
1. Wprowadzenie
Przegląd
To ćwiczenie wypełnia lukę między opracowaniem zaawansowanego systemu wieloagentowego a wdrożeniem go do użytku w rzeczywistych warunkach. Tworzenie agentów lokalnie to świetny początek, ale aplikacje produkcyjne wymagają platformy, która jest skalowalna, niezawodna i bezpieczna.
W tym laboratorium weźmiesz system wielu agentów utworzony za pomocą pakietu Google Agent Development Kit (ADK) i wdrożysz go w środowisku produkcyjnym w Google Kubernetes Engine (GKE).
Agent zespołu ds. koncepcji filmu
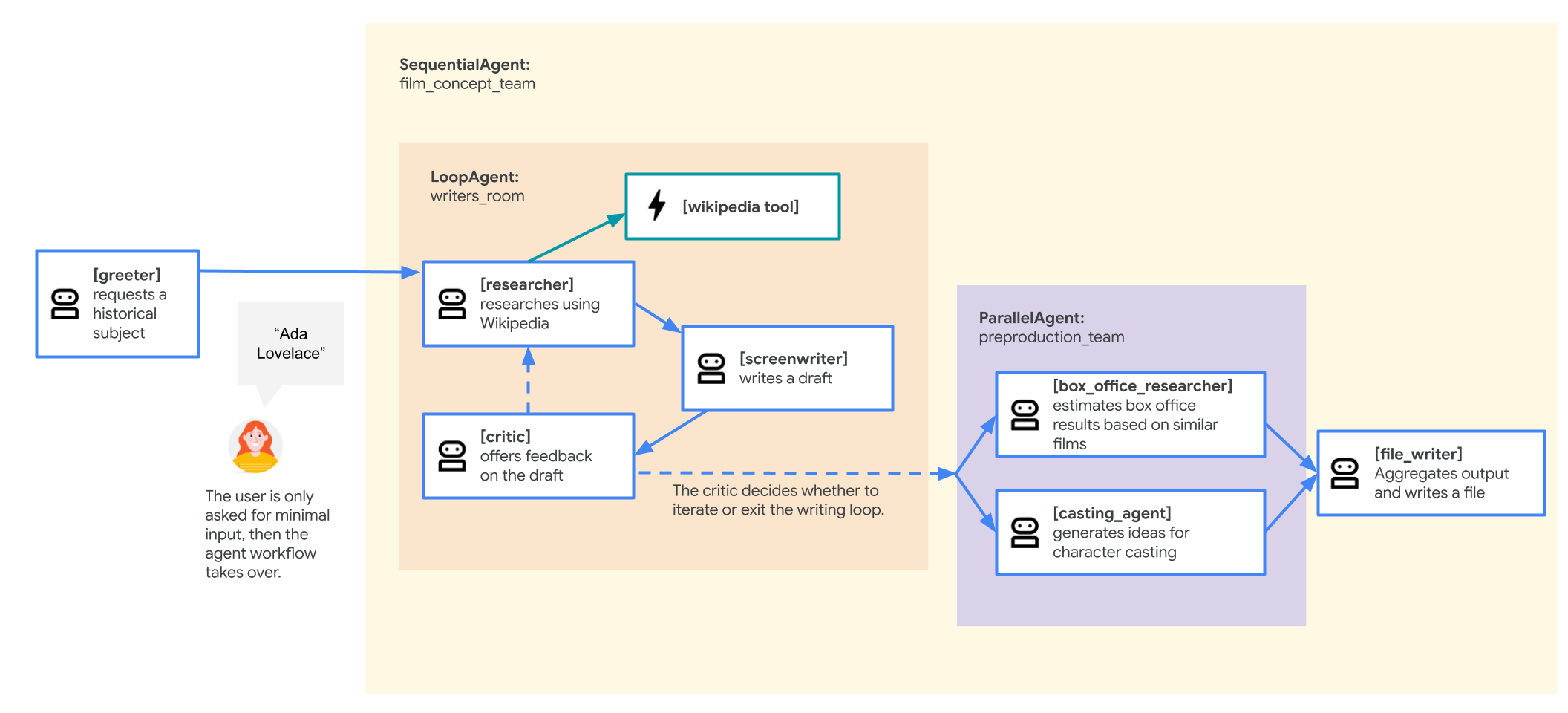
Przykładowa aplikacja używana w tym module to „zespół ds. koncepcji filmu”, który składa się z kilku współpracujących ze sobą agentów: badacza, scenarzysty i osoby zapisującej pliki. Te agenty współpracują ze sobą, aby pomóc użytkownikowi w przeprowadzeniu burzy mózgów i przygotowaniu zarysu prezentacji filmu o postaci historycznej.
Dlaczego warto wdrażać w GKE?
Aby przygotować agenta na wymagania środowiska produkcyjnego, potrzebujesz platformy zaprojektowanej z myślą o skalowalności, bezpieczeństwie i opłacalności. Google Kubernetes Engine (GKE) zapewnia solidną i elastyczną podstawę do uruchamiania skonteneryzowanych aplikacji.
Daje to kilka korzyści w przypadku zbioru zadań produkcyjnych:
- Automatyczne skalowanie i wydajność: radź sobie z nieprzewidywalnym ruchem dzięki HorizontalPodAutoscaler (HPA), który automatycznie dodaje lub usuwa repliki agenta na podstawie obciążenia. W przypadku bardziej wymagających zbiorów zadań AI możesz dołączyć akceleratory sprzętowe, takie jak GPU i TPU.
- Opłacalne zarządzanie zasobami: optymalizuj koszty dzięki Autopilotowi w GKE, który automatycznie zarządza infrastrukturą bazową, dzięki czemu płacisz tylko za zasoby, których żąda Twoja aplikacja.
- Zintegrowane zabezpieczenia i dostrzegalność: bezpiecznie łącz się z innymi usługami Google Cloud za pomocą Workload Identity, co eliminuje konieczność zarządzania kluczami kont usługi i ich przechowywania. Wszystkie logi aplikacji są automatycznie przesyłane strumieniowo do Cloud Logging na potrzeby scentralizowanego monitorowania i debugowania.
- Kontrola i przenośność: unikaj uzależnienia się od jednego dostawcy dzięki Kubernetes typu open source. Aplikacja jest przenośna i może działać w dowolnym klastrze Kubernetes, lokalnie lub w innych chmurach.
Czego się nauczysz
Z tego modułu nauczysz się, jak:
- Aprowizuj klaster GKE w trybie Autopilota.
- skonteneryzować aplikację za pomocą pliku Dockerfile i przesłać obraz do Artifact Registry;
- Bezpiecznie łącz aplikację z interfejsami Cloud API Google Cloud za pomocą Workload Identity.
- Pisać i stosować pliki manifestu Kubernetes dla wdrożenia i usługi.
- udostępnić aplikację w internecie za pomocą LoadBalancer;
- Skonfiguruj autoskalowanie za pomocą obiektu HorizontalPodAutoscaler (HPA).
2. Konfigurowanie projektu
Konto Google
Jeśli nie masz jeszcze osobistego konta Google, musisz je utworzyć.
Używaj konta osobistego zamiast konta służbowego lub szkolnego.
Logowanie się w konsoli Google Cloud
Zaloguj się w konsoli Google Cloud, korzystając z osobistego konta Google.
Włącz płatności
Konfigurowanie osobistego konta rozliczeniowego
Jeśli skonfigurujesz płatności za pomocą środków w Google Cloud, możesz pominąć ten krok.
Aby skonfigurować osobiste konto rozliczeniowe, włącz płatności w konsoli Google Cloud.
Uwagi:
- Pod względem opłat za zasoby chmury ukończenie tego modułu powinno kosztować mniej niż 1 USD.
- Jeśli chcesz uniknąć dalszych opłat, wykonaj czynności opisane na końcu tego modułu, aby usunąć zasoby.
- Nowi użytkownicy mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Tworzenie projektu (opcjonalnie)
Jeśli nie masz bieżącego projektu, którego chcesz użyć w tym ćwiczeniu, utwórz nowy projekt.
3. Otwórz edytor Cloud Shell
- Kliknij ten link, aby przejść bezpośrednio do edytora Cloud Shell
- Jeśli w dowolnym momencie pojawi się prośba o autoryzację, kliknij Autoryzuj, aby kontynuować.
- Jeśli terminal nie pojawi się u dołu ekranu, otwórz go:
- Kliknij Wyświetl.
- Kliknij Terminal
 .
.
- W terminalu ustaw projekt za pomocą tego polecenia:
gcloud config set project [PROJECT_ID]- Przykład:
gcloud config set project lab-project-id-example - Jeśli nie pamiętasz identyfikatora projektu, możesz wyświetlić listę wszystkich identyfikatorów projektów za pomocą tego polecenia:
gcloud projects list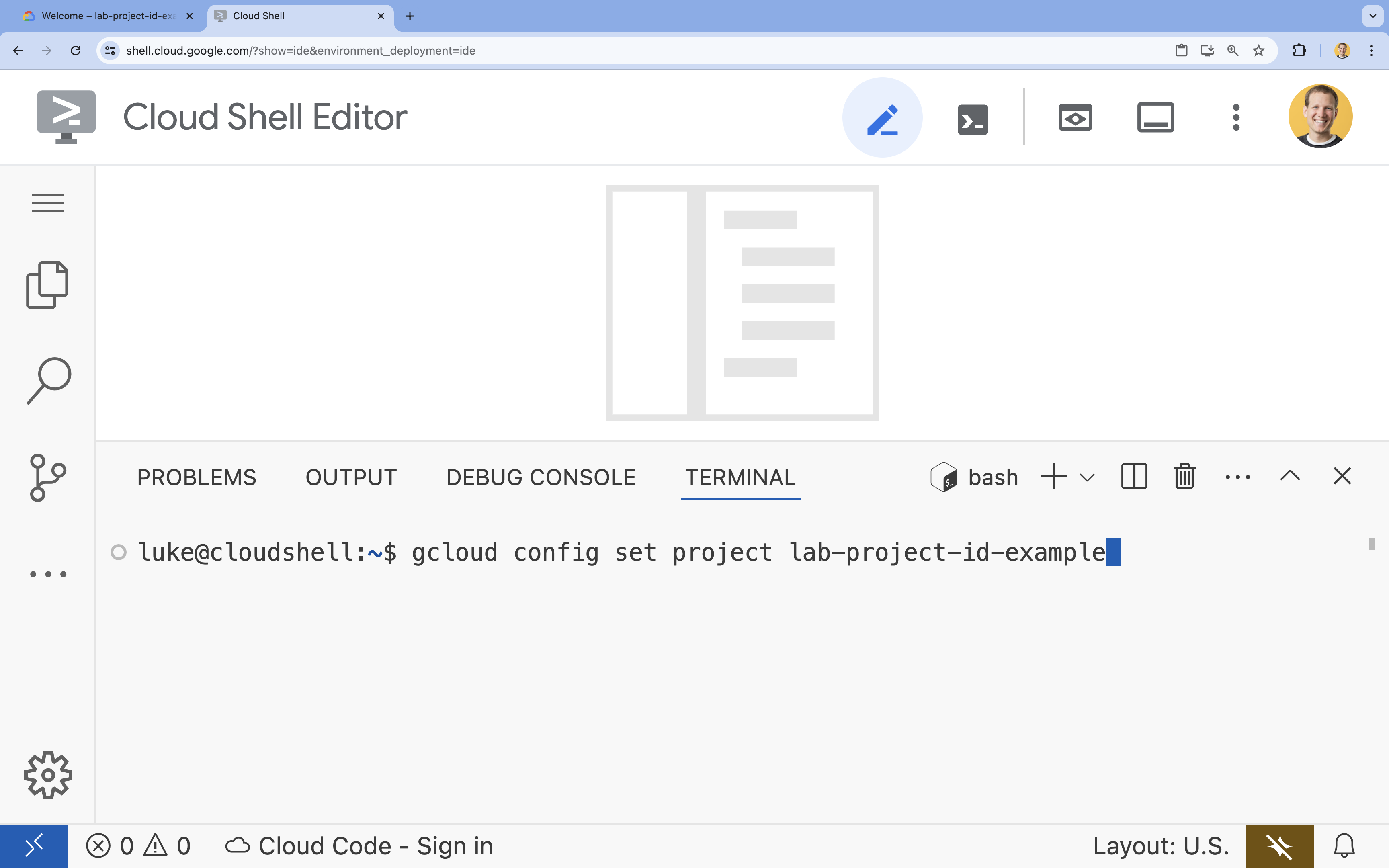
- Przykład:
- Powinien wyświetlić się ten komunikat:
Updated property [core/project].
4. Włącz interfejsy API
Aby korzystać z GKE, Artifact Registry, Cloud Build i Vertex AI, musisz włączyć odpowiednie interfejsy API w projekcie w chmurze Google Cloud.
- W terminalu włącz interfejsy API:
gcloud services enable \ container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.comOperation "operations/acf.p2-176675280136-b03ab5e4-3483-4ebf-9655-43dc3b345c63" finished successfully.
Przedstawiamy interfejsy API
- Google Kubernetes Engine API (
container.googleapis.com) umożliwia tworzenie klastra GKE, w którym działa agent, i zarządzanie nim. GKE to zarządzane środowisko służące do wdrażania i skalowania skonteneryzowanych aplikacji oraz do zarządzania nimi przy użyciu infrastruktury Google. - Artifact Registry API (
artifactregistry.googleapis.com) udostępnia bezpieczne, prywatne repozytorium do przechowywania obrazu kontenera agenta. Jest to rozwinięcie Container Registry, które jest w pełni zintegrowane z GKE i Cloud Build. - Cloud Build API (
cloudbuild.googleapis.com) jest używany przez poleceniegcloud builds submitdo tworzenia obrazu kontenera w chmurze na podstawie pliku Dockerfile. Jest to bezserwerowa platforma CI/CD, która uruchamia kompilacje w infrastrukturze w chmurze Google Cloud. - Vertex AI API (
aiplatform.googleapis.com) umożliwia wdrożonemu agentowi komunikację z modelami Gemini w celu wykonywania podstawowych zadań. Zapewnia ujednolicony interfejs API dla wszystkich usług AI Google Cloud.
5. Przygotowywanie środowiska programistycznego
Tworzenie struktury katalogów
- W terminalu utwórz katalog projektu i niezbędne podkatalogi:
mkdir -p ~/adk_multiagent_systems/workflow_agents cd ~/adk_multiagent_systems - W terminalu uruchom to polecenie, aby otworzyć katalog w eksploratorze edytora Cloud Shell.
cloudshell open-workspace ~/adk_multiagent_systems - Panel eksploratora po lewej stronie odświeży się. Powinny być teraz widoczne utworzone katalogi.
W trakcie tworzenia plików w kolejnych krokach będą one pojawiać się w tym katalogu.
Tworzenie plików początkowych
Teraz utworzysz niezbędne pliki początkowe aplikacji.
- Utwórz plik
callback_logging.py, uruchamiając w terminalu to polecenie: Ten plik obsługuje rejestrowanie na potrzeby obserwacji.cat <<EOF > ~/adk_multiagent_systems/callback_logging.py """ Provides helper functions for observability. Handles formatting and sending agent queries, responses, and tool calls to Google Cloud Logging to aid in monitoring and debugging. """ import logging import google.cloud.logging from google.adk.agents.callback_context import CallbackContext from google.adk.models import LlmResponse, LlmRequest def log_query_to_model(callback_context: CallbackContext, llm_request: LlmRequest): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_request.contents and llm_request.contents[-1].role == 'user': if llm_request.contents[-1].parts and "text" in llm_request.contents[-1].parts: last_user_message = llm_request.contents[-1].parts[0].text logging.info(f"[query to {callback_context.agent_name}]: " + last_user_message) def log_model_response(callback_context: CallbackContext, llm_response: LlmResponse): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_response.content and llm_response.content.parts: for part in llm_response.content.parts: if part.text: logging.info(f"[response from {callback_context.agent_name}]: " + part.text) elif part.function_call: logging.info(f"[function call from {callback_context.agent_name}]: " + part.function_call.name) EOF - Utwórz plik
workflow_agents/__init__.py, uruchamiając w terminalu to polecenie: Oznacza to katalog jako pakiet Pythona.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/__init__.py """ Marks the directory as a Python package and exposes the agent module, allowing the ADK to discover and register the agents defined within. """ from . import agent EOF - Utwórz plik
workflow_agents/agent.py, uruchamiając w terminalu to polecenie: Ten plik zawiera podstawową logikę działania zespołu wielu agentów.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/agent.py """ Defines the core multi-agent workflow. Configures individual agents (Researcher, Screenwriter, File Writer), assigns their specific tools, and orchestrates their collaboration using the ADK's SequentialAgent pattern. """ import os import logging import google.cloud.logging from callback_logging import log_query_to_model, log_model_response from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent, LoopAgent, ParallelAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool # import from google.genai import types from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL") print(model_name) # Tools def append_to_state( tool_context: ToolContext, field: str, response: str ) -> dict[str, str]: """Append new output to an existing state key. Args: field (str): a field name to append to response (str): a string to append to the field Returns: dict[str, str]: {"status": "success"} """ existing_state = tool_context.state.get(field, []) tool_context.state[field] = existing_state + [response] logging.info(f"[Added to {field}] {response}") return {"status": "success"} def write_file( tool_context: ToolContext, directory: str, filename: str, content: str ) -> dict[str, str]: target_path = os.path.join(directory, filename) os.makedirs(os.path.dirname(target_path), exist_ok=True) with open(target_path, "w") as f: f.write(content) return {"status": "success"} # Agents file_writer = Agent( name="file_writer", model=model_name, description="Creates marketing details and saves a pitch document.", instruction=""" PLOT_OUTLINE: { PLOT_OUTLINE? } INSTRUCTIONS: - Create a marketable, contemporary movie title suggestion for the movie described in the PLOT_OUTLINE. If a title has been suggested in PLOT_OUTLINE, you can use it, or replace it with a better one. - Use your 'write_file' tool to create a new txt file with the following arguments: - for a filename, use the movie title - Write to the 'movie_pitches' directory. - For the 'content' to write, extract the following from the PLOT_OUTLINE: - A logline - Synopsis or plot outline """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[write_file], ) screenwriter = Agent( name="screenwriter", model=model_name, description="As a screenwriter, write a logline and plot outline for a biopic about a historical character.", instruction=""" INSTRUCTIONS: Your goal is to write a logline and three-act plot outline for an inspiring movie about a historical character(s) described by the PROMPT: { PROMPT? } - If there is CRITICAL_FEEDBACK, use those thoughts to improve upon the outline. - If there is RESEARCH provided, feel free to use details from it, but you are not required to use it all. - If there is a PLOT_OUTLINE, improve upon it. - Use the 'append_to_state' tool to write your logline and three-act plot outline to the field 'PLOT_OUTLINE'. - Summarize what you focused on in this pass. PLOT_OUTLINE: { PLOT_OUTLINE? } RESEARCH: { research? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], ) researcher = Agent( name="researcher", model=model_name, description="Answer research questions using Wikipedia.", instruction=""" PROMPT: { PROMPT? } PLOT_OUTLINE: { PLOT_OUTLINE? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } INSTRUCTIONS: - If there is a CRITICAL_FEEDBACK, use your wikipedia tool to do research to solve those suggestions - If there is a PLOT_OUTLINE, use your wikipedia tool to do research to add more historical detail - If these are empty, use your Wikipedia tool to gather facts about the person in the PROMPT - Use the 'append_to_state' tool to add your research to the field 'research'. - Summarize what you have learned. Now, use your Wikipedia tool to do research. """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[ LangchainTool(tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())), append_to_state, ], ) film_concept_team = SequentialAgent( name="film_concept_team", description="Write a film plot outline and save it as a text file.", sub_agents=[ researcher, screenwriter, file_writer ], ) root_agent = Agent( name="greeter", model=model_name, description="Guides the user in crafting a movie plot.", instruction=""" - Let the user know you will help them write a pitch for a hit movie. Ask them for a historical figure to create a movie about. - When they respond, use the 'append_to_state' tool to store the user's response in the 'PROMPT' state key and transfer to the 'film_concept_team' agent """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], sub_agents=[film_concept_team], ) EOF
Struktura plików powinna teraz wyglądać tak: 
Konfigurowanie środowiska wirtualnego
- W terminalu utwórz i aktywuj środowisko wirtualne za pomocą polecenia
uv. Dzięki temu zależności projektu nie będą powodować konfliktów z systemowym Pythonem.uv venv source .venv/bin/activate
Wymagania dotyczące instalacji
- Aby utworzyć plik
requirements.txt, uruchom to polecenie w terminalu.cat <<EOF > ~/adk_multiagent_systems/requirements.txt # Lists all Python dependencies required to run the multi-agent system, # including the Google ADK, LangChain community tools, and web server libraries. langchain-community==0.4.1 wikipedia==1.4.0 google-adk==1.27.5 fastapi==0.135.2 uvicorn==0.42.0 EOF - Zainstaluj wymagane pakiety w środowisku wirtualnym w terminalu.
uv pip install -r requirements.txt
Konfigurowanie zmiennych środowiskowych
- Użyj tego polecenia w terminalu, aby utworzyć plik
.env, automatycznie wstawiając identyfikator projektu i region.cat <<EOF > ~/adk_multiagent_systems/.env GOOGLE_CLOUD_PROJECT="$(gcloud config get-value project)" GOOGLE_CLOUD_PROJECT_NUMBER="$(gcloud projects describe $(gcloud config get-value project) --format='value(projectNumber)')" GOOGLE_CLOUD_LOCATION="us-central1" GOOGLE_GENAI_USE_VERTEXAI=true MODEL="gemini-2.5-flash" EOF - W terminalu załaduj zmienne do sesji powłoki.
source .env
Podsumowanie
W tej sekcji utworzyliśmy lokalną podstawę projektu:
- Utworzono strukturę katalogów i niezbędne pliki startowe agenta (
agent.py,callback_logging.py,requirements.txt). - Odizoluj zależności za pomocą środowiska wirtualnego (
uv). - Skonfigurowane zmienne środowiskowe (
.env) do przechowywania szczegółów projektu, takich jak identyfikator projektu i region.
6. Przeglądanie pliku agenta
Masz skonfigurowany kod źródłowy modułu, w tym gotowy system z wieloma agentami. Zanim wdrożysz aplikację, warto dowiedzieć się, jak są zdefiniowane agenty. Główna logika agenta znajduje się w pliku workflow_agents/agent.py.
- W edytorze Cloud Shell użyj eksploratora plików po lewej stronie, aby przejść do katalogu
adk_multiagent_systems/workflow_agents/i otworzyć plikagent.py. - Poświęć chwilę na przejrzenie pliku. Nie musisz rozumieć każdego wiersza, ale zwróć uwagę na ogólną strukturę:
- Poszczególni agenci: plik definiuje 3 różne
Agentobiekty:researcher,screenwriterifile_writer. Każdy agent otrzymuje konkretnyinstruction(prompt) i listętools, których może używać (np. narzędzieWikipediaQueryRunlub niestandardowe narzędziewrite_file). - Kompozycja agenta: poszczególni agenci są połączeni w
SequentialAgento nazwiefilm_concept_team. Dzięki temu ADK będzie uruchamiać te agenty jeden po drugim, przekazując stan z jednego do drugiego. - Agent główny: agent
root_agent(o nazwie „greeter”) jest zdefiniowany do obsługi początkowej interakcji z użytkownikiem. Gdy użytkownik poda prompt, ten agent zapisuje go w stanie aplikacji, a następnie przekazuje kontrolę do przepływu pracyfilm_concept_team.
- Poszczególni agenci: plik definiuje 3 różne
Zrozumienie tej struktury pomoże Ci wyjaśnić, co zamierzasz wdrożyć: nie tylko pojedynczego agenta, ale skoordynowany zespół wyspecjalizowanych agentów zarządzanych przez ADK.
7. Tworzenie klastra GKE w trybie Autopilota
Po przygotowaniu środowiska kolejnym krokiem jest udostępnienie infrastruktury, w której będzie działać aplikacja agenta. Utworzysz klaster GKE Autopilot, który będzie podstawą wdrożenia. Używamy trybu Autopilota, ponieważ obsługuje on złożone zarządzanie bazowymi węzłami klastra, skalowaniem i zabezpieczeniami, dzięki czemu możesz skupić się wyłącznie na wdrażaniu aplikacji.
- W terminalu utwórz nowy klaster GKE w trybie Autopilota o nazwie
adk-cluster.gcloud container clusters create-auto adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT - Po utworzeniu klastra skonfiguruj
kubectl, aby się z nim połączyć. W tym celu uruchom to polecenie w terminalu:gcloud container clusters get-credentials adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT~/.kube/config). Od tego momentu narzędzie wiersza poleceńkubectlbędzie uwierzytelnione i skierowane do komunikacji z usługąadk-cluster.
Podsumowanie
W tej sekcji skonfigurowaliśmy infrastrukturę:
- Utworzono w pełni zarządzany klaster GKE Autopilot za pomocą
gcloud. - skonfigurować lokalne narzędzie
kubectl, aby uwierzytelniać się w nowym klastrze i komunikować się z nim.
8. Konteneryzowanie i wypychanie aplikacji
Kod agenta znajduje się obecnie tylko w środowisku Cloud Shell. Aby uruchomić go w GKE, musisz najpierw spakować go do obrazu kontenera. Obraz kontenera to statyczny, przenośny plik, który zawiera kod aplikacji wraz ze wszystkimi jej zależnościami. Gdy uruchomisz ten obraz, stanie się on aktywnym kontenerem.
Proces ten obejmuje 3 kluczowe etapy:
- Utwórz punkt wejścia: zdefiniuj plik
main.py, aby przekształcić logikę agenta w uruchamiany serwer WWW. - Zdefiniuj obraz kontenera: utwórz Dockerfile, który będzie służyć jako plan tworzenia obrazu kontenera.
- Kompilowanie i przenoszenie: użyj Cloud Build, aby wykonać plik Dockerfile, utworzyć obraz kontenera i przenieść go do Google Artifact Registry, czyli bezpiecznego repozytorium obrazów.
Przygotowywanie aplikacji do wdrożenia
Agent ADK potrzebuje serwera WWW do odbierania żądań. Plik main.py będzie służyć jako punkt wejścia, a platforma FastAPI będzie udostępniać funkcje agenta przez HTTP.
- W katalogu głównym
adk_multiagent_systemsw terminalu utwórz nowy plik o nazwiemain.py.cat <<EOF > ~/adk_multiagent_systems/main.py """ Serves as the application entry point. Initializes the FastAPI web server, discovers the agents defined in the workflow directory, and exposes them via HTTP endpoints for interaction. """ import os import uvicorn from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Get the directory where main.py is located AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) # Configure the session service (e.g., SQLite for local storage) SESSION_SERVICE_URI = "sqlite:///./sessions.db" # Configure CORS to allow requests from various origins for this lab ALLOWED_ORIGINS = ["http://localhost", "http://localhost:8080", "*"] # Enable the ADK's built-in web interface SERVE_WEB_INTERFACE = True # Call the ADK function to discover agents and create the FastAPI app app: FastAPI = get_fast_api_app( agents_dir=AGENT_DIR, session_service_uri=SESSION_SERVICE_URI, allow_origins=ALLOWED_ORIGINS, web=SERVE_WEB_INTERFACE, ) # You can add more FastAPI routes or configurations below if needed # Example: # @app.get("/hello") # async def read_root(): # return {"Hello": "World"} if __name__ == "__main__": # Get the port from the PORT environment variable provided by the container runtime # Run the Uvicorn server, listening on all available network interfaces (0.0.0.0) uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("PORT", 8080))) EOFuvicornuruchamia tę aplikację, nasłuchując na hoście0.0.0.0, aby akceptować połączenia z dowolnego adresu IP, oraz na porcie określonym przez zmienną środowiskowąPORT, którą ustawimy później w manifeście Kubernetes.
W tym momencie struktura plików widoczna w panelu eksploratora w edytorze Cloud Shell powinna wyglądać tak: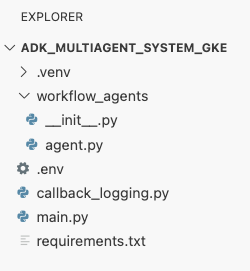
Konteneryzowanie agenta ADK za pomocą Dockera
Aby wdrożyć aplikację w GKE, musimy najpierw spakować ją w obraz kontenera, który zawiera kod aplikacji wraz ze wszystkimi bibliotekami i zależnościami potrzebnymi do jej uruchomienia. Do utworzenia tego obrazu kontenera użyjemy Dockera.
- W katalogu głównym
adk_multiagent_systemsw terminalu utwórz nowy plik o nazwieDockerfile.cat <<'EOF' > ~/adk_multiagent_systems/Dockerfile # Defines the blueprint for the container image. Installs dependencies, # sets up a secure non-root user, and specifies the startup command to run the # agent web server. # Use an official lightweight Python image as the base FROM python:3.13-slim # Set the working directory inside the container WORKDIR /app # Create a non-root user for security best practices RUN adduser --disabled-password --gecos "" myuser # Copy and install dependencies first to leverage Docker's layer caching COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt # Copy all application code into the container COPY . . # Create the directory where the agent will write files at runtime # The -p flag ensures the command doesn't fail if the directory already exists RUN mkdir -p movie_pitches # Change ownership of EVERYTHING in /app to the non-root user # Without this, the running agent would be denied permission to write files. RUN chown -R myuser:myuser /app # Switch the active user from root to the non-root user USER myuser # Add the user's local binary directory to the system's PATH ENV PATH="/home/myuser/.local/bin:$PATH" # Define the command to run when the container starts CMD ["sh", "-c", "uvicorn main:app --host 0.0.0.0 --port $PORT"] EOF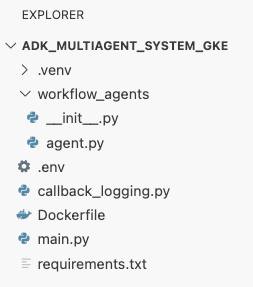
Tworzenie i przesyłanie obrazu kontenera do Artifact Registry
Teraz, gdy masz już plik Dockerfile, użyjesz Cloud Build do utworzenia obrazu i przeniesienia go do Artifact Registry, czyli bezpiecznego, prywatnego rejestru zintegrowanego z usługami Google Cloud. GKE pobierze obraz z tego rejestru, aby uruchomić aplikację.
- W terminalu utwórz nowe repozytorium Artifact Registry, w którym będziesz przechowywać obraz kontenera.
gcloud artifacts repositories create adk-repo \ --repository-format=docker \ --location=$GOOGLE_CLOUD_LOCATION \ --description="ADK repository" - W terminalu użyj polecenia
gcloud builds submit, aby utworzyć obraz kontenera i przesłać go do repozytorium.gcloud builds submit \ --tag $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo/adk-agent:latest \ --project=$GOOGLE_CLOUD_PROJECT \ .Dockerfile. Skompiluje obraz w chmurze, oznaczy go adresem repozytorium Artifact Registry i automatycznie go tam przeniesie. - W terminalu sprawdź, czy obraz został skompilowany:
gcloud artifacts docker images list \ $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo \ --project=$GOOGLE_CLOUD_PROJECT
Podsumowanie
W tej sekcji spakowaliśmy kod do wdrożenia:
- Utworzono punkt wejścia
main.py, aby umieścić agentów w serwerze WWW FastAPI. - zdefiniowano
Dockerfile, aby spakować kod i zależności w przenośny obraz. - używać Cloud Build do tworzenia obrazu i przenoszenia go do bezpiecznego repozytorium Artifact Registry;
9. Tworzenie manifestów Kubernetes
Gdy obraz kontenera zostanie utworzony i zapisany w Artifact Registry, musisz poinstruować GKE, jak go uruchomić. Obejmuje to 2 główne działania:
- Konfigurowanie uprawnień: utworzysz w klastrze dedykowaną tożsamość dla agenta i przyznasz jej bezpieczny dostęp do potrzebnych interfejsów Cloud API (w szczególności Vertex AI).
- Określanie stanu aplikacji: napiszesz plik manifestu Kubernetes, czyli dokument YAML, który deklaratywnie definiuje wszystko, czego aplikacja potrzebuje do działania, w tym obraz kontenera, zmienne środowiskowe i sposób udostępniania aplikacji w sieci.
Konfigurowanie konta usługi Kubernetes na potrzeby Vertex AI
Aby agent mógł korzystać z modeli Gemini, musi mieć uprawnienia do komunikacji z interfejsem Vertex AI API. Najbezpieczniejszą i zalecaną metodą przyznawania tego uprawnienia w GKE jest Workload Identity. Workload Identity umożliwia powiązanie tożsamości natywnej Kubernetes (konta usługi Kubernetes) z tożsamością Google Cloud (kontem usługi IAM), co całkowicie eliminuje konieczność pobierania, zarządzania i przechowywania statycznych kluczy JSON.
- W terminalu utwórz konto usługi Kubernetes (
adk-agent-sa). Utworzy to tożsamość agenta w klastrze GKE, z której mogą korzystać Twoje pody.kubectl create serviceaccount adk-agent-sa - W terminalu połącz konto usługi Kubernetes z Cloud IAM, tworząc powiązanie zasad. To polecenie przyznaje Twojemu
adk-agent-sarolęaiplatform.user, co umożliwia mu bezpieczne wywoływanie interfejsu Vertex AI API.gcloud projects add-iam-policy-binding projects/${GOOGLE_CLOUD_PROJECT} \ --role=roles/aiplatform.user \ --member=principal://iam.googleapis.com/projects/${GOOGLE_CLOUD_PROJECT_NUMBER}/locations/global/workloadIdentityPools/${GOOGLE_CLOUD_PROJECT}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \ --condition=None
Tworzenie plików manifestu Kubernetes
Kubernetes używa plików manifestu YAML do definiowania pożądanego stanu aplikacji. Utworzysz plik deployment.yaml zawierający 2 podstawowe obiekty Kubernetes: wdrożenie i usługę.
- W terminalu wygeneruj plik
deployment.yaml.cat <<EOF > ~/adk_multiagent_systems/deployment.yaml # Defines the Kubernetes resources required to deploy the application to GKE. # Includes the Deployment (to run the container pods) and the Service # (to expose the application via a Load Balancer). apiVersion: apps/v1 kind: Deployment metadata: name: adk-agent spec: replicas: 1 selector: matchLabels: app: adk-agent template: metadata: labels: app: adk-agent spec: # Assign the Kubernetes Service Account for Workload Identity serviceAccountName: adk-agent-sa containers: - name: adk-agent imagePullPolicy: Always # The path to the container image in Artifact Registry image: ${GOOGLE_CLOUD_LOCATION}-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/adk-repo/adk-agent:latest # Define the resources for GKE Autopilot to provision resources: limits: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" requests: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" ports: - containerPort: 8080 # Environment variables passed to the application env: - name: PORT value: "8080" - name: GOOGLE_CLOUD_PROJECT value: ${GOOGLE_CLOUD_PROJECT} - name: GOOGLE_CLOUD_LOCATION value: ${GOOGLE_CLOUD_LOCATION} - name: GOOGLE_GENAI_USE_VERTEXAI value: "true" - name: MODEL value: "gemini-2.5-flash" --- apiVersion: v1 kind: Service metadata: name: adk-agent spec: # Create a public-facing Network Load Balancer with an external IP type: LoadBalancer ports: - port: 80 targetPort: 8080 selector: app: adk-agent EOF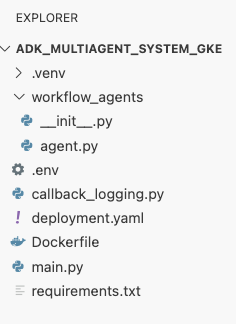
Podsumowanie
W tej sekcji zdefiniowano konfigurację zabezpieczeń i wdrożenia:
- Utworzono konto usługi Kubernetes i połączono je z Google Cloud IAM za pomocą Workload Identity, co umożliwia bezpieczny dostęp do Vertex AI bez zarządzania kluczami.
- Wygenerowano plik
deployment.yaml, który definiuje wdrożenie (sposób uruchamiania podów) i usługę (sposób udostępniania ich za pomocą systemu równoważenia obciążenia).
10. Wdrażanie aplikacji w GKE
Po zdefiniowaniu pliku manifestu i przesłaniu obrazu kontenera do Artifact Registry możesz wdrożyć aplikację. W tym zadaniu użyjesz kubectl, aby zastosować konfigurację do klastra GKE, a następnie monitorować stan, aby upewnić się, że agent uruchamia się prawidłowo.
- W terminalu zastosuj plik manifestu
deployment.yamldo klastra.kubectl apply -f deployment.yamlkubectl applywysyła plikdeployment.yamldo serwera Kubernetes API. Serwer odczytuje konfigurację i koordynuje tworzenie obiektów wdrożenia i usługi. - W terminalu sprawdzaj stan wdrożenia w czasie rzeczywistym. Poczekaj, aż pody będą w stanie
Running.kubectl get pods -l=app=adk-agent --watch- Oczekuje: pod został zaakceptowany przez klaster, ale kontener nie został jeszcze utworzony.
- Tworzenie kontenera: GKE pobiera obraz kontenera z Artifact Registry i uruchamia kontener.
- Uruchomiono: gotowe. Kontener działa, a aplikacja agenta jest aktywna.
- Gdy stan zmieni się na
Running, naciśnij CTRL+C w terminalu, aby zatrzymać polecenie watch i wrócić do wiersza poleceń.
Podsumowanie
W tej sekcji uruchomiliśmy zadanie:
- Użyj polecenia
kubectlapply, aby wysłać plik manifestu do klastra. - Monitorowanie cyklu życia poda (Pending -> ContainerCreating -> Running) w celu sprawdzenia, czy aplikacja została uruchomiona.
11. Interakcja z agentem
Agent ADK jest teraz uruchomiony w GKE i udostępniony w internecie za pomocą publicznego systemu równoważenia obciążenia. Połączysz się z interfejsem internetowym agenta, aby z nim wchodzić w interakcje i sprawdzić, czy cały system działa prawidłowo.
Znajdowanie zewnętrznego adresu IP usługi
Aby uzyskać dostęp do agenta, musisz najpierw pobrać publiczny adres IP udostępniony przez GKE dla usługi.
- W terminalu uruchom to polecenie, aby uzyskać szczegóły usługi.
kubectl get service adk-agent - Wyszukaj wartość w kolumnie
EXTERNAL-IP. Po pierwszym wdrożeniu usługi przypisanie adresu IP może potrwać minutę lub dwie. Jeśli wyświetla siępending, odczekaj minutę i ponownie uruchom polecenie. Dane wyjściowe będą wyglądać podobnie do tych:NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE adk-agent-service LoadBalancer 10.120.12.234 34.123.45.67 80:31234/TCP 5mEXTERNAL-IP(np. 34.123.45.67) to publiczny punkt wejścia do Twojego agenta.
Testowanie wdrożonego agenta
Teraz możesz użyć publicznego adresu IP, aby uzyskać dostęp do wbudowanego interfejsu internetowego ADK bezpośrednio z przeglądarki.
- Skopiuj zewnętrzny adres IP (
EXTERNAL-IP) z terminala. - Otwórz nową kartę w przeglądarce i wpisz
http://[EXTERNAL-IP], zastępując[EXTERNAL-IP]skopiowanym adresem IP. - Powinien pojawić się interfejs internetowy ADK.
- W menu agenta wybierz workflow_agents.
- Włącz Strumieniowanie tokenów.
- Wpisz
helloi naciśnij Enter, aby rozpocząć nową rozmowę. - Sprawdź wynik. Agent powinien szybko odpowiedzieć powitaniem: „Mogę Ci pomóc napisać opis hitu filmowego. O jakiej postaci historycznej chcesz nakręcić film?
- Gdy pojawi się prośba o wybranie postaci historycznej, wybierz tę, która Cię interesuje. Oto kilka pomysłów:
the most successful female pirate in historythe woman who invented the first computer compilera legendary lawman of the American Wild West
Podsumowanie
W tej sekcji sprawdziliśmy wdrożenie:
- Pobrano zewnętrzny adres IP przydzielony przez system równoważenia obciążenia.
- Otwórz interfejs ADK w przeglądarce, aby sprawdzić, czy system z wieloma agentami odpowiada i działa prawidłowo.
12. Skonfiguruj autoskalowanie
Kluczowym wyzwaniem w środowisku produkcyjnym jest obsługa nieprzewidywalnego ruchu użytkowników. Zakodowanie na stałe stałej liczby replik, jak w poprzednim zadaniu, oznacza, że albo płacisz za nieużywane zasoby, albo ryzykujesz niską wydajność w okresach wzmożonego ruchu. GKE rozwiązuje ten problem za pomocą automatycznego skalowania.
Skonfigurujesz poziome autoskalowanie podów (HPA), czyli kontroler Kubernetes, który automatycznie dostosowuje liczbę uruchomionych podów we wdrożeniu na podstawie wykorzystania procesora w czasie rzeczywistym.
- W terminalu edytora Cloud Shell utwórz nowy plik
hpa.yamlw katalogu głównymadk_multiagent_systems.cloudshell edit ~/adk_multiagent_systems/hpa.yaml - Dodaj do nowego pliku
hpa.yamlte wiersze:# Configures the HorizontalPodAutoscaler (HPA) to automatically scale # the number of running agent pods up or down based on CPU utilization # to handle varying traffic loads. apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: adk-agent-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: adk-agent minReplicas: 1 maxReplicas: 5 targetCPUUtilizationPercentage: 50adk-agent. Zapewnia to, że zawsze działa co najmniej 1 pod, ustawia maksymalną liczbę podów na 5 i dodaje lub usuwa repliki, aby utrzymać średnie wykorzystanie procesora na poziomie około 50%.W tym momencie struktura plików widoczna w panelu eksploratora w Edytorze Cloud Shell powinna wyglądać tak:
- Zastosuj HPA do klastra, wklejając ten kod do terminala.
kubectl apply -f hpa.yaml
Sprawdzanie autoskalera
HPA jest teraz aktywny i monitoruje Twoje wdrożenie. Możesz sprawdzić jego stan, aby zobaczyć, jak działa.
- Aby sprawdzić stan HPA, uruchom w terminalu to polecenie:
kubectl get hpa adk-agent-hpaNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE adk-agent-hpa Deployment/adk-agent 0%/50% 1 5 1 30s
Podsumowanie
W tej sekcji optymalizujesz ruch produkcyjny:
- Utworzono
hpa.yamlmanifest, aby zdefiniować reguły skalowania. - Wdrożono poziome autoskalowanie podów (HPA), aby automatycznie dostosowywać liczbę replik podów na podstawie wykorzystania procesora.
13. Przygotowanie do udostępnienia wersji produkcyjnej
Uwaga: poniższe sekcje mają charakter wyłącznie informacyjny i nie zawierają dalszych kroków do wykonania. Zostały one opracowane, aby zapewnić kontekst i sprawdzone metody wdrażania aplikacji w środowisku produkcyjnym.
Dostosowywanie wydajności za pomocą alokacji zasobów
W Autopilocie w GKE możesz kontrolować ilość procesora i pamięci udostępnianych aplikacji, określając zasoby requests w deployment.yaml.
Jeśli zauważysz, że agent działa wolno lub ulega awarii z powodu braku pamięci, możesz zwiększyć przydział zasobów, edytując blok resources w pliku deployment.yaml i ponownie stosując plik za pomocą polecenia kubectl apply.
Aby na przykład podwoić pamięć:
# In deployment.yaml
# ...
resources:
requests:
memory: "2Gi" # Increased from 1Gi
cpu: "1000m"
# ...
Automatyzowanie przepływu pracy za pomocą CI/CD
W tym module polecenia były wykonywane ręcznie. Zgodnie z dobrą praktyką należy utworzyć potok CI/CD (ciągła integracja/ciągłe wdrażanie). Łącząc repozytorium kodu źródłowego (np. GitHub) z aktywator kompilacji Cloud Build, możesz zautomatyzować cały proces wdrażania.
Dzięki potokowi za każdym razem, gdy wypychasz zmianę kodu, Cloud Build może automatycznie:
- Skompiluj nowy obraz kontenera.
- Prześlij obraz do Artifact Registry.
- Zastosuj zaktualizowane pliki manifestu Kubernetes w klastrze GKE.
Bezpieczne zarządzanie obiektami tajnymi
W tym module udało Ci się zapisać konfigurację w pliku .env i przekazać ją do aplikacji. Jest to wygodne w przypadku programowania, ale nie zapewnia bezpieczeństwa danych wrażliwych, takich jak klucze interfejsu API. Zalecamy używanie Secret Managera do bezpiecznego przechowywania obiektów tajnych.
GKE ma natywną integrację z usługą Secret Manager, która umożliwia montowanie obiektów tajnych bezpośrednio w podach jako zmiennych środowiskowych lub plików bez konieczności sprawdzania ich w kodzie źródłowym.
Oto sekcja Zwalnianie miejsca, o którą prosisz. Została ona wstawiona tuż przed sekcją Podsumowanie.
14. Zwalnianie miejsca
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby zużyte w tym samouczku, możesz usunąć projekt zawierający te zasoby lub zachować projekt i usunąć poszczególne zasoby.
Usuń klaster GKE.
Klaster GKE jest głównym czynnikiem kosztowym w tym laboratorium. Usunięcie go spowoduje zatrzymanie naliczania opłat za obliczenia.
- W terminalu uruchom to polecenie:
gcloud container clusters delete adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Usuwanie repozytorium Artifact Registry
Obrazy kontenerów przechowywane w Artifact Registry generują koszty miejsca na dane.
- W terminalu uruchom to polecenie:
gcloud artifacts repositories delete adk-repo \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Usuwanie projektu (opcjonalnie)
Jeśli masz projekt utworzony specjalnie na potrzeby tego ćwiczenia i nie zamierzasz już z niego korzystać, najłatwiej będzie usunąć cały projekt.
- W terminalu uruchom to polecenie (zastąp
[YOUR_PROJECT_ID]identyfikatorem projektu):gcloud projects delete [YOUR_PROJECT_ID]
15. Podsumowanie
Gratulacje! Udało Ci się wdrożyć aplikację ADK z wieloma agentami w klastrze GKE klasy produkcyjnej. To ważne osiągnięcie, które obejmuje podstawowy cykl życia nowoczesnej aplikacji natywnej dla chmury i zapewnia solidne podstawy do wdrażania własnych złożonych systemów opartych na agentach.
Podsumowanie
W tym laboratorium dowiesz się, jak:
- Aprowizuj klaster GKE w trybie Autopilota.
- Utwórz obraz kontenera za pomocą
Dockerfilei przenieś go do Artifact Registry. - Bezpiecznie łącz się z interfejsami Cloud API za pomocą Workload Identity.
- Napisz manifesty Kubernetes dla wdrożenia i usługi.
- udostępnić aplikację w internecie za pomocą LoadBalancer;
- Skonfiguruj autoskalowanie za pomocą obiektu HorizontalPodAutoscaler (HPA).