
1. Introdução
Visão geral
Este laboratório preenche a lacuna crítica entre o desenvolvimento de um sistema multiagente avançado e a implantação dele para uso no mundo real. Embora criar agentes localmente seja um ótimo começo, os aplicativos de produção exigem uma plataforma escalonável, confiável e segura.
Neste laboratório, você vai pegar um sistema multiagente criado com o Kit de Desenvolvimento de Agente (ADK) do Google e implantá-lo em um ambiente de produção no Google Kubernetes Engine (GKE).
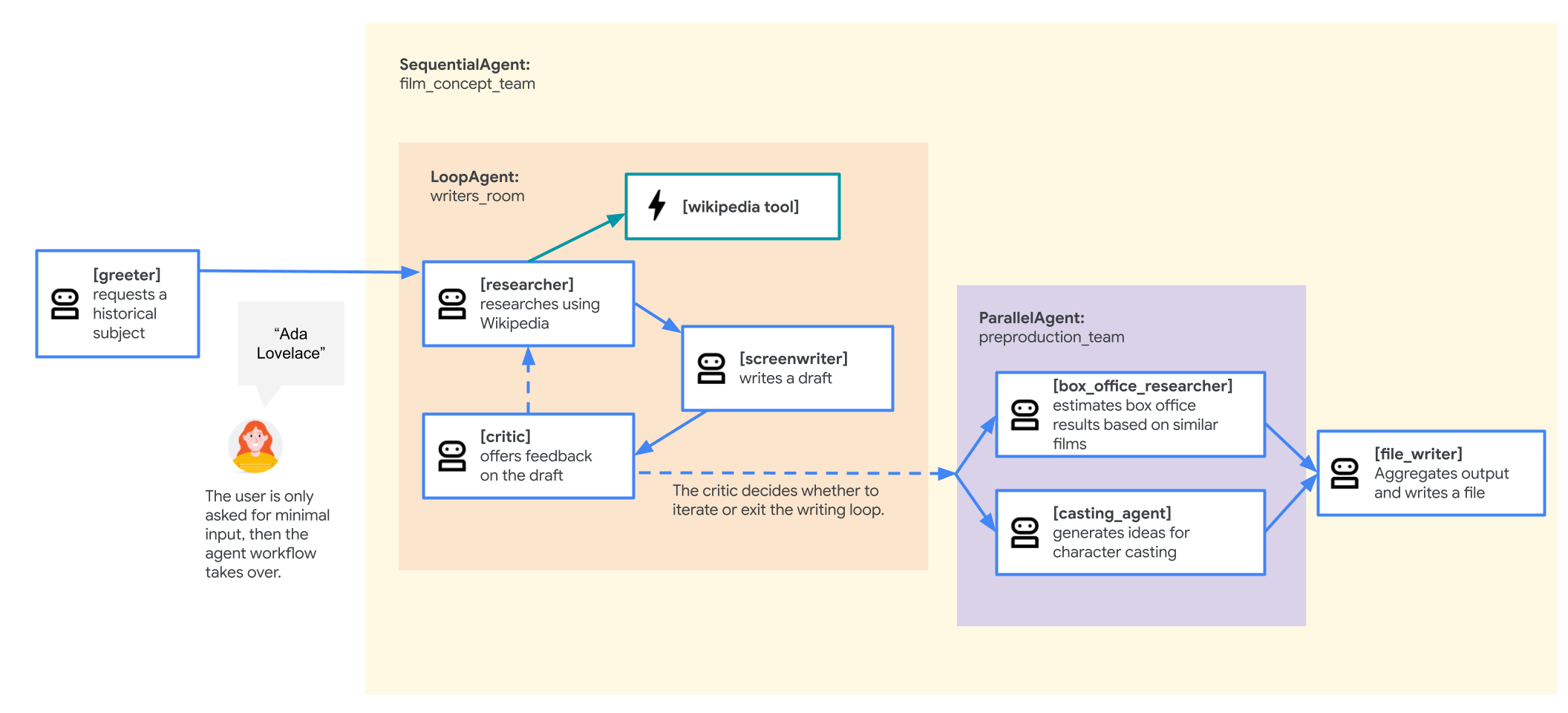
Agente da equipe de conceito de filme
O aplicativo de exemplo usado neste laboratório é uma "equipe de conceito de filme" composta por vários agentes colaboradores: um pesquisador, um roteirista e um gravador de arquivos. Esses agentes trabalham juntos para ajudar um usuário a ter ideias e criar um roteiro de filme sobre uma figura histórica.
Por que implantar no GKE?
Para preparar seu agente para as demandas de um ambiente de produção, você precisa de uma plataforma criada para escalonabilidade, segurança e eficiência de custos. O Google Kubernetes Engine (GKE) oferece essa base poderosa e flexível para executar seu aplicativo em contêineres.
Isso oferece várias vantagens para sua carga de trabalho de produção:
- Escalonamento automático e desempenho: lide com tráfego imprevisível usando o HorizontalPodAutoscaler (HPA), que adiciona ou remove automaticamente réplicas de agentes com base na carga. Para cargas de trabalho de IA mais exigentes, é possível anexar aceleradores de hardware, como GPUs e TPUs.
- Gerenciamento de recursos econômico: otimize os custos com o GKE Autopilot, que gerencia automaticamente a infraestrutura subjacente para que você pague apenas pelos recursos solicitados pelo aplicativo.
- Segurança e observabilidade integradas: conecte-se com segurança a outros serviços do Google Cloud usando a Identidade da carga de trabalho, que evita a necessidade de gerenciar e armazenar chaves de contas de serviço. Todos os registros de aplicativos são transmitidos automaticamente para o Cloud Logging para monitoramento e depuração centralizados.
- Controle e portabilidade: evite a dependência de fornecedores com o Kubernetes de código aberto. Seu aplicativo é portátil e pode ser executado em qualquer cluster do Kubernetes, no local ou em outras nuvens.
O que você vai aprender
Neste laboratório, você aprenderá a fazer o seguinte:
- Provisione um cluster do GKE Autopilot.
- Conteinerize um aplicativo com um Dockerfile e envie a imagem para o Artifact Registry.
- Conecte seu aplicativo com segurança às APIs do Cloud usando a Identidade da carga de trabalho.
- Escrever e aplicar manifestos do Kubernetes para uma implantação e um serviço.
- Exponha um aplicativo à Internet com um LoadBalancer.
- Configure o escalonamento automático com um HorizontalPodAutoscaler (HPA).
2. Configurar o projeto
Conta do Google
Se você ainda não tiver uma Conta do Google pessoal, crie uma.
Use uma conta pessoal em vez de uma conta escolar ou de trabalho.
Fazer login no console do Google Cloud
Faça login no console do Google Cloud usando uma Conta do Google pessoal.
Ativar faturamento
Configurar uma conta de faturamento pessoal
Se você configurou o faturamento usando créditos do Google Cloud, pule esta etapa.
Para configurar uma conta de faturamento pessoal, acesse este link e ative o faturamento no console do Cloud.
Algumas observações:
- A conclusão deste laboratório custa menos de US $1 em recursos do Cloud.
- Siga as etapas no final deste laboratório para excluir recursos e evitar mais cobranças.
- Novos usuários podem aproveitar o teste sem custos financeiros de US$300.
Criar um projeto (opcional)
Se você não tiver um projeto atual que gostaria de usar neste laboratório, crie um novo projeto aqui.
3. Abrir editor do Cloud Shell
- Clique neste link para navegar diretamente até o editor do Cloud Shell.
- Se for preciso autorizar em algum momento, clique em Autorizar para continuar.
- Se o terminal não aparecer na parte de baixo da tela, abra-o:
- Clique em Visualizar.
- Clique em Terminal
 .
.
- No terminal, defina o projeto com este comando:
gcloud config set project [PROJECT_ID]- Exemplo:
gcloud config set project lab-project-id-example - Se você não se lembrar do ID do projeto, liste todos os IDs com:
gcloud projects list
- Exemplo:
- Você vai receber esta mensagem:
Updated property [core/project].
4. Ativar APIs
Para usar o GKE, o Artifact Registry, o Cloud Build e a Vertex AI, é necessário ativar as APIs correspondentes no seu projeto na nuvem do Google.
- No terminal, ative as APIs:
gcloud services enable \ container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.comOperation "operations/acf.p2-176675280136-b03ab5e4-3483-4ebf-9655-43dc3b345c63" finished successfully.
Apresentação das APIs
- A API do Google Kubernetes Engine (
container.googleapis.com) permite criar e gerenciar o cluster do GKE que executa seu agente. O GKE oferece um ambiente gerenciado para implantação, gerenciamento e escalonamento de aplicativos conteinerizados usando a infraestrutura do Google. - A API Artifact Registry (
artifactregistry.googleapis.com) oferece um repositório seguro e particular para armazenar a imagem do contêiner do seu agente. Ele é a evolução do Container Registry e se integra perfeitamente ao GKE e ao Cloud Build. - A API Cloud Build (
cloudbuild.googleapis.com) é usada pelo comandogcloud builds submitpara criar a imagem do contêiner na nuvem com base no Dockerfile. É uma plataforma de CI/CD sem servidor que executa seus builds na infraestrutura em nuvem do Google. - A API Vertex AI (
aiplatform.googleapis.com) permite que o agente implantado se comunique com os modelos do Gemini para realizar as tarefas principais. Ela fornece a API unificada para todos os serviços de IA do Google Cloud.
5. Preparar seu ambiente de desenvolvimento
Criar a estrutura de diretórios
- No terminal, crie o diretório do projeto e os subdiretórios necessários:
mkdir -p ~/adk_multiagent_systems/workflow_agents cd ~/adk_multiagent_systems - No terminal, execute o comando a seguir para abrir o diretório no explorador do Editor do Cloud Shell.
cloudshell open-workspace ~/adk_multiagent_systems - O painel do explorador à esquerda será atualizado. Os diretórios criados vão aparecer.
À medida que você cria arquivos nas etapas a seguir, eles são preenchidos nesse diretório.
Criar arquivos iniciais
Agora, crie os arquivos iniciais necessários para o aplicativo.
- Crie
callback_logging.pyexecutando o seguinte no terminal. Esse arquivo processa o registro para observabilidade.cat <<EOF > ~/adk_multiagent_systems/callback_logging.py """ Provides helper functions for observability. Handles formatting and sending agent queries, responses, and tool calls to Google Cloud Logging to aid in monitoring and debugging. """ import logging import google.cloud.logging from google.adk.agents.callback_context import CallbackContext from google.adk.models import LlmResponse, LlmRequest def log_query_to_model(callback_context: CallbackContext, llm_request: LlmRequest): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_request.contents and llm_request.contents[-1].role == 'user': if llm_request.contents[-1].parts and "text" in llm_request.contents[-1].parts: last_user_message = llm_request.contents[-1].parts[0].text logging.info(f"[query to {callback_context.agent_name}]: " + last_user_message) def log_model_response(callback_context: CallbackContext, llm_response: LlmResponse): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_response.content and llm_response.content.parts: for part in llm_response.content.parts: if part.text: logging.info(f"[response from {callback_context.agent_name}]: " + part.text) elif part.function_call: logging.info(f"[function call from {callback_context.agent_name}]: " + part.function_call.name) EOF - Crie
workflow_agents/__init__.pyexecutando o seguinte no terminal. Isso marca o diretório como um pacote Python.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/__init__.py """ Marks the directory as a Python package and exposes the agent module, allowing the ADK to discover and register the agents defined within. """ from . import agent EOF - Crie
workflow_agents/agent.pyexecutando o seguinte no terminal. Esse arquivo contém a lógica principal da sua equipe multiagente.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/agent.py """ Defines the core multi-agent workflow. Configures individual agents (Researcher, Screenwriter, File Writer), assigns their specific tools, and orchestrates their collaboration using the ADK's SequentialAgent pattern. """ import os import logging import google.cloud.logging from callback_logging import log_query_to_model, log_model_response from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent, LoopAgent, ParallelAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool # import from google.genai import types from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL") print(model_name) # Tools def append_to_state( tool_context: ToolContext, field: str, response: str ) -> dict[str, str]: """Append new output to an existing state key. Args: field (str): a field name to append to response (str): a string to append to the field Returns: dict[str, str]: {"status": "success"} """ existing_state = tool_context.state.get(field, []) tool_context.state[field] = existing_state + [response] logging.info(f"[Added to {field}] {response}") return {"status": "success"} def write_file( tool_context: ToolContext, directory: str, filename: str, content: str ) -> dict[str, str]: target_path = os.path.join(directory, filename) os.makedirs(os.path.dirname(target_path), exist_ok=True) with open(target_path, "w") as f: f.write(content) return {"status": "success"} # Agents file_writer = Agent( name="file_writer", model=model_name, description="Creates marketing details and saves a pitch document.", instruction=""" PLOT_OUTLINE: { PLOT_OUTLINE? } INSTRUCTIONS: - Create a marketable, contemporary movie title suggestion for the movie described in the PLOT_OUTLINE. If a title has been suggested in PLOT_OUTLINE, you can use it, or replace it with a better one. - Use your 'write_file' tool to create a new txt file with the following arguments: - for a filename, use the movie title - Write to the 'movie_pitches' directory. - For the 'content' to write, extract the following from the PLOT_OUTLINE: - A logline - Synopsis or plot outline """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[write_file], ) screenwriter = Agent( name="screenwriter", model=model_name, description="As a screenwriter, write a logline and plot outline for a biopic about a historical character.", instruction=""" INSTRUCTIONS: Your goal is to write a logline and three-act plot outline for an inspiring movie about a historical character(s) described by the PROMPT: { PROMPT? } - If there is CRITICAL_FEEDBACK, use those thoughts to improve upon the outline. - If there is RESEARCH provided, feel free to use details from it, but you are not required to use it all. - If there is a PLOT_OUTLINE, improve upon it. - Use the 'append_to_state' tool to write your logline and three-act plot outline to the field 'PLOT_OUTLINE'. - Summarize what you focused on in this pass. PLOT_OUTLINE: { PLOT_OUTLINE? } RESEARCH: { research? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], ) researcher = Agent( name="researcher", model=model_name, description="Answer research questions using Wikipedia.", instruction=""" PROMPT: { PROMPT? } PLOT_OUTLINE: { PLOT_OUTLINE? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } INSTRUCTIONS: - If there is a CRITICAL_FEEDBACK, use your wikipedia tool to do research to solve those suggestions - If there is a PLOT_OUTLINE, use your wikipedia tool to do research to add more historical detail - If these are empty, use your Wikipedia tool to gather facts about the person in the PROMPT - Use the 'append_to_state' tool to add your research to the field 'research'. - Summarize what you have learned. Now, use your Wikipedia tool to do research. """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[ LangchainTool(tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())), append_to_state, ], ) film_concept_team = SequentialAgent( name="film_concept_team", description="Write a film plot outline and save it as a text file.", sub_agents=[ researcher, screenwriter, file_writer ], ) root_agent = Agent( name="greeter", model=model_name, description="Guides the user in crafting a movie plot.", instruction=""" - Let the user know you will help them write a pitch for a hit movie. Ask them for a historical figure to create a movie about. - When they respond, use the 'append_to_state' tool to store the user's response in the 'PROMPT' state key and transfer to the 'film_concept_team' agent """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], sub_agents=[film_concept_team], ) EOF
Sua estrutura de arquivos vai ficar assim: 
Configurar o ambiente virtual
- No terminal, crie e ative um ambiente virtual usando
uv. Isso garante que as dependências do projeto não entrem em conflito com o Python do sistema.uv venv source .venv/bin/activate
Requisitos de instalação
- Execute o comando a seguir no terminal para criar o arquivo
requirements.txt.cat <<EOF > ~/adk_multiagent_systems/requirements.txt # Lists all Python dependencies required to run the multi-agent system, # including the Google ADK, LangChain community tools, and web server libraries. langchain-community==0.4.1 wikipedia==1.4.0 google-adk==1.27.5 fastapi==0.135.2 uvicorn==0.42.0 EOF - Instale os pacotes necessários no ambiente virtual no terminal.
uv pip install -r requirements.txt
Configurar variáveis de ambiente
- Use o comando a seguir no terminal para criar o arquivo
.env, inserindo automaticamente o ID do projeto e a região.cat <<EOF > ~/adk_multiagent_systems/.env GOOGLE_CLOUD_PROJECT="$(gcloud config get-value project)" GOOGLE_CLOUD_PROJECT_NUMBER="$(gcloud projects describe $(gcloud config get-value project) --format='value(projectNumber)')" GOOGLE_CLOUD_LOCATION="us-central1" GOOGLE_GENAI_USE_VERTEXAI=true MODEL="gemini-2.5-flash" EOF - No terminal, carregue as variáveis na sua sessão do shell.
source .env
Recapitulação
Nesta seção, você estabeleceu a base local do seu projeto:
- Criou a estrutura de diretórios e os arquivos de inicialização do agente necessários (
agent.py,callback_logging.py,requirements.txt). - Isole as dependências usando um ambiente virtual (
uv). - Variáveis de ambiente configuradas (
.env) para armazenar detalhes específicos do projeto, como ID do projeto e região.
6. Analisar o arquivo do agente
Você configurou o código-fonte do laboratório, incluindo um sistema multiagente pré-programado. Antes de implantar o aplicativo, é útil entender como os agentes são definidos. A lógica principal do agente está em workflow_agents/agent.py.
- No editor do Cloud Shell, use o explorador de arquivos à esquerda para navegar até
adk_multiagent_systems/workflow_agents/e abra o arquivoagent.py. - Reserve um momento para analisar o arquivo. Não é necessário entender todas as linhas, mas observe a estrutura de alto nível:
- Agentes individuais:o arquivo define três objetos
Agentdistintos:researcher,screenwriterefile_writer. Cada agente recebe uminstructionespecífico (o comando) e uma lista detoolsque ele pode usar (como a ferramentaWikipediaQueryRunou uma ferramentawrite_filepersonalizada). - Composição do agente:os agentes individuais são encadeados em um
SequentialAgentchamadofilm_concept_team. Isso informa ao ADK para executar esses agentes um após o outro, transmitindo o estado de um para o próximo. - O agente raiz:um
root_agent(chamado "greeter") é definido para processar a interação inicial do usuário. Quando o usuário fornece um comando, esse agente o salva no estado do aplicativo e transfere o controle para o fluxo de trabalhofilm_concept_team.
- Agentes individuais:o arquivo define três objetos
Entender essa estrutura ajuda a esclarecer o que você está prestes a implantar: não apenas um único agente, mas uma equipe coordenada de agentes especializados orquestrada pelo ADK.
7. Criar um cluster do Autopilot do GKE
Com o ambiente preparado, a próxima etapa é provisionar a infraestrutura em que o aplicativo do agente será executado. Você vai criar um cluster do GKE Autopilot, que serve como base para sua implantação. Usamos o modo Autopilot porque ele lida com o gerenciamento complexo dos nós, do escalonamento e da segurança subjacentes do cluster, permitindo que você se concentre apenas na implantação do aplicativo.
- No terminal, crie um cluster do GKE Autopilot chamado
adk-cluster.gcloud container clusters create-auto adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT - Depois que o cluster for criado, configure
kubectlpara se conectar a ele executando este comando no terminal:gcloud container clusters get-credentials adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT~/.kube/config). A partir desse momento, a ferramenta de linha de comandokubectlserá autenticada e direcionada para se comunicar com seuadk-cluster.
Recapitulação
Nesta seção, você provisionou a infraestrutura:
- Criou um cluster Autopilot do GKE totalmente gerenciado usando
gcloud. - Configurou a ferramenta
kubectllocal para autenticar e se comunicar com o novo cluster.
8. Conteinerizar e enviar o aplicativo
No momento, o código do seu agente existe apenas no ambiente do Cloud Shell. Para executá-lo no GKE, primeiro é necessário empacotá-lo em uma imagem do contêiner. Uma imagem do contêiner é um arquivo estático e portátil que agrupa o código do aplicativo com todas as dependências dele. Quando você executa essa imagem, ela se torna um contêiner ativo.
Esse processo envolve três etapas principais:
- Crie um ponto de entrada: defina um arquivo
main.pypara transformar a lógica do seu agente em um servidor da Web executável. - Defina a imagem do contêiner: crie um Dockerfile que funcione como um modelo para criar a imagem do contêiner.
- Criar e enviar: use o Cloud Build para executar o Dockerfile, criando a imagem do contêiner e enviando-a para o Google Artifact Registry, um repositório seguro para suas imagens.
prepare o aplicativo para implantação
Seu agente do ADK precisa de um servidor da Web para receber solicitações. O arquivo main.py vai servir como esse ponto de entrada, usando o framework FastAPI para expor a funcionalidade do seu agente por HTTP.
- Na raiz do diretório
adk_multiagent_systemsno terminal, crie um arquivo chamadomain.py.cat <<EOF > ~/adk_multiagent_systems/main.py """ Serves as the application entry point. Initializes the FastAPI web server, discovers the agents defined in the workflow directory, and exposes them via HTTP endpoints for interaction. """ import os import uvicorn from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Get the directory where main.py is located AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) # Configure the session service (e.g., SQLite for local storage) SESSION_SERVICE_URI = "sqlite:///./sessions.db" # Configure CORS to allow requests from various origins for this lab ALLOWED_ORIGINS = ["http://localhost", "http://localhost:8080", "*"] # Enable the ADK's built-in web interface SERVE_WEB_INTERFACE = True # Call the ADK function to discover agents and create the FastAPI app app: FastAPI = get_fast_api_app( agents_dir=AGENT_DIR, session_service_uri=SESSION_SERVICE_URI, allow_origins=ALLOWED_ORIGINS, web=SERVE_WEB_INTERFACE, ) # You can add more FastAPI routes or configurations below if needed # Example: # @app.get("/hello") # async def read_root(): # return {"Hello": "World"} if __name__ == "__main__": # Get the port from the PORT environment variable provided by the container runtime # Run the Uvicorn server, listening on all available network interfaces (0.0.0.0) uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("PORT", 8080))) EOFuvicornexecuta esse aplicativo, detectando o host0.0.0.0para aceitar conexões de qualquer endereço IP e na porta especificada pela variável de ambientePORT, que será definida mais tarde no manifesto do Kubernetes.
Agora, sua estrutura de arquivos, conforme mostrado no painel do explorador no editor do Cloud Shell, deve ter esta aparência: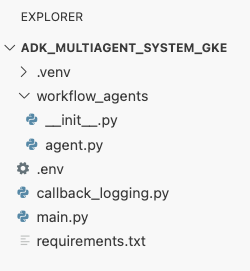
Conteinerizar o agente do ADK com o Docker
Para implantar o aplicativo no GKE, primeiro precisamos empacotá-lo em uma imagem de contêiner, que agrupa o código do aplicativo com todas as bibliotecas e dependências necessárias para a execução. Vamos usar o Docker para criar essa imagem do contêiner.
- Na raiz do diretório
adk_multiagent_systemsno terminal, crie um arquivo chamadoDockerfile.cat <<'EOF' > ~/adk_multiagent_systems/Dockerfile # Defines the blueprint for the container image. Installs dependencies, # sets up a secure non-root user, and specifies the startup command to run the # agent web server. # Use an official lightweight Python image as the base FROM python:3.13-slim # Set the working directory inside the container WORKDIR /app # Create a non-root user for security best practices RUN adduser --disabled-password --gecos "" myuser # Copy and install dependencies first to leverage Docker's layer caching COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt # Copy all application code into the container COPY . . # Create the directory where the agent will write files at runtime # The -p flag ensures the command doesn't fail if the directory already exists RUN mkdir -p movie_pitches # Change ownership of EVERYTHING in /app to the non-root user # Without this, the running agent would be denied permission to write files. RUN chown -R myuser:myuser /app # Switch the active user from root to the non-root user USER myuser # Add the user's local binary directory to the system's PATH ENV PATH="/home/myuser/.local/bin:$PATH" # Define the command to run when the container starts CMD ["sh", "-c", "uvicorn main:app --host 0.0.0.0 --port $PORT"] EOF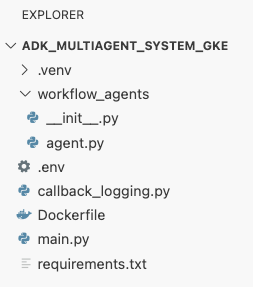
Criar e enviar a imagem do contêiner para o Artifact Registry
Agora que você tem um Dockerfile, use o Cloud Build para criar a imagem e enviá-la por push ao Artifact Registry, um registro particular e seguro integrado aos serviços do Google Cloud. O GKE vai extrair a imagem desse registro para executar o aplicativo.
- No terminal, crie um repositório do Artifact Registry para armazenar a imagem do contêiner.
gcloud artifacts repositories create adk-repo \ --repository-format=docker \ --location=$GOOGLE_CLOUD_LOCATION \ --description="ADK repository" - No terminal, use
gcloud builds submitpara criar a imagem do contêiner e enviá-la ao repositório.gcloud builds submit \ --tag $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo/adk-agent:latest \ --project=$GOOGLE_CLOUD_PROJECT \ .Dockerfile. Ele cria a imagem na nuvem, marca com o endereço do seu repositório do Artifact Registry e envia automaticamente. - No terminal, verifique se a imagem foi criada:
gcloud artifacts docker images list \ $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo \ --project=$GOOGLE_CLOUD_PROJECT
Recapitulação
Nesta seção, você empacotou o código para implantação:
- Criamos um ponto de entrada
main.pypara encapsular seus agentes em um servidor da Web FastAPI. - Defina um
Dockerfilepara agrupar seu código e dependências em uma imagem portátil. - Usei o Cloud Build para criar a imagem e enviá-la a um repositório seguro do Artifact Registry.
9. Criar manifestos do Kubernetes
Agora que a imagem do contêiner foi criada e armazenada no Artifact Registry, você precisa instruir o GKE sobre como executá-la. Isso envolve duas atividades principais:
- Configurar permissões: você vai criar uma identidade dedicada para seu agente no cluster e conceder acesso seguro às APIs do Cloud necessárias (especificamente, Vertex AI).
- Definir o estado do aplicativo: você vai escrever um arquivo de manifesto do Kubernetes, um documento YAML que define de maneira declarativa tudo o que o aplicativo precisa para ser executado, incluindo a imagem do contêiner, as variáveis de ambiente e como ele deve ser exposto à rede.
Configurar a conta de serviço do Kubernetes para a Vertex AI
Seu agente precisa de permissão para se comunicar com a API Vertex AI e acessar os modelos do Gemini. O método mais seguro e recomendado para conceder essa permissão no GKE é a Identidade da carga de trabalho. Com a Identidade da carga de trabalho, é possível vincular uma identidade nativa do Kubernetes (uma conta de serviço do Kubernetes) a uma identidade do Google Cloud (uma conta de serviço do IAM), evitando completamente a necessidade de baixar, gerenciar e armazenar chaves JSON estáticas.
- No terminal, crie a conta de serviço do Kubernetes (
adk-agent-sa). Isso cria uma identidade para seu agente no cluster do GKE que os pods podem usar.kubectl create serviceaccount adk-agent-sa - No terminal, vincule sua conta de serviço do Kubernetes ao Cloud IAM do Google Cloud criando uma vinculação de política. Esse comando concede o papel
aiplatform.userao seuadk-agent-sa, permitindo que ele invoque a API Vertex AI com segurança.gcloud projects add-iam-policy-binding projects/${GOOGLE_CLOUD_PROJECT} \ --role=roles/aiplatform.user \ --member=principal://iam.googleapis.com/projects/${GOOGLE_CLOUD_PROJECT_NUMBER}/locations/global/workloadIdentityPools/${GOOGLE_CLOUD_PROJECT}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \ --condition=None
Criar os arquivos de manifesto do Kubernetes
O Kubernetes usa arquivos de manifesto YAML para definir o estado desejado do seu aplicativo. Você vai criar um arquivo deployment.yaml que contém dois objetos essenciais do Kubernetes: uma implantação e um serviço.
- No terminal, gere o arquivo
deployment.yaml.cat <<EOF > ~/adk_multiagent_systems/deployment.yaml # Defines the Kubernetes resources required to deploy the application to GKE. # Includes the Deployment (to run the container pods) and the Service # (to expose the application via a Load Balancer). apiVersion: apps/v1 kind: Deployment metadata: name: adk-agent spec: replicas: 1 selector: matchLabels: app: adk-agent template: metadata: labels: app: adk-agent spec: # Assign the Kubernetes Service Account for Workload Identity serviceAccountName: adk-agent-sa containers: - name: adk-agent imagePullPolicy: Always # The path to the container image in Artifact Registry image: ${GOOGLE_CLOUD_LOCATION}-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/adk-repo/adk-agent:latest # Define the resources for GKE Autopilot to provision resources: limits: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" requests: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" ports: - containerPort: 8080 # Environment variables passed to the application env: - name: PORT value: "8080" - name: GOOGLE_CLOUD_PROJECT value: ${GOOGLE_CLOUD_PROJECT} - name: GOOGLE_CLOUD_LOCATION value: ${GOOGLE_CLOUD_LOCATION} - name: GOOGLE_GENAI_USE_VERTEXAI value: "true" - name: MODEL value: "gemini-2.5-flash" --- apiVersion: v1 kind: Service metadata: name: adk-agent spec: # Create a public-facing Network Load Balancer with an external IP type: LoadBalancer ports: - port: 80 targetPort: 8080 selector: app: adk-agent EOF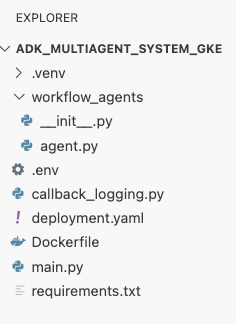
Recapitulação
Nesta seção, você definiu a configuração de segurança e implantação:
- Criamos uma conta de serviço do Kubernetes e a vinculamos ao IAM do Google Cloud usando a Identidade da carga de trabalho, permitindo que seus pods acessem a Vertex AI com segurança sem gerenciar chaves.
- Gerou um arquivo
deployment.yamlque define a implantação (como executar os pods) e o serviço (como expô-los por um balanceador de carga).
10. Implantar o aplicativo no GKE
Com o arquivo de manifesto definido e a imagem do contêiner enviada para o Artifact Registry, você está pronto para implantar o aplicativo. Nesta tarefa, você vai usar o kubectl para aplicar a configuração ao cluster do GKE e monitorar o status para garantir que o agente seja iniciado corretamente.
- No terminal, aplique o manifesto
deployment.yamlao cluster.kubectl apply -f deployment.yamlkubectl applyenvia seu arquivodeployment.yamlpara o servidor da API Kubernetes. Em seguida, o servidor lê sua configuração e organiza a criação dos objetos de implantação e serviço. - No terminal, verifique o status da implantação em tempo real. Aguarde até que os pods estejam no estado
Running.kubectl get pods -l=app=adk-agent --watch- Pendente: o pod foi aceito pelo cluster, mas o contêiner ainda não foi criado.
- Criação de contêiner: o GKE está extraindo a imagem do contêiner do Artifact Registry e iniciando o contêiner.
- Execução: sucesso! O contêiner está em execução, e o aplicativo do agente está ativo.
- Quando o status mostrar
Running, pressione CTRL+C no terminal para interromper o comando "watch" e voltar ao prompt de comando.
Recapitulação
Nesta seção, você iniciou a carga de trabalho:
- Use
kubectlapply para enviar o manifesto ao cluster. - Monitorou o ciclo de vida do pod (Pendente -> ContainerCreating -> Em execução) para garantir que o aplicativo fosse iniciado corretamente.
11. Interagir com o agente
Seu agente do ADK agora está sendo executado no GKE e exposto à Internet por um balanceador de carga público. Você vai se conectar à interface da Web do agente para interagir com ele e verificar se todo o sistema está funcionando corretamente.
Encontre o endereço IP externo do seu serviço
Para acessar o agente, primeiro você precisa receber o endereço IP público que o GKE provisionou para seu serviço.
- No terminal, execute o comando a seguir para receber os detalhes do serviço.
kubectl get service adk-agent - Procure o valor na coluna
EXTERNAL-IP. Pode levar um ou dois minutos para que o endereço IP seja atribuído após a primeira implantação do serviço. Se ele aparecer comopending, aguarde um minuto e execute o comando novamente. A saída será semelhante a esta:NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE adk-agent-service LoadBalancer 10.120.12.234 34.123.45.67 80:31234/TCP 5mEXTERNAL-IP(por exemplo, 34.123.45.67) é o ponto de entrada público do seu agente.
teste o agente implantado
Agora você pode usar o endereço IP público para acessar a interface da web integrada do ADK diretamente do navegador.
- Copie o endereço IP externo (
EXTERNAL-IP) do terminal. - Abra uma nova guia no navegador da Web e digite
http://[EXTERNAL-IP], substituindo[EXTERNAL-IP]pelo endereço IP copiado. - Agora você vai ver a interface da Web do ADK.
- Verifique se workflow_agents está selecionado no menu suspenso de agentes.
- Ative a opção Streaming de token.
- Digite
helloe pressione "Enter" para iniciar uma nova conversa. - Observe o resultado. O agente deve responder rapidamente com a saudação: "Posso ajudar você a escrever uma proposta para um filme de sucesso. Sobre qual figura histórica você gostaria de fazer um filme?"
- Quando solicitado a escolher um personagem histórico, escolha um de seu interesse. Algumas ideias incluem:
the most successful female pirate in historythe woman who invented the first computer compilera legendary lawman of the American Wild West
Recapitulação
Nesta seção, você verificou a implantação:
- Recuperou o endereço IP externo alocado pelo LoadBalancer.
- Acessou a interface da Web do ADK em um navegador para confirmar se o sistema multiagente é responsivo e funcional.
12. Configure o escalonamento automático
Um dos principais desafios na produção é lidar com o tráfego de usuários imprevisível. Codificar um número fixo de réplicas, como você fez na tarefa anterior, significa que você paga demais por recursos ociosos ou corre o risco de ter um desempenho ruim durante picos de tráfego. O GKE resolve isso com o escalonamento automático.
Você vai configurar um HorizontalPodAutoscaler (HPA), um controlador do Kubernetes que ajusta automaticamente o número de pods em execução na sua implantação com base na utilização da CPU em tempo real.
- No terminal do editor do Cloud Shell, crie um arquivo
hpa.yamlna raiz do diretórioadk_multiagent_systems.cloudshell edit ~/adk_multiagent_systems/hpa.yaml - Adicione o seguinte conteúdo ao novo arquivo
hpa.yaml:# Configures the HorizontalPodAutoscaler (HPA) to automatically scale # the number of running agent pods up or down based on CPU utilization # to handle varying traffic loads. apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: adk-agent-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: adk-agent minReplicas: 1 maxReplicas: 5 targetCPUUtilizationPercentage: 50adk-agent. Ele garante que haja sempre pelo menos um pod em execução, define um máximo de cinco pods e adiciona/remove réplicas para manter a utilização média da CPU em torno de 50%.Neste ponto, a estrutura de arquivos, conforme mostrado no painel do Explorer no editor do Cloud Shell, deve ser assim:
- Cole isso no terminal para aplicar o HPA ao cluster.
kubectl apply -f hpa.yaml
Verificar o escalonador automático
O HPA agora está ativo e monitorando sua implantação. Você pode inspecionar o status para vê-lo em ação.
- Execute o seguinte comando no terminal para conferir o status do HPA.
kubectl get hpa adk-agent-hpaNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE adk-agent-hpa Deployment/adk-agent 0%/50% 1 5 1 30s
Recapitulação
Nesta seção, você otimizou o tráfego de produção:
- Criou um manifesto
hpa.yamlpara definir regras de escalonamento. - Implantamos o HorizontalPodAutoscaler (HPA) para ajustar automaticamente o número de réplicas de pod com base na utilização da CPU.
13. Preparar para produção
Observação: as seções a seguir são apenas para fins informativos e não contêm mais etapas para execução. Elas foram criadas para fornecer contexto e práticas recomendadas para levar seu aplicativo à produção.
Ajustar a performance com alocação de recursos
No GKE Autopilot, você controla a quantidade de CPU e memória provisionada para seu aplicativo especificando o recurso requests no deployment.yaml.
Se você notar que o agente está lento ou falhando por falta de memória, aumente a alocação de recursos dele editando o bloco resources em deployment.yaml e reaplicando o arquivo com kubectl apply.
Por exemplo, para dobrar a memória:
# In deployment.yaml
# ...
resources:
requests:
memory: "2Gi" # Increased from 1Gi
cpu: "1000m"
# ...
Automatize seu fluxo de trabalho com CI/CD
Neste laboratório, você executou comandos manualmente. A prática profissional é criar um pipeline de CI/CD (integração contínua/implantação contínua). Ao conectar um repositório de código-fonte (como o GitHub) a um gatilho de build do Cloud Build, é possível automatizar toda a implantação.
Com um pipeline, toda vez que você envia uma mudança de código, o Cloud Build pode automaticamente:
- Crie a nova imagem do contêiner.
- Envie a imagem para o Artifact Registry
- Aplique os manifestos atualizados do Kubernetes ao seu cluster do GKE.
Gerenciar secrets com segurança
Neste laboratório, você armazenou a configuração em um arquivo .env e a transmitiu ao aplicativo. Isso é conveniente para o desenvolvimento, mas não é seguro para dados sensíveis, como chaves de API. A prática recomendada é usar o Secret Manager para armazenar secrets com segurança.
O GKE tem uma integração nativa com o Secret Manager que permite montar segredos diretamente nos seus pods como variáveis de ambiente ou arquivos, sem que eles sejam verificados no seu código-fonte.
Aqui está a seção Limpar recursos que você pediu, inserida logo antes da seção Conclusão.
14. Limpar recursos
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto ou mantenha o projeto e exclua cada um dos recursos.
Excluir o cluster do GKE
O cluster do GKE é o principal fator de custo neste laboratório. A exclusão interrompe as cobranças de computação.
- No terminal, execute o seguinte comando:
gcloud container clusters delete adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Exclua o repositório do Artifact Registry.
As imagens de contêiner armazenadas no Artifact Registry geram custos de armazenamento.
- No terminal, execute o seguinte comando:
gcloud artifacts repositories delete adk-repo \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Excluir o projeto (opcional)
Se você criou um projeto especificamente para este laboratório e não pretende usá-lo novamente, a maneira mais fácil de fazer a limpeza é excluir o projeto inteiro.
- No terminal, execute o seguinte comando (substitua
[YOUR_PROJECT_ID]pelo ID do projeto):gcloud projects delete [YOUR_PROJECT_ID]
15. Conclusão
Parabéns! Você implantou um aplicativo ADK multiagente em um cluster do GKE de nível de produção. Essa é uma conquista significativa que abrange o ciclo de vida principal de um aplicativo moderno nativo da nuvem, oferecendo uma base sólida para implantar seus próprios sistemas de agentes complexos.
Recapitulação
Neste laboratório, você aprendeu a:
- Provisione um cluster do GKE Autopilot.
- Crie uma imagem de contêiner com um
Dockerfilee envie-a para o Artifact Registry. - Conecte-se com segurança às APIs do Cloud usando a Identidade da carga de trabalho.
- Escreva manifestos do Kubernetes para uma implantação e um serviço.
- Exponha um aplicativo à Internet com um LoadBalancer.
- Configure o escalonamento automático com um HorizontalPodAutoscaler (HPA).