
1. Введение
Обзор
Эта лабораторная работа устраняет критически важный разрыв между разработкой мощной многоагентной системы и ее развертыванием в реальных условиях. Хотя создание агентов локально — это отличное начало, для производственных приложений необходима масштабируемая, надежная и безопасная платформа.
В этой лабораторной работе вы возьмете многоагентную систему, созданную с помощью Google Agent Development Kit (ADK) , и развернете ее в производственной среде на платформе Google Kubernetes Engine (GKE) .
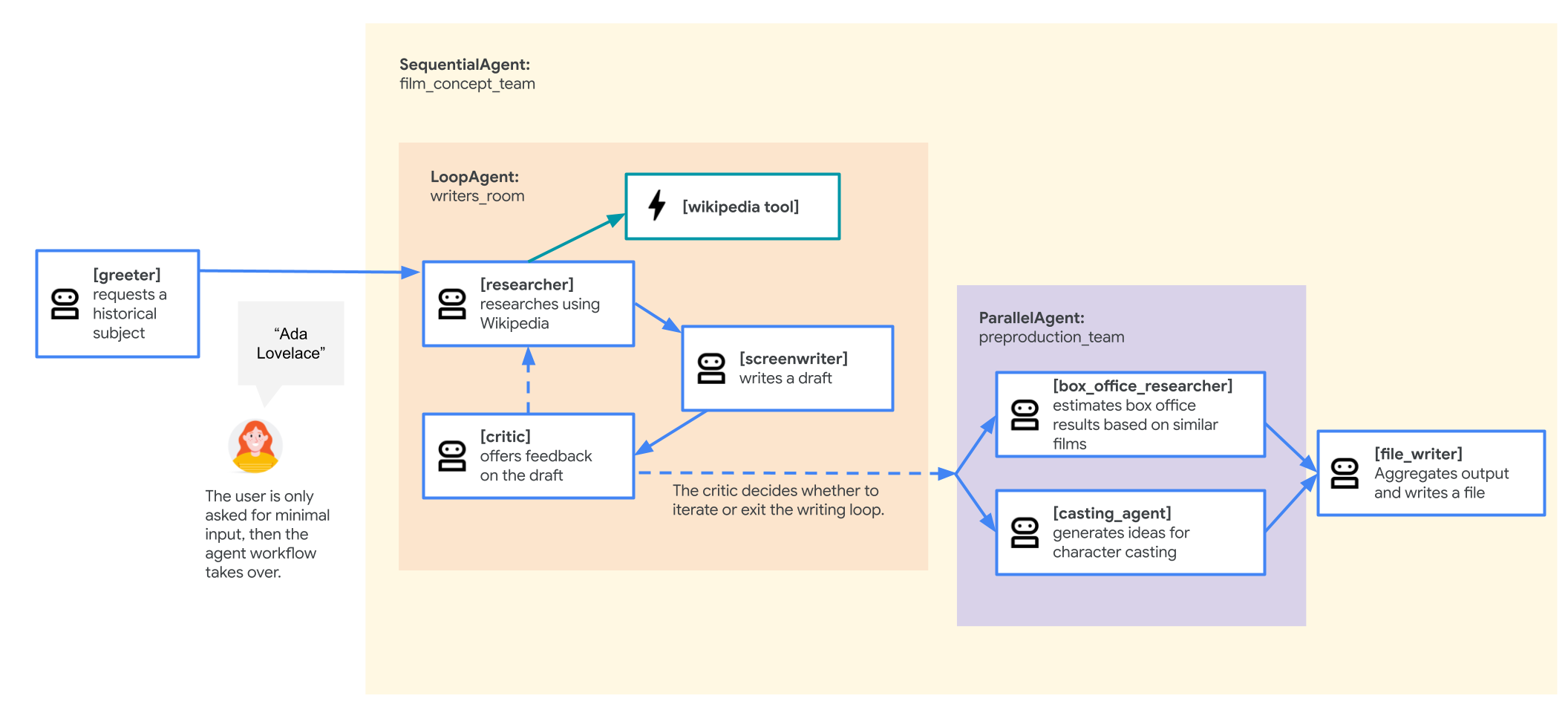
агент команды разработчиков концепции фильма
В качестве примера в этой лабораторной работе используется «команда по разработке концепции фильма», состоящая из нескольких сотрудничающих участников: исследователя, сценариста и автора файлов. Эти участники работают вместе, чтобы помочь пользователю придумать и спланировать сюжет фильма об исторической личности.
Почему стоит развертывать приложения в GKE?
Чтобы подготовить ваш агент к требованиям производственной среды, вам нужна платформа, созданная с учетом масштабируемости, безопасности и экономической эффективности. Google Kubernetes Engine (GKE) предоставляет эту мощную и гибкую основу для запуска вашего контейнеризированного приложения.
Это дает ряд преимуществ для вашей производственной нагрузки:
- Автоматическое масштабирование и повышение производительности : обрабатывайте непредсказуемый трафик с помощью HorizontalPodAutoscaler (HPA) , который автоматически добавляет или удаляет реплики агентов в зависимости от нагрузки. Для более ресурсоемких задач ИИ вы можете подключить аппаратные ускорители, такие как GPU и TPU .
- Экономически эффективное управление ресурсами : оптимизируйте затраты с помощью GKE Autopilot , который автоматически управляет базовой инфраструктурой, поэтому вы платите только за те ресурсы, которые запрашивает ваше приложение.
- Интегрированная безопасность и мониторинг : безопасное подключение к другим сервисам Google Cloud с помощью Workload Identity , что исключает необходимость управления и хранения ключей учетных записей сервисов. Все журналы приложений автоматически передаются в Cloud Logging для централизованного мониторинга и отладки.
- Управление и переносимость : Избегайте привязки к конкретному поставщику с помощью Kubernetes с открытым исходным кодом. Ваше приложение является переносимым и может работать на любом кластере Kubernetes, локально или в других облаках.
Что вы узнаете
В этой лабораторной работе вы научитесь выполнять следующие задачи:
- Создайте кластер GKE Autopilot .
- Создайте контейнер для приложения с помощью Dockerfile и загрузите образ в реестр артефактов .
- Надежно подключите свое приложение к API Google Cloud с помощью Workload Identity.
- Напишите и примените манифесты Kubernetes для развертывания и сервиса.
- Предоставьте доступ к приложению из интернета с помощью балансировщика нагрузки .
- Настройте автоматическое масштабирование с помощью HorizontalPodAutoscaler (HPA).
2. Настройка проекта
Аккаунт Google
Если у вас еще нет личного аккаунта Google, вам необходимо его создать .
Используйте личный аккаунт вместо рабочего или учебного.
Войдите в консоль Google Cloud.
Войдите в консоль Google Cloud, используя личную учетную запись Google.
Включить выставление счетов
Создайте личный платежный аккаунт.
Если вы настроили оплату с использованием кредитов Google Cloud, этот шаг можно пропустить.
Чтобы настроить личный платежный аккаунт, перейдите сюда, чтобы включить оплату в облачной консоли.
Несколько замечаний:
- Выполнение этой лабораторной работы должно обойтись менее чем в 1 доллар США в виде облачных ресурсов.
- В конце этой лабораторной работы вы можете выполнить действия по удалению ресурсов, чтобы избежать дальнейших списаний средств.
- Новые пользователи могут воспользоваться бесплатной пробной версией стоимостью 300 долларов США .
Создать проект (необязательно)
Если у вас нет текущего проекта, который вы хотели бы использовать для этой лабораторной работы, создайте новый проект здесь .
3. Откройте редактор Cloud Shell.
- Нажмите на эту ссылку, чтобы перейти непосредственно в редактор Cloud Shell.
- Если сегодня вам будет предложено авторизоваться, нажмите «Авторизовать» , чтобы продолжить.
- Если терминал не отображается внизу экрана, откройте его:
- Нажмите «Просмотреть».
- Нажмите «Терминал»
- В терминале настройте свой проект с помощью этой команды:
gcloud config set project [PROJECT_ID]- Пример:
gcloud config set project lab-project-id-example - Если вы не помните идентификатор своего проекта, вы можете перечислить все идентификаторы своих проектов с помощью следующей команды:
gcloud projects list
- Пример:
- Вы должны увидеть следующее сообщение:
Updated property [core/project].
4. Включите API.
Для использования GKE , Artifact Registry , Cloud Build и Vertex AI необходимо включить соответствующие API в вашем проекте Google Cloud.
- В терминале включите API:
gcloud services enable \ container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.comOperation "operations/acf.p2-176675280136-b03ab5e4-3483-4ebf-9655-43dc3b345c63" finished successfully.
Представляем API.
- API Google Kubernetes Engine (
container.googleapis.com) позволяет создавать и управлять кластером GKE, в котором работает ваш агент. GKE предоставляет управляемую среду для развертывания, управления и масштабирования контейнеризированных приложений с использованием инфраструктуры Google. - API реестра артефактов (
artifactregistry.googleapis.com) предоставляет безопасное, частное хранилище для образов контейнеров вашего агента. Это эволюция Container Registry, которая легко интегрируется с GKE и Cloud Build. - API Cloud Build (
cloudbuild.googleapis.com) используется командойgcloud builds submitдля сборки образа контейнера в облаке из вашего Dockerfile. Это бессерверная платформа CI/CD, которая выполняет сборки на инфраструктуре Google Cloud. - API Vertex AI (
aiplatform.googleapis.com) позволяет развернутому агенту взаимодействовать с моделями Gemini для выполнения основных задач. Он предоставляет единый API для всех сервисов искусственного интеллекта Google Cloud.
5. Подготовьте среду разработки.
Создайте структуру каталогов.
- В терминале создайте каталог проекта и необходимые подкаталоги:
mkdir -p ~/adk_multiagent_systems/workflow_agents cd ~/adk_multiagent_systems - В терминале выполните следующую команду, чтобы открыть каталог в обозревателе редактора Cloud Shell.
cloudshell open-workspace ~/adk_multiagent_systems - Панель проводника слева обновится. Теперь вы должны увидеть созданные вами каталоги.
В процессе создания файлов на следующих этапах вы увидите, как они появляются в этой директории.
Создайте стартовые файлы
Теперь вам предстоит создать необходимые стартовые файлы для приложения.
- Создайте
callback_logging.py, выполнив следующую команду в терминале . Этот файл отвечает за ведение логов для обеспечения наблюдаемости.cat <<EOF > ~/adk_multiagent_systems/callback_logging.py """ Provides helper functions for observability. Handles formatting and sending agent queries, responses, and tool calls to Google Cloud Logging to aid in monitoring and debugging. """ import logging import google.cloud.logging from google.adk.agents.callback_context import CallbackContext from google.adk.models import LlmResponse, LlmRequest def log_query_to_model(callback_context: CallbackContext, llm_request: LlmRequest): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_request.contents and llm_request.contents[-1].role == 'user': if llm_request.contents[-1].parts and "text" in llm_request.contents[-1].parts: last_user_message = llm_request.contents[-1].parts[0].text logging.info(f"[query to {callback_context.agent_name}]: " + last_user_message) def log_model_response(callback_context: CallbackContext, llm_response: LlmResponse): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_response.content and llm_response.content.parts: for part in llm_response.content.parts: if part.text: logging.info(f"[response from {callback_context.agent_name}]: " + part.text) elif part.function_call: logging.info(f"[function call from {callback_context.agent_name}]: " + part.function_call.name) EOF - Создайте
workflow_agents/__init__.py, выполнив в терминале следующую команду. Это пометит каталог как пакет Python.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/__init__.py """ Marks the directory as a Python package and exposes the agent module, allowing the ADK to discover and register the agents defined within. """ from . import agent EOF - Создайте файл
workflow_agents/agent.py, выполнив следующую команду в терминале . Этот файл содержит основную логику для вашей команды из нескольких агентов.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/agent.py """ Defines the core multi-agent workflow. Configures individual agents (Researcher, Screenwriter, File Writer), assigns their specific tools, and orchestrates their collaboration using the ADK's SequentialAgent pattern. """ import os import logging import google.cloud.logging from callback_logging import log_query_to_model, log_model_response from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent, LoopAgent, ParallelAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool # import from google.genai import types from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL") print(model_name) # Tools def append_to_state( tool_context: ToolContext, field: str, response: str ) -> dict[str, str]: """Append new output to an existing state key. Args: field (str): a field name to append to response (str): a string to append to the field Returns: dict[str, str]: {"status": "success"} """ existing_state = tool_context.state.get(field, []) tool_context.state[field] = existing_state + [response] logging.info(f"[Added to {field}] {response}") return {"status": "success"} def write_file( tool_context: ToolContext, directory: str, filename: str, content: str ) -> dict[str, str]: target_path = os.path.join(directory, filename) os.makedirs(os.path.dirname(target_path), exist_ok=True) with open(target_path, "w") as f: f.write(content) return {"status": "success"} # Agents file_writer = Agent( name="file_writer", model=model_name, description="Creates marketing details and saves a pitch document.", instruction=""" PLOT_OUTLINE: { PLOT_OUTLINE? } INSTRUCTIONS: - Create a marketable, contemporary movie title suggestion for the movie described in the PLOT_OUTLINE. If a title has been suggested in PLOT_OUTLINE, you can use it, or replace it with a better one. - Use your 'write_file' tool to create a new txt file with the following arguments: - for a filename, use the movie title - Write to the 'movie_pitches' directory. - For the 'content' to write, extract the following from the PLOT_OUTLINE: - A logline - Synopsis or plot outline """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[write_file], ) screenwriter = Agent( name="screenwriter", model=model_name, description="As a screenwriter, write a logline and plot outline for a biopic about a historical character.", instruction=""" INSTRUCTIONS: Your goal is to write a logline and three-act plot outline for an inspiring movie about a historical character(s) described by the PROMPT: { PROMPT? } - If there is CRITICAL_FEEDBACK, use those thoughts to improve upon the outline. - If there is RESEARCH provided, feel free to use details from it, but you are not required to use it all. - If there is a PLOT_OUTLINE, improve upon it. - Use the 'append_to_state' tool to write your logline and three-act plot outline to the field 'PLOT_OUTLINE'. - Summarize what you focused on in this pass. PLOT_OUTLINE: { PLOT_OUTLINE? } RESEARCH: { research? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], ) researcher = Agent( name="researcher", model=model_name, description="Answer research questions using Wikipedia.", instruction=""" PROMPT: { PROMPT? } PLOT_OUTLINE: { PLOT_OUTLINE? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } INSTRUCTIONS: - If there is a CRITICAL_FEEDBACK, use your wikipedia tool to do research to solve those suggestions - If there is a PLOT_OUTLINE, use your wikipedia tool to do research to add more historical detail - If these are empty, use your Wikipedia tool to gather facts about the person in the PROMPT - Use the 'append_to_state' tool to add your research to the field 'research'. - Summarize what you have learned. Now, use your Wikipedia tool to do research. """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[ LangchainTool(tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())), append_to_state, ], ) film_concept_team = SequentialAgent( name="film_concept_team", description="Write a film plot outline and save it as a text file.", sub_agents=[ researcher, screenwriter, file_writer ], ) root_agent = Agent( name="greeter", model=model_name, description="Guides the user in crafting a movie plot.", instruction=""" - Let the user know you will help them write a pitch for a hit movie. Ask them for a historical figure to create a movie about. - When they respond, use the 'append_to_state' tool to store the user's response in the 'PROMPT' state key and transfer to the 'film_concept_team' agent """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], sub_agents=[film_concept_team], ) EOF
Теперь структура ваших файлов должна выглядеть следующим образом: 
Настройте виртуальную среду.
- В терминале создайте и активируйте виртуальное окружение с помощью
uv. Это гарантирует, что зависимости вашего проекта не будут конфликтовать с системным Python.uv venv source .venv/bin/activate
Требования к установке
- Выполните следующую команду в терминале , чтобы создать файл
requirements.txt.cat <<EOF > ~/adk_multiagent_systems/requirements.txt # Lists all Python dependencies required to run the multi-agent system, # including the Google ADK, LangChain community tools, and web server libraries. langchain-community==0.4.1 wikipedia==1.4.0 google-adk==1.27.5 fastapi==0.135.2 uvicorn==0.42.0 EOF - Установите необходимые пакеты в виртуальную среду в терминале .
uv pip install -r requirements.txt
Настройте переменные среды.
- Используйте следующую команду в терминале для создания файла
.env, который автоматически добавит идентификатор вашего проекта и регион.cat <<EOF > ~/adk_multiagent_systems/.env GOOGLE_CLOUD_PROJECT="$(gcloud config get-value project)" GOOGLE_CLOUD_PROJECT_NUMBER="$(gcloud projects describe $(gcloud config get-value project) --format='value(projectNumber)')" GOOGLE_CLOUD_LOCATION="us-central1" GOOGLE_GENAI_USE_VERTEXAI=true MODEL="gemini-2.5-flash" EOF - В терминале загрузите переменные в свою сессию командной оболочки.
source .env
Краткий обзор
В этом разделе вы заложили локальную основу для своего проекта:
- Создана структура каталогов и необходимые стартовые файлы агента (
agent.py,callback_logging.py,requirements.txt). - Изолируйте свои зависимости, используя виртуальное окружение (
uv). - Настроены переменные среды (
.env) для хранения сведений, специфичных для проекта, таких как идентификатор проекта и регион.
6. Изучите файл агента.
Вы подготовили исходный код для лабораторной работы, включая предварительно написанную многоагентную систему. Перед развертыванием приложения полезно понять, как определяются агенты. Основная логика работы агентов находится в workflow_agents/agent.py .
- В редакторе Cloud Shell используйте файловый менеджер слева, чтобы перейти в папку
adk_multiagent_systems/workflow_agents/и открыть файлagent.py. - Уделите немного времени, чтобы просмотреть файл. Вам не нужно понимать каждую строку, но обратите внимание на общую структуру:
- Отдельные агенты: В файле определены три отдельных объекта
Agent:researcher,screenwriterиfile_writer. Каждому агенту дается конкретнаяinstruction(его подсказка) и списокtoolsкоторые ему разрешено использовать (например, инструментWikipediaQueryRunили пользовательский инструментwrite_file). - Состав агентов: Отдельные агенты объединены в цепочку
SequentialAgentпод названиемfilm_concept_team. Это указывает ADK запускать этих агентов один за другим, передавая состояние от одного к другому. - Основной агент: Для обработки первоначального взаимодействия с пользователем определяется
root_agent(с именем "greeter"). Когда пользователь отправляет запрос, этот агент сохраняет его в состоянии приложения, а затем передает управление рабочему процессуfilm_concept_team.
- Отдельные агенты: В файле определены три отдельных объекта
Понимание этой структуры помогает прояснить, что именно вы собираетесь развернуть: не просто одного агента, а скоординированную команду специализированных агентов, управляемую ADK.
7. Создайте кластер GKE Autopilot.
После подготовки среды следующим шагом будет создание инфраструктуры, на которой будет работать ваше агентское приложение. Вы создадите кластер GKE Autopilot , который послужит основой для развертывания. Мы используем режим Autopilot, поскольку он берет на себя сложное управление базовыми узлами кластера, масштабированием и безопасностью, позволяя вам сосредоточиться исключительно на развертывании вашего приложения.
- В терминале создайте новый кластер GKE Autopilot с именем
adk-cluster.gcloud container clusters create-auto adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT - После создания кластера настройте
kubectlдля подключения к нему, выполнив в терминале следующую команду:gcloud container clusters get-credentials adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT~/.kube/config). С этого момента инструмент командной строкиkubectlбудет аутентифицирован и направлен на взаимодействие с вашимadk-cluster.
Краткий обзор
В этом разделе вы выполнили настройку инфраструктуры:
- Создан полностью управляемый кластер GKE Autopilot с использованием
gcloud. - Настройте локальный инструмент
kubectlдля аутентификации и связи с новым кластером.
8. Создайте контейнер и загрузите приложение.
В настоящее время код вашего агента существует только в вашей среде Cloud Shell. Чтобы запустить его в GKE, необходимо сначала упаковать его в образ контейнера . Образ контейнера — это статический, переносимый файл, который объединяет код вашего приложения со всеми его зависимостями. При запуске этого образа он становится работающим контейнером.
Этот процесс включает три ключевых этапа:
- Создайте точку входа : определите файл
main.py, чтобы преобразовать логику вашего агента в работающий веб-сервер. - Определите образ контейнера : создайте Dockerfile , который будет служить шаблоном для сборки образа контейнера.
- Сборка и отправка : Используйте Cloud Build для выполнения Dockerfile, создания образа контейнера и его отправки в Google Artifact Registry — безопасное хранилище ваших образов.
Подготовьте приложение к развертыванию.
Вашему агенту ADK необходим веб-сервер для приема запросов. Файл main.py будет служить этой точкой входа, используя фреймворк FastAPI для предоставления доступа к функциональности вашего агента по протоколу HTTP.
- В корневом каталоге
adk_multiagent_systemsв терминале создайте новый файл с именемmain.pycat <<EOF > ~/adk_multiagent_systems/main.py """ Serves as the application entry point. Initializes the FastAPI web server, discovers the agents defined in the workflow directory, and exposes them via HTTP endpoints for interaction. """ import os import uvicorn from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Get the directory where main.py is located AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) # Configure the session service (e.g., SQLite for local storage) SESSION_SERVICE_URI = "sqlite:///./sessions.db" # Configure CORS to allow requests from various origins for this lab ALLOWED_ORIGINS = ["http://localhost", "http://localhost:8080", "*"] # Enable the ADK's built-in web interface SERVE_WEB_INTERFACE = True # Call the ADK function to discover agents and create the FastAPI app app: FastAPI = get_fast_api_app( agents_dir=AGENT_DIR, session_service_uri=SESSION_SERVICE_URI, allow_origins=ALLOWED_ORIGINS, web=SERVE_WEB_INTERFACE, ) # You can add more FastAPI routes or configurations below if needed # Example: # @app.get("/hello") # async def read_root(): # return {"Hello": "World"} if __name__ == "__main__": # Get the port from the PORT environment variable provided by the container runtime # Run the Uvicorn server, listening on all available network interfaces (0.0.0.0) uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("PORT", 8080))) EOFuvicornзапускает это приложение, прослушивая хост0.0.0.0для приема соединений с любого IP-адреса и на порту, указанном переменной средыPORT, которую мы установим позже в манифесте Kubernetes.
На этом этапе структура ваших файлов, отображаемая в панели проводника в редакторе Cloud Shell, должна выглядеть следующим образом: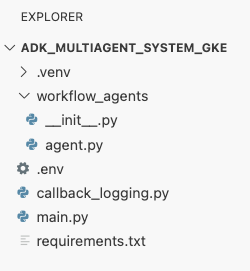
Создайте контейнер для агента ADK с помощью Docker.
Для развертывания нашего приложения в GKE нам сначала нужно упаковать его в образ контейнера, который будет включать в себя код приложения со всеми необходимыми для его работы библиотеками и зависимостями. Для создания этого образа контейнера мы будем использовать Docker .
- В корневом каталоге
adk_multiagent_systemsв терминале создайте новый файл с именемDockerfile.cat <<'EOF' > ~/adk_multiagent_systems/Dockerfile # Defines the blueprint for the container image. Installs dependencies, # sets up a secure non-root user, and specifies the startup command to run the # agent web server. # Use an official lightweight Python image as the base FROM python:3.13-slim # Set the working directory inside the container WORKDIR /app # Create a non-root user for security best practices RUN adduser --disabled-password --gecos "" myuser # Copy and install dependencies first to leverage Docker's layer caching COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt # Copy all application code into the container COPY . . # Create the directory where the agent will write files at runtime # The -p flag ensures the command doesn't fail if the directory already exists RUN mkdir -p movie_pitches # Change ownership of EVERYTHING in /app to the non-root user # Without this, the running agent would be denied permission to write files. RUN chown -R myuser:myuser /app # Switch the active user from root to the non-root user USER myuser # Add the user's local binary directory to the system's PATH ENV PATH="/home/myuser/.local/bin:$PATH" # Define the command to run when the container starts CMD ["sh", "-c", "uvicorn main:app --host 0.0.0.0 --port $PORT"] EOF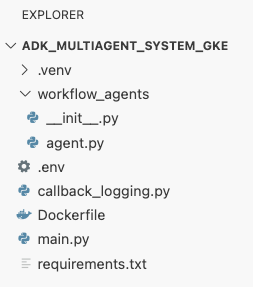
Соберите и загрузите образ контейнера в реестр артефактов.
Теперь, когда у вас есть Dockerfile, вы будете использовать Cloud Build для сборки образа и его загрузки в Artifact Registry — безопасный частный реестр, интегрированный с сервисами Google Cloud. GKE загрузит образ из этого реестра для запуска вашего приложения.
- В терминале создайте новый репозиторий Artifact Registry для хранения образа вашего контейнера.
gcloud artifacts repositories create adk-repo \ --repository-format=docker \ --location=$GOOGLE_CLOUD_LOCATION \ --description="ADK repository" - В терминале используйте
gcloud builds submitдля сборки образа контейнера и его отправки в репозиторий.gcloud builds submit \ --tag $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo/adk-agent:latest \ --project=$GOOGLE_CLOUD_PROJECT \ .Dockerfile. Она собирает образ в облаке, помечает его тегом с адресом вашего репозитория Artifact Registry и автоматически отправляет его туда. - В терминале убедитесь, что образ собран:
gcloud artifacts docker images list \ $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo \ --project=$GOOGLE_CLOUD_PROJECT
Краткий обзор
В этом разделе вы упаковали свой код для развертывания:
- Создан входной файл
main.pyдля интеграции ваших агентов в веб-сервер FastAPI. - Создан
Dockerfileдля сборки вашего кода и зависимостей в портативный образ. - Для сборки образа и его загрузки в защищенное хранилище Artifact Registry использовался Cloud Build.
9. Создайте манифесты Kubernetes.
Теперь, когда образ контейнера создан и сохранен в реестре артефактов, вам необходимо указать GKE, как его запустить. Это включает в себя два основных действия:
- Настройка разрешений : Вам потребуется создать выделенную учетную запись для вашего агента в кластере и предоставить ему безопасный доступ к необходимым API Google Cloud (в частности, к Vertex AI ).
- Определение состояния приложения : Вам необходимо будет написать файл манифеста Kubernetes — документ YAML, который декларативно определяет все, что необходимо вашему приложению для работы, включая образ контейнера, переменные среды и способ его доступа к сети.
Настройка учетной записи службы Kubernetes для Vertex AI
Вашему агенту необходимо разрешение на взаимодействие с API Vertex AI для доступа к моделям Gemini. Наиболее безопасный и рекомендуемый способ предоставления этого разрешения в GKE — это Workload Identity . Workload Identity позволяет связать идентификатор Kubernetes ( учетную запись службы Kubernetes ) с идентификатором Google Cloud ( учетной записью службы IAM ), полностью исключая необходимость загрузки, управления и хранения статических ключей JSON.
- В терминале создайте учетную запись службы Kubernetes (
adk-agent-sa). Это создаст идентификатор для вашего агента внутри кластера GKE, который смогут использовать ваши поды.kubectl create serviceaccount adk-agent-sa - В терминале свяжите свою учетную запись Kubernetes Service с Google Cloud IAM, создав привязку политики. Эта команда предоставит роль
aiplatform.userвашемуadk-agent-sa, что позволит ему безопасно вызывать API Vertex AI.gcloud projects add-iam-policy-binding projects/${GOOGLE_CLOUD_PROJECT} \ --role=roles/aiplatform.user \ --member=principal://iam.googleapis.com/projects/${GOOGLE_CLOUD_PROJECT_NUMBER}/locations/global/workloadIdentityPools/${GOOGLE_CLOUD_PROJECT}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \ --condition=None
Создайте файлы манифеста Kubernetes.
Kubernetes использует файлы манифеста YAML для определения желаемого состояния вашего приложения. Вам потребуется создать файл deployment.yaml , содержащий два основных объекта Kubernetes: объект Deployment и объект Service .
- В терминале сгенерируйте файл
deployment.yaml.cat <<EOF > ~/adk_multiagent_systems/deployment.yaml # Defines the Kubernetes resources required to deploy the application to GKE. # Includes the Deployment (to run the container pods) and the Service # (to expose the application via a Load Balancer). apiVersion: apps/v1 kind: Deployment metadata: name: adk-agent spec: replicas: 1 selector: matchLabels: app: adk-agent template: metadata: labels: app: adk-agent spec: # Assign the Kubernetes Service Account for Workload Identity serviceAccountName: adk-agent-sa containers: - name: adk-agent imagePullPolicy: Always # The path to the container image in Artifact Registry image: ${GOOGLE_CLOUD_LOCATION}-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/adk-repo/adk-agent:latest # Define the resources for GKE Autopilot to provision resources: limits: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" requests: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" ports: - containerPort: 8080 # Environment variables passed to the application env: - name: PORT value: "8080" - name: GOOGLE_CLOUD_PROJECT value: ${GOOGLE_CLOUD_PROJECT} - name: GOOGLE_CLOUD_LOCATION value: ${GOOGLE_CLOUD_LOCATION} - name: GOOGLE_GENAI_USE_VERTEXAI value: "true" - name: MODEL value: "gemini-2.5-flash" --- apiVersion: v1 kind: Service metadata: name: adk-agent spec: # Create a public-facing Network Load Balancer with an external IP type: LoadBalancer ports: - port: 80 targetPort: 8080 selector: app: adk-agent EOF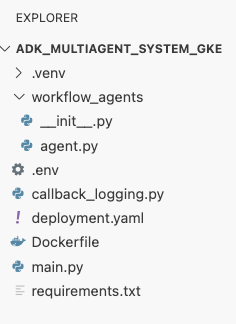
Краткий обзор
В этом разделе вы определили конфигурацию безопасности и развертывания:
- Создана учетная запись Kubernetes Service и связана с Google Cloud IAM с помощью Workload Identity, что позволяет вашим подам безопасно получать доступ к Vertex AI без управления ключами.
- Сгенерирован файл
deployment.yaml, определяющий Deployment (способ запуска подов) и Service (способ предоставления к ним доступа через балансировщик нагрузки).
10. Разверните приложение в GKE.
После определения файла манифеста и загрузки образа контейнера в реестр артефактов, вы готовы развернуть приложение. В этой задаче вы будете использовать kubectl для применения конфигурации к кластеру GKE, а затем отслеживать состояние, чтобы убедиться в корректном запуске агента.
- В терминале примените файл
deployment.yamlк вашему кластеру.kubectl apply -f deployment.yamlkubectl applyотправляет ваш файлdeployment.yamlна сервер API Kubernetes. Затем сервер считывает вашу конфигурацию и организует создание объектов `Deployment` и `Service`. - В терминале проверьте статус вашего развертывания в режиме реального времени. Дождитесь, пока поды перейдут в состояние
Running.kubectl get pods -l=app=adk-agent --watch- Ожидание : Под принят кластером, но контейнер еще не создан.
- Создание контейнера : GKE загружает образ вашего контейнера из реестра артефактов и запускает контейнер.
- Запуск : Успех! Контейнер запущен, и ваше агентское приложение работает.
- Как только статус отобразится
Running, нажмите CTRL+C в терминале , чтобы остановить команду watch и вернуться в командную строку.
Краткий обзор
В этом разделе вы запустили рабочую нагрузку:
- Используйте
kubectlapply` для отправки манифеста в кластер. - Отслеживал жизненный цикл Pod-а (Pending -> ContainerCreating -> Running), чтобы убедиться в успешном запуске приложения.
11. Взаимодействуйте с агентом.
Ваш агент ADK теперь работает в режиме реального времени в GKE и доступен из интернета через общедоступный балансировщик нагрузки. Вам нужно будет подключиться к веб-интерфейсу агента, чтобы взаимодействовать с ним и убедиться в корректной работе всей системы.
Найдите внешний IP-адрес вашей службы.
Для доступа к агенту вам сначала необходимо получить публичный IP-адрес, который GKE выделил для вашей службы.
- В терминале выполните следующую команду, чтобы получить подробную информацию о вашей службе.
kubectl get service adk-agent - Найдите значение в столбце
EXTERNAL-IP. Назначение IP-адреса после первого развертывания службы может занять одну-две минуты. Если отображается статусpending, подождите минуту и выполните команду снова. Вывод будет выглядеть примерно так:NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE adk-agent-service LoadBalancer 10.120.12.234 34.123.45.67 80:31234/TCP 5mEXTERNAL-IP(например, 34.123.45.67), является общедоступной точкой входа для вашего агента.
Протестируйте развернутого агента.
Теперь вы можете использовать публичный IP-адрес для доступа к встроенному веб-интерфейсу ADK непосредственно из своего браузера.
- Скопируйте внешний IP-адрес (
EXTERNAL-IP) с терминала . - Откройте новую вкладку в веб-браузере и введите
http://[EXTERNAL-IP], заменив[EXTERNAL-IP]скопированным IP-адресом. - Теперь вы должны увидеть веб-интерфейс ADK.
- Убедитесь, что в выпадающем меню «Агенты» выбран пункт workflow_agents .
- Включите потоковую передачу токенов .
- Напишите
helloи нажмите Enter, чтобы начать новый разговор. - Обратите внимание на результат. Агент должен быстро ответить своим приветствием: «Я могу помочь вам написать презентацию для успешного фильма. О какой исторической личности вы хотели бы снять фильм?»
- Когда вас попросят выбрать исторического персонажа, выберите того, кто вас интересует. Вот несколько вариантов:
-
the most successful female pirate in history -
the woman who invented the first computer compiler -
a legendary lawman of the American Wild West
-
Краткий обзор
В этом разделе вы проверили развертывание:
- Получен внешний IP-адрес, выделенный балансировщиком нагрузки.
- Для подтверждения работоспособности и корректности работы многоагентной системы был осуществлен доступ к веб-интерфейсу ADK через браузер.
12. Настройка автомасштабирования
Ключевая проблема в производственной среде — обработка непредсказуемого пользовательского трафика. Жесткое кодирование фиксированного количества реплик, как вы делали в предыдущем задании, означает либо переплату за простаивающие ресурсы, либо риск низкой производительности во время пиковых нагрузок. GKE решает эту проблему с помощью автоматического масштабирования.
Вам потребуется настроить HorizontalPodAutoscaler (HPA) — контроллер Kubernetes, который автоматически регулирует количество запущенных подов в вашем развертывании на основе загрузки ЦП в реальном времени.
- В терминале Cloud Shell Editor создайте новый файл
hpa.yamlв корневом каталогеadk_multiagent_systems.cloudshell edit ~/adk_multiagent_systems/hpa.yaml - Добавьте следующее содержимое в новый файл
hpa.yaml:# Configures the HorizontalPodAutoscaler (HPA) to automatically scale # the number of running agent pods up or down based on CPU utilization # to handle varying traffic loads. apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: adk-agent-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: adk-agent minReplicas: 1 maxReplicas: 5 targetCPUUtilizationPercentage: 50adk-agent. Он гарантирует, что всегда будет запущен как минимум 1 под, устанавливает максимальное количество подов — 5, и будет добавлять/удалять реплики для поддержания средней загрузки ЦП на уровне около 50%. На этом этапе структура файлов, отображаемая в панели проводника в редакторе Cloud Shell, должна выглядеть следующим образом:
- Для применения HPA к вашему кластеру, вставив этот код в терминал .
kubectl apply -f hpa.yaml
Проверьте автомасштабирование.
HPA теперь активна и отслеживает вашу систему развертывания. Вы можете проверить ее статус, чтобы увидеть ее работу.
- Выполните следующую команду в терминале , чтобы получить статус вашего HPA.
kubectl get hpa adk-agent-hpaNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE adk-agent-hpa Deployment/adk-agent 0%/50% 1 5 1 30s
Краткий обзор
В этом разделе вы оптимизировали сайт для производственного трафика:
- Создан манифест
hpa.yamlдля определения правил масштабирования. - Внедрен инструмент HorizontalPodAutoscaler (HPA) для автоматической регулировки количества реплик подов в зависимости от загрузки ЦП.
13. Подготовка к производству
Примечание : Следующие разделы носят исключительно информационный характер и не содержат дальнейших шагов по их выполнению. Они предназначены для предоставления контекста и рекомендаций по внедрению вашего приложения в рабочую среду.
Оптимизация производительности с помощью распределения ресурсов.
В GKE Autopilot вы управляете объемом ресурсов ЦП и памяти, выделяемых для вашего приложения, указывая requests на ресурсы в файле deployment.yaml .
Если вы обнаружили, что ваш агент работает медленно или аварийно завершает работу из-за нехватки памяти, вы можете увеличить объем выделяемых ему ресурсов, отредактировав блок resources в файле deployment.yaml и повторно применив файл с помощью kubectl apply .
Например, чтобы удвоить объем памяти:
# In deployment.yaml
# ...
resources:
requests:
memory: "2Gi" # Increased from 1Gi
cpu: "1000m"
# ...
Автоматизируйте свой рабочий процесс с помощью CI/CD.
В этой лабораторной работе вы выполняли команды вручную. Профессиональная практика предполагает создание конвейера CI/CD (непрерывная интеграция/непрерывное развертывание). Подключив репозиторий исходного кода (например, GitHub) к триггеру Cloud Build , вы можете автоматизировать весь процесс развертывания.
При использовании конвейера каждый раз, когда вы отправляете изменения в код, Cloud Build может автоматически:
- Создайте новый образ контейнера.
- Загрузите образ в Реестр артефактов.
- Примените обновленные манифесты Kubernetes к вашему кластеру GKE.
Обеспечьте безопасное управление секретами.
В этой лабораторной работе вы сохранили конфигурацию в файле .env и передали его своему приложению. Это удобно для разработки, но небезопасно для конфиденциальных данных, таких как ключи API. Рекомендуемая лучшая практика — использовать Secret Manager для безопасного хранения секретов.
GKE имеет встроенную интеграцию с Secret Manager, которая позволяет монтировать секреты непосредственно в ваши поды в качестве переменных окружения или файлов, без их добавления в исходный код.
Здесь, непосредственно перед разделом «Заключение» , размещен запрошенный вами раздел «Ресурсы для очистки» .
14. Очистка ресурсов
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, используемые в этом руководстве, либо удалите проект, содержащий эти ресурсы, либо сохраните проект и удалите отдельные ресурсы.
Удалите кластер GKE.
В этой лабораторной работе основной статьей расходов является кластер GKE. Его удаление прекращает взимание платы за вычислительные ресурсы.
- В терминале выполните следующую команду:
gcloud container clusters delete adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Удалите репозиторий Реестра артефактов.
Хранение изображений контейнеров в реестре артефактов влечет за собой расходы на хранение.
- В терминале выполните следующую команду:
gcloud artifacts repositories delete adk-repo \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Удалить проект (необязательно)
Если вы создали новый проект специально для этой лабораторной работы и не планируете использовать его снова, самый простой способ навести порядок — удалить весь проект.
- В терминале выполните следующую команду (замените
[YOUR_PROJECT_ID]на фактический идентификатор вашего проекта):gcloud projects delete [YOUR_PROJECT_ID]
15. Заключение
Поздравляем! Вы успешно развернули многоагентное ADK-приложение в кластере GKE производственного уровня. Это значительное достижение, охватывающее основной жизненный цикл современного облачного приложения и обеспечивающее прочную основу для развертывания собственных сложных агентных систем.
Краткий обзор
В этой лабораторной работе вы научились:
- Создайте кластер GKE Autopilot .
- Создайте образ контейнера с помощью
Dockerfileи загрузите его в реестр артефактов. - Безопасное подключение к API Google Cloud с помощью Workload Identity .
- Напишите манифесты Kubernetes для развертывания и сервиса.
- Предоставьте доступ к приложению из интернета с помощью балансировщика нагрузки .
- Настройте автоматическое масштабирование с помощью HorizontalPodAutoscaler (HPA).