
1. บทนำ
แล็บนี้มุ่งเน้นการใช้งานและการติดตั้งใช้งานบริการตัวแทนไคลเอ็นต์ คุณจะใช้ Agent Development Kit (ADK) เพื่อสร้าง AI Agent ที่ใช้เครื่องมือ
ในห้องทดลองนี้ เราจะสร้างเอเจนต์สวนสัตว์ที่ใช้ Wikipedia เพื่อตอบคำถามเกี่ยวกับสัตว์

สุดท้าย เราจะทำให้เอเจนต์ไกด์นำเที่ยวใช้งานได้ใน Cloud Run ของ Google แทนที่จะเรียกใช้ในเครื่องเท่านั้น
ข้อกำหนดเบื้องต้น
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
สิ่งที่คุณจะได้เรียนรู้
- วิธีวางโครงสร้างโปรเจ็กต์ Python สำหรับการติดตั้งใช้งาน ADK
- วิธีติดตั้งใช้งานเอเจนต์ที่ใช้เครื่องมือด้วย google-adk
- วิธีทำให้ใช้งานได้แอปพลิเคชัน Python เป็นคอนเทนเนอร์แบบ Serverless ใน Cloud Run
- วิธีกำหนดค่าการตรวจสอบสิทธิ์ที่ปลอดภัยแบบบริการต่อบริการโดยใช้บทบาท IAM
- วิธีลบทรัพยากรในระบบคลาวด์เพื่อหลีกเลี่ยงค่าใช้จ่ายในอนาคต
สิ่งที่คุณต้องมี
- บัญชี Google Cloud และโปรเจ็กต์ Google Cloud
- เว็บเบราว์เซอร์ เช่น Chrome
2. ทำไมจึงควรติดตั้งใช้งานใน Cloud Run
Cloud Run เป็นตัวเลือกที่ยอดเยี่ยมสำหรับการโฮสต์เอเจนต์ ADK เนื่องจากเป็นแพลตฟอร์มแบบ Serverless ซึ่งหมายความว่าคุณสามารถมุ่งเน้นที่โค้ดได้โดยไม่ต้องจัดการโครงสร้างพื้นฐาน เราจะจัดการงานด้านการปฏิบัติการให้คุณ
โดยจะทำงานเหมือนร้านค้าชั่วคราว ซึ่งจะเปิดและใช้ทรัพยากรเมื่อมีลูกค้า (คำขอ) เข้ามาเท่านั้น เมื่อไม่มีลูกค้า ร้านค้าจะปิดตัวลงอย่างสมบูรณ์ และคุณไม่ต้องจ่ายเงินสำหรับร้านค้าที่ว่างเปล่า
ฟีเจอร์หลัก
เรียกใช้คอนเทนเนอร์ได้ทุกที่
- คุณนำคอนเทนเนอร์ (อิมเมจ Docker) ที่มีแอปของคุณอยู่ภายในมา
- Cloud Run จะเรียกใช้ในโครงสร้างพื้นฐานของ Google
- ไม่ต้องกังวลเรื่องการแพตช์ระบบปฏิบัติการ การตั้งค่า VM หรือการปรับขนาด
การปรับขนาดอัตโนมัติ:
- หากมีผู้ใช้แอป 0 คน → มีอินสแตนซ์ที่ทำงาน 0 รายการ (ลดขนาดลงเหลือ 0 อินสแตนซ์ซึ่งประหยัดค่าใช้จ่าย)
- หากมีคำขอ 1,000 รายการเข้ามา ระบบจะหมุนเวียนสำเนาตามจำนวนที่จำเป็น
ไม่เก็บสถานะโดยค่าเริ่มต้น:
- คำขอแต่ละรายการอาจไปที่อินสแตนซ์ที่แตกต่างกัน
- หากต้องการจัดเก็บสถานะ ให้ใช้บริการภายนอก เช่น Cloud SQL, Firestore หรือ Memorystore
รองรับภาษาหรือเฟรมเวิร์กใดก็ได้
- Cloud Run ไม่สนใจว่าจะเป็น Python, Go, Node.js, Java หรือ .Net ตราบใดที่แอปพลิเคชันนั้นทำงานในคอนเทนเนอร์ Linux
จ่ายเงินตามการใช้งานจริง:
- การเรียกเก็บเงินตามคำขอ: เรียกเก็บเงินต่อคำขอ + เวลาในการคำนวณ (ต่ำสุด 100 มิลลิวินาที)
- การเรียกเก็บเงินตามอินสแตนซ์: เรียกเก็บเงินตลอดอายุการใช้งานของอินสแตนซ์ (ไม่มีค่าธรรมเนียมต่อคำขอ)
3. การตั้งค่าโปรเจ็กต์
บัญชี Google
หากยังไม่มีบัญชี Google ส่วนบุคคล คุณต้องสร้างบัญชี Google
ใช้บัญชีส่วนตัวแทนบัญชีของที่ทำงานหรือบัญชีโรงเรียน
ลงชื่อเข้าใช้คอนโซล Google Cloud
ลงชื่อเข้าใช้ คอนโซล Google Cloud โดยใช้บัญชี Google ส่วนบุคคล
เปิดใช้การเรียกเก็บเงิน
ตั้งค่าบัญชีสำหรับการเรียกเก็บเงินส่วนตัว
หากตั้งค่าการเรียกเก็บเงินโดยใช้เครดิต Google Cloud คุณจะข้ามขั้นตอนนี้ได้
หากต้องการตั้งค่าบัญชีสำหรับการเรียกเก็บเงินส่วนตัว ให้ไปที่นี่เพื่อเปิดใช้การเรียกเก็บเงินใน Cloud Console
ข้อควรทราบ
- การทำ Lab นี้ควรมีค่าใช้จ่ายน้อยกว่า $1 USD ในทรัพยากรระบบคลาวด์
- คุณสามารถทำตามขั้นตอนที่ส่วนท้ายของแล็บนี้เพื่อลบทรัพยากรเพื่อหลีกเลี่ยงการเรียกเก็บเงินเพิ่มเติม
- ผู้ใช้ใหม่มีสิทธิ์ใช้ช่วงทดลองใช้ฟรีมูลค่า$300 USD
สร้างโปรเจ็กต์ (ไม่บังคับ)
หากไม่มีโปรเจ็กต์ปัจจุบันที่ต้องการใช้สำหรับแล็บนี้ ให้สร้างโปรเจ็กต์ใหม่ที่นี่
4. เปิดเครื่องมือแก้ไข Cloud Shell
- คลิกลิงก์นี้เพื่อไปยัง Cloud Shell Editor โดยตรง
- หากระบบแจ้งให้ให้สิทธิ์ในวันนี้ ให้คลิกให้สิทธิ์เพื่อดำเนินการต่อ
- หากเทอร์มินัลไม่ปรากฏที่ด้านล่างของหน้าจอ ให้เปิดโดยทำดังนี้
- คลิกดู
- คลิก Terminal
5. ตั้งค่าโปรเจ็กต์
- ในเทอร์มินัล ให้ตั้งค่าโปรเจ็กต์ด้วยคำสั่งนี้
gcloud config set project [PROJECT_ID]gcloud config set project lab-project-id-example
- คุณควรเห็นข้อความต่อไปนี้
Updated property [core/project].
6. เปิดใช้ API
หากต้องการใช้ Cloud Run, Artifact Registry, Cloud Build, Vertex AI และ Compute Engine คุณต้องเปิดใช้ API ที่เกี่ยวข้องในโปรเจ็กต์ที่อยู่ในระบบคลาวด์ Google
- ในเทอร์มินัล ให้เปิดใช้ API ดังนี้
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.comOperation "operations/acat.p2-[GUID]" finished successfully.
ขอแนะนำ API
- Cloud Run Admin API (
run.googleapis.com) ช่วยให้คุณเรียกใช้บริการส่วนหน้าและบริการแบ็กเอนด์ งานแบบกลุ่ม หรือเว็บไซต์ในสภาพแวดล้อมที่มีการจัดการครบวงจรได้ โดยจะจัดการโครงสร้างพื้นฐานสำหรับการทำให้ใช้งานได้และปรับขนาดแอปพลิเคชันที่สร้างโดยใช้คอนเทนเนอร์ - Artifact Registry API (
artifactregistry.googleapis.com) มีที่เก็บข้อมูลส่วนตัวที่ปลอดภัยสำหรับจัดเก็บอิมเมจคอนเทนเนอร์ ซึ่งเป็นวิวัฒนาการของ Container Registry และผสานรวมกับ Cloud Run และ Cloud Build ได้อย่างราบรื่น - Cloud Build API (
cloudbuild.googleapis.com) เป็นแพลตฟอร์ม CI/CD แบบไร้เซิร์ฟเวอร์ที่ดำเนินการกับบิลด์ของคุณในโครงสร้างพื้นฐานของระบบคลาวด์ของ Google ใช้เพื่อสร้างอิมเมจคอนเทนเนอร์ในระบบคลาวด์จาก Dockerfile - Vertex AI API (
aiplatform.googleapis.com) ช่วยให้แอปพลิเคชันที่ติดตั้งใช้งานสามารถสื่อสารกับโมเดล Gemini เพื่อทำงาน AI หลักได้ โดยมี API แบบรวมสำหรับบริการ AI ทั้งหมดของ Google Cloud - Compute Engine API (
compute.googleapis.com) มีเครื่องเสมือนที่ปลอดภัยและปรับแต่งได้ซึ่งทำงานบนโครงสร้างพื้นฐานของ Google แม้ว่า Cloud Run จะได้รับการจัดการ แต่ก็มักจะต้องใช้ Compute Engine API เป็นการพึ่งพาพื้นฐานสำหรับทรัพยากรระบบเครือข่ายและการคำนวณต่างๆ
7. เตรียมสภาพแวดล้อมในการพัฒนาซอฟต์แวร์
สร้างไดเรกทอรี
- ในเทอร์มินัล ให้สร้างไดเรกทอรีโปรเจ็กต์และไดเรกทอรีย่อยที่จำเป็น
cd && mkdir zoo_guide_agent && cd zoo_guide_agent - ในเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้เพื่อเปิดไดเรกทอรี
zoo_guide_agentในโปรแกรมสำรวจ Cloud Shell Editorcloudshell open-workspace ~/zoo_guide_agent - แผง Explorer ทางด้านซ้ายจะรีเฟรช ตอนนี้คุณควรเห็นไดเรกทอรีที่สร้างขึ้น
ข้อกำหนดในการติดตั้ง
- เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัลเพื่อสร้างไฟล์
requirements.txtcloudshell edit requirements.txt - เพิ่มข้อมูลต่อไปนี้ลงในไฟล์
requirements.txtที่สร้างขึ้นใหม่google-adk==1.14.0 langchain-community==0.3.27 wikipedia==1.4.0 - ในเทอร์มินัล ให้สร้างและเปิดใช้งานสภาพแวดล้อมเสมือนโดยใช้ uv ซึ่งจะช่วยให้มั่นใจได้ว่าการขึ้นต่อกันของโปรเจ็กต์จะไม่ขัดแย้งกับ Python ของระบบ
uv venv source .venv/bin/activate - ติดตั้งแพ็กเกจที่จำเป็นลงในสภาพแวดล้อมเสมือนในเทอร์มินัล
uv pip install -r requirements.txt
ตั้งค่าตัวแปรสภาพแวดล้อม
- ใช้คำสั่งต่อไปนี้ในเทอร์มินัลเพื่อสร้างไฟล์
.env# 1. Set the variables in your terminal first PROJECT_ID=$(gcloud config get-value project) PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)") SA_NAME=lab2-cr-service # 2. Create the .env file using those variables cat <<EOF > .env PROJECT_ID=$PROJECT_ID PROJECT_NUMBER=$PROJECT_NUMBER SA_NAME=$SA_NAME SERVICE_ACCOUNT=${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com MODEL="gemini-2.5-flash" EOF
8. สร้างเวิร์กโฟลว์ของ Agent
สร้างไฟล์ __init__.py
- สร้างไฟล์ init.py โดยเรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล
cloudshell edit __init__.py - เพิ่มโค้ดต่อไปนี้ลงในไฟล์
__init__.pyใหม่from . import agent
สร้างไฟล์ agent.py
- สร้างไฟล์
agent.pyหลักโดยวางคำสั่งต่อไปนี้ลงในเทอร์มินัลcloudshell edit agent.py - การนําเข้าและการตั้งค่าเริ่มต้น: เพิ่มโค้ดต่อไปนี้ลงในไฟล์
agent.pyที่ว่างอยู่ในปัจจุบันimport os import logging import google.cloud.logging from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper import google.auth import google.auth.transport.requests import google.oauth2.id_token # --- Setup Logging and Environment --- cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL")agent.pyจะนำเข้าไลบรารีที่จำเป็นทั้งหมดจาก ADK และ Google Cloud นอกจากนี้ ยังตั้งค่าการบันทึกและโหลดตัวแปรสภาพแวดล้อมจากไฟล์.envซึ่งมีความสำคัญอย่างยิ่งต่อการเข้าถึง URL ของโมเดลและเซิร์ฟเวอร์ - กำหนดเครื่องมือ: Agent จะทำงานได้ดีก็ต่อเมื่อมีเครื่องมือที่ใช้ได้ เพิ่มโค้ดต่อไปนี้ที่ด้านล่างของ
agent.pyเพื่อกำหนดเครื่องมือ# Greet user and save their prompt def add_prompt_to_state( tool_context: ToolContext, prompt: str ) -> dict[str, str]: """Saves the user's initial prompt to the state.""" tool_context.state["PROMPT"] = prompt logging.info(f"[State updated] Added to PROMPT: {prompt}") return {"status": "success"} # Configuring the Wikipedia Tool wikipedia_tool = LangchainTool( tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper()) )add_prompt_to_state📝: เครื่องมือนี้จะจดจำสิ่งที่ผู้เข้าชมสวนสัตว์ถาม เมื่อผู้เข้าชมถามว่า "สิงโตอยู่ที่ไหน" เครื่องมือนี้จะบันทึกคำถามนั้นลงในหน่วยความจำของตัวแทน เพื่อให้ตัวแทนอื่นๆ ในเวิร์กโฟลว์รู้ว่าต้องค้นหาอะไร
วิธี: เป็นฟังก์ชัน Python ที่เขียนพรอมต์ของผู้เข้าชมลงในพจนานุกรมtool_context.stateที่แชร์ บริบทของเครื่องมือนี้แสดงถึงหน่วยความจำระยะสั้นของเอเจนต์สำหรับการสนทนาครั้งเดียว ตัวแทนรายหนึ่งบันทึกข้อมูลลงในสถานะ ตัวแทนรายถัดไปในเวิร์กโฟลว์จะอ่านข้อมูลนั้นได้LangchainTool🌍: การดำเนินการนี้จะช่วยให้ Agent ไกด์นำเที่ยวมีความรู้ทั่วไปเกี่ยวกับโลก เมื่อผู้เข้าชมถามคำถามที่ไม่ได้อยู่ในฐานข้อมูลของสวนสัตว์ เช่น "สิงโตกินอะไรในป่า" เครื่องมือนี้จะช่วยให้ตัวแทนค้นหาคำตอบใน Wikipedia ได้
วิธีการ: ทำหน้าที่เป็นตัวดัดแปลงที่ช่วยให้เอเจนต์ของเราใช้เครื่องมือ WikipediaQueryRun ที่สร้างไว้ล่วงหน้าจากไลบรารี LangChain ได้
- กำหนดตัวแทนผู้เชี่ยวชาญ: เพิ่มโค้ดต่อไปนี้ที่ด้านล่างของ
agent.pyเพื่อกำหนดตัวแทนcomprehensive_researcherและresponse_formatter# 1. Researcher Agent comprehensive_researcher = Agent( name="comprehensive_researcher", model=model_name, description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.", instruction=""" You are a helpful research assistant. Your goal is to fully answer the user's PROMPT. You have access to two tools: 1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations). 2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat). First, analyze the user's PROMPT. - If the prompt can be answered by only one tool, use that tool. - If the prompt is complex and requires information from both the zoo's database AND Wikipedia, you MUST use both tools to gather all necessary information. - Synthesize the results from the tool(s) you use into preliminary data outputs. PROMPT: { PROMPT } """, tools=[ wikipedia_tool ], output_key="research_data" # A key to store the combined findings ) # 2. Response Formatter Agent response_formatter = Agent( name="response_formatter", model=model_name, description="Synthesizes all information into a friendly, readable response.", instruction=""" You are the friendly voice of the Zoo Tour Guide. Your task is to take the RESEARCH_DATA and present it to the user in a complete and helpful answer. - First, present the specific information from the zoo (like names, ages, and where to find them). - Then, add the interesting general facts from the research. - If some information is missing, just present the information you have. - Be conversational and engaging. RESEARCH_DATA: { research_data } """ )comprehensive_researcherเอเจนต์คือ "สมอง" ของการทำงานของเรา โดยจะรับพรอมต์ของผู้ใช้จากStateที่แชร์ ตรวจสอบว่าพรอมต์นั้นเป็นเครื่องมือ Wikipedia หรือไม่ และตัดสินใจว่าจะใช้พรอมต์ใดเพื่อค้นหาคำตอบresponse_formatterบทบาทของเอเจนต์คือการนำเสนอ โดยจะใช้ข้อมูลดิบที่รวบรวมโดยตัวแทนนักวิจัย (ส่งผ่านทางสถานะ) และใช้ทักษะด้านภาษาของ LLM เพื่อเปลี่ยนข้อมูลดังกล่าวให้เป็นการตอบกลับแบบสนทนาที่เป็นมิตร
- กำหนด Agent เวิร์กโฟลว์: เพิ่มบล็อกโค้ดนี้ที่ด้านล่างของ
agent.pyเพื่อกำหนด Agent แบบลำดับtour_guide_workflowดังนี้tour_guide_workflow = SequentialAgent( name="tour_guide_workflow", description="The main workflow for handling a user's request about an animal.", sub_agents=[ comprehensive_researcher, # Step 1: Gather all data response_formatter, # Step 2: Format the final response ] )
วิธีการ: เป็นSequentialAgentซึ่งเป็น Agent ประเภทพิเศษที่ไม่คิดเอง หน้าที่ของมันมีเพียงการเรียกใช้รายการsub_agents(ผู้ค้นคว้าและผู้จัดรูปแบบ) ตามลำดับที่กำหนด โดยจะส่งต่อหน่วยความจำที่แชร์จากหนึ่งไปยังอีกหนึ่งโดยอัตโนมัติ - ประกอบเวิร์กโฟลว์หลัก: เพิ่มโค้ดบล็อกสุดท้ายนี้ที่ด้านล่างของ
agent.pyเพื่อกำหนดroot_agentroot_agent = Agent( name="greeter", model=model_name, description="The main entry point for the Zoo Tour Guide.", instruction=""" - Let the user know you will help them learn about the animals we have in the zoo. - When the user responds, use the 'add_prompt_to_state' tool to save their response. After using the tool, transfer control to the 'tour_guide_workflow' agent. """, tools=[add_prompt_to_state], sub_agents=[tour_guide_workflow] )root_agentเป็นจุดเริ่มต้นของการสนทนาใหม่ทั้งหมด โดยมีบทบาทหลักในการประสานงานกระบวนการโดยรวม โดยจะทำหน้าที่เป็นตัวควบคุมเริ่มต้นที่จัดการการสนทนาในรอบแรก

ไฟล์ agent.py แบบเต็ม
ไฟล์ agent.py ของคุณเสร็จสมบูรณ์แล้ว การสร้างในลักษณะนี้จะช่วยให้คุณเห็นว่าคอมโพเนนต์แต่ละอย่าง ไม่ว่าจะเป็นเครื่องมือ เอเจนต์ของผู้ปฏิบัติงาน และเอเจนต์ของผู้จัดการ มีบทบาทเฉพาะในการสร้างระบบอัจฉริยะขั้นสุดท้ายอย่างไร
ไฟล์ที่สมบูรณ์ควรมีลักษณะดังนี้
import os
import logging
import google.cloud.logging
from dotenv import load_dotenv
from google.adk import Agent
from google.adk.agents import SequentialAgent
from google.adk.tools.tool_context import ToolContext
from google.adk.tools.langchain_tool import LangchainTool
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
import google.auth
import google.auth.transport.requests
import google.oauth2.id_token
# --- Setup Logging and Environment ---
cloud_logging_client = google.cloud.logging.Client()
cloud_logging_client.setup_logging()
load_dotenv()
model_name = os.getenv("MODEL")
# Greet user and save their prompt
def add_prompt_to_state(
tool_context: ToolContext, prompt: str
) -> dict[str, str]:
"""Saves the user's initial prompt to the state."""
tool_context.state["PROMPT"] = prompt
logging.info(f"[State updated] Added to PROMPT: {prompt}")
return {"status": "success"}
# Configuring the Wikipedia Tool
wikipedia_tool = LangchainTool(
tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
)
# 1. Researcher Agent
comprehensive_researcher = Agent(
name="comprehensive_researcher",
model=model_name,
description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.",
instruction="""
You are a helpful research assistant. Your goal is to fully answer the user's PROMPT.
You have access to two tools:
1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations).
2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat).
First, analyze the user's PROMPT.
- If the prompt can be answered by only one tool, use that tool.
- If the prompt is complex and requires information from both the zoo's database AND Wikipedia,
you MUST use both tools to gather all necessary information.
- Synthesize the results from the tool(s) you use into preliminary data outputs.
PROMPT:
{ PROMPT }
""",
tools=[
wikipedia_tool
],
output_key="research_data" # A key to store the combined findings
)
# 2. Response Formatter Agent
response_formatter = Agent(
name="response_formatter",
model=model_name,
description="Synthesizes all information into a friendly, readable response.",
instruction="""
You are the friendly voice of the Zoo Tour Guide. Your task is to take the
RESEARCH_DATA and present it to the user in a complete and helpful answer.
- First, present the specific information from the zoo (like names, ages, and where to find them).
- Then, add the interesting general facts from the research.
- If some information is missing, just present the information you have.
- Be conversational and engaging.
RESEARCH_DATA:
{ research_data }
"""
)
tour_guide_workflow = SequentialAgent(
name="tour_guide_workflow",
description="The main workflow for handling a user's request about an animal.",
sub_agents=[
comprehensive_researcher, # Step 1: Gather all data
response_formatter, # Step 2: Format the final response
]
)
root_agent = Agent(
name="greeter",
model=model_name,
description="The main entry point for the Zoo Tour Guide.",
instruction="""
- Let the user know you will help them learn about the animals we have in the zoo.
- When the user responds, use the 'add_prompt_to_state' tool to save their response.
After using the tool, transfer control to the 'tour_guide_workflow' agent.
""",
tools=[add_prompt_to_state],
sub_agents=[tour_guide_workflow]
)
ขั้นตอนถัดไปคือการติดตั้งใช้งาน
9. เตรียมแอปพลิเคชันสำหรับการนำไปใช้งาน
ตรวจสอบโครงสร้างสุดท้าย
ก่อนที่จะติดตั้งใช้งาน ให้ตรวจสอบว่าไดเรกทอรีโปรเจ็กต์มีไฟล์ที่ถูกต้อง
- ตรวจสอบว่าโฟลเดอร์
zoo_guide_agentมีลักษณะดังนี้zoo_guide_agent/ ├── .env ├── __init__.py ├── agent.py └── requirements.txt
ตั้งค่าสิทธิ์ IAM
เมื่อโค้ดในเครื่องพร้อมแล้ว ขั้นตอนถัดไปคือการตั้งค่าข้อมูลประจำตัวที่เอเจนต์จะใช้ในระบบคลาวด์
- ในเทอร์มินัล ให้โหลดตัวแปรลงในเซสชันเชลล์
source .env - สร้างบัญชีบริการเฉพาะสำหรับบริการ Cloud Run เพื่อให้มีสิทธิ์เฉพาะของตัวเอง วางข้อความต่อไปนี้ลงในเทอร์มินัล
gcloud iam service-accounts create ${SA_NAME} \ --display-name="Service Account for lab 2 " - มอบบทบาทผู้ใช้ Vertex AI ให้กับบัญชีบริการ ซึ่งจะให้สิทธิ์ในการเรียกใช้โมเดลของ Google
# Grant the "Vertex AI User" role to your service account gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:$SERVICE_ACCOUNT" \ --role="roles/aiplatform.user"
10. ติดตั้งใช้งาน Agent โดยใช้ ADK CLI
เมื่อโค้ดในเครื่องพร้อมและโปรเจ็กต์ที่อยู่ในระบบคลาวด์ของ Google Cloud เตรียมพร้อมแล้ว ก็ถึงเวลาทำให้ใช้งานได้เอเจนต์ คุณจะใช้คำสั่ง adk deploy cloud_run ซึ่งเป็นเครื่องมือที่สะดวกสบายซึ่งจะทำให้เวิร์กโฟลว์การติดตั้งใช้งานทั้งหมดเป็นอัตโนมัติ คำสั่งเดียวนี้จะแพ็กเกจโค้ด สร้างอิมเมจคอนเทนเนอร์ พุชไปยัง Artifact Registry และเปิดใช้บริการใน Cloud Run ทำให้เข้าถึงได้บนเว็บ
- เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัลเพื่อติดตั้งใช้งานเอเจนต์
# Run the deployment command uvx --from google-adk==1.14.0 \ adk deploy cloud_run \ --project=$PROJECT_ID \ --region=europe-west1 \ --service_name=zoo-tour-guide \ --with_ui \ . \ -- \ --labels=dev-tutorial=codelab-adk \ --service-account=$SERVICE_ACCOUNTuvxช่วยให้คุณเรียกใช้เครื่องมือบรรทัดคำสั่งที่เผยแพร่เป็นแพ็กเกจ Python ได้โดยไม่ต้องติดตั้งเครื่องมือเหล่านั้นทั่วโลก - หากระบบแจ้งให้คุณดำเนินการต่อไปนี้
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [europe-west1] will be created. Do you want to continue (Y/n)?
Yแล้วกด Enter - หากระบบแจ้งให้คุณดำเนินการต่อไปนี้
Allow unauthenticated invocations to [your-service-name] (y/N)?.
yแล้วกด ENTER ซึ่งจะช่วยให้เรียกใช้ที่ไม่ผ่านการตรวจสอบสิทธิ์สำหรับห้องทดลองนี้ได้เพื่อการทดสอบที่ง่ายดาย เมื่อดำเนินการสำเร็จแล้ว คำสั่งจะแสดง URL ของบริการ Cloud Run ที่ทำให้ใช้งานได้ (จะมีลักษณะคล้ายกับhttps://zoo-tour-guide-123456789.europe-west1.run.app) - คัดลอก URL ของบริการ Cloud Run ที่ติดตั้งใช้งานแล้วสำหรับงานถัดไป
11. ทดสอบ Agent ที่ติดตั้งใช้งาน
เมื่อตัวแทนพร้อมใช้งานใน Cloud Run แล้ว คุณจะทำการทดสอบเพื่อยืนยันว่าการติดตั้งใช้งานสำเร็จและตัวแทนทำงานได้ตามที่คาดไว้ คุณจะใช้ URL ของบริการสาธารณะ (เช่น https://zoo-tour-guide-123456789.europe-west1.run.app/) เพื่อเข้าถึงอินเทอร์เฟซเว็บของ ADK และโต้ตอบกับตัวแทน
- เปิด URL ของบริการ Cloud Run สาธารณะในเว็บเบราว์เซอร์ เนื่องจากคุณใช้
--with_ui flagคุณจึงควรเห็น UI ของนักพัฒนาแอป ADK - เปิด
Token Streamingที่ด้านขวาบน
ตอนนี้คุณโต้ตอบกับตัวแทนสวนสัตว์ได้แล้ว - พิมพ์
helloแล้วกด Enter เพื่อเริ่มการสนทนาใหม่ - สังเกตผลลัพธ์ เอเจนต์ควรตอบกลับอย่างรวดเร็วด้วยคำทักทาย ซึ่งจะมีลักษณะดังนี้
"Hello! I'm your Zoo Tour Guide. I can help you learn about the amazing animals we have here. What would you like to know or explore today?"
- ถามคำถามตัวแทน เช่น
Where can I find the polar bears in the zoo and what is their diet?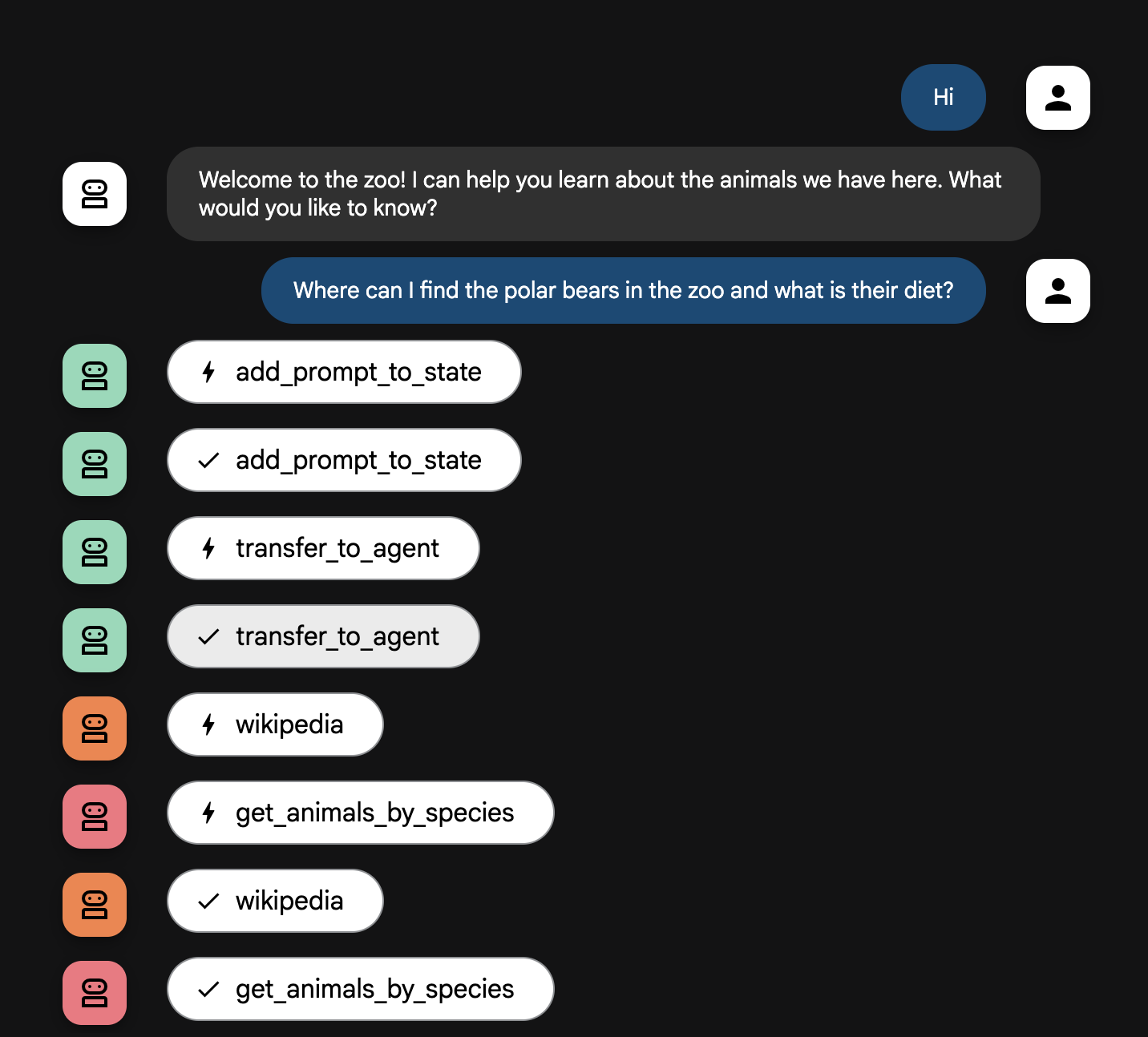

คำอธิบายโฟลว์ของ Agent
ระบบของคุณจะทำงานเป็นทีมที่มีหลายเอเจนต์อัจฉริยะ กระบวนการนี้ได้รับการจัดการตามลำดับที่ชัดเจนเพื่อให้มั่นใจว่าการไหลจากคำถามของผู้ใช้ไปจนถึงคำตอบสุดท้ายแบบละเอียดจะเป็นไปอย่างราบรื่นและมีประสิทธิภาพ
1. เจ้าหน้าที่ต้อนรับในสวนสัตว์ (โต๊ะต้อนรับ)
กระบวนการทั้งหมดเริ่มต้นด้วยตัวแทนต้อนรับ
- หน้าที่: เริ่มการสนทนา คำสั่งของฟังก์ชันนี้คือทักทายผู้ใช้และถามว่าต้องการเรียนรู้เกี่ยวกับสัตว์ชนิดใด
- เครื่องมือของ Greeter: เมื่อผู้ใช้ตอบกลับ Greeter จะใช้เครื่องมือ add_prompt_to_state เพื่อบันทึกคำพูดที่ผู้ใช้พูด (เช่น "เล่าเรื่องสิงโตให้ฟังหน่อย") และบันทึกลงในหน่วยความจำของระบบ
- การส่งต่อ: หลังจากบันทึกพรอมต์แล้ว ระบบจะส่งต่อการควบคุมไปยัง Agent ย่อย ซึ่งก็คือ tour_guide_workflow ทันที
2. นักวิจัยที่ครอบคลุม (นักวิจัยขั้นสุดยอด)
นี่คือขั้นตอนแรกในเวิร์กโฟลว์หลักและเป็น "หัวใจ" ของการดำเนินการ ตอนนี้คุณมีตัวแทนที่มีทักษะสูงเพียงคนเดียวที่เข้าถึงข้อมูลทั้งหมดที่มีได้ แทนที่จะมีทีมขนาดใหญ่
- หน้าที่: วิเคราะห์คำถามของผู้ใช้และวางแผนอย่างชาญฉลาด โดยจะใช้ความสามารถในการใช้เครื่องมือของโมเดลภาษาเพื่อพิจารณาว่าจำเป็นต้องทำสิ่งต่อไปนี้หรือไม่
- ความรู้ทั่วไปจากเว็บ (ผ่าน Wikipedia API)
- หรือทั้งสองอย่างสำหรับคำถามที่ซับซ้อน
3. Response Formatter (ผู้นำเสนอ)
เมื่อ Comprehensive Researcher รวบรวมข้อเท็จจริงทั้งหมดแล้ว นี่คือเอเจนต์สุดท้ายที่จะเรียกใช้
- หน้าที่: ทำหน้าที่เป็นเสียงที่เป็นมิตรของไกด์นำเที่ยวสวนสัตว์ โดยจะใช้ข้อมูลดิบ (ซึ่งอาจมาจากแหล่งข้อมูลใดแหล่งข้อมูลหนึ่งหรือทั้ง 2 แหล่ง) และปรับแต่งข้อมูล
- การทำงาน: สังเคราะห์ข้อมูลทั้งหมดเป็นคำตอบเดียวที่สอดคล้องและน่าสนใจ โดยจะแสดงข้อมูลสวนสัตว์ที่เฉพาะเจาะจงก่อน แล้วจึงเพิ่มข้อเท็จจริงทั่วไปที่น่าสนใจตามคำสั่ง
- ผลลัพธ์สุดท้าย: ข้อความที่เอเจนต์นี้สร้างขึ้นคือคำตอบที่สมบูรณ์และละเอียดซึ่งผู้ใช้จะเห็นในหน้าต่างแชท
หากสนใจเรียนรู้เพิ่มเติมเกี่ยวกับการสร้าง Agent โปรดดูแหล่งข้อมูลต่อไปนี้
12. ล้างข้อมูลในสภาพแวดล้อม
โปรดลบโปรเจ็กต์ที่มีทรัพยากรหรือเก็บโปรเจ็กต์ไว้และลบทรัพยากรแต่ละรายการเพื่อหลีกเลี่ยงการเรียกเก็บเงินจากบัญชี Google Cloud สำหรับทรัพยากรที่ใช้ในบทแนะนำนี้
ลบบริการและอิมเมจ Cloud Run
หากต้องการเก็บโปรเจ็กต์ที่อยู่ในระบบคลาวด์ Google ไว้แต่ลบทรัพยากรที่เฉพาะเจาะจงซึ่งสร้างขึ้นในห้องทดลองนี้ คุณต้องลบทั้งบริการที่กำลังทำงานและอิมเมจคอนเทนเนอร์ที่จัดเก็บไว้ในรีจิสทรี
- เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล
gcloud run services delete zoo-tour-guide --region=europe-west1 --quiet gcloud artifacts repositories delete cloud-run-source-deploy --location=europe-west1 --quiet
ลบโปรเจ็กต์ (ไม่บังคับ)
หากคุณสร้างโปรเจ็กต์ใหม่สําหรับแล็บนี้โดยเฉพาะและไม่มีแผนที่จะใช้โปรเจ็กต์อีกต่อไป วิธีที่ง่ายที่สุดในการล้างข้อมูลคือการลบทั้งโปรเจ็กต์ ซึ่งจะช่วยให้มั่นใจได้ว่าระบบจะนำทรัพยากรทั้งหมด (รวมถึงบัญชีบริการและอาร์ติแฟกต์การสร้างที่ซ่อนอยู่) ออกอย่างสมบูรณ์
- ในเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้ (แทนที่ [YOUR_PROJECT_ID] ด้วยรหัสโปรเจ็กต์จริง)
gcloud projects delete $PROJECT_ID
13. ขอแสดงความยินดี
คุณสร้างและทำให้แอปพลิเคชัน AI แบบหลาย Agent ใช้งานได้กับ Google Cloud เรียบร้อยแล้ว
สรุป
ในแล็บนี้ คุณได้เปลี่ยนจากไดเรกทอรีว่างเปล่าไปเป็นบริการ AI ที่ใช้งานได้จริงและเข้าถึงได้แบบสาธารณะ นี่คือสิ่งที่คุณสร้าง
- คุณสร้างทีมเฉพาะทาง: แทนที่จะใช้ AI ทั่วไปเพียงตัวเดียว คุณได้สร้าง "นักวิจัย" เพื่อค้นหาข้อเท็จจริง และ "ผู้จัดรูปแบบ" เพื่อขัดเกลาคำตอบ
- คุณมอบเครื่องมือให้พวกเขา: คุณเชื่อมต่อเอเจนต์กับโลกภายนอกโดยใช้ Wikipedia API
- คุณได้ส่งแล้ว: คุณนำโค้ด Python ในเครื่องไปทำให้ใช้งานได้เป็นคอนเทนเนอร์แบบ Serverless ใน Cloud Run และรักษาความปลอดภัยด้วยบัญชีบริการเฉพาะ
สิ่งที่เราได้พูดถึงไปแล้ว
- วิธีจัดโครงสร้างโปรเจ็กต์ Python เพื่อการติดตั้งใช้งานด้วย ADK
- วิธีใช้เวิร์กโฟลว์แบบหลายเอเจนต์โดยใช้
[SequentialAgent](https://google.github.io/adk-docs/agents/workflow-agents/sequential-agents/) - วิธีผสานรวมเครื่องมือภายนอก เช่น Wikipedia API
- วิธีติดตั้งใช้งาน Agent ใน Cloud Run โดยใช้คำสั่ง
adk deploy
14. แบบสำรวจ
เอาต์พุต: