
1. บทนำ
ภาพรวม
แล็บนี้จะช่วยเติมเต็มช่องว่างที่สำคัญระหว่างการพัฒนาระบบแบบหลายเอเจนต์ที่มีประสิทธิภาพกับการนำไปใช้ในโลกแห่งความเป็นจริง แม้ว่าการสร้างเอเจนต์ในเครื่องจะเป็นการเริ่มต้นที่ดี แต่แอปพลิเคชันเวอร์ชันที่ใช้งานจริงต้องใช้แพลตฟอร์มที่ปรับขนาดได้ เชื่อถือได้ และปลอดภัย
ในแล็บนี้ คุณจะได้ใช้ระบบแบบหลาย Agent ที่สร้างขึ้นด้วย Google Agent Development Kit (ADK) และทำให้ใช้งานได้ในสภาพแวดล้อมระดับการใช้งานจริงบน Google Kubernetes Engine (GKE)
ตัวแทนทีมแนวคิดภาพยนตร์
แอปพลิเคชันตัวอย่างที่ใช้ในแล็บนี้คือ "ทีมแนวคิดภาพยนตร์" ซึ่งประกอบด้วยเอเจนต์หลายรายที่ทำงานร่วมกัน ได้แก่ นักวิจัย นักเขียนบท และผู้เขียนไฟล์ เอเจนต์เหล่านี้ทำงานร่วมกันเพื่อช่วยผู้ใช้ระดมความคิดและร่างการเสนอภาพยนตร์เกี่ยวกับบุคคลสำคัญในประวัติศาสตร์
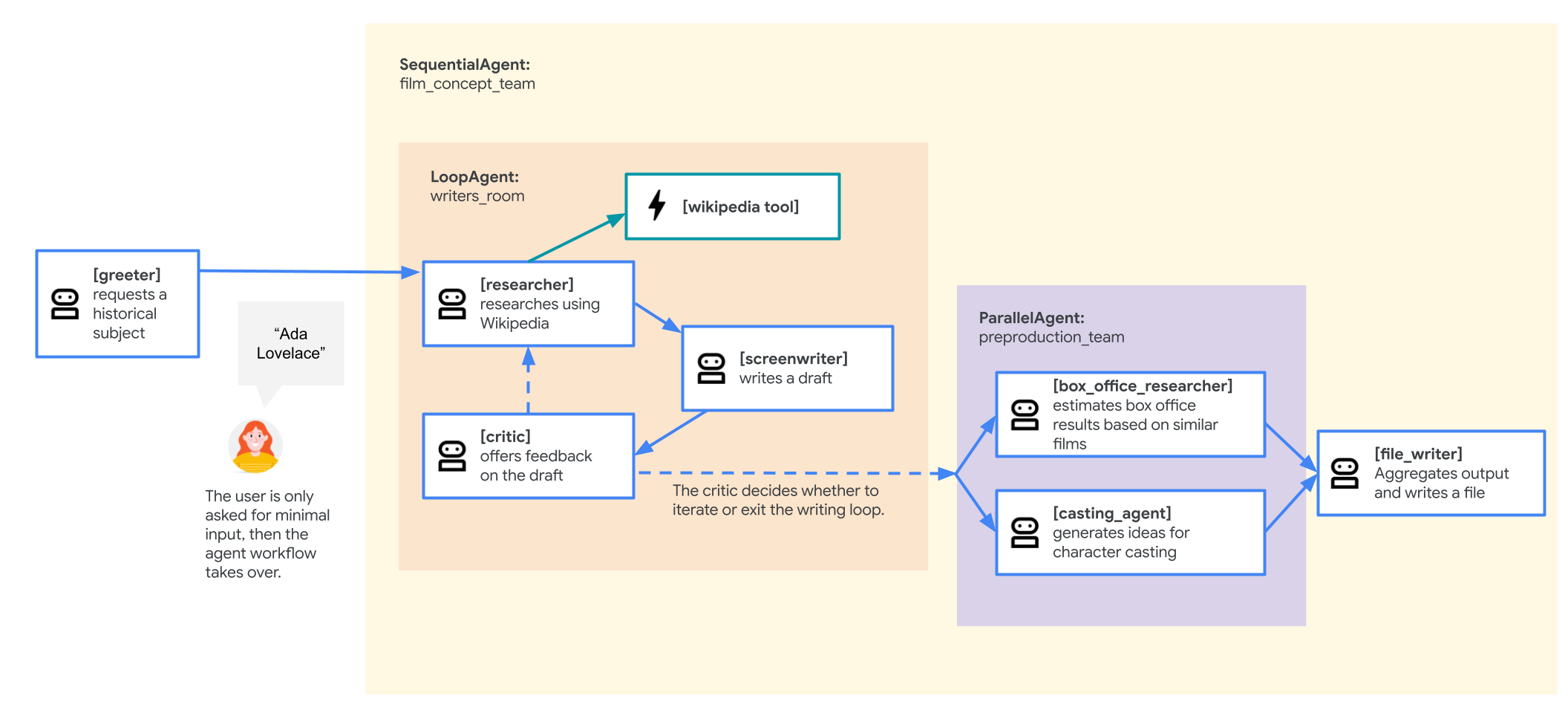
เหตุใดจึงควรทำให้ใช้งานได้ใน GKE
หากต้องการเตรียม Agent ให้พร้อมสำหรับความต้องการของสภาพแวดล้อมการใช้งานจริง คุณต้องมีแพลตฟอร์มที่สร้างขึ้นเพื่อความสามารถในการปรับขนาด ความปลอดภัย และความคุ้มค่า Google Kubernetes Engine (GKE) มอบรากฐานที่ทรงพลังและยืดหยุ่นนี้สำหรับการเรียกใช้แอปพลิเคชันที่มีคอนเทนเนอร์
ซึ่งมีข้อดีหลายประการสำหรับภาระงานเวอร์ชันที่ใช้งานจริง ดังนี้
- การปรับขนาดอัตโนมัติและประสิทธิภาพ: จัดการการรับส่งข้อมูลที่คาดการณ์ไม่ได้ด้วย HorizontalPodAutoscaler (HPA) ซึ่งจะเพิ่มหรือนำสำเนาของ Agent ออกโดยอัตโนมัติตามโหลด สำหรับภาระงาน AI ที่ต้องการประสิทธิภาพสูง คุณสามารถแนบตัวเร่งฮาร์ดแวร์ เช่น GPU และ TPU
- การจัดการทรัพยากรที่คุ้มค่า: เพิ่มประสิทธิภาพต้นทุนด้วย GKE Autopilot ซึ่งจะจัดการโครงสร้างพื้นฐานที่สำคัญโดยอัตโนมัติเพื่อให้คุณจ่ายเฉพาะทรัพยากรที่แอปพลิเคชันร้องขอเท่านั้น
- การรักษาความปลอดภัยและความสามารถในการสังเกตแบบผสานรวม: เชื่อมต่อกับบริการอื่นๆ ของ Google Cloud อย่างปลอดภัยโดยใช้ Workload Identity ซึ่งช่วยให้ไม่ต้องจัดการและจัดเก็บคีย์บัญชีบริการ ระบบจะสตรีมบันทึกของแอปพลิเคชันทั้งหมดไปยัง Cloud Logging โดยอัตโนมัติเพื่อการตรวจสอบและการแก้ไขข้อบกพร่องแบบรวมศูนย์
- การควบคุมและความสามารถในการพกพา: หลีกเลี่ยงการผูกมัดกับผู้ให้บริการด้วย Kubernetes แบบโอเพนซอร์ส แอปพลิเคชันของคุณสามารถพกพาได้และเรียกใช้ในคลัสเตอร์ Kubernetes ใดก็ได้ ไม่ว่าจะภายในองค์กรหรือในระบบคลาวด์อื่นๆ
สิ่งที่คุณจะได้เรียนรู้
ในแล็บนี้ คุณจะได้เรียนรู้วิธีทำงานต่อไปนี้
- จัดสรรคลัสเตอร์ GKE Autopilot
- สร้างคอนเทนเนอร์แอปพลิเคชันด้วย Dockerfile และพุชอิมเมจไปยัง Artifact Registry
- เชื่อมต่อแอปพลิเคชันกับ Google Cloud APIs อย่างปลอดภัยโดยใช้ Workload Identity
- เขียนและใช้ไฟล์ Manifest ของ Kubernetes สำหรับการทำให้ใช้งานได้และบริการ
- แสดงแอปพลิเคชันต่ออินเทอร์เน็ตด้วย LoadBalancer
- กำหนดค่าการปรับขนาดอัตโนมัติด้วย HorizontalPodAutoscaler (HPA)
2. การตั้งค่าโปรเจ็กต์
บัญชี Google
หากยังไม่มีบัญชี Google ส่วนบุคคล คุณต้องสร้างบัญชี Google
ใช้บัญชีส่วนตัวแทนบัญชีของที่ทำงานหรือบัญชีโรงเรียน
ลงชื่อเข้าใช้คอนโซล Google Cloud
ลงชื่อเข้าใช้ คอนโซล Google Cloud โดยใช้บัญชี Google ส่วนบุคคล
เปิดใช้การเรียกเก็บเงิน
ตั้งค่าบัญชีสำหรับการเรียกเก็บเงินส่วนตัว
หากตั้งค่าการเรียกเก็บเงินโดยใช้เครดิต Google Cloud คุณจะข้ามขั้นตอนนี้ได้
หากต้องการตั้งค่าบัญชีสำหรับการเรียกเก็บเงินส่วนตัว ให้ไปที่นี่เพื่อเปิดใช้การเรียกเก็บเงินใน Cloud Console
ข้อควรทราบ
- การทำ Lab นี้ควรมีค่าใช้จ่ายน้อยกว่า $1 USD ในทรัพยากรระบบคลาวด์
- คุณสามารถทำตามขั้นตอนที่ส่วนท้ายของแล็บนี้เพื่อลบทรัพยากรเพื่อหลีกเลี่ยงการเรียกเก็บเงินเพิ่มเติม
- ผู้ใช้ใหม่มีสิทธิ์ใช้ช่วงทดลองใช้ฟรีมูลค่า$300 USD
สร้างโปรเจ็กต์ (ไม่บังคับ)
หากไม่มีโปรเจ็กต์ปัจจุบันที่ต้องการใช้สำหรับแล็บนี้ ให้สร้างโปรเจ็กต์ใหม่ที่นี่
3. เปิดเครื่องมือแก้ไข Cloud Shell
- คลิกลิงก์นี้เพื่อไปยัง Cloud Shell Editor โดยตรง
- หากระบบแจ้งให้ให้สิทธิ์ในขั้นตอนใดก็ตามในวันนี้ ให้คลิกให้สิทธิ์เพื่อดำเนินการต่อ
- หากเทอร์มินัลไม่ปรากฏที่ด้านล่างของหน้าจอ ให้เปิดโดยทำดังนี้
- คลิกดู
- คลิก Terminal
- ในเทอร์มินัล ให้ตั้งค่าโปรเจ็กต์ด้วยคำสั่งนี้
gcloud config set project [PROJECT_ID]- ตัวอย่าง
gcloud config set project lab-project-id-example - หากจำรหัสโปรเจ็กต์ไม่ได้ คุณสามารถแสดงรหัสโปรเจ็กต์ทั้งหมดได้โดยใช้คำสั่งต่อไปนี้
gcloud projects list
- ตัวอย่าง
- คุณควรเห็นข้อความต่อไปนี้
Updated property [core/project].
4. เปิดใช้ API
หากต้องการใช้ GKE, Artifact Registry, Cloud Build และ Vertex AI คุณต้องเปิดใช้ API ที่เกี่ยวข้องในโปรเจ็กต์ที่อยู่ในระบบคลาวด์ของ Google
- ในเทอร์มินัล ให้เปิดใช้ API ดังนี้
gcloud services enable \ container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.comOperation "operations/acf.p2-176675280136-b03ab5e4-3483-4ebf-9655-43dc3b345c63" finished successfully.
ขอแนะนำ API
- Google Kubernetes Engine API (
container.googleapis.com) ช่วยให้คุณสร้างและจัดการคลัสเตอร์ GKE ที่เรียกใช้เอเจนต์ได้ GKE มีสภาพแวดล้อมที่มีการจัดการสำหรับการทําให้แอปพลิเคชันที่มีคอนเทนเนอร์ใช้งานได้ จัดการ และปรับขนาดโดยใช้โครงสร้างพื้นฐานของ Google - Artifact Registry API (
artifactregistry.googleapis.com) มีที่เก็บข้อมูลส่วนตัวที่ปลอดภัยสำหรับจัดเก็บอิมเมจคอนเทนเนอร์ของเอเจนต์ ซึ่งเป็นวิวัฒนาการของ Container Registry และผสานรวมกับ GKE และ Cloud Build ได้อย่างราบรื่น - Cloud Build API (
cloudbuild.googleapis.com) ใช้โดยคำสั่งgcloud builds submitเพื่อสร้างอิมเมจคอนเทนเนอร์ในระบบคลาวด์จาก Dockerfile ซึ่งเป็นแพลตฟอร์ม CI/CD แบบไร้เซิร์ฟเวอร์ที่เรียกใช้บิลด์บนโครงสร้างพื้นฐานของ Google Cloud - Vertex AI API (
aiplatform.googleapis.com) ช่วยให้ Agent ที่ติดตั้งใช้งานแล้วสื่อสารกับโมเดล Gemini เพื่อทำงานหลักได้ ซึ่งมี API แบบรวมสำหรับบริการ AI ทั้งหมดของ Google Cloud
5. เตรียมสภาพแวดล้อมในการพัฒนาซอฟต์แวร์
สร้างโครงสร้างไดเรกทอรี
- ในเทอร์มินัล ให้สร้างไดเรกทอรีโปรเจ็กต์และไดเรกทอรีย่อยที่จำเป็น
mkdir -p ~/adk_multiagent_systems/workflow_agents cd ~/adk_multiagent_systems - ในเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้เพื่อเปิดไดเรกทอรีในโปรแกรมสำรวจของ Cloud Shell Editor
cloudshell open-workspace ~/adk_multiagent_systems - แผง Explorer ทางด้านซ้ายจะรีเฟรช ตอนนี้คุณควรเห็นไดเรกทอรีที่สร้างขึ้น
เมื่อสร้างไฟล์ตามขั้นตอนต่อไปนี้ คุณจะเห็นไฟล์ปรากฏในไดเรกทอรีนี้
สร้างไฟล์เริ่มต้น
ตอนนี้คุณจะสร้างไฟล์เริ่มต้นที่จำเป็นสำหรับแอปพลิเคชัน
- สร้าง
callback_logging.pyโดยเรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล ไฟล์นี้จัดการการบันทึกสำหรับความสามารถในการสังเกตการณ์cat <<EOF > ~/adk_multiagent_systems/callback_logging.py """ Provides helper functions for observability. Handles formatting and sending agent queries, responses, and tool calls to Google Cloud Logging to aid in monitoring and debugging. """ import logging import google.cloud.logging from google.adk.agents.callback_context import CallbackContext from google.adk.models import LlmResponse, LlmRequest def log_query_to_model(callback_context: CallbackContext, llm_request: LlmRequest): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_request.contents and llm_request.contents[-1].role == 'user': if llm_request.contents[-1].parts and "text" in llm_request.contents[-1].parts: last_user_message = llm_request.contents[-1].parts[0].text logging.info(f"[query to {callback_context.agent_name}]: " + last_user_message) def log_model_response(callback_context: CallbackContext, llm_response: LlmResponse): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_response.content and llm_response.content.parts: for part in llm_response.content.parts: if part.text: logging.info(f"[response from {callback_context.agent_name}]: " + part.text) elif part.function_call: logging.info(f"[function call from {callback_context.agent_name}]: " + part.function_call.name) EOF - สร้าง
workflow_agents/__init__.pyโดยเรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล ซึ่งจะทำเครื่องหมายไดเรกทอรีเป็นแพ็กเกจ Pythoncat <<EOF > ~/adk_multiagent_systems/workflow_agents/__init__.py """ Marks the directory as a Python package and exposes the agent module, allowing the ADK to discover and register the agents defined within. """ from . import agent EOF - สร้าง
workflow_agents/agent.pyโดยเรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล ไฟล์นี้มีตรรกะหลักสำหรับทีมแบบหลายเอเจนต์cat <<EOF > ~/adk_multiagent_systems/workflow_agents/agent.py """ Defines the core multi-agent workflow. Configures individual agents (Researcher, Screenwriter, File Writer), assigns their specific tools, and orchestrates their collaboration using the ADK's SequentialAgent pattern. """ import os import logging import google.cloud.logging from callback_logging import log_query_to_model, log_model_response from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent, LoopAgent, ParallelAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool # import from google.genai import types from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL") print(model_name) # Tools def append_to_state( tool_context: ToolContext, field: str, response: str ) -> dict[str, str]: """Append new output to an existing state key. Args: field (str): a field name to append to response (str): a string to append to the field Returns: dict[str, str]: {"status": "success"} """ existing_state = tool_context.state.get(field, []) tool_context.state[field] = existing_state + [response] logging.info(f"[Added to {field}] {response}") return {"status": "success"} def write_file( tool_context: ToolContext, directory: str, filename: str, content: str ) -> dict[str, str]: target_path = os.path.join(directory, filename) os.makedirs(os.path.dirname(target_path), exist_ok=True) with open(target_path, "w") as f: f.write(content) return {"status": "success"} # Agents file_writer = Agent( name="file_writer", model=model_name, description="Creates marketing details and saves a pitch document.", instruction=""" PLOT_OUTLINE: { PLOT_OUTLINE? } INSTRUCTIONS: - Create a marketable, contemporary movie title suggestion for the movie described in the PLOT_OUTLINE. If a title has been suggested in PLOT_OUTLINE, you can use it, or replace it with a better one. - Use your 'write_file' tool to create a new txt file with the following arguments: - for a filename, use the movie title - Write to the 'movie_pitches' directory. - For the 'content' to write, extract the following from the PLOT_OUTLINE: - A logline - Synopsis or plot outline """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[write_file], ) screenwriter = Agent( name="screenwriter", model=model_name, description="As a screenwriter, write a logline and plot outline for a biopic about a historical character.", instruction=""" INSTRUCTIONS: Your goal is to write a logline and three-act plot outline for an inspiring movie about a historical character(s) described by the PROMPT: { PROMPT? } - If there is CRITICAL_FEEDBACK, use those thoughts to improve upon the outline. - If there is RESEARCH provided, feel free to use details from it, but you are not required to use it all. - If there is a PLOT_OUTLINE, improve upon it. - Use the 'append_to_state' tool to write your logline and three-act plot outline to the field 'PLOT_OUTLINE'. - Summarize what you focused on in this pass. PLOT_OUTLINE: { PLOT_OUTLINE? } RESEARCH: { research? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], ) researcher = Agent( name="researcher", model=model_name, description="Answer research questions using Wikipedia.", instruction=""" PROMPT: { PROMPT? } PLOT_OUTLINE: { PLOT_OUTLINE? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } INSTRUCTIONS: - If there is a CRITICAL_FEEDBACK, use your wikipedia tool to do research to solve those suggestions - If there is a PLOT_OUTLINE, use your wikipedia tool to do research to add more historical detail - If these are empty, use your Wikipedia tool to gather facts about the person in the PROMPT - Use the 'append_to_state' tool to add your research to the field 'research'. - Summarize what you have learned. Now, use your Wikipedia tool to do research. """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[ LangchainTool(tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())), append_to_state, ], ) film_concept_team = SequentialAgent( name="film_concept_team", description="Write a film plot outline and save it as a text file.", sub_agents=[ researcher, screenwriter, file_writer ], ) root_agent = Agent( name="greeter", model=model_name, description="Guides the user in crafting a movie plot.", instruction=""" - Let the user know you will help them write a pitch for a hit movie. Ask them for a historical figure to create a movie about. - When they respond, use the 'append_to_state' tool to store the user's response in the 'PROMPT' state key and transfer to the 'film_concept_team' agent """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], sub_agents=[film_concept_team], ) EOF
ตอนนี้โครงสร้างไฟล์ควรมีลักษณะดังนี้ 
ตั้งค่าสภาพแวดล้อมเสมือน
- ในเทอร์มินัล ให้สร้างและเปิดใช้งานสภาพแวดล้อมเสมือนโดยใช้
uvซึ่งจะช่วยให้มั่นใจได้ว่าการขึ้นต่อกันของโปรเจ็กต์จะไม่ขัดแย้งกับ Python ของระบบuv venv source .venv/bin/activate
ข้อกำหนดในการติดตั้ง
- เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัลเพื่อสร้างไฟล์
requirements.txtcat <<EOF > ~/adk_multiagent_systems/requirements.txt # Lists all Python dependencies required to run the multi-agent system, # including the Google ADK, LangChain community tools, and web server libraries. langchain-community==0.4.1 wikipedia==1.4.0 google-adk==1.27.5 fastapi==0.135.2 uvicorn==0.42.0 EOF - ติดตั้งแพ็กเกจที่จำเป็นลงในสภาพแวดล้อมเสมือนในเทอร์มินัล
uv pip install -r requirements.txt
ตั้งค่าตัวแปรสภาพแวดล้อม
- ใช้คำสั่งต่อไปนี้ในเทอร์มินัลเพื่อสร้างไฟล์
.envโดยจะแทรกรหัสโปรเจ็กต์และภูมิภาคของคุณโดยอัตโนมัติcat <<EOF > ~/adk_multiagent_systems/.env GOOGLE_CLOUD_PROJECT="$(gcloud config get-value project)" GOOGLE_CLOUD_PROJECT_NUMBER="$(gcloud projects describe $(gcloud config get-value project) --format='value(projectNumber)')" GOOGLE_CLOUD_LOCATION="us-central1" GOOGLE_GENAI_USE_VERTEXAI=true MODEL="gemini-2.5-flash" EOF - ในเทอร์มินัล ให้โหลดตัวแปรลงในเซสชันเชลล์
source .env
สรุป
ในส่วนนี้ คุณได้สร้างรากฐานในเครื่องสำหรับโปรเจ็กต์แล้ว ดังนี้
- สร้างโครงสร้างไดเรกทอรีและไฟล์เริ่มต้นของเอเจนต์ที่จำเป็น (
agent.py,callback_logging.py,requirements.txt) - แยกการอ้างอิงโดยใช้สภาพแวดล้อมเสมือน (
uv) - ตัวแปรสภาพแวดล้อมที่กำหนดค่าไว้ (
.env) เพื่อจัดเก็บรายละเอียดเฉพาะโปรเจ็กต์ เช่น รหัสโปรเจ็กต์และภูมิภาค
6. สำรวจไฟล์ตัวแทน
คุณได้ตั้งค่าซอร์สโค้ดสำหรับห้องทดลอง ซึ่งรวมถึงระบบแบบหลายเอเจนต์ที่เขียนไว้ล่วงหน้า ก่อนที่จะติดตั้งใช้งานแอปพลิเคชัน คุณควรทำความเข้าใจวิธีกำหนดเอเจนต์ ตรรกะหลักของเอเจนต์อยู่ใน workflow_agents/agent.py
- ใน Cloud Shell Editor ให้ใช้ File Explorer ทางด้านซ้ายเพื่อไปยัง
adk_multiagent_systems/workflow_agents/แล้วเปิดไฟล์agent.py - โปรดใช้เวลาสักครู่เพื่อดูไฟล์ คุณไม่จำเป็นต้องเข้าใจทุกบรรทัด แต่ให้สังเกตโครงสร้างระดับสูงต่อไปนี้
- ตัวแทนแต่ละราย: ไฟล์จะกำหนดออบเจ็กต์
Agentที่แตกต่างกัน 3 รายการ ได้แก่researcher,screenwriterและfile_writerเอเจนต์แต่ละตัวจะได้รับinstructionที่เฉพาะเจาะจง (พรอมต์ของเอเจนต์) และรายการtoolsที่ได้รับอนุญาตให้ใช้ (เช่น เครื่องมือWikipediaQueryRunหรือเครื่องมือwrite_fileที่กำหนดเอง) - การเรียบเรียง Agent: ระบบจะเชื่อมโยง Agent แต่ละรายเข้าด้วยกันเป็น
SequentialAgentที่เรียกว่าfilm_concept_teamซึ่งจะบอกให้ ADK เรียกใช้เอเจนต์เหล่านี้ทีละตัว โดยส่งต่อสถานะจากเอเจนต์หนึ่งไปยังอีกเอเจนต์หนึ่ง - เอเจนต์รูท: มีการกำหนด
root_agent(ชื่อ "greeter") เพื่อจัดการการโต้ตอบของผู้ใช้ครั้งแรก เมื่อผู้ใช้ระบุพรอมต์ เอเจนต์นี้จะบันทึกลงในสถานะของแอปพลิเคชัน จากนั้นจะโอนการควบคุมไปยังเวิร์กโฟลว์film_concept_team
- ตัวแทนแต่ละราย: ไฟล์จะกำหนดออบเจ็กต์
การทำความเข้าใจโครงสร้างนี้จะช่วยให้คุณทราบสิ่งที่จะติดตั้งใช้งานได้อย่างชัดเจน ซึ่งไม่ใช่แค่เอเจนต์เดียว แต่เป็นทีมเอเจนต์เฉพาะทางที่ทำงานร่วมกันซึ่ง ADK เป็นผู้ประสานงาน
7. สร้างคลัสเตอร์ GKE Autopilot
เมื่อเตรียมสภาพแวดล้อมแล้ว ขั้นตอนถัดไปคือการจัดสรรโครงสร้างพื้นฐานที่จะใช้เรียกใช้แอปพลิเคชันตัวแทน คุณจะสร้างคลัสเตอร์ GKE Autopilot ซึ่งเป็นรากฐานสำหรับการติดตั้งใช้งาน เราใช้โหมด Autopilot เนื่องจากโหมดนี้จะจัดการการจัดการที่ซับซ้อนของโหนดพื้นฐาน การปรับขนาด และการรักษาความปลอดภัยของคลัสเตอร์ ซึ่งช่วยให้คุณมุ่งเน้นไปที่การติดตั้งใช้งานแอปพลิเคชันได้อย่างเต็มที่
- ในเทอร์มินัล ให้สร้างคลัสเตอร์ GKE Autopilot ใหม่ชื่อ
adk-clustergcloud container clusters create-auto adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT - เมื่อสร้างคลัสเตอร์แล้ว ให้กำหนดค่า
kubectlเพื่อเชื่อมต่อกับคลัสเตอร์โดยเรียกใช้คำสั่งนี้ในเทอร์มินัลgcloud container clusters get-credentials adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT~/.kube/config) ตั้งแต่นี้เป็นต้นไป เครื่องมือบรรทัดคำสั่งkubectlจะได้รับการตรวจสอบสิทธิ์และนำไปใช้สื่อสารกับadk-cluster
สรุป
ในส่วนนี้ คุณได้จัดสรรโครงสร้างพื้นฐานดังนี้
- สร้างคลัสเตอร์ GKE Autopilot ที่มีการจัดการครบวงจรโดยใช้
gcloud - กำหนดค่าเครื่องมือ
kubectlในเครื่องเพื่อตรวจสอบสิทธิ์และสื่อสารกับคลัสเตอร์ใหม่
8. สร้างคอนเทนเนอร์และพุชแอปพลิเคชัน
ขณะนี้โค้ดของ Agent มีอยู่ในสภาพแวดล้อม Cloud Shell เท่านั้น หากต้องการดำเนินการใน GKE คุณต้องแพ็กเกจเป็นอิมเมจคอนเทนเนอร์ก่อน อิมเมจคอนเทนเนอร์คือไฟล์แบบคงที่ที่พกพาได้ ซึ่งรวมโค้ดของแอปพลิเคชันเข้ากับทรัพยากร Dependency ทั้งหมด เมื่อเรียกใช้รูปภาพนี้ รูปภาพจะกลายเป็นคอนเทนเนอร์ที่ใช้งานจริง
กระบวนการนี้มี 3 ขั้นตอนหลักๆ ดังนี้
- สร้างจุดแรกเข้า: กำหนดไฟล์
main.pyเพื่อเปลี่ยนตรรกะของเอเจนต์ให้เป็นเว็บเซิร์ฟเวอร์ที่เรียกใช้ได้ - กำหนดอิมเมจคอนเทนเนอร์: สร้าง Dockerfile ที่ทำหน้าที่เป็นพิมพ์เขียวสำหรับการสร้างอิมเมจคอนเทนเนอร์
- สร้างและพุช: ใช้ Cloud Build เพื่อเรียกใช้ Dockerfile สร้างอิมเมจคอนเทนเนอร์ และพุชไปยัง Google Artifact Registry ซึ่งเป็นที่เก็บที่ปลอดภัยสำหรับอิมเมจ
เตรียมแอปพลิเคชันสำหรับการนำไปใช้งาน
เอเจนต์ ADK ต้องมีเว็บเซิร์ฟเวอร์เพื่อรับคำขอ main.py จะทำหน้าที่เป็นจุดแรกเข้าโดยใช้เฟรมเวิร์ก FastAPI เพื่อแสดงฟังก์ชันการทำงานของเอเจนต์ผ่าน HTTP
- ในรูทของไดเรกทอรี
adk_multiagent_systemsในเทอร์มินัล ให้สร้างไฟล์ใหม่ชื่อmain.pycat <<EOF > ~/adk_multiagent_systems/main.py """ Serves as the application entry point. Initializes the FastAPI web server, discovers the agents defined in the workflow directory, and exposes them via HTTP endpoints for interaction. """ import os import uvicorn from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Get the directory where main.py is located AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) # Configure the session service (e.g., SQLite for local storage) SESSION_SERVICE_URI = "sqlite:///./sessions.db" # Configure CORS to allow requests from various origins for this lab ALLOWED_ORIGINS = ["http://localhost", "http://localhost:8080", "*"] # Enable the ADK's built-in web interface SERVE_WEB_INTERFACE = True # Call the ADK function to discover agents and create the FastAPI app app: FastAPI = get_fast_api_app( agents_dir=AGENT_DIR, session_service_uri=SESSION_SERVICE_URI, allow_origins=ALLOWED_ORIGINS, web=SERVE_WEB_INTERFACE, ) # You can add more FastAPI routes or configurations below if needed # Example: # @app.get("/hello") # async def read_root(): # return {"Hello": "World"} if __name__ == "__main__": # Get the port from the PORT environment variable provided by the container runtime # Run the Uvicorn server, listening on all available network interfaces (0.0.0.0) uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("PORT", 8080))) EOFuvicornเซิร์ฟเวอร์จะเรียกใช้แอปพลิเคชันนี้ โดยรอรับการเชื่อมต่อจากที่อยู่ IP ใดก็ได้ในโฮสต์0.0.0.0และในพอร์ตที่ระบุโดยตัวแปรสภาพแวดล้อมPORTซึ่งเราจะตั้งค่าในภายหลังในไฟล์ Manifest ของ Kubernetes
ณ จุดนี้ โครงสร้างไฟล์ของคุณตามที่เห็นในแผง Explorer ใน Cloud Shell Editor ควรมีลักษณะดังนี้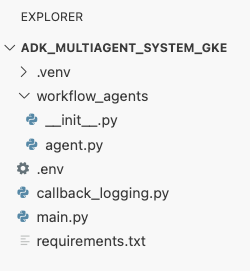
สร้างคอนเทนเนอร์ของ Agent ADK ด้วย Docker
หากต้องการติดตั้งใช้งานแอปพลิเคชันใน GKE เราต้องแพ็กเกจแอปพลิเคชันเป็นอิมเมจคอนเทนเนอร์ก่อน ซึ่งจะรวมโค้ดของแอปพลิเคชันเข้ากับไลบรารีและการขึ้นต่อกันทั้งหมดที่จำเป็นต่อการเรียกใช้ เราจะใช้ Docker เพื่อสร้างอิมเมจคอนเทนเนอร์นี้
- ในรูทของไดเรกทอรี
adk_multiagent_systemsในเทอร์มินัล ให้สร้างไฟล์ใหม่ชื่อDockerfilecat <<'EOF' > ~/adk_multiagent_systems/Dockerfile # Defines the blueprint for the container image. Installs dependencies, # sets up a secure non-root user, and specifies the startup command to run the # agent web server. # Use an official lightweight Python image as the base FROM python:3.13-slim # Set the working directory inside the container WORKDIR /app # Create a non-root user for security best practices RUN adduser --disabled-password --gecos "" myuser # Copy and install dependencies first to leverage Docker's layer caching COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt # Copy all application code into the container COPY . . # Create the directory where the agent will write files at runtime # The -p flag ensures the command doesn't fail if the directory already exists RUN mkdir -p movie_pitches # Change ownership of EVERYTHING in /app to the non-root user # Without this, the running agent would be denied permission to write files. RUN chown -R myuser:myuser /app # Switch the active user from root to the non-root user USER myuser # Add the user's local binary directory to the system's PATH ENV PATH="/home/myuser/.local/bin:$PATH" # Define the command to run when the container starts CMD ["sh", "-c", "uvicorn main:app --host 0.0.0.0 --port $PORT"] EOF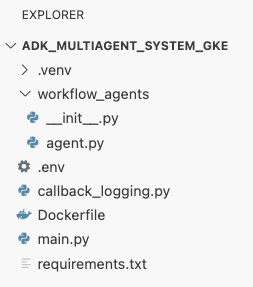
สร้างและพุชอิมเมจคอนเทนเนอร์ไปยัง Artifact Registry
เมื่อมี Dockerfile แล้ว คุณจะใช้ Cloud Build เพื่อสร้างอิมเมจและพุชไปยัง Artifact Registry ซึ่งเป็นรีจิสทรีส่วนตัวที่ปลอดภัยซึ่งผสานรวมกับบริการของ Google Cloud GKE จะดึงอิมเมจจากรีจิสทรีนี้เพื่อเรียกใช้แอปพลิเคชัน
- ในเทอร์มินัล ให้สร้างที่เก็บ Artifact Registry ใหม่เพื่อจัดเก็บอิมเมจคอนเทนเนอร์
gcloud artifacts repositories create adk-repo \ --repository-format=docker \ --location=$GOOGLE_CLOUD_LOCATION \ --description="ADK repository" - ในเทอร์มินัล ให้ใช้
gcloud builds submitเพื่อสร้างอิมเมจคอนเทนเนอร์และพุชไปยังที่เก็บgcloud builds submit \ --tag $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo/adk-agent:latest \ --project=$GOOGLE_CLOUD_PROJECT \ .Dockerfileโดยจะสร้างอิมเมจในระบบคลาวด์ ติดแท็กด้วยที่อยู่ของที่เก็บ Artifact Registry และพุชไปยังที่เก็บนั้นโดยอัตโนมัติ - จากเทอร์มินัล ให้ตรวจสอบว่าสร้างอิมเมจแล้ว
gcloud artifacts docker images list \ $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo \ --project=$GOOGLE_CLOUD_PROJECT
สรุป
ในส่วนนี้ คุณได้แพ็กเกจโค้ดสำหรับการติดตั้งใช้งานแล้ว
- สร้าง
main.pyจุดแรกเข้าเพื่อรวม Agent ไว้ในเว็บเซิร์ฟเวอร์ FastAPI - กำหนด
Dockerfileเพื่อรวมโค้ดและทรัพยากร Dependency ไว้ในอิมเมจแบบพกพา - ใช้ Cloud Build เพื่อสร้างอิมเมจและพุชไปยังที่เก็บ Artifact Registry ที่ปลอดภัย
9. สร้างไฟล์ Manifest ของ Kubernetes
ตอนนี้เมื่อสร้างอิมเมจคอนเทนเนอร์และจัดเก็บไว้ใน Artifact Registry แล้ว คุณต้องสั่งให้ GKE ดำเนินการ ซึ่งเกี่ยวข้องกับกิจกรรมหลัก 2 อย่าง ได้แก่
- การกำหนดค่าสิทธิ์: คุณจะสร้างข้อมูลประจำตัวเฉพาะสำหรับ Agent ภายในคลัสเตอร์และให้สิทธิ์เข้าถึง Google Cloud APIs ที่จำเป็นอย่างปลอดภัย (โดยเฉพาะ Vertex AI)
- การกำหนดสถานะแอปพลิเคชัน: คุณจะเขียนไฟล์ Manifest ของ Kubernetes ซึ่งเป็นเอกสาร YAML ที่กำหนดทุกอย่างที่แอปพลิเคชันต้องใช้ในการเรียกใช้ รวมถึงอิมเมจคอนเทนเนอร์ ตัวแปรสภาพแวดล้อม และวิธีที่ควรแสดงต่อเครือข่าย
กำหนดค่าบัญชีบริการ Kubernetes สำหรับ Vertex AI
เอเจนต์ของคุณต้องมีสิทธิ์สื่อสารกับ Vertex AI API เพื่อเข้าถึงโมเดล Gemini วิธีที่ปลอดภัยที่สุดและแนะนำสำหรับการให้สิทธิ์นี้ใน GKE คือ Workload Identity Workload Identity ช่วยให้คุณลิงก์ข้อมูลประจำตัวที่มาพร้อมกับ Kubernetes (บัญชีบริการของ Kubernetes) กับข้อมูลประจำตัวของ Google Cloud (บัญชีบริการ IAM) ได้โดยไม่ต้องดาวน์โหลด จัดการ และจัดเก็บคีย์ JSON แบบคงที่
- ในเทอร์มินัล ให้สร้างบัญชีบริการ Kubernetes (
adk-agent-sa) ซึ่งจะสร้างข้อมูลประจำตัวสำหรับตัวแทนภายในคลัสเตอร์ GKE ที่พ็อดใช้ได้kubectl create serviceaccount adk-agent-sa - ในเทอร์มินัล ให้ลิงก์บัญชีบริการ Kubernetes กับ Google Cloud IAM โดยสร้างการเชื่อมโยงนโยบาย คำสั่งนี้จะให้บทบาท
aiplatform.userแก่adk-agent-saซึ่งจะช่วยให้เรียกใช้ Vertex AI API ได้อย่างปลอดภัยgcloud projects add-iam-policy-binding projects/${GOOGLE_CLOUD_PROJECT} \ --role=roles/aiplatform.user \ --member=principal://iam.googleapis.com/projects/${GOOGLE_CLOUD_PROJECT_NUMBER}/locations/global/workloadIdentityPools/${GOOGLE_CLOUD_PROJECT}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \ --condition=None
สร้างไฟล์ Manifest ของ Kubernetes
Kubernetes ใช้ไฟล์ Manifest YAML เพื่อกำหนดสถานะที่ต้องการของแอปพลิเคชัน คุณจะสร้างไฟล์ที่มีออบเจ็กต์ Kubernetes ที่จำเป็น 2 รายการ ได้แก่ Deployment และ Servicedeployment.yaml
- สร้างไฟล์
deployment.yamlจากเทอร์มินัลcat <<EOF > ~/adk_multiagent_systems/deployment.yaml # Defines the Kubernetes resources required to deploy the application to GKE. # Includes the Deployment (to run the container pods) and the Service # (to expose the application via a Load Balancer). apiVersion: apps/v1 kind: Deployment metadata: name: adk-agent spec: replicas: 1 selector: matchLabels: app: adk-agent template: metadata: labels: app: adk-agent spec: # Assign the Kubernetes Service Account for Workload Identity serviceAccountName: adk-agent-sa containers: - name: adk-agent imagePullPolicy: Always # The path to the container image in Artifact Registry image: ${GOOGLE_CLOUD_LOCATION}-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/adk-repo/adk-agent:latest # Define the resources for GKE Autopilot to provision resources: limits: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" requests: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" ports: - containerPort: 8080 # Environment variables passed to the application env: - name: PORT value: "8080" - name: GOOGLE_CLOUD_PROJECT value: ${GOOGLE_CLOUD_PROJECT} - name: GOOGLE_CLOUD_LOCATION value: ${GOOGLE_CLOUD_LOCATION} - name: GOOGLE_GENAI_USE_VERTEXAI value: "true" - name: MODEL value: "gemini-2.5-flash" --- apiVersion: v1 kind: Service metadata: name: adk-agent spec: # Create a public-facing Network Load Balancer with an external IP type: LoadBalancer ports: - port: 80 targetPort: 8080 selector: app: adk-agent EOF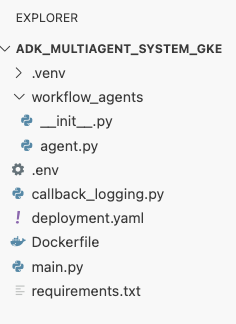
สรุป
ในส่วนนี้ คุณได้กำหนดค่าความปลอดภัยและการติดตั้งใช้งานดังนี้
- สร้างบัญชีบริการ Kubernetes และลิงก์กับ Google Cloud IAM โดยใช้ Workload Identity ซึ่งช่วยให้พ็อดเข้าถึง Vertex AI ได้อย่างปลอดภัยโดยไม่ต้องจัดการคีย์
- สร้างไฟล์
deployment.yamlที่กำหนดการทำให้ใช้งานได้ (วิธีเรียกใช้พ็อด) และบริการ (วิธีเปิดเผยผ่านตัวจัดสรรภาระงาน)
10. ทําให้แอปพลิเคชันใช้งานได้ใน GKE
เมื่อกำหนดไฟล์ Manifest และพุชอิมเมจคอนเทนเนอร์ไปยัง Artifact Registry แล้ว ตอนนี้คุณก็พร้อมที่จะติดตั้งใช้งานแอปพลิเคชันแล้ว ในงานนี้ คุณจะใช้ kubectl เพื่อใช้การกำหนดค่ากับคลัสเตอร์ GKE แล้วตรวจสอบสถานะเพื่อให้แน่ใจว่า Agent เริ่มทำงานอย่างถูกต้อง
- ในเทอร์มินัล ให้ใช้ไฟล์ Manifest
deployment.yamlกับคลัสเตอร์kubectl apply -f deployment.yamlkubectl applyจะส่งไฟล์deployment.yamlไปยังเซิร์ฟเวอร์ Kubernetes API จากนั้นเซิร์ฟเวอร์จะอ่านการกำหนดค่าและจัดระเบียบการสร้างออบเจ็กต์การติดตั้งใช้งานและออบเจ็กต์บริการ - ในเทอร์มินัล ให้ตรวจสอบสถานะการติดตั้งใช้งานแบบเรียลไทม์ รอให้พ็อดอยู่ในสถานะ
Runningkubectl get pods -l=app=adk-agent --watch- รอดำเนินการ: คลัสเตอร์ยอมรับพ็อดแล้ว แต่ยังไม่ได้สร้างคอนเทนเนอร์
- การสร้างคอนเทนเนอร์: GKE ดึงอิมเมจคอนเทนเนอร์จาก Artifact Registry และเริ่มคอนเทนเนอร์
- การวิ่ง: สำเร็จ! คอนเทนเนอร์ทำงานอยู่และแอปพลิเคชันตัวแทนของคุณพร้อมใช้งานแล้ว
- เมื่อสถานะแสดง
Runningให้กด CTRL+C ในเทอร์มินัลเพื่อหยุดคำสั่ง watch และกลับไปที่ Command Prompt
สรุป
ในส่วนนี้ คุณได้เปิดใช้เวิร์กโหลดแล้ว
- ใช้
kubectlapply เพื่อส่งไฟล์ Manifest ไปยังคลัสเตอร์ - ตรวจสอบวงจรของพ็อด (รอดำเนินการ -> ContainerCreating -> กำลังทำงาน) เพื่อให้แน่ใจว่าแอปพลิเคชันเริ่มต้นได้สำเร็จ
11. โต้ตอบกับตัวแทน
ตอนนี้เอเจนต์ ADK ทำงานจริงบน GKE และแสดงต่ออินเทอร์เน็ตผ่านตัวจัดสรรภาระงานสาธารณะแล้ว คุณจะเชื่อมต่อกับอินเทอร์เฟซเว็บของเอเจนต์เพื่อโต้ตอบกับเอเจนต์และยืนยันว่าทั้งระบบทำงานได้อย่างถูกต้อง
ค้นหาที่อยู่ IP ภายนอกของบริการ
หากต้องการเข้าถึงเอเจนต์ คุณต้องรับที่อยู่ IP สาธารณะที่ GKE จัดสรรให้สำหรับบริการของคุณก่อน
- ในเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้เพื่อดูรายละเอียดของบริการ
kubectl get service adk-agent - มองหาค่าในคอลัมน์
EXTERNAL-IPระบบอาจใช้เวลา 1-2 นาทีในการกำหนดที่อยู่ IP หลังจากที่คุณติดตั้งใช้งานบริการเป็นครั้งแรก หากแสดงเป็นpendingให้รอสักครู่แล้วเรียกใช้คำสั่งอีกครั้ง เอาต์พุตจะมีลักษณะคล้ายกับตัวอย่างต่อไปนี้NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE adk-agent-service LoadBalancer 10.120.12.234 34.123.45.67 80:31234/TCP 5mEXTERNAL-IP(เช่น 34.123.45.67) คือจุดแรกเข้าสาธารณะของ Agent
ทดสอบ Agent ที่ทําให้ใช้งานได้
ตอนนี้คุณสามารถใช้ที่อยู่ IP สาธารณะเพื่อเข้าถึงเว็บ UI ในตัวของ ADK ได้โดยตรงจากเบราว์เซอร์
- คัดลอกที่อยู่ IP ภายนอก (
EXTERNAL-IP) จากเทอร์มินัล - เปิดแท็บใหม่ในเว็บเบราว์เซอร์แล้วพิมพ์
http://[EXTERNAL-IP]โดยแทนที่[EXTERNAL-IP]ด้วยที่อยู่ IP ที่คุณคัดลอกไว้ - ตอนนี้คุณควรเห็นอินเทอร์เฟซเว็บของ ADK
- ตรวจสอบว่าได้เลือก workflow_agents ในเมนูแบบเลื่อนลงของตัวแทน
- เปิดใช้การสตรีมโทเค็น
- พิมพ์
helloแล้วกด Enter เพื่อเริ่มการสนทนาใหม่ - สังเกตผลลัพธ์ ตัวแทนควรตอบกลับอย่างรวดเร็วด้วยคำทักทายว่า "ฉันช่วยคุณเขียนการเสนอขายสำหรับภาพยนตร์ยอดนิยมได้ คุณอยากสร้างภาพยนตร์เกี่ยวกับบุคคลสำคัญในประวัติศาสตร์คนใด"
- เมื่อได้รับแจ้งให้เลือกตัวละครในประวัติศาสตร์ ให้เลือกตัวละครที่คุณสนใจ ตัวอย่างไอเดียมีดังนี้
the most successful female pirate in historythe woman who invented the first computer compilera legendary lawman of the American Wild West
สรุป
ในส่วนนี้ คุณได้ยืนยันการติดตั้งใช้งานแล้ว ดังนี้
- ดึงข้อมูลที่อยู่ IP ภายนอกที่ LoadBalancer จัดสรร
- เข้าถึง ADK Web UI ผ่านเบราว์เซอร์เพื่อยืนยันว่าระบบแบบหลายเอเจนต์ตอบสนองและทำงานได้
12. กำหนดค่าการปรับขนาดอัตโนมัติ
ความท้าทายที่สำคัญในการใช้งานจริงคือการจัดการการเข้าชมของผู้ใช้ที่คาดเดาไม่ได้ การฮาร์ดโค้ดจำนวนตัวจำลองที่แน่นอนเหมือนที่คุณทำในงานก่อนหน้าหมายความว่าคุณอาจจ่ายเงินมากเกินไปสำหรับทรัพยากรที่ไม่ได้ใช้งาน หรืออาจเสี่ยงต่อประสิทธิภาพที่ไม่ดีในช่วงที่มีการรับส่งข้อมูลสูง GKE แก้ปัญหานี้ด้วยการปรับขนาดอัตโนมัติ
คุณจะกำหนดค่า HorizontalPodAutoscaler (HPA) ซึ่งเป็นตัวควบคุม Kubernetes ที่ปรับจำนวนพ็อดที่ทำงานในการติดตั้งใช้งานโดยอัตโนมัติตามการใช้ CPU แบบเรียลไทม์
- ในเทอร์มินัลของ Cloud Shell Editor ให้สร้างไฟล์
hpa.yamlใหม่ในรูทของไดเรกทอรีadk_multiagent_systemscloudshell edit ~/adk_multiagent_systems/hpa.yaml - เพิ่มเนื้อหาต่อไปนี้ลงในไฟล์
hpa.yamlใหม่# Configures the HorizontalPodAutoscaler (HPA) to automatically scale # the number of running agent pods up or down based on CPU utilization # to handle varying traffic loads. apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: adk-agent-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: adk-agent minReplicas: 1 maxReplicas: 5 targetCPUUtilizationPercentage: 50adk-agentซึ่งจะช่วยให้มั่นใจได้ว่าจะมีพ็อดที่ทำงานอยู่อย่างน้อย 1 พ็อดเสมอ กำหนดพ็อดสูงสุด 5 พ็อด และจะเพิ่ม/นำรีพลิกาออกเพื่อให้การใช้ CPU โดยเฉลี่ยอยู่ที่ประมาณ 50% ณ จุดนี้ โครงสร้างไฟล์ของคุณตามที่เห็นในแผง Explorer ใน Cloud Shell Editor ควรมีลักษณะดังนี้
- ใช้ HPA กับคลัสเตอร์โดยวางคำสั่งนี้ลงในเทอร์มินัล
kubectl apply -f hpa.yaml
ยืนยันตัวปรับขนาดอัตโนมัติ
ตอนนี้ HPA ทำงานอยู่และกำลังตรวจสอบการทำให้ใช้งานได้ของคุณ คุณตรวจสอบสถานะเพื่อดูการทำงานได้
- เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัลเพื่อดูสถานะของ HPA
kubectl get hpa adk-agent-hpaNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE adk-agent-hpa Deployment/adk-agent 0%/50% 1 5 1 30s
สรุป
ในส่วนนี้ คุณได้เพิ่มประสิทธิภาพสำหรับการเข้าชมจริงแล้ว
- สร้าง
hpa.yamlไฟล์ Manifest เพื่อกำหนดกฎการปรับขนาด - ติดตั้งใช้งาน HorizontalPodAutoscaler (HPA) เพื่อปรับจำนวนสำเนาพ็อดโดยอัตโนมัติตามการใช้ CPU
13. การเตรียมพร้อมสำหรับเวอร์ชันที่ใช้งานจริง
หมายเหตุ: ส่วนต่อไปนี้มีไว้เพื่อให้ข้อมูลเท่านั้น และไม่มีขั้นตอนเพิ่มเติมในการดำเนินการ โดยออกแบบมาเพื่อให้บริบทและแนวทางปฏิบัติแนะนำสำหรับการนำแอปพลิเคชันไปใช้งานจริง
ปรับแต่งประสิทธิภาพด้วยการจัดสรรทรัพยากร
ใน GKE Autopilot คุณจะควบคุมจำนวน CPU และหน่วยความจำที่จัดสรรให้กับแอปพลิเคชันได้โดยการระบุทรัพยากร requests ใน deployment.yaml
หากพบว่าเอเจนต์ทำงานช้าหรือหยุดทำงานเนื่องจากหน่วยความจำไม่เพียงพอ คุณสามารถเพิ่มการจัดสรรทรัพยากรได้โดยแก้ไขบล็อก resources ใน deployment.yaml และใช้ไฟล์อีกครั้งด้วย kubectl apply
เช่น หากต้องการเพิ่มหน่วยความจำเป็น 2 เท่า ให้ทำดังนี้
# In deployment.yaml
# ...
resources:
requests:
memory: "2Gi" # Increased from 1Gi
cpu: "1000m"
# ...
ทำให้เวิร์กโฟลว์เป็นอัตโนมัติด้วย CI/CD
ในแล็บนี้ คุณได้เรียกใช้คำสั่งด้วยตนเอง แนวทางปฏิบัติระดับมืออาชีพคือการสร้างไปป์ไลน์ CI/CD (การรวมอย่างต่อเนื่อง/การติดตั้งใช้งานอย่างต่อเนื่อง) การเชื่อมต่อที่เก็บซอร์สโค้ด (เช่น GitHub) กับทริกเกอร์บิลด์ Cloud จะช่วยให้คุณทำให้การติดตั้งใช้งานทั้งหมดเป็นแบบอัตโนมัติได้
เมื่อใช้ไปป์ไลน์ ทุกครั้งที่คุณพุชการเปลี่ยนแปลงโค้ด Cloud Build จะทำสิ่งต่อไปนี้ได้โดยอัตโนมัติ
- สร้างอิมเมจคอนเทนเนอร์ใหม่
- พุชอิมเมจไปยัง Artifact Registry
- ใช้ไฟล์ Manifest ของ Kubernetes ที่อัปเดตแล้วกับคลัสเตอร์ GKE
จัดการข้อมูลลับอย่างปลอดภัย
ในแล็บนี้ คุณได้จัดเก็บการกำหนดค่าในไฟล์ .env และส่งไปยังแอปพลิเคชัน ซึ่งสะดวกสำหรับการพัฒนา แต่ไม่ปลอดภัยสำหรับข้อมูลที่ละเอียดอ่อน เช่น คีย์ API แนวทางปฏิบัติแนะนำคือการใช้ Secret Manager เพื่อจัดเก็บข้อมูลลับอย่างปลอดภัย
GKE มีการผสานรวมกับ Secret Manager โดยตรง ซึ่งช่วยให้คุณติดตั้ง Secret ลงในพ็อดได้โดยตรงเป็นตัวแปรสภาพแวดล้อมหรือไฟล์ โดยไม่ต้องตรวจสอบลงในซอร์สโค้ด
นี่คือส่วนล้างข้อมูลทรัพยากรที่คุณขอ ซึ่งแทรกไว้ก่อนส่วนสรุป
14. ล้างข้อมูลทรัพยากร
โปรดลบโปรเจ็กต์ที่มีทรัพยากรหรือเก็บโปรเจ็กต์ไว้และลบทรัพยากรแต่ละรายการเพื่อหลีกเลี่ยงการเรียกเก็บเงินจากบัญชี Google Cloud สำหรับทรัพยากรที่ใช้ในบทแนะนำนี้
ลบคลัสเตอร์ GKE
คลัสเตอร์ GKE เป็นตัวขับเคลื่อนต้นทุนหลักในแล็บนี้ การลบอินสแตนซ์จะหยุดการเรียกเก็บเงินค่าคอมพิวเตอร์
- จากนั้นเรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล
gcloud container clusters delete adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
ลบที่เก็บ Artifact Registry
อิมเมจคอนเทนเนอร์ที่จัดเก็บใน Artifact Registry จะมีค่าใช้จ่ายในการจัดเก็บ
- จากนั้นเรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล
gcloud artifacts repositories delete adk-repo \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
ลบโปรเจ็กต์ (ไม่บังคับ)
หากคุณสร้างโปรเจ็กต์ใหม่สำหรับ Lab นี้โดยเฉพาะและไม่มีแผนที่จะใช้โปรเจ็กต์อีกต่อไป วิธีที่ง่ายที่สุดในการล้างข้อมูลคือการลบทั้งโปรเจ็กต์
- ในเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้ (แทนที่
[YOUR_PROJECT_ID]ด้วยรหัสโปรเจ็กต์จริง)gcloud projects delete [YOUR_PROJECT_ID]
15. บทสรุป
ยินดีด้วย คุณได้ทําให้แอปพลิเคชัน ADK แบบหลายเอเจนต์ใช้งานได้ในคลัสเตอร์ GKE ระดับการผลิตเรียบร้อยแล้ว นี่เป็นความสำเร็จที่สำคัญซึ่งครอบคลุมวงจรหลักของแอปพลิเคชันสมัยใหม่ที่ดำเนินการบนระบบคลาวด์ ซึ่งจะช่วยให้คุณมีรากฐานที่มั่นคงสำหรับการติดตั้งใช้งานระบบเอเจนต์ที่ซับซ้อนของคุณเอง
สรุป
ในแล็บนี้ คุณได้เรียนรู้สิ่งต่อไปนี้
- จัดสรรคลัสเตอร์ GKE Autopilot
- สร้างอิมเมจคอนเทนเนอร์ด้วย
Dockerfileแล้วพุชไปยัง Artifact Registry - เชื่อมต่อกับ Google Cloud APIs อย่างปลอดภัยโดยใช้ Workload Identity
- เขียนไฟล์ Manifest ของ Kubernetes สำหรับการทำให้ใช้งานได้และบริการ
- แสดงแอปพลิเคชันต่ออินเทอร์เน็ตด้วย LoadBalancer
- กำหนดค่าการปรับขนาดอัตโนมัติด้วย HorizontalPodAutoscaler (HPA)