - متغیرهای محیطی پیکربندیشده (
.env) برای ذخیره جزئیات خاص پروژه مانند شناسه پروژه و منطقه شما.
۶. فایل عامل را بررسی کنید
شما کد منبع آزمایشگاه، شامل یک سیستم چندعاملی از پیش نوشته شده را تنظیم کردهاید. قبل از استقرار برنامه، درک نحوه تعریف عاملها مفید است. منطق اصلی عاملها در workflow_agents/agent.py قرار دارد.
- در ویرایشگر Cloud Shell، از فایل اکسپلورر سمت چپ برای رفتن به
adk_multiagent_systems/workflow_agents/استفاده کنید و فایلagent.pyرا باز کنید. - لحظهای وقت بگذارید و فایل را بررسی کنید. لازم نیست تک تک خطوط را بفهمید، اما به ساختار سطح بالای آن توجه کنید:
- عاملهای منفرد: این فایل سه شیء
Agentمجزا را تعریف میکند:researcher،screenwriterوfile_writer. به هر عامل یکinstructionخاص (دستور آن) و لیستی ازtoolsکه مجاز به استفاده از آنها است (مانند ابزارWikipediaQueryRunیا یک ابزارwrite_fileسفارشی) داده میشود. - ترکیب عاملها: عاملهای منفرد در یک
SequentialAgentبه نامfilm_concept_teamبه هم زنجیر شدهاند. این به ADK میگوید که این عاملها را یکی پس از دیگری اجرا کند و حالت را از یکی به دیگری منتقل کند. - عامل ریشه: یک
root_agent) (با نام "greeter") برای مدیریت تعامل اولیه کاربر تعریف شده است. وقتی کاربر درخواستی را ارائه میدهد، این عامل آن را در وضعیت برنامه ذخیره میکند و سپس کنترل را به گردش کارfilm_concept_teamمنتقل میکند.
- عاملهای منفرد: این فایل سه شیء
درک این ساختار به روشن شدن آنچه قرار است مستقر کنید کمک میکند: نه فقط یک عامل واحد، بلکه یک تیم هماهنگ از عوامل تخصصی که توسط ADK سازماندهی شدهاند.
۷. یک خوشه GKE Autopilot ایجاد کنید
با آمادهسازی محیط، گام بعدی فراهم کردن زیرساختی است که برنامه عامل شما در آن اجرا خواهد شد. شما یک خوشه GKE Autopilot ایجاد خواهید کرد که به عنوان پایه و اساس استقرار شما عمل میکند. ما از حالت Autopilot استفاده میکنیم زیرا مدیریت پیچیده گرههای زیربنایی خوشه، مقیاسپذیری و امنیت را بر عهده دارد و به شما امکان میدهد صرفاً بر استقرار برنامه خود تمرکز کنید.
- در ترمینال ، یک کلاستر جدید GKE Autopilot با نام
adk-clusterایجاد کنید.gcloud container clusters create-auto adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT - پس از ایجاد کلاستر، با اجرای دستور زیر در ترمینال ،
kubectlبرای اتصال به آن پیکربندی کنید:gcloud container clusters get-credentials adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT~/.kube/config) را بهروزرسانی میکند. از این نقطه به بعد، ابزار خط فرمانkubectlاحراز هویت شده و برای ارتباط باadk-clusterشما هدایت میشود.
خلاصه
در این بخش، شما زیرساخت را فراهم کردید:
- با استفاده از
gcloudیک کلاستر GKE Autopilot کاملاً مدیریتشده ایجاد کردم. - ابزار
kubectlمحلی خود را برای احراز هویت و ارتباط با کلاستر جدید پیکربندی کردید.
۸. برنامه را کانتینرایز و منتشر کنید
کد عامل شما در حال حاضر فقط در محیط Cloud Shell شما وجود دارد. برای اجرای آن در GKE، ابتدا باید آن را در یک تصویر کانتینر بستهبندی کنید. تصویر کانتینر یک فایل استاتیک و قابل حمل است که کد برنامه شما را با تمام وابستگیهای آن بستهبندی میکند. وقتی این تصویر را اجرا میکنید، به یک کانتینر زنده تبدیل میشود.
این فرآیند شامل سه مرحله کلیدی است:
- ایجاد یک نقطه ورود : یک فایل
main.pyتعریف کنید تا منطق عامل شما را به یک وب سرور قابل اجرا تبدیل کند. - تعریف تصویر کانتینر : یک فایل داکر ایجاد کنید که به عنوان نقشه راه برای ساخت تصویر کانتینر شما عمل کند.
- ساخت و ارسال : از Cloud Build برای اجرای Dockerfile، ایجاد تصویر کانتینر و ارسال آن به Google Artifact Registry ، یک مخزن امن برای تصاویر خود، استفاده کنید.
آمادهسازی برنامه برای استقرار
عامل ADK شما برای دریافت درخواستها به یک وب سرور نیاز دارد. فایل main.py به عنوان نقطه ورود این سرویس عمل میکند و با استفاده از چارچوب FastAPI ، عملکرد عامل شما را از طریق HTTP نمایش میدهد.
- در ریشه دایرکتوری
adk_multiagent_systemsدر ترمینال ، یک فایل جدید به نامmain.pyایجاد کنید.cat <<EOF > ~/adk_multiagent_systems/main.py """ Serves as the application entry point. Initializes the FastAPI web server, discovers the agents defined in the workflow directory, and exposes them via HTTP endpoints for interaction. """ import os import uvicorn from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Get the directory where main.py is located AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) # Configure the session service (e.g., SQLite for local storage) SESSION_SERVICE_URI = "sqlite:///./sessions.db" # Configure CORS to allow requests from various origins for this lab ALLOWED_ORIGINS = ["http://localhost", "http://localhost:8080", "*"] # Enable the ADK's built-in web interface SERVE_WEB_INTERFACE = True # Call the ADK function to discover agents and create the FastAPI app app: FastAPI = get_fast_api_app( agents_dir=AGENT_DIR, session_service_uri=SESSION_SERVICE_URI, allow_origins=ALLOWED_ORIGINS, web=SERVE_WEB_INTERFACE, ) # You can add more FastAPI routes or configurations below if needed # Example: # @app.get("/hello") # async def read_root(): # return {"Hello": "World"} if __name__ == "__main__": # Get the port from the PORT environment variable provided by the container runtime # Run the Uvicorn server, listening on all available network interfaces (0.0.0.0) uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("PORT", 8080))) EOFuvicornاین برنامه را اجرا میکند و به میزبان0.0.0.0گوش میدهد تا اتصالات را از هر آدرس IP و روی پورت مشخص شده توسط متغیر محیطیPORTبپذیرد، که بعداً در مانیفست Kubernetes خود تنظیم خواهیم کرد.
در این مرحله، ساختار فایل شما همانطور که در پنل اکسپلورر در ویرایشگر Cloud Shell مشاهده میشود، باید به این شکل باشد: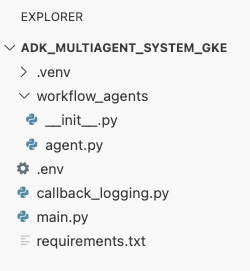
کانتینرایز کردن عامل ADK با داکر
برای استقرار برنامه خود در GKE، ابتدا باید آن را در یک تصویر کانتینر بستهبندی کنیم، که کد برنامه ما را با تمام کتابخانهها و وابستگیهای مورد نیاز برای اجرا، بستهبندی میکند. ما از Docker برای ایجاد این تصویر کانتینر استفاده خواهیم کرد.
- در ریشه دایرکتوری
adk_multiagent_systemsدر ترمینال ، یک فایل جدید به نامDockerfileایجاد کنید.cat <<'EOF' > ~/adk_multiagent_systems/Dockerfile # Defines the blueprint for the container image. Installs dependencies, # sets up a secure non-root user, and specifies the startup command to run the # agent web server. # Use an official lightweight Python image as the base FROM python:3.13-slim # Set the working directory inside the container WORKDIR /app # Create a non-root user for security best practices RUN adduser --disabled-password --gecos "" myuser # Copy and install dependencies first to leverage Docker's layer caching COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt # Copy all application code into the container COPY . . # Create the directory where the agent will write files at runtime # The -p flag ensures the command doesn't fail if the directory already exists RUN mkdir -p movie_pitches # Change ownership of EVERYTHING in /app to the non-root user # Without this, the running agent would be denied permission to write files. RUN chown -R myuser:myuser /app # Switch the active user from root to the non-root user USER myuser # Add the user's local binary directory to the system's PATH ENV PATH="/home/myuser/.local/bin:$PATH" # Define the command to run when the container starts CMD ["sh", "-c", "uvicorn main:app --host 0.0.0.0 --port $PORT"] EOF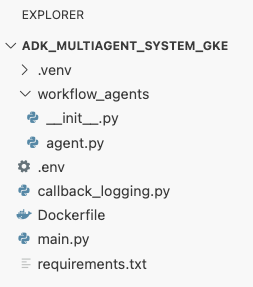
تصویر کانتینر را بسازید و به رجیستری مصنوعات منتقل کنید
حالا که یک Dockerfile دارید، از Cloud Build برای ساخت ایمیج و ارسال آن به Artifact Registry، یک رجیستری امن و خصوصی که با سرویسهای Google Cloud یکپارچه شده است، استفاده خواهید کرد. GKE ایمیج را از این رجیستری دریافت میکند تا برنامه شما را اجرا کند.
- در ترمینال ، یک مخزن جدید Artifact Registry برای ذخیره تصویر کانتینر خود ایجاد کنید.
gcloud artifacts repositories create adk-repo \ --repository-format=docker \ --location=$GOOGLE_CLOUD_LOCATION \ --description="ADK repository" - در ترمینال ، از
gcloud builds submitبرای ساخت ایمیج کانتینر و ارسال آن به مخزن استفاده کنید.gcloud builds submit \ --tag $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo/adk-agent:latest \ --project=$GOOGLE_CLOUD_PROJECT \ .Dockerfileشما استفاده میکند. این دستور، تصویر را در فضای ابری میسازد، آن را با آدرس مخزن Artifact Registry شما برچسبگذاری میکند و به طور خودکار آن را به آنجا منتقل میکند. - از طریق ترمینال ، تأیید کنید که ایمیج ساخته شده است:
gcloud artifacts docker images list \ $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo \ --project=$GOOGLE_CLOUD_PROJECT
خلاصه
در این بخش، کد خود را برای استقرار بستهبندی کردید:
- یک نقطه ورود
main.pyایجاد کردم تا عاملهای شما را در یک وب سرور FastAPI قرار دهم. - یک
Dockerfileتعریف کردم تا کد و وابستگیهای شما را در یک تصویر قابل حمل دستهبندی کند. - از Cloud Build برای ساخت تصویر و انتقال آن به یک مخزن امن Artifact Registry استفاده شد.
۹. ایجاد مانیفستهای Kubernetes
اکنون که تصویر کانتینر شما ساخته و در رجیستری Artifact ذخیره شده است، باید نحوه اجرای آن را به GKE آموزش دهید. این شامل دو فعالیت اصلی است:
- پیکربندی مجوزها : شما یک هویت اختصاصی برای عامل خود در داخل خوشه ایجاد خواهید کرد و به آن دسترسی ایمن به APIهای Google Cloud مورد نیازش (به طور خاص، Vertex AI ) اعطا خواهید کرد.
- تعریف وضعیت برنامه : شما یک فایل مانیفست Kubernetes خواهید نوشت، یک سند YAML که به صورت اعلانی هر آنچه برنامه شما برای اجرا نیاز دارد را تعریف میکند، از جمله تصویر کانتینر، متغیرهای محیطی و نحوه نمایش آن در شبکه.
پیکربندی حساب سرویس Kubernetes برای Vertex AI
نماینده شما برای ارتباط با Vertex AI API و دسترسی به مدلهای Gemini به مجوز نیاز دارد. امنترین و توصیهشدهترین روش برای اعطای این مجوز در GKE، Workload Identity است. Workload Identity به شما امکان میدهد یک هویت بومی Kubernetes (یک حساب سرویس Kubernetes ) را با یک هویت Google Cloud (یک حساب سرویس IAM ) پیوند دهید و کاملاً از نیاز به دانلود، مدیریت و ذخیره کلیدهای استاتیک JSON اجتناب کنید.
- در ترمینال ، حساب کاربری سرویس Kubernetes (
adk-agent-sa) را ایجاد کنید. این یک هویت برای عامل شما در داخل کلاستر GKE ایجاد میکند که پادهای شما میتوانند از آن استفاده کنند.kubectl create serviceaccount adk-agent-sa - در ترمینال ، حساب سرویس Kubernetes خود را با ایجاد یک اتصال سیاست به Google Cloud IAM پیوند دهید. این دستور نقش
aiplatform.userرا بهadk-agent-saشما اعطا میکند و به آن اجازه میدهد تا به طور ایمن API Vertex AI را فراخوانی کند.gcloud projects add-iam-policy-binding projects/${GOOGLE_CLOUD_PROJECT} \ --role=roles/aiplatform.user \ --member=principal://iam.googleapis.com/projects/${GOOGLE_CLOUD_PROJECT_NUMBER}/locations/global/workloadIdentityPools/${GOOGLE_CLOUD_PROJECT}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \ --condition=None
فایلهای مانیفست Kubernetes را ایجاد کنید
Kubernetes از فایلهای manifest YAML برای تعریف وضعیت مطلوب برنامه شما استفاده میکند. شما یک فایل deployment.yaml ایجاد خواهید کرد که شامل دو شیء ضروری Kubernetes است: یک Deployment و یک Service .
- از ترمینال ، فایل
deployment.yamlرا ایجاد کنید.cat <<EOF > ~/adk_multiagent_systems/deployment.yaml # Defines the Kubernetes resources required to deploy the application to GKE. # Includes the Deployment (to run the container pods) and the Service # (to expose the application via a Load Balancer). apiVersion: apps/v1 kind: Deployment metadata: name: adk-agent spec: replicas: 1 selector: matchLabels: app: adk-agent template: metadata: labels: app: adk-agent spec: # Assign the Kubernetes Service Account for Workload Identity serviceAccountName: adk-agent-sa containers: - name: adk-agent imagePullPolicy: Always # The path to the container image in Artifact Registry image: ${GOOGLE_CLOUD_LOCATION}-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/adk-repo/adk-agent:latest # Define the resources for GKE Autopilot to provision resources: limits: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" requests: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" ports: - containerPort: 8080 # Environment variables passed to the application env: - name: PORT value: "8080" - name: GOOGLE_CLOUD_PROJECT value: ${GOOGLE_CLOUD_PROJECT} - name: GOOGLE_CLOUD_LOCATION value: ${GOOGLE_CLOUD_LOCATION} - name: GOOGLE_GENAI_USE_VERTEXAI value: "true" - name: MODEL value: "gemini-2.5-flash" --- apiVersion: v1 kind: Service metadata: name: adk-agent spec: # Create a public-facing Network Load Balancer with an external IP type: LoadBalancer ports: - port: 80 targetPort: 8080 selector: app: adk-agent EOF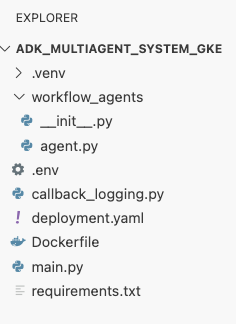
خلاصه
در این بخش، پیکربندی امنیتی و استقرار را تعریف کردید:
- یک حساب کاربری سرویس Kubernetes ایجاد کردم و آن را با استفاده از Workload Identity به Google Cloud IAM متصل کردم، که به پادهای شما اجازه میدهد بدون نیاز به مدیریت کلیدها، به طور ایمن به Vertex AI دسترسی داشته باشند.
- یک فایل
deployment.yamlایجاد شد که Deployment (نحوه اجرای podها) و Service (نحوه نمایش آنها از طریق Load Balancer) را تعریف میکند.
۱۰. برنامه را روی GKE مستقر کنید
با تعریف فایل مانیفست و قرار دادن تصویر کانتینر در رجیستری Artifact، اکنون آمادهی استقرار برنامهی خود هستید. در این مرحله، kubectl برای اعمال پیکربندی خود در کلاستر GKE استفاده خواهید کرد و سپس وضعیت را رصد خواهید کرد تا از راهاندازی صحیح عامل خود اطمینان حاصل کنید.
- در ترمینال خود، فایل
deployment.yamlmanifest را روی کلاستر خود اعمال کنید.kubectl apply -f deployment.yamlkubectl applyفایلdeployment.yamlشما را به سرور Kubernetes API ارسال میکند. سپس سرور پیکربندی شما را میخواند و ایجاد اشیاء Deployment و Service را هماهنگ میکند. - در ترمینال ، وضعیت استقرار خود را به صورت بلادرنگ بررسی کنید. منتظر بمانید تا پادها در حالت
Running) قرار گیرند.kubectl get pods -l=app=adk-agent --watch- در انتظار : پاد توسط کلاستر پذیرفته شده است، اما کانتینر هنوز ایجاد نشده است.
- ایجاد کانتینر : GKE تصویر کانتینر شما را از رجیستری Artifact دریافت کرده و کانتینر را راهاندازی میکند.
- اجرا : موفقیتآمیز بود! کانتینر در حال اجرا است و برنامه عامل شما فعال است.
- وقتی وضعیت «
Runningرا نشان داد، CTRL+C را در ترمینال فشار دهید تا دستور watch متوقف شود و به خط فرمان برگردید.
خلاصه
در این بخش، شما حجم کار را راهاندازی کردید:
-
kubectlapply برای ارسال مانیفست به کلاستر استفاده شد. - چرخه حیات Pod (در انتظار -> ایجاد کانتینر -> اجرا) را رصد کردم تا از شروع موفقیتآمیز برنامه اطمینان حاصل کنم.
۱۱. با نماینده تعامل داشته باشید
عامل ADK شما اکنون به صورت زنده روی GKE اجرا میشود و از طریق یک متعادلکننده بار عمومی در معرض اینترنت قرار دارد. شما به رابط وب عامل متصل خواهید شد تا با آن تعامل داشته باشید و تأیید کنید که کل سیستم به درستی کار میکند.
آدرس IP خارجی سرویس خود را پیدا کنید
برای دسترسی به عامل، ابتدا باید آدرس IP عمومی که GKE برای سرویس شما فراهم کرده است را دریافت کنید.
- در ترمینال ، دستور زیر را اجرا کنید تا جزئیات سرویس خود را دریافت کنید.
kubectl get service adk-agent - به دنبال مقدار موجود در ستون
EXTERNAL-IPبگردید. ممکن است یک یا دو دقیقه طول بکشد تا آدرس IP پس از اولین استقرار سرویس، اختصاص داده شود. اگر به صورتpendingنمایش داده شد، یک دقیقه صبر کنید و دوباره دستور را اجرا کنید. خروجی مشابه این خواهد بود:NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE adk-agent-service LoadBalancer 10.120.12.234 34.123.45.67 80:31234/TCP 5mEXTERNAL-IP(مثلاً 34.123.45.67) نقطه ورود عمومی به نماینده شما است.
عامل مستقر شده را آزمایش کنید
اکنون میتوانید از آدرس IP عمومی برای دسترسی مستقیم به رابط کاربری وب داخلی ADK از طریق مرورگر خود استفاده کنید.
- آدرس IP خارجی (
EXTERNAL-IP) را از ترمینال کپی کنید. - یک تب جدید در مرورگر وب خود باز کنید و
http://[EXTERNAL-IP]را تایپ کنید و به جای[EXTERNAL-IP]آدرس IP که کپی کردهاید را قرار دهید. - اکنون باید رابط وب ADK را ببینید.
- مطمئن شوید که گزینه workflow_agents در منوی کشویی agent انتخاب شده باشد.
- جریان توکن را فعال کنید.
- برای شروع مکالمه جدید،
helloرا تایپ کرده و اینتر را بزنید. - نتیجه را مشاهده کنید. نماینده باید سریعاً با این جمله پاسخ دهد: «من میتوانم به شما در نوشتن طرح اولیه برای یک فیلم پرفروش کمک کنم. دوست دارید در مورد کدام شخصیت تاریخی فیلم بسازید؟»
- وقتی از شما خواسته شد یک شخصیت تاریخی را انتخاب کنید، شخصیتی را انتخاب کنید که به آن علاقه دارید. برخی از ایدهها عبارتند از:
-
the most successful female pirate in history -
the woman who invented the first computer compiler -
a legendary lawman of the American Wild West
-
خلاصه
در این بخش، شما استقرار را تأیید کردید:
- آدرس IP خارجی اختصاص داده شده توسط LoadBalancer را بازیابی کرد.
- از طریق یک مرورگر به رابط کاربری وب ADK دسترسی پیدا کردم تا از واکنشگرا و کاربردی بودن سیستم چندعاملی اطمینان حاصل کنم.
۱۲. پیکربندی مقیاسبندی خودکار
یک چالش کلیدی در محیط تولید، مدیریت ترافیک غیرقابل پیشبینی کاربران است. کدنویسی ثابت تعداد ثابتی از کپیها، همانطور که در کار قبلی انجام دادید، به این معنی است که یا برای منابع بیکار هزینه اضافی پرداخت میکنید یا در هنگام افزایش ناگهانی ترافیک، ریسک عملکرد ضعیف را به جان میخرید. GKE این مشکل را با مقیاسبندی خودکار حل میکند.
شما یک HorizontalPodAutoscaler (HPA) را پیکربندی خواهید کرد، یک کنترلر Kubernetes که به طور خودکار تعداد podهای در حال اجرا در Deployment شما را بر اساس میزان استفاده از CPU در لحظه تنظیم میکند.
- در ترمینال ویرایشگر پوسته ابری (Cloud Shell Editor)، یک فایل
hpa.yamlجدید در ریشه دایرکتوریadk_multiagent_systemsایجاد کنید.cloudshell edit ~/adk_multiagent_systems/hpa.yaml - محتوای زیر را به فایل جدید
hpa.yamlاضافه کنید:# Configures the HorizontalPodAutoscaler (HPA) to automatically scale # the number of running agent pods up or down based on CPU utilization # to handle varying traffic loads. apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: adk-agent-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: adk-agent minReplicas: 1 maxReplicas: 5 targetCPUUtilizationPercentage: 50adk-agentما را هدف قرار میدهد. این شیء تضمین میکند که همیشه حداقل ۱ پاد در حال اجرا باشد، حداکثر ۵ پاد را تنظیم میکند و کپیها را اضافه/حذف میکند تا میانگین استفاده از CPU حدود ۵۰٪ حفظ شود. در این مرحله، ساختار فایل شما، همانطور که در پنل اکسپلورر در ویرایشگر Cloud Shell مشاهده میشود، باید به این شکل باشد:
- با قرار دادن این کد در ترمینال ، HPA را روی کلاستر خود اعمال کنید.
kubectl apply -f hpa.yaml
ترازوی خودکار را تأیید کنید
HPA اکنون فعال است و بر استقرار شما نظارت دارد. میتوانید وضعیت آن را بررسی کنید تا ببینید در حال اجرا است یا خیر.
- برای مشاهده وضعیت HPA خود، دستور زیر را در ترمینال اجرا کنید.
kubectl get hpa adk-agent-hpaNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE adk-agent-hpa Deployment/adk-agent 0%/50% 1 5 1 30s
خلاصه
در این بخش، شما برای ترافیک تولید بهینهسازی انجام دادید:
- یک مانیفست
hpa.yamlبرای تعریف قوانین مقیاسبندی ایجاد کردم. - برای تنظیم خودکار تعداد کپیهای پاد بر اساس میزان استفاده از پردازنده، از HorizontalPodAutoscaler (HPA) استفاده شد.
۱۳. آمادهسازی برای تولید
توجه : بخشهای زیر فقط برای اهداف اطلاعاتی هستند و شامل مراحل اجرایی بیشتری نیستند. این بخشها به گونهای طراحی شدهاند که زمینه و بهترین شیوهها را برای اجرای برنامه شما در محیط عملیاتی فراهم کنند.
تنظیم عملکرد با تخصیص منابع
در GKE Autopilot ، شما با مشخص کردن requests منابع در فایل deployment.yaml ، میزان CPU و حافظهی اختصاص داده شده به برنامهی خود را کنترل میکنید.
اگر متوجه شدید که عامل شما به دلیل کمبود حافظه کند یا از کار افتاده است، میتوانید با ویرایش بلوک resources در deployment.yaml و اعمال مجدد فایل با kubectl apply ، تخصیص منابع آن را افزایش دهید.
برای مثال، برای دو برابر کردن حافظه:
# In deployment.yaml
# ...
resources:
requests:
memory: "2Gi" # Increased from 1Gi
cpu: "1000m"
# ...
خودکارسازی گردش کار با CI/CD
در این آزمایش، شما دستورات را به صورت دستی اجرا کردید. روش حرفهای، ایجاد یک خط لوله CI/CD (یکپارچهسازی مداوم/استقرار مداوم) است. با اتصال یک مخزن کد منبع (مانند GitHub) به یک تریگر Cloud Build ، میتوانید کل فرآیند استقرار را خودکار کنید.
با یک خط لوله، هر بار که یک تغییر کد را اعمال میکنید، Cloud Build میتواند به طور خودکار:
- تصویر کانتینر جدید را بسازید.
- تصویر را به رجیستری مصنوعات منتقل کنید.
- مانیفستهای بهروز شده Kubernetes را در کلاستر GKE خود اعمال کنید.
مدیریت ایمن اسرار
در این آزمایش، شما پیکربندی را در یک فایل .env ذخیره کردید و آن را به برنامه خود منتقل کردید. این برای توسعه مناسب است اما برای دادههای حساس مانند کلیدهای API امن نیست. بهترین روش توصیه شده، استفاده از Secret Manager برای ذخیره ایمن اسرار است.
GKE با Secret Manager یکپارچهسازی بومی دارد که به شما امکان میدهد اسرار را مستقیماً به عنوان متغیرهای محیطی یا فایلها در پادهای خود مانت کنید، بدون اینکه هرگز در کد منبع شما بررسی شوند.
این بخش منابع پاکسازی مورد نظر شماست که درست قبل از بخش نتیجهگیری قرار داده شده است.
۱۴. منابع را پاکسازی کنید
برای جلوگیری از تحمیل هزینه به حساب گوگل کلود خود برای منابع استفاده شده در این آموزش، یا پروژهای که شامل منابع است را حذف کنید، یا پروژه را نگه دارید و منابع تکی را حذف کنید.
خوشه GKE را حذف کنید
خوشه GKE عامل اصلی هزینه در این آزمایشگاه است. حذف آن هزینههای محاسباتی را متوقف میکند.
- در ترمینال، دستور زیر را اجرا کنید:
gcloud container clusters delete adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
مخزن رجیستری Artifact را حذف کنید
تصاویر کانتینر ذخیره شده در رجیستری مصنوعات، هزینههای ذخیرهسازی را متحمل میشوند.
- در ترمینال، دستور زیر را اجرا کنید:
gcloud artifacts repositories delete adk-repo \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
حذف پروژه (اختیاری)
اگر پروژه جدیدی را بهطور خاص برای این آزمایشگاه ایجاد کردهاید و قصد ندارید دوباره از آن استفاده کنید، سادهترین راه برای پاکسازی، حذف کل پروژه است.
- در ترمینال، دستور زیر را اجرا کنید (به جای
[YOUR_PROJECT_ID]، شناسه پروژه واقعی خود را قرار دهید):gcloud projects delete [YOUR_PROJECT_ID]
۱۵. نتیجهگیری
تبریک! شما با موفقیت یک برنامه ADK چندعاملی را در یک کلاستر GKE در سطح تولید مستقر کردهاید. این یک دستاورد قابل توجه است که چرخه حیات اصلی یک برنامه مدرن مبتنی بر ابر را پوشش میدهد و پایه محکمی برای استقرار سیستمهای عامل پیچیده شما فراهم میکند.
خلاصه
در این آزمایشگاه، شما یاد گرفتهاید که:
- یک کلاستر خلبان خودکار GKE فراهم کنید.
- یک تصویر کانتینر با
Dockerfileبسازید و آن را به Artifact Registry منتقل کنید - با استفاده از Workload Identity به طور ایمن به API های Google Cloud متصل شوید.
- مانیفستهای Kubernetes را برای یک Deployment و Service بنویسید.
- یک برنامه را با استفاده از LoadBalancer به اینترنت متصل کنید.
- مقیاسبندی خودکار را با یک HorizontalPodAutoscaler (HPA) پیکربندی کنید.