
1. Wprowadzenie
Przegląd
Celem tego modułu jest zdobycie praktycznego doświadczenia we wdrażaniu otwartego modelu w Google Cloud. Zaczniesz od prostej konfiguracji lokalnej, a skończysz na wdrożeniu na poziomie produkcyjnym w Google Kubernetes Engine (GKE). Dowiesz się, jak korzystać z różnych narzędzi odpowiednich na każdym etapie cyklu życia programowania.
Laboratorium obejmuje następujące tematy:
- Szybkie prototypowanie: najpierw uruchomisz lokalnie model za pomocą Ollama, aby zobaczyć, jak łatwo jest zacząć.
- Wdrożenie produkcyjne: na koniec wdrożysz model w GKE Autopilot, używając Ollamy jako skalowalnego silnika obsługi.
Informacje o modelach otwartych
Określenie „otwarty model” odnosi się obecnie do generatywnego modelu uczenia maszynowego, który jest publicznie dostępny do pobrania i używania przez wszystkich. Oznacza to, że architektura modelu, a co najważniejsze, jego wytrenowane parametry lub „wagi” są udostępniane publicznie.
Ta przejrzystość ma kilka zalet w porównaniu z modelami zamkniętymi, do których dostęp jest zwykle możliwy tylko za pomocą restrykcyjnego interfejsu API:
- Informacje: deweloperzy i badacze mogą zajrzeć „pod maskę”, aby zrozumieć wewnętrzne działanie modelu.
- Dostosowywanie: użytkownicy mogą dostosowywać model do konkretnych zadań w procesie zwanym dostrajaniem.
- Innowacyjność: umożliwia społeczności tworzenie nowych i innowacyjnych aplikacji na podstawie zaawansowanych modeli.
Wkład Google i rodzina modeli Gemma
Od wielu lat Google jest jednym z głównych uczestników ruchu open source w dziedzinie AI. Rewolucyjna architektura Transformer, przedstawiona w publikacji z 2017 roku „Attention Is All You Need”, stanowi podstawę niemal wszystkich nowoczesnych dużych modeli językowych (LLM). Potem pojawiły się przełomowe modele otwarte, takie jak BERT, T5 i dostrojony do instrukcji Flan-T5, które przesuwały granice możliwości i napędzały badania i rozwój na całym świecie.
Kontynuując tę bogatą historię otwartych innowacji, Google wprowadził rodzinę modeli Gemma. Modele Gemma są tworzone na podstawie tych samych badań i technologii, które są wykorzystywane w przypadku zaawansowanych modeli Gemini o zamkniętym kodzie źródłowym, ale są udostępniane z otwartymi wagami. Dla klientów Google Cloud to potężne połączenie najnowocześniejszej technologii i elastyczności open source, które umożliwia im kontrolowanie cyklu życia modelu, integrację z różnorodnym ekosystemem i realizację strategii wielochmurowej.
Wyróżnienie: Gemma 3
W tym laboratorium skupimy się na modelu Gemma 3, najnowszej i najbardziej zaawansowanej generacji z tej rodziny. Modele Gemma 3 są lekkie, ale jednocześnie zaawansowane. Zostały zaprojektowane tak, aby wydajnie działać na pojedynczym procesorze graficznym lub nawet na procesorze.
- Wydajność i rozmiar: modele Gemma 3 są lekkie, ale jednocześnie zaawansowane. Zostały zaprojektowane tak, aby działać wydajnie na pojedynczym procesorze graficznym lub nawet na procesorze. Zapewniają one najwyższą jakość i najnowocześniejsze funkcje w swojej klasie.
- Modalność: Są multimodalne, co oznacza, że potrafią przetwarzać zarówno tekst, jak i obrazy, aby generować tekstowe dane wyjściowe.
- Najważniejsze funkcje: Gemma 3 ma duże okno kontekstu o rozmiarze 128 tys. tokenów i obsługuje ponad 140 języków.
- Przypadki użycia: te modele dobrze sprawdzają się w różnych zadaniach, w tym w odpowiadaniu na pytania, tworzeniu podsumowań i wnioskowaniu.
Kluczowe terminy
Podczas pracy z otwartymi modelami możesz napotkać te terminy:
- Wstępne trenowanie polega na trenowaniu modelu na ogromnym, zróżnicowanym zbiorze danych, aby nauczyć się ogólnych wzorców językowych. Modele te są w zasadzie zaawansowanymi narzędziami do automatycznego uzupełniania.
- Dostrajanie na podstawie instrukcji polega na dostrajaniu wstępnie wytrenowanego modelu, aby lepiej wykonywał konkretne instrukcje i prompty. Są to modele, które „wiedzą, jak rozmawiać”.
- Warianty modelu: modele otwarte są zwykle udostępniane w różnych rozmiarach (np. Gemma 3 ma wersje z 1 mld, 4 mld, 12 mld i 27 mld parametrów) i wariantach, takich jak dostrojone do instrukcji (-it), wstępnie wytrenowane lub skwantyzowane pod kątem wydajności.
- Potrzeby zasobowe: duże modele językowe są duże i wymagają znacznych zasobów obliczeniowych do hostowania. Chociaż można je uruchamiać lokalnie, wdrażanie ich w chmurze przynosi znaczne korzyści, zwłaszcza gdy są zoptymalizowane pod kątem wydajności i skalowalności za pomocą narzędzi takich jak Ollama.
Dlaczego warto używać GKE do obsługi modeli open source?
W tym ćwiczeniu przejdziesz od prostego, lokalnego wykonywania modelu do wdrożenia na pełną skalę w środowisku produkcyjnym w Google Kubernetes Engine (GKE). Narzędzia takie jak Ollama doskonale sprawdzają się w przypadku szybkiego prototypowania, ale środowiska produkcyjne mają wymagający zestaw wymagań, które GKE może spełnić w wyjątkowy sposób.
W przypadku aplikacji AI na dużą skalę potrzebujesz nie tylko działającego modelu, ale też odpornej, skalowalnej i wydajnej infrastruktury do obsługi. GKE zapewnia tę podstawę. Oto kiedy i dlaczego warto wybrać GKE:
- Uproszczone zarządzanie dzięki Autopilotowi: Autopilot w GKE zarządza za Ciebie infrastrukturą bazową. Skupiasz się na konfiguracji aplikacji, a Autopilot automatycznie udostępnia i skaluje węzły.
- Wysoka wydajność i skalowalność: radź sobie z wymagającym, zmiennym ruchem dzięki automatycznemu skalowaniu GKE. Dzięki temu aplikacja może zapewniać wysoką przepustowość przy krótkich czasach oczekiwania, skalując się w górę lub w dół w zależności od potrzeb.
- Opłacalność na dużą skalę: efektywne zarządzanie zasobami. GKE może zmniejszyć skalę zbiorów zadań do zera, aby uniknąć płacenia za nieaktywne zasoby. Możesz też korzystać z maszyn wirtualnych typu spot, aby znacznie obniżyć koszty bezstanowych zbiorów zadań wnioskowania.
- Przenośność i bogaty ekosystem: unikaj uzależnienia od jednego dostawcy dzięki przenośnemu wdrożeniu opartemu na Kubernetes. GKE zapewnia też dostęp do rozległego ekosystemu Cloud Native (CNCF) z najlepszymi w swojej klasie narzędziami do monitorowania, logowania i zabezpieczeń.
Krótko mówiąc, przejście na GKE następuje, gdy aplikacja AI jest gotowa do wdrożenia w środowisku produkcyjnym i wymaga platformy stworzonej z myślą o dużej skali, wydajności i dojrzałości operacyjnej.
Czego się nauczysz
Z tego modułu nauczysz się, jak:
- Uruchom lokalnie model otwarty za pomocą Ollama.
- Wdrażanie otwartego modelu w Google Kubernetes Engine (GKE) Autopilot z Ollamą na potrzeby obsługi.
- Poznaj proces przechodzenia od lokalnych platform programistycznych do architektury obsługi klasy produkcyjnej w GKE.
2. Konfigurowanie projektu
Konto Google
Jeśli nie masz jeszcze osobistego konta Google, musisz je utworzyć.
Używaj konta osobistego zamiast konta służbowego lub szkolnego.
Logowanie się w konsoli Google Cloud
Zaloguj się w konsoli Google Cloud, korzystając z osobistego konta Google.
Włącz płatności
Konfigurowanie osobistego konta rozliczeniowego
Jeśli skonfigurujesz płatności za pomocą środków w Google Cloud, możesz pominąć ten krok.
Aby skonfigurować osobiste konto rozliczeniowe, włącz płatności w konsoli Google Cloud.
Uwagi:
- Pod względem opłat za zasoby chmury ukończenie tego modułu powinno kosztować mniej niż 1 USD.
- Jeśli chcesz uniknąć dalszych opłat, wykonaj czynności opisane na końcu tego modułu, aby usunąć zasoby.
- Nowi użytkownicy mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Tworzenie projektu (opcjonalnie)
Jeśli nie masz bieżącego projektu, którego chcesz użyć w tym ćwiczeniu, utwórz nowy projekt.
3. Otwórz edytor Cloud Shell
- Kliknij ten link, aby przejść bezpośrednio do edytora Cloud Shell
- Jeśli w dowolnym momencie pojawi się prośba o autoryzację, kliknij Autoryzuj, aby kontynuować.
- Jeśli terminal nie pojawi się u dołu ekranu, otwórz go:
- Kliknij Wyświetl.
- Kliknij Terminal
 .
.
- W terminalu ustaw projekt za pomocą tego polecenia:
gcloud config set project [PROJECT_ID]- Przykład:
gcloud config set project lab-project-id-example - Jeśli nie pamiętasz identyfikatora projektu, możesz wyświetlić listę wszystkich identyfikatorów projektów za pomocą tego polecenia:
gcloud projects list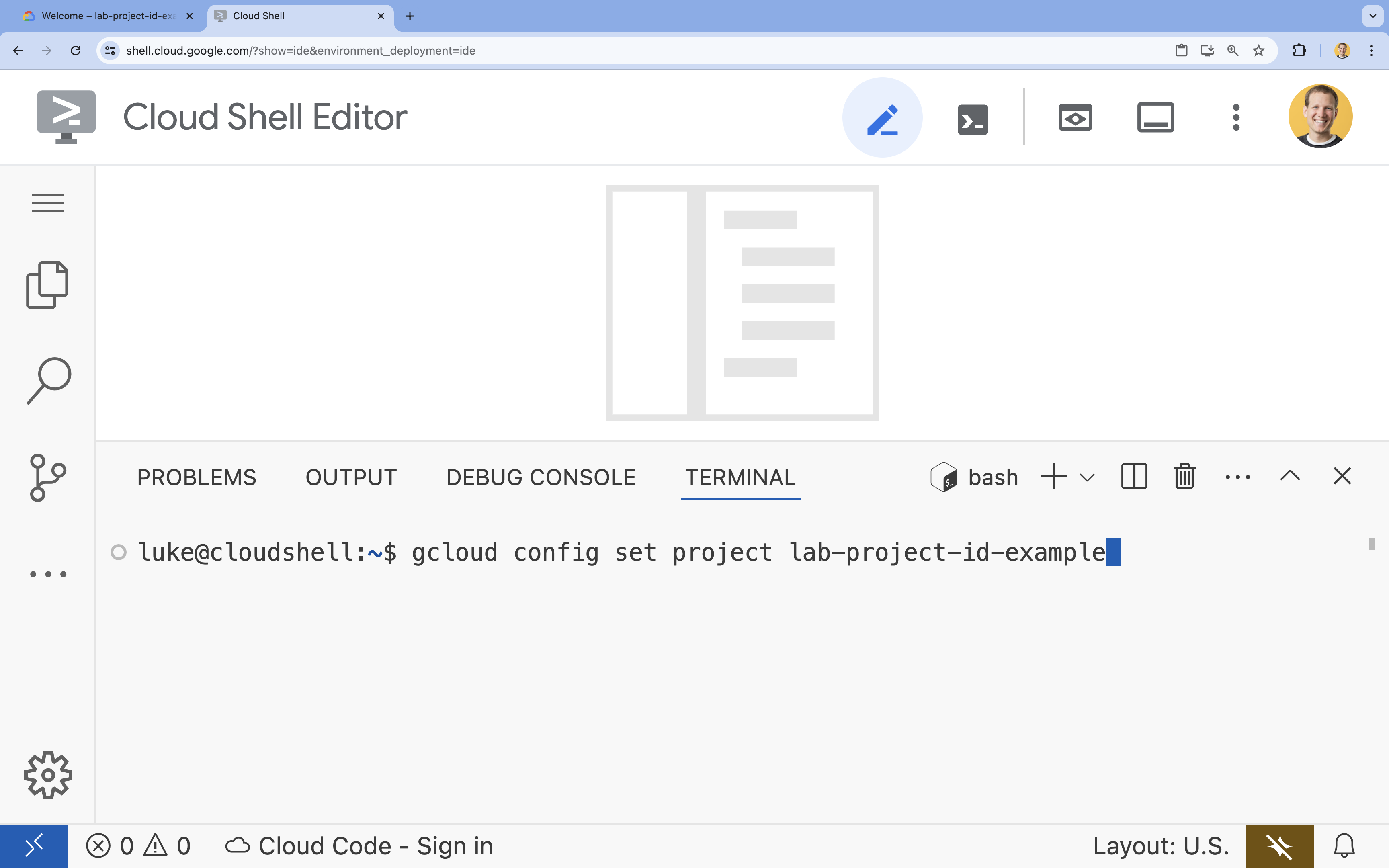
- Przykład:
- Powinien wyświetlić się ten komunikat:
Updated property [core/project].
4. Uruchamianie Gemma za pomocą Ollama
Twoim pierwszym celem jest jak najszybsze uruchomienie modelu Gemma 3 w środowisku programistycznym. Użyjesz Ollama, narzędzia, które znacznie upraszcza lokalne uruchamianie dużych modeli językowych. W tym zadaniu pokazujemy najprostszy sposób na rozpoczęcie eksperymentowania z modelem otwartym.
Ollama to bezpłatne narzędzie open source, które umożliwia użytkownikom uruchamianie modeli generatywnych (dużych modeli językowych, modeli wizualno-językowych i innych) lokalnie na własnym komputerze. Upraszcza to proces uzyskiwania dostępu do tych modeli i wchodzenia z nimi w interakcje, dzięki czemu są one bardziej dostępne, a użytkownicy mogą z nich korzystać w sposób prywatny.
Instalowanie i uruchamianie Ollamy
Teraz możesz zainstalować Ollamę, pobrać model Gemma 3 i korzystać z niego z poziomu wiersza poleceń.
- W terminalu Cloud Shell pobierz i zainstaluj Ollamę:
curl -fsSL https://ollama.com/install.sh | sh - Uruchom usługę Ollama w tle:
ollama serve & - Pobierz model Gemma 3 1B za pomocą Ollamy:
ollama pull gemma3:1b - Uruchom model lokalnie:
ollama run gemma3:1bollama runwyświetla prompt (>>>), w którym możesz zadawać pytania modelowi. - Przetestuj model, zadając mu pytanie. Wpisz na przykład
Why is the sky blue?i naciśnij ENTER. Powinna pojawić się odpowiedź podobna do tej:>>> Why is the sky blue? Okay, let's break down why the sky is blue – it's a fascinating phenomenon related to how light interacts with the Earth's atmosphere. Here's the explanation: **1. Sunlight and Colors:** * Sunlight appears white, but it's actually made up of all the colors of the rainbow (red, orange, yellow, green, blue, indigo, and violet). Think of a prism splitting sunlight. **2. Rayleigh Scattering:** * As sunlight enters the Earth's atmosphere... ...
- Aby zamknąć prompt Ollamy w terminalu, wpisz
/byei naciśnij ENTER.
Korzystanie z pakietu OpenAI SDK z Ollamą
Usługa Ollama działa, więc możesz wchodzić z nią w interakcje za pomocą kodu. Użyjesz pakietu OpenAI Python SDK, który jest zgodny z interfejsem API udostępnianym przez Ollamę.
- W terminalu Cloud Shell utwórz i aktywuj wirtualne środowisko za pomocą uv. Dzięki temu zależności projektu nie będą powodować konfliktów z systemowym Pythonem.
uv venv --python 3.14 source .venv/bin/activate - W terminalu zainstaluj pakiet OpenAI SDK:
uv pip install openai - Utwórz nowy plik o nazwie
ollama_chat.py, wpisując w terminalu:cloudshell edit ollama_chat.py - Wklej ten kod w Pythonie do pliku
ollama_chat.py. Ten kod wysyła żądanie do lokalnego serwera Ollama.from openai import OpenAI client = OpenAI( base_url = 'http://localhost:11434/v1', api_key='ollama', # required by OpenAI SDK, but not used by Ollama ) response = client.chat.completions.create( model="gemma3:1b", messages=[ { "role": "user", "content": "Why is the sky blue?" }, ], ) print(response.choices[0].message.content) - Uruchom skrypt w terminalu:
python3 ollama_chat.py - Aby wypróbować tryb przesyłania strumieniowego, utwórz kolejny plik o nazwie
ollama_stream.py, uruchamiając w terminalu to polecenie:cloudshell edit ollama_stream.py - Wklej do pliku
ollama_stream.pytę treść. Zwróć uwagę na parametrstream=Truew żądaniu. Dzięki temu model może zwracać tokeny od razu po ich wygenerowaniu.from openai import OpenAI client = OpenAI( base_url = 'http://localhost:11434/v1', api_key='ollama', ) stream = client.chat.completions.create( model="gemma3:1b", messages=[ { "role": "user", "content": "Why is the sky blue?" }, ], stream=True ) for chunk in stream: if chunk.choices[0].delta.content is not None: print(chunk.choices[0].delta.content, end="", flush=True) print() - Uruchom skrypt przesyłania strumieniowego w terminalu:
python3 ollama_stream.py
Streaming to przydatna funkcja, która pozwala zapewnić użytkownikom wygodę korzystania z aplikacji interaktywnych, takich jak czatboty. Zamiast czekać na wygenerowanie całej odpowiedzi, użytkownik może zobaczyć ją w strumieniu, w którym jest ona wyświetlana token po tokenie. Dzięki temu użytkownik od razu otrzymuje informację zwrotną, a aplikacja działa znacznie szybciej.
Czego się dowiesz: uruchamianie modeli open source za pomocą Ollama
Udało Ci się uruchomić otwarty model za pomocą Ollamy. Widzisz, jak łatwo można pobrać zaawansowany model, taki jak Gemma 3, i z nim pracować – zarówno za pomocą interfejsu wiersza poleceń, jak i programowo w języku Python. Ten przepływ pracy jest idealny do szybkiego prototypowania i lokalnego programowania. Masz teraz solidne podstawy do poznawania bardziej zaawansowanych opcji wdrażania.
5. Wdrażanie Gemma za pomocą Ollamy w Autopilocie w GKE
W przypadku zadań produkcyjnych, które wymagają uproszczonej obsługi i skalowalności, Google Kubernetes Engine (GKE) jest platformą z wyboru. W tym zadaniu wdrożysz model Gemma za pomocą Ollamy w klastrze GKE z Autopilotem.
Autopilot w GKE to tryb działania, w którym Google zarządza konfiguracją klastra, w tym węzłami, skalowaniem, zabezpieczeniami i innymi wstępnie skonfigurowanymi ustawieniami. Zapewnia prawdziwie „bezserwerowe” środowisko Kubernetes, które doskonale nadaje się do uruchamiania zbiorów zadań wnioskowania bez zarządzania bazową infrastrukturą obliczeniową.
Przygotowywanie środowiska GKE
W ramach ostatniego zadania, czyli wdrożenia w Kubernetes, utworzysz klaster GKE z Autopilotem.
- W terminalu Cloud Shell ustaw zmienne środowiskowe dla projektu i wybranego regionu.
export PROJECT_ID=$(gcloud config get-value project) export REGION=europe-west1 gcloud config set compute/region $REGION - Włącz GKE API w projekcie, wykonując w terminalu to polecenie:
gcloud services enable container.googleapis.com - Utwórz klaster GKE w trybie Autopilota, wpisując w terminalu to polecenie:
gcloud container clusters create-auto gemma-cluster \ --region $REGION \ --release-channel rapid - Pobierz dane logowania do nowego klastra, uruchamiając w terminalu to polecenie:
gcloud container clusters get-credentials gemma-cluster \ --region $REGION
Wdrażanie Ollamy i Gemma
Teraz, gdy masz już klaster GKE z Autopilotem, możesz wdrożyć serwer Ollama. Autopilot automatycznie udostępnia zasoby obliczeniowe (procesor i pamięć) na podstawie wymagań zdefiniowanych w manifeście wdrożenia.
- Utwórz nowy plik o nazwie
gemma-deployment.yaml, uruchamiając w terminalu to polecenie:cloudshell edit gemma-deployment.yaml - Wklej do
gemma-deployment.yamltę konfigurację YAML. Ta konfiguracja definiuje wdrożenie, które używa oficjalnego obrazu Ollama do uruchamiania na procesorze.apiVersion: apps/v1 kind: Deployment metadata: name: ollama-gemma spec: replicas: 1 selector: matchLabels: app: ollama-gemma template: metadata: labels: app: ollama-gemma spec: containers: - name: ollama-gemma-container image: ollama/ollama:0.12.10 resources: requests: cpu: "8" memory: "8Gi" ephemeral-storage: "10Gi" limits: cpu: "8" memory: "8Gi" ephemeral-storage: "10Gi" # We use a script to start the server and pull the model command: ["/bin/bash", "-c"] args: - | ollama serve & OLLAMA_PID=$! echo "Waiting for Ollama server to start..." sleep 5 echo "Pulling Gemma model..." ollama pull gemma3:1b echo "Model pulled. Ready to serve." wait $OLLAMA_PID ports: - containerPort: 11434 env: - name: OLLAMA_HOST value: "0.0.0.0" --- apiVersion: v1 kind: Service metadata: name: llm-service spec: selector: app: ollama-gemma type: ClusterIP ports: - protocol: TCP port: 8000 targetPort: 11434image: ollama/ollama:latest: określa oficjalny obraz Dockera Ollama.resources: wyraźnie żądamy 8 procesorów wirtualnych i 8 GiB pamięci. GKE Autopilot używa tych wartości do udostępniania bazowych zasobów obliczeniowych. Ponieważ nie używamy procesorów graficznych, model będzie działać na procesorze. 8 GB pamięci wystarczy, aby pomieścić model Gemma 1B i jego kontekst.command/args: zastępujemy polecenie uruchamiania, aby mieć pewność, że model zostanie pobrany po uruchomieniu poda. Skrypt uruchamia serwer w tle, czeka na jego gotowość, pobiera modelgemma3:1b, a następnie utrzymuje serwer w stanie działania.OLLAMA_HOST: ustawienie tej wartości na0.0.0.0zapewnia, że Ollama nasłuchuje na wszystkich interfejsach sieciowych w kontenerze, dzięki czemu jest dostępna dla usługi Kubernetes.
- W terminalu zastosuj plik manifestu wdrożenia do klastra:
kubectl apply -f gemma-deployment.yamlkubectl get pods --watchRunning, a wartośćREADYbędzie równa1/1.
Testowanie punktu końcowego GKE
Usługa Ollama działa teraz w klastrze GKE z Autopilotem. Aby przetestować go w terminalu Cloud Shell, użyj polecenia kubectl port-forward.
- Otwórz nową kartę terminala Cloud Shell (kliknij ikonę + w oknie terminala). Polecenie
port-forwardjest procesem blokującym, więc wymaga własnej sesji terminala. - W nowym terminalu uruchom to polecenie, aby przekierować port lokalny (np.
8000) na port usługi (8000):kubectl port-forward service/llm-service 8000:8000 - Wróć do pierwotnego terminala.
- Wyślij prośbę do lokalnego portu
8000. Serwer Ollama udostępnia interfejs API zgodny z OpenAI, a dzięki przekierowaniu portu możesz teraz uzyskać do niego dostęp pod adresemhttp://127.0.0.1:8000.curl http://127.0.0.1:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "gemma3:1b", "messages": [ {"role": "user", "content": "Explain why the sky is blue."} ] }'
6. Porządkowanie roszczeń
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby zużyte w tym ćwiczeniu, wykonaj te czynności, aby usunąć klaster GKE.
- W terminalu Cloud Shell usuń klaster GKE w trybie Autopilota:
gcloud container clusters delete gemma-cluster \ --region $REGION --quiet
7. Podsumowanie
Brawo! W tym laboratorium poznaliśmy kilka kluczowych metod wdrażania otwartych modeli w Google Cloud. Zaczęliśmy od prostoty i szybkości lokalnego programowania z użyciem Ollamy. Na koniec wdrożysz model Gemma w skalowalnym środowisku produkcyjnym za pomocą Autopilota w Google Kubernetes Engine i platformy Ollama.
Masz już wiedzę, która pozwoli Ci wdrażać otwarte modele w Google Kubernetes Engine w przypadku wymagających, skalowalnych zadań bez konieczności zarządzania infrastrukturą bazową.
Podsumowanie
W tym laboratorium dowiedzieliśmy się, że:
- Czym są otwarte modele i dlaczego są ważne.
- Jak uruchomić lokalnie model otwarty za pomocą Ollama.
- Jak wdrożyć otwarty model w Google Kubernetes Engine (GKE) Autopilot przy użyciu Ollama do wnioskowania.
Więcej informacji
- Więcej informacji o modelach Gemma znajdziesz w oficjalnej dokumentacji.
- Więcej przykładów znajdziesz w repozytorium dotyczącym generatywnej AI w Google Cloud na GitHubie.
- Dowiedz się więcej o Autopilocie w GKE.
- Przejrzyj bazę modeli Vertex AI, aby znaleźć inne dostępne modele otwarte i zastrzeżone.