
1. מבוא
סקירה כללית
במעבדה הזו נסביר איך לגשר על הפער בין פיתוח מערכת רבת-עוצמה של סוכנים לבין פריסת המערכת לשימוש בעולם האמיתי. פיתוח סוכנים באופן מקומי הוא התחלה מצוינת, אבל אפליקציות בסביבת ייצור צריכות פלטפורמה שניתנת להרחבה, אמינה ומאובטחת.
במעבדה הזו תלמדו איך לקחת מערכת מרובת סוכנים שנבנתה באמצעות הערכה לפיתוח סוכנים (ADK) של Google ולפרוס אותה בסביבת ייצור ב-Google Kubernetes Engine (GKE).
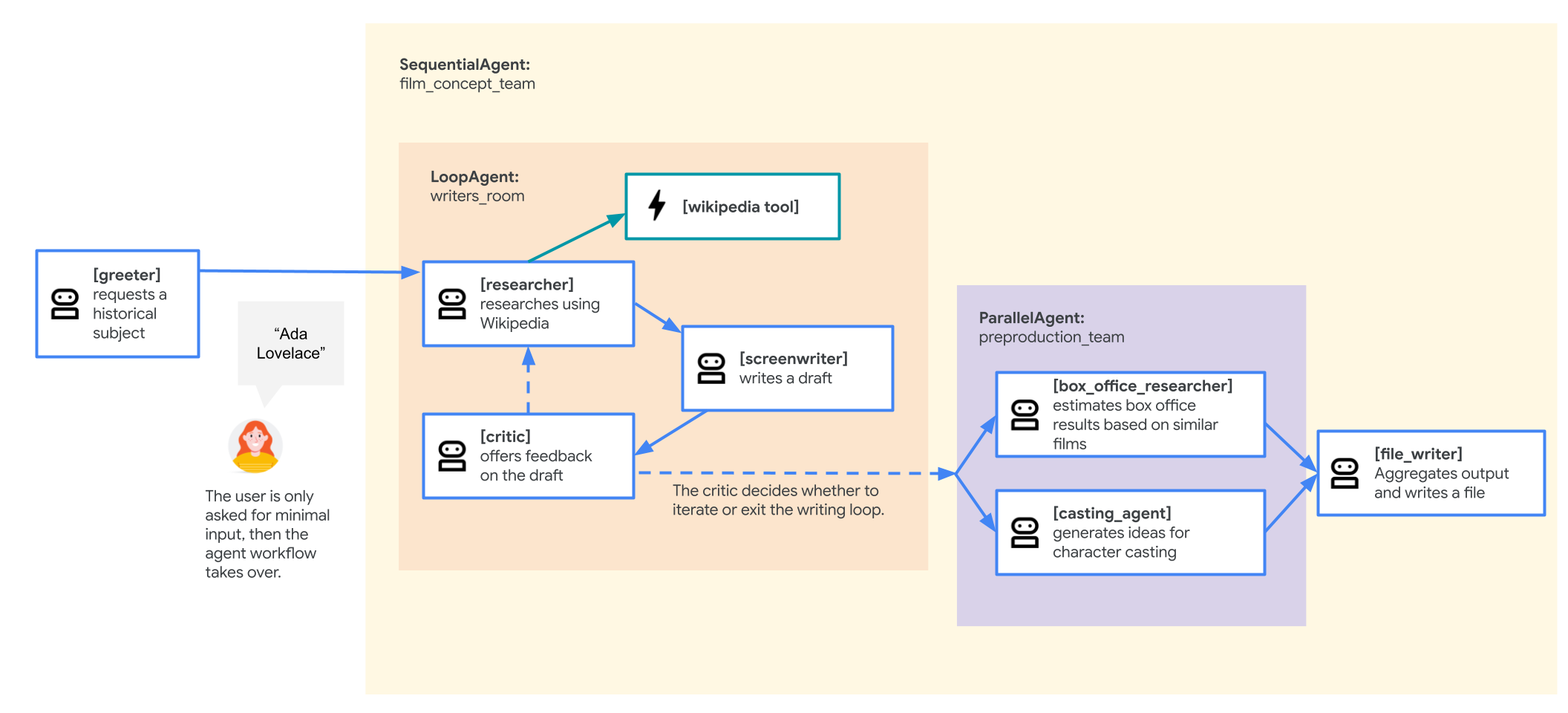
סוכן של צוות קונספט לסרט
אפליקציית הדוגמה שבה נעשה שימוש בשיעור Lab הזה היא "צוות קונספט לסרט" שמורכב מכמה סוכנים שמשתפים פעולה: חוקר, תסריטאי וכותב קבצים. הסוכנים האלה פועלים יחד כדי לעזור למשתמש להעלות רעיונות ולנסח הצעה לסרט על דמות היסטורית.
למה כדאי לפרוס ל-GKE?
כדי להכין את הסוכן לדרישות של סביבת ייצור, אתם צריכים פלטפורמה שנועדה לספק יכולת הרחבה, אבטחה וחיסכון בעלויות. Google Kubernetes Engine (GKE) מספק את הבסיס העוצמתי והגמיש הזה להפעלת האפליקציה בקונטיינר.
הגישה הזו מספקת כמה יתרונות לעומס העבודה שלכם בסביבת הייצור:
- התאמה אוטומטית לעומס וביצועים: אפשר להתמודד עם תנועה בלתי צפויה באמצעות HorizontalPodAutoscaler (HPA), שמוסיף או מסיר באופן אוטומטי עותקים של סוכנים בהתאם לעומס. לעומסי עבודה תובעניים יותר של AI, אפשר לצרף מאיצי חומרה כמו GPU ו-TPU.
- ניהול משאבים חסכוני: אפשר לייעל את העלויות באמצעות GKE Autopilot, שמנהל אוטומטית את התשתית הבסיסית, כך שמשלמים רק על המשאבים שהאפליקציה מבקשת.
- אבטחה וניטור משולבים: אפשר להתחבר בצורה מאובטחת לשירותים אחרים של Google Cloud באמצעות Workload Identity, וכך להימנע מהצורך לנהל ולאחסן מפתחות של חשבונות שירות. כל יומני האפליקציות מועברים אוטומטית ל-Cloud Logging לצורך ניטור וניפוי באגים מרכזיים.
- שליטה וניידות: כדי להימנע מנעילת ספק, אפשר להשתמש ב-Kubernetes בקוד פתוח. האפליקציה ניידת ויכולה לפעול בכל אשכול Kubernetes, מקומי או בעננים אחרים.
מה תלמדו
בשיעור ה-Lab הזה תלמדו איך לבצע את המשימות הבאות:
- הקצאת אשכול GKE Autopilot.
- להכניס אפליקציה לקונטיינר באמצעות Dockerfile ולהעביר את קובץ האימג' בדחיפה אל Artifact Registry.
- חיבור מאובטח של האפליקציה ל-Google Cloud APIs באמצעות Workload Identity.
- כתיבה והחלה של מניפסטים של Kubernetes לפריסה ולשירות.
- חשיפת אפליקציה לאינטרנט באמצעות LoadBalancer.
- הגדרת התאמה אוטומטית לעומס (autoscaling) באמצעות HorizontalPodAutoscaler (HPA).
2. הגדרת הפרויקט
חשבון Google
אם אין לכם חשבון Google אישי, אתם צריכים ליצור חשבון Google.
משתמשים בחשבון לשימוש אישי במקום בחשבון לצורכי עבודה או בחשבון בית ספרי.
כניסה למסוף Google Cloud
נכנסים למסוף Google Cloud באמצעות חשבון Google אישי.
הפעלת חיוב
הגדרה של חשבון לחיוב לשימוש אישי
אם הגדרתם חיוב באמצעות קרדיטים ל-Google Cloud, אתם יכולים לדלג על השלב הזה.
כדי להגדיר חשבון לחיוב לשימוש אישי, עוברים לכאן כדי להפעיל את החיוב ב-Cloud Console.
הערות:
- העלות של השלמת ה-Lab הזה במשאבי Cloud צריכה להיות פחות מ-1$.
- כדי להימנע מחיובים נוספים, אפשר למחוק את המשאבים בסיום ה-Lab.
- משתמשים חדשים זכאים לתקופת ניסיון בחינם בשווי 300$.
יצירת פרויקט (אופציונלי)
אם אין לכם פרויקט שאתם רוצים להשתמש בו בסדנה הזו, אתם יכולים ליצור פרויקט חדש כאן.
3. פתיחת Cloud Shell Editor
- כדי לעבור ישירות אל Cloud Shell Editor, לוחצים על הקישור הזה.
- אם תתבקשו לאשר בשלב כלשהו היום, תצטרכו ללחוץ על אישור כדי להמשיך.
- אם הטרמינל לא מופיע בתחתית המסך, פותחים אותו:
- לוחצים על הצגה.
- לוחצים על Terminal (מסוף)
 .
.
- בטרמינל, מגדירים את הפרויקט באמצעות הפקודה הבאה:
gcloud config set project [PROJECT_ID]- דוגמה:
gcloud config set project lab-project-id-example - אם אתם לא זוכרים את מזהה הפרויקט, אתם יכולים להציג רשימה של כל מזהי הפרויקטים באמצעות הפקודה:
gcloud projects list
- דוגמה:
- תוצג ההודעה הבאה:
Updated property [core/project].
4. הפעלת ממשקי ה-API
כדי להשתמש ב-GKE, ב-Artifact Registry, ב-Cloud Build וב-Vertex AI, צריך להפעיל את ממשקי ה-API שלהם בפרויקט Google Cloud.
- בטרמינל, מפעילים את ממשקי ה-API:
gcloud services enable \ container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.comOperation "operations/acf.p2-176675280136-b03ab5e4-3483-4ebf-9655-43dc3b345c63" finished successfully.
מבוא לממשקי ה-API
- Google Kubernetes Engine API (
container.googleapis.com) מאפשר לכם ליצור ולנהל את אשכול GKE שמריץ את הסוכן. GKE מספק סביבה מנוהלת לפריסה, לניהול ולהתאמה לעומס (scaling) של אפליקציות בקונטיינרים באמצעות התשתית של Google. - Artifact Registry API (
artifactregistry.googleapis.com) מספק מאגר פרטי ומאובטח לאחסון קובץ אימג' של קונטיינר של הסוכן. הוא מהווה התפתחות של Container Registry ומשתלב בצורה חלקה עם GKE ו-Cloud Build. - Cloud Build API (
cloudbuild.googleapis.com) משמש את הפקודהgcloud builds submitכדי ליצור את קובץ אימג' של קונטיינר בענן מ-Dockerfile. זוהי פלטפורמת CI/CD בלי שרת (serverless) שמריצה את גרסאות ה-build שלכם בתשתית ענן של Google Cloud. - Vertex AI API (
aiplatform.googleapis.com) מאפשר לסוכן הפרוס לתקשר עם מודלים של Gemini כדי לבצע את משימות הליבה שלו. הוא מספק API מאוחד לכל שירותי ה-AI של Google Cloud.
5. הכנת סביבת הפיתוח
יצירת מבנה הספריות
- בטרמינל, יוצרים את ספריית הפרויקט ואת ספריות המשנה הנדרשות:
mkdir -p ~/adk_multiagent_systems/workflow_agents cd ~/adk_multiagent_systems - בטרמינל, מריצים את הפקודה הבאה כדי לפתוח את הספרייה בסייר של Cloud Shell Editor.
cloudshell open-workspace ~/adk_multiagent_systems - חלונית הסייר בצד ימין תעבור רענון. עכשיו אמורות להופיע הספריות שיצרתם.
כשיוצרים קבצים בשלבים הבאים, הם יופיעו בספרייה הזו.
יצירת קבצים התחלתיים
עכשיו יוצרים את קובצי ההתחלה הנדרשים לאפליקציה.
- כדי ליצור את
callback_logging.py, מריצים את הפקודה הבאה בטרמינל. הקובץ הזה מטפל ברישום ביומן לצורך יכולת צפייה.cat <<EOF > ~/adk_multiagent_systems/callback_logging.py """ Provides helper functions for observability. Handles formatting and sending agent queries, responses, and tool calls to Google Cloud Logging to aid in monitoring and debugging. """ import logging import google.cloud.logging from google.adk.agents.callback_context import CallbackContext from google.adk.models import LlmResponse, LlmRequest def log_query_to_model(callback_context: CallbackContext, llm_request: LlmRequest): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_request.contents and llm_request.contents[-1].role == 'user': if llm_request.contents[-1].parts and "text" in llm_request.contents[-1].parts: last_user_message = llm_request.contents[-1].parts[0].text logging.info(f"[query to {callback_context.agent_name}]: " + last_user_message) def log_model_response(callback_context: CallbackContext, llm_response: LlmResponse): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_response.content and llm_response.content.parts: for part in llm_response.content.parts: if part.text: logging.info(f"[response from {callback_context.agent_name}]: " + part.text) elif part.function_call: logging.info(f"[function call from {callback_context.agent_name}]: " + part.function_call.name) EOF - כדי ליצור את
workflow_agents/__init__.py, מריצים את הפקודה הבאה בטרמינל. הפעולה הזו מסמנת את הספרייה כחבילת Python.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/__init__.py """ Marks the directory as a Python package and exposes the agent module, allowing the ADK to discover and register the agents defined within. """ from . import agent EOF - כדי ליצור את
workflow_agents/agent.py, מריצים את הפקודה הבאה בטרמינל. הקובץ הזה מכיל את לוגיקת הליבה של צוות המולטי-אייג'נט.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/agent.py """ Defines the core multi-agent workflow. Configures individual agents (Researcher, Screenwriter, File Writer), assigns their specific tools, and orchestrates their collaboration using the ADK's SequentialAgent pattern. """ import os import logging import google.cloud.logging from callback_logging import log_query_to_model, log_model_response from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent, LoopAgent, ParallelAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool # import from google.genai import types from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL") print(model_name) # Tools def append_to_state( tool_context: ToolContext, field: str, response: str ) -> dict[str, str]: """Append new output to an existing state key. Args: field (str): a field name to append to response (str): a string to append to the field Returns: dict[str, str]: {"status": "success"} """ existing_state = tool_context.state.get(field, []) tool_context.state[field] = existing_state + [response] logging.info(f"[Added to {field}] {response}") return {"status": "success"} def write_file( tool_context: ToolContext, directory: str, filename: str, content: str ) -> dict[str, str]: target_path = os.path.join(directory, filename) os.makedirs(os.path.dirname(target_path), exist_ok=True) with open(target_path, "w") as f: f.write(content) return {"status": "success"} # Agents file_writer = Agent( name="file_writer", model=model_name, description="Creates marketing details and saves a pitch document.", instruction=""" PLOT_OUTLINE: { PLOT_OUTLINE? } INSTRUCTIONS: - Create a marketable, contemporary movie title suggestion for the movie described in the PLOT_OUTLINE. If a title has been suggested in PLOT_OUTLINE, you can use it, or replace it with a better one. - Use your 'write_file' tool to create a new txt file with the following arguments: - for a filename, use the movie title - Write to the 'movie_pitches' directory. - For the 'content' to write, extract the following from the PLOT_OUTLINE: - A logline - Synopsis or plot outline """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[write_file], ) screenwriter = Agent( name="screenwriter", model=model_name, description="As a screenwriter, write a logline and plot outline for a biopic about a historical character.", instruction=""" INSTRUCTIONS: Your goal is to write a logline and three-act plot outline for an inspiring movie about a historical character(s) described by the PROMPT: { PROMPT? } - If there is CRITICAL_FEEDBACK, use those thoughts to improve upon the outline. - If there is RESEARCH provided, feel free to use details from it, but you are not required to use it all. - If there is a PLOT_OUTLINE, improve upon it. - Use the 'append_to_state' tool to write your logline and three-act plot outline to the field 'PLOT_OUTLINE'. - Summarize what you focused on in this pass. PLOT_OUTLINE: { PLOT_OUTLINE? } RESEARCH: { research? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], ) researcher = Agent( name="researcher", model=model_name, description="Answer research questions using Wikipedia.", instruction=""" PROMPT: { PROMPT? } PLOT_OUTLINE: { PLOT_OUTLINE? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } INSTRUCTIONS: - If there is a CRITICAL_FEEDBACK, use your wikipedia tool to do research to solve those suggestions - If there is a PLOT_OUTLINE, use your wikipedia tool to do research to add more historical detail - If these are empty, use your Wikipedia tool to gather facts about the person in the PROMPT - Use the 'append_to_state' tool to add your research to the field 'research'. - Summarize what you have learned. Now, use your Wikipedia tool to do research. """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[ LangchainTool(tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())), append_to_state, ], ) film_concept_team = SequentialAgent( name="film_concept_team", description="Write a film plot outline and save it as a text file.", sub_agents=[ researcher, screenwriter, file_writer ], ) root_agent = Agent( name="greeter", model=model_name, description="Guides the user in crafting a movie plot.", instruction=""" - Let the user know you will help them write a pitch for a hit movie. Ask them for a historical figure to create a movie about. - When they respond, use the 'append_to_state' tool to store the user's response in the 'PROMPT' state key and transfer to the 'film_concept_team' agent """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], sub_agents=[film_concept_team], ) EOF
מבנה הקובץ אמור להיראות כך: 
הגדרת הסביבה הווירטואלית
- בטרמינל, יוצרים ומפעילים סביבה וירטואלית באמצעות
uv. כך תוכלו לוודא שיחסי התלות של הפרויקט לא יתנגשו עם Python של המערכת.uv venv source .venv/bin/activate
דרישות ההתקנה
- מריצים את הפקודה הבאה בטרמינל כדי ליצור את הקובץ
requirements.txt.cat <<EOF > ~/adk_multiagent_systems/requirements.txt # Lists all Python dependencies required to run the multi-agent system, # including the Google ADK, LangChain community tools, and web server libraries. langchain-community==0.4.1 wikipedia==1.4.0 google-adk==1.27.5 fastapi==0.135.2 uvicorn==0.42.0 EOF - מתקינים את החבילות הנדרשות בסביבה הווירטואלית בטרמינל.
uv pip install -r requirements.txt
הגדרה של משתני סביבה
- כדי ליצור את הקובץ
.env, מריצים את הפקודה הבאה בטרמינל. מזהה הפרויקט והאזור שלכם יוכנסו אוטומטית.cat <<EOF > ~/adk_multiagent_systems/.env GOOGLE_CLOUD_PROJECT="$(gcloud config get-value project)" GOOGLE_CLOUD_PROJECT_NUMBER="$(gcloud projects describe $(gcloud config get-value project) --format='value(projectNumber)')" GOOGLE_CLOUD_LOCATION="us-central1" GOOGLE_GENAI_USE_VERTEXAI=true MODEL="gemini-2.5-flash" EOF - בטרמינל, טוענים את המשתנים לסשן של המעטפת.
source .env
Recap
בקטע הזה יצרתם את הבסיס המקומי לפרויקט:
- נוצרה מבנה הספריות וקבצי ההפעלה של הסוכן (
agent.py, callback_logging.py, requirements.txt). - בידוד התלות באמצעות סביבה וירטואלית (
uv). - משתני סביבה שהוגדרו (
.env) לאחסון פרטים ספציפיים לפרויקט, כמו מזהה הפרויקט והאזור.
6. עיון בקובץ של הנציג
הגדרתם את קוד המקור של ה-Lab, כולל מערכת מרובת סוכנים שנכתבה מראש. לפני שפורסים את האפליקציה, כדאי להבין איך מוגדרים הסוכנים. הלוגיקה המרכזית של הסוכן נמצאת ב-workflow_agents/agent.py.
- ב-Cloud Shell Editor, משתמשים בסייר הקבצים בצד ימין כדי לנווט אל
adk_multiagent_systems/workflow_agents/ולפתוח את הקובץagent.py. - כדאי להקדיש רגע כדי לעיין בקובץ. אתם לא צריכים להבין כל שורה, אבל כדאי לשים לב למבנה הכללי:
- נציגים פרטיים: הקובץ מגדיר שלושה אובייקטים נפרדים של
Agent: researcher,screenwriterו-file_writer. לכל סוכן מוקצהinstructionספציפי (ההנחיה שלו) ורשימה שלtoolsשהוא יכול להשתמש בהם (כמו הכליWikipediaQueryRunאו כליwrite_fileמותאם אישית). - הרכב הסוכן: הסוכנים האישיים משורשרים יחד ל
SequentialAgentשנקראfilm_concept_team. ההגדרה הזו אומרת ל-ADK להריץ את הסוכנים האלה אחד אחרי השני, ולהעביר את המצב מאחד לשני. - הנציג הראשי: מוגדר
root_agent(שנקרא 'מציג') לטיפול באינטראקציה הראשונית של המשתמש. כשהמשתמש מספק הנחיה, הסוכן הזה שומר אותה במצב האפליקציה ואז מעביר את השליטה לתהליך העבודה שלfilm_concept_team.
- נציגים פרטיים: הקובץ מגדיר שלושה אובייקטים נפרדים של
הבנת המבנה הזה עוזרת להבין מה אתם עומדים לפרוס: לא רק סוכן יחיד, אלא צוות מתואם של סוכנים מומחים שמנוהל על ידי ה-ADK.
7. יצירת אשכול GKE Autopilot
אחרי שמכינים את הסביבה, השלב הבא הוא הקצאת התשתית שבה תפעל אפליקציית הסוכן. תצרו אשכול GKE Autopilot, שישמש כבסיס לפריסה. אנחנו משתמשים במצב Autopilot כי הוא מטפל בניהול המורכב של הצמתים הבסיסיים, ההרחבה והאבטחה של האשכול, ומאפשר לכם להתמקד רק בפריסת האפליקציה.
- בטרמינל, יוצרים אשכול GKE Autopilot חדש בשם
adk-cluster.gcloud container clusters create-auto adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT - אחרי שיוצרים את האשכול, מריצים את הפקודה הבאה בטרמינל כדי להגדיר את
kubectlלהתחבר אליו:gcloud container clusters get-credentials adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT~/.kube/config). מעכשיו, כלי שורת הפקודהkubectlיאומת ויכוון לתקשר עםadk-cluster.
Recap
בקטע הזה הקציתם את התשתית:
- יצירת אשכול GKE Autopilot מנוהל באופן מלא באמצעות
gcloud. - הגדרתם את הכלי המקומי
kubectlלאימות ולתקשורת עם האשכול החדש.
8. העברת האפליקציה ל-Container ודחיפה שלה
הקוד של הסוכן קיים כרגע רק בסביבת Cloud Shell. כדי להפעיל אותו ב-GKE, צריך קודם לארוז אותו בקובץ אימג' של קונטיינר. קובץ אימג' של קונטיינר הוא קובץ סטטי ונייד שכולל את קוד האפליקציה עם כל יחסי התלות שלה. כשמריצים את התמונה הזו, היא הופכת לקונטיינר פעיל.
התהליך הזה כולל שלושה שלבים מרכזיים:
- יצירת נקודת כניסה: מגדירים קובץ
main.pyכדי להפוך את הלוגיקה של הסוכן לשרת אינטרנט שניתן להפעלה. - הגדרת קובץ האימג' של הקונטיינר: יוצרים Dockerfile שמשמש כתוכנית ליצירת קובץ האימג' של הקונטיינר.
- יצירה והעברה בדחיפה: משתמשים ב-Cloud Build כדי להריץ את קובץ ה-Dockerfile, ליצור את קובץ האימג' של הקונטיינר ולהעביר אותו בדחיפה אל Google Artifact Registry, מאגר מאובטח של קובצי האימג'.
הכנת האפליקציה לפריסה
סוכן ה-ADK צריך שרת אינטרנט כדי לקבל בקשות. קובץ main.py ישמש כנקודת הכניסה הזו, באמצעות מסגרת FastAPI כדי לחשוף את הפונקציונליות של הסוכן באמצעות HTTP.
- בשורש של הספרייה
adk_multiagent_systemsבטרמינל, יוצרים קובץ חדש בשםmain.py.cat <<EOF > ~/adk_multiagent_systems/main.py """ Serves as the application entry point. Initializes the FastAPI web server, discovers the agents defined in the workflow directory, and exposes them via HTTP endpoints for interaction. """ import os import uvicorn from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Get the directory where main.py is located AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) # Configure the session service (e.g., SQLite for local storage) SESSION_SERVICE_URI = "sqlite:///./sessions.db" # Configure CORS to allow requests from various origins for this lab ALLOWED_ORIGINS = ["http://localhost", "http://localhost:8080", "*"] # Enable the ADK's built-in web interface SERVE_WEB_INTERFACE = True # Call the ADK function to discover agents and create the FastAPI app app: FastAPI = get_fast_api_app( agents_dir=AGENT_DIR, session_service_uri=SESSION_SERVICE_URI, allow_origins=ALLOWED_ORIGINS, web=SERVE_WEB_INTERFACE, ) # You can add more FastAPI routes or configurations below if needed # Example: # @app.get("/hello") # async def read_root(): # return {"Hello": "World"} if __name__ == "__main__": # Get the port from the PORT environment variable provided by the container runtime # Run the Uvicorn server, listening on all available network interfaces (0.0.0.0) uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("PORT", 8080))) EOFuvicornמריץ את האפליקציה הזו, ומאזין למארח0.0.0.0כדי לקבל חיבורים מכל כתובת IP וביציאה שצוינה על ידי משתנה הסביבהPORT, שנגדיר בהמשך במניפסט של Kubernetes.
בשלב הזה, מבנה הקבצים שמוצג בחלונית הסייר ב-Cloud Shell Editor אמור להיראות כך: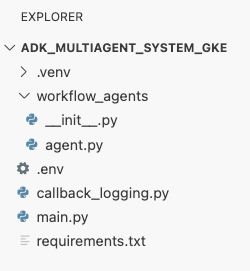
העברת סוכן ADK לקונטיינר באמצעות Docker
כדי לפרוס את האפליקציה שלנו ב-GKE, אנחנו צריכים קודם לארוז אותה בקובץ אימג' של קונטיינר, שכולל את קוד האפליקציה עם כל הספריות והתלויות שנדרשות להפעלה שלה. נשתמש ב-Docker כדי ליצור את קובץ האימג' הזה של הקונטיינר.
- בשורש של הספרייה
adk_multiagent_systemsבטרמינל, יוצרים קובץ חדש בשםDockerfile.cat <<'EOF' > ~/adk_multiagent_systems/Dockerfile # Defines the blueprint for the container image. Installs dependencies, # sets up a secure non-root user, and specifies the startup command to run the # agent web server. # Use an official lightweight Python image as the base FROM python:3.13-slim # Set the working directory inside the container WORKDIR /app # Create a non-root user for security best practices RUN adduser --disabled-password --gecos "" myuser # Copy and install dependencies first to leverage Docker's layer caching COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt # Copy all application code into the container COPY . . # Create the directory where the agent will write files at runtime # The -p flag ensures the command doesn't fail if the directory already exists RUN mkdir -p movie_pitches # Change ownership of EVERYTHING in /app to the non-root user # Without this, the running agent would be denied permission to write files. RUN chown -R myuser:myuser /app # Switch the active user from root to the non-root user USER myuser # Add the user's local binary directory to the system's PATH ENV PATH="/home/myuser/.local/bin:$PATH" # Define the command to run when the container starts CMD ["sh", "-c", "uvicorn main:app --host 0.0.0.0 --port $PORT"] EOF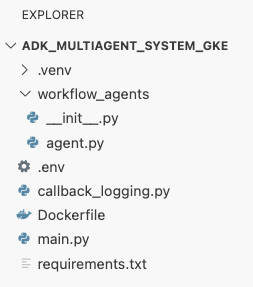
יצירה של קובץ אימג' של קונטיינר והעברה שלו בדחיפה ל-Artifact Registry
אחרי שיצרתם קובץ Dockerfile, תשתמשו ב-Cloud Build כדי ליצור את האימג' ולהעביר אותו בדחיפה ל-Artifact Registry, מאגר פרטי ומאובטח שמשולב עם שירותי Google Cloud. GKE ישלוף את התמונה מהמאגר הזה כדי להריץ את האפליקציה.
- בטרמינל, יוצרים מאגר חדש ב-Artifact Registry לאחסון אימג' הקונטיינר.
gcloud artifacts repositories create adk-repo \ --repository-format=docker \ --location=$GOOGLE_CLOUD_LOCATION \ --description="ADK repository" - בטרמינל, משתמשים בפקודה
gcloud builds submitכדי ליצור את קובץ אימג' של קונטיינר ולהעביר אותו בדחיפה למאגר.gcloud builds submit \ --tag $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo/adk-agent:latest \ --project=$GOOGLE_CLOUD_PROJECT \ .Dockerfile. הוא יוצר את קובץ האימג' בענן, מתייג אותו בכתובת של מאגר Artifact Registry ומעביר אותו לשם אוטומטית. - בטרמינל, מוודאים שהתמונה נוצרה:
gcloud artifacts docker images list \ $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo \ --project=$GOOGLE_CLOUD_PROJECT
Recap
בקטע הזה, ארזתם את הקוד לפריסה:
- נוצרה
main.pyנקודת כניסה כדי לעטוף את הסוכנים בשרת אינטרנט של FastAPI. - הגדרתם
Dockerfileכדי לארוז את הקוד והתלויות בתמונה ניידת. - השתמשתי ב-Cloud Build כדי ליצור את קובץ האימג' ולהעביר אותו בדחיפה למאגר מאובטח של Artifact Registry.
9. יצירת מניפסטים של Kubernetes
אחרי שקובץ האימג' של הקונטיינר נוצר ונשמר ב-Artifact Registry, צריך להגדיר ל-GKE איך להריץ אותו. התהליך הזה כולל שתי פעולות עיקריות:
- הגדרת הרשאות: תיצרו זהות ייעודית לסוכן שלכם באשכול ותעניקו לו גישה מאובטחת ל-Google Cloud APIs שהוא צריך (במיוחד ל-Vertex AI).
- הגדרת מצב האפליקציה: תכתבו קובץ מניפסט של Kubernetes, מסמך YAML שמגדיר באופן הצהרתי את כל מה שהאפליקציה צריכה כדי לפעול, כולל קובץ אימג' של קונטיינר, משתני הסביבה והאופן שבו היא צריכה להיות חשופה לרשת.
הגדרת חשבון שירות של Kubernetes ל-Vertex AI
הסוכן צריך הרשאה לתקשר עם Vertex AI API כדי לגשת למודלים של Gemini. השיטה המומלצת והמאובטחת ביותר למתן ההרשאה הזו ב-GKE היא Workload Identity. Workload Identity מאפשר לקשר בין זהות מקורית של Kubernetes (חשבון שירות של Kubernetes) לבין זהות של Google Cloud (חשבון שירות של IAM), וכך להימנע לחלוטין מהצורך להוריד, לנהל ולאחסן מפתחות JSON סטטיים.
- בטרמינל, יוצרים את חשבון השירות של Kubernetes (
adk-agent-sa). כך נוצרת זהות לסוכן בתוך אשכול GKE שה-Pods יכולים להשתמש בה.kubectl create serviceaccount adk-agent-sa - בטרמינל, מקשרים את חשבון השירות של Kubernetes ל-Cloud IAM ב-Google Cloud על ידי יצירת קישור מדיניות. הפקודה הזו מקצה את התפקיד
aiplatform.userל-adk-agent-sa, ומאפשרת לו להפעיל את Vertex AI API בצורה מאובטחת.gcloud projects add-iam-policy-binding projects/${GOOGLE_CLOUD_PROJECT} \ --role=roles/aiplatform.user \ --member=principal://iam.googleapis.com/projects/${GOOGLE_CLOUD_PROJECT_NUMBER}/locations/global/workloadIdentityPools/${GOOGLE_CLOUD_PROJECT}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \ --condition=None
יצירת קובצי המניפסט של Kubernetes
מערכת Kubernetes משתמשת בקובצי מניפסט של YAML כדי להגדיר את המצב הרצוי של האפליקציה. תצרו קובץ deployment.yaml שמכיל שני אובייקטים חיוניים של Kubernetes: Deployment ו-Service.
- מהטרמינל, יוצרים את הקובץ
deployment.yaml.cat <<EOF > ~/adk_multiagent_systems/deployment.yaml # Defines the Kubernetes resources required to deploy the application to GKE. # Includes the Deployment (to run the container pods) and the Service # (to expose the application via a Load Balancer). apiVersion: apps/v1 kind: Deployment metadata: name: adk-agent spec: replicas: 1 selector: matchLabels: app: adk-agent template: metadata: labels: app: adk-agent spec: # Assign the Kubernetes Service Account for Workload Identity serviceAccountName: adk-agent-sa containers: - name: adk-agent imagePullPolicy: Always # The path to the container image in Artifact Registry image: ${GOOGLE_CLOUD_LOCATION}-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/adk-repo/adk-agent:latest # Define the resources for GKE Autopilot to provision resources: limits: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" requests: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" ports: - containerPort: 8080 # Environment variables passed to the application env: - name: PORT value: "8080" - name: GOOGLE_CLOUD_PROJECT value: ${GOOGLE_CLOUD_PROJECT} - name: GOOGLE_CLOUD_LOCATION value: ${GOOGLE_CLOUD_LOCATION} - name: GOOGLE_GENAI_USE_VERTEXAI value: "true" - name: MODEL value: "gemini-2.5-flash" --- apiVersion: v1 kind: Service metadata: name: adk-agent spec: # Create a public-facing Network Load Balancer with an external IP type: LoadBalancer ports: - port: 80 targetPort: 8080 selector: app: adk-agent EOF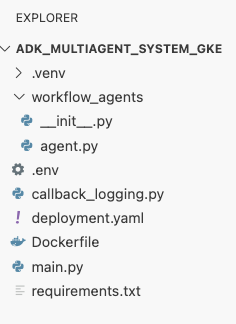
Recap
בקטע הזה הגדרתם את האבטחה ואת פריסת ההגדרות:
- יצרתם חשבון שירות ב-Kubernetes וקישרתם אותו ל-Google Cloud IAM באמצעות Workload Identity, כדי שה-Pods יוכלו לגשת ל-Vertex AI בצורה מאובטחת בלי לנהל מפתחות.
- נוצר קובץ
deployment.yamlשמגדיר את הפריסה (איך להריץ את ה-pods) ואת השירות (איך לחשוף אותם באמצעות איזון עומסים).
10. פריסת האפליקציה ב-GKE
אחרי שהגדרתם את קובץ המניפסט והעברתם את קובץ אימג' של קונטיינר אל Artifact Registry, אתם מוכנים לפרוס את האפליקציה. במשימה הזו תשתמשו ב-kubectl כדי להחיל את ההגדרה על אשכול GKE, ואז תעקבו אחרי הסטטוס כדי לוודא שהסוכן מופעל בצורה תקינה.
- במסוף, מחילים את מניפסט
deployment.yamlעל האשכול.kubectl apply -f deployment.yamlkubectl applyשולחת את הקובץdeployment.yamlלשרת Kubernetes API. השרת קורא את ההגדרות שלכם ומבצע תזמור של יצירת אובייקטים של פריסה ושירות. - בטרמינל, בודקים את סטטוס הפריסה בזמן אמת. ממתינים עד שה-pods יהיו במצב
Running.kubectl get pods -l=app=adk-agent --watch- בהמתנה: הפוד התקבל על ידי האשכול, אבל הקונטיינר עדיין לא נוצר.
- יצירת קונטיינר: מערכת GKE מושכת את קובץ האימג' של הקונטיינר מ-Artifact Registry ומתחילה את הקונטיינר.
- פועל: הצלחה! הקונטיינר פועל והאפליקציה של הסוכן פעילה.
- אחרי שהסטטוס מופיע
Running, מקישים על CTRL+C בטרמינל כדי להפסיק את פקודת הצפייה ולחזור לשורת הפקודה.
Recap
בקטע הזה הפעלתם את עומס העבודה:
- משתמשים ב-
kubectlapply כדי לשלוח את המניפסט לאשכול. - עקבתי אחרי מחזור החיים של ה-Pod (בהמתנה -> יצירת קונטיינר -> פועל) כדי לוודא שהאפליקציה הופעלה בהצלחה.
11. אינטראקציה עם הנציג
סוכן ה-ADK פועל עכשיו ב-GKE וחשוף לאינטרנט דרך מאזן עומסים ציבורי. תתחברו לממשק האינטרנט של הסוכן כדי ליצור איתו אינטראקציה ולוודא שהמערכת כולה פועלת בצורה תקינה.
איך מוצאים את כתובת ה-IP החיצונית של השירות
כדי לגשת לסוכן, קודם צריך לקבל את כתובת ה-IP הציבורית ש-GKE הקצה לשירות.
- בטרמינל, מריצים את הפקודה הבאה כדי לקבל את פרטי השירות.
kubectl get service adk-agent - מחפשים את הערך בעמודה
EXTERNAL-IP. יכול להיות שיחלפו דקה או שתיים עד שכתובת ה-IP תוקצה אחרי הפריסה הראשונה של השירות. אם מופיעpending, מחכים דקה ומריצים את הפקודה שוב. הפלט אמור להיראות כך:NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE adk-agent-service LoadBalancer 10.120.12.234 34.123.45.67 80:31234/TCP 5mEXTERNAL-IP(לדוגמה, 34.123.45.67) היא נקודת הכניסה הציבורית לסוכן שלכם.
בדיקת הסוכן הפעיל
עכשיו אפשר להשתמש בכתובת ה-IP הציבורית כדי לגשת ישירות לממשק המשתמש המובנה באינטרנט של ADK מהדפדפן.
- מעתיקים את כתובת ה-IP החיצונית (
EXTERNAL-IP) מהמסוף. - פותחים כרטיסייה חדשה בדפדפן האינטרנט ומקלידים
http://[EXTERNAL-IP], ומחליפים את[EXTERNAL-IP]בכתובת ה-IP שהעתקתם. - עכשיו אמור להופיע ממשק האינטרנט של ADK.
- בתפריט הנפתח של הסוכן, מוודאים שהאפשרות workflow_agents מסומנת.
- מפעילים את האפשרות Token Streaming.
- כדי להתחיל שיחה חדשה, מקלידים
helloולוחצים על Enter. - בודקים את התוצאה. הסוכן צריך להגיב במהירות עם ההודעה הבאה: "I can help you write a pitch for a hit movie. על איזו דמות היסטורית היית רוצה ליצור סרט?"
- כשמתבקשים לבחור דמות היסטורית, בוחרים דמות שמעניינת אתכם. הנה כמה רעיונות:
the most successful female pirate in historythe woman who invented the first computer compilera legendary lawman of the American Wild West
Recap
בקטע הזה אימתתם את הפריסה:
- כתובת ה-IP החיצונית שהוקצתה על ידי LoadBalancer אוחזרה.
- ניגשתי לממשק המשתמש באינטרנט של ADK דרך דפדפן כדי לוודא שמערכת מרובת הסוכנים מגיבה ופועלת.
12. הגדרת התאמה אוטומטית לעומס
אחד האתגרים העיקריים בסביבת הייצור הוא טיפול בתנועת משתמשים בלתי צפויה. קידוד קשיח של מספר קבוע של רפליקות, כמו שעשיתם במשימה הקודמת, אומר שאתם משלמים יותר מדי על משאבים לא פעילים או מסתכנים בביצועים ירודים בזמן שיאי תנועה. ב-GKE, הבעיה הזו נפתרת באמצעות התאמה אוטומטית לעומס.
תגדירו HorizontalPodAutoscaler (HPA), בקר Kubernetes שמשנה באופן אוטומטי את מספר הפודים הפועלים בפריסה על סמך ניצול המעבד בזמן אמת.
- בטרמינל של Cloud Shell Editor, יוצרים קובץ
hpa.yamlחדש בספריית הבסיסadk_multiagent_systems.cloudshell edit ~/adk_multiagent_systems/hpa.yaml - מוסיפים את התוכן הבא לקובץ
hpa.yamlהחדש:# Configures the HorizontalPodAutoscaler (HPA) to automatically scale # the number of running agent pods up or down based on CPU utilization # to handle varying traffic loads. apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: adk-agent-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: adk-agent minReplicas: 1 maxReplicas: 5 targetCPUUtilizationPercentage: 50adk-agentשלנו. הוא מבטיח שתמיד יפעל לפחות פוד אחד, מגדיר מקסימום של 5 פודים ויוסיף או יסיר רפליקות כדי לשמור על ניצול ממוצע של CPU בסביבות 50%.בשלב הזה, מבנה הקבצים שלכם כפי שמוצג בחלונית הסייר בכלי Cloud Shell Editor צריך להיראות כך:
- כדי להחיל את ה-HPA על האשכול, מדביקים את הפקודה הבאה בטרמינל.
kubectl apply -f hpa.yaml
אימות של קנה המידה האוטומטי
ה-HPA פעיל עכשיו ועוקב אחרי הפריסה. אפשר לבדוק את הסטטוס שלו כדי לראות אותו בפעולה.
- מריצים את הפקודה הבאה בטרמינל כדי לקבל את הסטטוס של ה-HPA.
kubectl get hpa adk-agent-hpaNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE adk-agent-hpa Deployment/adk-agent 0%/50% 1 5 1 30s
Recap
בקטע הזה, ביצעתם אופטימיזציה לתנועת גולשים בסביבת הייצור:
- יצירת
hpa.yamlמניפסט להגדרת כללי שינוי גודל. - הפריסה של HorizontalPodAutoscaler (HPA) כדי להתאים באופן אוטומטי את מספר הרפליקות של ה-Pod על סמך ניצול המעבד.
13. הכנה לסביבת הייצור
הערה: הקטעים הבאים מיועדים למתן מידע בלבד, ולא כוללים שלבים נוספים לביצוע. הם נועדו לספק הקשר ושיטות מומלצות להעברת האפליקציה לסביבת הייצור.
שיפור הביצועים באמצעות הקצאת משאבים
ב-GKE Autopilot, אתם קובעים את כמות המעבד והזיכרון שמוקצים לאפליקציה על ידי ציון משאב requests ב-deployment.yaml.
אם אתם מגלים שהסוכן פועל לאט או קורס בגלל חוסר זיכרון, אתם יכולים להגדיל את הקצאת המשאבים שלו על ידי עריכת הבלוק resources בקובץ deployment.yaml והחלת הקובץ מחדש באמצעות kubectl apply.
לדוגמה, כדי להכפיל את הזיכרון:
# In deployment.yaml
# ...
resources:
requests:
memory: "2Gi" # Increased from 1Gi
cpu: "1000m"
# ...
אוטומציה של תהליך העבודה באמצעות CI/CD
בשיעור ה-Lab הזה הפעלתם פקודות באופן ידני. השיטה המומלצת היא ליצור פייפליין של CI/CD (אינטגרציה רציפה/פריסה רציפה). אם מחברים מאגר של קוד מקור (כמו GitHub) לטריגר לפיתוח גרסת Build של Cloud Build, אפשר להפוך את כל הפריסה לאוטומטית.
באמצעות צינור עיבוד נתונים, בכל פעם שדוחפים שינוי בקוד, Cloud Build יכול לבצע באופן אוטומטי את הפעולות הבאות:
- יוצרים את קובץ האימג' החדש של הקונטיינר.
- מעבירים את האימג' בדחיפה ל-Artifact Registry.
- מחילים את מניפסטים Kubernetes המעודכנים על אשכול GKE.
ניהול סודות בצורה מאובטחת
בשיעור ה-Lab הזה שמרתם את ההגדרות בקובץ .env והעברתם אותו לאפליקציה. זה נוח לפיתוח, אבל לא מאובטח למידע אישי רגיש כמו מפתחות API. השיטה המומלצת היא להשתמש ב-Secret Manager כדי לאחסן סודות בצורה מאובטחת.
ל-GKE יש שילוב מקורי עם Secret Manager שמאפשר לכם להטמיע סודות ישירות בפודים שלכם כמשתני סביבה או כקבצים, בלי שהם ייבדקו בקוד המקור.
הנה הקטע ניקוי משאבים שביקשת, שמופיע לפני הקטע מסקנה.
14. פינוי משאבים
כדי להימנע מחיובים בחשבון Google Cloud בגלל השימוש במשאבים שנעשה במסגרת המדריך הזה, אפשר למחוק את הפרויקט שמכיל את המשאבים, או להשאיר את הפרויקט ולמחוק את המשאבים בנפרד.
מחיקת אשכול GKE
אשכול GKE הוא הגורם העיקרי לעלויות בשיעור ה-Lab הזה. מחיקת המכונה תפסיק את החיובים על השימוש במחשוב.
- במסוף, מריצים את הפקודה הבאה:
gcloud container clusters delete adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
מחיקת מאגר Artifact Registry
יש עלויות אחסון של קובצי אימג' של קונטיינרים שמאוחסנים ב-Artifact Registry.
- במסוף, מריצים את הפקודה הבאה:
gcloud artifacts repositories delete adk-repo \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
מחיקת הפרויקט (אופציונלי)
אם יצרתם פרויקט חדש במיוחד בשביל ה-Lab הזה ואתם לא מתכננים להשתמש בו שוב, הדרך הכי קלה לנקות אותו היא למחוק את הפרויקט כולו.
- בטרמינל, מריצים את הפקודה הבאה (מחליפים את
[YOUR_PROJECT_ID]במזהה הפרויקט בפועל):gcloud projects delete [YOUR_PROJECT_ID]
15. סיכום
מעולה! פרסתם בהצלחה אפליקציית ADK מרובת סוכנים באשכול GKE ברמת ייצור. זהו הישג משמעותי שכולל את מחזור החיים המרכזי של אפליקציה מודרנית מבוססת-ענן, ומספק לכם בסיס איתן לפריסת מערכות סוכני מורכבות משלכם.
Recap
בשיעור ה-Lab הזה למדתם איך:
- הקצאת אשכול GKE Autopilot.
- יצירת קובץ אימג' של קונטיינר באמצעות
Dockerfileוהעברה שלו בדחיפה אל Artifact Registry - חיבור מאובטח אל Google Cloud APIs באמצעות Workload Identity.
- כתיבת מניפסטים של Kubernetes לפריסה ולשירות.
- חשיפת אפליקציה לאינטרנט באמצעות LoadBalancer.
- הגדרת התאמה אוטומטית לעומס (autoscaling) באמצעות HorizontalPodAutoscaler (HPA).