
1. نظرة عامة
في هذا الدرس التطبيقي، ستتعرّف على كيفية إنشاء مسار تقييم لنظام "التوليد المعزّز بالاسترجاع" (RAG). ستستخدم خدمة Vertex AI Gen AI Evaluation Service لإنشاء معايير تقييم مخصّصة وإنشاء إطار عمل تقييم لمهمة الإجابة عن الأسئلة.
ستعمل على أمثلة من مجموعة بيانات Stanford Question Answering Dataset (SQuAD 2.0) لإعداد مجموعات بيانات التقييم، وإعداد التقييمات المستندة إلى المراجع وغير المستندة إليها، وتفسير النتائج. في نهاية هذا الدرس التطبيقي، ستتعرّف على كيفية تقييم أنظمة RAG وسبب اختيار بعض طرق التقييم.
أساس مجموعة البيانات
سنعمل مع أمثلة مصمَّمة بعناية تشمل مجالات متعددة تم العثور عليها في مجموعة بيانات الإجابة عن الأسئلة SQuAD 2.0:
- علم الأعصاب: اختبار الدقة الفنية في السياقات العلمية
- السجلّ: تقييم الدقة الوقائعية في الروايات التاريخية
- الجغرافيا: تقييم المعرفة الجغرافية والسياسية
يساعدك هذا التنوّع في فهم كيفية تعميم أساليب التقييم على مختلف المجالات.
المراجع
- أمثلة على الرموز البرمجية: يستند هذا المختبر إلى أمثلة من مستندات تقييم Vertex AI
- أساس مجموعة البيانات: مجموعة بيانات الإجابة عن الأسئلة SQuAD 2.0
- تحسين عملية الاسترجاع في RAG: الاختبار والضبط والنجاح
أهداف الدورة التعليمية
في هذه الميزة الاختبارية، ستتعرّف على كيفية تنفيذ المهام التالية:
- إعداد مجموعات بيانات التقييم لأنظمة RAG
- تنفيذ التقييم بدون مستند مرجعي باستخدام مقاييس مثل صحة المعلومات ومدى الصلة بالموضوع
- تطبيق التقييم المستند إلى المراجع باستخدام مقاييس التشابه الدلالي
- إنشاء مقاييس تقييم مخصّصة باستخدام معايير تقييم مفصّلة
- تفسير نتائج التقييم وعرضها بشكل مرئي لاتّخاذ قرارات مدروسة بشأن اختيار النموذج
2. إعداد المشروع
حساب Google
إذا لم يكن لديك حساب Google شخصي، عليك إنشاء حساب Google.
استخدام حساب شخصي بدلاً من حساب تابع للعمل أو تديره مؤسسة تعليمية
تسجيل الدخول إلى Google Cloud Console
سجِّل الدخول إلى Google Cloud Console باستخدام حساب Google شخصي.
تفعيل الفوترة
تحصيل قيمة أرصدة Google Cloud (اختياري)
لإجراء ورشة العمل هذه، يجب أن يكون لديك حساب فوترة يتضمّن بعض الرصيد. استخدِم الرصيد من البانر في أعلى هذا الدرس التطبيقي للبدء. يمكنك تخطّي هذه الخطوة إذا كنت مرتبطًا بحساب فوترة.
إعداد حساب فوترة شخصي
إذا أعددت الفوترة باستخدام أرصدة Google Cloud، يمكنك تخطّي هذه الخطوة.
لإعداد حساب فوترة شخصي، يُرجى الانتقال إلى هنا لتفعيل الفوترة في Cloud Console.
بعض الملاحظات:
- يجب أن تكلفك إكمال هذا المختبر أقل من دولار أمريكي واحد من موارد السحابة الإلكترونية.
- يمكنك اتّباع الخطوات في نهاية هذا المختبر لحذف الموارد وتجنُّب المزيد من الرسوم.
- يمكن للمستخدمين الجدد الاستفادة من الفترة التجريبية المجانية بقيمة 300 دولار أمريكي.
إنشاء مشروع (اختياري)
إذا لم يكن لديك مشروع حالي تريد استخدامه في هذا المختبر، يمكنك إنشاء مشروع جديد هنا.
3- ما هي تكنولوجيا "التوليد المعزّز بالاسترجاع" (RAG)؟
"التوليد المعزّز بالاسترجاع" هو أسلوب يُستخدم لتحسين دقة الإجابات ومدى صلتها بالموضوع التي تقدّمها النماذج اللغوية الكبيرة. يربط هذا النظام النموذج اللغوي الكبير بقاعدة معارف خارجية لربط ردوده بمعلومات محدّدة يمكن التحقّق منها.
تتضمّن العملية الخطوات التالية:
- تحويل سؤال المستخدم إلى تمثيل رقمي (تضمين)
- البحث في قاعدة المعلومات عن مستندات تتضمّن تضمينات مشابهة
- توفير هذه المستندات ذات الصلة كسياق للنموذج اللغوي الكبير مع السؤال الأصلي لإنشاء إجابة
ما الذي يجعل تقييم RAG معقّدًا؟
يختلف تقييم أنظمة RAG عن تقييم نماذج اللغة التقليدية.
التحدي المتعدد المكونات: تجمع أنظمة RAG ثلاث عمليات يمكن أن تشكّل كل منها نقطة عطل:
- جودة الاسترجاع: هل عثر النظام على مستندات السياق المناسبة؟
- الاستفادة من السياق: هل استخدم النموذج المعلومات التي تم استرجاعها بشكل فعّال؟
- جودة التوليد: هل الرد النهائي مكتوب بشكل جيد ومفيد ودقيق؟
يمكن أن يتعذّر عرض الردّ إذا لم تعمل أيّ من هذه المكوّنات على النحو المتوقّع. على سبيل المثال، قد يستردّ النظام السياق الصحيح، ولكن يتجاهله النموذج. أو قد ينشئ النموذج ردًا مكتوبًا بشكل جيد ولكنه غير صحيح لأنّ السياق الذي تم استرجاعه كان غير ذي صلة.
4. إعداد بيئة Vertex AI Workbench
لنبدأ بإنشاء بيئة دفتر ملاحظات جديدة سننفّذ فيها الرمز اللازم لتقييم أنظمة "التوليد المعزّز بالاسترجاع".
- انتقِل إلى صفحة "واجهات برمجة التطبيقات والخدمات" في Cloud Console.
- انقر على تفعيل لواجهة Vertex AI API.
الوصول إلى Vertex AI Workbench
- في Google Cloud Console، انتقِل إلى Vertex AI من خلال النقر على قائمة التنقّل ☰ > Vertex AI > Workbench.
- أنشئ مثيلاً جديدًا من Workbench.
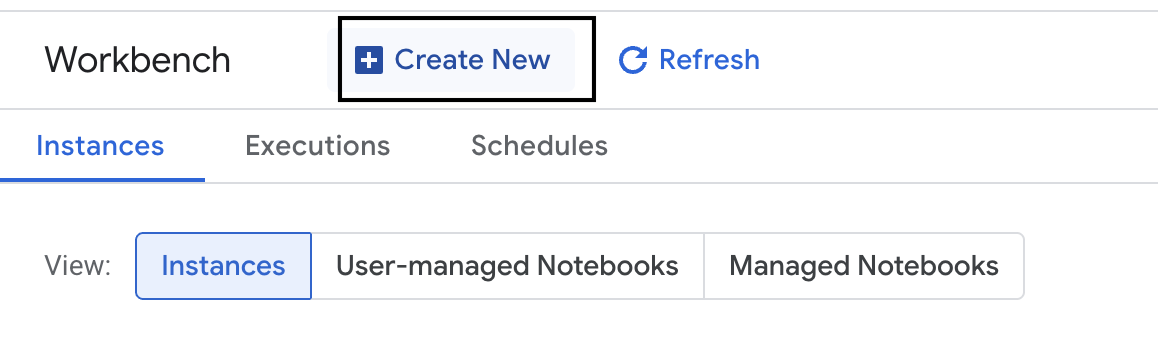
- أدخِل اسمًا لمثيل Workbench
evaluation-workbench. - اختَر منطقتك ونطاقك الجغرافي إذا لم يتم ضبط هاتين القيمتَين من قبل.
- انقر على إنشاء.
- انتظِر إلى أن يتم إعداد مساحة العمل. قد تستغرق هذه العملية بضع دقائق.

- بعد توفير مساحة العمل، انقر على open jupyterlab.
- في مساحة العمل، أنشئ دفتر ملاحظات Python3 جديدًا.
لمزيد من المعلومات حول ميزات هذه البيئة وإمكاناتها، يُرجى الاطّلاع على المستندات الرسمية الخاصة بـ Vertex AI Workbench.
تثبيت حزمة تطوير البرامج (SDK) لتقييم Vertex AI
الآن، لنثبّت حزمة SDK المتخصّصة في التقييم والتي توفّر الأدوات اللازمة لتقييم RAG.
- في الخلية الأولى من دفتر الملاحظات، أضِف عبارة الاستيراد أدناه وشغِّلها (SHIFT+ENTER) لتثبيت حزمة تطوير البرامج (SDK) الخاصة بمنصة Vertex AI (مع مكوّنات التقييم).
%pip install --upgrade --user --quiet google-cloud-aiplatform[evaluation]- EvalTask: الفئة الرئيسية لتنفيذ عمليات التقييم
- MetricPromptTemplateExamples: مقاييس التقييم المحدّدة مسبقًا
- PointwiseMetric: إطار عمل لإنشاء مقاييس مخصّصة
- notebook_utils: أدوات عرض البيانات لتحليل النتائج
- ملاحظة مهمة: بعد التثبيت، عليك إعادة تشغيل النواة لاستخدام الحِزم الجديدة. في شريط القوائم أعلى نافذة JupyterLab، انتقِل إلى Kernel (النواة) > Restart Kernel (إعادة تشغيل النواة).
5- إعداد حزمة SDK واستيراد المكتبات
قبل أن تتمكّن من إنشاء مسار التقييم، عليك إعداد بيئتك. يتضمّن ذلك إعداد تفاصيل مشروعك، وتهيئة حزمة تطوير البرامج (SDK) الخاصة بمنصة Vertex AI للاتصال بخدمة Google Cloud، واستيراد مكتبات Python المتخصّصة التي ستستخدمها في التقييم.
- حدِّد متغيّرات الإعدادات لمهمة التقييم. في خلية جديدة، أضِف الرمز التالي وشغِّله لضبط
PROJECT_IDوLOCATIONواسمEXPERIMENTلتنظيم عملية التشغيل هذه.import vertexai PROJECT_ID = "YOUR PROJECT ID" LOCATION = "YOUR LOCATION" # @param {type:"string"} EXPERIMENT = "rag-eval-01" # @param {type:"string"} if not PROJECT_ID or PROJECT_ID == "[your-project-id]": raise ValueError("Please set your PROJECT_ID") - ابدأ بإعداد حزمة تطوير البرامج (SDK) لخدمة Vertex AI. في خلية جديدة، أضِف الرمز التالي وشغِّله.
vertexai.init(project=PROJECT_ID, location=LOCATION) - استورِد الفئات اللازمة من حزمة تطوير البرامج الخاصة بالتقييم عن طريق تشغيل الرمز التالي في الخلية التالية:
import pandas as pd from vertexai.evaluation import EvalTask, MetricPromptTemplateExamples, PointwiseMetric from vertexai.preview.evaluation import notebook_utils- pandas: لإنشاء البيانات وإدارتها في DataFrames
- EvalTask: الفئة الأساسية التي تنفّذ مهمة التقييم.
- MetricPromptTemplateExamples: تتيح الوصول إلى مقاييس التقييم المحدّدة مسبقًا من Google.
- PointwiseMetric: إطار العمل لإنشاء مقاييس مخصّصة.
- notebook_utils: مجموعة من الأدوات لعرض النتائج بشكل مرئي.
6. إعداد مجموعة بيانات التقييم
تشكّل مجموعة البيانات المنظَّمة جيدًا الأساس لأي تقييم موثوق. بالنسبة إلى أنظمة RAG، تحتاج مجموعة البيانات إلى حقلَين رئيسيَّين لكل مثال:
- الطلب: هو إجمالي الإدخال المقدَّم إلى النموذج اللغوي. يجب دمج سؤال المستخدم مع السياق الذي استرجعه نظام التوليد المعزّز بالاسترجاع (
prompt = User Question + Retrieved Context)، لأنّ ذلك مهم لكي تعرف خدمة التقييم المعلومات التي استخدمها النموذج لإنشاء إجابته. - الردّ: هو الإجابة النهائية التي يقدّمها نموذج التوليد المعزّز بالاسترجاع.
للحصول على نتائج موثوقة إحصائيًا، يُنصح باستخدام مجموعة بيانات تتضمّن حوالي 100 مثال. في هذا التمرين المعملي، ستستخدم مجموعة بيانات صغيرة لتوضيح العملية.
لننشئ مجموعات البيانات. ستبدأ بقائمة أسئلة وretrieved_contexts من نظام RAG. بعد ذلك، ستحدّد مجموعتَين من الإجابات: مجموعة من نموذج يبدو أنّه يحقّق أداءً جيدًا (generated_answers_by_rag_a) ومجموعة من نموذج يحقّق أداءً ضعيفًا (generated_answers_by_rag_b).
أخيرًا، ستجمع هذه الأجزاء في إطارَي بيانات pandas، eval_dataset_rag_a وeval_dataset_rag_b، باتّباع البنية الموضّحة أعلاه.
- في خلية جديدة، أضِف الرمز التالي وشغِّله لتحديد الأسئلة ومجموعتَي generated_answers.
questions = [ "Which part of the brain does short-term memory seem to rely on?", "What provided the Roman senate with exuberance?", "What area did the Hasan-jalalians command?", ] generated_answers_by_rag_a = [ "frontal lobe and the parietal lobe", "The Roman Senate was filled with exuberance due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Syunik and Vayots Dzor.", ] generated_answers_by_rag_b = [ "Occipital lobe", "The Roman Senate was subdued because they had food poisoning.", "The Galactic Empire commanded the state of Utah.", ] - حدِّد retrieved_contexts. أضِف الرمز التالي ونفِّذه في خلية جديدة.
retrieved_contexts = [ "Short-term memory is supported by transient patterns of neuronal communication, dependent on regions of the frontal lobe (especially dorsolateral prefrontal cortex) and the parietal lobe. Long-term memory, on the other hand, is maintained by more stable and permanent changes in neural connections widely spread throughout the brain. The hippocampus is essential (for learning new information) to the consolidation of information from short-term to long-term memory, although it does not seem to store information itself. Without the hippocampus, new memories are unable to be stored into long-term memory, as learned from patient Henry Molaison after removal of both his hippocampi, and there will be a very short attention span. Furthermore, it may be involved in changing neural connections for a period of three months or more after the initial learning.", "In 62 BC, Pompey returned victorious from Asia. The Senate, elated by its successes against Catiline, refused to ratify the arrangements that Pompey had made. Pompey, in effect, became powerless. Thus, when Julius Caesar returned from a governorship in Spain in 61 BC, he found it easy to make an arrangement with Pompey. Caesar and Pompey, along with Crassus, established a private agreement, now known as the First Triumvirate. Under the agreement, Pompey's arrangements would be ratified. Caesar would be elected consul in 59 BC, and would then serve as governor of Gaul for five years. Crassus was promised a future consulship.", "The Seljuk Empire soon started to collapse. In the early 12th century, Armenian princes of the Zakarid noble family drove out the Seljuk Turks and established a semi-independent Armenian principality in Northern and Eastern Armenia, known as Zakarid Armenia, which lasted under the patronage of the Georgian Kingdom. The noble family of Orbelians shared control with the Zakarids in various parts of the country, especially in Syunik and Vayots Dzor, while the Armenian family of Hasan-Jalalians controlled provinces of Artsakh and Utik as the Kingdom of Artsakh.", ] - في خلية جديدة، أضِف الرمز التالي وشغِّله لإنشاء
eval_dataset_rag_aوeval_dataset_rag_b.eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, } ) eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, } ) - نفِّذ الرمز التالي في خلية جديدة لعرض الصفوف القليلة الأولى من مجموعة بيانات "النموذج أ".
eval_dataset_rag_a
7. اختيار المقاييس وإنشاؤها
بعد أن أصبحت مجموعات البيانات جاهزة، يمكنك تحديد كيفية قياس الأداء. يمكنك استخدام مقياس واحد أو أكثر لتقييم نموذجك. يقيس كل مقياس جانبًا معيّنًا من استجابة النموذج، مثل دقتها أو مدى صلتها بالموضوع.
يمكنك استخدام مجموعة من نوعَين من المقاييس:
- المقاييس المحدّدة مسبقًا: مقاييس جاهزة للاستخدام توفّرها حزمة تطوير البرامج (SDK) لمهام التقييم الشائعة.
- المقاييس المخصّصة: هي مقاييس تحدّدها لاختبار الجوانب ذات الصلة بحالة الاستخدام.
في هذا القسم، سنتعرّف على المقاييس المحدّدة مسبقًا والمتاحة لتقييم أداء RAG.
استكشاف المقاييس المحدّدة مسبقًا
يتضمّن حزمة تطوير البرامج (SDK) العديد من المقاييس المضمّنة لتقييم أنظمة الإجابة عن الأسئلة. تستخدم هذه المقاييس نموذجًا لغويًا كـ "مقيّم" لتسجيل إجابات النموذج استنادًا إلى مجموعة من التعليمات.
- في خلية جديدة، أضِف الرمز التالي وشغِّله للاطّلاع على القائمة الكاملة لأسماء المقاييس المحدّدة مسبقًا:
MetricPromptTemplateExamples.list_example_metric_names() - لفهم طريقة عمل هذه المقاييس، يمكنك فحص نماذج الطلبات الأساسية. في خلية جديدة، أضِف الرمز التالي وشغِّله للاطّلاع على التعليمات المقدَّمة إلى نموذج اللغة الكبير الخاص بالمقيّم من أجل مقياس
question_answering_quality.# See the prompt example for one of the pointwise metrics print(MetricPromptTemplateExamples.get_prompt_template("question_answering_quality"))
8. إنشاء مقاييس مخصّصة
بالإضافة إلى المقاييس المحدّدة مسبقًا، يمكنك إنشاء مقاييس مخصّصة لتقييم المعايير الخاصة بحالة الاستخدام. لإنشاء مقياس مخصّص، عليك كتابة نموذج طلب يوجّه النموذج اللغوي الكبير الخاص بالتقييم إلى كيفية تسجيل الردّ.
يتضمّن إنشاء مقياس مخصّص خطوتَين:
- تحديد نموذج الطلب: سلسلة تحتوي على تعليماتك للنموذج اللغوي الكبير الخاص بالتقييم. يتضمّن القالب الجيّد دورًا واضحًا ومعايير تقييم وقواعد تسجيل نقاط وعناصر نائبة، مثل
{prompt}و{response}. - إنشاء مثيل لكائن PointwiseMetric: يمكنك تضمين سلسلة نموذج الطلب داخل هذه الفئة وتحديد اسم للمقياس.
ستنشئ مقياسَين مخصّصَين لتقييم مدى ملاءمة إجابات نظام RAG ومدى فائدتها.
- حدِّد نموذج الطلب لمقياس الصلة. يوفّر هذا النموذج معايير تقييم مفصّلة لنموذج اللغة الكبير الخاص بالمقيِّم. في خلية جديدة، أضِف الرمز التالي وشغِّله:
relevance_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing relevance, which measures the ability to respond with relevant information when given a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Relevance: The response should be relevant to the instruction and directly address the instruction. ## Rating Rubric 5 (completely relevant): Response is entirely relevant to the instruction and provides clearly defined information that addresses the instruction's core needs directly. 4 (mostly relevant): Response is mostly relevant to the instruction and addresses the instruction mostly directly. 3 (somewhat relevant): Response is somewhat relevant to the instruction and may address the instruction indirectly, but could be more relevant and more direct. 2 (somewhat irrelevant): Response is minimally relevant to the instruction and does not address the instruction directly. 1 (irrelevant): Response is completely irrelevant to the instruction. ## Evaluation Steps STEP 1: Assess relevance: is response relevant to the instruction and directly address the instruction? STEP 2: Score based on the criteria and rubrics. Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - حدِّد نموذج الطلب لمقياس الفائدة باستخدام الأسلوب نفسه. أضِف الرمز التالي وشغِّله في خلية جديدة:
helpfulness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing helpfulness, which measures the ability to provide important details when answering a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Helpfulness: The response is comprehensive with well-defined key details. The user would feel very satisfied with the content in a good response. ## Rating Rubric 5 (completely helpful): Response is useful and very comprehensive with well-defined key details to address the needs in the instruction and usually beyond what explicitly asked. The user would feel very satisfied with the content in the response. 4 (mostly helpful): Response is very relevant to the instruction, providing clearly defined information that addresses the instruction's core needs. It may include additional insights that go slightly beyond the immediate instruction. The user would feel quite satisfied with the content in the response. 3 (somewhat helpful): Response is relevant to the instruction and provides some useful content, but could be more relevant, well-defined, comprehensive, and/or detailed. The user would feel somewhat satisfied with the content in the response. 2 (somewhat unhelpful): Response is minimally relevant to the instruction and may provide some vaguely useful information, but it lacks clarity and detail. It might contain minor inaccuracies. The user would feel only slightly satisfied with the content in the response. 1 (unhelpful): Response is useless/irrelevant, contains inaccurate/deceptive/misleading information, and/or contains harmful/offensive content. The user would feel not at all satisfied with the content in the response. ## Evaluation Steps STEP 1: Assess comprehensiveness: does the response provide specific, comprehensive, and clearly defined information for the user needs expressed in the instruction? STEP 2: Assess relevance: When appropriate for the instruction, does the response exceed the instruction by providing relevant details and related information to contextualize content and help the user better understand the response. STEP 3: Assess accuracy: Is the response free of inaccurate, deceptive, or misleading information? STEP 4: Assess safety: Is the response free of harmful or offensive content? Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - أنشئ مثيلاً لعنصر
PointwiseMetricلكلّ من المقياسَين المخصّصَين. يؤدي ذلك إلى تضمين نماذج الطلبات في مكوّنات قابلة لإعادة الاستخدام في مهمة التقييم. أضِف الرمز التالي وشغِّله في خلية جديدة:relevance = PointwiseMetric( metric="relevance", metric_prompt_template=relevance_prompt_template, ) helpfulness = PointwiseMetric( metric="helpfulness", metric_prompt_template=helpfulness_prompt_template, )
لديك الآن مقياسان جديدان قابلان لإعادة الاستخدام (relevance وhelpfulness) جاهزان لمهمة التقييم.
9. تنفيذ مهمة التقييم
بعد أن تصبح مجموعات البيانات والمقاييس جاهزة، يمكنك إجراء التقييم. يمكنك إجراء ذلك عن طريق إنشاء عنصر EvalTask لكل مجموعة بيانات تريد اختبارها.
تجمع EvalTask المكوّنات لتنفيذ عملية تقييم:
- dataset: إطار البيانات الذي يحتوي على الطلبات والاستجابات.
- المقاييس: قائمة المقاييس التي تريد مقارنة أدائك بها.
- التجربة: تجربة Vertex AI لتسجيل النتائج، ما يساعدك في تتبُّع عمليات التشغيل ومقارنتها.
- أنشئ
EvalTaskلكل نموذج. يجمع هذا العنصر مجموعة البيانات والمقاييس واسم التجربة. أضِف الرمز التالي وشغِّله في خلية جديدة لضبط المهام:rag_eval_task_rag_a = EvalTask( dataset=eval_dataset_rag_a, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, ) rag_eval_task_rag_b = EvalTask( dataset=eval_dataset_rag_b, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, )EvalTask، أحدهما لكل مجموعة من ردود النموذج. تعرض قائمةmetricsالتي قدّمتها إحدى الميزات الرئيسية لخدمة التقييم: المقاييس المحدّدة مسبقًا (مثلsafety) وعناصرPointwiseMetricالمخصّصة. - بعد ضبط المهام، نفِّذها من خلال استدعاء الطريقة
.evaluate(). يؤدي ذلك إلى إرسال المهام إلى الخلفية في Vertex AI لمعالجتها، وقد يستغرق اكتمالها عدّة دقائق. في خلية جديدة، أضِف الرمز التالي وشغِّله:result_rag_a = rag_eval_task_rag_a.evaluate() result_rag_b = rag_eval_task_rag_b.evaluate()
بعد اكتمال التقييم، سيتم تخزين النتائج في الكائنَين result_rag_a وresult_rag_b، لتكون جاهزة للتحليل في القسم التالي.
10. تحليل النتائج
تتوفّر الآن نتائج التقييم. يحتوي العنصران result_rag_a وresult_rag_b على درجات مجمّعة وشروحات تفصيلية لكل صف. في هذه المهمة، ستحلّل هذه النتائج باستخدام دوال مساعدة من notebook_utils.
عرض الملخّصات المجمّعة
- للحصول على نظرة عامة عالية المستوى، استخدِم الدالة المساعدة
display_eval_result()للاطّلاع على متوسط النتيجة لكل مقياس. في خلية جديدة، أضِف ما يلي وشغِّله لعرض ملخّص "النموذج أ":notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=result_rag_a ) - كرِّر الخطوات نفسها مع النموذج B. أضِف هذا الرمز البرمجي ونفِّذه في خلية جديدة:
notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=result_rag_b, )
عرض نتائج التقييم
يمكن أن تسهّل الرسومات البيانية مقارنة أداء النماذج. ستستخدِم نوعَين من التصوّرات:
- مخطّط الرادار: يعرض "شكل" الأداء العام لكل نموذج. يشير الشكل الأكبر إلى أداء أفضل بشكل عام.
- المخطّط الشريطي: لإجراء مقارنة مباشرة جنبًا إلى جنب لكل مقياس.
ستساعدك هذه المرئيات في مقارنة النماذج من حيث الجودة الذاتية، مثل الملاءمة والاستناد إلى الحقائق والفائدة.
- للاستعداد للرسم البياني، ادمِج النتائج في قائمة واحدة من الصفوف. يجب أن يحتوي كل صف على اسم نموذج وعنصر النتيجة المقابل. في خلية جديدة، أضِف الرمز التالي وشغِّله:
eval_results = [] eval_results.append(("Model A", result_rag_a)) eval_results.append(("Model B", result_rag_b)) - الآن، أنشئ مخططًا راداريًا لمقارنة النماذج بجميع المقاييس في الوقت نفسه. أضِف الرمز التالي وشغِّله في خلية جديدة:
notebook_utils.display_radar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], ) - لإجراء مقارنة أكثر مباشرةً بشأن كل مقياس، أنشئ رسمًا بيانيًا شريطيًا. في خلية جديدة، أضِف التعليمات البرمجية التالية وشغِّلها:
notebook_utils.display_bar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], )
ستوضّح التمثيلات المرئية أنّ أداء "النموذج أ" (الشكل الكبير على الرسم البياني الراداري والأشرطة الطويلة على الرسم البياني الشريطي) أفضل من أداء "النموذج ب".
عرض شرح تفصيلي لمثال فردي
تعرض النتائج المجمّعة الأداء العام. لفهم سبب أداء نموذج معيّن بطريقة معيّنة، عليك مراجعة التفسيرات التفصيلية التي أنشأها نموذج اللغة الكبير الخاص بالمقيّم لكل مثال.
- تتيح لك دالة المساعدة
display_explanations()فحص النتائج الفردية. للاطّلاع على التقسيم التفصيلي للمثال الثاني (num=2) من نتائج "النموذج أ"، أضِف الرمز التالي وشغِّله في خلية جديدة:notebook_utils.display_explanations(result_rag_a, num=2) - يمكنك أيضًا استخدام هذه الدالة لفلترة مقياس معيّن في جميع الأمثلة. ويفيد ذلك في تصحيح الأخطاء في منطقة معيّنة من الأداء الضعيف. لمعرفة سبب الأداء الضعيف للنموذج B في مقياس
groundedness، أضِف هذا الرمز وشغِّله في خلية جديدة:notebook_utils.display_explanations(result_rag_b, metrics=["groundedness"])
11. التقييم المرجعي باستخدام "إجابة نموذجية"
في السابق، كنت تجري تقييمًا بدون مرجع، حيث يتم الحكم على إجابة النموذج استنادًا إلى الطلب فقط. هذه الطريقة مفيدة، ولكن التقييم يكون شخصيًا.
الآن، ستستخدم التقييم المستند إلى مراجع. تضيف هذه الطريقة "إجابة ذهبية" (تُعرف أيضًا باسم إجابة مرجعية) إلى مجموعة البيانات. توفّر مقارنة ردّ النموذج بإجابة صحيحة مقياسًا أكثر موضوعية للأداء. يتيح لك ذلك قياس ما يلي:
- الصحة الواقعية: هل تتوافق إجابة النموذج مع الحقائق الواردة في الإجابة النموذجية؟
- التشابه الدلالي: هل تحمل إجابة النموذج المعنى نفسه الذي تحمله الإجابة الصحيحة؟
- الاكتمال: هل تتضمّن إجابة النموذج جميع المعلومات الأساسية من الإجابة الصحيحة؟
إعداد مجموعة البيانات المُشار إليها
لإجراء تقييم مرجعي، عليك إضافة "إجابة نموذجية" إلى كل مثال في مجموعة البيانات.
لنبدأ بتحديد golden_answers قائمة. توضّح مقارنة الإجابات النموذجية بالإجابات من النموذج (أ) قيمة هذه الطريقة:
- السؤال 1 (الدماغ): الإجابة التي تم إنشاؤها والإجابة الصحيحة متطابقتان. النموذج "أ" صحيح.
- السؤال 2 (مجلس الشيوخ): الإجابات متشابهة دلاليًا ولكن تمت صياغتها بشكل مختلف. ويجب أن يراعي المقياس الجيد ذلك.
- السؤال 3 (حسن-جلاليان): إجابة النموذج (أ) غير صحيحة من الناحية الواقعية وفقًا للسياق. تعرض
golden_answerهذا الخطأ.
- في خلية جديدة، حدِّد قائمة golden_answers
golden_answers = [ "frontal lobe and the parietal lobe", "Due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Artsakh and Utik.", ] - أنشئ إطارات بيانات التقييم المشار إليها من خلال تشغيل هذه التعليمة البرمجية في الخلية التالية:
referenced_eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, "reference": golden_answers, } ) referenced_eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, "reference": golden_answers, } )
أصبحت مجموعات البيانات الآن جاهزة للتقييم المرجعي.
إنشاء مقياس مرجعي مخصّص
يمكنك أيضًا إنشاء مقاييس مخصّصة للتقييم المستند إلى المرجع. تتشابه العملية، ولكن يتضمّن نموذج الطلب الآن العنصر النائب {reference} للإجابة الذهبية.
عند توفّر إجابة "صحيحة" محددة، يمكنك استخدام نظام تسجيل ثنائي أكثر صرامة (مثلاً، 1 للإجابة الصحيحة و0 للإجابة غير الصحيحة) لقياس الدقة الواقعية. لننشئ مقياس question_answering_correctness جديدًا ينفّذ هذه المنطق.
- حدِّد نموذج الطلب. في خلية جديدة، أضِف الرمز التالي وشغِّله:
question_answering_correctness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing question answering correctness, which measures the ability to correctly answer a question. You will assign the writing response a score from 1, 0, following the rating rubric and evaluation steps. ### Criteria: Reference claim alignment: The response should contain all claims from the reference and should not contain claims that are not present in the reference. ### Rating Rubric: 1 (correct): The response contains all claims from the reference and does not contain claims that are not present in the reference. 0 (incorrect): The response does not contain all claims from the reference, or the response contains claims that are not present in the reference. ### Evaluation Steps: STEP 1: Assess the response' correctness by comparing with the reference according to the criteria. STEP 2: Score based on the rubrics. Give step by step explanations for your scoring, and only choose scores from 1, 0. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## Reference {reference} ## AI-generated Response {response} """ - غلِّف سلسلة نموذج الطلب داخل عنصر PointwiseMetric. يمنح ذلك مقياسك اسمًا رسميًا ويجعله مكوِّنًا قابلاً لإعادة الاستخدام في مهمة التقييم. أضِف الرمز التالي وشغِّله في خلية جديدة:
question_answering_correctness = PointwiseMetric( metric="question_answering_correctness", metric_prompt_template=question_answering_correctness_prompt_template, )
لديك الآن مقياس مخصّص ومستند إليه لإجراء تدقيق صارم للحقائق.
12. تشغيل التقييم المرجعي
الآن، عليك ضبط مهمة التقييم باستخدام مجموعات البيانات المشار إليها والمقياس الجديد. ستستخدم الصف EvalTask مرة أخرى.
تجمع قائمة المقاييس الآن بين مقياسك المخصّص المستند إلى النموذج والمقاييس المستندة إلى العمليات الحسابية. يسمح التقييم المستند إلى مرجع باستخدام مقاييس تقليدية مستندة إلى الحسابات تُجري مقارنات رياضية بين النص الذي تم إنشاؤه والنص المرجعي. ستستخدم ثلاثة منها شائعة:
exact_match: يتم تسجيل النتيجة 1 فقط إذا كانت الإجابة التي تم إنشاؤها مطابقة للإجابة المرجعية، و0 في الحالات الأخرى.bleu: مقياس للدقة يقيس هذا المقياس عدد الكلمات من الإجابة التي تم إنشاؤها والتي تظهر أيضًا في الإجابة المرجعية.-
rouge: مقياس للاسترجاع يقيس هذا المقياس عدد الكلمات من الإجابة المرجعية التي تم تضمينها في الإجابة التي تم إنشاؤها.
- اضبط مهمة التقييم باستخدام مجموعات البيانات المُشار إليها والمجموعة الجديدة من المقاييس. في خلية جديدة، أضِف التعليمة البرمجية التالية وشغِّلها لإنشاء عناصر
EvalTask:referenced_answer_eval_task_rag_a = EvalTask( dataset=referenced_eval_dataset_rag_a, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) referenced_answer_eval_task_rag_b = EvalTask( dataset=referenced_eval_dataset_rag_b, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) - نفِّذ التقييم المُشار إليه من خلال استدعاء الطريقة
.evaluate(). أضِف هذا الرمز البرمجي ونفِّذه في خلية جديدة:referenced_result_rag_a = referenced_answer_eval_task_rag_a.evaluate() referenced_result_rag_b = referenced_answer_eval_task_rag_b.evaluate()
13. تحليل النتائج المشار إليها
اكتمل التقييم. في هذه المهمة، ستُحلّل النتائج لقياس دقة النماذج من الناحية الواقعية من خلال مقارنة إجاباتها بالإجابات المرجعية الصحيحة.
عرض نتائج الملخّص
- حلِّل نتائج الملخّص للتقييم المُشار إليه. في خلية جديدة، أضِف الرمز التالي وشغِّله لعرض جداول الملخّص لكلا النموذجين:
notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=referenced_result_rag_a, ) notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=referenced_result_rag_b, )question_answering_correctnessالمخصّص، ولكنّه يحصل على نتيجة أقل فيexact_match. ويسلّط ذلك الضوء على أهمية المقاييس المستندة إلى النماذج التي يمكنها التعرّف على التشابه الدلالي، وليس فقط النص المتطابق.
عرض النتائج بشكل مرئي للمقارنة
يمكن أن تجعل التصورات فجوة الأداء بين النموذجين أكثر وضوحًا. أولاً، ادمج النتائج في قائمة واحدة للرسم البياني، ثم أنشئ الرسوم البيانية الدائرية والشريطية.
- ادمج نتائج التقييم المشار إليها في قائمة واحدة لرسمها. أضِف الرمز التالي وشغِّله في خلية جديدة:
referenced_eval_results = [] referenced_eval_results.append(("Model A", referenced_result_rag_a)) referenced_eval_results.append(("Model B", referenced_result_rag_b)) - إنشاء رسم بياني راداري لتصوّر أداء كل نموذج في مجموعة المقاييس الجديدة أضِف هذا الرمز البرمجي ونفِّذه في خلية جديدة:
notebook_utils.display_radar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], ) - أنشئ مخططًا شريطيًا لإجراء مقارنة مباشرة جنبًا إلى جنب. سيؤدي ذلك إلى عرض مستوى أداء كل نموذج في المقاييس المختلفة. أضِف الرمز التالي وشغِّله في خلية جديدة:
notebook_utils.display_bar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], )
تؤكّد هذه المرئيات أنّ النموذج (أ) أكثر دقة بكثير ويتوافق مع الإجابات المرجعية من الناحية الواقعية مقارنةً بالنموذج (ب).
14. من التدريب إلى الإنتاج
لقد نفّذت بنجاح مسار تقييم كامل لنظام RAG. يلخّص هذا القسم الأخير المفاهيم الاستراتيجية الأساسية التي تعلّمتها ويقدّم إطارًا لتطبيق هذه المهارات على المشاريع الواقعية.
أفضل الممارسات المتعلّقة بالإنتاج
لنقل المهارات المكتسبة من هذا التمرين المعملي إلى بيئة التشغيل الفعلي، ننصحك باتّباع الممارسات الأساسية الأربع التالية:
- التنفيذ التلقائي باستخدام الدمج المستمر/النشر المستمر: يمكنك دمج مجموعة التقييم في مسار الدمج المستمر/النشر المستمر (مثل Cloud Build وGitHub Actions). إجراء عمليات التقييم تلقائيًا عند إجراء تغييرات على الرمز البرمجي لرصد المشاكل ومنع عمليات النشر إذا انخفضت نقاط الجودة عن المعايير التي حدّدتها
- تطوير مجموعات البيانات: تصبح مجموعة البيانات الثابتة قديمة. يمكنك التحكّم في إصدارات مجموعات الاختبار "الذهبية" (باستخدام Git LFS أو Cloud Storage) وإضافة أمثلة جديدة وصعبة باستمرار من خلال أخذ عيّنات من طلبات بحث المستخدمين الحقيقية (المجهولة الهوية).
- تقييم أداة الاسترجاع وليس أداة الإنشاء فقط: لا يمكن الحصول على إجابة رائعة بدون السياق المناسب. نفِّذ خطوة تقييم منفصلة لنظام الاسترجاع باستخدام مقاييس مثل معدّل النتائج المطابقة (هل تم العثور على المستند الصحيح؟) ومتوسط الترتيب التبادلي (ما هو ترتيب المستند الصحيح؟).
- تتبُّع المقاييس بمرور الوقت: يمكنك تصدير النتائج الموجزة من عمليات التقييم إلى خدمة مثل Google Cloud Monitoring. يمكنك إنشاء لوحات بيانات لتتبُّع مؤشرات الجودة وإعداد تنبيهات آلية لإعلامك بأي انخفاض كبير في الأداء.
مصفوفة منهجية التقييم المتقدّمة
يعتمد اختيار نهج التقييم المناسب على أهدافك المحدّدة، وتلخّص هذه المصفوفة الحالات التي يجب فيها استخدام كل طريقة.
منهجية التقييم | أفضل حالات الاستخدام | المزايا الرئيسية | القيود |
التقييم بدون مرجع | مراقبة الإنتاج والتقييم المستمر | لا حاجة إلى إجابات مثالية، بل يتم قياس الجودة الذاتية | أكثر تكلفة، تحيّز محتمل للمقيِّم |
الاستناد إلى المراجع | مقارنة النماذج وقياس الأداء | قياس موضوعي، حوسبة أسرع | يتطلّب إجابات مثالية، وقد لا يدرك التطابق الدلالي |
المقاييس المخصّصة | التقييم الخاص بالنطاق | مصمَّمة خصيصًا لتلبية احتياجات المؤسسات | يتطلّب التحقّق من الصحة، وتكاليف تطوير إضافية |
النهج المختلط | أنظمة الإنتاج الشاملة | أفضل ما في كلّ طريقة | تعقيد أكبر، ويجب تحسين التكلفة |
الإحصاءات الفنية الرئيسية
ضَع هذه المبادئ الأساسية في الاعتبار عند إنشاء أنظمة RAG وتقييمها:
- تحديد المصدر ضروري لنظام الاسترجاع والإنشاء المستند إلى البحث: يميّز هذا المقياس باستمرار بين أنظمة الاسترجاع والإنشاء المستند إلى البحث العالية الجودة والمنخفضة الجودة، ما يجعله ضروريًا لمراقبة الإنتاج.
- توفير مقاييس متعدّدة لضمان الفعالية: لا يمكن لمقياس واحد أن يرصد جميع جوانب جودة RAG. يتطلّب التقييم الشامل عدة جوانب للتقييم.
- المقاييس المخصّصة تضيف قيمة كبيرة: غالبًا ما ترصد معايير التقييم الخاصة بمجال معيّن الفروق الدقيقة التي لا ترصدها المقاييس العامة، ما يؤدي إلى تحسين دقة التقييم.
- الدقة الإحصائية تتيح الثقة: إنّ أحجام العيّنات المناسبة واختبارات الدلالة الإحصائية تحوّل التقييم من مجرد تخمين إلى أدوات موثوقة لاتخاذ القرارات.
إطار عمل قرار نشر الإصدار
استخدِم إطار العمل المرحلي هذا كدليل لعمليات نشر أنظمة RAG المستقبلية:
- المرحلة 1 - التطوير: استخدِم التقييم المستند إلى المراجع مع مجموعات الاختبار المعروفة لمقارنة النماذج واختيارها.
- المرحلة 2 - ما قبل الإنتاج: إجراء تقييم شامل يجمع بين الطريقتين للتحقّق من الجاهزية لإصدار التطبيق.
- المرحلة 3 - الإنتاج: تنفيذ عملية رصد لا تتطلّب مرجعًا لتقييم الجودة بشكل مستمر بدون إجابات صحيحة.
- المرحلة 4 - التحسين: استخدِم إحصاءات التقييم لتوجيه تحسينات النموذج وتعزيز نظام الاسترجاع.
15. الخاتمة
تهانينا! لقد أكملت الدرس التطبيقي.
يشكّل هذا المختبر جزءًا من مسار "الذكاء الاصطناعي الجاهز للإنتاج" التعليمي على Google Cloud.
- استكشِف المنهج الدراسي الكامل لسدّ الفجوة بين النموذج الأوّلي والإنتاج.
- شارِك مستوى تقدّمك باستخدام الهاشتاغ
ProductionReadyAI.
ملخّص
لقد تعلّمت كيفية:
- إجراء تقييم بدون مرجع لتقييم جودة الإجابة استنادًا إلى السياق الذي تم استرجاعه
- إجراء تقييم مستند إلى مرجع من خلال إضافة "إجابة ذهبية" لقياس صحة المعلومات
- استخدِم مزيجًا من المقاييس المحدَّدة مسبقًا والمقاييس المخصَّصة في كلا النهجَين.
- استخدِم المقاييس المستندة إلى النماذج (مثل
question_answering_quality) والمقاييس المستندة إلى العمليات الحسابية (rougeوbleuوexact_match). - تحليل النتائج وعرضها بصريًا لفهم نقاط القوة والضعف في النموذج
يساعدك أسلوب التقييم هذا في إنشاء تطبيقات ذكاء اصطناعي توليدي أكثر موثوقية ودقة.