
1. Einführung
In diesem Lab geht es um die Implementierung und Bereitstellung eines Client-KI-Agentendienstes. Sie verwenden das Agent Development Kit (ADK), um einen KI-Agenten zu erstellen, der Tools verwendet.
In diesem Lab erstellen wir einen Zoo-Agenten, der Wikipedia verwendet, um Fragen zu Tieren zu beantworten.

Zum Schluss stellen wir den Zooführungs-KI-Agenten in Google Cloud Run bereit, damit er nicht nur lokal ausgeführt wird.
Vorbereitung
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion.
Lerninhalte
- Wie Sie ein Python-Projekt für die ADK-Bereitstellung strukturieren.
- Mit google-adk einen KI-Agenten implementieren, der Tools verwendet
- So stellen Sie eine Python-Anwendung als serverlosen Container in Cloud Run bereit.
- So konfigurieren Sie die sichere Dienst-zu-Dienst-Authentifizierung mit IAM-Rollen.
- Cloud-Ressourcen löschen, um zukünftige Kosten zu vermeiden
Voraussetzungen
- Ein Google Cloud-Konto und ein Google Cloud-Projekt
- Ein Webbrowser wie Chrome
2. Warum in Cloud Run bereitstellen?
Cloud Run ist eine hervorragende Wahl für das Hosting von ADK-KI-Agenten, da es sich um eine serverlose Plattform handelt. Sie können sich also auf Ihren Code konzentrieren und müssen sich nicht um die Verwaltung der zugrunde liegenden Infrastruktur kümmern. Wir übernehmen die operative Arbeit für Sie.
Stellen Sie sich das wie einen Pop-up-Store vor: Er öffnet nur, wenn Kundinnen und Kunden (Anfragen) kommen, und nutzt dann Ressourcen. Wenn keine Kundinnen und Kunden da sind, schließt er komplett und Sie zahlen nicht für ein leeres Geschäft.
Wichtigste Features
Container überall ausführen:
- Sie stellen einen Container (Docker-Image) mit Ihrer Anwendung darin bereit.
- Cloud Run führt sie in der Infrastruktur von Google aus.
- Es sind kein Patching des Betriebssystems und keine VM-Einrichtung nötig und es gibt keine Skalierungsprobleme.
Autoscaling:
- Wenn niemand Ihre App verwendet, werden 0 Instanzen ausgeführt (die Anzahl der Instanzen wird auf null reduziert, was kostengünstig ist).
- Wenn 1.000 Anfragen eingehen, werden so viele Kopien wie nötig erstellt.
Standardmäßig zustandslos:
- Jede Anfrage kann an eine andere Instanz gehen.
- Wenn Sie einen Zustand speichern müssen, verwenden Sie einen externen Dienst wie Cloud SQL, Firestore oder Memorystore.
Unterstützt jede Sprache und jedes Framework:
- Solange die Anwendung in einem Linux-Container ausgeführt wird, ist es Cloud Run egal, ob sie in Python, Go, Node.js, Java oder .NET geschrieben ist.
Nur für die tatsächliche Nutzung zahlen:
- Anfragebasierte Abrechnung: Die Abrechnung erfolgt pro Anfrage und Rechenzeit (bis auf 100 ms genau).
- Instanzbasierte Abrechnung: Die Abrechnung erfolgt für die gesamte Lebensdauer der Instanz (keine Gebühr pro Anfrage).
3. Projekt einrichten
Google-Konto
Wenn Sie noch kein privates Google-Konto haben, müssen Sie ein Google-Konto erstellen.
Verwenden Sie stattdessen ein privates Konto.
In der Google Cloud Console anmelden
Melden Sie sich mit einem privaten Google-Konto in der Google Cloud Console an.
Abrechnung aktivieren
Privates Rechnungskonto einrichten
Wenn Sie die Abrechnung mit Google Cloud-Guthaben eingerichtet haben, können Sie diesen Schritt überspringen.
Aktivieren Sie die Abrechnung in der Cloud Console, um ein privates Rechnungskonto einzurichten.
Hinweise:
- Die Cloud-Ressourcen, die für dieses Lab benötigt werden, sollten weniger als 1 $kosten.
- Sie können die Schritte am Ende dieses Labs ausführen, um Ressourcen zu löschen und so weitere Kosten zu vermeiden.
- Neue Nutzer haben Anspruch auf die kostenlose Testversion mit einem Guthaben von 300$.
Projekt erstellen (optional)
Wenn Sie kein aktuelles Projekt haben, das Sie für dieses Lab verwenden möchten, erstellen Sie hier ein neues Projekt.
4. Cloud Shell-Editor öffnen
- Klicken Sie auf diesen Link, um direkt zum Cloud Shell-Editor zu gelangen.
- Wenn Sie heute an irgendeinem Punkt zur Autorisierung aufgefordert werden, klicken Sie auf Autorisieren, um fortzufahren.
- Wenn das Terminal nicht unten auf dem Bildschirm angezeigt wird, öffnen Sie es:
- Klicken Sie auf Ansehen.
- Klicken Sie auf Terminal
 .
.
5. Projekt festlegen
- Legen Sie im Terminal Ihr Projekt mit diesem Befehl fest:
gcloud config set project [PROJECT_ID]gcloud config set project lab-project-id-example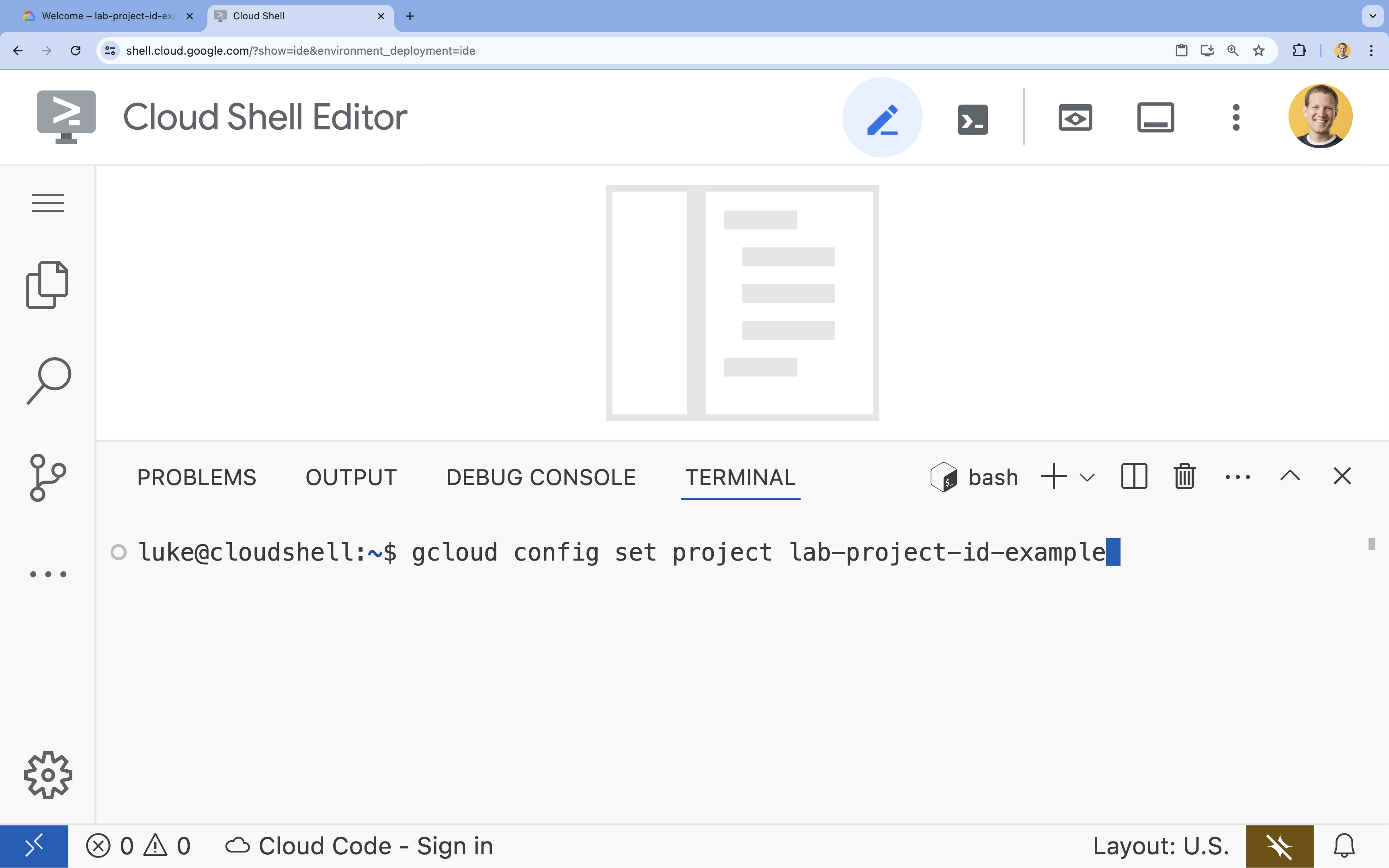
- Es sollte folgende Meldung angezeigt werden:
Updated property [core/project].
6. APIs aktivieren
Wenn Sie Cloud Run, Artifact Registry, Cloud Build, Vertex AI und Compute Engine verwenden möchten, müssen Sie die entsprechenden APIs in Ihrem Google Cloud-Projekt aktivieren.
- Aktivieren Sie die APIs im Terminal:
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.comOperation "operations/acat.p2-[GUID]" finished successfully.
Einführung der APIs
- Mit der Cloud Run Admin API (
run.googleapis.com) können Sie Frontend- und Backend-Dienste, Batchjobs oder Websites in einer vollständig verwalteten Umgebung ausführen. Die Infrastruktur für die Bereitstellung und Skalierung Ihrer Containeranwendungen wird von GKE übernommen. - Die Artifact Registry API (
artifactregistry.googleapis.com) bietet ein sicheres, privates Repository zum Speichern Ihrer Container-Images. Es ist die Weiterentwicklung von Container Registry und lässt sich nahtlos in Cloud Run und Cloud Build einbinden. - Die Cloud Build API (
cloudbuild.googleapis.com) ist eine serverlose CI/CD-Plattform, die Ihre Builds in der Google Cloud-Infrastruktur ausführt. Damit wird Ihr Container-Image in der Cloud aus Ihrem Dockerfile erstellt. - Mit der Vertex AI API (
aiplatform.googleapis.com) kann Ihre bereitgestellte Anwendung mit Gemini-Modellen kommunizieren, um KI-Kernaufgaben auszuführen. Sie bietet die einheitliche API für alle KI-Dienste von Google Cloud. - Die Compute Engine API (
compute.googleapis.com) bietet sichere und anpassbare virtuelle Maschinen, die in der Infrastruktur von Google ausgeführt werden. Cloud Run wird zwar verwaltet, die Compute Engine API ist jedoch häufig als grundlegende Abhängigkeit für verschiedene Netzwerk- und Rechenressourcen erforderlich.
7. Bereiten Sie Ihre Entwicklungsumgebung vor
Verzeichnis erstellen
- Erstellen Sie im Terminal das Projektverzeichnis und die erforderlichen Unterverzeichnisse:
cd && mkdir zoo_guide_agent && cd zoo_guide_agent - Führen Sie im Terminal den folgenden Befehl aus, um das Verzeichnis
zoo_guide_agentim Explorer des Cloud Shell-Editors zu öffnen:cloudshell open-workspace ~/zoo_guide_agent - Der Explorer-Bereich auf der linken Seite wird aktualisiert. Das von Ihnen erstellte Verzeichnis sollte jetzt angezeigt werden.
Installationsanforderungen
- Führen Sie den folgenden Befehl im Terminal aus, um die Datei
requirements.txtzu erstellen.cloudshell edit requirements.txt - Fügen Sie der neu erstellten Datei
requirements.txtFolgendes hinzu:google-adk==1.14.0 langchain-community==0.3.27 wikipedia==1.4.0 - Erstellen und aktivieren Sie im Terminal eine virtuelle Umgebung mit uv. So wird sichergestellt, dass die Projektabhängigkeiten nicht mit dem System-Python in Konflikt stehen.
uv venv source .venv/bin/activate - Installieren Sie die erforderlichen Pakete in Ihrer virtuellen Umgebung im Terminal.
uv pip install -r requirements.txt
Umgebungsvariablen einrichten
- Verwenden Sie den folgenden Befehl im Terminal, um die Datei
.envzu erstellen.# 1. Set the variables in your terminal first PROJECT_ID=$(gcloud config get-value project) PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)") SA_NAME=lab2-cr-service # 2. Create the .env file using those variables cat <<EOF > .env PROJECT_ID=$PROJECT_ID PROJECT_NUMBER=$PROJECT_NUMBER SA_NAME=$SA_NAME SERVICE_ACCOUNT=${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com MODEL="gemini-2.5-flash" EOF
8. KI‑Agentenworkflow erstellen
__init__.py-Datei erstellen
- Erstellen Sie die Datei init.py, indem Sie Folgendes im Terminal ausführen:
cloudshell edit __init__.py - Fügen Sie der neuen
__init__.py-Datei den folgenden Code hinzu:from . import agent
Erstellen der agent.py-Datei
- Erstellen Sie die Hauptdatei
agent.py, indem Sie den folgenden Befehl in das Terminal einfügen.cloudshell edit agent.py - Importe und Ersteinrichtung: Fügen Sie der derzeit leeren Datei
agent.pyden folgenden Code hinzu:import os import logging import google.cloud.logging from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper import google.auth import google.auth.transport.requests import google.oauth2.id_token # --- Setup Logging and Environment --- cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL")agent.pyruft alle erforderlichen Bibliotheken aus dem ADK und Google Cloud ab. Außerdem werden das Logging eingerichtet und die Umgebungsvariablen werden aus der Datei.envgeladen, was für den Zugriff auf das Modell und die Server-URL entscheidend ist. - Tools definieren: Ein KI-Agent ist nur so gut wie die Tools, die er nutzen kann. Fügen Sie den folgenden Code am Ende von
agent.pyein, um die Tools zu definieren:# Greet user and save their prompt def add_prompt_to_state( tool_context: ToolContext, prompt: str ) -> dict[str, str]: """Saves the user's initial prompt to the state.""" tool_context.state["PROMPT"] = prompt logging.info(f"[State updated] Added to PROMPT: {prompt}") return {"status": "success"} # Configuring the Wikipedia Tool wikipedia_tool = LangchainTool( tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper()) )add_prompt_to_state📝: Dieses Tool merkt sich die Fragen der Zoobesucherinnen und -besucher. Wenn eine Besucherin oder ein Besucher fragt: „Wo sind die Löwen?“, speichert dieses Tool die Frage im Gedächtnis des KI-Agenten, sodass die anderen KI-Agenten im Workflow wissen, wonach sie suchen müssen.
Funktionsweise:Es handelt sich um eine Python-Funktion, die den Prompt der Besucherin bzw. des Besuchers in das gemeinsame Wörterbuchtool_context.stateschreibt. Dieser Toolkontext stellt das Kurzzeitgedächtnis des KI-Agenten für eine einzelne Unterhaltung dar. Daten, die von einem KI-Agenten im Zustand gespeichert wurden, können vom nächsten KI-Agenten im Workflow gelesen werden.LangchainTool🌍: Damit erhält der Zooführungs-KI-Agent allgemeines Weltwissen. Wenn eine Besucherin oder ein Besucher eine Frage stellt, die nicht in der Datenbank des Zoos enthalten ist, wie z. B.: „Was fressen Löwen in freier Wildbahn?“, kann der KI-Agent mit diesem Tool die Antwort bei Wikipedia nachschlagen.
Funktionsweise:Das Tool fungiert als Adapter, sodass unser KI-Agent das vorhandene Tool „WikipediaQueryRun“ aus der LangChain-Bibliothek verwenden kann.
- Spezialisten-Agents definieren: Fügen Sie den folgenden Code am Ende von
agent.pyein, um die Agentscomprehensive_researcherundresponse_formatterzu definieren:# 1. Researcher Agent comprehensive_researcher = Agent( name="comprehensive_researcher", model=model_name, description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.", instruction=""" You are a helpful research assistant. Your goal is to fully answer the user's PROMPT. You have access to two tools: 1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations). 2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat). First, analyze the user's PROMPT. - If the prompt can be answered by only one tool, use that tool. - If the prompt is complex and requires information from both the zoo's database AND Wikipedia, you MUST use both tools to gather all necessary information. - Synthesize the results from the tool(s) you use into preliminary data outputs. PROMPT: { PROMPT } """, tools=[ wikipedia_tool ], output_key="research_data" # A key to store the combined findings ) # 2. Response Formatter Agent response_formatter = Agent( name="response_formatter", model=model_name, description="Synthesizes all information into a friendly, readable response.", instruction=""" You are the friendly voice of the Zoo Tour Guide. Your task is to take the RESEARCH_DATA and present it to the user in a complete and helpful answer. - First, present the specific information from the zoo (like names, ages, and where to find them). - Then, add the interesting general facts from the research. - If some information is missing, just present the information you have. - Be conversational and engaging. RESEARCH_DATA: { research_data } """ )- Der
comprehensive_researcher-Agent ist das „Gehirn“ unseres Dienstes. Er nimmt den Prompt des Nutzers aus dem gemeinsamenState, prüft das Wikipedia-Tool und entscheidet, welche verwendet werden sollen, um die Antwort zu finden. - Die Rolle des
response_formatter-Agenten ist die Präsentation. Stattdessen werden die vom Recherche-KI-Agenten gesammelten Rohdaten (über den Zustand übergeben) übernommen und mithilfe der Sprachkenntnisse des LLM in eine freundliche Antwort wie bei einer normalen Unterhaltung umwandelt.
- Der
- Workflow-KI-Agenten definieren: Fügen Sie diesen Codeblock am Ende von
agent.pyein, um den sequenziellen KI-Agententour_guide_workflowzu definieren:tour_guide_workflow = SequentialAgent( name="tour_guide_workflow", description="The main workflow for handling a user's request about an animal.", sub_agents=[ comprehensive_researcher, # Step 1: Gather all data response_formatter, # Step 2: Format the final response ] )
Funktionsweise:Es ist einSequentialAgent, eine spezielle Art von KI-Agent, der nicht selbstständig denkt. Seine einzige Aufgabe ist es, eine Liste vonsub_agents(für Recherche und Formatierung) in einer festen Reihenfolge auszuführen und die gemerkten Informationen automatisch von einem zum nächsten zu übergeben. - Hauptworkflow zusammenstellen: Fügen Sie diesen letzten Codeblock am Ende von
agent.pyein, umroot_agentzu definieren:root_agent = Agent( name="greeter", model=model_name, description="The main entry point for the Zoo Tour Guide.", instruction=""" - Let the user know you will help them learn about the animals we have in the zoo. - When the user responds, use the 'add_prompt_to_state' tool to save their response. After using the tool, transfer control to the 'tour_guide_workflow' agent. """, tools=[add_prompt_to_state], sub_agents=[tour_guide_workflow] )root_agentals Ausgangspunkt für alle neuen Unterhaltungen. Die Hauptaufgabe dieses KI-Agenten ist die Orchestrierung des gesamten Prozesses. Er fungiert als anfänglicher Controller und verwaltet die erste Runde der Unterhaltung.

Die vollständige agent.py-Datei
Ihre agent.py-Datei ist jetzt fertig. So können Sie sehen, wie jede Komponente – Tools, Worker-KI-Agenten und Manager-KI-Agenten – eine bestimmte Rolle bei der Erstellung des endgültigen, intelligenten Systems spielt.
Die vollständige Datei sollte so aussehen:
import os
import logging
import google.cloud.logging
from dotenv import load_dotenv
from google.adk import Agent
from google.adk.agents import SequentialAgent
from google.adk.tools.tool_context import ToolContext
from google.adk.tools.langchain_tool import LangchainTool
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
import google.auth
import google.auth.transport.requests
import google.oauth2.id_token
# --- Setup Logging and Environment ---
cloud_logging_client = google.cloud.logging.Client()
cloud_logging_client.setup_logging()
load_dotenv()
model_name = os.getenv("MODEL")
# Greet user and save their prompt
def add_prompt_to_state(
tool_context: ToolContext, prompt: str
) -> dict[str, str]:
"""Saves the user's initial prompt to the state."""
tool_context.state["PROMPT"] = prompt
logging.info(f"[State updated] Added to PROMPT: {prompt}")
return {"status": "success"}
# Configuring the Wikipedia Tool
wikipedia_tool = LangchainTool(
tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
)
# 1. Researcher Agent
comprehensive_researcher = Agent(
name="comprehensive_researcher",
model=model_name,
description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.",
instruction="""
You are a helpful research assistant. Your goal is to fully answer the user's PROMPT.
You have access to two tools:
1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations).
2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat).
First, analyze the user's PROMPT.
- If the prompt can be answered by only one tool, use that tool.
- If the prompt is complex and requires information from both the zoo's database AND Wikipedia,
you MUST use both tools to gather all necessary information.
- Synthesize the results from the tool(s) you use into preliminary data outputs.
PROMPT:
{ PROMPT }
""",
tools=[
wikipedia_tool
],
output_key="research_data" # A key to store the combined findings
)
# 2. Response Formatter Agent
response_formatter = Agent(
name="response_formatter",
model=model_name,
description="Synthesizes all information into a friendly, readable response.",
instruction="""
You are the friendly voice of the Zoo Tour Guide. Your task is to take the
RESEARCH_DATA and present it to the user in a complete and helpful answer.
- First, present the specific information from the zoo (like names, ages, and where to find them).
- Then, add the interesting general facts from the research.
- If some information is missing, just present the information you have.
- Be conversational and engaging.
RESEARCH_DATA:
{ research_data }
"""
)
tour_guide_workflow = SequentialAgent(
name="tour_guide_workflow",
description="The main workflow for handling a user's request about an animal.",
sub_agents=[
comprehensive_researcher, # Step 1: Gather all data
response_formatter, # Step 2: Format the final response
]
)
root_agent = Agent(
name="greeter",
model=model_name,
description="The main entry point for the Zoo Tour Guide.",
instruction="""
- Let the user know you will help them learn about the animals we have in the zoo.
- When the user responds, use the 'add_prompt_to_state' tool to save their response.
After using the tool, transfer control to the 'tour_guide_workflow' agent.
""",
tools=[add_prompt_to_state],
sub_agents=[tour_guide_workflow]
)
Als Nächstes erfolgt die Bereitstellung.
9. Anwendung auf die Bereitstellung vorbereiten
Endgültige Struktur prüfen
Prüfen Sie vor der Bereitstellung, ob Ihr Projektverzeichnis die richtigen Dateien enthält.
- Ihr
zoo_guide_agent-Ordner sollte so aussehen:zoo_guide_agent/ ├── .env ├── __init__.py ├── agent.py └── requirements.txt
IAM-Berechtigungen einrichten
Nachdem Sie Ihren lokalen Code fertiggestellt haben, müssen Sie die Identität einrichten, die Ihr KI-Agent in der Cloud verwenden wird.
- Laden Sie die Variablen im Terminal in Ihre Shell-Sitzung.
source .env - Erstellen Sie ein dediziertes Dienstkonto für Ihren Cloud Run-Dienst, damit es über eine eigene spezifische Berechtigung verfügt. Fügen Sie Folgendes in das Terminal ein:
gcloud iam service-accounts create ${SA_NAME} \ --display-name="Service Account for lab 2 " - Weisen Sie dem Dienstkonto die Rolle „Vertex AI-Nutzer“ zu. Damit hat es die Berechtigung, Modelle von Google aufzurufen.
# Grant the "Vertex AI User" role to your service account gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:$SERVICE_ACCOUNT" \ --role="roles/aiplatform.user"
10. KI-Agenten mit der ADK-CLI bereitstellen
Ihr lokaler Code ist fertig und Ihr Google Cloud-Projekt ist vorbereitet. Jetzt können Sie den KI-Agenten bereitstellen. Sie verwenden den Befehl adk deploy cloud_run, ein praktisches Tool, das den gesamten Bereitstellungsworkflow automatisiert. Mit diesem einen Befehl wird Ihr Code verpackt, ein Container-Image erstellt und in Artifact Registry gepusht und der Dienst in Cloud Run gestartet, sodass er im Web zugänglich ist.
- Führen Sie im Terminal den folgenden Befehl aus, um den Agenten bereitzustellen.
# Run the deployment command uvx --from google-adk==1.14.0 \ adk deploy cloud_run \ --project=$PROJECT_ID \ --region=europe-west1 \ --service_name=zoo-tour-guide \ --with_ui \ . \ -- \ --labels=dev-tutorial=codelab-adk \ --service-account=$SERVICE_ACCOUNTuvxkönnen Sie Befehlszeilentools ausführen, die als Python-Pakete veröffentlicht wurden, ohne dass diese Tools global installiert werden müssen. - Wenn Sie die folgende Meldung sehen:
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [europe-west1] will be created. Do you want to continue (Y/n)?
Yein und drücken Sie die Eingabetaste. - Wenn Sie die folgende Meldung sehen:
Allow unauthenticated invocations to [your-service-name] (y/N)?.
yein und drücken Sie die Eingabetaste. So sind für dieses Lab nicht authentifizierte Aufrufe möglich, was das Testen erleichtert. Bei erfolgreicher Ausführung wird mit dem Befehl die URL des bereitgestellten Cloud Run-Dienstes zurückgegeben. (Das sieht etwa so aus:https://zoo-tour-guide-123456789.europe-west1.run.app) - Kopieren Sie die URL des bereitgestellten Cloud Run-Dienstes für die nächste Aufgabe.
11. Bereitgestellten KI-Agenten testen
Ihr KI-Agent ist jetzt in Cloud Run aktiv. In dieser Aufgabe führen Sie einen Test durch, um zu bestätigen, dass die Bereitstellung erfolgreich war und der KI-Agent wie erwartet funktioniert. Über die öffentliche Dienst-URL (z. B. https://zoo-tour-guide-123456789.europe-west1.run.app/) können Sie auf die Weboberfläche des ADK zugreifen und mit dem KI-Agenten interagieren.
- Öffnen Sie die öffentliche Cloud Run-Dienst-URL in Ihrem Webbrowser. Da Sie
--with_ui flagverwendet haben, sollte die ADK-Entwickler-UI angezeigt werden. - Aktivieren Sie
Token Streamingrechts oben.
Sie können jetzt mit dem Zoo-KI-Agenten interagieren. - Geben Sie
helloein und drücken Sie die Eingabetaste, um eine neue Unterhaltung zu beginnen. - Sehen Sie sich das Ergebnis an. Der KI-Agent sollte schnell mit seiner Begrüßung antworten, die in etwa so aussehen wird:
"Hello! I'm your Zoo Tour Guide. I can help you learn about the amazing animals we have here. What would you like to know or explore today?"
- Stellen Sie dem Agenten Fragen wie:
Where can I find the polar bears in the zoo and what is their diet?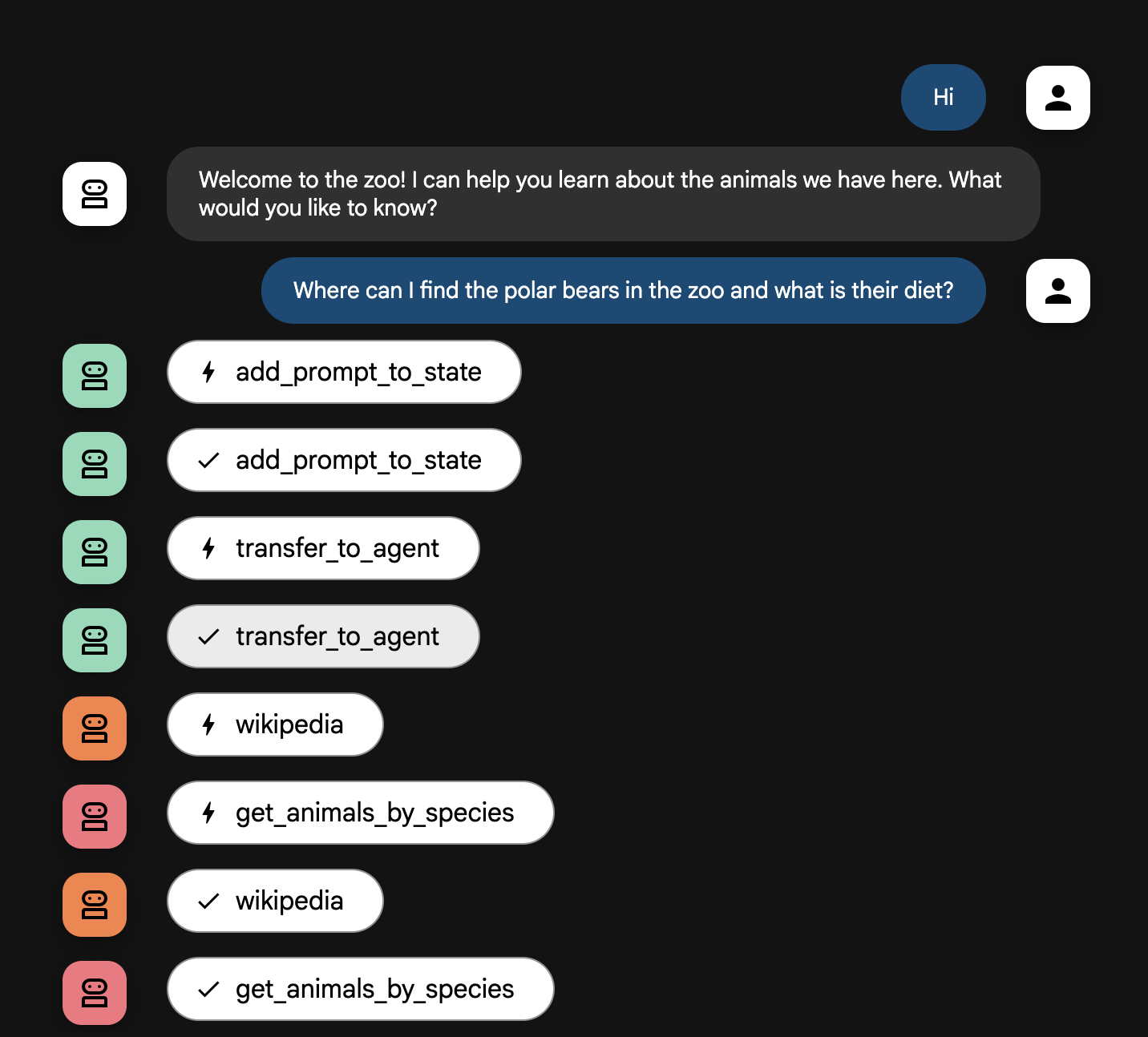

KI-Agentenablauf
Ihr System funktioniert wie ein intelligentes Multi-KI-Agententeam. Der Prozess wird durch eine klare Abfolge gesteuert, um einen reibungslosen und effizienten Ablauf von der Frage einer Nutzerin oder eines Nutzers bis zur detaillierten Antwort zu gewährleisten.
1. Die Zoobegrüßung (der Empfangstresen)
Der gesamte Prozess beginnt mit dem Begrüßungs-KI-Agenten.
- Aufgabe: Die Unterhaltung beginnen. Die Anweisung lautet, die Nutzerin bzw. den Nutzer zu begrüßen und zu fragen, über welches Tier die Person mehr erfahren möchte.
- Tool:Wenn die Nutzerin bzw. der Nutzer antwortet, verwendet der Begrüßungs-KI-Agent das Tool „add_prompt_to_state“, um die genauen Worte der Person zu erfassen (z. B. „Erzähl mir etwas über Löwen“) und im Arbeitsspeicher des Systems zu speichern.
- Übergabe: Nachdem der Prompt gespeichert wurde, übergibt er die Steuerung sofort an seinen Unter-KI-Agenten, den tour_guide_workflow.
2. Der gründliche Rechercheur (der Superrechercheur)
Dies ist der erste Schritt im Hauptworkflow und das „Gehirn“ des Dienstes. Statt eines großen Teams haben Sie jetzt einen einzigen, hochqualifizierten KI-Agenten, der auf alle verfügbaren Informationen zugreifen kann.
- Aufgabe: Die Frage der Nutzerin bzw. des Nutzers analysieren und einen intelligenten Plan erstellen. Der Recherche-KI-Agent nutzt die Fähigkeit des Sprachmodells zur Toolnutzung, um zu entscheiden, ob er Folgendes benötigt:
- Allgemeinwissen aus dem Web (über die Wikipedia API)
- Beides im Fall komplexer Fragen
3. Der Antwortformatierer (der Präsentator)
Sobald der gründliche Rechercheur alle Fakten zusammengetragen hat, ist dies der letzte KI-Agent, der ausgeführt wird.
- Aufgabe: Als freundliche Stimme der Zooführung fungieren. Dieser KI-Agent nimmt die Rohdaten (die aus einer oder aus beiden Quellen stammen können) und bereitet sie auf.
- Aktion: Die Informationen werden in einer einzigen, zusammenhängenden und ansprechenden Antwort zusammengefasst. Gemäß den Anweisungen werden zuerst die spezifischen Zoo-Informationen und dann die interessanten allgemeinen Fakten präsentiert.
- Endergebnis: Der von diesem KI-Agenten generierte Text ist die vollständige, detaillierte Antwort, die im Chatfenster zu sehen ist.
Wenn Sie mehr über das Erstellen von KI-Agenten erfahren möchten, finden Sie hier einige Ressourcen:
12. Umgebung bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, können Sie entweder das Projekt löschen, das die Ressourcen enthält, oder das Projekt beibehalten und die einzelnen Ressourcen löschen.
Cloud Run-Dienste und -Images löschen
Wenn Sie das Google Cloud-Projekt beibehalten, aber die in diesem Lab erstellten Ressourcen entfernen möchten, müssen Sie sowohl den laufenden Dienst als auch das in der Registry gespeicherte Container-Image löschen.
- Führen Sie im Terminal die folgenden Befehle aus:
gcloud run services delete zoo-tour-guide --region=europe-west1 --quiet gcloud artifacts repositories delete cloud-run-source-deploy --location=europe-west1 --quiet
Projekt löschen (optional)
Wenn Sie ein neues Projekt speziell für dieses Lab erstellt haben und es nicht noch einmal verwenden möchten, löschen Sie es am besten. So werden alle Ressourcen (einschließlich des Dienstkontos und aller verborgenen Build-Artefakte) vollständig entfernt.
- Führen Sie im Terminal den folgenden Befehl aus und ersetzen Sie [YOUR_PROJECT_ID] durch Ihre tatsächliche Projekt-ID:
gcloud projects delete $PROJECT_ID
13. Glückwunsch
Sie haben eine Multi-Agenten-KI-Anwendung erfolgreich in Google Cloud erstellt und bereitgestellt.
Zusammenfassung
In diesem Lab haben Sie aus einem leeren Verzeichnis einen aktiven, öffentlich zugänglichen KI-Dienst erstellt. So sieht das Ergebnis aus:
- Sie haben ein spezialisiertes Team erstellt: Anstelle einer generischen KI haben Sie einen „Researcher“ (Recherchierer) zum Auffinden von Fakten und einen „Formatter“ (Formatierer) zum Überarbeiten der Antwort erstellt.
- Sie haben ihnen Tools zur Verfügung gestellt: Sie haben Ihre Agents über die Wikipedia API mit der Außenwelt verbunden.
- Sie haben es geschafft: Sie haben Ihren lokalen Python-Code als serverlosen Container in Cloud Run bereitgestellt und mit einem dedizierten Dienstkonto gesichert.
Behandelte Themen
- Wie Sie ein Python-Projekt für die Bereitstellung mit dem ADK strukturieren.
- Multi-Agenten-Workflow mit
[SequentialAgent](https://google.github.io/adk-docs/agents/workflow-agents/sequential-agents/)implementieren - Externe Tools wie die Wikipedia API einbinden
- So stellen Sie einen Agent mit dem Befehl
adk deployin Cloud Run bereit.
14. Umfrage
Ausgabe: