
1. Einführung
Übersicht
In diesem Lab lernen Sie, wie Sie ein offenes Modell in Google Cloud bereitstellen. Dabei beginnen Sie mit einer einfachen lokalen Einrichtung und arbeiten sich bis zu einer produktionsreifen Bereitstellung in Google Kubernetes Engine (GKE) vor. Sie lernen, wie Sie verschiedene Tools verwenden, die für die einzelnen Phasen des Entwicklungszyklus geeignet sind.
Das Lab folgt dem folgenden Pfad:
- Rapid Prototyping: Sie führen zuerst ein Modell mit Ollama lokal aus, um zu sehen, wie einfach der Einstieg ist.
- Produktionsbereitstellung: Schließlich stellen Sie das Modell mit Ollama als skalierbare Bereitstellungs-Engine in GKE Autopilot bereit.
Offene Modelle
Mit „offenes Modell“ ist heutzutage in der Regel ein generatives Modell für maschinelles Lernen gemeint, das öffentlich verfügbar ist und von jedem heruntergeladen und verwendet werden kann. Das bedeutet, dass die Architektur des Modells und vor allem seine trainierten Parameter oder „Gewichtungen“ öffentlich freigegeben werden.
Diese Transparenz bietet mehrere Vorteile gegenüber geschlossenen Modellen, auf die in der Regel nur über eine restriktive API zugegriffen werden kann:
- Was dir dieser Wert verrät: Entwickler und Forscher können sich die Funktionsweise des Modells genauer ansehen.
- Anpassung: Nutzer können das Modell durch einen Prozess namens Feinabstimmung an bestimmte Aufgaben anpassen.
- Innovation: Die Community kann neue und innovative Anwendungen auf Basis leistungsstarker vorhandener Modelle entwickeln.
Beitrag von Google und die Gemma-Familie
Google ist seit vielen Jahren ein wichtiger Beitragender zur Open-Source-KI-Bewegung. Die revolutionäre Transformer-Architektur, die 2017 im Artikel Attention Is All You Need vorgestellt wurde, ist die Grundlage für fast alle modernen Large Language Models. Es folgten bahnbrechende offene Modelle wie BERT, T5 und das auf Anweisungen abgestimmte Flan-T5, die jeweils die Grenzen des Möglichen verschoben und Forschung und Entwicklung weltweit vorangetrieben haben.
Aufbauend auf dieser langen Geschichte offener Innovationen hat Google die Gemma-Modellfamilie eingeführt. Gemma-Modelle basieren auf derselben Forschung und Technologie wie die leistungsstarken Gemini-Modelle mit geschlossenem Quellcode, sind aber mit offenen Gewichten verfügbar. Für Google Cloud-Kunden bietet dies eine leistungsstarke Kombination aus modernster Technologie und der Flexibilität von Open Source. So können sie den Modelllebenszyklus steuern, in ein vielfältiges Ökosystem integrieren und eine Multi-Cloud-Strategie verfolgen.
Gemma 3 im Fokus
In diesem Lab konzentrieren wir uns auf Gemma 3, die neueste und leistungsstärkste Generation dieser Familie. Gemma 3-Modelle sind leichtgewichtig, aber hochmodern und so konzipiert, dass sie effizient auf einer einzelnen GPU oder sogar einer CPU ausgeführt werden können.
- Leistung und Größe: Gemma 3-Modelle sind leichtgewichtig, aber dennoch hochmodern und so konzipiert, dass sie effizient auf einer einzelnen GPU oder sogar einer CPU ausgeführt werden können. Sie bieten eine hervorragende Qualität und eine erstklassige Leistung für ihre Größe.
- Modalität: Sie sind multimodal und können sowohl Text- als auch Bildeingaben verarbeiten, um Textausgaben zu generieren.
- Wichtige Funktionen: Gemma 3 hat ein großes Kontextfenster von 128.000 Tokens und unterstützt über 140 Sprachen.
- Anwendungsfälle: Diese Modelle eignen sich gut für eine Vielzahl von Aufgaben, darunter Question Answering, Zusammenfassung und Schlussfolgern.
Schlüsselterminologie
Bei der Arbeit mit offenen Modellen werden Ihnen einige gängige Begriffe begegnen:
- Beim Vortraining wird ein Modell mit einem umfangreichen, vielfältigen Dataset trainiert, um allgemeine Sprachmuster zu lernen. Diese Modelle sind im Grunde leistungsstarke Autovervollständigungsmaschinen.
- Beim Instruction Tuning wird ein vortrainiertes Modell so feinabgestimmt, dass es bestimmten Anweisungen und Prompts besser folgt. Diese Modelle „wissen, wie man chattet“.
- Modellvarianten: Offene Modelle werden in der Regel in verschiedenen Größen (z. B. Gemma 3 mit Versionen mit 1B, 4B, 12B und 27B Parametern) und Varianten veröffentlicht, z. B. anweisungsorientiert (-it), vortrainiert oder zur Effizienzsteigerung quantisiert.
- Ressourcenbedarf: Large Language Models sind groß und erfordern erhebliche Rechenressourcen für das Hosting. Sie können zwar lokal ausgeführt werden, die Bereitstellung in der Cloud bietet jedoch erhebliche Vorteile, insbesondere wenn sie mit Tools wie Ollama für Leistung und Skalierbarkeit optimiert werden.
Warum GKE zum Bereitstellen offener Modelle?
In diesem Lab werden Sie von der einfachen, lokalen Ausführung eines Modells bis hin zu einer umfassenden Produktionsbereitstellung in Google Kubernetes Engine (GKE) geführt. Tools wie Ollama eignen sich hervorragend für schnelles Prototyping, aber Produktionsumgebungen haben anspruchsvolle Anforderungen, die GKE in einzigartiger Weise erfüllen kann.
Für KI-Anwendungen im großen Maßstab benötigen Sie mehr als nur ein laufendes Modell. Sie benötigen eine robuste, skalierbare und effiziente Bereitstellungsinfrastruktur. GKE bietet diese Grundlage. Wann und warum Sie sich für GKE entscheiden sollten:
- Vereinfachte Verwaltung mit Autopilot: GKE Autopilot verwaltet die zugrunde liegende Infrastruktur für Sie. Sie konzentrieren sich auf die Konfiguration Ihrer Anwendung und Autopilot stellt die Knoten automatisch bereit und skaliert sie.
- Hohe Leistung und Skalierbarkeit: Mit der automatischen Skalierung von GKE können Sie anspruchsvollen, variablen Traffic bewältigen. So kann Ihre Anwendung einen hohen Durchsatz bei niedriger Latenz bieten und je nach Bedarf skaliert werden.
- Kosteneffizienz im großen Maßstab: Ressourcen effizient verwalten. GKE kann Arbeitslasten auf null skalieren, um zu vermeiden, dass Sie für inaktive Ressourcen bezahlen. Außerdem können Sie Spot-VMs nutzen, um die Kosten für zustandslose Inferenzarbeitslasten erheblich zu senken.
- Portabilität und umfangreiches Ökosystem: Vermeiden Sie Anbieterabhängigkeit mit einer portablen, Kubernetes-basierten Bereitstellung. GKE bietet auch Zugriff auf das umfangreiche Cloud Native-Ökosystem (CNCF) für erstklassige Monitoring-, Logging- und Sicherheitstools.
Kurz gesagt: Sie wechseln zu GKE, wenn Ihre KI-Anwendung produktionsreif ist und eine Plattform benötigt, die für hohe Skalierbarkeit, Leistung und betriebliche Reife entwickelt wurde.
Lerninhalte
Aufgaben in diesem Lab:
- Offenes Modell lokal mit Ollama ausführen
- Offenes Modell mit Ollama für die Bereitstellung in Google Kubernetes Engine (GKE) Autopilot bereitstellen
- Sie verstehen die Entwicklung von lokalen Entwicklungsframeworks zu einer produktionsreifen Bereitstellungsarchitektur in GKE.
2. Projekt einrichten
Google-Konto
Wenn Sie noch kein privates Google-Konto haben, müssen Sie ein Google-Konto erstellen.
Verwenden Sie stattdessen ein privates Konto.
In der Google Cloud Console anmelden
Melden Sie sich mit einem privaten Google-Konto in der Google Cloud Console an.
Abrechnung aktivieren
Privates Rechnungskonto einrichten
Wenn Sie die Abrechnung mit Google Cloud-Guthaben eingerichtet haben, können Sie diesen Schritt überspringen.
Aktivieren Sie die Abrechnung in der Cloud Console, um ein privates Rechnungskonto einzurichten.
Hinweise:
- Die Cloud-Ressourcen, die für dieses Lab benötigt werden, sollten weniger als 1 $kosten.
- Sie können die Schritte am Ende dieses Labs ausführen, um Ressourcen zu löschen und so weitere Kosten zu vermeiden.
- Neue Nutzer haben Anspruch auf die kostenlose Testversion mit einem Guthaben von 300$.
Projekt erstellen (optional)
Wenn Sie kein aktuelles Projekt haben, das Sie für dieses Lab verwenden möchten, erstellen Sie hier ein neues Projekt.
3. Cloud Shell-Editor öffnen
- Klicken Sie auf diesen Link, um direkt zum Cloud Shell-Editor zu gelangen.
- Wenn Sie heute an irgendeinem Punkt zur Autorisierung aufgefordert werden, klicken Sie auf Autorisieren, um fortzufahren.
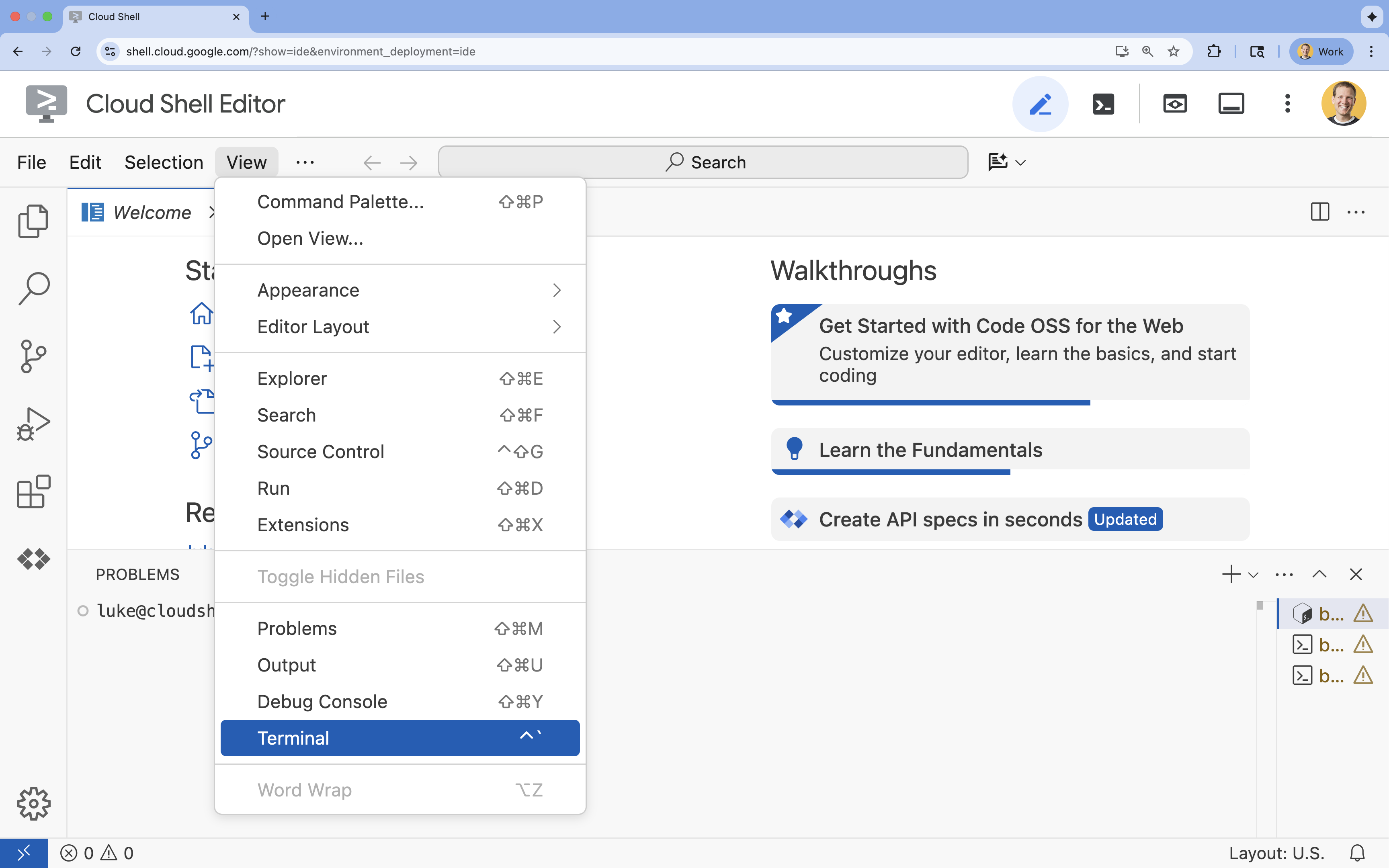
- Wenn das Terminal nicht unten auf dem Bildschirm angezeigt wird, öffnen Sie es:
- Klicken Sie auf Ansehen.
- Klicken Sie auf Terminal
 .
.
- Legen Sie im Terminal Ihr Projekt mit diesem Befehl fest:
gcloud config set project [PROJECT_ID]- Beispiel:
gcloud config set project lab-project-id-example - Wenn Sie sich nicht mehr an Ihre Projekt-ID erinnern, können Sie alle Ihre Projekt-IDs mit folgendem Befehl auflisten:
gcloud projects list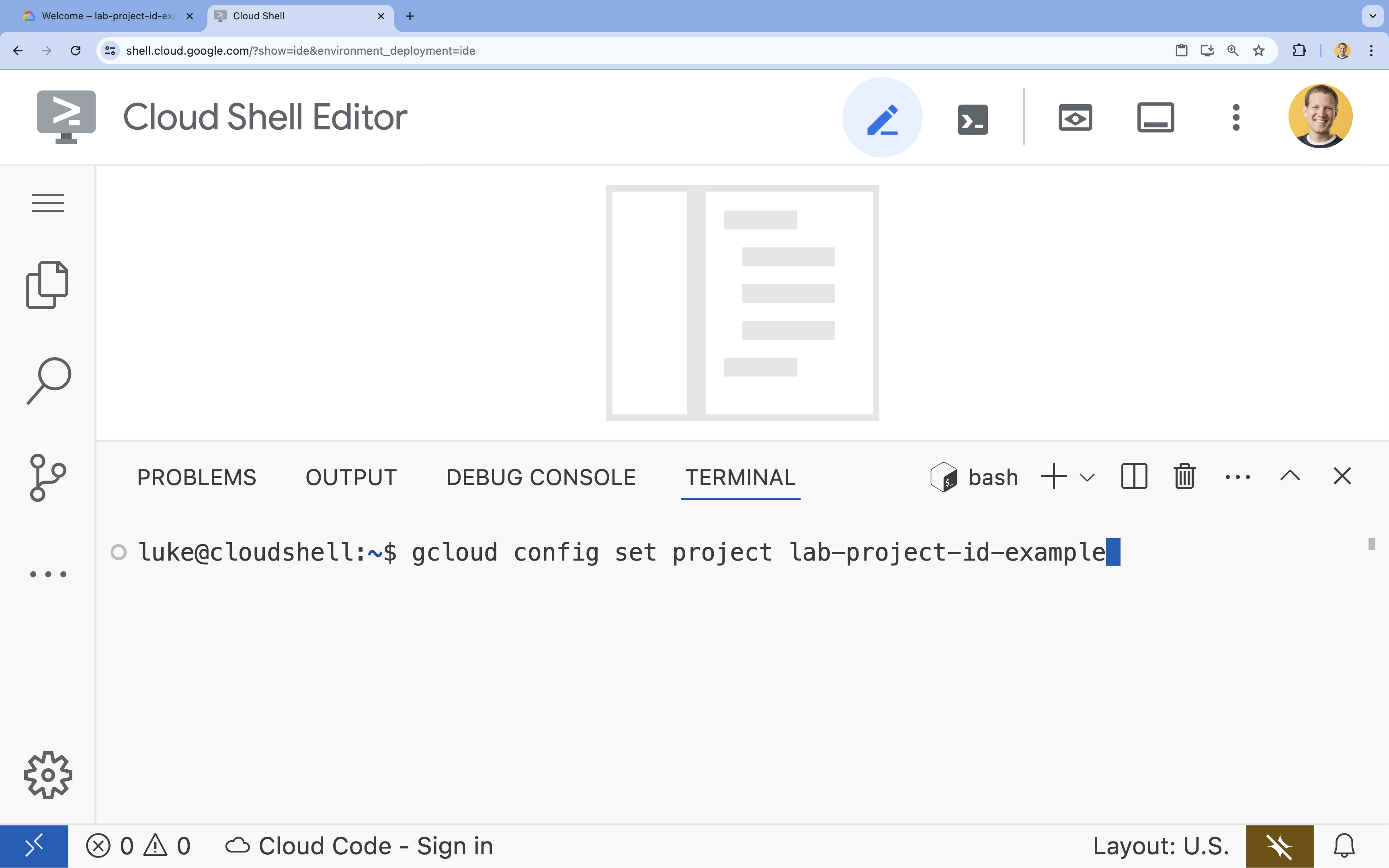
- Beispiel:
- Es sollte folgende Meldung angezeigt werden:
Updated property [core/project].
4. Gemma mit Ollama ausführen
Ihr erstes Ziel ist es, Gemma 3 so schnell wie möglich in einer Entwicklungsumgebung zum Laufen zu bringen. Sie verwenden Ollama, ein Tool, das die lokale Ausführung von Large Language Models erheblich vereinfacht. In dieser Aufgabe wird die einfachste Möglichkeit gezeigt, mit einem offenen Modell zu experimentieren.
Ollama ist ein kostenloses Open-Source-Tool, mit dem Nutzer generative Modelle (Large Language Models, Vision-Language Models usw.) lokal auf ihrem eigenen Computer ausführen können. Dadurch wird der Zugriff auf diese Modelle und die Interaktion mit ihnen vereinfacht. Nutzer können sie so leichter verwenden und privat damit arbeiten.
Ollama installieren und ausführen
Jetzt können Sie Ollama installieren, das Gemma 3-Modell herunterladen und über die Befehlszeile damit interagieren.
- Laden Sie Ollama im Cloud Shell-Terminal herunter und installieren Sie es:
curl -fsSL https://ollama.com/install.sh | sh - Starten Sie den Ollama-Dienst im Hintergrund:
ollama serve & - Rufen Sie das Gemma 3 1B-Modell mit Ollama ab (laden Sie es herunter):
ollama pull gemma3:1b - Modell lokal ausführen:
ollama run gemma3:1bollama runwird ein Prompt (>>>) angezeigt, in dem Sie dem Modell Fragen stellen können. - Testen Sie das Modell mit einer Frage. Geben Sie beispielsweise
Why is the sky blue?ein und drücken Sie die Eingabetaste. Die Antwort sieht ungefähr so aus:>>> Why is the sky blue? Okay, let's break down why the sky is blue – it's a fascinating phenomenon related to how light interacts with the Earth's atmosphere. Here's the explanation: **1. Sunlight and Colors:** * Sunlight appears white, but it's actually made up of all the colors of the rainbow (red, orange, yellow, green, blue, indigo, and violet). Think of a prism splitting sunlight. **2. Rayleigh Scattering:** * As sunlight enters the Earth's atmosphere... ...
- Geben Sie zum Beenden des Ollama-Prompts im Terminal
/byeein und drücken Sie die Eingabetaste.
OpenAI SDK mit Ollama verwenden
Da der Ollama-Dienst jetzt ausgeführt wird, können Sie programmatisch mit ihm interagieren. Sie verwenden das OpenAI Python SDK, das mit der API kompatibel ist, die von Ollama bereitgestellt wird.
- Erstellen und aktivieren Sie im Cloud Shell-Terminal eine virtuelle Umgebung mit uv. So wird sichergestellt, dass die Projektabhängigkeiten nicht mit dem System-Python in Konflikt stehen.
uv venv --python 3.14 source .venv/bin/activate - Installieren Sie das OpenAI SDK im Terminal:
uv pip install openai - Erstellen Sie eine neue Datei mit dem Namen
ollama_chat.py, indem Sie im Terminal Folgendes eingeben:cloudshell edit ollama_chat.py - Fügen Sie den folgenden Python-Code in
ollama_chat.pyein. Mit diesem Code wird eine Anfrage an den lokalen Ollama-Server gesendet.from openai import OpenAI client = OpenAI( base_url = 'http://localhost:11434/v1', api_key='ollama', # required by OpenAI SDK, but not used by Ollama ) response = client.chat.completions.create( model="gemma3:1b", messages=[ { "role": "user", "content": "Why is the sky blue?" }, ], ) print(response.choices[0].message.content) - Führen Sie das Skript in Ihrem Terminal aus:
python3 ollama_chat.py - Wenn Sie den Streamingmodus ausprobieren möchten, erstellen Sie eine weitere Datei mit dem Namen
ollama_stream.py, indem Sie Folgendes im Terminal ausführen:cloudshell edit ollama_stream.py - Fügen Sie den folgenden Inhalt in die Datei
ollama_stream.pyein. Beachten Sie den Parameterstream=Truein der Anfrage. So kann das Modell Tokens zurückgeben, sobald sie generiert werden.from openai import OpenAI client = OpenAI( base_url = 'http://localhost:11434/v1', api_key='ollama', ) stream = client.chat.completions.create( model="gemma3:1b", messages=[ { "role": "user", "content": "Why is the sky blue?" }, ], stream=True ) for chunk in stream: if chunk.choices[0].delta.content is not None: print(chunk.choices[0].delta.content, end="", flush=True) print() - Führen Sie das Streaming-Skript im Terminal aus:
python3 ollama_stream.py
Streaming ist eine nützliche Funktion, um eine gute Nutzererfahrung in interaktiven Anwendungen wie Chatbots zu schaffen. Anstatt den Nutzer warten zu lassen, bis die gesamte Antwort generiert wurde, wird die Antwort beim Streaming Token für Token angezeigt, sobald sie erstellt wird. So erhalten Sie sofortiges Feedback und die Anwendung wirkt viel reaktionsschneller.
Das haben Sie gelernt: Offene Modelle mit Ollama ausführen
Sie haben ein offenes Modell mit Ollama ausgeführt. Sie haben gesehen, wie einfach es sein kann, ein leistungsstarkes Modell wie Gemma 3 herunterzuladen und damit zu interagieren – sowohl über eine Befehlszeilenschnittstelle als auch programmatisch mit Python. Dieser Workflow ist ideal für schnelles Prototyping und die lokale Entwicklung. Sie haben jetzt eine solide Grundlage, um erweiterte Bereitstellungsoptionen zu erkunden.
5. Gemma mit Ollama in GKE Autopilot bereitstellen
Für Produktionsarbeitslasten, die einen vereinfachten Betrieb und Skalierbarkeit erfordern, ist die Google Kubernetes Engine (GKE) die Plattform der Wahl. In dieser Aufgabe stellen Sie Gemma mit Ollama in einem GKE Autopilot-Cluster bereit.
GKE Autopilot ist ein Betriebsmodus in GKE, in dem Google Ihre Clusterkonfiguration verwaltet, einschließlich Knoten, Skalierung, Sicherheit und anderer vorkonfigurierter Einstellungen. So wird eine wirklich „serverlose“ Kubernetes-Umgebung geschaffen, die sich perfekt für die Ausführung von Inferenzarbeitslasten eignet, ohne dass die zugrunde liegende Recheninfrastruktur verwaltet werden muss.
GKE-Umgebung vorbereiten
Für die letzte Aufgabe, die Bereitstellung in Kubernetes, stellen Sie einen GKE Autopilot-Cluster bereit.
- Legen Sie im Cloud Shell-Terminal Umgebungsvariablen für Ihr Projekt und die gewünschte Region fest.
export PROJECT_ID=$(gcloud config get-value project) export REGION=europe-west1 gcloud config set compute/region $REGION - Aktivieren Sie die GKE API für Ihr Projekt, indem Sie Folgendes im Terminal ausführen:
gcloud services enable container.googleapis.com - Erstellen Sie einen GKE Autopilot-Cluster, indem Sie Folgendes im Terminal ausführen:
gcloud container clusters create-auto gemma-cluster \ --region $REGION \ --release-channel rapid - Rufen Sie Anmeldedaten für den neuen Cluster ab, indem Sie im Terminal Folgendes ausführen:
gcloud container clusters get-credentials gemma-cluster \ --region $REGION
Ollama und Gemma bereitstellen
Nachdem Sie einen GKE Autopilot-Cluster haben, können Sie den Ollama-Server bereitstellen. Autopilot stellt automatisch Rechenressourcen (CPU und Arbeitsspeicher) basierend auf den Anforderungen bereit, die Sie in Ihrem Deployment-Manifest definieren.
- Erstellen Sie eine neue Datei mit dem Namen
gemma-deployment.yaml, indem Sie Folgendes im Terminal ausführen:cloudshell edit gemma-deployment.yaml - Fügen Sie die folgende YAML-Konfiguration in
gemma-deployment.yamlein. Diese Konfiguration definiert ein Deployment, das das offizielle Ollama-Image zur Ausführung auf der CPU verwendet.apiVersion: apps/v1 kind: Deployment metadata: name: ollama-gemma spec: replicas: 1 selector: matchLabels: app: ollama-gemma template: metadata: labels: app: ollama-gemma spec: containers: - name: ollama-gemma-container image: ollama/ollama:0.12.10 resources: requests: cpu: "8" memory: "8Gi" ephemeral-storage: "10Gi" limits: cpu: "8" memory: "8Gi" ephemeral-storage: "10Gi" # We use a script to start the server and pull the model command: ["/bin/bash", "-c"] args: - | ollama serve & OLLAMA_PID=$! echo "Waiting for Ollama server to start..." sleep 5 echo "Pulling Gemma model..." ollama pull gemma3:1b echo "Model pulled. Ready to serve." wait $OLLAMA_PID ports: - containerPort: 11434 env: - name: OLLAMA_HOST value: "0.0.0.0" --- apiVersion: v1 kind: Service metadata: name: llm-service spec: selector: app: ollama-gemma type: ClusterIP ports: - protocol: TCP port: 8000 targetPort: 11434image: ollama/ollama:latest: Gibt das offizielle Ollama-Docker-Image an.resources: Wir fordern explizit 8 vCPUs und 8 GiB Arbeitsspeicher an. GKE Autopilot verwendet diese Werte, um die zugrunde liegenden Rechenressourcen bereitzustellen. Da wir keine GPUs verwenden, wird das Modell auf der CPU ausgeführt. Die 8 GiB Arbeitsspeicher reichen aus, um das Gemma 1B-Modell und seinen Kontext zu speichern.command/args: Wir überschreiben den Startbefehl, um sicherzustellen, dass das Modell beim Start des Pods abgerufen wird. Das Skript startet den Server im Hintergrund, wartet, bis er bereit ist, ruft dasgemma3:1b-Modell ab und lässt den Server dann weiterlaufen.OLLAMA_HOST: Wenn Sie diesen Wert auf0.0.0.0festlegen, lauscht Ollama auf allen Netzwerkschnittstellen im Container und ist so für den Kubernetes-Dienst zugänglich.
- Wenden Sie das Deployment-Manifest im Terminal auf Ihren Cluster an:
kubectl apply -f gemma-deployment.yamlkubectl get pods --watchRunningundREADY1/1lautet, bevor Sie fortfahren.
GKE-Endpunkt testen
Ihr Ollama-Dienst wird jetzt in Ihrem GKE Autopilot-Cluster ausgeführt. Um sie über das Cloud Shell-Terminal zu testen, verwenden Sie kubectl port-forward.
- Öffnen Sie einen neuen Cloud Shell-Terminaltab. Klicken Sie dazu im Terminalfenster auf das Symbol +. Der Befehl
port-forwardist ein blockierender Prozess und benötigt daher eine eigene Terminalsitzung. - Führen Sie im neuen Terminal den folgenden Befehl aus, um einen lokalen Port (z.B.
8000) an den Port des Dienstes (8000) weiterzuleiten:kubectl port-forward service/llm-service 8000:8000 - Kehren Sie zu Ihrem ursprünglichen Terminal zurück.
- Senden Sie eine Anfrage an den lokalen Port
8000. Der Ollama-Server stellt eine OpenAI-kompatible API bereit. Aufgrund der Portweiterleitung können Sie jetzt unterhttp://127.0.0.1:8000darauf zugreifen.curl http://127.0.0.1:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "gemma3:1b", "messages": [ {"role": "user", "content": "Explain why the sky is blue."} ] }'
6. Klären
So vermeiden Sie, dass Ihrem Google Cloud-Konto die in diesem Lab verwendeten Ressourcen in Rechnung gestellt werden:
- Löschen Sie den GKE Autopilot-Cluster im Cloud Shell-Terminal:
gcloud container clusters delete gemma-cluster \ --region $REGION --quiet
7. Fazit
Gut gemacht! In diesem Lab haben Sie mehrere wichtige Methoden zum Bereitstellen offener Modelle in Google Cloud kennengelernt. Sie haben mit der Einfachheit und Geschwindigkeit der lokalen Entwicklung mit Ollama begonnen. Schließlich haben Sie Gemma in einer produktionsreifen, skalierbaren Umgebung mit Google Kubernetes Engine Autopilot und dem Ollama-Framework bereitgestellt.
Sie haben jetzt das Wissen, um offene Modelle in Google Kubernetes Engine für anspruchsvolle, skalierbare Arbeitslasten bereitzustellen, ohne die zugrunde liegende Infrastruktur verwalten zu müssen.
Zusammenfassung
In diesem Lab haben Sie Folgendes gelernt:
- Was offene Modelle sind und warum sie wichtig sind
- So führen Sie ein offenes Modell lokal mit Ollama aus.
- So stellen Sie ein offenes Modell in Google Kubernetes Engine (GKE) Autopilot mit Ollama für die Inferenz bereit.
Weitere Informationen
- Weitere Informationen zu Gemma-Modellen finden Sie in der offiziellen Dokumentation.
- Weitere Beispiele finden Sie im Repository „Google Cloud Generative AI“ auf GitHub.
- Weitere Informationen zu GKE Autopilot
- Im Vertex AI Model Garden finden Sie weitere verfügbare offene und proprietäre Modelle.