
1. Введение
Эта лабораторная работа посвящена реализации и развертыванию клиентского агентского сервиса. Вы будете использовать Agent Development Kit (ADK) для создания агента искусственного интеллекта , использующего соответствующие инструменты.
В этой лабораторной работе мы создаём агента зоопарка, который использует Википедию для ответа на вопросы о животных.

Наконец, мы развернем агента гида в Google Cloud Run , а не будем запускать его локально.
Предварительные требования
- Проект Google Cloud с включенной функцией выставления счетов.
Что вы узнаете
- Как структурировать проект на Python для развертывания в ADK .
- Как реализовать агента, использующего инструменты, с помощью Google AdK.
- Как развернуть приложение Python в виде бессерверного контейнера в Cloud Run .
- Как настроить безопасную аутентификацию между сервисами с использованием ролей IAM .
- Как удалить облачные ресурсы, чтобы избежать будущих затрат.
Что вам понадобится
- Аккаунт Google Cloud и проект Google Cloud
- Веб-браузер, например Chrome.
2. Почему стоит развертывать приложения в Cloud Run?
Cloud Run — отличный выбор для размещения агентов ADK , поскольку это бессерверная платформа, а это значит, что вы можете сосредоточиться на своем коде, а не на управлении базовой инфраструктурой. Мы берем на себя операционную работу.
Представьте это как временный магазин: он открывается и использует ресурсы только тогда, когда поступают заказы. Когда заказов нет, он полностью закрывается, и вы не платите за пустой магазин.
Основные характеристики
Запускает контейнеры где угодно:
- Вы предоставляете контейнер (образ Docker), внутри которого находится ваше приложение.
- Cloud Run запускает его на инфраструктуре Google.
- Никаких проблем с обновлением ОС, настройкой виртуальных машин или масштабированием.
Автоматическое масштабирование:
- Если приложением пользуются 0 человек, то запускается 0 экземпляров (масштабирование до нуля экземпляров экономически выгодно).
- Если поступает 1000 запросов, то запускается столько копий, сколько необходимо.
По умолчанию не сохраняющее состояние:
- Каждый запрос может быть направлен в отдельный экземпляр.
- Если вам необходимо хранить состояние, используйте внешний сервис, такой как Cloud SQL, Firestore или Memorystore.
Поддерживает любой язык программирования или фреймворк:
- Пока приложение работает в контейнере Linux, Cloud Run неважно, используется ли Python, Go, Node.js, Java или .Net.
Платите только за то, что используете:
- Оплата по запросам : оплата производится за каждый запрос + время вычислений (до 100 мс).
- Оплата на основе экземпляра : оплата производится за весь срок службы экземпляра (без платы за каждый запрос).
3. Настройка проекта
Аккаунт Google
Если у вас еще нет личного аккаунта Google, вам необходимо его создать .
Используйте личный аккаунт вместо рабочего или учебного.
Войдите в консоль Google Cloud.
Войдите в консоль Google Cloud, используя личную учетную запись Google.
Включить выставление счетов
Создайте личный платежный аккаунт.
Если вы настроили оплату с использованием кредитов Google Cloud, этот шаг можно пропустить.
Чтобы настроить личный платежный аккаунт, перейдите сюда, чтобы включить оплату в облачной консоли.
Несколько замечаний:
- Выполнение этой лабораторной работы должно обойтись менее чем в 1 доллар США в виде облачных ресурсов.
- В конце этой лабораторной работы вы можете выполнить действия по удалению ресурсов, чтобы избежать дальнейших списаний средств.
- Новые пользователи могут воспользоваться бесплатной пробной версией стоимостью 300 долларов США .
Создать проект (необязательно)
Если у вас нет текущего проекта, который вы хотели бы использовать для этой лабораторной работы, создайте новый проект здесь .
4. Откройте редактор Cloud Shell.
- Нажмите на эту ссылку, чтобы перейти непосредственно в редактор Cloud Shell.
- Если сегодня вам будет предложено авторизоваться, нажмите «Авторизовать» , чтобы продолжить.
- Если терминал не отображается внизу экрана, откройте его:
- Нажмите «Просмотреть».
- Нажмите «Терминал»
5. Назначьте проект.
- В терминале настройте свой проект с помощью этой команды:
gcloud config set project [PROJECT_ID]gcloud config set project lab-project-id-example
- Вы должны увидеть следующее сообщение:
Updated property [core/project].
6. Включите API.
Для использования Cloud Run , Artifact Registry , Cloud Build , Vertex AI и Compute Engine необходимо включить соответствующие API в вашем проекте Google Cloud.
- В терминале включите API:
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.comOperation "operations/acat.p2-[GUID]" finished successfully.
Представляем API.
- Cloud Run Admin API (
run.googleapis.com) позволяет запускать фронтенд и бэкенд сервисы, пакетные задания или веб-сайты в полностью управляемой среде. Он обеспечивает инфраструктуру для развертывания и масштабирования ваших контейнеризированных приложений. - API реестра артефактов (
artifactregistry.googleapis.com) предоставляет безопасное, приватное хранилище для ваших образов контейнеров. Это эволюция Container Registry, которая легко интегрируется с Cloud Run и Cloud Build. - Cloud Build API (
cloudbuild.googleapis.com) — это бессерверная платформа CI/CD, которая выполняет сборки на инфраструктуре Google Cloud. Она используется для сборки образа контейнера в облаке из вашего Dockerfile. - API Vertex AI (
aiplatform.googleapis.com) позволяет вашему развернутому приложению взаимодействовать с моделями Gemini для выполнения основных задач искусственного интеллекта. Он предоставляет единый API для всех сервисов Google Cloud в области ИИ. - API Compute Engine (
compute.googleapis.com) предоставляет безопасные и настраиваемые виртуальные машины, работающие на инфраструктуре Google. В то время как Cloud Run является управляемым сервисом, API Compute Engine часто требуется в качестве базовой зависимости для различных сетевых и вычислительных ресурсов.
7. Подготовьте среду разработки.
Создайте каталог
- В терминале создайте каталог проекта и необходимые подкаталоги:
cd && mkdir zoo_guide_agent && cd zoo_guide_agent - В терминале выполните следующую команду, чтобы открыть каталог
zoo_guide_agentв обозревателе Cloud Shell Editor:cloudshell open-workspace ~/zoo_guide_agent - Панель проводника слева обновится. Теперь вы должны увидеть созданную вами директорию.
Требования к установке
- Выполните следующую команду в терминале , чтобы создать файл
requirements.txt.cloudshell edit requirements.txt - Добавьте следующее в только что созданный файл
requirements.txtgoogle-adk==1.14.0 langchain-community==0.3.27 wikipedia==1.4.0 - В терминале создайте и активируйте виртуальное окружение с помощью команды `uv`. Это гарантирует, что зависимости вашего проекта не будут конфликтовать с системным Python.
uv venv source .venv/bin/activate - Установите необходимые пакеты в виртуальную среду в терминале .
uv pip install -r requirements.txt
Настройте переменные среды.
- Для создания файла
.envиспользуйте следующую команду в терминале .# 1. Set the variables in your terminal first PROJECT_ID=$(gcloud config get-value project) PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)") SA_NAME=lab2-cr-service # 2. Create the .env file using those variables cat <<EOF > .env PROJECT_ID=$PROJECT_ID PROJECT_NUMBER=$PROJECT_NUMBER SA_NAME=$SA_NAME SERVICE_ACCOUNT=${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com MODEL="gemini-2.5-flash" EOF
8. Создание рабочего процесса для агента
Создайте файл __init__.py
- Создайте файл init.py , выполнив в терминале следующую команду:
cloudshell edit __init__.py - Добавьте следующий код в новый файл
__init__.py:from . import agent
Создайте файл agent.py
- Создайте основной файл
agent.py, вставив следующую команду в терминал .cloudshell edit agent.py - Импорт и начальная настройка : добавьте следующий код в ваш пустой файл
agent.py:import os import logging import google.cloud.logging from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper import google.auth import google.auth.transport.requests import google.oauth2.id_token # --- Setup Logging and Environment --- cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL")agent.pyподключает все необходимые библиотеки из ADK и Google Cloud. Он также настраивает логирование и загружает переменные окружения из вашего файла.env, что крайне важно для доступа к вашей модели и URL-адресу сервера. - Определите инструменты : Эффективность агента напрямую зависит от имеющихся у него инструментов. Добавьте следующий код в конец файла
agent.py, чтобы определить инструменты:# Greet user and save their prompt def add_prompt_to_state( tool_context: ToolContext, prompt: str ) -> dict[str, str]: """Saves the user's initial prompt to the state.""" tool_context.state["PROMPT"] = prompt logging.info(f"[State updated] Added to PROMPT: {prompt}") return {"status": "success"} # Configuring the Wikipedia Tool wikipedia_tool = LangchainTool( tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper()) )-
add_prompt_to_state📝: Этот инструмент запоминает вопросы посетителей зоопарка. Когда посетитель спрашивает: «Где львы?», этот инструмент сохраняет конкретный вопрос в памяти агента, чтобы другие агенты в рабочем процессе знали, что искать.
Как это работает: это функция на Python, которая записывает подсказку посетителя в общий словарьtool_context.state. Этот контекст инструмента представляет собой кратковременную память агента для одного разговора. Данные, сохраненные в состоянии одним агентом, могут быть прочитаны следующим агентом в рабочем процессе. -
LangchainTool🌍: Этот инструмент предоставляет гиду общие знания о мире. Когда посетитель задает вопрос, которого нет в базе данных зоопарка, например: «Чем питаются львы в дикой природе?», этот инструмент позволяет гиду найти ответ в Википедии.
Как это работает: Он выступает в качестве адаптера, позволяя нашему агенту использовать встроенный инструмент WikipediaQueryRun из библиотеки LangChain.
-
- Определите агентов-специалистов : добавьте следующий код в конец файла
agent.py, чтобы определить агентовcomprehensive_researcherиresponse_formatter:# 1. Researcher Agent comprehensive_researcher = Agent( name="comprehensive_researcher", model=model_name, description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.", instruction=""" You are a helpful research assistant. Your goal is to fully answer the user's PROMPT. You have access to two tools: 1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations). 2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat). First, analyze the user's PROMPT. - If the prompt can be answered by only one tool, use that tool. - If the prompt is complex and requires information from both the zoo's database AND Wikipedia, you MUST use both tools to gather all necessary information. - Synthesize the results from the tool(s) you use into preliminary data outputs. PROMPT: { PROMPT } """, tools=[ wikipedia_tool ], output_key="research_data" # A key to store the combined findings ) # 2. Response Formatter Agent response_formatter = Agent( name="response_formatter", model=model_name, description="Synthesizes all information into a friendly, readable response.", instruction=""" You are the friendly voice of the Zoo Tour Guide. Your task is to take the RESEARCH_DATA and present it to the user in a complete and helpful answer. - First, present the specific information from the zoo (like names, ages, and where to find them). - Then, add the interesting general facts from the research. - If some information is missing, just present the information you have. - Be conversational and engaging. RESEARCH_DATA: { research_data } """ )- Агент
comprehensive_researcher— это «мозг» нашей работы. Он берет запрос пользователя из общегоState, анализирует его с помощью инструмента Википедии и решает, какие из них использовать для поиска ответа. - Роль агента
response_formatterзаключается в представлении информации. Он берет необработанные данные, собранные агентом Researcher (переданные через State), и использует языковые навыки LLM для преобразования их в дружелюбный, разговорный ответ.
- Агент
- Определите агента рабочего процесса : добавьте этот блок кода в конец файла
agent.py, чтобы определить агента последовательногоtour_guide_workflow:tour_guide_workflow = SequentialAgent( name="tour_guide_workflow", description="The main workflow for handling a user's request about an animal.", sub_agents=[ comprehensive_researcher, # Step 1: Gather all data response_formatter, # Step 2: Format the final response ] )
Как это работает: этоSequentialAgent, особый тип агента, который не мыслит самостоятельно. Его единственная задача — запускать списокsub_agents(исследователя и форматировщика) в фиксированной последовательности, автоматически передавая общую память от одного к другому. - Создайте основной рабочий процесс : добавьте этот заключительный блок кода в конец файла
agent.py, чтобы определитьroot_agent:root_agent = Agent( name="greeter", model=model_name, description="The main entry point for the Zoo Tour Guide.", instruction=""" - Let the user know you will help them learn about the animals we have in the zoo. - When the user responds, use the 'add_prompt_to_state' tool to save their response. After using the tool, transfer control to the 'tour_guide_workflow' agent. """, tools=[add_prompt_to_state], sub_agents=[tour_guide_workflow] )root_agent. Его основная роль заключается в организации всего процесса. Он выступает в качестве начального контроллера, управляя первым этапом диалога.
Полный файл agent.py
Ваш файл agent.py готов! Собрав его таким образом, вы сможете увидеть, как каждый компонент — инструменты, рабочие агенты и агенты-менеджеры — играет определенную роль в создании конечной интеллектуальной системы.
Полный файл должен выглядеть следующим образом:
import os
import logging
import google.cloud.logging
from dotenv import load_dotenv
from google.adk import Agent
from google.adk.agents import SequentialAgent
from google.adk.tools.tool_context import ToolContext
from google.adk.tools.langchain_tool import LangchainTool
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
import google.auth
import google.auth.transport.requests
import google.oauth2.id_token
# --- Setup Logging and Environment ---
cloud_logging_client = google.cloud.logging.Client()
cloud_logging_client.setup_logging()
load_dotenv()
model_name = os.getenv("MODEL")
# Greet user and save their prompt
def add_prompt_to_state(
tool_context: ToolContext, prompt: str
) -> dict[str, str]:
"""Saves the user's initial prompt to the state."""
tool_context.state["PROMPT"] = prompt
logging.info(f"[State updated] Added to PROMPT: {prompt}")
return {"status": "success"}
# Configuring the Wikipedia Tool
wikipedia_tool = LangchainTool(
tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
)
# 1. Researcher Agent
comprehensive_researcher = Agent(
name="comprehensive_researcher",
model=model_name,
description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.",
instruction="""
You are a helpful research assistant. Your goal is to fully answer the user's PROMPT.
You have access to two tools:
1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations).
2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat).
First, analyze the user's PROMPT.
- If the prompt can be answered by only one tool, use that tool.
- If the prompt is complex and requires information from both the zoo's database AND Wikipedia,
you MUST use both tools to gather all necessary information.
- Synthesize the results from the tool(s) you use into preliminary data outputs.
PROMPT:
{ PROMPT }
""",
tools=[
wikipedia_tool
],
output_key="research_data" # A key to store the combined findings
)
# 2. Response Formatter Agent
response_formatter = Agent(
name="response_formatter",
model=model_name,
description="Synthesizes all information into a friendly, readable response.",
instruction="""
You are the friendly voice of the Zoo Tour Guide. Your task is to take the
RESEARCH_DATA and present it to the user in a complete and helpful answer.
- First, present the specific information from the zoo (like names, ages, and where to find them).
- Then, add the interesting general facts from the research.
- If some information is missing, just present the information you have.
- Be conversational and engaging.
RESEARCH_DATA:
{ research_data }
"""
)
tour_guide_workflow = SequentialAgent(
name="tour_guide_workflow",
description="The main workflow for handling a user's request about an animal.",
sub_agents=[
comprehensive_researcher, # Step 1: Gather all data
response_formatter, # Step 2: Format the final response
]
)
root_agent = Agent(
name="greeter",
model=model_name,
description="The main entry point for the Zoo Tour Guide.",
instruction="""
- Let the user know you will help them learn about the animals we have in the zoo.
- When the user responds, use the 'add_prompt_to_state' tool to save their response.
After using the tool, transfer control to the 'tour_guide_workflow' agent.
""",
tools=[add_prompt_to_state],
sub_agents=[tour_guide_workflow]
)
Следующий этап — развертывание!
9. Подготовьте приложение к развертыванию.
Проверьте окончательную структуру.
Перед развертыванием убедитесь, что в каталоге вашего проекта находятся правильные файлы.
- Убедитесь, что папка
zoo_guide_agentвыглядит следующим образом:zoo_guide_agent/ ├── .env ├── __init__.py ├── agent.py └── requirements.txt
Настройте разрешения IAM.
После подготовки локального кода следующим шагом будет настройка идентификатора, который ваш агент будет использовать в облаке.
- В терминале загрузите переменные в свою сессию командной оболочки.
source .env - Создайте отдельный сервисный аккаунт для вашей службы Cloud Run, чтобы у неё были свои специфические права доступа. Вставьте следующее в терминал :
gcloud iam service-accounts create ${SA_NAME} \ --display-name="Service Account for lab 2 " - Предоставьте учетной записи службы роль пользователя Vertex AI, которая даст ей разрешение на вызов моделей Google.
# Grant the "Vertex AI User" role to your service account gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:$SERVICE_ACCOUNT" \ --role="roles/aiplatform.user"
10. Разверните агент с помощью интерфейса командной строки ADK.
После того, как ваш локальный код готов, а проект Google Cloud подготовлен, пришло время развернуть агент. Вы будете использовать команду adk deploy cloud_run — удобный инструмент, автоматизирующий весь процесс развертывания. Эта единственная команда упаковывает ваш код, создает образ контейнера, загружает его в реестр артефактов и запускает службу в Cloud Run , делая ее доступной в сети.
- Для развертывания агента выполните следующую команду в терминале .
# Run the deployment command uvx --from google-adk==1.14.0 \ adk deploy cloud_run \ --project=$PROJECT_ID \ --region=europe-west1 \ --service_name=zoo-tour-guide \ --with_ui \ . \ -- \ --labels=dev-tutorial=codelab-adk \ --service-account=$SERVICE_ACCOUNTuvxпозволяет запускать инструменты командной строки, опубликованные в виде пакетов Python, без необходимости глобальной установки этих инструментов. - Если вам будет предложено следующее:
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [europe-west1] will be created. Do you want to continue (Y/n)?
Yи нажмите ENTER. - Если вам будет предложено следующее:
Allow unauthenticated invocations to [your-service-name] (y/N)?.
yи нажмите ENTER. Это позволит запускать данную лабораторную работу без аутентификации для удобства тестирования. В случае успешного выполнения команда предоставит URL-адрес развернутой службы Cloud Run. (Он будет выглядеть примерно так:https://zoo-tour-guide-123456789.europe-west1.run.app). - Скопируйте URL-адрес развернутой службы Cloud Run для выполнения следующей задачи.
11. Протестируйте развернутого агента.
После запуска агента в Cloud Run вам потребуется провести тест, чтобы убедиться в успешности развертывания и корректной работе агента. Для доступа к веб-интерфейсу ADK и взаимодействия с агентом используйте общедоступный URL-адрес сервиса (например, https://zoo-tour-guide-123456789.europe-west1.run.app/ ).
- Откройте общедоступный URL-адрес Cloud Run Service в веб-браузере. Поскольку вы использовали
--with_ui flag, вы должны увидеть пользовательский интерфейс разработчика ADK. - Включите функцию
Token Streamingв правом верхнем углу.
Теперь вы можете взаимодействовать с агентом зоопарка. - Напишите
helloи нажмите Enter, чтобы начать новый разговор. - Обратите внимание на результат. Агент должен быстро ответить своим приветствием, которое будет выглядеть примерно так:
"Hello! I'm your Zoo Tour Guide. I can help you learn about the amazing animals we have here. What would you like to know or explore today?"
- Задавайте агенту такие вопросы:
Where can I find the polar bears in the zoo and what is their diet?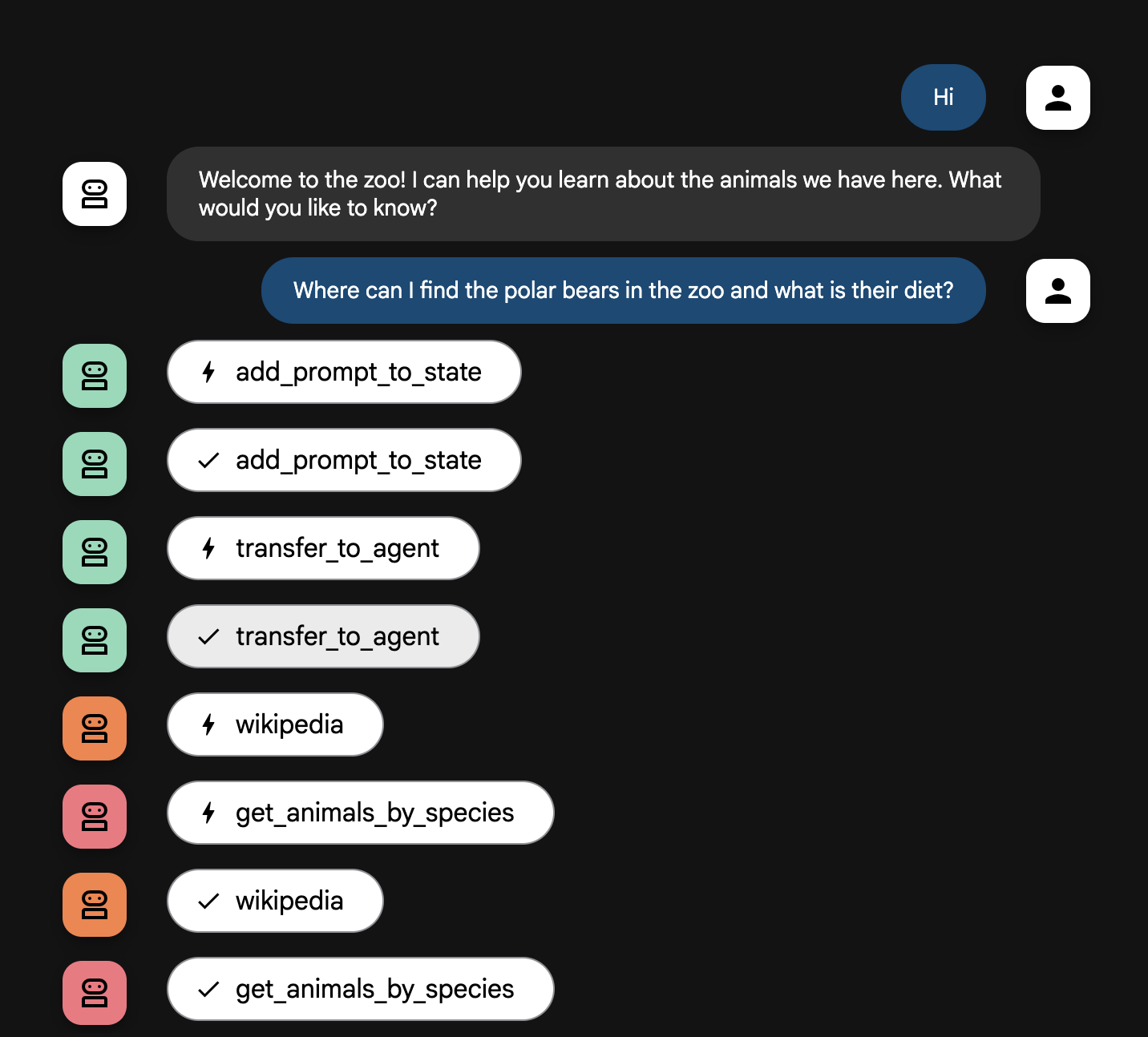

Объяснение потока агентов
Ваша система работает как интеллектуальная многоагентная команда . Процесс управляется в соответствии с четкой последовательностью, обеспечивающей плавный и эффективный переход от вопроса пользователя к окончательному, подробному ответу.
1. Сотрудник зоопарка, встречающий посетителей (стойка регистрации)
Весь процесс начинается с сотрудника, встречающего гостей.
- Его задача: начать разговор. Его инструкция — поприветствовать пользователя и спросить, о каком животном он хотел бы узнать больше.
- Инструмент: Когда пользователь отвечает, приветствующая система использует инструмент add_prompt_to_state, чтобы зафиксировать его точные слова (например, "расскажите мне о львах") и сохранить их в памяти системы.
- Передача управления: После сохранения запроса управление немедленно передается его субагенту, рабочему процессу гида-экскурсовода.
2. Исследователь-всесторонне развитый (Супер-исследователь)
Это первый этап основного рабочего процесса и «мозг» операции. Вместо большой команды у вас теперь есть один высококвалифицированный агент, имеющий доступ ко всей доступной информации.
- Его задача: проанализировать вопрос пользователя и сформировать интеллектуальный план. Он использует возможности инструментария языковой модели, чтобы определить, нуждается ли он в следующем:
- Общие сведения из интернета (через API Википедии).
- Или, в случае сложных вопросов, и то, и другое.
3. Форматировщик ответов (докладчик)
После того как исследователь соберет все необходимые данные, это будет последний агент, который необходимо запустить.
- Его задача: выступать в роли дружелюбного голоса гида зоопарка. Он берет необработанные данные (которые могут поступать из одного или обоих источников) и обрабатывает их.
- Принцип действия: Он синтезирует всю информацию в единый, связный и увлекательный ответ. Следуя инструкциям, он сначала представляет конкретную информацию о зоопарке, а затем добавляет интересные общие факты.
- Итоговый результат: текст, сгенерированный этим агентом, представляет собой полный, подробный ответ, который пользователь видит в окне чата.
Если вас интересует более подробная информация о создании агентов , ознакомьтесь со следующими ресурсами:
12. Очистка окружающей среды
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, используемые в этом руководстве, либо удалите проект, содержащий эти ресурсы, либо сохраните проект и удалите отдельные ресурсы.
Удалите службы и образы Cloud Run.
Если вы хотите сохранить проект Google Cloud, но удалить определенные ресурсы, созданные в этой лабораторной работе, вам необходимо удалить как работающую службу, так и образ контейнера, хранящиеся в реестре.
- Выполните следующие команды в терминале :
gcloud run services delete zoo-tour-guide --region=europe-west1 --quiet gcloud artifacts repositories delete cloud-run-source-deploy --location=europe-west1 --quiet
Удалить проект (необязательно)
Если вы создали новый проект специально для этой лабораторной работы и не планируете использовать его снова, самый простой способ очистки — удалить весь проект. Это гарантирует полное удаление всех ресурсов (включая учетную запись службы и любые скрытые артефакты сборки).
- В терминале выполните следующую команду (замените [YOUR_PROJECT_ID] на фактический идентификатор вашего проекта):
gcloud projects delete $PROJECT_ID
13. Поздравляем!
Вы успешно создали и развернули многоагентное приложение искусственного интеллекта в Google Cloud!
Краткий обзор
В этой лабораторной работе вы создали действующий, общедоступный сервис искусственного интеллекта, начав с пустого каталога. Вот что у вас получилось:
- Вы создали специализированную команду : вместо одного универсального ИИ вы создали «Исследователя» для поиска фактов и «Форматировщика» для уточнения ответа.
- Вы предоставили им инструменты : вы связали своих агентов с внешним миром, используя API Википедии.
- Вы его выпустили : вы взяли свой локальный код на Python и развернули его в виде бессерверного контейнера на Cloud Run , защитив его с помощью выделенной учетной записи службы.
Что мы рассмотрели
- Как структурировать проект на Python для развертывания с помощью ADK .
- Как реализовать многоагентный рабочий процесс с использованием
[SequentialAgent](https://google.github.io/adk-docs/agents/workflow-agents/sequential-agents/). - Как интегрировать внешние инструменты, такие как API Википедии.
- Как развернуть агент в Cloud Run с помощью команды
adk deploy.
14. Опрос
Выход: