
1. Giriş
Bu laboratuvarda, istemci aracısı hizmetinin uygulanması ve dağıtımı üzerinde durulmaktadır. Araçları kullanan bir yapay zeka ajanı oluşturmak için Agent Development Kit'i (ADK) kullanacaksınız.
Bu laboratuvarda, hayvanlarla ilgili soruları yanıtlamak için Wikipedia'yı kullanan bir hayvanat bahçesi temsilcisi oluşturacağız.

Son olarak, tur rehberi aracısını yalnızca yerel olarak çalıştırmak yerine Google Cloud Run'a dağıtacağız.
Ön koşullar
- Faturalandırmanın etkin olduğu bir Google Cloud projesi.
Neler öğreneceksiniz?
- ADK dağıtımı için Python projesini yapılandırma
- google-adk ile araç kullanan bir aracı uygulama
- Python uygulamasını Cloud Run'a sunucusuz container olarak dağıtma
- IAM rollerini kullanarak hizmetten hizmete güvenli kimlik doğrulama yapılandırma
- Gelecekteki maliyetlerden kaçınmak için Cloud kaynaklarını silme
İhtiyacınız olanlar
- Google Cloud hesabı ve Google Cloud projesi
- Chrome gibi bir web tarayıcısı
2. Neden Cloud Run'a dağıtmalısınız?
Cloud Run, ADK aracılarını barındırmak için mükemmel bir seçimdir. Sunucusuz bir platform olduğu için altyapıyı yönetmek yerine kodunuza odaklanabilirsiniz. Operasyonel işleri sizin için biz hallederiz.
Bunu bir pop-up mağaza gibi düşünebilirsiniz: Yalnızca müşteriler (istekler) geldiğinde açılır ve kaynakları kullanır. Müşteri olmadığında tamamen kapanır ve boş bir mağaza için ödeme yapmazsınız.
Temel Özellikler
Her Yerde Kapsayıcı Çalıştırma:
- Uygulamanızın bulunduğu bir container (Docker görüntüsü) getirirsiniz.
- Cloud Run, bu işlemi Google'ın altyapısında gerçekleştirir.
- İşletim sistemi yaması, sanal makine kurulumu veya ölçeklendirme ile ilgili sorunlar yok.
Otomatik Ölçeklendirme:
- Uygulamanızı kullanan kişi sayısı 0 ise → 0 örnek çalıştırılır (maliyet açısından avantajlı olan sıfır örneğe kadar ölçeklendirilir).
- 1.000 istek gelirse → gerektiği kadar kopya oluşturur.
Varsayılan olarak durum bilgisi yok:
- Her istek farklı bir örneğe gidebilir.
- Durumu depolamanız gerekiyorsa Cloud SQL, Firestore veya Memorystore gibi harici bir hizmet kullanın.
Herhangi bir dili veya çerçeveyi destekler:
- Cloud Run, Linux kapsayıcısında çalıştığı sürece Python, Go, Node.js, Java veya .Net olup olmadığını önemsemez.
Kullandığınız Kadar Ödeyin:
- İsteğe dayalı faturalandırma: İstek başına + bilgi işlem süresi (100 ms'ye kadar) faturalandırılır.
- Örnek tabanlı faturalandırma: Örnek kullanım süresinin tamamı için faturalandırılır (istek başına ücret alınmaz).
3. Proje ayarlama
Google Hesabı
Kişisel Google Hesabınız yoksa Google Hesabı oluşturmanız gerekir.
İş veya okul hesabı yerine kişisel hesap kullanın.
Google Cloud Console'da oturum açma
Kişisel bir Google Hesabı kullanarak Google Cloud Console'da oturum açın.
Faturalandırmayı Etkinleştir
Kişisel faturalandırma hesabı oluşturma
Faturalandırmayı Google Cloud kredilerini kullanarak ayarladıysanız bu adımı atlayabilirsiniz.
Kişisel faturalandırma hesabı oluşturmak için Cloud Console'da faturalandırmayı etkinleştirmek üzere buraya gidin.
Bazı notlar:
- Bu laboratuvarı tamamlamak için 1 ABD dolarından daha az tutarda bulut kaynağı kullanmanız gerekir.
- Daha fazla ücret ödememek için bu laboratuvarın sonundaki adımları uygulayarak kaynakları silebilirsiniz.
- Yeni kullanıcılar 300 ABD doları değerinde ücretsiz deneme sürümünden yararlanabilir.
Proje oluşturma (isteğe bağlı)
Bu laboratuvarda kullanmak istediğiniz mevcut bir projeniz yoksa buradan yeni bir proje oluşturun.
4. Cloud Shell Düzenleyici'yi açma
- Doğrudan Cloud Shell Düzenleyici'ye gitmek için bu bağlantıyı tıklayın.
- Bugün herhangi bir noktada yetkilendirmeniz istenirse devam etmek için Yetkilendir'i tıklayın.
- Terminal ekranın alt kısmında görünmüyorsa açın:
- Görünüm'ü tıklayın.
- Terminal'i tıklayın.
5. Projenizi ayarlama
- Terminalde şu komutla projenizi ayarlayın:
gcloud config set project [PROJECT_ID]gcloud config set project lab-project-id-example
- Şu mesajı görmeniz gerekir:
Updated property [core/project].
6. API'leri etkinleştir
Cloud Run, Artifact Registry, Cloud Build, Vertex AI ve Compute Engine'i kullanmak için Google Cloud projenizde ilgili API'leri etkinleştirmeniz gerekir.
- Terminalde API'leri etkinleştirin:
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.comOperation "operations/acat.p2-[GUID]" finished successfully.
API'lerle tanışın
- Cloud Run Admin API (
run.googleapis.com), ön uç ve arka uç hizmetlerini, toplu işleri veya web sitelerini tümüyle yönetilen bir ortamda çalıştırmanıza olanak tanır. Container mimarisine alınmış uygulamalarınızı dağıtma ve ölçeklendirme altyapısını yönetir. - Artifact Registry API (
artifactregistry.googleapis.com), kapsayıcı resimlerinizi depolamak için güvenli ve özel bir depo sağlar. Container Registry'nin gelişmiş sürümüdür ve Cloud Run ile Cloud Build'e sorunsuz bir şekilde entegre olur. - Cloud Build API (
cloudbuild.googleapis.com), derlemelerinizi Google Cloud altyapısında yürüten sunucusuz bir CI/CD platformudur. Container görüntünüzü Dockerfile'ınızdan bulutta oluşturmak için kullanılır. - Vertex AI API (
aiplatform.googleapis.com), dağıtılan uygulamanızın temel yapay zeka görevlerini gerçekleştirmek için Gemini modelleriyle iletişim kurmasını sağlar. Google Cloud'un tüm yapay zeka hizmetleri için birleşik API sağlar. - Compute Engine API (
compute.googleapis.com), Google'ın altyapısında çalışan güvenli ve özelleştirilebilir sanal makineler sağlar. Cloud Run yönetilirken çeşitli ağ ve bilgi işlem kaynakları için temel bağımlılık olarak genellikle Compute Engine API gerekir.
7. Geliştirme ortamınızı hazırlama
Dizini oluşturma
- Terminalde proje dizinini ve gerekli alt dizinleri oluşturun:
cd && mkdir zoo_guide_agent && cd zoo_guide_agent - Terminalde aşağıdaki komutu çalıştırarak Cloud Shell Düzenleyici Gezgin'de
zoo_guide_agentdizinini açın:cloudshell open-workspace ~/zoo_guide_agent - Soldaki Gezgin paneli yenilenir. Oluşturduğunuz dizini göreceksiniz.
Yükleme şartları
requirements.txtdosyasını oluşturmak için terminalde aşağıdaki komutu çalıştırın.cloudshell edit requirements.txt- Yeni oluşturulan
requirements.txtdosyasına aşağıdakileri ekleyin.google-adk==1.14.0 langchain-community==0.3.27 wikipedia==1.4.0 - Terminalde, uv'yi kullanarak sanal bir ortam oluşturun ve etkinleştirin. Bu şekilde, proje bağımlılıklarınızın sistem Python'uyla çakışmaması sağlanır.
uv venv source .venv/bin/activate - Gerekli paketleri terminalde sanal ortamınıza yükleyin.
uv pip install -r requirements.txt
Ortam değişkenlerini ayarlama
.envdosyasını oluşturmak için terminalde aşağıdaki komutu kullanın.# 1. Set the variables in your terminal first PROJECT_ID=$(gcloud config get-value project) PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)") SA_NAME=lab2-cr-service # 2. Create the .env file using those variables cat <<EOF > .env PROJECT_ID=$PROJECT_ID PROJECT_NUMBER=$PROJECT_NUMBER SA_NAME=$SA_NAME SERVICE_ACCOUNT=${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com MODEL="gemini-2.5-flash" EOF
8. Aracı İş Akışı Oluşturma
__init__.py dosyası oluşturma
- Terminalde aşağıdaki komutu çalıştırarak init.py dosyasını oluşturun:
cloudshell edit __init__.py - Yeni
__init__.pydosyasına aşağıdaki kodu ekleyin:from . import agent
agent.py dosyasını oluşturma
- Aşağıdaki komutu terminale yapıştırarak ana
agent.pydosyasını oluşturun.cloudshell edit agent.py - İçe Aktarma ve İlk Kurulum: Şu anda boş olan
agent.pydosyanıza aşağıdaki kodu ekleyin:import os import logging import google.cloud.logging from dotenv import load_dotenv from google.adk import Agent from google.adk.agents import SequentialAgent from google.adk.tools.tool_context import ToolContext from google.adk.tools.langchain_tool import LangchainTool from langchain_community.tools import WikipediaQueryRun from langchain_community.utilities import WikipediaAPIWrapper import google.auth import google.auth.transport.requests import google.oauth2.id_token # --- Setup Logging and Environment --- cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() load_dotenv() model_name = os.getenv("MODEL")agent.pydosyasının bu ilk bloğu, ADK ve Google Cloud'dan gerekli tüm kitaplıkları getirir. Ayrıca, modelinize ve sunucu URL'nize erişmek için çok önemli olan.envdosyanızdaki ortam değişkenlerini yükler ve günlük kaydını ayarlar. - Araçları tanımlayın: Bir ajanın performansı, kullanabileceği araçlarla sınırlıdır. Araçları tanımlamak için
agent.pydosyasının en altına aşağıdaki kodu ekleyin:# Greet user and save their prompt def add_prompt_to_state( tool_context: ToolContext, prompt: str ) -> dict[str, str]: """Saves the user's initial prompt to the state.""" tool_context.state["PROMPT"] = prompt logging.info(f"[State updated] Added to PROMPT: {prompt}") return {"status": "success"} # Configuring the Wikipedia Tool wikipedia_tool = LangchainTool( tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper()) )add_prompt_to_state📝: Bu araç, hayvanat bahçesi ziyaretçisinin sorduklarını hatırlar. Bir ziyaretçi "Aslanlar nerede?" diye sorduğunda bu araç, söz konusu soruyu temsilcinin belleğine kaydeder. Böylece iş akışındaki diğer temsilciler neyi araştırmaları gerektiğini bilir.
Nasıl çalışır? Ziyaretçinin istemini paylaşılantool_context.statesözlüğüne yazan bir Python işlevidir. Bu araç bağlamı, aracının tek bir görüşmedeki kısa süreli belleğini temsil eder. Bir temsilci tarafından duruma kaydedilen veriler, iş akışındaki bir sonraki temsilci tarafından okunabilir.LangchainTool🌍: Bu, tur rehberi aracısına genel dünya bilgisi verir. Bir ziyaretçi, hayvanat bahçesinin veritabanında bulunmayan bir soru sorduğunda (ör. "Aslanlar vahşi doğada ne yer?") bu araç, temsilcinin Wikipedia'da yanıtı aramasına olanak tanır.
Nasıl: Bir bağdaştırıcı görevi görerek aracımızın LangChain kitaplığındaki önceden oluşturulmuş WikipediaQueryRun aracını kullanmasına olanak tanır.
- Uzman aracıları tanımlayın:
comprehensive_researcherveresponse_formatteraracılarını tanımlamak içinagent.pydosyasının en altına aşağıdaki kodu ekleyin:# 1. Researcher Agent comprehensive_researcher = Agent( name="comprehensive_researcher", model=model_name, description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.", instruction=""" You are a helpful research assistant. Your goal is to fully answer the user's PROMPT. You have access to two tools: 1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations). 2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat). First, analyze the user's PROMPT. - If the prompt can be answered by only one tool, use that tool. - If the prompt is complex and requires information from both the zoo's database AND Wikipedia, you MUST use both tools to gather all necessary information. - Synthesize the results from the tool(s) you use into preliminary data outputs. PROMPT: { PROMPT } """, tools=[ wikipedia_tool ], output_key="research_data" # A key to store the combined findings ) # 2. Response Formatter Agent response_formatter = Agent( name="response_formatter", model=model_name, description="Synthesizes all information into a friendly, readable response.", instruction=""" You are the friendly voice of the Zoo Tour Guide. Your task is to take the RESEARCH_DATA and present it to the user in a complete and helpful answer. - First, present the specific information from the zoo (like names, ages, and where to find them). - Then, add the interesting general facts from the research. - If some information is missing, just present the information you have. - Be conversational and engaging. RESEARCH_DATA: { research_data } """ )comprehensive_researchertemsilcisi, operasyonumuzun "beynidir". PaylaşılanState'dan kullanıcının istemini alır, Wikipedia Aracı'nı inceler ve yanıtı bulmak için hangilerinin kullanılacağına karar verir.response_formattertemsilcisinin rolü sunumdur. Araştırmacı aracısı tarafından toplanan ham verileri (State üzerinden iletilir) alır ve LLM'nin dil becerilerini kullanarak bunları samimi ve sohbet tarzında bir yanıta dönüştürür.
- İş akışı aracısını tanımlayın: Sıralı aracıyı
tour_guide_workflowtanımlamak için bu kod bloğunuagent.pyöğesinin en altına ekleyin:tour_guide_workflow = SequentialAgent( name="tour_guide_workflow", description="The main workflow for handling a user's request about an animal.", sub_agents=[ comprehensive_researcher, # Step 1: Gather all data response_formatter, # Step 2: Format the final response ] )
Nasıl:SequentialAgent, kendi başına düşünmeyen özel bir aracı türüdür. Tek görevi,sub_agents(araştırmacı ve biçimlendirici) listesini sabit bir sırayla çalıştırmak ve paylaşılan belleği otomatik olarak birinden diğerine aktarmaktır. - Ana iş akışını oluşturun:
agent.pydosyasının en altına aşağıdaki son kod bloğunu ekleyerekroot_agentöğesini tanımlayın:root_agent = Agent( name="greeter", model=model_name, description="The main entry point for the Zoo Tour Guide.", instruction=""" - Let the user know you will help them learn about the animals we have in the zoo. - When the user responds, use the 'add_prompt_to_state' tool to save their response. After using the tool, transfer control to the 'tour_guide_workflow' agent. """, tools=[add_prompt_to_state], sub_agents=[tour_guide_workflow] )root_agentsimgesini kullanır. Birincil rolü, genel süreci yönetmektir. İlk kontrolör olarak hareket eder ve görüşmenin ilk dönüşünü yönetir.

Tam agent.py dosyası
agent.py dosyanız tamamlandı. Bu şekilde oluşturarak her bileşenin (araçlar, çalışan aracıları ve yönetici aracıları) nihai ve akıllı sistemi oluşturmada nasıl belirli bir role sahip olduğunu görebilirsiniz.
Dosyanın tamamı şu şekilde görünmelidir:
import os
import logging
import google.cloud.logging
from dotenv import load_dotenv
from google.adk import Agent
from google.adk.agents import SequentialAgent
from google.adk.tools.tool_context import ToolContext
from google.adk.tools.langchain_tool import LangchainTool
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
import google.auth
import google.auth.transport.requests
import google.oauth2.id_token
# --- Setup Logging and Environment ---
cloud_logging_client = google.cloud.logging.Client()
cloud_logging_client.setup_logging()
load_dotenv()
model_name = os.getenv("MODEL")
# Greet user and save their prompt
def add_prompt_to_state(
tool_context: ToolContext, prompt: str
) -> dict[str, str]:
"""Saves the user's initial prompt to the state."""
tool_context.state["PROMPT"] = prompt
logging.info(f"[State updated] Added to PROMPT: {prompt}")
return {"status": "success"}
# Configuring the Wikipedia Tool
wikipedia_tool = LangchainTool(
tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
)
# 1. Researcher Agent
comprehensive_researcher = Agent(
name="comprehensive_researcher",
model=model_name,
description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.",
instruction="""
You are a helpful research assistant. Your goal is to fully answer the user's PROMPT.
You have access to two tools:
1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations).
2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat).
First, analyze the user's PROMPT.
- If the prompt can be answered by only one tool, use that tool.
- If the prompt is complex and requires information from both the zoo's database AND Wikipedia,
you MUST use both tools to gather all necessary information.
- Synthesize the results from the tool(s) you use into preliminary data outputs.
PROMPT:
{ PROMPT }
""",
tools=[
wikipedia_tool
],
output_key="research_data" # A key to store the combined findings
)
# 2. Response Formatter Agent
response_formatter = Agent(
name="response_formatter",
model=model_name,
description="Synthesizes all information into a friendly, readable response.",
instruction="""
You are the friendly voice of the Zoo Tour Guide. Your task is to take the
RESEARCH_DATA and present it to the user in a complete and helpful answer.
- First, present the specific information from the zoo (like names, ages, and where to find them).
- Then, add the interesting general facts from the research.
- If some information is missing, just present the information you have.
- Be conversational and engaging.
RESEARCH_DATA:
{ research_data }
"""
)
tour_guide_workflow = SequentialAgent(
name="tour_guide_workflow",
description="The main workflow for handling a user's request about an animal.",
sub_agents=[
comprehensive_researcher, # Step 1: Gather all data
response_formatter, # Step 2: Format the final response
]
)
root_agent = Agent(
name="greeter",
model=model_name,
description="The main entry point for the Zoo Tour Guide.",
instruction="""
- Let the user know you will help them learn about the animals we have in the zoo.
- When the user responds, use the 'add_prompt_to_state' tool to save their response.
After using the tool, transfer control to the 'tour_guide_workflow' agent.
""",
tools=[add_prompt_to_state],
sub_agents=[tour_guide_workflow]
)
Sıradaki adım: Dağıtım
9. Uygulamayı dağıtıma hazırlama
Son yapıyı kontrol etme
Dağıtmadan önce proje dizininizin doğru dosyaları içerdiğini doğrulayın.
zoo_guide_agentklasörünüzün şu şekilde göründüğünden emin olun:zoo_guide_agent/ ├── .env ├── __init__.py ├── agent.py └── requirements.txt
IAM izinlerini ayarlama
Yerel kodunuz hazır olduğunda bir sonraki adım, aracınızın bulutta kullanacağı kimliği ayarlamaktır.
- Terminalde değişkenleri kabuk oturumunuza yükleyin.
source .env - Cloud Run hizmetiniz için özel bir hizmet hesabı oluşturarak hizmetin kendi iznine sahip olmasını sağlayın. Aşağıdakileri terminale yapıştırın:
gcloud iam service-accounts create ${SA_NAME} \ --display-name="Service Account for lab 2 " - Hizmet hesabına, Google'ın modellerini çağırma izni veren Vertex AI Kullanıcısı rolünü atayın.
# Grant the "Vertex AI User" role to your service account gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:$SERVICE_ACCOUNT" \ --role="roles/aiplatform.user"
10. ADK CLI'yı kullanarak ajanı dağıtma
Yerel kodunuz hazır ve Google Cloud projeniz hazırlanmış durumdayken artık aracı dağıtma zamanı. Tüm dağıtım iş akışını otomatikleştiren kullanışlı bir araç olan adk deploy cloud_run komutunu kullanacaksınız. Bu tek komut, kodunuzu paketler, bir container görüntüsü oluşturur, bu görüntüyü Artifact Registry'ye gönderir ve hizmeti Cloud Run'da başlatarak web'de erişilebilir hale getirir.
- Aracınızı dağıtmak için terminalde aşağıdaki komutu çalıştırın.
# Run the deployment command uvx --from google-adk==1.14.0 \ adk deploy cloud_run \ --project=$PROJECT_ID \ --region=europe-west1 \ --service_name=zoo-tour-guide \ --with_ui \ . \ -- \ --labels=dev-tutorial=codelab-adk \ --service-account=$SERVICE_ACCOUNTuvxkomutu, Python paketleri olarak yayınlanan komut satırı araçlarını bu araçların genel olarak yüklenmesini gerektirmeden çalıştırmanıza olanak tanır. - Aşağıdaki mesajı görürseniz:
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [europe-west1] will be created. Do you want to continue (Y/n)?
Yyazıp ENTER tuşuna basın. - Aşağıdaki mesajı görürseniz:
Allow unauthenticated invocations to [your-service-name] (y/N)?.
yyazıp ENTER tuşuna basın. Bu sayede, kolay test için bu laboratuvarda kimliği doğrulanmamış çağırmalara izin verilir. Başarılı bir şekilde yürütüldüğünde komut, dağıtılan Cloud Run hizmetinin URL'sini sağlar. (https://zoo-tour-guide-123456789.europe-west1.run.appgibi görünür.) - Sonraki görev için dağıtılan Cloud Run hizmetinin URL'sini kopyalayın.
11. Dağıtılan temsilciyi test etme
Temsilciniz artık Cloud Run'da yayında olduğuna göre, dağıtımın başarılı olduğunu ve temsilcinin beklendiği gibi çalıştığını onaylamak için bir test yapacaksınız. ADK'nın web arayüzüne erişmek ve aracıyla etkileşim kurmak için herkese açık hizmet URL'sini (https://zoo-tour-guide-123456789.europe-west1.run.app/ gibi) kullanırsınız.
- Herkese açık Cloud Run hizmeti URL'sini web tarayıcınızda açın.
--with_ui flagkullandığınız için ADK geliştirici kullanıcı arayüzünü görmeniz gerekir. - Sağ üstteki
Token Streamingsimgesini açın.
Artık hayvanat bahçesi temsilcisiyle etkileşim kurabilirsiniz. - Yeni bir görüşme başlatmak için
helloyazıp Enter tuşuna basın. - Sonucu inceleyin. Aracı, selamlama mesajıyla hızlı bir şekilde yanıt vermelidir. Bu mesaj şu şekilde olabilir:
"Hello! I'm your Zoo Tour Guide. I can help you learn about the amazing animals we have here. What would you like to know or explore today?"
- Ajana şu gibi sorular sorun:
Where can I find the polar bears in the zoo and what is their diet?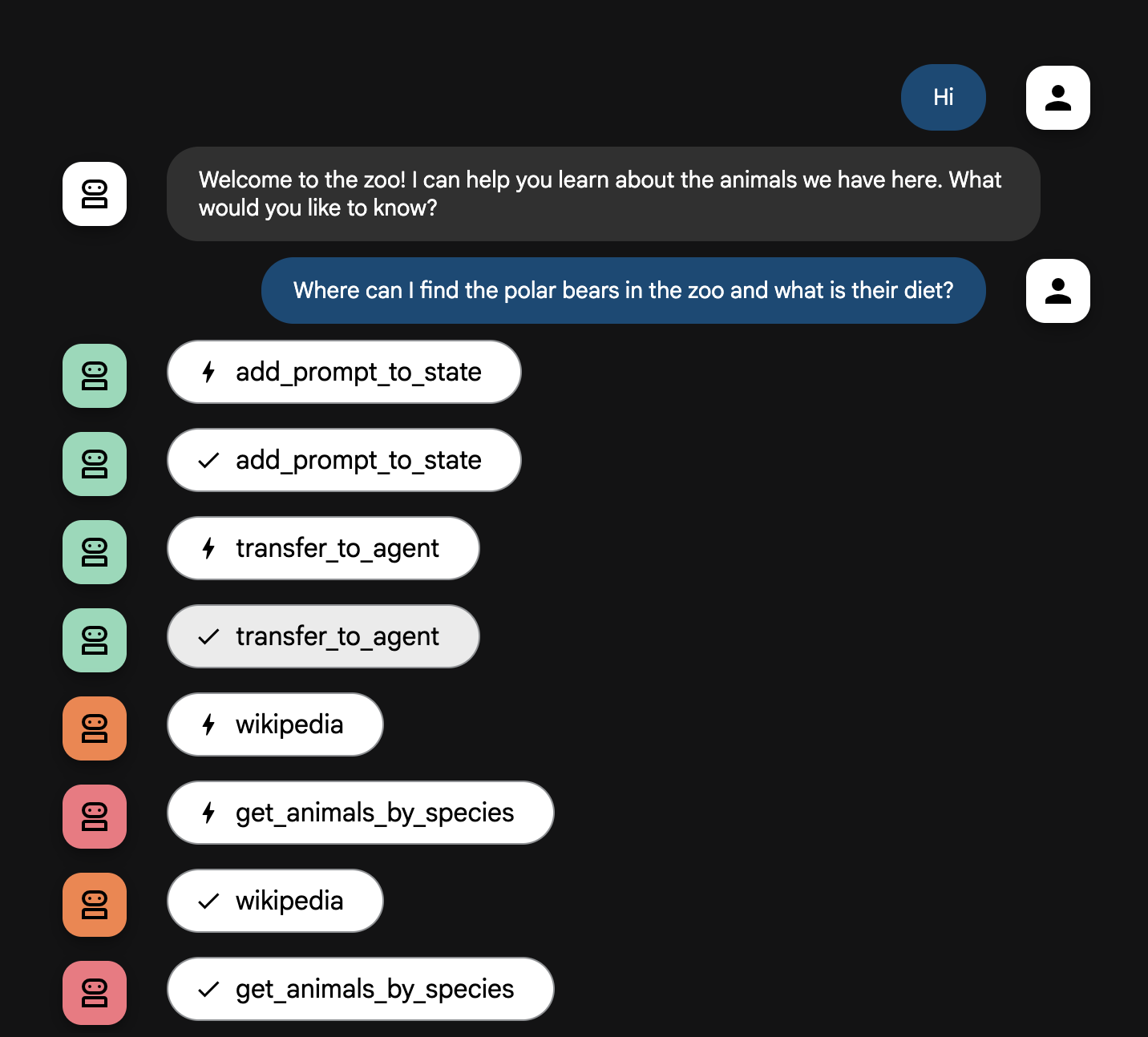

Temsilci Akışı Açıklaması
Sisteminiz akıllı bir çoklu aracı ekibi olarak çalışır. Süreç, kullanıcının sorusundan nihai ve ayrıntılı cevaba kadar sorunsuz ve verimli bir akış sağlamak için net bir sırayla yönetilir.
1. Hayvanat Bahçesi Karşılama Görevlisi (Karşılama Masası)
Tüm süreç, karşılama temsilcisiyle başlar.
- Görevi: Sohbeti başlatmak. Kullanıcıyı karşılayıp hangi hayvan hakkında bilgi edinmek istediğini sorar.
- Its Tool: Kullanıcı yanıt verdiğinde Karşılayıcı, kullanıcının tam olarak ne söylediğini (ör. "bana aslanlar hakkında bilgi ver") yakalamak ve bunları sistemin belleğine kaydetmek için add_prompt_to_state aracını kullanır.
- Devretme: Talimat kaydedildikten sonra kontrol hemen alt aracısı olan tour_guide_workflow'a geçer.
2. Kapsamlı Araştırmacı (Süper Araştırmacı)
Bu, ana iş akışının ilk adımı ve operasyonun "beynidir". Artık büyük bir ekibiniz yerine, mevcut tüm bilgilere erişebilen tek bir yüksek vasıflı temsilciniz var.
- Görevi: Kullanıcının sorusunu analiz edip akıllı bir plan oluşturmak. Aşağıdaki durumlarda dil modelinin araç kullanma özelliğinden yararlanır:
- Web'den (Wikipedia API aracılığıyla) alınan genel bilgiler.
- Karmaşık sorular için ise her ikisini de kullanabilirsiniz.
3. Yanıt Biçimlendirici (Sunucu)
Kapsamlı Araştırmacı tüm bilgileri topladıktan sonra çalıştırılacak son aracıdır.
- Görevi: Hayvanat Bahçesi Turu Rehberi'nin samimi sesi olarak hareket etmek. Bu işlev, ham verileri (bir veya iki kaynaktan alınmış olabilir) alıp düzenler.
- İşlemi: Tüm bilgileri tek, tutarlı ve ilgi çekici bir yanıtta birleştirir. Talimatlarına uyarak önce belirli hayvanat bahçesi bilgilerini sunuyor, ardından ilginç genel bilgileri ekliyor.
- Nihai Sonuç: Bu aracı tarafından oluşturulan metin, kullanıcının sohbet penceresinde gördüğü eksiksiz ve ayrıntılı yanıttır.
Aracı oluşturma hakkında daha fazla bilgi edinmek isterseniz aşağıdaki kaynakları inceleyin:
12. Ortamı temizleme
Bu eğitimde kullanılan kaynaklar için Google Cloud hesabınızın ücretlendirilmesini önlemek amacıyla kaynakları içeren projeyi silin veya projeyi koruyup tek tek kaynakları silin.
Cloud Run hizmetlerini ve görüntülerini silme
Google Cloud projesini korumak ancak bu laboratuvarda oluşturulan belirli kaynakları kaldırmak istiyorsanız hem çalışan hizmeti hem de kayıt defterinde depolanan kapsayıcı görüntüsünü silmeniz gerekir.
- Terminalde aşağıdaki komutları çalıştırın:
gcloud run services delete zoo-tour-guide --region=europe-west1 --quiet gcloud artifacts repositories delete cloud-run-source-deploy --location=europe-west1 --quiet
Projeyi silme (isteğe bağlı)
Bu laboratuvar için özel olarak yeni bir proje oluşturduysanız ve projeyi tekrar kullanmayı planlamıyorsanız temizlemenin en kolay yolu projenin tamamını silmektir. Bu işlem, hizmet hesabı ve gizli derleme yapıları da dahil olmak üzere tüm kaynakların tamamen kaldırılmasını sağlar.
- Terminalde aşağıdaki komutu çalıştırın ([YOUR_PROJECT_ID] yerine gerçek proje kimliğinizi girin):
gcloud projects delete $PROJECT_ID
13. Tebrikler
Google Cloud'da çoklu aracı içeren bir yapay zeka uygulamasını başarıyla oluşturup dağıttınız.
Özet
Bu laboratuvarda, boş bir dizinden canlı ve herkese açık bir yapay zeka hizmetine geçtiniz. İşte oluşturduğunuz öğeler:
- Özel bir ekip oluşturdunuz: Genel bir yapay zeka yerine, olguları bulmak için "Araştırmacı" ve yanıtı düzenlemek için "Biçimlendirici" oluşturdunuz.
- Onlara araçlar verdiniz: Wikipedia API'yi kullanarak temsilcilerinizi dış dünyaya bağladınız.
- Başardınız: Yerel Python kodunuzu alıp Cloud Run'da sunucusuz bir kapsayıcı olarak dağıttınız ve özel bir hizmet hesabıyla güvenliğini sağladınız.
İşlediğimiz konular
- ADK ile dağıtım için Python projesi oluşturma
[SequentialAgent](https://google.github.io/adk-docs/agents/workflow-agents/sequential-agents/)kullanarak çoklu aracı iş akışı uygulama.- Wikipedia API gibi harici araçları entegre etme
adk deploykomutunu kullanarak Cloud Run'a nasıl aracı dağıtılacağı
14. Anket
Çıkış: