
۱. مقدمه
این آزمایشگاه بر پیادهسازی و استقرار سرویس عامل کلاینت تمرکز دارد. شما از کیت توسعه عامل (ADK) برای ساخت یک عامل هوش مصنوعی که از ابزارها استفاده میکند، استفاده خواهید کرد.
در این آزمایشگاه، ما در حال ساخت یک عامل باغ وحش هستیم که از ویکی پدیا برای پاسخ به سوالات مربوط به حیوانات استفاده میکند.

در نهایت، ما راهنمای تور را به جای اینکه فقط به صورت محلی اجرا شود، در Google Cloud Run مستقر خواهیم کرد.
پیشنیازها
- یک پروژه گوگل کلود با قابلیت پرداخت.
آنچه یاد خواهید گرفت
- نحوه ساختاردهی یک پروژه پایتون برای استقرار ADK .
- نحوه پیادهسازی یک عامل استفادهکننده از ابزار با google-adk.
- نحوه استقرار یک برنامه پایتون به عنوان یک کانتینر بدون سرور در Cloud Run .
- نحوه پیکربندی احراز هویت امن سرویس به سرویس با استفاده از نقشهای IAM .
- نحوه حذف منابع ابری برای جلوگیری از هزینههای آینده.
آنچه نیاز دارید
- یک حساب کاربری گوگل کلود و پروژه گوگل کلود
- یک مرورگر وب مانند کروم
۲. چرا باید روی Cloud Run مستقر شویم؟
Cloud Run یک انتخاب عالی برای میزبانی از عوامل ADK است زیرا یک پلتفرم بدون سرور است، به این معنی که میتوانید روی کد خود تمرکز کنید و نیازی به مدیریت زیرساختهای اساسی ندارید. ما کارهای عملیاتی را برای شما انجام میدهیم.
آن را مانند یک فروشگاه موقت در نظر بگیرید: فقط زمانی باز میشود و از منابع استفاده میکند که مشتریان (درخواستها) برسند. وقتی هیچ مشتری وجود نداشته باشد، کاملاً بسته میشود و شما برای یک فروشگاه خالی هزینهای نمیپردازید.
ویژگیهای کلیدی
کانتینرها را در هر مکانی اجرا میکند:
- شما یک کانتینر (تصویر داکر) که برنامه شما درون آن قرار دارد، میآورید.
- کلود ران آن را روی زیرساخت گوگل اجرا میکند.
- بدون نیاز به وصله کردن سیستم عامل، تنظیم ماشین مجازی یا دردسرهای مربوط به مقیاسپذیری.
مقیاسبندی خودکار:
- اگر ۰ نفر از برنامه شما استفاده میکنند → ۰ نمونه اجرا میشود (مقیاس به صفر نمونه کاهش مییابد که مقرون به صرفه است).
- اگر ۱۰۰۰ درخواست به آن برسد → به تعداد مورد نیاز کپی تهیه میکند.
بدون تابعیت به طور پیشفرض:
- هر درخواست میتواند به یک نمونه متفاوت برود.
- اگر نیاز به ذخیره وضعیت (state) دارید، از یک سرویس خارجی مانند Cloud SQL، Firestore یا Memorystore استفاده کنید.
پشتیبانی از هر زبان یا چارچوبی:
- تا زمانی که در یک کانتینر لینوکس اجرا شود، Cloud Run اهمیتی نمیدهد که پایتون، گو، نودجیاس، جاوا یا داتنت باشد.
برای آنچه استفاده میکنید، هزینه بپردازید:
- صورتحساب مبتنی بر درخواست : صورتحساب به ازای هر درخواست + زمان محاسبه (تا ۱۰۰ میلیثانیه) صادر میشود.
- صورتحساب مبتنی بر نمونه : صورتحساب برای کل طول عمر نمونه (بدون هزینه برای هر درخواست) صادر میشود.
۳. راهاندازی پروژه
حساب گوگل
اگر از قبل حساب گوگل شخصی ندارید، باید یک حساب گوگل ایجاد کنید .
به جای حساب کاری یا تحصیلی از حساب شخصی استفاده کنید .
ورود به کنسول ابری گوگل
با استفاده از یک حساب کاربری شخصی گوگل، وارد کنسول ابری گوگل شوید.
فعال کردن صورتحساب
یک حساب پرداخت شخصی تنظیم کنید
اگر صورتحساب را با استفاده از اعتبارهای Google Cloud تنظیم کردهاید، میتوانید از این مرحله صرف نظر کنید.
برای تنظیم یک حساب پرداخت شخصی، به اینجا بروید تا پرداخت را در کنسول ابری فعال کنید .
برخی نکات:
- تکمیل این آزمایشگاه باید کمتر از ۱ دلار آمریکا از طریق منابع ابری هزینه داشته باشد.
- شما میتوانید مراحل انتهای این آزمایش را برای حذف منابع دنبال کنید تا از هزینههای بیشتر جلوگیری شود.
- کاربران جدید واجد شرایط استفاده از دوره آزمایشی رایگان ۳۰۰ دلاری هستند.
ایجاد پروژه (اختیاری)
اگر پروژه فعلی ندارید که بخواهید برای این آزمایشگاه استفاده کنید، اینجا یک پروژه جدید ایجاد کنید .
۴. ویرایشگر Cloud Shell را باز کنید
- برای دسترسی مستقیم به ویرایشگر Cloud Shell ، روی این لینک کلیک کنید.
- اگر امروز در هر مرحلهای از شما خواسته شد که مجوز دهید، برای ادامه روی تأیید کلیک کنید.
- اگر ترمینال در پایین صفحه نمایش داده نشد، آن را باز کنید:
- روی مشاهده کلیک کنید
- روی ترمینال کلیک کنید
۵. پروژه خود را تنظیم کنید
- در ترمینال، پروژه خود را با این دستور تنظیم کنید:
gcloud config set project [PROJECT_ID]gcloud config set project lab-project-id-example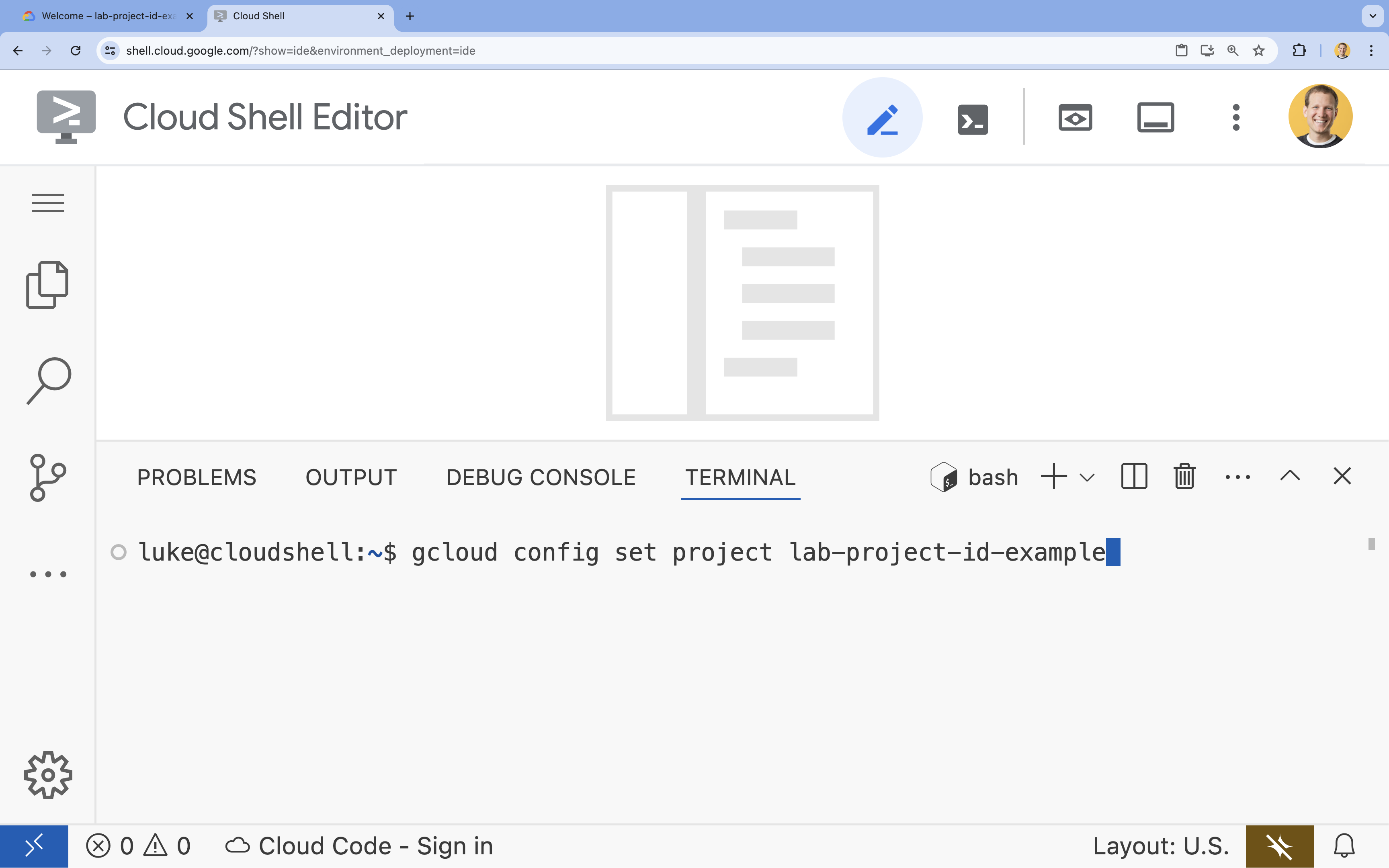
- شما باید این پیام را ببینید:
Updated property [core/project].
۶. فعال کردن APIها
برای استفاده از Cloud Run ، Artifact Registry ، Cloud Build ، Vertex AI و Compute Engine ، باید API های مربوط به آنها را در پروژه Google Cloud خود فعال کنید.
- در ترمینال ، APIها را فعال کنید:
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.comOperation "operations/acat.p2-[GUID]" finished successfully.
معرفی API ها
- رابط برنامهنویسی کاربردی مدیریت ابری (Cloud Run Admin API )
run.googleapis.comبه شما امکان میدهد سرویسهای frontend و backend، کارهای دستهای یا وبسایتها را در یک محیط کاملاً مدیریتشده اجرا کنید. این رابط، زیرساخت لازم برای استقرار و مقیاسبندی برنامههای کانتینری شما را مدیریت میکند. - رابط برنامهنویسی کاربردی (API) رجیستری مصنوعات (
artifactregistry.googleapis.com) یک مخزن امن و خصوصی برای ذخیره تصاویر کانتینر شما فراهم میکند. این تکامل رجیستری کانتینر است و به طور یکپارچه با Cloud Run و Cloud Build ادغام میشود. - Cloud Build API (
cloudbuild.googleapis.com) یک پلتفرم CI/CD بدون سرور است که buildهای شما را روی زیرساخت Google Cloud اجرا میکند. این API برای ساخت تصویر کانتینر شما در فضای ابری از Dockerfile شما استفاده میشود. - رابط برنامهنویسی کاربردی هوش مصنوعی ورتکس (
aiplatform.googleapis.com) به برنامهی مستقر شما این امکان را میدهد که با مدلهای Gemini برای انجام وظایف اصلی هوش مصنوعی ارتباط برقرار کند. این رابط، رابط برنامهنویسی کاربردی یکپارچهای را برای تمام سرویسهای هوش مصنوعی گوگل کلود فراهم میکند. - رابط برنامهنویسی کاربردی موتور محاسباتی (compute Engine API ) (
compute.googleapis.com) ماشینهای مجازی امن و قابل تنظیمی را فراهم میکند که روی زیرساخت گوگل اجرا میشوند. در حالی که Cloud Run مدیریت میشود، رابط برنامهنویسی کاربردی موتور محاسباتی اغلب به عنوان یک وابستگی اساسی برای منابع مختلف شبکه و محاسباتی مورد نیاز است.
۷. محیط توسعه خود را آماده کنید
دایرکتوری ایجاد کنید
- در ترمینال ، دایرکتوری پروژه و زیرشاخههای لازم را ایجاد کنید:
cd && mkdir zoo_guide_agent && cd zoo_guide_agent - در ترمینال، دستور زیر را اجرا کنید تا پوشه
zoo_guide_agentدر مرورگر ویرایشگر Cloud Shell باز شود:cloudshell open-workspace ~/zoo_guide_agent - پنل اکسپلورر در سمت چپ رفرش میشود. اکنون باید دایرکتوری که ایجاد کردهاید را ببینید.
الزامات نصب
- دستور زیر را در ترمینال اجرا کنید تا فایل
requirements.txtایجاد شود.cloudshell edit requirements.txt - موارد زیر را به فایل
requirements.txtکه اخیراً ایجاد شده است اضافه کنیدgoogle-adk==1.14.0 langchain-community==0.3.27 wikipedia==1.4.0 - در ترمینال ، با استفاده از uv یک محیط مجازی ایجاد و فعال کنید. این کار تضمین میکند که وابستگیهای پروژه شما با پایتون سیستم تداخل نداشته باشند.
uv venv source .venv/bin/activate - بستههای مورد نیاز را در محیط مجازی خود در ترمینال نصب کنید.
uv pip install -r requirements.txt
تنظیم متغیرهای محیطی
- برای ایجاد فایل
.envاز دستور زیر در ترمینال استفاده کنید.# 1. Set the variables in your terminal first PROJECT_ID=$(gcloud config get-value project) PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)") SA_NAME=lab2-cr-service # 2. Create the .env file using those variables cat <<EOF > .env PROJECT_ID=$PROJECT_ID PROJECT_NUMBER=$PROJECT_NUMBER SA_NAME=$SA_NAME SERVICE_ACCOUNT=${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com MODEL="gemini-2.5-flash" EOF
۸. ایجاد گردش کار برای اپراتور
فایل __init__.py را ایجاد کنید
- با اجرای دستور زیر در ترمینال ، فایل init.py را ایجاد کنید:
cloudshell edit __init__.py - کد زیر را به فایل جدید
__init__.pyاضافه کنید:from . import agent
فایل agent.py را ایجاد کنید
- با وارد کردن دستور زیر در ترمینال، فایل اصلی
agent.pyرا ایجاد کنید.cloudshell edit agent.py - وارد کردنها و راهاندازی اولیه : کد زیر را به فایل
agent.pyکه در حال حاضر خالی است اضافه کنید:import os import logging import google.cloud.logging from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper import google.auth import google.auth.transport.requests import google.oauth2.id_token # --- Setup Logging and Environment --- cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL")agent.pyتمام کتابخانههای لازم را از ADK و Google Cloud میآورد. همچنین ثبت وقایع را تنظیم میکند و متغیرهای محیطی را از فایل.envشما بارگذاری میکند که برای دسترسی به مدل و URL سرور شما بسیار مهم است. - ابزارها را تعریف کنید : یک عامل فقط به اندازه ابزارهایی که میتواند استفاده کند خوب است. کد زیر را به انتهای
agent.pyاضافه کنید تا ابزارها را تعریف کنید:# Greet user and save their prompt def add_prompt_to_state( tool_context: ToolContext, prompt: str ) -> dict[str, str]: """Saves the user's initial prompt to the state.""" tool_context.state["PROMPT"] = prompt logging.info(f"[State updated] Added to PROMPT: {prompt}") return {"status": "success"} # Configuring the Wikipedia Tool wikipedia_tool = LangchainTool( tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper()) )-
add_prompt_to_state📝: این ابزار آنچه را که یک بازدیدکننده باغ وحش میپرسد به خاطر میسپارد. وقتی بازدیدکنندهای میپرسد: «شیرها کجا هستند؟»، این ابزار آن سوال خاص را در حافظه عامل ذخیره میکند تا سایر عوامل در گردش کار بدانند چه چیزی را باید تحقیق کنند.
نحوهی انجام: این یک تابع پایتون است که اعلان بازدیدکننده را در دیکشنری مشترکtool_context.stateمینویسد. این زمینهی ابزار، حافظهی کوتاهمدت عامل را برای یک مکالمهی واحد نشان میدهد. دادههای ذخیرهشده در وضعیت توسط یک عامل، میتواند توسط عامل بعدی در گردش کار خوانده شود. -
LangchainTool🌍: این ابزار به راهنمای تور، دانش عمومی از جهان میدهد. وقتی بازدیدکنندهای سوالی میپرسد که در پایگاه داده باغوحش نیست، مانند «شیرها در طبیعت چه میخورند؟»، این ابزار به راهنمای تور اجازه میدهد تا پاسخ را در ویکیپدیا جستجو کند.
چگونه: به عنوان یک آداپتور عمل میکند و به عامل ما اجازه میدهد از ابزار از پیش ساخته شده WikipediaQueryRun از کتابخانه LangChain استفاده کند.
-
- تعریف عاملهای متخصص : کد زیر را به انتهای
agent.pyاضافه کنید تا عاملهایcomprehensive_researcherوresponse_formatterتعریف شوند:# 1. Researcher Agent comprehensive_researcher = Agent( name="comprehensive_researcher", model=model_name, description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.", instruction=""" You are a helpful research assistant. Your goal is to fully answer the user's PROMPT. You have access to two tools: 1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations). 2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat). First, analyze the user's PROMPT. - If the prompt can be answered by only one tool, use that tool. - If the prompt is complex and requires information from both the zoo's database AND Wikipedia, you MUST use both tools to gather all necessary information. - Synthesize the results from the tool(s) you use into preliminary data outputs. PROMPT: { PROMPT } """, tools=[ wikipedia_tool ], output_key="research_data" # A key to store the combined findings ) # 2. Response Formatter Agent response_formatter = Agent( name="response_formatter", model=model_name, description="Synthesizes all information into a friendly, readable response.", instruction=""" You are the friendly voice of the Zoo Tour Guide. Your task is to take the RESEARCH_DATA and present it to the user in a complete and helpful answer. - First, present the specific information from the zoo (like names, ages, and where to find them). - Then, add the interesting general facts from the research. - If some information is missing, just present the information you have. - Be conversational and engaging. RESEARCH_DATA: { research_data } """ )- عامل
comprehensive_researcher«مغز» عملیات ماست. این عامل درخواست کاربر را ازStateمشترک میگیرد، ابزار ویکیپدیا را بررسی میکند و تصمیم میگیرد که از کدام یک برای یافتن پاسخ استفاده کند. - نقش عامل
response_formatterارائه است. این عامل دادههای خام جمعآوریشده توسط عامل محقق (که از طریق ایالت ارسال شده است) را دریافت کرده و از مهارتهای زبانی LLM برای تبدیل آن به یک پاسخ دوستانه و محاورهای استفاده میکند.
- عامل
- تعریف عامل گردش کار : این بلوک کد را به انتهای
agent.pyاضافه کنید تا عامل ترتیبیtour_guide_workflowتعریف کنید:tour_guide_workflow = SequentialAgent( name="tour_guide_workflow", description="The main workflow for handling a user's request about an animal.", sub_agents=[ comprehensive_researcher, # Step 1: Gather all data response_formatter, # Step 2: Format the final response ] )
نحوهی کار: این یکSequentialAgentاست، نوع خاصی از عامل که به خودی خود فکر نمیکند. تنها وظیفهی آن اجرای لیستی ازsub_agents(محقق و قالبدهنده) در یک توالی ثابت است و به طور خودکار حافظهی مشترک را از یکی به دیگری منتقل میکند. - گردش کار اصلی را مونتاژ کنید : این بلوک کد نهایی را به انتهای
agent.pyاضافه کنید تاroot_agentتعریف کنید:root_agent = Agent( name="greeter", model=model_name, description="The main entry point for the Zoo Tour Guide.", instruction=""" - Let the user know you will help them learn about the animals we have in the zoo. - When the user responds, use the 'add_prompt_to_state' tool to save their response. After using the tool, transfer control to the 'tour_guide_workflow' agent. """, tools=[add_prompt_to_state], sub_agents=[tour_guide_workflow] )root_agentبه عنوان نقطه شروع برای همه مکالمات جدید استفاده میکند. نقش اصلی آن هماهنگسازی فرآیند کلی است. این عامل به عنوان کنترلکننده اولیه عمل میکند و اولین نوبت مکالمه را مدیریت میکند.
فایل کامل agent.py
فایل agent.py شما اکنون کامل شده است! با ساختن آن به این روش، میتوانید ببینید که چگونه هر جزء - ابزارها، عاملهای کارگر و عاملهای مدیر - نقش خاصی در ایجاد سیستم هوشمند نهایی دارند.
فایل کامل باید به این شکل باشد:
import os
import logging
import google.cloud.logging
from dotenv import load_dotenv
from google.adk import Agent
from google.adk.agents import SequentialAgent
from google.adk.tools.tool_context import ToolContext
from google.adk.tools.langchain_tool import LangchainTool
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
import google.auth
import google.auth.transport.requests
import google.oauth2.id_token
# --- Setup Logging and Environment ---
cloud_logging_client = google.cloud.logging.Client()
cloud_logging_client.setup_logging()
load_dotenv()
model_name = os.getenv("MODEL")
# Greet user and save their prompt
def add_prompt_to_state(
tool_context: ToolContext, prompt: str
) -> dict[str, str]:
"""Saves the user's initial prompt to the state."""
tool_context.state["PROMPT"] = prompt
logging.info(f"[State updated] Added to PROMPT: {prompt}")
return {"status": "success"}
# Configuring the Wikipedia Tool
wikipedia_tool = LangchainTool(
tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
)
# 1. Researcher Agent
comprehensive_researcher = Agent(
name="comprehensive_researcher",
model=model_name,
description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.",
instruction="""
You are a helpful research assistant. Your goal is to fully answer the user's PROMPT.
You have access to two tools:
1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations).
2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat).
First, analyze the user's PROMPT.
- If the prompt can be answered by only one tool, use that tool.
- If the prompt is complex and requires information from both the zoo's database AND Wikipedia,
you MUST use both tools to gather all necessary information.
- Synthesize the results from the tool(s) you use into preliminary data outputs.
PROMPT:
{ PROMPT }
""",
tools=[
wikipedia_tool
],
output_key="research_data" # A key to store the combined findings
)
# 2. Response Formatter Agent
response_formatter = Agent(
name="response_formatter",
model=model_name,
description="Synthesizes all information into a friendly, readable response.",
instruction="""
You are the friendly voice of the Zoo Tour Guide. Your task is to take the
RESEARCH_DATA and present it to the user in a complete and helpful answer.
- First, present the specific information from the zoo (like names, ages, and where to find them).
- Then, add the interesting general facts from the research.
- If some information is missing, just present the information you have.
- Be conversational and engaging.
RESEARCH_DATA:
{ research_data }
"""
)
tour_guide_workflow = SequentialAgent(
name="tour_guide_workflow",
description="The main workflow for handling a user's request about an animal.",
sub_agents=[
comprehensive_researcher, # Step 1: Gather all data
response_formatter, # Step 2: Format the final response
]
)
root_agent = Agent(
name="greeter",
model=model_name,
description="The main entry point for the Zoo Tour Guide.",
instruction="""
- Let the user know you will help them learn about the animals we have in the zoo.
- When the user responds, use the 'add_prompt_to_state' tool to save their response.
After using the tool, transfer control to the 'tour_guide_workflow' agent.
""",
tools=[add_prompt_to_state],
sub_agents=[tour_guide_workflow]
)
مرحلهی بعدی، استقرار نیروها!
۹. برنامه را برای استقرار آماده کنید
بررسی ساختار نهایی
قبل از استقرار، بررسی کنید که دایرکتوری پروژه شما حاوی فایلهای صحیح باشد.
- مطمئن شوید که پوشه
zoo_guide_agentشما به این شکل است:zoo_guide_agent/ ├── .env ├── __init__.py ├── agent.py └── requirements.txt
مجوزهای IAM را تنظیم کنید
با آماده شدن کد محلی، مرحله بعدی تنظیم هویتی است که نماینده شما در فضای ابری از آن استفاده خواهد کرد.
- در ترمینال ، متغیرها را در جلسه پوسته خود بارگذاری کنید.
source .env - یک حساب کاربری اختصاصی برای سرویس Cloud Run خود ایجاد کنید تا مجوزهای خاص خود را داشته باشد. دستور زیر را در ترمینال وارد کنید:
gcloud iam service-accounts create ${SA_NAME} \ --display-name="Service Account for lab 2 " - به حساب کاربری سرویس، نقش Vertex AI User را اعطا کنید، که به آن اجازه میدهد مدلهای گوگل را فراخوانی کند.
# Grant the "Vertex AI User" role to your service account gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:$SERVICE_ACCOUNT" \ --role="roles/aiplatform.user"
۱۰. با استفاده از ADK CLI، عامل را مستقر کنید
با آماده شدن کد محلی و پروژه Google Cloud شما، زمان استقرار عامل فرا رسیده است. شما از دستور adk deploy cloud_run استفاده خواهید کرد، ابزاری مناسب که کل گردش کار استقرار را خودکار میکند. این دستور واحد، کد شما را بستهبندی میکند، یک تصویر کانتینر میسازد، آن را به Artifact Registry ارسال میکند و سرویس را در Cloud Run راهاندازی میکند و آن را در وب قابل دسترسی میسازد.
- برای نصب و راهاندازی Agent خود، دستور زیر را در ترمینال اجرا کنید.
# Run the deployment command uvx --from google-adk==1.14.0 \ adk deploy cloud_run \ --project=$PROJECT_ID \ --region=europe-west1 \ --service_name=zoo-tour-guide \ --with_ui \ . \ -- \ --labels=dev-tutorial=codelab-adk \ --service-account=$SERVICE_ACCOUNTuvxبه شما امکان میدهد ابزارهای خط فرمان منتشر شده به عنوان بستههای پایتون را بدون نیاز به نصب سراسری آن ابزارها، اجرا کنید. - اگر با موارد زیر مواجه شدید:
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [europe-west1] will be created. Do you want to continue (Y/n)?
Yرا تایپ کنید و ENTER را بزنید. - اگر با موارد زیر مواجه شدید:
Allow unauthenticated invocations to [your-service-name] (y/N)?.
yرا تایپ کنید و ENTER را بزنید. این کار امکان فراخوانیهای احراز هویت نشده را برای این آزمایشگاه فراهم میکند تا آزمایش آسان شود. پس از اجرای موفقیتآمیز، دستور، URL سرویس Cloud Run مستقر شده را ارائه میدهد. (چیزی شبیه بهhttps://zoo-tour-guide-123456789.europe-west1.run.appخواهد بود). - برای کار بعدی، آدرس اینترنتی سرویس Cloud Run مستقر شده را کپی کنید.
۱۱. تست عامل مستقر شده
حالا که عامل شما روی Cloud Run قرار دارد، آزمایشی انجام خواهید داد تا تأیید کنید که استقرار موفقیتآمیز بوده و عامل طبق انتظار کار میکند. برای دسترسی به رابط وب ADK و تعامل با عامل، از URL عمومی سرویس (چیزی شبیه به https://zoo-tour-guide-123456789.europe-west1.run.app/ ) استفاده خواهید کرد.
- آدرس اینترنتی عمومی سرویس Cloud Run را در مرورگر وب خود باز کنید. از آنجا که از
--with_ui flagاستفاده کردهاید، باید رابط کاربری توسعهدهنده ADK را ببینید. - در بالا سمت راست، گزینه
Token Streamingفعال کنید.
اکنون میتوانید با نماینده باغ وحش تعامل داشته باشید. - برای شروع مکالمه جدید،
helloرا تایپ کرده و اینتر را بزنید. - نتیجه را مشاهده کنید. عامل باید به سرعت با خوشامدگویی خود پاسخ دهد، که چیزی شبیه به این خواهد بود:
"Hello! I'm your Zoo Tour Guide. I can help you learn about the amazing animals we have here. What would you like to know or explore today?"
- از نماینده سوالاتی مانند موارد زیر بپرسید:
Where can I find the polar bears in the zoo and what is their diet?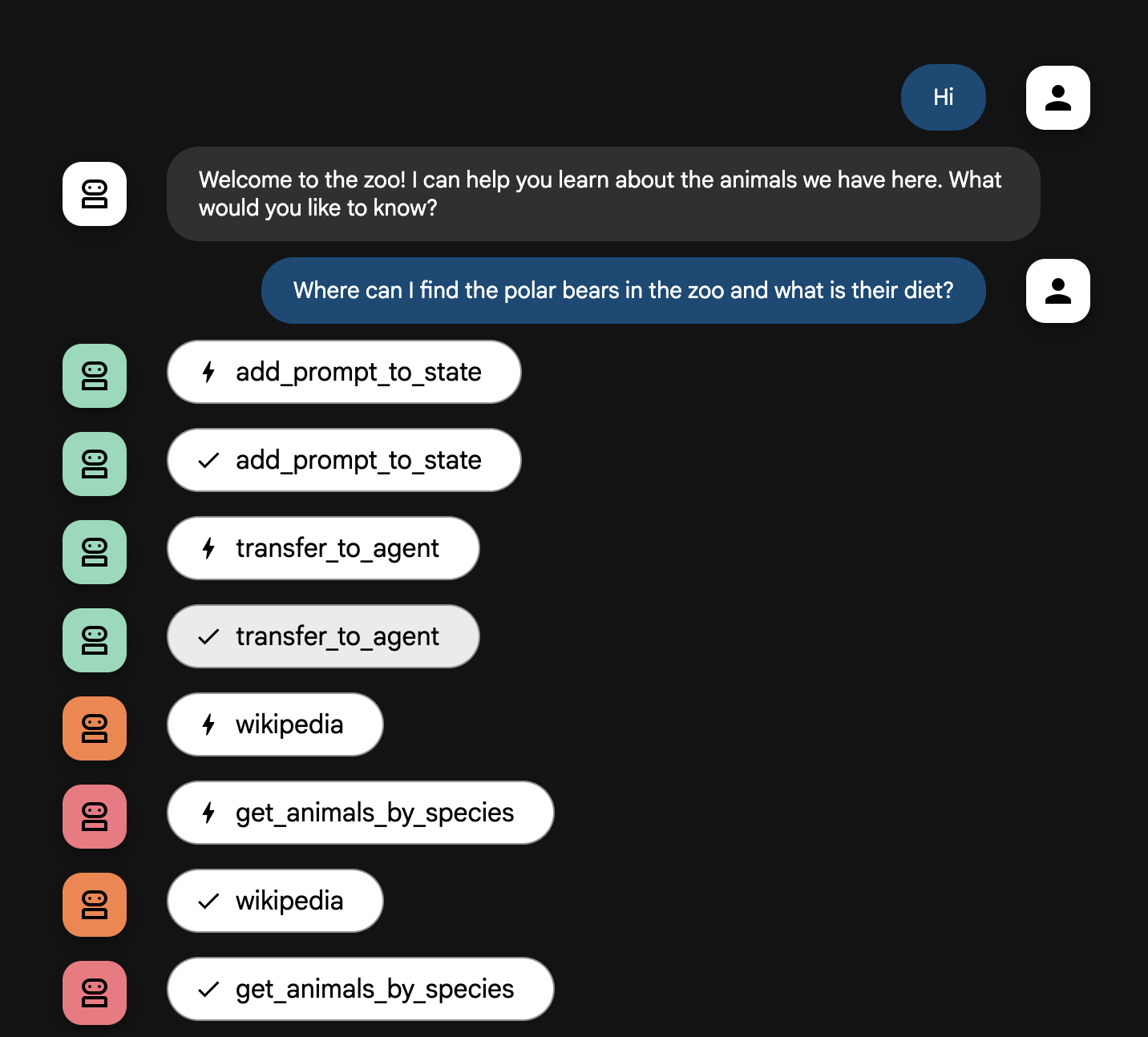

جریان عامل توضیح داده شده است
سیستم شما به عنوان یک تیم هوشمند و چند عاملی عمل میکند. این فرآیند با یک توالی مشخص مدیریت میشود تا جریانی روان و کارآمد از سوال کاربر تا پاسخ نهایی و دقیق تضمین شود.
۱. پیشخدمت باغ وحش (میز خوشامدگویی)
کل فرآیند با عامل خوشامدگویی آغاز میشود.
- وظیفه آن: شروع مکالمه. دستورالعمل آن این است که به کاربر سلام کند و بپرسد که دوست دارد درباره چه حیوانی اطلاعات کسب کند.
- ابزار آن: وقتی کاربر پاسخ میدهد، خوشامدگو از ابزار add_prompt_to_state خود برای دریافت دقیق کلمات او (مثلاً «درباره شیرها به من بگو») و ذخیره آنها در حافظه سیستم استفاده میکند.
- انتقال: پس از ذخیره اعلان، بلافاصله کنترل به عامل فرعی خود، tour_guide_workflow، منتقل میشود.
۲. محقق جامع (ابر محقق)
این اولین قدم در گردش کار اصلی و "مغز" عملیات است. به جای یک تیم بزرگ، اکنون یک عامل واحد و بسیار ماهر دارید که میتواند به تمام اطلاعات موجود دسترسی داشته باشد.
- وظیفه آن: تجزیه و تحلیل سوال کاربر و ایجاد یک طرح هوشمند. این برنامه از قابلیت استفاده از ابزار مدل زبان برای تصمیم گیری در مورد نیاز به موارد زیر استفاده میکند:
- دانش عمومی از وب (از طریق API ویکیپدیا).
- یا، برای سوالات پیچیده، هر دو.
۳. قالبدهنده پاسخ (ارائهدهنده)
وقتی محقق جامع تمام حقایق را جمعآوری کرد، این آخرین عاملی است که باید اجرا شود.
- وظیفه آن: ایفای نقش صدای دوستانه راهنمای تور باغ وحش. دادههای خام (که میتواند از یک یا هر دو منبع باشد) را دریافت و آنها را اصلاح میکند.
- عملکرد آن: تمام اطلاعات را در یک پاسخ واحد، منسجم و جذاب ترکیب میکند. طبق دستورالعملهای آن، ابتدا اطلاعات خاص باغوحش را ارائه میدهد و سپس حقایق کلی جالب را اضافه میکند.
- نتیجه نهایی: متن تولید شده توسط این عامل، پاسخ کامل و مفصلی است که کاربر در پنجره چت مشاهده میکند.
اگر علاقهمند به کسب اطلاعات بیشتر در مورد عوامل سازنده هستید ، منابع زیر را بررسی کنید:
۱۲. محیط را تمیز کنید
برای جلوگیری از تحمیل هزینه به حساب گوگل کلود خود برای منابع استفاده شده در این آموزش، یا پروژهای که شامل منابع است را حذف کنید، یا پروژه را نگه دارید و منابع تکی را حذف کنید.
سرویسها و تصاویر Cloud Run را حذف کنید
اگر میخواهید پروژه Google Cloud را حفظ کنید اما منابع خاص ایجاد شده در این آزمایشگاه را حذف کنید، باید هم سرویس در حال اجرا و هم تصویر کانتینر ذخیره شده در رجیستری را حذف کنید.
- دستورات زیر را در ترمینال اجرا کنید:
gcloud run services delete zoo-tour-guide --region=europe-west1 --quiet gcloud artifacts repositories delete cloud-run-source-deploy --location=europe-west1 --quiet
حذف پروژه (اختیاری)
اگر پروژه جدیدی را بهطور خاص برای این آزمایشگاه ایجاد کردهاید و قصد ندارید دوباره از آن استفاده کنید، سادهترین راه برای پاکسازی، حذف کل پروژه است. این کار تضمین میکند که تمام منابع (از جمله حساب سرویس و هرگونه مصنوعات ساخت پنهان) بهطور کامل حذف میشوند.
- در ترمینال ، دستور زیر را اجرا کنید (به جای [YOUR_PROJECT_ID]، شناسه پروژه واقعی خود را قرار دهید)
gcloud projects delete $PROJECT_ID
۱۳. تبریک
شما با موفقیت یک برنامه هوش مصنوعی چندعاملی را ساخته و در فضای ابری گوگل مستقر کردهاید!
خلاصه
در این آزمایش، شما از یک دایرکتوری خالی به یک سرویس هوش مصنوعی زنده و قابل دسترس برای عموم تبدیل شدید. در اینجا نگاهی به آنچه ساختید، میاندازیم:
- شما یک تیم تخصصی ایجاد کردید : به جای یک هوش مصنوعی عمومی، یک «محقق» برای یافتن حقایق و یک «قالببند» برای اصلاح پاسخ ساختید.
- شما به آنها ابزار دادید : شما با استفاده از API ویکیپدیا، عوامل خود را به دنیای خارج متصل کردید.
- شما آن را ارسال کردید : شما کد پایتون محلی خود را گرفتید و آن را به عنوان یک کانتینر بدون سرور در Cloud Run مستقر کردید و آن را با یک حساب کاربری سرویس اختصاصی ایمن کردید.
آنچه ما پوشش دادهایم
- نحوه ساختاردهی یک پروژه پایتون برای استقرار با ADK
- نحوه پیادهسازی یک گردش کار چند عاملی با استفاده از
[SequentialAgent](https://google.github.io/adk-docs/agents/workflow-agents/sequential-agents/). - نحوه ادغام ابزارهای خارجی مانند API ویکی پدیا.
- نحوهی استقرار یک عامل در Cloud Run با استفاده از دستور
adk deploy.
۱۴. نظرسنجی
خروجی: