
1. บทนำ
ภาพรวม
เป้าหมายของแล็บนี้คือการมอบประสบการณ์การใช้งานจริงในการติดตั้งใช้งานโมเดลแบบเปิดใน Google Cloud โดยเริ่มจากการตั้งค่าในเครื่องแบบง่ายๆ ไปจนถึงการติดตั้งใช้งานระดับโปรดักชันใน Google Kubernetes Engine (GKE) คุณจะได้เรียนรู้วิธีใช้เครื่องมือต่างๆ ที่เหมาะสมกับแต่ละขั้นตอนของวงจรการพัฒนา
ห้องทดลองจะดำเนินการตามเส้นทางต่อไปนี้
- การสร้างต้นแบบอย่างรวดเร็ว: คุณจะเรียกใช้โมเดลด้วย Ollama ในเครื่องก่อนเพื่อดูว่าการเริ่มต้นใช้งานนั้นง่ายเพียงใด
- การทำให้ใช้งานได้จริง: สุดท้ายนี้ คุณจะทำให้โมเดลใช้งานได้ใน GKE Autopilot โดยใช้ Ollama เป็นเครื่องมือการแสดงผลที่รองรับการปรับขนาด
ทำความเข้าใจโมเดลแบบเปิด
ปัจจุบันคำว่า "โมเดลแบบเปิด" มักหมายถึงโมเดลแมชชีนเลิร์นนิงแบบ Generative ที่เปิดให้ทุกคนดาวน์โหลดและใช้งานได้แบบสาธารณะ ซึ่งหมายความว่าสถาปัตยกรรมของโมเดล และที่สำคัญที่สุดคือพารามิเตอร์ที่ฝึกแล้วหรือ "น้ำหนัก" จะได้รับการเผยแพร่ต่อสาธารณะ
ความโปร่งใสนี้มีข้อดีหลายประการเหนือกว่าโมเดลแบบปิด ซึ่งโดยปกติแล้วจะเข้าถึงได้ผ่าน API ที่จำกัดเท่านั้น ดังนี้
- ข้อมูลเชิงลึก: นักพัฒนาแอปและนักวิจัยสามารถดู "เบื้องหลัง" เพื่อทำความเข้าใจการทำงานภายในของโมเดล
- การปรับแต่ง: ผู้ใช้สามารถปรับโมเดลสำหรับงานที่เฉพาะเจาะจงผ่านกระบวนการที่เรียกว่าการปรับแต่ง
- นวัตกรรม: ช่วยให้ชุมชนสร้างแอปพลิเคชันใหม่ๆ ที่เป็นนวัตกรรมบนโมเดลที่มีอยู่ซึ่งมีประสิทธิภาพ
การมีส่วนร่วมของ Google และตระกูล Gemma
Google เป็นผู้มีส่วนร่วมขั้นพื้นฐานในการเคลื่อนไหวของ AI แบบโอเพนซอร์สมาหลายปีแล้ว สถาปัตยกรรม Transformer ที่ปฏิวัติวงการซึ่งเปิดตัวในเอกสาร "Attention Is All You Need" ปี 2017 เป็นพื้นฐานของโมเดลภาษาขนาดใหญ่ที่ทันสมัยเกือบทั้งหมด ตามมาด้วยโมเดลโอเพนซอร์สที่สำคัญอย่าง BERT, T5 และ Flan-T5 ที่ได้รับการปรับแต่งตามคำสั่ง ซึ่งแต่ละโมเดลได้ขยายขอบเขตของสิ่งที่เป็นไปได้และกระตุ้นการวิจัยและพัฒนาทั่วโลก
Google ได้ต่อยอดประวัติศาสตร์อันยาวนานด้านนวัตกรรมแบบเปิดนี้ด้วยการเปิดตัวโมเดลตระกูล Gemma โมเดล Gemma สร้างขึ้นจากการวิจัยและเทคโนโลยีเดียวกันกับที่ใช้สำหรับโมเดล Gemini ที่มีประสิทธิภาพสูงและเป็นแบบปิด แต่จะพร้อมใช้งานโดยมีน้ำหนักแบบเปิด สำหรับลูกค้า Google Cloud การผสานรวมนี้จะมอบการผสมผสานที่ทรงพลังระหว่างเทคโนโลยีล้ำสมัยและความยืดหยุ่นของโอเพนซอร์ส ซึ่งช่วยให้ลูกค้าควบคุมวงจรของโมเดล ผสานรวมกับระบบนิเวศที่หลากหลาย และดำเนินกลยุทธ์มัลติคลาวด์ได้
สปอตไลท์เกี่ยวกับ Gemma 3
ในห้องทดลองนี้ เราจะมุ่งเน้นไปที่ Gemma 3 ซึ่งเป็นรุ่นล่าสุดและมีความสามารถมากที่สุดในตระกูลนี้ โมเดล Gemma 3 มีขนาดเล็กแต่เป็นเทคโนโลยีที่ล้ำสมัย ออกแบบมาให้ทำงานได้อย่างมีประสิทธิภาพบน GPU เดียวหรือแม้แต่ CPU
- ประสิทธิภาพและขนาด: โมเดล Gemma 3 มีน้ำหนักเบาแต่ก็เป็นโมเดลที่ล้ำสมัย ซึ่งออกแบบมาให้ทำงานได้อย่างมีประสิทธิภาพบน GPU เดียวหรือแม้แต่ CPU โดยให้คุณภาพที่เหนือกว่าและประสิทธิภาพที่ทันสมัย (SOTA) เมื่อเทียบกับขนาด
- รูปแบบ: โมเดลเหล่านี้เป็นแบบหลายรูปแบบ ซึ่งสามารถจัดการทั้งอินพุตข้อความและรูปภาพเพื่อสร้างเอาต์พุตข้อความ
- ฟีเจอร์หลัก: Gemma 3 มีหน้าต่างบริบทขนาดใหญ่ 128K และรองรับมากกว่า 140 ภาษา
- กรณีการใช้งาน: โมเดลเหล่านี้เหมาะสำหรับงานต่างๆ รวมถึงการตอบคำถาม การสรุป และการให้เหตุผล
คำศัพท์สำคัญ
เมื่อทำงานกับโมเดลแบบเปิด คุณจะพบคำศัพท์ที่ใช้กันโดยทั่วไป 2-3 คำ ดังนี้
- การฝึกเบื้องต้นเกี่ยวข้องกับการฝึกโมเดลในชุดข้อมูลขนาดใหญ่และหลากหลายเพื่อเรียนรู้รูปแบบภาษาทั่วไป โมเดลเหล่านี้เป็นเครื่องมือเติมข้อความอัตโนมัติที่มีประสิทธิภาพ
- การปรับแต่งตามคำสั่งจะปรับแต่งโมเดลที่ได้รับการฝึกมาก่อนเพื่อให้ทำตามคำสั่งและพรอมต์ที่เฉพาะเจาะจงได้ดียิ่งขึ้น โมเดลเหล่านี้คือโมเดลที่ "รู้วิธีแชท"
- โมเดลย่อย: โดยปกติแล้ว โมเดลแบบเปิดจะเปิดตัวในหลายขนาด (เช่น Gemma 3 มีเวอร์ชันพารามิเตอร์ 1B, 4B, 12B และ 27B) และโมเดลย่อย เช่น โมเดลที่ปรับแต่งตามคำสั่ง (-it), โมเดลที่ฝึกไว้ล่วงหน้า หรือโมเดลที่แปลงเป็นจำนวนเต็มเพื่อประสิทธิภาพ
- ความต้องการด้านทรัพยากร: โมเดลภาษาขนาดใหญ่มีขนาดใหญ่และต้องใช้ทรัพยากรการประมวลผลจำนวนมากในการโฮสต์ แม้ว่าจะเรียกใช้โมเดลเหล่านี้ในเครื่องได้ แต่การติดตั้งใช้งานในระบบคลาวด์ก็มีประโยชน์อย่างมาก โดยเฉพาะเมื่อเพิ่มประสิทธิภาพเพื่อประสิทธิภาพและความสามารถในการปรับขนาดด้วยเครื่องมืออย่าง Ollama
เหตุใดจึงควรใช้ GKE เพื่อแสดง Open Model
แล็บนี้จะแนะนำคุณตั้งแต่การดำเนินการโมเดลแบบง่ายๆ ในเครื่องไปจนถึงการติดตั้งใช้งานจริงแบบเต็มรูปแบบใน Google Kubernetes Engine (GKE) แม้ว่าเครื่องมืออย่าง Ollama จะเหมาะอย่างยิ่งสำหรับการสร้างต้นแบบอย่างรวดเร็ว แต่สภาพแวดล้อมการใช้งานจริงมีชุดข้อกำหนดที่เข้มงวดซึ่ง GKE มีความพร้อมที่จะตอบสนองข้อกำหนดเหล่านี้
สำหรับแอปพลิเคชัน AI ขนาดใหญ่ คุณต้องมีมากกว่าแค่โมเดลที่ทำงานอยู่ คุณต้องมีโครงสร้างพื้นฐานในการให้บริการที่ยืดหยุ่น ปรับขนาดได้ และมีประสิทธิภาพ GKE เป็นรากฐานของสิ่งนี้ คุณควรเลือกใช้ GKE ในกรณีต่อไปนี้
- การจัดการที่ง่ายขึ้นด้วย Autopilot: GKE Autopilot จะจัดการโครงสร้างพื้นฐานที่สำคัญให้คุณ คุณมุ่งเน้นที่การกำหนดค่าแอปพลิเคชัน ส่วน Autopilot จะจัดสรรและปรับขนาดโหนดโดยอัตโนมัติ
- ประสิทธิภาพสูงและความสามารถในการปรับขนาด: จัดการการรับส่งข้อมูลที่ต้องการและมีการเปลี่ยนแปลงด้วยการปรับขนาดอัตโนมัติของ GKE วิธีนี้ช่วยให้มั่นใจว่าแอปพลิเคชันจะส่งข้อความปริมาณมากโดยมีเวลาในการตอบสนองต่ำ และปรับขนาดขึ้นหรือลงได้ตามต้องการ
- ความคุ้มค่าในวงกว้าง: จัดการทรัพยากรอย่างมีประสิทธิภาพ GKE สามารถลดขนาดภาระงานลงเหลือ 0 เพื่อหลีกเลี่ยงการชำระเงินสำหรับทรัพยากรที่ไม่ได้ใช้งาน และคุณสามารถใช้ประโยชน์จาก Spot VM เพื่อลดต้นทุนสำหรับภาระงานการอนุมานแบบไม่เก็บสถานะได้อย่างมาก
- ความสามารถในการพกพาและระบบนิเวศที่สมบูรณ์: หลีกเลี่ยงการผูกมัดกับผู้ให้บริการด้วยการติดตั้งใช้งานแบบพกพาที่ใช้ Kubernetes นอกจากนี้ GKE ยังให้สิทธิ์เข้าถึงระบบนิเวศ Cloud Native (CNCF) ขนาดใหญ่เพื่อใช้เครื่องมือตรวจสอบ การบันทึก และการรักษาความปลอดภัยที่ดีที่สุด
กล่าวโดยย่อคือ คุณจะย้ายไปใช้ GKE เมื่อแอปพลิเคชัน AI พร้อมใช้งานจริงและต้องใช้แพลตฟอร์มที่สร้างขึ้นเพื่อการปรับขนาด ประสิทธิภาพ และความพร้อมในการปฏิบัติงานอย่างจริงจัง
สิ่งที่คุณจะได้เรียนรู้
ในแล็บนี้ คุณจะได้เรียนรู้วิธีทำงานต่อไปนี้
- เรียกใช้โมเดลแบบเปิดในเครื่องด้วย Ollama
- ทำให้โมเดลแบบเปิดใช้งานได้ใน Google Kubernetes Engine (GKE) Autopilot ด้วย Ollama เพื่อให้บริการ
- ทําความเข้าใจการพัฒนาจากเฟรมเวิร์กการพัฒนาภายในไปจนถึงสถาปัตยกรรมการแสดงผลระดับโปรดักชันใน GKE
2. การตั้งค่าโปรเจ็กต์
บัญชี Google
หากยังไม่มีบัญชี Google ส่วนบุคคล คุณต้องสร้างบัญชี Google
ใช้บัญชีส่วนตัวแทนบัญชีของที่ทำงานหรือบัญชีโรงเรียน
ลงชื่อเข้าใช้คอนโซล Google Cloud
ลงชื่อเข้าใช้ คอนโซล Google Cloud โดยใช้บัญชี Google ส่วนบุคคล
เปิดใช้การเรียกเก็บเงิน
ตั้งค่าบัญชีสำหรับการเรียกเก็บเงินส่วนตัว
หากตั้งค่าการเรียกเก็บเงินโดยใช้เครดิต Google Cloud คุณจะข้ามขั้นตอนนี้ได้
หากต้องการตั้งค่าบัญชีสำหรับการเรียกเก็บเงินส่วนตัว ให้ไปที่นี่เพื่อเปิดใช้การเรียกเก็บเงินใน Cloud Console
ข้อควรทราบ
- การทำ Lab นี้ควรมีค่าใช้จ่ายน้อยกว่า $1 USD ในทรัพยากรระบบคลาวด์
- คุณสามารถทำตามขั้นตอนที่ส่วนท้ายของแล็บนี้เพื่อลบทรัพยากรเพื่อหลีกเลี่ยงการเรียกเก็บเงินเพิ่มเติม
- ผู้ใช้ใหม่มีสิทธิ์ใช้ช่วงทดลองใช้ฟรีมูลค่า$300 USD
สร้างโปรเจ็กต์ (ไม่บังคับ)
หากไม่มีโปรเจ็กต์ปัจจุบันที่ต้องการใช้สำหรับแล็บนี้ ให้สร้างโปรเจ็กต์ใหม่ที่นี่
3. เปิดเครื่องมือแก้ไข Cloud Shell
- คลิกลิงก์นี้เพื่อไปยัง Cloud Shell Editor โดยตรง
- หากระบบแจ้งให้ให้สิทธิ์ในวันนี้ ให้คลิกให้สิทธิ์เพื่อดำเนินการต่อ
- หากเทอร์มินัลไม่ปรากฏที่ด้านล่างของหน้าจอ ให้เปิดโดยทำดังนี้
- คลิกดู
- คลิก Terminal
- ในเทอร์มินัล ให้ตั้งค่าโปรเจ็กต์ด้วยคำสั่งนี้
gcloud config set project [PROJECT_ID]- ตัวอย่าง
gcloud config set project lab-project-id-example - หากจำรหัสโปรเจ็กต์ไม่ได้ คุณสามารถแสดงรหัสโปรเจ็กต์ทั้งหมดได้โดยใช้คำสั่งต่อไปนี้
gcloud projects list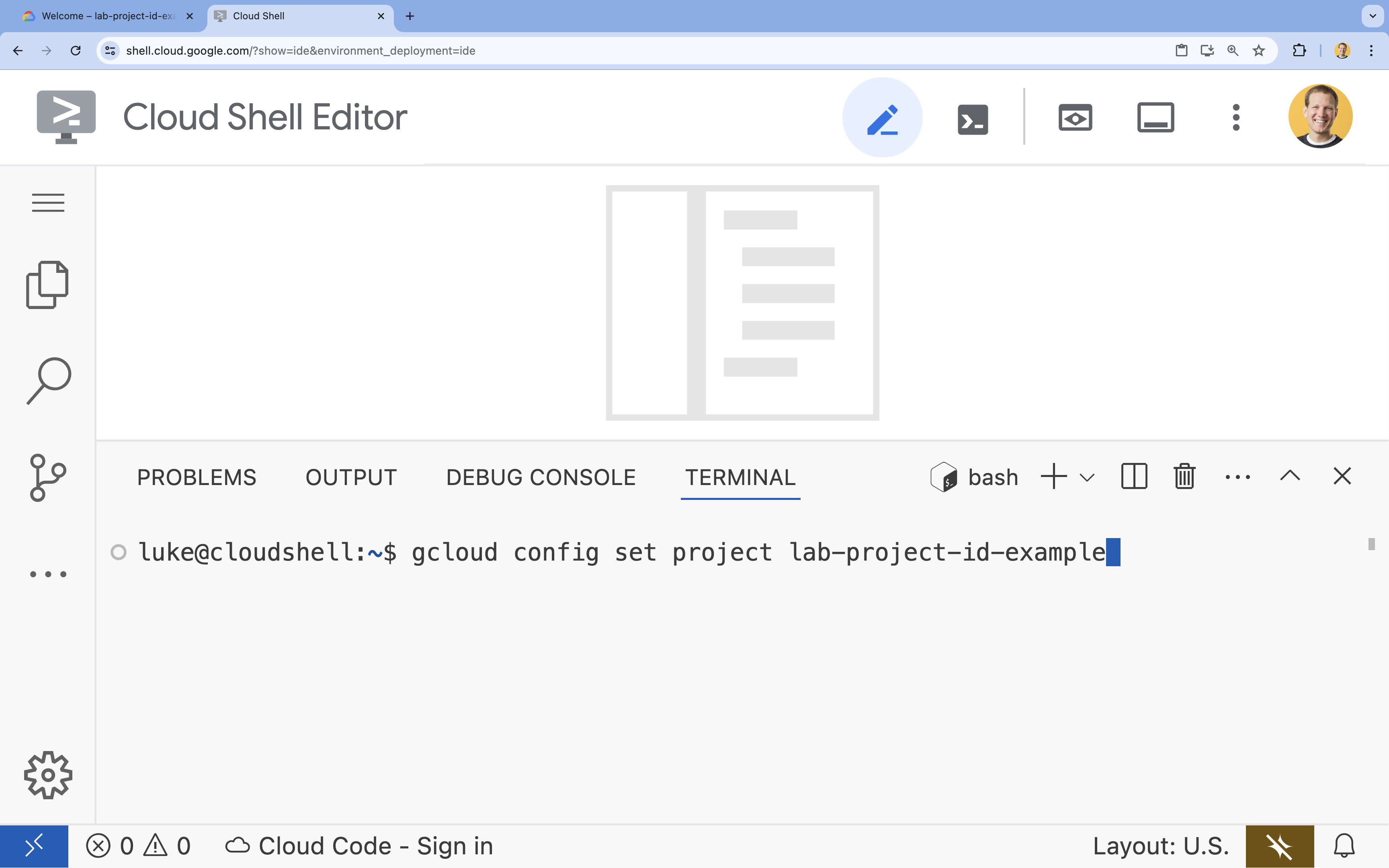
- ตัวอย่าง
- คุณควรเห็นข้อความต่อไปนี้
Updated property [core/project].
4. เรียกใช้ Gemma ด้วย Ollama
เป้าหมายแรกของคุณคือการทำให้ Gemma 3 ทำงานในสภาพแวดล้อมในการพัฒนาซอฟต์แวร์ได้เร็วที่สุด คุณจะใช้ Ollama ซึ่งเป็นเครื่องมือที่ช่วยลดความซับซ้อนในการเรียกใช้โมเดลภาษาขนาดใหญ่ในเครื่องได้อย่างมาก งานนี้จะแสดงวิธีที่ตรงไปตรงมาที่สุดในการเริ่มทดลองใช้โมเดลแบบเปิด
Ollama เป็นเครื่องมือโอเพนซอร์สแบบไม่มีค่าใช้จ่ายที่ช่วยให้ผู้ใช้เรียกใช้โมเดล Generative (โมเดลภาษาขนาดใหญ่ โมเดลวิชันภาษา และอื่นๆ) ในเครื่องบนคอมพิวเตอร์ของตนเองได้ ซึ่งจะช่วยลดความซับซ้อนของกระบวนการเข้าถึงและโต้ตอบกับโมเดลเหล่านี้ ทำให้ผู้ใช้เข้าถึงได้ง่ายขึ้นและทำงานกับโมเดลได้อย่างเป็นส่วนตัว
ติดตั้งและเรียกใช้ Ollama
ตอนนี้คุณพร้อมที่จะติดตั้ง Ollama, ดาวน์โหลดโมเดล Gemma 3 และโต้ตอบกับโมเดลจากบรรทัดคำสั่งแล้ว
- ในเทอร์มินัล Cloud Shell ให้ดาวน์โหลดและติดตั้ง Ollama โดยทำดังนี้
curl -fsSL https://ollama.com/install.sh | sh - เริ่มบริการ Ollama ในเบื้องหลัง
ollama serve & - ดึง (ดาวน์โหลด) โมเดล Gemma 3 1B ด้วย Ollama
ollama pull gemma3:1b - เรียกใช้โมเดลในเครื่อง
ollama run gemma3:1bollama runจะแสดงพรอมต์ (>>>) ให้คุณถามคำถามกับโมเดล - ทดสอบโมเดลด้วยคำถาม เช่น พิมพ์
Why is the sky blue?แล้วกด ENTER คุณควรเห็นคำตอบที่คล้ายกับคำตอบต่อไปนี้>>> Why is the sky blue? Okay, let's break down why the sky is blue – it's a fascinating phenomenon related to how light interacts with the Earth's atmosphere. Here's the explanation: **1. Sunlight and Colors:** * Sunlight appears white, but it's actually made up of all the colors of the rainbow (red, orange, yellow, green, blue, indigo, and violet). Think of a prism splitting sunlight. **2. Rayleigh Scattering:** * As sunlight enters the Earth's atmosphere... ...
- หากต้องการออกจากพรอมต์ Ollama ในเทอร์มินัล ให้พิมพ์
/byeแล้วกด ENTER
ใช้ OpenAI SDK กับ Ollama
เมื่อบริการ Ollama ทำงานแล้ว คุณจะโต้ตอบกับบริการนี้แบบเป็นโปรแกรมได้ คุณจะใช้ OpenAI Python SDK ซึ่งเข้ากันได้กับ API ที่ Ollama แสดง
- สร้างและเปิดใช้งานสภาพแวดล้อมเสมือนโดยใช้ uv ในเทอร์มินัล Cloud Shell ซึ่งจะช่วยให้มั่นใจได้ว่าการขึ้นต่อกันของโปรเจ็กต์จะไม่ขัดแย้งกับ Python ของระบบ
uv venv --python 3.14 source .venv/bin/activate - ติดตั้ง OpenAI SDK ในเทอร์มินัลโดยทำดังนี้
uv pip install openai - สร้างไฟล์ใหม่ชื่อ
ollama_chat.pyโดยป้อนในเทอร์มินัลดังนี้cloudshell edit ollama_chat.py - วางโค้ด Python ต่อไปนี้ลงใน
ollama_chat.pyโค้ดนี้จะส่งคำขอไปยังเซิร์ฟเวอร์ Ollama ในเครื่องfrom openai import OpenAI client = OpenAI( base_url = 'http://localhost:11434/v1', api_key='ollama', # required by OpenAI SDK, but not used by Ollama ) response = client.chat.completions.create( model="gemma3:1b", messages=[ { "role": "user", "content": "Why is the sky blue?" }, ], ) print(response.choices[0].message.content) - เรียกใช้สคริปต์ในเทอร์มินัลด้วยคำสั่งนี้
python3 ollama_chat.py - หากต้องการลองใช้โหมดสตรีมมิง ให้สร้างไฟล์อื่นชื่อ
ollama_stream.pyโดยเรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัลcloudshell edit ollama_stream.py - วางเนื้อหาต่อไปนี้ลงในไฟล์
ollama_stream.pyสังเกตพารามิเตอร์stream=Trueในคำขอ ซึ่งจะช่วยให้โมเดลแสดงโทเค็นได้ทันทีที่สร้างขึ้นfrom openai import OpenAI client = OpenAI( base_url = 'http://localhost:11434/v1', api_key='ollama', ) stream = client.chat.completions.create( model="gemma3:1b", messages=[ { "role": "user", "content": "Why is the sky blue?" }, ], stream=True ) for chunk in stream: if chunk.choices[0].delta.content is not None: print(chunk.choices[0].delta.content, end="", flush=True) print() - เรียกใช้สคริปต์การสตรีมในเทอร์มินัลโดยใช้คำสั่งต่อไปนี้
python3 ollama_stream.py
การสตรีมเป็นฟีเจอร์ที่มีประโยชน์ในการสร้างประสบการณ์การใช้งานที่ดีในแอปพลิเคชันแบบอินเทอร์แอกทีฟ เช่น แชทบ็อต การสตรีมจะแสดงโทเค็นคำตอบทีละรายการขณะที่สร้างขึ้น แทนที่จะให้ผู้ใช้รอจนกว่าระบบจะสร้างคำตอบทั้งหมดเสร็จ ซึ่งจะให้ความคิดเห็นได้ทันทีและทำให้แอปพลิเคชันตอบสนองได้ดีขึ้นมาก
สิ่งที่คุณได้เรียนรู้: การเรียกใช้ Open Model ด้วย Ollama
คุณเรียกใช้โมเดลแบบเปิดโดยใช้ Ollama เรียบร้อยแล้ว คุณได้เห็นแล้วว่าการดาวน์โหลดโมเดลที่มีประสิทธิภาพอย่าง Gemma 3 และการโต้ตอบกับโมเดลนั้นง่ายเพียงใด ทั้งผ่านอินเทอร์เฟซบรรทัดคำสั่งและแบบเป็นโปรแกรมด้วย Python เวิร์กโฟลว์นี้เหมาะสำหรับการสร้างต้นแบบอย่างรวดเร็วและการพัฒนาในเครื่อง ตอนนี้คุณมีพื้นฐานที่มั่นคงในการสำรวจตัวเลือกการติดตั้งใช้งานขั้นสูงเพิ่มเติมแล้ว
5. ทำให้ Gemma ใช้งานได้ด้วย Ollama ใน GKE Autopilot
สำหรับภาระงานการผลิตที่ต้องการการดำเนินการที่ง่ายขึ้นและความสามารถในการปรับขนาด Google Kubernetes Engine (GKE) คือแพลตฟอร์มที่ควรเลือกใช้ ในงานนี้ คุณจะได้ติดตั้งใช้งาน Gemma โดยใช้ Ollama ในคลัสเตอร์ GKE Autopilot
GKE Autopilot เป็นโหมดการทำงานใน GKE ที่ Google จัดการการกำหนดค่าคลัสเตอร์ของคุณ ซึ่งรวมถึงโหนด การปรับขนาด ความปลอดภัย และการตั้งค่าอื่นๆ ที่กำหนดค่าไว้ล่วงหน้า ซึ่งจะสร้างประสบการณ์การใช้งาน Kubernetes แบบ "Serverless" อย่างแท้จริง เหมาะสำหรับการเรียกใช้ภาระงานการอนุมานโดยไม่ต้องจัดการโครงสร้างพื้นฐานการประมวลผลที่อยู่เบื้องหลัง
เตรียมสภาพแวดล้อม GKE
สำหรับงานสุดท้ายในการติดตั้งใช้งาน Kubernetes คุณจะต้องจัดสรรคลัสเตอร์ GKE Autopilot
- ในเทอร์มินัล Cloud Shell ให้ตั้งค่าตัวแปรสภาพแวดล้อมสำหรับโปรเจ็กต์และภูมิภาคที่ต้องการ
export PROJECT_ID=$(gcloud config get-value project) export REGION=europe-west1 gcloud config set compute/region $REGION - เปิดใช้ GKE API สำหรับโปรเจ็กต์โดยเรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล
gcloud services enable container.googleapis.com - สร้างคลัสเตอร์ GKE Autopilot โดยเรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล
gcloud container clusters create-auto gemma-cluster \ --region $REGION \ --release-channel rapid - รับข้อมูลเข้าสู่ระบบสำหรับคลัสเตอร์ใหม่โดยเรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล
gcloud container clusters get-credentials gemma-cluster \ --region $REGION
ติดตั้งใช้งาน Ollama และ Gemma
ตอนนี้คุณมีคลัสเตอร์ GKE Autopilot แล้ว คุณสามารถติดตั้งใช้งานเซิร์ฟเวอร์ Ollama ได้ Autopilot จะจัดสรรทรัพยากรการประมวลผล (CPU และหน่วยความจำ) โดยอัตโนมัติตามข้อกำหนดที่คุณกำหนดไว้ในไฟล์ Manifest ของการติดตั้งใช้งาน
- สร้างไฟล์ใหม่ชื่อ
gemma-deployment.yamlโดยเรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัลcloudshell edit gemma-deployment.yaml - วางการกำหนดค่า YAML ต่อไปนี้ลงใน
gemma-deployment.yamlการกำหนดค่านี้กำหนดการทำให้ใช้งานได้ซึ่งใช้รูปภาพ Ollama อย่างเป็นทางการเพื่อเรียกใช้ใน CPUapiVersion: apps/v1 kind: Deployment metadata: name: ollama-gemma spec: replicas: 1 selector: matchLabels: app: ollama-gemma template: metadata: labels: app: ollama-gemma spec: containers: - name: ollama-gemma-container image: ollama/ollama:0.12.10 resources: requests: cpu: "8" memory: "8Gi" ephemeral-storage: "10Gi" limits: cpu: "8" memory: "8Gi" ephemeral-storage: "10Gi" # We use a script to start the server and pull the model command: ["/bin/bash", "-c"] args: - | ollama serve & OLLAMA_PID=$! echo "Waiting for Ollama server to start..." sleep 5 echo "Pulling Gemma model..." ollama pull gemma3:1b echo "Model pulled. Ready to serve." wait $OLLAMA_PID ports: - containerPort: 11434 env: - name: OLLAMA_HOST value: "0.0.0.0" --- apiVersion: v1 kind: Service metadata: name: llm-service spec: selector: app: ollama-gemma type: ClusterIP ports: - protocol: TCP port: 8000 targetPort: 11434image: ollama/ollama:latest: ระบุอิมเมจ Docker อย่างเป็นทางการของ Ollamaresources: เราขอ vCPU 8 รายการและหน่วยความจำ 8Gi อย่างชัดเจน GKE Autopilot ใช้ค่าเหล่านี้ในการจัดสรรการประมวลผลพื้นฐาน เนื่องจากเราไม่ได้ใช้ GPU โมเดลจึงจะทำงานบน CPU หน่วยความจำ 8Gi เพียงพอที่จะรองรับโมเดล Gemma 1B และบริบทของโมเดลcommand/args: เราจะลบล้างคำสั่งเริ่มต้นเพื่อให้แน่ใจว่าระบบจะดึงโมเดลเมื่อพ็อดเริ่มทำงาน สคริปต์จะเริ่มเซิร์ฟเวอร์ในเบื้องหลัง รอให้เซิร์ฟเวอร์พร้อมใช้งาน ดึงโมเดลgemma3:1bแล้วทำให้เซิร์ฟเวอร์ทำงานต่อไปOLLAMA_HOST: การตั้งค่านี้เป็น0.0.0.0จะช่วยให้มั่นใจได้ว่า Ollama จะรับฟังในอินเทอร์เฟซเครือข่ายทั้งหมดภายในคอนเทนเนอร์ ซึ่งทำให้บริการ Kubernetes เข้าถึงได้
- ในเทอร์มินัล ให้ใช้ไฟล์ Manifest การติดตั้งใช้งานกับคลัสเตอร์
kubectl apply -f gemma-deployment.yamlkubectl get pods --watchRunningและREADYเป็น1/1ก่อนดำเนินการต่อ
ทดสอบปลายทาง GKE
ตอนนี้บริการ Ollama ทำงานในคลัสเตอร์ GKE Autopilot แล้ว หากต้องการทดสอบจากเทอร์มินัล Cloud Shell คุณจะต้องใช้ kubectl port-forward
- เปิดแท็บเทอร์มินัล Cloud Shell ใหม่ (คลิกไอคอน + ในหน้าต่างเทอร์มินัล) คำสั่ง
port-forwardเป็นกระบวนการบล็อก จึงต้องมีเซสชันเทอร์มินัลของตัวเอง - ในเทอร์มินัลใหม่ ให้เรียกใช้คำสั่งต่อไปนี้เพื่อส่งต่อพอร์ตภายใน (เช่น
8000) ไปยังพอร์ตของบริการ (8000)kubectl port-forward service/llm-service 8000:8000 - กลับไปที่เทอร์มินัลเดิม
- ส่งคำขอไปยังพอร์ตในพื้นที่
8000เซิร์ฟเวอร์ Ollama แสดง API ที่เข้ากันได้กับ OpenAI และเนื่องจากการส่งต่อพอร์ต ตอนนี้คุณจึงเข้าถึงได้ที่http://127.0.0.1:8000curl http://127.0.0.1:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "gemma3:1b", "messages": [ {"role": "user", "content": "Explain why the sky is blue."} ] }'
6. การจัดระเบียบ
โปรดทำตามขั้นตอนต่อไปนี้เพื่อลบคลัสเตอร์ GKE เพื่อเลี่ยงไม่ให้เกิดการเรียกเก็บเงินกับบัญชี Google Cloud สำหรับทรัพยากรที่ใช้ใน Lab นี้
- ลบคลัสเตอร์ GKE Autopilot ในเทอร์มินัล Cloud Shell โดยทำดังนี้
gcloud container clusters delete gemma-cluster \ --region $REGION --quiet
7. บทสรุป
เก่งมาก ในแล็บนี้ คุณได้เรียนรู้เกี่ยวกับวิธีการสำคัญหลายอย่างในการติดตั้งใช้งานโมเดลแบบเปิดใน Google Cloud คุณเริ่มต้นด้วยความเรียบง่ายและความเร็วของการพัฒนาในเครื่องด้วย Ollama สุดท้ายนี้ คุณได้ติดตั้งใช้งาน Gemma ในสภาพแวดล้อมที่ปรับขนาดได้ระดับการใช้งานจริงโดยใช้ Google Kubernetes Engine Autopilot และเฟรมเวิร์ก Ollama
ตอนนี้คุณมีความรู้ในการติดตั้งใช้งานโมเดลแบบเปิดใน Google Kubernetes Engine สำหรับภาระงานที่ต้องใช้ทรัพยากรมากและรองรับการปรับขนาดได้โดยไม่ต้องจัดการโครงสร้างพื้นฐานที่อยู่เบื้องหลัง
สรุป
ใน Lab นี้ คุณได้เรียนรู้สิ่งต่อไปนี้
- โมเดลแบบเปิดคืออะไรและเหตุใดจึงสำคัญ
- วิธีเรียกใช้โมเดลแบบเปิดในเครื่องด้วย Ollama
- วิธีติดตั้งใช้งานโมเดลแบบเปิดใน Google Kubernetes Engine (GKE) Autopilot โดยใช้ Ollama สำหรับการอนุมาน
ดูข้อมูลเพิ่มเติม
- ดูข้อมูลเพิ่มเติมเกี่ยวกับโมเดล Gemma ได้ในเอกสารประกอบอย่างเป็นทางการ
- ดูตัวอย่างเพิ่มเติมได้ในที่เก็บ Generative AI ของ Google Cloud บน GitHub
- อ่านเพิ่มเติมเกี่ยวกับ GKE Autopilot
- เรียกดูโมเดลแบบเปิดและโมเดลที่เป็นกรรมสิทธิ์อื่นๆ ที่พร้อมใช้งานใน Vertex AI Model Garden