
1. Giriş
Genel Bakış
Bu laboratuvarın amacı, Google Cloud'da açık bir modeli dağıtma konusunda uygulamalı deneyim kazanmanızı sağlamaktır. Bu süreçte, basit bir yerel kurulumdan Google Kubernetes Engine (GKE) üzerinde üretime hazır bir dağıtıma geçeceksiniz. Geliştirme yaşam döngüsünün her aşamasına uygun farklı araçları nasıl kullanacağınızı öğreneceksiniz.
Laboratuvar aşağıdaki yolu izler:
- Hızlı Prototip Oluşturma: Başlamanın ne kadar kolay olduğunu görmek için önce Ollama ile yerel olarak bir model çalıştıracaksınız.
- Üretime Dağıtım: Son olarak, ölçeklenebilir bir sunum motoru olarak Ollama'yı kullanarak modeli GKE Autopilot'a dağıtacaksınız.
Açık Modelleri Anlama
Günümüzde "açık model" ifadesi genellikle herkesin indirip kullanabileceği, herkese açık bir üretken makine öğrenimi modelini ifade eder. Bu, modelin mimarisinin ve en önemlisi de eğitilmiş parametrelerinin veya "ağırlıklarının" herkese açık olarak yayınlandığı anlamına gelir.
Bu şeffaflık, genellikle yalnızca kısıtlayıcı bir API aracılığıyla erişilebilen kapalı modellere kıyasla çeşitli avantajlar sunar:
- Analiz: Geliştiriciler ve araştırmacılar, modelin iç işleyişini anlamak için "kaputun altına" bakabilir.
- Özelleştirme: Kullanıcılar, ince ayar adı verilen bir işlemle modeli belirli görevlere uyarlayabilir.
- Yenilik: Topluluğun, mevcut güçlü modellerin üzerine yeni ve yenilikçi uygulamalar geliştirmesini sağlar.
Google'ın katkısı ve Gemma ailesi
Google, uzun yıllardır açık kaynaklı yapay zeka hareketine temel katkılar sağlamaktadır. 2017'de yayımlanan "Attention Is All You Need" (İlgi, İhtiyacınız Olan Tek Şeydir) adlı makalede tanıtılan devrim niteliğindeki Transformer mimarisi, neredeyse tüm modern büyük dil modellerinin temelini oluşturur. Bunu, her biri mümkün olanın sınırlarını zorlayan ve dünya çapında araştırma ve geliştirmeyi destekleyen BERT, T5 ve talimatlara göre ayarlanmış Flan-T5 gibi önemli açık modeller izledi.
Google, açık inovasyon alanındaki bu zengin geçmişten yararlanarak Gemma model ailesini tanıttı. Gemma modelleri, güçlü ve kapalı kaynaklı Gemini modellerinde kullanılan araştırma ve teknolojiden yararlanılarak oluşturulur ancak açık ağırlıklarla kullanıma sunulur. Google Cloud müşterileri için bu, en yeni teknolojinin ve açık kaynağın esnekliğinin güçlü bir kombinasyonunu sunar. Bu sayede müşteriler, model yaşam döngüsünü kontrol edebilir, çeşitli bir ekosistemle entegre olabilir ve çoklu bulut stratejisi izleyebilir.
Gemma 3 ile ilgili öne çıkanlar
Bu laboratuvarda, bu ailenin en yeni ve en yetenekli nesli olan Gemma 3'e odaklanacağız. Gemma 3 modelleri, tek bir GPU'da veya hatta CPU'da verimli bir şekilde çalışacak şekilde tasarlanmış, hafif ancak son teknoloji ürünü modellerdir.
- Performans ve Boyut: Gemma 3 modelleri, tek bir GPU'da veya hatta CPU'da verimli bir şekilde çalışacak şekilde tasarlanmış, hafif ancak son teknoloji ürünü modellerdir. Boyutlarına göre üstün kalite ve son teknoloji (SOTA) performans sunarlar.
- Modalite: Çok modaldırlar, metin çıkışı oluşturmak için hem metin hem de görüntü girişini işleyebilirler.
- Temel Özellikler: Gemma 3, 128 bin tokenlik büyük bir bağlam penceresine sahiptir ve 140'tan fazla dili destekler.
- Kullanım alanları: Bu modeller, soru yanıtlama, özetleme ve akıl yürütme gibi çeşitli görevler için uygundur.
Temel terminoloji
Açık modellerle çalışırken karşılaşacağınız bazı yaygın terimler şunlardır:
- Ön eğitim, genel dil kalıplarını öğrenmek için bir modeli büyük ve çeşitli bir veri kümesi üzerinde eğitme işlemidir. Bu modeller temelde güçlü otomatik tamamlama makineleridir.
- Talimat ayarlama, önceden eğitilmiş bir modeli belirli talimatları ve istemleri daha iyi takip edecek şekilde ince ayarlar. Bu modeller "nasıl sohbet edileceğini bilir".
- Model Varyantları: Açık modeller genellikle birden fazla boyutta (ör.Gemma 3'ün 1B, 4B, 12B ve 27B parametre sürümleri vardır) ve varyantta (ör. talimatlara göre ayarlanmış (-it), önceden eğitilmiş veya verimlilik için nicelenmiş) yayınlanır.
- Kaynak İhtiyaçları: Büyük dil modelleri büyüktür ve barındırılmak için önemli işlem kaynakları gerektirir. Yerel olarak çalıştırılabilseler de özellikle Ollama gibi araçlarla performans ve ölçeklenebilirlik için optimize edildiklerinde bulutta dağıtılmaları önemli bir değer sağlar.
Açık Modelleri Sunmak İçin Neden GKE?
Bu laboratuvarda, basit ve yerel model yürütme işleminden Google Kubernetes Engine'de (GKE) tam ölçekli üretim dağıtımına kadar olan süreçte size rehberlik edilir. Ollama gibi araçlar hızlı prototip oluşturma için mükemmel olsa da üretim ortamları, GKE'nin benzersiz bir şekilde karşılayabileceği zorlu bir gereksinimler kümesine sahiptir.
Büyük ölçekli yapay zeka uygulamaları için çalışan bir modelden daha fazlasına, yani esnek, ölçeklenebilir ve verimli bir sunma altyapısına ihtiyacınız vardır. GKE bu temeli sağlar. GKE'yi ne zaman ve neden seçmelisiniz?
- Autopilot ile Basitleştirilmiş Yönetim: GKE Autopilot, temel altyapıyı sizin için yönetir. Uygulama yapılandırmanıza odaklanırsınız. Autopilot, düğümleri otomatik olarak sağlar ve ölçeklendirir.
- Yüksek performans ve ölçeklenebilirlik: GKE'nin otomatik ölçeklendirme özelliği sayesinde zorlu ve değişken trafiği yönetin. Bu sayede uygulamanız, gerektiğinde yukarı veya aşağı ölçeklendirilerek düşük gecikmeyle yüksek gönderim hacmi sunabilir.
- Geniş Ölçekte Maliyet Etkinliği: Kaynakları verimli bir şekilde yönetin. GKE, boştaki kaynaklar için ödeme yapmamak amacıyla iş yüklerini sıfıra kadar ölçeklendirebilir. Ayrıca, durum bilgisi içermeyen çıkarım iş yüklerinin maliyetlerini önemli ölçüde azaltmak için Spot sanal makinelerden yararlanabilirsiniz.
- Taşınabilirlik ve Zengin Ekosistem: Kubernetes tabanlı taşınabilir bir dağıtımla tedarikçilere bağımlı kalmayın. GKE ayrıca sınıfının en iyisi izleme, günlük kaydı ve güvenlik araçları için geniş Cloud Native (CNCF) ekosistemine erişim sağlar.
Kısacası, yapay zeka uygulamanız üretime hazır olduğunda ve ciddi ölçek, performans ve operasyonel olgunluk için tasarlanmış bir platform gerektiğinde GKE'ye geçersiniz.
Neler öğreneceksiniz?
Bu laboratuvarda, aşağıdaki görevleri nasıl gerçekleştireceğinizi öğreneceksiniz:
- Ollama ile açık bir modeli yerel olarak çalıştırın.
- Hizmet sunmak için Ollama ile Google Kubernetes Engine (GKE) Autopilot'a açık bir model dağıtın.
- Yerel geliştirme çerçevelerinden GKE'de üretime hazır bir sunma mimarisine geçişi anlayın.
2. Proje ayarlama
Google Hesabı
Kişisel Google Hesabınız yoksa Google Hesabı oluşturmanız gerekir.
İş veya okul hesabı yerine kişisel hesap kullanın.
Google Cloud Console'da oturum açma
Kişisel bir Google Hesabı kullanarak Google Cloud Console'da oturum açın.
Faturalandırmayı Etkinleştir
Kişisel faturalandırma hesabı oluşturma
Faturalandırmayı Google Cloud kredilerini kullanarak ayarladıysanız bu adımı atlayabilirsiniz.
Kişisel faturalandırma hesabı oluşturmak için Cloud Console'da faturalandırmayı etkinleştirmek üzere buraya gidin.
Bazı notlar:
- Bu laboratuvarı tamamlamak için 1 ABD dolarından daha az tutarda bulut kaynağı kullanmanız gerekir.
- Daha fazla ücret ödememek için bu laboratuvarın sonundaki adımları uygulayarak kaynakları silebilirsiniz.
- Yeni kullanıcılar 300 ABD doları değerinde ücretsiz deneme sürümünden yararlanabilir.
Proje oluşturma (isteğe bağlı)
Bu laboratuvarda kullanmak istediğiniz mevcut bir projeniz yoksa buradan yeni bir proje oluşturun.
3. Cloud Shell Düzenleyici'yi açma
- Doğrudan Cloud Shell Düzenleyici'ye gitmek için bu bağlantıyı tıklayın.
- Bugün herhangi bir noktada yetkilendirmeniz istenirse devam etmek için Yetkilendir'i tıklayın.
- Terminal ekranın alt kısmında görünmüyorsa açın:
- Görünüm'ü tıklayın.
- Terminal'i tıklayın.
- Terminalde şu komutla projenizi ayarlayın:
gcloud config set project [PROJECT_ID]- Örnek:
gcloud config set project lab-project-id-example - Proje kimliğinizi hatırlamıyorsanız tüm proje kimliklerinizi şu komutla listeleyebilirsiniz:
gcloud projects list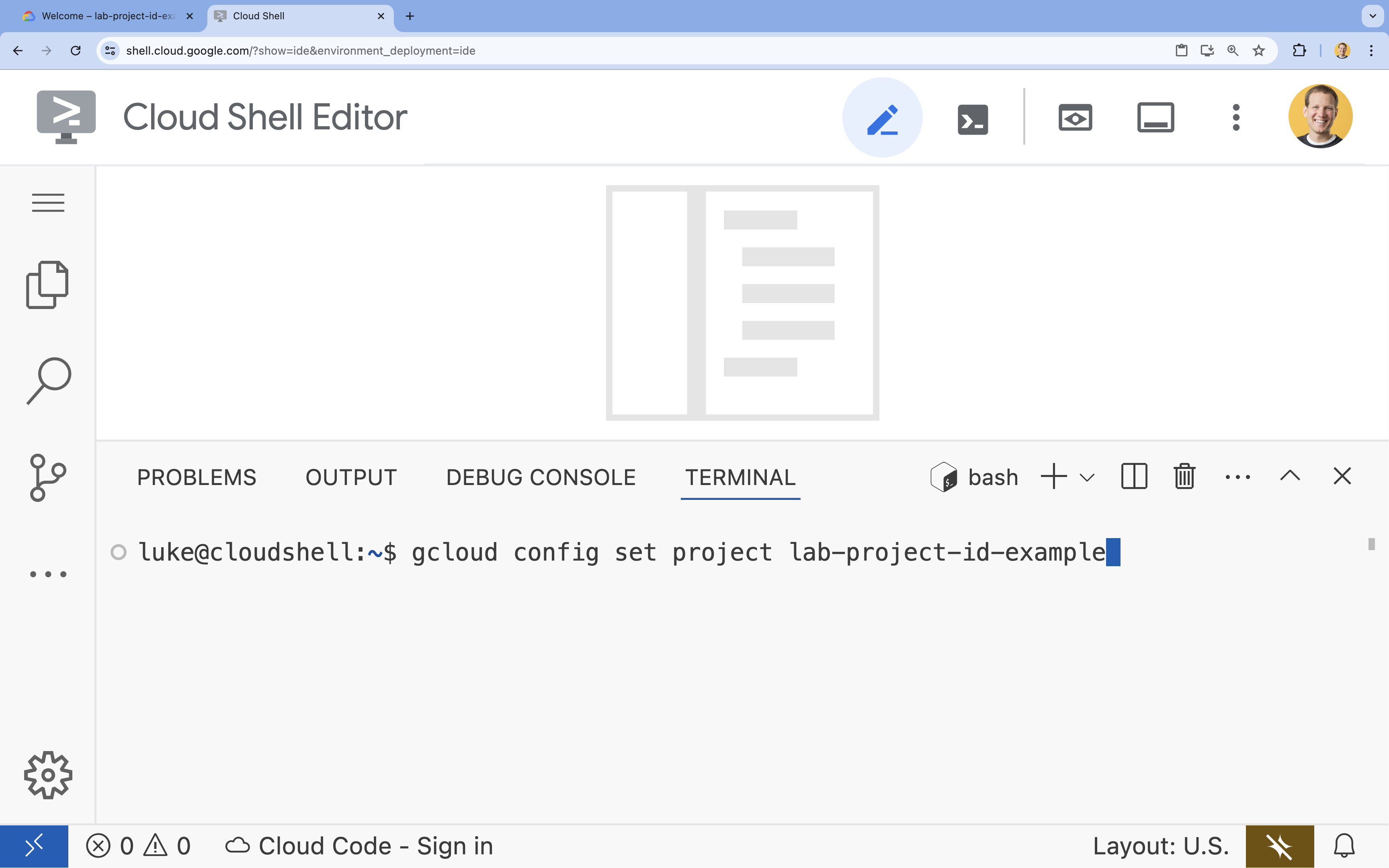
- Örnek:
- Şu mesajı görmeniz gerekir:
Updated property [core/project].
4. Gemma'yı Ollama ile çalıştırma
İlk hedefiniz, Gemma 3'ü mümkün olduğunca hızlı bir şekilde geliştirme ortamında çalıştırmaktır. Büyük dil modellerini yerel olarak çalıştırmayı önemli ölçüde basitleştiren bir araç olan Ollama'yı kullanacaksınız. Bu görevde, açık bir modeli denemeye başlamanın en basit yolu gösterilmektedir.
Ollama, kullanıcıların üretken modelleri (büyük dil modelleri, görme-dil modelleri vb.) kendi bilgisayarlarında yerel olarak çalıştırmasına olanak tanıyan ücretsiz ve açık kaynaklı bir araçtır. Bu modellerle etkileşim kurma ve bunlara erişme sürecini basitleştirerek daha erişilebilir hale getirir ve kullanıcıların bu modellerle gizli bir şekilde çalışmasına olanak tanır.
Ollama'yı yükleyip çalıştırma
Artık Ollama'yı yüklemeye, Gemma 3 modelini indirmeye ve komut satırından bu modelle etkileşime geçmeye hazırsınız.
- Cloud Shell terminalinde Ollama'yı indirip yükleyin:
curl -fsSL https://ollama.com/install.sh | sh - Ollama hizmetini arka planda başlatın:
ollama serve & - Ollama ile Gemma 3 1B modelini çekin (indirin):
ollama pull gemma3:1b - Modeli yerel olarak çalıştırma:
ollama run gemma3:1bollama runkomutu, modele soru sormanız için bir istem (>>>) sunar. - Modeli bir soruyla test edin. Örneğin,
Why is the sky blue?yazıp ENTER tuşuna basın. Aşağıdakine benzer bir yanıt görmeniz gerekir:>>> Why is the sky blue? Okay, let's break down why the sky is blue – it's a fascinating phenomenon related to how light interacts with the Earth's atmosphere. Here's the explanation: **1. Sunlight and Colors:** * Sunlight appears white, but it's actually made up of all the colors of the rainbow (red, orange, yellow, green, blue, indigo, and violet). Think of a prism splitting sunlight. **2. Rayleigh Scattering:** * As sunlight enters the Earth's atmosphere... ...
- Terminal'deki Ollama isteminden çıkmak için
/byeyazıp ENTER tuşuna basın.
OpenAI SDK'yı Ollama ile kullanma
Ollama hizmeti çalıştığına göre artık programatik olarak etkileşimde bulunabilirsiniz. Ollama'nın sunduğu API ile uyumlu olan OpenAI Python SDK'yı kullanacaksınız.
- Cloud Shell terminalinde uv'yi kullanarak bir sanal ortam oluşturun ve etkinleştirin. Bu şekilde, proje bağımlılıklarınızın sistem Python'uyla çakışmaması sağlanır.
uv venv --python 3.14 source .venv/bin/activate - Terminalde OpenAI SDK'sını yükleyin:
uv pip install openai - Terminalde şunu girerek
ollama_chat.pyadlı yeni bir dosya oluşturun:cloudshell edit ollama_chat.py - Aşağıdaki Python kodunu
ollama_chat.pyiçine yapıştırın. Bu kod, yerel Ollama sunucusuna bir istek gönderir.from openai import OpenAI client = OpenAI( base_url = 'http://localhost:11434/v1', api_key='ollama', # required by OpenAI SDK, but not used by Ollama ) response = client.chat.completions.create( model="gemma3:1b", messages=[ { "role": "user", "content": "Why is the sky blue?" }, ], ) print(response.choices[0].message.content) - Komut dosyasını terminalinizde çalıştırın:
python3 ollama_chat.py - Akış modunu denemek için terminalde aşağıdakileri çalıştırarak
ollama_stream.pyadlı başka bir dosya oluşturun:cloudshell edit ollama_stream.py - Aşağıdaki içeriği
ollama_stream.pydosyasına yapıştırın. İsteklerdekistream=Trueparametresine dikkat edin. Bu sayede model, oluşturulan jetonları hemen döndürebilir.from openai import OpenAI client = OpenAI( base_url = 'http://localhost:11434/v1', api_key='ollama', ) stream = client.chat.completions.create( model="gemma3:1b", messages=[ { "role": "user", "content": "Why is the sky blue?" }, ], stream=True ) for chunk in stream: if chunk.choices[0].delta.content is not None: print(chunk.choices[0].delta.content, end="", flush=True) print() - Terminalde akış komut dosyasını çalıştırın:
python3 ollama_stream.py
Yayın, chatbot'lar gibi etkileşimli uygulamalarda iyi bir kullanıcı deneyimi oluşturmak için faydalı bir özelliktir. Akış, kullanıcının yanıtın tamamının oluşturulmasını beklemesini sağlamak yerine, yanıtı oluşturuldukça jeton jeton gösterir. Bu sayede anında geri bildirim sağlanır ve uygulama çok daha hızlı yanıt verir.
Öğrendikleriniz: Ollama ile açık modeller çalıştırma
Ollama kullanarak açık bir modeli başarıyla çalıştırdınız. Gemma 3 gibi güçlü bir modeli indirmenin ve hem komut satırı arayüzü hem de Python ile programatik olarak etkileşim kurmanın ne kadar kolay olduğunu gördünüz. Bu iş akışı, hızlı prototip oluşturma ve yerel geliştirme için idealdir. Artık daha gelişmiş dağıtım seçeneklerini keşfetmek için sağlam bir temeliniz var.
5. GKE Autopilot'ta Ollama ile Gemma'yı dağıtma
Basitleştirilmiş işlemler ve ölçeklenebilirlik gerektiren üretim iş yükleri için Google Kubernetes Engine (GKE) tercih edilen platformdur. Bu görevde, GKE Autopilot kümesinde Ollama kullanarak Gemma'yı dağıtacaksınız.
GKE Autopilot, GKE'de bir işlem modudur. Bu modda Google, düğümleriniz, ölçeklendirme, güvenlik ve önceden yapılandırılmış diğer ayarlar dahil olmak üzere küme yapılandırmanızı yönetir. Temel işlem altyapısını yönetmeden çıkarım iş yüklerini çalıştırmak için mükemmel olan gerçek anlamda "sunucusuz" bir Kubernetes deneyimi oluşturur.
GKE ortamını hazırlama
Kubernetes'e dağıtım yapma son görevi için bir GKE Autopilot kümesi sağlayacaksınız.
- Cloud Shell terminalinde projeniz ve istediğiniz bölge için ortam değişkenlerini ayarlayın.
export PROJECT_ID=$(gcloud config get-value project) export REGION=europe-west1 gcloud config set compute/region $REGION - Terminalde aşağıdakileri çalıştırarak projeniz için GKE API'yi etkinleştirin:
gcloud services enable container.googleapis.com - Terminalde aşağıdakileri çalıştırarak GKE Autopilot kümesi oluşturun:
gcloud container clusters create-auto gemma-cluster \ --region $REGION \ --release-channel rapid - Terminalde aşağıdakileri çalıştırarak yeni kümenizin kimlik bilgilerini alın:
gcloud container clusters get-credentials gemma-cluster \ --region $REGION
Ollama ve Gemma'yı dağıtma
Artık bir GKE Autopilot kümeniz olduğuna göre Ollama sunucusunu dağıtabilirsiniz. Autopilot, dağıtım manifestonuzda tanımladığınız gereksinimlere göre işlem kaynaklarını (CPU ve bellek) otomatik olarak sağlar.
- Terminalde aşağıdakileri çalıştırarak
gemma-deployment.yamladlı yeni bir dosya oluşturun:cloudshell edit gemma-deployment.yaml - Aşağıdaki YAML yapılandırmasını
gemma-deployment.yamliçine yapıştırın. Bu yapılandırma, CPU'da çalışmak için resmi Ollama görüntüsünü kullanan bir dağıtımı tanımlar.apiVersion: apps/v1 kind: Deployment metadata: name: ollama-gemma spec: replicas: 1 selector: matchLabels: app: ollama-gemma template: metadata: labels: app: ollama-gemma spec: containers: - name: ollama-gemma-container image: ollama/ollama:0.12.10 resources: requests: cpu: "8" memory: "8Gi" ephemeral-storage: "10Gi" limits: cpu: "8" memory: "8Gi" ephemeral-storage: "10Gi" # We use a script to start the server and pull the model command: ["/bin/bash", "-c"] args: - | ollama serve & OLLAMA_PID=$! echo "Waiting for Ollama server to start..." sleep 5 echo "Pulling Gemma model..." ollama pull gemma3:1b echo "Model pulled. Ready to serve." wait $OLLAMA_PID ports: - containerPort: 11434 env: - name: OLLAMA_HOST value: "0.0.0.0" --- apiVersion: v1 kind: Service metadata: name: llm-service spec: selector: app: ollama-gemma type: ClusterIP ports: - protocol: TCP port: 8000 targetPort: 11434image: ollama/ollama:latest: Bu, resmi Ollama Docker görüntüsünü belirtir.resources: 8 vCPU ve 8 GiB bellek açıkça isteniyor. GKE Autopilot, temel işlem kaynaklarını sağlamak için bu değerleri kullanır. GPU kullanmadığımız için model CPU'da çalışır. 8 GiB bellek, Gemma 1B modelini ve bağlamını tutmak için yeterlidir.command/args: Pod başladığında modelin çekilmesini sağlamak için başlangıç komutunu geçersiz kılarız. Komut dosyası, sunucuyu arka planda başlatır, hazır olmasını bekler,gemma3:1bmodelini çeker ve ardından sunucuyu çalışır durumda tutar.OLLAMA_HOST: Bu değeri0.0.0.0olarak ayarladığınızda Ollama, kapsayıcıdaki tüm ağ arayüzlerini dinler ve Kubernetes hizmeti tarafından erişilebilir hale gelir.
- Terminalde, dağıtım manifestini kümenize uygulayın:
kubectl apply -f gemma-deployment.yamlkubectl get pods --watchRunningveREADYdurumunun1/1olmasını bekleyin.
GKE uç noktasını test etme
Ollama hizmetiniz artık GKE Autopilot kümenizde çalışıyor. Cloud Shell terminalinizden test etmek için kubectl port-forward kullanacaksınız.
- Yeni bir Cloud Shell terminali sekmesi açın (terminal penceresinde + simgesini tıklayın).
port-forwardkomutu, engelleme işlemi olduğundan kendi terminal oturumunu gerektirir. - Yeni terminalde, yerel bir bağlantı noktasını (ör.
8000) hizmetin bağlantı noktasına (8000) yönlendirmek için aşağıdaki komutu çalıştırın:kubectl port-forward service/llm-service 8000:8000 - Orijinal terminalinize dönün.
- Yerel bağlantı noktanıza
8000istek gönderin. Ollama sunucusu, OpenAI ile uyumlu bir API sunar ve bağlantı noktası yönlendirme sayesinde artıkhttp://127.0.0.1:8000adresinden erişebilirsiniz.curl http://127.0.0.1:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "gemma3:1b", "messages": [ {"role": "user", "content": "Explain why the sky is blue."} ] }'
6. Temizleme
Bu laboratuvarda kullanılan kaynaklar için Google Cloud hesabınızın ücretlendirilmesini istemiyorsanız GKE kümesini silmek için aşağıdaki adımları uygulayın.
- Cloud Shell terminalinde GKE Autopilot kümesini silin:
gcloud container clusters delete gemma-cluster \ --region $REGION --quiet
7. Sonuç
Tebrikler! Bu laboratuvarda, açık modelleri Google Cloud'da dağıtmak için kullanılan çeşitli temel yöntemleri incelediniz. Ollama ile yerel geliştirmenin basitliği ve hızıyla başladınız. Son olarak, Gemma'yı Google Kubernetes Engine Autopilot ve Ollama çerçevesini kullanarak üretime hazır, ölçeklenebilir bir ortama dağıttınız.
Artık temel altyapıyı yönetmeden zorlu ve ölçeklenebilir iş yükleri için Google Kubernetes Engine'de açık modeller dağıtma konusunda bilgi sahibisiniz.
Özet
Bu laboratuvarda şunları öğrendiniz:
- Açık modellerin ne olduğu ve neden önemli olduğu
- Ollama ile açık bir modeli yerel olarak çalıştırma
- Çıkarım için Ollama'yı kullanarak Google Kubernetes Engine (GKE) Autopilot'ta açık model dağıtma
Daha fazla bilgi
- Gemma modelleri hakkında daha fazla bilgiyi resmi belgelerde bulabilirsiniz.
- GitHub'daki Google Cloud Üretken Yapay Zeka deposunda daha fazla örnek inceleyin.
- GKE Autopilot hakkında daha fazla bilgi edinin.
- Diğer kullanılabilir açık ve tescilli modeller için Vertex AI Model Garden'a göz atın.