
1. Introduction
Présentation
L'objectif de cet atelier est de vous fournir une expérience pratique du déploiement d'un modèle ouvert sur Google Cloud, en passant d'une configuration locale simple à un déploiement de qualité production sur Google Kubernetes Engine (GKE). Vous apprendrez à utiliser différents outils adaptés à chaque étape du cycle de vie du développement.
L'atelier suit le parcours suivant :
- Prototypage rapide : vous exécuterez d'abord un modèle avec Ollama en local pour voir à quel point il est facile de commencer.
- Déploiement en production : enfin, vous déploierez le modèle sur GKE Autopilot à l'aide d'Ollama comme moteur de diffusion évolutif.
Comprendre les modèles ouverts
De nos jours, l'expression "modèle ouvert" fait généralement référence à un modèle de machine learning génératif que tout le monde peut télécharger et utiliser publiquement. Cela signifie que l'architecture du modèle et, plus important encore, ses paramètres entraînés ou "pondérations" sont publiés.
Cette transparence offre plusieurs avantages par rapport aux modèles fermés, qui ne sont généralement accessibles que via une API restrictive :
- Informations : les développeurs et les chercheurs peuvent "regarder sous le capot" pour comprendre le fonctionnement interne du modèle.
- Personnalisation : les utilisateurs peuvent adapter le modèle à des tâches spécifiques grâce à un processus appelé réglage fin.
- Innovation : elle permet à la communauté de créer des applications nouvelles et innovantes basées sur des modèles existants puissants.
Contribution de Google et famille Gemma
Google est un contributeur fondamental au mouvement d'IA Open Source depuis de nombreuses années. L'architecture révolutionnaire Transformer, présentée dans l'article de 2017 "Attention Is All You Need", est à la base de presque tous les grands modèles de langage modernes. Elle a été suivie par des modèles ouverts emblématiques tels que BERT, T5 et Flan-T5 avec réglage des instructions, qui ont chacun repoussé les limites du possible et alimenté la recherche et le développement dans le monde entier.
S'appuyant sur cette riche histoire d'innovation ouverte, Google a présenté la famille de modèles Gemma. Les modèles Gemma sont créés à partir des mêmes recherches et technologies que celles utilisées pour les puissants modèles Gemini à code source fermé, mais sont mis à disposition avec des pondérations ouvertes. Pour les clients Google Cloud, cela offre une combinaison puissante de technologies de pointe et de flexibilité Open Source, ce qui leur permet de contrôler le cycle de vie du modèle, de s'intégrer à un écosystème diversifié et de poursuivre une stratégie multicloud.
Coup de projecteur sur Gemma 3
Dans cet atelier, nous nous concentrerons sur Gemma 3, la dernière génération la plus performante de cette famille. Les modèles Gemma 3 sont légers, mais à la pointe de la technologie. Ils sont conçus pour s'exécuter efficacement sur un seul GPU ou même un seul processeur.
- Performances et taille : les modèles Gemma 3 sont légers, mais à la pointe de la technologie. Ils sont conçus pour s'exécuter efficacement sur un seul GPU ou même un seul processeur. Ils offrent une qualité supérieure et des performances de pointe (SOTA) pour leur taille.
- Modalité : ils sont multimodaux et peuvent gérer à la fois des entrées de texte et d'image pour générer des sorties de texte.
- Fonctionnalités clés : Gemma 3 dispose d'une grande fenêtre de contexte de 128 000 et est compatible avec plus de 140 langues.
- Cas d'utilisation : ces modèles sont parfaitement adaptés à diverses tâches, comme répondre à des questions, résumer et raisonner.
Terminologie clé
Lorsque vous travaillez avec des modèles ouverts, vous rencontrerez quelques termes courants :
- Le pré-entraînement consiste à entraîner un modèle sur un ensemble de données volumineux et diversifié pour apprendre des schémas de langage généraux. Ces modèles sont essentiellement des machines de saisie semi-automatique puissantes.
- Le réglage des instructions affine un modèle pré-entraîné pour mieux suivre des instructions et des requêtes spécifiques. Ce sont les modèles qui "savent comment discuter".
- Variantes de modèle : les modèles ouverts sont généralement disponibles en plusieurs tailles (par exemple, Gemma 3 comporte des versions de 1 milliard, 4 milliards, 12 milliards et 27 milliards de paramètres) et variantes, telles que le réglage des instructions (-it), le pré-entraînement ou la quantification pour plus d'efficacité.
- Besoins en ressources : les grands modèles de langage sont volumineux et nécessitent des ressources de calcul importantes pour être hébergés. Bien qu'ils puissent être exécutés en local, leur déploiement dans le cloud offre une valeur ajoutée significative, en particulier lorsqu'ils sont optimisés pour les performances et l'évolutivité avec des outils tels qu'Ollama.
Pourquoi utiliser GKE pour diffuser des modèles ouverts ?
Cet atelier vous guide de l'exécution simple d'un modèle local à un déploiement en production à grande échelle sur Google Kubernetes Engine (GKE). Bien que des outils tels qu'Ollama soient excellents pour le prototypage rapide, les environnements de production ont un ensemble d'exigences strictes que GKE est particulièrement bien placé pour satisfaire.
Pour les applications d'IA à grande échelle, vous avez besoin de plus qu'un simple modèle en cours d'exécution. Vous avez besoin d'une infrastructure de diffusion résiliente, évolutive et efficace. GKE fournit cette base. Voici quand et pourquoi choisir GKE :
- Gestion simplifiée avec Autopilot : GKE Autopilot gère l'infrastructure sous-jacente pour vous. Vous vous concentrez sur la configuration de votre application, et Autopilot provisionne et met à l'échelle les nœuds automatiquement.
- Hautes performances et évolutivité : gérez le trafic variable et exigeant grâce à la mise à l'échelle automatique de GKE. Cela garantit que votre application peut offrir un débit élevé avec une faible latence, en augmentant ou en diminuant l'échelle selon les besoins.
- Rentabilité à grande échelle : gérez les ressources efficacement. GKE peut réduire les charges de travail à zéro pour éviter de payer pour les ressources inactives, et vous pouvez tirer parti des VM Spot pour réduire considérablement les coûts des charges de travail d'inférence sans état.
- Portabilité et écosystème riche : évitez la dépendance vis-à-vis d'un fournisseur grâce à un déploiement portable basé sur Kubernetes. GKE fournit également un accès au vaste écosystème Cloud Native (CNCF) pour des outils de surveillance, de journalisation et de sécurité de pointe.
En bref, vous passez à GKE lorsque votre application d'IA est prête pour la production et nécessite une plate-forme conçue pour une évolutivité, des performances et une maturité opérationnelle importantes.
Points abordés
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
- Exécuter un modèle ouvert en local avec Ollama.
- Déployer un modèle ouvert sur Google Kubernetes Engine (GKE) Autopilot avec Ollama pour la diffusion.
- Comprendre la progression des frameworks de développement locaux vers une architecture de diffusion de qualité production sur GKE.
2. Configuration du projet
Compte Google
Si vous ne possédez pas encore de compte Google personnel, vous devez en créer un.
Utilisez un compte personnel au lieu d'un compte professionnel ou scolaire.
Se connecter à la console Google Cloud
Connectez-vous à la console Google Cloud à l'aide d'un compte Google personnel.
Activer la facturation
Configurer un compte de facturation personnel
Si vous configurez la facturation à l'aide de crédits Google Cloud, vous pouvez ignorer cette étape.
Pour configurer un compte de facturation personnel, accédez à cette page pour activer la facturation dans la console Cloud.
Quelques remarques :
- L'exécution de cet atelier ne devrait pas coûter plus de 1 $en ressources cloud.
- Vous pouvez suivre les étapes à la fin de cet atelier pour supprimer les ressources et éviter d'autres frais.
- Les nouveaux utilisateurs peuvent bénéficier de l'essai sans frais de 300$.
Créer un projet (facultatif)
Si vous ne disposez pas d'un projet actuel que vous souhaitez utiliser pour cet atelier, créez-en un ici.
3. Ouvrir l'éditeur Cloud Shell
- Cliquez sur ce lien pour accéder directement à l'éditeur Cloud Shell.
- Si vous êtes invité à autoriser à tout moment aujourd'hui, cliquez sur Autoriser pour continuer.
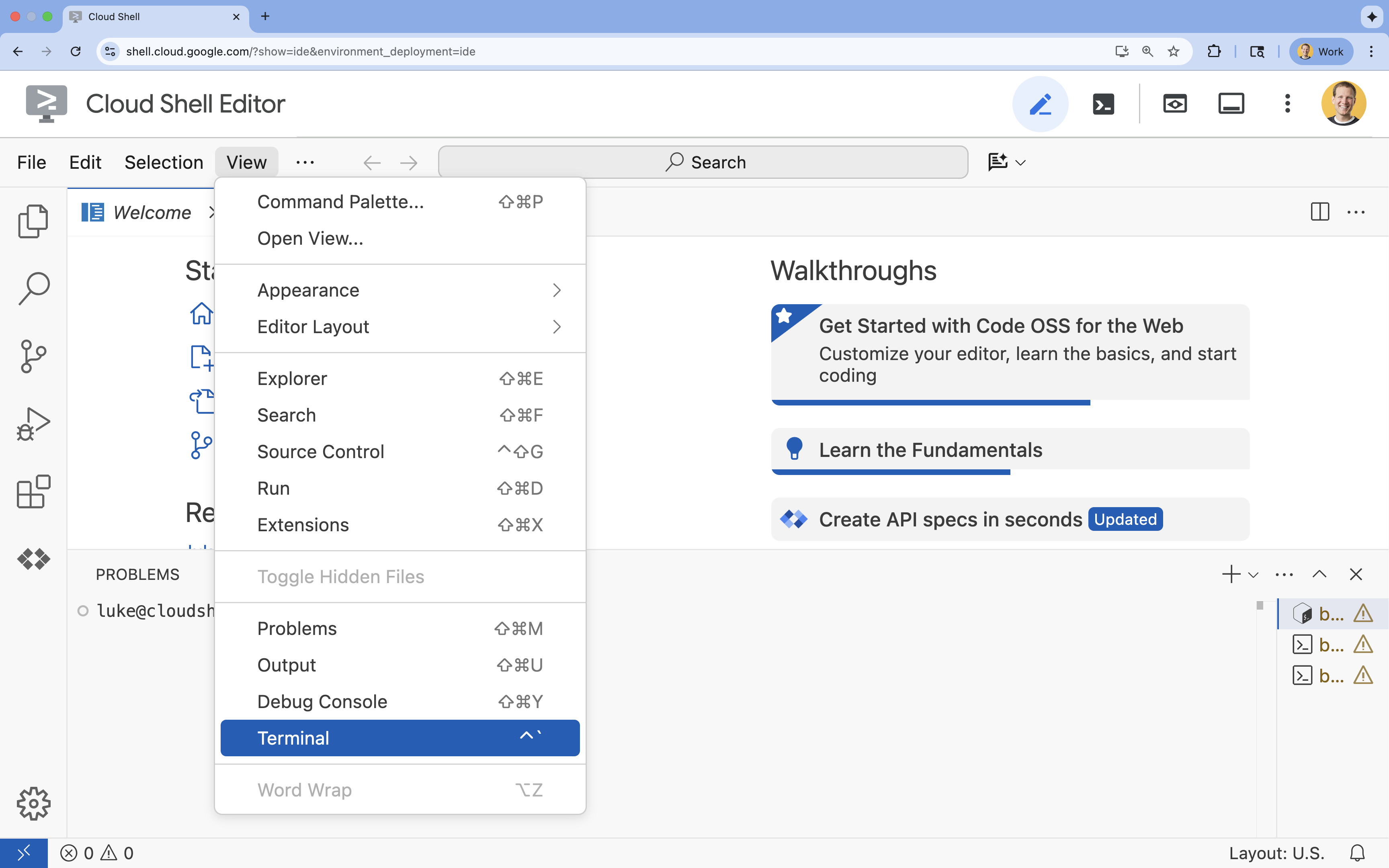
- Si le terminal ne s'affiche pas en bas de l'écran, ouvrez-le :
- Cliquez sur Afficher.
- Cliquez sur Terminal
 .
.
- Dans le terminal, définissez votre projet à l'aide de la commande suivante :
gcloud config set project [PROJECT_ID]- Exemple :
gcloud config set project lab-project-id-example - Si vous ne vous souvenez pas de votre ID de projet, vous pouvez lister tous vos ID de projet avec :
gcloud projects list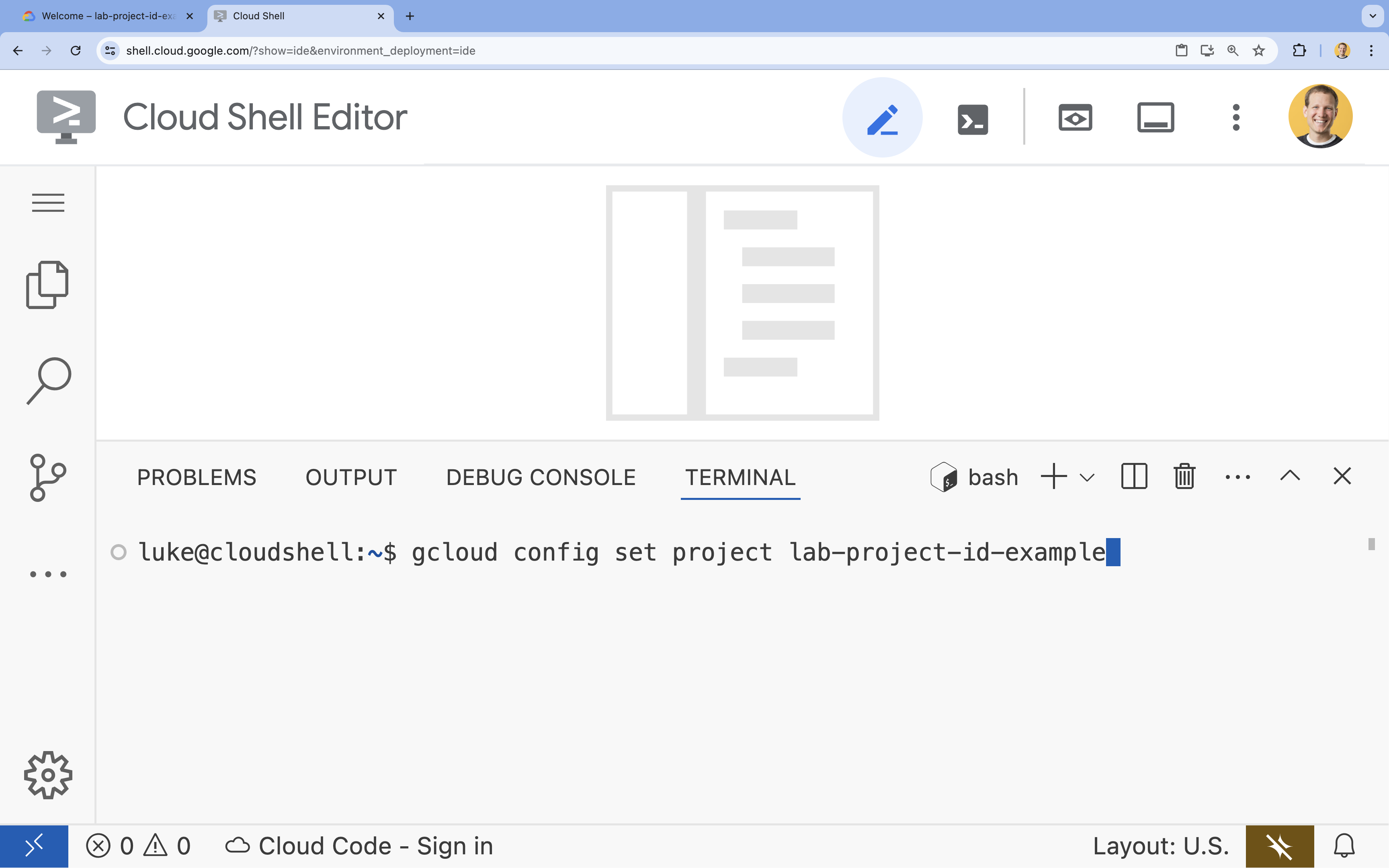
- Exemple :
- Le message suivant doit s'afficher :
Updated property [core/project].
4. Exécuter Gemma avec Ollama
Votre premier objectif est d'exécuter Gemma 3 le plus rapidement possible dans un environnement de développement. Vous utiliserez Ollama, un outil qui simplifie considérablement l'exécution de grands modèles de langage en local. Cette tâche vous montre la manière la plus simple de commencer à expérimenter avec un modèle ouvert.
Ollama est un outil Open Source sans frais qui permet aux utilisateurs d'exécuter des modèles génératifs (grands modèles de langage, modèles de langage visuel, etc.) en local sur leur propre ordinateur. Il simplifie le processus d'accès et d'interaction avec ces modèles, les rendant plus accessibles et permettant aux utilisateurs de travailler avec eux en privé.
Installer et exécuter Ollama
Vous êtes maintenant prêt à installer Ollama, à télécharger le modèle Gemma 3 et à interagir avec lui à partir de la ligne de commande.
- Dans le terminal Cloud Shell, téléchargez et installez Ollama :
curl -fsSL https://ollama.com/install.sh | sh - Démarrez le service Ollama en arrière-plan :
ollama serve & - Extrayez (téléchargez) le modèle Gemma 3 1B avec Ollama :
ollama pull gemma3:1b - Exécutez le modèle en local :
ollama run gemma3:1bollama runprésente une invite (>>>) pour que vous puissiez poser des questions au modèle. - Testez le modèle avec une question. Par exemple, saisissez
Why is the sky blue?et appuyez sur Entrée. Un résultat semblable à celui-ci doit s'afficher :>>> Why is the sky blue? Okay, let's break down why the sky is blue – it's a fascinating phenomenon related to how light interacts with the Earth's atmosphere. Here's the explanation: **1. Sunlight and Colors:** * Sunlight appears white, but it's actually made up of all the colors of the rainbow (red, orange, yellow, green, blue, indigo, and violet). Think of a prism splitting sunlight. **2. Rayleigh Scattering:** * As sunlight enters the Earth's atmosphere... ...
- Pour quitter l'invite Ollama dans le terminal, saisissez
/byeet appuyez sur Entrée.
Utiliser le SDK OpenAI avec Ollama
Maintenant que le service Ollama est en cours d'exécution, vous pouvez interagir avec lui par programmation. Vous utiliserez le SDK Python OpenAI, qui est compatible avec l'API exposée par Ollama.
- Dans le terminal Cloud Shell, créez et activez un environnement virtuel à l'aide d'uv. Cela garantit que les dépendances de votre projet n'entrent pas en conflit avec Python du système.
uv venv --python 3.14 source .venv/bin/activate - Dans le terminal, installez le SDK OpenAI :
uv pip install openai - Créez un fichier nommé
ollama_chat.pyen saisissant dans le terminal :cloudshell edit ollama_chat.py - Collez le code Python suivant dans
ollama_chat.py. Ce code envoie une requête au serveur Ollama local.from openai import OpenAI client = OpenAI( base_url = 'http://localhost:11434/v1', api_key='ollama', # required by OpenAI SDK, but not used by Ollama ) response = client.chat.completions.create( model="gemma3:1b", messages=[ { "role": "user", "content": "Why is the sky blue?" }, ], ) print(response.choices[0].message.content) - Exécutez le script dans votre terminal :
python3 ollama_chat.py - Pour essayer le mode de streaming, créez un autre fichier nommé
ollama_stream.pyen exécutant la commande suivante dans le terminal :cloudshell edit ollama_stream.py - Collez le contenu suivant dans le fichier
ollama_stream.py. Notez le paramètrestream=Truedans la requête. Cela permet au modèle de renvoyer des jetons dès qu'ils sont générés.from openai import OpenAI client = OpenAI( base_url = 'http://localhost:11434/v1', api_key='ollama', ) stream = client.chat.completions.create( model="gemma3:1b", messages=[ { "role": "user", "content": "Why is the sky blue?" }, ], stream=True ) for chunk in stream: if chunk.choices[0].delta.content is not None: print(chunk.choices[0].delta.content, end="", flush=True) print() - Exécutez le script de streaming dans le terminal :
python3 ollama_stream.py
Le streaming est une fonctionnalité utile pour créer une bonne expérience utilisateur dans les applications interactives telles que les chatbots. Au lieu de faire attendre l'utilisateur que la réponse entière soit générée, le streaming affiche la réponse jeton par jeton au fur et à mesure de sa création. Cela fournit un retour immédiat et rend l'application beaucoup plus réactive.
Ce que vous avez appris : exécuter des modèles ouverts avec Ollama
Vous avez exécuté un modèle ouvert avec Ollama. Vous avez vu à quel point il peut être simple de télécharger un modèle puissant tel que Gemma 3 et d'interagir avec lui, à la fois via une interface de ligne de commande et par programmation avec Python. Ce workflow est idéal pour le prototypage rapide et le développement local. Vous disposez désormais d'une base solide pour explorer des options de déploiement plus avancées.
5. Déployer Gemma avec Ollama sur GKE Autopilot
Pour les charges de travail de production qui nécessitent des opérations simplifiées et une évolutivité, Google Kubernetes Engine (GKE) est la plate-forme de choix. Dans cette tâche, vous allez déployer Gemma à l'aide d'Ollama sur un cluster GKE Autopilot.
GKE Autopilot est un mode de fonctionnement de GKE dans lequel Google gère la configuration de votre cluster, y compris vos nœuds, le scaling, la sécurité et d'autres paramètres préconfigurés. Il crée une expérience Kubernetes véritablement "sans serveur", idéale pour exécuter des charges de travail d'inférence sans gérer l'infrastructure de calcul sous-jacente.
Préparer l'environnement GKE
Pour la dernière tâche de déploiement sur Kubernetes, vous allez provisionner un cluster GKE Autopilot.
- Dans le terminal Cloud Shell, définissez les variables d'environnement pour votre projet et la région souhaitée.
export PROJECT_ID=$(gcloud config get-value project) export REGION=europe-west1 gcloud config set compute/region $REGION - Activez l'API GKE pour votre projet en exécutant la commande suivante dans le terminal :
gcloud services enable container.googleapis.com - Créez un cluster GKE Autopilot en exécutant la commande suivante dans le terminal :
gcloud container clusters create-auto gemma-cluster \ --region $REGION \ --release-channel rapid - Obtenez les identifiants pour votre nouveau cluster en exécutant la commande suivante dans le terminal :
gcloud container clusters get-credentials gemma-cluster \ --region $REGION
Déployer Ollama et Gemma
Maintenant que vous disposez d'un cluster GKE Autopilot, vous pouvez déployer le serveur Ollama. Autopilot provisionnera automatiquement les ressources de calcul (processeur et mémoire) en fonction des exigences que vous définissez dans votre fichier manifeste de déploiement.
- Créez un fichier nommé
gemma-deployment.yamlen exécutant la commande suivante dans le terminal :cloudshell edit gemma-deployment.yaml - Collez la configuration YAML suivante dans
gemma-deployment.yaml. Cette configuration définit un déploiement qui utilise l'image Ollama officielle pour s'exécuter sur le processeur.apiVersion: apps/v1 kind: Deployment metadata: name: ollama-gemma spec: replicas: 1 selector: matchLabels: app: ollama-gemma template: metadata: labels: app: ollama-gemma spec: containers: - name: ollama-gemma-container image: ollama/ollama:0.12.10 resources: requests: cpu: "8" memory: "8Gi" ephemeral-storage: "10Gi" limits: cpu: "8" memory: "8Gi" ephemeral-storage: "10Gi" # We use a script to start the server and pull the model command: ["/bin/bash", "-c"] args: - | ollama serve & OLLAMA_PID=$! echo "Waiting for Ollama server to start..." sleep 5 echo "Pulling Gemma model..." ollama pull gemma3:1b echo "Model pulled. Ready to serve." wait $OLLAMA_PID ports: - containerPort: 11434 env: - name: OLLAMA_HOST value: "0.0.0.0" --- apiVersion: v1 kind: Service metadata: name: llm-service spec: selector: app: ollama-gemma type: ClusterIP ports: - protocol: TCP port: 8000 targetPort: 11434image: ollama/ollama:latest: spécifie l'image Docker Ollama officielle.resources: nous demandons explicitement 8 processeurs virtuels et 8 Gio de mémoire. GKE Autopilot utilise ces valeurs pour provisionner le calcul sous-jacent. Comme nous n'utilisons pas de GPU, le modèle s'exécute sur le processeur. Les 8 Gio de mémoire suffisent pour contenir le modèle Gemma 1B et son contexte.command/args: nous remplaçons la commande de démarrage pour nous assurer que le modèle est extrait au démarrage du pod. Le script démarre le serveur en arrière-plan, attend qu'il soit prêt, extrait le modèlegemma3:1b, puis maintient le serveur en cours d'exécution.OLLAMA_HOST: la définition de cette valeur sur0.0.0.0garantit qu'Ollama écoute sur toutes les interfaces réseau du conteneur, ce qui le rend accessible au service Kubernetes.
- Dans le terminal, appliquez le fichier manifeste de déploiement à votre cluster :
kubectl apply -f gemma-deployment.yamlkubectl get pods --watchRunninget queREADYsoit1/1avant de continuer.
Tester le point de terminaison GKE
Votre service Ollama est maintenant en cours d'exécution sur votre cluster GKE Autopilot. Pour le tester à partir de votre terminal Cloud Shell, vous utiliserez kubectl port-forward.
- Ouvrez un nouvel onglet de terminal Cloud Shell (cliquez sur l'icône + dans la fenêtre du terminal). La commande
port-forwardest un processus bloquant. Elle a donc besoin de sa propre session de terminal. - Dans le nouveau terminal, exécutez la commande suivante pour transférer un port local (par exemple,
8000) vers le port du service (8000) :kubectl port-forward service/llm-service 8000:8000 - Revenez à votre terminal d'origine.
- Envoyez une requête à votre port local
8000. Le serveur Ollama expose une API compatible avec OpenAI. Grâce au transfert de port, vous pouvez désormais y accéder à l'adressehttp://127.0.0.1:8000.curl http://127.0.0.1:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "gemma3:1b", "messages": [ {"role": "user", "content": "Explain why the sky is blue."} ] }'
6. Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cet atelier ne soient facturées sur votre compte Google Cloud, suivez ces étapes pour supprimer le cluster GKE.
- Dans le terminal Cloud Shell, supprimez le cluster GKE Autopilot :
gcloud container clusters delete gemma-cluster \ --region $REGION --quiet
7. Conclusion
Bravo ! Dans cet atelier, vous avez découvert plusieurs méthodes clés pour déployer des modèles ouverts sur Google Cloud. Vous avez commencé par la simplicité et la rapidité du développement local avec Ollama. Enfin, vous avez déployé Gemma dans un environnement évolutif de qualité production à l'aide de Google Kubernetes Engine Autopilot et du framework Ollama.
Vous disposez désormais des connaissances nécessaires pour déployer des modèles ouverts sur Google Kubernetes Engine pour des charges de travail exigeantes et évolutives sans gérer l'infrastructure sous-jacente.
Récapitulatif
Dans cet atelier, vous avez appris :
- ce que sont les modèles ouverts et pourquoi ils sont importants ;
- comment exécuter un modèle ouvert en local avec Ollama ;
- comment déployer un modèle ouvert sur Google Kubernetes Engine (GKE) Autopilot à l'aide d'Ollama pour l'inférence.
En savoir plus
- En savoir plus sur les modèles Gemma dans la documentation officielle.
- Découvrez d'autres exemples dans le dépôt Google Cloud Generative AI sur GitHub.
- En savoir plus sur GKE Autopilot.
- Parcourez le Vertex AI Model Garden pour découvrir d'autres modèles ouverts et propriétaires disponibles.