
1. Giriş
Genel Bakış
Bu laboratuvar, güçlü bir çoklu aracı sistemi geliştirme ile bu sistemi gerçek dünyada kullanıma sunma arasındaki kritik boşluğu doldurur. Yerel olarak aracı oluşturmak harika bir başlangıç olsa da üretim uygulamaları için ölçeklenebilir, güvenilir ve güvenli bir platform gerekir.
Bu laboratuvarda, Google Agent Development Kit (ADK) ile oluşturulmuş çok aracılı bir sistemi alıp Google Kubernetes Engine (GKE) üzerinde üretime hazır bir ortama dağıtacaksınız.
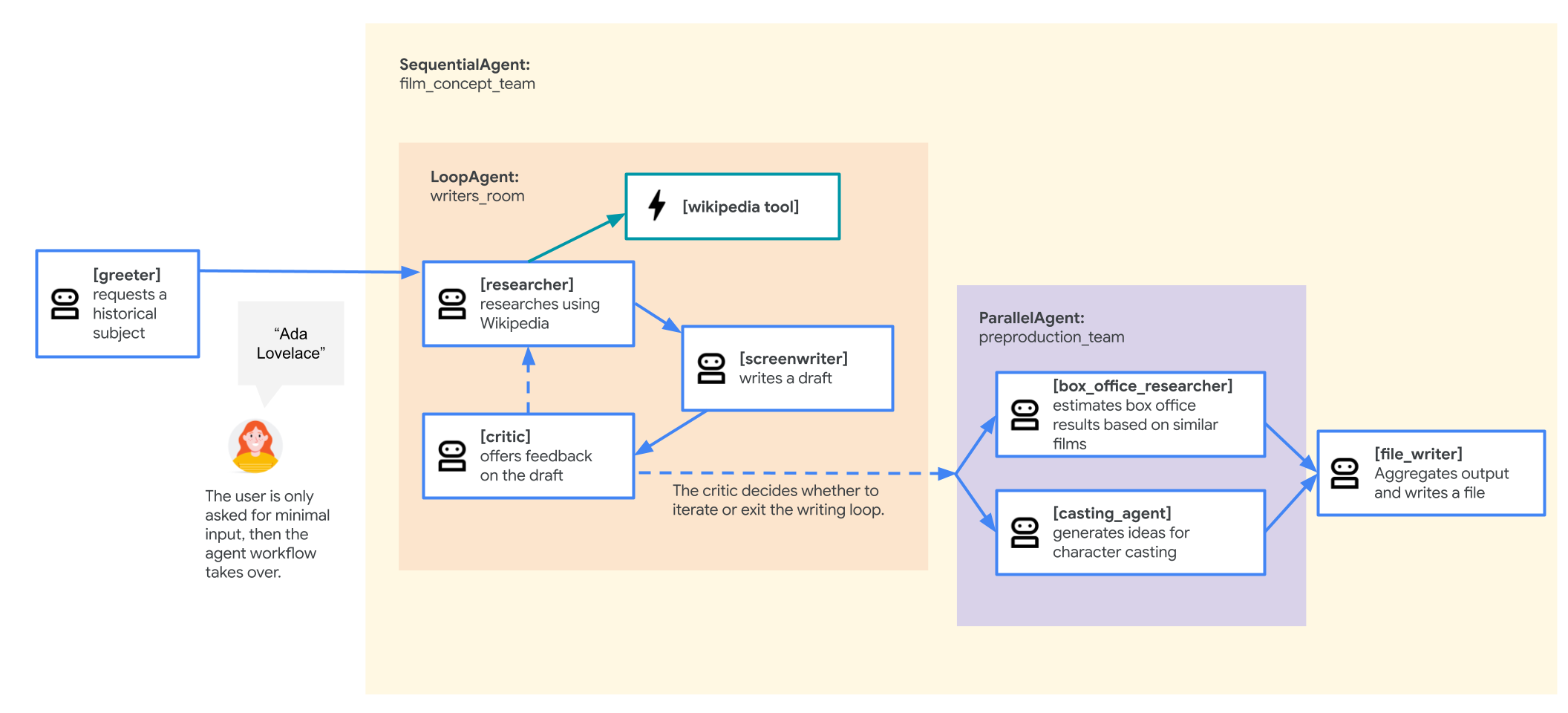
Film konsepti ekibi temsilcisi
Bu laboratuvarda kullanılan örnek uygulama, işbirliği yapan birden fazla aracıdan (bir araştırmacı, bir senarist ve bir dosya yazarı) oluşan bir "film konsepti ekibi"dir. Bu aracılar, kullanıcının bir tarihi şahsiyetle ilgili film önerisi için beyin fırtınası yapmasına ve taslak oluşturmasına yardımcı olmak için birlikte çalışır.
Neden GKE'ye dağıtmalısınız?
Aracınızı üretim ortamının taleplerine hazırlamak için ölçeklenebilirlik, güvenlik ve maliyet verimliliği için tasarlanmış bir platforma ihtiyacınız vardır. Google Kubernetes Engine (GKE), kapsayıcıya alınmış uygulamanızı çalıştırmak için bu güçlü ve esnek temeli sağlar.
Bu, üretim iş yükünüz için çeşitli avantajlar sağlar:
- Otomatik ölçeklendirme ve performans: Yüke göre otomatik olarak aracı replikaları ekleyen veya kaldıran HorizontalPodAutoscaler (HPA) ile öngörülemeyen trafiği yönetin. Daha zorlu yapay zeka iş yükleri için GPU ve TPU gibi donanım hızlandırıcılar ekleyebilirsiniz.
- Uygun maliyetli kaynak yönetimi: Altyapıyı otomatik olarak yöneten GKE Autopilot ile maliyetleri optimize edin. Böylece yalnızca uygulamanızın istediği kaynaklar için ödeme yaparsınız.
- Entegre güvenlik ve gözlemlenebilirlik: Hizmet hesabı anahtarlarını yönetme ve depolama ihtiyacını ortadan kaldıran Workload Identity'yi kullanarak diğer Google Cloud hizmetlerine güvenli bir şekilde bağlanın. Tüm uygulama günlükleri, merkezi izleme ve hata ayıklama için otomatik olarak Cloud Logging'e aktarılır.
- Kontrol ve taşınabilirlik: Açık kaynak Kubernetes ile tedarikçilere bağlı kalmayın. Uygulamanız taşınabilir ve şirket içinde veya diğer bulutlarda herhangi bir Kubernetes kümesinde çalıştırılabilir.
Neler öğreneceksiniz?
Bu laboratuvarda, aşağıdaki görevleri nasıl gerçekleştireceğinizi öğreneceksiniz:
- GKE Autopilot kümesi sağlama
- Dockerfile ile bir uygulamayı kapsayıcıya dönüştürme ve görüntüyü Artifact Registry'ye gönderme
- Workload Identity'yi kullanarak uygulamanızı Google Cloud API'lerine güvenli bir şekilde bağlayın.
- Bir dağıtım ve hizmet için Kubernetes manifestleri yazın ve uygulayın.
- LoadBalancer ile bir uygulamayı internete açın.
- HorizontalPodAutoscaler (HPA) ile otomatik ölçeklendirmeyi yapılandırın.
2. Proje ayarlama
Google Hesabı
Kişisel Google Hesabınız yoksa Google Hesabı oluşturmanız gerekir.
İş veya okul hesabı yerine kişisel hesap kullanın.
Google Cloud Console'da oturum açma
Kişisel bir Google Hesabı kullanarak Google Cloud Console'da oturum açın.
Faturalandırmayı Etkinleştir
Kişisel faturalandırma hesabı oluşturma
Faturalandırmayı Google Cloud kredilerini kullanarak ayarladıysanız bu adımı atlayabilirsiniz.
Kişisel faturalandırma hesabı oluşturmak için Cloud Console'da faturalandırmayı etkinleştirmek üzere buraya gidin.
Bazı notlar:
- Bu laboratuvarı tamamlamak için 1 ABD dolarından daha az tutarda bulut kaynağı kullanmanız gerekir.
- Daha fazla ücret ödememek için bu laboratuvarın sonundaki adımları uygulayarak kaynakları silebilirsiniz.
- Yeni kullanıcılar 300 ABD doları değerinde ücretsiz deneme sürümünden yararlanabilir.
Proje oluşturma (isteğe bağlı)
Bu laboratuvarda kullanmak istediğiniz mevcut bir projeniz yoksa buradan yeni bir proje oluşturun.
3. Cloud Shell Düzenleyici'yi açma
- Doğrudan Cloud Shell Düzenleyici'ye gitmek için bu bağlantıyı tıklayın.
- Bugün herhangi bir noktada yetkilendirmeniz istenirse devam etmek için Yetkilendir'i tıklayın.
- Terminal ekranın alt kısmında görünmüyorsa açın:
- Görünüm'ü tıklayın.
- Terminal'i tıklayın.
- Terminalde şu komutla projenizi ayarlayın:
gcloud config set project [PROJECT_ID]- Örnek:
gcloud config set project lab-project-id-example - Proje kimliğinizi hatırlamıyorsanız tüm proje kimliklerinizi şu komutla listeleyebilirsiniz:
gcloud projects list
- Örnek:
- Şu mesajı görmeniz gerekir:
Updated property [core/project].
4. API'leri etkinleştir
GKE, Artifact Registry, Cloud Build ve Vertex AI'ı kullanmak için Google Cloud projenizde ilgili API'leri etkinleştirmeniz gerekir.
- Terminalde API'leri etkinleştirin:
gcloud services enable \ container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.comOperation "operations/acf.p2-176675280136-b03ab5e4-3483-4ebf-9655-43dc3b345c63" finished successfully.
API'lerle tanışın
- Google Kubernetes Engine API (
container.googleapis.com), aracınızı çalıştıran GKE kümesini oluşturmanıza ve yönetmenize olanak tanır. GKE, container mimarisine alınmış uygulamalarınızı Google altyapısını kullanarak dağıtmanız, yönetmeniz ve ölçeklendirmeniz için yönetilen bir ortam sunar. - Artifact Registry API (
artifactregistry.googleapis.com), aracınızın kapsayıcı resmini depolamak için güvenli ve özel bir depo sağlar. Container Registry'nin gelişmiş sürümüdür ve GKE ile Cloud Build ile sorunsuz bir şekilde entegre olur. - Cloud Build API (
cloudbuild.googleapis.com), Dockerfile'ınızdan bulutta kapsayıcı resminizi oluşturmak içingcloud builds submitkomutu tarafından kullanılır. Google Cloud altyapısında derlemelerinizi yürüten sunucusuz bir CI/CD platformudur. - Vertex AI API (
aiplatform.googleapis.com), dağıtılan temsilcinizin temel görevlerini yerine getirmek için Gemini modelleriyle iletişim kurmasını sağlar. Google Cloud'un tüm yapay zeka hizmetleri için birleşik API sağlar.
5. Geliştirme ortamınızı hazırlama
Dizin yapısını oluşturma
- Terminalde proje dizinini ve gerekli alt dizinleri oluşturun:
mkdir -p ~/adk_multiagent_systems/workflow_agents cd ~/adk_multiagent_systems - Dizini Cloud Shell Düzenleyici Gezgin'de açmak için terminalde aşağıdaki komutu çalıştırın.
cloudshell open-workspace ~/adk_multiagent_systems - Soldaki Gezgin paneli yenilenir. Oluşturduğunuz dizinleri göreceksiniz.
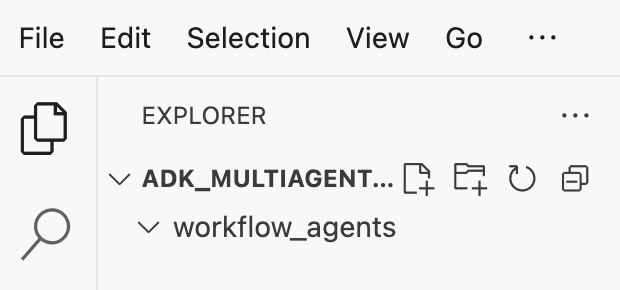
Aşağıdaki adımlarda dosya oluştururken bu dizinde dosyaların doldurulduğunu görürsünüz.
Başlangıç dosyaları oluşturma
Şimdi uygulama için gerekli başlangıç dosyalarını oluşturacaksınız.
- Terminalde aşağıdaki komutu çalıştırarak
callback_logging.pyoluşturun. Bu dosya, gözlemlenebilirlik için günlük kaydını işler.cat <<EOF > ~/adk_multiagent_systems/callback_logging.py """ Provides helper functions for observability. Handles formatting and sending agent queries, responses, and tool calls to Google Cloud Logging to aid in monitoring and debugging. """ import logging import google.cloud.logging from google.adk.agents.callback_context import CallbackContext from google.adk.models import LlmResponse, LlmRequest def log_query_to_model(callback_context: CallbackContext, llm_request: LlmRequest): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_request.contents and llm_request.contents[-1].role == 'user': if llm_request.contents[-1].parts and "text" in llm_request.contents[-1].parts: last_user_message = llm_request.contents[-1].parts[0].text logging.info(f"[query to {callback_context.agent_name}]: " + last_user_message) def log_model_response(callback_context: CallbackContext, llm_response: LlmResponse): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_response.content and llm_response.content.parts: for part in llm_response.content.parts: if part.text: logging.info(f"[response from {callback_context.agent_name}]: " + part.text) elif part.function_call: logging.info(f"[function call from {callback_context.agent_name}]: " + part.function_call.name) EOF - Terminalde aşağıdaki komutu çalıştırarak
workflow_agents/__init__.pyoluşturun. Bu, dizini bir Python paketi olarak işaretler.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/__init__.py """ Marks the directory as a Python package and exposes the agent module, allowing the ADK to discover and register the agents defined within. """ from . import agent EOF - Terminalde aşağıdaki komutu çalıştırarak
workflow_agents/agent.pyoluşturun. Bu dosya, çok agentlı ekibinizin temel mantığını içerir.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/agent.py """ Defines the core multi-agent workflow. Configures individual agents (Researcher, Screenwriter, File Writer), assigns their specific tools, and orchestrates their collaboration using the ADK's SequentialAgent pattern. """ import os import logging import google.cloud.logging from callback_logging import log_query_to_model, log_model_response from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent, LoopAgent, ParallelAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool # import from google.genai import types from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL") print(model_name) # Tools def append_to_state( tool_context: ToolContext, field: str, response: str ) -> dict[str, str]: """Append new output to an existing state key. Args: field (str): a field name to append to response (str): a string to append to the field Returns: dict[str, str]: {"status": "success"} """ existing_state = tool_context.state.get(field, []) tool_context.state[field] = existing_state + [response] logging.info(f"[Added to {field}] {response}") return {"status": "success"} def write_file( tool_context: ToolContext, directory: str, filename: str, content: str ) -> dict[str, str]: target_path = os.path.join(directory, filename) os.makedirs(os.path.dirname(target_path), exist_ok=True) with open(target_path, "w") as f: f.write(content) return {"status": "success"} # Agents file_writer = Agent( name="file_writer", model=model_name, description="Creates marketing details and saves a pitch document.", instruction=""" PLOT_OUTLINE: { PLOT_OUTLINE? } INSTRUCTIONS: - Create a marketable, contemporary movie title suggestion for the movie described in the PLOT_OUTLINE. If a title has been suggested in PLOT_OUTLINE, you can use it, or replace it with a better one. - Use your 'write_file' tool to create a new txt file with the following arguments: - for a filename, use the movie title - Write to the 'movie_pitches' directory. - For the 'content' to write, extract the following from the PLOT_OUTLINE: - A logline - Synopsis or plot outline """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[write_file], ) screenwriter = Agent( name="screenwriter", model=model_name, description="As a screenwriter, write a logline and plot outline for a biopic about a historical character.", instruction=""" INSTRUCTIONS: Your goal is to write a logline and three-act plot outline for an inspiring movie about a historical character(s) described by the PROMPT: { PROMPT? } - If there is CRITICAL_FEEDBACK, use those thoughts to improve upon the outline. - If there is RESEARCH provided, feel free to use details from it, but you are not required to use it all. - If there is a PLOT_OUTLINE, improve upon it. - Use the 'append_to_state' tool to write your logline and three-act plot outline to the field 'PLOT_OUTLINE'. - Summarize what you focused on in this pass. PLOT_OUTLINE: { PLOT_OUTLINE? } RESEARCH: { research? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], ) researcher = Agent( name="researcher", model=model_name, description="Answer research questions using Wikipedia.", instruction=""" PROMPT: { PROMPT? } PLOT_OUTLINE: { PLOT_OUTLINE? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } INSTRUCTIONS: - If there is a CRITICAL_FEEDBACK, use your wikipedia tool to do research to solve those suggestions - If there is a PLOT_OUTLINE, use your wikipedia tool to do research to add more historical detail - If these are empty, use your Wikipedia tool to gather facts about the person in the PROMPT - Use the 'append_to_state' tool to add your research to the field 'research'. - Summarize what you have learned. Now, use your Wikipedia tool to do research. """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[ LangchainTool(tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())), append_to_state, ], ) film_concept_team = SequentialAgent( name="film_concept_team", description="Write a film plot outline and save it as a text file.", sub_agents=[ researcher, screenwriter, file_writer ], ) root_agent = Agent( name="greeter", model=model_name, description="Guides the user in crafting a movie plot.", instruction=""" - Let the user know you will help them write a pitch for a hit movie. Ask them for a historical figure to create a movie about. - When they respond, use the 'append_to_state' tool to store the user's response in the 'PROMPT' state key and transfer to the 'film_concept_team' agent """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], sub_agents=[film_concept_team], ) EOF
Dosya yapınız artık şu şekilde görünmelidir: 
Sanal ortamı ayarlama
- Terminalde,
uvkullanarak sanal bir ortam oluşturun ve etkinleştirin. Bu şekilde, proje bağımlılıklarınızın sistem Python'uyla çakışmaması sağlanır.uv venv source .venv/bin/activate
Yükleme koşulları
requirements.txtdosyasını oluşturmak için terminalde aşağıdaki komutu çalıştırın.cat <<EOF > ~/adk_multiagent_systems/requirements.txt # Lists all Python dependencies required to run the multi-agent system, # including the Google ADK, LangChain community tools, and web server libraries. langchain-community==0.4.1 wikipedia==1.4.0 google-adk==1.27.5 fastapi==0.135.2 uvicorn==0.42.0 EOF- Gerekli paketleri terminalde sanal ortamınıza yükleyin.
uv pip install -r requirements.txt
Ortam değişkenlerini ayarlama
.envdosyasını oluşturmak için terminalde aşağıdaki komutu kullanın. Bu komut, proje kimliğinizi ve bölgenizi otomatik olarak ekler.cat <<EOF > ~/adk_multiagent_systems/.env GOOGLE_CLOUD_PROJECT="$(gcloud config get-value project)" GOOGLE_CLOUD_PROJECT_NUMBER="$(gcloud projects describe $(gcloud config get-value project) --format='value(projectNumber)')" GOOGLE_CLOUD_LOCATION="us-central1" GOOGLE_GENAI_USE_VERTEXAI=true MODEL="gemini-2.5-flash" EOF- Terminalde değişkenleri kabuk oturumunuza yükleyin.
source .env
Özet
Bu bölümde, projenizin yerel temelini oluşturdunuz:
- Dizin yapısını ve gerekli aracı başlatıcı dosyalarını (
agent.py,callback_logging.py,requirements.txt) oluşturdu. - Sanal ortam (
uv) kullanarak bağımlılıklarınızı izole edin. - Proje kimliğiniz ve bölgeniz gibi projeye özgü ayrıntıları depolamak için yapılandırılmış ortam değişkenleri (
.env).
6. Aracı dosyasını keşfetme
Önceden yazılmış, çoklu aracı sistem de dahil olmak üzere laboratuvarın kaynak kodunu ayarlamış olmanız gerekir. Uygulamayı dağıtmadan önce aracıların nasıl tanımlandığını anlamanız faydalı olur. Temel aracı mantığı workflow_agents/agent.py içinde yer alır.
- Cloud Shell Düzenleyici'de, sol taraftaki dosya gezginini kullanarak
adk_multiagent_systems/workflow_agents/konumuna gidin veagent.pydosyasını açın. - Biraz zaman ayırıp dosyaya göz atın. Her satırı anlamanız gerekmez ancak üst düzey yapıyı inceleyin:
- Ayrı ayrı temsilciler: Dosyada üç farklı
Agentnesnesi tanımlanıyor:researcher,screenwritervefile_writer. Her aracıya belirli birinstruction(istem) ve kullanmasına izin verilentoolslistesi (ör.WikipediaQueryRunaracı veya özelwrite_filearacı) verilir. - Aracı bileşimi: Ayrı ayrı aracılar,
SequentialAgentiçindefilm_concept_teamolarak birbirine bağlanır. Bu, ADK'ya bu aracıları sırayla çalıştırmasını ve durumu birinden diğerine aktarmasını söyler. - Kök temsilci: İlk kullanıcı etkileşimini yönetmek için
root_agent(karşılayıcı olarak adlandırılır) tanımlanır. Kullanıcı bir istem sağladığında bu aracı, istemi uygulamanın durumuna kaydeder ve ardından kontrolüfilm_concept_teamiş akışına aktarır.
- Ayrı ayrı temsilciler: Dosyada üç farklı
Bu yapıyı anlamak, dağıtmak üzere olduğunuz şeyin ne olduğunu netleştirmenize yardımcı olur: Yalnızca tek bir aracı değil, ADK tarafından yönetilen, uzmanlaşmış aracıların koordineli bir ekibi.
7. GKE Autopilot kümesi oluşturma
Ortamınız hazır olduğunda, sonraki adım aracı uygulamanızın çalışacağı altyapıyı sağlamaktır. Dağıtımınızın temelini oluşturan bir GKE Autopilot kümesi oluşturacaksınız. Kümenin temel düğümlerinin, ölçeklendirmenin ve güvenliğin karmaşık yönetimini ele aldığından Autopilot modunu kullanırız. Bu sayede tamamen uygulamanızı dağıtmaya odaklanabilirsiniz.
- Terminalde
adk-clusteradlı yeni bir GKE Autopilot kümesi oluşturun.gcloud container clusters create-auto adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT - Küme oluşturulduktan sonra
kubectl'yı kümeye bağlanacak şekilde yapılandırmak için terminalde şunu çalıştırın:gcloud container clusters get-credentials adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT~/.kube/config) günceller. Bu noktadan itibarenkubectlkomut satırı aracı kimliği doğrulanır veadk-clusterile iletişim kurması için yönlendirilir.
Özet
Bu bölümde altyapıyı sağladınız:
gcloudkullanarak tümüyle yönetilen bir GKE Autopilot kümesi oluşturduysanız.- Yeni kümeyle kimlik doğrulaması yapmak ve iletişim kurmak için yerel
kubectlaracınızı yapılandırdıysanız
8. Uygulamayı kapsayıcıya alma ve aktarma
Ajanınızın kodu şu anda yalnızca Cloud Shell ortamınızda bulunuyor. GKE'de çalıştırmak için önce container görüntüsüne paketlemeniz gerekir. Kapsayıcı resmi, uygulamanızın kodunu tüm bağımlılıklarıyla birlikte paketleyen statik ve taşınabilir bir dosyadır. Bu resmi çalıştırdığınızda canlı bir kapsayıcı haline gelir.
Bu süreç üç temel adımdan oluşur:
- Giriş noktası oluşturma: Aracı mantığınızı çalıştırılabilir bir web sunucusuna dönüştürmek için bir
main.pydosyası tanımlayın. - Container görüntüsünü tanımlayın: Container görüntünüzü oluşturmak için plan görevi gören bir Dockerfile oluşturun.
- Derleme ve aktarma: Dockerfile'ı yürütmek, container görüntüsü oluşturmak ve bu görüntüyü Google Artifact Registry'ye (görüntüleriniz için güvenli bir depo) aktarmak üzere Cloud Build'i kullanın.
Uygulamayı dağıtıma hazırlama
ADK aracınızın istek alabilmesi için bir web sunucusuna ihtiyacı vardır. main.py dosyası, aracınızın işlevini HTTP üzerinden kullanıma sunmak için FastAPI çerçevesini kullanarak bu giriş noktası olarak görev yapar.
- Terminaldeki
adk_multiagent_systemsdizininin kök dizinindemain.pyadlı yeni bir dosya oluşturun.cat <<EOF > ~/adk_multiagent_systems/main.py """ Serves as the application entry point. Initializes the FastAPI web server, discovers the agents defined in the workflow directory, and exposes them via HTTP endpoints for interaction. """ import os import uvicorn from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Get the directory where main.py is located AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) # Configure the session service (e.g., SQLite for local storage) SESSION_SERVICE_URI = "sqlite:///./sessions.db" # Configure CORS to allow requests from various origins for this lab ALLOWED_ORIGINS = ["http://localhost", "http://localhost:8080", "*"] # Enable the ADK's built-in web interface SERVE_WEB_INTERFACE = True # Call the ADK function to discover agents and create the FastAPI app app: FastAPI = get_fast_api_app( agents_dir=AGENT_DIR, session_service_uri=SESSION_SERVICE_URI, allow_origins=ALLOWED_ORIGINS, web=SERVE_WEB_INTERFACE, ) # You can add more FastAPI routes or configurations below if needed # Example: # @app.get("/hello") # async def read_root(): # return {"Hello": "World"} if __name__ == "__main__": # Get the port from the PORT environment variable provided by the container runtime # Run the Uvicorn server, listening on all available network interfaces (0.0.0.0) uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("PORT", 8080))) EOFuvicornsunucusu bu uygulamayı çalıştırır. Herhangi bir IP adresinden gelen bağlantıları kabul etmek için0.0.0.0ana makinesinde vePORTortam değişkeniyle belirtilen bağlantı noktasında dinleme yapar. Bu değişkeni daha sonra Kubernetes manifestimizde ayarlayacağız.
Bu noktada, Cloud Shell Düzenleyici'deki Gezgin panelinde görünen dosya yapınız şu şekilde görünmelidir: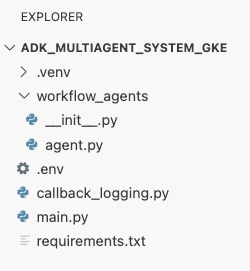
ADK aracısını Docker ile kapsülleme
Uygulamamızı GKE'ye dağıtmak için önce uygulamamızın kodunu, çalışması için gereken tüm kitaplıklar ve bağımlılıklarla birlikte paketleyerek bir kapsayıcı görüntüsü oluşturmamız gerekir. Bu kapsayıcı görüntüsünü oluşturmak için Docker'ı kullanacağız.
- Terminaldeki
adk_multiagent_systemsdizininin kök dizinindeDockerfileadlı yeni bir dosya oluşturun.cat <<'EOF' > ~/adk_multiagent_systems/Dockerfile # Defines the blueprint for the container image. Installs dependencies, # sets up a secure non-root user, and specifies the startup command to run the # agent web server. # Use an official lightweight Python image as the base FROM python:3.13-slim # Set the working directory inside the container WORKDIR /app # Create a non-root user for security best practices RUN adduser --disabled-password --gecos "" myuser # Copy and install dependencies first to leverage Docker's layer caching COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt # Copy all application code into the container COPY . . # Create the directory where the agent will write files at runtime # The -p flag ensures the command doesn't fail if the directory already exists RUN mkdir -p movie_pitches # Change ownership of EVERYTHING in /app to the non-root user # Without this, the running agent would be denied permission to write files. RUN chown -R myuser:myuser /app # Switch the active user from root to the non-root user USER myuser # Add the user's local binary directory to the system's PATH ENV PATH="/home/myuser/.local/bin:$PATH" # Define the command to run when the container starts CMD ["sh", "-c", "uvicorn main:app --host 0.0.0.0 --port $PORT"] EOF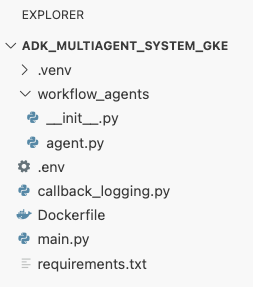
Container görüntüsünü oluşturup Artifact Registry'ye aktarma
Artık bir Dockerfile'ınız olduğuna göre, görüntüyü oluşturmak ve Google Cloud hizmetleriyle entegre edilmiş güvenli ve özel bir kayıt defteri olan Artifact Registry'ye aktarmak için Cloud Build'i kullanacaksınız. GKE, uygulamanızı çalıştırmak için bu kayıt otoritesinden görüntüyü çeker.
- Terminalde, container görüntünüzü depolamak için yeni bir Artifact Registry deposu oluşturun.
gcloud artifacts repositories create adk-repo \ --repository-format=docker \ --location=$GOOGLE_CLOUD_LOCATION \ --description="ADK repository" - Terminalde, container görüntünüzü oluşturmak ve depoya aktarmak için
gcloud builds submitkomutunu kullanın.gcloud builds submit \ --tag $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo/adk-agent:latest \ --project=$GOOGLE_CLOUD_PROJECT \ .Dockerfileiçindeki adımları yürütmek için sunucusuz bir CI/CD platformu olan Cloud Build'ü kullanır. Görüntüyü bulutta oluşturur, Artifact Registry deponuzun adresiyle etiketler ve otomatik olarak oraya gönderir. - Terminalden, görüntünün oluşturulduğunu doğrulayın:
gcloud artifacts docker images list \ $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo \ --project=$GOOGLE_CLOUD_PROJECT
Özet
Bu bölümde, kodunuzu dağıtım için paketlediniz:
- Aracılarınızı FastAPI web sunucusuna sarmak için
main.pygiriş noktası oluşturuldu. - Kodunuzu ve bağımlılıklarınızı taşınabilir bir resimde paketlemek için
Dockerfiletanımlayın. - Görüntüyü oluşturmak ve güvenli bir Artifact Registry deposuna aktarmak için Cloud Build'i kullandım.
9. Kubernetes manifestleri oluşturma
Container görüntünüz oluşturulup Artifact Registry'de depolandığına göre GKE'ye nasıl çalıştırılacağını bildirmeniz gerekir. Bu işlem iki ana aktiviteyi içerir:
- İzinleri yapılandırma: Küme içinde aracınız için özel bir kimlik oluşturacak ve bu kimliğe ihtiyaç duyduğu Google Cloud API'lerine (özellikle Vertex AI) güvenli erişim izni vereceksiniz.
- Uygulama durumunu tanımlama: Uygulamanızın çalışması için gereken her şeyi (ör. kapsayıcı resmi, ortam değişkenleri ve ağa nasıl sunulması gerektiği) bildirimli olarak tanımlayan bir YAML belgesi olan Kubernetes manifest dosyası yazacaksınız.
Vertex AI için Kubernetes hizmet hesabını yapılandırma
Ajanınızın, Gemini modellerine erişmek için Vertex AI API ile iletişim kurma izni olması gerekir. GKE'de bu izni vermek için en güvenli ve önerilen yöntem Workload Identity'dir. Workload Identity, Kubernetes'e özgü bir kimliği (Kubernetes hizmet hesabı) bir Google Cloud kimliğiyle (IAM hizmet hesabı) bağlamanıza olanak tanır. Böylece statik JSON anahtarlarını indirmeniz, yönetmeniz ve depolamanız gerekmez.
- Terminalde Kubernetes hizmet hesabını oluşturun (
adk-agent-sa). Bu işlem, GKE kümesinde aracılarınız için bir kimlik oluşturur. Pod'larınız bu kimliği kullanabilir.kubectl create serviceaccount adk-agent-sa - Terminalde politika bağlama işlemi oluşturarak Kubernetes hizmet hesabınızı Google Cloud IAM'e bağlayın. Bu komut,
aiplatform.userrolünüadk-agent-sahizmet hesabınıza vererek Vertex AI API'yi güvenli bir şekilde çağırmasına olanak tanır.gcloud projects add-iam-policy-binding projects/${GOOGLE_CLOUD_PROJECT} \ --role=roles/aiplatform.user \ --member=principal://iam.googleapis.com/projects/${GOOGLE_CLOUD_PROJECT_NUMBER}/locations/global/workloadIdentityPools/${GOOGLE_CLOUD_PROJECT}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \ --condition=None
Kubernetes manifest dosyalarını oluşturma
Kubernetes, uygulamanızın istenen durumunu tanımlamak için YAML manifest dosyalarını kullanır. İki temel Kubernetes nesnesi (Deployment ve Service) içeren bir deployment.yaml dosyası oluşturacaksınız.
- Terminalden
deployment.yamldosyasını oluşturun.cat <<EOF > ~/adk_multiagent_systems/deployment.yaml # Defines the Kubernetes resources required to deploy the application to GKE. # Includes the Deployment (to run the container pods) and the Service # (to expose the application via a Load Balancer). apiVersion: apps/v1 kind: Deployment metadata: name: adk-agent spec: replicas: 1 selector: matchLabels: app: adk-agent template: metadata: labels: app: adk-agent spec: # Assign the Kubernetes Service Account for Workload Identity serviceAccountName: adk-agent-sa containers: - name: adk-agent imagePullPolicy: Always # The path to the container image in Artifact Registry image: ${GOOGLE_CLOUD_LOCATION}-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/adk-repo/adk-agent:latest # Define the resources for GKE Autopilot to provision resources: limits: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" requests: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" ports: - containerPort: 8080 # Environment variables passed to the application env: - name: PORT value: "8080" - name: GOOGLE_CLOUD_PROJECT value: ${GOOGLE_CLOUD_PROJECT} - name: GOOGLE_CLOUD_LOCATION value: ${GOOGLE_CLOUD_LOCATION} - name: GOOGLE_GENAI_USE_VERTEXAI value: "true" - name: MODEL value: "gemini-2.5-flash" --- apiVersion: v1 kind: Service metadata: name: adk-agent spec: # Create a public-facing Network Load Balancer with an external IP type: LoadBalancer ports: - port: 80 targetPort: 8080 selector: app: adk-agent EOF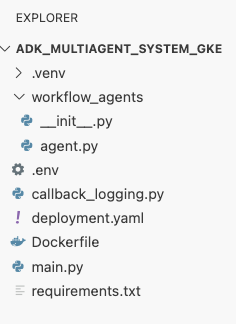
Özet
Bu bölümde, güvenlik ve dağıtım yapılandırmasını tanımladınız:
- Workload Identity'yi kullanarak bir Kubernetes hizmet hesabı oluşturup Google Cloud IAM'ye bağladınız. Bu sayede, anahtarları yönetmeden podlarınızın Vertex AI'ye güvenli bir şekilde erişmesini sağladınız.
- Dağıtımı (kapsüllerin nasıl çalıştırılacağı) ve Hizmeti (yük dengeleyici aracılığıyla nasıl kullanıma sunulacağı) tanımlayan bir
deployment.yamldosyası oluşturdu.
10. Uygulamayı GKE'ye dağıtma
Manifest dosyanız tanımlandığına ve kapsayıcı görüntünüz Artifact Registry'ye aktarıldığına göre artık uygulamanızı dağıtmaya hazırsınız. Bu görevde, yapılandırmanızı GKE kümesine uygulamak için kubectl komutunu kullanacak ve ardından aracınızın doğru şekilde başlatıldığından emin olmak için durumu izleyeceksiniz.
- Terminalinizde
deployment.yamlmanifest dosyasını kümenize uygulayın.kubectl apply -f deployment.yamlkubectl applykomutu,deployment.yamldosyanızı Kubernetes API sunucusuna gönderir. Ardından sunucu, yapılandırmanızı okur ve dağıtım ile hizmet nesnelerinin oluşturulmasını düzenler. - Terminalde dağıtımınızın durumunu gerçek zamanlı olarak kontrol edin. Kapsüllerin
Runningdurumuna gelmesini bekleyin.kubectl get pods -l=app=adk-agent --watch- Beklemede: Pod, küme tarafından kabul edilmiştir ancak kapsayıcı henüz oluşturulmamıştır.
- Container oluşturma: GKE, container görüntünüzü Artifact Registry'den çekiyor ve container'ı başlatıyor.
- Koşu: İşlem tamamlandı. Kapsayıcı çalışıyor ve aracı uygulamanız yayında.
- Durum
Runningolarak gösterildiğinde, watch komutunu durdurmak ve komut istemine dönmek için terminalde CTRL+C tuşlarına basın.
Özet
Bu bölümde iş yükünü başlattınız:
- Manifestinizi kümeye göndermek için
kubectlapply komutunu kullanın. - Uygulamanın başarıyla başlatıldığından emin olmak için Pod yaşam döngüsünü (Beklemede -> ContainerCreating -> Çalışıyor) izledi.
11. Temsilciyle etkileşim kurma
ADK aracınız artık GKE'de canlı olarak çalışıyor ve herkese açık bir yük dengeleyici aracılığıyla internete sunuluyor. Etkileşim kurmak ve sistemin tamamının doğru çalıştığını doğrulamak için aracının web arayüzüne bağlanırsınız.
Hizmetinizin harici IP adresini bulma
Temsilciye erişmek için öncelikle GKE'nin Hizmetiniz için sağladığı herkese açık IP adresini almanız gerekir.
- Terminalde, hizmetinizin ayrıntılarını almak için aşağıdaki komutu çalıştırın.
kubectl get service adk-agent EXTERNAL-IPsütunundaki değeri bulun. Hizmeti ilk kez dağıttıktan sonra IP adresinin atanması bir veya iki dakika sürebilir.pendingolarak gösteriliyorsa bir dakika bekleyip komutu tekrar çalıştırın. Çıkış şuna benzer şekilde görünür:NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE adk-agent-service LoadBalancer 10.120.12.234 34.123.45.67 80:31234/TCP 5mEXTERNAL-IPaltında listelenen adres (ör. 34.123.45.67), aracınıza herkese açık giriş noktasıdır.
Dağıtılan temsilciyi test etme
Artık herkese açık IP adresini kullanarak ADK'nın yerleşik web kullanıcı arayüzüne doğrudan tarayıcınızdan erişebilirsiniz.
- Terminalden harici IP adresini (
EXTERNAL-IP) kopyalayın. - Web tarayıcınızda yeni bir sekme açın ve
http://[EXTERNAL-IP]yazın.[EXTERNAL-IP]yerine kopyaladığınız IP adresini girin. - ADK web arayüzünü görmeniz gerekir.
- Aracı açılır menüsünde workflow_agents seçeneğinin belirlendiğinden emin olun.
- Token Streaming'i açın.
- Yeni bir görüşme başlatmak için
helloyazıp Enter tuşuna basın. - Sonucu inceleyin. Temsilci, selamlama mesajıyla hızlıca yanıt vermelidir: "Gişe rekorları kıracak bir film için tanıtım yazısı yazmanıza yardımcı olabilirim. Hangi tarihi şahsiyet hakkında film çekmek istersiniz?"
- Geçmişten bir karakter seçmeniz istendiğinde ilginizi çeken bir karakteri seçin. Bazı fikirler:
the most successful female pirate in historythe woman who invented the first computer compilera legendary lawman of the American Wild West
Özet
Bu bölümde dağıtımı doğruladınız:
- LoadBalancer tarafından ayrılan harici IP adresini aldım.
- Çok aracı sistemin yanıt verdiğini ve çalıştığını doğrulamak için bir tarayıcı üzerinden ADK Web kullanıcı arayüzüne erişildi.
12. Otomatik ölçeklendirmeyi yapılandır
Üretimdeki temel zorluklardan biri, tahmin edilemeyen kullanıcı trafiğini yönetmektir. Önceki görevde yaptığınız gibi sabit sayıda kopya için kodlama yapmak, boşta kalan kaynaklar için fazla ödeme yapmanız veya trafik artışları sırasında performansın düşmesi riskini taşımanız anlamına gelir. GKE, otomatik ölçeklendirme ile bu sorunu çözer.
HorizontalPodAutoscaler (HPA)'ı yapılandıracaksınız. Bu, dağıtımınızdaki çalışan pod sayısını gerçek zamanlı CPU kullanımına göre otomatik olarak ayarlayan bir Kubernetes denetleyicisidir.
- Cloud Shell Düzenleyici terminalinde,
adk_multiagent_systemsdizininin kökünde yeni birhpa.yamldosyası oluşturun.cloudshell edit ~/adk_multiagent_systems/hpa.yaml - Yeni
hpa.yamldosyasına aşağıdaki içeriği ekleyin:# Configures the HorizontalPodAutoscaler (HPA) to automatically scale # the number of running agent pods up or down based on CPU utilization # to handle varying traffic loads. apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: adk-agent-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: adk-agent minReplicas: 1 maxReplicas: 5 targetCPUUtilizationPercentage: 50adk-agentdağıtımımızı hedefler. Her zaman en az 1 pod'un çalışmasını sağlar, maksimum 5 pod ayarlar ve ortalama CPU kullanımını %50 civarında tutmak için kopyaları ekler/kaldırır. Bu noktada, Cloud Shell Düzenleyici'deki Gezgin panelinde görünen dosya yapınız şu şekilde olmalıdır:
- Bu kodu terminale yapıştırarak HPA'yı kümenize uygulayın.
kubectl apply -f hpa.yaml
Otomatik ölçekleyiciyi doğrulama
HPA artık etkin ve dağıtımınızı izliyor. Çalışırken görmek için durumunu inceleyebilirsiniz.
- HPA'nızın durumunu almak için terminalde aşağıdaki komutu çalıştırın.
kubectl get hpa adk-agent-hpaNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE adk-agent-hpa Deployment/adk-agent 0%/50% 1 5 1 30s
Özet
Bu bölümde, üretim trafiği için optimizasyon yaptınız:
- Ölçeklendirme kurallarını tanımlamak için
hpa.yamlmanifest dosyası oluşturduysanız. - Pod replikalarının sayısını CPU kullanımına göre otomatik olarak ayarlamak için HorizontalPodAutoscaler (HPA) dağıtıldı.
13. Üretime hazırlanma
Not: Aşağıdaki bölümler yalnızca bilgilendirme amaçlıdır ve uygulanacak başka adımlar içermez. Uygulamanızı üretime alma konusunda bağlam ve en iyi uygulamalar sağlamak için tasarlanmıştır.
Kaynak ayırma ile performansı ayarlama
GKE Autopilot'ta, requests kaynağını deployment.yaml içinde belirterek uygulamanız için sağlanan CPU ve bellek miktarını kontrol edebilirsiniz.
Bellek yetersizliği nedeniyle aracınızın yavaş çalıştığını veya kilitlendiğini fark ederseniz deployment.yaml içindeki resources bloğunu düzenleyerek ve dosyayı kubectl apply ile yeniden uygulayarak kaynak ayırımını artırabilirsiniz.
Örneğin, belleği iki katına çıkarmak için:
# In deployment.yaml
# ...
resources:
requests:
memory: "2Gi" # Increased from 1Gi
cpu: "1000m"
# ...
CI/CD ile iş akışınızı otomatikleştirme
Bu laboratuvarda komutları manuel olarak çalıştırdınız. Profesyonel uygulama, CI/CD (Sürekli Entegrasyon/Sürekli Dağıtım) ardışık düzeni oluşturmaktır. Bir kaynak kodu deposunu (ör. GitHub) Cloud Build derleme tetikleyicisine bağlayarak dağıtımın tamamını otomatikleştirebilirsiniz.
Bir ardışık düzenle, her kod değişikliği aktardığınızda Cloud Build otomatik olarak şunları yapabilir:
- Yeni kapsayıcı görüntüsünü oluşturun.
- Görüntüyü Artifact Registry'ye aktarın.
- Güncellenen Kubernetes manifestlerini GKE kümenize uygulayın.
Gizli anahtarları güvenli bir şekilde yönetme
Bu laboratuvarda, yapılandırmayı bir .env dosyasında sakladınız ve uygulamanıza ilettiniz. Bu yöntem geliştirme için uygundur ancak API anahtarları gibi hassas veriler için güvenli değildir. Önerilen en iyi uygulama, gizli anahtarları güvenli bir şekilde depolamak için Secret Manager'ı kullanmaktır.
GKE, Secret Manager ile yerel entegrasyona sahiptir. Bu entegrasyon sayesinde, kaynak kodunuza hiç eklenmeden sırları doğrudan podlarınıza ortam değişkenleri veya dosyalar olarak yerleştirebilirsiniz.
İstediğiniz Kaynakları temizleme bölümü, Sonuç bölümünden hemen önce eklenmiştir.
14. Kaynakları temizleme
Bu eğitimde kullanılan kaynaklar için Google Cloud hesabınızın ücretlendirilmesini önlemek amacıyla kaynakları içeren projeyi silin veya projeyi koruyup tek tek kaynakları silin.
GKE kümesini silme
Bu laboratuvarda maliyeti en çok etkileyen faktör GKE kümesidir. Bu işlem silindiğinde işlem ücretleri durdurulur.
- Terminalde aşağıdaki komutu çalıştırın:
gcloud container clusters delete adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Artifact Registry deposunu silme
Artifact Registry'de depolanan container görüntüleri için depolama maliyetleri uygulanır.
- Terminalde aşağıdaki komutu çalıştırın:
gcloud artifacts repositories delete adk-repo \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Projeyi silme (isteğe bağlı)
Bu laboratuvar için özel olarak yeni bir proje oluşturduysanız ve projeyi tekrar kullanmayı planlamıyorsanız temizlemenin en kolay yolu projenin tamamını silmektir.
- Terminalde aşağıdaki komutu çalıştırın (
[YOUR_PROJECT_ID]yerine gerçek proje kimliğinizi girin):gcloud projects delete [YOUR_PROJECT_ID]
15. Sonuç
Tebrikler! Üretim düzeyinde bir GKE kümesine çok aracılı bir ADK uygulamasını başarıyla dağıttınız. Bu önemli başarı, modern bir bulutta yerel uygulamanın temel yaşam döngüsünü kapsar ve kendi karmaşık ajan tabanlı sistemlerinizi dağıtmak için sağlam bir temel sunar.
Özet
Bu laboratuvarda şunları öğrendiniz:
- GKE Autopilot kümesi sağlama
Dockerfileile container görüntüsü oluşturma ve Artifact Registry'ye aktarma- Workload Identity'yi kullanarak Google Cloud API'lerine güvenli bir şekilde bağlanın.
- Dağıtım ve Hizmet için Kubernetes manifestleri yazın.
- LoadBalancer ile bir uygulamayı internete açın.
- HorizontalPodAutoscaler (HPA) ile otomatik ölçeklendirmeyi yapılandırın.