
1. はじめに
概要
このラボでは、強力なマルチエージェント システムの開発と、実世界での使用を目的としたデプロイの間の重要なギャップを埋めます。エージェントをローカルで構築することは良いスタートですが、本番環境のアプリケーションには、スケーラブルで信頼性が高く、安全なプラットフォームが必要です。
このラボでは、Google Agent Development Kit(ADK)で構築されたマルチエージェント システムを Google Kubernetes Engine(GKE)の本番環境にデプロイします。
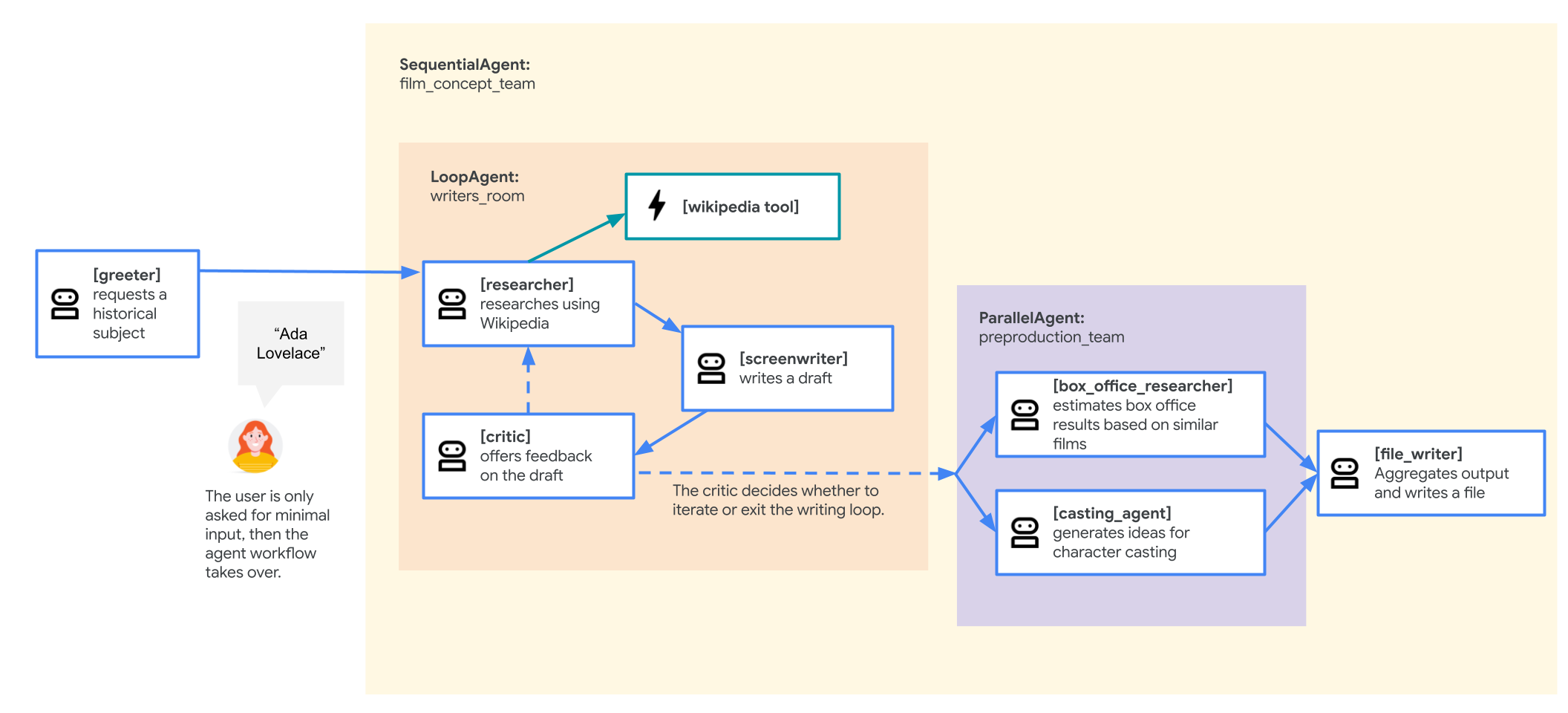
映画コンセプト チーム エージェント
このラボで使用するサンプル アプリケーションは、複数の連携エージェント(研究者、脚本家、ファイル ライター)で構成される「映画コンセプト チーム」です。これらのエージェントは連携して、歴史上の人物に関する映画の企画をユーザーがブレインストーミングして概要を説明するのを支援します。
GKE にデプロイする理由
本番環境の要件を満たすエージェントを準備するには、スケーラビリティ、セキュリティ、費用対効果に優れたプラットフォームが必要です。Google Kubernetes Engine(GKE)は、コンテナ化されたアプリケーションを実行するための強力で柔軟な基盤を提供します。
これにより、本番環境のワークロードに次のようなメリットがあります。
- 自動スケーリングとパフォーマンス: HorizontalPodAutoscaler(HPA)を使用して、予測不可能なトラフィックを処理します。HPA は、負荷に基づいてエージェント レプリカを自動的に追加または削除します。要求の厳しい AI ワークロードの場合は、GPU や TPU などのハードウェア アクセラレータをアタッチできます。
- 費用対効果の高いリソース管理: GKE Autopilot を使用して費用を最適化します。これにより、基盤となるインフラストラクチャが自動的に管理され、アプリケーションがリクエストしたリソースに対してのみ料金が発生します。
- 統合されたセキュリティとオブザーバビリティ: Workload Identity を使用して他の Google Cloud サービスに安全に接続します。これにより、サービス アカウント キーの管理と保存が不要になります。すべてのアプリケーション ログは、一元的なモニタリングとデバッグのために Cloud Logging に自動的にストリーミングされます。
- 制御とポータビリティ: オープンソースの Kubernetes でベンダー ロックインを回避します。アプリケーションは移植可能で、オンプレミスや他のクラウドの任意の Kubernetes クラスタで実行できます。
学習内容
このラボでは、次のタスクの実行方法について学びます。
- GKE Autopilot クラスタをプロビジョニングします。
- Dockerfile を使用してアプリケーションをコンテナ化し、イメージを Artifact Registry に push します。
- Workload Identity を使用して、アプリケーションを Google Cloud APIs に安全に接続します。
- Deployment と Service の Kubernetes マニフェストを作成して適用する。
- LoadBalancer を使用してアプリケーションをインターネットに公開します。
- HorizontalPodAutoscaler(HPA)を使用して自動スケーリングを構成します。
2. プロジェクトの設定
Google アカウント
個人の Google アカウントをお持ちでない場合は、Google アカウントを作成する必要があります。
仕事用または学校用アカウントではなく、個人アカウントを使用します。
Google Cloud コンソールにログインする
個人の Google アカウントを使用して Google Cloud コンソールにログインします。
課金を有効にする
個人用の請求先アカウントを設定する
Google Cloud クレジットを使用して課金を設定した場合は、この手順をスキップできます。
個人用の請求先アカウントを設定するには、Cloud コンソールでこちらに移動して課金を有効にします。
注意事項:
- このラボを完了するのにかかる Cloud リソースの費用は 1 米ドル未満です。
- このラボの最後の手順に沿ってリソースを削除すると、それ以上の料金は発生しません。
- 新規ユーザーは、300 米ドル分の無料トライアルをご利用いただけます。
プロジェクトの作成(省略可)
このラボで使用する現在のプロジェクトがない場合は、こちらで新しいプロジェクトを作成します。
3. Cloud Shell エディタを開く
- このリンクをクリックすると、Cloud Shell エディタに直接移動します。
- 本日、承認を求めるメッセージがどこかの時点で表示された場合は、[承認] をクリックして続行します。
- ターミナルが画面の下部に表示されない場合は、ターミナルを開きます。
- [表示] をクリックします。
- [ターミナル] をクリックします。
- ターミナルで、次のコマンドを使用してプロジェクトを設定します。
gcloud config set project [PROJECT_ID]- 例:
gcloud config set project lab-project-id-example - プロジェクト ID が思い出せない場合は、次のコマンドでプロジェクト ID をすべて一覧表示できます。
gcloud projects list
- 例:
- 次のようなメッセージが表示されます。
Updated property [core/project].
4. API を有効にする
GKE、Artifact Registry、Cloud Build、Vertex AI を使用するには、Google Cloud プロジェクトでそれぞれの API を有効にする必要があります。
- ターミナルで、API を有効にします。
gcloud services enable \ container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.comOperation "operations/acf.p2-176675280136-b03ab5e4-3483-4ebf-9655-43dc3b345c63" finished successfully.
API の概要
- Google Kubernetes Engine API(
container.googleapis.com)を使用すると、エージェントを実行する GKE クラスタを作成して管理できます。GKE は、Google のインフラストラクチャを使用して、コンテナ化されたアプリケーションをデプロイ、管理、スケーリングするためのマネージド環境です。 - Artifact Registry API(
artifactregistry.googleapis.com)は、エージェントのコンテナ イメージを保存するための安全な非公開リポジトリを提供します。これは Container Registry の進化版であり、GKE および Cloud Build とシームレスに統合されています。 - Cloud Build API(
cloudbuild.googleapis.com)は、gcloud builds submitコマンドで使用され、Dockerfile からクラウドでコンテナ イメージをビルドします。これは、Google Cloud インフラストラクチャでビルドを実行するサーバーレス CI/CD プラットフォームです。 - Vertex AI API(
aiplatform.googleapis.com)を使用すると、デプロイされたエージェントが Gemini モデルと通信して、コアタスクを実行できます。Google Cloud のすべての AI サービスに統合 API を提供します。
5. 開発環境を準備する
ディレクトリ構造を作成する
- ターミナルで、プロジェクト ディレクトリと必要なサブディレクトリを作成します。
mkdir -p ~/adk_multiagent_systems/workflow_agents cd ~/adk_multiagent_systems - ターミナルで次のコマンドを実行して、Cloud Shell エディタのエクスプローラでディレクトリを開きます。
cloudshell open-workspace ~/adk_multiagent_systems - 左側のエクスプローラ パネルが更新されます。作成したディレクトリが表示されます。
次の手順でファイルを作成すると、このディレクトリにファイルが追加されます。
スターター ファイルを作成する
次に、アプリケーションに必要なスターター ファイルを作成します。
- ターミナルで次のコマンドを実行して、
callback_logging.pyを作成します。このファイルは、オブザーバビリティのロギングを処理します。cat <<EOF > ~/adk_multiagent_systems/callback_logging.py """ Provides helper functions for observability. Handles formatting and sending agent queries, responses, and tool calls to Google Cloud Logging to aid in monitoring and debugging. """ import logging import google.cloud.logging from google.adk.agents.callback_context import CallbackContext from google.adk.models import LlmResponse, LlmRequest def log_query_to_model(callback_context: CallbackContext, llm_request: LlmRequest): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_request.contents and llm_request.contents[-1].role == 'user': if llm_request.contents[-1].parts and "text" in llm_request.contents[-1].parts: last_user_message = llm_request.contents[-1].parts[0].text logging.info(f"[query to {callback_context.agent_name}]: " + last_user_message) def log_model_response(callback_context: CallbackContext, llm_response: LlmResponse): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_response.content and llm_response.content.parts: for part in llm_response.content.parts: if part.text: logging.info(f"[response from {callback_context.agent_name}]: " + part.text) elif part.function_call: logging.info(f"[function call from {callback_context.agent_name}]: " + part.function_call.name) EOF - ターミナルで次のコマンドを実行して、
workflow_agents/__init__.pyを作成します。これにより、ディレクトリが Python パッケージとしてマークされます。cat <<EOF > ~/adk_multiagent_systems/workflow_agents/__init__.py """ Marks the directory as a Python package and exposes the agent module, allowing the ADK to discover and register the agents defined within. """ from . import agent EOF - ターミナルで次のコマンドを実行して、
workflow_agents/agent.pyを作成します。このファイルには、マルチエージェント チームのコアロジックが含まれています。cat <<EOF > ~/adk_multiagent_systems/workflow_agents/agent.py """ Defines the core multi-agent workflow. Configures individual agents (Researcher, Screenwriter, File Writer), assigns their specific tools, and orchestrates their collaboration using the ADK's SequentialAgent pattern. """ import os import logging import google.cloud.logging from callback_logging import log_query_to_model, log_model_response from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent, LoopAgent, ParallelAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool # import from google.genai import types from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL") print(model_name) # Tools def append_to_state( tool_context: ToolContext, field: str, response: str ) -> dict[str, str]: """Append new output to an existing state key. Args: field (str): a field name to append to response (str): a string to append to the field Returns: dict[str, str]: {"status": "success"} """ existing_state = tool_context.state.get(field, []) tool_context.state[field] = existing_state + [response] logging.info(f"[Added to {field}] {response}") return {"status": "success"} def write_file( tool_context: ToolContext, directory: str, filename: str, content: str ) -> dict[str, str]: target_path = os.path.join(directory, filename) os.makedirs(os.path.dirname(target_path), exist_ok=True) with open(target_path, "w") as f: f.write(content) return {"status": "success"} # Agents file_writer = Agent( name="file_writer", model=model_name, description="Creates marketing details and saves a pitch document.", instruction=""" PLOT_OUTLINE: { PLOT_OUTLINE? } INSTRUCTIONS: - Create a marketable, contemporary movie title suggestion for the movie described in the PLOT_OUTLINE. If a title has been suggested in PLOT_OUTLINE, you can use it, or replace it with a better one. - Use your 'write_file' tool to create a new txt file with the following arguments: - for a filename, use the movie title - Write to the 'movie_pitches' directory. - For the 'content' to write, extract the following from the PLOT_OUTLINE: - A logline - Synopsis or plot outline """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[write_file], ) screenwriter = Agent( name="screenwriter", model=model_name, description="As a screenwriter, write a logline and plot outline for a biopic about a historical character.", instruction=""" INSTRUCTIONS: Your goal is to write a logline and three-act plot outline for an inspiring movie about a historical character(s) described by the PROMPT: { PROMPT? } - If there is CRITICAL_FEEDBACK, use those thoughts to improve upon the outline. - If there is RESEARCH provided, feel free to use details from it, but you are not required to use it all. - If there is a PLOT_OUTLINE, improve upon it. - Use the 'append_to_state' tool to write your logline and three-act plot outline to the field 'PLOT_OUTLINE'. - Summarize what you focused on in this pass. PLOT_OUTLINE: { PLOT_OUTLINE? } RESEARCH: { research? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], ) researcher = Agent( name="researcher", model=model_name, description="Answer research questions using Wikipedia.", instruction=""" PROMPT: { PROMPT? } PLOT_OUTLINE: { PLOT_OUTLINE? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } INSTRUCTIONS: - If there is a CRITICAL_FEEDBACK, use your wikipedia tool to do research to solve those suggestions - If there is a PLOT_OUTLINE, use your wikipedia tool to do research to add more historical detail - If these are empty, use your Wikipedia tool to gather facts about the person in the PROMPT - Use the 'append_to_state' tool to add your research to the field 'research'. - Summarize what you have learned. Now, use your Wikipedia tool to do research. """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[ LangchainTool(tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())), append_to_state, ], ) film_concept_team = SequentialAgent( name="film_concept_team", description="Write a film plot outline and save it as a text file.", sub_agents=[ researcher, screenwriter, file_writer ], ) root_agent = Agent( name="greeter", model=model_name, description="Guides the user in crafting a movie plot.", instruction=""" - Let the user know you will help them write a pitch for a hit movie. Ask them for a historical figure to create a movie about. - When they respond, use the 'append_to_state' tool to store the user's response in the 'PROMPT' state key and transfer to the 'film_concept_team' agent """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], sub_agents=[film_concept_team], ) EOF
ファイル構造は次のようになります。
仮想環境を設定する
- ターミナルで、
uvを使用して仮想環境を作成して有効にします。これにより、プロジェクトの依存関係がシステムの Python と競合しないようになります。uv venv source .venv/bin/activate
インストール要件
- ターミナルで次のコマンドを実行して、
requirements.txtファイルを作成します。cat <<EOF > ~/adk_multiagent_systems/requirements.txt # Lists all Python dependencies required to run the multi-agent system, # including the Google ADK, LangChain community tools, and web server libraries. langchain-community==0.4.1 wikipedia==1.4.0 google-adk==1.27.5 fastapi==0.135.2 uvicorn==0.42.0 EOF - ターミナルで、必要なパッケージを仮想環境にインストールします。
uv pip install -r requirements.txt
環境変数を設定する
- ターミナルで次のコマンドを使用して
.envファイルを作成します。プロジェクト ID とリージョンが自動的に挿入されます。cat <<EOF > ~/adk_multiagent_systems/.env GOOGLE_CLOUD_PROJECT="$(gcloud config get-value project)" GOOGLE_CLOUD_PROJECT_NUMBER="$(gcloud projects describe $(gcloud config get-value project) --format='value(projectNumber)')" GOOGLE_CLOUD_LOCATION="us-central1" GOOGLE_GENAI_USE_VERTEXAI=true MODEL="gemini-2.5-flash" EOF - ターミナルで、変数をシェル セッションに読み込みます。
source .env
内容のまとめ
このセクションでは、プロジェクトのローカル基盤を確立しました。
- ディレクトリ構造と必要なエージェント スターター ファイル(
agent.py、callback_logging.py、requirements.txt)を作成しました。 - 仮想環境(
uv)を使用して依存関係を分離しました。 - プロジェクト ID やリージョンなどのプロジェクト固有の詳細を格納するように構成された環境変数(
.env)。
6. エージェント ファイルを調べる
あらかじめ記述されたマルチエージェント システムなど、ラボのソースコードを設定しました。アプリケーションをデプロイする前に、エージェントの定義方法を理解しておくと役立ちます。コア エージェント ロジックは workflow_agents/agent.py にあります。
- Cloud Shell エディタで、左側のファイル エクスプローラを使用して
adk_multiagent_systems/workflow_agents/に移動し、agent.pyファイルを開きます。 - 少し時間を取ってファイルを確認します。すべての行を理解する必要はありませんが、大まかな構造に注目してください。
- 個々のエージェント: このファイルでは、
researcher、screenwriter、file_writerの 3 つの異なるAgentオブジェクトを定義しています。各エージェントには、特定のinstruction(プロンプト)と、使用が許可されているtoolsのリスト(WikipediaQueryRunツールやカスタムwrite_fileツールなど)が与えられます。 - エージェントの構成: 個々のエージェントが
film_concept_teamというSequentialAgentに連結されます。これにより、ADK はこれらのエージェントを順次実行し、状態を次のエージェントに渡します。 - ルート エージェント: 最初のユーザー インタラクションを処理するために
root_agent(「greeter」という名前)が定義されています。ユーザーがプロンプトを入力すると、このエージェントはプロンプトをアプリケーションの状態に保存し、film_concept_teamワークフローに制御を移します。
- 個々のエージェント: このファイルでは、
この構造を理解すると、デプロイしようとしているものが、単一のエージェントではなく、ADK によってオーケストレートされた専門エージェントの連携チームであることが明確になります。
7. GKE Autopilot クラスタを作成する
環境の準備が整ったら、次のステップはエージェント アプリケーションを実行するインフラストラクチャのプロビジョニングです。デプロイの基盤となる GKE Autopilot クラスタを作成します。Autopilot モードを使用するのは、クラスタの基盤となるノード、スケーリング、セキュリティの複雑な管理を処理するためです。これにより、アプリケーションのデプロイに専念できます。
- ターミナルで、
adk-clusterという名前の新しい GKE Autopilot クラスタを作成します。gcloud container clusters create-auto adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT - クラスタが作成されたら、ターミナルで次のコマンドを実行して、クラスタに接続するように
kubectlを構成します。gcloud container clusters get-credentials adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT~/.kube/config)が更新されます。この時点から、kubectlコマンドライン ツールが認証され、adk-clusterとの通信を行うように指示されます。
内容のまとめ
このセクションでは、インフラストラクチャをプロビジョニングしました。
gcloudを使用して、フルマネージドの GKE Autopilot クラスタを作成しました。- 新しいクラスタに対する認証と通信を行うようにローカルの
kubectlツールを構成しました。
8. アプリケーションをコンテナ化して push する
エージェントのコードは現在、Cloud Shell 環境にのみ存在します。GKE で実行するには、まずコンテナ イメージにパッケージ化する必要があります。コンテナ イメージは、アプリケーションのコードとそのすべての依存関係をバンドルした静的でポータブルなファイルです。このイメージを実行すると、ライブ コンテナになります。
このプロセスには、次の 3 つの主要なステップがあります。
- エントリ ポイントを作成する:
main.pyファイルを定義して、エージェント ロジックを実行可能なウェブサーバーに変換します。 - コンテナ イメージを定義する: コンテナ イメージのビルドのブループリントとして機能する Dockerfile を作成します。
- ビルドして push: Cloud Build を使用して Dockerfile を実行し、コンテナ イメージを作成して、イメージの安全なリポジトリである Google Artifact Registry に push します。
デプロイに向けてアプリケーションを準備する
ADK エージェントには、リクエストを受信するウェブサーバーが必要です。main.py ファイルは、FastAPI フレームワークを使用して、HTTP 経由でエージェントの機能を公開するエントリ ポイントとして機能します。
- ターミナルの
adk_multiagent_systemsディレクトリのルートに、main.pyという名前の新しいファイルを作成します。cat <<EOF > ~/adk_multiagent_systems/main.py """ Serves as the application entry point. Initializes the FastAPI web server, discovers the agents defined in the workflow directory, and exposes them via HTTP endpoints for interaction. """ import os import uvicorn from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Get the directory where main.py is located AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) # Configure the session service (e.g., SQLite for local storage) SESSION_SERVICE_URI = "sqlite:///./sessions.db" # Configure CORS to allow requests from various origins for this lab ALLOWED_ORIGINS = ["http://localhost", "http://localhost:8080", "*"] # Enable the ADK's built-in web interface SERVE_WEB_INTERFACE = True # Call the ADK function to discover agents and create the FastAPI app app: FastAPI = get_fast_api_app( agents_dir=AGENT_DIR, session_service_uri=SESSION_SERVICE_URI, allow_origins=ALLOWED_ORIGINS, web=SERVE_WEB_INTERFACE, ) # You can add more FastAPI routes or configurations below if needed # Example: # @app.get("/hello") # async def read_root(): # return {"Hello": "World"} if __name__ == "__main__": # Get the port from the PORT environment variable provided by the container runtime # Run the Uvicorn server, listening on all available network interfaces (0.0.0.0) uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("PORT", 8080))) EOFuvicornサーバーは、このアプリケーションを実行し、ホスト0.0.0.0でリッスンして、任意の IP アドレスからの接続を受け入れます。また、PORT環境変数で指定されたポートでリッスンします。この環境変数は、後で Kubernetes マニフェストで設定します。
この時点で、Cloud Shell エディタのエクスプローラ パネルに表示されるファイル構造は次のようになります。
Docker を使用して ADK エージェントをコンテナ化する
アプリケーションを GKE にデプロイするには、まずアプリケーションをコンテナ イメージにパッケージ化する必要があります。これにより、アプリケーションのコードが、実行に必要なすべてのライブラリと依存関係とともにバンドルされます。このコンテナ イメージは Docker を使用して作成します。
- ターミナルの
adk_multiagent_systemsディレクトリのルートに、Dockerfileという名前の新しいファイルを作成します。cat <<'EOF' > ~/adk_multiagent_systems/Dockerfile # Defines the blueprint for the container image. Installs dependencies, # sets up a secure non-root user, and specifies the startup command to run the # agent web server. # Use an official lightweight Python image as the base FROM python:3.13-slim # Set the working directory inside the container WORKDIR /app # Create a non-root user for security best practices RUN adduser --disabled-password --gecos "" myuser # Copy and install dependencies first to leverage Docker's layer caching COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt # Copy all application code into the container COPY . . # Create the directory where the agent will write files at runtime # The -p flag ensures the command doesn't fail if the directory already exists RUN mkdir -p movie_pitches # Change ownership of EVERYTHING in /app to the non-root user # Without this, the running agent would be denied permission to write files. RUN chown -R myuser:myuser /app # Switch the active user from root to the non-root user USER myuser # Add the user's local binary directory to the system's PATH ENV PATH="/home/myuser/.local/bin:$PATH" # Define the command to run when the container starts CMD ["sh", "-c", "uvicorn main:app --host 0.0.0.0 --port $PORT"] EOF
コンテナ イメージをビルドして Artifact Registry に push する
Dockerfile が作成されたので、Cloud Build を使用してイメージをビルドし、Google Cloud サービスと統合された安全な非公開レジストリである Artifact Registry に push します。GKE は、このレジストリからイメージを pull してアプリケーションを実行します。
- ターミナルで、コンテナ イメージを保存する新しい Artifact Registry リポジトリを作成します。
gcloud artifacts repositories create adk-repo \ --repository-format=docker \ --location=$GOOGLE_CLOUD_LOCATION \ --description="ADK repository" - ターミナルで、
gcloud builds submitを使用してコンテナ イメージをビルドし、リポジトリに push します。gcloud builds submit \ --tag $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo/adk-agent:latest \ --project=$GOOGLE_CLOUD_PROJECT \ .Dockerfileの手順を実行します。イメージはクラウドでビルドされ、Artifact Registry リポジトリのアドレスでタグ付けされて、自動的に push されます。 - ターミナルから、イメージがビルドされていることを確認します。
gcloud artifacts docker images list \ $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo \ --project=$GOOGLE_CLOUD_PROJECT
内容のまとめ
このセクションでは、デプロイ用にコードをパッケージ化しました。
main.pyエントリ ポイントを作成して、エージェントを FastAPI ウェブサーバーでラップしました。- コードと依存関係をポータブル イメージにバンドルする
Dockerfileを定義しました。 - Cloud Build を使用してイメージをビルドし、安全な Artifact Registry リポジトリに push します。
9. Kubernetes マニフェストを作成する
コンテナ イメージがビルドされ、Artifact Registry に保存されたので、GKE に実行方法を指示する必要があります。これには、次の 2 つの主なアクティビティが含まれます。
- 権限の構成: クラスタ内にエージェント専用の ID を作成し、必要な Google Cloud APIs(具体的には Vertex AI)への安全なアクセス権を付与します。
- アプリケーションの状態を定義する: Kubernetes マニフェスト ファイル(コンテナ イメージ、環境変数、ネットワークへの公開方法など、アプリケーションの実行に必要なすべてのものを宣言的に定義する YAML ドキュメント)を作成します。
Vertex AI 用の Kubernetes サービス アカウントを構成する
エージェントが Gemini モデルにアクセスするには、Vertex AI API と通信する権限が必要です。GKE でこの権限を付与する最も安全で推奨される方法は、Workload Identity です。Workload Identity を使用すると、Kubernetes ネイティブ ID(Kubernetes Service アカウント)を Google Cloud ID(IAM サービス アカウント)にリンクできます。これにより、静的 JSON キーのダウンロード、管理、保存が不要になります。
- ターミナルで、Kubernetes サービス アカウント(
adk-agent-sa)を作成します。これにより、Pod が使用できる GKE クラスタ内にエージェントの ID が作成されます。kubectl create serviceaccount adk-agent-sa - ターミナルで、ポリシー バインディングを作成して Kubernetes サービス アカウントを Google Cloud IAM にリンクします。このコマンドは、
adk-agent-saにaiplatform.userロールを付与し、Vertex AI API を安全に呼び出せるようにします。gcloud projects add-iam-policy-binding projects/${GOOGLE_CLOUD_PROJECT} \ --role=roles/aiplatform.user \ --member=principal://iam.googleapis.com/projects/${GOOGLE_CLOUD_PROJECT_NUMBER}/locations/global/workloadIdentityPools/${GOOGLE_CLOUD_PROJECT}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \ --condition=None
Kubernetes マニフェスト ファイルを作成する
Kubernetes は、YAML マニフェスト ファイルを使用してアプリケーションの望ましい状態を定義します。2 つの重要な Kubernetes オブジェクト(Deployment と Service)を含む deployment.yaml ファイルを作成します。
- ターミナルから、
deployment.yamlファイルを生成します。cat <<EOF > ~/adk_multiagent_systems/deployment.yaml # Defines the Kubernetes resources required to deploy the application to GKE. # Includes the Deployment (to run the container pods) and the Service # (to expose the application via a Load Balancer). apiVersion: apps/v1 kind: Deployment metadata: name: adk-agent spec: replicas: 1 selector: matchLabels: app: adk-agent template: metadata: labels: app: adk-agent spec: # Assign the Kubernetes Service Account for Workload Identity serviceAccountName: adk-agent-sa containers: - name: adk-agent imagePullPolicy: Always # The path to the container image in Artifact Registry image: ${GOOGLE_CLOUD_LOCATION}-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/adk-repo/adk-agent:latest # Define the resources for GKE Autopilot to provision resources: limits: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" requests: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" ports: - containerPort: 8080 # Environment variables passed to the application env: - name: PORT value: "8080" - name: GOOGLE_CLOUD_PROJECT value: ${GOOGLE_CLOUD_PROJECT} - name: GOOGLE_CLOUD_LOCATION value: ${GOOGLE_CLOUD_LOCATION} - name: GOOGLE_GENAI_USE_VERTEXAI value: "true" - name: MODEL value: "gemini-2.5-flash" --- apiVersion: v1 kind: Service metadata: name: adk-agent spec: # Create a public-facing Network Load Balancer with an external IP type: LoadBalancer ports: - port: 80 targetPort: 8080 selector: app: adk-agent EOF
内容のまとめ
このセクションでは、セキュリティとデプロイの構成を定義しました。
- Kubernetes サービス アカウントを作成し、Workload Identity を使用して Google Cloud IAM にリンクしました。これにより、キーを管理しなくても Pod から Vertex AI に安全にアクセスできます。
- Deployment(Pod の実行方法)と Service(ロードバランサを介して公開する方法)を定義する
deployment.yamlファイルを生成しました。
10. アプリケーションを GKE にデプロイする
マニフェスト ファイルを定義し、コンテナ イメージを Artifact Registry に push したら、アプリケーションをデプロイする準備が整いました。このタスクでは、kubectl を使用して構成を GKE クラスタに適用し、ステータスをモニタリングしてエージェントが正しく起動することを確認します。
- ターミナルで、
deployment.yamlマニフェストをクラスタに適用します。kubectl apply -f deployment.yamlkubectl applyコマンドは、deployment.yamlファイルを Kubernetes API サーバーに送信します。サーバーは構成を読み取り、Deployment オブジェクトと Service オブジェクトの作成をオーケストレートします。 - ターミナルで、デプロイのステータスをリアルタイムで確認します。Pod が
Running状態になるまで待ちます。kubectl get pods -l=app=adk-agent --watch- Pending: Pod はクラスタによって受け入れられましたが、コンテナはまだ作成されていません。
- コンテナの作成: GKE が Artifact Registry からコンテナ イメージを pull し、コンテナを起動しています。
- 実行中: 成功しました。コンテナが実行され、エージェント アプリケーションが稼働しています。
- ステータスが
Runningになったら、ターミナルで Ctrl+C キーを押して watch コマンドを停止し、コマンド プロンプトに戻ります。
内容のまとめ
このセクションでは、ワークロードを起動しました。
kubectl適用を使用して、マニフェストをクラスタに送信しました。- Pod のライフサイクル(Pending -> ContainerCreating -> Running)をモニタリングして、アプリケーションが正常に起動したことを確認しました。
11. エージェントと対話する
ADK エージェントが GKE でライブ実行され、パブリック ロードバランサを介してインターネットに公開されました。エージェントのウェブ インターフェースに接続してエージェントを操作し、システム全体が正しく動作していることを確認します。
サービスの外部 IP アドレスを確認する
エージェントにアクセスするには、まず GKE が Service にプロビジョニングしたパブリック IP アドレスを取得する必要があります。
- ターミナルで、次のコマンドを実行してサービスの詳細を取得します。
kubectl get service adk-agent EXTERNAL-IP列の値を探します。サービスを最初にデプロイしてから IP アドレスが割り当てられるまでに 1 ~ 2 分かかることがあります。pendingと表示された場合は、少し待ってからコマンドを再度実行します。出力は次のようになります。NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE adk-agent-service LoadBalancer 10.120.12.234 34.123.45.67 80:31234/TCP 5mEXTERNAL-IPに表示されているアドレス(34.123.45.67 など)は、エージェントへのパブリック エントリ ポイントです。
デプロイしたエージェントをテストする
これで、パブリック IP アドレスを使用して、ブラウザから ADK の組み込みウェブ UI に直接アクセスできるようになりました。
- ターミナルから外部 IP アドレス(
EXTERNAL-IP)をコピーします。 - ウェブブラウザで新しいタブを開き、「
http://[EXTERNAL-IP]」と入力します。[EXTERNAL-IP]はコピーした IP アドレスに置き換えます。 - ADK ウェブ インターフェースが表示されます。
- エージェントのプルダウン メニューで [workflow_agents] が選択されていることを確認します。
- [トークンのストリーミング] をオンに切り替えます。
- 「
hello」と入力して Enter キーを押すと、新しい会話が始まります。 - 結果を確認します。エージェントは、挨拶をすぐに返します。「I can help you write a pitch for a hit movie. どんな歴史上の人物を題材にした映画を作りたいですか?」
- 歴史上の人物を選択するよう求められたら、関心のある人物を選んでください。たとえば、次のようなアイデアが挙げられます。
the most successful female pirate in historythe woman who invented the first computer compilera legendary lawman of the American Wild West
内容のまとめ
このセクションでは、デプロイを検証しました。
- LoadBalancer によって割り当てられた外部 IP アドレスを取得しました。
- ブラウザから ADK ウェブ UI にアクセスし、マルチエージェント システムが応答して機能していることを確認しました。
12. 自動スケーリングを構成する
本番環境における重要な課題は、予測不可能なユーザー トラフィックの処理です。前のタスクで行ったように、レプリカの数を固定でハードコードすると、アイドル状態のリソースに対して過剰な料金を支払うか、トラフィックの急増時にパフォーマンスが低下するリスクが生じます。GKE は自動スケーリングでこの問題を解決します。
HorizontalPodAutoscaler(HPA)を構成します。これは、リアルタイムの CPU 使用率に基づいて Deployment で実行されている Pod の数を自動的に調整する Kubernetes コントローラです。
- Cloud Shell エディタのターミナルで、
adk_multiagent_systemsディレクトリのルートに新しいhpa.yamlファイルを作成します。cloudshell edit ~/adk_multiagent_systems/hpa.yaml - 新しい
hpa.yamlファイルに次の内容を追加します。# Configures the HorizontalPodAutoscaler (HPA) to automatically scale # the number of running agent pods up or down based on CPU utilization # to handle varying traffic loads. apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: adk-agent-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: adk-agent minReplicas: 1 maxReplicas: 5 targetCPUUtilizationPercentage: 50adk-agentDeployment をターゲットにしています。常に 1 つ以上の Pod が実行され、最大 5 つの Pod が設定され、レプリカが追加または削除されて平均 CPU 使用率が約 50% に維持されます。この時点で、Cloud Shell エディタのエクスプローラ パネルに表示されるファイル構造は次のようになります。
- この内容をターミナルに貼り付けて、HPA をクラスタに適用します。
kubectl apply -f hpa.yaml
オートスケーラーを確認する
HPA が有効になり、デプロイをモニタリングしています。ステータスを検査して、動作を確認できます。
- ターミナルで次のコマンドを実行して、HPA のステータスを取得します。
kubectl get hpa adk-agent-hpaNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE adk-agent-hpa Deployment/adk-agent 0%/50% 1 5 1 30s
内容のまとめ
このセクションでは、本番環境のトラフィック用に最適化しました。
- スケーリング ルールを定義する
hpa.yamlマニフェストを作成しました。 - HorizontalPodAutoscaler(HPA)をデプロイして、CPU 使用率に基づいて Pod レプリカの数を自動的に調整しました。
13. 本番環境用の準備
注: 以下のセクションは情報提供のみを目的としており、実行する手順は含まれていません。これらは、アプリケーションを本番環境に移行するためのコンテキストとベスト プラクティスを提供することを目的としています。
リソース割り当てでパフォーマンスを調整する
GKE Autopilot では、deployment.yaml でリソース requests を指定して、アプリケーションにプロビジョニングされる CPU とメモリの量を制御します。
メモリ不足が原因でエージェントの動作が遅い場合やクラッシュする場合は、deployment.yaml の resources ブロックを編集してリソース割り当てを増やし、kubectl apply でファイルを再適用します。
たとえば、メモリを 2 倍にするには:
# In deployment.yaml
# ...
resources:
requests:
memory: "2Gi" # Increased from 1Gi
cpu: "1000m"
# ...
CI/CD でワークフローを自動化する
このラボでは、コマンドを手動で実行しました。専門的なプラクティスは、CI/CD(継続的インテグレーション/継続的デプロイ)パイプラインを作成することです。ソースコード リポジトリ(GitHub など)を Cloud Build トリガーに接続することで、デプロイ全体を自動化できます。
パイプラインを使用すると、コード変更を push するたびに、Cloud Build が自動的に次の処理を行います。
- 新しいコンテナ イメージをビルドします。
- イメージを Artifact Registry に push します。
- 更新された Kubernetes マニフェストを GKE クラスタに適用します。
シークレットを安全に管理する
このラボでは、構成を .env ファイルに保存して、アプリケーションに渡しました。これは開発には便利ですが、API キーなどのセンシティブ データには安全ではありません。推奨される効果的な手法は、Secret Manager を使用してシークレットを安全に保存することです。
GKE には Secret Manager とのネイティブ統合があり、シークレットをソースコードにチェックインすることなく、環境変数またはファイルとして Pod に直接マウントできます。
リクエストされたリソースのクリーンアップ セクションを、まとめセクションの直前に挿入しました。
14. リソースをクリーンアップする
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
GKE クラスタの削除
このラボでは、GKE クラスタが主な費用要因となります。削除すると、コンピューティング料金が停止します。
- 次のコマンドをターミナルで実行します。
gcloud container clusters delete adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Artifact Registry リポジトリを削除する
Artifact Registry に保存されたコンテナ イメージにはストレージ費用が発生します。
- 次のコマンドをターミナルで実行します。
gcloud artifacts repositories delete adk-repo \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
プロジェクトを削除する(省略可)
このラボ専用に新しいプロジェクトを作成し、今後使用する予定がない場合は、プロジェクト全体を削除するのが最も簡単なクリーンアップ方法です。
- ターミナルで次のコマンドを実行します(
[YOUR_PROJECT_ID]は実際のプロジェクト ID に置き換えます)。gcloud projects delete [YOUR_PROJECT_ID]
15. まとめ
おめでとうございます!マルチエージェント ADK アプリケーションを本番環境グレードの GKE クラスタに正常にデプロイしました。これは、最新のクラウドネイティブ アプリケーションのコア ライフサイクルを網羅する重要な成果であり、独自の複雑なエージェント システムをデプロイするための確固たる基盤となります。
内容のまとめ
このラボでは、次のことを学びました。
- GKE Autopilot クラスタをプロビジョニングします。
Dockerfileを使用してコンテナ イメージをビルドし、Artifact Registry に push する- Workload Identity を使用して Google Cloud APIs に安全に接続します。
- Deployment と Service の Kubernetes マニフェストを作成します。
- LoadBalancer を使用してアプリケーションをインターネットに公開します。
- HorizontalPodAutoscaler(HPA)を使用して自動スケーリングを構成します。