
১. ভূমিকা
সংক্ষিপ্ত বিবরণ
এই ল্যাবের উদ্দেশ্য হলো আপনাকে গুগল ক্লাউডে একটি ওপেন মডেল ডেপ্লয় করার হাতে-কলমে অভিজ্ঞতা দেওয়া, যা একটি সাধারণ লোকাল সেটআপ থেকে শুরু করে গুগল কুবারনেটিস ইঞ্জিন (GKE)- এ প্রোডাকশন-গ্রেড ডেপ্লয়মেন্ট পর্যন্ত অগ্রসর হবে। আপনি শিখবেন কীভাবে ডেভেলপমেন্ট লাইফসাইকেলের প্রতিটি ধাপের জন্য উপযুক্ত বিভিন্ন টুল ব্যবহার করতে হয়।
ল্যাবটি নিম্নলিখিত পথ অনুসরণ করে:
- দ্রুত প্রোটোটাইপিং : কাজ শুরু করা কতটা সহজ তা দেখার জন্য আপনি প্রথমে স্থানীয়ভাবে Ollama-তে একটি মডেল চালাবেন।
- প্রোডাকশন ডেপ্লয়মেন্ট : অবশেষে, আপনি Ollama-কে একটি স্কেলেবল সার্ভিং ইঞ্জিন হিসেবে ব্যবহার করে মডেলটি GKE Autopilot-এ ডেপ্লয় করবেন।
উন্মুক্ত মডেল বোঝা
আজকাল 'ওপেন মডেল' বলতে সাধারণত এমন একটি জেনারেটিভ মেশিন লার্নিং মডেলকে বোঝানো হয়, যা সকলের ডাউনলোড ও ব্যবহারের জন্য উন্মুক্ত থাকে । এর অর্থ হলো, মডেলটির আর্কিটেকচার এবং সবচেয়ে গুরুত্বপূর্ণভাবে, এর প্রশিক্ষিত প্যারামিটার বা 'ওয়েট'গুলো সর্বজনীনভাবে প্রকাশ করা হয়।
এই স্বচ্ছতা ক্লোজড মডেলের তুলনায় বেশ কিছু সুবিধা প্রদান করে, যেগুলোতে সাধারণত শুধুমাত্র একটি সীমাবদ্ধ এপিআই (API)-এর মাধ্যমে প্রবেশ করা যায়:
- অন্তর্দৃষ্টি : ডেভেলপার এবং গবেষকরা মডেলটির অভ্যন্তরীণ কার্যপ্রণালী বোঝার জন্য এর খুঁটিনাটি বিষয়গুলো খতিয়ে দেখতে পারেন।
- কাস্টমাইজেশন : ব্যবহারকারীরা ফাইন-টিউনিং নামক একটি প্রক্রিয়ার মাধ্যমে নির্দিষ্ট কাজের জন্য মডেলটিকে মানিয়ে নিতে পারেন।
- উদ্ভাবন : এটি সম্প্রদায়কে শক্তিশালী বিদ্যমান মডেলগুলোর ওপর ভিত্তি করে নতুন ও উদ্ভাবনী অ্যাপ্লিকেশন তৈরি করতে সক্ষম করে।
গুগলের অবদান এবং জেমা পরিবার
গুগল বহু বছর ধরে ওপেন-সোর্স এআই আন্দোলনে একটি মৌলিক অবদানকারী হিসেবে কাজ করে আসছে। ২০১৭ সালের "অ্যাটেনশন ইজ অল ইউ নিড" শীর্ষক গবেষণাপত্রে প্রবর্তিত বৈপ্লবিক ট্রান্সফর্মার আর্কিটেকচারটি প্রায় সমস্ত আধুনিক বৃহৎ ল্যাঙ্গুয়েজ মডেলের ভিত্তি। এর পরে আসে বার্ট (BERT), টি৫ (T5), এবং ইনস্ট্রাকশন-টিউনড ফ্ল্যান-টি৫ (Flan-T5)-এর মতো যুগান্তকারী ওপেন মডেলগুলো, যেগুলোর প্রতিটিই সম্ভাবনার সীমাকে প্রসারিত করেছে এবং বিশ্বজুড়ে গবেষণা ও উন্নয়নে গতি সঞ্চার করেছে।
উন্মুক্ত উদ্ভাবনের এই সমৃদ্ধ ইতিহাসের উপর ভিত্তি করে, গুগল জেমা মডেল পরিবার চালু করেছে। জেমা মডেলগুলো শক্তিশালী, ক্লোজড-সোর্স জেমিনি মডেলের জন্য ব্যবহৃত একই গবেষণা ও প্রযুক্তি দিয়ে তৈরি, কিন্তু এগুলো উন্মুক্ত ওয়েটসহ উপলব্ধ করা হয়েছে। গুগল ক্লাউড গ্রাহকদের জন্য, এটি অত্যাধুনিক প্রযুক্তি এবং ওপেন সোর্সের নমনীয়তার একটি শক্তিশালী সমন্বয় প্রদান করে, যা তাদের মডেলের জীবনচক্র নিয়ন্ত্রণ করতে, একটি বৈচিত্র্যময় ইকোসিস্টেমের সাথে একীভূত হতে এবং একটি মাল্টি-ক্লাউড কৌশল অনুসরণ করতে সক্ষম করে।
জেমা ৩-এর উপর আলোকপাত
এই ল্যাবে আমরা জেমা ৩-এর উপর মনোযোগ দেব, যা এই সিরিজের সর্বশেষ এবং সবচেয়ে সক্ষম প্রজন্ম। জেমা ৩ মডেলগুলো হালকা অথচ অত্যাধুনিক, যা একটিমাত্র জিপিইউ বা এমনকি একটি সিপিইউ-তেও দক্ষতার সাথে চলার জন্য ডিজাইন করা হয়েছে।
- পারফরম্যান্স এবং আকার : জেমা ৩ মডেলগুলো ওজনে হালকা হলেও অত্যাধুনিক, যা একটিমাত্র জিপিইউ বা এমনকি একটি সিপিইউ-তেও দক্ষতার সাথে চলার জন্য ডিজাইন করা হয়েছে। এগুলো নিজেদের আকারের তুলনায় উন্নত মানের এবং সর্বাধুনিক (SOTA) পারফরম্যান্স প্রদান করে।
- পদ্ধতি : এগুলি বহু-মাধ্যম বিশিষ্ট, যা টেক্সট আউটপুট তৈরি করার জন্য টেক্সট এবং ইমেজ উভয় ইনপুটই গ্রহণ করতে সক্ষম।
- মূল বৈশিষ্ট্য : জেমা ৩-এ একটি বড় ১২৮কেবি কনটেক্সট উইন্ডো রয়েছে এবং এটি ১৪০টিরও বেশি ভাষা সমর্থন করে।
- ব্যবহারের ক্ষেত্র : এই মডেলগুলো প্রশ্নোত্তর, সারসংক্ষেপ তৈরি এবং যুক্তিনির্মাণসহ বিভিন্ন ধরনের কাজের জন্য বিশেষভাবে উপযোগী।
মূল পরিভাষা
ওপেন মডেল নিয়ে কাজ করার সময় আপনি কয়েকটি সাধারণ পরিভাষার সম্মুখীন হবেন:
- প্রি-ট্রেনিং- এর মাধ্যমে একটি মডেলকে বিশাল ও বৈচিত্র্যময় ডেটাসেটের উপর প্রশিক্ষণ দেওয়া হয়, যাতে এটি ভাষার সাধারণ প্যাটার্নগুলো শিখতে পারে। এই মডেলগুলো মূলত শক্তিশালী অটো-কমপ্লিট মেশিন।
- ইনস্ট্রাকশন টিউনিং একটি পূর্ব-প্রশিক্ষিত মডেলকে নির্দিষ্ট নির্দেশাবলী এবং প্রম্পট আরও ভালোভাবে অনুসরণ করার জন্য সূক্ষ্মভাবে সমন্বয় করে। এই মডেলগুলোই জানে কীভাবে কথা বলতে হয়।
- মডেলের প্রকারভেদ : ওপেন মডেলগুলো সাধারণত একাধিক আকারে (যেমন, জেমা ৩-এর ১বি, ৪বি, ১২বি, এবং ২৭বি প্যারামিটার সংস্করণ রয়েছে) এবং বিভিন্ন প্রকারভেদে প্রকাশ করা হয়; যেমন—দক্ষতা বৃদ্ধির জন্য ইন্সট্রাকশন-টিউনড (-it), প্রি-ট্রেইনড, বা কোয়ান্টাইজড।
- সম্পদের প্রয়োজনীয়তা : বৃহৎ ল্যাঙ্গুয়েজ মডেলগুলো আকারে বড় হয় এবং হোস্ট করার জন্য উল্লেখযোগ্য পরিমাণ কম্পিউটিং রিসোর্সের প্রয়োজন হয়। যদিও এগুলো স্থানীয়ভাবে চালানো যায়, ক্লাউডে স্থাপন করলে তা অত্যন্ত সুবিধাজনক হয়, বিশেষ করে যখন Ollama-র মতো টুল ব্যবহার করে পারফরম্যান্স এবং স্কেলেবিলিটির জন্য অপ্টিমাইজ করা হয়।
ওপেন মডেল পরিবেশনের জন্য GKE কেন?
এই ল্যাবটি আপনাকে সাধারণ, স্থানীয় মডেল এক্সিকিউশন থেকে শুরু করে গুগল কুবারনেটিস ইঞ্জিন (GKE)-এ একটি পূর্ণাঙ্গ প্রোডাকশন ডেপ্লয়মেন্ট পর্যন্ত ধাপে ধাপে নির্দেশনা দেয়। যদিও ওলামার মতো টুলগুলো দ্রুত প্রোটোটাইপিংয়ের জন্য চমৎকার, প্রোডাকশন এনভায়রনমেন্টের কিছু কঠোর প্রয়োজনীয়তা রয়েছে যা পূরণের জন্য GKE বিশেষভাবে উপযুক্ত।
বৃহৎ পরিসরের এআই অ্যাপ্লিকেশনের জন্য, আপনার শুধু একটি চলমান মডেলই যথেষ্ট নয়; আপনার প্রয়োজন একটি স্থিতিস্থাপক, পরিবর্ধনযোগ্য এবং দক্ষ পরিসেবা পরিকাঠামো। GKE এই ভিত্তিটি প্রদান করে। কখন এবং কেন আপনি GKE বেছে নেবেন, তা নিচে দেওয়া হলো:
- অটোপাইলটের মাধ্যমে সরলীকৃত ব্যবস্থাপনা : GKE অটোপাইলট আপনার জন্য অন্তর্নিহিত পরিকাঠামো পরিচালনা করে। আপনি আপনার অ্যাপ্লিকেশন কনফিগারেশনের উপর মনোযোগ দিন, এবং অটোপাইলট স্বয়ংক্রিয়ভাবে নোডগুলির ব্যবস্থা করে ও সেগুলির পরিধি বাড়ায়।
- উচ্চ কর্মক্ষমতা ও প্রসারণযোগ্যতা : GKE-এর স্বয়ংক্রিয় স্কেলিংয়ের মাধ্যমে চাহিদাপূর্ণ ও পরিবর্তনশীল ট্র্যাফিক সামলান। এটি নিশ্চিত করে যে আপনার অ্যাপ্লিকেশনটি কম লেটেন্সিতে উচ্চ থ্রুপুট প্রদান করতে পারে এবং প্রয়োজন অনুযায়ী আপ বা ডাউন স্কেল করতে পারে।
- বৃহৎ পরিসরে ব্যয়-সাশ্রয়ীতা : রিসোর্স দক্ষতার সাথে পরিচালনা করুন। GKE ওয়ার্কলোডকে শূন্য পর্যন্ত কমিয়ে আনতে পারে, ফলে অব্যবহৃত রিসোর্সের জন্য কোনো অর্থ প্রদান করতে হয় না, এবং আপনি স্টেটলেস ইনফারেন্স ওয়ার্কলোডের খরচ উল্লেখযোগ্যভাবে কমাতে স্পট ভিএম (Spot VM) ব্যবহার করতে পারেন।
- বহনযোগ্যতা ও সমৃদ্ধ ইকোসিস্টেম : একটি বহনযোগ্য, কুবারনেটিস-ভিত্তিক ডেপ্লয়মেন্টের মাধ্যমে ভেন্ডর লক-ইন এড়িয়ে চলুন। GKE সেরা মানের মনিটরিং, লগিং এবং সিকিউরিটি টুলিংয়ের জন্য সুবিশাল ক্লাউড নেটিভ (CNCF) ইকোসিস্টেমেও অ্যাক্সেস প্রদান করে।
সংক্ষেপে, আপনি GKE-তে তখনই স্থানান্তরিত হন, যখন আপনার AI অ্যাপ্লিকেশনটি প্রোডাকশনের জন্য প্রস্তুত হয় এবং এর জন্য ব্যাপক স্কেল, পারফরম্যান্স ও পরিচালনগত পরিপক্কতার কথা মাথায় রেখে তৈরি একটি প্ল্যাটফর্মের প্রয়োজন হয়।
আপনি যা শিখবেন
এই ল্যাবে, আপনি নিম্নলিখিত কাজগুলো কীভাবে সম্পাদন করতে হয় তা শিখবেন:
- Ollama ব্যবহার করে স্থানীয়ভাবে একটি ওপেন মডেল চালান।
- সার্ভিংয়ের জন্য Ollama ব্যবহার করে Google Kubernetes Engine (GKE) Autopilot-এ একটি ওপেন মডেল ডেপ্লয় করুন।
- GKE-তে স্থানীয় উন্নয়ন ফ্রেমওয়ার্ক থেকে প্রোডাকশন-গ্রেড সার্ভিং আর্কিটেকচারে উত্তরণের প্রক্রিয়াটি বুঝুন।
২. প্রজেক্ট সেটআপ
গুগল অ্যাকাউন্ট
যদি আপনার আগে থেকে কোনো ব্যক্তিগত গুগল অ্যাকাউন্ট না থাকে, তাহলে আপনাকে অবশ্যই একটি গুগল অ্যাকাউন্ট তৈরি করতে হবে।
কর্মক্ষেত্র বা শিক্ষা প্রতিষ্ঠানের অ্যাকাউন্টের পরিবর্তে ব্যক্তিগত অ্যাকাউন্ট ব্যবহার করুন ।
গুগল ক্লাউড কনসোলে সাইন-ইন করুন
আপনার ব্যক্তিগত গুগল অ্যাকাউন্ট ব্যবহার করে গুগল ক্লাউড কনসোলে সাইন-ইন করুন।
বিলিং সক্ষম করুন
একটি ব্যক্তিগত বিলিং অ্যাকাউন্ট তৈরি করুন
আপনি যদি গুগল ক্লাউড ক্রেডিট ব্যবহার করে বিলিং সেট আপ করেন, তাহলে এই ধাপটি এড়িয়ে যেতে পারেন।
একটি ব্যক্তিগত বিলিং অ্যাকাউন্ট তৈরি করতে, ক্লাউড কনসোলে বিলিং চালু করার জন্য এখানে যান ।
কিছু নোট:
- এই ল্যাবটি সম্পন্ন করতে ক্লাউড রিসোর্সে ১ মার্কিন ডলারেরও কম খরচ হওয়া উচিত।
- পরবর্তী চার্জ এড়াতে, এই ল্যাবের শেষে দেওয়া ধাপগুলো অনুসরণ করে আপনি রিসোর্সগুলো মুছে ফেলতে পারেন।
- নতুন ব্যবহারকারীরা ৩০০ মার্কিন ডলারের ফ্রি ট্রায়ালের জন্য যোগ্য।
একটি প্রকল্প তৈরি করুন (ঐচ্ছিক)
এই ল্যাবের জন্য ব্যবহার করার মতো আপনার যদি কোনো চলমান প্রজেক্ট না থাকে, তাহলে এখানে একটি নতুন প্রজেক্ট তৈরি করুন ।
৩. ক্লাউড শেল এডিটর খুলুন
- সরাসরি ক্লাউড শেল এডিটর- এ যেতে এই লিঙ্কে ক্লিক করুন।
- আজ যেকোনো সময়ে অনুমোদনের জন্য অনুরোধ করা হলে, চালিয়ে যাওয়ার জন্য 'অনুমোদন করুন' (Authorize) বোতামে ক্লিক করুন।
- যদি স্ক্রিনের নীচে টার্মিনালটি দেখা না যায়, তাহলে এটি খুলুন:
- ভিউ ক্লিক করুন
- টার্মিনালে ক্লিক করুন
- টার্মিনালে এই কমান্ডটি দিয়ে আপনার প্রজেক্ট সেট করুন:
gcloud config set project [PROJECT_ID]- উদাহরণ:
gcloud config set project lab-project-id-example - আপনি যদি আপনার প্রজেক্ট আইডি মনে রাখতে না পারেন, তাহলে নিম্নলিখিত উপায়ে আপনার সমস্ত প্রজেক্ট আইডি তালিকাভুক্ত করতে পারেন:
gcloud projects list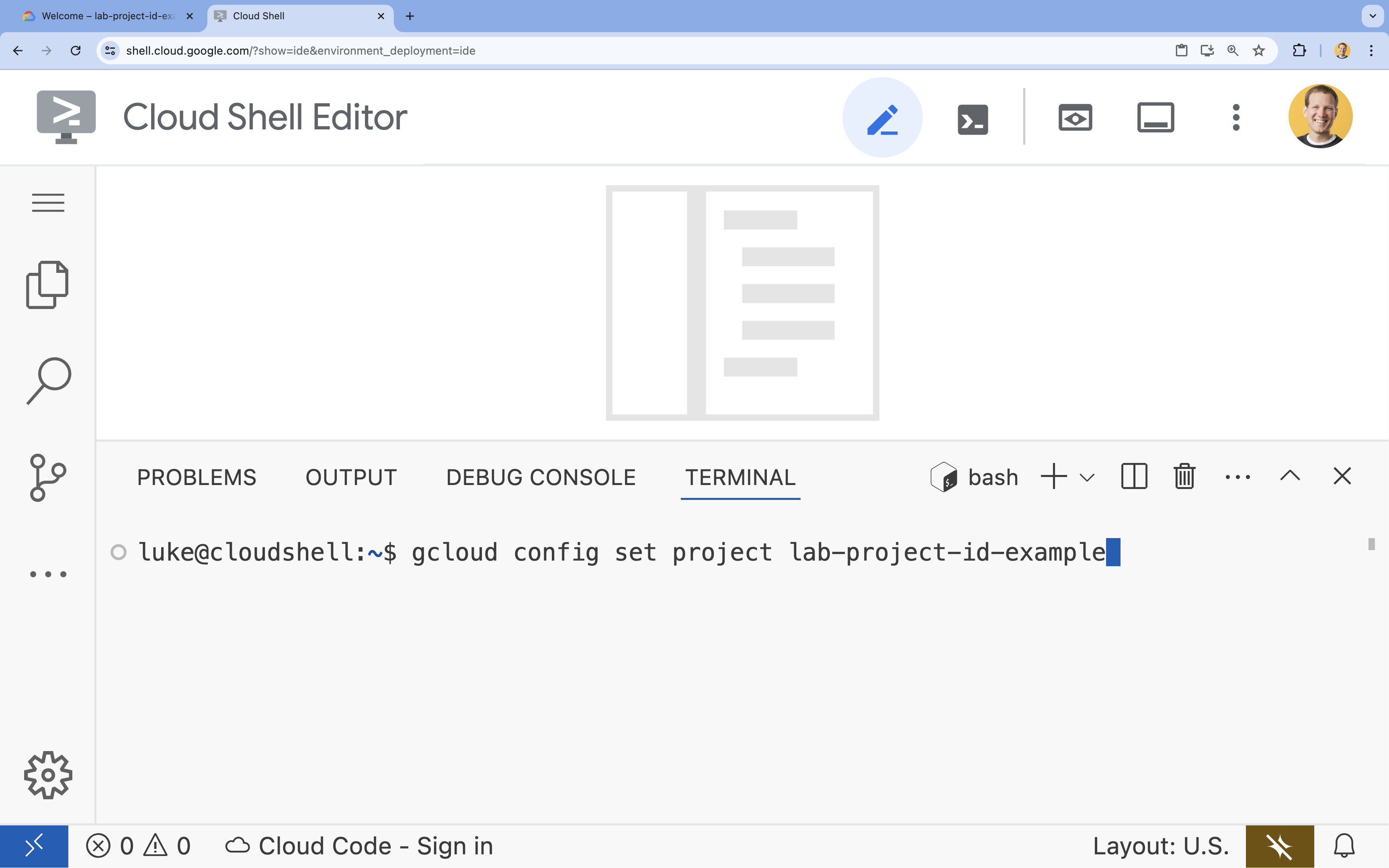
- উদাহরণ:
- আপনার এই বার্তাটি দেখা উচিত:
Updated property [core/project].
৪. ওলামার সাথে জেমাকে চালান
আপনার প্রথম লক্ষ্য হলো একটি ডেভেলপমেন্ট এনভায়রনমেন্টে যত দ্রুত সম্ভব জেমা ৩ (Gemma 3) চালু করা। আপনি ওলামা (Ollama) ব্যবহার করবেন, যা স্থানীয়ভাবে বড় ল্যাঙ্গুয়েজ মডেল চালানোকে ব্যাপকভাবে সহজ করে তোলে। এই কাজটি আপনাকে একটি ওপেন মডেল নিয়ে পরীক্ষা-নিরীক্ষা শুরু করার সবচেয়ে সহজ উপায়টি দেখাবে।
ওলামা একটি বিনামূল্যের, ওপেন-সোর্স টুল যা ব্যবহারকারীদের তাদের নিজেদের কম্পিউটারে স্থানীয়ভাবে জেনারেটিভ মডেল (বৃহৎ ল্যাঙ্গুয়েজ মডেল, ভিশন-ল্যাঙ্গুয়েজ মডেল এবং আরও অনেক কিছু) চালাতে দেয়। এটি এই মডেলগুলিতে প্রবেশ এবং সেগুলির সাথে কাজ করার প্রক্রিয়াকে সহজ করে, সেগুলিকে আরও সহজলভ্য করে তোলে এবং ব্যবহারকারীদের ব্যক্তিগতভাবে সেগুলির সাথে কাজ করতে সক্ষম করে।
Ollama ইনস্টল এবং চালান
এখন আপনি Ollama ইনস্টল করতে, Gemma 3 মডেলটি ডাউনলোড করতে এবং কমান্ড লাইন থেকে এটি ব্যবহার করতে প্রস্তুত।
- ক্লাউড শেল টার্মিনালে Ollama ডাউনলোড ও ইনস্টল করুন:
curl -fsSL https://ollama.com/install.sh | sh - ব্যাকগ্রাউন্ডে ওলামা পরিষেবাটি চালু করুন:
ollama serve & - Ollama-র সাহায্যে Gemma 3 1B মডেলটি পুল (ডাউনলোড) করুন:
ollama pull gemma3:1b - মডেলটি স্থানীয়ভাবে চালান:
ollama run gemma3:1bollama runকমান্ডটি মডেলকে প্রশ্ন করার জন্য একটি প্রম্পট (>>>) প্রদর্শন করে। - একটি প্রশ্ন দিয়ে মডেলটি পরীক্ষা করুন। উদাহরণস্বরূপ, '
Why is the sky blue?টাইপ করুন এবং এন্টার চাপুন। আপনি নিম্নলিখিতের মতো একটি প্রতিক্রিয়া দেখতে পাবেন:>>> Why is the sky blue? Okay, let's break down why the sky is blue – it's a fascinating phenomenon related to how light interacts with the Earth's atmosphere. Here's the explanation: **1. Sunlight and Colors:** * Sunlight appears white, but it's actually made up of all the colors of the rainbow (red, orange, yellow, green, blue, indigo, and violet). Think of a prism splitting sunlight. **2. Rayleigh Scattering:** * As sunlight enters the Earth's atmosphere... ...
- টার্মিনালে ওলামা প্রম্পট থেকে বের হতে,
/byeটাইপ করে এন্টার চাপুন।
Ollama-এর সাথে OpenAI SDK ব্যবহার করুন
এখন যেহেতু Ollama পরিষেবাটি চালু আছে, আপনি প্রোগ্রাম্যাটিকভাবে এর সাথে ইন্টারঅ্যাক্ট করতে পারবেন। আপনি OpenAI Python SDK ব্যবহার করবেন, যা Ollama-র উন্মুক্ত করা API-এর সাথে সামঞ্জস্যপূর্ণ।
- ক্লাউড শেল টার্মিনালে, uv ব্যবহার করে একটি ভার্চুয়াল এনভায়রনমেন্ট তৈরি ও সক্রিয় করুন। এটি নিশ্চিত করে যে আপনার প্রোজেক্টের ডিপেন্ডেন্সিগুলো সিস্টেম পাইথনের সাথে সাংঘর্ষিক হবে না।
uv venv --python 3.14 source .venv/bin/activate - টার্মিনালে OpenAI SDK ইনস্টল করুন:
uv pip install openai - টার্মিনালে নিম্নলিখিত টাইপ করে
ollama_chat.pyনামের একটি নতুন ফাইল তৈরি করুন:cloudshell edit ollama_chat.py - নিচের পাইথন কোডটি
ollama_chat.pyফাইলে পেস্ট করুন। এই কোডটি স্থানীয় Ollama সার্ভারে একটি অনুরোধ পাঠায়।from openai import OpenAI client = OpenAI( base_url = 'http://localhost:11434/v1', api_key='ollama', # required by OpenAI SDK, but not used by Ollama ) response = client.chat.completions.create( model="gemma3:1b", messages=[ { "role": "user", "content": "Why is the sky blue?" }, ], ) print(response.choices[0].message.content) - আপনার টার্মিনালে স্ক্রিপ্টটি চালান:
python3 ollama_chat.py - স্ট্রিমিং মোড ব্যবহার করে দেখতে, টার্মিনালে নিম্নলিখিত কমান্ডটি চালিয়ে
ollama_stream.pyনামে আরেকটি ফাইল তৈরি করুন:cloudshell edit ollama_stream.py - নিম্নলিখিত বিষয়বস্তু
ollama_stream.pyফাইলে পেস্ট করুন। request-এstream=Trueপ্যারামিটারটি লক্ষ্য করুন। এটি মডেলটিকে টোকেন তৈরি হওয়ার সাথে সাথেই ফেরত দিতে সাহায্য করে।from openai import OpenAI client = OpenAI( base_url = 'http://localhost:11434/v1', api_key='ollama', ) stream = client.chat.completions.create( model="gemma3:1b", messages=[ { "role": "user", "content": "Why is the sky blue?" }, ], stream=True ) for chunk in stream: if chunk.choices[0].delta.content is not None: print(chunk.choices[0].delta.content, end="", flush=True) print() - টার্মিনালে স্ট্রিমিং স্ক্রিপ্টটি চালান:
python3 ollama_stream.py
চ্যাটবটের মতো ইন্টারেক্টিভ অ্যাপ্লিকেশনগুলিতে একটি ভালো ইউজার এক্সপেরিয়েন্স তৈরি করার জন্য স্ট্রিমিং একটি সহায়ক ফিচার। সম্পূর্ণ উত্তরটি তৈরি হওয়ার জন্য ব্যবহারকারীকে অপেক্ষা করানোর পরিবর্তে, স্ট্রিমিং উত্তরটি তৈরি হওয়ার সাথে সাথেই টোকেন-বাই-টোকেন প্রদর্শন করে। এটি তাৎক্ষণিক প্রতিক্রিয়া প্রদান করে এবং অ্যাপ্লিকেশনটিকে অনেক বেশি রেসপন্সিভ করে তোলে।
আপনি যা শিখেছেন: ওলামার সাহায্যে ওপেন মডেল চালানো
আপনি Ollama ব্যবহার করে সফলভাবে একটি ওপেন মডেল রান করেছেন। আপনি দেখেছেন যে, Gemma 3-এর মতো একটি শক্তিশালী মডেল ডাউনলোড করা এবং কমান্ড-লাইন ইন্টারফেসের মাধ্যমে ও পাইথন ব্যবহার করে প্রোগ্রাম্যাটিকভাবে এর সাথে ইন্টারঅ্যাক্ট করা কতটা সহজ হতে পারে। এই ওয়ার্কফ্লোটি দ্রুত প্রোটোটাইপিং এবং লোকাল ডেভেলপমেন্টের জন্য আদর্শ। আরও উন্নত ডেপ্লয়মেন্ট অপশনগুলো অন্বেষণ করার জন্য এখন আপনার একটি মজবুত ভিত্তি তৈরি হয়েছে।
৫. GKE অটোপাইলটে Ollama-এর সাথে Gemma স্থাপন করুন
যেসব প্রোডাকশন ওয়ার্কলোডে সরলীকৃত অপারেশন এবং স্কেলেবিলিটির প্রয়োজন হয়, সেগুলোর জন্য গুগল কুবারনেটিস ইঞ্জিন (GKE) হলো সর্বোত্তম প্ল্যাটফর্ম। এই টাস্কে, আপনি একটি GKE অটোপাইলট ক্লাস্টারে Ollama ব্যবহার করে Gemma ডেপ্লয় করবেন।
GKE অটোপাইলট হলো GKE-এর একটি কার্যপ্রণালী, যেখানে গুগল আপনার ক্লাস্টার কনফিগারেশন পরিচালনা করে, যার মধ্যে আপনার নোড, স্কেলিং, নিরাপত্তা এবং অন্যান্য পূর্ব-কনফিগার করা সেটিংস অন্তর্ভুক্ত থাকে। এটি একটি সত্যিকারের "সার্ভারবিহীন" কুবারনেটিস অভিজ্ঞতা তৈরি করে, যা অন্তর্নিহিত কম্পিউট পরিকাঠামো পরিচালনা না করেই ইনফারেন্স ওয়ার্কলোড চালানোর জন্য আদর্শ।
GKE পরিবেশ প্রস্তুত করুন
Kubernetes-এ ডেপ্লয় করার চূড়ান্ত কাজের জন্য, আপনাকে একটি GKE Autopilot ক্লাস্টার প্রোভিশন করতে হবে।
- ক্লাউড শেল টার্মিনালে আপনার প্রজেক্ট এবং কাঙ্ক্ষিত অঞ্চলের জন্য এনভায়রনমেন্ট ভেরিয়েবল সেট করুন।
export PROJECT_ID=$(gcloud config get-value project) export REGION=europe-west1 gcloud config set compute/region $REGION - আপনার প্রোজেক্টের জন্য GKE API সক্রিয় করতে টার্মিনালে নিম্নলিখিত কমান্ডটি চালান:
gcloud services enable container.googleapis.com - টার্মিনালে নিম্নলিখিত কমান্ডটি চালিয়ে একটি GKE Autopilot ক্লাস্টার তৈরি করুন:
gcloud container clusters create-auto gemma-cluster \ --region $REGION \ --release-channel rapid - টার্মিনালে নিম্নলিখিত কমান্ডটি চালিয়ে আপনার নতুন ক্লাস্টারের জন্য ক্রেডেনশিয়াল সংগ্রহ করুন:
gcloud container clusters get-credentials gemma-cluster \ --region $REGION
ওলামা এবং জেমাকে মোতায়েন করুন
এখন যেহেতু আপনার একটি GKE Autopilot ক্লাস্টার আছে, আপনি Ollama সার্ভারটি ডেপ্লয় করতে পারেন। আপনার ডেপ্লয়মেন্ট ম্যানিফেস্টে সংজ্ঞায়িত প্রয়োজনীয়তার উপর ভিত্তি করে Autopilot স্বয়ংক্রিয়ভাবে কম্পিউট রিসোর্স (সিপিইউ এবং মেমরি) সরবরাহ করবে।
- টার্মিনালে নিম্নলিখিত কমান্ডটি চালিয়ে
gemma-deployment.yamlনামের একটি নতুন ফাইল তৈরি করুন:cloudshell edit gemma-deployment.yaml - নিম্নলিখিত YAML কনফিগারেশনটি
gemma-deployment.yamlএ পেস্ট করুন। এই কনফিগারেশনটি এমন একটি ডেপ্লয়মেন্ট নির্ধারণ করে, যা সিপিইউ-তে চালানোর জন্য অফিসিয়াল Ollama ইমেজ ব্যবহার করে।apiVersion: apps/v1 kind: Deployment metadata: name: ollama-gemma spec: replicas: 1 selector: matchLabels: app: ollama-gemma template: metadata: labels: app: ollama-gemma spec: containers: - name: ollama-gemma-container image: ollama/ollama:0.12.10 resources: requests: cpu: "8" memory: "8Gi" ephemeral-storage: "10Gi" limits: cpu: "8" memory: "8Gi" ephemeral-storage: "10Gi" # We use a script to start the server and pull the model command: ["/bin/bash", "-c"] args: - | ollama serve & OLLAMA_PID=$! echo "Waiting for Ollama server to start..." sleep 5 echo "Pulling Gemma model..." ollama pull gemma3:1b echo "Model pulled. Ready to serve." wait $OLLAMA_PID ports: - containerPort: 11434 env: - name: OLLAMA_HOST value: "0.0.0.0" --- apiVersion: v1 kind: Service metadata: name: llm-service spec: selector: app: ollama-gemma type: ClusterIP ports: - protocol: TCP port: 8000 targetPort: 11434-
image: ollama/ollama:latest: এটি অফিসিয়াল ওলামা ডকার ইমেজকে নির্দেশ করে। -
resources: আমরা স্পষ্টভাবে ৮টি vCPU এবং ৮Gi মেমরির জন্য অনুরোধ করছি। GKE Autopilot এই মানগুলো ব্যবহার করে অন্তর্নিহিত কম্পিউট সরবরাহ করে। যেহেতু আমরা GPU ব্যবহার করছি না, তাই মডেলটি CPU-তে চলবে। ৮Gi মেমরি Gemma 1B মডেল এবং এর কনটেক্সট ধারণ করার জন্য যথেষ্ট। -
command/args: পড চালু হওয়ার সাথে সাথে মডেলটি যেন পুল করা হয়, তা নিশ্চিত করতে আমরা স্টার্টআপ কমান্ডটি ওভাররাইড করি। স্ক্রিপ্টটি ব্যাকগ্রাউন্ডে সার্ভার চালু করে, এটি প্রস্তুত হওয়ার জন্য অপেক্ষা করে,gemma3:1bমডেলটি পুল করে এবং তারপর সার্ভারটিকে চালু রাখে। -
OLLAMA_HOST: এটিকে0.0.0.0এ সেট করলে Ollama কন্টেইনারের ভেতরের সমস্ত নেটওয়ার্ক ইন্টারফেসে লিসেন করবে, ফলে এটি Kubernetes সার্ভিসের কাছে অ্যাক্সেসযোগ্য হয়ে উঠবে।
-
- টার্মিনালে, আপনার ক্লাস্টারে ডিপ্লয়মেন্ট ম্যানিফেস্টটি প্রয়োগ করুন:
kubectl apply -f gemma-deployment.yamlkubectl get pods --watchRunningএবংREADY1/1না হওয়া পর্যন্ত অপেক্ষা করুন।
GKE এন্ডপয়েন্ট পরীক্ষা করুন
আপনার Ollama পরিষেবাটি এখন আপনার GKE Autopilot ক্লাস্টারে চলছে। আপনার Cloud Shell টার্মিনাল থেকে এটি পরীক্ষা করার জন্য, আপনি kubectl port-forward ব্যবহার করবেন।
- একটি নতুন ক্লাউড শেল টার্মিনাল ট্যাব খুলুন (টার্মিনাল উইন্ডোতে থাকা + আইকনে ক্লিক করুন)।
port-forwardকমান্ডটি একটি ব্লকিং প্রসেস, তাই এর জন্য নিজস্ব একটি টার্মিনাল সেশন প্রয়োজন। - নতুন টার্মিনালে, একটি লোকাল পোর্ট (যেমন,
8000) সার্ভিসের পোর্টে (8000) ফরওয়ার্ড করতে নিম্নলিখিত কমান্ডটি চালান:kubectl port-forward service/llm-service 8000:8000 - আপনার মূল টার্মিনালে ফিরে যান।
- আপনার লোকাল পোর্ট
8000এ একটি অনুরোধ পাঠান। ওলামা সার্ভার একটি ওপেনএআই-উপযোগী এপিআই উন্মুক্ত করে, এবং পোর্ট ফরওয়ার্ড করার কারণে, আপনি এখনhttp://127.0.0.1:8000ঠিকানায় এটি অ্যাক্সেস করতে পারবেন।curl http://127.0.0.1:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "gemma3:1b", "messages": [ {"role": "user", "content": "Explain why the sky is blue."} ] }'
৬. পরিষ্কার-পরিচ্ছন্নতা
এই ল্যাবে ব্যবহৃত রিসোর্সের জন্য আপনার গুগল ক্লাউড অ্যাকাউন্টে চার্জ হওয়া এড়াতে, GKE ক্লাস্টারটি ডিলিট করার জন্য এই ধাপগুলো অনুসরণ করুন।
- ক্লাউড শেল টার্মিনালে, GKE অটোপাইলট ক্লাস্টারটি ডিলিট করুন:
gcloud container clusters delete gemma-cluster \ --region $REGION --quiet
৭. উপসংহার
চমৎকার কাজ! এই ল্যাবে, আপনি গুগল ক্লাউডে ওপেন মডেল ডেপ্লয় করার বেশ কয়েকটি গুরুত্বপূর্ণ পদ্ধতি শিখেছেন। আপনি Ollama ব্যবহার করে লোকাল ডেভেলপমেন্টের সরলতা এবং গতি দিয়ে শুরু করেছিলেন। অবশেষে, আপনি গুগল কুবারনেটিস ইঞ্জিন অটোপাইলট এবং Ollama ফ্রেমওয়ার্ক ব্যবহার করে Gemma-কে একটি প্রোডাকশন-গ্রেড ও স্কেলেবল পরিবেশে ডেপ্লয় করেছেন।
আপনি এখন অন্তর্নিহিত পরিকাঠামো পরিচালনা না করেই, চাহিদা সম্পন্ন ও স্কেলেবল ওয়ার্কলোডের জন্য গুগল কুবারনেটিস ইঞ্জিনে ওপেন মডেল স্থাপন করার জ্ঞান অর্জন করেছেন।
পুনরালোচনা
এই ল্যাবে, আপনি শিখেছেন:
- ওপেন মডেল কী এবং কেন তা গুরুত্বপূর্ণ।
- Ollama ব্যবহার করে কীভাবে স্থানীয়ভাবে একটি ওপেন মডেল চালানো যায়।
- ইনফারেন্সের জন্য Ollama ব্যবহার করে Google Kubernetes Engine (GKE) Autopilot-এ কীভাবে একটি ওপেন মডেল ডেপ্লয় করবেন।
আরও জানুন
- অফিসিয়াল ডকুমেন্টেশনে জেমা মডেল সম্পর্কে আরও জানুন।
- গিটহাবে গুগল ক্লাউড জেনারেটিভ এআই রিপোজিটরিতে আরও উদাহরণ দেখুন।
- GKE অটোপাইলট সম্পর্কে আরও পড়ুন।
- অন্যান্য উপলব্ধ উন্মুক্ত এবং মালিকানাধীন মডেলগুলির জন্য ভার্টেক্স এআই মডেল গার্ডেন ব্রাউজ করুন।