
1. परिचय
खास जानकारी
यह लैब, एक बेहतरीन मल्टी-एजेंट सिस्टम को डेवलप करने और उसे असल दुनिया में इस्तेमाल करने के बीच के अंतर को कम करती है. एजेंट को स्थानीय तौर पर बनाना एक अच्छा विकल्प है. हालांकि, प्रोडक्शन ऐप्लिकेशन के लिए एक ऐसे प्लैटफ़ॉर्म की ज़रूरत होती है जो बढ़ाया जा सके, भरोसेमंद हो, और सुरक्षित हो.
इस लैब में, Google Agent Development Kit (ADK) का इस्तेमाल करके बनाए गए मल्टी-एजेंट सिस्टम को Google Kubernetes Engine (GKE) पर प्रोडक्शन-ग्रेड एनवायरमेंट में डिप्लॉय किया जाएगा.
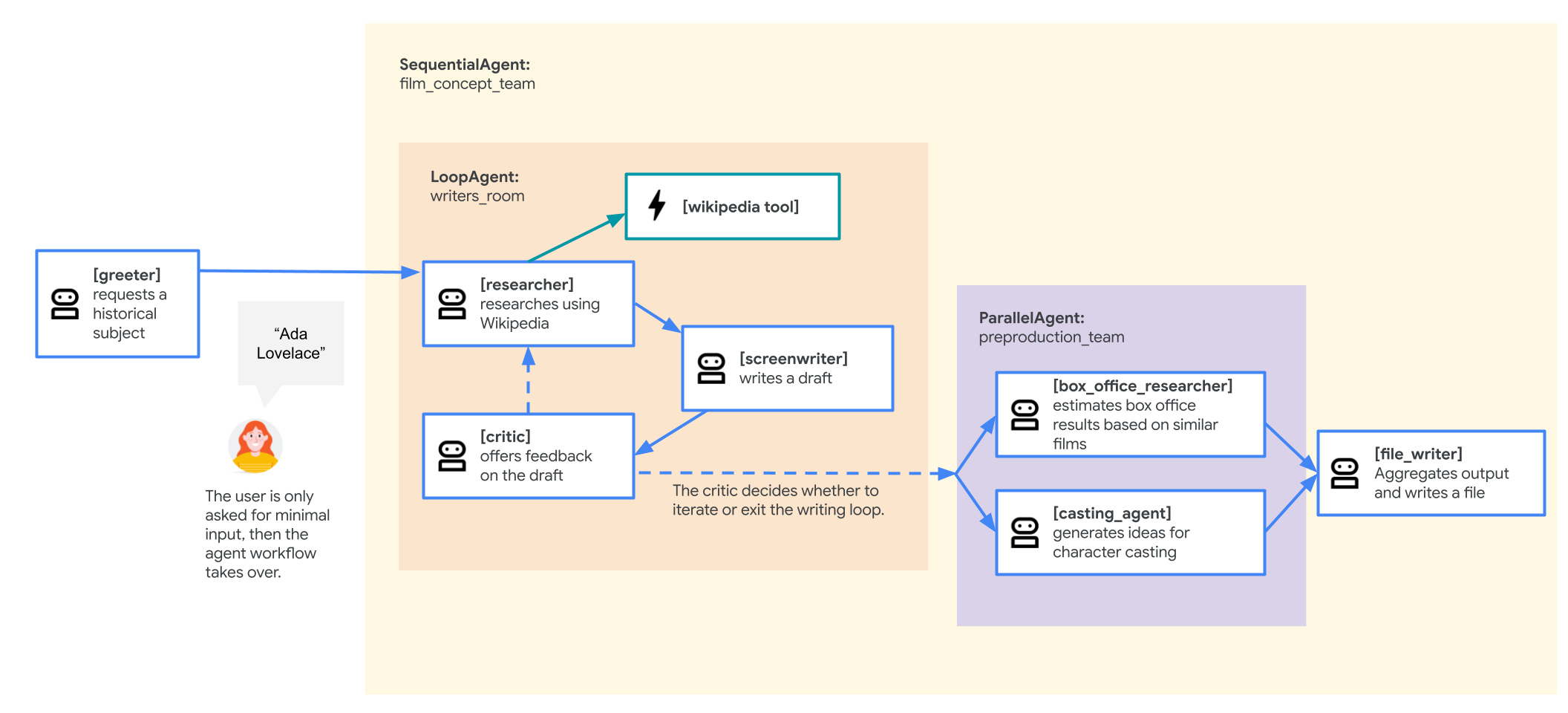
फ़िल्म के कॉन्सेप्ट पर काम करने वाली टीम का एजेंट
इस लैब में इस्तेमाल किया गया सैंपल ऐप्लिकेशन, "फ़िल्म कॉन्सेप्ट टीम" है. इसमें एक साथ काम करने वाले कई एजेंट शामिल हैं: एक रिसर्चर, एक स्क्रीनराइटर, और एक फ़ाइल राइटर. ये एजेंट, किसी ऐतिहासिक व्यक्ति के बारे में फ़िल्म की पिच तैयार करने के लिए, उपयोगकर्ता को मिलकर आइडिया देने और आउटलाइन बनाने में मदद करते हैं.
GKE पर क्यों डिप्लॉय करें?
अपने एजेंट को प्रोडक्शन एनवायरमेंट की ज़रूरतों के लिए तैयार करने के लिए, आपको एक ऐसे प्लैटफ़ॉर्म की ज़रूरत होती है जिसे स्केलेबिलिटी, सुरक्षा, और लागत को कम करने के लिए बनाया गया हो. Google Kubernetes Engine (GKE), कंटेनर में बदले गए ऐप्लिकेशन को चलाने के लिए एक मज़बूत और फ़्लेक्सिबल प्लैटफ़ॉर्म उपलब्ध कराता है.
इससे आपके प्रोडक्शन वर्कलोड को कई फ़ायदे मिलते हैं:
- अपने-आप स्केल होने की सुविधा और परफ़ॉर्मेंस: HorizontalPodAutoscaler (HPA) की मदद से, अचानक बढ़ने वाले ट्रैफ़िक को मैनेज करें. यह सुविधा, लोड के आधार पर एजेंट रेप्लिका को अपने-आप जोड़ती या हटाती है. एआई के ज़्यादा लोड वाले वर्कलोड के लिए, जीपीयू और टीपीयू जैसे हार्डवेयर ऐक्सलरेटर अटैच किए जा सकते हैं.
- कम लागत में संसाधनों को मैनेज करना: GKE Autopilot की मदद से लागत को ऑप्टिमाइज़ करें. यह बुनियादी ढांचे को अपने-आप मैनेज करता है, ताकि आपको सिर्फ़ उन संसाधनों के लिए पेमेंट करना पड़े जिनका अनुरोध आपका ऐप्लिकेशन करता है.
- सुरक्षा और निगरानी की सुविधा: वर्कलोड आइडेंटिटी का इस्तेमाल करके, Google Cloud की अन्य सेवाओं से सुरक्षित तरीके से कनेक्ट करें. इससे सेवा खाते की कुंजियों को मैनेज और सेव करने की ज़रूरत नहीं पड़ती. सभी ऐप्लिकेशन लॉग, Cloud Logging में अपने-आप स्ट्रीम हो जाते हैं. इससे, एक ही जगह पर निगरानी करने और डीबग करने में मदद मिलती है.
- कंट्रोल और पोर्टेबिलिटी: ओपन-सोर्स Kubernetes का इस्तेमाल करके, वेंडर लॉक-इन से बचें. आपका ऐप्लिकेशन पोर्टेबल है और इसे किसी भी Kubernetes क्लस्टर, ऑन-प्रिमाइसेस या अन्य क्लाउड पर चलाया जा सकता है.
आपको क्या सीखने को मिलेगा
इस लैब में, आपको ये टास्क करने का तरीका बताया जाएगा:
- GKE Autopilot क्लस्टर उपलब्ध कराएं.
- Dockerfile की मदद से किसी ऐप्लिकेशन को कंटेनर में बदलें और इमेज को Artifact Registry में पुश करें.
- Workload Identity का इस्तेमाल करके, अपने ऐप्लिकेशन को Google Cloud API से सुरक्षित तरीके से कनेक्ट करें.
- डिप्लॉयमेंट और सर्विस के लिए Kubernetes मेनिफ़ेस्ट लिखें और लागू करें.
- LoadBalancer की मदद से, किसी ऐप्लिकेशन को इंटरनेट पर उपलब्ध कराना.
- HorizontalPodAutoscaler (HPA) की मदद से, अपने-आप स्केल होने की सुविधा कॉन्फ़िगर करें.
2. प्रोजेक्ट सेटअप करना
Google खाता
अगर आपके पास पहले से कोई निजी Google खाता नहीं है, तो आपको Google खाता बनाना होगा.
ऑफ़िस या स्कूल वाले खाते के बजाय, निजी खाते का इस्तेमाल करें.
Google Cloud Console में साइन इन करना
किसी निजी Google खाते का इस्तेमाल करके, Google Cloud Console में साइन इन करें.
बिलिंग चालू करें
निजी बिलिंग खाता सेट अप करना
अगर आपने Google Cloud क्रेडिट का इस्तेमाल करके बिलिंग सेट अप की है, तो इस चरण को छोड़ें.
निजी बिलिंग खाता सेट अप करने के लिए, Cloud Console में बिलिंग की सुविधा चालू करने के लिए यहां जाएं.
ध्यान दें:
- इस लैब को पूरा करने में, Cloud संसाधनों पर 1 डॉलर से कम का खर्च आना चाहिए.
- ज़्यादा शुल्क से बचने के लिए, इस लैब के आखिर में दिए गए निर्देशों का पालन करके संसाधनों को मिटाया जा सकता है.
- नए उपयोगकर्ता, 300 डॉलर के मुफ़्त में आज़माने की सुविधा का फ़ायदा पा सकते हैं.
कोई प्रोजेक्ट बनाएं (ज़रूरी नहीं)
अगर आपके पास कोई ऐसा मौजूदा प्रोजेक्ट नहीं है जिसका इस्तेमाल आपको इस लैब के लिए करना है, तो यहां नया प्रोजेक्ट बनाएं.
3. Cloud Shell Editor खोलें
- सीधे Cloud Shell Editor पर जाने के लिए, इस लिंक पर क्लिक करें
- अगर आज किसी भी समय अनुमति देने के लिए कहा जाता है, तो जारी रखने के लिए अनुमति दें पर क्लिक करें.
- अगर टर्मिनल स्क्रीन पर सबसे नीचे नहीं दिखता है, तो इसे खोलें:
- देखें पर क्लिक करें
- टर्मिनल
 पर क्लिक करें
पर क्लिक करें
- टर्मिनल में, इस कमांड का इस्तेमाल करके अपना प्रोजेक्ट सेट करें:
gcloud config set project [PROJECT_ID]- उदाहरण:
gcloud config set project lab-project-id-example - अगर आपको अपना प्रोजेक्ट आईडी याद नहीं है, तो इन कमांड का इस्तेमाल करके अपने सभी प्रोजेक्ट आईडी की सूची देखी जा सकती है:
gcloud projects list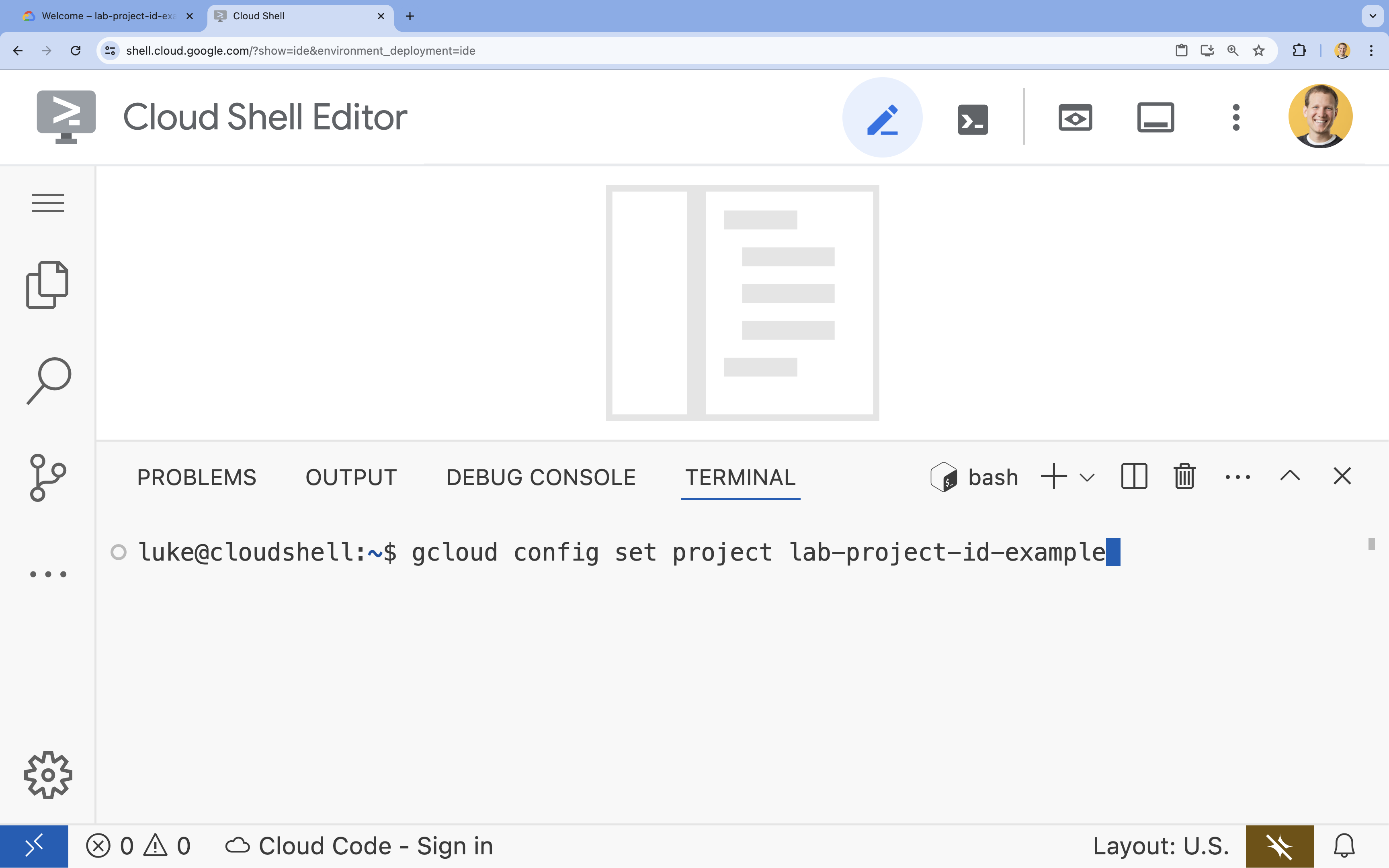
- उदाहरण:
- आपको यह मैसेज दिखेगा:
Updated property [core/project].
4. एपीआई चालू करें
GKE, Artifact Registry, Cloud Build, और Vertex AI का इस्तेमाल करने के लिए, आपको अपने Google Cloud प्रोजेक्ट में इनके एपीआई चालू करने होंगे.
- टर्मिनल में, इन एपीआई को चालू करें:
gcloud services enable \ container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.comOperation "operations/acf.p2-176675280136-b03ab5e4-3483-4ebf-9655-43dc3b345c63" finished successfully.
एपीआई के बारे में जानकारी
- Google Kubernetes Engine API (
container.googleapis.com) की मदद से, GKE क्लस्टर बनाया और मैनेज किया जा सकता है. यह क्लस्टर, आपके एजेंट को चलाता है. GKE, Google के इंफ़्रास्ट्रक्चर का इस्तेमाल करके, कंटेनर वाले ऐप्लिकेशन को डिप्लॉय, मैनेज, और स्केल करने के लिए मैनेज किया गया एनवायरमेंट उपलब्ध कराता है. - Artifact Registry API (
artifactregistry.googleapis.com) आपके एजेंट की कंटेनर इमेज को सेव करने के लिए, सुरक्षित और निजी रिपॉज़िटरी उपलब्ध कराता है. यह Container Registry का नया वर्शन है. यह GKE और Cloud Build के साथ आसानी से इंटिग्रेट हो जाता है. gcloud builds submitकमांड, Cloud Build API (cloudbuild.googleapis.com) का इस्तेमाल करके, आपके Dockerfile से क्लाउड में कंटेनर इमेज बनाता है. यह बिना सर्वर वाला CI/CD प्लैटफ़ॉर्म है. यह Google Cloud के इंफ़्रास्ट्रक्चर पर आपकी बिल्ड को एक्ज़ीक्यूट करता है.- Vertex AI API (
aiplatform.googleapis.com) की मदद से, डिप्लॉय किया गया एजेंट, Gemini मॉडल के साथ कम्यूनिकेट कर पाता है. इससे वह अपने मुख्य टास्क पूरे कर पाता है. यह Google Cloud की सभी एआई सेवाओं के लिए, एक ही एपीआई उपलब्ध कराता है.
5. डेवलपमेंट एनवायरमेंट तैयार करना
डायरेक्ट्री स्ट्रक्चर बनाना
- टर्मिनल में, प्रोजेक्ट डायरेक्ट्री और ज़रूरी सबडायरेक्ट्री बनाएं:
mkdir -p ~/adk_multiagent_systems/workflow_agents cd ~/adk_multiagent_systems - Cloud Shell Editor एक्सप्लोरर में डायरेक्ट्री खोलने के लिए, टर्मिनल में यह कमांड चलाएं.
cloudshell open-workspace ~/adk_multiagent_systems - बाईं ओर मौजूद एक्सप्लोरर पैनल रीफ़्रेश हो जाएगा. अब आपको अपनी बनाई गई डायरेक्ट्री दिखेंगी.
यहां दिए गए चरणों को पूरा करने के बाद, आपको इस डायरेक्ट्री में फ़ाइलें दिखेंगी.
स्टार्टर फ़ाइलें बनाना
अब ऐप्लिकेशन के लिए ज़रूरी स्टार्टर फ़ाइलें बनाएं.
- टर्मिनल में यह कमांड चलाकर,
callback_logging.pyबनाएं. यह फ़ाइल, निगरानी के लिए लॉगिंग को मैनेज करती है.cat <<EOF > ~/adk_multiagent_systems/callback_logging.py """ Provides helper functions for observability. Handles formatting and sending agent queries, responses, and tool calls to Google Cloud Logging to aid in monitoring and debugging. """ import logging import google.cloud.logging from google.adk.agents.callback_context import CallbackContext from google.adk.models import LlmResponse, LlmRequest def log_query_to_model(callback_context: CallbackContext, llm_request: LlmRequest): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_request.contents and llm_request.contents[-1].role == 'user': if llm_request.contents[-1].parts and "text" in llm_request.contents[-1].parts: last_user_message = llm_request.contents[-1].parts[0].text logging.info(f"[query to {callback_context.agent_name}]: " + last_user_message) def log_model_response(callback_context: CallbackContext, llm_response: LlmResponse): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_response.content and llm_response.content.parts: for part in llm_response.content.parts: if part.text: logging.info(f"[response from {callback_context.agent_name}]: " + part.text) elif part.function_call: logging.info(f"[function call from {callback_context.agent_name}]: " + part.function_call.name) EOF - टर्मिनल में यह कमांड चलाकर,
workflow_agents/__init__.pyबनाएं. इससे डायरेक्ट्री को Python पैकेज के तौर पर मार्क किया जाता है.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/__init__.py """ Marks the directory as a Python package and exposes the agent module, allowing the ADK to discover and register the agents defined within. """ from . import agent EOF - टर्मिनल में यह कमांड चलाकर,
workflow_agents/agent.pyबनाएं. इस फ़ाइल में, आपकी मल्टी-एजेंट टीम के लिए मुख्य लॉजिक होता है.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/agent.py """ Defines the core multi-agent workflow. Configures individual agents (Researcher, Screenwriter, File Writer), assigns their specific tools, and orchestrates their collaboration using the ADK's SequentialAgent pattern. """ import os import logging import google.cloud.logging from callback_logging import log_query_to_model, log_model_response from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent, LoopAgent, ParallelAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool # import from google.genai import types from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL") print(model_name) # Tools def append_to_state( tool_context: ToolContext, field: str, response: str ) -> dict[str, str]: """Append new output to an existing state key. Args: field (str): a field name to append to response (str): a string to append to the field Returns: dict[str, str]: {"status": "success"} """ existing_state = tool_context.state.get(field, []) tool_context.state[field] = existing_state + [response] logging.info(f"[Added to {field}] {response}") return {"status": "success"} def write_file( tool_context: ToolContext, directory: str, filename: str, content: str ) -> dict[str, str]: target_path = os.path.join(directory, filename) os.makedirs(os.path.dirname(target_path), exist_ok=True) with open(target_path, "w") as f: f.write(content) return {"status": "success"} # Agents file_writer = Agent( name="file_writer", model=model_name, description="Creates marketing details and saves a pitch document.", instruction=""" PLOT_OUTLINE: { PLOT_OUTLINE? } INSTRUCTIONS: - Create a marketable, contemporary movie title suggestion for the movie described in the PLOT_OUTLINE. If a title has been suggested in PLOT_OUTLINE, you can use it, or replace it with a better one. - Use your 'write_file' tool to create a new txt file with the following arguments: - for a filename, use the movie title - Write to the 'movie_pitches' directory. - For the 'content' to write, extract the following from the PLOT_OUTLINE: - A logline - Synopsis or plot outline """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[write_file], ) screenwriter = Agent( name="screenwriter", model=model_name, description="As a screenwriter, write a logline and plot outline for a biopic about a historical character.", instruction=""" INSTRUCTIONS: Your goal is to write a logline and three-act plot outline for an inspiring movie about a historical character(s) described by the PROMPT: { PROMPT? } - If there is CRITICAL_FEEDBACK, use those thoughts to improve upon the outline. - If there is RESEARCH provided, feel free to use details from it, but you are not required to use it all. - If there is a PLOT_OUTLINE, improve upon it. - Use the 'append_to_state' tool to write your logline and three-act plot outline to the field 'PLOT_OUTLINE'. - Summarize what you focused on in this pass. PLOT_OUTLINE: { PLOT_OUTLINE? } RESEARCH: { research? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], ) researcher = Agent( name="researcher", model=model_name, description="Answer research questions using Wikipedia.", instruction=""" PROMPT: { PROMPT? } PLOT_OUTLINE: { PLOT_OUTLINE? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } INSTRUCTIONS: - If there is a CRITICAL_FEEDBACK, use your wikipedia tool to do research to solve those suggestions - If there is a PLOT_OUTLINE, use your wikipedia tool to do research to add more historical detail - If these are empty, use your Wikipedia tool to gather facts about the person in the PROMPT - Use the 'append_to_state' tool to add your research to the field 'research'. - Summarize what you have learned. Now, use your Wikipedia tool to do research. """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[ LangchainTool(tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())), append_to_state, ], ) film_concept_team = SequentialAgent( name="film_concept_team", description="Write a film plot outline and save it as a text file.", sub_agents=[ researcher, screenwriter, file_writer ], ) root_agent = Agent( name="greeter", model=model_name, description="Guides the user in crafting a movie plot.", instruction=""" - Let the user know you will help them write a pitch for a hit movie. Ask them for a historical figure to create a movie about. - When they respond, use the 'append_to_state' tool to store the user's response in the 'PROMPT' state key and transfer to the 'film_concept_team' agent """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], sub_agents=[film_concept_team], ) EOF
अब आपकी फ़ाइल का स्ट्रक्चर ऐसा दिखना चाहिए: 
वर्चुअल एनवायरमेंट सेट अप करना
- टर्मिनल में,
uvका इस्तेमाल करके वर्चुअल एनवायरमेंट बनाएं और उसे चालू करें. इससे यह पक्का किया जाता है कि आपके प्रोजेक्ट की डिपेंडेंसी, सिस्टम Python के साथ काम करती हैं.uv venv source .venv/bin/activate
ऐप्लिकेशन इंस्टॉल करने से जुड़ी ज़रूरी शर्तें
requirements.txtफ़ाइल बनाने के लिए, टर्मिनल में यह कमांड चलाएं.cat <<EOF > ~/adk_multiagent_systems/requirements.txt # Lists all Python dependencies required to run the multi-agent system, # including the Google ADK, LangChain community tools, and web server libraries. langchain-community==0.4.1 wikipedia==1.4.0 google-adk==1.27.5 fastapi==0.135.2 uvicorn==0.42.0 EOF- टर्मिनल में, अपने वर्चुअल एनवायरमेंट में ज़रूरी पैकेज इंस्टॉल करें.
uv pip install -r requirements.txt
एनवायरमेंट वैरिएबल सेट अप करना
.envफ़ाइल बनाने के लिए, टर्मिनल में यह कमांड इस्तेमाल करें. इससे आपका प्रोजेक्ट आईडी और क्षेत्र अपने-आप जुड़ जाएगा.cat <<EOF > ~/adk_multiagent_systems/.env GOOGLE_CLOUD_PROJECT="$(gcloud config get-value project)" GOOGLE_CLOUD_PROJECT_NUMBER="$(gcloud projects describe $(gcloud config get-value project) --format='value(projectNumber)')" GOOGLE_CLOUD_LOCATION="us-central1" GOOGLE_GENAI_USE_VERTEXAI=true MODEL="gemini-2.5-flash" EOF- टर्मिनल में, वैरिएबल को अपने शेल सेशन में लोड करें.
source .env
रीकैप
इस सेक्शन में, आपने अपने प्रोजेक्ट के लिए स्थानीय फ़ाउंडेशन बनाया है:
- डायरेक्ट्री स्ट्रक्चर और ज़रूरी एजेंट स्टार्टर फ़ाइलें (
agent.py,callback_logging.py,requirements.txt) बनाई गई हैं. - वर्चुअल एनवायरमेंट (
uv) का इस्तेमाल करके, अपनी डिपेंडेंसी को अलग किया हो. - कॉन्फ़िगर किए गए एनवायरमेंट वैरिएबल (
.env), ताकि प्रोजेक्ट से जुड़ी जानकारी सेव की जा सके. जैसे, आपका प्रोजेक्ट आईडी और क्षेत्र.
6. एजेंट फ़ाइल एक्सप्लोर करना
आपने लैब के लिए सोर्स कोड सेट अप किया हो. इसमें पहले से लिखा गया मल्टी-एजेंट सिस्टम शामिल है. ऐप्लिकेशन को डिप्लॉय करने से पहले, यह समझना ज़रूरी है कि एजेंट कैसे तय किए जाते हैं. एजेंट का मुख्य लॉजिक, workflow_agents/agent.py में मौजूद होता है.
- Cloud Shell Editor में, बाईं ओर मौजूद फ़ाइल एक्सप्लोरर का इस्तेमाल करके
adk_multiagent_systems/workflow_agents/पर जाएं औरagent.pyफ़ाइल खोलें. - थोड़ा समय निकालकर फ़ाइल देखें. आपको हर लाइन को समझने की ज़रूरत नहीं है. हालांकि, इस स्ट्रक्चर पर ध्यान दें:
- अलग-अलग एजेंट: फ़ाइल में तीन अलग-अलग
Agentऑब्जेक्ट तय किए गए हैं:researcher,screenwriter, औरfile_writer. हर एजेंट को एक खासinstruction(उसका प्रॉम्प्ट) औरtoolsकी एक सूची दी जाती है. इसमें एजेंट को इस्तेमाल करने की अनुमति होती है. जैसे,WikipediaQueryRunटूल या कस्टमwrite_fileटूल. - एजेंट कंपोज़िशन: अलग-अलग एजेंट को एक साथ जोड़कर
SequentialAgentबनाया जाता है, जिसेfilm_concept_teamकहा जाता है. इससे ADK को यह पता चलता है कि इन एजेंट को एक के बाद एक चलाना है. साथ ही, एक एजेंट से दूसरे एजेंट को स्थिति पास करनी है. - रूट एजेंट: उपयोगकर्ता के शुरुआती इंटरैक्शन को मैनेज करने के लिए,
root_agent(जिसे "ग्रीटर" कहा जाता है) को तय किया जाता है. जब उपयोगकर्ता कोई प्रॉम्प्ट देता है, तो यह एजेंट उसे ऐप्लिकेशन की स्थिति में सेव करता है. इसके बाद, कंट्रोल कोfilm_concept_teamवर्कफ़्लो में ट्रांसफ़र कर देता है.
- अलग-अलग एजेंट: फ़ाइल में तीन अलग-अलग
इस स्ट्रक्चर को समझने से, यह साफ़ तौर पर पता चलता है कि आपको क्या डिप्लॉय करना है: सिर्फ़ एक एजेंट नहीं, बल्कि खास एजेंट की एक ऐसी टीम जो ADK के ज़रिए काम करती है.
7. GKE Autopilot क्लस्टर बनाना
एनवायरमेंट तैयार होने के बाद, अगला चरण उस इन्फ़्रास्ट्रक्चर को उपलब्ध कराना है जहां आपका एजेंट ऐप्लिकेशन चलेगा. आपको एक GKE Autopilot क्लस्टर बनाना होगा. यह आपके डिप्लॉयमेंट के लिए आधार का काम करेगा. हम Autopilot मोड का इस्तेमाल करते हैं, क्योंकि यह क्लस्टर के नोड, स्केलिंग, और सुरक्षा को मैनेज करने का मुश्किल काम करता है. इससे आपको सिर्फ़ अपने ऐप्लिकेशन को डिप्लॉय करने पर फ़ोकस करने में मदद मिलती है.
- टर्मिनल में,
adk-clusterनाम का नया GKE Autopilot क्लस्टर बनाएं.gcloud container clusters create-auto adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT - क्लस्टर बन जाने के बाद, इससे कनेक्ट करने के लिए
kubectlको कॉन्फ़िगर करें. इसके लिए, टर्मिनल में यह कमांड चलाएं:gcloud container clusters get-credentials adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT~/.kube/config) को अपडेट करता है. इसके बाद,kubectlकमांड-लाइन टूल की पुष्टि हो जाएगी और इसे आपकेadk-clusterसे कम्यूनिकेट करने के लिए डायरेक्ट किया जाएगा.
रीकैप
इस सेक्शन में, आपने इंफ़्रास्ट्रक्चर को प्रोविज़न किया:
gcloudका इस्तेमाल करके, पूरी तरह से मैनेज किया गया GKE Autopilot क्लस्टर बनाया गया हो.- आपने नए क्लस्टर के साथ पुष्टि करने और कम्यूनिकेट करने के लिए, अपने लोकल
kubectlटूल को कॉन्फ़िगर किया हो.
8. ऐप्लिकेशन को कंटेनर में बदलना और उसे पुश करना
फ़िलहाल, आपके एजेंट का कोड सिर्फ़ आपके Cloud Shell एनवायरमेंट में मौजूद है. इसे GKE पर चलाने के लिए, आपको पहले इसे कंटेनर इमेज में पैकेज करना होगा. कंटेनर इमेज एक स्टैटिक और पोर्टेबल फ़ाइल होती है. इसमें आपके ऐप्लिकेशन का कोड और उसकी सभी डिपेंडेंसी शामिल होती हैं. इस इमेज को चलाने पर, यह एक लाइव कंटेनर बन जाता है.
इस प्रोसेस में तीन मुख्य चरण शामिल हैं:
- एंट्री पॉइंट बनाएं: अपने एजेंट के लॉजिक को चालू किए जा सकने वाले वेब सर्वर में बदलने के लिए,
main.pyफ़ाइल तय करें. - कंटेनर इमेज तय करना: एक Dockerfile बनाएं. यह आपकी कंटेनर इमेज बनाने के लिए ब्लूप्रिंट के तौर पर काम करता है.
- बनाएं और पुश करें: Dockerfile को एक्ज़ीक्यूट करने के लिए, Cloud Build का इस्तेमाल करें. इससे कंटेनर इमेज बनेगी और उसे Google Artifact Registry में पुश किया जा सकेगा. यह आपकी इमेज के लिए एक सुरक्षित रिपॉज़िटरी है.
ऐप्लिकेशन को डिप्लॉयमेंट के लिए तैयार करना
आपके एडीके एजेंट को अनुरोध पाने के लिए, वेब सर्वर की ज़रूरत होती है. main.py फ़ाइल को एंट्री पॉइंट के तौर पर इस्तेमाल किया जाएगा. यह एचटीटीपी पर आपके एजेंट की सुविधा को दिखाने के लिए, FastAPI फ़्रेमवर्क का इस्तेमाल करेगी.
- टर्मिनल में
adk_multiagent_systemsडायरेक्ट्री के रूट में,main.pyनाम की नई फ़ाइल बनाएं.cat <<EOF > ~/adk_multiagent_systems/main.py """ Serves as the application entry point. Initializes the FastAPI web server, discovers the agents defined in the workflow directory, and exposes them via HTTP endpoints for interaction. """ import os import uvicorn from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Get the directory where main.py is located AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) # Configure the session service (e.g., SQLite for local storage) SESSION_SERVICE_URI = "sqlite:///./sessions.db" # Configure CORS to allow requests from various origins for this lab ALLOWED_ORIGINS = ["http://localhost", "http://localhost:8080", "*"] # Enable the ADK's built-in web interface SERVE_WEB_INTERFACE = True # Call the ADK function to discover agents and create the FastAPI app app: FastAPI = get_fast_api_app( agents_dir=AGENT_DIR, session_service_uri=SESSION_SERVICE_URI, allow_origins=ALLOWED_ORIGINS, web=SERVE_WEB_INTERFACE, ) # You can add more FastAPI routes or configurations below if needed # Example: # @app.get("/hello") # async def read_root(): # return {"Hello": "World"} if __name__ == "__main__": # Get the port from the PORT environment variable provided by the container runtime # Run the Uvicorn server, listening on all available network interfaces (0.0.0.0) uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("PORT", 8080))) EOFuvicornसर्वर इस ऐप्लिकेशन को चलाता है. यह किसी भी आईपी पते से कनेक्शन स्वीकार करने के लिए, होस्ट0.0.0.0पर सुनता है. साथ ही, यहPORTएनवायरमेंट वैरिएबल से तय किए गए पोर्ट पर सुनता है. हम इसे बाद में अपने Kubernetes मेनिफ़ेस्ट में सेट करेंगे.
इस समय, Cloud Shell Editor के एक्सप्लोरर पैनल में आपकी फ़ाइल का स्ट्रक्चर ऐसा दिखना चाहिए:
Docker की मदद से ADK एजेंट को कंटेनर में बदलना
अपने ऐप्लिकेशन को GKE पर डिप्लॉय करने के लिए, हमें सबसे पहले इसे कंटेनर इमेज में पैकेज करना होगा. इसमें हमारे ऐप्लिकेशन का कोड, सभी लाइब्रेरी, और इसे चलाने के लिए ज़रूरी डिपेंडेंसी शामिल होती हैं. हम इस कंटेनर इमेज को बनाने के लिए, Docker का इस्तेमाल करेंगे.
- टर्मिनल में
adk_multiagent_systemsडायरेक्ट्री के रूट में,Dockerfileनाम की नई फ़ाइल बनाएं.cat <<'EOF' > ~/adk_multiagent_systems/Dockerfile # Defines the blueprint for the container image. Installs dependencies, # sets up a secure non-root user, and specifies the startup command to run the # agent web server. # Use an official lightweight Python image as the base FROM python:3.13-slim # Set the working directory inside the container WORKDIR /app # Create a non-root user for security best practices RUN adduser --disabled-password --gecos "" myuser # Copy and install dependencies first to leverage Docker's layer caching COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt # Copy all application code into the container COPY . . # Create the directory where the agent will write files at runtime # The -p flag ensures the command doesn't fail if the directory already exists RUN mkdir -p movie_pitches # Change ownership of EVERYTHING in /app to the non-root user # Without this, the running agent would be denied permission to write files. RUN chown -R myuser:myuser /app # Switch the active user from root to the non-root user USER myuser # Add the user's local binary directory to the system's PATH ENV PATH="/home/myuser/.local/bin:$PATH" # Define the command to run when the container starts CMD ["sh", "-c", "uvicorn main:app --host 0.0.0.0 --port $PORT"] EOF
कंटेनर इमेज को Artifact Registry में बनाएं और पुश करें
अब आपके पास Dockerfile है. इसका इस्तेमाल करके, इमेज बनाई जाएगी और उसे Artifact Registry में पुश किया जाएगा. Artifact Registry, Google Cloud सेवाओं के साथ इंटिग्रेट की गई एक सुरक्षित और निजी रजिस्ट्री है. GKE, आपके ऐप्लिकेशन को चलाने के लिए इस रजिस्ट्री से इमेज को पुल करेगा.
- टर्मिनल में, कंटेनर इमेज को सेव करने के लिए नई Artifact Registry रिपॉज़िटरी बनाएं.
gcloud artifacts repositories create adk-repo \ --repository-format=docker \ --location=$GOOGLE_CLOUD_LOCATION \ --description="ADK repository" - टर्मिनल में, कंटेनर इमेज बनाने के लिए
gcloud builds submitका इस्तेमाल करें. इसके बाद, इसे रिपॉज़िटरी में पुश करें.gcloud builds submit \ --tag $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo/adk-agent:latest \ --project=$GOOGLE_CLOUD_PROJECT \ .Dockerfileमें दिए गए चरणों को पूरा करने के लिए किया जाता है. यह इमेज को क्लाउड में बनाता है, उसे आपकी Artifact Registry रिपॉज़िटरी के पते के साथ टैग करता है, और उसे वहां अपने-आप पुश करता है. - टर्मिनल से पुष्टि करें कि इमेज बन गई है:
gcloud artifacts docker images list \ $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo \ --project=$GOOGLE_CLOUD_PROJECT
रीकैप
इस सेक्शन में, आपने डिप्लॉयमेंट के लिए कोड को पैकेज किया है:
- आपके एजेंटों को FastAPI वेब सर्वर में रैप करने के लिए,
main.pyएंट्री पॉइंट बनाया गया है. Dockerfileको पोर्टेबल इमेज में बंडल करने के लिए, कोड और डिपेंडेंसी तय की गई हैं.- इमेज बनाने के लिए Cloud Build का इस्तेमाल किया गया है. साथ ही, इसे सुरक्षित Artifact Registry रिपॉज़िटरी में पुश किया गया है.
9. Kubernetes मेनिफ़ेस्ट बनाना
कंटेनर इमेज बनाने और उसे Artifact Registry में सेव करने के बाद, आपको GKE को यह निर्देश देना होगा कि उसे कैसे चलाया जाए. इसमें दो मुख्य गतिविधियां शामिल हैं:
- अनुमतियां कॉन्फ़िगर करना: क्लस्टर में अपने एजेंट के लिए एक खास पहचान बनाएं. साथ ही, उसे उन Google Cloud API का सुरक्षित ऐक्सेस दें जिनकी उसे ज़रूरत है. खास तौर पर, Vertex AI.
- ऐप्लिकेशन की स्थिति तय करना: आपको Kubernetes मेनिफ़ेस्ट फ़ाइल लिखनी होगी. यह एक YAML दस्तावेज़ होता है. इसमें आपके ऐप्लिकेशन को चलाने के लिए ज़रूरी हर चीज़ के बारे में बताया जाता है. जैसे, कंटेनर इमेज, एनवायरमेंट वैरिएबल, और इसे नेटवर्क पर कैसे दिखाया जाना चाहिए.
Vertex AI के लिए Kubernetes सेवा खाता कॉन्फ़िगर करना
Gemini के मॉडल ऐक्सेस करने के लिए, आपके एजेंट को Vertex AI API के साथ कम्यूनिकेट करने की अनुमति चाहिए. GKE में यह अनुमति देने का सबसे सुरक्षित और सुझाया गया तरीका, Workload Identity है. Workload Identity की मदद से, Kubernetes-नेटिव आइडेंटिटी (Kubernetes सेवा खाता) को Google Cloud आइडेंटिटी (IAM सेवा खाता) से लिंक किया जा सकता है. इससे स्टैटिक JSON कुंजियों को डाउनलोड, मैनेज, और सेव करने की ज़रूरत नहीं पड़ती.
- टर्मिनल में, Kubernetes सेवा खाता (
adk-agent-sa) बनाएं. इससे GKE क्लस्टर में आपके एजेंट के लिए एक पहचान बनती है, जिसका इस्तेमाल आपके पॉड कर सकते हैं.kubectl create serviceaccount adk-agent-sa - टर्मिनल में, नीति बाइंडिंग बनाकर अपने Kubernetes सेवा खाते को Google Cloud IAM से लिंक करें. इस निर्देश से, आपके
aiplatform.userकोaiplatform.userकी भूमिका मिल जाती है. इससे वह Vertex AI API को सुरक्षित तरीके से कॉल कर सकता है.adk-agent-sagcloud projects add-iam-policy-binding projects/${GOOGLE_CLOUD_PROJECT} \ --role=roles/aiplatform.user \ --member=principal://iam.googleapis.com/projects/${GOOGLE_CLOUD_PROJECT_NUMBER}/locations/global/workloadIdentityPools/${GOOGLE_CLOUD_PROJECT}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \ --condition=None
Kubernetes मेनिफ़ेस्ट फ़ाइलें बनाना
Kubernetes, YAML मेनिफ़ेस्ट फ़ाइलों का इस्तेमाल करके, आपके ऐप्लिकेशन की मनचाही स्थिति तय करता है. आपको एक deployment.yaml फ़ाइल बनानी होगी. इसमें दो ज़रूरी Kubernetes ऑब्जेक्ट होंगे: एक Deployment और एक Service.
- टर्मिनल से,
deployment.yamlफ़ाइल जनरेट करें.cat <<EOF > ~/adk_multiagent_systems/deployment.yaml # Defines the Kubernetes resources required to deploy the application to GKE. # Includes the Deployment (to run the container pods) and the Service # (to expose the application via a Load Balancer). apiVersion: apps/v1 kind: Deployment metadata: name: adk-agent spec: replicas: 1 selector: matchLabels: app: adk-agent template: metadata: labels: app: adk-agent spec: # Assign the Kubernetes Service Account for Workload Identity serviceAccountName: adk-agent-sa containers: - name: adk-agent imagePullPolicy: Always # The path to the container image in Artifact Registry image: ${GOOGLE_CLOUD_LOCATION}-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/adk-repo/adk-agent:latest # Define the resources for GKE Autopilot to provision resources: limits: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" requests: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" ports: - containerPort: 8080 # Environment variables passed to the application env: - name: PORT value: "8080" - name: GOOGLE_CLOUD_PROJECT value: ${GOOGLE_CLOUD_PROJECT} - name: GOOGLE_CLOUD_LOCATION value: ${GOOGLE_CLOUD_LOCATION} - name: GOOGLE_GENAI_USE_VERTEXAI value: "true" - name: MODEL value: "gemini-2.5-flash" --- apiVersion: v1 kind: Service metadata: name: adk-agent spec: # Create a public-facing Network Load Balancer with an external IP type: LoadBalancer ports: - port: 80 targetPort: 8080 selector: app: adk-agent EOF
रीकैप
इस सेक्शन में, आपने सुरक्षा और डिप्लॉयमेंट कॉन्फ़िगरेशन तय किया है:
- Kubernetes सेवा खाता बनाया गया है और इसे Workload Identity का इस्तेमाल करके Google Cloud IAM से लिंक किया गया है. इससे आपके पॉड, कुंजियों को मैनेज किए बिना Vertex AI को सुरक्षित तरीके से ऐक्सेस कर सकते हैं.
- एक
deployment.yamlफ़ाइल जनरेट की गई है. इसमें डिप्लॉयमेंट (पॉड को कैसे चलाना है) और सेवा (उन्हें लोड बैलेंसर के ज़रिए कैसे दिखाना है) के बारे में बताया गया है.
10. ऐप्लिकेशन को GKE पर डिप्लॉय करना
मेनिफ़ेस्ट फ़ाइल तय करने और कंटेनर इमेज को Artifact Registry में पुश करने के बाद, अब आपके पास अपना ऐप्लिकेशन डिप्लॉय करने का विकल्प है. इस टास्क में, आपको kubectl का इस्तेमाल करके, GKE क्लस्टर पर अपना कॉन्फ़िगरेशन लागू करना होगा. इसके बाद, आपको स्टेटस की निगरानी करनी होगी, ताकि यह पक्का किया जा सके कि आपका एजेंट सही तरीके से शुरू हो गया है.
- अपने टर्मिनल में, अपने क्लस्टर पर
deployment.yamlमेनिफ़ेस्ट लागू करें.kubectl apply -f deployment.yamlkubectl applyकमांड, आपकीdeployment.yamlफ़ाइल को Kubernetes API सर्वर पर भेजती है. इसके बाद, सर्वर आपके कॉन्फ़िगरेशन को पढ़ता है और डिप्लॉयमेंट और सेवा ऑब्जेक्ट बनाने की प्रोसेस को मैनेज करता है. - टर्मिनल में, डिप्लॉयमेंट का स्टेटस रीयल टाइम में देखें. पॉड के
Runningस्थिति में आने तक इंतज़ार करें.kubectl get pods -l=app=adk-agent --watch- लंबित है: पॉड को क्लस्टर ने स्वीकार कर लिया है, लेकिन कंटेनर अब तक नहीं बनाया गया है.
- कंटेनर बनाया जा रहा है: GKE, Artifact Registry से आपकी कंटेनर इमेज को पुल कर रहा है और कंटेनर शुरू कर रहा है.
- दौड़ना: हो गया! कंटेनर चल रहा है और एजेंट ऐप्लिकेशन लाइव है.
- जब स्थिति
Runningके तौर पर दिखे, तब टर्मिनल में CTRL+C दबाकर, वॉच कमांड को रोकें और कमांड प्रॉम्प्ट पर वापस जाएं.
रीकैप
इस सेक्शन में, आपने वर्कलोड लॉन्च किया:
kubectlapply का इस्तेमाल करके, क्लस्टर को अपना मेनिफ़ेस्ट भेजें.- ऐप्लिकेशन के सही तरीके से शुरू होने की पुष्टि करने के लिए, पॉड के लाइफ़साइकल (लंबित -> कंटेनर बनाना -> चल रहा है) की निगरानी की गई.
11. एजेंट के साथ इंटरैक्ट करना
आपका ADK एजेंट अब GKE पर लाइव चल रहा है. साथ ही, यह सार्वजनिक लोड बैलेंसर के ज़रिए इंटरनेट पर उपलब्ध है. आपको एजेंट के वेब इंटरफ़ेस से कनेक्ट किया जाएगा, ताकि आप उससे इंटरैक्ट कर सकें. साथ ही, यह पुष्टि कर सकें कि पूरा सिस्टम सही तरीके से काम कर रहा है.
अपनी सेवा का बाहरी आईपी पता ढूंढना
एजेंट को ऐक्सेस करने के लिए, आपको सबसे पहले वह सार्वजनिक आईपी पता पाना होगा जो GKE ने आपकी सेवा के लिए उपलब्ध कराया है.
- अपनी सेवा की जानकारी पाने के लिए, टर्मिनल में यह कमांड चलाएं.
kubectl get service adk-agent EXTERNAL-IPकॉलम में वैल्यू देखें. पहली बार सेवा को डिप्लॉय करने के बाद, आईपी पते को असाइन होने में एक या दो मिनट लग सकते हैं. अगर यहpendingके तौर पर दिखता है, तो एक मिनट इंतज़ार करें और कमांड को फिर से चलाएं. आउटपुट कुछ ऐसा दिखेगा:NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE adk-agent-service LoadBalancer 10.120.12.234 34.123.45.67 80:31234/TCP 5mEXTERNAL-IPमें दिया गया पता (जैसे, 34.123.45.67) आपके एजेंट का सार्वजनिक एंट्री पॉइंट है.
डिप्लॉय किए गए एजेंट को टेस्ट करना
अब सार्वजनिक आईपी पते का इस्तेमाल करके, ADK के पहले से मौजूद वेब यूज़र इंटरफ़ेस (यूआई) को सीधे अपने ब्राउज़र से ऐक्सेस किया जा सकता है.
- टर्मिनल से, बाहरी आईपी पता (
EXTERNAL-IP) कॉपी करें. - अपने वेब ब्राउज़र में एक नया टैब खोलें और उसमें
http://[EXTERNAL-IP]टाइप करें. इसके बाद,[EXTERNAL-IP]की जगह पर वह आईपी पता डालें जिसे आपने कॉपी किया है. - अब आपको ADK का वेब इंटरफ़ेस दिखेगा.
- पक्का करें कि एजेंट के ड्रॉप-डाउन मेन्यू में, workflow_agents चुना गया हो.
- टोकन स्ट्रीमिंग की सुविधा चालू करें.
- नई बातचीत शुरू करने के लिए,
helloटाइप करें और Enter दबाएं. - नतीजे देखें. एजेंट को तुरंत जवाब देना चाहिए और अभिवादन करना चाहिए: "मैं किसी हिट फ़िल्म के लिए पिच लिखने में आपकी मदद कर सकता हूँ. आपको किस ऐतिहासिक व्यक्ति पर फ़िल्म बनानी है?"
- जब आपसे किसी ऐतिहासिक किरदार को चुनने के लिए कहा जाए, तो अपनी पसंद का किरदार चुनें. इसके लिए, यहां कुछ आइडिया दिए गए हैं:
the most successful female pirate in historythe woman who invented the first computer compilera legendary lawman of the American Wild West
रीकैप
इस सेक्शन में, आपने इन बातों की पुष्टि की:
- LoadBalancer ने जो एक्सटर्नल आईपी पता असाइन किया है उसे वापस पाया गया.
- ब्राउज़र के ज़रिए ADK Web UI को ऐक्सेस किया गया, ताकि यह पुष्टि की जा सके कि मल्टी-एजेंट सिस्टम काम कर रहा है और जवाब दे रहा है.
12. ऑटोस्केलिंग की सुविधा कॉन्फ़िगर करना
प्रोडक्शन में सबसे बड़ी चुनौती, उपयोगकर्ता के अनचाहे ट्रैफ़िक को मैनेज करना है. पिछले टास्क में आपने रेप्लिका की संख्या को हार्ड-कोड किया था. इसका मतलब है कि आपको बिना इस्तेमाल किए गए संसाधनों के लिए ज़्यादा पेमेंट करना होगा या ट्रैफ़िक बढ़ने के दौरान परफ़ॉर्मेंस खराब होने का जोखिम होगा. GKE, ऑटोमैटिक स्केलिंग की सुविधा के ज़रिए इस समस्या को हल करता है.
आपको HorizontalPodAutoscaler (HPA) को कॉन्फ़िगर करना होगा. यह एक Kubernetes कंट्रोलर है. यह रीयल-टाइम में सीपीयू के इस्तेमाल के आधार पर, आपके डिप्लॉयमेंट में चल रहे पॉड की संख्या को अपने-आप अडजस्ट करता है.
- Cloud Shell Editor के टर्मिनल में,
adk_multiagent_systemsडायरेक्ट्री के रूट में एक नईhpa.yamlफ़ाइल बनाएं.cloudshell edit ~/adk_multiagent_systems/hpa.yaml - नई
hpa.yamlफ़ाइल में यह कॉन्टेंट जोड़ें:# Configures the HorizontalPodAutoscaler (HPA) to automatically scale # the number of running agent pods up or down based on CPU utilization # to handle varying traffic loads. apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: adk-agent-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: adk-agent minReplicas: 1 maxReplicas: 5 targetCPUUtilizationPercentage: 50adk-agentडिप्लॉयमेंट को टारगेट करता है. इससे यह पक्का होता है कि कम से कम एक पॉड हमेशा चालू रहे. साथ ही, यह ज़्यादा से ज़्यादा पांच पॉड सेट करता है. यह सीपीयू के इस्तेमाल को औसतन 50% के आस-पास रखने के लिए, रेप्लिका जोड़ता/हटाता रहेगा. इस समय, Cloud Shell Editor में एक्सप्लोरर पैनल में दिखने वाला आपका फ़ाइल स्ट्रक्चर ऐसा दिखना चाहिए:
- इस कोड को टर्मिनल में चिपकाकर, अपने क्लस्टर पर एचपीए लागू करें.
kubectl apply -f hpa.yaml
ऑटोसकेलर की पुष्टि करना
अब एचपीए चालू हो गया है और आपके डिप्लॉयमेंट पर नज़र रख रहा है. इसे काम करते हुए देखने के लिए, इसके स्टेटस की जांच करें.
- अपने एचपीए की स्थिति जानने के लिए, टर्मिनल में यह कमांड चलाएं.
kubectl get hpa adk-agent-hpaNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE adk-agent-hpa Deployment/adk-agent 0%/50% 1 5 1 30s
रीकैप
इस सेक्शन में, आपने प्रोडक्शन ट्रैक के ट्रैफ़िक के लिए ऑप्टिमाइज़ किया है:
- स्केलिंग के नियमों को तय करने के लिए,
hpa.yamlमेनिफ़ेस्ट बनाया गया हो. - सीपीयू के इस्तेमाल के आधार पर, पॉड रेप्लिका की संख्या को अपने-आप अडजस्ट करने के लिए, HorizontalPodAutoscaler (HPA) को डिप्लॉय किया गया है.
13. प्रोडक्शन के लिए तैयारी करना
ध्यान दें: यहां दिए गए सेक्शन सिर्फ़ जानकारी के लिए हैं. इनमें कोई कार्रवाई करने के बारे में नहीं बताया गया है. इन्हें इस तरह से डिज़ाइन किया गया है कि ये आपके ऐप्लिकेशन को प्रोडक्शन में ले जाने के लिए, कॉन्टेक्स्ट और सबसे सही तरीके उपलब्ध करा सकें.
संसाधन के बंटवारे की मदद से परफ़ॉर्मेंस को बेहतर बनाना
GKE Autopilot में, अपने ऐप्लिकेशन के लिए सीपीयू और मेमोरी की तय की गई मात्रा को कंट्रोल किया जा सकता है. इसके लिए, आपको अपने deployment.yaml में संसाधन requests तय करना होगा.
अगर आपको लगता है कि मेमोरी कम होने की वजह से आपका एजेंट ठीक से काम नहीं कर रहा है या क्रैश हो रहा है, तो उसके लिए ज़्यादा संसाधन उपलब्ध कराए जा सकते हैं. इसके लिए, deployment.yaml में मौजूद resources ब्लॉक में बदलाव करें और kubectl apply की मदद से फ़ाइल को फिर से लागू करें.
उदाहरण के लिए, मेमोरी को दोगुना करने के लिए:
# In deployment.yaml
# ...
resources:
requests:
memory: "2Gi" # Increased from 1Gi
cpu: "1000m"
# ...
सीआई/सीडी की मदद से अपने वर्कफ़्लो को ऑटोमेट करना
इस लैब में, आपने कमांड को मैन्युअल तरीके से चलाया. प्रोफ़ेशनल प्रैक्टिस के तौर पर, सीआई/सीडी (कंटिन्यूअस इंटिग्रेशन/कंटिन्यूअस डिप्लॉयमेंट) पाइपलाइन बनाई जाती है. सोर्स कोड रिपॉज़िटरी (जैसे, GitHub) को Cloud Build ट्रिगर से कनेक्ट करके, पूरे डिप्लॉयमेंट को अपने-आप होने वाली प्रोसेस में बदला जा सकता है.
पाइपलाइन की मदद से, कोड में बदलाव करने पर Cloud Build अपने-आप ये काम कर सकता है:
- नई कंटेनर इमेज बनाएं.
- इमेज को Artifact Registry में पुश करें.
- अपडेट किए गए Kubernetes मेनिफ़ेस्ट को अपने GKE क्लस्टर पर लागू करें.
सीक्रेट को सुरक्षित तरीके से मैनेज करना
इस लैब में, आपने कॉन्फ़िगरेशन को .env फ़ाइल में सेव किया और उसे अपने ऐप्लिकेशन को पास किया. यह डेवलपमेंट के लिए सुविधाजनक है, लेकिन एपीआई कुंजियों जैसे संवेदनशील डेटा के लिए सुरक्षित नहीं है. हमारा सुझाव है कि सीक्रेट को सुरक्षित तरीके से सेव करने के लिए, Secret Manager का इस्तेमाल करें.
GKE, Secret Manager के साथ नेटिव तौर पर इंटिग्रेट होता है. इससे, सीक्रेट को सीधे तौर पर अपने पॉड में एनवायरमेंट वैरिएबल या फ़ाइलों के तौर पर माउंट किया जा सकता है. ऐसा करने पर, उन्हें कभी भी आपके सोर्स कोड में शामिल नहीं किया जाता.
यहां संसाधन हटाएं सेक्शन दिया गया है. इसे आपके अनुरोध पर, निष्कर्ष सेक्शन से ठीक पहले डाला गया है.
14. संसाधन मिटाना
इस ट्यूटोरियल में इस्तेमाल किए गए संसाधनों के लिए, अपने Google Cloud खाते से शुल्क न लिए जाने के लिए, संसाधनों वाला प्रोजेक्ट मिटाएं. इसके अलावा, प्रोजेक्ट को बनाए रखने और अलग-अलग संसाधनों को मिटाने का विकल्प भी है.
GKE क्लस्टर मिटाना
इस लैब में, GKE क्लस्टर की वजह से सबसे ज़्यादा लागत आती है. इसे मिटाने पर, कंप्यूट के लिए लगने वाले शुल्क बंद हो जाते हैं.
- टर्मिनल में, यह कमांड चलाएं:
gcloud container clusters delete adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Artifact Registry की रिपॉज़िटरी मिटाना
Artifact Registry में सेव की गई कंटेनर इमेज के लिए, स्टोरेज का शुल्क लगता है.
- टर्मिनल में, यह कमांड चलाएं:
gcloud artifacts repositories delete adk-repo \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
प्रोजेक्ट मिटाना (ज़रूरी नहीं)
अगर आपने इस लैब के लिए कोई नया प्रोजेक्ट बनाया है और आपको इसका दोबारा इस्तेमाल नहीं करना है, तो पूरे प्रोजेक्ट को मिटाना सबसे आसान तरीका है.
- टर्मिनल में यह कमांड चलाएं.
[YOUR_PROJECT_ID]की जगह अपना असल प्रोजेक्ट आईडी डालें:gcloud projects delete [YOUR_PROJECT_ID]
15. नतीजा
बधाई हो! आपने प्रोडक्शन-ग्रेड GKE क्लस्टर पर, मल्टी-एजेंट ADK ऐप्लिकेशन को सफलतापूर्वक डिप्लॉय कर लिया है. यह एक अहम उपलब्धि है. इसमें क्लाउड-नेटिव ऐप्लिकेशन के मुख्य लाइफ़साइकल को शामिल किया गया है. इससे आपको अपने जटिल एजेंटिक सिस्टम को डिप्लॉय करने के लिए एक मज़बूत आधार मिलता है.
रीकैप
इस लैब में, आपने इनके बारे में सीखा:
- GKE Autopilot क्लस्टर उपलब्ध कराएं.
Dockerfileकी मदद से कंटेनर इमेज बनाएं और उसे Artifact Registry में पुश करें- वर्कलोड आइडेंटिटी का इस्तेमाल करके, Google Cloud API से सुरक्षित तरीके से कनेक्ट करें.
- डिप्लॉयमेंट और सेवा के लिए Kubernetes मेनिफ़ेस्ट लिखें.
- LoadBalancer की मदद से, किसी ऐप्लिकेशन को इंटरनेट पर उपलब्ध कराना.
- HorizontalPodAutoscaler (HPA) की मदद से, अपने-आप स्केल होने की सुविधा कॉन्फ़िगर करें.