
1. Giới thiệu
Tổng quan
Phòng thí nghiệm này giúp thu hẹp khoảng cách quan trọng giữa việc phát triển một hệ thống đa tác nhân mạnh mẽ và triển khai hệ thống đó để sử dụng trong thực tế. Mặc dù việc xây dựng các tác nhân cục bộ là một khởi đầu tốt, nhưng các ứng dụng sản xuất cần một nền tảng có khả năng mở rộng, đáng tin cậy và an toàn.
Trong phòng thí nghiệm này, bạn sẽ sử dụng một hệ thống đa tác nhân được xây dựng bằng Bộ công cụ phát triển tác nhân (ADK) của Google và triển khai hệ thống đó vào một môi trường cấp sản xuất trên Google Kubernetes Engine (GKE).
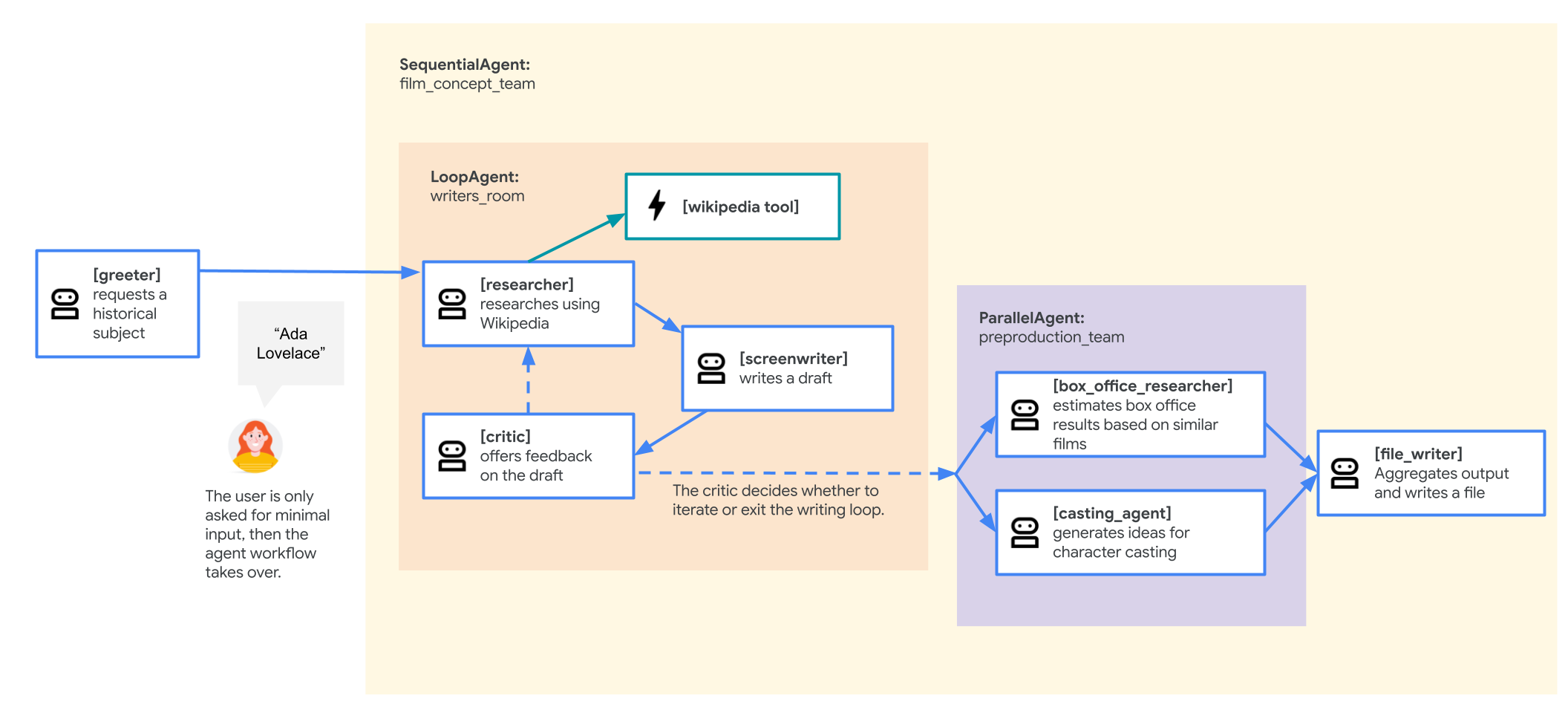
Nhân viên hỗ trợ của nhóm ý tưởng về phim
Ứng dụng mẫu được dùng trong lớp học này là một "nhóm ý tưởng về phim" bao gồm nhiều tác nhân cộng tác: một nhà nghiên cứu, một nhà biên kịch và một người viết tệp. Các đặc vụ này phối hợp với nhau để giúp người dùng lên ý tưởng và phác thảo một bản đề cử phim về một nhân vật lịch sử.
Tại sao nên triển khai đến GKE?
Để chuẩn bị cho tác nhân của bạn đáp ứng các yêu cầu của môi trường sản xuất, bạn cần một nền tảng được xây dựng để có khả năng mở rộng, bảo mật và tiết kiệm chi phí. Google Kubernetes Engine (GKE) cung cấp nền tảng mạnh mẽ và linh hoạt này để chạy ứng dụng được đóng gói trong vùng chứa.
Điều này mang lại một số lợi ích cho khối lượng công việc sản xuất của bạn:
- Tự động cấp tài nguyên bổ sung và hiệu suất: Xử lý lưu lượng truy cập khó dự đoán bằng HorizontalPodAutoscaler (HPA). Công cụ này sẽ tự động thêm hoặc xoá các bản sao của tác nhân dựa trên tải. Đối với các quy trình AI đòi hỏi nhiều tài nguyên hơn, bạn có thể đính kèm các bộ tăng tốc phần cứng như GPU và TPU.
- Quản lý tài nguyên hiệu quả về chi phí: Tối ưu hoá chi phí bằng GKE Autopilot. Tính năng này tự động quản lý cơ sở hạ tầng cơ bản để bạn chỉ phải trả tiền cho những tài nguyên mà ứng dụng của bạn yêu cầu.
- Bảo mật và khả năng ghi nhận tích hợp: Kết nối an toàn với các dịch vụ khác của Google Cloud bằng Workload Identity. Nhờ đó, bạn không cần quản lý và lưu trữ khoá tài khoản dịch vụ. Tất cả nhật ký ứng dụng đều tự động được truyền trực tuyến đến Cloud Logging để giám sát và gỡ lỗi tập trung.
- Quyền kiểm soát và khả năng di chuyển: Tránh lệ thuộc vào nhà cung cấp bằng Kubernetes nguồn mở. Ứng dụng của bạn có tính di động và có thể chạy trên mọi cụm Kubernetes, tại chỗ hoặc trong các đám mây khác.
Kiến thức bạn sẽ học được
Trong bài thực hành này, bạn sẽ tìm hiểu cách thực hiện các thao tác sau:
- Cung cấp một cụm GKE Autopilot.
- Đóng gói một ứng dụng bằng tệp Docker và đẩy hình ảnh đó vào Artifact Registry.
- Kết nối ứng dụng của bạn với API Google Cloud một cách an toàn bằng Workload Identity.
- Viết và áp dụng tệp kê khai Kubernetes cho một Deployment và Service.
- Đưa một ứng dụng lên Internet bằng LoadBalancer.
- Định cấu hình tính năng tự động mở rộng quy mô bằng HorizontalPodAutoscaler (HPA).
2. Thiết lập dự án
Tài khoản Google
Nếu chưa có Tài khoản Google cá nhân, bạn phải tạo một Tài khoản Google.
Sử dụng tài khoản cá nhân thay vì tài khoản do nơi làm việc hoặc trường học cấp.
Đăng nhập vào Google Cloud Console
Đăng nhập vào Google Cloud Console bằng Tài khoản Google cá nhân.
Bật thanh toán
Thiết lập tài khoản thanh toán cá nhân
Nếu thiết lập thông tin thanh toán bằng tín dụng Google Cloud, bạn có thể bỏ qua bước này.
Để thiết lập tài khoản thanh toán cá nhân, hãy truy cập vào đây để bật tính năng thanh toán trong Cloud Console.
Một số lưu ý:
- Việc hoàn thành bài thực hành này sẽ tốn ít hơn 1 USD cho các tài nguyên trên đám mây.
- Bạn có thể làm theo các bước ở cuối bài thực hành này để xoá tài nguyên nhằm tránh bị tính thêm phí.
- Người dùng mới đủ điều kiện dùng thử miễn phí trị giá 300 USD.
Tạo dự án (không bắt buộc)
Nếu bạn không có dự án hiện tại nào muốn sử dụng cho lớp học này, hãy tạo một dự án mới tại đây.
3. Mở Trình chỉnh sửa Cloud Shell
- Nhấp vào đường liên kết này để chuyển trực tiếp đến Cloud Shell Editor
- Nếu được nhắc uỷ quyền vào bất kỳ thời điểm nào trong ngày hôm nay, hãy nhấp vào Uỷ quyền để tiếp tục.
- Nếu thiết bị đầu cuối không xuất hiện ở cuối màn hình, hãy mở thiết bị đầu cuối:
- Nhấp vào Xem
- Nhấp vào Terminal (Thiết bị đầu cuối)
- Trong cửa sổ dòng lệnh, hãy thiết lập dự án bằng lệnh sau:
gcloud config set project [PROJECT_ID]- Ví dụ:
gcloud config set project lab-project-id-example - Nếu không nhớ mã dự án, bạn có thể liệt kê tất cả mã dự án bằng cách dùng lệnh:
gcloud projects list
- Ví dụ:
- Bạn sẽ thấy thông báo sau:
Updated property [core/project].
4. Bật API
Để sử dụng GKE, Artifact Registry, Cloud Build và Vertex AI, bạn cần bật các API tương ứng của chúng trong dự án trên đám mây của Google.
- Trong thiết bị đầu cuối, hãy bật các API:
gcloud services enable \ container.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.comOperation "operations/acf.p2-176675280136-b03ab5e4-3483-4ebf-9655-43dc3b345c63" finished successfully.
Giới thiệu về các API
- Google Kubernetes Engine API (
container.googleapis.com) cho phép bạn tạo và quản lý cụm GKE chạy tác nhân của bạn. GKE cung cấp một môi trường được quản lý để triển khai, quản lý và mở rộng quy mô các ứng dụng trong vùng chứa bằng cơ sở hạ tầng của Google. - Artifact Registry API (
artifactregistry.googleapis.com) cung cấp một kho lưu trữ riêng tư, an toàn để lưu trữ hình ảnh vùng chứa của tác nhân. Đây là phiên bản nâng cấp của Container Registry và tích hợp liền mạch với GKE và Cloud Build. - Lệnh
gcloud builds submitdùng Cloud Build API (cloudbuild.googleapis.com) để tạo hình ảnh vùng chứa trên đám mây từ Dockerfile. Đây là một nền tảng CI/CD không máy chủ, giúp thực thi các bản dựng trên cơ sở hạ tầng của Google Cloud. - Vertex AI API (
aiplatform.googleapis.com) cho phép tác nhân đã triển khai của bạn giao tiếp với các mô hình Gemini để thực hiện các tác vụ cốt lõi. Nền tảng này cung cấp API hợp nhất cho tất cả các dịch vụ AI của Google Cloud.
5. Chuẩn bị môi trường phát triển
Tạo cấu trúc thư mục
- Trong thiết bị đầu cuối, hãy tạo thư mục dự án và các thư mục con cần thiết:
mkdir -p ~/adk_multiagent_systems/workflow_agents cd ~/adk_multiagent_systems - Trong cửa sổ dòng lệnh, hãy chạy lệnh sau để mở thư mục trong trình khám phá Cloud Shell Editor.
cloudshell open-workspace ~/adk_multiagent_systems - Bảng điều khiển trình khám phá ở bên trái sẽ làm mới. Lúc này, bạn sẽ thấy các thư mục mà mình đã tạo.
Khi tạo tệp theo các bước sau, bạn sẽ thấy các tệp xuất hiện trong thư mục này.
Tạo tệp bắt đầu
Bây giờ, bạn sẽ tạo các tệp khởi động cần thiết cho ứng dụng.
- Tạo
callback_logging.pybằng cách chạy lệnh sau trong terminal. Tệp này xử lý việc ghi nhật ký để có khả năng ghi nhận.cat <<EOF > ~/adk_multiagent_systems/callback_logging.py """ Provides helper functions for observability. Handles formatting and sending agent queries, responses, and tool calls to Google Cloud Logging to aid in monitoring and debugging. """ import logging import google.cloud.logging from google.adk.agents.callback_context import CallbackContext from google.adk.models import LlmResponse, LlmRequest def log_query_to_model(callback_context: CallbackContext, llm_request: LlmRequest): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_request.contents and llm_request.contents[-1].role == 'user': if llm_request.contents[-1].parts and "text" in llm_request.contents[-1].parts: last_user_message = llm_request.contents[-1].parts[0].text logging.info(f"[query to {callback_context.agent_name}]: " + last_user_message) def log_model_response(callback_context: CallbackContext, llm_response: LlmResponse): cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() if llm_response.content and llm_response.content.parts: for part in llm_response.content.parts: if part.text: logging.info(f"[response from {callback_context.agent_name}]: " + part.text) elif part.function_call: logging.info(f"[function call from {callback_context.agent_name}]: " + part.function_call.name) EOF - Tạo
workflow_agents/__init__.pybằng cách chạy lệnh sau trong terminal. Thao tác này đánh dấu thư mục là một gói Python.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/__init__.py """ Marks the directory as a Python package and exposes the agent module, allowing the ADK to discover and register the agents defined within. """ from . import agent EOF - Tạo
workflow_agents/agent.pybằng cách chạy lệnh sau trong terminal. Tệp này chứa lôgic cốt lõi cho nhóm gồm nhiều tác nhân của bạn.cat <<EOF > ~/adk_multiagent_systems/workflow_agents/agent.py """ Defines the core multi-agent workflow. Configures individual agents (Researcher, Screenwriter, File Writer), assigns their specific tools, and orchestrates their collaboration using the ADK's SequentialAgent pattern. """ import os import logging import google.cloud.logging from callback_logging import log_query_to_model, log_model_response from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent, LoopAgent, ParallelAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool # import from google.genai import types from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL") print(model_name) # Tools def append_to_state( tool_context: ToolContext, field: str, response: str ) -> dict[str, str]: """Append new output to an existing state key. Args: field (str): a field name to append to response (str): a string to append to the field Returns: dict[str, str]: {"status": "success"} """ existing_state = tool_context.state.get(field, []) tool_context.state[field] = existing_state + [response] logging.info(f"[Added to {field}] {response}") return {"status": "success"} def write_file( tool_context: ToolContext, directory: str, filename: str, content: str ) -> dict[str, str]: target_path = os.path.join(directory, filename) os.makedirs(os.path.dirname(target_path), exist_ok=True) with open(target_path, "w") as f: f.write(content) return {"status": "success"} # Agents file_writer = Agent( name="file_writer", model=model_name, description="Creates marketing details and saves a pitch document.", instruction=""" PLOT_OUTLINE: { PLOT_OUTLINE? } INSTRUCTIONS: - Create a marketable, contemporary movie title suggestion for the movie described in the PLOT_OUTLINE. If a title has been suggested in PLOT_OUTLINE, you can use it, or replace it with a better one. - Use your 'write_file' tool to create a new txt file with the following arguments: - for a filename, use the movie title - Write to the 'movie_pitches' directory. - For the 'content' to write, extract the following from the PLOT_OUTLINE: - A logline - Synopsis or plot outline """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[write_file], ) screenwriter = Agent( name="screenwriter", model=model_name, description="As a screenwriter, write a logline and plot outline for a biopic about a historical character.", instruction=""" INSTRUCTIONS: Your goal is to write a logline and three-act plot outline for an inspiring movie about a historical character(s) described by the PROMPT: { PROMPT? } - If there is CRITICAL_FEEDBACK, use those thoughts to improve upon the outline. - If there is RESEARCH provided, feel free to use details from it, but you are not required to use it all. - If there is a PLOT_OUTLINE, improve upon it. - Use the 'append_to_state' tool to write your logline and three-act plot outline to the field 'PLOT_OUTLINE'. - Summarize what you focused on in this pass. PLOT_OUTLINE: { PLOT_OUTLINE? } RESEARCH: { research? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], ) researcher = Agent( name="researcher", model=model_name, description="Answer research questions using Wikipedia.", instruction=""" PROMPT: { PROMPT? } PLOT_OUTLINE: { PLOT_OUTLINE? } CRITICAL_FEEDBACK: { CRITICAL_FEEDBACK? } INSTRUCTIONS: - If there is a CRITICAL_FEEDBACK, use your wikipedia tool to do research to solve those suggestions - If there is a PLOT_OUTLINE, use your wikipedia tool to do research to add more historical detail - If these are empty, use your Wikipedia tool to gather facts about the person in the PROMPT - Use the 'append_to_state' tool to add your research to the field 'research'. - Summarize what you have learned. Now, use your Wikipedia tool to do research. """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[ LangchainTool(tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())), append_to_state, ], ) film_concept_team = SequentialAgent( name="film_concept_team", description="Write a film plot outline and save it as a text file.", sub_agents=[ researcher, screenwriter, file_writer ], ) root_agent = Agent( name="greeter", model=model_name, description="Guides the user in crafting a movie plot.", instruction=""" - Let the user know you will help them write a pitch for a hit movie. Ask them for a historical figure to create a movie about. - When they respond, use the 'append_to_state' tool to store the user's response in the 'PROMPT' state key and transfer to the 'film_concept_team' agent """, generate_content_config=types.GenerateContentConfig( temperature=0, ), tools=[append_to_state], sub_agents=[film_concept_team], ) EOF
Lúc này, cấu trúc tệp của bạn sẽ có dạng như sau: 
Thiết lập môi trường ảo
- Trong thiết bị đầu cuối, hãy tạo và kích hoạt một môi trường ảo bằng
uv. Điều này đảm bảo các phần phụ thuộc của dự án không xung đột với Python hệ thống.uv venv source .venv/bin/activate
Yêu cầu về việc cài đặt
- Chạy lệnh sau trong dòng lệnh để tạo tệp
requirements.txt.cat <<EOF > ~/adk_multiagent_systems/requirements.txt # Lists all Python dependencies required to run the multi-agent system, # including the Google ADK, LangChain community tools, and web server libraries. langchain-community==0.4.1 wikipedia==1.4.0 google-adk==1.27.5 fastapi==0.135.2 uvicorn==0.42.0 EOF - Cài đặt các gói bắt buộc vào môi trường ảo trong terminal (thiết bị đầu cuối).
uv pip install -r requirements.txt
Thiết lập các biến môi trường
- Sử dụng lệnh sau trong terminal để tạo tệp
.env, tự động chèn mã dự án và khu vực của bạn.cat <<EOF > ~/adk_multiagent_systems/.env GOOGLE_CLOUD_PROJECT="$(gcloud config get-value project)" GOOGLE_CLOUD_PROJECT_NUMBER="$(gcloud projects describe $(gcloud config get-value project) --format='value(projectNumber)')" GOOGLE_CLOUD_LOCATION="us-central1" GOOGLE_GENAI_USE_VERTEXAI=true MODEL="gemini-2.5-flash" EOF - Trong thiết bị đầu cuối, hãy tải các biến vào phiên shell.
source .env
Tóm tắt
Trong phần này, bạn đã thiết lập nền tảng cục bộ cho dự án của mình:
- Đã tạo cấu trúc thư mục và các tệp khởi động tác nhân cần thiết (
agent.py,callback_logging.py,requirements.txt). - Cách ly các phần phụ thuộc bằng môi trường ảo (
uv). - Đã định cấu hình các biến môi trường (
.env) để lưu trữ thông tin chi tiết cụ thể của dự án, chẳng hạn như mã dự án và khu vực.
6. Khám phá tệp tác nhân
Bạn đã thiết lập mã nguồn cho lớp học, bao gồm cả một hệ thống nhiều tác nhân được viết sẵn. Trước khi triển khai ứng dụng, bạn nên tìm hiểu cách xác định các tác nhân. Logic cốt lõi của tác nhân nằm trong workflow_agents/agent.py.
- Trong Cloud Shell Editor, hãy dùng trình khám phá tệp ở bên trái để chuyển đến
adk_multiagent_systems/workflow_agents/rồi mở tệpagent.py. - Dành chút thời gian để xem qua tệp này. Bạn không cần hiểu từng dòng, nhưng hãy chú ý đến cấu trúc cấp cao:
- Từng tác nhân: Tệp này xác định 3 đối tượng
Agentriêng biệt:researcher,screenwritervàfile_writer. Mỗi tác nhân được cung cấp mộtinstructioncụ thể (lời nhắc của tác nhân) và danh sáchtoolsmà tác nhân được phép sử dụng (chẳng hạn như công cụWikipediaQueryRunhoặc công cụwrite_filetuỳ chỉnh). - Thành phần của tác nhân: Các tác nhân riêng lẻ được liên kết với nhau thành một
SequentialAgentgọi làfilm_concept_team. Điều này cho biết ADK sẽ chạy các tác nhân này lần lượt, truyền trạng thái từ tác nhân này sang tác nhân tiếp theo. - Tác nhân gốc:
root_agent(có tên là "greeter") được xác định để xử lý lượt tương tác của người dùng ban đầu. Khi người dùng đưa ra một câu lệnh, tác nhân này sẽ lưu câu lệnh đó vào trạng thái của ứng dụng, sau đó chuyển quyền kiểm soát cho quy trìnhfilm_concept_team.
- Từng tác nhân: Tệp này xác định 3 đối tượng
Việc nắm rõ cấu trúc này sẽ giúp bạn hiểu rõ những gì bạn sắp triển khai: không chỉ một tác nhân duy nhất mà còn là một nhóm tác nhân chuyên biệt phối hợp với nhau do ADK điều phối.
7. Tạo một cụm GKE Autopilot
Sau khi chuẩn bị môi trường, bước tiếp theo là cung cấp cơ sở hạ tầng nơi ứng dụng tác nhân của bạn sẽ chạy. Bạn sẽ tạo một cụm GKE Autopilot đóng vai trò là nền tảng cho việc triển khai của bạn. Chúng tôi sử dụng chế độ Tự vận hành vì chế độ này xử lý việc quản lý phức tạp các nút, hoạt động mở rộng quy mô và bảo mật cơ bản của cụm, cho phép bạn chỉ tập trung vào việc triển khai ứng dụng.
- Trong thiết bị đầu cuối, hãy tạo một cụm GKE Autopilot mới có tên là
adk-cluster.gcloud container clusters create-auto adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT - Sau khi cụm được tạo, hãy định cấu hình
kubectlđể kết nối với cụm đó bằng cách chạy lệnh này trong terminal:gcloud container clusters get-credentials adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --project=$GOOGLE_CLOUD_PROJECT~/.kube/config). Kể từ thời điểm này, công cụ dòng lệnhkubectlsẽ được xác thực và hướng dẫn giao tiếp vớiadk-clustercủa bạn.
Tóm tắt
Trong phần này, bạn đã cung cấp cơ sở hạ tầng:
- Tạo một cụm GKE Autopilot được quản lý hoàn toàn bằng
gcloud. - Đã định cấu hình công cụ
kubectlcục bộ để xác thực và giao tiếp với cụm mới.
8. Tạo vùng chứa và đẩy ứng dụng
Mã của tác nhân hiện chỉ tồn tại trong môi trường Cloud Shell của bạn. Để chạy ứng dụng này trên GKE, trước tiên, bạn phải đóng gói ứng dụng vào một hình ảnh vùng chứa. Hình ảnh vùng chứa là một tệp tĩnh, di động, kết hợp mã của ứng dụng với tất cả các phần phụ thuộc của ứng dụng. Khi bạn chạy hình ảnh này, hình ảnh đó sẽ trở thành một vùng chứa đang hoạt động.
Quy trình này bao gồm 3 bước chính:
- Tạo một điểm truy cập: Xác định tệp
main.pyđể chuyển đổi logic của tác nhân thành một máy chủ web có thể chạy. - Xác định hình ảnh vùng chứa: Tạo một Dockerfile đóng vai trò là bản thiết kế để tạo hình ảnh vùng chứa.
- Tạo và đẩy: Sử dụng Cloud Build để thực thi tệp Docker, tạo hình ảnh vùng chứa và đẩy hình ảnh đó vào Google Artifact Registry, một kho lưu trữ an toàn cho hình ảnh của bạn.
Chuẩn bị ứng dụng để triển khai
Tác nhân ADK cần một máy chủ web để nhận yêu cầu. Tệp main.py sẽ đóng vai trò là điểm truy cập này, sử dụng khung FastAPI để hiển thị chức năng của tác nhân qua HTTP.
- Trong thư mục gốc của thư mục
adk_multiagent_systemstrong thiết bị đầu cuối, hãy tạo một tệp mới có tên làmain.py.cat <<EOF > ~/adk_multiagent_systems/main.py """ Serves as the application entry point. Initializes the FastAPI web server, discovers the agents defined in the workflow directory, and exposes them via HTTP endpoints for interaction. """ import os import uvicorn from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Get the directory where main.py is located AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) # Configure the session service (e.g., SQLite for local storage) SESSION_SERVICE_URI = "sqlite:///./sessions.db" # Configure CORS to allow requests from various origins for this lab ALLOWED_ORIGINS = ["http://localhost", "http://localhost:8080", "*"] # Enable the ADK's built-in web interface SERVE_WEB_INTERFACE = True # Call the ADK function to discover agents and create the FastAPI app app: FastAPI = get_fast_api_app( agents_dir=AGENT_DIR, session_service_uri=SESSION_SERVICE_URI, allow_origins=ALLOWED_ORIGINS, web=SERVE_WEB_INTERFACE, ) # You can add more FastAPI routes or configurations below if needed # Example: # @app.get("/hello") # async def read_root(): # return {"Hello": "World"} if __name__ == "__main__": # Get the port from the PORT environment variable provided by the container runtime # Run the Uvicorn server, listening on all available network interfaces (0.0.0.0) uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("PORT", 8080))) EOFuvicornchạy ứng dụng này, lắng nghe trên máy chủ lưu trữ0.0.0.0để chấp nhận các kết nối từ mọi địa chỉ IP và trên cổng do biến môi trườngPORTchỉ định. Chúng ta sẽ đặt biến này sau trong tệp kê khai Kubernetes.
Lúc này, cấu trúc tệp của bạn như trong bảng điều khiển trình khám phá trong Cloud Shell Editor sẽ có dạng như sau: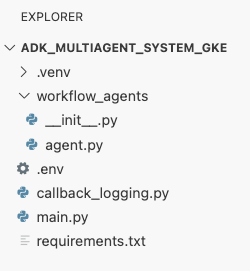
Đóng gói tác nhân ADK vào vùng chứa bằng Docker
Để triển khai ứng dụng của mình lên GKE, trước tiên, chúng ta cần đóng gói ứng dụng đó vào một hình ảnh vùng chứa. Hình ảnh này sẽ kết hợp mã của ứng dụng với tất cả các thư viện và phần phụ thuộc cần thiết để chạy ứng dụng. Chúng ta sẽ dùng Docker để tạo hình ảnh vùng chứa này.
- Trong thư mục gốc của thư mục
adk_multiagent_systemstrong thiết bị đầu cuối, hãy tạo một tệp mới có tên làDockerfile.cat <<'EOF' > ~/adk_multiagent_systems/Dockerfile # Defines the blueprint for the container image. Installs dependencies, # sets up a secure non-root user, and specifies the startup command to run the # agent web server. # Use an official lightweight Python image as the base FROM python:3.13-slim # Set the working directory inside the container WORKDIR /app # Create a non-root user for security best practices RUN adduser --disabled-password --gecos "" myuser # Copy and install dependencies first to leverage Docker's layer caching COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt # Copy all application code into the container COPY . . # Create the directory where the agent will write files at runtime # The -p flag ensures the command doesn't fail if the directory already exists RUN mkdir -p movie_pitches # Change ownership of EVERYTHING in /app to the non-root user # Without this, the running agent would be denied permission to write files. RUN chown -R myuser:myuser /app # Switch the active user from root to the non-root user USER myuser # Add the user's local binary directory to the system's PATH ENV PATH="/home/myuser/.local/bin:$PATH" # Define the command to run when the container starts CMD ["sh", "-c", "uvicorn main:app --host 0.0.0.0 --port $PORT"] EOF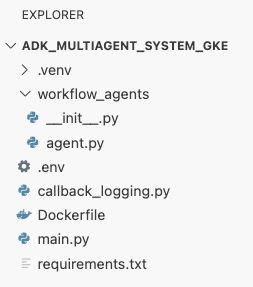
Tạo và đẩy hình ảnh vùng chứa lên Artifact Registry
Giờ đây, khi đã có tệp Dockerfile, bạn sẽ dùng Cloud Build để tạo hình ảnh và chuyển hình ảnh đó đến Artifact Registry, một sổ đăng ký riêng tư, an toàn được tích hợp với các dịch vụ của Google Cloud. GKE sẽ kéo hình ảnh từ sổ đăng ký này để chạy ứng dụng của bạn.
- Trong thiết bị đầu cuối, hãy tạo một kho lưu trữ Artifact Registry mới để lưu trữ hình ảnh vùng chứa.
gcloud artifacts repositories create adk-repo \ --repository-format=docker \ --location=$GOOGLE_CLOUD_LOCATION \ --description="ADK repository" - Trong Terminal, hãy dùng
gcloud builds submitđể tạo hình ảnh vùng chứa và đẩy hình ảnh đó vào kho lưu trữ.gcloud builds submit \ --tag $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo/adk-agent:latest \ --project=$GOOGLE_CLOUD_PROJECT \ .Dockerfile. Thao tác này sẽ tạo hình ảnh trên đám mây, gắn thẻ hình ảnh đó bằng địa chỉ kho lưu trữ Artifact Registry của bạn và tự động đẩy hình ảnh đó vào kho lưu trữ. - Từ thiết bị đầu cuối, hãy xác minh rằng hình ảnh đã được tạo:
gcloud artifacts docker images list \ $GOOGLE_CLOUD_LOCATION-docker.pkg.dev/$GOOGLE_CLOUD_PROJECT/adk-repo \ --project=$GOOGLE_CLOUD_PROJECT
Tóm tắt
Trong phần này, bạn đã đóng gói mã để triển khai:
- Tạo một điểm truy cập
main.pyđể bao bọc các tác nhân của bạn trong một máy chủ web FastAPI. - Xác định một
Dockerfileđể gói mã và các phần phụ thuộc của bạn vào một hình ảnh di động. - Sử dụng Cloud Build để tạo hình ảnh và đẩy hình ảnh đó vào một kho lưu trữ Artifact Registry an toàn.
9. Tạo tệp kê khai Kubernetes
Giờ đây, khi hình ảnh vùng chứa của bạn đã được tạo và lưu trữ trong Artifact Registry, bạn cần hướng dẫn GKE cách chạy hình ảnh đó. Việc này bao gồm 2 hoạt động chính:
- Định cấu hình quyền: Bạn sẽ tạo một danh tính riêng cho tác nhân trong cụm và cấp cho danh tính đó quyền truy cập an toàn vào Google Cloud APIs mà tác nhân cần (cụ thể là Vertex AI).
- Xác định trạng thái ứng dụng: Bạn sẽ viết một tệp kê khai Kubernetes, một tài liệu YAML xác định một cách khai báo mọi thứ mà ứng dụng của bạn cần để chạy, bao gồm cả hình ảnh vùng chứa, biến môi trường và cách ứng dụng được hiển thị trên mạng.
Định cấu hình Tài khoản dịch vụ Kubernetes cho Vertex AI
Tác nhân của bạn cần có quyền giao tiếp với API Vertex AI để truy cập vào các mô hình Gemini. Phương thức an toàn nhất và được đề xuất để cấp quyền này trong GKE là Workload Identity. Workload Identity cho phép bạn liên kết một danh tính gốc của Kubernetes (một Tài khoản dịch vụ Kubernetes) với một danh tính trên Google Cloud (một Tài khoản dịch vụ IAM), hoàn toàn không cần tải xuống, quản lý và lưu trữ các khoá JSON tĩnh.
- Trong thiết bị đầu cuối, hãy tạo Tài khoản dịch vụ Kubernetes (
adk-agent-sa). Thao tác này sẽ tạo một danh tính cho tác nhân của bạn trong cụm GKE mà các nhóm có thể sử dụng.kubectl create serviceaccount adk-agent-sa - Trong thiết bị đầu cuối, hãy liên kết Tài khoản dịch vụ Kubernetes với Cloud IAM của Google bằng cách tạo một liên kết chính sách. Lệnh này cấp vai trò
aiplatform.userchoadk-agent-sacủa bạn, cho phépadk-agent-sagọi Vertex AI API một cách an toàn.gcloud projects add-iam-policy-binding projects/${GOOGLE_CLOUD_PROJECT} \ --role=roles/aiplatform.user \ --member=principal://iam.googleapis.com/projects/${GOOGLE_CLOUD_PROJECT_NUMBER}/locations/global/workloadIdentityPools/${GOOGLE_CLOUD_PROJECT}.svc.id.goog/subject/ns/default/sa/adk-agent-sa \ --condition=None
Tạo tệp kê khai Kubernetes
Kubernetes sử dụng tệp kê khai YAML để xác định trạng thái mong muốn của ứng dụng. Bạn sẽ tạo một tệp deployment.yaml chứa 2 đối tượng Kubernetes thiết yếu: một Deployment và một Service.
- Từ thiết bị đầu cuối, hãy tạo tệp
deployment.yaml.cat <<EOF > ~/adk_multiagent_systems/deployment.yaml # Defines the Kubernetes resources required to deploy the application to GKE. # Includes the Deployment (to run the container pods) and the Service # (to expose the application via a Load Balancer). apiVersion: apps/v1 kind: Deployment metadata: name: adk-agent spec: replicas: 1 selector: matchLabels: app: adk-agent template: metadata: labels: app: adk-agent spec: # Assign the Kubernetes Service Account for Workload Identity serviceAccountName: adk-agent-sa containers: - name: adk-agent imagePullPolicy: Always # The path to the container image in Artifact Registry image: ${GOOGLE_CLOUD_LOCATION}-docker.pkg.dev/${GOOGLE_CLOUD_PROJECT}/adk-repo/adk-agent:latest # Define the resources for GKE Autopilot to provision resources: limits: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" requests: memory: "1Gi" cpu: "1000m" ephemeral-storage: "512Mi" ports: - containerPort: 8080 # Environment variables passed to the application env: - name: PORT value: "8080" - name: GOOGLE_CLOUD_PROJECT value: ${GOOGLE_CLOUD_PROJECT} - name: GOOGLE_CLOUD_LOCATION value: ${GOOGLE_CLOUD_LOCATION} - name: GOOGLE_GENAI_USE_VERTEXAI value: "true" - name: MODEL value: "gemini-2.5-flash" --- apiVersion: v1 kind: Service metadata: name: adk-agent spec: # Create a public-facing Network Load Balancer with an external IP type: LoadBalancer ports: - port: 80 targetPort: 8080 selector: app: adk-agent EOF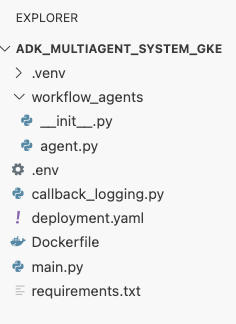
Tóm tắt
Trong phần này, bạn đã xác định cấu hình bảo mật và triển khai:
- Tạo một Tài khoản dịch vụ Kubernetes và liên kết tài khoản đó với Cloud IAM của Google Cloud bằng cách sử dụng Workload Identity, cho phép các nhóm của bạn truy cập an toàn vào Vertex AI mà không cần quản lý khoá.
- Đã tạo một tệp
deployment.yamlxác định Deployment (cách chạy các pod) và Service (cách hiển thị các pod thông qua Load Balancer).
10. Triển khai ứng dụng vào GKE
Sau khi xác định tệp kê khai và đẩy hình ảnh vùng chứa vào Artifact Registry, bạn đã sẵn sàng triển khai ứng dụng. Trong nhiệm vụ này, bạn sẽ sử dụng kubectl để áp dụng cấu hình cho cụm GKE, sau đó theo dõi trạng thái để đảm bảo tác nhân khởi động đúng cách.
- Trong thiết bị đầu cuối, hãy áp dụng tệp kê khai
deployment.yamlcho cụm của bạn.kubectl apply -f deployment.yamlkubectl applysẽ gửi tệpdeployment.yamlcủa bạn đến máy chủ API Kubernetes. Sau đó, máy chủ sẽ đọc cấu hình của bạn và điều phối việc tạo các đối tượng Triển khai và Dịch vụ. - Trong thiết bị đầu cuối, hãy kiểm tra trạng thái triển khai theo thời gian thực. Đợi các pod ở trạng thái
Running.kubectl get pods -l=app=adk-agent --watch- Đang chờ xử lý: Cụm đã chấp nhận nhóm, nhưng vùng chứa chưa được tạo.
- Tạo vùng chứa: GKE đang kéo hình ảnh vùng chứa của bạn từ Artifact Registry và khởi động vùng chứa.
- Chạy: Thành công! Vùng chứa đang chạy và ứng dụng tác nhân của bạn đang hoạt động.
- Khi trạng thái hiển thị
Running, hãy nhấn tổ hợp phím CTRL+C trong terminal để dừng lệnh watch và quay lại dấu nhắc lệnh.
Tóm tắt
Trong phần này, bạn đã chạy tải:
- Sử dụng
kubectlđể gửi tệp kê khai đến cụm. - Theo dõi vòng đời của Pod (Đang chờ xử lý -> ContainerCreating -> Đang chạy) để đảm bảo ứng dụng khởi động thành công.
11. Tương tác với trợ lý
Tác nhân ADK hiện đang chạy trực tiếp trên GKE và được kết nối với Internet thông qua một Trình cân bằng tải công khai. Bạn sẽ kết nối với giao diện web của tác nhân để tương tác với tác nhân đó và xác minh rằng toàn bộ hệ thống đang hoạt động chính xác.
Tìm địa chỉ IP ngoài của dịch vụ
Để truy cập vào tác nhân, trước tiên, bạn cần lấy địa chỉ IP công khai mà GKE đã cung cấp cho Dịch vụ của bạn.
- Trong thiết bị đầu cuối, hãy chạy lệnh sau để xem thông tin chi tiết về dịch vụ của bạn.
kubectl get service adk-agent - Tìm giá trị trong cột
EXTERNAL-IP. Có thể mất một hoặc hai phút để địa chỉ IP được chỉ định sau khi bạn triển khai dịch vụ lần đầu tiên. Nếu kết quả làpending, hãy đợi một phút rồi chạy lại lệnh. Kết quả sẽ có dạng như sau:NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE adk-agent-service LoadBalancer 10.120.12.234 34.123.45.67 80:31234/TCP 5mEXTERNAL-IP(ví dụ: 34.123.45.67) là điểm truy cập công khai vào tác nhân của bạn.
Kiểm thử nhân viên hỗ trợ đã triển khai
Giờ đây, bạn có thể sử dụng địa chỉ IP công khai để truy cập trực tiếp vào giao diện người dùng web tích hợp của ADK thông qua trình duyệt.
- Sao chép địa chỉ IP ngoài (
EXTERNAL-IP) từ thiết bị đầu cuối. - Mở một thẻ mới trong trình duyệt web rồi nhập
http://[EXTERNAL-IP], thay thế[EXTERNAL-IP]bằng địa chỉ IP mà bạn đã sao chép. - Lúc này, bạn sẽ thấy giao diện web ADK.
- Đảm bảo bạn đã chọn workflow_agents trong trình đơn thả xuống của tác nhân.
- Bật Truyền trực tuyến mã thông báo.
- Nhập
hellorồi nhấn phím Enter để bắt đầu một cuộc trò chuyện mới. - Quan sát kết quả. Tác nhân cần nhanh chóng phản hồi bằng lời chào: "Tôi có thể giúp bạn viết một bản đề cử cho một bộ phim ăn khách. Bạn muốn làm phim về nhân vật lịch sử nào?"
- Khi được nhắc chọn một nhân vật lịch sử, hãy chọn một nhân vật mà bạn quan tâm. Một số ý tưởng bao gồm:
the most successful female pirate in historythe woman who invented the first computer compilera legendary lawman of the American Wild West
Tóm tắt
Trong phần này, bạn đã xác minh việc triển khai:
- Truy xuất địa chỉ IP ngoài do LoadBalancer phân bổ.
- Truy cập vào giao diện người dùng web ADK thông qua trình duyệt để xác nhận rằng hệ thống nhiều tác nhân có phản hồi và hoạt động.
12. Định cấu hình tính năng tự động cấp tài nguyên bổ sung
Một thách thức chính trong quá trình sản xuất là xử lý lưu lượng truy cập không dự đoán được của người dùng. Việc mã hoá cứng một số lượng bản sao cố định (như bạn đã làm trong tác vụ trước) có nghĩa là bạn sẽ trả quá nhiều tiền cho các tài nguyên không hoạt động hoặc có nguy cơ hiệu suất kém trong thời gian lưu lượng truy cập tăng đột biến. GKE giải quyết vấn đề này bằng tính năng tự động cấp tài nguyên bổ sung.
Bạn sẽ định cấu hình HorizontalPodAutoscaler (HPA), một bộ điều khiển Kubernetes tự động điều chỉnh số lượng nhóm đang chạy trong Triển khai dựa trên mức sử dụng CPU theo thời gian thực.
- Trong thiết bị đầu cuối của Cloud Shell Editor, hãy tạo một tệp
hpa.yamlmới trong thư mục gốc của thư mụcadk_multiagent_systems.cloudshell edit ~/adk_multiagent_systems/hpa.yaml - Thêm nội dung sau vào tệp
hpa.yamlmới:# Configures the HorizontalPodAutoscaler (HPA) to automatically scale # the number of running agent pods up or down based on CPU utilization # to handle varying traffic loads. apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: adk-agent-hpa spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: adk-agent minReplicas: 1 maxReplicas: 5 targetCPUUtilizationPercentage: 50adk-agentcủa chúng ta. Việc này đảm bảo luôn có ít nhất 1 nhóm chạy, đặt tối đa 5 nhóm và sẽ thêm/xoá các bản sao để duy trì mức sử dụng CPU trung bình khoảng 50%.Tại thời điểm này, cấu trúc tệp của bạn như trong bảng điều khiển trình khám phá trong Cloud Shell Editor sẽ có dạng như sau:
- Áp dụng HPA cho cụm của bạn bằng cách dán nội dung này vào thiết bị đầu cuối.
kubectl apply -f hpa.yaml
Xác minh bộ mở rộng quy mô tự động
HPA hiện đang hoạt động và giám sát việc triển khai của bạn. Bạn có thể kiểm tra trạng thái của bộ đếm để xem bộ đếm đang hoạt động.
- Chạy lệnh sau trong terminal để xem trạng thái của HPA.
kubectl get hpa adk-agent-hpaNAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE adk-agent-hpa Deployment/adk-agent 0%/50% 1 5 1 30s
Tóm tắt
Trong phần này, bạn đã tối ưu hoá cho lưu lượng truy cập phát hành công khai:
- Tạo một tệp kê khai
hpa.yamlđể xác định các quy tắc chia tỷ lệ. - Triển khai HorizontalPodAutoscaler (HPA) để tự động điều chỉnh số lượng bản sao của nhóm dựa trên mức sử dụng CPU.
13. Chuẩn bị phát hành công khai
Lưu ý: Các phần sau đây chỉ nhằm cung cấp thông tin và không có các bước tiếp theo để thực hiện. Các khoá học này được thiết kế để cung cấp bối cảnh và các phương pháp hay nhất để đưa ứng dụng của bạn vào giai đoạn phát hành công khai.
Điều chỉnh hiệu suất bằng cách phân bổ tài nguyên
Trong GKE Autopilot, bạn kiểm soát lượng CPU và bộ nhớ được cung cấp cho ứng dụng bằng cách chỉ định tài nguyên requests trong deployment.yaml.
Nếu thấy tác nhân của bạn hoạt động chậm hoặc gặp sự cố do thiếu bộ nhớ, bạn có thể tăng mức phân bổ tài nguyên bằng cách chỉnh sửa khối resources trong deployment.yaml và áp dụng lại tệp bằng kubectl apply.
Ví dụ: để tăng gấp đôi bộ nhớ:
# In deployment.yaml
# ...
resources:
requests:
memory: "2Gi" # Increased from 1Gi
cpu: "1000m"
# ...
Tự động hoá quy trình công việc bằng CI/CD
Trong lớp học này, bạn đã chạy các lệnh theo cách thủ công. Phương pháp chuyên nghiệp là tạo một quy trình CI/CD (Tích hợp liên tục/Triển khai liên tục). Bằng cách kết nối một kho lưu trữ mã nguồn (chẳng hạn như GitHub) với một điều kiện kích hoạt Cloud Build, bạn có thể tự động hoá toàn bộ quá trình triển khai.
Với một quy trình, mỗi khi bạn đẩy một thay đổi về mã, Cloud Build có thể tự động:
- Tạo hình ảnh vùng chứa mới.
- Đẩy hình ảnh vào Artifact Registry.
- Áp dụng tệp kê khai Kubernetes đã cập nhật cho cụm GKE.
Quản lý bí mật một cách an toàn
Trong lớp học lập trình này, bạn đã lưu trữ cấu hình trong tệp .env và truyền cấu hình đó đến ứng dụng của mình. Điều này thuận tiện cho quá trình phát triển nhưng không an toàn cho dữ liệu nhạy cảm như khoá API. Phương pháp hay nhất nên áp dụng là sử dụng Secret Manager để lưu trữ các khoá bí mật một cách an toàn.
GKE có một chế độ tích hợp gốc với Secret Manager, cho phép bạn gắn các bí mật trực tiếp vào các nhóm của mình dưới dạng biến môi trường hoặc tệp mà không cần kiểm tra chúng vào mã nguồn.
Đây là phần Dọn dẹp tài nguyên mà bạn yêu cầu, được chèn ngay trước phần Kết luận.
14. Dọn dẹp tài nguyên
Để tránh bị tính phí vào tài khoản Google Cloud của bạn cho các tài nguyên được dùng trong hướng dẫn này, hãy xoá dự án chứa các tài nguyên đó hoặc giữ lại dự án rồi xoá từng tài nguyên.
Xoá cụm GKE
Cụm GKE là yếu tố chính quyết định chi phí trong phòng thí nghiệm này. Việc xoá phiên bản này sẽ dừng tính phí điện toán.
- Trong cửa sổ dòng lệnh, hãy chạy lệnh sau:
gcloud container clusters delete adk-cluster \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Xoá kho lưu trữ Artifact Registry
Hình ảnh vùng chứa được lưu trữ trong Artifact Registry sẽ phát sinh chi phí lưu trữ.
- Trong cửa sổ dòng lệnh, hãy chạy lệnh sau:
gcloud artifacts repositories delete adk-repo \ --location=$GOOGLE_CLOUD_LOCATION \ --quiet
Xoá dự án (Không bắt buộc)
Nếu bạn đã tạo một dự án mới dành riêng cho lớp học này và không có ý định sử dụng lại, thì cách dễ nhất để dọn dẹp là xoá toàn bộ dự án.
- Trong thiết bị đầu cuối, hãy chạy lệnh sau (thay
[YOUR_PROJECT_ID]bằng mã dự án thực tế của bạn):gcloud projects delete [YOUR_PROJECT_ID]
15. Kết luận
Xin chúc mừng! Bạn đã triển khai thành công một ứng dụng ADK có nhiều tác nhân vào một cụm GKE cấp sản xuất. Đây là một thành tựu đáng kể bao gồm vòng đời cốt lõi của một ứng dụng hiện đại dựa trên đám mây, mang đến cho bạn nền tảng vững chắc để triển khai các hệ thống phức tạp của riêng bạn.
Tóm tắt
Trong phòng thí nghiệm này, bạn đã tìm hiểu cách:
- Cung cấp một cụm GKE Autopilot.
- Tạo một hình ảnh vùng chứa bằng
Dockerfilevà đẩy hình ảnh đó vào Artifact Registry - Kết nối an toàn với API Google Cloud bằng Workload Identity.
- Viết tệp kê khai Kubernetes cho một Deployment và Service.
- Đưa một ứng dụng lên Internet bằng LoadBalancer.
- Định cấu hình tính năng tự động mở rộng quy mô bằng HorizontalPodAutoscaler (HPA).