
1. Wprowadzenie
Ten moduł dotyczy wdrażania i wdrażania usługi agenta klienta. Do utworzenia agenta AI, który korzysta z narzędzi, użyjesz pakietu Agent Development Kit (ADK).
W tym laboratorium utworzymy agenta zoo, który będzie odpowiadał na pytania o zwierzęta na podstawie informacji z Wikipedii.

Na koniec wdrożymy agenta przewodnika w usłudze Google Cloud Run, zamiast uruchamiać go lokalnie.
Wymagania wstępne
- Projekt Google Cloud z włączonymi płatnościami.
Czego się nauczysz
- Jak skonstruować projekt w Pythonie na potrzeby wdrożenia ADK.
- Jak wdrożyć agenta korzystającego z narzędzi za pomocą pakietu google-adk.
- Jak wdrożyć aplikację w Pythonie jako bezserwerowy kontener w Cloud Run.
- Jak skonfigurować bezpieczne uwierzytelnianie między usługami za pomocą ról uprawnień.
- Jak usunąć zasoby w chmurze, aby uniknąć przyszłych kosztów.
Czego potrzebujesz
- Konto Google Cloud i projekt Google Cloud
- przeglądarka, np. Chrome;
2. Dlaczego warto wdrożyć aplikację w Cloud Run?
Cloud Run to świetny wybór do hostowania agentów ADK, ponieważ jest to platforma bezserwerowa, co oznacza, że możesz skupić się na kodzie, a nie na zarządzaniu infrastrukturą bazową. Zajmiemy się za Ciebie pracą operacyjną.
Można to porównać do sklepu tymczasowego: jest otwarty i korzysta z zasobów tylko wtedy, gdy pojawiają się klienci (żądania). Gdy nie ma klientów, sklep jest całkowicie zamykany i nie płacisz za pusty sklep.
Najważniejsze funkcje
Uruchamianie kontenerów w dowolnym miejscu:
- Dostarczasz kontener (obraz Dockera) z aplikacją.
- Cloud Run uruchamia go w infrastrukturze Google.
- Nie musisz się martwić instalowaniem poprawek systemu operacyjnego, konfigurowaniem maszyn wirtualnych ani skalowaniem.
Automatyczne skalowanie:
- Jeśli z aplikacji nie korzysta żadna osoba → uruchomionych jest 0 instancji (skalowanie w dół do zera instancji, co jest opłacalne).
- Jeśli dotrze do niego 1000 żądań, utworzy on tyle kopii, ile będzie potrzebne.
Bezstanowe domyślnie:
- Każde żądanie może być kierowane do innego wystąpienia.
- Jeśli musisz przechowywać stan, użyj usługi zewnętrznej, takiej jak Cloud SQL, Firestore lub Memorystore.
Obsługa dowolnego języka lub platformy:
- Cloud Run nie ma znaczenia, czy jest to Python, Go, Node.js, Java czy .Net, o ile działa w kontenerze Linux.
Płać za to, z czego korzystasz:
- Rozliczenia na podstawie żądań: opłaty są naliczane za żądanie i czas obliczeń (z dokładnością do 100 ms).
- Opłaty określane na podstawie instancji: opłaty są naliczane za cały okres istnienia instancji (bez opłat za żądanie).
3. Konfigurowanie projektu
Konto Google
Jeśli nie masz jeszcze osobistego konta Google, musisz je utworzyć.
Używaj konta osobistego zamiast konta służbowego lub szkolnego.
Logowanie się w konsoli Google Cloud
Zaloguj się w konsoli Google Cloud, korzystając z osobistego konta Google.
Włącz płatności
Konfigurowanie osobistego konta rozliczeniowego
Jeśli skonfigurujesz płatności za pomocą środków w Google Cloud, możesz pominąć ten krok.
Aby skonfigurować osobiste konto rozliczeniowe, włącz płatności w konsoli Google Cloud.
Uwagi:
- Pod względem opłat za zasoby chmury ukończenie tego modułu powinno kosztować mniej niż 1 USD.
- Jeśli chcesz uniknąć dalszych opłat, wykonaj czynności opisane na końcu tego modułu, aby usunąć zasoby.
- Nowi użytkownicy mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Tworzenie projektu (opcjonalnie)
Jeśli nie masz bieżącego projektu, którego chcesz użyć w tym ćwiczeniu, utwórz nowy projekt.
4. Otwórz edytor Cloud Shell
- Kliknij ten link, aby przejść bezpośrednio do edytora Cloud Shell
- Jeśli w dowolnym momencie pojawi się prośba o autoryzację, kliknij Autoryzuj, aby kontynuować.
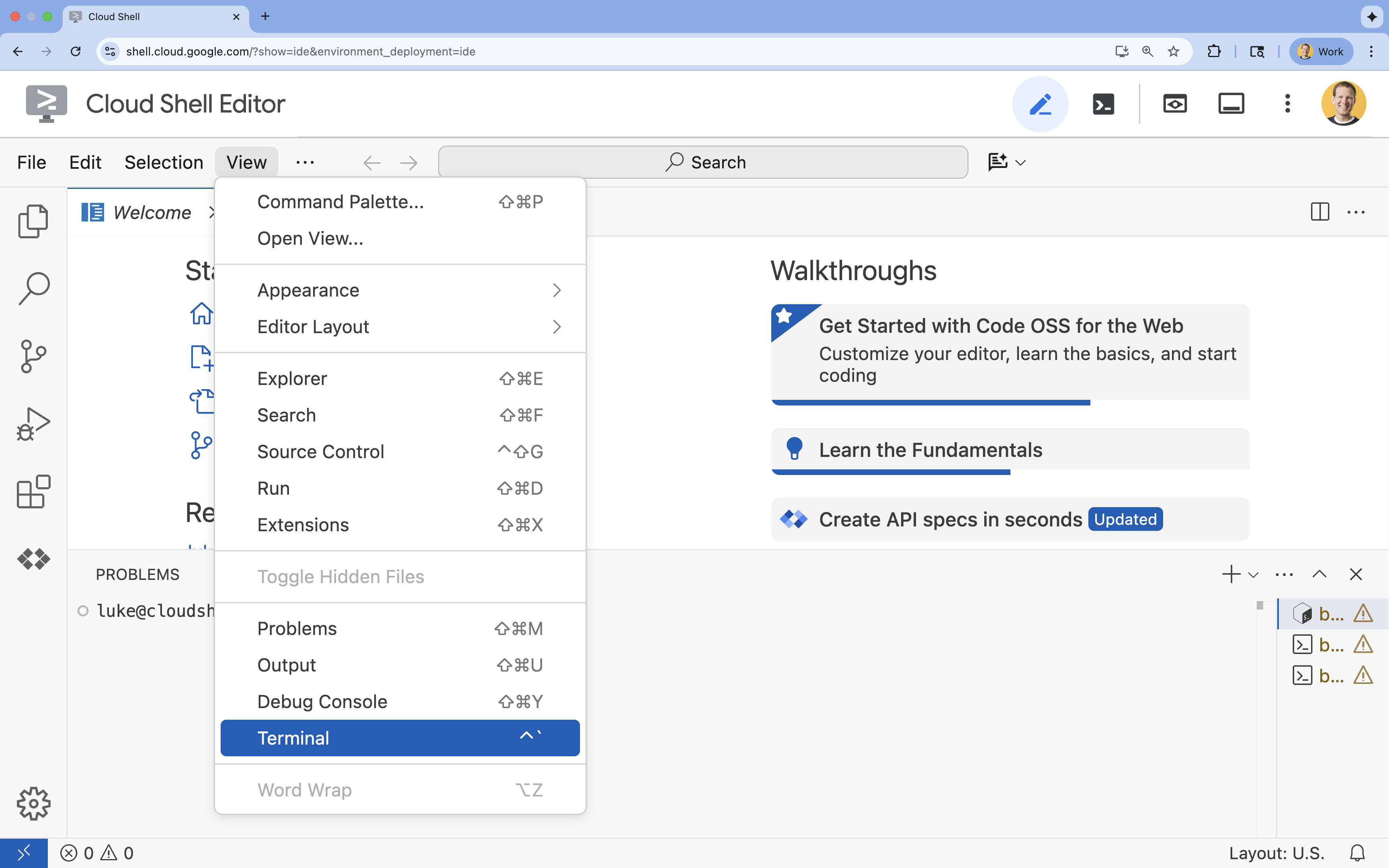
- Jeśli terminal nie pojawi się u dołu ekranu, otwórz go:
- Kliknij Wyświetl.
- Kliknij Terminal
 .
.
5. Ustawianie projektu
- W terminalu ustaw projekt za pomocą tego polecenia:
gcloud config set project [PROJECT_ID]gcloud config set project lab-project-id-example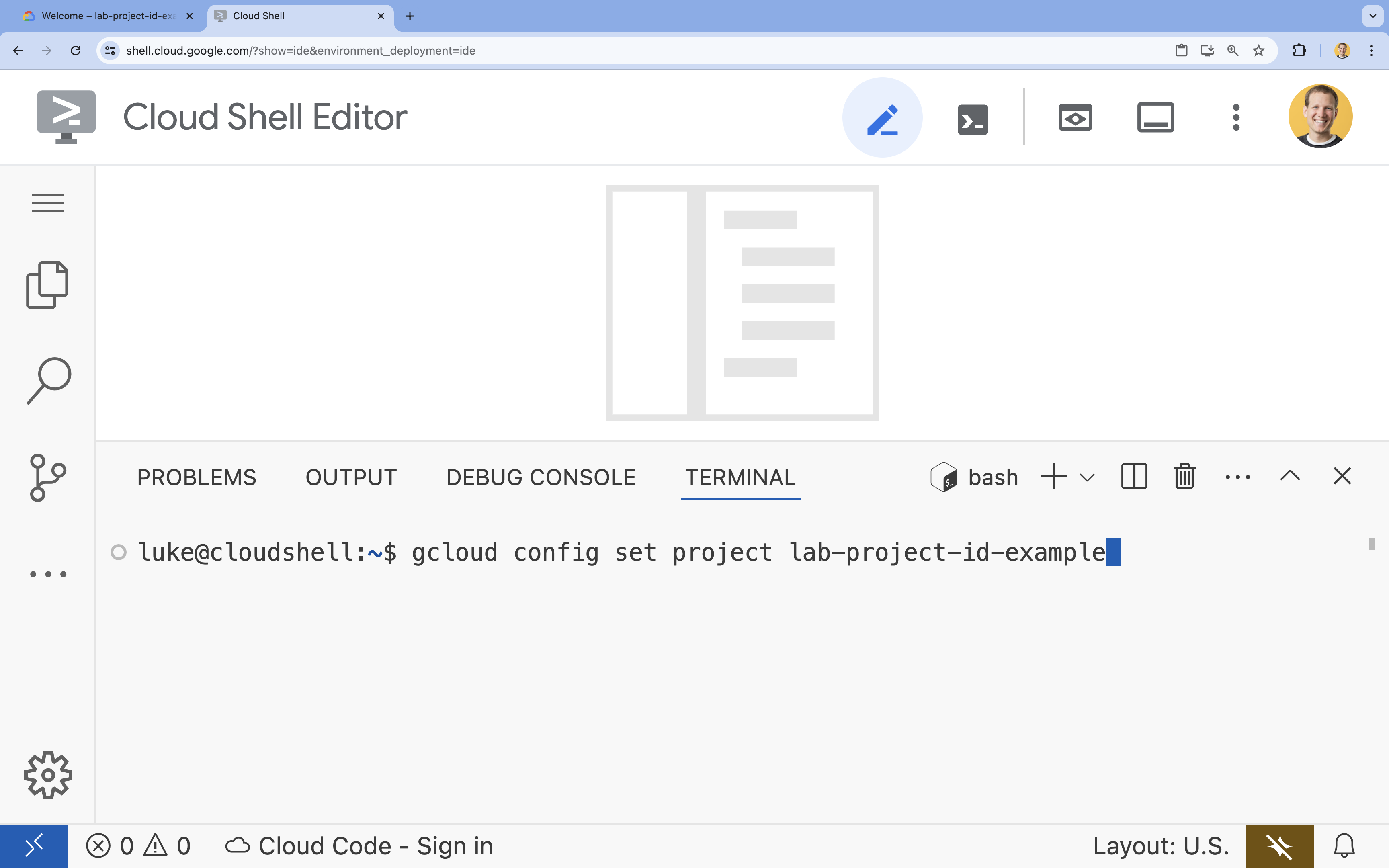
- Powinien wyświetlić się ten komunikat:
Updated property [core/project].
6. Włącz interfejsy API
Aby korzystać z usług Cloud Run, Artifact Registry, Cloud Build, Vertex AI i Compute Engine, musisz włączyć ich interfejsy API w projekcie Google Cloud.
- W terminalu włącz interfejsy API:
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.comOperation "operations/acat.p2-[GUID]" finished successfully.
Przedstawiamy interfejsy API
- Cloud Run Admin API (
run.googleapis.com) umożliwia uruchamianie usług frontendu i backendu, zadań wsadowych lub witryn w pełni zarządzanym środowisku. Zajmuje się infrastrukturą do wdrażania i skalowania aplikacji w kontenerach. - Artifact Registry API (
artifactregistry.googleapis.com) udostępnia bezpieczne, prywatne repozytorium do przechowywania obrazów kontenerów. Jest to rozwinięcie Container Registry, które jest w pełni zintegrowane z Cloud Run i Cloud Build. - Cloud Build API (
cloudbuild.googleapis.com) to bezserwerowa platforma CI/CD, która wykonuje kompilacje w infrastrukturze w chmurze Google Cloud. Służy do kompilowania obrazu kontenera w chmurze na podstawie pliku Dockerfile. - Vertex AI API (
aiplatform.googleapis.com) umożliwia wdrożonej aplikacji komunikację z modelami Gemini w celu wykonywania podstawowych zadań związanych z AI. Zapewnia ujednolicony interfejs API dla wszystkich usług AI Google Cloud. - Interfejs Compute Engine API (
compute.googleapis.com) udostępnia bezpieczne i konfigurowalne maszyny wirtualne działające w infrastrukturze Google. Cloud Run jest usługą zarządzaną, ale interfejs Compute Engine API jest często wymagany jako podstawowa zależność w przypadku różnych zasobów sieciowych i obliczeniowych.
7. Przygotowywanie środowiska programistycznego
Tworzenie katalogu
- W terminalu utwórz katalog projektu i niezbędne podkatalogi:
cd && mkdir zoo_guide_agent && cd zoo_guide_agent - W terminalu uruchom to polecenie, aby otworzyć katalog
zoo_guide_agentw eksploratorze edytora Cloud Shell:cloudshell open-workspace ~/zoo_guide_agent - Panel eksploratora po lewej stronie odświeży się. Powinien być widoczny utworzony katalog.
Wymagania dotyczące instalacji
- Aby utworzyć plik
requirements.txt, uruchom to polecenie w terminalu.cloudshell edit requirements.txt - Dodaj do nowo utworzonego pliku
requirements.txtte wiersze:google-adk==1.14.0 langchain-community==0.3.27 wikipedia==1.4.0 - W terminalu utwórz i aktywuj środowisko wirtualne za pomocą uv. Dzięki temu zależności projektu nie będą powodować konfliktów z systemowym Pythonem.
uv venv source .venv/bin/activate - Zainstaluj wymagane pakiety w środowisku wirtualnym w terminalu.
uv pip install -r requirements.txt
Konfigurowanie zmiennych środowiskowych
- Aby utworzyć plik
.env, użyj tego polecenia w terminalu.# 1. Set the variables in your terminal first PROJECT_ID=$(gcloud config get-value project) PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)") SA_NAME=lab2-cr-service # 2. Create the .env file using those variables cat <<EOF > .env PROJECT_ID=$PROJECT_ID PROJECT_NUMBER=$PROJECT_NUMBER SA_NAME=$SA_NAME SERVICE_ACCOUNT=${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com MODEL="gemini-2.5-flash" EOF
8. Tworzenie przepływu pracy agenta
Tworzenie pliku __init__.py
- Utwórz plik init.py, uruchamiając w terminalu to polecenie:
cloudshell edit __init__.py - Dodaj do nowego pliku
__init__.pyten kod:from . import agent
Tworzenie pliku agent.py
- Utwórz główny plik
agent.py, wklejając to polecenie do terminala.cloudshell edit agent.py - Importy i konfiguracja początkowa: dodaj ten kod do pustego pliku
agent.py:import os import logging import google.cloud.logging from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper import google.auth import google.auth.transport.requests import google.oauth2.id_token # --- Setup Logging and Environment --- cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL")agent.pyzawiera wszystkie niezbędne biblioteki z ADK i Google Cloud. Konfiguruje też rejestrowanie i wczytuje zmienne środowiskowe z pliku.env, co jest kluczowe w przypadku dostępu do modelu i adresu URL serwera. - Określ narzędzia: agent jest tak dobry, jak narzędzia, z których może korzystać. Aby zdefiniować narzędzia, dodaj ten kod na końcu pliku
agent.py:# Greet user and save their prompt def add_prompt_to_state( tool_context: ToolContext, prompt: str ) -> dict[str, str]: """Saves the user's initial prompt to the state.""" tool_context.state["PROMPT"] = prompt logging.info(f"[State updated] Added to PROMPT: {prompt}") return {"status": "success"} # Configuring the Wikipedia Tool wikipedia_tool = LangchainTool( tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper()) )add_prompt_to_state📝: to narzędzie zapamiętuje pytania zadawane przez osoby odwiedzające zoo. Gdy gość zapyta „Gdzie są lwy?”, to narzędzie zapisze to konkretne pytanie w pamięci agenta, aby inni agenci w przepływie pracy wiedzieli, czego szukać.
Jak: jest to funkcja Pythona, która zapisuje prompt użytkownika w udostępnionym słownikutool_context.state. Kontekst narzędzia to pamięć krótkotrwała agenta w przypadku pojedynczej rozmowy. Dane zapisane w stanie przez jednego agenta mogą być odczytywane przez kolejnego agenta w przepływie pracy.LangchainTool🌍: dzięki temu agent przewodnik będzie miał ogólną wiedzę o świecie. Gdy odwiedzający zada pytanie, którego nie ma w bazie danych zoo, np. „Co jedzą lwy na wolności?”, narzędzie to umożliwia pracownikowi znalezienie odpowiedzi w Wikipedii.
Działanie: działa jako adapter, umożliwiając naszemu agentowi korzystanie z gotowego narzędzia WikipediaQueryRun z biblioteki LangChain.
- Określ agentów specjalistów: dodaj ten kod na końcu sekcji
agent.py, aby określić agentówcomprehensive_researcheriresponse_formatter:# 1. Researcher Agent comprehensive_researcher = Agent( name="comprehensive_researcher", model=model_name, description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.", instruction=""" You are a helpful research assistant. Your goal is to fully answer the user's PROMPT. You have access to two tools: 1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations). 2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat). First, analyze the user's PROMPT. - If the prompt can be answered by only one tool, use that tool. - If the prompt is complex and requires information from both the zoo's database AND Wikipedia, you MUST use both tools to gather all necessary information. - Synthesize the results from the tool(s) you use into preliminary data outputs. PROMPT: { PROMPT } """, tools=[ wikipedia_tool ], output_key="research_data" # A key to store the combined findings ) # 2. Response Formatter Agent response_formatter = Agent( name="response_formatter", model=model_name, description="Synthesizes all information into a friendly, readable response.", instruction=""" You are the friendly voice of the Zoo Tour Guide. Your task is to take the RESEARCH_DATA and present it to the user in a complete and helpful answer. - First, present the specific information from the zoo (like names, ages, and where to find them). - Then, add the interesting general facts from the research. - If some information is missing, just present the information you have. - Be conversational and engaging. RESEARCH_DATA: { research_data } """ )- Agent
comprehensive_researcherto „mózg” naszej operacji. Pobiera prompt użytkownika z udostępnionegoState, sprawdza, czy jest to narzędzie Wikipedia, i decyduje, których z nich użyć, aby znaleźć odpowiedź. - Rola agenta
response_formatterto prezentacja. Pobiera surowe dane zebrane przez agenta Researcher (przekazywane za pomocą stanu) i wykorzystuje umiejętności językowe LLM, aby przekształcić je w przyjazną, konwersacyjną odpowiedź.
- Agent
- Zdefiniuj agenta przepływu pracy: dodaj ten blok kodu na dole sekcji
agent.py, aby zdefiniować agenta sekwencyjnegotour_guide_workflow:tour_guide_workflow = SequentialAgent( name="tour_guide_workflow", description="The main workflow for handling a user's request about an animal.", sub_agents=[ comprehensive_researcher, # Step 1: Gather all data response_formatter, # Step 2: Format the final response ] )
Jak: toSequentialAgent, czyli specjalny typ agenta, który nie myśli samodzielnie. Jego jedynym zadaniem jest uruchamianie listysub_agents(badacza i formatera) w ustalonej kolejności oraz automatyczne przekazywanie pamięci współdzielonej z jednego do drugiego. - Złóż główny przepływ pracy: dodaj ten ostatni blok kodu na dole pliku
agent.py, aby zdefiniowaćroot_agent:root_agent = Agent( name="greeter", model=model_name, description="The main entry point for the Zoo Tour Guide.", instruction=""" - Let the user know you will help them learn about the animals we have in the zoo. - When the user responds, use the 'add_prompt_to_state' tool to save their response. After using the tool, transfer control to the 'tour_guide_workflow' agent. """, tools=[add_prompt_to_state], sub_agents=[tour_guide_workflow] )root_agentjako punktu początkowego dla wszystkich nowych rozmów. Jego głównym zadaniem jest koordynowanie całego procesu. Pełni on funkcję początkowego kontrolera, który zarządza pierwszą turą rozmowy.

pełny plik agent.py,
Plik agent.py jest gotowy. Dzięki temu możesz zobaczyć, jak każdy komponent – narzędzia, agenci roboczy i agenci zarządzający – odgrywa określoną rolę w tworzeniu końcowego, inteligentnego systemu.
Gotowy plik powinien wyglądać tak:
import os
import logging
import google.cloud.logging
from dotenv import load_dotenv
from google.adk import Agent
from google.adk.agents import SequentialAgent
from google.adk.tools.tool_context import ToolContext
from google.adk.tools.langchain_tool import LangchainTool
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
import google.auth
import google.auth.transport.requests
import google.oauth2.id_token
# --- Setup Logging and Environment ---
cloud_logging_client = google.cloud.logging.Client()
cloud_logging_client.setup_logging()
load_dotenv()
model_name = os.getenv("MODEL")
# Greet user and save their prompt
def add_prompt_to_state(
tool_context: ToolContext, prompt: str
) -> dict[str, str]:
"""Saves the user's initial prompt to the state."""
tool_context.state["PROMPT"] = prompt
logging.info(f"[State updated] Added to PROMPT: {prompt}")
return {"status": "success"}
# Configuring the Wikipedia Tool
wikipedia_tool = LangchainTool(
tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
)
# 1. Researcher Agent
comprehensive_researcher = Agent(
name="comprehensive_researcher",
model=model_name,
description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.",
instruction="""
You are a helpful research assistant. Your goal is to fully answer the user's PROMPT.
You have access to two tools:
1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations).
2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat).
First, analyze the user's PROMPT.
- If the prompt can be answered by only one tool, use that tool.
- If the prompt is complex and requires information from both the zoo's database AND Wikipedia,
you MUST use both tools to gather all necessary information.
- Synthesize the results from the tool(s) you use into preliminary data outputs.
PROMPT:
{ PROMPT }
""",
tools=[
wikipedia_tool
],
output_key="research_data" # A key to store the combined findings
)
# 2. Response Formatter Agent
response_formatter = Agent(
name="response_formatter",
model=model_name,
description="Synthesizes all information into a friendly, readable response.",
instruction="""
You are the friendly voice of the Zoo Tour Guide. Your task is to take the
RESEARCH_DATA and present it to the user in a complete and helpful answer.
- First, present the specific information from the zoo (like names, ages, and where to find them).
- Then, add the interesting general facts from the research.
- If some information is missing, just present the information you have.
- Be conversational and engaging.
RESEARCH_DATA:
{ research_data }
"""
)
tour_guide_workflow = SequentialAgent(
name="tour_guide_workflow",
description="The main workflow for handling a user's request about an animal.",
sub_agents=[
comprehensive_researcher, # Step 1: Gather all data
response_formatter, # Step 2: Format the final response
]
)
root_agent = Agent(
name="greeter",
model=model_name,
description="The main entry point for the Zoo Tour Guide.",
instruction="""
- Let the user know you will help them learn about the animals we have in the zoo.
- When the user responds, use the 'add_prompt_to_state' tool to save their response.
After using the tool, transfer control to the 'tour_guide_workflow' agent.
""",
tools=[add_prompt_to_state],
sub_agents=[tour_guide_workflow]
)
Następny krok to wdrożenie.
9. Przygotowywanie aplikacji do wdrożenia
Sprawdzanie ostatecznej struktury
Przed wdrożeniem sprawdź, czy katalog projektu zawiera prawidłowe pliki.
- Sprawdź, czy folder
zoo_guide_agentwygląda tak:zoo_guide_agent/ ├── .env ├── __init__.py ├── agent.py └── requirements.txt
Konfigurowanie uprawnień
Gdy masz już gotowy kod lokalny, następnym krokiem jest skonfigurowanie tożsamości, której agent będzie używać w chmurze.
- W terminalu załaduj zmienne do sesji powłoki.
source .env - Utwórz dedykowane konto usługi dla usługi Cloud Run, aby miało ono własne, konkretne uprawnienia. Wklej w terminalu ten tekst:
gcloud iam service-accounts create ${SA_NAME} \ --display-name="Service Account for lab 2 " - Przyznaj kontu usługi rolę użytkownika Vertex AI, która daje mu uprawnienia do wywoływania modeli Google.
# Grant the "Vertex AI User" role to your service account gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:$SERVICE_ACCOUNT" \ --role="roles/aiplatform.user"
10. Wdrażanie agenta za pomocą interfejsu wiersza poleceń ADK
Gdy lokalny kod jest gotowy, a projekt w chmurze Google Cloud przygotowany, możesz wdrożyć agenta. Użyjesz polecenia adk deploy cloud_run, czyli wygodnego narzędzia, które automatyzuje cały proces wdrażania. To jedno polecenie pakuje kod, tworzy obraz kontenera, przenosi go do Artifact Registry i uruchamia usługę w Cloud Run, dzięki czemu jest ona dostępna w internecie.
- Aby wdrożyć agenta, uruchom w terminalu to polecenie:
# Run the deployment command uvx --from google-adk==1.14.0 \ adk deploy cloud_run \ --project=$PROJECT_ID \ --region=europe-west1 \ --service_name=zoo-tour-guide \ --with_ui \ . \ -- \ --labels=dev-tutorial=codelab-adk \ --service-account=$SERVICE_ACCOUNTuvxumożliwia uruchamianie narzędzi wiersza poleceń opublikowanych jako pakiety Pythona bez konieczności globalnej instalacji tych narzędzi. - Jeśli pojawi się ten komunikat:
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [europe-west1] will be created. Do you want to continue (Y/n)?
Yi naciśnij ENTER. - Jeśli pojawi się ten komunikat:
Allow unauthenticated invocations to [your-service-name] (y/N)?.
yi naciśnij ENTER. Umożliwia to wywoływanie bez uwierzytelniania na potrzeby tego modułu, co ułatwia testowanie. Po pomyślnym wykonaniu polecenia wyświetli się adres URL wdrożonej usługi Cloud Run. (Będzie wyglądać mniej więcej tak:https://zoo-tour-guide-123456789.europe-west1.run.app). - Skopiuj adres URL wdrożonej usługi Cloud Run, aby użyć go w następnym zadaniu.
11. Testowanie wdrożonego agenta
Gdy agent będzie już działać w Cloud Run, przeprowadź test, aby potwierdzić, że wdrożenie się powiodło i agent działa zgodnie z oczekiwaniami. Aby uzyskać dostęp do interfejsu internetowego ADK i interakcji z agentem, użyjesz publicznego adresu URL usługi (np. https://zoo-tour-guide-123456789.europe-west1.run.app/).
- Otwórz publiczny adres URL usługi Cloud Run w przeglądarce. Ponieważ używasz
--with_ui flag, powinien być widoczny interfejs programisty ADK. - W prawym górnym rogu włącz
Token Streaming.
Możesz teraz korzystać z usług agenta Zoo. - Wpisz
helloi naciśnij Enter, aby rozpocząć nową rozmowę. - Sprawdź wynik. Agent powinien szybko odpowiedzieć powitaniem, które będzie wyglądać mniej więcej tak:
"Hello! I'm your Zoo Tour Guide. I can help you learn about the amazing animals we have here. What would you like to know or explore today?"
- Zadaj agentowi pytania takie jak:
Where can I find the polar bears in the zoo and what is their diet?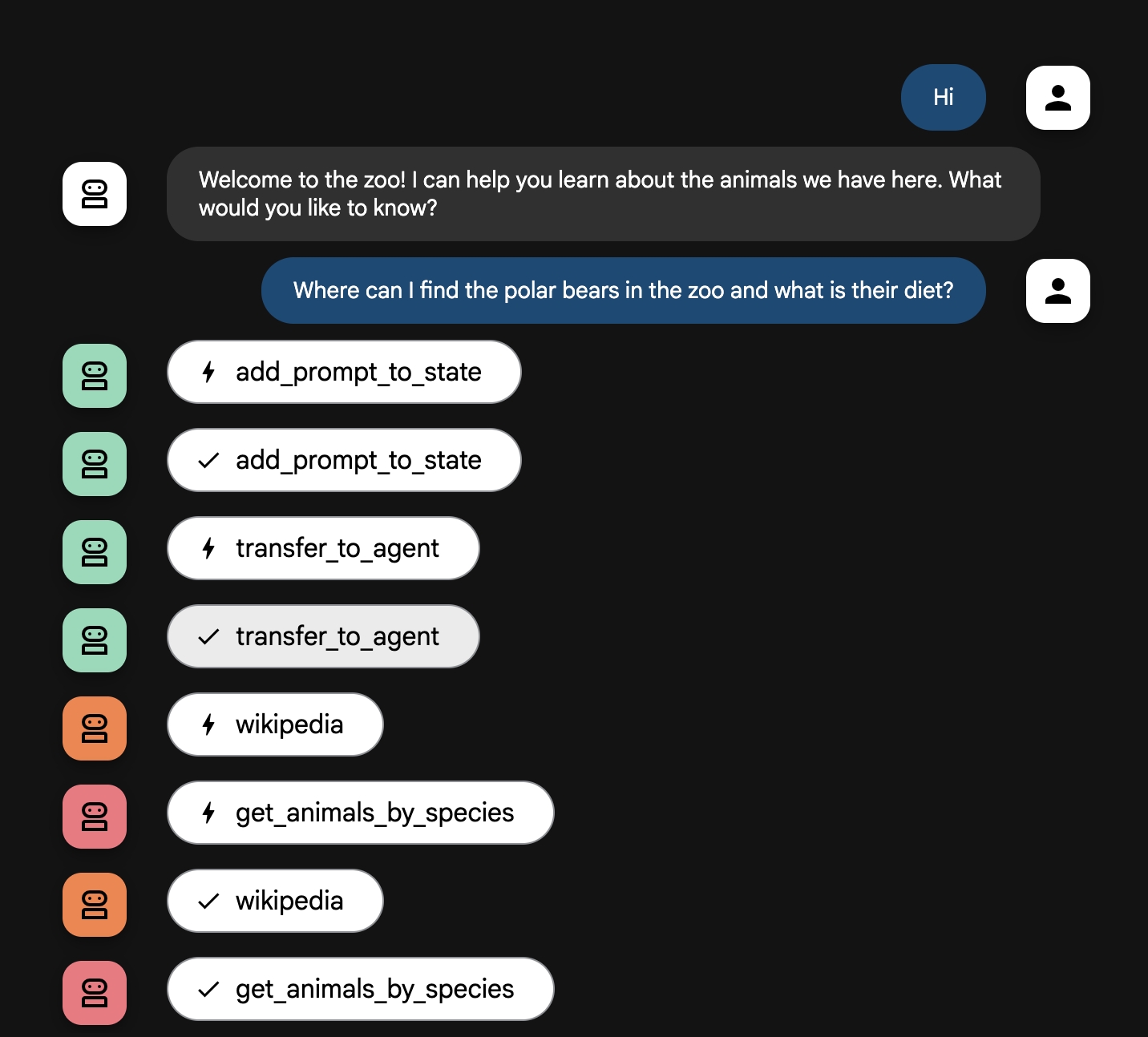

Wyjaśnienie funkcji typu flow agenta
System działa jako inteligentny zespół wielu agentów. Proces ten jest zarządzany przez jasną sekwencję, aby zapewnić płynny i wydajny przepływ informacji od pytania użytkownika do ostatecznej, szczegółowej odpowiedzi.
1. Osoba witająca gości w zoo (stanowisko powitalne)
Cały proces zaczyna się od agenta witającego.
- Jego zadanie: rozpoczęcie rozmowy. Jego instrukcja to powitanie użytkownika i zapytanie, o jakim zwierzęciu chce się dowiedzieć więcej.
- Narzędzie: gdy użytkownik odpowie, Greeter użyje narzędzia add_prompt_to_state, aby zapisać jego dokładne słowa (np. „opowiedz mi o lwach”) w pamięci systemu.
- Przekazanie kontroli: po zapisaniu promptu natychmiast przekazuje on kontrolę do swojego sub-agenta, czyli tour_guide_workflow.
2. Wszechstronny badacz (superbadacz)
Jest to pierwszy krok w głównym procesie i „mózg” całej operacji. Zamiast dużego zespołu masz teraz jednego, wysoce wykwalifikowanego agenta, który ma dostęp do wszystkich dostępnych informacji.
- Jego zadanie: analizowanie pytania użytkownika i tworzenie inteligentnego planu. Wykorzystuje funkcję używania narzędzi modelu językowego, aby zdecydować, czy potrzebuje:
- ogólna wiedza z internetu (za pomocą interfejsu Wikipedia API);
- W przypadku złożonych pytań może to być jedno i drugie.
3. Formatowanie odpowiedzi (prowadzący)
Gdy wszechstronny badacz zbierze wszystkie fakty, jest to ostatni agent, który zostanie uruchomiony.
- Jego zadanie: być przyjaznym głosem przewodnika po zoo. Pobiera ona dane pierwotne (które mogą pochodzić z jednego lub obu źródeł) i je przetwarza.
- Działanie: syntezuje wszystkie informacje w jedną, spójną i angażującą odpowiedź. Zgodnie z instrukcjami najpierw podaje konkretne informacje o zoo, a potem dodaje ciekawe ogólne fakty.
- Wynik końcowy: tekst wygenerowany przez tego agenta to pełna, szczegółowa odpowiedź, którą użytkownik widzi w oknie czatu.
Jeśli chcesz dowiedzieć się więcej o tworzeniu agentów, zapoznaj się z tymi materiałami:
12. Zwalnianie miejsca w środowisku
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby zużyte w tym samouczku, możesz usunąć projekt zawierający te zasoby lub zachować projekt i usunąć poszczególne zasoby.
Usuwanie usług i obrazów Cloud Run
Jeśli chcesz zachować projekt w chmurze Google Cloud, ale usunąć konkretne zasoby utworzone w tym laboratorium, musisz usunąć zarówno działającą usługę, jak i obraz kontenera przechowywany w rejestrze.
- Uruchom w terminalu te polecenia:
gcloud run services delete zoo-tour-guide --region=europe-west1 --quiet gcloud artifacts repositories delete cloud-run-source-deploy --location=europe-west1 --quiet
Usuwanie projektu (opcjonalnie)
Jeśli masz projekt utworzony specjalnie na potrzeby tego ćwiczenia i nie zamierzasz już z niego korzystać, najłatwiej będzie usunąć cały projekt. Dzięki temu wszystkie zasoby (w tym konto usługi i wszelkie ukryte artefakty kompilacji) zostaną całkowicie usunięte.
- W terminalu uruchom to polecenie (zastąp [YOUR_PROJECT_ID] identyfikatorem swojego projektu):
gcloud projects delete $PROJECT_ID
13. Gratulacje
Udało Ci się utworzyć i wdrożyć w Google Cloud aplikację AI z wieloma agentami.
Podsumowanie
W tym laboratorium udało Ci się przekształcić pusty katalog w działającą, publicznie dostępną usługę AI. Oto, co udało Ci się stworzyć:
- Utworzono specjalistyczny zespół: zamiast jednej ogólnej AI utworzono „Badacza”, który wyszukuje fakty, oraz „Formatującego”, który dopracowuje odpowiedź.
- Udostępniasz im narzędzia: łączysz agentów ze światem zewnętrznym za pomocą interfejsu Wikipedia API.
- Wdrożono: lokalny kod Pythona został wdrożony jako kontener bezserwerowy w Cloud Run i zabezpieczony za pomocą dedykowanego konta usługi.
Omówione zagadnienia
- Jak skonstruować projekt w Pythonie do wdrożenia za pomocą ADK.
- Jak wdrożyć przepływ pracy z udziałem wielu agentów za pomocą
[SequentialAgent](https://google.github.io/adk-docs/agents/workflow-agents/sequential-agents/). - Jak zintegrować narzędzia zewnętrzne, takie jak interfejs API Wikipedii.
- Jak wdrożyć agenta w Cloud Run za pomocą polecenia
adk deploy.
14. Ankieta
Dane wyjściowe: