
1. Introduzione
Panoramica
Questo lab colma il divario fondamentale tra lo sviluppo di un potente sistema multi-agente e il suo deployment per l'utilizzo nel mondo reale. Sebbene la creazione di agenti in locale sia un ottimo inizio, le applicazioni di produzione richiedono una piattaforma scalabile, affidabile e sicura.
In questo lab, prenderai un sistema multi-agente creato con Google Agent Development Kit (ADK) ed eseguirai il deployment in un ambiente di livello di produzione su Google Kubernetes Engine (GKE).
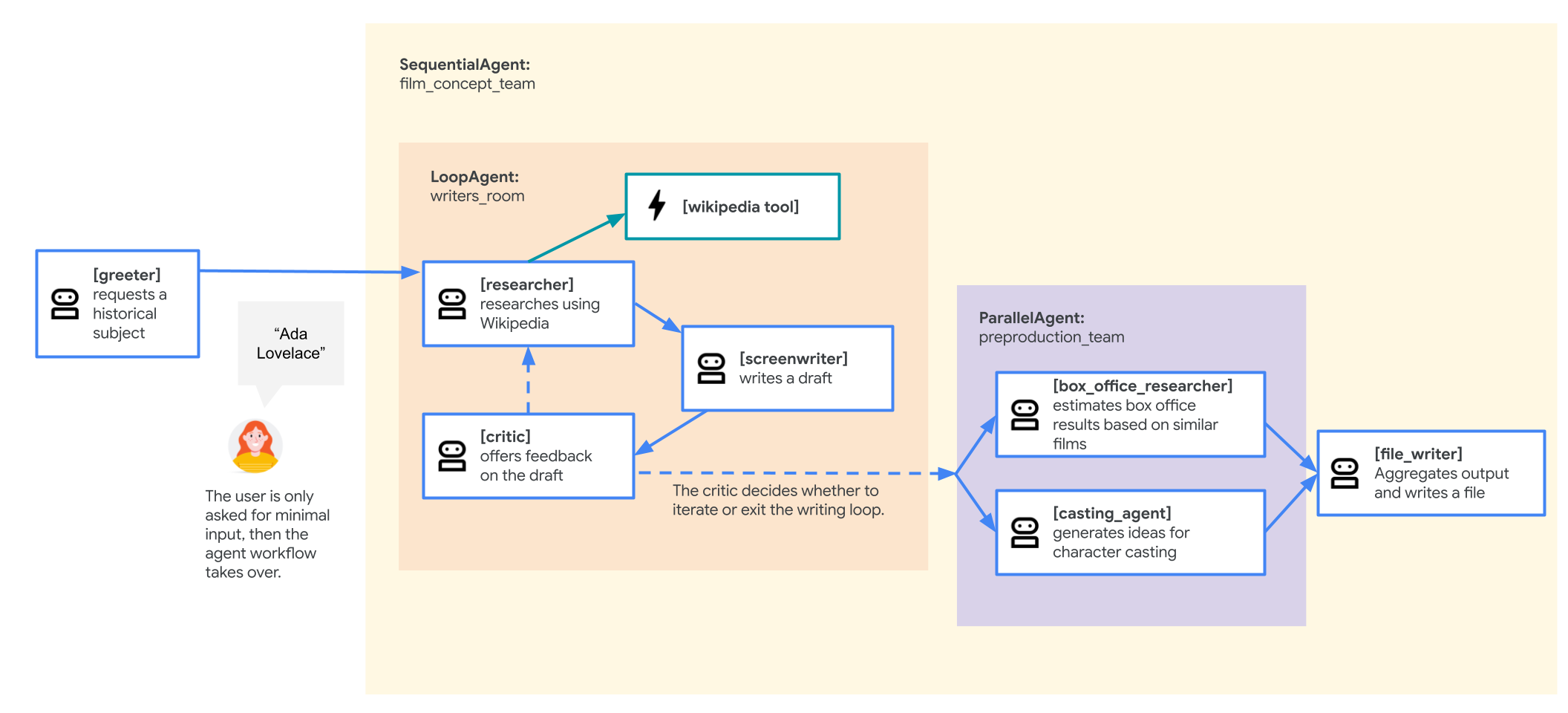
Agente del team di ideazione di film
L'applicazione di esempio utilizzata in questo lab è un "team di ideazione di un film" composto da più agenti che collaborano: un ricercatore, uno sceneggiatore e un autore di file. Questi agenti collaborano per aiutare un utente a fare brainstorming e a delineare la proposta di un film su una figura storica.
Perché eseguire il deployment su GKE?
Per preparare l'agente alle esigenze di un ambiente di produzione, hai bisogno di una piattaforma progettata per scalabilità, sicurezza ed efficienza dei costi. Google Kubernetes Engine (GKE) fornisce questa base potente e flessibile per l'esecuzione dell'applicazione containerizzata.
Questo offre diversi vantaggi per il tuo workload di produzione:
- Scalabilità automatica e prestazioni: gestisci il traffico imprevedibile con HorizontalPodAutoscaler (HPA), che aggiunge o rimuove automaticamente le repliche dell'agente in base al carico. Per i workload AI più impegnativi, puoi collegare acceleratori hardware come GPU e TPU.
- Gestione delle risorse conveniente: ottimizza i costi con GKE Autopilot, che gestisce automaticamente l'infrastruttura sottostante in modo da pagare solo le risorse richieste dalla tua applicazione.
- Sicurezza e osservabilità integrate: connettiti in modo sicuro ad altri servizi Google Cloud utilizzando Workload Identity, che evita la necessità di gestire e archiviare le chiavi dell'account di servizio. Tutti i log delle applicazioni vengono trasmessi automaticamente in streaming a Cloud Logging per il monitoraggio e il debug centralizzati.
- Controllo e portabilità: evita i vincoli al fornitore con Kubernetes open source. La tua applicazione è portabile e può essere eseguita su qualsiasi cluster Kubernetes, on-premise o in altri cloud.
Obiettivi didattici
In questo lab imparerai a:
- Esegui il provisioning di un cluster GKE Autopilot.
- Containerizza un'applicazione con un Dockerfile ed esegui il push dell'immagine in Artifact Registry.
- Connetti in modo sicuro la tua applicazione alle API Google Cloud utilizzando Workload Identity.
- Scrivi e applica i manifest Kubernetes per un deployment e un servizio.
- Esporre un'applicazione a internet con un LoadBalancer.
- Configura la scalabilità automatica con un HorizontalPodAutoscaler (HPA).
2. Configurazione del progetto
Account Google
Se non hai ancora un Account Google personale, devi crearne uno.
Utilizza un account personale anziché un account di lavoro o della scuola.
Accedi alla console Google Cloud
Accedi a Google Cloud Console utilizzando un Account Google personale.
Abilita fatturazione
Configurare un account di fatturazione personale
Se hai configurato la fatturazione utilizzando i crediti Google Cloud, puoi saltare questo passaggio.
Per configurare un account di fatturazione personale, vai qui per abilitare la fatturazione nella console Cloud.
Alcune note:
- Il completamento di questo lab dovrebbe costare meno di 1 $in risorse cloud.
- Per evitare ulteriori addebiti, puoi seguire i passaggi alla fine di questo lab per eliminare le risorse.
- I nuovi utenti hanno diritto alla prova senza costi di 300$.
Creare un progetto (facoltativo)
Se non hai un progetto attuale che vuoi utilizzare per questo lab, creane uno nuovo qui.
3. Apri editor di Cloud Shell
- Fai clic su questo link per andare direttamente all'editor di Cloud Shell.
- Se ti viene richiesto di concedere l'autorizzazione in qualsiasi momento della giornata, fai clic su Autorizza per continuare.
- Se il terminale non viene visualizzato nella parte inferiore dello schermo, aprilo:
- Fai clic su Visualizza.
- Fai clic su Terminale
 .
.
- Nel terminale, imposta il progetto con questo comando:
gcloud config set project [PROJECT_ID]- Esempio:
gcloud config set project lab-project-id-example - Se non ricordi l'ID progetto, puoi elencare tutti i tuoi ID progetto con:
gcloud projects list
- Esempio:
- Dovresti visualizzare questo messaggio:
Updated property [core/project].
4. Abilita API
Per utilizzare GKE, Artifact Registry, Cloud Build e Vertex AI, devi abilitare le rispettive API nel tuo progetto Google Cloud.
- Nel terminale, abilita le API:
gcloud services enable \ container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.comOperation "operations/acf.p2-176675280136-b03ab5e4-3483-4ebf-9655-43dc3b345c63" finished successfully.
Presentazione delle API
- L'API Google Kubernetes Engine (
container.googleapis.com) ti consente di creare e gestire il cluster GKE che esegue l'agente. GKE fornisce un ambiente gestito per il deployment, la gestione e la scalabilità delle applicazioni containerizzate utilizzando l'infrastruttura Google. - L'API Artifact Registry (
artifactregistry.googleapis.com) fornisce un repository sicuro e privato per archiviare l'immagine container dell'agente. È l'evoluzione di Container Registry e si integra perfettamente con GKE e Cloud Build. - L'API Cloud Build (
cloudbuild.googleapis.com) viene utilizzata dal comandogcloud builds submitper creare l'immagine container nel cloud dal Dockerfile. È una piattaforma CI/CD serverless che esegue le build sull'infrastruttura Google Cloud. - L'API Vertex AI (
aiplatform.googleapis.com) consente all'agente di cui è stato eseguito il deployment di comunicare con i modelli Gemini per svolgere le sue attività principali. Fornisce l'API unificata per tutti i servizi AI di Google Cloud.
5. Prepara l'ambiente di sviluppo
Crea la struttura di directory
- Nel terminale, crea la directory del progetto e le sottodirectory necessarie:
mkdir -p ~/adk_multiagent_systems/workflow_agents cd ~/adk_multiagent_systems - Nel terminale, esegui questo comando per aprire la directory in Esplora dell'editor di Cloud Shell.
cloudshell open-workspace ~/adk_multiagent_systems - Il riquadro di esplorazione a sinistra verrà aggiornato. Ora dovresti vedere le directory che hai creato.
Man mano che crei i file nei passaggi successivi, vedrai i file compilati in questa directory.
Creare file iniziali
Ora creerai i file iniziali necessari per l'applicazione.
- Crea
callback_logging.pyeseguendo questo comando nel terminale. Questo file gestisce la registrazione per l'osservabilità.cat <<EOF > ~/adk_multiagent_systems/callback_logging.py """ Provides helper functions for observability. Handles formatting and sending agent queries, responses, and tool calls to Google Cloud Logging to aid in monitoring and debugging. """ import logging import google.cloud.logging from google.adk.agents.callback_context import CallbackContext from google.adk.models import LlmResponse, LlmRequest def log_query_to_model(callback_context: CallbackContext, llm_request: LlmRequest): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_request.contents and llm_request.contents[-1].role == 'user': if llm_request.contents[-1].parts and "text" in llm_request.contents[-1].parts: last_user_message = llm_request.contents[-1].parts[0].text logging.info(f"[query to {callback_context.agent_name}]: " + last_user_message) def log_model_response(callback_context: CallbackContext, llm_response: LlmResponse): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_response.content and llm_response.content.parts: for part in llm_response.content.parts: if part.text: logging.info(f"[response from {callback_context.agent_name}]: " + part.text) elif part.function_call: logging.info(f"[function call from {callback_context.agent_name}]: " + part.function_call.name) EOF - Crea
workflow_agents/__init__.pyeseguendo questo comando nel terminale. In questo modo la directory viene contrassegnata come pacchetto Python.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/__init__.py """ Marks the directory as a Python package and exposes the agent module, allowing the ADK to discover and register the agents defined within. """ from . import agent EOF - Crea
workflow_agents/agent.pyeseguendo questo comando nel terminale. Questo file contiene la logica principale per il tuo team multiagente.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/agent.py """ Defines the core multi-agent workflow. Configures individual agents (Researcher, Screenwriter, File Writer), assigns their specific tools, and orchestrates their collaboration using the ADK's SequentialAgent pattern. """ import os import logging import google.cloud.logging from callback_logging import log_query_to_model, log_model_response from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent, LoopAgent, ParallelAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool # import from google.genai import types from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL") print(model_name) # Tools def append_to_state( tool_context: ToolContext, field: str, response: str ) -> dict[str, str]: """Append new output to an existing state key. Args: field (str): a field name to append to response (str): a string to append to the field Returns: dict[str, str]: {"status": "success"} """ existing_state = tool_context.state.get(field, []) tool_context.state[field] = existing_state + [response] logging.info(f"[Added to {field}] {response}") return {"status": "success"} def write_file( tool_context: ToolContext, directory: str, filename: str, content: str ) -> dict[str, str]: target_path = os.path.join(directory, filename) os.makedirs(os.path.dirname(target_path), exist_ok=True) with open(target_path, "w") as f: f.write(content) return {"status": "success"} # Agents file_writer = Agent( name="file_writer", model=model_name, description="Creates marketing details and saves a pitch document.", instruction=""" PLOT_OUTLINE: { PLOT_OUTLINE? } INSTRUCTIONS: - Create a marketable, contemporary movie title suggestion for the movie described in the PLOT_OUTLINE. If a title has been suggested in PLOT_OUTLINE, you can use it, or replace it with a better one. - Use your 'write_file' tool to create a new txt file with the following arguments: - for a filename, use the movie title - Write to the 'movie_pitches' directory. - For the 'content' to write, extract the following from the PLOT_OUTLINE: - A logline - Synopsis or plot outline """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[write_file], ) screenwriter = Agent( name="screenwriter", model=model_name, description="As a screenwriter, write a logline and plot outline for a biopic about a historical character.", instruction=""" INSTRUCTIONS: Your goal is to write a logline and three-act plot outline for an inspiring movie about a historical character(s) described by the PROMPT: { PROMPT? } - If there is CRITICAL_FEEDBACK, use those thoughts to improve upon the outline. - If there is RESEARCH provided, feel free to use details from it, but you are not required to use it all. - If there is a PLOT_OUTLINE, improve upon it. - Use the 'append_to_state' tool to write your logline and three-act plot outline to the field 'PLOT_OUTLINE'. - Summarize what you focused on in this pass. PLOT_OUTLINE: { PLOT_OUTLINE? } RESEARCH: { research? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], ) researcher = Agent( name="researcher", model=model_name, description="Answer research questions using Wikipedia.", instruction=""" PROMPT: { PROMPT? } PLOT_OUTLINE: { PLOT_OUTLINE? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } INSTRUCTIONS: - If there is a CRITICAL_FEEDBACK, use your wikipedia tool to do research to solve those suggestions - If there is a PLOT_OUTLINE, use your wikipedia tool to do research to add more historical detail - If these are empty, use your Wikipedia tool to gather facts about the person in the PROMPT - Use the 'append_to_state' tool to add your research to the field 'research'. - Summarize what you have learned. Now, use your Wikipedia tool to do research. """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[ LangchainTool(tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())), append_to_state, ], ) film_concept_team = SequentialAgent( name="film_concept_team", description="Write a film plot outline and save it as a text file.", sub_agents=[ researcher, screenwriter, file_writer ], ) root_agent = Agent( name="greeter", model=model_name, description="Guides the user in crafting a movie plot.", instruction=""" - Let the user know you will help them write a pitch for a hit movie. Ask them for a historical figure to create a movie about. - When they respond, use the 'append_to_state' tool to store the user's response in the 'PROMPT' state key and transfer to the 'film_concept_team' agent """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], sub_agents=[film_concept_team], ) EOF
La struttura dei file dovrebbe ora avere il seguente aspetto: 
Configura l'ambiente virtuale
- Nel terminale, crea e attiva un ambiente virtuale utilizzando
uv. In questo modo, le dipendenze del progetto non entrano in conflitto con Python di sistema.uv venv source .venv/bin/activate
Requisiti di installazione
- Esegui questo comando nel terminale per creare il file
requirements.txt.cat <<EOF > ~/adk_multiagent_systems/requirements.txt # Lists all Python dependencies required to run the multi-agent system, # including the Google ADK, LangChain community tools, and web server libraries. langchain-community==0.4.1 wikipedia==1.4.0 google-adk==1.27.5 fastapi==0.135.2 uvicorn==0.42.0 EOF - Installa i pacchetti richiesti nell'ambiente virtuale nel terminale.
uv pip install -r requirements.txt
Imposta le variabili di ambiente
- Utilizza il seguente comando nel terminale per creare il file
.env, inserendo automaticamente l'ID progetto e la regione.cat <<EOF > ~/adk_multiagent_systems/.env GOOGLE_CLOUD_PROJECT="$(gcloud config get-value project)" GOOGLE_CLOUD_PROJECT_NUMBER="$(gcloud projects describe $(gcloud config get-value project) --format='value(projectNumber)')" GOOGLE_CLOUD_LOCATION="us-central1" GOOGLE_GENAI_USE_VERTEXAI=true MODEL="gemini-2.5-flash" EOF - Nel terminale, carica le variabili nella sessione della shell.
source .env
Riepilogo
In questa sezione hai stabilito le basi locali per il tuo progetto:
- È stata creata la struttura di directory e i file di avvio dell'agente necessari (
agent.py,callback_logging.py,requirements.txt). - Isola le dipendenze utilizzando un ambiente virtuale (
uv). - Variabili di ambiente configurate (
.env) per archiviare dettagli specifici del progetto, come l'ID progetto e la regione.
6. Esplorare il file dell'agente
Hai configurato il codice sorgente per il lab, incluso un sistema multi-agente precompilato. Prima di eseguire il deployment dell'applicazione, è utile capire come vengono definiti gli agenti. La logica principale dell'agente si trova in workflow_agents/agent.py.
- Nell'editor di Cloud Shell, utilizza Esplora file a sinistra per andare a
adk_multiagent_systems/workflow_agents/e aprire il fileagent.py. - Dai un'occhiata al file. Non è necessario comprendere ogni riga, ma nota la struttura di alto livello:
- Agenti individuali:il file definisce tre oggetti
Agentdistinti:researcher,screenwriterefile_writer. A ogni agente viene assegnato uninstructionspecifico (il prompt) e un elenco ditoolsche può utilizzare (come lo strumentoWikipediaQueryRuno uno strumentowrite_filepersonalizzato). - Composizione dell'agente:i singoli agenti sono concatenati in un
SequentialAgentchiamatofilm_concept_team. In questo modo, l'ADK esegue questi agenti uno dopo l'altro, passando lo stato da uno all'altro. - L'agente principale:un
root_agent(denominato "greeter") è definito per gestire l'interazione utente iniziale. Quando l'utente fornisce un prompt, questo agente lo salva nello stato dell'applicazione e poi trasferisce il controllo al flusso di lavorofilm_concept_team.
- Agenti individuali:il file definisce tre oggetti
Comprendere questa struttura ti aiuta a chiarire cosa stai per eseguire il deployment: non solo un singolo agente, ma un team coordinato di agenti specializzati orchestrati dall'ADK.
7. Crea un cluster GKE Autopilot
Dopo aver preparato l'ambiente, il passaggio successivo consiste nel eseguire il provisioning dell'infrastruttura in cui verrà eseguita l'applicazione agente. Creerai un cluster GKE Autopilot, che funge da base per il deployment. Utilizziamo la modalità Autopilot perché gestisce la complessa gestione dei nodi, della scalabilità e della sicurezza sottostanti del cluster, consentendoti di concentrarti esclusivamente sul deployment dell'applicazione.
- Nel terminale, crea un nuovo cluster GKE Autopilot denominato
adk-cluster.gcloud container clusters create-auto adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT - Una volta creato il cluster, configura
kubectlper connetterti eseguendo questo comando nel terminale:gcloud container clusters get-credentials adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT~/.kube/config). Da questo momento in poi, lo strumento a riga di comandokubectlverrà autenticato e indirizzato a comunicare con il tuoadk-cluster.
Riepilogo
In questa sezione hai eseguito il provisioning dell'infrastruttura:
- È stato creato un cluster GKE Autopilot completamente gestito utilizzando
gcloud. - Hai configurato lo strumento
kubectllocale per l'autenticazione e la comunicazione con il nuovo cluster.
8. Containerizza ed esegui il push dell'applicazione
Il codice del tuo agente esiste attualmente solo nel tuo ambiente Cloud Shell. Per eseguirlo su GKE, devi prima pacchettizzarlo in un'immagine container. Un'immagine container è un file statico e portabile che raggruppa il codice dell'applicazione con tutte le sue dipendenze. Quando esegui questa immagine, diventa un container attivo.
Questa procedura prevede tre passaggi chiave:
- Crea un punto di ingresso: definisci un file
main.pyper trasformare la logica dell'agente in un server web eseguibile. - Definisci l'immagine container: crea un Dockerfile che funge da progetto per la creazione dell'immagine container.
- Crea ed esegui il push: utilizza Cloud Build per eseguire il Dockerfile, creare l'immagine container ed eseguirne il push in Google Artifact Registry, un repository sicuro per le tue immagini.
Preparare l'applicazione per il deployment
L'agente ADK ha bisogno di un server web per ricevere le richieste. Il file main.py fungerà da punto di ingresso, utilizzando il framework FastAPI per esporre le funzionalità dell'agente tramite HTTP.
- Nella radice della directory
adk_multiagent_systemsnel terminale, crea un nuovo file denominatomain.py.cat <<EOF > ~/adk_multiagent_systems/main.py """ Serves as the application entry point. Initializes the FastAPI web server, discovers the agents defined in the workflow directory, and exposes them via HTTP endpoints for interaction. """ import os import uvicorn from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Get the directory where main.py is located AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) # Configure the session service (e.g., SQLite for local storage) SESSION_SERVICE_URI = "sqlite:///./sessions.db" # Configure CORS to allow requests from various origins for this lab ALLOWED_ORIGINS = ["http://localhost", "http://localhost:8080", "*"] # Enable the ADK's built-in web interface SERVE_WEB_INTERFACE = True # Call the ADK function to discover agents and create the FastAPI app app: FastAPI = get_fast_api_app( agents_dir=AGENT_DIR, session_service_uri=SESSION_SERVICE_URI, allow_origins=ALLOWED_ORIGINS, web=SERVE_WEB_INTERFACE, ) # You can add more FastAPI routes or configurations below if needed # Example: # @app.get("/hello") # async def read_root(): # return {"Hello": "World"} if __name__ == "__main__": # Get the port from the PORT environment variable provided by the container runtime # Run the Uvicorn server, listening on all available network interfaces (0.0.0.0) uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("PORT", 8080))) EOFuvicornesegue questa applicazione, in ascolto sull'host0.0.0.0per accettare connessioni da qualsiasi indirizzo IP e sulla porta specificata dalla variabile di ambientePORT, che imposteremo in un secondo momento nel manifest Kubernetes.
A questo punto, la struttura dei file visualizzata nel riquadro Explorer dell'editor di Cloud Shell dovrebbe essere simile a questa:
Contenere l'agente ADK con Docker
Per eseguire il deployment della nostra applicazione in GKE, dobbiamo prima pacchettizzarla in un'immagine container, che raggruppa il codice dell'applicazione con tutte le librerie e le dipendenze necessarie per l'esecuzione. Utilizzeremo Docker per creare questa immagine container.
- Nella radice della directory
adk_multiagent_systemsnel terminale, crea un nuovo file denominatoDockerfile.cat <<'EOF' > ~/adk_multiagent_systems/Dockerfile # Defines the blueprint for the container image. Installs dependencies, # sets up a secure non-root user, and specifies the startup command to run the # agent web server. # Use an official lightweight Python image as the base FROM python:3.13-slim # Set the working directory inside the container WORKDIR /app # Create a non-root user for security best practices RUN adduser --disabled-password --gecos "" myuser # Copy and install dependencies first to leverage Docker's layer caching COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt # Copy all application code into the container COPY . . # Create the directory where the agent will write files at runtime # The -p flag ensures the command doesn't fail if the directory already exists RUN mkdir -p movie_pitches # Change ownership of EVERYTHING in /app to the non-root user # Without this, the running agent would be denied permission to write files. RUN chown -R myuser:myuser /app # Switch the active user from root to the non-root user USER myuser # Add the user's local binary directory to the system's PATH ENV PATH="/home/myuser/.local/bin:$PATH" # Define the command to run when the container starts CMD ["sh", "-c", "uvicorn main:app --host 0.0.0.0 --port $PORT"] EOF
Crea ed esegui il push dell'immagine container in Artifact Registry
Ora che hai un Dockerfile, utilizzerai Cloud Build per creare l'immagine ed eseguirne il push su Artifact Registry, un registro privato e sicuro integrato con i servizi Google Cloud. GKE eseguirà il pull dell'immagine da questo registro per eseguire l'applicazione.
- Nel terminale, crea un nuovo repository Artifact Registry per archiviare l'immagine container.
gcloud artifacts repositories create adk-repo \ --repository-format=docker \ --location=$GOOGLE_CLOUD_LOCATION \ --description="ADK repository" - Nel terminale, utilizza
gcloud builds submitper creare l'immagine container ed eseguirne il push nel repository.gcloud builds submit \ --tag $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo/adk-agent:latest \ --project=$GOOGLE_CLOUD_PROJECT \ .Dockerfile. Crea l'immagine nel cloud, la tagga con l'indirizzo del repository Artifact Registry ed esegue automaticamente il push. - Dal terminale, verifica che l'immagine sia stata creata:
gcloud artifacts docker images list \ $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo \ --project=$GOOGLE_CLOUD_PROJECT
Riepilogo
In questa sezione hai creato il pacchetto del codice per il deployment:
- È stato creato un punto di ingresso
main.pyper racchiudere gli agenti in un server web FastAPI. - Definisci un
Dockerfileper raggruppare il codice e le dipendenze in un'immagine portabile. - Utilizzato Cloud Build per creare l'immagine ed eseguirne il push in un repository Artifact Registry sicuro.
9. Crea manifest Kubernetes
Ora che l'immagine container è stata creata e archiviata in Artifact Registry, devi indicare a GKE come eseguirla. Ciò comporta due attività principali:
- Configurazione delle autorizzazioni: creerai un'identità dedicata per l'agente all'interno del cluster e gli concederai l'accesso sicuro alle API Cloud di cui ha bisogno (in particolare, Vertex AI).
- Definizione dello stato dell'applicazione: scriverai un file manifest Kubernetes, un documento YAML che definisce in modo dichiarativo tutto ciò che serve alla tua applicazione per essere eseguita, inclusi l'immagine container, le variabili di ambiente e il modo in cui deve essere esposta alla rete.
Configura il service account Kubernetes per Vertex AI
L'agente deve disporre dell'autorizzazione per comunicare con l'API Vertex AI per accedere ai modelli Gemini. Il metodo più sicuro e consigliato per concedere questa autorizzazione in GKE è Workload Identity. Workload Identity ti consente di collegare un'identità nativa di Kubernetes (un service account Kubernetes) a un'identità Google Cloud (un service account IAM), evitando completamente la necessità di scaricare, gestire e archiviare chiavi JSON statiche.
- Nel terminale, crea il service account Kubernetes (
adk-agent-sa). In questo modo viene creata un'identità per l'agente all'interno del cluster GKE che i pod possono utilizzare.kubectl create serviceaccount adk-agent-sa - Nel terminale, collega il service account Kubernetes a Google Cloud IAM creando un'associazione dei criteri. Questo comando concede il ruolo
aiplatform.useral tuoadk-agent-sa, consentendogli di richiamare in modo sicuro l'API Vertex AI.gcloud projects add-iam-policy-binding projects/${GOOGLE_CLOUD_PROJECT} \ --role=roles/aiplatform.user \ --member=principal://iam.googleapis.com/projects/${GOOGLE_CLOUD_PROJECT_NUMBER}/locations/global/workloadIdentityPools/${GOOGLE_CLOUD_PROJECT}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \ --condition=None
Crea i file manifest Kubernetes
Kubernetes utilizza i file manifest YAML per definire lo stato desiderato della tua applicazione. Creerai un file deployment.yaml contenente due oggetti Kubernetes essenziali: un deployment e un servizio.
- Dal terminale, genera il file
deployment.yaml.cat <<EOF > ~/adk_multiagent_systems/deployment.yaml # Defines the Kubernetes resources required to deploy the application to GKE. # Includes the Deployment (to run the container pods) and the Service # (to expose the application via a Load Balancer). apiVersion: apps/v1 kind: Deployment metadata: name: adk-agent spec: replicas: 1 selector: matchLabels: app: adk-agent template: metadata: labels: app: adk-agent spec: # Assign the Kubernetes Service Account for Workload Identity serviceAccountName: adk-agent-sa containers: - name: adk-agent imagePullPolicy: Always # The path to the container image in Artifact Registry image: ${GOOGLE_CLOUD_LOCATION}-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/adk-repo/adk-agent:latest # Define the resources for GKE Autopilot to provision resources: limits: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" requests: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" ports: - containerPort: 8080 # Environment variables passed to the application env: - name: PORT value: "8080" - name: GOOGLE_CLOUD_PROJECT value: ${GOOGLE_CLOUD_PROJECT} - name: GOOGLE_CLOUD_LOCATION value: ${GOOGLE_CLOUD_LOCATION} - name: GOOGLE_GENAI_USE_VERTEXAI value: "true" - name: MODEL value: "gemini-2.5-flash" --- apiVersion: v1 kind: Service metadata: name: adk-agent spec: # Create a public-facing Network Load Balancer with an external IP type: LoadBalancer ports: - port: 80 targetPort: 8080 selector: app: adk-agent EOF
Riepilogo
In questa sezione hai definito la configurazione di sicurezza e deployment:
- È stato creato un service account Kubernetes e collegato a Google Cloud IAM utilizzando Workload Identity, consentendo ai pod di accedere in modo sicuro a Vertex AI senza gestire le chiavi.
- È stato generato un file
deployment.yamlche definisce il deployment (come eseguire i pod) e il servizio (come esporli tramite un bilanciatore del carico).
10. Esegui il deployment dell'applicazione in GKE
Ora che il file manifest è definito e l'immagine container è stata inviata ad Artifact Registry, puoi eseguire il deployment dell'applicazione. In questa attività utilizzerai kubectl per applicare la configurazione al cluster GKE e quindi monitorare lo stato per assicurarti che l'agente venga avviato correttamente.
- Nel terminale, applica il manifest
deployment.yamlal cluster.kubectl apply -f deployment.yamlkubectl applyinvia il filedeployment.yamlal server API Kubernetes. Il server legge quindi la configurazione e orchestra la creazione degli oggetti Deployment e Service. - Nel terminale, controlla lo stato della tua implementazione in tempo reale. Attendi che i pod siano nello stato
Running.kubectl get pods -l=app=adk-agent --watch- In attesa: il pod è stato accettato dal cluster, ma il container non è ancora stato creato.
- Creazione del container: GKE sta eseguendo il pull dell'immagine container da Artifact Registry e avviando il container.
- Corsa: operazione riuscita. Il container è in esecuzione e l'applicazione dell'agente è attiva.
- Quando lo stato mostra
Running, premi Ctrl+C nel terminale per interrompere il comando watch e tornare al prompt dei comandi.
Riepilogo
In questa sezione hai avviato il carico di lavoro:
- Utilizza
kubectlapply per inviare il manifest al cluster. - Monitoraggio del ciclo di vita del pod (In attesa -> Creazione container -> In esecuzione) per garantire l'avvio corretto dell'applicazione.
11. Interagire con l'agente
L'agente ADK è ora in esecuzione su GKE ed è esposto a internet tramite un bilanciatore del carico pubblico. Ti connetterai all'interfaccia web dell'agente per interagire con lui e verificare che l'intero sistema funzioni correttamente.
Trovare l'indirizzo IP esterno del tuo servizio
Per accedere all'agente, devi prima ottenere l'indirizzo IP pubblico che GKE ha eseguito il provisioning per il tuo servizio.
- Nel terminale, esegui questo comando per ottenere i dettagli del servizio.
kubectl get service adk-agent - Cerca il valore nella colonna
EXTERNAL-IP. Potrebbe essere necessario attendere un minuto o due prima che l'indirizzo IP venga assegnato dopo il primo deployment del servizio. Se viene visualizzatopending, attendi un minuto ed esegui di nuovo il comando. L'output sarà simile a questo:NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE adk-agent-service LoadBalancer 10.120.12.234 34.123.45.67 80:31234/TCP 5mEXTERNAL-IP(ad es. 34.123.45.67) è il punto di accesso pubblico al tuo agente.
Testa l'agente di cui è stato eseguito il deployment
Ora puoi utilizzare l'indirizzo IP pubblico per accedere all'interfaccia utente web integrata dell'ADK direttamente dal browser.
- Copia l'indirizzo IP esterno (
EXTERNAL-IP) dal terminale. - Apri una nuova scheda nel browser web e digita
http://[EXTERNAL-IP], sostituendo[EXTERNAL-IP]con l'indirizzo IP che hai copiato. - Ora dovresti vedere l'interfaccia web dell'ADK.
- Assicurati che workflow_agents sia selezionato nel menu a discesa degli agenti.
- Attiva Streaming di token.
- Digita
helloe premi Invio per iniziare una nuova conversazione. - Osserva il risultato. L'agente dovrebbe rispondere rapidamente con il suo saluto: "Posso aiutarti a scrivere la proposta per un film di successo. Su quale personaggio storico vorresti fare un film?"
- Quando ti viene chiesto di scegliere un personaggio storico, scegli quello che ti interessa. Ecco alcune idee:
the most successful female pirate in historythe woman who invented the first computer compilera legendary lawman of the American Wild West
Riepilogo
In questa sezione hai verificato il deployment:
- Recuperato l'indirizzo IP esterno allocato da LoadBalancer.
- Ha eseguito l'accesso alla UI web di ADK tramite un browser per verificare che il sistema multi-agente sia reattivo e funzionale.
12. Configura scalabilità automatica
Una delle principali sfide nella produzione è la gestione del traffico utente imprevedibile. Codificare in modo rigido un numero fisso di repliche, come hai fatto nell'attività precedente, significa pagare troppo per le risorse inattive o rischiare prestazioni scarse durante i picchi di traffico. GKE risolve questo problema con la scalabilità automatica.
Configurerai un HorizontalPodAutoscaler (HPA), un controller Kubernetes che regola automaticamente il numero di pod in esecuzione nel deployment in base all'utilizzo della CPU in tempo reale.
- Nel terminale dell'editor di Cloud Shell, crea un nuovo file
hpa.yamlnella radice della directoryadk_multiagent_systems.cloudshell edit ~/adk_multiagent_systems/hpa.yaml - Aggiungi i seguenti contenuti al nuovo file
hpa.yaml:# Configures the HorizontalPodAutoscaler (HPA) to automatically scale # the number of running agent pods up or down based on CPU utilization # to handle varying traffic loads. apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: adk-agent-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: adk-agent minReplicas: 1 maxReplicas: 5 targetCPUUtilizationPercentage: 50adk-agent. Garantisce che sia sempre in esecuzione almeno un pod, imposta un massimo di 5 pod e aggiunge/rimuove repliche per mantenere l'utilizzo medio della CPU intorno al 50%.A questo punto, la struttura dei file visualizzata nel riquadro dell'explorer nell'editor di Cloud Shell dovrebbe essere simile a questa:
- Applica HPA al cluster incollando questo codice nel terminale.
kubectl apply -f hpa.yaml
Verifica il gestore della scalabilità automatica
L'HPA è ora attivo e monitora il deployment. Puoi controllare il suo stato per vederlo in azione.
- Esegui questo comando nel terminale per ottenere lo stato di HPA.
kubectl get hpa adk-agent-hpaNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE adk-agent-hpa Deployment/adk-agent 0%/50% 1 5 1 30s
Riepilogo
In questa sezione, hai ottimizzato il traffico di produzione:
- È stato creato un manifest
hpa.yamlper definire le regole di scalabilità. - È stato eseguito il deployment di HorizontalPodAutoscaler (HPA) per regolare automaticamente il numero di repliche dei pod in base all'utilizzo della CPU.
13. Preparazione alla produzione
Nota: le sezioni seguenti sono fornite solo a scopo informativo e non contengono ulteriori passaggi da eseguire. Sono progettati per fornire contesto e best practice per portare la tua applicazione in produzione.
Ottimizzare il rendimento con l'allocazione delle risorse
In GKE Autopilot, controlli la quantità di CPU e memoria di cui viene eseguito il provisioning per la tua applicazione specificando requests risorse nel deployment.yaml.
Se noti che l'agente è lento o si arresta in modo anomalo a causa della mancanza di memoria, puoi aumentare l'allocazione delle risorse modificando il blocco resources in deployment.yaml e riapplicando il file con kubectl apply.
Ad esempio, per raddoppiare la memoria:
# In deployment.yaml
# ...
resources:
requests:
memory: "2Gi" # Increased from 1Gi
cpu: "1000m"
# ...
Automatizza il tuo flusso di lavoro con CI/CD
In questo lab hai eseguito i comandi manualmente. La prassi professionale prevede la creazione di una pipeline CI/CD (integrazione continua/deployment continuo). Se colleghi un repository di codice sorgente (come GitHub) a un trigger di build di Cloud Build, puoi automatizzare l'intero deployment.
Con una pipeline, ogni volta che esegui il push di una modifica del codice, Cloud Build può automaticamente:
- Crea la nuova immagine container.
- Esegui il push dell'immagine in Artifact Registry.
- Applica i manifest Kubernetes aggiornati al tuo cluster GKE.
Gestire i secret in modo sicuro
In questo lab, hai archiviato la configurazione in un file .env e l'hai passata all'applicazione. È una soluzione pratica per lo sviluppo, ma non è sicura per i dati sensibili come le chiavi API. La best practice consigliata è utilizzare Secret Manager per archiviare in modo sicuro i secret.
GKE ha un'integrazione nativa con Secret Manager che ti consente di montare i secret direttamente nei pod come variabili di ambiente o file, senza che vengano mai archiviati nel codice sorgente.
Ecco la sezione Liberare spazio che hai richiesto, inserita appena prima della sezione Conclusione.
14. Libera spazio
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Elimina il cluster GKE
Il cluster GKE è il principale fattore di costo in questo lab. Se lo elimini, gli addebiti per il calcolo vengono interrotti.
- Nel terminale, esegui questo comando:
gcloud container clusters delete adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Elimina il repository Artifact Registry
Le immagini container archiviate in Artifact Registry comportano costi di archiviazione.
- Nel terminale, esegui questo comando:
gcloud artifacts repositories delete adk-repo \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Elimina il progetto (facoltativo)
Se hai creato un nuovo progetto appositamente per questo lab e non prevedi di utilizzarlo di nuovo, il modo più semplice per liberare spazio è eliminare l'intero progetto.
- Nel terminale, esegui questo comando (sostituisci
[YOUR_PROJECT_ID]con l'ID progetto effettivo):gcloud projects delete [YOUR_PROJECT_ID]
15. Conclusione
Complimenti! Hai eseguito correttamente il deployment di un'applicazione ADK multi-agente in un cluster GKE di livello di produzione. Si tratta di un risultato significativo che copre il ciclo di vita principale di un'applicazione cloud-native moderna, fornendoti una base solida per il deployment dei tuoi sistemi agentici complessi.
Riepilogo
In questo lab hai imparato a:
- Esegui il provisioning di un cluster GKE Autopilot.
- Crea un'immagine container con un
Dockerfileed eseguine il push in Artifact Registry - Connettiti in modo sicuro alle API Cloud utilizzando Workload Identity.
- Scrivi i manifest Kubernetes per un deployment e un servizio.
- Esporre un'applicazione a internet con un LoadBalancer.
- Configura la scalabilità automatica con un HorizontalPodAutoscaler (HPA).