
1. 소개
개요
이 실습의 목표는 간단한 로컬 설정에서 Google Kubernetes Engine (GKE)의 프로덕션급 배포로 진행하면서 Google Cloud에서 오픈 모델을 배포하는 실무 경험을 제공하는 것입니다. 개발 수명 주기의 각 단계에 적합한 다양한 도구를 사용하는 방법을 알아봅니다.
실습은 다음 경로를 따릅니다.
- 신속한 프로토타입 제작: 먼저 Ollama를 사용하여 로컬에서 모델을 실행하여 시작하는 것이 얼마나 쉬운지 확인합니다.
- 프로덕션 배포: 마지막으로 Ollama를 확장 가능한 서빙 엔진으로 사용하여 모델을 GKE Autopilot에 배포합니다.
개방형 모델 이해
요즘 '개방형 모델'은 일반적으로 모든 사용자가 다운로드하고 사용할 수 있도록 공개적으로 제공되는 생성형 머신러닝 모델 을 의미합니다. 즉, 모델의 아키텍처와 가장 중요한 학습된 매개변수 또는 '가중치'가 공개적으로 출시됩니다.
이러한 투명성은 일반적으로 제한적인 API를 통해서만 액세스할 수 있는 비공개 모델에 비해 여러 가지 이점을 제공합니다.
- 통찰력: 개발자와 연구자는 "내부"를 살펴보고 모델의 내부 작동 방식을 이해할 수 있습니다.
- 맞춤설정: 사용자는 세부 조정이라는 프로세스를 통해 특정 작업에 맞게 모델을 조정할 수 있습니다.
- 혁신: 커뮤티니가 강력한 기존 모델을 기반으로 새롭고 혁신적인 애플리케이션을 빌드할 수 있도록 지원합니다.
Google의 기여 및 Gemma 제품군
Google은 수년 동안 오픈소스 AI 운동에 근본적인 기여를 해왔습니다. 2017년 논문 "Attention Is All You Need"에서 소개된 혁신적인 Transformer 아키텍처는 거의 모든 최신 대규모 언어 모델의 기반입니다. 이후 BERT, T5, 조정된 Flan-T5와 같은 획기적인 오픈 모델이 등장하여 가능성의 한계를 넓히고 전 세계의 연구 개발을 촉진했습니다.
Google은 이러한 풍부한 오픈 이노베이션의 역사를 바탕으로 Gemma 모델 제품군을 도입했습니다. Gemma 모델은 강력한 비공개 Gemini 모델에 사용된 것과 동일한 연구 및 기술로 만들어지지만 개방형 가중치로 제공됩니다. Google Cloud 고객에게는 최첨단 기술과 오픈소스의 유연성이 결합된 강력한 조합을 제공하여 모델 수명 주기를 제어하고, 다양한 생태계와 통합하고, 멀티 클라우드 전략을 추구할 수 있도록 지원합니다.
Gemma 3 집중 분석
이 실습에서는 이 제품군에서 가장 최신이자 가장 강력한 세대인 Gemma 3에 중점을 둡니다. Gemma 3 모델은 경량이지만 최첨단이며 단일 GPU 또는 CPU에서 효율적으로 실행되도록 설계되었습니다.
- 성능 및 크기: Gemma 3 모델은 경량이지만 최첨단이며 단일 GPU 또는 CPU에서 효율적으로 실행되도록 설계되었습니다. 크기에 비해 우수한 품질과 최첨단 (SOTA) 성능을 제공합니다.
- 모달리티: 텍스트 및 이미지 입력을 모두 처리하여 텍스트 출력을 생성할 수 있는 멀티모달입니다.
- 주요 기능: Gemma 3에는 대규모 128K 컨텍스트 윈도우가 있으며 140개 이상의 언어를 지원합니다.
- 사용 사례: 이러한 모델은 질의 응답, 요약, 추론을 비롯한 다양한 작업에 적합합니다.
주요 용어
개방형 모델을 사용하다 보면 몇 가지 일반적인 용어를 접하게 됩니다.
- 사전 학습 은 일반적인 언어 패턴을 학습하기 위해 대규모의 다양한 데이터 세트에서 모델을 학습시키는 것입니다. 이러한 모델은 기본적으로 강력한 자동 완성 머신입니다.
- 명령 조정 은 특정 명령어와 프롬프트를 더 잘 따르도록 사전 학습된 모델을 세부 조정합니다. 이러한 모델은 '채팅하는 방법'을 알고 있습니다.
- 모델 변형: 오픈 모델은 일반적으로 여러 크기(예: Gemma 3에는 1B, 4B, 12B, 27B 매개변수 버전이 있음)와 변형(예: 조정된 명령어(-it), 사전 학습됨, 효율성을 위해 양자화됨)으로 출시됩니다.
- 리소스 요구사항: 대규모 언어 모델은 크고 호스팅하는 데 상당한 컴퓨팅 리소스가 필요합니다. 로컬에서 실행할 수 있지만 클라우드에 배포하면 특히 Ollama와 같은 도구로 성능과 확장성을 최적화할 때 상당한 가치를 제공합니다.
개방형 모델 서빙에 GKE를 사용하는 이유
이 실습에서는 간단한 로컬 모델 실행에서 Google Kubernetes Engine (GKE)의 대규모 프로덕션 배포로 안내합니다. Ollama와 같은 도구는 신속한 프로토타입 제작에 적합하지만 프로덕션 환경에는 GKE가 고유하게 충족할 수 있는 까다로운 요구사항이 있습니다.
대규모 AI 애플리케이션의 경우 실행 중인 모델뿐만 아니라 복원력 있고 확장 가능하며 효율적인 서빙 인프라가 필요합니다. GKE는 이러한 기반을 제공합니다. GKE를 선택하는 시점과 이유는 다음과 같습니다.
- Autopilot으로 간소화된 관리: GKE Autopilot은 기본 인프라를 관리합니다. 애플리케이션 구성에 집중하면 Autopilot이 노드를 자동으로 프로비저닝하고 확장합니다.
- 고성능 및 확장성: GKE의 자동 확장을 통해 까다롭고 가변적인 트래픽을 처리합니다. 이렇게 하면 애플리케이션이 필요에 따라 확장 또는 축소되면서 낮은 지연 시간으로 높은 처리량을 제공할 수 있습니다.
- 규모에 맞는 비용 효율성: 리소스를 효율적으로 관리합니다. GKE는 유휴 리소스에 대한 비용을 지불하지 않도록 워크로드를 0으로 축소할 수 있으며 스팟 VM을 활용하여 상태 비저장 추론 워크로드의 비용을 크게 절감할 수 있습니다.
- 이식성 및 풍부한 생태계: 이식 가능한 Kubernetes 기반 배포로 공급업체 종속을 방지합니다. GKE는 또한 동급 최고의 모니터링, 로깅, 보안 도구를 위해 광범위한 클라우드 네이티브 (CNCF) 생태계에 대한 액세스를 제공합니다.
즉, AI 애플리케이션이 프로덕션에 적합하고 대규모, 성능, 운영 성숙도를 위해 빌드된 플랫폼이 필요한 경우 GKE로 이동합니다.
학습할 내용
이 실습에서는 다음 작업을 수행하는 방법을 알아봅니다.
- Ollama를 사용하여 로컬에서 오픈 모델을 실행합니다.
- 서빙을 위해 Ollama를 사용하여 오픈 모델을 Google Kubernetes Engine (GKE) Autopilot에 배포합니다.
- 로컬 개발 프레임워크에서 GKE의 프로덕션급 서빙 아키텍처로 진행되는 과정을 이해합니다.
2. 프로젝트 설정
Google 계정
아직 개인 Google 계정이 없다면 Google 계정을 만들어야 합니다.
직장 또는 학교 계정 대신 개인 계정을 사용 하세요.
Google Cloud 콘솔에 로그인
개인 Google 계정을 사용하여 Google Cloud 콘솔에 로그인합니다.
결제 사용 설정
개인 결제 계정 설정
Google Cloud 크레딧을 사용하여 결제를 설정하는 경우 이 단계를 건너뛰어도 됩니다.
개인 결제 계정을 설정하려면 여기로 이동하여 결제를 사용 설정하세요.
몇 가지 참고사항:
- 이 실습을 완료하는 데 클라우드 리소스 비용이 $1(USD) 미만으로 소요됩니다.
- 이 실습의 마지막 단계에 따라 리소스를 삭제하여 추가 요금이 발생하지 않도록 할 수 있습니다.
- 신규 사용자는 $300(USD) 상당의 무료 체험판을 이용할 수 있습니다.
프로젝트 만들기 (선택사항)
이 실습에 사용할 현재 프로젝트가 없는 경우 여기에서 새 프로젝트를 만드세요.
3. Cloud Shell 편집기 열기
- 이 링크를 클릭하여 Cloud Shell 편집기로 바로 이동합니다.
- 오늘 언제든지 승인하라는 메시지가 표시되면 승인 을 클릭하여 계속합니다.
- 화면 하단에 터미널이 표시되지 않으면 다음을 수행하여 엽니다.
- 보기 를 클릭합니다.
- 터미널
 을 클릭합니다.
을 클릭합니다.
- 터미널에서 다음 명령어를 사용하여 프로젝트를 설정합니다.
gcloud config set project [PROJECT_ID]- 예:
gcloud config set project lab-project-id-example - 프로젝트 ID가 기억나지 않는 경우 다음을 사용하여 모든 프로젝트 ID를 나열할 수 있습니다.
gcloud projects list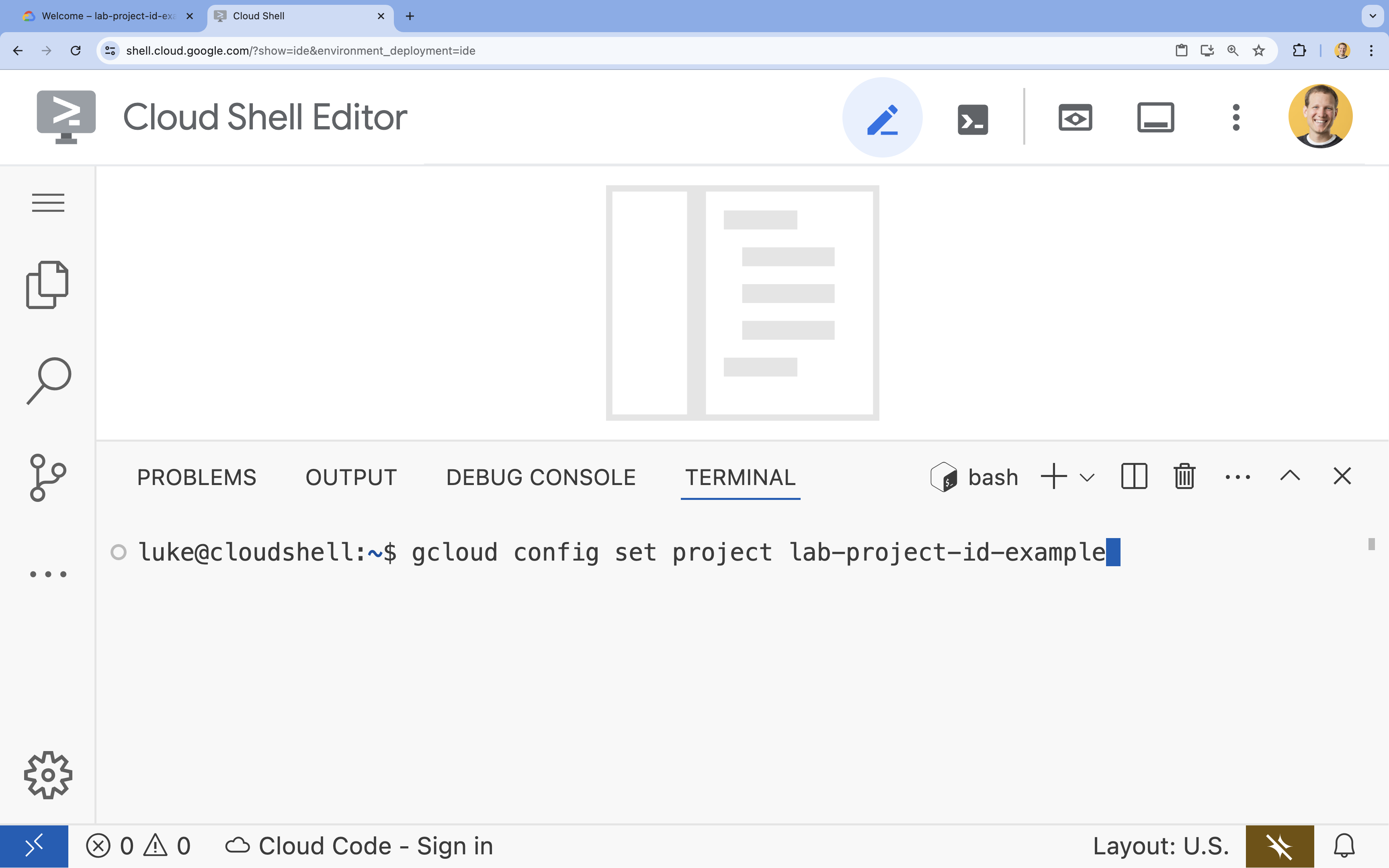
- 예:
- 다음 메시지가 표시되어야 합니다.
Updated property [core/project].
4. Ollama로 Gemma 실행
첫 번째 목표는 개발 환경에서 Gemma 3를 최대한 빨리 실행하는 것입니다. 대규모 언어 모델을 로컬에서 실행하는 것을 크게 간소화하는 도구인 Ollama를 사용합니다. 이 작업에서는 오픈 모델로 실험을 시작하는 가장 간단한 방법을 보여줍니다.
Ollama는 사용자가 자체 컴퓨터에서 생성형 모델 (대규모 언어 모델, 비전 언어 모델 등)을 로컬로 실행할 수 있는 무료 오픈소스 도구입니다. 이러한 모델에 액세스하고 상호작용하는 프로세스를 간소화하여 모델에 더 쉽게 액세스할 수 있도록 하고 사용자가 비공개로 작업할 수 있도록 지원합니다.
Ollama 설치 및 실행
이제 Ollama를 설치하고 Gemma 3 모델을 다운로드하고 명령줄에서 모델과 상호작용할 준비가 되었습니다.
- Cloud Shell 터미널에서 Ollama를 다운로드하고 설치합니다.
curl -fsSL https://ollama.com/install.sh | sh - 백그라운드에서 Ollama 서비스를 시작합니다.
ollama serve & - Ollama를 사용하여 Gemma 3 1B 모델을 가져옵니다 (다운로드).
ollama pull gemma3:1b - 로컬에서 모델을 실행합니다.
ollama run gemma3:1bollama run명령어는 모델에 질문할 수 있는 프롬프트 (>>>)를 표시합니다. - 질문으로 모델을 테스트합니다. 예를 들어
Why is the sky blue?를 입력하고 Enter 키를 누릅니다. 다음과 비슷한 응답이 표시됩니다.>>> Why is the sky blue? Okay, let's break down why the sky is blue – it's a fascinating phenomenon related to how light interacts with the Earth's atmosphere. Here's the explanation: **1. Sunlight and Colors:** * Sunlight appears white, but it's actually made up of all the colors of the rainbow (red, orange, yellow, green, blue, indigo, and violet). Think of a prism splitting sunlight. **2. Rayleigh Scattering:** * As sunlight enters the Earth's atmosphere... ...
- 터미널에서 Ollama 프롬프트를 종료하려면
/bye를 입력하고 Enter 키를 누릅니다.
Ollama와 함께 OpenAI SDK 사용
이제 Ollama 서비스가 실행 중이므로 프로그래매틱 방식으로 상호작용할 수 있습니다. Ollama가 노출하는 API와 호환되는 OpenAI Python SDK를 사용합니다.
- Cloud Shell 터미널에서 uv를 사용하여 가상 환경을 만들고 활성화합니다. 이렇게 하면 프로젝트 종속 항목이 시스템 Python과 충돌하지 않습니다.
uv venv --python 3.14 source .venv/bin/activate - 터미널에서 OpenAI SDK를 설치합니다.
uv pip install openai - 터미널에서 다음을 입력하여
ollama_chat.py라는 새 파일을 만듭니다.cloudshell edit ollama_chat.py - 다음 Python 코드를
ollama_chat.py에 붙여넣습니다. 이 코드는 로컬 Ollama 서버에 요청을 보냅니다.from openai import OpenAI client = OpenAI( base_url = 'http://localhost:11434/v1', api_key='ollama', # required by OpenAI SDK, but not used by Ollama ) response = client.chat.completions.create( model="gemma3:1b", messages=[ { "role": "user", "content": "Why is the sky blue?" }, ], ) print(response.choices[0].message.content) - 터미널에서 스크립트를 실행합니다.
python3 ollama_chat.py - 스트리밍 모드를 사용해 보려면 터미널에서 다음을 실행하여
ollama_stream.py라는 다른 파일을 만듭니다.cloudshell edit ollama_stream.py - 다음 콘텐츠를
ollama_stream.py파일에 붙여넣습니다. 요청의stream=True매개변수를 확인하세요. 이렇게 하면 모델이 생성되는 즉시 토큰을 반환할 수 있습니다.from openai import OpenAI client = OpenAI( base_url = 'http://localhost:11434/v1', api_key='ollama', ) stream = client.chat.completions.create( model="gemma3:1b", messages=[ { "role": "user", "content": "Why is the sky blue?" }, ], stream=True ) for chunk in stream: if chunk.choices[0].delta.content is not None: print(chunk.choices[0].delta.content, end="", flush=True) print() - 터미널에서 스트리밍 스크립트를 실행합니다.
python3 ollama_stream.py
스트리밍은 챗봇과 같은 대화형 애플리케이션에서 우수한 사용자 환경을 만드는 데 유용한 기능입니다. 스트리밍은 사용자가 전체 답변이 생성될 때까지 기다리게 하는 대신 답변이 생성될 때 토큰별로 표시합니다. 이렇게 하면 즉각적인 피드백이 제공되고 애플리케이션이 훨씬 더 반응성이 좋은 것처럼 느껴집니다.
학습한 내용: Ollama로 오픈 모델 실행
Ollama를 사용하여 오픈 모델을 실행했습니다. Gemma 3와 같은 강력한 모델을 다운로드하고 명령줄 인터페이스와 Python을 사용하여 프로그래매틱 방식으로 상호작용하는 것이 얼마나 간단한지 확인했습니다. 이 워크플로는 신속한 프로토타입 제작 및 로컬 개발에 적합합니다. 이제 고급 배포 옵션을 살펴볼 수 있는 견고한 기반이 마련되었습니다.
5. GKE Autopilot에서 Ollama로 Gemma 배포
간소화된 작업과 확장성이 필요한 프로덕션 워크로드의 경우 Google Kubernetes Engine (GKE)이 선택하는 플랫폼입니다. 이 작업에서는 GKE Autopilot 클러스터에서 Ollama를 사용하여 Gemma를 배포합니다.
GKE Autopilot은 노드, 확장, 보안, 기타 사전 구성된 설정을 포함한 클러스터 구성을 Google에서 관리하는 GKE의 작동 모드입니다. 기본 컴퓨팅 인프라를 관리하지 않고도 추론 워크로드를 실행하는 데 적합한 진정한 '서버리스' Kubernetes 환경을 만듭니다.
GKE 환경 준비
Kubernetes에 배포하는 마지막 작업으로 GKE Autopilot 클러스터를 프로비저닝합니다.
- Cloud Shell 터미널에서 프로젝트 및 원하는 리전의 환경 변수를 설정합니다.
export PROJECT_ID=$(gcloud config get-value project) export REGION=europe-west1 gcloud config set compute/region $REGION - 터미널에서 다음을 실행하여 프로젝트에 GKE API를 사용 설정합니다.
gcloud services enable container.googleapis.com - 터미널에서 다음을 실행하여 GKE Autopilot 클러스터를 만듭니다.
gcloud container clusters create-auto gemma-cluster \ --region $REGION \ --release-channel rapid - 터미널에서 다음을 실행하여 새 클러스터의 사용자 인증 정보를 가져옵니다.
gcloud container clusters get-credentials gemma-cluster \ --region $REGION
Ollama 및 Gemma 배포
이제 GKE Autopilot 클러스터가 있으므로 Ollama 서버를 배포할 수 있습니다. Autopilot은 배포 매니페스트에서 정의한 요구사항에 따라 컴퓨팅 리소스 (CPU 및 메모리)를 자동으로 프로비저닝합니다.
- 터미널에서 다음을 실행하여
gemma-deployment.yaml이라는 새 파일을 만듭니다.cloudshell edit gemma-deployment.yaml - 다음 YAML 구성을
gemma-deployment.yaml에 붙여넣습니다. 이 구성은 공식 Ollama 이미지를 사용하여 CPU에서 실행되는 배포를 정의합니다.apiVersion: apps/v1 kind: Deployment metadata: name: ollama-gemma spec: replicas: 1 selector: matchLabels: app: ollama-gemma template: metadata: labels: app: ollama-gemma spec: containers: - name: ollama-gemma-container image: ollama/ollama:0.12.10 resources: requests: cpu: "8" memory: "8Gi" ephemeral-storage: "10Gi" limits: cpu: "8" memory: "8Gi" ephemeral-storage: "10Gi" # We use a script to start the server and pull the model command: ["/bin/bash", "-c"] args: - | ollama serve & OLLAMA_PID=$! echo "Waiting for Ollama server to start..." sleep 5 echo "Pulling Gemma model..." ollama pull gemma3:1b echo "Model pulled. Ready to serve." wait $OLLAMA_PID ports: - containerPort: 11434 env: - name: OLLAMA_HOST value: "0.0.0.0" --- apiVersion: v1 kind: Service metadata: name: llm-service spec: selector: app: ollama-gemma type: ClusterIP ports: - protocol: TCP port: 8000 targetPort: 11434image: ollama/ollama:latest: 공식 Ollama Docker 이미지를 지정합니다.resources: vCPU 8개와 메모리 8Gi를 명시적으로 요청합니다. GKE Autopilot은 이러한 값을 사용하여 기본 컴퓨팅을 프로비저닝합니다. GPU를 사용하지 않으므로 모델은 CPU에서 실행됩니다. 메모리 8Gi는 Gemma 1B 모델과 컨텍스트를 저장하기에 충분합니다.command/args: 포드가 시작될 때 모델이 가져오도록 시작 명령어를 재정의합니다. 스크립트는 백그라운드에서 서버를 시작하고, 준비될 때까지 기다리고,gemma3:1b모델을 가져온 후 서버를 계속 실행합니다.OLLAMA_HOST: 이를0.0.0.0으로 설정하면 Ollama가 컨테이너 내의 모든 네트워크 인터페이스에서 수신 대기하여 Kubernetes 서비스에서 액세스할 수 있도록 합니다.
- 터미널에서 배포 매니페스트를 클러스터에 적용합니다.
kubectl apply -f gemma-deployment.yamlkubectl get pods --watchRunning이고READY가1/1이 될 때까지 기다립니다.
GKE 엔드포인트 테스트
이제 Ollama 서비스가 GKE Autopilot 클러스터에서 실행 중입니다. Cloud Shell 터미널에서 테스트하려면 kubectl port-forward를 사용합니다.
- 새 Cloud Shell 터미널 탭을 엽니다 (터미널 창에서 + 아이콘 클릭).
port-forward명령어는 차단 프로세스이므로 자체 터미널 세션이 필요합니다. - 새 터미널에서 다음 명령어를 실행하여 로컬 포트 (예:
8000)를 서비스의 포트 (8000)로 전달합니다.kubectl port-forward service/llm-service 8000:8000 - 원래 터미널 로 돌아갑니다.
- 로컬 포트
8000에 요청을 보냅니다. Ollama 서버는 OpenAI 호환 API를 노출하며 포트 전달로 인해 이제http://127.0.0.1:8000에서 액세스할 수 있습니다.curl http://127.0.0.1:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "gemma3:1b", "messages": [ {"role": "user", "content": "Explain why the sky is blue."} ] }'
6. 삭제
이 실습에서 사용한 리소스의 비용이 Google Cloud 계정에 청구되지 않도록 하려면 다음 단계에 따라 GKE 클러스터를 삭제하세요.
- Cloud Shell 터미널에서 GKE Autopilot 클러스터를 삭제합니다.
gcloud container clusters delete gemma-cluster \ --region $REGION --quiet
7. 결론
아주 좋습니다. 이 실습에서는 Google Cloud에서 오픈 모델을 배포하는 몇 가지 주요 방법을 살펴보았습니다. Ollama를 사용한 로컬 개발의 단순성과 속도로 시작했습니다. 마지막으로 Google Kubernetes Engine Autopilot 및 Ollama 프레임워크를 사용하여 Gemma를 프로덕션급 확장 가능한 환경에 배포했습니다.
이제 기본 인프라를 관리하지 않고도 까다롭고 확장 가능한 워크로드에 Google Kubernetes Engine에서 오픈 모델을 배포할 수 있는 지식을 갖추게 되었습니다.
요약
이 실습에서는 다음을 배웠습니다.
- 개방형 모델이란 무엇이며 왜 중요한가요?
- Ollama를 사용하여 로컬에서 오픈 모델을 실행하는 방법
- 추론을 위해 Ollama를 사용하여 오픈 모델을 Google Kubernetes Engine (GKE) Autopilot에 배포하는 방법
자세히 알아보기
- 공식 문서에서 Gemma 모델에 대해 자세히 알아보세요.
- GitHub의 Google Cloud 생성형 AI 저장소에서 더 많은 예시를 살펴보세요.
- GKE Autopilot에 대해 자세히 알아보세요.
- Vertex AI Model Garden에서 사용 가능한 다른 오픈 모델과 독점 모델을 찾아보세요.