
1. Introduction
This lab focuses on the implementation and deployment of a client agent service. You will use Agent Development Kit (ADK) to build an AI agent that uses tools.
In this lab, we are building a zoo agent that uses wikipedia to answer questions about animals.

Finally, we'll deploy the tour guide agent to Google Cloud Run, rather than just running locally.
Prerequisites
- A Google Cloud project with billing enabled.
What you'll learn
- How to structure a Python project for ADK deployment.
- How to implement a tool-using agent with google-adk.
- How to deploy a Python application as a serverless container to Cloud Run.
- How to configure secure, service-to-service authentication using IAM roles.
- How to delete Cloud resources to avoid incurring future costs.
What you'll need
- A Google Cloud Account and Google Cloud Project
- A web browser such as Chrome
2. Why deploy to Cloud Run?
Cloud Run is a great choice for hosting ADK agents because it's a serverless platform, which means you can focus on your code and not on managing the underlying infrastructure. We handle the operational work for you.
Think of it like a pop-up shop: it only opens and uses resources when customers (requests) arrive. When there are no customers, it closes down completely, and you don't pay for an empty store.
Key Features
Runs Containers Anywhere:
- You bring a container (Docker image) that has your app inside.
- Cloud Run runs it on Google's infrastructure.
- No OS patching, VM setup, or scaling headaches.
Automatic Scaling:
- If 0 people are using your app → 0 instances run (scales down to zero instance which is cost effective).
- If 1000 requests hit it → it spins up as many copies as needed.
Stateless by Default:
- Each request could go to a different instance.
- If you need to store state, use an external service like Cloud SQL, Firestore, or Memorystore.
Supports Any Language or Framework:
- As long as it runs in a Linux container, Cloud Run doesn't care if it's Python, Go, Node.js, Java, or .Net.
Pay for What You Use:
- Request-based billing: Billed per request + compute time (down to 100 ms).
- Instance-based billing: Billed for full instance lifetime (no per-request fee).
3. Project setup
Google Account
If you don't already have a personal Google Account, you must create a Google Account.
Use a personal account instead of a work or school account.
Sign-in to the Google Cloud Console
Sign-in to the Google Cloud Console using a personal Google account.
Enable Billing
Set up a personal billing account
If you set up billing using Google Cloud credits, you can skip this step.
To set up a personal billing account, go here to enable billing in the Cloud Console.
Some Notes:
- Completing this lab should cost less than $1 USD in Cloud resources.
- You can follow the steps at the end of this lab to delete resources to avoid further charges.
- New users are eligible for the $300 USD Free Trial.
Create a project (optional)
If you do not have a current project you'd like to use for this lab, create a new project here.
4. Open Cloud Shell Editor
- Click this link to navigate directly to Cloud Shell Editor
- If prompted to authorize at any point today, click Authorize to continue.
- If the terminal doesn't appear at the bottom of the screen, open it:
- Click View
- Click Terminal
5. Set your project
- In the terminal, set your project with this command:
gcloud config set project [PROJECT_ID]gcloud config set project lab-project-id-example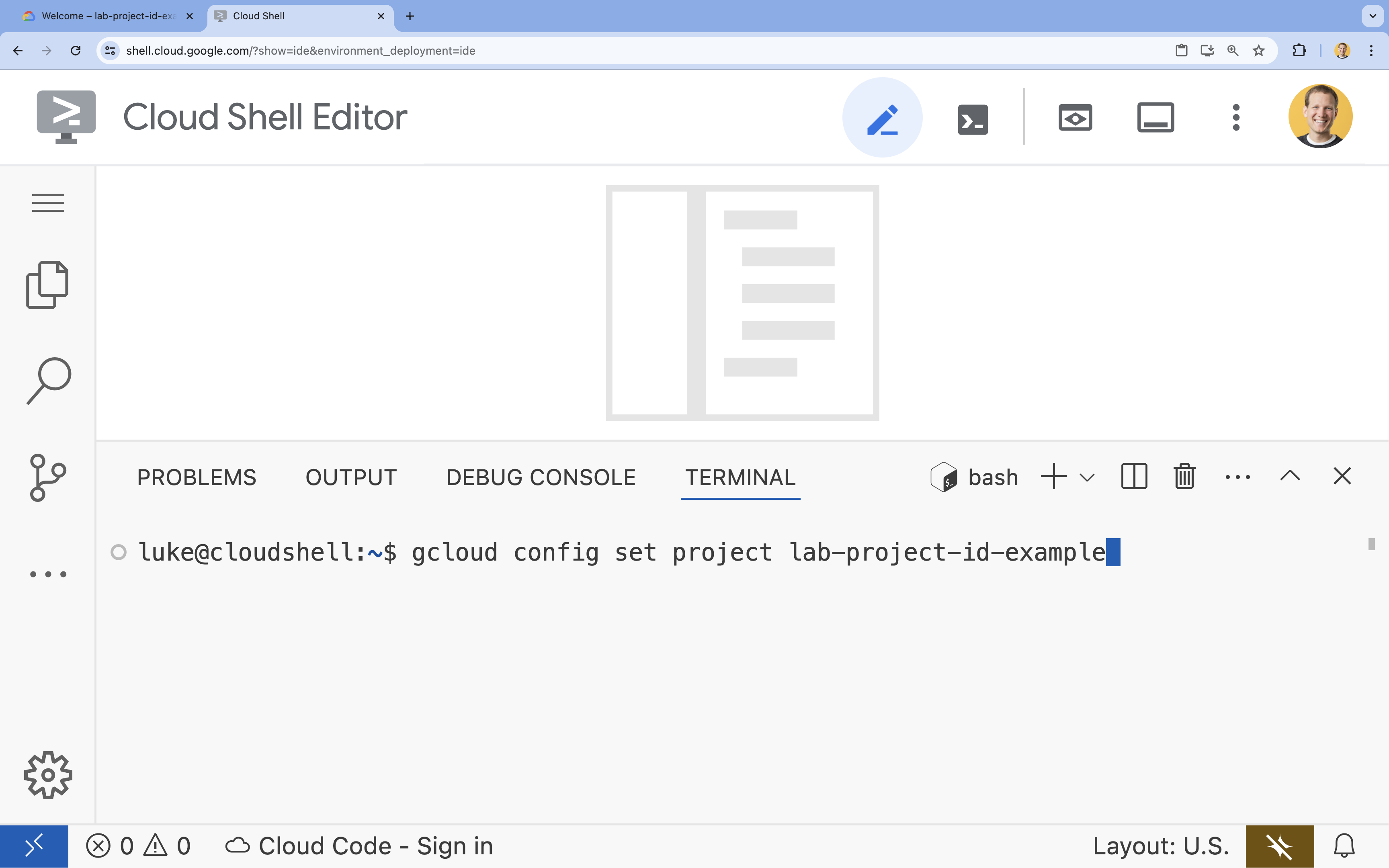
- You should see this message:
Updated property [core/project].
6. Enable APIs
To use Cloud Run, Artifact Registry, Cloud Build, Vertex AI, and Compute Engine, you need to enable their respective APIs in your Google Cloud project.
- In the terminal, enable the APIs:
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.comOperation "operations/acat.p2-[GUID]" finished successfully.
Introducing the APIs
- Cloud Run Admin API (
run.googleapis.com) allows you to run frontend and backend services, batch jobs, or websites in a fully managed environment. It handles the infrastructure for deploying and scaling your containerized applications. - Artifact Registry API (
artifactregistry.googleapis.com) provides a secure, private repository to store your container images. It is the evolution of Container Registry and integrates seamlessly with Cloud Run and Cloud Build. - Cloud Build API (
cloudbuild.googleapis.com) is a serverless CI/CD platform that executes your builds on Google Cloud infrastructure. It is used to build your container image in the cloud from your Dockerfile. - Vertex AI API (
aiplatform.googleapis.com) enables your deployed application to communicate with Gemini models to perform core AI tasks. It provides the unified API for all of Google Cloud's AI services. - Compute Engine API (
compute.googleapis.com) provides secure and customizable virtual machines that run on Google's infrastructure. While Cloud Run is managed, the Compute Engine API is often required as a foundational dependency for various networking and compute resources.
7. Prepare your development environment
Create the directory
- In the terminal, create the project directory and the necessary subdirectories:
cd && mkdir zoo_guide_agent && cd zoo_guide_agent - In the terminal, run the following command to open the
zoo_guide_agentdirectory in the Cloud Shell Editor explorer:cloudshell open-workspace ~/zoo_guide_agent - The explorer panel on the left will refresh. You should now see the directory you created.
Install requirements
- Run the following command in the terminal to create the
requirements.txtfile.cloudshell edit requirements.txt - Add the following into the newly created
requirements.txtfilegoogle-adk==1.14.0 langchain-community==0.3.27 wikipedia==1.4.0 - In the terminal, create and activate a virtual environment using uv. This ensures your project dependencies don't conflict with the system Python.
uv venv source .venv/bin/activate - Install the required packages into your virtual environment in the terminal.
uv pip install -r requirements.txt
Set up environment variables
- Use the following command in the terminal to create the
.envfile.# 1. Set the variables in your terminal first PROJECT_ID=$(gcloud config get-value project) PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)") SA_NAME=lab2-cr-service # 2. Create the .env file using those variables cat <<EOF > .env PROJECT_ID=$PROJECT_ID PROJECT_NUMBER=$PROJECT_NUMBER SA_NAME=$SA_NAME SERVICE_ACCOUNT=${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com MODEL="gemini-2.5-flash" EOF
8. Create Agent Workflow
Create __init__.py file
- Create the init.py file by running the following in the terminal:
cloudshell edit __init__.py - Add the following code to the new
__init__.pyfile:from . import agent
Create the agent.py file
- Create the main
agent.pyfile by pasting the following command into the terminal.cloudshell edit agent.py - Imports and Initial Setup: Add the following code to your currently empty
agent.pyfile:import os import logging import google.cloud.logging from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper import google.auth import google.auth.transport.requests import google.oauth2.id_token # --- Setup Logging and Environment --- cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL")agent.pyfile brings in all the necessary libraries from the ADK and Google Cloud. It also sets up logging and loads the environment variables from your.envfile, which is crucial for accessing your model and server URL. - Define the tools: An agent is only as good as the tools it can use. Add the following code to the bottom of
agent.pyto define the tools:# Greet user and save their prompt def add_prompt_to_state( tool_context: ToolContext, prompt: str ) -> dict[str, str]: """Saves the user's initial prompt to the state.""" tool_context.state["PROMPT"] = prompt logging.info(f"[State updated] Added to PROMPT: {prompt}") return {"status": "success"} # Configuring the Wikipedia Tool wikipedia_tool = LangchainTool( tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper()) )add_prompt_to_state📝: This tool remembers what a zoo visitor asks. When a visitor asks, "Where are the lions?", this tool saves that specific question into the agent's memory so the other agents in the workflow know what to research.
How: It's a Python function that writes the visitor's prompt into the sharedtool_context.statedictionary. This tool context represents the agent's short-term memory for a single conversation. Data saved to the state by one agent can be read by the next agent in the workflow.LangchainTool🌍: This gives the tour guide agent general world knowledge. When a visitor asks a question that isn't in the zoo's database, like "What do lions eat in the wild?", this tool lets the agent look up the answer on Wikipedia.
How: It acts as an adapter, allowing our agent to use the pre-built WikipediaQueryRun tool from the LangChain library.
- Define the Specialist agents: Add the following code to the bottom of
agent.pyto define thecomprehensive_researcherandresponse_formatteragents:# 1. Researcher Agent comprehensive_researcher = Agent( name="comprehensive_researcher", model=model_name, description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.", instruction=""" You are a helpful research assistant. Your goal is to fully answer the user's PROMPT. You have access to two tools: 1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations). 2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat). First, analyze the user's PROMPT. - If the prompt can be answered by only one tool, use that tool. - If the prompt is complex and requires information from both the zoo's database AND Wikipedia, you MUST use both tools to gather all necessary information. - Synthesize the results from the tool(s) you use into preliminary data outputs. PROMPT: { PROMPT } """, tools=[ wikipedia_tool ], output_key="research_data" # A key to store the combined findings ) # 2. Response Formatter Agent response_formatter = Agent( name="response_formatter", model=model_name, description="Synthesizes all information into a friendly, readable response.", instruction=""" You are the friendly voice of the Zoo Tour Guide. Your task is to take the RESEARCH_DATA and present it to the user in a complete and helpful answer. - First, present the specific information from the zoo (like names, ages, and where to find them). - Then, add the interesting general facts from the research. - If some information is missing, just present the information you have. - Be conversational and engaging. RESEARCH_DATA: { research_data } """ )- The
comprehensive_researcheragent is the "brain" of our operation. It takes the user's prompt from the sharedState, examines it's the Wikipedia Tool, and decides which ones to use to find the answer. - The
response_formatteragent's role is presentation. It takes the raw data gathered by the Researcher agent (passed via the State) and uses the LLM's language skills to transform it into a friendly, conversational response.
- The
- Define the Workflow agent: Add this block of code to the bottom of
agent.pyto define the sequential agenttour_guide_workflow:tour_guide_workflow = SequentialAgent( name="tour_guide_workflow", description="The main workflow for handling a user's request about an animal.", sub_agents=[ comprehensive_researcher, # Step 1: Gather all data response_formatter, # Step 2: Format the final response ] )
How: It's aSequentialAgent, a special type of agent that doesn't think for itself. Its only job is to run a list ofsub_agents(the researcher and formatter) in a fixed sequence, automatically passing the shared memory from one to the next. - Assemble the main workflow: Add this final block of code to the bottom of
agent.pyto define theroot_agent:root_agent = Agent( name="greeter", model=model_name, description="The main entry point for the Zoo Tour Guide.", instruction=""" - Let the user know you will help them learn about the animals we have in the zoo. - When the user responds, use the 'add_prompt_to_state' tool to save their response. After using the tool, transfer control to the 'tour_guide_workflow' agent. """, tools=[add_prompt_to_state], sub_agents=[tour_guide_workflow] )root_agentas the starting point for all new conversations. Its primary role is to orchestrate the overall process. It acts as the initial controller, managing the first turn of the conversation.

The full agent.py file
Your agent.py file is now complete! By building it this way, you can see how each component—tools, worker agents, and manager agents—has a specific role in creating the final, intelligent system.
The complete file should look like this:
import os
import logging
import google.cloud.logging
from dotenv import load_dotenv
from google.adk import Agent
from google.adk.agents import SequentialAgent
from google.adk.tools.tool_context import ToolContext
from google.adk.tools.langchain_tool import LangchainTool
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
import google.auth
import google.auth.transport.requests
import google.oauth2.id_token
# --- Setup Logging and Environment ---
cloud_logging_client = google.cloud.logging.Client()
cloud_logging_client.setup_logging()
load_dotenv()
model_name = os.getenv("MODEL")
# Greet user and save their prompt
def add_prompt_to_state(
tool_context: ToolContext, prompt: str
) -> dict[str, str]:
"""Saves the user's initial prompt to the state."""
tool_context.state["PROMPT"] = prompt
logging.info(f"[State updated] Added to PROMPT: {prompt}")
return {"status": "success"}
# Configuring the Wikipedia Tool
wikipedia_tool = LangchainTool(
tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
)
# 1. Researcher Agent
comprehensive_researcher = Agent(
name="comprehensive_researcher",
model=model_name,
description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.",
instruction="""
You are a helpful research assistant. Your goal is to fully answer the user's PROMPT.
You have access to two tools:
1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations).
2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat).
First, analyze the user's PROMPT.
- If the prompt can be answered by only one tool, use that tool.
- If the prompt is complex and requires information from both the zoo's database AND Wikipedia,
you MUST use both tools to gather all necessary information.
- Synthesize the results from the tool(s) you use into preliminary data outputs.
PROMPT:
{ PROMPT }
""",
tools=[
wikipedia_tool
],
output_key="research_data" # A key to store the combined findings
)
# 2. Response Formatter Agent
response_formatter = Agent(
name="response_formatter",
model=model_name,
description="Synthesizes all information into a friendly, readable response.",
instruction="""
You are the friendly voice of the Zoo Tour Guide. Your task is to take the
RESEARCH_DATA and present it to the user in a complete and helpful answer.
- First, present the specific information from the zoo (like names, ages, and where to find them).
- Then, add the interesting general facts from the research.
- If some information is missing, just present the information you have.
- Be conversational and engaging.
RESEARCH_DATA:
{ research_data }
"""
)
tour_guide_workflow = SequentialAgent(
name="tour_guide_workflow",
description="The main workflow for handling a user's request about an animal.",
sub_agents=[
comprehensive_researcher, # Step 1: Gather all data
response_formatter, # Step 2: Format the final response
]
)
root_agent = Agent(
name="greeter",
model=model_name,
description="The main entry point for the Zoo Tour Guide.",
instruction="""
- Let the user know you will help them learn about the animals we have in the zoo.
- When the user responds, use the 'add_prompt_to_state' tool to save their response.
After using the tool, transfer control to the 'tour_guide_workflow' agent.
""",
tools=[add_prompt_to_state],
sub_agents=[tour_guide_workflow]
)
Next up, deployment!
9. Prepare the application for deployment
Check the final structure
Before deploying, verify that your project directory contains the correct files.
- Ensure your
zoo_guide_agentfolder looks like this:zoo_guide_agent/ ├── .env ├── __init__.py ├── agent.py └── requirements.txt
Set up IAM permissions
With your local code ready, the next step is to set up the identity your agent will use in the cloud.
- In the terminal, load the variables into your shell session.
source .env - Create a dedicated service account for your Cloud Run service so that it has its own specific permission. Paste the following into the terminal:
gcloud iam service-accounts create ${SA_NAME} \ --display-name="Service Account for lab 2 " - Grant the service account the Vertex AI User role, which gives it permission to call Google's models.
# Grant the "Vertex AI User" role to your service account gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:$SERVICE_ACCOUNT" \ --role="roles/aiplatform.user"
10. Deploy the agent using the ADK CLI
With your local code ready and your Google Cloud project prepared, it's time to deploy the agent. You will use the adk deploy cloud_run command, a convenient tool that automates the entire deployment workflow. This single command packages your code, builds a container image, pushes it to Artifact Registry, and launches the service on Cloud Run, making it accessible on the web.
- Run the following command in the terminal to deploy your agent.
# Run the deployment command uvx --from google-adk==1.14.0 \ adk deploy cloud_run \ --project=$PROJECT_ID \ --region=europe-west1 \ --service_name=zoo-tour-guide \ --with_ui \ . \ -- \ --labels=dev-tutorial=codelab-adk \ --service-account=$SERVICE_ACCOUNTuvxcommand allows you to run command line tools published as Python packages without requiring a global installation of those tools. - If you are prompted with the following:
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [europe-west1] will be created. Do you want to continue (Y/n)?
Yand hit ENTER. - If you are prompted with the following:
Allow unauthenticated invocations to [your-service-name] (y/N)?.
yand hit ENTER. This allows unauthenticated invocations for this lab for easy testing. Upon successful execution, the command will provide the URL of the deployed Cloud Run service. (It will look something likehttps://zoo-tour-guide-123456789.europe-west1.run.app). - Copy the URL of the deployed Cloud Run service for the next task.
11. Test the deployed agent
With your agent now live on Cloud Run, you'll perform a test to confirm that the deployment was successful and the agent is working as expected. You'll use the public Service URL (something like https://zoo-tour-guide-123456789.europe-west1.run.app/) to access the ADK's web interface and interact with the agent.
- Open the public Cloud Run Service URL in your web browser. Because you used the
--with_ui flag, you should see the ADK developer UI. - Toggle on
Token Streamingin the upper right.
You can now interact with the Zoo agent. - Type
helloand hit enter to begin a new conversation. - Observe the result. The agent should respond quickly with its greeting, which will be something like this:
"Hello! I'm your Zoo Tour Guide. I can help you learn about the amazing animals we have here. What would you like to know or explore today?"
- Ask the agent questions like:
Where can I find the polar bears in the zoo and what is their diet?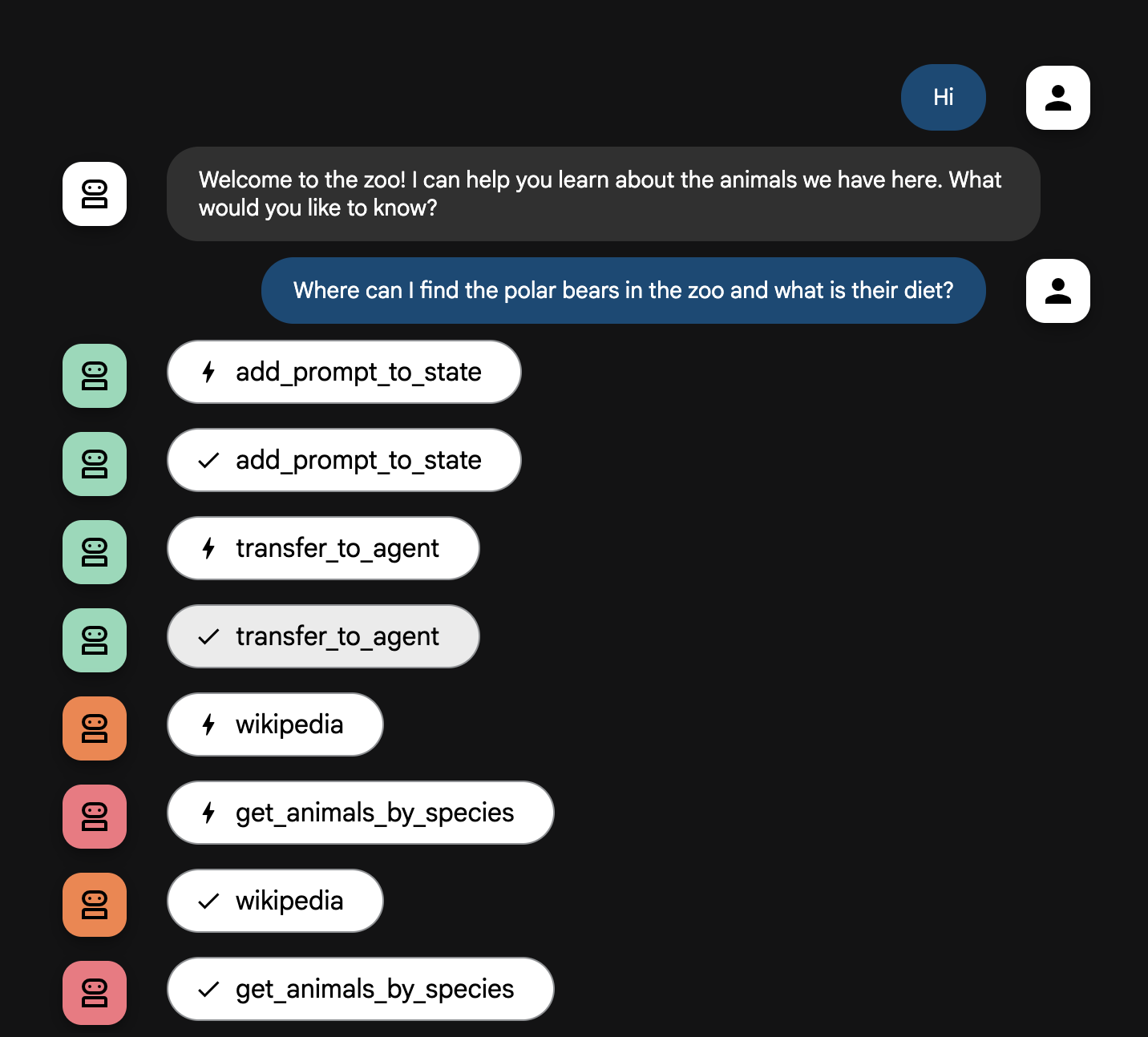

Agent Flow Explained
Your system operates as an intelligent, multi-agent team. The process is managed by a clear sequence to ensure a smooth and efficient flow from a user's question to the final, detailed answer.
1. The Zoo Greeter (The Welcome Desk)
The entire process begins with the greeter agent.
- Its Job: To start the conversation. Its instruction is to greet the user and ask what animal they would like to learn about.
- Its Tool: When the user replies, the Greeter uses its add_prompt_to_state tool to capture their exact words (e.g., "tell me about the lions") and save them in the system's memory.
- The Handoff: After saving the prompt, it immediately passes control to its sub-agent, the tour_guide_workflow.
2. The Comprehensive Researcher (The Super-Researcher)
This is the first step in the main workflow and the "brain" of the operation. Instead of a large team, you now have a single, highly-skilled agent that can access all the available information.
- Its Job: To analyze the user's question and form an intelligent plan. It uses the language model's tool use capability to decide if it needs:
- General knowledge from the web (via the Wikipedia API).
- Or, for complex questions, both.
3. The Response Formatter (The Presenter)
Once the Comprehensive Researcher has gathered all the facts, this is the final agent to run.
- Its Job: To act as the friendly voice of the Zoo Tour Guide. It takes the raw data (which could be from one or both sources) and polishes it.
- Its Action: It synthesizes all the information into a single, cohesive, and engaging answer. Following its instructions, it first presents the specific zoo information and then adds the interesting general facts.
- The Final Result: The text generated by this agent is the complete, detailed answer that the user sees in the chat window.
If you interested in learning more about building Agents, check out the following resources:
12. Clean up environment
To avoid incurring charges to your Google Cloud account for the resources used in this tutorial, either delete the project that contains the resources, or keep the project and delete the individual resources.
Delete the Cloud Run services and images
If you wish to keep the Google Cloud project but remove the specific resources created in this lab, you must delete both the running service and the container image stored in the registry.
- Run the following commands in the terminal:
gcloud run services delete zoo-tour-guide --region=europe-west1 --quiet gcloud artifacts repositories delete cloud-run-source-deploy --location=europe-west1 --quiet
Delete the project (Optional)
If you created a new project specifically for this lab and don't plan to use it again, the easiest way to clean up is to delete the entire project. This ensures all resources (including the Service Account and any hidden build artifacts) are completely removed.
- In the terminal, run the following command (replace [YOUR_PROJECT_ID] with your actual project ID)
gcloud projects delete $PROJECT_ID
13. Congratulations
You have successfully built and deployed a multi-agent AI application to Google Cloud!
Recap
In this lab, you went from an empty directory to a live, publicly accessible AI service. Here is a look at what you built:
- You created a specialized team: Instead of one generic AI, you built a "Researcher" to find facts and a "Formatter" to polish the answer.
- You gave them tools: You connected your agents to the outside world using the Wikipedia API.
- You shipped it: You took your local Python code and deployed it as a serverless container on Cloud Run, securing it with a dedicated Service Account.
What we've covered
- How to structure a Python project for deployment with the ADK.
- How to implement a multi-agent workflow using
[SequentialAgent](https://google.github.io/adk-docs/agents/workflow-agents/sequential-agents/). - How to integrate external tools like the Wikipedia API.
- How to deploy an agent to Cloud Run using the
adk deploycommand.
14. Survey
Output: