
1. Introduction
Présentation
Cet atelier comble le fossé essentiel entre le développement d'un système multi-agent puissant et son déploiement pour un cas d'utilisation concret. Bien que la création d'agents en local soit un bon point de départ, les applications de production nécessitent une plate-forme évolutive, fiable et sécurisée.
Dans cet atelier, vous allez prendre un système multi-agents créé avec le Google Agent Development Kit (ADK) et le déployer dans un environnement de production sur Google Kubernetes Engine (GKE).
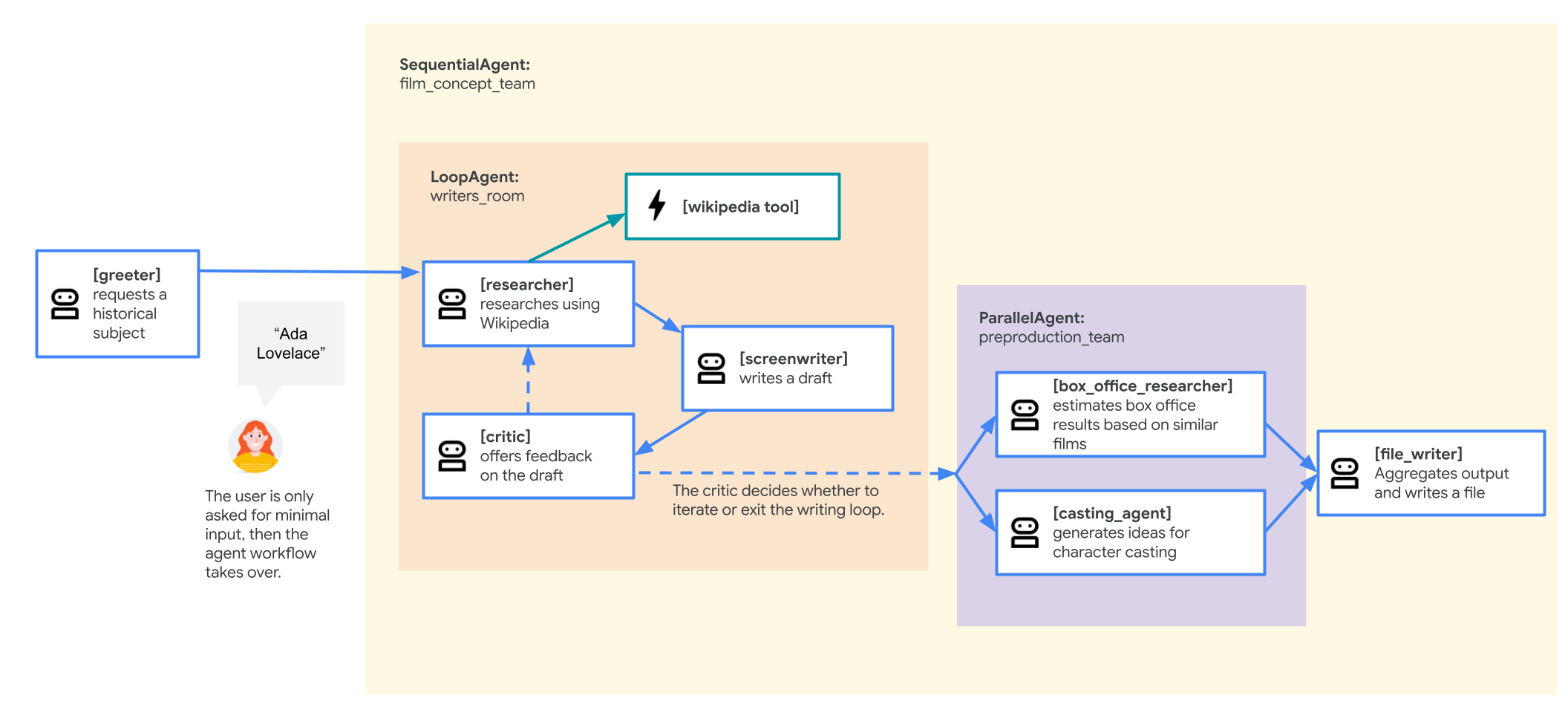
Agent de l'équipe de conception de films
L'application exemple utilisée dans cet atelier est une "équipe de conception de films" composée de plusieurs agents collaboratifs : un chercheur, un scénariste et un rédacteur de fichiers. Ces agents travaillent ensemble pour aider un utilisateur à réfléchir et à élaborer un pitch de film sur une figure historique.
Pourquoi déployer sur GKE ?
Pour préparer votre agent aux exigences d'un environnement de production, vous avez besoin d'une plate-forme conçue pour l'évolutivité, la sécurité et la rentabilité. Google Kubernetes Engine (GKE) fournit cette base puissante et flexible pour exécuter votre application conteneurisée.
Cela présente plusieurs avantages pour votre charge de travail de production :
- Scaling et performances automatiques : gérez le trafic imprévisible avec l'autoscaler horizontal de pods (HPA), qui ajoute ou supprime automatiquement des répliques d'agents en fonction de la charge. Pour les charges de travail d'IA plus exigeantes, vous pouvez associer des accélérateurs matériels tels que des GPU et des TPU.
- Gestion économique des ressources : optimisez les coûts avec GKE Autopilot, qui gère automatiquement l'infrastructure sous-jacente pour que vous ne payiez que les ressources demandées par votre application.
- Sécurité et observabilité intégrées : connectez-vous de manière sécurisée à d'autres services Google Cloud à l'aide de Workload Identity, ce qui vous évite d'avoir à gérer et stocker les clés de compte de service. Tous les journaux d'application sont automatiquement diffusés dans Cloud Logging pour une surveillance et un débogage centralisés.
- Contrôle et portabilité : évitez la dépendance vis-à-vis d'un fournisseur grâce à Kubernetes Open Source. Votre application est portable et peut s'exécuter sur n'importe quel cluster Kubernetes, sur site ou dans d'autres clouds.
Points abordés
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
- Provisionnez un cluster GKE Autopilot.
- Conteneurisez une application avec un Dockerfile et transférez l'image vers Artifact Registry.
- Connectez votre application de manière sécurisée aux API Google Cloud à l'aide de Workload Identity.
- Écrivez et appliquez des fichiers manifestes Kubernetes pour un déploiement et un service.
- Exposez une application sur Internet avec un LoadBalancer.
- Configurez l'autoscaling avec un HorizontalPodAutoscaler (HPA).
2. Configuration du projet
Compte Google
Si vous ne possédez pas encore de compte Google personnel, vous devez en créer un.
Utilisez un compte personnel au lieu d'un compte professionnel ou scolaire.
Se connecter à la console Google Cloud
Connectez-vous à la console Google Cloud à l'aide d'un compte Google personnel.
Activer la facturation
Configurer un compte de facturation personnel
Si vous avez configuré la facturation à l'aide de crédits Google Cloud, vous pouvez ignorer cette étape.
Pour configurer un compte de facturation personnel, cliquez ici pour activer la facturation dans la console Cloud.
Remarques :
- Cet atelier devrait vous coûter moins de 1 USD en ressources Cloud.
- Vous pouvez suivre les étapes à la fin de cet atelier pour supprimer les ressources et éviter ainsi des frais supplémentaires.
- Les nouveaux utilisateurs peuvent bénéficier d'un essai sans frais pour bénéficier d'un crédit de 300$.
Créer un projet (facultatif)
Si vous n'avez pas de projet que vous souhaitez utiliser pour cet atelier, créez-en un.
3. Ouvrir l'éditeur Cloud Shell
- Cliquez sur ce lien pour accéder directement à l'éditeur Cloud Shell.
- Si vous êtes invité à autoriser l'accès à un moment donné aujourd'hui, cliquez sur Autoriser pour continuer.
- Si le terminal ne s'affiche pas en bas de l'écran, ouvrez-le :
- Cliquez sur Afficher.
- Cliquez sur Terminal
 .
.
- Dans le terminal, définissez votre projet à l'aide de la commande suivante :
gcloud config set project [PROJECT_ID]- Exemple :
gcloud config set project lab-project-id-example - Si vous ne vous souvenez pas de l'ID de votre projet, vous pouvez lister tous vos ID de projet avec la commande suivante :
gcloud projects list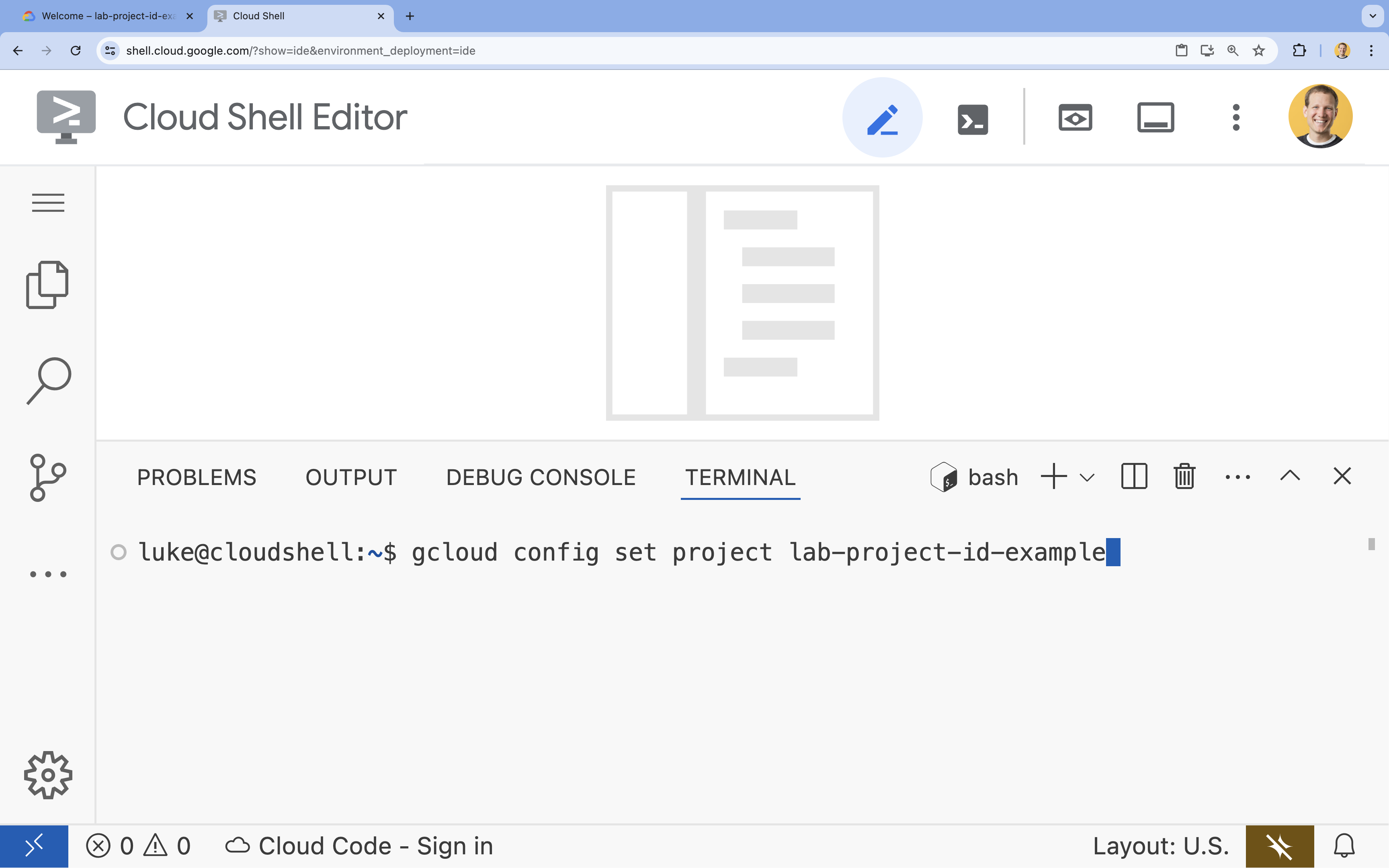
- Exemple :
- Le message suivant doit s'afficher :
Updated property [core/project].
4. Activer les API
Pour utiliser GKE, Artifact Registry, Cloud Build et Vertex AI, vous devez activer leurs API respectives dans votre projet Google Cloud.
- Dans le terminal, activez les API :
gcloud services enable \ container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.comOperation "operations/acf.p2-176675280136-b03ab5e4-3483-4ebf-9655-43dc3b345c63" finished successfully.
Présentation des API
- L'API Google Kubernetes Engine (
container.googleapis.com) vous permet de créer et de gérer le cluster GKE qui exécute votre agent. GKE fournit un environnement géré permettant de déployer, gérer et faire évoluer vos applications conteneurisées à l'aide de l'infrastructure Google. - L'API Artifact Registry (
artifactregistry.googleapis.com) fournit un dépôt sécurisé et privé pour stocker l'image de conteneur de votre agent. Il s'agit de l'évolution de Container Registry, et il s'intègre parfaitement à GKE et Cloud Build. - L'API Cloud Build (
cloudbuild.googleapis.com) est utilisée par la commandegcloud builds submitpour créer votre image de conteneur dans le cloud à partir de votre fichier Dockerfile. Il s'agit d'une plate-forme CI/CD sans serveur qui exécute vos compilations sur l'infrastructure Google Cloud. - L'API Vertex AI (
aiplatform.googleapis.com) permet à votre agent déployé de communiquer avec les modèles Gemini pour effectuer ses tâches principales. Elle fournit l'API unifiée pour tous les services d'IA de Google Cloud.
5. Préparer votre environnement de développement
Créer la structure de répertoires
- Dans le terminal, créez le répertoire du projet et les sous-répertoires nécessaires :
mkdir -p ~/adk_multiagent_systems/workflow_agents cd ~/adk_multiagent_systems - Dans le terminal, exécutez la commande suivante pour ouvrir le répertoire dans l'explorateur de l'éditeur Cloud Shell.
cloudshell open-workspace ~/adk_multiagent_systems - Le panneau de l'explorateur à gauche s'actualise. Vous devriez maintenant voir les répertoires que vous avez créés.
À mesure que vous créerez des fichiers au cours des étapes suivantes, ils s'afficheront dans ce répertoire.
Créer des fichiers de démarrage
Vous allez maintenant créer les fichiers de démarrage nécessaires pour l'application.
- Créez
callback_logging.pyen exécutant la commande suivante dans le terminal. Ce fichier gère la journalisation pour l'observabilité.cat <<EOF > ~/adk_multiagent_systems/callback_logging.py """ Provides helper functions for observability. Handles formatting and sending agent queries, responses, and tool calls to Google Cloud Logging to aid in monitoring and debugging. """ import logging import google.cloud.logging from google.adk.agents.callback_context import CallbackContext from google.adk.models import LlmResponse, LlmRequest def log_query_to_model(callback_context: CallbackContext, llm_request: LlmRequest): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_request.contents and llm_request.contents[-1].role == 'user': if llm_request.contents[-1].parts and "text" in llm_request.contents[-1].parts: last_user_message = llm_request.contents[-1].parts[0].text logging.info(f"[query to {callback_context.agent_name}]: " + last_user_message) def log_model_response(callback_context: CallbackContext, llm_response: LlmResponse): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_response.content and llm_response.content.parts: for part in llm_response.content.parts: if part.text: logging.info(f"[response from {callback_context.agent_name}]: " + part.text) elif part.function_call: logging.info(f"[function call from {callback_context.agent_name}]: " + part.function_call.name) EOF - Créez
workflow_agents/__init__.pyen exécutant la commande suivante dans le terminal. Cela marque le répertoire comme package Python.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/__init__.py """ Marks the directory as a Python package and exposes the agent module, allowing the ADK to discover and register the agents defined within. """ from . import agent EOF - Créez
workflow_agents/agent.pyen exécutant la commande suivante dans le terminal. Ce fichier contient la logique de base de votre équipe multi-agents.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/agent.py """ Defines the core multi-agent workflow. Configures individual agents (Researcher, Screenwriter, File Writer), assigns their specific tools, and orchestrates their collaboration using the ADK's SequentialAgent pattern. """ import os import logging import google.cloud.logging from callback_logging import log_query_to_model, log_model_response from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent, LoopAgent, ParallelAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool # import from google.genai import types from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL") print(model_name) # Tools def append_to_state( tool_context: ToolContext, field: str, response: str ) -> dict[str, str]: """Append new output to an existing state key. Args: field (str): a field name to append to response (str): a string to append to the field Returns: dict[str, str]: {"status": "success"} """ existing_state = tool_context.state.get(field, []) tool_context.state[field] = existing_state + [response] logging.info(f"[Added to {field}] {response}") return {"status": "success"} def write_file( tool_context: ToolContext, directory: str, filename: str, content: str ) -> dict[str, str]: target_path = os.path.join(directory, filename) os.makedirs(os.path.dirname(target_path), exist_ok=True) with open(target_path, "w") as f: f.write(content) return {"status": "success"} # Agents file_writer = Agent( name="file_writer", model=model_name, description="Creates marketing details and saves a pitch document.", instruction=""" PLOT_OUTLINE: { PLOT_OUTLINE? } INSTRUCTIONS: - Create a marketable, contemporary movie title suggestion for the movie described in the PLOT_OUTLINE. If a title has been suggested in PLOT_OUTLINE, you can use it, or replace it with a better one. - Use your 'write_file' tool to create a new txt file with the following arguments: - for a filename, use the movie title - Write to the 'movie_pitches' directory. - For the 'content' to write, extract the following from the PLOT_OUTLINE: - A logline - Synopsis or plot outline """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[write_file], ) screenwriter = Agent( name="screenwriter", model=model_name, description="As a screenwriter, write a logline and plot outline for a biopic about a historical character.", instruction=""" INSTRUCTIONS: Your goal is to write a logline and three-act plot outline for an inspiring movie about a historical character(s) described by the PROMPT: { PROMPT? } - If there is CRITICAL_FEEDBACK, use those thoughts to improve upon the outline. - If there is RESEARCH provided, feel free to use details from it, but you are not required to use it all. - If there is a PLOT_OUTLINE, improve upon it. - Use the 'append_to_state' tool to write your logline and three-act plot outline to the field 'PLOT_OUTLINE'. - Summarize what you focused on in this pass. PLOT_OUTLINE: { PLOT_OUTLINE? } RESEARCH: { research? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], ) researcher = Agent( name="researcher", model=model_name, description="Answer research questions using Wikipedia.", instruction=""" PROMPT: { PROMPT? } PLOT_OUTLINE: { PLOT_OUTLINE? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } INSTRUCTIONS: - If there is a CRITICAL_FEEDBACK, use your wikipedia tool to do research to solve those suggestions - If there is a PLOT_OUTLINE, use your wikipedia tool to do research to add more historical detail - If these are empty, use your Wikipedia tool to gather facts about the person in the PROMPT - Use the 'append_to_state' tool to add your research to the field 'research'. - Summarize what you have learned. Now, use your Wikipedia tool to do research. """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[ LangchainTool(tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())), append_to_state, ], ) film_concept_team = SequentialAgent( name="film_concept_team", description="Write a film plot outline and save it as a text file.", sub_agents=[ researcher, screenwriter, file_writer ], ) root_agent = Agent( name="greeter", model=model_name, description="Guides the user in crafting a movie plot.", instruction=""" - Let the user know you will help them write a pitch for a hit movie. Ask them for a historical figure to create a movie about. - When they respond, use the 'append_to_state' tool to store the user's response in the 'PROMPT' state key and transfer to the 'film_concept_team' agent """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], sub_agents=[film_concept_team], ) EOF
La structure de votre fichier devrait maintenant se présenter comme suit : 
Configurer l'environnement virtuel
- Dans le terminal, créez et activez un environnement virtuel à l'aide de
uv. Cela permet de s'assurer que les dépendances de votre projet ne sont pas en conflit avec le système Python.uv venv source .venv/bin/activate
Installer les éléments requis
- Exécutez la commande suivante dans le terminal pour créer le fichier
requirements.txt.cat <<EOF > ~/adk_multiagent_systems/requirements.txt # Lists all Python dependencies required to run the multi-agent system, # including the Google ADK, LangChain community tools, and web server libraries. langchain-community==0.4.1 wikipedia==1.4.0 google-adk==1.27.5 fastapi==0.135.2 uvicorn==0.42.0 EOF - Installez les packages requis dans votre environnement virtuel dans le terminal.
uv pip install -r requirements.txt
Configurer des variables d'environnement
- Utilisez la commande suivante dans le terminal pour créer le fichier
.env, en insérant automatiquement votre ID de projet et votre région.cat <<EOF > ~/adk_multiagent_systems/.env GOOGLE_CLOUD_PROJECT="$(gcloud config get-value project)" GOOGLE_CLOUD_PROJECT_NUMBER="$(gcloud projects describe $(gcloud config get-value project) --format='value(projectNumber)')" GOOGLE_CLOUD_LOCATION="us-central1" GOOGLE_GENAI_USE_VERTEXAI=true MODEL="gemini-2.5-flash" EOF - Dans le terminal, chargez les variables dans votre session shell.
source .env
Récapitulatif
Dans cette section, vous avez établi les bases locales de votre projet :
- Création de la structure de répertoire et des fichiers de démarrage de l'agent nécessaires (
agent.py,callback_logging.py,requirements.txt). - Isolez vos dépendances à l'aide d'un environnement virtuel (
uv). - Variables d'environnement configurées (
.env) pour stocker des informations spécifiques au projet, comme l'ID et la région de votre projet.
6. Explorer le fichier de l'agent
Vous avez configuré le code source de l'atelier, y compris un système multi-agents pré-écrit. Avant de déployer l'application, il est utile de comprendre comment les agents sont définis. La logique de l'agent principal se trouve dans workflow_agents/agent.py.
- Dans l'éditeur Cloud Shell, utilisez l'explorateur de fichiers sur la gauche pour accéder à
adk_multiagent_systems/workflow_agents/et ouvrir le fichieragent.py. - Prenez quelques instants pour parcourir le fichier. Vous n'avez pas besoin de comprendre chaque ligne, mais notez la structure générale :
- Agents individuels : le fichier définit trois objets
Agentdistincts :researcher,screenwriteretfile_writer. Chaque agent reçoit uninstructionspécifique (son invite) et une liste detoolsqu'il est autorisé à utiliser (comme l'outilWikipediaQueryRunou un outilwrite_filepersonnalisé). - Composition de l'agent : les agents individuels sont enchaînés dans un
SequentialAgentappeléfilm_concept_team. Cela indique à l'ADK d'exécuter ces agents les uns après les autres, en transmettant l'état de l'un à l'autre. - L'agent racine : un
root_agent(nommé "greeter") est défini pour gérer l'interaction initiale de l'utilisateur. Lorsque l'utilisateur fournit un prompt, cet agent l'enregistre dans l'état de l'application, puis transfère le contrôle au workflowfilm_concept_team.
- Agents individuels : le fichier définit trois objets
Comprendre cette structure permet de clarifier ce que vous êtes sur le point de déployer : non pas un seul agent, mais une équipe coordonnée d'agents spécialisés orchestrée par l'ADK.
7. Créer un cluster GKE Autopilot
Maintenant que votre environnement est prêt, vous devez provisionner l'infrastructure sur laquelle votre application d'agent s'exécutera. Vous allez créer un cluster GKE Autopilot, qui servira de base à votre déploiement. Nous utilisons le mode Autopilot, car il gère la complexité de la gestion des nœuds, du scaling et de la sécurité sous-jacents du cluster, ce qui vous permet de vous concentrer uniquement sur le déploiement de votre application.
- Dans le terminal, créez un cluster GKE Autopilot nommé
adk-cluster.gcloud container clusters create-auto adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT - Une fois le cluster créé, configurez
kubectlpour vous y connecter en exécutant la commande suivante dans le terminal :gcloud container clusters get-credentials adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT~/.kube/config). À partir de ce moment, l'outil de ligne de commandekubectlsera authentifié et dirigé pour communiquer avec votreadk-cluster.
Récapitulatif
Dans cette section, vous avez provisionné l'infrastructure :
- Création d'un cluster GKE Autopilot entièrement géré à l'aide de
gcloud. - Vous avez configuré votre outil
kubectllocal pour l'authentification et la communication avec le nouveau cluster.
8. Conteneuriser et transférer l'application
Le code de votre agent n'existe actuellement que dans votre environnement Cloud Shell. Pour l'exécuter sur GKE, vous devez d'abord l'empaqueter dans une image de conteneur. Une image de conteneur est un fichier statique et portable qui regroupe le code de votre application avec toutes ses dépendances. Lorsque vous exécutez cette image, elle devient un conteneur actif.
Ce processus comprend trois étapes clés :
- Créez un point d'entrée : définissez un fichier
main.pypour transformer la logique de votre agent en serveur Web exécutable. - Définissez l'image de conteneur : créez un Dockerfile qui sert de plan pour créer votre image de conteneur.
- Compiler et transférer : utilisez Cloud Build pour exécuter le Dockerfile, créer l'image de conteneur et la transférer vers Google Artifact Registry, un dépôt sécurisé pour vos images.
Préparer l'application pour le déploiement
Votre agent ADK a besoin d'un serveur Web pour recevoir les requêtes. Le fichier main.py servira de point d'entrée, en utilisant le framework FastAPI pour exposer les fonctionnalités de votre agent sur HTTP.
- Dans la racine du répertoire
adk_multiagent_systemsdu terminal, créez un fichier nommémain.py.cat <<EOF > ~/adk_multiagent_systems/main.py """ Serves as the application entry point. Initializes the FastAPI web server, discovers the agents defined in the workflow directory, and exposes them via HTTP endpoints for interaction. """ import os import uvicorn from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Get the directory where main.py is located AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) # Configure the session service (e.g., SQLite for local storage) SESSION_SERVICE_URI = "sqlite:///./sessions.db" # Configure CORS to allow requests from various origins for this lab ALLOWED_ORIGINS = ["http://localhost", "http://localhost:8080", "*"] # Enable the ADK's built-in web interface SERVE_WEB_INTERFACE = True # Call the ADK function to discover agents and create the FastAPI app app: FastAPI = get_fast_api_app( agents_dir=AGENT_DIR, session_service_uri=SESSION_SERVICE_URI, allow_origins=ALLOWED_ORIGINS, web=SERVE_WEB_INTERFACE, ) # You can add more FastAPI routes or configurations below if needed # Example: # @app.get("/hello") # async def read_root(): # return {"Hello": "World"} if __name__ == "__main__": # Get the port from the PORT environment variable provided by the container runtime # Run the Uvicorn server, listening on all available network interfaces (0.0.0.0) uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("PORT", 8080))) EOFuvicornexécute cette application, en écoutant l'hôte0.0.0.0pour accepter les connexions depuis n'importe quelle adresse IP et sur le port spécifié par la variable d'environnementPORT, que nous définirons plus tard dans notre fichier manifeste Kubernetes.
À ce stade, la structure de vos fichiers, telle qu'elle apparaît dans le panneau de l'explorateur de l'éditeur Cloud Shell, devrait ressembler à ceci :
Conteneuriser l'agent ADK avec Docker
Pour déployer notre application sur GKE, nous devons d'abord l'empaqueter dans une image de conteneur, qui regroupe le code de notre application avec toutes les bibliothèques et dépendances dont elle a besoin pour s'exécuter. Nous utiliserons Docker pour créer cette image de conteneur.
- Dans la racine du répertoire
adk_multiagent_systemsdu terminal, créez un fichier nomméDockerfile.cat <<'EOF' > ~/adk_multiagent_systems/Dockerfile # Defines the blueprint for the container image. Installs dependencies, # sets up a secure non-root user, and specifies the startup command to run the # agent web server. # Use an official lightweight Python image as the base FROM python:3.13-slim # Set the working directory inside the container WORKDIR /app # Create a non-root user for security best practices RUN adduser --disabled-password --gecos "" myuser # Copy and install dependencies first to leverage Docker's layer caching COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt # Copy all application code into the container COPY . . # Create the directory where the agent will write files at runtime # The -p flag ensures the command doesn't fail if the directory already exists RUN mkdir -p movie_pitches # Change ownership of EVERYTHING in /app to the non-root user # Without this, the running agent would be denied permission to write files. RUN chown -R myuser:myuser /app # Switch the active user from root to the non-root user USER myuser # Add the user's local binary directory to the system's PATH ENV PATH="/home/myuser/.local/bin:$PATH" # Define the command to run when the container starts CMD ["sh", "-c", "uvicorn main:app --host 0.0.0.0 --port $PORT"] EOF
Créer et transférer l'image de conteneur vers Artifact Registry
Maintenant que vous disposez d'un Dockerfile, vous allez utiliser Cloud Build pour créer l'image et la transférer vers Artifact Registry, un registre privé et sécurisé intégré aux services Google Cloud. GKE extrait l'image de ce registre pour exécuter votre application.
- Dans le terminal, créez un dépôt Artifact Registry pour stocker votre image de conteneur.
gcloud artifacts repositories create adk-repo \ --repository-format=docker \ --location=$GOOGLE_CLOUD_LOCATION \ --description="ADK repository" - Dans le terminal, utilisez
gcloud builds submitpour créer votre image de conteneur et la transférer vers le dépôt.gcloud builds submit \ --tag $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo/adk-agent:latest \ --project=$GOOGLE_CLOUD_PROJECT \ .Dockerfile. Il crée l'image dans le cloud, lui ajoute un tag avec l'adresse de votre dépôt Artifact Registry et l'y transfère automatiquement. - Dans le terminal, vérifiez que l'image est créée :
gcloud artifacts docker images list \ $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo \ --project=$GOOGLE_CLOUD_PROJECT
Récapitulatif
Dans cette section, vous avez empaqueté votre code pour le déploiement :
- Création d'un point d'entrée
main.pypour encapsuler vos agents dans un serveur Web FastAPI. - Définissez un fichier
Dockerfilepour regrouper votre code et vos dépendances dans une image portable. - Utilisé Cloud Build pour créer l'image et la transférer vers un dépôt Artifact Registry sécurisé.
9. Créer des fichiers manifestes Kubernetes
Maintenant que votre image de conteneur est créée et stockée dans Artifact Registry, vous devez indiquer à GKE comment l'exécuter. Cela implique deux activités principales :
- Configurer les autorisations : vous allez créer une identité dédiée pour votre agent dans le cluster et lui accorder un accès sécurisé aux API Google Cloud dont il a besoin (en particulier Vertex AI).
- Définir l'état de l'application : vous allez écrire un fichier manifeste Kubernetes, un document YAML qui définit de manière déclarative tout ce dont votre application a besoin pour s'exécuter, y compris l'image de conteneur, les variables d'environnement et la façon dont elle doit être exposée au réseau.
Configurer le compte de service Kubernetes pour Vertex AI
Votre agent a besoin d'une autorisation pour communiquer avec l'API Vertex AI afin d'accéder aux modèles Gemini. La méthode la plus sécurisée et recommandée pour accorder cette autorisation dans GKE est Workload Identity. Workload Identity vous permet d'associer une identité native Kubernetes (un compte de service Kubernetes) à une identité Google Cloud (un compte de service IAM), ce qui vous évite complètement d'avoir à télécharger, gérer et stocker des clés JSON statiques.
- Dans le terminal, créez le compte de service Kubernetes (
adk-agent-sa). Cela crée une identité pour votre agent dans le cluster GKE que vos pods peuvent utiliser.kubectl create serviceaccount adk-agent-sa - Dans le terminal, associez votre compte de service Kubernetes à Google Cloud IAM en créant une liaison de stratégie. Cette commande attribue le rôle
aiplatform.userà votreadk-agent-sa, ce qui lui permet d'appeler l'API Vertex AI de manière sécurisée.gcloud projects add-iam-policy-binding projects/${GOOGLE_CLOUD_PROJECT} \ --role=roles/aiplatform.user \ --member=principal://iam.googleapis.com/projects/${GOOGLE_CLOUD_PROJECT_NUMBER}/locations/global/workloadIdentityPools/${GOOGLE_CLOUD_PROJECT}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \ --condition=None
Créer les fichiers manifestes Kubernetes
Kubernetes utilise des fichiers manifestes YAML pour définir l'état souhaité de votre application. Vous allez créer un fichier deployment.yaml contenant deux objets Kubernetes essentiels : un déploiement et un service.
- À partir du terminal, générez le fichier
deployment.yaml.cat <<EOF > ~/adk_multiagent_systems/deployment.yaml # Defines the Kubernetes resources required to deploy the application to GKE. # Includes the Deployment (to run the container pods) and the Service # (to expose the application via a Load Balancer). apiVersion: apps/v1 kind: Deployment metadata: name: adk-agent spec: replicas: 1 selector: matchLabels: app: adk-agent template: metadata: labels: app: adk-agent spec: # Assign the Kubernetes Service Account for Workload Identity serviceAccountName: adk-agent-sa containers: - name: adk-agent imagePullPolicy: Always # The path to the container image in Artifact Registry image: ${GOOGLE_CLOUD_LOCATION}-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/adk-repo/adk-agent:latest # Define the resources for GKE Autopilot to provision resources: limits: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" requests: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" ports: - containerPort: 8080 # Environment variables passed to the application env: - name: PORT value: "8080" - name: GOOGLE_CLOUD_PROJECT value: ${GOOGLE_CLOUD_PROJECT} - name: GOOGLE_CLOUD_LOCATION value: ${GOOGLE_CLOUD_LOCATION} - name: GOOGLE_GENAI_USE_VERTEXAI value: "true" - name: MODEL value: "gemini-2.5-flash" --- apiVersion: v1 kind: Service metadata: name: adk-agent spec: # Create a public-facing Network Load Balancer with an external IP type: LoadBalancer ports: - port: 80 targetPort: 8080 selector: app: adk-agent EOF
Récapitulatif
Dans cette section, vous avez défini la configuration de sécurité et de déploiement :
- Vous avez créé un compte de service Kubernetes et l'avez associé à Google Cloud IAM à l'aide de Workload Identity, ce qui permet à vos pods d'accéder de manière sécurisée à Vertex AI sans avoir à gérer de clés.
- Générez un fichier
deployment.yamlqui définit le déploiement (comment exécuter les pods) et le service (comment les exposer via un équilibreur de charge).
10. Déployer l'application sur GKE
Maintenant que vous avez défini votre fichier manifeste et transféré votre image de conteneur vers Artifact Registry, vous êtes prêt à déployer votre application. Dans cette tâche, vous allez utiliser kubectl pour appliquer votre configuration au cluster GKE, puis surveiller l'état pour vous assurer que votre agent démarre correctement.
- Dans votre terminal, appliquez le fichier manifeste
deployment.yamlà votre cluster.kubectl apply -f deployment.yamlkubectl applyenvoie votre fichierdeployment.yamlau serveur d'API Kubernetes. Le serveur lit ensuite votre configuration et orchestre la création des objets Deployment et Service. - Dans le terminal, vérifiez l'état de votre déploiement en temps réel. Attendez que les pods soient à l'état
Running.kubectl get pods -l=app=adk-agent --watch- En attente : le pod a été accepté par le cluster, mais le conteneur n'a pas encore été créé.
- Création du conteneur : GKE extrait votre image de conteneur d'Artifact Registry et démarre le conteneur.
- Course à pied : félicitations ! Le conteneur est en cours d'exécution et votre application d'agent est en ligne.
- Une fois que l'état affiche
Running, appuyez sur CTRL+C dans le terminal pour arrêter la commande watch et revenir à l'invite de commande.
Récapitulatif
Dans cette section, vous avez lancé la charge de travail :
- Utilisez
kubectlapply pour envoyer votre fichier manifeste au cluster. - Surveillance du cycle de vie du pod (en attente → création du conteneur → en cours d'exécution) pour s'assurer que l'application a bien démarré.
11. Interagir avec l'agent
Votre agent ADK est désormais en cours d'exécution sur GKE et est exposé à Internet via un équilibreur de charge public. Vous vous connecterez à l'interface Web de l'agent pour interagir avec lui et vérifier que l'ensemble du système fonctionne correctement.
Rechercher l'adresse IP externe de votre service
Pour accéder à l'agent, vous devez d'abord obtenir l'adresse IP publique que GKE a provisionnée pour votre service.
- Dans le terminal, exécutez la commande suivante pour obtenir les détails de votre service.
kubectl get service adk-agent - Recherchez la valeur dans la colonne
EXTERNAL-IP. L'attribution de l'adresse IP peut prendre une ou deux minutes après le premier déploiement du service. Si l'état estpending, patientez une minute, puis exécutez à nouveau la commande. Le résultat devrait ressembler à ceci :NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE adk-agent-service LoadBalancer 10.120.12.234 34.123.45.67 80:31234/TCP 5mEXTERNAL-IP(par exemple, 34.123.45.67) est le point d'entrée public de votre agent.
Tester l'agent déployé
Vous pouvez désormais utiliser l'adresse IP publique pour accéder à l'interface utilisateur Web intégrée de l'ADK directement depuis votre navigateur.
- Copiez l'adresse IP externe (
EXTERNAL-IP) depuis le terminal. - Ouvrez un nouvel onglet dans votre navigateur Web et saisissez
http://[EXTERNAL-IP], en remplaçant[EXTERNAL-IP]par l'adresse IP que vous avez copiée. - L'interface Web ADK devrait maintenant s'afficher.
- Assurez-vous que workflow_agents est sélectionné dans le menu déroulant de l'agent.
- Activez l'option Distribution de jetons.
- Saisissez
helloet appuyez sur Entrée pour démarrer une nouvelle conversation. - Observez le résultat. L'agent doit répondre rapidement en présentant son message de bienvenue : "Je peux vous aider à rédiger un pitch pour un film à succès. Sur quelle figure historique aimerais-tu faire un film ?"
- Lorsque vous êtes invité à choisir un personnage historique, proposez-en un qui vous intéresse. Voici quelques idées :
the most successful female pirate in historythe woman who invented the first computer compilera legendary lawman of the American Wild West
Récapitulatif
Dans cette section, vous avez vérifié le déploiement :
- Récupérez l'adresse IP externe allouée par l'équilibreur de charge.
- Accédez à l'interface utilisateur Web de l'ADK via un navigateur pour vérifier que le système multi-agents est réactif et fonctionnel.
12. Configurer l'autoscaling
L'un des principaux défis de la production consiste à gérer le trafic utilisateur imprévisible. Le codage en dur d'un nombre fixe de répliques, comme vous l'avez fait dans la tâche précédente, signifie que vous payez trop cher pour les ressources inactives ou que vous risquez de mauvaises performances lors des pics de trafic. GKE résout ce problème grâce au scaling automatique.
Vous allez configurer un HorizontalPodAutoscaler (HPA), un contrôleur Kubernetes qui ajuste automatiquement le nombre de pods en cours d'exécution dans votre déploiement en fonction de l'utilisation du processeur en temps réel.
- Dans le terminal de l'éditeur Cloud Shell, créez un fichier
hpa.yamlà la racine du répertoireadk_multiagent_systems.cloudshell edit ~/adk_multiagent_systems/hpa.yaml - Ajoutez le contenu suivant au nouveau fichier
hpa.yaml:# Configures the HorizontalPodAutoscaler (HPA) to automatically scale # the number of running agent pods up or down based on CPU utilization # to handle varying traffic loads. apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: adk-agent-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: adk-agent minReplicas: 1 maxReplicas: 5 targetCPUUtilizationPercentage: 50adk-agent. Il garantit qu'au moins un pod est toujours en cours d'exécution, définit un maximum de cinq pods et ajoute/supprime des répliques pour maintenir l'utilisation moyenne du processeur autour de 50 %.À ce stade, la structure de votre fichier, telle qu'elle apparaît dans le panneau de l'explorateur de l'éditeur Cloud Shell, devrait ressembler à ceci :
- Appliquez le HPA à votre cluster en collant ce code dans le terminal.
kubectl apply -f hpa.yaml
Vérifier l'autoscaler
Le HPA est désormais actif et surveille votre déploiement. Vous pouvez inspecter son état pour le voir en action.
- Exécutez la commande suivante dans le terminal pour obtenir l'état de votre HPA.
kubectl get hpa adk-agent-hpaNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE adk-agent-hpa Deployment/adk-agent 0%/50% 1 5 1 30s
Récapitulatif
Dans cette section, vous avez optimisé le trafic de production :
- Création d'un fichier manifeste
hpa.yamlpour définir les règles de scaling. - Déployez HorizontalPodAutoscaler (HPA) pour ajuster automatiquement le nombre de répliques de pods en fonction de l'utilisation du processeur.
13. Préparer la production
Remarque : Les sections suivantes sont fournies à titre d'information uniquement et ne contiennent pas d'étapes supplémentaires à suivre. Ils sont conçus pour fournir du contexte et des bonnes pratiques pour déployer votre application en production.
Optimiser les performances grâce à l'allocation des ressources
Dans GKE Autopilot, vous contrôlez la quantité de processeur et de mémoire provisionnée pour votre application en spécifiant les requests de ressources dans votre deployment.yaml.
Si vous constatez que votre agent est lent ou plante en raison d'un manque de mémoire, vous pouvez augmenter l'allocation de ressources en modifiant le bloc resources dans votre deployment.yaml et en réappliquant le fichier avec kubectl apply.
Par exemple, pour doubler la mémoire :
# In deployment.yaml
# ...
resources:
requests:
memory: "2Gi" # Increased from 1Gi
cpu: "1000m"
# ...
Automatiser votre workflow avec la CI/CD
Dans cet atelier, vous avez exécuté des commandes manuellement. La pratique professionnelle consiste à créer un pipeline CI/CD (intégration continue/déploiement continu). En connectant un dépôt de code source (comme GitHub) à un déclencheur Cloud Build, vous pouvez automatiser l'ensemble du déploiement.
Avec un pipeline, chaque fois que vous transmettez une modification de code, Cloud Build peut automatiquement :
- Créez la nouvelle image de conteneur.
- Transférer l'image vers Artifact Registry
- Appliquez les fichiers manifestes Kubernetes mis à jour à votre cluster GKE.
Gérer les secrets de manière sécurisée
Dans cet atelier, vous avez stocké la configuration dans un fichier .env et l'avez transmise à votre application. Cette méthode est pratique pour le développement, mais n'est pas sécurisée pour les données sensibles telles que les clés API. Il est recommandé d'utiliser Secret Manager pour stocker les secrets de manière sécurisée.
GKE est intégré à Secret Manager, ce qui vous permet de monter des secrets directement dans vos pods en tant que variables d'environnement ou fichiers, sans qu'ils ne soient jamais enregistrés dans votre code source.
Voici la section Nettoyer les ressources que vous avez demandée, insérée juste avant la section Conclusion.
14. Effectuer un nettoyage des ressources
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez chaque ressource individuellement.
Supprimer le cluster GKE
Le cluster GKE est le principal facteur de coût dans cet atelier. Si vous la supprimez, les frais de calcul s'arrêteront.
- Dans le terminal, exécutez la commande suivante :
gcloud container clusters delete adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Supprimer le dépôt Artifact Registry
Les images de conteneurs stockées dans Artifact Registry entraînent des frais de stockage.
- Dans le terminal, exécutez la commande suivante :
gcloud artifacts repositories delete adk-repo \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Supprimer le projet (facultatif)
Si vous avez créé un projet spécifiquement pour cet atelier et que vous ne prévoyez pas de l'utiliser à nouveau, le moyen le plus simple d'effectuer un nettoyage consiste à supprimer l'intégralité du projet.
- Dans le terminal, exécutez la commande suivante (remplacez
[YOUR_PROJECT_ID]par l'ID de votre projet) :gcloud projects delete [YOUR_PROJECT_ID]
15. Conclusion
Félicitations ! Vous avez déployé une application ADK multi-agents sur un cluster GKE de niveau production. Il s'agit d'une réussite importante qui couvre le cycle de vie principal d'une application cloud native moderne. Vous disposez ainsi d'une base solide pour déployer vos propres systèmes agentiques complexes.
Récapitulatif
Dans cet atelier, vous avez appris à :
- Provisionnez un cluster GKE Autopilot.
- Créez une image de conteneur avec un
Dockerfileet transférez-la vers Artifact Registry. - Connectez-vous de manière sécurisée aux API Google Cloud à l'aide de Workload Identity.
- Écrivez des fichiers manifestes Kubernetes pour un déploiement et un service.
- Exposez une application sur Internet avec un LoadBalancer.
- Configurez l'autoscaling avec un HorizontalPodAutoscaler (HPA).