
1. מבוא
ב-Lab הזה מתמקדים בהטמעה ובפריסה של שירות סוכן לקוח. תשתמשו ב-ערכה לפיתוח סוכנים (ADK) כדי ליצור סוכן AI שמשתמש בכלים.
בשיעור ה-Lab הזה נבנה סוכן גן חיות שמשתמש בוויקיפדיה כדי לענות על שאלות לגבי חיות.

לבסוף, נבצע פריסה של סוכן מדריך הטיולים ב-Cloud Run של Google, במקום להריץ אותו רק באופן מקומי.
דרישות מוקדמות
- פרויקט ב-Google Cloud שהחיוב בו מופעל.
מה תלמדו
- איך לבנות פרויקט Python לפריסה של ADK.
- איך מטמיעים סוכן שמשתמש בכלי באמצעות google-adk.
- איך פורסים אפליקציית Python כקונטיינר ללא שרת ב-Cloud Run.
- איך מגדירים אימות מאובטח משירות לשירות באמצעות תפקידים ב-IAM.
- איך מוחקים משאבי Cloud כדי להימנע מעלויות עתידיות.
הדרישות
- חשבון Google Cloud ופרויקט Google Cloud
- דפדפן אינטרנט כמו Chrome
2. למה כדאי לפרוס ל-Cloud Run?
Cloud Run היא פלטפורמה מצוינת לאירוח סוכני ADK כי היא פלטפורמה ללא שרתים, כלומר אתם יכולים להתמקד בקוד ולא בניהול התשתית הבסיסית. אנחנו מטפלים בעבודה התפעולית בשבילכם.
אפשר לחשוב על זה כמו על חנות פופ-אפ: היא נפתחת ומשתמשת במשאבים רק כשהלקוחות (הבקשות) מגיעים. אם אין לקוחות, החנות נסגרת לגמרי ולא תשלמו על חנות ריקה.
תכונות עיקריות
הפעלת Containers Anywhere:
- אתם מביאים קונטיינר (קובץ אימג' של Docker) שהאפליקציה שלכם נמצאת בתוכו.
- Cloud Run מריץ אותו בתשתית של Google.
- אין צורך בתיקון מערכת ההפעלה, בהגדרת מכונה וירטואלית או בהתמודדות עם בעיות בהתאמה לעומס.
התאמה אוטומטית של נפח האחסון:
- אם אף אחד לא משתמש באפליקציה → 0 מופעים פועלים (ההיקף מצטמצם ל-0 מופעים, מה שחוסך עלויות).
- אם נשלחות 1,000 בקשות → המערכת מפעילה כמה עותקים שצריך.
בלי שמירת מצב כברירת מחדל:
- כל בקשה יכולה להישלח למופע אחר.
- אם אתם צריכים לאחסן מצב, אתם יכולים להשתמש בשירות חיצוני כמו Cloud SQL, Firestore או Memorystore.
תמיכה בכל שפה או מסגרת:
- כל עוד האפליקציה פועלת במאגר Linux, לא משנה ל-Cloud Run אם היא כתובה ב-Python, ב-Go, ב-Node.js, ב-Java או ב- .Net.
תשלום לפי שימוש:
- חיוב לפי בקשה: חיוב לפי בקשה + זמן מחשוב (עד 100 אלפיות השנייה).
- חיוב לפי מופע: חיוב על משך החיים המלא של המופע (ללא עמלה לכל בקשה).
3. הגדרת הפרויקט
חשבון Google
אם אין לכם חשבון Google אישי, אתם צריכים ליצור חשבון Google.
משתמשים בחשבון לשימוש אישי במקום בחשבון לצורכי עבודה או בחשבון בית ספרי.
כניסה למסוף Google Cloud
נכנסים למסוף Google Cloud באמצעות חשבון Google אישי.
הפעלת חיוב
הגדרה של חשבון לחיוב לשימוש אישי
אם הגדרתם חיוב באמצעות קרדיטים ל-Google Cloud, אתם יכולים לדלג על השלב הזה.
כדי להגדיר חשבון לחיוב לשימוש אישי, עוברים לכאן כדי להפעיל את החיוב ב-Cloud Console.
הערות:
- העלות של השלמת ה-Lab הזה במשאבי Cloud צריכה להיות פחות מ-1$.
- כדי למחוק משאבים ולמנוע חיובים נוספים, אפשר לבצע את השלבים בסוף ה-Lab הזה.
- משתמשים חדשים זכאים לתקופת ניסיון בחינם בשווי 300$.
יצירת פרויקט (אופציונלי)
אם אין לכם פרויקט שאתם רוצים להשתמש בו בסדנה הזו, אתם יכולים ליצור פרויקט חדש כאן.
4. פתיחת Cloud Shell Editor
- כדי לעבור ישירות אל Cloud Shell Editor, לוחצים על הקישור הזה.
- אם תתבקשו לאשר בשלב כלשהו היום, תצטרכו ללחוץ על אישור כדי להמשיך.
- אם הטרמינל לא מופיע בתחתית המסך, פותחים אותו:
- לוחצים על הצגה.
- לוחצים על Terminal (מסוף)
 .
.
5. הגדרת הפרויקט
- בטרמינל, מגדירים את הפרויקט באמצעות הפקודה הבאה:
gcloud config set project [PROJECT_ID]gcloud config set project lab-project-id-example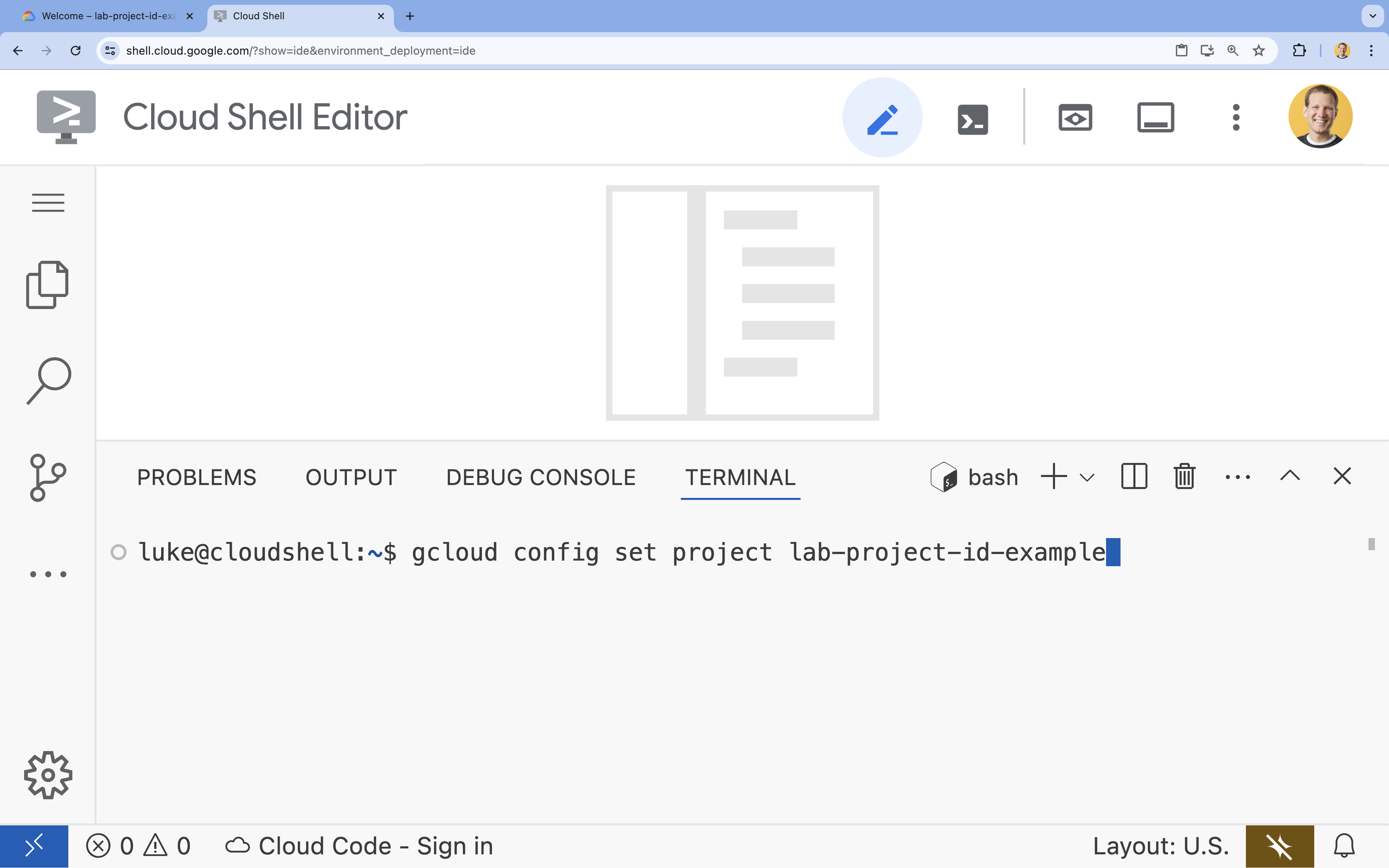
- תוצג ההודעה הבאה:
Updated property [core/project].
6. הפעלת ממשקי ה-API
כדי להשתמש ב-Cloud Run, ב-Artifact Registry, ב-Cloud Build, ב-Vertex AI וב-Compute Engine, צריך להפעיל את ממשקי ה-API שלהם בפרויקט בענן של Google.
- בטרמינל, מפעילים את ממשקי ה-API:
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.comOperation "operations/acat.p2-[GUID]" finished successfully.
מבוא לממשקי ה-API
- Cloud Run Admin API (
run.googleapis.com) מאפשר להפעיל שירותי חזית עורפית (frontend) וחזית אחורית (backend), משימות אצווה או אתרים בסביבה מנוהלת לחלוטין. השירות מטפל בתשתית לפריסה ולהתאמה לעומס (scaling) של האפליקציות שלכם בקונטיינרים. - Artifact Registry API (
artifactregistry.googleapis.com) מספק מאגר פרטי ומאובטח לאחסון תמונות של קונטיינרים. זוהי הגרסה המתקדמת של Container Registry, והיא משתלבת בצורה חלקה עם Cloud Run ו-Cloud Build. - Cloud Build API (
cloudbuild.googleapis.com) הוא פלטפורמת CI/CD ללא שרתים שמבצעת את הבנייה שלכם בתשתית ענן של Google Cloud. הוא משמש ליצירת קובץ אימג' של קונטיינר בענן מקובץ Dockerfile. - Vertex AI API (
aiplatform.googleapis.com) מאפשר לאפליקציה שפרסתם לתקשר עם מודלים של Gemini כדי לבצע משימות ליבה של AI. הוא מספק API מאוחד לכל שירותי ה-AI של Google Cloud. - Compute Engine API (
compute.googleapis.com) מספק מכונות וירטואליות מאובטחות שניתנות להתאמה אישית ופועלות בתשתית של Google. למרות ש-Cloud Run הוא שירות מנוהל, לעיתים קרובות נדרש Compute Engine API כתלות בסיסית במשאבי רשת ומחשוב שונים.
7. הכנת סביבת הפיתוח
יצירת הספרייה
- בטרמינל, יוצרים את ספריית הפרויקט ואת ספריות המשנה הנדרשות:
cd && mkdir zoo_guide_agent && cd zoo_guide_agent - בטרמינל, מריצים את הפקודה הבאה כדי לפתוח את הספרייה
zoo_guide_agentבסייר של Cloud Shell Editor:cloudshell open-workspace ~/zoo_guide_agent - חלונית הסייר בצד ימין תעבור רענון. עכשיו אמורה להופיע הספרייה שיצרתם.
דרישות ההתקנה
- מריצים את הפקודה הבאה בטרמינל כדי ליצור את הקובץ
requirements.txt.cloudshell edit requirements.txt - מוסיפים את הטקסט הבא לקובץ
requirements.txtהחדש שיצרתםgoogle-adk==1.14.0 langchain-community==0.3.27 wikipedia==1.4.0 - בטרמינל, יוצרים ומפעילים סביבה וירטואלית באמצעות uv. כך תוכלו לוודא שיחסי התלות של הפרויקט לא יתנגשו עם Python של המערכת.
uv venv source .venv/bin/activate - מתקינים את החבילות הנדרשות בסביבה הווירטואלית בטרמינל.
uv pip install -r requirements.txt
הגדרה של משתני סביבה
- כדי ליצור את הקובץ
.env, משתמשים בפקודה הבאה בטרמינל.# 1. Set the variables in your terminal first PROJECT_ID=$(gcloud config get-value project) PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)") SA_NAME=lab2-cr-service # 2. Create the .env file using those variables cat <<EOF > .env PROJECT_ID=$PROJECT_ID PROJECT_NUMBER=$PROJECT_NUMBER SA_NAME=$SA_NAME SERVICE_ACCOUNT=${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com MODEL="gemini-2.5-flash" EOF
8. יצירת תהליך עבודה של סוכן
יצירת קובץ __init__.py
- כדי ליצור את הקובץ init.py, מריצים את הפקודה הבאה בטרמינל:
cloudshell edit __init__.py - מוסיפים את הקוד הבא לקובץ
__init__.pyהחדש:from . import agent
יצירת קובץ agent.py
- כדי ליצור את הקובץ הראשי
agent.py, מדביקים את הפקודה הבאה בטרמינל.cloudshell edit agent.py - ייבוא והגדרה ראשונית: מוסיפים את הקוד הבא לקובץ
agent.pyהריק:import os import logging import google.cloud.logging from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper import google.auth import google.auth.transport.requests import google.oauth2.id_token # --- Setup Logging and Environment --- cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL")agent.pyכולל את כל הספריות הנדרשות מ-ADK ומ-Google Cloud. הסקריפט גם מגדיר רישום ביומן ומטען את משתני הסביבה מקובץ.env, וזה חיוני לגישה לכתובת ה-URL של המודל והשרת. - הגדרת הכלים: היכולות של סוכן מוגבלות לכלים שהוא יכול להשתמש בהם. מוסיפים את הקוד הבא לחלק התחתון של
agent.pyכדי להגדיר את הכלים:# Greet user and save their prompt def add_prompt_to_state( tool_context: ToolContext, prompt: str ) -> dict[str, str]: """Saves the user's initial prompt to the state.""" tool_context.state["PROMPT"] = prompt logging.info(f"[State updated] Added to PROMPT: {prompt}") return {"status": "success"} # Configuring the Wikipedia Tool wikipedia_tool = LangchainTool( tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper()) )-
add_prompt_to_state📝: הכלי הזה זוכר את השאלות של המבקרים בגן החיות. כשמבקר שואל "איפה האריות?", הכלי הזה שומר את השאלה הספציפית הזו בזיכרון של הסוכן, כדי שהסוכנים האחרים בתהליך העבודה יידעו מה לחפש.
איך: זו פונקציית Python שכותבת את ההנחיה של המבקר למילוןtool_context.stateהמשותף. ההקשר של הכלי הזה מייצג את הזיכרון לטווח קצר של הסוכן לשיחה אחת. נתונים שנשמרו במצב על ידי סוכן אחד יכולים להיקרא על ידי הסוכן הבא בתהליך העבודה. -
LangchainTool🌍: האפשרות הזו מעניקה לסוכן מדריך הטיולים ידע כללי על העולם. אם מבקר שואל שאלה שלא מופיעה במסד הנתונים של גן החיות, כמו "מה אריות אוכלים בטבע?", הכלי הזה מאפשר לנציג לחפש את התשובה בוויקיפדיה.
איך: הוא פועל כמתאם, ומאפשר לסוכן שלנו להשתמש בכלי WikipediaQueryRun שנבנה מראש מספריית LangChain.
-
- הגדרת סוכנים מומחים: מוסיפים את הקוד הבא לתחתית של
agent.pyכדי להגדיר את הסוכניםcomprehensive_researcherו-response_formatter:# 1. Researcher Agent comprehensive_researcher = Agent( name="comprehensive_researcher", model=model_name, description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.", instruction=""" You are a helpful research assistant. Your goal is to fully answer the user's PROMPT. You have access to two tools: 1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations). 2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat). First, analyze the user's PROMPT. - If the prompt can be answered by only one tool, use that tool. - If the prompt is complex and requires information from both the zoo's database AND Wikipedia, you MUST use both tools to gather all necessary information. - Synthesize the results from the tool(s) you use into preliminary data outputs. PROMPT: { PROMPT } """, tools=[ wikipedia_tool ], output_key="research_data" # A key to store the combined findings ) # 2. Response Formatter Agent response_formatter = Agent( name="response_formatter", model=model_name, description="Synthesizes all information into a friendly, readable response.", instruction=""" You are the friendly voice of the Zoo Tour Guide. Your task is to take the RESEARCH_DATA and present it to the user in a complete and helpful answer. - First, present the specific information from the zoo (like names, ages, and where to find them). - Then, add the interesting general facts from the research. - If some information is missing, just present the information you have. - Be conversational and engaging. RESEARCH_DATA: { research_data } """ )- הסוכן
comprehensive_researcherהוא ה "מוח" של הפעולה שלנו. הוא מקבל את ההנחיה של המשתמש מStateהמשותף, בודק אם היא מתאימה לכלי של ויקיפדיה ומחליט באילו כלים להשתמש כדי למצוא את התשובה. - התפקיד של נציג
response_formatterהוא הצגה. הוא מקבל את הנתונים הגולמיים שנאספו על ידי סוכן המחקר (שמועברים דרך הסטטוס) ומשתמש ביכולות השפה של ה-LLM כדי להפוך אותם לתשובה ידידותית ושיחתית.
- הסוכן
- הגדרת סוכן Workflow: מוסיפים את בלוק הקוד הזה לחלק התחתון של
agent.pyכדי להגדיר את הסוכן הרציףtour_guide_workflow:tour_guide_workflow = SequentialAgent( name="tour_guide_workflow", description="The main workflow for handling a user's request about an animal.", sub_agents=[ comprehensive_researcher, # Step 1: Gather all data response_formatter, # Step 2: Format the final response ] )
איך: זהוSequentialAgent, סוג מיוחד של סוכן שלא חושב בעצמו. התפקיד היחיד שלו הוא להריץ רשימה שלsub_agents(החוקר ומעצב הפלט) ברצף קבוע, ולהעביר באופן אוטומטי את הזיכרון המשותף מאחד לשני. - הרכבת תהליך העבודה הראשי: מוסיפים את בלוק הקוד הסופי הזה לחלק התחתון של
agent.pyכדי להגדיר אתroot_agent:root_agent = Agent( name="greeter", model=model_name, description="The main entry point for the Zoo Tour Guide.", instruction=""" - Let the user know you will help them learn about the animals we have in the zoo. - When the user responds, use the 'add_prompt_to_state' tool to save their response. After using the tool, transfer control to the 'tour_guide_workflow' agent. """, tools=[add_prompt_to_state], sub_agents=[tour_guide_workflow] )root_agentכנקודת התחלה לכל השיחות החדשות. התפקיד העיקרי שלו הוא לתזמן את התהליך הכולל. הוא פועל כבקר הראשוני, ומנהל את התור הראשון של השיחה.

הקובץ המלא agent.py
הקובץ agent.py הושלם. כך תוכלו לראות איך לכל רכיב – כלים, סוכני עובדים וסוכני ניהול – יש תפקיד ספציפי ביצירת המערכת הסופית והחכמה.
הקובץ המלא צריך להיראות כך:
import os
import logging
import google.cloud.logging
from dotenv import load_dotenv
from google.adk import Agent
from google.adk.agents import SequentialAgent
from google.adk.tools.tool_context import ToolContext
from google.adk.tools.langchain_tool import LangchainTool
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
import google.auth
import google.auth.transport.requests
import google.oauth2.id_token
# --- Setup Logging and Environment ---
cloud_logging_client = google.cloud.logging.Client()
cloud_logging_client.setup_logging()
load_dotenv()
model_name = os.getenv("MODEL")
# Greet user and save their prompt
def add_prompt_to_state(
tool_context: ToolContext, prompt: str
) -> dict[str, str]:
"""Saves the user's initial prompt to the state."""
tool_context.state["PROMPT"] = prompt
logging.info(f"[State updated] Added to PROMPT: {prompt}")
return {"status": "success"}
# Configuring the Wikipedia Tool
wikipedia_tool = LangchainTool(
tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
)
# 1. Researcher Agent
comprehensive_researcher = Agent(
name="comprehensive_researcher",
model=model_name,
description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.",
instruction="""
You are a helpful research assistant. Your goal is to fully answer the user's PROMPT.
You have access to two tools:
1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations).
2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat).
First, analyze the user's PROMPT.
- If the prompt can be answered by only one tool, use that tool.
- If the prompt is complex and requires information from both the zoo's database AND Wikipedia,
you MUST use both tools to gather all necessary information.
- Synthesize the results from the tool(s) you use into preliminary data outputs.
PROMPT:
{ PROMPT }
""",
tools=[
wikipedia_tool
],
output_key="research_data" # A key to store the combined findings
)
# 2. Response Formatter Agent
response_formatter = Agent(
name="response_formatter",
model=model_name,
description="Synthesizes all information into a friendly, readable response.",
instruction="""
You are the friendly voice of the Zoo Tour Guide. Your task is to take the
RESEARCH_DATA and present it to the user in a complete and helpful answer.
- First, present the specific information from the zoo (like names, ages, and where to find them).
- Then, add the interesting general facts from the research.
- If some information is missing, just present the information you have.
- Be conversational and engaging.
RESEARCH_DATA:
{ research_data }
"""
)
tour_guide_workflow = SequentialAgent(
name="tour_guide_workflow",
description="The main workflow for handling a user's request about an animal.",
sub_agents=[
comprehensive_researcher, # Step 1: Gather all data
response_formatter, # Step 2: Format the final response
]
)
root_agent = Agent(
name="greeter",
model=model_name,
description="The main entry point for the Zoo Tour Guide.",
instruction="""
- Let the user know you will help them learn about the animals we have in the zoo.
- When the user responds, use the 'add_prompt_to_state' tool to save their response.
After using the tool, transfer control to the 'tour_guide_workflow' agent.
""",
tools=[add_prompt_to_state],
sub_agents=[tour_guide_workflow]
)
השלב הבא הוא פריסה.
9. הכנת האפליקציה לפריסה
בדיקת המבנה הסופי
לפני הפריסה, מוודאים שספריית הפרויקט מכילה את הקבצים הנכונים.
- מוודאים שהתיקייה
zoo_guide_agentנראית כך:zoo_guide_agent/ ├── .env ├── __init__.py ├── agent.py └── requirements.txt
הגדרת הרשאות IAM
אחרי שהקוד המקומי מוכן, השלב הבא הוא להגדיר את הזהות שבה הסוכן ישתמש בענן.
- בטרמינל, טוענים את המשתנים לסשן של המעטפת.
source .env - יוצרים חשבון שירות ייעודי לשירות Cloud Run, כדי שיהיו לו הרשאות ספציפיות משלו. מדביקים את הטקסט הבא בטרמינל:
gcloud iam service-accounts create ${SA_NAME} \ --display-name="Service Account for lab 2 " - נותנים לחשבון השירות את התפקיד Vertex AI User (משתמש Vertex AI), שמעניק לו הרשאה להפעיל את המודלים של Google.
# Grant the "Vertex AI User" role to your service account gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:$SERVICE_ACCOUNT" \ --role="roles/aiplatform.user"
10. פריסת הסוכן באמצעות ADK CLI
אחרי שהקוד המקומי מוכן והפרויקט בענן מוכן, הגיע הזמן לפרוס את הסוכן. תשתמשו בפקודה adk deploy cloud_run, כלי נוח שמבצע אוטומציה של כל תהליך הפריסה. הפקודה הזו אורזת את הקוד, יוצרת קובץ אימג' של קונטיינר, מעבירה אותו בדחיפה אל Artifact Registry ומפעילה את השירות ב-Cloud Run, כך שאפשר לגשת אליו באינטרנט.
- מריצים את הפקודה הבאה בטרמינל כדי לפרוס את הסוכן.
# Run the deployment command uvx --from google-adk==1.14.0 \ adk deploy cloud_run \ --project=$PROJECT_ID \ --region=europe-west1 \ --service_name=zoo-tour-guide \ --with_ui \ . \ -- \ --labels=dev-tutorial=codelab-adk \ --service-account=$SERVICE_ACCOUNTuvxמאפשרת להריץ כלי שורת פקודה שפורסמו כחבילות Python בלי להתקין את הכלים האלה באופן גלובלי. - אם מוצגת ההודעה הבאה:
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [europe-west1] will be created. Do you want to continue (Y/n)?
Yומקישים על Enter. - אם מוצגת ההודעה הבאה:
Allow unauthenticated invocations to [your-service-name] (y/N)?.
yומקישים על ENTER. ההגדרה הזו מאפשרת הפעלות לא מאומתות של המעבדה הזו לצורך בדיקה קלה. אם הפקודה תופעל בהצלחה, היא תחזיר את כתובת ה-URL של שירות Cloud Run שנפרס. (היא תיראה בערך כך:https://zoo-tour-guide-123456789.europe-west1.run.app). - מעתיקים את כתובת ה-URL של שירות Cloud Run שנפרס למשימה הבאה.
11. בדיקת הסוכן שנפרס
אחרי שהסוכן יפעל ב-Cloud Run, תריצו בדיקה כדי לוודא שהפריסה הצליחה ושהסוכן פועל כמו שצריך. תשתמשו בכתובת ה-URL הציבורית של השירות (למשל https://zoo-tour-guide-123456789.europe-west1.run.app/) כדי לגשת לממשק האינטרנט של ADK ולקיים אינטראקציה עם הסוכן.
- פותחים את כתובת ה-URL הציבורית של שירות Cloud Run בדפדפן האינטרנט. בגלל שהשתמשת ב-
--with_ui flag, אמור להופיע ממשק המשתמש של מפתח ה-ADK. - מעבירים את המתג
Token Streamingבפינה השמאלית העליונה למצב מופעל.
עכשיו אפשר לתקשר עם נציג התמיכה של Zoo. - כדי להתחיל שיחה חדשה, מקלידים
helloולוחצים על Enter. - בודקים את התוצאה. הסוכן צריך להגיב במהירות עם הודעת הפתיחה שלו, שתהיה בערך כזו:
"Hello! I'm your Zoo Tour Guide. I can help you learn about the amazing animals we have here. What would you like to know or explore today?"
- אפשר לשאול את הסוכן שאלות כמו:
Where can I find the polar bears in the zoo and what is their diet?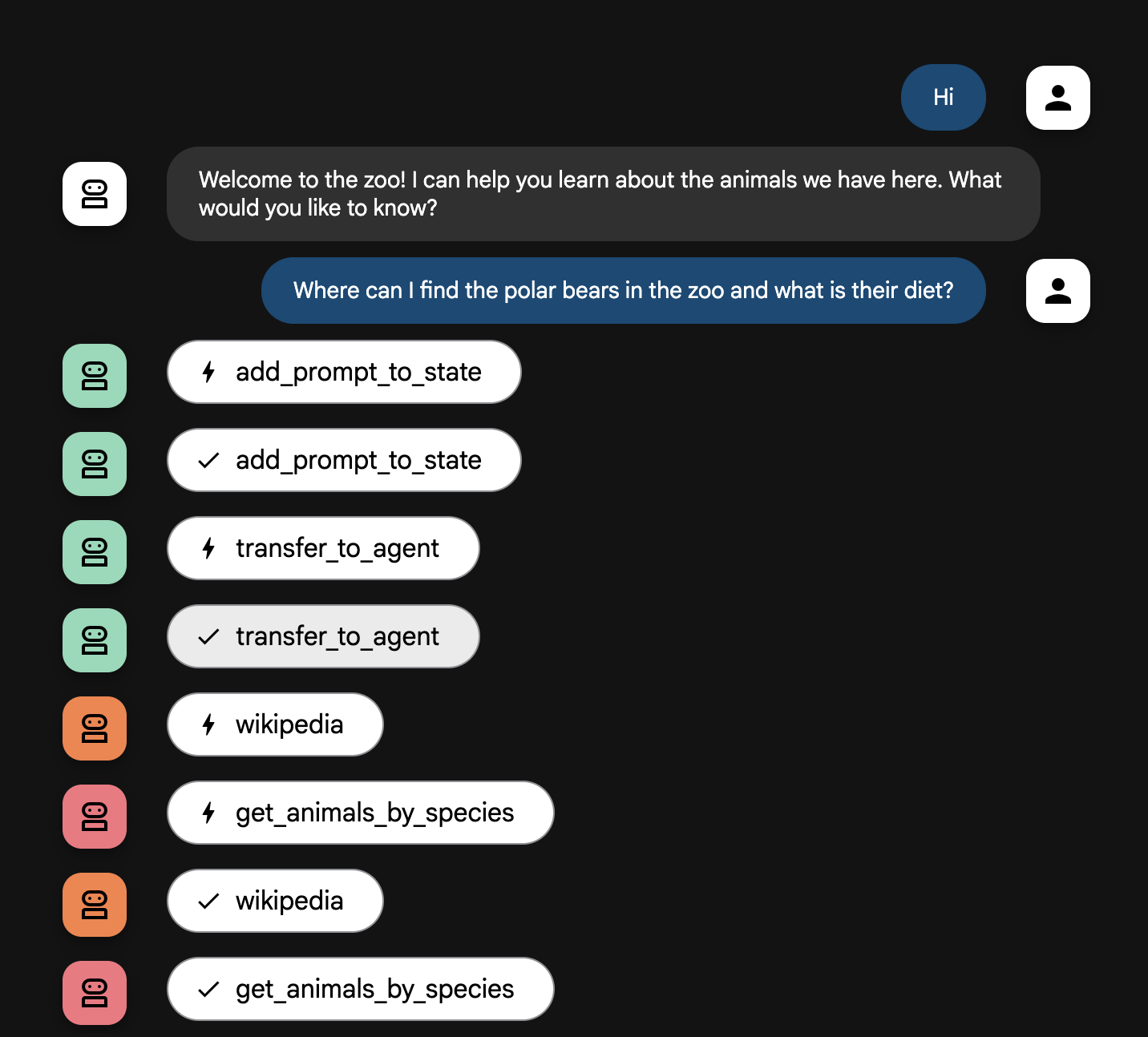

הסבר על תהליך העבודה של הסוכן
המערכת פועלת כצוות חכם של כמה סוכנים. התהליך מנוהל באמצעות רצף ברור כדי להבטיח זרימה חלקה ויעילה מהשאלה של המשתמש ועד לתשובה המפורטת הסופית.
1. הדלפק לקבלת פנים בגן החיות
התהליך כולו מתחיל בסוכן המקבל את הפנייה.
- התפקיד שלו: להתחיל את השיחה. ההוראה היא לברך את המשתמש ולשאול אותו על איזו חיה הוא רוצה לקבל מידע.
- הכלי שלו: כשהמשתמש משיב, הסוכן משתמש בכלי add_prompt_to_state כדי לתעד את המילים המדויקות שלו (למשל, "תספר לי על אריות") ולשמור אותן בזיכרון של המערכת.
- העברת השליטה: אחרי ששומרים את ההנחיה, השליטה מועברת מיד לסוכן המשנה, tour_guide_workflow.
2. החוקר המקיף (החוקר המעולה)
זהו השלב הראשון בתהליך העבודה הראשי ו "המוח" של הפעולה. במקום צוות גדול, יש לכם עכשיו נציג אחד מיומן מאוד שיכול לגשת לכל המידע הזמין.
- התפקיד שלו: לנתח את השאלה של המשתמש וליצור תוכנית חכמה. הוא משתמש ביכולת השימוש בכלים של מודל השפה כדי להחליט אם הוא צריך:
- ידע כללי מהאינטרנט (באמצעות Wikipedia API).
- או בשתיהן, אם השאלה מורכבת.
3. כלי לעיצוב תשובות (המציג/ה)
אחרי שסוכן המחקר המקיף אוסף את כל העובדות, זה הסוכן האחרון שמופעל.
- התפקיד שלו: לשמש כקול הידידותי של מדריך הסיור בגן החיות. הוא לוקח את הנתונים הגולמיים (שיכולים להגיע ממקור אחד או משני המקורות) ומבצע בהם שיפורים.
- הפעולה שלו: הוא מסנתז את כל המידע לתשובה אחת מגובשת ומעניינת. בהתאם להוראות, הוא מציג קודם את המידע הספציפי על גן החיות ואז מוסיף את העובדות הכלליות המעניינות.
- התוצאה הסופית: הטקסט שנוצר על ידי הסוכן הזה הוא התשובה המלאה והמפורטת שהמשתמש רואה בחלון הצ'אט.
אם אתם מעוניינים ללמוד עוד על יצירת סוכנים, כדאי לעיין במקורות המידע הבאים:
12. ניקוי הסביבה
כדי להימנע מחיובים בחשבון Google Cloud בגלל השימוש במשאבים שנעשה במסגרת המדריך הזה, אפשר למחוק את הפרויקט שמכיל את המשאבים, או להשאיר את הפרויקט ולמחוק את המשאבים בנפרד.
מחיקת השירותים והתמונות של Cloud Run
אם אתם רוצים לשמור את הפרויקט בענן של Google Cloud אבל להסיר את המשאבים הספציפיים שנוצרו בשיעור Lab הזה, אתם צריכים למחוק גם את השירות הפעיל וגם את קובץ אימג' של קונטיינר שמאוחסן במאגר.
- מריצים את הפקודות הבאות בטרמינל:
gcloud run services delete zoo-tour-guide --region=europe-west1 --quiet gcloud artifacts repositories delete cloud-run-source-deploy --location=europe-west1 --quiet
מחיקת הפרויקט (אופציונלי)
אם יצרתם פרויקט חדש במיוחד בשביל שיעור ה-Lab הזה ואתם לא מתכננים להשתמש בו שוב, הדרך הכי קלה לפנות היא למחוק את הפרויקט כולו. כך מוודאים שכל המשאבים (כולל חשבון השירות וכל ארטיפקט של בנייה מוסתר) יוסרו לחלוטין.
- בטרמינל, מריצים את הפקודה הבאה (מחליפים את [YOUR_PROJECT_ID] במזהה הפרויקט בפועל):
gcloud projects delete $PROJECT_ID
13. מזל טוב
הצלחתם ליצור ולפרוס אפליקציית AI עם כמה סוכנים ב-Google Cloud.
Recap
בשיעור ה-Lab הזה, התחלתם עם ספרייה ריקה והגעתם לשירות AI פעיל שנגיש לכולם. ריכזנו בשבילך את הפריטים שיצרת:
- יצרתם צוות מומחים: במקום AI גנרי אחד, יצרתם "חוקר" שימצא עובדות ו "מעצב" שישפר את התשובה.
- נתתם להם כלים: חיברתם את הסוכנים שלכם לעולם החיצוני באמצעות Wikipedia API.
- העברתם את הקוד: לקחתם את קוד Python המקומי ופרסתם אותו כקונטיינר ללא שרת ב-Cloud Run, תוך אבטחה שלו באמצעות חשבון שירות ייעודי.
מה נכלל
- איך לבנות פרויקט Python לפריסה באמצעות ADK.
- איך מטמיעים תהליך עבודה עם כמה סוכנים באמצעות
[SequentialAgent](https://google.github.io/adk-docs/agents/workflow-agents/sequential-agents/) - איך משלבים כלים חיצוניים כמו Wikipedia API.
- איך פורסים סוכן ל-Cloud Run באמצעות הפקודה
adk deploy.
14. סקר
פלט: