
1. Giới thiệu
Tổng quan
Mục tiêu của phòng thí nghiệm này là giúp bạn có trải nghiệm thực tế khi triển khai một mô hình mở trên Google Cloud, từ một chế độ thiết lập cục bộ đơn giản đến một hoạt động triển khai cấp sản xuất trên Google Kubernetes Engine (GKE). Bạn sẽ tìm hiểu cách sử dụng các công cụ phù hợp cho từng giai đoạn của vòng đời phát triển.
Phòng thí nghiệm này sẽ đi theo lộ trình sau:
- Tạo mẫu nhanh: Trước tiên, bạn sẽ chạy một mô hình bằng Ollama trên máy để xem việc bắt đầu dễ dàng như thế nào.
- Triển khai sản xuất: Cuối cùng, bạn sẽ triển khai mô hình này lên GKE Autopilot bằng Ollama làm công cụ phân phát có khả năng mở rộng.
Tìm hiểu về Mô hình mở
Ngày nay, khi nói đến "mô hình mở", mọi người thường đề cập đến một mô hình học máy tạo sinh mà mọi người có thể tải xuống và sử dụng công khai. Điều này có nghĩa là cấu trúc của mô hình và quan trọng nhất là các thông số hoặc "trọng số" được huấn luyện của mô hình sẽ được phát hành công khai.
Tính minh bạch này mang lại một số lợi ích so với các mô hình khép kín (thường chỉ được truy cập thông qua một API hạn chế):
- Thông tin chi tiết: Các nhà phát triển và nhà nghiên cứu có thể tìm hiểu "cấu trúc bên trong" để nắm được cách thức hoạt động của mô hình.
- Tuỳ chỉnh: Người dùng có thể điều chỉnh mô hình cho các tác vụ cụ thể thông qua một quy trình gọi là tinh chỉnh.
- Đổi mới: Cho phép cộng đồng xây dựng các ứng dụng mới và cải tiến dựa trên các mô hình hiện có mạnh mẽ.
Đóng góp của Google và họ mô hình Gemma
Google đã đóng góp nền tảng cho phong trào AI nguồn mở trong nhiều năm. Kiến trúc Transformer mang tính cách mạng, được giới thiệu trong bài viết năm 2017 "Attention Is All You Need" (Sự chú ý là tất cả những gì bạn cần), là cơ sở cho hầu hết các mô hình ngôn ngữ lớn hiện đại. Sau đó là các mô hình nguồn mở mang tính đột phá như BERT, T5 và Flan-T5 được tinh chỉnh theo hướng dẫn. Mỗi mô hình này đều phá bỏ giới hạn về những gì có thể và thúc đẩy hoạt động nghiên cứu và phát triển trên toàn thế giới.
Dựa trên bề dày kinh nghiệm đổi mới trên nền tảng mở này, Google đã giới thiệu họ mô hình Gemma. Các mô hình Gemma được tạo ra từ cùng một nghiên cứu và công nghệ được dùng cho các mô hình Gemini mạnh mẽ, mã nguồn đóng, nhưng được cung cấp với trọng số mở. Đối với khách hàng của Google Cloud, sự kết hợp mạnh mẽ này giữa công nghệ tiên tiến và tính linh hoạt của nguồn mở giúp họ kiểm soát vòng đời của mô hình, tích hợp với một hệ sinh thái đa dạng và theo đuổi chiến lược đa đám mây.
Tiêu điểm về Gemma 3
Trong phòng thí nghiệm này, chúng ta sẽ tập trung vào Gemma 3, thế hệ mới nhất và có nhiều khả năng nhất trong dòng mô hình này. Các mô hình Gemma 3 có kích thước nhỏ nhưng vẫn là mô hình tiên tiến, được thiết kế để chạy hiệu quả trên một GPU hoặc thậm chí là CPU.
- Hiệu suất và kích thước: Các mô hình Gemma 3 có kích thước nhỏ nhưng vẫn có hiệu suất vượt trội, được thiết kế để chạy hiệu quả trên một GPU hoặc thậm chí là CPU. Chúng có chất lượng vượt trội và hiệu suất tiên tiến (SOTA) so với kích thước của mình.
- Phương thức: Các mô hình này có nhiều phương thức, có khả năng xử lý cả văn bản và hình ảnh đầu vào để tạo văn bản đầu ra.
- Các tính năng chính: Gemma 3 có cửa sổ ngữ cảnh lớn (128K) và hỗ trợ hơn 140 ngôn ngữ.
- Trường hợp sử dụng: Các mô hình này rất phù hợp với nhiều nhiệm vụ, bao gồm trả lời câu hỏi, tóm tắt và suy luận.
Thuật ngữ chính
Khi làm việc với các mô hình mở, bạn sẽ gặp một số thuật ngữ phổ biến:
- Huấn luyện trước là quá trình huấn luyện một mô hình trên một tập dữ liệu khổng lồ và đa dạng để tìm hiểu các mẫu ngôn ngữ chung. Về cơ bản, những mô hình này là các công cụ tự động hoàn thành mạnh mẽ.
- Tinh chỉnh theo chỉ dẫn giúp tinh chỉnh một mô hình được huấn luyện tiền kỳ để tuân theo các chỉ dẫn và câu lệnh cụ thể một cách hiệu quả hơn. Đây là những mô hình "biết cách trò chuyện".
- Biến thể mô hình: Các mô hình mở thường được phát hành với nhiều kích thước (ví dụ: Gemma 3 có các phiên bản tham số 1B, 4B, 12B và 27B) và biến thể, chẳng hạn như được điều chỉnh theo hướng dẫn (-it), được huấn luyện trước hoặc được lượng tử hoá để tăng hiệu quả.
- Nhu cầu về tài nguyên: Mô hình ngôn ngữ lớn có kích thước lớn và cần có tài nguyên điện toán đáng kể để lưu trữ. Mặc dù có thể chạy cục bộ, nhưng việc triển khai các mô hình này trên đám mây mang lại giá trị đáng kể, đặc biệt là khi được tối ưu hoá về hiệu suất và khả năng mở rộng bằng các công cụ như Ollama.
Tại sao nên dùng GKE để phân phát Mô hình mở?
Phòng thí nghiệm này hướng dẫn bạn từ việc thực thi mô hình cục bộ, đơn giản đến việc triển khai sản xuất quy mô lớn trên Google Kubernetes Engine (GKE). Mặc dù các công cụ như Ollama rất phù hợp để tạo mẫu nhanh, nhưng môi trường sản xuất có một bộ yêu cầu khắt khe mà GKE có thể đáp ứng một cách đặc biệt.
Đối với các ứng dụng AI quy mô lớn, bạn cần nhiều hơn một mô hình đang chạy; bạn cần một cơ sở hạ tầng phân phát hiệu quả, có khả năng mở rộng và linh hoạt. GKE cung cấp nền tảng này. Sau đây là thời điểm và lý do bạn nên chọn GKE:
- Quản lý đơn giản bằng Autopilot: GKE Autopilot quản lý cơ sở hạ tầng cơ bản cho bạn. Bạn tập trung vào cấu hình ứng dụng của mình, còn Autopilot sẽ tự động cung cấp và mở rộng quy mô các nút.
- Hiệu suất và khả năng mở rộng cao: Xử lý lưu lượng truy cập biến động, đòi hỏi nhiều tài nguyên bằng tính năng tự động cấp tài nguyên bổ sung của GKE. Điều này đảm bảo ứng dụng của bạn có thể mang lại thông lượng cao với độ trễ thấp, tăng hoặc giảm quy mô khi cần.
- Hiệu quả về chi phí trên quy mô lớn: Quản lý tài nguyên một cách hiệu quả. GKE có thể giảm quy mô khối lượng công việc xuống 0 để tránh phải trả tiền cho các tài nguyên không hoạt động, đồng thời bạn có thể tận dụng Spot VM để giảm đáng kể chi phí cho các khối lượng công việc suy luận không trạng thái.
- Tính di động và hệ sinh thái phong phú: Tránh lệ thuộc vào nhà cung cấp bằng một hoạt động triển khai dựa trên Kubernetes có tính di động. GKE cũng cung cấp quyền truy cập vào hệ sinh thái Cloud Native (CNCF) rộng lớn để có được các công cụ giám sát, ghi nhật ký và bảo mật hàng đầu.
Nói tóm lại, bạn sẽ chuyển sang GKE khi ứng dụng AI của bạn đã sẵn sàng cho giai đoạn phát hành công khai và cần một nền tảng được xây dựng để có quy mô, hiệu suất và độ hoàn thiện về hoạt động ở mức cao.
Kiến thức bạn sẽ học được
Trong bài thực hành này, bạn sẽ tìm hiểu cách thực hiện các thao tác sau:
- Chạy một mô hình mở trên máy cục bộ bằng Ollama.
- Triển khai một mô hình mở vào chế độ Tự động của Google Kubernetes Engine (GKE) bằng Ollama để phân phát.
- Tìm hiểu quá trình chuyển đổi từ các khung phát triển cục bộ sang một kiến trúc phân phát cấp sản xuất trên GKE.
2. Thiết lập dự án
Tài khoản Google
Nếu chưa có Tài khoản Google cá nhân, bạn phải tạo một Tài khoản Google.
Sử dụng tài khoản cá nhân thay vì tài khoản do nơi làm việc hoặc trường học cấp.
Đăng nhập vào Google Cloud Console
Đăng nhập vào Google Cloud Console bằng Tài khoản Google cá nhân.
Bật thanh toán
Thiết lập tài khoản thanh toán cá nhân
Nếu thiết lập thông tin thanh toán bằng tín dụng Google Cloud, bạn có thể bỏ qua bước này.
Để thiết lập tài khoản thanh toán cá nhân, hãy truy cập vào đây để bật tính năng thanh toán trong Cloud Console.
Một số lưu ý:
- Việc hoàn thành bài tập thực hành này sẽ tốn ít hơn 1 USD cho các tài nguyên trên đám mây.
- Bạn có thể làm theo các bước ở cuối bài thực hành này để xoá tài nguyên nhằm tránh bị tính thêm phí.
- Người dùng mới đủ điều kiện dùng thử miễn phí trị giá 300 USD.
Tạo dự án (không bắt buộc)
Nếu bạn không có dự án hiện tại nào muốn sử dụng cho lớp học này, hãy tạo một dự án mới tại đây.
3. Mở Trình chỉnh sửa Cloud Shell
- Nhấp vào đường liên kết này để chuyển trực tiếp đến Cloud Shell Editor
- Nếu được nhắc uỷ quyền vào bất kỳ thời điểm nào trong ngày hôm nay, hãy nhấp vào Uỷ quyền để tiếp tục.
- Nếu thiết bị đầu cuối không xuất hiện ở cuối màn hình, hãy mở thiết bị đầu cuối:
- Nhấp vào Xem
- Nhấp vào Terminal (Thiết bị đầu cuối)
- Trong cửa sổ dòng lệnh, hãy thiết lập dự án bằng lệnh sau:
gcloud config set project [PROJECT_ID]- Ví dụ:
gcloud config set project lab-project-id-example - Nếu không nhớ mã dự án, bạn có thể liệt kê tất cả mã dự án bằng cách dùng lệnh:
gcloud projects list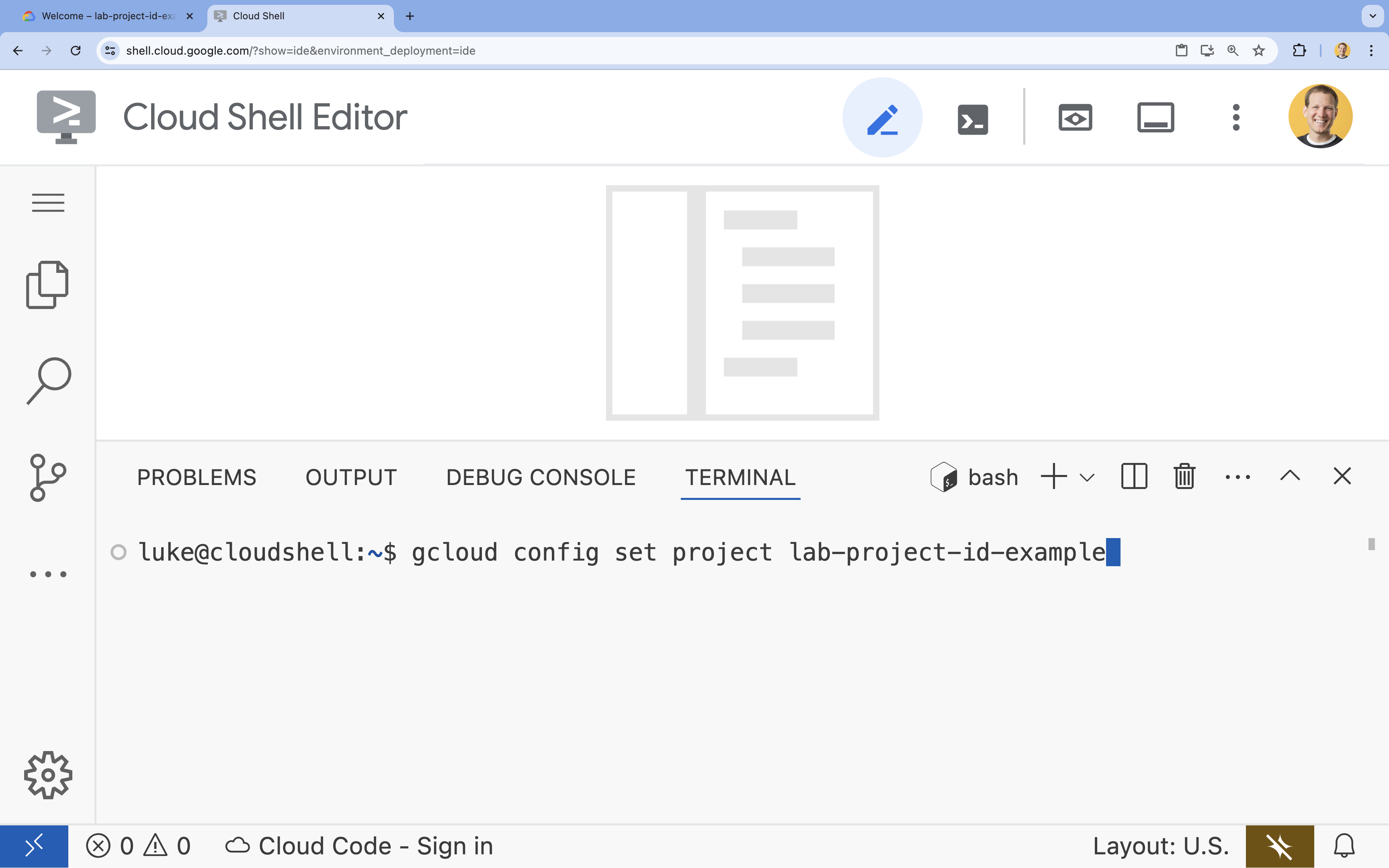
- Ví dụ:
- Bạn sẽ thấy thông báo sau:
Updated property [core/project].
4. Chạy Gemma bằng Ollama
Mục tiêu đầu tiên của bạn là chạy Gemma 3 nhanh nhất có thể trong môi trường phát triển. Bạn sẽ sử dụng Ollama, một công cụ giúp đơn giản hoá đáng kể việc chạy các mô hình ngôn ngữ lớn trên máy cục bộ. Tác vụ này cho bạn thấy cách đơn giản nhất để bắt đầu thử nghiệm với một mô hình mở.
Ollama là một công cụ mã nguồn mở miễn phí, cho phép người dùng chạy các Mô hình tạo sinh (mô hình ngôn ngữ lớn, mô hình ngôn ngữ thị giác và nhiều mô hình khác) cục bộ trên máy tính của riêng họ. Nhờ đó, người dùng có thể dễ dàng truy cập và tương tác với các mô hình này, đồng thời làm việc riêng tư với các mô hình.
Cài đặt và chạy Ollama
Giờ đây, bạn đã sẵn sàng cài đặt Ollama, tải mô hình Gemma 3 xuống và tương tác với mô hình này từ dòng lệnh.
- Trong cửa sổ dòng lệnh Cloud Shell, hãy tải xuống và cài đặt Ollama:
curl -fsSL https://ollama.com/install.sh | sh - Khởi động dịch vụ Ollama ở chế độ nền:
ollama serve & - Kéo (tải) mô hình Gemma 3 1B bằng Ollama:
ollama pull gemma3:1b - Chạy mô hình cục bộ:
ollama run gemma3:1bollama runsẽ hiện một lời nhắc (>>>) để bạn đặt câu hỏi cho mô hình. - Kiểm thử mô hình bằng một câu hỏi. Ví dụ: nhập
Why is the sky blue?rồi nhấn ENTER. Bạn sẽ thấy một phản hồi tương tự như sau:>>> Why is the sky blue? Okay, let's break down why the sky is blue – it's a fascinating phenomenon related to how light interacts with the Earth's atmosphere. Here's the explanation: **1. Sunlight and Colors:** * Sunlight appears white, but it's actually made up of all the colors of the rainbow (red, orange, yellow, green, blue, indigo, and violet). Think of a prism splitting sunlight. **2. Rayleigh Scattering:** * As sunlight enters the Earth's atmosphere... ...
- Để thoát khỏi lời nhắc Ollama trong Terminal, hãy nhập
/byerồi nhấn ENTER.
Sử dụng OpenAI SDK với Ollama
Giờ đây, khi dịch vụ Ollama đang chạy, bạn có thể tương tác với dịch vụ này theo phương thức lập trình. Bạn sẽ sử dụng OpenAI Python SDK, tương thích với API mà Ollama cung cấp.
- Trong cửa sổ dòng lệnh Cloud Shell, hãy tạo và kích hoạt một môi trường ảo bằng uv. Điều này đảm bảo các phần phụ thuộc của dự án không xung đột với Python hệ thống.
uv venv --python 3.14 source .venv/bin/activate - Trong cửa sổ dòng lệnh, hãy cài đặt OpenAI SDK:
uv pip install openai - Tạo một tệp mới có tên
ollama_chat.pybằng cách nhập vào thiết bị đầu cuối:cloudshell edit ollama_chat.py - Dán mã Python sau vào
ollama_chat.py. Mã này gửi một yêu cầu đến máy chủ Ollama cục bộ.from openai import OpenAI client = OpenAI( base_url = 'http://localhost:11434/v1', api_key='ollama', # required by OpenAI SDK, but not used by Ollama ) response = client.chat.completions.create( model="gemma3:1b", messages=[ { "role": "user", "content": "Why is the sky blue?" }, ], ) print(response.choices[0].message.content) - Chạy tập lệnh trong thiết bị đầu cuối:
python3 ollama_chat.py - Để thử chế độ truyền phát trực tiếp, hãy tạo một tệp khác có tên
ollama_stream.pybằng cách chạy lệnh sau trong cửa sổ dòng lệnh:cloudshell edit ollama_stream.py - Dán nội dung sau vào tệp
ollama_stream.py. Hãy chú ý đến tham sốstream=Truetrong yêu cầu. Điều này cho phép mô hình trả về mã thông báo ngay khi chúng được tạo.from openai import OpenAI client = OpenAI( base_url = 'http://localhost:11434/v1', api_key='ollama', ) stream = client.chat.completions.create( model="gemma3:1b", messages=[ { "role": "user", "content": "Why is the sky blue?" }, ], stream=True ) for chunk in stream: if chunk.choices[0].delta.content is not None: print(chunk.choices[0].delta.content, end="", flush=True) print() - Chạy tập lệnh truyền phát trực tiếp trong thiết bị đầu cuối:
python3 ollama_stream.py
Truyền phát trực tiếp là một tính năng hữu ích để tạo trải nghiệm người dùng tốt trong các ứng dụng tương tác như chatbot. Thay vì bắt người dùng đợi toàn bộ câu trả lời được tạo, tính năng truyền trực tuyến sẽ hiển thị từng mã thông báo phản hồi khi mã thông báo đó được tạo. Điều này giúp cung cấp phản hồi ngay lập tức và giúp ứng dụng phản hồi nhanh hơn nhiều.
Kiến thức bạn học được: Chạy Mô hình mở bằng Ollama
Bạn đã chạy thành công một mô hình mở bằng Ollama. Bạn đã thấy việc tải một mô hình mạnh mẽ như Gemma 3 và tương tác với mô hình này có thể đơn giản như thế nào, cả thông qua giao diện dòng lệnh và theo phương thức lập trình bằng Python. Quy trình này lý tưởng cho việc tạo nguyên mẫu nhanh và phát triển cục bộ. Giờ đây, bạn đã có một nền tảng vững chắc để khám phá các lựa chọn triển khai nâng cao hơn.
5. Triển khai Gemma bằng Ollama trên GKE Autopilot
Đối với những tải công việc sản xuất đòi hỏi hoạt động đơn giản và khả năng mở rộng, Google Kubernetes Engine (GKE) là nền tảng được lựa chọn. Trong nhiệm vụ này, bạn sẽ triển khai Gemma bằng Ollama trên một cụm GKE Autopilot.
GKE Autopilot là một chế độ hoạt động trong GKE, trong đó Google quản lý cấu hình cụm của bạn, bao gồm cả các nút, hoạt động mở rộng quy mô, bảo mật và các chế độ cài đặt được định cấu hình sẵn khác. Nó tạo ra trải nghiệm Kubernetes thực sự "không máy chủ", phù hợp để chạy các tải suy luận mà không cần quản lý cơ sở hạ tầng điện toán cơ bản.
Chuẩn bị môi trường GKE
Đối với nhiệm vụ cuối cùng là triển khai vào Kubernetes, bạn sẽ cung cấp một cụm GKE Autopilot.
- Trong thiết bị đầu cuối Cloud Shell, hãy thiết lập các biến môi trường cho dự án và khu vực mong muốn.
export PROJECT_ID=$(gcloud config get-value project) export REGION=europe-west1 gcloud config set compute/region $REGION - Bật GKE API cho dự án của bạn bằng cách chạy lệnh sau trong thiết bị đầu cuối:
gcloud services enable container.googleapis.com - Tạo một cụm GKE Autopilot bằng cách chạy lệnh sau trong thiết bị đầu cuối:
gcloud container clusters create-auto gemma-cluster \ --region $REGION \ --release-channel rapid - Lấy thông tin đăng nhập cho cụm mới bằng cách chạy lệnh sau trong cửa sổ dòng lệnh:
gcloud container clusters get-credentials gemma-cluster \ --region $REGION
Triển khai Ollama và Gemma
Giờ đây, khi đã có một cụm GKE Autopilot, bạn có thể triển khai máy chủ Ollama. Autopilot sẽ tự động cung cấp tài nguyên điện toán (CPU và Bộ nhớ) dựa trên các yêu cầu mà bạn xác định trong tệp kê khai triển khai.
- Tạo một tệp mới có tên
gemma-deployment.yamlbằng cách chạy lệnh sau trong thiết bị đầu cuối:cloudshell edit gemma-deployment.yaml - Dán cấu hình YAML sau vào
gemma-deployment.yaml. Cấu hình này xác định một quy trình triển khai sử dụng hình ảnh Ollama chính thức để chạy trên CPU.apiVersion: apps/v1 kind: Deployment metadata: name: ollama-gemma spec: replicas: 1 selector: matchLabels: app: ollama-gemma template: metadata: labels: app: ollama-gemma spec: containers: - name: ollama-gemma-container image: ollama/ollama:0.12.10 resources: requests: cpu: "8" memory: "8Gi" ephemeral-storage: "10Gi" limits: cpu: "8" memory: "8Gi" ephemeral-storage: "10Gi" # We use a script to start the server and pull the model command: ["/bin/bash", "-c"] args: - | ollama serve & OLLAMA_PID=$! echo "Waiting for Ollama server to start..." sleep 5 echo "Pulling Gemma model..." ollama pull gemma3:1b echo "Model pulled. Ready to serve." wait $OLLAMA_PID ports: - containerPort: 11434 env: - name: OLLAMA_HOST value: "0.0.0.0" --- apiVersion: v1 kind: Service metadata: name: llm-service spec: selector: app: ollama-gemma type: ClusterIP ports: - protocol: TCP port: 8000 targetPort: 11434image: ollama/ollama:latest: Chỉ định hình ảnh Docker chính thức của Ollama.resources: Chúng tôi yêu cầu rõ ràng 8 vCPU và 8Gi bộ nhớ. Tính năng tự động điều khiển GKE sử dụng các giá trị này để cung cấp tài nguyên điện toán cơ bản. Vì chúng ta không sử dụng GPU, nên mô hình sẽ chạy trên CPU. Bộ nhớ 8Gi là đủ để lưu trữ mô hình Gemma 1B và ngữ cảnh của mô hình này.command/args: Chúng tôi ghi đè lệnh khởi động để đảm bảo mô hình được kéo khi nhóm bắt đầu. Tập lệnh này khởi động máy chủ ở chế độ nền, đợi máy chủ sẵn sàng, kéo mô hìnhgemma3:1brồi tiếp tục chạy máy chủ.OLLAMA_HOST: Việc đặt giá trị này thành0.0.0.0đảm bảo rằng Ollama sẽ lắng nghe trên tất cả các giao diện mạng trong vùng chứa, giúp Dịch vụ Kubernetes có thể truy cập vào Ollama.
- Trong thiết bị đầu cuối, hãy áp dụng tệp kê khai triển khai cho cụm của bạn:
kubectl apply -f gemma-deployment.yamlkubectl get pods --watchRunningvàREADYlà1/1rồi mới tiếp tục.
Kiểm thử điểm cuối GKE
Dịch vụ Ollama hiện đang chạy trên cụm GKE Autopilot. Để kiểm thử từ thiết bị đầu cuối Cloud Shell, bạn sẽ sử dụng kubectl port-forward.
- Mở thẻ dòng lệnh Cloud Shell mới (nhấp vào biểu tượng + trong cửa sổ dòng lệnh). Lệnh
port-forwardlà một quy trình chặn, vì vậy, lệnh này cần có phiên thiết bị đầu cuối riêng. - Trong cửa sổ dòng lệnh mới, hãy chạy lệnh sau để chuyển tiếp một cổng cục bộ (ví dụ:
8000) đến cổng của dịch vụ (8000):kubectl port-forward service/llm-service 8000:8000 - Quay lại thiết bị đầu cuối ban đầu.
- Gửi yêu cầu đến cổng
8000tại địa phương. Máy chủ Ollama cung cấp một API tương thích với OpenAI và nhờ tính năng chuyển tiếp cổng, giờ đây bạn có thể truy cập vào API này tạihttp://127.0.0.1:8000.curl http://127.0.0.1:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "gemma3:1b", "messages": [ {"role": "user", "content": "Explain why the sky is blue."} ] }'
6. Dọn dẹp
Để tránh phát sinh phí cho tài khoản Google Cloud của bạn đối với các tài nguyên được dùng trong bài tập thực hành này, hãy làm theo các bước sau để xoá cụm GKE.
- Trong thiết bị đầu cuối Cloud Shell, hãy xoá cụm GKE Autopilot:
gcloud container clusters delete gemma-cluster \ --region $REGION --quiet
7. Kết luận
Tuyệt vời! Trong phòng thí nghiệm này, bạn đã tìm hiểu một số phương pháp chính để triển khai các mô hình mở trên Google Cloud. Bạn bắt đầu với sự đơn giản và tốc độ của quá trình phát triển cục bộ bằng Ollama. Cuối cùng, bạn đã triển khai Gemma vào một môi trường có thể mở rộng, cấp sản xuất bằng cách sử dụng Google Kubernetes Engine Autopilot và khung Ollama.
Giờ đây, bạn đã có kiến thức để triển khai các mô hình mở trên Google Kubernetes Engine cho các khối lượng công việc có nhu cầu cao và có thể mở rộng mà không cần quản lý cơ sở hạ tầng cơ bản.
Tóm tắt
Trong phòng thí nghiệm này, bạn đã tìm hiểu:
- Mô hình mở là gì và tại sao mô hình mở lại quan trọng.
- Cách chạy một mô hình mở trên máy cục bộ bằng Ollama.
- Cách triển khai một mô hình mở trên chế độ Tự động điều khiển của Google Kubernetes Engine (GKE) bằng Ollama để suy luận.
Tìm hiểu thêm
- Tìm hiểu thêm về các mô hình Gemma trong tài liệu chính thức.
- Khám phá thêm các ví dụ trong kho lưu trữ AI tạo sinh của Google Cloud trên GitHub.
- Tìm hiểu thêm về chế độ Tự vận hành của GKE.
- Duyệt xem Vertex AI Model Garden để biết các mô hình nguồn mở và độc quyền khác hiện có.