
1. परिचय
इस लैब में, क्लाइंट एजेंट सेवा को लागू करने और डिप्लॉय करने पर फ़ोकस किया गया है. आपको टूल का इस्तेमाल करने वाले एआई एजेंट को बनाने के लिए, एजेंट डेवलपमेंट किट (एडीके) का इस्तेमाल करना होगा.
इस लैब में, हम एक चिड़ियाघर एजेंट बना रहे हैं. यह एजेंट, जानवरों के बारे में सवालों के जवाब देने के लिए Wikipedia का इस्तेमाल करता है.

आखिर में, हम टूर गाइड एजेंट को सिर्फ़ स्थानीय तौर पर चलाने के बजाय, Google Cloud Run पर डिप्लॉय करेंगे.
ज़रूरी शर्तें
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट.
आपको क्या सीखने को मिलेगा
- ADK को डिप्लॉय करने के लिए, Python प्रोजेक्ट को कैसे स्ट्रक्चर करें.
- google-adk की मदद से, टूल का इस्तेमाल करने वाले एजेंट को कैसे लागू करें.
- Python ऐप्लिकेशन को Cloud Run पर, बिना सर्वर वाले कंटेनर के तौर पर डिप्लॉय करने का तरीका.
- आईएएम भूमिकाओं का इस्तेमाल करके, सेवा से सेवा के बीच सुरक्षित पुष्टि करने की सुविधा को कॉन्फ़िगर करने का तरीका.
- आने वाले समय में लगने वाले शुल्क से बचने के लिए, Cloud संसाधनों को मिटाने का तरीका.
आपको किन चीज़ों की ज़रूरत होगी
- Google Cloud खाता और Google Cloud प्रोजेक्ट
- कोई वेब ब्राउज़र, जैसे कि Chrome
2. Cloud Run पर डिप्लॉय क्यों करें?
Cloud Run, ADK एजेंट को होस्ट करने के लिए एक बेहतरीन विकल्प है. ऐसा इसलिए, क्योंकि यह बिना सर्वर वाला प्लैटफ़ॉर्म है. इसका मतलब है कि आपको बुनियादी इंफ़्रास्ट्रक्चर को मैनेज करने के बजाय, अपने कोड पर ध्यान देने का मौका मिलता है. हम आपके लिए ऑपरेशनल काम करते हैं.
इसे पॉप-अप शॉप की तरह समझें: यह सिर्फ़ तब खुलती है और संसाधनों का इस्तेमाल करती है, जब ग्राहक (अनुरोध) आते हैं. जब कोई खरीदार नहीं होता है, तो यह पूरी तरह से बंद हो जाता है. साथ ही, आपको खाली स्टोर के लिए कोई शुल्क नहीं देना पड़ता.
मुख्य सुविधाएं
'किसी भी जगह पर कंटेनर चलाने की सुविधा' के बारे में जानकारी:
- आपको एक कंटेनर (Docker इमेज) मिलता है, जिसमें आपका ऐप्लिकेशन मौजूद होता है.
- Cloud Run, इसे Google के इंफ़्रास्ट्रक्चर पर चलाता है.
- ओएस पैचिंग, वीएम सेटअप या स्केलिंग से जुड़ी कोई समस्या नहीं होती.
अपने-आप स्केल होने की सुविधा:
- अगर कोई भी व्यक्ति आपके ऐप्लिकेशन का इस्तेमाल नहीं कर रहा है, तो 0 इंस्टेंस चलेंगे. इससे इंस्टेंस की संख्या कम होकर शून्य हो जाएगी, जिससे लागत कम हो जाएगी.
- अगर इस पर 1,000 अनुरोध आते हैं, तो यह ज़रूरत के हिसाब से उतनी ही कॉपी बना लेता है.
डिफ़ॉल्ट रूप से स्टेटलेस:
- हर अनुरोध, किसी दूसरे इंस्टेंस पर जा सकता है.
- अगर आपको स्थिति को सेव करना है, तो Cloud SQL, Firestore या Memorystore जैसी बाहरी सेवा का इस्तेमाल करें.
किसी भी भाषा या फ़्रेमवर्क के साथ काम करता है:
- Cloud Run को इससे कोई फ़र्क़ नहीं पड़ता कि आपका ऐप्लिकेशन Python, Go, Node.js, Java या .Net में लिखा गया है. बस, वह Linux कंटेनर में चलना चाहिए.
जितना इस्तेमाल करें सिर्फ़ उतने के लिए पैसे चुकाएं:
- अनुरोध के आधार पर बिलिंग: हर अनुरोध के हिसाब से बिलिंग की जाती है. इसमें कंप्यूटिंग में लगने वाला समय (100 मि॰से॰ तक) भी शामिल होता है.
- इंस्टेंस के आधार पर बिलिंग: पूरे इंस्टेंस के लिए बिल किया जाता है (हर अनुरोध के लिए कोई शुल्क नहीं).
3. प्रोजेक्ट सेटअप करना
Google खाता
अगर आपके पास पहले से कोई निजी Google खाता नहीं है, तो आपको Google खाता बनाना होगा.
ऑफ़िस या स्कूल वाले खाते के बजाय, निजी खाते का इस्तेमाल करें.
Google Cloud Console में साइन इन करना
किसी निजी Google खाते का इस्तेमाल करके, Google Cloud Console में साइन इन करें.
बिलिंग चालू करें
निजी बिलिंग खाता सेट अप करना
अगर आपने Google Cloud क्रेडिट का इस्तेमाल करके बिलिंग सेट अप की है, तो इस चरण को छोड़ें.
निजी बिलिंग खाता सेट अप करने के लिए, Cloud Console में बिलिंग की सुविधा चालू करने के लिए यहां जाएं.
ध्यान दें:
- इस लैब को पूरा करने में, Cloud संसाधनों पर 1 डॉलर से कम का खर्च आना चाहिए.
- ज़्यादा शुल्क से बचने के लिए, इस लैब के आखिर में दिए गए निर्देशों का पालन करके संसाधनों को मिटाया जा सकता है.
- नए उपयोगकर्ता, 300 डॉलर के मुफ़्त में आज़माने की सुविधा का फ़ायदा पा सकते हैं.
कोई प्रोजेक्ट बनाएं (ज़रूरी नहीं)
अगर आपको इस लैब के लिए किसी मौजूदा प्रोजेक्ट का इस्तेमाल नहीं करना है, तो यहां नया प्रोजेक्ट बनाएं.
4. Cloud Shell Editor खोलें
- सीधे Cloud Shell Editor पर जाने के लिए, इस लिंक पर क्लिक करें
- अगर आज किसी भी समय अनुमति देने के लिए कहा जाता है, तो जारी रखने के लिए अनुमति दें पर क्लिक करें.
- अगर टर्मिनल स्क्रीन पर सबसे नीचे नहीं दिखता है, तो इसे खोलें:
- देखें पर क्लिक करें
- टर्मिनल
 पर क्लिक करें
पर क्लिक करें
5. अपना प्रोजेक्ट सेट करना
- टर्मिनल में, इस कमांड का इस्तेमाल करके अपना प्रोजेक्ट सेट करें:
gcloud config set project [PROJECT_ID]gcloud config set project lab-project-id-example
- आपको यह मैसेज दिखेगा:
Updated property [core/project].
6. एपीआई चालू करें
Cloud Run, Artifact Registry, Cloud Build, Vertex AI, और Compute Engine का इस्तेमाल करने के लिए, आपको अपने Google Cloud प्रोजेक्ट में इनसे जुड़े एपीआई चालू करने होंगे.
- टर्मिनल में, इन एपीआई को चालू करें:
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.comOperation "operations/acat.p2-[GUID]" finished successfully.
एपीआई के बारे में जानकारी
- Cloud Run Admin API (
run.googleapis.com) की मदद से, पूरी तरह से मैनेज किए गए एनवायरमेंट में फ़्रंटएंड और बैकएंड सेवाएं, बैच जॉब या वेबसाइटें चलाई जा सकती हैं. यह कंटेनर वाले ऐप्लिकेशन को डिप्लॉय करने और उन्हें स्केल करने के लिए, इंफ़्रास्ट्रक्चर को मैनेज करता है. - Artifact Registry API (
artifactregistry.googleapis.com) आपकी कंटेनर इमेज को सेव करने के लिए, सुरक्षित और निजी रिपॉज़िटरी उपलब्ध कराता है. यह Container Registry का नया वर्शन है. यह Cloud Run और Cloud Build के साथ आसानी से इंटिग्रेट हो जाता है. - Cloud Build API (
cloudbuild.googleapis.com) एक सर्वरलेस CI/CD प्लैटफ़ॉर्म है. यह Google Cloud के इन्फ़्रास्ट्रक्चर पर आपकी बिल्ड प्रोसेस को पूरा करता है. इसका इस्तेमाल, Dockerfile से क्लाउड में कंटेनर इमेज बनाने के लिए किया जाता है. - Vertex AI API (
aiplatform.googleapis.com) की मदद से, डिप्लॉय किया गया आपका ऐप्लिकेशन, Gemini मॉडल के साथ कम्यूनिकेट कर सकता है. इससे एआई से जुड़े मुख्य टास्क पूरे किए जा सकते हैं. यह Google Cloud की सभी एआई सेवाओं के लिए, एक ही एपीआई उपलब्ध कराता है. - Compute Engine API (
compute.googleapis.com) सुरक्षित और पसंद के मुताबिक बनाए जा सकने वाले वर्चुअल मशीन उपलब्ध कराता है. ये वर्चुअल मशीन, Google के इन्फ़्रास्ट्रक्चर पर काम करती हैं. Cloud Run को मैनेज किया जाता है. हालांकि, कई नेटवर्किंग और कंप्यूट संसाधनों के लिए, Compute Engine API की अक्सर बुनियादी तौर पर ज़रूरत होती है.
7. डेवलपमेंट एनवायरमेंट तैयार करना
डायरेक्ट्री बनाना
- टर्मिनल में, प्रोजेक्ट डायरेक्ट्री और ज़रूरी सबडायरेक्ट्री बनाएं:
cd && mkdir zoo_guide_agent && cd zoo_guide_agent - Cloud Shell Editor एक्सप्लोरर में
zoo_guide_agentडायरेक्ट्री खोलने के लिए, टर्मिनल में यह कमांड चलाएं:cloudshell open-workspace ~/zoo_guide_agent - बाईं ओर मौजूद एक्सप्लोरर पैनल रीफ़्रेश हो जाएगा. अब आपको बनाई गई डायरेक्ट्री दिखेगी.
ऐप्लिकेशन इंस्टॉल करने से जुड़ी ज़रूरी शर्तें
requirements.txtफ़ाइल बनाने के लिए, टर्मिनल में यह कमांड चलाएं.cloudshell edit requirements.txt- नई बनाई गई
requirements.txtफ़ाइल में यह जानकारी जोड़ेंgoogle-adk==1.14.0 langchain-community==0.3.27 wikipedia==1.4.0 - टर्मिनल में, uv का इस्तेमाल करके वर्चुअल एनवायरमेंट बनाएं और उसे चालू करें. इससे यह पक्का किया जाता है कि आपके प्रोजेक्ट की डिपेंडेंसी, सिस्टम Python के साथ काम करती हैं.
uv venv source .venv/bin/activate - टर्मिनल में, अपने वर्चुअल एनवायरमेंट में ज़रूरी पैकेज इंस्टॉल करें.
uv pip install -r requirements.txt
एनवायरमेंट वैरिएबल सेट अप करना
.envफ़ाइल बनाने के लिए, टर्मिनल में यह कमांड इस्तेमाल करें.# 1. Set the variables in your terminal first PROJECT_ID=$(gcloud config get-value project) PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)") SA_NAME=lab2-cr-service # 2. Create the .env file using those variables cat <<EOF > .env PROJECT_ID=$PROJECT_ID PROJECT_NUMBER=$PROJECT_NUMBER SA_NAME=$SA_NAME SERVICE_ACCOUNT=${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com MODEL="gemini-2.5-flash" EOF
8. एजेंट वर्कफ़्लो बनाना
__init__.py फ़ाइल बनाएं
- टर्मिनल में यह कमांड चलाकर, init.py फ़ाइल बनाएं:
cloudshell edit __init__.py - नई
__init__.pyफ़ाइल में यह कोड जोड़ें:from . import agent
agent.py फ़ाइल बनाना
- टर्मिनल में यहां दी गई कमांड चिपकाकर, मुख्य
agent.pyफ़ाइल बनाएं.cloudshell edit agent.py - इंपोर्ट और शुरुआती सेटअप: अपनी मौजूदा खाली
agent.pyफ़ाइल में यह कोड जोड़ें:import os import logging import google.cloud.logging from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper import google.auth import google.auth.transport.requests import google.oauth2.id_token # --- Setup Logging and Environment --- cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL")agent.pyफ़ाइल का यह पहला ब्लॉक, ADK और Google Cloud से सभी ज़रूरी लाइब्रेरी लाता है. यह लॉगिंग भी सेट अप करता है और आपकी.envफ़ाइल से एनवायरमेंट वैरिएबल लोड करता है. यह आपके मॉडल और सर्वर यूआरएल को ऐक्सेस करने के लिए ज़रूरी है. - टूल तय करना: एजेंट सिर्फ़ उन टूल का इस्तेमाल कर सकता है जो उसे दिए गए हैं. टूल तय करने के लिए,
agent.pyमें सबसे नीचे यह कोड जोड़ें:# Greet user and save their prompt def add_prompt_to_state( tool_context: ToolContext, prompt: str ) -> dict[str, str]: """Saves the user's initial prompt to the state.""" tool_context.state["PROMPT"] = prompt logging.info(f"[State updated] Added to PROMPT: {prompt}") return {"status": "success"} # Configuring the Wikipedia Tool wikipedia_tool = LangchainTool( tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper()) )add_prompt_to_state📝: यह टूल, चिड़ियाघर आने वाले व्यक्ति के सवालों को याद रखता है. जब कोई व्यक्ति पूछता है कि "शेर कहां हैं?", तो यह टूल उस सवाल को एजेंट की मेमोरी में सेव कर लेता है. इससे वर्कफ़्लो में शामिल अन्य एजेंट को पता चलता है कि उन्हें किस बारे में रिसर्च करनी है.
कैसे: यह एक Python फ़ंक्शन है, जो वेबसाइट पर आने वाले व्यक्ति के प्रॉम्प्ट को शेयर किए गएtool_context.stateडिक्शनरी में लिखता है. इस टूल का कॉन्टेक्स्ट, किसी बातचीत के दौरान एजेंट की शॉर्ट-टर्म मेमोरी को दिखाता है. किसी एजेंट के सेव किए गए डेटा को, वर्कफ़्लो में अगला एजेंट पढ़ सकता है.LangchainTool🌍: इससे टूर गाइड एजेंट को दुनिया के बारे में सामान्य जानकारी मिलती है. जब कोई व्यक्ति ऐसा सवाल पूछता है जो चिड़ियाघर के डेटाबेस में मौजूद नहीं है, जैसे कि "जंगल में शेर क्या खाते हैं?", तो यह टूल एजेंट को Wikipedia पर जवाब खोजने की सुविधा देता है.
कैसे: यह एक अडैप्टर के तौर पर काम करता है. इससे हमारा एजेंट, LangChain लाइब्रेरी से पहले से तैयार WikipediaQueryRun टूल का इस्तेमाल कर पाता है.
- स्पेशलिस्ट एजेंट तय करना:
comprehensive_researcherऔरresponse_formatterएजेंट तय करने के लिए,agent.pyके सबसे नीचे यह कोड जोड़ें:# 1. Researcher Agent comprehensive_researcher = Agent( name="comprehensive_researcher", model=model_name, description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.", instruction=""" You are a helpful research assistant. Your goal is to fully answer the user's PROMPT. You have access to two tools: 1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations). 2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat). First, analyze the user's PROMPT. - If the prompt can be answered by only one tool, use that tool. - If the prompt is complex and requires information from both the zoo's database AND Wikipedia, you MUST use both tools to gather all necessary information. - Synthesize the results from the tool(s) you use into preliminary data outputs. PROMPT: { PROMPT } """, tools=[ wikipedia_tool ], output_key="research_data" # A key to store the combined findings ) # 2. Response Formatter Agent response_formatter = Agent( name="response_formatter", model=model_name, description="Synthesizes all information into a friendly, readable response.", instruction=""" You are the friendly voice of the Zoo Tour Guide. Your task is to take the RESEARCH_DATA and present it to the user in a complete and helpful answer. - First, present the specific information from the zoo (like names, ages, and where to find them). - Then, add the interesting general facts from the research. - If some information is missing, just present the information you have. - Be conversational and engaging. RESEARCH_DATA: { research_data } """ )comprehensive_researcherएजेंट, हमारे ऑपरेशन का "दिमाग" है. यह शेयर किए गएStateसे उपयोगकर्ता का प्रॉम्प्ट लेता है. इसके बाद, यह जांच करता है कि यह Wikipedia टूल है या नहीं. इसके बाद, यह तय करता है कि जवाब ढूंढने के लिए किन टूल का इस्तेमाल करना है.response_formatterएजेंट की भूमिका प्रज़ेंटेशन की है. यह रिसर्चर एजेंट से मिले रॉ डेटा को लेता है. यह डेटा, स्टेट के ज़रिए पास किया जाता है. इसके बाद, यह एलएलएम की भाषा से जुड़ी क्षमताओं का इस्तेमाल करके, इसे बातचीत के लहज़े में जवाब में बदल देता है.
- वर्कफ़्लो एजेंट तय करना: क्रम से काम करने वाले एजेंट
tour_guide_workflowको तय करने के लिए, कोड के इस ब्लॉक कोagent.pyके सबसे नीचे जोड़ें:tour_guide_workflow = SequentialAgent( name="tour_guide_workflow", description="The main workflow for handling a user's request about an animal.", sub_agents=[ comprehensive_researcher, # Step 1: Gather all data response_formatter, # Step 2: Format the final response ] )
कैसे: यह एकSequentialAgentहै. यह एक खास तरह का एजेंट है, जो अपने-आप नहीं सोचता. इसका काम सिर्फ़sub_agents(रिसर्चर और फ़ॉर्मेटर) की सूची को एक तय क्रम में चलाना है. साथ ही, शेयर की गई मेमोरी को एक से दूसरे में अपने-आप पास करना है. - मुख्य वर्कफ़्लो को असेंबल करना:
root_agentको तय करने के लिए, कोड के इस फ़ाइनल ब्लॉक कोagent.pyके सबसे नीचे जोड़ें:root_agent = Agent( name="greeter", model=model_name, description="The main entry point for the Zoo Tour Guide.", instruction=""" - Let the user know you will help them learn about the animals we have in the zoo. - When the user responds, use the 'add_prompt_to_state' tool to save their response. After using the tool, transfer control to the 'tour_guide_workflow' agent. """, tools=[add_prompt_to_state], sub_agents=[tour_guide_workflow] )root_agentका इस्तेमाल करता है. इसकी मुख्य भूमिका, पूरी प्रोसेस को मैनेज करना है. यह शुरुआती कंट्रोलर के तौर पर काम करता है और बातचीत के पहले चरण को मैनेज करता है.

पूरी agent.py फ़ाइल
आपकी agent.py फ़ाइल अब पूरी हो गई है! इस तरह से इसे बनाने पर, यह देखा जा सकता है कि फ़ाइनल, इंटेलिजेंट सिस्टम बनाने में हर कॉम्पोनेंट—टूल, वर्कर एजेंट, और मैनेजर एजेंट—की क्या भूमिका है.
पूरी फ़ाइल ऐसी दिखनी चाहिए:
import os
import logging
import google.cloud.logging
from dotenv import load_dotenv
from google.adk import Agent
from google.adk.agents import SequentialAgent
from google.adk.tools.tool_context import ToolContext
from google.adk.tools.langchain_tool import LangchainTool
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
import google.auth
import google.auth.transport.requests
import google.oauth2.id_token
# --- Setup Logging and Environment ---
cloud_logging_client = google.cloud.logging.Client()
cloud_logging_client.setup_logging()
load_dotenv()
model_name = os.getenv("MODEL")
# Greet user and save their prompt
def add_prompt_to_state(
tool_context: ToolContext, prompt: str
) -> dict[str, str]:
"""Saves the user's initial prompt to the state."""
tool_context.state["PROMPT"] = prompt
logging.info(f"[State updated] Added to PROMPT: {prompt}")
return {"status": "success"}
# Configuring the Wikipedia Tool
wikipedia_tool = LangchainTool(
tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
)
# 1. Researcher Agent
comprehensive_researcher = Agent(
name="comprehensive_researcher",
model=model_name,
description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.",
instruction="""
You are a helpful research assistant. Your goal is to fully answer the user's PROMPT.
You have access to two tools:
1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations).
2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat).
First, analyze the user's PROMPT.
- If the prompt can be answered by only one tool, use that tool.
- If the prompt is complex and requires information from both the zoo's database AND Wikipedia,
you MUST use both tools to gather all necessary information.
- Synthesize the results from the tool(s) you use into preliminary data outputs.
PROMPT:
{ PROMPT }
""",
tools=[
wikipedia_tool
],
output_key="research_data" # A key to store the combined findings
)
# 2. Response Formatter Agent
response_formatter = Agent(
name="response_formatter",
model=model_name,
description="Synthesizes all information into a friendly, readable response.",
instruction="""
You are the friendly voice of the Zoo Tour Guide. Your task is to take the
RESEARCH_DATA and present it to the user in a complete and helpful answer.
- First, present the specific information from the zoo (like names, ages, and where to find them).
- Then, add the interesting general facts from the research.
- If some information is missing, just present the information you have.
- Be conversational and engaging.
RESEARCH_DATA:
{ research_data }
"""
)
tour_guide_workflow = SequentialAgent(
name="tour_guide_workflow",
description="The main workflow for handling a user's request about an animal.",
sub_agents=[
comprehensive_researcher, # Step 1: Gather all data
response_formatter, # Step 2: Format the final response
]
)
root_agent = Agent(
name="greeter",
model=model_name,
description="The main entry point for the Zoo Tour Guide.",
instruction="""
- Let the user know you will help them learn about the animals we have in the zoo.
- When the user responds, use the 'add_prompt_to_state' tool to save their response.
After using the tool, transfer control to the 'tour_guide_workflow' agent.
""",
tools=[add_prompt_to_state],
sub_agents=[tour_guide_workflow]
)
अगला चरण है, डिप्लॉयमेंट!
9. ऐप्लिकेशन को डिप्लॉयमेंट के लिए तैयार करना
फ़ाइनल स्ट्रक्चर की जांच करना
डिप्लॉय करने से पहले, पुष्टि करें कि आपकी प्रोजेक्ट डायरेक्ट्री में सही फ़ाइलें मौजूद हों.
- पक्का करें कि आपका
zoo_guide_agentफ़ोल्डर ऐसा दिखता हो:zoo_guide_agent/ ├── .env ├── __init__.py ├── agent.py └── requirements.txt
आईएएम अनुमतियां सेट अप करना
लोकल कोड तैयार होने के बाद, अगला चरण यह तय करना है कि आपका एजेंट क्लाउड में किस आइडेंटिटी का इस्तेमाल करेगा.
- टर्मिनल में, वैरिएबल को अपने शेल सेशन में लोड करें.
source .env - Cloud Run सेवा के लिए, एक अलग सेवा खाता बनाएं, ताकि उसके पास अपनी खास अनुमति हो. नीचे दिए गए कोड को टर्मिनल में चिपकाएं:
gcloud iam service-accounts create ${SA_NAME} \ --display-name="Service Account for lab 2 " - सेवा खाते को Vertex AI उपयोगकर्ता की भूमिका असाइन करें. इससे उसे Google के मॉडल को कॉल करने की अनुमति मिलती है.
# Grant the "Vertex AI User" role to your service account gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:$SERVICE_ACCOUNT" \ --role="roles/aiplatform.user"
10. ADK सीएलआई का इस्तेमाल करके एजेंट को डिप्लॉय करना
लोकल कोड तैयार होने और Google Cloud प्रोजेक्ट सेट अप होने के बाद, एजेंट को डिप्लॉय करने का समय आ गया है. आपको adk deploy cloud_run कमांड का इस्तेमाल करना होगा. यह एक ऐसा सुविधाजनक टूल है जो पूरे डिप्लॉयमेंट वर्कफ़्लो को अपने-आप पूरा करता है. इस एक कमांड से, आपका कोड पैकेज हो जाता है, कंटेनर इमेज बन जाती है, और उसे Artifact Registry पर पुश कर दिया जाता है. साथ ही, Cloud Run पर सेवा लॉन्च हो जाती है, ताकि इसे वेब पर ऐक्सेस किया जा सके.
- अपने एजेंट को डिप्लॉय करने के लिए, टर्मिनल में यह कमांड चलाएं.
# Run the deployment command uvx --from google-adk==1.14.0 \ adk deploy cloud_run \ --project=$PROJECT_ID \ --region=europe-west1 \ --service_name=zoo-tour-guide \ --with_ui \ . \ -- \ --labels=dev-tutorial=codelab-adk \ --service-account=$SERVICE_ACCOUNTuvxकमांड की मदद से, Python पैकेज के तौर पर पब्लिश किए गए कमांड लाइन टूल को चलाया जा सकता है. इसके लिए, इन टूल को ग्लोबल तौर पर इंस्टॉल करने की ज़रूरत नहीं होती. - अगर आपको यह मैसेज दिखता है:
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [europe-west1] will be created. Do you want to continue (Y/n)?
Yटाइप करें और ENTER दबाएं. - अगर आपको यह मैसेज दिखता है:
Allow unauthenticated invocations to [your-service-name] (y/N)?.
yटाइप करें और ENTER दबाएं. इससे, इस लैब के लिए बिना पुष्टि किए गए अनुरोधों को आसानी से टेस्ट किया जा सकता है. कमांड के पूरा होने पर, यह डिप्लॉय की गई Cloud Run सेवा का यूआरएल उपलब्ध कराएगी. (यह कुछ ऐसा दिखेगाhttps://zoo-tour-guide-123456789.europe-west1.run.app). - अगले टास्क के लिए, डिप्लॉय की गई Cloud Run सेवा का यूआरएल कॉपी करें.
11. डिप्लॉय किए गए एजेंट को टेस्ट करना
आपका एजेंट अब Cloud Run पर लाइव हो गया है. इसलिए, आपको यह पुष्टि करने के लिए एक टेस्ट करना होगा कि एजेंट को सही तरीके से डिप्लॉय किया गया है और वह उम्मीद के मुताबिक काम कर रहा है. ADK के वेब इंटरफ़ेस को ऐक्सेस करने और एजेंट से इंटरैक्ट करने के लिए, आपको सार्वजनिक सेवा यूआरएल (https://zoo-tour-guide-123456789.europe-west1.run.app/ जैसा कुछ) का इस्तेमाल करना होगा.
- अपने वेब ब्राउज़र में, Cloud Run सेवा का सार्वजनिक यूआरएल खोलें. आपने
--with_ui flagका इस्तेमाल किया है. इसलिए, आपको ADK डेवलपर यूज़र इंटरफ़ेस (यूआई) दिखना चाहिए. - सबसे ऊपर दाईं ओर मौजूद,
Token Streamingको टॉगल करके चालू करें.
अब ज़ू एजेंट से बातचीत की जा सकती है. - नई बातचीत शुरू करने के लिए,
helloटाइप करें और Enter दबाएं. - नतीजे देखें. एजेंट को तुरंत जवाब देना चाहिए. इसमें उसे अभिवादन करना चाहिए. यह कुछ इस तरह का होगा:
"Hello! I'm your Zoo Tour Guide. I can help you learn about the amazing animals we have here. What would you like to know or explore today?"
- एजेंट से इस तरह के सवाल पूछें:
Where can I find the polar bears in the zoo and what is their diet?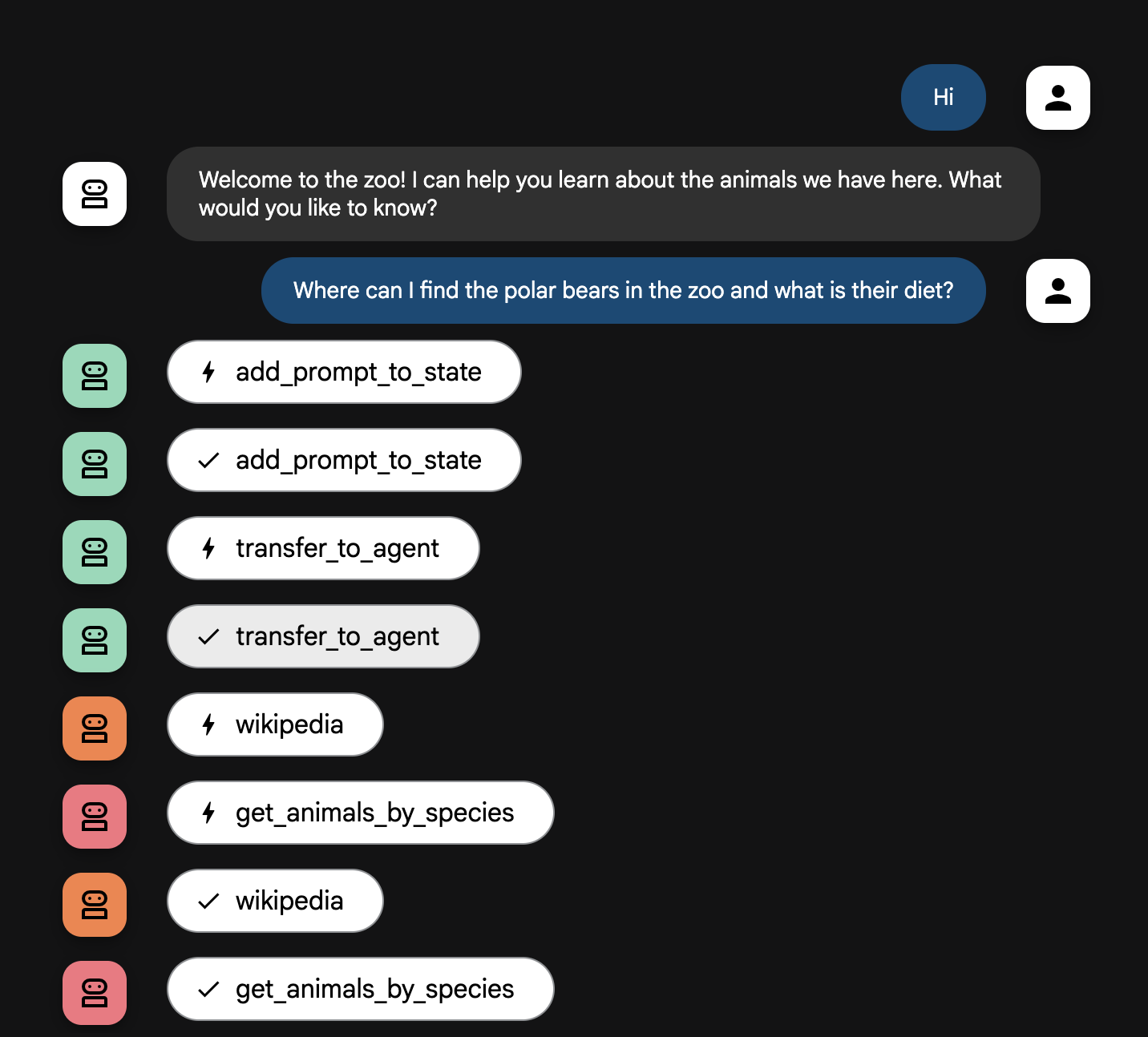

एजेंट फ़्लो के बारे में जानकारी
आपका सिस्टम, मल्टी-एजेंट टीम के तौर पर काम करता है. इस प्रोसेस को एक तय क्रम में मैनेज किया जाता है, ताकि उपयोगकर्ता के सवाल से लेकर जवाब तक की प्रोसेस को आसान और असरदार बनाया जा सके.
1. ज़ू में स्वागत करने वाला (वेलकम डेस्क)
पूरी प्रोसेस, ग्रीटर एजेंट से शुरू होती है.
- इसका काम: बातचीत शुरू करना. इसमें उपयोगकर्ता का अभिवादन करने और यह पूछने का निर्देश दिया गया है कि उसे किस जानवर के बारे में जानना है.
- इसका टूल: जब उपयोगकर्ता जवाब देता है, तो Greeter, add_prompt_to_state टूल का इस्तेमाल करके उसके सटीक शब्दों (जैसे, "मुझे शेरों के बारे में बताओ") को कैप्चर करता है और उन्हें सिस्टम की मेमोरी में सेव करता है.
- हैंडऑफ़: प्रॉम्प्ट सेव करने के बाद, यह तुरंत कंट्रोल को अपने सब-एजेंट, tour_guide_workflow को पास कर देता है.
2. बेहतरीन रिसर्चर (सुपर-रिसर्चर)
यह मुख्य वर्कफ़्लो का पहला चरण है और इसे ऑपरेशन का "दिमाग" कहा जाता है. अब आपके पास बड़ी टीम के बजाय, एक ऐसा एजेंट है जिसके पास सभी उपलब्ध जानकारी को ऐक्सेस करने की सुविधा है.
- इसका काम: उपयोगकर्ता के सवाल का विश्लेषण करना और एक बेहतर प्लान बनाना. यह भाषा मॉडल के टूल इस्तेमाल करने की सुविधा का इस्तेमाल करके यह तय करता है कि इसे इनकी ज़रूरत है या नहीं:
- वेब से सामान्य जानकारी (Wikipedia API के ज़रिए).
- इसके अलावा, मुश्किल सवालों के लिए दोनों का इस्तेमाल किया जा सकता है.
3. जवाब को फ़ॉर्मैट करने वाला (प्रज़ेंटर)
रिसर्चर के तौर पर काम करने वाला यह एजेंट, सभी तथ्यों को इकट्ठा करता है. इसके बाद, यह आखिरी एजेंट होता है जो काम करता है.
- इसका काम: चिड़ियाघर के टूर गाइड की तरह दोस्ताना लहजे में जवाब देना. यह रॉ डेटा (जो एक या दोनों सोर्स से मिल सकता है) लेता है और उसे बेहतर बनाता है.
- इसकी कार्रवाई: यह सभी जानकारी को एक साथ जोड़कर, सही क्रम में, और दिलचस्प जवाब तैयार करता है. इसमें दिए गए निर्देशों के मुताबिक, यह सबसे पहले चिड़ियाघर के बारे में खास जानकारी देता है. इसके बाद, सामान्य जानकारी देता है.
- आखिरी नतीजा: इस एजेंट से जनरेट किया गया टेक्स्ट, पूरा और ज़्यादा जानकारी वाला जवाब होता है. यह जवाब, उपयोगकर्ता को चैट विंडो में दिखता है.
अगर आपको एजेंट बनाने के बारे में ज़्यादा जानना है, तो यहां दिए गए संसाधन देखें:
12. एनवायरमेंट को साफ़ करना
इस ट्यूटोरियल में इस्तेमाल किए गए संसाधनों के लिए, अपने Google Cloud खाते से शुल्क न लिए जाने के लिए, संसाधनों वाला प्रोजेक्ट मिटाएं. इसके अलावा, प्रोजेक्ट को बनाए रखने और अलग-अलग संसाधनों को मिटाने का विकल्प भी है.
Cloud Run सेवाओं और इमेज को मिटाना
अगर आपको Google Cloud प्रोजेक्ट को चालू रखना है, लेकिन इस लैब में बनाए गए कुछ संसाधनों को हटाना है, तो आपको चालू सेवा और रजिस्ट्री में सेव की गई कंटेनर इमेज, दोनों को मिटाना होगा.
- टर्मिनल में ये कमांड चलाएं:
gcloud run services delete zoo-tour-guide --region=europe-west1 --quiet gcloud artifacts repositories delete cloud-run-source-deploy --location=europe-west1 --quiet
प्रोजेक्ट मिटाना (ज़रूरी नहीं)
अगर आपने इस लैब के लिए कोई नया प्रोजेक्ट बनाया है और आपको इसका दोबारा इस्तेमाल नहीं करना है, तो पूरे प्रोजेक्ट को मिटाना सबसे आसान तरीका है. इससे यह पक्का किया जाता है कि सभी संसाधन (जैसे कि सेवा खाता और छिपे हुए बिल्ड आर्टफ़ैक्ट) पूरी तरह से हटा दिए गए हैं.
- टर्मिनल में, यह कमांड चलाएं. [YOUR_PROJECT_ID] की जगह अपना असल प्रोजेक्ट आईडी डालें
gcloud projects delete $PROJECT_ID
13. बधाई हो
आपने Google Cloud पर, एक से ज़्यादा एजेंट वाला एआई ऐप्लिकेशन बना लिया है और उसे डिप्लॉय कर दिया है!
रीकैप
इस लैब में, आपने एक खाली डायरेक्ट्री से लेकर, लाइव और सार्वजनिक तौर पर ऐक्सेस की जा सकने वाली एआई सेवा तक का सफ़र तय किया. यहां देखें कि आपने क्या बनाया है:
- आपने एक खास टीम बनाई: आपने एक सामान्य एआई के बजाय, तथ्यों का पता लगाने के लिए "रिसर्चर" और जवाब को बेहतर बनाने के लिए "फ़ॉर्मेटर" बनाया.
- आपने उन्हें टूल दिए: आपने Wikipedia API का इस्तेमाल करके, अपने एजेंट को बाहरी दुनिया से कनेक्ट किया.
- आपने इसे शिप किया: आपने अपने लोकल Python कोड को लिया और उसे Cloud Run पर सर्वरलेस कंटेनर के तौर पर डिप्लॉय किया. साथ ही, इसे एक खास सेवा खाते से सुरक्षित किया.
हमने क्या-क्या कवर किया है
- ADK की मदद से डिप्लॉयमेंट के लिए, Python प्रोजेक्ट को कैसे स्ट्रक्चर करें.
[SequentialAgent](https://google.github.io/adk-docs/agents/workflow-agents/sequential-agents/)का इस्तेमाल करके, एक से ज़्यादा एजेंट वाले वर्कफ़्लो को लागू करने का तरीका.- Wikipedia API जैसे बाहरी टूल को इंटिग्रेट करने का तरीका.
adk deployकमांड का इस्तेमाल करके, किसी एजेंट को Cloud Run पर डिप्लॉय करने का तरीका.
14. सर्वे
आउटपुट: