
1. 소개
개요
이 실습은 강력한 멀티 에이전트 시스템을 개발하는 것과 실제 사용을 위해 배포하는 것 사이의 중요한 격차를 해소합니다. 로컬에서 에이전트를 빌드하는 것도 좋은 시작이지만 프로덕션 애플리케이션에는 확장 가능하고 안정적이며 안전한 플랫폼이 필요합니다.
이 실습에서는 Google 에이전트 개발 키트 (ADK)로 빌드된 멀티 에이전트 시스템을 가져와 Google Kubernetes Engine (GKE)의 프로덕션 등급 환경에 배포합니다.
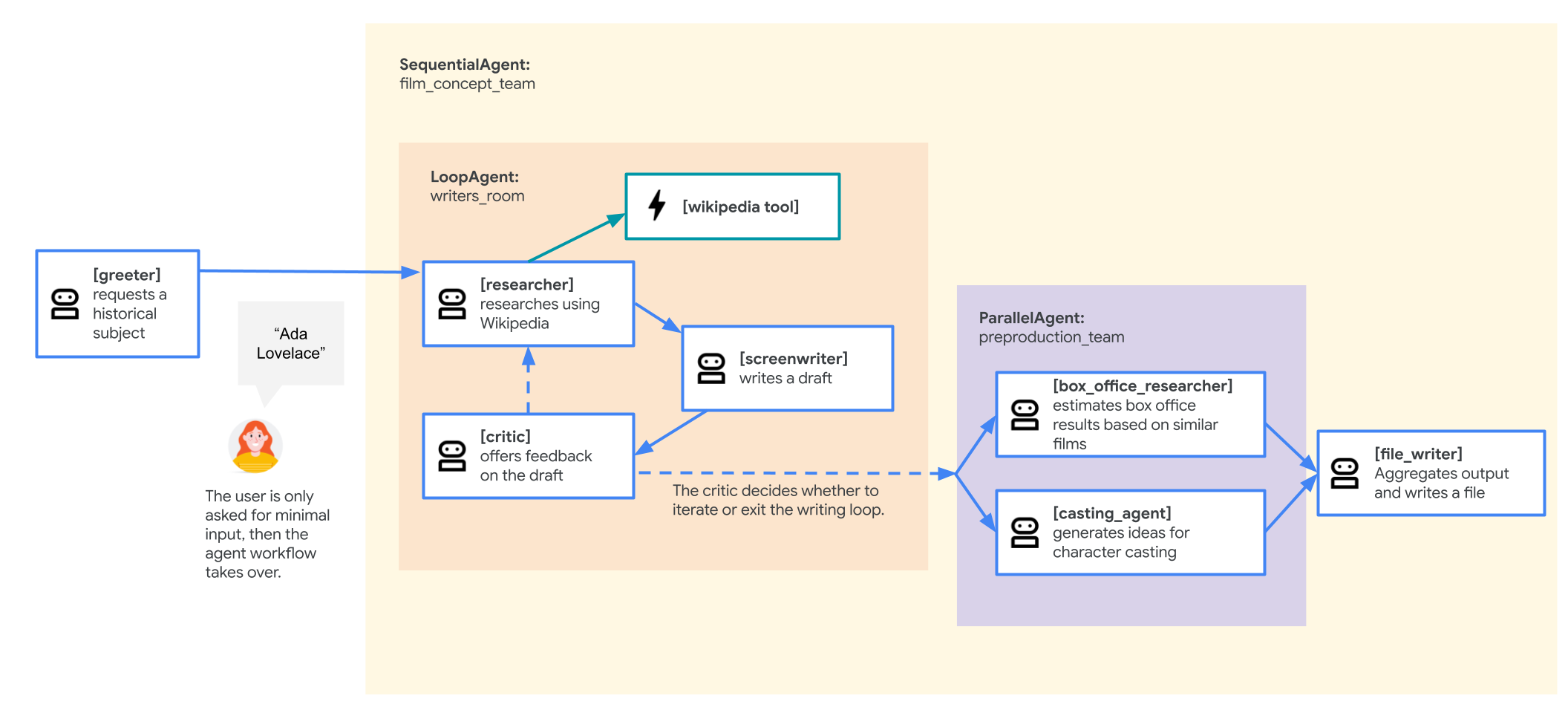
영화 컨셉팀 에이전트
이 실습에서 사용되는 샘플 애플리케이션은 연구원, 시나리오 작가, 파일 작성자 등 여러 공동작업 에이전트로 구성된 '영화 컨셉팀'입니다. 이러한 에이전트는 사용자가 역사적 인물에 관한 영화 피치를 브레인스토밍하고 개요를 작성하도록 지원합니다.
GKE에 배포해야 하는 이유
프로덕션 환경의 요구사항에 맞게 에이전트를 준비하려면 확장성, 보안, 비용 효율성을 위해 빌드된 플랫폼이 필요합니다. Google Kubernetes Engine (GKE)는 컨테이너화된 애플리케이션을 실행하기 위한 강력하고 유연한 기반을 제공합니다.
이렇게 하면 프로덕션 워크로드에 다음과 같은 여러 이점이 있습니다.
- 자동 확장 및 성능: 부하에 따라 에이전트 복제본을 자동으로 추가하거나 삭제하는 HorizontalPodAutoscaler (HPA)를 사용하여 예측할 수 없는 트래픽을 처리합니다. 더 까다로운 AI 워크로드의 경우 GPU 및 TPU와 같은 하드웨어 가속기를 연결할 수 있습니다.
- 비용 효율적인 리소스 관리: 기본 인프라를 자동으로 관리하여 애플리케이션에서 요청한 리소스에 대해서만 비용을 지불하는 GKE Autopilot으로 비용을 최적화합니다.
- 통합 보안 및 관측 가능성: 서비스 계정 키를 관리하고 저장할 필요가 없는 워크로드 아이덴티티를 사용하여 다른 Google Cloud 서비스에 안전하게 연결합니다. 모든 애플리케이션 로그는 중앙 집중식 모니터링 및 디버깅을 위해 Cloud Logging으로 자동 스트리밍됩니다.
- 제어 및 이식성: 오픈소스 Kubernetes로 공급업체 종속을 방지하세요. 애플리케이션은 이식 가능하며 온프레미스 또는 다른 클라우드의 모든 Kubernetes 클러스터에서 실행할 수 있습니다.
학습할 내용
이 실습에서는 다음 작업을 수행하는 방법을 알아봅니다.
- GKE Autopilot 클러스터를 프로비저닝합니다.
- Dockerfile로 애플리케이션을 컨테이너화하고 이미지를 Artifact Registry에 푸시합니다.
- 워크로드 아이덴티티를 사용하여 애플리케이션을 Google Cloud API에 안전하게 연결합니다.
- 배포 및 서비스용 Kubernetes 매니페스트를 작성하고 적용합니다.
- LoadBalancer를 사용하여 애플리케이션을 인터넷에 노출합니다.
- HorizontalPodAutoscaler (HPA)로 자동 확장 구성
2. 프로젝트 설정
Google 계정
아직 개인 Google 계정이 없다면 Google 계정을 만들어야 합니다.
직장 또는 학교 계정 대신 개인 계정을 사용합니다.
Google Cloud 콘솔에 로그인
개인 Google 계정을 사용하여 Google Cloud 콘솔에 로그인합니다.
결제 사용 설정
개인 결제 계정 설정
Google Cloud 크레딧을 사용하여 결제를 설정한 경우 이 단계를 건너뛸 수 있습니다.
개인 결제 계정을 설정하려면 Cloud 콘솔에서 여기에서 결제를 사용 설정하세요.
참고 사항:
- 이 실습을 완료하는 데 드는 Cloud 리소스 비용은 1달러 미만입니다.
- 이 실습이 끝나면 단계에 따라 리소스를 삭제하여 추가 요금이 발생하지 않도록 할 수 있습니다.
- 신규 사용자는 미화$300 상당의 무료 체험판을 사용할 수 있습니다.
프로젝트 만들기(선택사항)
이 실습에 사용할 현재 프로젝트가 없는 경우 여기에서 새 프로젝트를 만드세요.
3. Cloud Shell 편집기 열기
- 이 링크를 클릭하여 Cloud Shell 편집기로 바로 이동합니다.
- 오늘 언제든지 승인하라는 메시지가 표시되면 승인을 클릭하여 계속합니다.
- 터미널이 화면 하단에 표시되지 않으면 다음 단계에 따라 엽니다.
- 보기를 클릭합니다.
- 터미널을 클릭합니다.
- 터미널에서 다음 명령어를 사용하여 프로젝트를 설정합니다.
gcloud config set project [PROJECT_ID]- 예:
gcloud config set project lab-project-id-example - 프로젝트 ID가 기억나지 않는 경우 다음을 사용하여 모든 프로젝트 ID를 나열할 수 있습니다.
gcloud projects list
- 예:
- 다음 메시지가 표시되어야 합니다.
Updated property [core/project].
4. API 사용 설정
GKE, Artifact Registry, Cloud Build, Vertex AI를 사용하려면 Google Cloud 프로젝트에서 각 API를 사용 설정해야 합니다.
- 터미널에서 API를 사용 설정합니다.
gcloud services enable \ container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.comOperation "operations/acf.p2-176675280136-b03ab5e4-3483-4ebf-9655-43dc3b345c63" finished successfully.
API 소개
- Google Kubernetes Engine API (
container.googleapis.com)를 사용하면 에이전트를 실행하는 GKE 클러스터를 만들고 관리할 수 있습니다. GKE에서는 Google 인프라를 사용하여 컨테이너화된 애플리케이션을 배포, 관리, 확장할 수 있는 관리형 환경을 제공합니다. - Artifact Registry API (
artifactregistry.googleapis.com)는 에이전트의 컨테이너 이미지를 저장할 보안 비공개 저장소를 제공합니다. Container Registry의 후속 버전이며 GKE 및 Cloud Build와 원활하게 통합됩니다. - Cloud Build API (
cloudbuild.googleapis.com)는gcloud builds submit명령어가 Dockerfile에서 클라우드로 컨테이너 이미지를 빌드하는 데 사용됩니다. Google Cloud 인프라에서 빌드를 실행하는 서버리스 CI/CD 플랫폼입니다. - Vertex AI API (
aiplatform.googleapis.com)를 사용하면 배포된 에이전트가 Gemini 모델과 통신하여 핵심 작업을 실행할 수 있습니다. Google Cloud의 모든 AI 서비스에 대한 통합 API를 제공합니다.
5. 개발 환경 준비
디렉터리 구조 만들기
- 터미널에서 프로젝트 디렉터리와 필요한 하위 디렉터리를 만듭니다.
mkdir -p ~/adk_multiagent_systems/workflow_agents cd ~/adk_multiagent_systems - 터미널에서 다음 명령어를 실행하여 Cloud Shell 편집기 탐색기에서 디렉터리를 엽니다.
cloudshell open-workspace ~/adk_multiagent_systems - 왼쪽의 탐색기 패널이 새로고침됩니다. 이제 생성한 디렉터리가 표시됩니다.
다음 단계에서 파일을 만들면 이 디렉터리에 파일이 채워집니다.
시작 파일 만들기
이제 애플리케이션에 필요한 스타터 파일을 만듭니다.
- 터미널에서 다음을 실행하여
callback_logging.py을 만듭니다. 이 파일은 관측 가능성을 위한 로깅을 처리합니다.cat <<EOF > ~/adk_multiagent_systems/callback_logging.py """ Provides helper functions for observability. Handles formatting and sending agent queries, responses, and tool calls to Google Cloud Logging to aid in monitoring and debugging. """ import logging import google.cloud.logging from google.adk.agents.callback_context import CallbackContext from google.adk.models import LlmResponse, LlmRequest def log_query_to_model(callback_context: CallbackContext, llm_request: LlmRequest): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_request.contents and llm_request.contents[-1].role == 'user': if llm_request.contents[-1].parts and "text" in llm_request.contents[-1].parts: last_user_message = llm_request.contents[-1].parts[0].text logging.info(f"[query to {callback_context.agent_name}]: " + last_user_message) def log_model_response(callback_context: CallbackContext, llm_response: LlmResponse): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_response.content and llm_response.content.parts: for part in llm_response.content.parts: if part.text: logging.info(f"[response from {callback_context.agent_name}]: " + part.text) elif part.function_call: logging.info(f"[function call from {callback_context.agent_name}]: " + part.function_call.name) EOF - 터미널에서 다음을 실행하여
workflow_agents/__init__.py을 만듭니다. 이렇게 하면 디렉터리가 Python 패키지로 표시됩니다.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/__init__.py """ Marks the directory as a Python package and exposes the agent module, allowing the ADK to discover and register the agents defined within. """ from . import agent EOF - 터미널에서 다음을 실행하여
workflow_agents/agent.py을 만듭니다. 이 파일에는 멀티 에이전트 팀의 핵심 로직이 포함되어 있습니다.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/agent.py """ Defines the core multi-agent workflow. Configures individual agents (Researcher, Screenwriter, File Writer), assigns their specific tools, and orchestrates their collaboration using the ADK's SequentialAgent pattern. """ import os import logging import google.cloud.logging from callback_logging import log_query_to_model, log_model_response from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent, LoopAgent, ParallelAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool # import from google.genai import types from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL") print(model_name) # Tools def append_to_state( tool_context: ToolContext, field: str, response: str ) -> dict[str, str]: """Append new output to an existing state key. Args: field (str): a field name to append to response (str): a string to append to the field Returns: dict[str, str]: {"status": "success"} """ existing_state = tool_context.state.get(field, []) tool_context.state[field] = existing_state + [response] logging.info(f"[Added to {field}] {response}") return {"status": "success"} def write_file( tool_context: ToolContext, directory: str, filename: str, content: str ) -> dict[str, str]: target_path = os.path.join(directory, filename) os.makedirs(os.path.dirname(target_path), exist_ok=True) with open(target_path, "w") as f: f.write(content) return {"status": "success"} # Agents file_writer = Agent( name="file_writer", model=model_name, description="Creates marketing details and saves a pitch document.", instruction=""" PLOT_OUTLINE: { PLOT_OUTLINE? } INSTRUCTIONS: - Create a marketable, contemporary movie title suggestion for the movie described in the PLOT_OUTLINE. If a title has been suggested in PLOT_OUTLINE, you can use it, or replace it with a better one. - Use your 'write_file' tool to create a new txt file with the following arguments: - for a filename, use the movie title - Write to the 'movie_pitches' directory. - For the 'content' to write, extract the following from the PLOT_OUTLINE: - A logline - Synopsis or plot outline """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[write_file], ) screenwriter = Agent( name="screenwriter", model=model_name, description="As a screenwriter, write a logline and plot outline for a biopic about a historical character.", instruction=""" INSTRUCTIONS: Your goal is to write a logline and three-act plot outline for an inspiring movie about a historical character(s) described by the PROMPT: { PROMPT? } - If there is CRITICAL_FEEDBACK, use those thoughts to improve upon the outline. - If there is RESEARCH provided, feel free to use details from it, but you are not required to use it all. - If there is a PLOT_OUTLINE, improve upon it. - Use the 'append_to_state' tool to write your logline and three-act plot outline to the field 'PLOT_OUTLINE'. - Summarize what you focused on in this pass. PLOT_OUTLINE: { PLOT_OUTLINE? } RESEARCH: { research? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], ) researcher = Agent( name="researcher", model=model_name, description="Answer research questions using Wikipedia.", instruction=""" PROMPT: { PROMPT? } PLOT_OUTLINE: { PLOT_OUTLINE? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } INSTRUCTIONS: - If there is a CRITICAL_FEEDBACK, use your wikipedia tool to do research to solve those suggestions - If there is a PLOT_OUTLINE, use your wikipedia tool to do research to add more historical detail - If these are empty, use your Wikipedia tool to gather facts about the person in the PROMPT - Use the 'append_to_state' tool to add your research to the field 'research'. - Summarize what you have learned. Now, use your Wikipedia tool to do research. """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[ LangchainTool(tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())), append_to_state, ], ) film_concept_team = SequentialAgent( name="film_concept_team", description="Write a film plot outline and save it as a text file.", sub_agents=[ researcher, screenwriter, file_writer ], ) root_agent = Agent( name="greeter", model=model_name, description="Guides the user in crafting a movie plot.", instruction=""" - Let the user know you will help them write a pitch for a hit movie. Ask them for a historical figure to create a movie about. - When they respond, use the 'append_to_state' tool to store the user's response in the 'PROMPT' state key and transfer to the 'film_concept_team' agent """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], sub_agents=[film_concept_team], ) EOF
이제 파일 구조가 다음과 같이 표시됩니다. 
가상 환경 설정
- 터미널에서
uv를 사용하여 가상 환경을 만들고 활성화합니다. 이렇게 하면 프로젝트 종속 항목이 시스템 Python과 충돌하지 않습니다.uv venv source .venv/bin/activate
설치 요구사항
- 터미널에서 다음 명령어를 실행하여
requirements.txt파일을 만듭니다.cat <<EOF > ~/adk_multiagent_systems/requirements.txt # Lists all Python dependencies required to run the multi-agent system, # including the Google ADK, LangChain community tools, and web server libraries. langchain-community==0.4.1 wikipedia==1.4.0 google-adk==1.27.5 fastapi==0.135.2 uvicorn==0.42.0 EOF - 터미널에서 가상 환경에 필요한 패키지를 설치합니다.
uv pip install -r requirements.txt
환경 변수 설정
- 터미널에서 다음 명령어를 사용하여
.env파일을 만들고 프로젝트 ID와 리전을 자동으로 삽입합니다.cat <<EOF > ~/adk_multiagent_systems/.env GOOGLE_CLOUD_PROJECT="$(gcloud config get-value project)" GOOGLE_CLOUD_PROJECT_NUMBER="$(gcloud projects describe $(gcloud config get-value project) --format='value(projectNumber)')" GOOGLE_CLOUD_LOCATION="us-central1" GOOGLE_GENAI_USE_VERTEXAI=true MODEL="gemini-2.5-flash" EOF - 터미널에서 변수를 셸 세션에 로드합니다.
source .env
요약
이 섹션에서는 프로젝트의 로컬 기반을 설정했습니다.
- 디렉터리 구조와 필요한 에이전트 스타터 파일 (
agent.py,callback_logging.py,requirements.txt)을 만들었습니다. - 가상 환경 (
uv)을 사용하여 종속 항목을 격리했습니다. - 프로젝트 ID 및 리전과 같은 프로젝트별 세부정보를 저장하도록 환경 변수 (
.env)를 구성했습니다.
6. 에이전트 파일 살펴보기
미리 작성된 멀티 에이전트 시스템을 비롯한 실습용 소스 코드를 설정했습니다. 애플리케이션을 배포하기 전에 에이전트가 정의되는 방식을 이해하는 것이 좋습니다. 핵심 에이전트 로직은 workflow_agents/agent.py에 있습니다.
- Cloud Shell 편집기에서 왼쪽의 파일 탐색기를 사용하여
adk_multiagent_systems/workflow_agents/로 이동하고agent.py파일을 엽니다. - 잠시 시간을 내어 파일을 살펴보세요. 각 줄을 이해할 필요는 없지만,
- 개별 에이전트: 파일은
researcher,screenwriter,file_writer의 세 가지Agent객체를 정의합니다. 각 에이전트에는 특정instruction(프롬프트)와 사용할 수 있는tools목록 (예:WikipediaQueryRun도구 또는 맞춤write_file도구)이 제공됩니다. - 에이전트 구성: 개별 에이전트가
film_concept_team이라는SequentialAgent로 연결됩니다. 이렇게 하면 ADK가 이러한 에이전트를 하나씩 차례로 실행하여 한 에이전트에서 다음 에이전트로 상태를 전달합니다. - 루트 에이전트: 초기 사용자 상호작용을 처리하도록
root_agent('greeter'라는 이름)가 정의됩니다. 사용자가 프롬프트를 제공하면 이 에이전트는 프롬프트를 애플리케이션의 상태에 저장한 다음film_concept_team워크플로로 제어권을 이전합니다.
- 개별 에이전트: 파일은
이 구조를 이해하면 단일 에이전트가 아닌 ADK로 조정된 전문 에이전트의 공동작업 팀을 배포한다는 점을 명확히 알 수 있습니다.
7. GKE Autopilot 클러스터 만들기
환경이 준비되면 다음 단계는 에이전트 애플리케이션이 실행될 인프라를 프로비저닝하는 것입니다. 배포의 기반이 되는 GKE Autopilot 클러스터를 만듭니다. Autopilot 모드는 클러스터의 기본 노드, 확장, 보안의 복잡한 관리를 처리하므로 애플리케이션 배포에만 집중할 수 있습니다.
- 터미널에서
adk-cluster라는 새 GKE Autopilot 클러스터를 만듭니다.gcloud container clusters create-auto adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT - 클러스터가 생성되면 터미널에서 다음을 실행하여 클러스터에 연결하도록
kubectl을 구성합니다.gcloud container clusters get-credentials adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT~/.kube/config)을 업데이트합니다. 이제부터kubectl명령줄 도구가 인증되고adk-cluster와 통신하도록 지시됩니다.
요약
이 섹션에서는 다음 인프라를 프로비저닝했습니다.
gcloud를 사용하여 완전 관리형 GKE Autopilot 클러스터를 만들었습니다.- 새 클러스터와 인증하고 통신하도록 로컬
kubectl도구를 구성했습니다.
8. 애플리케이션 컨테이너화 및 푸시
현재 에이전트의 코드는 Cloud Shell 환경에만 있습니다. GKE에서 실행하려면 먼저 컨테이너 이미지로 패키징해야 합니다. 컨테이너 이미지는 애플리케이션의 코드를 모든 종속 항목과 함께 번들로 묶는 정적이고 이동 가능한 파일입니다. 이 이미지를 실행하면 라이브 컨테이너가 됩니다.
이 프로세스에는 다음 세 가지 주요 단계가 포함됩니다.
- 진입점 만들기: 에이전트 로직을 실행 가능한 웹 서버로 전환하도록
main.py파일을 정의합니다. - 컨테이너 이미지 정의: 컨테이너 이미지 빌드의 청사진 역할을 하는 Dockerfile을 만듭니다.
- 빌드 및 푸시: Cloud Build를 사용하여 Dockerfile을 실행하고 컨테이너 이미지를 만들어 이미지의 보안 저장소인 Google Artifact Registry에 푸시합니다.
배포를 위한 애플리케이션 준비
ADK 에이전트에는 요청을 수신할 웹 서버가 필요합니다. main.py 파일은 FastAPI 프레임워크를 사용하여 HTTP를 통해 에이전트의 기능을 노출하는 이 진입점 역할을 합니다.
- 터미널의
adk_multiagent_systems디렉터리 루트에서main.py이라는 새 파일을 만듭니다.cat <<EOF > ~/adk_multiagent_systems/main.py """ Serves as the application entry point. Initializes the FastAPI web server, discovers the agents defined in the workflow directory, and exposes them via HTTP endpoints for interaction. """ import os import uvicorn from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Get the directory where main.py is located AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) # Configure the session service (e.g., SQLite for local storage) SESSION_SERVICE_URI = "sqlite:///./sessions.db" # Configure CORS to allow requests from various origins for this lab ALLOWED_ORIGINS = ["http://localhost", "http://localhost:8080", "*"] # Enable the ADK's built-in web interface SERVE_WEB_INTERFACE = True # Call the ADK function to discover agents and create the FastAPI app app: FastAPI = get_fast_api_app( agents_dir=AGENT_DIR, session_service_uri=SESSION_SERVICE_URI, allow_origins=ALLOWED_ORIGINS, web=SERVE_WEB_INTERFACE, ) # You can add more FastAPI routes or configurations below if needed # Example: # @app.get("/hello") # async def read_root(): # return {"Hello": "World"} if __name__ == "__main__": # Get the port from the PORT environment variable provided by the container runtime # Run the Uvicorn server, listening on all available network interfaces (0.0.0.0) uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("PORT", 8080))) EOFuvicorn서버는 이 애플리케이션을 실행하여 호스트0.0.0.0에서 수신 대기하여 모든 IP 주소의 연결을 허용하고PORT환경 변수로 지정된 포트에서 수신 대기합니다.PORT환경 변수는 나중에 Kubernetes 매니페스트에서 설정합니다.
이 시점에서 Cloud Shell 편집기의 탐색기 패널에 표시되는 파일 구조는 다음과 같습니다.
Docker를 사용하여 ADK 에이전트 컨테이너화
애플리케이션을 GKE에 배포하려면 먼저 애플리케이션의 코드를 실행에 필요한 모든 라이브러리 및 종속 항목과 함께 번들로 묶는 컨테이너 이미지로 패키징해야 합니다. Docker를 사용하여 이 컨테이너 이미지를 만듭니다.
- 터미널의
adk_multiagent_systems디렉터리 루트에서Dockerfile이라는 새 파일을 만듭니다.cat <<'EOF' > ~/adk_multiagent_systems/Dockerfile # Defines the blueprint for the container image. Installs dependencies, # sets up a secure non-root user, and specifies the startup command to run the # agent web server. # Use an official lightweight Python image as the base FROM python:3.13-slim # Set the working directory inside the container WORKDIR /app # Create a non-root user for security best practices RUN adduser --disabled-password --gecos "" myuser # Copy and install dependencies first to leverage Docker's layer caching COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt # Copy all application code into the container COPY . . # Create the directory where the agent will write files at runtime # The -p flag ensures the command doesn't fail if the directory already exists RUN mkdir -p movie_pitches # Change ownership of EVERYTHING in /app to the non-root user # Without this, the running agent would be denied permission to write files. RUN chown -R myuser:myuser /app # Switch the active user from root to the non-root user USER myuser # Add the user's local binary directory to the system's PATH ENV PATH="/home/myuser/.local/bin:$PATH" # Define the command to run when the container starts CMD ["sh", "-c", "uvicorn main:app --host 0.0.0.0 --port $PORT"] EOF
컨테이너 이미지를 빌드하여 Artifact Registry에 푸시
이제 Dockerfile이 있으므로 Cloud Build를 사용하여 이미지를 빌드하고 Google Cloud 서비스와 통합된 안전한 비공개 레지스트리인 Artifact Registry에 푸시합니다. GKE는 이 레지스트리에서 이미지를 가져와 애플리케이션을 실행합니다.
- 터미널에서 컨테이너 이미지를 저장할 새 Artifact Registry 저장소를 만듭니다.
gcloud artifacts repositories create adk-repo \ --repository-format=docker \ --location=$GOOGLE_CLOUD_LOCATION \ --description="ADK repository" - 터미널에서
gcloud builds submit를 사용하여 컨테이너 이미지를 빌드하고 저장소에 푸시합니다.gcloud builds submit \ --tag $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo/adk-agent:latest \ --project=$GOOGLE_CLOUD_PROJECT \ .Dockerfile의 단계를 실행합니다. 클라우드에서 이미지를 빌드하고 Artifact Registry 저장소의 주소로 태그를 지정한 후 자동으로 푸시합니다. - 터미널에서 이미지가 빌드되었는지 확인합니다.
gcloud artifacts docker images list \ $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo \ --project=$GOOGLE_CLOUD_PROJECT
요약
이 섹션에서는 배포를 위해 코드를 패키징했습니다.
- 에이전트를 FastAPI 웹 서버로 래핑하는
main.py진입점을 만들었습니다. - 코드를 번들링하고 종속 항목을 휴대용 이미지로 만들기 위해
Dockerfile를 정의했습니다. - Cloud Build를 사용하여 이미지를 빌드하고 보안 Artifact Registry 저장소에 푸시했습니다.
9. Kubernetes 매니페스트 만들기
컨테이너 이미지가 빌드되어 Artifact Registry에 저장되었으므로 GKE에 실행 방법을 알려야 합니다. 여기에는 두 가지 주요 활동이 포함됩니다.
- 권한 구성: 클러스터 내에서 에이전트 전용 ID를 만들고 필요한 Google Cloud API (특히 Vertex AI)에 대한 보안 액세스 권한을 부여합니다.
- 애플리케이션 상태 정의: 컨테이너 이미지, 환경 변수, 네트워크에 노출되는 방식 등 애플리케이션을 실행하는 데 필요한 모든 것을 선언적으로 정의하는 YAML 문서인 Kubernetes 매니페스트 파일을 작성합니다.
Vertex AI용 Kubernetes 서비스 계정 구성
에이전트가 Gemini 모델에 액세스하려면 Vertex AI API와 통신할 수 있는 권한이 필요합니다. GKE에서 이 권한을 부여하는 가장 안전하고 권장되는 방법은 워크로드 아이덴티티입니다. 워크로드 아이덴티티를 사용하면 Kubernetes 네이티브 ID (Kubernetes 서비스 계정)를 Google Cloud ID (IAM 서비스 계정)에 연결하여 정적 JSON 키를 다운로드, 관리, 저장할 필요가 없습니다.
- 터미널에서 Kubernetes 서비스 계정 (
adk-agent-sa)을 만듭니다. 이렇게 하면 포드가 사용할 수 있는 GKE 클러스터 내에서 에이전트의 ID가 생성됩니다.kubectl create serviceaccount adk-agent-sa - 터미널에서 정책 바인딩을 만들어 Kubernetes 서비스 계정을 Google Cloud IAM에 연결합니다. 이 명령어는
adk-agent-sa에aiplatform.user역할을 부여하여 Vertex AI API를 안전하게 호출할 수 있도록 합니다.gcloud projects add-iam-policy-binding projects/${GOOGLE_CLOUD_PROJECT} \ --role=roles/aiplatform.user \ --member=principal://iam.googleapis.com/projects/${GOOGLE_CLOUD_PROJECT_NUMBER}/locations/global/workloadIdentityPools/${GOOGLE_CLOUD_PROJECT}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \ --condition=None
Kubernetes 매니페스트 파일 만들기
Kubernetes는 YAML 매니페스트 파일을 사용하여 애플리케이션의 원하는 상태를 정의합니다. Deployment와 Service라는 두 가지 필수 Kubernetes 객체가 포함된 deployment.yaml 파일을 만듭니다.
- 터미널에서
deployment.yaml파일을 생성합니다.cat <<EOF > ~/adk_multiagent_systems/deployment.yaml # Defines the Kubernetes resources required to deploy the application to GKE. # Includes the Deployment (to run the container pods) and the Service # (to expose the application via a Load Balancer). apiVersion: apps/v1 kind: Deployment metadata: name: adk-agent spec: replicas: 1 selector: matchLabels: app: adk-agent template: metadata: labels: app: adk-agent spec: # Assign the Kubernetes Service Account for Workload Identity serviceAccountName: adk-agent-sa containers: - name: adk-agent imagePullPolicy: Always # The path to the container image in Artifact Registry image: ${GOOGLE_CLOUD_LOCATION}-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/adk-repo/adk-agent:latest # Define the resources for GKE Autopilot to provision resources: limits: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" requests: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" ports: - containerPort: 8080 # Environment variables passed to the application env: - name: PORT value: "8080" - name: GOOGLE_CLOUD_PROJECT value: ${GOOGLE_CLOUD_PROJECT} - name: GOOGLE_CLOUD_LOCATION value: ${GOOGLE_CLOUD_LOCATION} - name: GOOGLE_GENAI_USE_VERTEXAI value: "true" - name: MODEL value: "gemini-2.5-flash" --- apiVersion: v1 kind: Service metadata: name: adk-agent spec: # Create a public-facing Network Load Balancer with an external IP type: LoadBalancer ports: - port: 80 targetPort: 8080 selector: app: adk-agent EOF
요약
이 섹션에서는 보안 및 배포 구성을 정의했습니다.
- 워크로드 아이덴티티를 사용하여 Kubernetes 서비스 계정을 만들고 이를 Google Cloud IAM에 연결하여 포드가 키를 관리하지 않고도 Vertex AI에 안전하게 액세스할 수 있도록 했습니다.
- 배포 (포드를 실행하는 방법)와 서비스 (부하 분산기를 통해 노출하는 방법)를 정의하는
deployment.yaml파일을 생성했습니다.
10. GKE에 애플리케이션 배포
매니페스트 파일이 정의되고 컨테이너 이미지가 Artifact Registry에 푸시되었으므로 이제 애플리케이션을 배포할 수 있습니다. 이 작업에서는 kubectl를 사용하여 GKE 클러스터에 구성을 적용한 다음 상태를 모니터링하여 에이전트가 올바르게 시작되는지 확인합니다.
- 터미널에서
deployment.yaml매니페스트를 클러스터에 적용합니다.kubectl apply -f deployment.yamlkubectl apply명령어는deployment.yaml파일을 Kubernetes API 서버로 전송합니다. 그러면 서버가 구성을 읽고 배포 및 서비스 객체 생성을 오케스트레이션합니다. - 터미널에서 배포 상태를 실시간으로 확인합니다. 포드가
Running상태가 될 때까지 기다립니다.kubectl get pods -l=app=adk-agent --watch- 대기 중: 포드가 클러스터에서 수락되었지만 컨테이너가 아직 생성되지 않았습니다.
- 컨테이너 생성: GKE가 Artifact Registry에서 컨테이너 이미지를 가져와 컨테이너를 시작하고 있습니다.
- 실행 중: 성공 컨테이너가 실행 중이고 에이전트 애플리케이션이 작동합니다.
- 상태가
Running로 표시되면 터미널에서 Ctrl+C를 눌러 watch 명령어를 중지하고 명령 프롬프트로 돌아갑니다.
요약
이 섹션에서는 다음 워크로드를 실행했습니다.
kubectlapply를 사용하여 매니페스트를 클러스터에 전송합니다.- 애플리케이션이 성공적으로 시작되었는지 확인하기 위해 포드 수명 주기 (대기 -> ContainerCreating -> 실행)를 모니터링했습니다.
11. 에이전트와의 상호작용
이제 ADK 에이전트가 GKE에서 라이브로 실행되고 공개 부하 분산기를 통해 인터넷에 노출됩니다. 에이전트의 웹 인터페이스에 연결하여 에이전트와 상호작용하고 전체 시스템이 올바르게 작동하는지 확인합니다.
서비스의 외부 IP 주소 찾기
에이전트에 액세스하려면 먼저 GKE에서 서비스에 프로비저닝한 공개 IP 주소를 가져와야 합니다.
- 터미널에서 다음 명령어를 실행하여 서비스의 세부정보를 가져옵니다.
kubectl get service adk-agent EXTERNAL-IP열에서 값을 찾습니다. 서비스를 처음 배포한 후 IP 주소가 할당되기까지 1~2분 정도 걸릴 수 있습니다.pending로 표시되면 1분 정도 기다린 후 명령어를 다시 실행합니다. 출력은 다음과 비슷하게 표시됩니다.NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE adk-agent-service LoadBalancer 10.120.12.234 34.123.45.67 80:31234/TCP 5mEXTERNAL-IP에 나열된 주소 (예: 34.123.45.67)는 에이전트의 공개 진입점입니다.
배포된 에이전트 테스트
이제 공개 IP 주소를 사용하여 브라우저에서 ADK의 내장 웹 UI에 직접 액세스할 수 있습니다.
- 터미널에서 외부 IP 주소 (
EXTERNAL-IP)를 복사합니다. - 웹브라우저에서 새 탭을 열고
http://[EXTERNAL-IP]을 입력합니다. 여기서[EXTERNAL-IP]은 복사한 IP 주소로 바꿉니다. - 이제 ADK 웹 인터페이스가 표시됩니다.
- 에이전트 드롭다운 메뉴에서 workflow_agents가 선택되어 있는지 확인합니다.
- 토큰 스트리밍을 사용 설정합니다.
hello를 입력하고 Enter 키를 눌러 새 대화를 시작합니다.- 결과를 확인합니다. 에이전트는 '히트 영화의 추천곡을 작성해 드릴 수 있습니다. 어떤 역사적 인물에 대한 영화를 만들고 싶으신가요?'
- 역사적 인물을 선택하라는 메시지가 표시되면 관심 있는 인물을 선택합니다. 다음은 몇 가지 아이디어입니다.
the most successful female pirate in historythe woman who invented the first computer compilera legendary lawman of the American Wild West
요약
이 섹션에서는 다음과 같이 배포를 확인했습니다.
- LoadBalancer에서 할당한 외부 IP 주소를 가져왔습니다.
- 브라우저를 통해 ADK 웹 UI에 액세스하여 멀티 에이전트 시스템이 응답하고 작동하는지 확인했습니다.
12. 자동 확장 구성
프로덕션의 주요 과제는 예측할 수 없는 사용자 트래픽을 처리하는 것입니다. 이전 작업에서와 같이 고정된 복제본 수를 하드코딩하면 유휴 리소스에 대해 과도하게 비용을 지불하거나 트래픽 급증 시 성능이 저하될 위험이 있습니다. GKE는 자동 확장을 통해 이 문제를 해결합니다.
실시간 CPU 사용률에 따라 배포에서 실행 중인 포드 수를 자동으로 조정하는 Kubernetes 컨트롤러인 HorizontalPodAutoscaler (HPA)를 구성합니다.
- Cloud Shell 편집기 터미널에서
adk_multiagent_systems디렉터리의 루트에 새hpa.yaml파일을 만듭니다.cloudshell edit ~/adk_multiagent_systems/hpa.yaml - 새
hpa.yaml파일에 다음 콘텐츠를 추가합니다.# Configures the HorizontalPodAutoscaler (HPA) to automatically scale # the number of running agent pods up or down based on CPU utilization # to handle varying traffic loads. apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: adk-agent-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: adk-agent minReplicas: 1 maxReplicas: 5 targetCPUUtilizationPercentage: 50adk-agent배포를 타겟팅합니다. 항상 1개 이상의 포드가 실행되도록 하고, 포드를 최대 5개로 설정하며, 평균 CPU 사용률을 50%로 유지하기 위해 복제본을 추가/삭제합니다. 이때 Cloud Shell 편집기의 탐색기 패널에 표시되는 파일 구조는 다음과 같습니다.
- 터미널에 이를 붙여넣어 HPA를 클러스터에 적용합니다.
kubectl apply -f hpa.yaml
자동 확장 처리기 확인
이제 HPA가 활성화되어 배포를 모니터링합니다. 상태를 검사하여 작동 중인 것을 확인할 수 있습니다.
- 터미널에서 다음 명령어를 실행하여 HPA의 상태를 가져옵니다.
kubectl get hpa adk-agent-hpaNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE adk-agent-hpa Deployment/adk-agent 0%/50% 1 5 1 30s
요약
이 섹션에서는 프로덕션 트래픽에 맞게 최적화했습니다.
- 확장 규칙을 정의하는
hpa.yaml매니페스트를 만들었습니다. - CPU 사용률에 따라 포드 복제본 수를 자동으로 조정하기 위해 HorizontalPodAutoscaler (HPA)를 배포했습니다.
13. 프로덕션 준비
참고: 다음 섹션은 정보 제공 목적으로만 제공되며 실행할 추가 단계는 포함되어 있지 않습니다. 이러한 가이드는 애플리케이션을 프로덕션으로 가져가는 데 필요한 컨텍스트와 권장사항을 제공하도록 설계되었습니다.
리소스 할당으로 성능 조정
GKE Autopilot에서는 deployment.yaml에 리소스 requests를 지정하여 애플리케이션에 프로비저닝된 CPU 및 메모리 양을 제어합니다.
메모리 부족으로 인해 에이전트가 느리거나 비정상 종료되는 경우 deployment.yaml에서 resources 블록을 수정하고 kubectl apply로 파일을 다시 적용하여 리소스 할당을 늘릴 수 있습니다.
예를 들어 메모리를 두 배로 늘리려면 다음을 실행합니다.
# In deployment.yaml
# ...
resources:
requests:
memory: "2Gi" # Increased from 1Gi
cpu: "1000m"
# ...
CI/CD로 워크플로 자동화
이 실습에서는 명령어를 수동으로 실행했습니다. 전문적인 방법은 CI/CD (지속적 통합/지속적 배포) 파이프라인을 만드는 것입니다. 소스 코드 저장소 (예: GitHub)를 Cloud Build 트리거에 연결하면 전체 배포를 자동화할 수 있습니다.
파이프라인을 사용하면 코드를 변경하여 푸시할 때마다 Cloud Build가 다음 작업을 자동으로 실행할 수 있습니다.
- 새 컨테이너 이미지를 빌드합니다.
- 이미지를 Artifact Registry로 내보내기
- 업데이트된 Kubernetes 매니페스트를 GKE 클러스터에 적용합니다.
보안 비밀을 안전하게 관리
이 실습에서는 .env 파일에 구성을 저장하고 애플리케이션에 전달했습니다. 이는 개발에는 편리하지만 API 키와 같은 민감한 데이터에는 안전하지 않습니다. Secret Manager를 사용하여 보안 비밀을 안전하게 저장하는 것이 좋습니다.
GKE는 Secret Manager와 기본적으로 통합되어 있어 소스 코드에 체크인되지 않고도 환경 변수 또는 파일로 보안 비밀을 포드에 직접 마운트할 수 있습니다.
요청하신 리소스 정리 섹션이 결론 섹션 바로 앞에 삽입되었습니다.
14. 리소스 삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
GKE 클러스터 삭제
이 실습에서는 GKE 클러스터가 주요 비용 동인입니다. 삭제하면 컴퓨팅 요금이 중지됩니다.
- 터미널에서 다음 명령어를 실행합니다.
gcloud container clusters delete adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Artifact Registry 저장소 삭제
Artifact Registry에 저장된 컨테이너 이미지에는 스토리지 비용이 발생합니다.
- 터미널에서 다음 명령어를 실행합니다.
gcloud artifacts repositories delete adk-repo \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
프로젝트 삭제 (선택사항)
이 실습을 위해 특별히 새 프로젝트를 만들었으며 다시 사용할 계획이 없다면 전체 프로젝트를 삭제하는 것이 가장 쉬운 정리 방법입니다.
- 터미널에서 다음 명령어를 실행합니다 (
[YOUR_PROJECT_ID]를 실제 프로젝트 ID로 바꿈).gcloud projects delete [YOUR_PROJECT_ID]
15. 결론
축하합니다. 프로덕션 등급 GKE 클러스터에 다중 에이전트 ADK 애플리케이션을 성공적으로 배포했습니다. 이는 최신 클라우드 네이티브 애플리케이션의 핵심 수명 주기를 다루는 중요한 성과로, 복잡한 자체 에이전트 시스템을 배포할 수 있는 견고한 기반을 제공합니다.
요약
이 실습에서는 다음 작업을 수행하는 방법을 배웠습니다.
- GKE Autopilot 클러스터를 프로비저닝합니다.
Dockerfile로 컨테이너 이미지를 빌드하고 Artifact Registry에 푸시합니다.- 워크로드 아이덴티티를 사용하여 Google Cloud API에 안전하게 연결합니다.
- 배포 및 서비스용 Kubernetes 매니페스트를 작성합니다.
- LoadBalancer를 사용하여 애플리케이션을 인터넷에 노출합니다.
- HorizontalPodAutoscaler (HPA)로 자동 확장 구성