
1. Введение
Обзор
Цель этой лабораторной работы — предоставить вам практический опыт развертывания открытой модели в Google Cloud, начиная с простой локальной настройки и заканчивая развертыванием производственного уровня в Google Kubernetes Engine (GKE) . Вы научитесь использовать различные инструменты, подходящие для каждого этапа жизненного цикла разработки.
Лаборатория работает по следующему алгоритму:
- Быстрое прототипирование : Сначала вы запустите модель локально с помощью Ollama, чтобы убедиться, насколько легко начать работу.
- Развертывание в производственной среде : В заключение, вы развернете модель в GKE Autopilot, используя Ollama в качестве масштабируемого механизма развертывания.
Понимание открытых моделей
Под «открытой моделью» в наши дни обычно подразумевают генеративную модель машинного обучения, которая находится в открытом доступе для скачивания и использования всеми желающими . Это означает, что архитектура модели и, что наиболее важно, её обученные параметры или «веса» являются общедоступными.
Такая прозрачность дает ряд преимуществ по сравнению с закрытыми моделями, доступ к которым обычно осуществляется только через ограниченный API:
- Полезная информация : Разработчики и исследователи могут заглянуть «под капот», чтобы понять внутреннюю работу модели.
- Настройка : Пользователи могут адаптировать модель для решения конкретных задач посредством процесса, называемого тонкой настройкой.
- Инновации : Это дает сообществу возможность создавать новые и инновационные приложения на основе мощных существующих моделей.
Вклад Google и семья Джеммы
Компания Google на протяжении многих лет вносит основополагающий вклад в движение искусственного интеллекта с открытым исходным кодом. Революционная архитектура Transformer, представленная в статье 2017 года «Attention Is All You Need» , лежит в основе почти всех современных больших языковых моделей. За ней последовали знаковые открытые модели, такие как BERT, T5 и оптимизированная для инструкций Flan-T5, каждая из которых расширяла границы возможного и стимулировала исследования и разработки по всему миру.
Опираясь на богатую историю открытых инноваций, Google представил семейство моделей Gemma . Модели Gemma созданы на основе тех же исследований и технологий, что и мощные модели Gemini с закрытым исходным кодом, но доступны с открытыми весами. Для клиентов Google Cloud это обеспечивает мощное сочетание передовых технологий и гибкости открытого исходного кода, позволяя им контролировать жизненный цикл модели, интегрироваться с разнообразной экосистемой и реализовывать многооблачную стратегию.
В центре внимания — Джемма 3.
В этой лабораторной работе мы сосредоточимся на Gemma 3, новейшем и самом производительном поколении в этом семействе. Модели Gemma 3 отличаются легкостью и передовыми технологиями, разработанными для эффективной работы на одном графическом процессоре или даже на одном центральном процессоре.
- Производительность и размер : Модели Gemma 3 — это легкие, но при этом самые современные видеокарты, разработанные для эффективной работы на одном графическом процессоре или даже на одном центральном процессоре. Они обеспечивают превосходное качество и самую высокую производительность (SOTA) для своих размеров.
- Модальность : Они являются мультимодальными, способными обрабатывать как текстовый, так и графический ввод для генерации текстового вывода.
- Основные особенности : Gemma 3 имеет большое контекстное окно размером 128 КБ и поддерживает более 140 языков.
- Примеры применения : Эти модели хорошо подходят для решения самых разных задач, включая ответы на вопросы, обобщение информации и логическое мышление.
Ключевые термины
При работе с открытыми моделями вы столкнетесь с несколькими распространенными терминами:
- Предварительное обучение включает в себя подготовку модели на огромном, разнообразном наборе данных для изучения общих языковых закономерностей. По сути, эти модели представляют собой мощные системы автозаполнения.
- Настройка инструкций позволяет доработать предварительно обученную модель, чтобы она лучше следовала конкретным инструкциям и подсказкам. Это модели, которые "умеют общаться".
- Варианты моделей : Открытые модели обычно выпускаются в нескольких размерах (например, Gemma 3 имеет версии с 1, 4, 12 и 27 параметрами) и вариантах, таких как оптимизированные для инструкций (-it), предварительно обученные или квантованные для повышения эффективности.
- Потребности в ресурсах : Большие языковые модели требуют значительных вычислительных ресурсов для размещения. Хотя их можно запускать локально, развертывание в облаке обеспечивает существенную выгоду, особенно при оптимизации производительности и масштабируемости с помощью таких инструментов, как Ollama.
Почему именно GKE для обслуживания открытых моделей?
В этом практическом занятии вы пройдете путь от простого локального выполнения модели до полномасштабного развертывания в производственной среде на Google Kubernetes Engine (GKE). Хотя такие инструменты, как Ollama, отлично подходят для быстрого прототипирования, производственные среды предъявляют очень высокие требования, которым GKE способен в полной мере соответствовать.
Для крупномасштабных приложений искусственного интеллекта требуется не просто работающая модель, а отказоустойчивая, масштабируемая и эффективная инфраструктура для обслуживания моделей. GKE обеспечивает эту основу. Вот когда и почему стоит выбрать GKE:
- Упрощенное управление с помощью Autopilot : GKE Autopilot управляет базовой инфраструктурой за вас. Вы сосредотачиваетесь на настройке приложений, а Autopilot автоматически выделяет и масштабирует узлы.
- Высокая производительность и масштабируемость : автоматическое масштабирование GKE позволяет обрабатывать ресурсоемкий, переменный трафик. Это гарантирует высокую пропускную способность вашего приложения с низкой задержкой, масштабируясь вверх или вниз по мере необходимости.
- Экономическая эффективность в масштабе : эффективное управление ресурсами. GKE может масштабировать рабочие нагрузки до нуля, чтобы избежать оплаты за простаивающие ресурсы, а использование спотовых виртуальных машин позволяет значительно снизить затраты на рабочие нагрузки вывода без сохранения состояния.
- Портативность и богатая экосистема : Избегайте привязки к конкретному поставщику благодаря портативному развертыванию на основе Kubernetes. GKE также предоставляет доступ к обширной экосистеме Cloud Native (CNCF) для лучших в своем классе инструментов мониторинга, логирования и безопасности.
Короче говоря, вы переходите на GKE, когда ваше приложение на основе ИИ готово к внедрению в производство и требует платформы, рассчитанной на серьезный масштаб, высокую производительность и операционную зрелость.
Что вы узнаете
В этой лабораторной работе вы научитесь выполнять следующие задачи:
- Запустите открытую модель локально с помощью Ollama.
- Разверните открытую модель в Google Kubernetes Engine (GKE) Autopilot с использованием Ollama для обслуживания.
- Разберитесь в переходе от локальных фреймворков разработки к архитектуре, готовой к использованию в производственной среде GKE.
2. Настройка проекта
Аккаунт Google
Если у вас еще нет личного аккаунта Google, вам необходимо его создать .
Используйте личный аккаунт вместо рабочего или учебного.
Войдите в консоль Google Cloud.
Войдите в консоль Google Cloud, используя личную учетную запись Google.
Включить выставление счетов
Создайте личный платежный аккаунт.
Если вы настроили оплату с использованием кредитов Google Cloud, этот шаг можно пропустить.
Чтобы настроить личный платежный аккаунт, перейдите сюда, чтобы включить оплату в облачной консоли.
Несколько замечаний:
- Выполнение этой лабораторной работы должно обойтись менее чем в 1 доллар США в виде облачных ресурсов.
- В конце этой лабораторной работы вы можете выполнить действия по удалению ресурсов, чтобы избежать дальнейших списаний средств.
- Новые пользователи могут воспользоваться бесплатной пробной версией стоимостью 300 долларов США .
Создать проект (необязательно)
Если у вас нет текущего проекта, который вы хотели бы использовать для этой лабораторной работы, создайте новый проект здесь .
3. Откройте редактор Cloud Shell.
- Нажмите на эту ссылку, чтобы перейти непосредственно в редактор Cloud Shell.
- Если сегодня вам будет предложено авторизоваться, нажмите «Авторизовать» , чтобы продолжить.
- Если терминал не отображается внизу экрана, откройте его:
- Нажмите «Просмотреть».
- Нажмите «Терминал»
- В терминале настройте свой проект с помощью этой команды:
gcloud config set project [PROJECT_ID]- Пример:
gcloud config set project lab-project-id-example - Если вы не помните идентификатор своего проекта, вы можете перечислить все идентификаторы своих проектов с помощью следующей команды:
gcloud projects list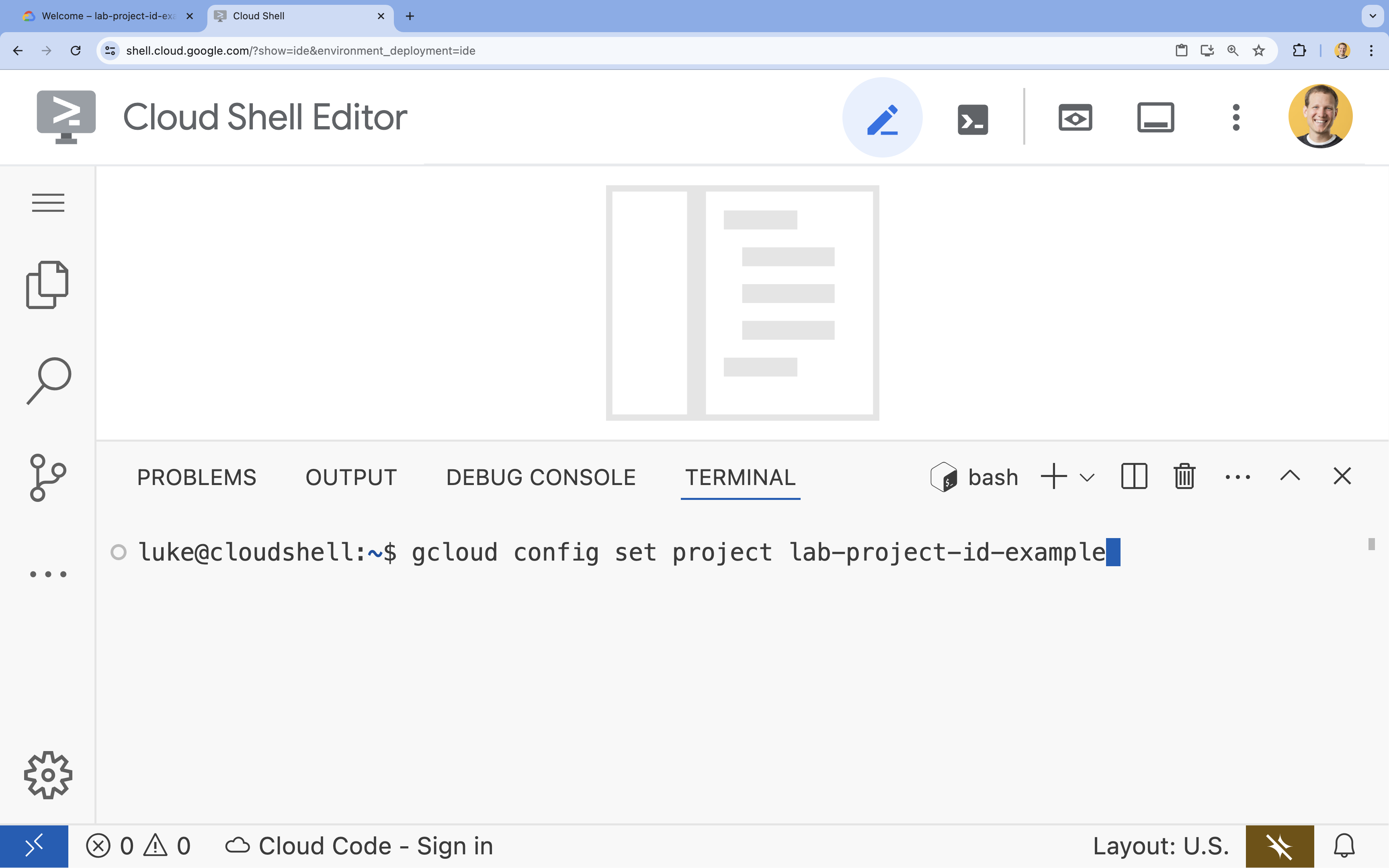
- Пример:
- Вы должны увидеть следующее сообщение:
Updated property [core/project].
4. Запустите Джемму с помощью ламы.
Ваша первая задача — как можно быстрее запустить Gemma 3 в среде разработки. Вы будете использовать Ollama — инструмент, который значительно упрощает запуск больших языковых моделей локально. Это задание покажет вам самый простой способ начать экспериментировать с открытой моделью.
Ollama — это бесплатный инструмент с открытым исходным кодом, позволяющий пользователям запускать генеративные модели (большие языковые модели, модели обработки изображений и языка и многое другое) локально на своих компьютерах. Он упрощает процесс доступа к этим моделям и взаимодействия с ними, делая их более доступными и позволяя пользователям работать с ними в приватном режиме.
Установите и запустите Ollama.
Теперь вы готовы установить Ollama, загрузить модель Gemma 3 и взаимодействовать с ней из командной строки.
- В терминале Cloud Shell загрузите и установите Ollama:
curl -fsSL https://ollama.com/install.sh | sh - Запустите службу Ollama в фоновом режиме:
ollama serve & - Загрузите (скачать) модель Gemma 3 1B с помощью Ollama:
ollama pull gemma3:1b - Запустите модель локально:
ollama run gemma3:1bollama runотображает приглашение (>>>), позволяющее задавать вопросы модели. - Проверьте модель, задав вопрос. Например, введите «
Why is the sky blue?и нажмите ENTER. Вы должны увидеть ответ, похожий на следующий:>>> Why is the sky blue? Okay, let's break down why the sky is blue – it's a fascinating phenomenon related to how light interacts with the Earth's atmosphere. Here's the explanation: **1. Sunlight and Colors:** * Sunlight appears white, but it's actually made up of all the colors of the rainbow (red, orange, yellow, green, blue, indigo, and violet). Think of a prism splitting sunlight. **2. Rayleigh Scattering:** * As sunlight enters the Earth's atmosphere... ...
- Чтобы выйти из командной строки Ollama в терминале, введите
/byeи нажмите ENTER.
Используйте SDK OpenAI с Ollama.
Теперь, когда сервис Ollama запущен, вы можете взаимодействовать с ним программно. Вы будете использовать Python SDK от OpenAI, который совместим с API, предоставляемым Ollama.
- В терминале Cloud Shell создайте и активируйте виртуальное окружение с помощью команды `uv`. Это гарантирует, что зависимости вашего проекта не будут конфликтовать с системным Python.
uv venv --python 3.14 source .venv/bin/activate - В терминале установите OpenAI SDK:
uv pip install openai - Создайте новый файл с именем
ollama_chat.py, введя в терминале следующую команду:cloudshell edit ollama_chat.py - Вставьте следующий код на Python в файл
ollama_chat.py. Этот код отправляет запрос на локальный сервер Ollama.from openai import OpenAI client = OpenAI( base_url = 'http://localhost:11434/v1', api_key='ollama', # required by OpenAI SDK, but not used by Ollama ) response = client.chat.completions.create( model="gemma3:1b", messages=[ { "role": "user", "content": "Why is the sky blue?" }, ], ) print(response.choices[0].message.content) - Запустите скрипт в терминале:
python3 ollama_chat.py - Чтобы попробовать потоковый режим, создайте еще один файл с именем
ollama_stream.py, выполнив в терминале следующую команду:cloudshell edit ollama_stream.py - Вставьте следующее содержимое в файл
ollama_stream.py. Обратите внимание на параметрstream=Trueв запросе. Это позволяет модели возвращать токены сразу после их генерации.from openai import OpenAI client = OpenAI( base_url = 'http://localhost:11434/v1', api_key='ollama', ) stream = client.chat.completions.create( model="gemma3:1b", messages=[ { "role": "user", "content": "Why is the sky blue?" }, ], stream=True ) for chunk in stream: if chunk.choices[0].delta.content is not None: print(chunk.choices[0].delta.content, end="", flush=True) print() - Запустите скрипт потоковой передачи в терминале:
python3 ollama_stream.py
Потоковая обработка — полезная функция для создания удобного пользовательского интерфейса в интерактивных приложениях, таких как чат-боты. Вместо того чтобы заставлять пользователя ждать полной генерации ответа, потоковая обработка отображает токен ответа по мере его создания. Это обеспечивает мгновенную обратную связь и делает приложение гораздо более отзывчивым.
Что вы узнали: Запуск открытых моделей с помощью Ollama
Вы успешно запустили открытую модель с помощью Ollama. Вы убедились, насколько просто загрузить мощную модель, такую как Gemma 3, и взаимодействовать с ней как через интерфейс командной строки, так и программно с помощью Python. Этот рабочий процесс идеально подходит для быстрого прототипирования и локальной разработки. Теперь у вас есть прочная основа для изучения более сложных вариантов развертывания.
5. Развертывание Gemma с Ollama на GKE Autopilot
Для производственных нагрузок, требующих упрощения операций и масштабируемости, Google Kubernetes Engine (GKE) является предпочтительной платформой. В этом задании вы развернете Gemma с помощью Ollama в кластере GKE Autopilot.
GKE Autopilot — это режим работы в GKE, в котором Google управляет конфигурацией кластера, включая узлы, масштабирование, безопасность и другие предварительно настроенные параметры. Он создает по-настоящему «бессерверную» среду Kubernetes, идеально подходящую для запуска рабочих нагрузок вывода без управления базовой вычислительной инфраструктурой.
Подготовьте среду GKE.
Для завершения развертывания в Kubernetes вам потребуется создать кластер GKE Autopilot.
- В терминале Cloud Shell установите переменные среды для вашего проекта и нужного региона.
export PROJECT_ID=$(gcloud config get-value project) export REGION=europe-west1 gcloud config set compute/region $REGION - Включите API GKE для вашего проекта, выполнив в терминале следующую команду:
gcloud services enable container.googleapis.com - Создайте кластер GKE Autopilot, выполнив в терминале следующую команду:
gcloud container clusters create-auto gemma-cluster \ --region $REGION \ --release-channel rapid - Чтобы получить учетные данные для нового кластера, выполните в терминале следующую команду:
gcloud container clusters get-credentials gemma-cluster \ --region $REGION
Запустите Олламу и Джемму.
Теперь, когда у вас есть кластер GKE Autopilot, вы можете развернуть сервер Ollama. Autopilot автоматически выделит вычислительные ресурсы (процессор и память) в соответствии с требованиями, которые вы определите в манифесте развертывания.
- Создайте новый файл с именем
gemma-deployment.yaml, выполнив в терминале следующую команду:cloudshell edit gemma-deployment.yaml - Вставьте следующий YAML-файл конфигурации в
gemma-deployment.yaml. Эта конфигурация определяет развертывание, использующее официальный образ Ollama для работы на ЦП.apiVersion: apps/v1 kind: Deployment metadata: name: ollama-gemma spec: replicas: 1 selector: matchLabels: app: ollama-gemma template: metadata: labels: app: ollama-gemma spec: containers: - name: ollama-gemma-container image: ollama/ollama:0.12.10 resources: requests: cpu: "8" memory: "8Gi" ephemeral-storage: "10Gi" limits: cpu: "8" memory: "8Gi" ephemeral-storage: "10Gi" # We use a script to start the server and pull the model command: ["/bin/bash", "-c"] args: - | ollama serve & OLLAMA_PID=$! echo "Waiting for Ollama server to start..." sleep 5 echo "Pulling Gemma model..." ollama pull gemma3:1b echo "Model pulled. Ready to serve." wait $OLLAMA_PID ports: - containerPort: 11434 env: - name: OLLAMA_HOST value: "0.0.0.0" --- apiVersion: v1 kind: Service metadata: name: llm-service spec: selector: app: ollama-gemma type: ClusterIP ports: - protocol: TCP port: 8000 targetPort: 11434-
image: ollama/ollama:latest: Это указывает на официальный образ Docker для Ollama. -
resources: Мы явно запрашиваем 8 виртуальных процессоров и 8 ГБ памяти. GKE Autopilot использует эти значения для выделения вычислительных ресурсов. Поскольку мы не используем графические процессоры, модель будет работать на центральном процессоре. 8 ГБ памяти достаточно для размещения модели Gemma 1B и ее контекста. -
command/args: Мы переопределяем команду запуска, чтобы гарантировать загрузку модели при запуске пода. Скрипт запускает сервер в фоновом режиме, ждет его готовности, загружает модельgemma3:1b, а затем поддерживает работу сервера. -
OLLAMA_HOST: Установка этого параметра на0.0.0.0гарантирует, что Ollama будет прослушивать все сетевые интерфейсы внутри контейнера, что сделает его доступным для службы Kubernetes.
-
- В терминале примените манифест развертывания к вашему кластеру:
kubectl apply -f gemma-deployment.yamlkubectl get pods --watchRunning, аREADYне станет1/1прежде чем продолжить.
Проверьте конечную точку GKE.
Сервис Ollama теперь запущен в вашем кластере GKE Autopilot. Чтобы протестировать его из терминала Cloud Shell, используйте kubectl port-forward .
- Откройте новую вкладку терминала Cloud Shell (нажмите значок «+» в окне терминала). Команда
port-forwardявляется блокирующим процессом, поэтому для нее требуется отдельная сессия терминала. - В новом терминале выполните следующую команду, чтобы перенаправить локальный порт (например,
8000) на порт службы (8000):kubectl port-forward service/llm-service 8000:8000 - Вернитесь к исходному терминалу .
- Отправьте запрос на локальный порт
8000Сервер Ollama предоставляет API, совместимый с OpenAI, и благодаря переадресации портов вы теперь можете получить к нему доступ по адресуhttp://127.0.0.1:8000.curl http://127.0.0.1:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "gemma3:1b", "messages": [ {"role": "user", "content": "Explain why the sky is blue."} ] }'
6. Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этой лабораторной работе, выполните следующие действия для удаления кластера GKE.
- В терминале Cloud Shell удалите кластер GKE Autopilot:
gcloud container clusters delete gemma-cluster \ --region $REGION --quiet
7. Заключение
Отличная работа! В этой лабораторной работе вы изучили несколько ключевых методов развертывания открытых моделей в Google Cloud. Вы начали с простоты и скорости локальной разработки с помощью Ollama. Наконец, вы развернули Gemma в масштабируемой среде производственного уровня, используя Google Kubernetes Engine Autopilot и фреймворк Ollama.
Теперь вы обладаете знаниями, позволяющими развертывать открытые модели на Google Kubernetes Engine для ресурсоемких, масштабируемых рабочих нагрузок без необходимости управления базовой инфраструктурой.
Краткий обзор
В этой лабораторной работе вы изучили:
- Что такое открытые модели и почему они важны.
- Как запустить открытую модель локально с помощью Ollama.
- Как развернуть открытую модель в Google Kubernetes Engine (GKE) Autopilot с использованием Ollama для вывода результатов.
Узнать больше
- Подробнее о моделях Gemma можно узнать в официальной документации .
- Больше примеров можно найти в репозитории Google Cloud Generative AI на GitHub.
- Узнайте больше об автопилоте GKE .
- Ознакомьтесь с моделью сада Vertex AI Model Garden , чтобы увидеть другие доступные открытые и проприетарные модели.